大涛学长
- 浏览: 116646 次
- 性别:

- 来自: 北京
-

最新评论
Struct复杂数据类型的UDF编写、GenericUDF编写
**一、背景介绍:**
MaxCompute 2.0版本升级后,Java UDF支持的数据类型从原来的BIGINT、STRING、DOUBLE、BOOLEAN扩展了更多基本的数据类型,同时还扩展支持了ARRAY、MAP、STRUCT等复杂类型,以及Writable参数。Java UDF使用复杂数据类型的方法,STRUCT对应com.aliyun.odps.data.Struct。com.aliyun.odps.data.Struct从反射看不出Field Name和Field Type,所以需要用@Resolve注解来辅助。即如果需要在UDF中使用STRUCT,要求在UDF Class上也标注上@Resolve注解。但是当我们Struct类型中的field有很多字段的时候,这个时候需要我们去手动的添加@Resolve注解就不是那么的友好。针对这一个问题,我们可以使用Hive 中的GenericUDF去实现。MaxCompute 2.0支持Hive风格的UDF,部分Hive UDF、UDTF可以直接在MaxCompute上使用。
**二、复杂数据类型UDF示例**
示例定义了一个有三个复杂数据类型的UDF,其中第一个用ARRAY作为参数,第二个用MAP作为参数,第三个用STRUCT作为参数。由于第三个Overloads用了STRUCT作为参数或者返回值,因此要求必须对UDF Class添加@Resolve注解,指定STRUCT的具体类型。
**1.代码编写**
```
@Resolve("struct<a:bigint>,string->string")
public class UdfArray extends UDF {
public String evaluate(List<String> vals, Long len) {
return vals.get(len.intValue());
}
public String evaluate(Map<String,String> map, String key) {
return map.get(key);
}
public String evaluate(Struct struct, String key) {
return struct.getFieldValue("a") + key;
}
}
```

**2.打jar包添加资源**
```
add jar UdfArray.jar
```

**3.创建函数**
```
create function my_index as 'UdfArray' using 'UdfArray.jar';
```

**4.使用UDF函数**
```
select id, my_index(array('red', 'yellow', 'green'), colorOrdinal) as color_name from colors;
```

**三、使用Hive的GenericUDF**
这里我们使用Struct复杂数据类型作为示例,主要处理的逻辑是当我们结构体中两个字段前后没有差异时不返回,如果前后有差异将新的字段及其值组成新的结构体返回。示例中Struct的Field为3个。使用GenericUDF方式可以解决需要手动添加@Resolve注解。
**1.创建一个MaxCompute表**
```
CREATE TABLE IF NOT EXISTS `tmp_ab_struct_type_1` (
`a1` struct<a:STRING,b:STRING,c:string>,
`b1` struct<a:STRING,b:STRING,c:string>
);
```

**2.表中数据结构如下**
```
insert into table tmp_ab_struct_type_1 SELECT named_struct('a',1,'b',3,'c','2019-12-17 16:27:00'), named_struct('a',5,'b',6,'c','2019-12-18 16:30:00');
```

查询数据如下所示:

