大涛学长
- 浏览: 121837 次
- 性别:

- 来自: 北京
-

最新评论
大数据上云第一课:(1)MaxCompute授权和外表操作躲坑指南
**一、子账号创建、AK信息绑定**
如果您是第一次使用子账号登录数加平台和使用DataWorks,需要确认以下信息:
• 该子账号所属主账号的企业别名。
• 该子账号的用户名和密码。
• 该子账号的AccessKey ID和AccessKey Secret。
• 确认主账号已经允许子账号启用控制台登录。
• 确认主账号已经允许子账号自主管理AccessKey。
**1、子账号创建**
(1)创建子账号
(2)绑定AK信息
(3)DataWorks给定角色
(1)使用阿里云账号(主账号)登录RAM控制台。
(2)在左侧导航栏的人员管理菜单下,单击用户。
(3)单击新建用户。
(4)输入登录名称和显示名称。
(5)在访问方式区域下,选择控制台密码登录。
(6)单击确认。
```
说明:
(1)单击添加用户,可一次性创建多个RAM用户。
(2)RAM用户创建完成后,务必保存用户名和登录密码,并将其告知子账号。
```

**2、创建RAM子账号的访问密钥**
访问密钥对开发人员在DataWorks中创建的任务顺利运行非常重要,该密钥区别于登录时填写的账号和密码,主要用于在阿里云各产品间互相认证使用权限。因此主账号需要为子账号创建AccessKey。创建成功后,请尽可能保证AccessKey ID和AccessKey Secret的安全,切勿让他人知晓,一旦有泄漏的风险,请及时禁用和更新。运行密钥AK包括AccessKey ID和AccessKey Secret两部分。如果云账号允许RAM用户自主管理AccessKey,RAM用户也可以自行创建AccessKey。
为子账号创建AccessKey的操作如下所示。
(1)在左侧导航栏的人员管理菜单下,单击用户。
(2)在用户登录名称/显示名称列表下,单击目标RAM用户名称。
(3)在用户AccessKey 区域下,单击创建新的AccessKey。
(4)单击确认。
```
说明:
首次创建时需填写手机验证码。
AccessKeySecret只在创建时显示,不提供查询,请妥善保管。若AccessKey泄露或丢失,则需要创建新的AccessKey,最多可以创建2个AccessKey。
```

**3、给RAM子账号授权**
如果您需要让子账号能够创建DataWorks工作空间,需要给子账号授予AliyunDataWorksFullAccess权限。
(1)在左侧导航栏的人员管理菜单下,单击用户。
(2)在用户登录名称/显示名称列表下,找到目标RAM用户。
(3)单击添加权限,被授权主体会自动填入。
(4)在左侧权限策略名称列表下,单击需要授予RAM用户的权限策略。
(5)单击确定。
(6)单击完成。
```
说明:在右侧区域框,选择某条策略并单击×,可撤销该策略。
```

**二、子账号生产环境创建函数、访问资源授权,OSS外部表授权**
**1、账号生产环境创建函数、访问资源授权**
子账号登录DataWorks控制台之后,单击工作空间管理,成员管理给该子账号一个相应的角色。各角色对应的权限可以在工作空间管理界面的权限列表查看。此处添加的成员角色对生产环境是隔离的。下面介绍一下生产环境创建函数、访问资源授权。
(1)创建一个新的角色,给角色授权。
```
创建角色:create role worker;
角色指派:grant worker TO ram$建伟MaxCompute:banzhan;(ram$建伟MaxCompute:banzhan为RAM账号)
对角色授权:grant CreateInstance, CreateResource, CreateFunction, CreateTable, List ON PROJECT wei_wwww TO ROLE worker;
```

(2)创建UDF函数。
```
CREATE FUNCTION banzha_udf as 'com.aliyun.udf.test.UDF_DEMO' using '1218.jar';
```

前提条件是已经上传1818.jar包。资源上传结合搬站第一课视频。
**2、OSS访问授权**
MaxCompute需要直接访问OSS的数据,前提是需要您将OSS的数据相关权限赋给MaxCompute的访问账号。如果没有进行相应授权创,创建外部表会发现报错如下:
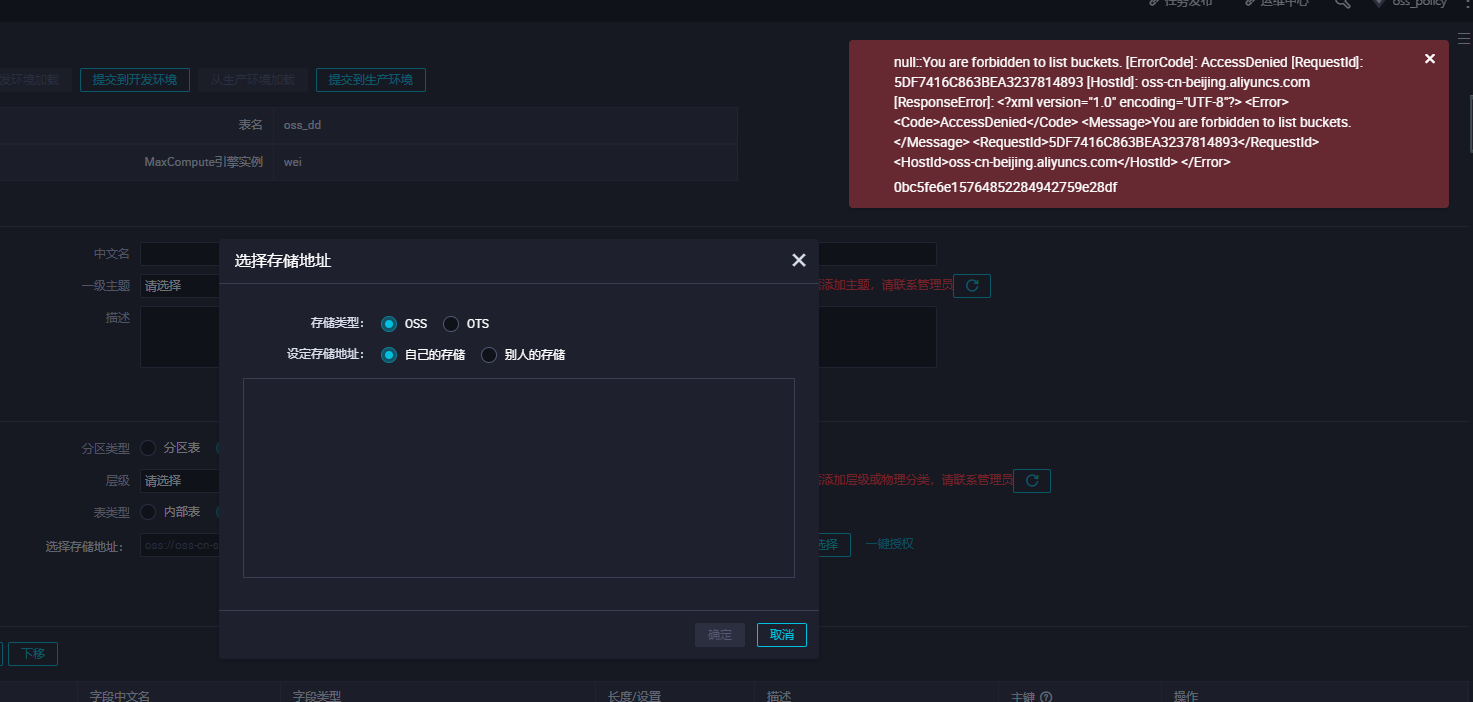
此时需要我们授权去访问OSS
授权方式有两种:
(1)当MaxCompute和OSS的Owner是同一个账号时,可以直接登录阿里云账号后,单击此处完成一键授权。[一键授权](https://ram.console.aliyun.com/?spm=a2c4g.11186623.2.9.7cec6a06eVvMBs#/role/authorize?request=%7B%22Requests%22:%20%7B%22request1%22:%20%7B%22RoleName%22:%20%22AliyunODPSDefaultRole%22,%20%22TemplateId%22:%20%22DefaultRole%22%7D%7D,%20%22ReturnUrl%22:%20%22https:%2F%2Fram.console.aliyun.com%2F%22,%20%22Service%22:%20%22ODPS%22%7D),我们可以在访问控制给改子账号添加管理对象存储服务(OSS)权限(AliyunOSSFullAccess)。
(2)自定义授权
a.新增一个RAM角色oss-admin
b.修改角色策略内容设置
```
--当MaxCompute和OSS的Owner是同一个账号,设置如下。
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"Service": [
"odps.aliyuncs.com"
]
}
}
],
"Version": "1"
}
--当MaxCompute和OSS的Owner不是同一个账号,设置如下。
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"Service": [
"MaxCompute的Owner云账号id@odps.aliyuncs.com"
]
}
}
],
"Version": "1"
}
```

