еӨ§ж¶ӣеӯҰй•ҝ
- жөҸи§Ҳ: 121570 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
дёҮеӯ—е№Іиҙ§ | жҜҸз§’7дәҝж¬ЎиҜ·жұӮпјҢйҳҝйҮҢж–°дёҖд»Јж•°жҚ®еә“еҰӮдҪ•ж”Ҝж’‘пјҹ
еҜјиҜ»
--
LindormпјҢе°ұжҳҜдә‘ж“ҚдҪңзі»з»ҹйЈһеӨ©дёӯйқўеҗ‘еӨ§ж•°жҚ®еӯҳеӮЁеӨ„зҗҶзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶгҖӮLindormжҳҜеҹәдәҺHBaseз ”еҸ‘зҡ„гҖҒйқўеҗ‘еӨ§ж•°жҚ®йўҶеҹҹзҡ„еҲҶеёғејҸNoSQLж•°жҚ®еә“пјҢйӣҶеӨ§и§„жЁЎгҖҒй«ҳеҗһеҗҗгҖҒеҝ«йҖҹзҒөжҙ»гҖҒе®һж—¶ж··еҗҲиғҪеҠӣдәҺдёҖиә«пјҢйқўеҗ‘жө·йҮҸж•°жҚ®еңәжҷҜжҸҗдҫӣдё–з•ҢйўҶе…Ҳзҡ„й«ҳжҖ§иғҪгҖҒеҸҜи·ЁеҹҹгҖҒеӨҡдёҖиҮҙгҖҒеӨҡжЁЎеһӢзҡ„ж··еҗҲеӯҳеӮЁеӨ„зҗҶиғҪеҠӣгҖӮ
зӣ®еүҚпјҢLindormе·Із»Ҹе…ЁйқўжңҚеҠЎдәҺйҳҝйҮҢз»ҸжөҺдҪ“дёӯзҡ„еӨ§ж•°жҚ®з»“жһ„еҢ–гҖҒеҚҠз»“жһ„еҢ–еӯҳеӮЁеңәжҷҜгҖӮ
жіЁпјҡLindormжҳҜйҳҝйҮҢеҶ…йғЁHBaseеҲҶж”Ҝзҡ„еҲ«з§°пјҢеңЁйҳҝйҮҢдә‘дёҠеҜ№еӨ–е”®еҚ–зҡ„зүҲжң¬еҸ«еҒҡHBaseеўһејәзүҲпјҢд№ӢеҗҺж–ҮдёӯеҮәзҺ°зҡ„HBaseеўһејәзүҲе’ҢLindormйғҪжҢҮеҗҢдёҖдёӘдә§е“ҒгҖӮ
2019е№ҙд»ҘжқҘпјҢLindormе·Із»ҸжңҚеҠЎдәҶеҢ…жӢ¬ж·ҳе®қгҖҒеӨ©зҢ«гҖҒиҡӮиҡҒгҖҒиҸңйёҹгҖҒеҰҲеҰҲгҖҒдјҳй…·гҖҒй«ҳеҫ·гҖҒеӨ§ж–ҮеЁұзӯүж•°еҚҒдёӘBUпјҢеңЁд»Ҡе№ҙзҡ„еҸҢеҚҒдёҖдёӯпјҢLindormеі°еҖјиҜ·жұӮиҫҫеҲ°дәҶ7.5дәҝж¬ЎжҜҸз§’пјҢеӨ©еҗһеҗҗ22.9дёҮдәҝж¬ЎпјҢе№іеқҮе“Қеә”ж—¶й—ҙдҪҺдәҺ3msпјҢж•ҙдҪ“еӯҳеӮЁзҡ„ж•°жҚ®йҮҸиҫҫеҲ°дәҶж•°зҷҫPBгҖӮ
иҝҷдәӣж•°еӯ—зҡ„иғҢеҗҺпјҢеҮқиҒҡдәҶHBase&LindormеӣўйҳҹеӨҡе№ҙд»ҘжқҘзҡ„жұ—ж°ҙе’ҢеҝғиЎҖгҖӮLindormи„ұиғҺдәҺHBaseпјҢжҳҜеӣўйҳҹеӨҡе№ҙд»ҘжқҘжүҝиҪҪж•°зҷҫPBж•°жҚ®пјҢдәҝзә§иҜ·жұӮйҮҸпјҢдёҠеҚғдёӘдёҡеҠЎеҗҺпјҢеңЁйқўеҜ№и§„жЁЎжҲҗжң¬еҺӢеҠӣпјҢд»ҘеҸҠHBaseиҮӘиә«зјәйҷ·дёӢпјҢе…ЁйқўйҮҚжһ„е’Ңеј•ж“ҺеҚҮзә§зҡ„е…Ёж–°дә§е“ҒгҖӮ
зӣёжҜ”HBaseпјҢLindormж— и®әжҳҜжҖ§иғҪпјҢеҠҹиғҪиҝҳжҳҜеҸҜз”ЁжҖ§дёҠпјҢйғҪжңүдәҶе·ЁеӨ§йЈһи·ғгҖӮжң¬ж–Үе°Ҷд»ҺеҠҹиғҪгҖҒеҸҜз”ЁжҖ§гҖҒжҖ§иғҪжҲҗжң¬гҖҒжңҚеҠЎз”ҹжҖҒзӯүз»ҙеәҰд»Ӣз»ҚLindormзҡ„ж ёеҝғиғҪеҠӣдёҺдёҡеҠЎиЎЁзҺ°пјҢжңҖеҗҺеҲҶдә«йғЁеҲҶжҲ‘们жӯЈеңЁиҝӣиЎҢдёӯзҡ„дёҖдәӣйЎ№зӣ®гҖӮ
жһҒиҮҙдјҳеҢ–пјҢи¶…ејәжҖ§иғҪ
---------
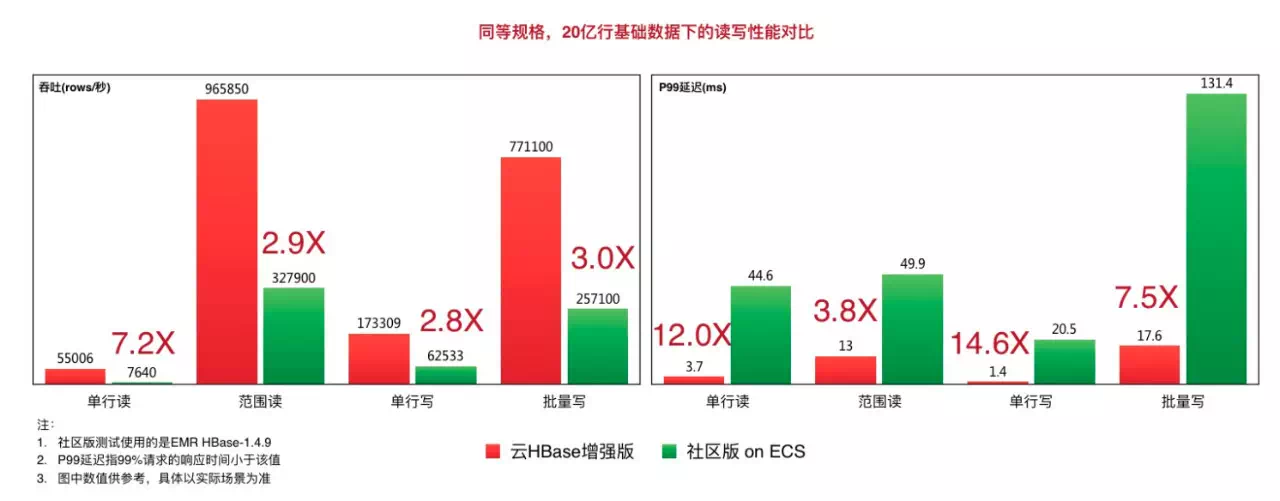
LindormжҜ”HBaseеңЁRPCгҖҒеҶ…еӯҳз®ЎзҗҶпјҢзј“еӯҳгҖҒж—Ҙеҝ—еҶҷе…Ҙзӯүж–№йқўеҒҡдәҶж·ұеәҰзҡ„дјҳеҢ–пјҢеј•е…ҘдәҶдј—еӨҡж–°жҠҖжңҜпјҢеӨ§е№…жҸҗеҚҮдәҶиҜ»еҶҷжҖ§иғҪпјҢеңЁзӣёеҗҢ硬件зҡ„жғ…еҶөдёӢпјҢеҗһеҗҗеҸҜиҫҫеҲ°HBaseзҡ„5еҖҚд»ҘдёҠпјҢжҜӣеҲәжӣҙжҳҜеҸҜд»ҘиҫҫеҲ°HBaseзҡ„1/10гҖӮ
иҝҷдәӣжҖ§иғҪж•°жҚ®пјҢ并дёҚжҳҜеңЁе®һйӘҢе®ӨжқЎд»¶дёӢдә§з”ҹзҡ„пјҢиҖҢжҳҜеңЁдёҚж”№еҠЁд»»дҪ•еҸӮж•°зҡ„еүҚжҸҗдёӢпјҢдҪҝз”ЁејҖжәҗжөӢиҜ•е·Ҙе…·YCSBи·‘еҮәжқҘзҡ„жҲҗз»©гҖӮжҲ‘们жҠҠжөӢиҜ•зҡ„е·Ҙе…·е’ҢеңәжҷҜйғҪе…¬еёғеңЁйҳҝйҮҢдә‘зҡ„её®еҠ©ж–Ү件дёӯпјҢд»»дҪ•дәәйғҪеҸҜд»Ҙдҫқз…§жҢҮеҚ—иҮӘе·ұи·‘еҮәдёҖж ·зҡ„з»“жһңгҖӮ
еҸ–еҫ—иҝҷд№ҲдјҳејӮзҡ„жҖ§иғҪзҡ„иғҢеҗҺпјҢжҳҜLindormдёӯз§Ҝж”’еӨҡе№ҙзҡ„вҖң黑科жҠҖвҖқпјҢдёӢйқўпјҢжҲ‘们з®ҖеҚ•д»Ӣз»ҚдёӢLindormеҶ…ж ёдёӯдҪҝз”ЁеҲ°зҡ„йғЁеҲҶвҖң黑科жҠҖвҖқгҖӮ
#### Trie Index
Lindorm зҡ„ж–Ү件LDFileпјҲзұ»дјјHBaseдёӯзҡ„HFileпјүжҳҜеҸӘиҜ» B+ ж ‘з»“жһ„пјҢе…¶дёӯж–Ү件зҙўеј•жҳҜиҮіе…ійҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„гҖӮеңЁ block cache дёӯжңүй«ҳдјҳе…Ҳзә§пјҢйңҖиҰҒе°ҪйҮҸеёёй©»еҶ…еӯҳгҖӮеҰӮжһңиғҪйҷҚдҪҺж–Ү件зҙўеј•жүҖеҚ з©әй—ҙеӨ§е°ҸпјҢжҲ‘们еҸҜд»ҘиҠӮзңҒ block cache дёӯзҙўеј•жүҖйңҖиҰҒзҡ„е®қиҙөеҶ…еӯҳз©әй—ҙгҖӮжҲ–иҖ…еңЁзҙўеј•з©әй—ҙдёҚеҸҳзҡ„жғ…еҶөдёӢпјҢеўһеҠ зҙўеј•еҜҶеәҰпјҢйҷҚдҪҺ data block зҡ„еӨ§е°ҸпјҢд»ҺиҖҢжҸҗй«ҳжҖ§иғҪгҖӮиҖҢHBaseдёӯзҡ„зҙўеј•blockдёӯеӯҳзҡ„жҳҜе…ЁйҮҸзҡ„RowkeyпјҢиҖҢеңЁдёҖдёӘе·Із»ҸжҺ’еәҸеҘҪзҡ„ж–Ү件дёӯпјҢеҫҲеӨҡRowkeyйғҪжҳҜжңүе…ұеҗҢеүҚзјҖзҡ„гҖӮ
ж•°жҚ®з»“жһ„дёӯзҡ„Trie (еүҚзјҖж ‘) з»“жһ„иғҪеӨҹи®©е…ұеҗҢеүҚзјҖеҸӘеӯҳдёҖд»ҪпјҢйҒҝе…ҚйҮҚеӨҚеӯҳеӮЁеёҰжқҘзҡ„жөӘиҙ№гҖӮдҪҶжҳҜдј з»ҹеүҚзјҖж ‘з»“жһ„дёӯпјҢд»ҺдёҖдёӘиҠӮзӮ№еҲ°дёӢдёҖдёӘиҠӮзӮ№зҡ„жҢҮй’ҲеҚ з”Ёз©әй—ҙеӨӘеӨҡпјҢж•ҙдҪ“иҖҢиЁҖеҫ—дёҚеҒҝеӨұгҖӮиҝҷдёҖжғ…еҶөжңүжңӣз”Ё Succinct Prefix Tree жқҘи§ЈеҶігҖӮSIGMOD2018е№ҙзҡ„жңҖдҪіи®әж–Ү Surf дёӯжҸҗеҮәдәҶдёҖз§Қз”Ё Succinct Prefix Tree жқҘеҸ–д»Ј bloom filterпјҢ并еҗҢж—¶жҸҗдҫӣ range filtering зҡ„еҠҹиғҪгҖӮжҲ‘们д»ҺиҝҷзҜҮж–Үз« еҫ—еҲ°еҗҜеҸ‘пјҢз”Ё Succinct Trie жқҘеҒҡ file block indexгҖӮ
жҲ‘们еңЁзәҝдёҠзҡ„еӨҡдёӘдёҡеҠЎдёӯдҪҝз”ЁдәҶTrie indexе®һзҺ°зҡ„зҙўеј•з»“жһ„гҖӮз»“жһңеҸ‘зҺ°пјҢеҗ„дёӘеңәжҷҜдёӯпјҢTrie indexеҸҜд»ҘеӨ§еӨ§зј©е°Ҹзҙўеј•зҡ„дҪ“з§ҜпјҢжңҖеӨҡеҸҜд»ҘеҺӢзј©12еҖҚзҡ„зҙўеј•з©әй—ҙпјҒиҠӮзңҒзҡ„иҝҷдәӣе®қиҙөз©әй—ҙи®©еҶ…еӯҳCacheдёӯиғҪеӨҹеӯҳж”ҫжӣҙеӨҡзҡ„зҙўеј•е’Ңж•°жҚ®ж–Ү件пјҢеӨ§еӨ§жҸҗй«ҳдәҶиҜ·жұӮзҡ„жҖ§иғҪгҖӮ
### ZGCеҠ жҢҒпјҢзҷҫGBе Ҷе№іеқҮ5msжҡӮеҒң
ZGC(Powerd by Dragonwell JDK)жҳҜдёӢдёҖд»ЈPauseless GCз®—жі•зҡ„д»ЈиЎЁд№ӢдёҖпјҢе…¶ж ёеҝғжҖқжғіжҳҜMutatorеҲ©з”ЁеҶ…еӯҳиҜ»еұҸйҡң(Read Barrier)иҜҶеҲ«жҢҮй’ҲеҸҳеҢ–пјҢдҪҝеҫ—еӨ§йғЁеҲҶзҡ„ж Үи®°(Mark)дёҺеҗҲ并(Relocate)е·ҘдҪңеҸҜд»Ҙж”ҫеңЁе№¶еҸ‘йҳ¶ж®өжү§иЎҢгҖӮ
иҝҷж ·дёҖйЎ№е®һйӘҢжҖ§жҠҖжңҜпјҢеңЁLindormеӣўйҳҹдёҺAJDKеӣўйҳҹзҡ„зҙ§еҜҶеҗҲдҪңдёӢпјҢиҝӣиЎҢдәҶеӨ§йҮҸзҡ„ж”№иҝӣдёҺж”№йҖ е·ҘдҪңгҖӮдҪҝеҫ—ZGCеңЁLindormиҝҷдёӘеңәжҷҜдёҠе®һзҺ°дәҶз”ҹдә§зә§еҸҜз”ЁпјҢдё»иҰҒе·ҘдҪңеҢ…жӢ¬пјҡ
1. LindormеҶ…еӯҳиҮӘз®ЎзҗҶжҠҖжңҜпјҢж•°йҮҸзә§еҮҸе°‘еҜ№иұЎж•°дёҺеҶ…еӯҳеҲҶй…ҚйҖҹзҺҮгҖӮ(жҜ”еҰӮиҜҙйҳҝйҮҢHBaseеӣўйҳҹиҙЎзҢ®з»ҷзӨҫеҢәзҡ„CCSMap)гҖӮ
2. AJDK ZGC Pageзј“еӯҳжңәеҲ¶дјҳеҢ–(й”ҒгҖҒPageзј“еӯҳзӯ–з•Ҙ)гҖӮ
3. AJDK ZGC и§ҰеҸ‘ж—¶жңәдјҳеҢ–пјҢZGCж— е№¶еҸ‘еӨұиҙҘгҖӮAJDK ZGCеңЁLindormдёҠзЁіе®ҡиҝҗиЎҢдёӨдёӘжңҲпјҢ并йЎәеҲ©йҖҡиҝҮеҸҢеҚҒдёҖеӨ§иҖғгҖӮе…¶JVMжҡӮеҒңж—¶й—ҙзЁіе®ҡеңЁ5msе·ҰеҸіпјҢжңҖеӨ§жҡӮеҒңж—¶й—ҙдёҚи¶…иҝҮ8msгҖӮZGCеӨ§еӨ§ж”№е–„дәҶзәҝдёҠиҝҗиЎҢйӣҶзҫӨзҡ„RTдёҺжҜӣеҲәжҢҮж ҮпјҢе№іеқҮRTдјҳеҢ–15%пҪһ20%пјҢP999 RTеҮҸе°‘дёҖеҖҚгҖӮеңЁд»Ҡе№ҙеҸҢеҚҒдёҖиҡӮиҡҒйЈҺжҺ§йӣҶзҫӨдёӯпјҢеңЁZGCзҡ„еҠ жҢҒдёӢпјҢP999ж—¶й—ҙд»Һ12msйҷҚдҪҺеҲ°дәҶ5msгҖӮ