**3.编写GenericUDF处理逻辑**
(1)QSC\_DEMOO类
```
package com.aliyun.udf.struct;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import java.util.ArrayList;
import java.util.List;
/**
* Created by ljw on 2019-12-17
* Description:
*/
@SuppressWarnings("Duplicates")
public class QSC_DEMOO extends GenericUDF {
StructObjectInspector soi1;
StructObjectInspector soi2;
/**
* 避免频繁Struct对象
*/
private PubSimpleStruct resultStruct = new PubSimpleStruct();
private List<? extends StructField> allStructFieldRefs;
//1. 这个方法只调用一次,并且在evaluate()方法之前调用。该方法接受的参数是一个arguments数组。该方法检查接受正确的参数类型和参数个数。
//2. 输出类型的定义
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
String error = "";
//检验参数个数是否正确
if (arguments.length != 2) {
throw new UDFArgumentException("需要两个参数");
}
//判断参数类型是否正确-struct
ObjectInspector.Category arg1 = arguments[0].getCategory();
ObjectInspector.Category arg2 = arguments[1].getCategory();
if (!(arg1.equals(ObjectInspector.Category.STRUCT))) {
error += arguments[0].getClass().getSimpleName();
throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \"" +
arg1.name() + "\" " + "is found" + "\n" + error);
}
if (!(arg2.equals(ObjectInspector.Category.STRUCT))) {
error += arguments[1].getClass().getSimpleName();
throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \""
+ arg2.name() + "\" " + "is found" + "\n" + error);
}
//输出结构体定义
ArrayList<String> structFieldNames = new ArrayList();
ArrayList<ObjectInspector> structFieldObjectInspectors = new ArrayList();
soi1 = (StructObjectInspector) arguments[0];
soi2 = (StructObjectInspector) arguments[1];
StructObjectInspector toValid = null;
if (soi1 == null)
toValid = soi2;
else toValid = soi1;
//设置返回类型
allStructFieldRefs = toValid.getAllStructFieldRefs();
for (StructField structField : allStructFieldRefs) {
structFieldNames.add(structField.getFieldName());
structFieldObjectInspectors.add(structField.getFieldObjectInspector());
}
return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);
}
//这个方法类似UDF的evaluate()方法。它处理真实的参数,并返回最终结果。
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
//将hive中的struct类型转换成com.aliyun.odps.data.Struct, 如果有错误,请调试,查看deferredObjects的数据是什么样子的
//然后自己进行重新封装 !!!
ArrayList list1 = (ArrayList) deferredObjects[0].get();
ArrayList list2 = (ArrayList) deferredObjects[1].get();
int len = list1.size();
ArrayList fieldNames = new ArrayList<>();
ArrayList fieldValues = new ArrayList<>();
for (int i = 0; i < len ; i++) {
if (!list1.get(i).equals(list2.get(i))) {
fieldNames.add(allStructFieldRefs.get(i).getFieldName());
fieldValues.add(list2.get(i));
}
}
if (fieldValues.size() == 0) return null;
return fieldValues;
}
//这个方法用于当实现的GenericUDF出错的时候,打印出提示信息。而提示信息就是你实现该方法最后返回的字符串。
@Override
public String getDisplayString(String[] strings) {
return "Usage:" + this.getClass().getName() + "(" + strings[0] + ")";
}
}
```

(2)PubSimpleStruct类
```
package com.aliyun.udf.struct;
import com.aliyun.odps.data.Struct;
import com.aliyun.odps.type.StructTypeInfo;
import com.aliyun.odps.type.TypeInfo;
import java.util.List;
public class PubSimpleStruct implements Struct {
private StructTypeInfo typeInfo;
private List<Object> fieldValues;
public StructTypeInfo getTypeInfo() {
return typeInfo;
}
public void setTypeInfo(StructTypeInfo typeInfo) {
this.typeInfo = typeInfo;
}
public void setFieldValues(List<Object> fieldValues) {
this.fieldValues = fieldValues;
}
public int getFieldCount() {
return fieldValues.size();
}
public String getFieldName(int index) {
return typeInfo.getFieldNames().get(index);
}
public TypeInfo getFieldTypeInfo(int index) {
return typeInfo.getFieldTypeInfos().get(index);
}
public Object getFieldValue(int index) {
return fieldValues.get(index);
}
public TypeInfo getFieldTypeInfo(String fieldName) {
for (int i = 0; i < typeInfo.getFieldCount(); ++i) {
if (typeInfo.getFieldNames().get(i).equalsIgnoreCase(fieldName)) {
return typeInfo.getFieldTypeInfos().get(i);
}
}
return null;
}
public Object getFieldValue(String fieldName) {
for (int i = 0; i < typeInfo.getFieldCount(); ++i) {
if (typeInfo.getFieldNames().get(i).equalsIgnoreCase(fieldName)) {
return fieldValues.get(i);
}
}
return null;
}
public List<Object> getFieldValues() {
return fieldValues;
}
@Override
public String toString() {
return "PubSimpleStruct{" +
"typeInfo=" + typeInfo +
", fieldValues=" + fieldValues +
'}';
}
}
```