c.授予角色访问OSS必要的权限AliyunODPSRolePolicy
```
{
"Version": "1",
"Statement": [
{
"Action": [
"oss:ListBuckets",
"oss:GetObject",
"oss:ListObjects",
"oss:PutObject",
"oss:DeleteObject",
"oss:AbortMultipartUpload",
"oss:ListParts"
],
"Resource": "*",
"Effect": "Allow"
}
]
}
--可自定义其它权限。
```

d.将权限AliyunODPSRolePolicy授权给该角色。
**三、OSS外部表创建指引**
**1、外部表创建的语法格式介绍**
**(1)外部表创建示例:**
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_rcfile
( `id` int,
`name` string
)
PARTITIONED BY ( `time_ds` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS RCFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/fc_rcfile/';
```

**(2)LOCATION说明**
LOCATION必须指定一个OSS目录,默认系统会读取这个目录下所有的文件。
建议您使用OSS提供的内网域名,否则将产生OSS流量费用。
访问OSS外部表,目前不支持使用外网Endpoint。
目前STORE AS单个文件大小不能超过3G,如果文件过大,建议split拆分。
建议您OSS数据存放的区域对应您开通MaxCompute的区域。由于MaxCompute只有在部分区域部署,我们不承诺跨区域的数据连通性。
```
OSS的连接格式为oss://oss-cn-shanghai-internal.aliyuncs.com/Bucket名称/目录名称/。目录后不要加文件名称,以下为错误用法。
http://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo/ -- 不支持http连接。
https://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo/ -- 不支持https连接。
oss://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo -- 连接地址错误。
oss://oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/vehicle.csv
-- 不必指定文件名。
```

**(3)外部表创建格式说明**
语法格式与Hive的语法相当接近,但需注意以下问题。
```
a.STORED AS关键字,在该语法格式中不是创建普通非结构化外部表时用的STORED BY关键字,这是目前在读取开源兼容数据时独有的。STORED AS后面接的是文件格式名字,例如ORC/PARQUET/RCFILE/SEQUENCEFILE/TEXTFILE等。
b.外部表的column schemas必须与具体OSS上存储的数据的schema相符合。
c.ROW FORMAT SERDE:非必选选项,只有在使用一些特殊的格式上,比如TEXTFILE时才需要使用。
d.WITH SERDEPROPERTIES:当关联OSS权限使用STS模式授权时,需要该参数指定odps.properties.rolearn属性,属性值为RAM中具体使用的Role的Arn的信息。您可以在配置STORED AS <file format>的同时也通过<serde class>说明file format文件格式。
以ORC文件格式为例,如下所示。
CREATE EXTERNAL TABLE [IF NOT EXISTS] <external_table>
(<column schemas>)
[PARTITIONED BY (partition column schemas)]
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
WITH SERDEPROPERTIES ('odps.properties.rolearn'='${roleran}'
STORED AS ORC
LOCATION 'oss://${endpoint}/${bucket}/${userfilePath}/'
e.不同file format对应的serde class如下:
• ALIORC: com.aliyun.apsara.serde.AliOrcSerDe
• SEQUENCEFILE: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
• TEXTFILE: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
• RCFILE: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe
• ORC: org.apache.hadoop.hive.ql.io.orc.OrcSerde
• ORCFILE: org.apache.hadoop.hive.ql.io.orc.OrcSerde
• PARQUET: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
• AVRO: org.apache.hadoop.hive.serde2.avro.AvroSerDe
```

**(4)用Arn、AK两种认证方式建外表示例**
**a.用RAM中具体使用的Role的Arn的信息创建外部表**
当关联OSS权限使用STS模式授权时,需要该参数指定odps.properties.rolearn属性,属性值为RAM中具体使用的Role的Arn的信息。
```
WITH SERDEPROPERTIES ('odps.properties.rolearn'='${roleran}'
```

示例如下:
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_csv
(
vehicleId string,
recordId string,
patientId string,
calls string,
locationLatitute string,
locationLongtitue string,
recordTime string,
direction string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
('separatorChar'=',',
'odps.properties.rolearn'='acs:ram::1928466352305391:role/oss-admin'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-odps-bucket/extra_test/fc_csv';
```

**b.明文AK创建外部表(不推荐使用这种方式)**
如果不使用STS模式授权,则无需指定odps.properties.rolearn属性,直接在Location传入明文AccessKeyId和AccessKeySecret。
Location如果关联OSS,需使用明文AK,写法如下所示。
```
LOCATION 'oss://${accessKeyId}:${accessKeySecret}@${endpoint}/${bucket}/${userPath}/'
```

