众所周知 Flink 是当前广泛使用的计算引擎,Flink 使用 checkpoint 机制进行容错处理\[1\],Flink 的 checkpoint 会将状态快照备份到分布式存储系统,供后续恢复使用。在 Alibaba 内部我们使用的存储主要是 HDFS,当同一个集群的 Job 到达一定数量后,会对 HDFS 造成非常大的压力,本文将介绍一种大幅度降低 HDFS 压力的方法 -- 小文件合并。
背景
==
不管使用 FsStateBackend、RocksDBStateBackend 还是 NiagaraStateBackend,Flink 在进行 checkpoint 的时候,TM 会将状态快照写到分布式文件系统中,然后将文件句柄发给 JM,JM 完成全局 checkpoint 快照的存储,如下图所示。
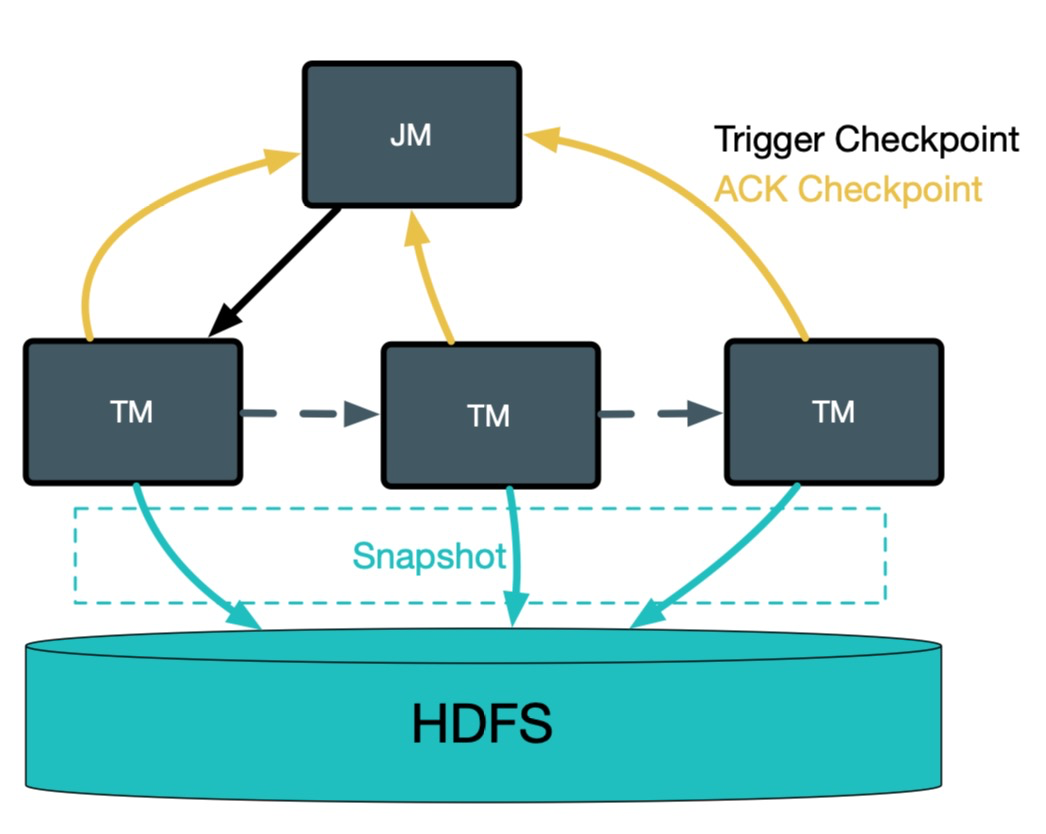
对于全量 checkpoint 来说,TM 将每个 checkpoint 内部的数据都写到同一个文件,而对于 RocksDBStateBackend/NiagaraStateBackend 的增量 checkpoint \[2\]来说,则会将每个 sst 文件写到一个分布式系统的文件内。当作业量很大,且作业的并发很大时,则会对底层 HDFS 形成非常大的压力:1)大量的 RPC 请求会影响 RPC 的响应时间(如下图所示);2)大量文件对 NameNode 内存造成很大压力。
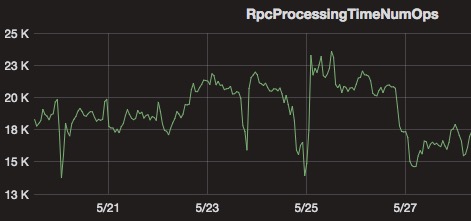
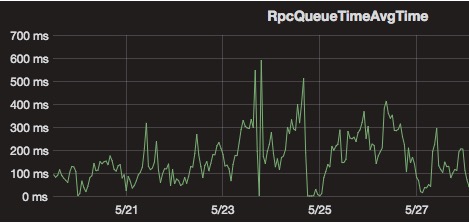