**3、打jar包,添加资源**
```
add jar test.jar;
```

**4、创建函数**
```
CREATE FUNCTION UDF_DEMO as 'com.aliyun.udf.test.UDF_DEMOO' using 'test.jar';
```

**5、测试使用UDF函数**
```
set odps.sql.hive.compatible=true;
select UDF_DEMO(a1,b1) from tmp_ab_struct_type_1;
```

查询结果如下所示:
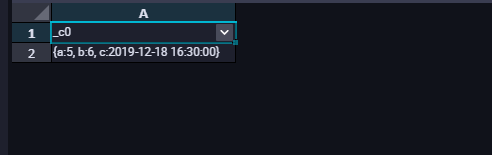
**__注意:__**
(1)在使用兼容的Hive UDF的时候,需要在SQL前加set odps.sql.hive.compatible=true;语句,set语句和SQL语句一起提交执行。
(2)目前支持兼容的Hive版本为2.1.0,对应Hadoop版本为2.7.2。如果UDF是在其他版本的Hive/Hadoop开发的,则可能需要使用此Hive/Hadoop版本重新编译。
有疑问可以咨询阿里云MaxCompute技术支持:刘建伟
```
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
```

[原文链接](https://yq.aliyun.com/articles/740002?utm_content=g_1000095436)
本文为阿里云内容,未经允许不得转载。
MaxCompute 2.0版本升级后,Java UDF支持的数据类型从原来的BIGINT、STRING、DOUBLE、BOOLEAN扩展了更多基本的数据类型,同时还扩展支持了ARRAY、MAP、STRUCT等复杂类型,以及Writable参数。Java UDF使用复杂数据类型的方法,STRUCT对应com.aliyun.odps.data.Struct。com.aliyun.odps.data.Struct从反射看不出Field Name和Field Type,所以需要用@Resolve注解来辅助。即如果需要在UDF中使用STRUCT,要求在UDF Class上也标注上@Resolve注解。但是当我们Struct类型中的field有很多字段的时候,这个时候需要我们去手动的添加@Resolve注解就不是那么的友好。针对这一个问题,我们可以使用Hive 中的GenericUDF去实现。MaxCompute 2.0支持Hive风格的UDF,部分Hive UDF、UDTF可以直接在MaxCompute上使用。
**二、复杂数据类型UDF示例**
示例定义了一个有三个复杂数据类型的UDF,其中第一个用ARRAY作为参数,第二个用MAP作为参数,第三个用STRUCT作为参数。由于第三个Overloads用了STRUCT作为参数或者返回值,因此要求必须对UDF Class添加@Resolve注解,指定STRUCT的具体类型。
**1.代码编写**
```
@Resolve("struct<a:bigint>,string->string")
public class UdfArray extends UDF {
public String evaluate(List<String> vals, Long len) {
return vals.get(len.intValue());
}
public String evaluate(Map<String,String> map, String key) {
return map.get(key);
}
public String evaluate(Struct struct, String key) {
return struct.getFieldValue("a") + key;
}
}
```

**2.打jar包添加资源**
```
add jar UdfArray.jar
```

**3.创建函数**
```
create function my_index as 'UdfArray' using 'UdfArray.jar';
```

**4.使用UDF函数**
```
select id, my_index(array('red', 'yellow', 'green'), colorOrdinal) as color_name from colors;
```

**三、使用Hive的GenericUDF**
这里我们使用Struct复杂数据类型作为示例,主要处理的逻辑是当我们结构体中两个字段前后没有差异时不返回,如果前后有差异将新的字段及其值组成新的结构体返回。示例中Struct的Field为3个。使用GenericUDF方式可以解决需要手动添加@Resolve注解。
**1.创建一个MaxCompute表**
```
CREATE TABLE IF NOT EXISTS `tmp_ab_struct_type_1` (
`a1` struct<a:STRING,b:STRING,c:string>,
`b1` struct<a:STRING,b:STRING,c:string>
);
```