示例如下:
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_csv1
(
vehicleId string,
recordId string,
patientId string,
calls string,
locationLatitute string,
locationLongtitue string,
recordTime string,
direction string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
('separatorChar'=',',
'odps.properties.rolearn'='acs:ram::1928466352305391:role/oss-admin'
)
STORED AS TEXTFILE
-- LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-odps-bucket/extra_test/fc_csv';
LOCATION 'oss://LTAI4FfgVEQQwsNQ*******:J8FGZaoj2CMcunFrVn1FrL*****wM@oss-cn-beijing-internal.aliyuncs.com/oss-odps-bucket/extra_test/fc_csv';
```

**2、创建 Rcfile 类型的外部表**
(1)查询HIVE表schema
```
show create table fc_rcfile;**
```

结果如下:
```
CREATE TABLE `fc_rcfile`(
`id` int,
`name` string)
PARTITIONED BY (
`time_ds` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.RCFileInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
LOCATION
'hdfs://emr-header-1.cluster-138804:9000/user/hive/warehouse/extra_demo.db/fc_rcfile'
```

(2)在MaxCompute创建外部表
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_rcfile
( `id` int,
`name` string)
PARTITIONED BY ( `time_ds` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS RCFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/fc_rcfile/';
```

(3)添加分区
```
alter table fc_rcfile ADD PARTITION (time_ds = '20191209') ;
alter table fc_rcfile ADD PARTITION (time_ds = '20191210') ;
alter table fc_rcfile ADD PARTITION (time_ds = '20191211') ; 批量创建分区可参数使用MMA工具
```

(4)查询数据
```
select * from fc_rcfile where time_ds = '20191209' ;
select * from fc_rcfile where time_ds = '20191210' ;
select * from fc_rcfile where time_ds = '20191211' ;
```

**3、创建Json类型的外部表**
(1)创建Json类型的外部表
```
CREATE EXTERNAL TABLE `student`(
`student` map<string,string> COMMENT 'from deserializer',
`class` map<string,string> COMMENT 'from deserializer',
`teacher` map<string,string> COMMENT 'from deserializer')
COMMENT '学生课程信息'
ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE
LOCATION
'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/student'
```

(2)在对应的OSS控制台bucket上传Json文件数据。
(3)查询外部表的数据
报错信息如下所示:
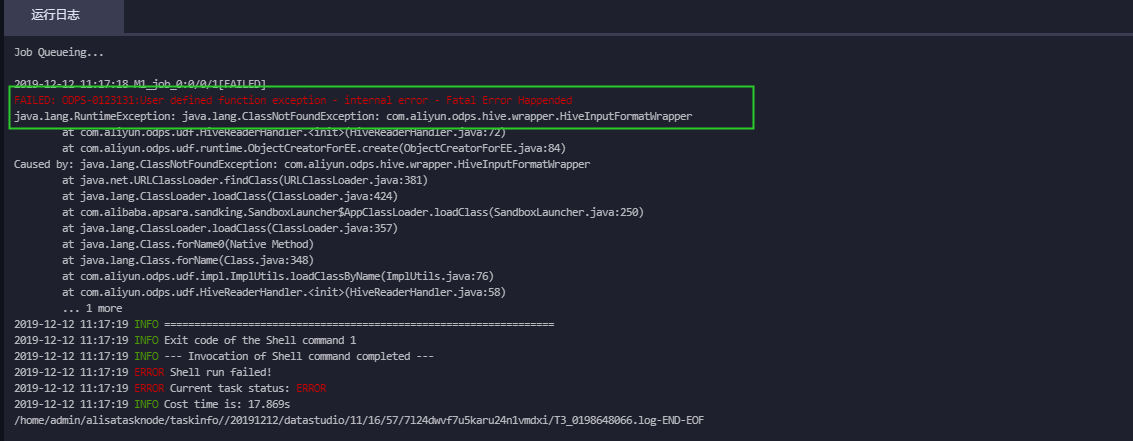
解决办法:需要设置开启hive兼容的flag。
```
set odps.sql.hive.compatible=true;
```

重新查询数据即可正确返回Json数据。
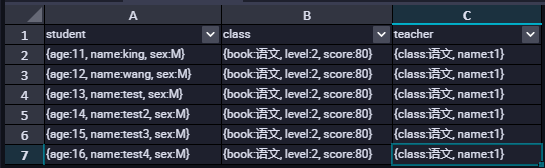
以下是在Hive中查询的数据,可以看到这两处数据是一致的。

**4、创建CSV格式的外部表**
(1)创建CSV格式的外部表
```
建表语句示例如下:
CREATE EXTERNAL TABLE IF NOT EXISTS fc_csv
(
vehicleId string,
recordId string,
patientId string,
calls string,
locationLatitute string,
locationLongtitue string,
recordTime string,
direction string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
('separatorChar'=','
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/fc_csv';
```

(2)查询数据
```
set odps.sql.hive.compatible=true;
select * from fc_csv;
```

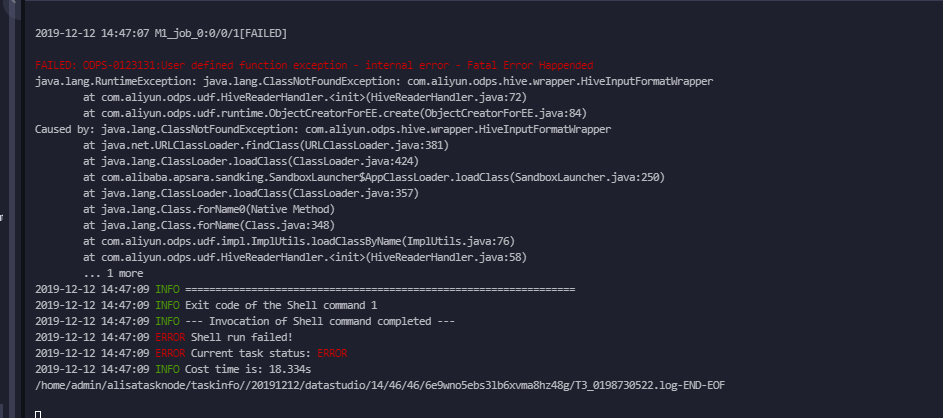
不加Hive兼容的flag设置会发现有如下报错信息:
```
FAILED: ODPS-0123131:User defined function exception - internal error - Fatal Error Happended
```


**5、创建压缩格式的外部表**
创建外部表时列分隔符需要使用field.delim。选择delimiter会报错或数据没有按照预期的分割符去分割。以下分别按照两种方式去创建外部表。
需要设置以下说明的属性flag。

(1)创建外部表
```
a.列分隔符定义为:delimiter
drop TABLE if exists oss_gzip;
CREATE EXTERNAL TABLE IF NOT EXISTS `oss_gzip` (
`userid` string,
`job` string,
`education` string,
`region` string
)
PARTITIONED BY (dt STRING COMMENT '日期')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'delimiter'='\t',
'odps.text.option.gzip.input.enabled'='true',
'odps.text.option.gzip.output.enabled'='true'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/gzipfile/';
```