жіЁпјҡеӣҫдёӯзҡ„еҚ•дҪҚеә”иҜҘдёәusпјҢе№іеқҮGCеңЁ5ms
#### LindormBlockingQueue
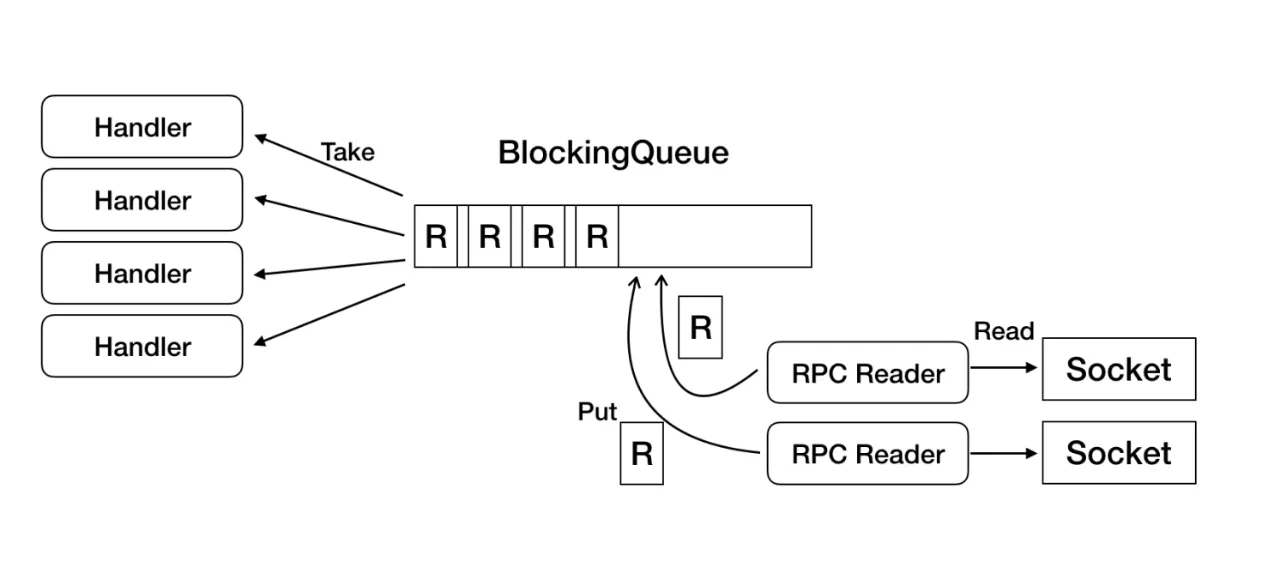
дёҠеӣҫжҳҜHBaseдёӯзҡ„RegionServerд»ҺзҪ‘з»ңдёҠиҜ»еҸ–RPCиҜ·жұӮ并еҲҶеҸ‘еҲ°еҗ„дёӘHandlerдёҠжү§иЎҢзҡ„жөҒзЁӢгҖӮHBaseдёӯзҡ„RPC Readerд»ҺSocketдёҠиҜ»еҸ–RPCиҜ·жұӮж”ҫе…ҘBlockingQueueпјҢHandlerи®ўйҳ…иҝҷдёӘQueue并жү§иЎҢиҜ·жұӮгҖӮиҖҢиҝҷдёӘBlockingQueueпјҢHBaseдҪҝз”Ёзҡ„жҳҜJavaеҺҹз”ҹзҡ„JDKиҮӘеёҰзҡ„LinkedBlockingQueueгҖӮ
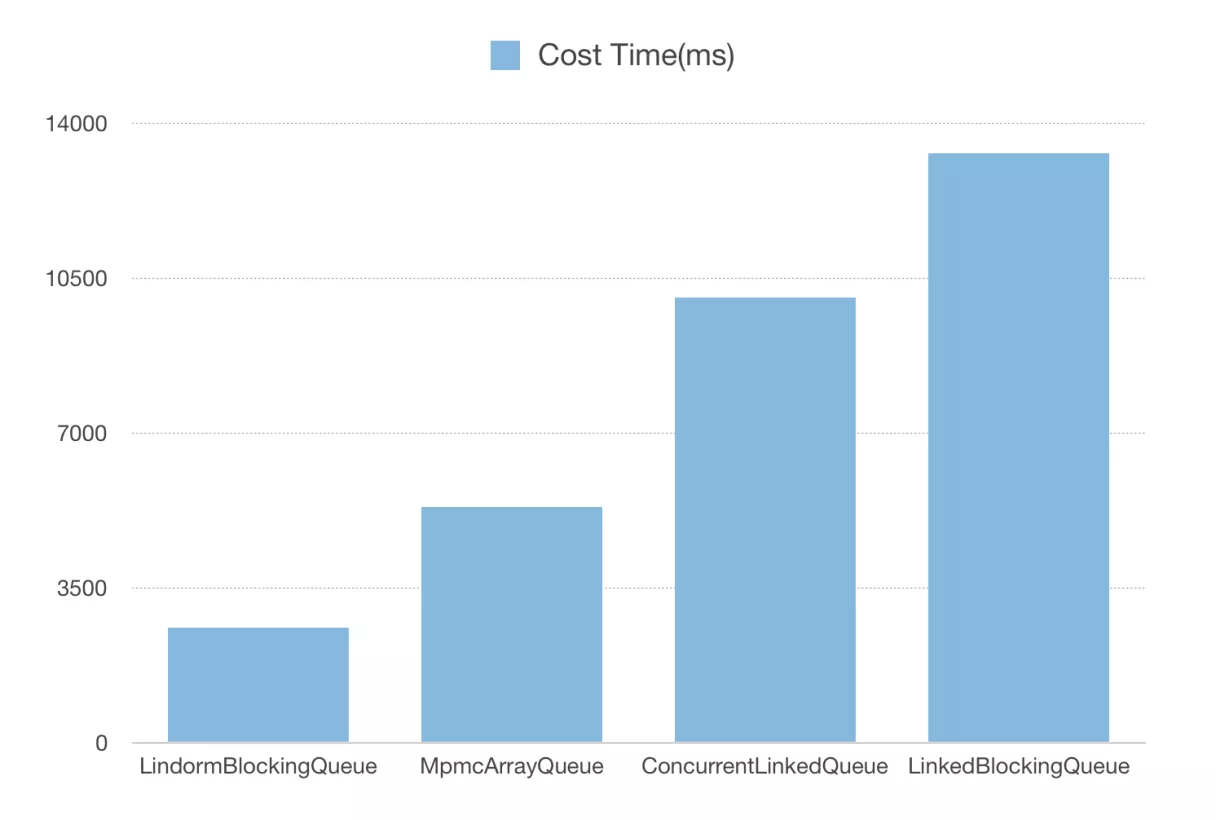
LinkedBlockingQueueеҲ©з”ЁLockдёҺConditionдҝқиҜҒзәҝзЁӢе®үе…ЁдёҺзәҝзЁӢд№Ӣй—ҙзҡ„еҗҢжӯҘпјҢиҷҪ然з»Ҹе…ёжҳ“жҮӮпјҢдҪҶеҪ“еҗһеҗҗеўһеӨ§ж—¶пјҢиҝҷдёӘqueueдјҡйҖ жҲҗдёҘйҮҚзҡ„жҖ§иғҪ瓶йўҲгҖӮ
еӣ жӯӨеңЁLindormдёӯе…Ёж–°и®ҫи®ЎдәҶLindormBlockingQueueпјҢе°Ҷе…ғзҙ з»ҙжҠӨеңЁSlotж•°з»„дёӯгҖӮз»ҙжҠӨheadдёҺtailжҢҮй’ҲпјҢйҖҡиҝҮCASж“ҚдҪңеҜ№иҝӣйҳҹеҲ—иҝӣиЎҢиҜ»еҶҷж“ҚдҪңпјҢж¶ҲйҷӨдәҶдёҙз•ҢеҢәгҖӮ并дҪҝз”ЁCache Line PaddingдёҺи„ҸиҜ»зј“еӯҳеҠ йҖҹпјҢеҗҢж—¶еҸҜе®ҡеҲ¶еӨҡз§Қзӯүеҫ…зӯ–з•Ҙ(Spin/Yield/Block)пјҢйҒҝе…ҚйҳҹеҲ—дёәз©әжҲ–дёәж»Ўж—¶пјҢйў‘з№Ғиҝӣе…ҘParkзҠ¶жҖҒгҖӮLindormBlockingQueueзҡ„жҖ§иғҪйқһеёёзӘҒеҮәпјҢзӣёжҜ”дәҺеҺҹе…Ҳзҡ„LinkedBlockingQueueжҖ§иғҪжҸҗеҚҮ4еҖҚд»ҘдёҠгҖӮ
#### VersionBasedSynchronizer
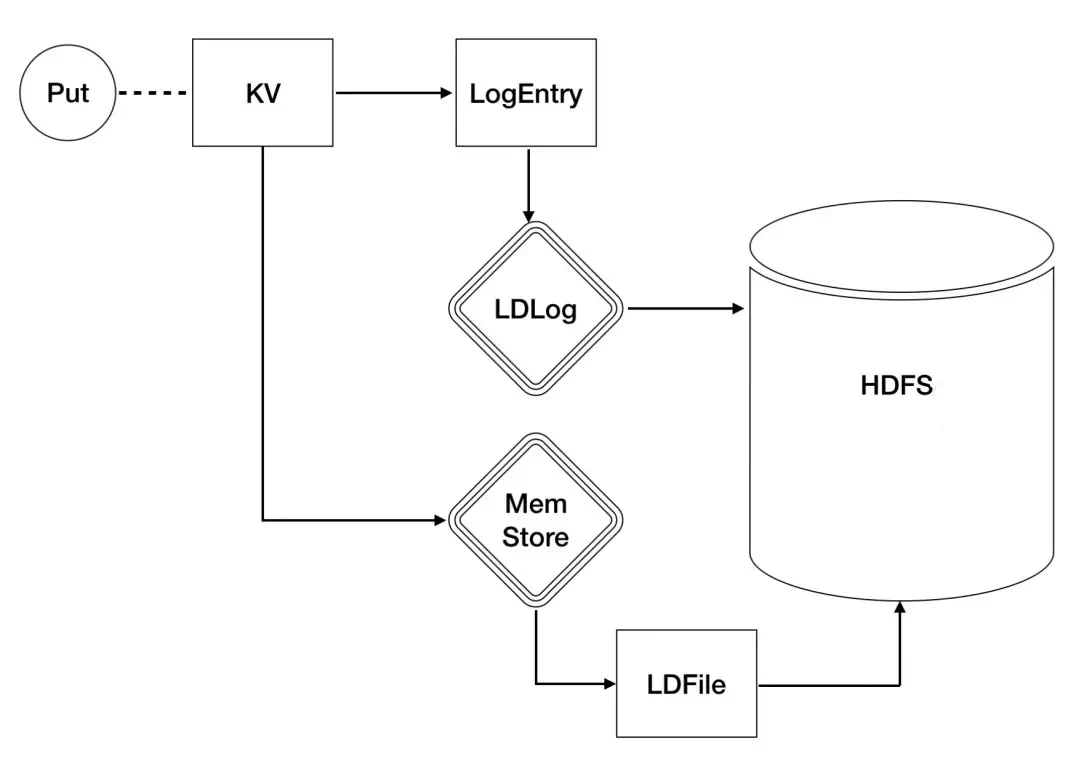
LDLogжҳҜLindormдёӯз”ЁдәҺзі»з»ҹfailoverж—¶иҝӣиЎҢж•°жҚ®жҒўеӨҚж—¶зҡ„ж—Ҙеҝ—пјҢд»Ҙдҝқйҡңж•°жҚ®зҡ„еҺҹеӯҗжҖ§е’ҢеҸҜйқ жҖ§гҖӮеңЁжҜҸж¬Ўж•°жҚ®еҶҷе…Ҙж—¶пјҢйғҪеҝ…йЎ»е…ҲеҶҷе…ҘLDLogгҖӮ
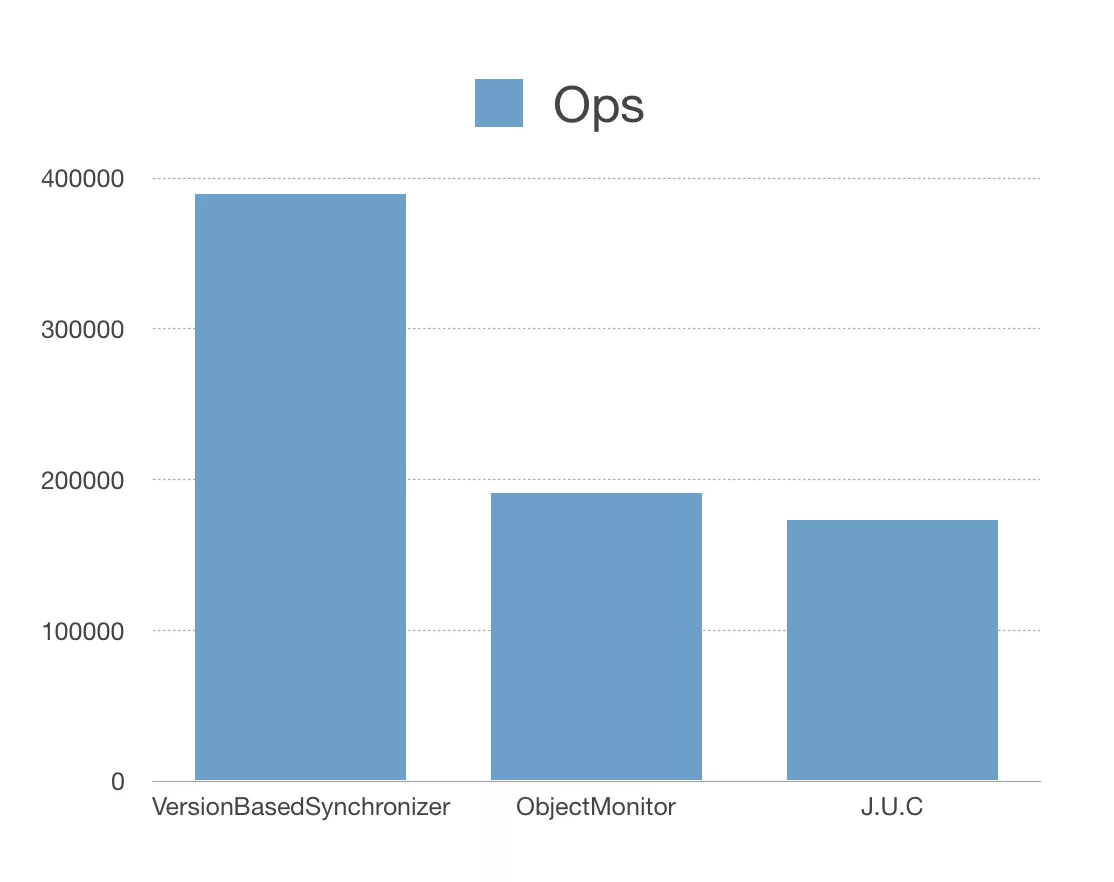
LDLogеҶҷе…ҘжҲҗеҠҹд№ӢеҗҺпјҢжүҚеҸҜд»ҘиҝӣиЎҢеҗҺз»ӯзҡ„еҶҷе…Ҙmemstoreзӯүж“ҚдҪңгҖӮеӣ жӯӨLindormдёӯзҡ„HandlerйғҪеҝ…йЎ»зӯүеҫ…WALеҶҷе…Ҙе®ҢжҲҗеҗҺеҶҚиў«е”ӨйҶ’д»ҘиҝӣиЎҢдёӢдёҖжӯҘж“ҚдҪңпјҢеңЁй«ҳеҺӢжқЎд»¶дёӢпјҢж— з”Ёе”ӨйҶ’дјҡйҖ жҲҗеӨ§йҮҸзҡ„CPU Context SwitchйҖ жҲҗжҖ§иғҪдёӢйҷҚгҖӮй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢLindormз ”еҸ‘дәҶеҹәдәҺзүҲжң¬зҡ„й«ҳ并еҸ‘еӨҡи·ҜзәҝзЁӢеҗҢжӯҘжңәеҲ¶(VersionBasedSynchronizer)жқҘеӨ§е№…дјҳеҢ–дёҠдёӢж–ҮеҲҮжҚўгҖӮ
VersionBasedSynchronizerзҡ„дё»иҰҒжҖқи·ҜжҳҜи®©Handlerзҡ„зӯүеҫ…жқЎд»¶иў«Notifierж„ҹзҹҘпјҢеҮҸе°‘Notifierзҡ„е”ӨйҶ’еҺӢеҠӣгҖӮз»ҸиҝҮжЁЎеқ—жөӢиҜ•VersionBasedSynchronizerзҡ„ж•ҲзҺҮжҳҜJDKиҮӘеёҰзҡ„ObjectMonitorе’ҢJ.U.C(java util concurrentеҢ…)зҡ„дёӨеҖҚд»ҘдёҠгҖӮ
#### е…Ёйқўж— й”ҒеҢ–
HBaseеҶ…ж ёеңЁе…ій”®и·Ҝеҫ„дёҠжңүеӨ§йҮҸзҡ„й”ҒпјҢеңЁй«ҳ并еҸ‘еңәжҷҜдёӢпјҢиҝҷдәӣй”ҒйғҪдјҡйҖ жҲҗзәҝзЁӢдәүжҠўе’ҢжҖ§иғҪдёӢйҷҚгҖӮLindormеҶ…ж ёеҜ№е…ій”®й“ҫи·ҜдёҠзҡ„й”ҒйғҪеҒҡдәҶж— й”ҒеҢ–еӨ„зҗҶпјҢеҰӮMVCCпјҢWALжЁЎеқ—дёӯзҡ„й”ҒгҖӮ
еҸҰеӨ–пјҢHBaseеңЁиҝҗиЎҢиҝҮзЁӢдёӯдјҡдә§з”ҹзҡ„еҗ„з§ҚжҢҮж ҮпјҢеҰӮqpsпјҢrtпјҢcacheе‘ҪдёӯзҺҮзӯүзӯүгҖӮиҖҢеңЁи®°еҪ•иҝҷдәӣMetricsзҡ„вҖңдёҚиө·зңјвҖқж“ҚдҪңдёӯпјҢд№ҹдјҡжңүеӨ§йҮҸзҡ„й”ҒгҖӮйқўеҜ№иҝҷж ·зҡ„й—®йўҳпјҢLindormеҖҹйүҙдәҶtcmallocзҡ„жҖқжғіпјҢејҖеҸ‘дәҶLindormThreadCacheCounterпјҢжқҘи§ЈеҶіMetricsзҡ„жҖ§иғҪй—®йўҳгҖӮ
#### HandlerеҚҸзЁӢеҢ–
еңЁй«ҳ并еҸ‘еә”з”ЁдёӯпјҢдёҖдёӘRPCиҜ·жұӮзҡ„е®һзҺ°еҫҖеҫҖеҢ…еҗ«еӨҡдёӘеӯҗжЁЎеқ—пјҢж¶үеҸҠеҲ°иӢҘе№Іж¬ЎIOгҖӮиҝҷдәӣеӯҗжЁЎеқ—зҡ„зӣёдә’еҚҸдҪңпјҢзі»з»ҹзҡ„ContextSwitchзӣёеҪ“йў‘з№ҒгҖӮ
ContextSwitchзҡ„дјҳеҢ–жҳҜй«ҳ并еҸ‘зі»з»ҹз»•дёҚејҖзҡ„иҜқйўҳпјҢеҗ„дҪҚй«ҳжүӢйғҪеҗ„жҳҫзҘһйҖҡпјҢдёҡз•ҢжңүйқһеёёеӨҡзҡ„жҖқжғідёҺе®һи·өгҖӮе…¶дёӯcoroutine(еҚҸзЁӢ)е’ҢSEDA(еҲҶйҳ¶ж®өдәӢ件й©ұеҠЁ)ж–№жЎҲжҳҜжҲ‘们зқҖйҮҚиҖғеҜҹзҡ„ж–№жЎҲгҖӮ
еҹәдәҺе·ҘзЁӢд»Јд»·пјҢеҸҜз»ҙжҠӨжҖ§пјҢд»Јз ҒеҸҜиҜ»жҖ§дёүдёӘи§’еәҰиҖғиҷ‘пјҢLindormйҖүжӢ©дәҶеҚҸзЁӢзҡ„ж–№ејҸиҝӣиЎҢејӮжӯҘеҢ–дјҳеҢ–гҖӮжҲ‘们еҲ©з”ЁдәҶйҳҝйҮҢJVMеӣўйҳҹжҸҗдҫӣзҡ„Dragonwell JDKеҶ…зҪ®зҡ„Wisp2.0еҠҹиғҪе®һзҺ°дәҶHBase Handlerзҡ„еҚҸзЁӢеҢ–пјҢWisp2.0ејҖз®ұеҚіз”ЁпјҢжңүж•Ҳең°еҮҸе°‘дәҶзі»з»ҹзҡ„иө„жәҗж¶ҲиҖ—пјҢдјҳеҢ–ж•ҲжһңжҜ”иҫғе®ўи§ӮгҖӮ
#### е…Ёж–°Encodingз®—жі•
д»ҺжҖ§иғҪи§’еәҰиҖғиҷ‘пјҢHBaseйҖҡеёёйңҖиҰҒе°ҶMetaдҝЎжҒҜиЈ…иҪҪиҝӣblock cacheгҖӮеҰӮжһңе°ҶblockеӨ§е°Ҹиҫғе°ҸпјҢMetaдҝЎжҒҜиҫғеӨҡпјҢдјҡеҮәзҺ°Metaж— жі•е®Ңе…ЁиЈ…е…ҘCacheзҡ„жғ…еҶө, жҖ§иғҪдёӢйҷҚгҖӮеҰӮжһңblockеӨ§е°ҸиҫғеӨ§пјҢз»ҸиҝҮEncodingзҡ„blockзҡ„йЎәеәҸжҹҘиҜўзҡ„жҖ§иғҪдјҡжҲҗдёәйҡҸжңәиҜ»зҡ„жҖ§иғҪ瓶йўҲгҖӮй’ҲеҜ№иҝҷдёҖжғ…еҶөпјҢLindormе…Ёж–°ејҖеҸ‘дәҶIndexable Delta EncodingпјҢеңЁblockеҶ…йғЁд№ҹеҸҜд»ҘйҖҡиҝҮзҙўеј•иҝӣиЎҢеҝ«йҖҹжҹҘиҜўпјҢseekжҖ§иғҪжңүдәҶиҫғеӨ§жҸҗй«ҳгҖӮIndexable Delta EncodingеҺҹзҗҶеҰӮеӣҫжүҖзӨәпјҡ
йҖҡиҝҮIndexable Delta EncodingпјҢ HFileзҡ„йҡҸжңәseekжҖ§иғҪзӣёеҜ№дәҺдҪҝз”Ёд№ӢеүҚзҝ»дәҶдёҖеҖҚпјҢд»Ҙ64K blockдёәдҫӢпјҢйҡҸжңәseekжҖ§иғҪеҹәжң¬дёҺдёҚеҒҡencodingзӣёиҝ‘пјҲе…¶д»–encodingз®—жі•дјҡжңүдёҖе®ҡжҖ§иғҪжҚҹеӨұпјүгҖӮеңЁе…Ёcacheе‘Ҫдёӯзҡ„йҡҸжңәGetеңәжҷҜдёӢпјҢзӣёеҜ№дәҺDiff encoding RTдёӢйҷҚ50%гҖӮ
#### е…¶д»–
зӣёжҜ”зӨҫеҢәзүҲHBaseпјҢLindormиҝҳжңүеӨҡиҫҫеҮ еҚҒйЎ№зҡ„жҖ§иғҪдјҳеҢ–е’ҢйҮҚжһ„пјҢеј•е…ҘдәҶдј—еӨҡж–°жҠҖжңҜпјҢз”ұдәҺзҜҮе№…жңүйҷҗпјҢиҝҷйҮҢеҸӘиғҪеҲ—дёҫдёҖйғЁеҲҶпјҢе…¶д»–зҡ„ж ёеҝғжҠҖжңҜпјҢжҜ”еҰӮпјҡ
> CCSMapВ
> иҮӘеҠЁи§„йҒҝж•…йҡңиҠӮзӮ№зҡ„并еҸ‘дёүеүҜжң¬ж—Ҙеҝ—еҚҸи®® (Quorum-based write)В
> й«ҳж•Ҳзҡ„жү№йҮҸз»„жҸҗдәӨ(Group Commit)В
> ж— зўҺзүҮзҡ„й«ҳжҖ§иғҪзј“еӯҳвҖ”Shared BucketCacheВ
> Memstore BloomfilterВ
> йқўеҗ‘иҜ»еҶҷзҡ„й«ҳж•Ҳж•°жҚ®з»“жһ„В
> GC-InvisibleеҶ…еӯҳз®ЎзҗҶВ
> еңЁзәҝи®Ўз®—дёҺзҰ»зәҝдҪңдёҡжһ¶жһ„еҲҶзҰ»В