在 Flink 中曾经尝试使用 ByteStreamStateHandle 来解决小文件多的问题\[3\],将小于一定阈值的 state 直接发送到 JM,由 JM 统一写到分布式文件中,从而避免在 TM 端生成小文件。但是这个方案有一定的局限性,阈值设置太小,还会有很多小文件生成,阈值设置太大,则会导致 JM 内存消耗太多有 OOM 的风险。
1 小文件合并方案
=========
针对上面的问题我们提出一种解决方案 -- 小文件合并。
在原来的实现中,每个 sst 文件会打开一个
CheckpointOutputStream,每个 CheckpointOutputStream 对应一个 FSDataOutputStream,将本地文件写往一个分布式文件,然后关闭 FSDataOutputStream,生成一个 StateHandle。如下图所示:
小文件合并则会重用打开的 FSDataOutputStream,直至文件大小达到预设的阈值为止,换句话说多个 sst 文件会重用同一个 DFS 上的文件,每个 sst 文件占用 DFS 文件中的一部分,最终多个 StateHandle 共用一个物理文件,如下图所示。
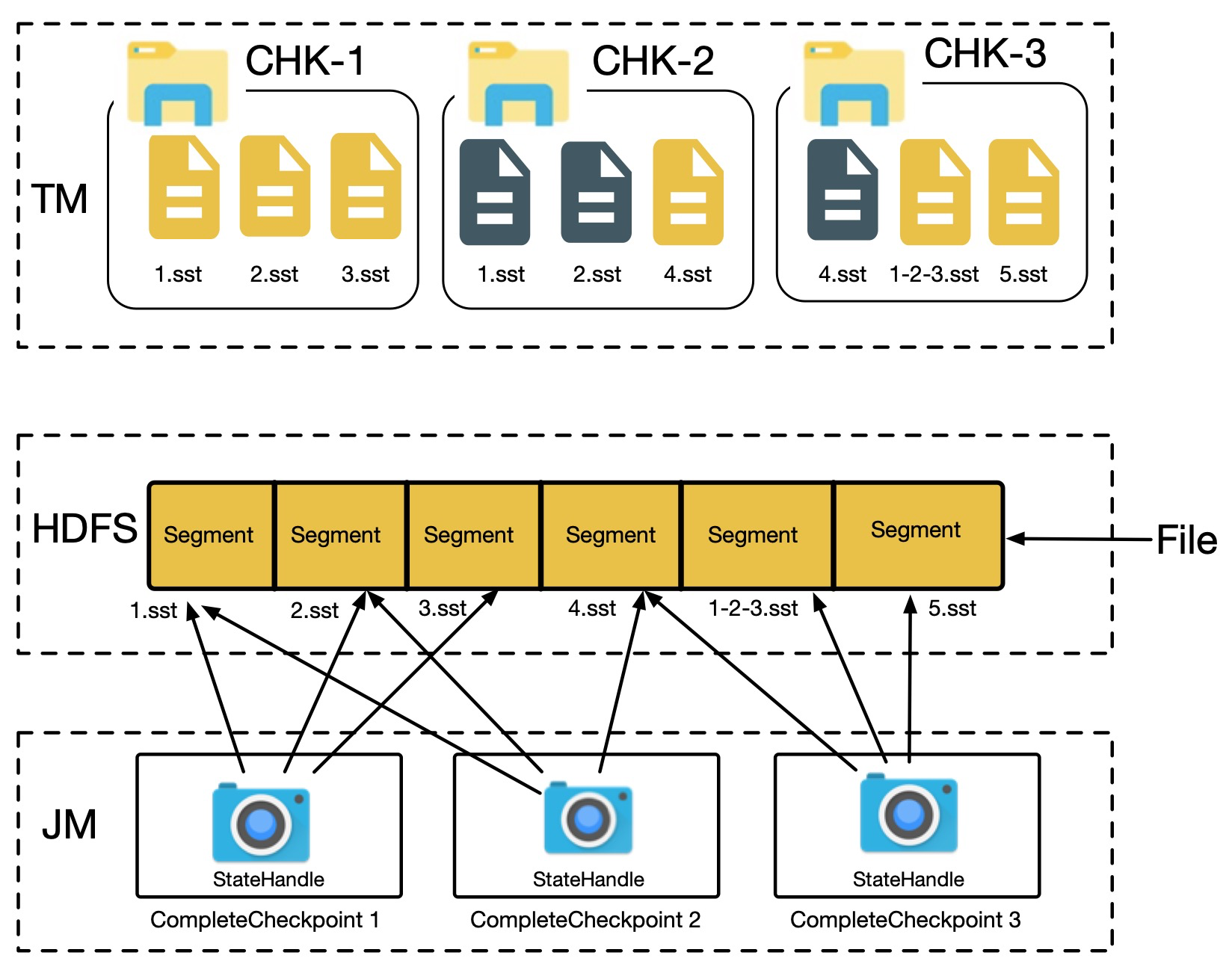
在接下来的章节中我们会描述实现的细节,其中需要重点考虑的地方包括:
1. 并发 checkpoint 的支持
Flink 天生支持并发 checkpoint,小文件合并方案则会将多个文件写往同一个分布式存储文件中,如果考虑不当,数据会写串或者损坏,因此我们需要有一种机制保证该方案的正确性,详细描述参考 2.1 节
2. 防止误删文件
我们使用引用计数来记录文件的使用情况,仅通过文件引用计数是否降为 0 进行判断删除,则可能误删文件,如何保证文件不会被错误删除,我们将会在 2.2 节进行阐述