**2.表中数据结构如下**
```
insert into table tmp_ab_struct_type_1 SELECT named_struct('a',1,'b',3,'c','2019-12-17 16:27:00'), named_struct('a',5,'b',6,'c','2019-12-18 16:30:00');
```

查询数据如下所示:

**3.编写GenericUDF处理逻辑**
(1)QSC\_DEMOO类
```
package com.aliyun.udf.struct;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import java.util.ArrayList;
import java.util.List;
/**
* Created by ljw on 2019-12-17
* Description:
*/
@SuppressWarnings("Duplicates")
public class QSC_DEMOO extends GenericUDF {
StructObjectInspector soi1;
StructObjectInspector soi2;
/**
* 避免频繁Struct对象
*/
private PubSimpleStruct resultStruct = new PubSimpleStruct();
private List<? extends StructField> allStructFieldRefs;
//1. 这个方法只调用一次,并且在evaluate()方法之前调用。该方法接受的参数是一个arguments数组。该方法检查接受正确的参数类型和参数个数。
//2. 输出类型的定义
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
String error = "";
//检验参数个数是否正确
if (arguments.length != 2) {
throw new UDFArgumentException("需要两个参数");
}
//判断参数类型是否正确-struct
ObjectInspector.Category arg1 = arguments[0].getCategory();
ObjectInspector.Category arg2 = arguments[1].getCategory();
if (!(arg1.equals(ObjectInspector.Category.STRUCT))) {
error += arguments[0].getClass().getSimpleName();
throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \"" +
arg1.name() + "\" " + "is found" + "\n" + error);
}
if (!(arg2.equals(ObjectInspector.Category.STRUCT))) {
error += arguments[1].getClass().getSimpleName();
throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \""
+ arg2.name() + "\" " + "is found" + "\n" + error);
}
//输出结构体定义
ArrayList<String> structFieldNames = new ArrayList();
ArrayList<ObjectInspector> structFieldObjectInspectors = new ArrayList();
soi1 = (StructObjectInspector) arguments[0];
soi2 = (StructObjectInspector) arguments[1];
StructObjectInspector toValid = null;
if (soi1 == null)
toValid = soi2;
else toValid = soi1;
//设置返回类型
allStructFieldRefs = toValid.getAllStructFieldRefs();
for (StructField structField : allStructFieldRefs) {
structFieldNames.add(structField.getFieldName());
structFieldObjectInspectors.add(structField.getFieldObjectInspector());
}
return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);
}
//这个方法类似UDF的evaluate()方法。它处理真实的参数,并返回最终结果。
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
//将hive中的struct类型转换成com.aliyun.odps.data.Struct, 如果有错误,请调试,查看deferredObjects的数据是什么样子的
//然后自己进行重新封装 !!!
ArrayList list1 = (ArrayList) deferredObjects[0].get();
ArrayList list2 = (ArrayList) deferredObjects[1].get();
int len = list1.size();
ArrayList fieldNames = new ArrayList<>();
ArrayList fieldValues = new ArrayList<>();
for (int i = 0; i < len ; i++) {
if (!list1.get(i).equals(list2.get(i))) {
fieldNames.add(allStructFieldRefs.get(i).getFieldName());
fieldValues.add(list2.get(i));
}
}
if (fieldValues.size() == 0) return null;
return fieldValues;
}
//这个方法用于当实现的GenericUDF出错的时候,打印出提示信息。而提示信息就是你实现该方法最后返回的字符串。
@Override
public String getDisplayString(String[] strings) {
return "Usage:" + this.getClass().getName() + "(" + strings[0] + ")";
}
}
```