> JDK/ж“ҚдҪңзі»з»ҹж·ұеәҰдјҳеҢ–В
> FPGA offloading CompactionВ
> з”ЁжҲ·жҖҒTCPеҠ йҖҹВ
> вҖҰвҖҰ
дё°еҜҢзҡ„жҹҘиҜўжЁЎеһӢпјҢйҷҚдҪҺејҖеҸ‘й—Ёж§ӣ
--------------
еҺҹз”ҹзҡ„HBaseеҸӘж”ҜжҢҒKVз»“жһ„зҡ„жҹҘиҜўпјҢиҷҪ然з®ҖеҚ•пјҢдҪҶжҳҜеңЁйқўеҜ№еҗ„йЎ№дёҡеҠЎзҡ„еӨҚжқӮйңҖжұӮж—¶пјҢжҳҫзҡ„жңүзӮ№еҠӣдёҚд»ҺеҝғгҖӮеӣ жӯӨпјҢеңЁLindormдёӯпјҢжҲ‘们й’ҲеҜ№дёҚеҗҢдёҡеҠЎзҡ„зү№зӮ№пјҢз ”еҸ‘дәҶеӨҡз§ҚжҹҘиҜўжЁЎеһӢпјҢйҖҡиҝҮжӣҙйқ иҝ‘еңәжҷҜзҡ„APIе’Ңзҙўеј•и®ҫи®ЎпјҢйҷҚдҪҺејҖеҸ‘й—Ёж§ӣгҖӮ
#### WideColumn жЁЎеһӢпјҲеҺҹз”ҹHBase APIпјү
WideColumnжҳҜдёҖз§ҚдёҺHBaseе®Ңе…ЁдёҖиҮҙзҡ„и®ҝй—®жЁЎеһӢе’Ңж•°жҚ®з»“жһ„пјҢд»ҺиҖҢдҪҝеҫ—LindromиғҪ100%е…је®№HBaseзҡ„APIгҖӮз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮLindormжҸҗдҫӣзҡ„й«ҳжҖ§иғҪеҺҹз”ҹе®ўжҲ·з«Ҝдёӯзҡ„WideColumn APIи®ҝй—®LindormпјҢд№ҹеҸҜд»ҘйҖҡиҝҮalihbase-connectorиҝҷдёӘжҸ’件пјҢдҪҝз”ЁHBaseе®ўжҲ·з«ҜеҸҠAPI(ж— йңҖд»»дҪ•д»Јз Ғж”№йҖ )зӣҙжҺҘи®ҝй—®LindormгҖӮ
еҗҢж—¶пјҢLindormдҪҝз”ЁдәҶиҪ»е®ўжҲ·з«Ҝзҡ„и®ҫи®ЎпјҢе°ҶеӨ§йҮҸж•°жҚ®и·Ҝз”ұгҖҒжү№йҮҸеҲҶеҸ‘гҖҒи¶…ж—¶гҖҒйҮҚиҜ•зӯүйҖ»иҫ‘дёӢжІүеҲ°жңҚеҠЎз«ҜпјҢ并еңЁзҪ‘з»ңдј иҫ“еұӮеҒҡдәҶеӨ§йҮҸзҡ„дјҳеҢ–пјҢдҪҝеҫ—еә”з”Ёз«Ҝзҡ„CPUж¶ҲиҖ—еҸҜд»ҘеӨ§еӨ§иҠӮзңҒгҖӮеғҸдёӢиЎЁдёӯпјҢзӣёжҜ”дәҺHBaseпјҢдҪҝз”ЁLindormеҗҺзҡ„еә”з”Ёдҫ§CPUдҪҝз”Ёж•ҲзҺҮжҸҗеҚҮ60%пјҢзҪ‘з»ңеёҰе®Ҫж•ҲзҺҮжҸҗеҚҮ25%гҖӮ
жіЁпјҡиЎЁдёӯзҡ„е®ўжҲ·з«ҜCPUд»ЈиЎЁHBase/Lindormе®ўжҲ·з«Ҝж¶ҲиҖ—зҡ„CPUиө„жәҗпјҢи¶Ҡе°Ҹи¶ҠеҘҪгҖӮ
еңЁHBaseеҺҹз”ҹAPIдёҠпјҢжҲ‘们иҝҳзӢ¬е®¶ж”ҜжҢҒдәҶй«ҳжҖ§иғҪдәҢзә§зҙўеј•пјҢз”ЁжҲ·еҸҜд»ҘдҪҝз”ЁHBaseеҺҹз”ҹAPIеҶҷе…Ҙж•°жҚ®иҝҮзЁӢдёӯпјҢзҙўеј•ж•°жҚ®йҖҸжҳҺең°еҶҷе…Ҙзҙўеј•иЎЁгҖӮеңЁжҹҘиҜўиҝҮзЁӢдёӯпјҢжҠҠеҸҜиғҪе…ЁиЎЁжү«зҡ„Scan + FilterеӨ§жҹҘиҜўпјҢеҸҳжҲҗеҸҜд»Ҙе…ҲеҺ»жҹҘиҜўзҙўеј•иЎЁпјҢеӨ§еӨ§жҸҗй«ҳдәҶжҹҘиҜўжҖ§иғҪгҖӮе…ідәҺй«ҳжҖ§иғҪеҺҹз”ҹдәҢзә§зҙўеј•пјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғпјҡ
[https://help.aliyun.com/document\_detail/144577.html](https://help.aliyun.com/document_detail/144577.html)
#### TableServiceжЁЎеһӢ(SQLгҖҒдәҢзә§зҙўеј•)
HBaseдёӯеҸӘж”ҜжҢҒRowkeyиҝҷдёҖз§Қзҙўеј•ж–№ејҸпјҢеҜ№дәҺеӨҡеӯ—ж®өжҹҘиҜўж—¶пјҢйҖҡеёёж•ҲзҺҮдҪҺдёӢгҖӮдёәжӯӨпјҢз”ЁжҲ·йңҖиҰҒз»ҙжҠӨеӨҡдёӘиЎЁжқҘж»Ўи¶ідёҚеҗҢеңәжҷҜзҡ„жҹҘиҜўйңҖжұӮпјҢиҝҷеңЁдёҖе®ҡзЁӢеәҰдёҠж—ўеўһеҠ дәҶеә”з”Ёзҡ„ејҖеҸ‘еӨҚжқӮжҖ§пјҢд№ҹдёҚиғҪеҫҲе®ҢзҫҺең°дҝқиҜҒж•°жҚ®дёҖиҮҙжҖ§е’ҢеҶҷе…Ҙж•ҲзҺҮгҖӮ并且HBaseдёӯеҸӘжҸҗдҫӣдәҶKV APIпјҢеҸӘиғҪеҒҡPutгҖҒGetгҖҒScanзӯүз®ҖеҚ•APIж“ҚдҪңпјҢд№ҹжІЎжңүж•°жҚ®зұ»еһӢпјҢжүҖжңүзҡ„ж•°жҚ®йғҪеҝ…йЎ»з”ЁжҲ·иҮӘе·ұиҪ¬жҚўе’ҢеӮЁеӯҳгҖӮеҜ№дәҺд№ жғҜдәҶSQLиҜӯиЁҖзҡ„ејҖеҸ‘иҖ…жқҘиҜҙпјҢе…Ҙй—Ёзҡ„й—Ёж§ӣйқһеёёй«ҳпјҢиҖҢдё”е®№жҳ“еҮәй”ҷгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёҖз—ӣзӮ№пјҢйҷҚдҪҺз”ЁжҲ·дҪҝз”Ёй—Ёж§ӣпјҢжҸҗй«ҳејҖеҸ‘ж•ҲзҺҮпјҢеңЁLindormдёӯжҲ‘们еўһеҠ дәҶTableServiceжЁЎеһӢпјҢе…¶жҸҗдҫӣдё°еҜҢзҡ„ж•°жҚ®зұ»еһӢгҖҒз»“жһ„еҢ–жҹҘиҜўиЎЁиҫҫAPIпјҢ并еҺҹз”ҹж”ҜжҢҒSQLи®ҝй—®е’Ңе…ЁеұҖдәҢзә§зҙўеј•пјҢи§ЈеҶідәҶдј—еӨҡзҡ„жҠҖжңҜжҢ‘жҲҳпјҢеӨ§е№…йҷҚдҪҺжҷ®йҖҡз”ЁжҲ·зҡ„ејҖеҸ‘й—Ёж§ӣгҖӮйҖҡиҝҮSQLе’ҢSQL likeзҡ„APIпјҢз”ЁжҲ·еҸҜд»Ҙж–№дҫҝең°еғҸдҪҝз”Ёе…ізі»ж•°жҚ®еә“йӮЈж ·дҪҝз”ЁLindormгҖӮдёӢйқўжҳҜдёҖдёӘLindorm SQLзҡ„з®ҖеҚ•зӨәдҫӢгҖӮ
\*иҜ·е·ҰеҸіж»‘еҠЁйҳ…и§Ҳ
```
-- дё»иЎЁе’Ңзҙўеј•DDL
create table shop_item_relation (
shop_id varchar,
item_id varchar,
status varchar
constraint primary key(shop_id, item_id)) ;
create index idx1 on shop_item_relation (item_id) include (ALL); -- еҜ№з¬¬дәҢеҲ—дё»й”®е»әзҙўеј•пјҢеҶ—дҪҷжүҖжңүеҲ—
create index idx2 on shop_item_relation (shop_id, status) include (ALL); -- еӨҡеҲ—зҙўеј•пјҢеҶ—дҪҷжүҖжңүеҲ—
-- еҶҷе…Ҙж•°жҚ®пјҢдјҡеҗҢжӯҘжӣҙж–°2дёӘзҙўеј•
upsert into shop_item_relation values('shop1', 'item1', 'active');
upsert into shop_item_relation values('shop1', 'item2', 'invalid');
-- ж №жҚ®WHEREеӯҗеҸҘиҮӘеҠЁйҖүжӢ©еҗҲйҖӮзҡ„зҙўеј•жү§иЎҢжҹҘиҜў
select * from shop_item_relation where item_id = 'item2'; -- е‘Ҫдёӯidx1
select * from shop_item_relation where shop_id = 'shop1' and status = 'invalid'; -- е‘Ҫдёӯidx2
```

зӣёжҜ”дәҺе…ізі»ж•°жҚ®еә“зҡ„SQLпјҢLindormдёҚе…·еӨҮеӨҡиЎҢдәӢеҠЎе’ҢеӨҚжқӮеҲҶжһҗ(еҰӮJoinгҖҒGroupby)зҡ„иғҪеҠӣпјҢиҝҷд№ҹжҳҜдёӨиҖ…д№Ӣй—ҙзҡ„е®ҡдҪҚе·®ејӮгҖӮ
зӣёжҜ”дәҺHBaseдёҠPhoenix组件жҸҗдҫӣзҡ„дәҢзә§зҙўеј•пјҢLindormзҡ„дәҢзә§зҙўеј•еңЁеҠҹиғҪгҖҒжҖ§иғҪгҖҒзЁіе®ҡжҖ§дёҠиҝңиҝңи¶…иҝҮPhoenixпјҢдёӢеӣҫжҳҜдёҖдёӘз®ҖеҚ•зҡ„жҖ§иғҪеҜ№жҜ”гҖӮ
жіЁпјҡиҜҘжЁЎеһӢе·Із»ҸеңЁйҳҝйҮҢдә‘HBaseеўһејәзүҲдёҠеҶ…жөӢпјҢж„ҹе…ҙи¶Јзҡ„з”ЁжҲ·еҸҜд»ҘиҒ”зі»дә‘HBaseзӯ”з–‘й’үй’үеҸ·жҲ–иҖ…еңЁйҳҝйҮҢдә‘дёҠеҸ‘иө·е·ҘеҚ•е’ЁиҜўгҖӮ
#### FeedStreamжЁЎеһӢ
зҺ°д»Јдә’иҒ”зҪ‘жһ¶жһ„дёӯпјҢж¶ҲжҒҜйҳҹеҲ—жүҝжӢ…дәҶйқһеёёйҮҚиҰҒзҡ„иҒҢиҙЈпјҢеҸҜд»ҘжһҒеӨ§зҡ„жҸҗеҚҮж ёеҝғзі»з»ҹзҡ„жҖ§иғҪе’ҢзЁіе®ҡжҖ§гҖӮе…¶е…ёеһӢзҡ„еә”з”ЁеңәжҷҜжңүеҢ…жӢ¬зі»з»ҹи§ЈиҖҰпјҢеүҠеі°йҷҗжөҒпјҢж—Ҙеҝ—йҮҮйӣҶпјҢжңҖз»ҲдёҖиҮҙдҝқиҜҒпјҢеҲҶеҸ‘жҺЁйҖҒзӯүзӯүгҖӮ
еёёи§Ғзҡ„ж¶ҲжҒҜйҳҹеҲ—еҢ…жӢ¬RabbitMqпјҢKafkaд»ҘеҸҠRocketMqзӯүзӯүгҖӮиҝҷдәӣж•°жҚ®еә“е°Ҫз®Ўд»Һжһ¶жһ„е’ҢдҪҝз”Ёж–№ејҸе’ҢжҖ§иғҪдёҠз•ҘжңүдёҚеҗҢпјҢдҪҶе…¶еҹәжң¬дҪҝз”ЁеңәжҷҜйғҪзӣёеҜ№жҺҘиҝ‘гҖӮ然иҖҢпјҢдј з»ҹзҡ„ж¶ҲжҒҜйҳҹеҲ—并йқһе®ҢзҫҺпјҢе…¶еңЁж¶ҲжҒҜжҺЁйҖҒпјҢfeedжөҒзӯүеңәжҷҜеӯҳеңЁд»ҘдёӢй—®йўҳпјҡ
> еӯҳеӮЁпјҡдёҚйҖӮеҗҲй•ҝжңҹдҝқеӯҳж•°жҚ®пјҢйҖҡеёёиҝҮжңҹж—¶й—ҙйғҪеңЁеӨ©зә§В
> еҲ йҷӨиғҪеҠӣпјҡдёҚж”ҜжҢҒеҲ йҷӨжҢҮе®ҡж•°жҚ®entryВ
> жҹҘиҜўиғҪеҠӣпјҡдёҚж”ҜжҢҒиҫғдёәеӨҚжқӮзҡ„жҹҘиҜўе’ҢиҝҮж»ӨжқЎд»¶В