3. 降低空间放大
使用小文件合并之后,只要文件中还有一个 statehandle 被使用,整个分布式文件就不能被删除,因此会占用更多的空间,我们在 2.3 节描述了解决该问题的详细方案
4. 异常处理
我们将在 2.4 节阐述如何处理异常情况,包括 JM 异常和 TM 异常的情况
5. 2.5 节中会详细描述在 Checkpoint 被取消或者失败后,如何取消 TM 端的 Snapshot,如果不取消 TM 端的 Snapshot,则会导致 TM 端实际运行的 Snapshot 比正常的多
在第 3 节中阐述了小文件合并方案与现有方案的兼容性;第 4 节则会描述小文件合并方案的优势和不足;最后在第 5 节我们展示在生产环境下取得的效果。
2 设计实现
======
本节中我们会详细描述整个小文件合并的细节,以及其中的设计要点。
这里我们大致回忆一下 TM 端 Snapshot 的过程
1. TM 端 barrier 对齐
2. TM Snapshot 同步操作
3. TM Snapshot 异步操作
其中上传 sst 文件到分布式存储系统在上面的第三步,同一个 checkpoint 内的文件顺序上传,多个 checkpoint 的文件上传可能同时进行。
2.1 并发 checkpoint 支持
--------------------
Flink 天生支持并发 checkpoint,因此小文件合并方案也需要能够支持并发 checkpoint,如果不同 checkpoint 的 sst 文件同时写往一个分布式文件,则会导致文件内容损坏,后续无法从该文件进行 restore。