查询数据的时候会发现数据并没有按照我们的分隔符去进行分割,如下图所示:
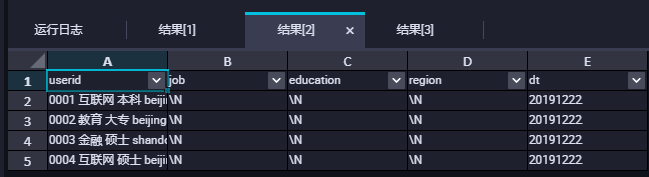
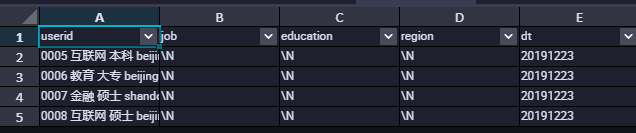
```
b.列分隔符定义为:field.delim
drop TABLE if exists oss_gzip2;
CREATE EXTERNAL TABLE IF NOT EXISTS `oss_gzip2` (
`userid` string,
`job` string,
`education` string,
`region` string
)
PARTITIONED BY (dt STRING COMMENT '日期')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'odps.text.option.gzip.input.enabled'='true',
'odps.text.option.gzip.output.enabled'='true'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/gzipfile/';
```


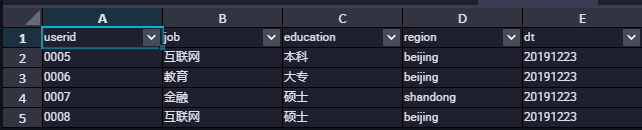
```
注意:在进行列分隔符定义时使用field.delim,不可以使用delimiter
```

**6、创建存在新数据类型的外部表**
当外部表创建字段涉及新数据类型时,需要开启新类型flag。
```
set odps.sql.type.system.odps2=true;
```

否则会报如下错误:
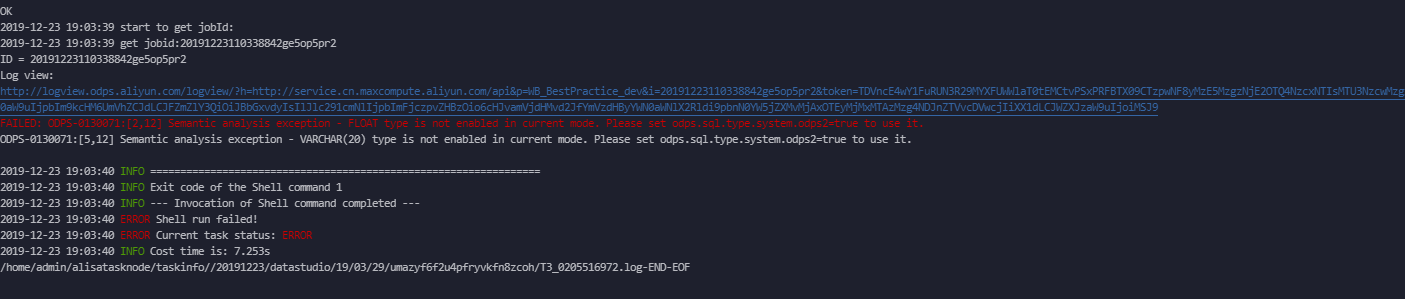
```
set odps.sql.type.system.odps2=true ;
drop TABLE if exists oss_gzip3;
CREATE EXTERNAL TABLE IF NOT EXISTS `oss_gzip3` (
`userid` FLOAT ,
`job` string,
`education` string,
`region` VARCHAR(20)
)
PARTITIONED BY (dt STRING COMMENT '日期')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'odps.text.option.gzip.input.enabled'='true',
'odps.text.option.gzip.output.enabled'='true'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/flag_file/';
添加对应的分区:
alter table oss_gzip3 add if NOT EXISTS partition(dt='20191224');
查询数据:
select * from oss_gzip3 where dt='20191224';
```

**四、利用Information Schema元数据查看project、table的操作行为以及费用计算**
**1、主账号安装package**
开始使用前,需要以Project Owner身份安装Information Schema的权限包,获得访问本项目元数据的权限。
以下错误是没有安装对应的Information Schema的权限包和子账号没有相关的权限

安装Information Schema的权限包方式有如下两种:
(1)在MaxCompute命令行工具(odpscmd)中执行如下命令。
```
odps@myproject1>install package information_schema.systables;
```

(2)在DataWorks中的数据开发 > 临时查询中执行如下语句。
```
install package information_schema.systables;
```