> дёҖиҮҙжҖ§е’ҢжҖ§иғҪйҡҫд»ҘеҗҢж—¶дҝқиҜҒпјҡзұ»дјјдәҺKafkaд№Ӣзұ»зҡ„ж•°жҚ®еә“жӣҙйҮҚеҗһеҗҗпјҢдёәдәҶжҸҗй«ҳжҖ§иғҪеӯҳеңЁдәҶжҹҗдәӣзҠ¶еҶөдёӢдёўж•°жҚ®зҡ„еҸҜиғҪпјҢиҖҢдәӢеҠЎеӨ„зҗҶиғҪеҠӣиҫғеҘҪзҡ„ж¶ҲжҒҜйҳҹеҲ—еҗһеҗҗеҸҲиҫғдёәеҸ—йҷҗгҖӮВ
> Partitionеҝ«йҖҹжӢ“еұ•иғҪеҠӣпјҡйҖҡеёёдёҖдёӘTopcдёӢзҡ„partitionж•°зӣ®йғҪжҳҜеӣәе®ҡпјҢдёҚж”ҜжҢҒеҝ«йҖҹжү©еұ•гҖӮВ
> зү©зҗҶйҳҹеҲ—/йҖ»иҫ‘йҳҹеҲ—пјҡйҖҡеёёеҸӘж”ҜжҢҒе°‘йҮҸзү©зҗҶйҳҹеҲ—(еҰӮжҜҸдёӘpartitionеҸҜд»ҘзңӢжҲҗдёҖдёӘйҳҹеҲ—)пјҢиҖҢдёҡеҠЎйңҖиҰҒзҡ„еңЁзү©зҗҶйҳҹеҲ—зҡ„еҹәзЎҖдёҠжЁЎжӢҹеҮәйҖ»иҫ‘йҳҹеҲ—пјҢеҰӮIMзі»з»ҹдёӯдёәжҜҸдёӘз”ЁжҲ·з»ҙжҠӨдёҖдёӘйҖ»иҫ‘дёҠзҡ„ж¶ҲжҒҜйҳҹеҲ—пјҢз”ЁжҲ·еҫҖеҫҖйңҖиҰҒеҫҲеӨҡйўқеӨ–зҡ„ејҖеҸ‘е·ҘдҪңгҖӮ
й’ҲеҜ№дёҠиҝ°йңҖжұӮпјҢLindormжҺЁеҮәдәҶйҳҹеҲ—жЁЎеһӢFeedStreamServiceпјҢиғҪеӨҹи§ЈеҶіжө·йҮҸз”ЁжҲ·дёӢзҡ„ж¶ҲжҒҜеҗҢжӯҘпјҢи®ҫеӨҮйҖҡзҹҘпјҢиҮӘеўһIDеҲҶй…Қзӯүй—®йўҳгҖӮ
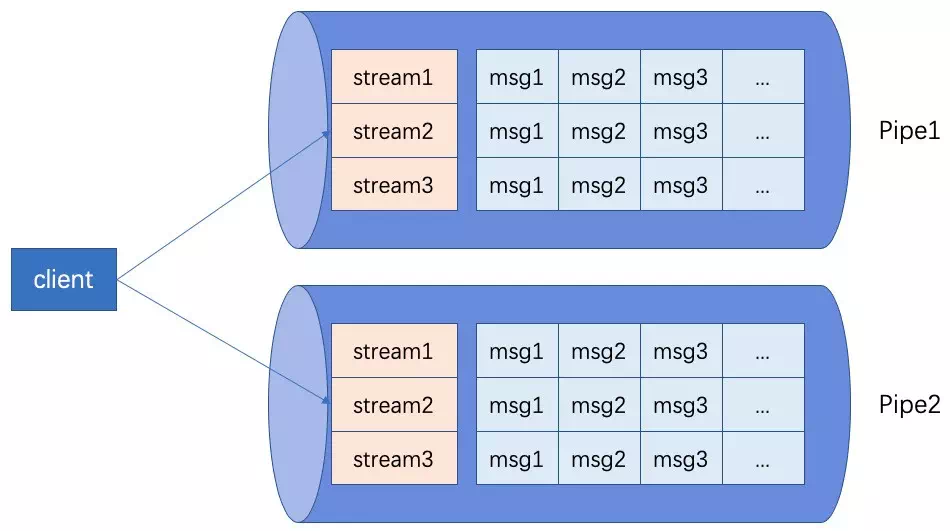
FeedStreamжЁЎеһӢеңЁд»Ҡе№ҙжүӢжңәж·ҳе®қж¶ҲжҒҜзі»з»ҹдёӯжү®жј”дәҶйҮҚиҰҒи§’иүІпјҢи§ЈеҶідәҶжүӢжңәж·ҳе®қж¶ҲжҒҜжҺЁйҖҒдҝқеәҸпјҢе№ӮзӯүзӯүйҡҫйўҳгҖӮеңЁд»Ҡе№ҙеҸҢеҚҒдёҖдёӯпјҢжүӢж·ҳзҡ„зӣ–жҘје’ҢеӣһиЎҖеӨ§зәўеҢ…жҺЁйҖҒйғҪжңүLindormзҡ„иә«еҪұгҖӮжүӢж·ҳж¶ҲжҒҜзҡ„жҺЁйҖҒдёӯпјҢеі°еҖји¶…иҝҮдәҶ100w/sпјҢеҒҡеҲ°дәҶеҲҶй’ҹзә§жҺЁйҖҒе…ЁзҪ‘з”ЁжҲ·гҖӮ
жіЁпјҡиҜҘжЁЎеһӢе·Із»ҸеңЁйҳҝйҮҢдә‘HBaseеўһејәзүҲдёҠеҶ…жөӢпјҢж„ҹе…ҙи¶Јзҡ„з”ЁжҲ·еҸҜд»ҘиҒ”зі»дә‘HBaseзӯ”з–‘й’үй’үеҸ·жҲ–иҖ…еңЁйҳҝйҮҢдә‘дёҠеҸ‘иө·е·ҘеҚ•е’ЁиҜўгҖӮ
е…Ёж–Үзҙўеј•жЁЎеһӢ
------
иҷҪ然Lindormдёӯзҡ„TableServiceжЁЎеһӢжҸҗдҫӣдәҶж•°жҚ®зұ»еһӢе’ҢдәҢзә§зҙўеј•гҖӮдҪҶжҳҜпјҢеңЁйқўеҜ№еҗ„з§ҚеӨҚжқӮжқЎд»¶жҹҘиҜўе’Ңе…Ёж–Үзҙўеј•зҡ„йңҖжұӮдёӢпјҢиҝҳжҳҜжҳҫеҫ—еҠӣдёҚд»ҺеҝғпјҢиҖҢSolrе’ҢESжҳҜдјҳз§Җзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺгҖӮ
дҪҝз”ЁLindorm+Solr/ESпјҢеҸҜд»ҘжңҖеӨ§йҷҗеәҰеҸ‘жҢҘLindormе’ҢSolr/ESеҗ„иҮӘзҡ„дјҳзӮ№пјҢд»ҺиҖҢдҪҝеҫ—жҲ‘们еҸҜд»Ҙжһ„е»әеӨҚжқӮзҡ„еӨ§ж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўжңҚеҠЎгҖӮLindormеҶ…зҪ®дәҶеӨ–йғЁзҙўеј•еҗҢжӯҘ组件пјҢиғҪеӨҹиҮӘеҠЁең°е°ҶеҶҷе…ҘLindormзҡ„ж•°жҚ®еҗҢжӯҘеҲ°еӨ–йғЁзҙўеј•з»„件еҰӮSolrжҲ–иҖ…ESдёӯгҖӮиҝҷз§ҚжЁЎеһӢйқһеёёйҖӮеҗҲйңҖиҰҒдҝқеӯҳеӨ§йҮҸж•°жҚ®пјҢиҖҢжҹҘиҜўжқЎд»¶зҡ„еӯ—ж®өж•°жҚ®д»…еҚ еҺҹж•°жҚ®зҡ„дёҖе°ҸйғЁеҲҶпјҢ并且йңҖиҰҒеҗ„з§ҚжқЎд»¶з»„еҗҲжҹҘиҜўзҡ„дёҡеҠЎпјҢдҫӢеҰӮпјҡ
> еёёи§Ғзү©жөҒдёҡеҠЎеңәжҷҜпјҢйңҖиҰҒеӯҳеӮЁеӨ§йҮҸиҪЁиҝ№зү©жөҒдҝЎжҒҜпјҢ并йңҖж №жҚ®еӨҡдёӘеӯ—ж®өд»»ж„Ҹз»„еҗҲжҹҘиҜўжқЎд»¶В
> дәӨйҖҡзӣ‘жҺ§дёҡеҠЎеңәжҷҜпјҢдҝқеӯҳеӨ§йҮҸиҝҮиҪҰи®°еҪ•пјҢеҗҢж—¶дјҡж №жҚ®иҪҰиҫҶдҝЎжҒҜд»»ж„ҸжқЎд»¶з»„еҗҲжЈҖзҙўеҮәж„ҹе…ҙи¶Јзҡ„и®°еҪ•В
> еҗ„з§ҚзҪ‘з«ҷдјҡе‘ҳгҖҒе•Ҷе“ҒдҝЎжҒҜжЈҖзҙўеңәжҷҜпјҢдёҖиҲ¬дҝқеӯҳеӨ§йҮҸзҡ„е•Ҷе“Ғ/дјҡе‘ҳдҝЎжҒҜпјҢ并йңҖиҰҒж №жҚ®е°‘йҮҸжқЎд»¶иҝӣиЎҢеӨҚжқӮдё”д»»ж„Ҹзҡ„жҹҘиҜўпјҢд»Ҙж»Ўи¶ізҪ‘з«ҷз”ЁжҲ·д»»ж„ҸжҗңзҙўйңҖжұӮзӯүгҖӮ
е…Ёж–Үзҙўеј•жЁЎеһӢе·Із»ҸеңЁйҳҝйҮҢдә‘дёҠзәҝпјҢж”ҜжҢҒSolr/ESеӨ–йғЁзҙўеј•гҖӮзӣ®еүҚпјҢзҙўеј•зҡ„жҹҘиҜўз”ЁжҲ·иҝҳйңҖиҰҒзӣҙжҺҘжҹҘиҜўSolr/ESеҶҚжқҘеҸҚжҹҘLindormпјҢеҗҺз»ӯжҲ‘们дјҡз”ЁTableServiceзҡ„иҜӯжі•жҠҠжҹҘиҜўеӨ–йғЁзҙўеј•зҡ„иҝҮзЁӢеҢ…иЈ…иө·жқҘпјҢз”ЁжҲ·е…ЁзЁӢеҸӘйңҖиҰҒе’ҢLindormдәӨдә’пјҢеҚіеҸҜиҺ·еҫ—е…Ёж–Үзҙўеј•зҡ„иғҪеҠӣгҖӮ
#### жӣҙеӨҡжЁЎеһӢеңЁи·ҜдёҠ
йҷӨдәҶдёҠиҝ°иҝҷдәӣжЁЎеһӢпјҢжҲ‘们иҝҳдјҡж №жҚ®дёҡеҠЎзҡ„йңҖжұӮе’Ңз—ӣзӮ№пјҢејҖеҸ‘жӣҙеӨҡз®ҖеҚ•жҳ“з”Ёзҡ„жЁЎеһӢпјҢж–№дҫҝз”ЁжҲ·дҪҝз”ЁпјҢйҷҚдҪҺдҪҝз”Ёй—Ёж§ӣгҖӮеғҸж—¶еәҸжЁЎеһӢпјҢеӣҫжЁЎеһӢзӯүпјҢйғҪе·Із»ҸеңЁи·ҜдёҠпјҢ敬иҜ·жңҹеҫ…гҖӮ
йӣ¶е№Ійў„гҖҒз§’жҒўеӨҚзҡ„й«ҳеҸҜз”ЁиғҪеҠӣ
-------------
д»ҺдёҖдёӘе©ҙе„ҝжҲҗй•ҝдёәйқ’е№ҙпјҢйҳҝйҮҢHBaseж‘”иҝҮеҫҲеӨҡж¬ЎпјҢз”ҡиҮіеӨҙз ҙиЎҖжөҒпјҢжҲ‘们еңЁе®ўжҲ·зҡ„дҝЎд»»д№ӢдёӢе№ёиҝҗзҡ„жҲҗй•ҝгҖӮеңЁ9е№ҙзҡ„йҳҝйҮҢеә”з”ЁиҝҮзЁӢдёӯпјҢжҲ‘们з§ҜзҙҜдәҶеӨ§йҮҸзҡ„й«ҳеҸҜз”ЁжҠҖжңҜпјҢиҖҢиҝҷдәӣжҠҖжңҜпјҢйғҪеә”з”ЁеҲ°дәҶHBaseеўһејәзүҲдёӯгҖӮ
#### MTTRдјҳеҢ–
HBaseжҳҜеҸӮз…§Gooogleи‘—еҗҚи®әж–ҮBigTableзҡ„ејҖжәҗе®һзҺ°пјҢе…¶дёӯжңҖж ёеҝғзү№зӮ№жҳҜж•°жҚ®жҢҒд№…еҢ–еӯҳеӮЁдәҺеә•еұӮзҡ„еҲҶеёғејҸж–Ү件系з»ҹHDFSпјҢйҖҡиҝҮHDFSеҜ№ж•°жҚ®зҡ„еӨҡеүҜжң¬з»ҙжҠӨжқҘдҝқйҡңж•ҙдёӘзі»з»ҹзҡ„й«ҳеҸҜйқ жҖ§пјҢиҖҢHBaseиҮӘиә«дёҚйңҖиҰҒеҺ»е…іеҝғж•°жҚ®зҡ„еӨҡеүҜжң¬еҸҠе…¶дёҖиҮҙжҖ§пјҢиҝҷжңүеҠ©дәҺж•ҙдҪ“е·ҘзЁӢзҡ„з®ҖеҢ–пјҢдҪҶд№ҹеј•е…ҘдәҶ"жңҚеҠЎеҚ•зӮ№"зҡ„зјәйҷ·пјҢеҚіеҜ№дәҺзЎ®е®ҡзҡ„ж•°жҚ®зҡ„иҜ»еҶҷжңҚеҠЎеҸӘжңүеҸ‘з”ҹеӣәе®ҡзҡ„жҹҗдёӘиҠӮзӮ№жңҚеҠЎеҷЁпјҢиҝҷж„Ҹе‘ізқҖеҪ“дёҖдёӘиҠӮзӮ№е®•жңәеҗҺпјҢж•°жҚ®йңҖиҰҒйҖҡиҝҮйҮҚж”ҫLogжҒўеӨҚеҶ…еӯҳзҠ¶жҖҒпјҢ并且йҮҚж–°жҙҫеҸ‘з»ҷж–°зҡ„иҠӮзӮ№еҠ иҪҪеҗҺпјҢжүҚиғҪжҒўеӨҚжңҚеҠЎгҖӮ
еҪ“йӣҶзҫӨ规模иҫғеӨ§ж—¶пјҢHBaseеҚ•зӮ№ж•…йҡңеҗҺжҒўеӨҚж—¶й—ҙеҸҜиғҪдјҡиҫҫеҲ°10-20еҲҶй’ҹпјҢеӨ§и§„жЁЎйӣҶзҫӨе®•жңәзҡ„жҒўеӨҚж—¶й—ҙеҸҜиғҪйңҖиҰҒеҘҪеҮ дёӘе°Ҹж—¶пјҒиҖҢеңЁLindormеҶ…ж ёдёӯпјҢжҲ‘们еҜ№MTTRпјҲе№іеқҮж•…йҡңжҒўеӨҚж—¶й—ҙпјүеҒҡдәҶдёҖзі»еҲ—зҡ„дјҳеҢ–пјҢеҢ…жӢ¬ж•…йҡңжҒўеӨҚж—¶е…ҲдёҠзәҝregionгҖҒ并иЎҢreplayгҖҒеҮҸе°‘е°Ҹж–Ү件дә§з”ҹзӯүдј—еӨҡжҠҖжңҜгҖӮе°Ҷж•…йҡңжҒўеӨҚйҖҹеәҰжҸҗеҚҮ10еҖҚд»ҘдёҠпјҒеҹәжң¬дёҠжҺҘиҝ‘дәҶHBaseи®ҫи®Ўзҡ„зҗҶи®әеҖјгҖӮ
#### еҸҜи°ғзҡ„еӨҡдёҖиҮҙжҖ§
еңЁеҺҹжқҘзҡ„HBaseжһ¶жһ„дёӯпјҢжҜҸдёӘregionеҸӘиғҪеңЁдёҖдёӘRegionServerдёӯдёҠзәҝпјҢеҰӮжһңиҝҷдёӘregion serverе®•жңәпјҢregionйңҖиҰҒз»ҸеҺҶRe-assginпјҢWALжҢүregionеҲҮеҲҶпјҢWALж•°жҚ®еӣһж”ҫзӯүжӯҘйӘӨеҗҺпјҢжүҚиғҪжҒўеӨҚиҜ»еҶҷгҖӮ
иҝҷдёӘжҒўеӨҚж—¶й—ҙеҸҜиғҪйңҖиҰҒж•°еҲҶй’ҹпјҢеҜ№дәҺжҹҗдәӣй«ҳиҰҒжұӮзҡ„дёҡеҠЎжқҘиҜҙпјҢиҝҷжҳҜдёҖдёӘж— жі•и§ЈеҶізҡ„з—ӣзӮ№гҖӮеҸҰеӨ–пјҢиҷҪ然HBaseдёӯжңүдё»еӨҮеҗҢжӯҘпјҢдҪҶж•…йҡңдёӢеҸӘиғҪйӣҶзҫӨзІ’еәҰзҡ„жүӢеҠЁеҲҮжҚўпјҢ并且主е’ҢеӨҮзҡ„ж•°жҚ®еҸӘиғҪеҒҡеҲ°жңҖз»ҲдёҖиҮҙжҖ§пјҢиҖҢжңүдёҖдәӣдёҡеҠЎеҸӘиғҪжҺҘеҸ—ејәдёҖиҮҙпјҢHBaseеңЁиҝҷзӮ№дёҠжңӣе°ҳиҺ«еҸҠгҖӮ