在 FLINK-11937\[4\] 的提案中,我们会将每个 checkpoint 的 state 文件写到同一个 HDFS 文件,不同 checkpoint 的 state 写到不同的 HDFS 文件 -- 换句话说,HDFS 文件不跨 Checkpoint 共用,从而避免了多个客户端同时写入同一个文件的情况。
后续我们会继续推进跨 Checkpoint 共用文件的方案,当然在跨 Checkpoint 共用文件的方案中,并行的 Checkpoint 也会写往不同的 HDFS 文件。
2.2 防止误删文件
----------
复用底层文件之后,我们使用引用计数追踪文件的使用情况,在文件引用数降为 0 的情况下删除文件。但是在某些情况下,文件引用数为 0 的时候,并不代表文件不会被继续使用,可能导致文件误删。下面我们会详>细描述开启并发 checkpoint 后可能导致文件误删的情况,以及解决方案。
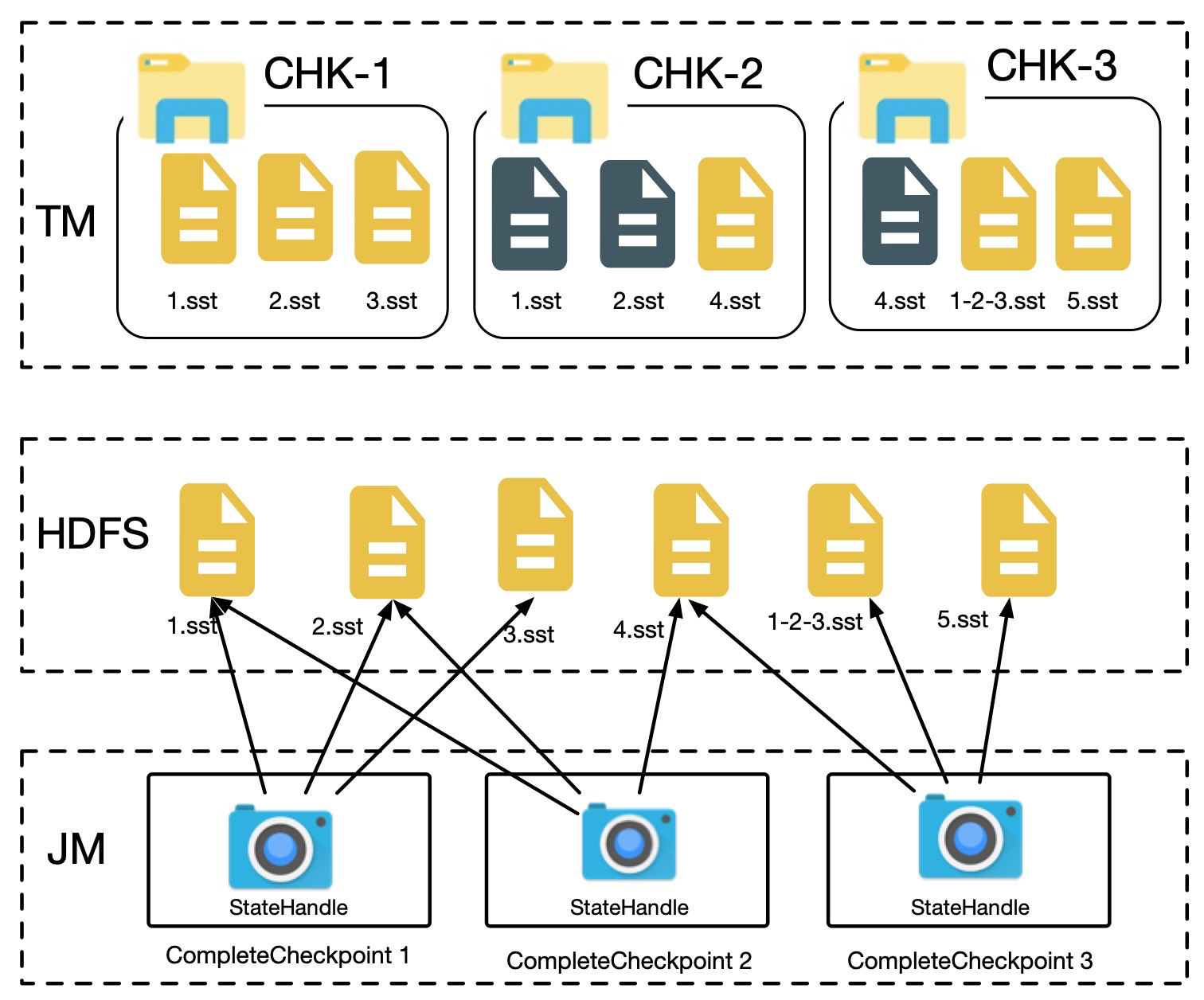
我们以下图为例,maxConcurrentlyCheckpoint = 2
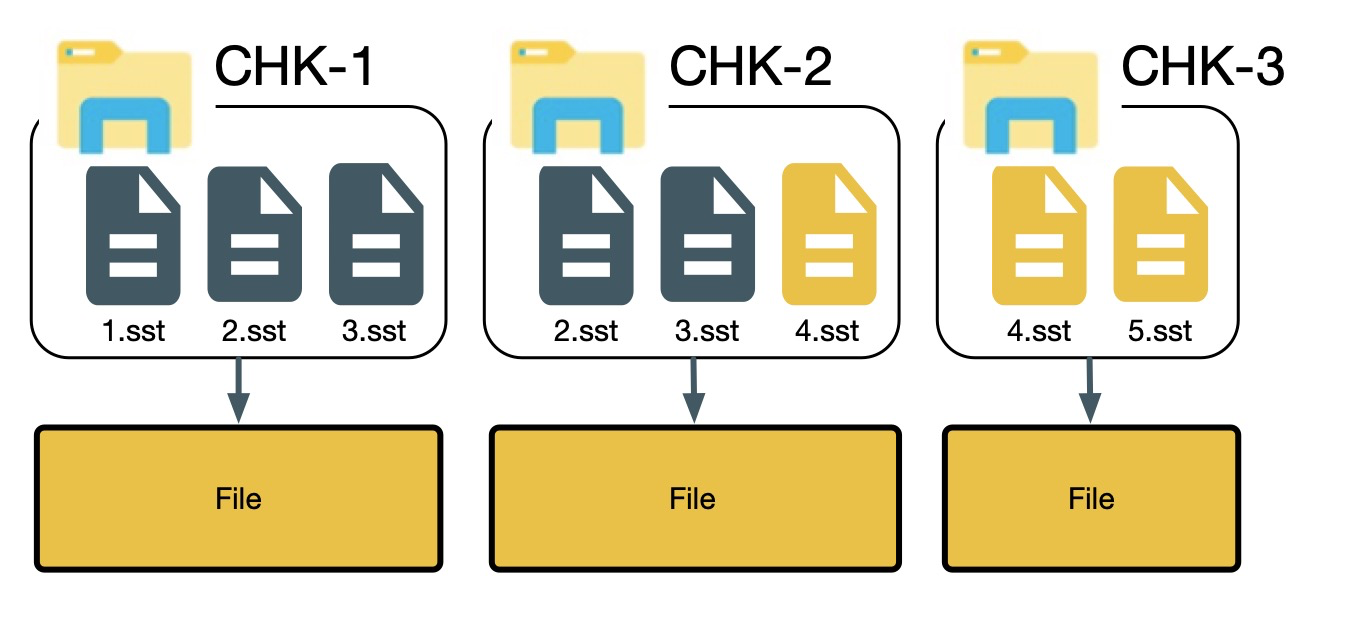
上图中共有 3 个 checkpoint,其中 chk-1 已经完成,chk-2 和 chk-3 都基于 chk-1 进行,chk-2 在 chk-3 前完成,chk-3 在注册`4.sst`的时候发现,发现`4.sst`在 chk-2 中已经注册过,会重用 chk-2 中`4.sst`对应的 stateHandle,然后取消 chk-3 中的`4.sst`的注册,并且删除 stateHandle,在处理完 chk-3 中`4.sst`之后,该 stateHandle 对应的分布式文件的引用计数为 0,如果我们这个时候删除分布式文件,则会同时删除`5.sst`对应的内容,导致后续无法从 chk-3 恢复。