**2、给子账号授权**
```
grant read on package information_schema.systables to role worker;
```

**3、查询元数据信息**
```
select * from information_schema.tasks_history limit 20;
```

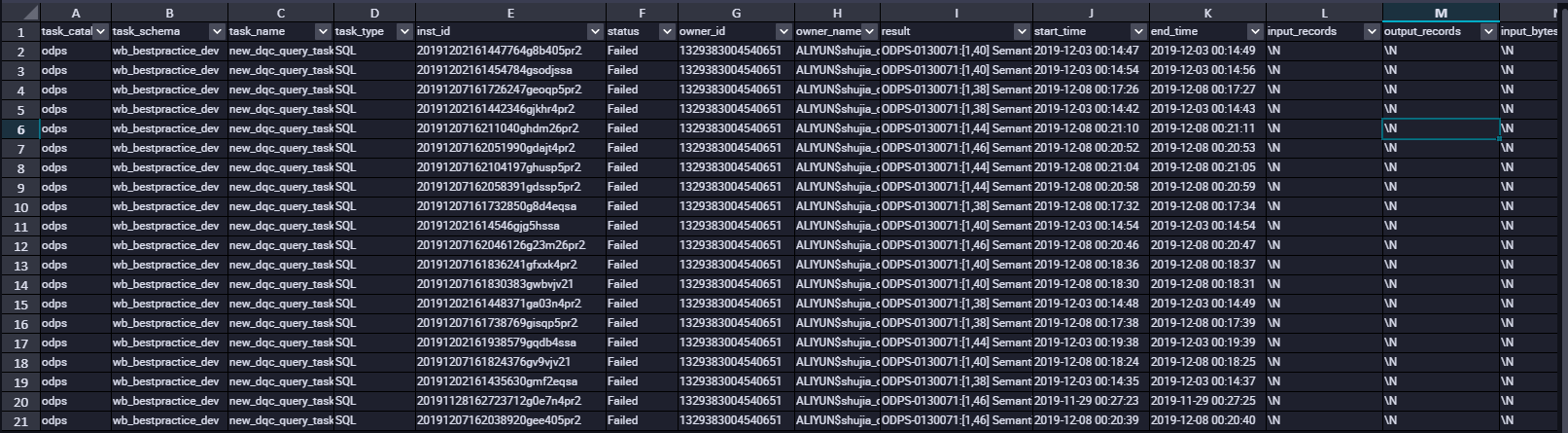
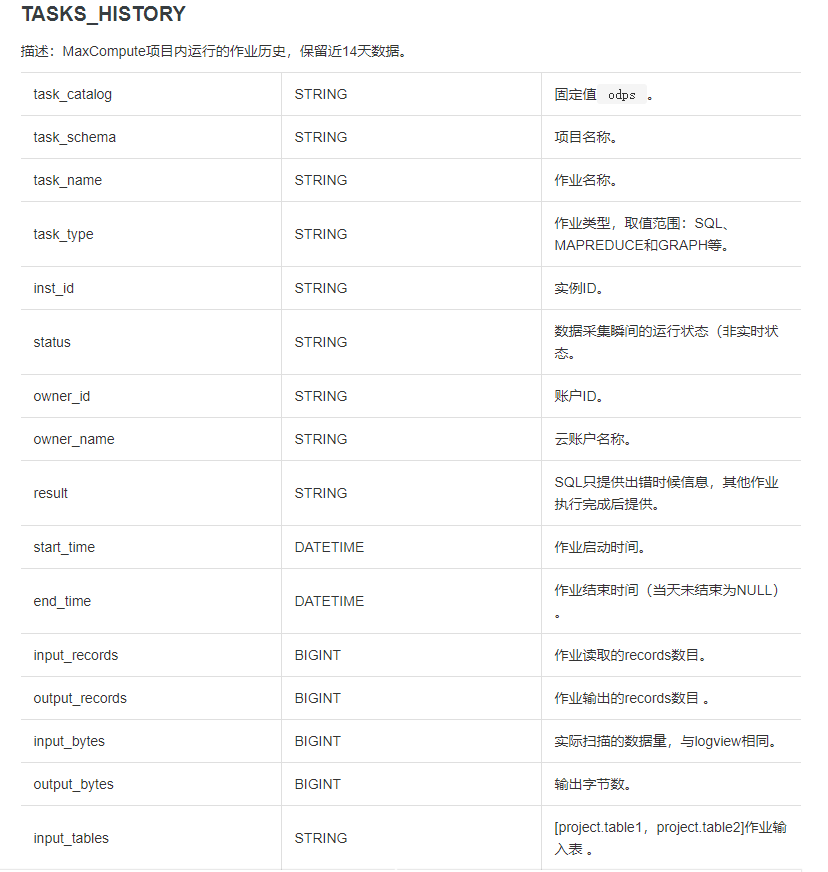
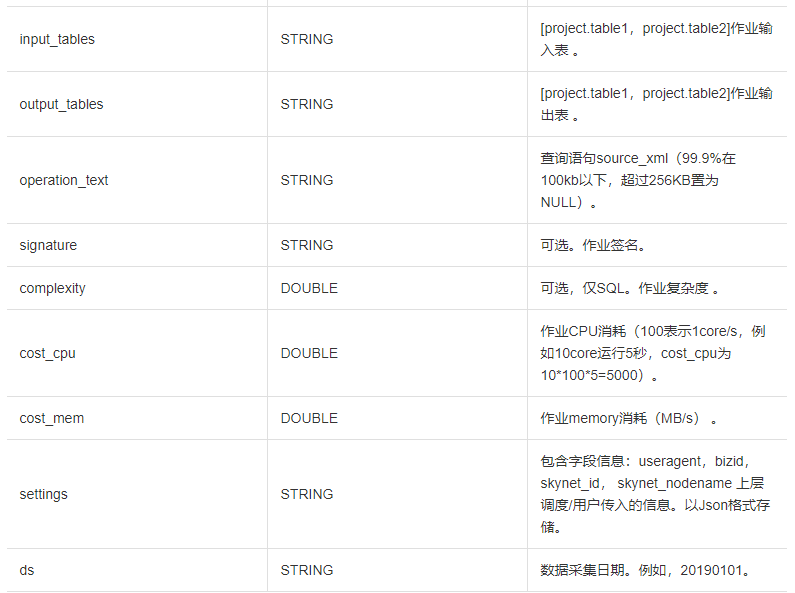
**TASKS\_HISTORY字段列信息如下:**
**4、通过 TASKS\_HISTORY 计算SQL费用**
SQL任务按量计费:您每执行一条SQL作业,MaxCompute将根据该作业的输入数据及该SQL的复杂度进行计费。该费用在SQL执行完成后产生,并在第二天做一次性的计费结算。
```
开发者版SQL计算任务的计费公式为:
一次SQL计算费用 = 计算输入数据量 * 单价(0.15元/GB)
标准版SQL计算任务的计费公式为:
一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * 单价(0.3元/GB)
按量付费一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * 单价(0.3元/GB)
```

计算输入数据量:指一条SQL语句实际扫描的数据量,大部分的SQL语句有分区过滤和列裁剪,所以一般情况下这个值会远小于源表数据大小。
在 information\_schema.tasks\_history中字段input\_bytes为实际扫描的数据量也就是我们的计算输入数据量。字段complexity为sql复杂度。所以我们可以根据以下公式来计算SQL费用。
[原文链接](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/739645%3Futm_content%3Dg_1000094672)
本文为阿里云内容,未经允许不得转载。
如果您是第一次使用子账号登录数加平台和使用DataWorks,需要确认以下信息:
• 该子账号所属主账号的企业别名。
• 该子账号的用户名和密码。
• 该子账号的AccessKey ID和AccessKey Secret。
• 确认主账号已经允许子账号启用控制台登录。
• 确认主账号已经允许子账号自主管理AccessKey。
**1、子账号创建**
(1)创建子账号
(2)绑定AK信息
(3)DataWorks给定角色
(1)使用阿里云账号(主账号)登录RAM控制台。
(2)在左侧导航栏的人员管理菜单下,单击用户。
(3)单击新建用户。
(4)输入登录名称和显示名称。
(5)在访问方式区域下,选择控制台密码登录。
(6)单击确认。
```
说明:
(1)单击添加用户,可一次性创建多个RAM用户。
(2)RAM用户创建完成后,务必保存用户名和登录密码,并将其告知子账号。
```