(2)PubSimpleStruct类
```
package com.aliyun.udf.struct;
import com.aliyun.odps.data.Struct;
import com.aliyun.odps.type.StructTypeInfo;
import com.aliyun.odps.type.TypeInfo;
import java.util.List;
public class PubSimpleStruct implements Struct {
private StructTypeInfo typeInfo;
private List<Object> fieldValues;
public StructTypeInfo getTypeInfo() {
return typeInfo;
}
public void setTypeInfo(StructTypeInfo typeInfo) {
this.typeInfo = typeInfo;
}
public void setFieldValues(List<Object> fieldValues) {
this.fieldValues = fieldValues;
}
public int getFieldCount() {
return fieldValues.size();
}
public String getFieldName(int index) {
return typeInfo.getFieldNames().get(index);
}
public TypeInfo getFieldTypeInfo(int index) {
return typeInfo.getFieldTypeInfos().get(index);
}
public Object getFieldValue(int index) {
return fieldValues.get(index);
}
public TypeInfo getFieldTypeInfo(String fieldName) {
for (int i = 0; i < typeInfo.getFieldCount(); ++i) {
if (typeInfo.getFieldNames().get(i).equalsIgnoreCase(fieldName)) {
return typeInfo.getFieldTypeInfos().get(i);
}
}
return null;
}
public Object getFieldValue(String fieldName) {
for (int i = 0; i < typeInfo.getFieldCount(); ++i) {
if (typeInfo.getFieldNames().get(i).equalsIgnoreCase(fieldName)) {
return fieldValues.get(i);
}
}
return null;
}
public List<Object> getFieldValues() {
return fieldValues;
}
@Override
public String toString() {
return "PubSimpleStruct{" +
"typeInfo=" + typeInfo +
", fieldValues=" + fieldValues +
'}';
}
}
```

**3、打jar包,添加资源**
```
add jar test.jar;
```

**4、创建函数**
```
CREATE FUNCTION UDF_DEMO as 'com.aliyun.udf.test.UDF_DEMOO' using 'test.jar';
```

**5、测试使用UDF函数**
```
set odps.sql.hive.compatible=true;
select UDF_DEMO(a1,b1) from tmp_ab_struct_type_1;
```

查询结果如下所示:

**__注意:__**
(1)在使用兼容的Hive UDF的时候,需要在SQL前加set odps.sql.hive.compatible=true;语句,set语句和SQL语句一起提交执行。
(2)目前支持兼容的Hive版本为2.1.0,对应Hadoop版本为2.7.2。如果UDF是在其他版本的Hive/Hadoop开发的,则可能需要使用此Hive/Hadoop版本重新编译。
有疑问可以咨询阿里云MaxCompute技术支持:刘建伟
```
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
```

[原文链接](https://yq.aliyun.com/articles/740002?utm_content=g_1000095436)
本文为阿里云内容,未经允许不得转载。
分享到:


发表评论

相关推荐
Hive作为一个大数据分析工具,提供了多种数据类型,其中包括了复杂数据类型如Array、Map和Struct。这些复杂数据类型可以满足各种复杂的数据存储需求。 一、Array类型 Array类型是Hive中的一种复杂数据类型,用于...
本章主要介绍了C语言中的三种复杂数据类型:结构体(struct)、共用体(union)以及枚举(enum),并且涉及到结构数组、指向结构的指针、线性链表以及复杂数据类型在函数中的应用。 1. 结构体(struct) 结构体允许...
对于不包含数组的结构体,如`SecondData`,发送和接收的流程基本相同,只是初始化和处理的数据类型不同。结构体的每个成员都会按照它们在内存中的顺序和大小被序列化和反序列化。 值得注意的是,`send`和`recv`函数...
【工学C复杂数据类型】 在C语言中,复杂数据类型是指除了基本数据类型(如int、char、float等)之外的自定义数据结构,它们允许程序员创建更灵活的数据组织方式,以适应不同的编程需求。本章主要讨论四种复杂数据...
其中,结构体(`struct`)作为C语言中的一个重要组成部分,为程序员提供了一种构建复杂数据类型的有效手段。本文将详细介绍C语言中的结构体,包括其定义、使用方法及应用场景,旨在帮助读者更好地理解和运用这一强大的...
`成员1` 和 `成员2` 是结构体内部的变量,它们可以是任何基本数据类型,如 int、char、float 等,也可以是其他结构体或数组等复杂类型。定义完结构体后,我们需要使用 `struct Tag` 来声明结构体变量,如下: ```c ...
这意味着结构体内的成员只能是C++的基本数据类型(如int, char, bool等)或这些基本类型的固定大小数组。例如,以下是一个符合这一约束的结构体示例: ```cpp typedef struct _tag_user_info_ { char cUserID[20]; ...
在编程领域,结构体(struct)是一种非常重要的数据类型,特别是在C/C++等语言中,它允许我们将多个相关的变量组合成一个单一的实体,便于管理和操作。本项目"利用struct架构编写学生、教师系统"正是基于这一概念,...
- 支持复杂数据类型,如结构体(STRUCT),数组(ARRAY) - 支持功能块(FUNCTION_BLOCK)和函数(FUNCTION)的调用,可以处理更复杂的逻辑和算法 4. **和利时(Hollysys)系列**: 和利时的PLC数据类型可能包括...
构造数据类型允许开发者创建更复杂的数据结构,如数组、结构体(struct)、联合体(union)和枚举类型(enum)。这些类型使得C语言能够处理更加复杂的现实世界问题,比如一组相关的数据或不同类型数据的组合。 - **数组...
首先,MATLAB中的结构体是一种复杂的数据类型,可以存储各种不同类型的数据,包括数字、字符串、数组等。结构体由字段(field)和对应的值组成,可以看作是键值对的集合。例如,一个简单的结构体定义如下: ```...
本文将详细介绍结构体(struct),作为C++中一种重要的自定义数据类型之一。 #### 二、结构体定义与作用 **结构体**是一种复合数据类型,它可以容纳不同类型的数据成员。这使得结构体成为一种非常实用的数据组织工具...
直接require 该文件,然后传入struct结构体数据,返回json数据
复杂数据类型,如结构体(STRUCT)和数组(ARRAY),允许更灵活的数据组织。结构体可以包含不同类型的数据项,如`Motor`结构体包含`Speed`(INT)、`Current`(REAL)等成员。数组则是一组相同类型的数据集合,如`...
06.hive数据类型--复合类型--struct结构类型的使用.mp4
结构体是一种自定义的数据类型,它允许我们把多个不同类型的变量组合在一起作为一个单一的实体。在C++和C#中,struct都是用来定义这种复合类型的工具。 在C++中,struct是值类型。当你将一个struct对象作为参数传递...
在Linux内核中,UDF文件系统的实现通常包括解析文件系统的元数据区,这包括Volume descriptors(卷描述符),它们包含了关于文件系统的各种信息,比如文件系统类型、版本、标签和UUID。源代码可能涉及的函数可能有`...
此外,复杂数据类型如STRUCT允许创建结构化的数据单元,将多个相关变量打包在一起,例如定义一个名为Motor的结构体,包含Enable(BOOL)、Set_speed(REAL)和Actual_speed(REAL)等成员。 用户自定义数据类型...
在IT行业中,编程语言间的数据类型转换和时间戳处理是两个关键的概念,尤其在多语言交互或跨平台开发时更为重要。本项目"TypeByte@2019_C#_C++_C数据类型转换时间戳转换_"显然是针对C#、C++和C这三种编程语言,提供...
相反,C语言的struct是二进制数据结构,它允许程序员定义自定义的数据类型,组合基本数据类型如整型、浮点型等。例如,上述XML可以对应到以下C语言的struct: ```c typedef struct { char* name; int age; ...