LindormеҶ…йғЁе®һзҺ°дәҶдёҖз§ҚеҹәдәҺShared Logзҡ„дёҖиҮҙжҖ§еҚҸи®®пјҢйҖҡиҝҮеҲҶеҢәеӨҡеүҜжң¬жңәеҲ¶иҫҫеҲ°ж•…йҡңдёӢзҡ„жңҚеҠЎиҮӘеҠЁеҝ«йҖҹжҒўеӨҚзҡ„иғҪеҠӣпјҢе®ҢзҫҺйҖӮй…ҚдәҶеӯҳеӮЁеҲҶзҰ»зҡ„жһ¶жһ„, еҲ©з”ЁеҗҢдёҖеҘ—дҪ“зі»еҚіеҸҜж”ҜжҢҒејәдёҖиҮҙиҜӯд№үпјҢеҸҲеҸҜд»ҘйҖүжӢ©еңЁзүәзүІдёҖиҮҙжҖ§зҡ„еүҚжҸҗжҚўеҸ–жӣҙдҪізҡ„жҖ§иғҪе’ҢеҸҜз”ЁжҖ§пјҢе®һзҺ°еӨҡжҙ»пјҢй«ҳеҸҜз”ЁзӯүеӨҡз§ҚиғҪеҠӣгҖӮ
еңЁиҝҷеҘ—жһ¶жһ„дёӢпјҢLindormжӢҘжңүдәҶд»ҘдёӢеҮ дёӘдёҖиҮҙжҖ§зә§еҲ«пјҢз”ЁжҲ·еҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎиҮӘз”ұйҖүжӢ©дёҖиҮҙжҖ§зә§еҲ«пјҡ

жіЁпјҡиҜҘеҠҹиғҪжҡӮж—¶жңӘеңЁйҳҝйҮҢдә‘HBaseеўһејәзүҲдёҠеҜ№еӨ–ејҖж”ҫ
#### е®ўжҲ·з«Ҝй«ҳеҸҜз”ЁеҲҮжҚў
иҷҪ然иҜҙзӣ®еүҚHBaseеҸҜд»Ҙз»„жҲҗдё»еӨҮпјҢдҪҶжҳҜзӣ®еүҚеёӮйқўдёҠжІЎжңүдёҖдёӘй«ҳж•Ҳең°е®ўжҲ·з«ҜеҲҮжҚўи®ҝй—®ж–№жЎҲгҖӮHBaseзҡ„е®ўжҲ·з«ҜеҸӘиғҪи®ҝй—®еӣәе®ҡең°еқҖзҡ„HBaseйӣҶзҫӨгҖӮеҰӮжһңдё»йӣҶзҫӨеҸ‘з”ҹж•…йҡңпјҢз”ЁжҲ·йңҖиҰҒеҒңжӯўHBaseе®ўжҲ·з«ҜпјҢдҝ®ж”№HBaseзҡ„й…ҚзҪ®еҗҺйҮҚеҗҜпјҢжүҚиғҪиҝһжҺҘеӨҮйӣҶзҫӨи®ҝй—®гҖӮжҲ–иҖ…з”ЁжҲ·еңЁдёҡеҠЎдҫ§еҝ…йЎ»и®ҫи®ЎдёҖеҘ—еӨҚжқӮең°и®ҝй—®йҖ»иҫ‘жқҘе®һзҺ°дё»еӨҮйӣҶзҫӨзҡ„и®ҝй—®гҖӮ
йҳҝйҮҢHBaseж”№йҖ дәҶHBaseе®ўжҲ·з«ҜпјҢжөҒйҮҸзҡ„еҲҮжҚўеҸ‘з”ҹеңЁе®ўжҲ·з«ҜеҶ…йғЁпјҢйҖҡиҝҮй«ҳеҸҜз”Ёзҡ„йҖҡйҒ“е°ҶеҲҮжҚўе‘Ҫд»ӨеҸ‘йҖҒз»ҷе®ўжҲ·з«ҜпјҢе®ўжҲ·з«Ҝдјҡе…ій—ӯж—§зҡ„й“ҫжҺҘпјҢжү“ејҖдёҺеӨҮйӣҶзҫӨзҡ„й“ҫжҺҘпјҢ然еҗҺйҮҚиҜ•иҜ·жұӮгҖӮ
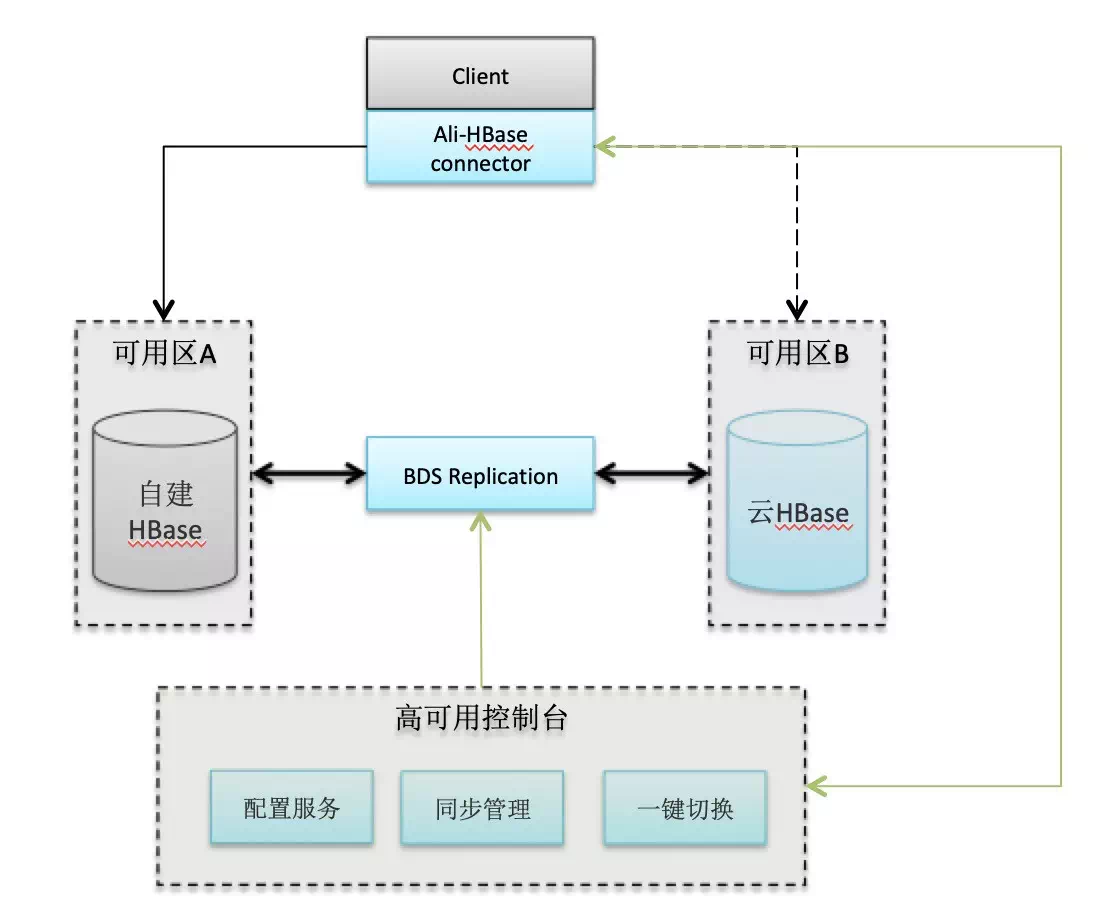
еҰӮжһңйңҖиҰҒдҪҝз”ЁжӯӨйЎ№еҠҹиғҪпјҢиҜ·еҸӮиҖғй«ҳеҸҜз”Ёеё®еҠ©ж–ҮжЎЈпјҡ
[https://help.aliyun.com/document\_detail/140940.html](https://help.aliyun.com/document_detail/140940.html)
дә‘еҺҹз”ҹпјҢжӣҙдҪҺдҪҝз”ЁжҲҗжң¬
----------
Lindormд»Һз«ӢйЎ№д№ӢеҲқе°ұиҖғиҷ‘еҲ°дёҠдә‘пјҢеҗ„з§Қи®ҫи®Ўд№ҹиғҪе°ҪйҮҸеӨҚз”Ёдә‘дёҠеҹәзЎҖи®ҫж–ҪпјҢдёәдә‘зҡ„зҺҜеўғдё“й—ЁдјҳеҢ–гҖӮжҜ”еҰӮеңЁдә‘дёҠпјҢжҲ‘们йҷӨдәҶж”ҜжҢҒдә‘зӣҳд№ӢеӨ–пјҢжҲ‘们иҝҳж”ҜжҢҒе°Ҷж•°жҚ®еӯҳеӮЁеңЁOSSиҝҷз§ҚдҪҺжҲҗжң¬зҡ„еҜ№иұЎеӯҳеӮЁдёӯеҮҸе°‘жҲҗжң¬гҖӮжҲ‘们иҝҳй’ҲеҜ№ECSйғЁзҪІеҒҡдәҶдёҚе°‘дјҳеҢ–пјҢйҖӮй…Қе°ҸеҶ…еӯҳи§„ж јжңәеһӢпјҢеҠ ејәйғЁзҪІеј№жҖ§пјҢдёҖеҲҮдёәдәҶдә‘еҺҹз”ҹпјҢдёәдәҶиҠӮзңҒе®ўжҲ·жҲҗжң¬гҖӮ
ECS+дә‘зӣҳзҡ„жһҒиҮҙеј№жҖ§
зӣ®еүҚLindormеңЁдә‘дёҠзҡ„зүҲжң¬HBaseеўһејәзүҲеқҮйҮҮз”ЁECS+дә‘зӣҳйғЁзҪІпјҲйғЁеҲҶеӨ§е®ўжҲ·еҸҜиғҪйҮҮз”Ёжң¬ең°зӣҳпјүпјҢECS+дә‘зӣҳйғЁзҪІзҡ„еҪўжҖҒз»ҷLindormеёҰжқҘдәҶжһҒиҮҙзҡ„еј№жҖ§гҖӮ

жңҖејҖе§Ӣзҡ„ж—¶еҖҷпјҢHBaseеңЁйӣҶеӣўзҡ„йғЁзҪІеқҮйҮҮз”Ёзү©зҗҶжңәзҡ„еҪўејҸгҖӮжҜҸдёӘдёҡеҠЎдёҠзәҝеүҚпјҢйғҪеҝ…йЎ»е…Ҳ规еҲ’еҘҪжңәеҷЁж•°йҮҸе’ҢзЈҒзӣҳеӨ§е°ҸгҖӮеңЁзү©зҗҶжңәйғЁзҪІдёӢпјҢеҫҖеҫҖдјҡйҒҮеҲ°еҮ дёӘйҡҫд»Ҙи§ЈеҶізҡ„й—®йўҳпјҡ
> дёҡеҠЎеј№жҖ§йҡҫд»Ҙж»Ўи¶іпјҡеҪ“йҒҮеҲ°дёҡеҠЎзӘҒеҸ‘жөҒйҮҸй«ҳеі°жҲ–иҖ…ејӮеёёиҜ·жұӮж—¶пјҢеҫҲйҡҫеңЁзҹӯж—¶й—ҙеҶ…жүҫеҲ°ж–°зҡ„зү©зҗҶжңәжү©е®№гҖӮ
>
> еӯҳеӮЁе’Ңи®Ўз®—з»‘е®ҡпјҢзҒөжҙ»жҖ§е·®пјҡзү©зҗҶжңәдёҠCPUе’ҢзЈҒзӣҳзҡ„жҜ”дҫӢйғҪжҳҜдёҖе®ҡзҡ„пјҢдҪҶжҳҜжҜҸдёӘдёҡеҠЎзҡ„зү№зӮ№йғҪдёҚдёҖж ·пјҢйҮҮз”ЁдёҖж ·зҡ„зү©зҗҶжңәпјҢжңүдёҖдәӣдёҡеҠЎи®Ўз®—иө„жәҗдёҚеӨҹпјҢдҪҶеӯҳеӮЁиҝҮеү©пјҢиҖҢжңүдәӣдёҡеҠЎи®Ўз®—иө„жәҗиҝҮеү©пјҢиҖҢеӯҳеӮЁз“¶йўҲгҖӮзү№еҲ«жҳҜеңЁHBaseеј•е…Ҙж··еҗҲеӯҳеӮЁеҗҺпјҢHDDе’ҢSSDзҡ„жҜ”дҫӢйқһеёёйҡҫзЎ®е®ҡпјҢжңүдәӣй«ҳиҰҒжұӮзҡ„дёҡеҠЎеёёеёёдјҡжҠҠSSDз”Ёж»ЎиҖҢHDDжңүеү©дҪҷпјҢиҖҢдёҖдәӣжө·йҮҸзҡ„зҰ»зәҝеһӢдёҡеҠЎSSDзӣҳеҸҲж— жі•еҲ©з”ЁдёҠгҖӮ
>
> иҝҗз»ҙеҺӢеҠӣеӨ§пјҡдҪҝз”Ёзү©зҗҶжңәж—¶пјҢиҝҗз»ҙйңҖиҰҒж—¶еҲ»жіЁж„Ҹзү©зҗҶжңәжҳҜеҗҰиҝҮдҝқпјҢжҳҜеҗҰжңүзЈҒзӣҳеқҸпјҢзҪ‘еҚЎеқҸзӯү硬件故йҡңйңҖиҰҒеӨ„зҗҶпјҢзү©зҗҶжңәзҡ„жҠҘдҝ®жҳҜдёҖдёӘжј«й•ҝзҡ„иҝҮзЁӢпјҢеҗҢж—¶йңҖиҰҒеҒңжңәпјҢиҝҗз»ҙеҺӢеҠӣе·ЁеӨ§гҖӮеҜ№дәҺHBaseиҝҷз§Қжө·йҮҸеӯҳеӮЁдёҡеҠЎжқҘиҜҙпјҢжҜҸеӨ©еқҸеҮ еқ—зЈҒзӣҳжҳҜйқһеёёжӯЈеёёзҡ„дәӢжғ…гҖӮиҖҢеҪ“LindormйҮҮз”ЁдәҶECS+дә‘зӣҳйғЁзҪІеҗҺпјҢиҝҷдәӣй—®йўҳйғҪиҝҺеҲғиҖҢи§ЈгҖӮ
ECSжҸҗдҫӣдәҶдёҖдёӘиҝ‘дјјж— йҷҗзҡ„иө„жәҗжұ гҖӮеҪ“йқўеҜ№дёҡеҠЎзҡ„зҙ§жҖҘжү©е®№ж—¶пјҢжҲ‘们еҸӘйңҖеңЁиө„жәҗжұ дёӯз”іиҜ·ж–°зҡ„ECSжӢүиө·еҗҺпјҢеҚіеҸҜеҠ е…ҘйӣҶзҫӨпјҢж—¶й—ҙеңЁеҲҶй’ҹзә§еҲ«д№ӢеҶ…пјҢж— жғ§дёҡеҠЎжөҒйҮҸй«ҳеі°гҖӮй…ҚеҗҲдә‘зӣҳиҝҷж ·зҡ„еӯҳеӮЁи®Ўз®—еҲҶзҰ»жһ¶жһ„гҖӮжҲ‘们еҸҜд»ҘзҒөжҙ»ең°дёәеҗ„з§ҚдёҡеҠЎеҲҶй…ҚдёҚеҗҢзҡ„зЈҒзӣҳз©әй—ҙгҖӮ
еҪ“з©әй—ҙдёҚеӨҹж—¶пјҢеҸҜд»ҘзӣҙжҺҘеңЁзәҝжү©зј©е®№зЈҒзӣҳгҖӮеҗҢж—¶пјҢиҝҗз»ҙеҶҚд№ҹдёҚз”ЁиҖғиҷ‘硬件故йҡңпјҢеҪ“ECSжңүж•…йҡңж—¶пјҢECSеҸҜд»ҘеңЁеҸҰеӨ–дёҖеҸ°е®ҝдё»жңәдёҠжӢүиө·пјҢиҖҢдә‘зӣҳе®Ңе…ЁеҜ№дёҠеұӮеұҸи”ҪдәҶеқҸзӣҳзҡ„еӨ„зҗҶгҖӮжһҒиҮҙзҡ„еј№жҖ§еҗҢж ·еёҰжқҘдәҶжҲҗжң¬зҡ„дјҳеҢ–гҖӮжҲ‘们дёҚйңҖиҰҒдёәдёҡеҠЎйў„з•ҷеӨӘеӨҡзҡ„иө„жәҗпјҢеҗҢж—¶еҪ“дёҡеҠЎзҡ„еӨ§дҝғз»“жқҹеҗҺпјҢиғҪеӨҹеҝ«йҖҹең°зј©е®№йҷҚдҪҺжҲҗжң¬гҖӮ

#### дёҖдҪ“еҢ–еҶ·зғӯеҲҶзҰ»
еңЁжө·йҮҸеӨ§ж•°жҚ®еңәжҷҜдёӢпјҢдёҖеј иЎЁдёӯзҡ„йғЁеҲҶдёҡеҠЎж•°жҚ®йҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»д»…дҪңдёәеҪ’жЎЈж•°жҚ®жҲ–иҖ…и®ҝй—®йў‘зҺҮеҫҲдҪҺпјҢеҗҢж—¶иҝҷйғЁеҲҶеҺҶеҸІж•°жҚ®дҪ“йҮҸйқһеёёеӨ§пјҢжҜ”еҰӮи®ўеҚ•ж•°жҚ®жҲ–иҖ…зӣ‘жҺ§ж•°жҚ®пјҢйҷҚдҪҺиҝҷйғЁеҲҶж•°жҚ®зҡ„еӯҳеӮЁжҲҗжң¬е°ҶдјҡжһҒеӨ§зҡ„иҠӮзңҒдјҒдёҡзҡ„жҲҗжң¬гҖӮ
еҰӮдҪ•д»ҘжһҒз®Җзҡ„иҝҗз»ҙй…ҚзҪ®жҲҗжң¬е°ұиғҪдёәдјҒдёҡжһҒеӨ§йҷҚдҪҺеӯҳеӮЁжҲҗжң¬пјҢLindormеҶ·зғӯеҲҶзҰ»еҠҹиғҪеә”иҝҗиҖҢз”ҹгҖӮLindormдёәеҶ·ж•°жҚ®жҸҗдҫӣж–°зҡ„еӯҳеӮЁд»ӢиҙЁпјҢж–°зҡ„еӯҳеӮЁд»ӢиҙЁеӯҳеӮЁжҲҗжң¬д»…дёәй«ҳж•Ҳдә‘зӣҳзҡ„1/3гҖӮ