**2、创建RAM子账号的访问密钥**
访问密钥对开发人员在DataWorks中创建的任务顺利运行非常重要,该密钥区别于登录时填写的账号和密码,主要用于在阿里云各产品间互相认证使用权限。因此主账号需要为子账号创建AccessKey。创建成功后,请尽可能保证AccessKey ID和AccessKey Secret的安全,切勿让他人知晓,一旦有泄漏的风险,请及时禁用和更新。运行密钥AK包括AccessKey ID和AccessKey Secret两部分。如果云账号允许RAM用户自主管理AccessKey,RAM用户也可以自行创建AccessKey。
为子账号创建AccessKey的操作如下所示。
(1)在左侧导航栏的人员管理菜单下,单击用户。
(2)在用户登录名称/显示名称列表下,单击目标RAM用户名称。
(3)在用户AccessKey 区域下,单击创建新的AccessKey。
(4)单击确认。
```
说明:
首次创建时需填写手机验证码。
AccessKeySecret只在创建时显示,不提供查询,请妥善保管。若AccessKey泄露或丢失,则需要创建新的AccessKey,最多可以创建2个AccessKey。
```

**3、给RAM子账号授权**
如果您需要让子账号能够创建DataWorks工作空间,需要给子账号授予AliyunDataWorksFullAccess权限。
(1)在左侧导航栏的人员管理菜单下,单击用户。
(2)在用户登录名称/显示名称列表下,找到目标RAM用户。
(3)单击添加权限,被授权主体会自动填入。
(4)在左侧权限策略名称列表下,单击需要授予RAM用户的权限策略。
(5)单击确定。
(6)单击完成。
```
说明:在右侧区域框,选择某条策略并单击×,可撤销该策略。
```

**二、子账号生产环境创建函数、访问资源授权,OSS外部表授权**
**1、账号生产环境创建函数、访问资源授权**
子账号登录DataWorks控制台之后,单击工作空间管理,成员管理给该子账号一个相应的角色。各角色对应的权限可以在工作空间管理界面的权限列表查看。此处添加的成员角色对生产环境是隔离的。下面介绍一下生产环境创建函数、访问资源授权。
(1)创建一个新的角色,给角色授权。
```
创建角色:create role worker;
角色指派:grant worker TO ram$建伟MaxCompute:banzhan;(ram$建伟MaxCompute:banzhan为RAM账号)
对角色授权:grant CreateInstance, CreateResource, CreateFunction, CreateTable, List ON PROJECT wei_wwww TO ROLE worker;
```

(2)创建UDF函数。
```
CREATE FUNCTION banzha_udf as 'com.aliyun.udf.test.UDF_DEMO' using '1218.jar';
```

前提条件是已经上传1818.jar包。资源上传结合搬站第一课视频。
**2、OSS访问授权**
MaxCompute需要直接访问OSS的数据,前提是需要您将OSS的数据相关权限赋给MaxCompute的访问账号。如果没有进行相应授权创,创建外部表会发现报错如下:

此时需要我们授权去访问OSS
授权方式有两种:
(1)当MaxCompute和OSS的Owner是同一个账号时,可以直接登录阿里云账号后,单击此处完成一键授权。[一键授权](https://ram.console.aliyun.com/?spm=a2c4g.11186623.2.9.7cec6a06eVvMBs#/role/authorize?request=%7B%22Requests%22:%20%7B%22request1%22:%20%7B%22RoleName%22:%20%22AliyunODPSDefaultRole%22,%20%22TemplateId%22:%20%22DefaultRole%22%7D%7D,%20%22ReturnUrl%22:%20%22https:%2F%2Fram.console.aliyun.com%2F%22,%20%22Service%22:%20%22ODPS%22%7D),我们可以在访问控制给改子账号添加管理对象存储服务(OSS)权限(AliyunOSSFullAccess)。
(2)自定义授权
a.新增一个RAM角色oss-admin
b.修改角色策略内容设置
```
--当MaxCompute和OSS的Owner是同一个账号,设置如下。
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"Service": [
"odps.aliyuncs.com"
]
}
}
],
"Version": "1"
}
--当MaxCompute和OSS的Owner不是同一个账号,设置如下。
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"Service": [
"MaxCompute的Owner云账号id@odps.aliyuncs.com"
]
}
}
],
"Version": "1"
}
```

c.授予角色访问OSS必要的权限AliyunODPSRolePolicy
```
{
"Version": "1",
"Statement": [
{
"Action": [
"oss:ListBuckets",
"oss:GetObject",
"oss:ListObjects",
"oss:PutObject",
"oss:DeleteObject",
"oss:AbortMultipartUpload",
"oss:ListParts"
],
"Resource": "*",
"Effect": "Allow"
}
]
}
--可自定义其它权限。
```

d.将权限AliyunODPSRolePolicy授权给该角色。
**三、OSS外部表创建指引**
**1、外部表创建的语法格式介绍**
**(1)外部表创建示例:**
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_rcfile
( `id` int,
`name` string
)
PARTITIONED BY ( `time_ds` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS RCFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/fc_rcfile/';
```

**(2)LOCATION说明**
LOCATION必须指定一个OSS目录,默认系统会读取这个目录下所有的文件。
建议您使用OSS提供的内网域名,否则将产生OSS流量费用。
访问OSS外部表,目前不支持使用外网Endpoint。
目前STORE AS单个文件大小不能超过3G,如果文件过大,建议split拆分。
建议您OSS数据存放的区域对应您开通MaxCompute的区域。由于MaxCompute只有在部分区域部署,我们不承诺跨区域的数据连通性。
```
OSS的连接格式为oss://oss-cn-shanghai-internal.aliyuncs.com/Bucket名称/目录名称/。目录后不要加文件名称,以下为错误用法。
http://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo/ -- 不支持http连接。
https://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo/ -- 不支持https连接。
oss://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo -- 连接地址错误。
oss://oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/vehicle.csv
-- 不必指定文件名。
```

**(3)外部表创建格式说明**
语法格式与Hive的语法相当接近,但需注意以下问题。
```
a.STORED AS关键字,在该语法格式中不是创建普通非结构化外部表时用的STORED BY关键字,这是目前在读取开源兼容数据时独有的。STORED AS后面接的是文件格式名字,例如ORC/PARQUET/RCFILE/SEQUENCEFILE/TEXTFILE等。
b.外部表的column schemas必须与具体OSS上存储的数据的schema相符合。
c.ROW FORMAT SERDE:非必选选项,只有在使用一些特殊的格式上,比如TEXTFILE时才需要使用。
d.WITH SERDEPROPERTIES:当关联OSS权限使用STS模式授权时,需要该参数指定odps.properties.rolearn属性,属性值为RAM中具体使用的Role的Arn的信息。您可以在配置STORED AS <file format>的同时也通过<serde class>说明file format文件格式。
以ORC文件格式为例,如下所示。
CREATE EXTERNAL TABLE [IF NOT EXISTS] <external_table>
(<column schemas>)
[PARTITIONED BY (partition column schemas)]
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
WITH SERDEPROPERTIES ('odps.properties.rolearn'='${roleran}'
STORED AS ORC
LOCATION 'oss://${endpoint}/${bucket}/${userfilePath}/'
e.不同file format对应的serde class如下:
• ALIORC: com.aliyun.apsara.serde.AliOrcSerDe
• SEQUENCEFILE: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
• TEXTFILE: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
• RCFILE: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe
• ORC: org.apache.hadoop.hive.ql.io.orc.OrcSerde
• ORCFILE: org.apache.hadoop.hive.ql.io.orc.OrcSerde
• PARQUET: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
• AVRO: org.apache.hadoop.hive.serde2.avro.AvroSerDe
```

**(4)用Arn、AK两种认证方式建外表示例**
**a.用RAM中具体使用的Role的Arn的信息创建外部表**
当关联OSS权限使用STS模式授权时,需要该参数指定odps.properties.rolearn属性,属性值为RAM中具体使用的Role的Arn的信息。
```
WITH SERDEPROPERTIES ('odps.properties.rolearn'='${roleran}'
```

示例如下:
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_csv
(
vehicleId string,
recordId string,
patientId string,
calls string,
locationLatitute string,
locationLongtitue string,
recordTime string,
direction string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
('separatorChar'=',',
'odps.properties.rolearn'='acs:ram::1928466352305391:role/oss-admin'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-odps-bucket/extra_test/fc_csv';
```