这里的问题是如何在`stateHandle`对应的分布式文件引用计数降为 0 的时候正确判断是否还会继续引用该文件,因此在整个 checkpoint 完成处理之后再判断某个分布式文件能否删除,如果真个 checkpoint 完成发现文件没有被引用,则可以安全删除,否则不进行删除。
2.3 降低空间放大
----------
使用小文件合并方案后,每个 sst 文件对应分布式文件中的一个 segment,如下图所示
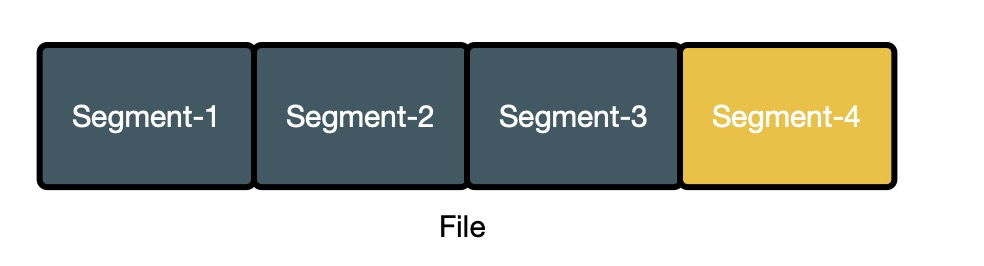
文件仅能在所有 segment 都不再使用时进行删除,上图中有 4 个 segment,仅 segment-4 被使用,但是整个文件都不能删除,其中 segment\[1-3\] 的空间被浪费掉了,从实际生产环境中的数据可知,整体的空间放大率(实际占用的空间 / 真实有用的空间)在 1.3 - 1.6 之间。
为了解决空间放大的问题,在 TM 端起异步线程对放大率超过阈值的文件进行压缩。而且仅对已经关闭的文件进行压缩。
整个压缩的流程如下所示:
1. 计算每个文件的放大率
2. 如果放大率较小则直接跳到步骤 7
3. 如果文件 A 的放大率超过阈值,则生成一个对应的新文件 A‘(如果这个过程中创建文件失败,则由 TM 负责清理工作)
4. 记录 A 与 A’ 的映射关系
5. 在下一次 checkpoint X 往 JM 发送落在文件 A 中的 StateHandle 时,则使用 A\` 中的信息生成一个新的 StateHandle 发送给 JM