LindormеңЁеҗҢдёҖеј иЎЁйҮҢе®һзҺ°дәҶж•°жҚ®зҡ„еҶ·зғӯеҲҶзҰ»пјҢзі»з»ҹдјҡиҮӘеҠЁж №жҚ®з”ЁжҲ·и®ҫзҪ®зҡ„еҶ·зғӯеҲҶз•ҢзәҝиҮӘеҠЁе°ҶиЎЁдёӯзҡ„еҶ·ж•°жҚ®еҪ’жЎЈеҲ°еҶ·еӯҳеӮЁдёӯгҖӮеңЁз”ЁжҲ·зҡ„и®ҝй—®ж–№ејҸдёҠе’Ңжҷ®йҖҡиЎЁеҮ д№ҺжІЎжңүд»»дҪ•е·®ејӮпјҢеңЁжҹҘиҜўзҡ„иҝҮзЁӢдёӯпјҢз”ЁжҲ·еҸӘйңҖй…ҚзҪ®жҹҘиҜўHintжҲ–иҖ…TimeRangeпјҢзі»з»ҹж №жҚ®жқЎд»¶иҮӘеҠЁең°еҲӨж–ӯжҹҘиҜўеә”иҜҘиҗҪеңЁзғӯж•°жҚ®еҢәиҝҳжҳҜеҶ·ж•°жҚ®еҢәгҖӮеҜ№з”ЁжҲ·иҖҢиЁҖе§Ӣз»ҲжҳҜдёҖеј иЎЁпјҢеҜ№з”ЁжҲ·еҮ д№ҺеҒҡеҲ°е®Ңе…Ёзҡ„йҖҸжҳҺгҖӮиҜҰз»Ҷд»Ӣз»ҚиҜ·еҸӮиҖғпјҡ
[https://yq.aliyun.com/articles/718395](https://yq.aliyun.com/articles/718395)
#### ZSTD-V2пјҢеҺӢзј©жҜ”еҶҚжҸҗеҚҮ100%
ж—©еңЁдёӨе№ҙеүҚпјҢжҲ‘们е°ұжҠҠйӣҶеӣўеҶ…зҡ„еӯҳеӮЁеҺӢзј©з®—жі•жӣҝжҚўжҲҗдәҶZSTDпјҢзӣёжҜ”еҺҹжқҘзҡ„SNAPPYз®—жі•пјҢиҺ·еҫ—дәҶйўқеӨ–25%зҡ„еҺӢ缩收зӣҠгҖӮд»Ҡе№ҙжҲ‘们еҜ№жӯӨиҝӣдёҖжӯҘдјҳеҢ–пјҢејҖеҸ‘е®һзҺ°дәҶж–°зҡ„ZSTD-v2з®—жі•пјҢе…¶еҜ№дәҺе°Ҹеқ—ж•°жҚ®зҡ„еҺӢзј©пјҢжҸҗеҮәдәҶдҪҝз”Ёйў„е…ҲйҮҮж ·ж•°жҚ®иҝӣиЎҢи®ӯз»ғеӯ—е…ёпјҢ然еҗҺз”Ёеӯ—е…ёиҝӣиЎҢеҠ йҖҹзҡ„ж–№жі•гҖӮ
жҲ‘们еҲ©з”ЁдәҶиҝҷдёҖж–°зҡ„еҠҹиғҪпјҢеңЁLindormжһ„е»әLDFileзҡ„ж—¶еҖҷпјҢе…ҲеҜ№ж•°жҚ®иҝӣиЎҢйҮҮж ·и®ӯз»ғпјҢжһ„е»әеӯ—е…ёпјҢ然еҗҺеңЁиҝӣиЎҢеҺӢзј©гҖӮеңЁдёҚеҗҢдёҡеҠЎзҡ„ж•°жҚ®жөӢиҜ•дёӯпјҢжҲ‘们жңҖй«ҳиҺ·еҫ—дәҶи¶…иҝҮеҺҹз”ҹZSTDз®—жі•100%зҡ„еҺӢзј©жҜ”пјҢиҝҷж„Ҹе‘ізқҖжҲ‘们еҸҜд»Ҙдёәе®ўжҲ·еҶҚиҠӮзңҒ50%зҡ„еӯҳеӮЁиҙ№з”ЁгҖӮ
#### HBase ServerlessзүҲпјҢе…Ҙй—ЁйҰ–йҖү
йҳҝйҮҢдә‘HBase Serverless зүҲжҳҜеҹәдәҺLindormеҶ…ж ёпјҢдҪҝз”ЁServerlessжһ¶жһ„жһ„е»әзҡ„дёҖеҘ—ж–°еһӢзҡ„HBase жңҚеҠЎгҖӮйҳҝйҮҢдә‘HBase ServerlessзүҲзңҹжӯЈжҠҠHBaseеҸҳжҲҗдәҶдёҖдёӘжңҚеҠЎпјҢз”ЁжҲ·ж— йңҖжҸҗеүҚ规еҲ’иө„жәҗпјҢйҖүжӢ©CPUпјҢеҶ…еӯҳиө„жәҗж•°йҮҸпјҢиҙӯд№°йӣҶзҫӨгҖӮеңЁеә”еҜ№дёҡеҠЎй«ҳеі°пјҢдёҡеҠЎз©әй—ҙеўһй•ҝж—¶пјҢд№ҹж— йңҖиҝӣиЎҢжү©е®№зӯүеӨҚжқӮиҝҗз»ҙж“ҚдҪңпјҢеңЁдёҡеҠЎдҪҺи°·ж—¶пјҢд№ҹж— йңҖжөӘиҙ№й—ІзҪ®иө„жәҗгҖӮ
еңЁдҪҝз”ЁиҝҮзЁӢдёӯпјҢз”ЁжҲ·еҸҜд»Ҙе®Ңе…Ёж №жҚ®еҪ“еүҚдёҡеҠЎйҮҸпјҢжҢүйңҖиҙӯд№°иҜ·жұӮйҮҸе’Ңз©әй—ҙиө„жәҗеҚіеҸҜгҖӮдҪҝз”ЁйҳҝйҮҢдә‘HBase ServerlessзүҲжң¬пјҢз”ЁжҲ·е°ұеҘҪеғҸеңЁдҪҝз”ЁдёҖдёӘж— йҷҗиө„жәҗзҡ„HBaseйӣҶзҫӨпјҢйҡҸж—¶ж»Ўи¶ідёҡеҠЎжөҒйҮҸзӘҒ然зҡ„еҸҳеҢ–пјҢиҖҢеҗҢж—¶еҸӘйңҖиҰҒж”Ҝд»ҳиҮӘе·ұзңҹжӯЈдҪҝз”Ёзҡ„йӮЈдёҖйғЁеҲҶиө„жәҗзҡ„й’ұгҖӮ
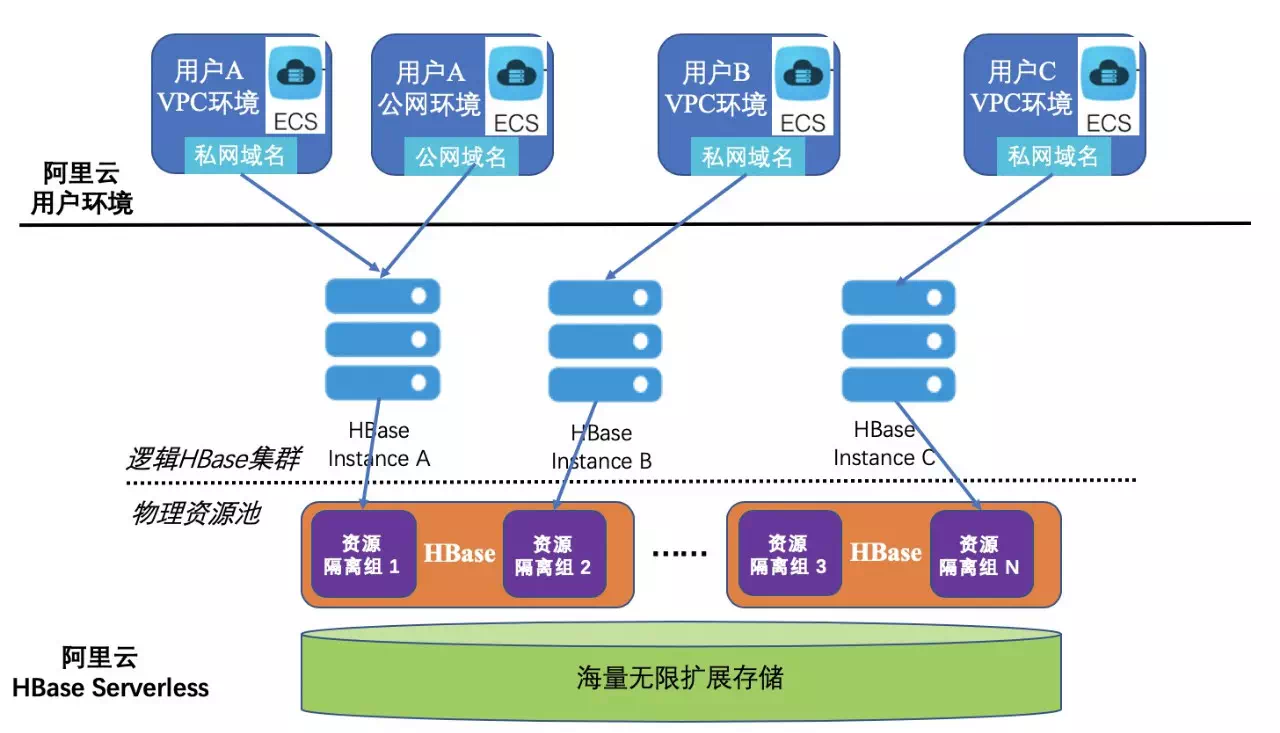
е…ідәҺHBase Serverlessзҡ„д»Ӣз»Қе’ҢдҪҝз”ЁпјҢеҸҜд»ҘеҸӮиҖғпјҡ
[https://developer.aliyun.com/article/719206](https://developer.aliyun.com/article/719206)
йқўеҗ‘еӨ§е®ўжҲ·зҡ„е®үе…Ёе’ҢеӨҡз§ҹжҲ·иғҪеҠӣ
--------------
Lindormеј•ж“ҺеҶ…зҪ®дәҶе®Ңж•ҙзҡ„з”ЁжҲ·еҗҚеҜҶз ҒдҪ“зі»пјҢжҸҗдҫӣеӨҡз§Қзә§еҲ«зҡ„жқғйҷҗжҺ§еҲ¶пјҢ并еҜ№жҜҸдёҖж¬ЎиҜ·жұӮйүҙжқғпјҢйҳІжӯўжңӘжҺҲжқғзҡ„ж•°жҚ®и®ҝй—®пјҢзЎ®дҝқз”ЁжҲ·ж•°жҚ®зҡ„и®ҝй—®е®үе…ЁгҖӮеҗҢж—¶пјҢй’ҲеҜ№дјҒдёҡзә§еӨ§е®ўжҲ·зҡ„иҜүжұӮпјҢLindormеҶ…зҪ®дәҶGroupпјҢQuotaйҷҗеҲ¶зӯүеӨҡз§ҹжҲ·йҡ”зҰ»еҠҹиғҪпјҢдҝқиҜҒдјҒдёҡдёӯеҗ„дёӘдёҡеҠЎеңЁдҪҝз”ЁеҗҢдёҖдёӘHBaseйӣҶзҫӨж—¶дёҚдјҡиў«зӣёдә’еҪұе“ҚпјҢе®үе…Ёй«ҳж•Ҳең°е…ұдә«еҗҢдёҖдёӘеӨ§ж•°жҚ®е№іеҸ°гҖӮ
#### з”ЁжҲ·е’ҢACLдҪ“зі»
LindormеҶ…ж ёжҸҗдҫӣдёҖеҘ—з®ҖеҚ•жҳ“з”Ёзҡ„з”ЁжҲ·и®ӨиҜҒе’ҢACLдҪ“зі»гҖӮз”ЁжҲ·зҡ„и®ӨиҜҒеҸӘйңҖиҰҒеңЁй…ҚзҪ®дёӯз®ҖеҚ•зҡ„еЎ«еҶҷз”ЁжҲ·еҗҚеҜҶз ҒеҚіеҸҜгҖӮз”ЁжҲ·зҡ„еҜҶз ҒеңЁжңҚеҠЎеҷЁз«ҜйқһжҳҺж–ҮеӯҳеӮЁпјҢ并且еңЁи®ӨиҜҒиҝҮзЁӢдёӯдёҚдјҡжҳҺж–Үдј иҫ“еҜҶз ҒпјҢеҚідҪҝйӘҢиҜҒиҝҮзЁӢзҡ„еҜҶж–Үиў«жӢҰжҲӘпјҢз”Ёд»Ҙи®ӨиҜҒзҡ„йҖҡдҝЎеҶ…е®№дёҚеҸҜйҮҚеӨҚдҪҝз”ЁпјҢж— жі•иў«дјӘйҖ гҖӮ
LindormдёӯжңүдёүдёӘжқғйҷҗеұӮзә§гҖӮGlobalпјҢNamespaceе’ҢTableгҖӮиҝҷдёүиҖ…жҳҜзӣёдә’иҰҶзӣ–зҡ„е…ізі»гҖӮжҜ”еҰӮз»ҷuser1иөӢдәҲдәҶGlobalзҡ„иҜ»еҶҷжқғйҷҗпјҢеҲҷд»–е°ұжӢҘжңүдәҶжүҖжңүnamespaceдёӢжүҖжңүTableзҡ„иҜ»еҶҷжқғйҷҗгҖӮеҰӮжһңз»ҷuser2иөӢдәҲдәҶNamespace1зҡ„иҜ»еҶҷжқғйҷҗпјҢйӮЈд№Ҳд»–дјҡиҮӘеҠЁжӢҘжңүNamespace1дёӯжүҖжңүиЎЁзҡ„иҜ»еҶҷжқғйҷҗгҖӮ
#### Groupйҡ”зҰ»
еҪ“еӨҡдёӘз”ЁжҲ·жҲ–иҖ…дёҡеҠЎеңЁдҪҝз”ЁеҗҢдёҖдёӘHBaseйӣҶзҫӨж—¶пјҢеҫҖеҫҖдјҡеӯҳеңЁиө„жәҗдәүжҠўзҡ„й—®йўҳгҖӮдёҖдәӣйҮҚиҰҒзҡ„еңЁзәҝдёҡеҠЎзҡ„иҜ»еҶҷпјҢеҸҜиғҪдјҡиў«зҰ»зәҝдёҡеҠЎжү№йҮҸиҜ»еҶҷжүҖеҪұе“ҚгҖӮиҖҢGroupеҠҹиғҪпјҢеҲҷжҳҜHBaseеўһејәзүҲпјҲLindormпјүжҸҗдҫӣзҡ„з”ЁжқҘи§ЈеҶіеӨҡз§ҹжҲ·йҡ”зҰ»й—®йўҳзҡ„еҠҹиғҪгҖӮ
йҖҡиҝҮжҠҠRegionServerеҲ’еҲҶеҲ°дёҚеҗҢзҡ„GroupеҲҶз»„пјҢжҜҸдёӘеҲҶз»„дёҠhostдёҚеҗҢзҡ„иЎЁпјҢд»ҺиҖҢиҫҫеҲ°иө„жәҗйҡ”зҰ»зҡ„зӣ®зҡ„гҖӮ
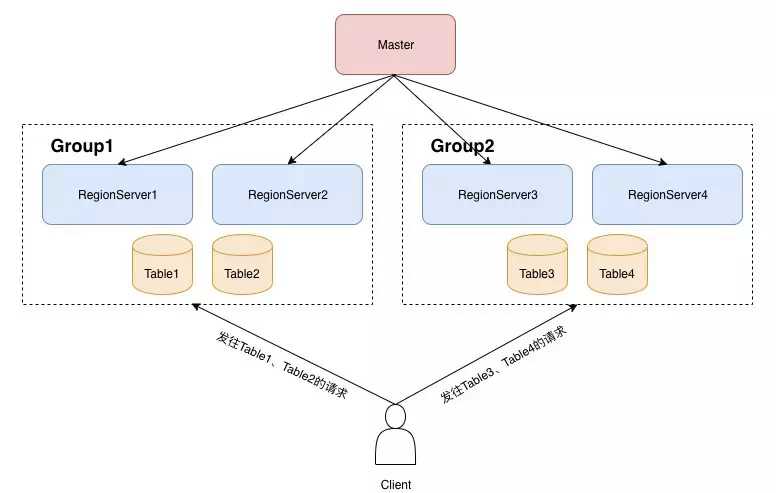
дҫӢеҰӮпјҢеңЁдёҠеӣҫдёӯпјҢжҲ‘们еҲӣе»әдәҶдёҖдёӘGroup1пјҢжҠҠRegionServer1е’ҢRegionServer2еҲ’еҲҶеҲ°Group1дёӯпјҢеҲӣе»әдәҶдёҖдёӘGroup2пјҢжҠҠRegionServer3е’ҢRegionServer4еҲ’еҲҶеҲ°Group2гҖӮеҗҢж—¶пјҢжҲ‘们жҠҠTable1е’ҢTable2д№ҹ移еҠЁеҲ°Group1еҲҶз»„гҖӮиҝҷж ·зҡ„иҜқпјҢTable1е’ҢTable2зҡ„жүҖжңүregionпјҢйғҪеҸӘдјҡеҲҶй…ҚеҲ°Group1дёӯзҡ„RegionServer1е’ҢRegionServer2иҝҷдёӨеҸ°жңәеҷЁдёҠгҖӮ
еҗҢж ·пјҢеұһдәҺGroup2зҡ„Table3е’ҢTable4зҡ„RegionеңЁеҲҶй…Қе’ҢbalanceиҝҮзЁӢдёӯпјҢд№ҹеҸӘдјҡиҗҪеңЁRegionServer3е’ҢRegionServer4дёҠгҖӮеӣ жӯӨпјҢз”ЁжҲ·еңЁиҜ·жұӮиҝҷдәӣиЎЁж—¶пјҢеҸ‘еҫҖTable1гҖҒTable2зҡ„иҜ·жұӮпјҢеҸӘдјҡз”ұRegionServer1е’ҢRegionServer2жңҚеҠЎпјҢиҖҢеҸ‘еҫҖTable3е’ҢTable4зҡ„иҜ·жұӮпјҢеҸӘдјҡз”ұRegionServer3е’ҢRegionServer4жңҚеҠЎпјҢд»ҺиҖҢиҫҫеҲ°иө„жәҗйҡ”зҰ»зҡ„зӣ®зҡ„
#### QuotaйҷҗжөҒ
LindormеҶ…ж ёдёӯеҶ…зҪ®дәҶдёҖеҘ—е®Ңж•ҙзҡ„QuotaдҪ“зі»пјҢжқҘеҜ№еҗ„дёӘз”ЁжҲ·зҡ„иө„жәҗдҪҝз”ЁеҒҡйҷҗеҲ¶гҖӮеҜ№дәҺжҜҸдёҖдёӘиҜ·жұӮпјҢLindormеҶ…ж ёйғҪжңүзІҫзЎ®зҡ„и®Ўз®—жүҖж¶ҲиҖ—зҡ„CUпјҲCapacity UnitпјүпјҢCUдјҡд»Ҙе®һйҷ…ж¶ҲиҖ—зҡ„иө„жәҗжқҘи®Ўз®—гҖӮ
жҜ”еҰӮз”ЁжҲ·дёҖдёӘScanиҜ·жұӮпјҢз”ұдәҺfilterзҡ„еӯҳеңЁпјҢиҷҪ然иҝ”еӣһзҡ„ж•°жҚ®еҫҲе°‘пјҢдҪҶеҸҜиғҪе·Із»ҸеңЁRegionServerе·Із»Ҹж¶ҲиҖ—еӨ§йҮҸзҡ„CPUе’ҢIOиө„жәҗжқҘиҝҮж»Өж•°жҚ®пјҢиҝҷдәӣзңҹе®һиө„жәҗзҡ„ж¶ҲиҖ—пјҢйғҪдјҡи®Ўз®—еңЁCUйҮҢгҖӮ