**b.明文AK创建外部表(不推荐使用这种方式)**
如果不使用STS模式授权,则无需指定odps.properties.rolearn属性,直接在Location传入明文AccessKeyId和AccessKeySecret。
Location如果关联OSS,需使用明文AK,写法如下所示。
```
LOCATION 'oss://${accessKeyId}:${accessKeySecret}@${endpoint}/${bucket}/${userPath}/'
```

示例如下:
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_csv1
(
vehicleId string,
recordId string,
patientId string,
calls string,
locationLatitute string,
locationLongtitue string,
recordTime string,
direction string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
('separatorChar'=',',
'odps.properties.rolearn'='acs:ram::1928466352305391:role/oss-admin'
)
STORED AS TEXTFILE
-- LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-odps-bucket/extra_test/fc_csv';
LOCATION 'oss://LTAI4FfgVEQQwsNQ*******:J8FGZaoj2CMcunFrVn1FrL*****wM@oss-cn-beijing-internal.aliyuncs.com/oss-odps-bucket/extra_test/fc_csv';
```

**2、创建 Rcfile 类型的外部表**
(1)查询HIVE表schema
```
show create table fc_rcfile;**
```

结果如下:
```
CREATE TABLE `fc_rcfile`(
`id` int,
`name` string)
PARTITIONED BY (
`time_ds` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.RCFileInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
LOCATION
'hdfs://emr-header-1.cluster-138804:9000/user/hive/warehouse/extra_demo.db/fc_rcfile'
```

(2)在MaxCompute创建外部表
```
CREATE EXTERNAL TABLE IF NOT EXISTS fc_rcfile
( `id` int,
`name` string)
PARTITIONED BY ( `time_ds` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS RCFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/fc_rcfile/';
```

(3)添加分区
```
alter table fc_rcfile ADD PARTITION (time_ds = '20191209') ;
alter table fc_rcfile ADD PARTITION (time_ds = '20191210') ;
alter table fc_rcfile ADD PARTITION (time_ds = '20191211') ; 批量创建分区可参数使用MMA工具
```

(4)查询数据
```
select * from fc_rcfile where time_ds = '20191209' ;
select * from fc_rcfile where time_ds = '20191210' ;
select * from fc_rcfile where time_ds = '20191211' ;
```

**3、创建Json类型的外部表**
(1)创建Json类型的外部表
```
CREATE EXTERNAL TABLE `student`(
`student` map<string,string> COMMENT 'from deserializer',
`class` map<string,string> COMMENT 'from deserializer',
`teacher` map<string,string> COMMENT 'from deserializer')
COMMENT '学生课程信息'
ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE
LOCATION
'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/student'
```

(2)在对应的OSS控制台bucket上传Json文件数据。
(3)查询外部表的数据
报错信息如下所示:

解决办法:需要设置开启hive兼容的flag。
```
set odps.sql.hive.compatible=true;
```

重新查询数据即可正确返回Json数据。

以下是在Hive中查询的数据,可以看到这两处数据是一致的。

**4、创建CSV格式的外部表**
(1)创建CSV格式的外部表
```
建表语句示例如下:
CREATE EXTERNAL TABLE IF NOT EXISTS fc_csv
(
vehicleId string,
recordId string,
patientId string,
calls string,
locationLatitute string,
locationLongtitue string,
recordTime string,
direction string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
('separatorChar'=','
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/fc_csv';
```

(2)查询数据
```
set odps.sql.hive.compatible=true;
select * from fc_csv;
```

不加Hive兼容的flag设置会发现有如下报错信息:
```
FAILED: ODPS-0123131:User defined function exception - internal error - Fatal Error Happended
```



**5、创建压缩格式的外部表**
创建外部表时列分隔符需要使用field.delim。选择delimiter会报错或数据没有按照预期的分割符去分割。以下分别按照两种方式去创建外部表。
需要设置以下说明的属性flag。

(1)创建外部表
```
a.列分隔符定义为:delimiter
drop TABLE if exists oss_gzip;
CREATE EXTERNAL TABLE IF NOT EXISTS `oss_gzip` (
`userid` string,
`job` string,
`education` string,
`region` string
)
PARTITIONED BY (dt STRING COMMENT '日期')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'delimiter'='\t',
'odps.text.option.gzip.input.enabled'='true',
'odps.text.option.gzip.output.enabled'='true'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/gzipfile/';
```

查询数据的时候会发现数据并没有按照我们的分隔符去进行分割,如下图所示:


```
b.列分隔符定义为:field.delim
drop TABLE if exists oss_gzip2;
CREATE EXTERNAL TABLE IF NOT EXISTS `oss_gzip2` (
`userid` string,
`job` string,
`education` string,
`region` string
)
PARTITIONED BY (dt STRING COMMENT '日期')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'odps.text.option.gzip.input.enabled'='true',
'odps.text.option.gzip.output.enabled'='true'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/gzipfile/';
```



```
注意:在进行列分隔符定义时使用field.delim,不可以使用delimiter
```

**6、创建存在新数据类型的外部表**
当外部表创建字段涉及新数据类型时,需要开启新类型flag。
```
set odps.sql.type.system.odps2=true;
```

否则会报如下错误:

```
set odps.sql.type.system.odps2=true ;
drop TABLE if exists oss_gzip3;
CREATE EXTERNAL TABLE IF NOT EXISTS `oss_gzip3` (
`userid` FLOAT ,
`job` string,
`education` string,
`region` VARCHAR(20)
)
PARTITIONED BY (dt STRING COMMENT '日期')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'odps.text.option.gzip.input.enabled'='true',
'odps.text.option.gzip.output.enabled'='true'
)
STORED AS TEXTFILE
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/oss-huabei2/jianwei/flag_file/';
添加对应的分区:
alter table oss_gzip3 add if NOT EXISTS partition(dt='20191224');
查询数据:
select * from oss_gzip3 where dt='20191224';
```

**四、利用Information Schema元数据查看project、table的操作行为以及费用计算**
**1、主账号安装package**
开始使用前,需要以Project Owner身份安装Information Schema的权限包,获得访问本项目元数据的权限。
以下错误是没有安装对应的Information Schema的权限包和子账号没有相关的权限

安装Information Schema的权限包方式有如下两种:
(1)在MaxCompute命令行工具(odpscmd)中执行如下命令。
```
odps@myproject1>install package information_schema.systables;
```

(2)在DataWorks中的数据开发 > 临时查询中执行如下语句。
```
install package information_schema.systables;
```

**2、给子账号授权**
```
grant read on package information_schema.systables to role worker;
```

**3、查询元数据信息**
```
select * from information_schema.tasks_history limit 20;
```


**TASKS\_HISTORY字段列信息如下:**


**4、通过 TASKS\_HISTORY 计算SQL费用**
SQL任务按量计费:您每执行一条SQL作业,MaxCompute将根据该作业的输入数据及该SQL的复杂度进行计费。该费用在SQL执行完成后产生,并在第二天做一次性的计费结算。
```
开发者版SQL计算任务的计费公式为:
一次SQL计算费用 = 计算输入数据量 * 单价(0.15元/GB)
标准版SQL计算任务的计费公式为:
一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * 单价(0.3元/GB)
按量付费一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * 单价(0.3元/GB)
```

计算输入数据量:指一条SQL语句实际扫描的数据量,大部分的SQL语句有分区过滤和列裁剪,所以一般情况下这个值会远小于源表数据大小。
在 information\_schema.tasks\_history中字段input\_bytes为实际扫描的数据量也就是我们的计算输入数据量。字段complexity为sql复杂度。所以我们可以根据以下公式来计算SQL费用。
[原文链接](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/739645%3Futm_content%3Dg_1000094672)
本文为阿里云内容,未经允许不得转载。
分享到:


发表评论

相关推荐
阿里大数据计算服务MaxCompute入门指南 本资源摘要信息涵盖了阿里大数据计算服务MaxCompute的入门指南,包括准备工作、创建项目空间、快速开始使用MaxCompute、加载MaxCompute项目空间到大数据开发平台、创建...
- **领先性**:MaxCompute在云计算领域具有明显的优势,特别是在数据处理速度、扩展性和易用性方面表现突出。 #### 二、生态技术架构对比 ##### 2.1 Hadoop生态技术架构 Hadoop生态系统包括一系列组件和服务,...
大数据与社会认识论:追本溯源、领域拓展及其实践探索.pdf
Python金融大数据风控建模实战:基于机器学习源代码+文档说明,含有代码注释,新手也可看懂,个人手打98分项目,导师非常认可的高分项目,毕业设计、期末大作业和课程设计高分必看,下载下来,简单部署,就可以使用...
《决战大数据(升级版):大数据的关键思考》一书深入探讨了大数据在现代信息技术领域的核心价值和重要性。这本书以Java编程语言为技术背景,详细阐述了如何利用Java技术栈来处理和分析大规模数据。 大数据,...
毕设项目:商品大数据实时推荐系统。前端:Vue + TypeScript + ElementUI,后端 Spring + Spark 毕设项目:商品大数据实时推荐系统。前端:Vue + TypeScript + ElementUI,后端 Spring + Spark 毕设项目:商品大数据...
《阿里大数据之路:阿里巴巴大数据实践》是一本深入探讨阿里巴巴集团在大数据领域实践经验的书籍,共计339页,全面展示了阿里巴巴在大数据领域的技术积累和创新应用。这本书籍旨在分享阿里巴巴如何利用大数据技术来...
《大数据技术原理与应用》是一本深入探讨大数据领域核心概念、存储、处理、分析与实际应用的书籍。这本书全面解析了大数据技术的全貌,旨在帮助读者理解和掌握大数据的精髓,提升在信息时代的数据处理能力。 大数据...
阿里大数据计算服务MaxCompute入门指南 MaxCompute是阿里云提供的一种大数据计算服务,允许用户快速处理大量数据。为帮助用户快速开始使用MaxCompute,本文档提供了详细的入门指南。 一、准备工作 在使用...
【大数据】大数据的前世今生:大数据特征与发展历程 说明:大数据的前世今生:大数据特征与发展历程.zip 文件列表: 大数据的前世今生:大数据特征与发展历程.pdf (714822, 2022-12-11) 【大数据】大数据的前世今生:...
【MapReduce初级编程实践】是大数据处理中的一项基础任务,主要应用于大规模数据集的并行计算。在这个实验中,我们关注的是如何利用MapReduce来实现文件的合并与去重操作。MapReduce是一种分布式计算模型,由Google...
《大数据》配套之十一:第10章行业大数据.pptx
大数据技术原理与应用:概念、存储、处理、分析与应用
大数据技术原理与应用:概念、存储、处理、分析与应用(第2版)
阿里大数据计算服务MaxCompute安全指南 本文档主要面向MaxCompute项目空间所有者、管理员以及对MaxCompute多租户数据安全体系感兴趣的用户,旨在指导用户如何使用MaxCompute中的安全机制来保护项目空间中的敏感数据...
01.《大数据》配套PPT之一:第1章 大数据概念与应用。01.《大数据》配套PPT之一:第1章 大数据概念与应用
大数据开发入门指南是一份全面介绍大数据领域的文档,涵盖了从基础概念到实际应用的各个环节,旨在帮助初学者系统地理解和掌握大数据技术。以下是这份指南中可能包含的重要知识点: 1. **大数据概念**:大数据指的...
* 灵活性:MaxCompute 提供了灵活的数据处理方式,支持多种数据源和处理方式。 * 可靠性:MaxCompute 提供了可靠的数据处理服务,确保数据的安全和可靠性。 MaxCompute 的应用场景 MaxCompute 的应用场景包括: *...
阿里大数据计算服务MaxCompute是一款强大的云数据处理平台,旨在提供高效、可扩展的批处理能力。这个工具指南主要关注如何使用客户端工具与MaxCompute进行交互,实现数据的处理和分析。 首先,MaxCompute客户端是一...