6. checkpoint X 完成后,我们增加 A‘ 的引用计数,减少 A 的引用计数,在引用计数降为 0 后将文件 A 删除(如果 JM 增加了 A’ 的引用,然后出现异常,则会从上次成功的 checkpoint 重新构建整个引用计数器)
7. 文件压缩完成
2.4 异常情况处理
----------
在 checkpoint 的过程中,主要有两种异常:JM 异常和 TM 异常,我们将分情况阐述。
### 2.4.1 JM 异常
JM 端主要记录 StateHandle 以及文件的引用计数,引用计数相关数据不需要持久化到外存中,因此不需要特殊的处理,也不需要考虑 transaction 等相关操作,如果 JM 发送 failover,则可以直接从最近一次 complete checkpoint 恢复,并重建引用计数即可。
### 2.4.2 TM 异常
TM 异常可以分为两种:1)该文件在之前 checkpoint 中已经汇报过给 JM;2)文件尚未汇报过给 JM,我们会分情况阐述。
1. 文件已经汇报过给 JM
文件汇报过给 JM,因此在 JM 端有文件的引用计数,文件的删除由 JM 控制,当文件的引用计数变为 0 之后,JM 将删除该文件。
2. 文件尚未汇报给 JM
该文件暂时尚未汇报过给 JM,该文件不再被使用,也不会被 JM 感知,成为孤儿文件。这种情况暂时有外围工具统一进行清理。
2.5 取消 TM 端 snapshot
--------------------
像前面章节所说,我们需要在 checkpoint 超时/失败时,取消 TM 端的 snapshot,而 Flink 则没有相应的通知机制,现在 FLINK-8871\[5\] 在追踪相应的优化,我们在内部增加了相关实现,当 checkpoint 失败时会发送 RPC 数据给 TM,TM 端接受到相应的 RPC 消息后,会取消相应的 snapshot。