еңЁжҠҠLindormеҪ“еҒҡдёҖдёӘеӨ§ж•°жҚ®е№іеҸ°дҪҝз”Ёж—¶пјҢдјҒдёҡз®ЎзҗҶе‘ҳеҸҜд»Ҙе…Ҳз»ҷдёҚеҗҢдёҡеҠЎеҲҶй…ҚдёҚеҗҢзҡ„з”ЁжҲ·пјҢ然еҗҺйҖҡиҝҮQuotaзі»з»ҹйҷҗеҲ¶жҹҗдёӘз”ЁжҲ·жҜҸз§’зҡ„иҜ»CUдёҚиғҪи¶…иҝҮеӨҡе°‘пјҢжҲ–иҖ…жҖ»зҡ„CUдёҚиғҪи¶…иҝҮеӨҡе°‘пјҢд»ҺиҖҢйҷҗеҲ¶з”ЁжҲ·еҚ з”ЁиҝҮеӨҡзҡ„иө„жәҗпјҢеҪұе“Қе…¶д»–з”ЁжҲ·гҖӮеҗҢж—¶пјҢQuotaйҷҗжөҒд№ҹж”ҜжҢҒNamesapceзә§еҲ«е’ҢиЎЁзә§еҲ«йҷҗеҲ¶гҖӮ
жңҖеҗҺ
--
е…Ёж–°дёҖд»ЈNoSQLж•°жҚ®еә“LindormжҳҜйҳҝйҮҢе·ҙе·ҙHBase&Lindormеӣўйҳҹ9е№ҙд»ҘжқҘжҠҖжңҜз§ҜзҙҜзҡ„з»“жҷ¶пјҢLindormеңЁйқўеҗ‘жө·йҮҸж•°жҚ®еңәжҷҜжҸҗдҫӣдё–з•ҢйўҶе…Ҳзҡ„й«ҳжҖ§иғҪгҖҒеҸҜи·ЁеҹҹгҖҒеӨҡдёҖиҮҙгҖҒеӨҡжЁЎеһӢзҡ„ж··еҗҲеӯҳеӮЁеӨ„зҗҶиғҪеҠӣгҖӮеҜ№з„ҰдәҺеҗҢж—¶и§ЈеҶіеӨ§ж•°жҚ®(ж— йҷҗжү©еұ•гҖҒй«ҳеҗһеҗҗ)гҖҒеңЁзәҝжңҚеҠЎ(дҪҺ延时гҖҒй«ҳеҸҜз”Ё)гҖҒеӨҡеҠҹиғҪжҹҘиҜўзҡ„иҜүжұӮпјҢдёәз”ЁжҲ·жҸҗдҫӣж— зјқжү©еұ•гҖҒй«ҳеҗһеҗҗгҖҒжҢҒз»ӯеҸҜз”ЁгҖҒжҜ«з§’зә§зЁіе®ҡе“Қеә”гҖҒејәејұдёҖиҮҙеҸҜи°ғгҖҒдҪҺеӯҳеӮЁжҲҗжң¬гҖҒдё°еҜҢзҙўеј•зҡ„ж•°жҚ®е®һж—¶ж··еҗҲеӯҳеҸ–иғҪеҠӣгҖӮ
[еҺҹж–Үй“ҫжҺҘ](https://yq.aliyun.com/articles/738755?utm_content=g_1000096254)
жң¬ж–ҮдёәйҳҝйҮҢдә‘еҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
--
LindormпјҢе°ұжҳҜдә‘ж“ҚдҪңзі»з»ҹйЈһеӨ©дёӯйқўеҗ‘еӨ§ж•°жҚ®еӯҳеӮЁеӨ„зҗҶзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶгҖӮLindormжҳҜеҹәдәҺHBaseз ”еҸ‘зҡ„гҖҒйқўеҗ‘еӨ§ж•°жҚ®йўҶеҹҹзҡ„еҲҶеёғејҸNoSQLж•°жҚ®еә“пјҢйӣҶеӨ§и§„жЁЎгҖҒй«ҳеҗһеҗҗгҖҒеҝ«йҖҹзҒөжҙ»гҖҒе®һж—¶ж··еҗҲиғҪеҠӣдәҺдёҖиә«пјҢйқўеҗ‘жө·йҮҸж•°жҚ®еңәжҷҜжҸҗдҫӣдё–з•ҢйўҶе…Ҳзҡ„й«ҳжҖ§иғҪгҖҒеҸҜи·ЁеҹҹгҖҒеӨҡдёҖиҮҙгҖҒеӨҡжЁЎеһӢзҡ„ж··еҗҲеӯҳеӮЁеӨ„зҗҶиғҪеҠӣгҖӮ
зӣ®еүҚпјҢLindormе·Із»Ҹе…ЁйқўжңҚеҠЎдәҺйҳҝйҮҢз»ҸжөҺдҪ“дёӯзҡ„еӨ§ж•°жҚ®з»“жһ„еҢ–гҖҒеҚҠз»“жһ„еҢ–еӯҳеӮЁеңәжҷҜгҖӮ
жіЁпјҡLindormжҳҜйҳҝйҮҢеҶ…йғЁHBaseеҲҶж”Ҝзҡ„еҲ«з§°пјҢеңЁйҳҝйҮҢдә‘дёҠеҜ№еӨ–е”®еҚ–зҡ„зүҲжң¬еҸ«еҒҡHBaseеўһејәзүҲпјҢд№ӢеҗҺж–ҮдёӯеҮәзҺ°зҡ„HBaseеўһејәзүҲе’ҢLindormйғҪжҢҮеҗҢдёҖдёӘдә§е“ҒгҖӮ
2019е№ҙд»ҘжқҘпјҢLindormе·Із»ҸжңҚеҠЎдәҶеҢ…жӢ¬ж·ҳе®қгҖҒеӨ©зҢ«гҖҒиҡӮиҡҒгҖҒиҸңйёҹгҖҒеҰҲеҰҲгҖҒдјҳй…·гҖҒй«ҳеҫ·гҖҒеӨ§ж–ҮеЁұзӯүж•°еҚҒдёӘBUпјҢеңЁд»Ҡе№ҙзҡ„еҸҢеҚҒдёҖдёӯпјҢLindormеі°еҖјиҜ·жұӮиҫҫеҲ°дәҶ7.5дәҝж¬ЎжҜҸз§’пјҢеӨ©еҗһеҗҗ22.9дёҮдәҝж¬ЎпјҢе№іеқҮе“Қеә”ж—¶й—ҙдҪҺдәҺ3msпјҢж•ҙдҪ“еӯҳеӮЁзҡ„ж•°жҚ®йҮҸиҫҫеҲ°дәҶж•°зҷҫPBгҖӮ
иҝҷдәӣж•°еӯ—зҡ„иғҢеҗҺпјҢеҮқиҒҡдәҶHBase&LindormеӣўйҳҹеӨҡе№ҙд»ҘжқҘзҡ„жұ—ж°ҙе’ҢеҝғиЎҖгҖӮLindormи„ұиғҺдәҺHBaseпјҢжҳҜеӣўйҳҹеӨҡе№ҙд»ҘжқҘжүҝиҪҪж•°зҷҫPBж•°жҚ®пјҢдәҝзә§иҜ·жұӮйҮҸпјҢдёҠеҚғдёӘдёҡеҠЎеҗҺпјҢеңЁйқўеҜ№и§„жЁЎжҲҗжң¬еҺӢеҠӣпјҢд»ҘеҸҠHBaseиҮӘиә«зјәйҷ·дёӢпјҢе…ЁйқўйҮҚжһ„е’Ңеј•ж“ҺеҚҮзә§зҡ„е…Ёж–°дә§е“ҒгҖӮ
зӣёжҜ”HBaseпјҢLindormж— и®әжҳҜжҖ§иғҪпјҢеҠҹиғҪиҝҳжҳҜеҸҜз”ЁжҖ§дёҠпјҢйғҪжңүдәҶе·ЁеӨ§йЈһи·ғгҖӮжң¬ж–Үе°Ҷд»ҺеҠҹиғҪгҖҒеҸҜз”ЁжҖ§гҖҒжҖ§иғҪжҲҗжң¬гҖҒжңҚеҠЎз”ҹжҖҒзӯүз»ҙеәҰд»Ӣз»ҚLindormзҡ„ж ёеҝғиғҪеҠӣдёҺдёҡеҠЎиЎЁзҺ°пјҢжңҖеҗҺеҲҶдә«йғЁеҲҶжҲ‘们жӯЈеңЁиҝӣиЎҢдёӯзҡ„дёҖдәӣйЎ№зӣ®гҖӮ
жһҒиҮҙдјҳеҢ–пјҢи¶…ејәжҖ§иғҪ
---------
LindormжҜ”HBaseеңЁRPCгҖҒеҶ…еӯҳз®ЎзҗҶпјҢзј“еӯҳгҖҒж—Ҙеҝ—еҶҷе…Ҙзӯүж–№йқўеҒҡдәҶж·ұеәҰзҡ„дјҳеҢ–пјҢеј•е…ҘдәҶдј—еӨҡж–°жҠҖжңҜпјҢеӨ§е№…жҸҗеҚҮдәҶиҜ»еҶҷжҖ§иғҪпјҢеңЁзӣёеҗҢ硬件зҡ„жғ…еҶөдёӢпјҢеҗһеҗҗеҸҜиҫҫеҲ°HBaseзҡ„5еҖҚд»ҘдёҠпјҢжҜӣеҲәжӣҙжҳҜеҸҜд»ҘиҫҫеҲ°HBaseзҡ„1/10гҖӮ
иҝҷдәӣжҖ§иғҪж•°жҚ®пјҢ并дёҚжҳҜеңЁе®һйӘҢе®ӨжқЎд»¶дёӢдә§з”ҹзҡ„пјҢиҖҢжҳҜеңЁдёҚж”№еҠЁд»»дҪ•еҸӮж•°зҡ„еүҚжҸҗдёӢпјҢдҪҝз”ЁејҖжәҗжөӢиҜ•е·Ҙе…·YCSBи·‘еҮәжқҘзҡ„жҲҗз»©гҖӮжҲ‘们жҠҠжөӢиҜ•зҡ„е·Ҙе…·е’ҢеңәжҷҜйғҪе…¬еёғеңЁйҳҝйҮҢдә‘зҡ„её®еҠ©ж–Ү件дёӯпјҢд»»дҪ•дәәйғҪеҸҜд»Ҙдҫқз…§жҢҮеҚ—иҮӘе·ұи·‘еҮәдёҖж ·зҡ„з»“жһңгҖӮ

еҸ–еҫ—иҝҷд№ҲдјҳејӮзҡ„жҖ§иғҪзҡ„иғҢеҗҺпјҢжҳҜLindormдёӯз§Ҝж”’еӨҡе№ҙзҡ„вҖң黑科жҠҖвҖқпјҢдёӢйқўпјҢжҲ‘们з®ҖеҚ•д»Ӣз»ҚдёӢLindormеҶ…ж ёдёӯдҪҝз”ЁеҲ°зҡ„йғЁеҲҶвҖң黑科жҠҖвҖқгҖӮ
#### Trie Index
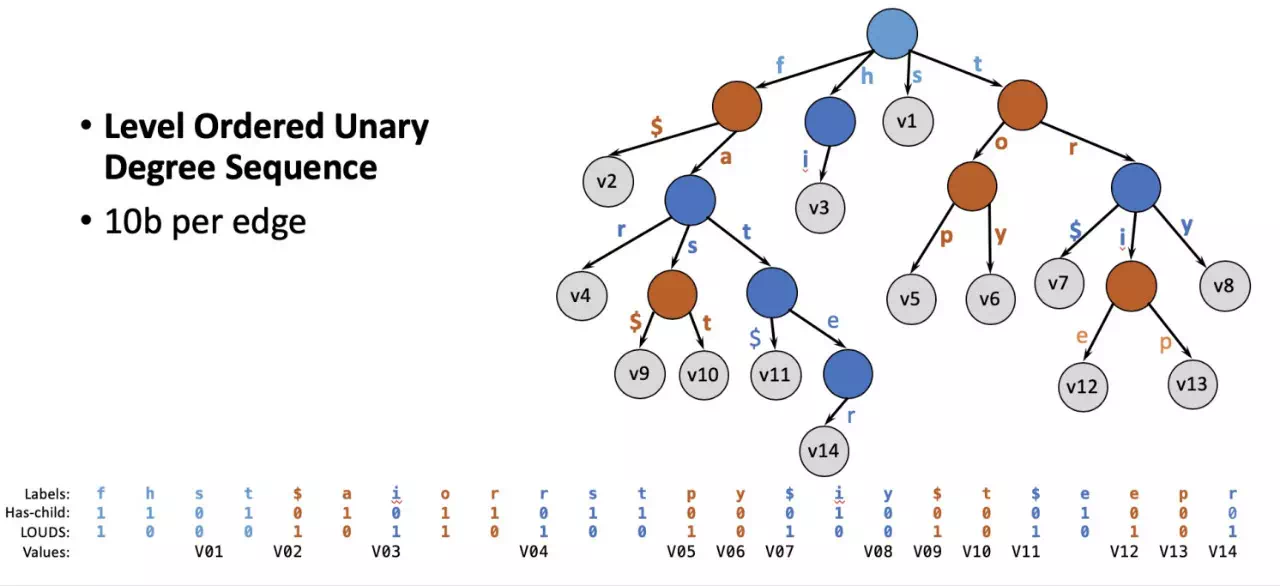
Lindorm зҡ„ж–Ү件LDFileпјҲзұ»дјјHBaseдёӯзҡ„HFileпјүжҳҜеҸӘиҜ» B+ ж ‘з»“жһ„пјҢе…¶дёӯж–Ү件зҙўеј•жҳҜиҮіе…ійҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„гҖӮеңЁ block cache дёӯжңүй«ҳдјҳе…Ҳзә§пјҢйңҖиҰҒе°ҪйҮҸеёёй©»еҶ…еӯҳгҖӮеҰӮжһңиғҪйҷҚдҪҺж–Ү件зҙўеј•жүҖеҚ з©әй—ҙеӨ§е°ҸпјҢжҲ‘们еҸҜд»ҘиҠӮзңҒ block cache дёӯзҙўеј•жүҖйңҖиҰҒзҡ„е®қиҙөеҶ…еӯҳз©әй—ҙгҖӮжҲ–иҖ…еңЁзҙўеј•з©әй—ҙдёҚеҸҳзҡ„жғ…еҶөдёӢпјҢеўһеҠ зҙўеј•еҜҶеәҰпјҢйҷҚдҪҺ data block зҡ„еӨ§е°ҸпјҢд»ҺиҖҢжҸҗй«ҳжҖ§иғҪгҖӮиҖҢHBaseдёӯзҡ„зҙўеј•blockдёӯеӯҳзҡ„жҳҜе…ЁйҮҸзҡ„RowkeyпјҢиҖҢеңЁдёҖдёӘе·Із»ҸжҺ’еәҸеҘҪзҡ„ж–Ү件дёӯпјҢеҫҲеӨҡRowkeyйғҪжҳҜжңүе…ұеҗҢеүҚзјҖзҡ„гҖӮ
ж•°жҚ®з»“жһ„дёӯзҡ„Trie (еүҚзјҖж ‘) з»“жһ„иғҪеӨҹи®©е…ұеҗҢеүҚзјҖеҸӘеӯҳдёҖд»ҪпјҢйҒҝе…ҚйҮҚеӨҚеӯҳеӮЁеёҰжқҘзҡ„жөӘиҙ№гҖӮдҪҶжҳҜдј з»ҹеүҚзјҖж ‘з»“жһ„дёӯпјҢд»ҺдёҖдёӘиҠӮзӮ№еҲ°дёӢдёҖдёӘиҠӮзӮ№зҡ„жҢҮй’ҲеҚ з”Ёз©әй—ҙеӨӘеӨҡпјҢж•ҙдҪ“иҖҢиЁҖеҫ—дёҚеҒҝеӨұгҖӮиҝҷдёҖжғ…еҶөжңүжңӣз”Ё Succinct Prefix Tree жқҘи§ЈеҶігҖӮSIGMOD2018е№ҙзҡ„жңҖдҪіи®әж–Ү Surf дёӯжҸҗеҮәдәҶдёҖз§Қз”Ё Succinct Prefix Tree жқҘеҸ–д»Ј bloom filterпјҢ并еҗҢж—¶жҸҗдҫӣ range filtering зҡ„еҠҹиғҪгҖӮжҲ‘们д»ҺиҝҷзҜҮж–Үз« еҫ—еҲ°еҗҜеҸ‘пјҢз”Ё Succinct Trie жқҘеҒҡ file block indexгҖӮ

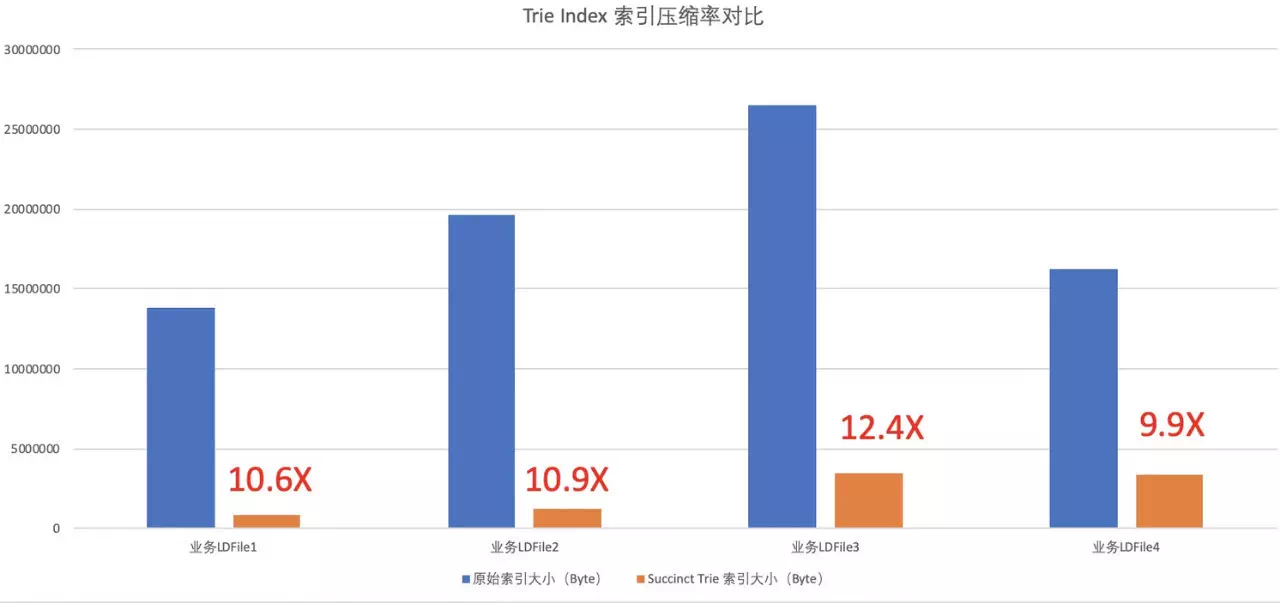
жҲ‘们еңЁзәҝдёҠзҡ„еӨҡдёӘдёҡеҠЎдёӯдҪҝз”ЁдәҶTrie indexе®һзҺ°зҡ„зҙўеј•з»“жһ„гҖӮз»“жһңеҸ‘зҺ°пјҢеҗ„дёӘеңәжҷҜдёӯпјҢTrie indexеҸҜд»ҘеӨ§еӨ§зј©е°Ҹзҙўеј•зҡ„дҪ“з§ҜпјҢжңҖеӨҡеҸҜд»ҘеҺӢзј©12еҖҚзҡ„зҙўеј•з©әй—ҙпјҒиҠӮзңҒзҡ„иҝҷдәӣе®қиҙөз©әй—ҙи®©еҶ…еӯҳCacheдёӯиғҪеӨҹеӯҳж”ҫжӣҙеӨҡзҡ„зҙўеј•е’Ңж•°жҚ®ж–Ү件пјҢеӨ§еӨ§жҸҗй«ҳдәҶиҜ·жұӮзҡ„жҖ§иғҪгҖӮ