3 兼容性
=====
小文件合并功能支持从之前的版本无缝迁移过来。从之前的 checkpoint restore 的的步骤如下:
1. 每个 TM 分到自己需要 restore 的 state handle
2. TM 从远程下载 state handle 对应的数据
3. 从本地进行恢复
小文件合并主要影响的是第 2 步,从远程下载对应数据的时候对不同的 StateHandle 进行适配,因此不影响整体的兼容性。
4 优势和不足
=======
* 优势:大幅度降低 HDFS 的
* 压力:包括 RPC 压力以及 NameNode 内存的压力
* 不足:不支持 State 多线程上传的功能(State 上传暂时不是 checkpoint 的瓶颈)
5 线上环境的结果
=========
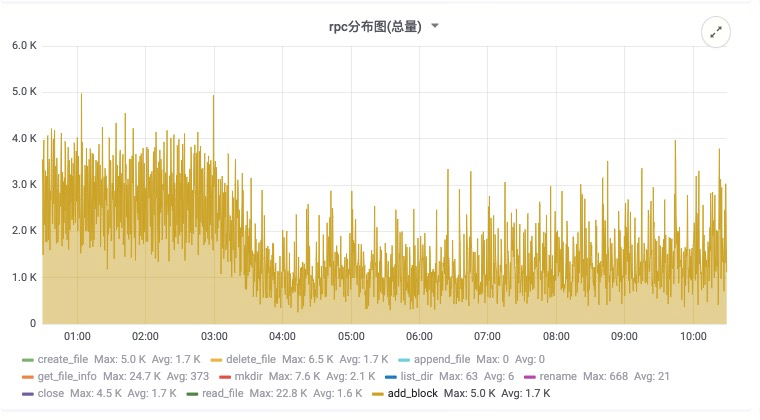
在该方案上线后,对 Namenode 的压力大幅降低,下面的截图来自线上生产集群,从数据来看,文件创建和关闭的 RPC 有明显下降,RPC 的响应时间也有大幅度降低,确保顺利度过双十一。
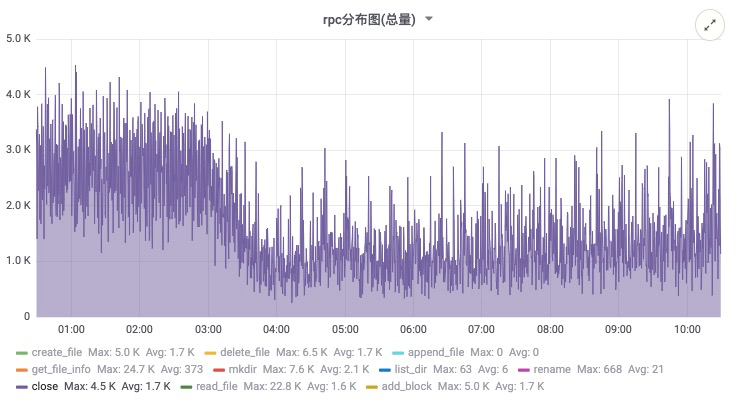
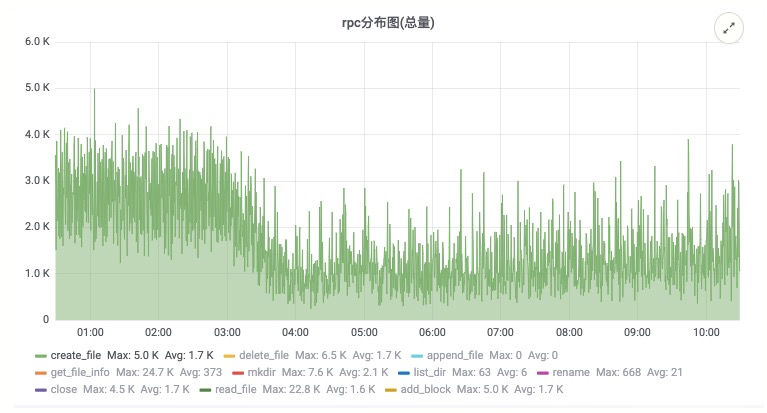
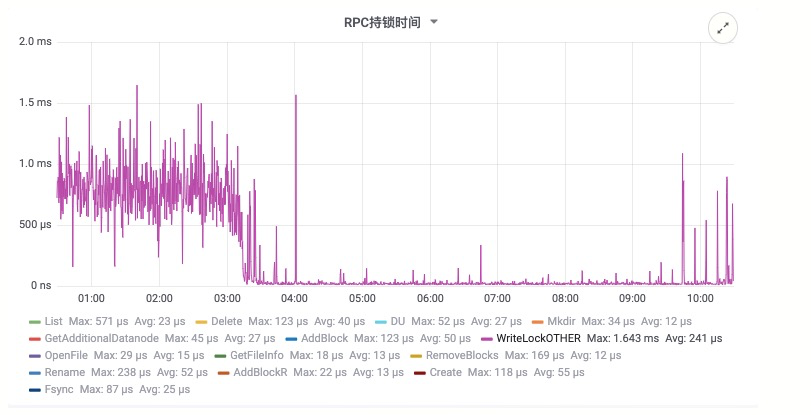
上云就看云栖号,点此[查看更多](https://link.zhihu.com/?target=https%3A//yqh.aliyun.com)!
本文为阿里云原创内容,未经允许不得转载。
分享到:





相关推荐
Apache Flink大规模...阿里巴巴在Flink大规模持久化存储的实践中,提出了三个原则:External State、Internal State和 Distributed FileSystem,并提供了四个阶段的实践经验,表明大规模存储在Flink中是非常重要的。
### Flink在阿里巴巴电商业务中的应用 ...综上所述,Flink在阿里巴巴电商业务中的应用不仅极大地提高了数据处理效率,还为业务团队提供了实时的数据支持,使得阿里巴巴能够在激烈的市场竞争中保持领先地位。
为了提升Flink在阿里巴巴内部的大规模应用表现,Blink团队进行了多方面的优化: - **资源管理的原生集成**:以YARN为例,Blink实现了与YARN的无缝对接,充分利用其资源管理功能。 - **性能优化**: - **增量检查点...
Flink起源于2009年德国柏林工业大学的“StratoSphere”研究项目,该项目的目标是提高大规模数据分析的效率。Flink在2014年4月加入Apache孵化器,并于同年12月毕业成为Apache顶级项目。Flink的成长和认可展现了其技术...
HBase作为Google发表BigTable论文的开源实现版本,是一种分布式列式存储的数据库,构建在HDFS之上的NoSQL数据库,非常适合大规模实时查询,因此HBase在实时计算领域使用非常广泛。可以实时写HBase,也可以利用...
根据提供的文档信息,我们可以总结出关于“阿里超大规模Flink集群运维”的一系列关键知识点: ### 一、Flink概述 **Apache Flink** 是一个开源流处理框架,它支持高吞吐量、低延迟的数据流处理。Flink 的设计目标...
基于 Flink 构建大规模实时风控系统在阿里巴巴的落地 基于 Flink 构建大规模实时风控系统是阿里巴巴集团在风控领域的一项关键技术。该系统旨在实现在大规模、实时、风控业务中的高效处理和分析。该系统基于 Apache ...
NULL 博文链接:https://bnmnba.iteye.com/blog/2322332
这暗示了在实际应用中,Flink和HBase不仅处理数据流和存储大规模数据,而且可能提供了SQL查询接口,用于执行复杂的查询和分析任务,同时还关注性能指标,例如每秒查询数(qps),这对于大规模电商系统来说至关重要。...
Apache Flink,作为大数据处理领域的重要成员,其发展历程和在阿里巴巴的应用实践,对于理解现代大数据处理技术具有重要意义。本文将深入探讨Flink的技术演进、核心特性以及在阿里巴巴集团的实际应用。 Flink的起源...
阿里巴巴flink介绍
- **易用性**:管理式的存储,提供数据库级别的使用体验,减少外部依赖,使得操作简洁明了,支持大规模的数据更新。 2. **Flink Table Store 的使用** - **配置设置**:通过设置根路径、桶数以及日志系统(如 ...
本主题聚焦于“大规模游戏社交网络节点相似性算法及其应用”,并特别讨论了Flink Table Store在流批一体存储中的角色。下面我们将深入探讨这些知识点。 首先,我们来看“大规模游戏社交网络节点相似性算法”。在...
flink-es7:为了使用Elasticsearch连接器,使用构建自动化工具(如Maven或SBT)的两个项目和带有SQL
Hadoop生态系统中的工具远不止HDFS和MapReduce,还包括了Hive、Pig、HBase、Spark、Storm、Kafka、Flume、Oozie、Zookeeper、Mahout、Flink、Cassandra、Solr、Nifi、Sqoop等。这些工具在不同的场景下发挥着重要作用...
6. Flink在阿里巴巴集团的应用:阿里巴巴集团早在2016年就开始大规模上线使用实时计算产品,基于Flink的实时计算平台产品,开始服务于整个阿里巴巴集团,并在2018年产品正式上云。 7. Flink的技术优势:Flink具备强...
### 阿里巴巴开发手册知识点解析 #### 1. 编程规约 ##### (一) 命名风格 - **变量命名**: 应采用有意义的名称,避免使用如`a`、`b`等无意义的单字母命名。例如,表示年龄的变量应命名为`age`而不是`a`。 - **方法...
flink-sql-hdfs-connector支持根据数据的事件时间落到对应的分区目录分支说明master分支不放代码,分支对应适应相同版本的flink,例如分支flink-1.10就仅在flink 1.10版本上测试通过使用方法下载代码编译cd flink-...
阿里巴巴资深技术专家强琦在第五届云计算大会上分享了关于大数据开发平台的主题,这揭示了阿里巴巴在大数据领域的深入研究和实践。大数据开发平台是支撑现代企业数据驱动决策的核心基础设施,它涵盖了数据采集、处理...