### ZGCеҠ жҢҒпјҢзҷҫGBе Ҷе№іеқҮ5msжҡӮеҒң
ZGC(Powerd by Dragonwell JDK)жҳҜдёӢдёҖд»ЈPauseless GCз®—жі•зҡ„д»ЈиЎЁд№ӢдёҖпјҢе…¶ж ёеҝғжҖқжғіжҳҜMutatorеҲ©з”ЁеҶ…еӯҳиҜ»еұҸйҡң(Read Barrier)иҜҶеҲ«жҢҮй’ҲеҸҳеҢ–пјҢдҪҝеҫ—еӨ§йғЁеҲҶзҡ„ж Үи®°(Mark)дёҺеҗҲ并(Relocate)е·ҘдҪңеҸҜд»Ҙж”ҫеңЁе№¶еҸ‘йҳ¶ж®өжү§иЎҢгҖӮ
иҝҷж ·дёҖйЎ№е®һйӘҢжҖ§жҠҖжңҜпјҢеңЁLindormеӣўйҳҹдёҺAJDKеӣўйҳҹзҡ„зҙ§еҜҶеҗҲдҪңдёӢпјҢиҝӣиЎҢдәҶеӨ§йҮҸзҡ„ж”№иҝӣдёҺж”№йҖ е·ҘдҪңгҖӮдҪҝеҫ—ZGCеңЁLindormиҝҷдёӘеңәжҷҜдёҠе®һзҺ°дәҶз”ҹдә§зә§еҸҜз”ЁпјҢдё»иҰҒе·ҘдҪңеҢ…жӢ¬пјҡ
1. LindormеҶ…еӯҳиҮӘз®ЎзҗҶжҠҖжңҜпјҢж•°йҮҸзә§еҮҸе°‘еҜ№иұЎж•°дёҺеҶ…еӯҳеҲҶй…ҚйҖҹзҺҮгҖӮ(жҜ”еҰӮиҜҙйҳҝйҮҢHBaseеӣўйҳҹиҙЎзҢ®з»ҷзӨҫеҢәзҡ„CCSMap)гҖӮ
2. AJDK ZGC Pageзј“еӯҳжңәеҲ¶дјҳеҢ–(й”ҒгҖҒPageзј“еӯҳзӯ–з•Ҙ)гҖӮ
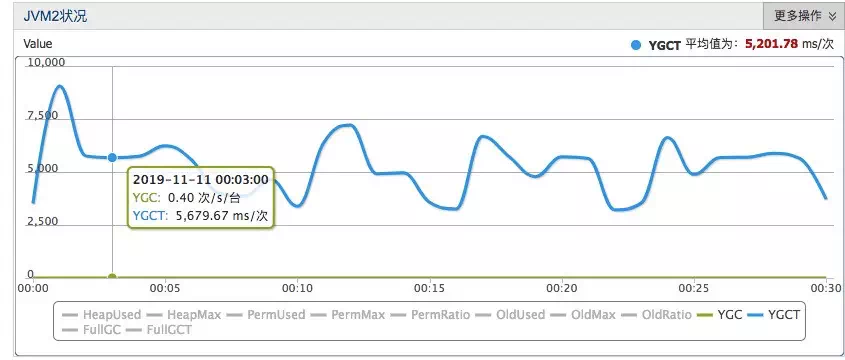
3. AJDK ZGC и§ҰеҸ‘ж—¶жңәдјҳеҢ–пјҢZGCж— е№¶еҸ‘еӨұиҙҘгҖӮAJDK ZGCеңЁLindormдёҠзЁіе®ҡиҝҗиЎҢдёӨдёӘжңҲпјҢ并йЎәеҲ©йҖҡиҝҮеҸҢеҚҒдёҖеӨ§иҖғгҖӮе…¶JVMжҡӮеҒңж—¶й—ҙзЁіе®ҡеңЁ5msе·ҰеҸіпјҢжңҖеӨ§жҡӮеҒңж—¶й—ҙдёҚи¶…иҝҮ8msгҖӮZGCеӨ§еӨ§ж”№е–„дәҶзәҝдёҠиҝҗиЎҢйӣҶзҫӨзҡ„RTдёҺжҜӣеҲәжҢҮж ҮпјҢе№іеқҮRTдјҳеҢ–15%пҪһ20%пјҢP999 RTеҮҸе°‘дёҖеҖҚгҖӮеңЁд»Ҡе№ҙеҸҢеҚҒдёҖиҡӮиҡҒйЈҺжҺ§йӣҶзҫӨдёӯпјҢеңЁZGCзҡ„еҠ жҢҒдёӢпјҢP999ж—¶й—ҙд»Һ12msйҷҚдҪҺеҲ°дәҶ5msгҖӮ

жіЁпјҡеӣҫдёӯзҡ„еҚ•дҪҚеә”иҜҘдёәusпјҢе№іеқҮGCеңЁ5ms
#### LindormBlockingQueue

дёҠеӣҫжҳҜHBaseдёӯзҡ„RegionServerд»ҺзҪ‘з»ңдёҠиҜ»еҸ–RPCиҜ·жұӮ并еҲҶеҸ‘еҲ°еҗ„дёӘHandlerдёҠжү§иЎҢзҡ„жөҒзЁӢгҖӮHBaseдёӯзҡ„RPC Readerд»ҺSocketдёҠиҜ»еҸ–RPCиҜ·жұӮж”ҫе…ҘBlockingQueueпјҢHandlerи®ўйҳ…иҝҷдёӘQueue并жү§иЎҢиҜ·жұӮгҖӮиҖҢиҝҷдёӘBlockingQueueпјҢHBaseдҪҝз”Ёзҡ„жҳҜJavaеҺҹз”ҹзҡ„JDKиҮӘеёҰзҡ„LinkedBlockingQueueгҖӮ
LinkedBlockingQueueеҲ©з”ЁLockдёҺConditionдҝқиҜҒзәҝзЁӢе®үе…ЁдёҺзәҝзЁӢд№Ӣй—ҙзҡ„еҗҢжӯҘпјҢиҷҪ然з»Ҹе…ёжҳ“жҮӮпјҢдҪҶеҪ“еҗһеҗҗеўһеӨ§ж—¶пјҢиҝҷдёӘqueueдјҡйҖ жҲҗдёҘйҮҚзҡ„жҖ§иғҪ瓶йўҲгҖӮ
еӣ жӯӨеңЁLindormдёӯе…Ёж–°и®ҫи®ЎдәҶLindormBlockingQueueпјҢе°Ҷе…ғзҙ з»ҙжҠӨеңЁSlotж•°з»„дёӯгҖӮз»ҙжҠӨheadдёҺtailжҢҮй’ҲпјҢйҖҡиҝҮCASж“ҚдҪңеҜ№иҝӣйҳҹеҲ—иҝӣиЎҢиҜ»еҶҷж“ҚдҪңпјҢж¶ҲйҷӨдәҶдёҙз•ҢеҢәгҖӮ并дҪҝз”ЁCache Line PaddingдёҺи„ҸиҜ»зј“еӯҳеҠ йҖҹпјҢеҗҢж—¶еҸҜе®ҡеҲ¶еӨҡз§Қзӯүеҫ…зӯ–з•Ҙ(Spin/Yield/Block)пјҢйҒҝе…ҚйҳҹеҲ—дёәз©әжҲ–дёәж»Ўж—¶пјҢйў‘з№Ғиҝӣе…ҘParkзҠ¶жҖҒгҖӮLindormBlockingQueueзҡ„жҖ§иғҪйқһеёёзӘҒеҮәпјҢзӣёжҜ”дәҺеҺҹе…Ҳзҡ„LinkedBlockingQueueжҖ§иғҪжҸҗеҚҮ4еҖҚд»ҘдёҠгҖӮ

#### VersionBasedSynchronizer

LDLogжҳҜLindormдёӯз”ЁдәҺзі»з»ҹfailoverж—¶иҝӣиЎҢж•°жҚ®жҒўеӨҚж—¶зҡ„ж—Ҙеҝ—пјҢд»Ҙдҝқйҡңж•°жҚ®зҡ„еҺҹеӯҗжҖ§е’ҢеҸҜйқ жҖ§гҖӮеңЁжҜҸж¬Ўж•°жҚ®еҶҷе…Ҙж—¶пјҢйғҪеҝ…йЎ»е…ҲеҶҷе…ҘLDLogгҖӮ
LDLogеҶҷе…ҘжҲҗеҠҹд№ӢеҗҺпјҢжүҚеҸҜд»ҘиҝӣиЎҢеҗҺз»ӯзҡ„еҶҷе…Ҙmemstoreзӯүж“ҚдҪңгҖӮеӣ жӯӨLindormдёӯзҡ„HandlerйғҪеҝ…йЎ»зӯүеҫ…WALеҶҷе…Ҙе®ҢжҲҗеҗҺеҶҚиў«е”ӨйҶ’д»ҘиҝӣиЎҢдёӢдёҖжӯҘж“ҚдҪңпјҢеңЁй«ҳеҺӢжқЎд»¶дёӢпјҢж— з”Ёе”ӨйҶ’дјҡйҖ жҲҗеӨ§йҮҸзҡ„CPU Context SwitchйҖ жҲҗжҖ§иғҪдёӢйҷҚгҖӮй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢLindormз ”еҸ‘дәҶеҹәдәҺзүҲжң¬зҡ„й«ҳ并еҸ‘еӨҡи·ҜзәҝзЁӢеҗҢжӯҘжңәеҲ¶(VersionBasedSynchronizer)жқҘеӨ§е№…дјҳеҢ–дёҠдёӢж–ҮеҲҮжҚўгҖӮ
VersionBasedSynchronizerзҡ„дё»иҰҒжҖқи·ҜжҳҜи®©Handlerзҡ„зӯүеҫ…жқЎд»¶иў«Notifierж„ҹзҹҘпјҢеҮҸе°‘Notifierзҡ„е”ӨйҶ’еҺӢеҠӣгҖӮз»ҸиҝҮжЁЎеқ—жөӢиҜ•VersionBasedSynchronizerзҡ„ж•ҲзҺҮжҳҜJDKиҮӘеёҰзҡ„ObjectMonitorе’ҢJ.U.C(java util concurrentеҢ…)зҡ„дёӨеҖҚд»ҘдёҠгҖӮ

#### е…Ёйқўж— й”ҒеҢ–
HBaseеҶ…ж ёеңЁе…ій”®и·Ҝеҫ„дёҠжңүеӨ§йҮҸзҡ„й”ҒпјҢеңЁй«ҳ并еҸ‘еңәжҷҜдёӢпјҢиҝҷдәӣй”ҒйғҪдјҡйҖ жҲҗзәҝзЁӢдәүжҠўе’ҢжҖ§иғҪдёӢйҷҚгҖӮLindormеҶ…ж ёеҜ№е…ій”®й“ҫи·ҜдёҠзҡ„й”ҒйғҪеҒҡдәҶж— й”ҒеҢ–еӨ„зҗҶпјҢеҰӮMVCCпјҢWALжЁЎеқ—дёӯзҡ„й”ҒгҖӮ
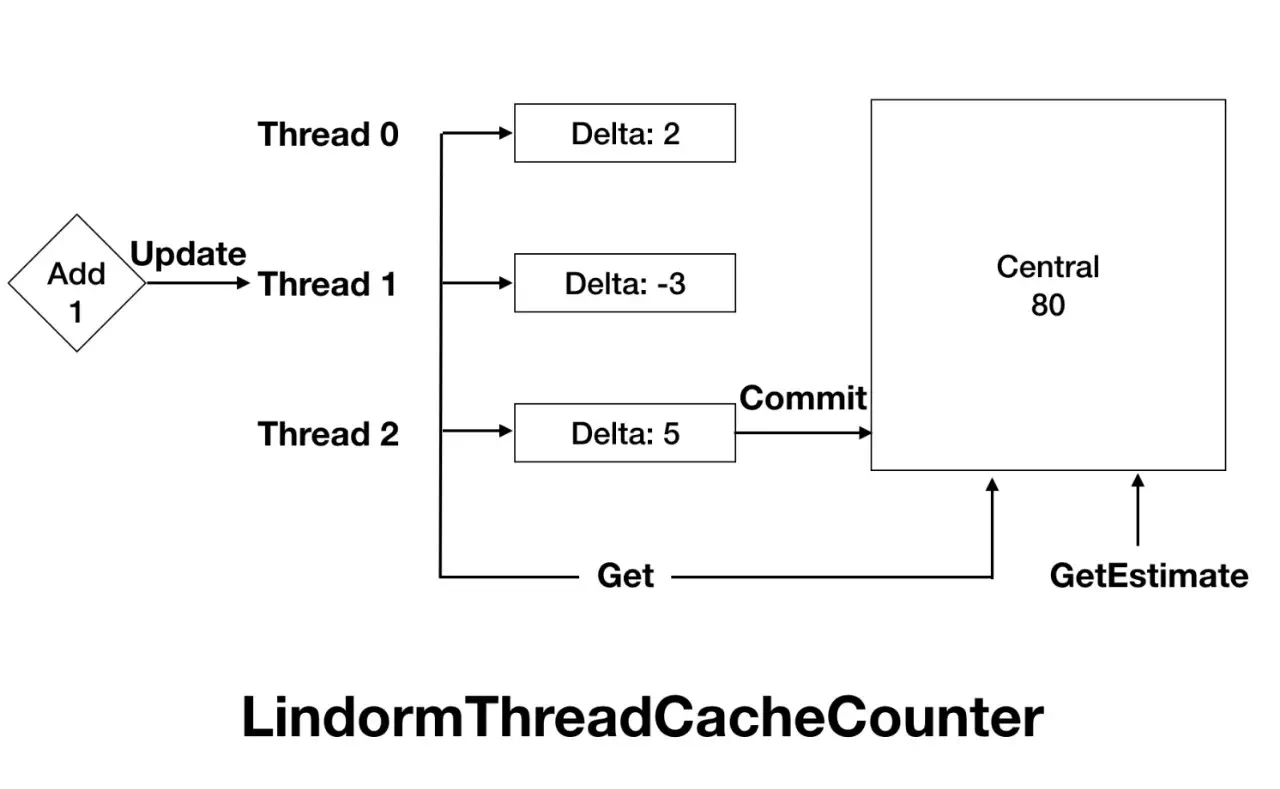
еҸҰеӨ–пјҢHBaseеңЁиҝҗиЎҢиҝҮзЁӢдёӯдјҡдә§з”ҹзҡ„еҗ„з§ҚжҢҮж ҮпјҢеҰӮqpsпјҢrtпјҢcacheе‘ҪдёӯзҺҮзӯүзӯүгҖӮиҖҢеңЁи®°еҪ•иҝҷдәӣMetricsзҡ„вҖңдёҚиө·зңјвҖқж“ҚдҪңдёӯпјҢд№ҹдјҡжңүеӨ§йҮҸзҡ„й”ҒгҖӮйқўеҜ№иҝҷж ·зҡ„й—®йўҳпјҢLindormеҖҹйүҙдәҶtcmallocзҡ„жҖқжғіпјҢејҖеҸ‘дәҶLindormThreadCacheCounterпјҢжқҘи§ЈеҶіMetricsзҡ„жҖ§иғҪй—®йўҳгҖӮ

#### HandlerеҚҸзЁӢеҢ–
еңЁй«ҳ并еҸ‘еә”з”ЁдёӯпјҢдёҖдёӘRPCиҜ·жұӮзҡ„е®һзҺ°еҫҖеҫҖеҢ…еҗ«еӨҡдёӘеӯҗжЁЎеқ—пјҢж¶үеҸҠеҲ°иӢҘе№Іж¬ЎIOгҖӮиҝҷдәӣеӯҗжЁЎеқ—зҡ„зӣёдә’еҚҸдҪңпјҢзі»з»ҹзҡ„ContextSwitchзӣёеҪ“йў‘з№ҒгҖӮ
ContextSwitchзҡ„дјҳеҢ–жҳҜй«ҳ并еҸ‘зі»з»ҹз»•дёҚејҖзҡ„иҜқйўҳпјҢеҗ„дҪҚй«ҳжүӢйғҪеҗ„жҳҫзҘһйҖҡпјҢдёҡз•ҢжңүйқһеёёеӨҡзҡ„жҖқжғідёҺе®һи·өгҖӮе…¶дёӯcoroutine(еҚҸзЁӢ)е’ҢSEDA(еҲҶйҳ¶ж®өдәӢ件й©ұеҠЁ)ж–№жЎҲжҳҜжҲ‘们зқҖйҮҚиҖғеҜҹзҡ„ж–№жЎҲгҖӮ
еҹәдәҺе·ҘзЁӢд»Јд»·пјҢеҸҜз»ҙжҠӨжҖ§пјҢд»Јз ҒеҸҜиҜ»жҖ§дёүдёӘи§’еәҰиҖғиҷ‘пјҢLindormйҖүжӢ©дәҶеҚҸзЁӢзҡ„ж–№ејҸиҝӣиЎҢејӮжӯҘеҢ–дјҳеҢ–гҖӮжҲ‘们еҲ©з”ЁдәҶйҳҝйҮҢJVMеӣўйҳҹжҸҗдҫӣзҡ„Dragonwell JDKеҶ…зҪ®зҡ„Wisp2.0еҠҹиғҪе®һзҺ°дәҶHBase Handlerзҡ„еҚҸзЁӢеҢ–пјҢWisp2.0ејҖз®ұеҚіз”ЁпјҢжңүж•Ҳең°еҮҸе°‘дәҶзі»з»ҹзҡ„иө„жәҗж¶ҲиҖ—пјҢдјҳеҢ–ж•ҲжһңжҜ”иҫғе®ўи§ӮгҖӮ
#### е…Ёж–°Encodingз®—жі•
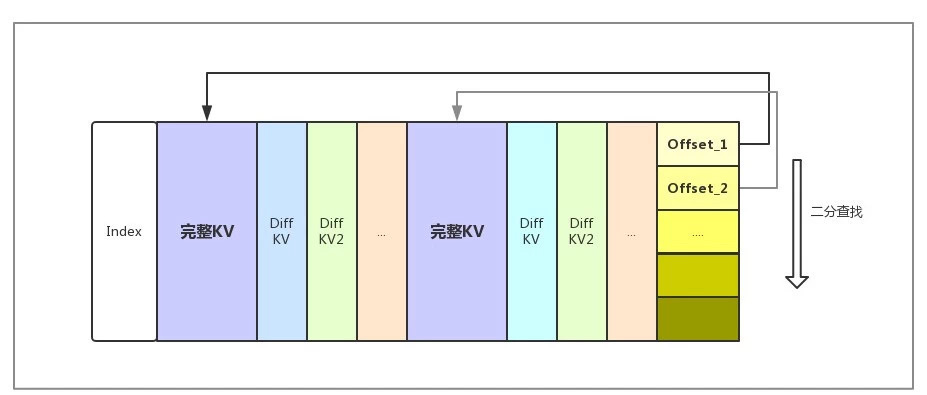
д»ҺжҖ§иғҪи§’еәҰиҖғиҷ‘пјҢHBaseйҖҡеёёйңҖиҰҒе°ҶMetaдҝЎжҒҜиЈ…иҪҪиҝӣblock cacheгҖӮеҰӮжһңе°ҶblockеӨ§е°Ҹиҫғе°ҸпјҢMetaдҝЎжҒҜиҫғеӨҡпјҢдјҡеҮәзҺ°Metaж— жі•е®Ңе…ЁиЈ…е…ҘCacheзҡ„жғ…еҶө, жҖ§иғҪдёӢйҷҚгҖӮеҰӮжһңblockеӨ§е°ҸиҫғеӨ§пјҢз»ҸиҝҮEncodingзҡ„blockзҡ„йЎәеәҸжҹҘиҜўзҡ„жҖ§иғҪдјҡжҲҗдёәйҡҸжңәиҜ»зҡ„жҖ§иғҪ瓶йўҲгҖӮй’ҲеҜ№иҝҷдёҖжғ…еҶөпјҢLindormе…Ёж–°ејҖеҸ‘дәҶIndexable Delta EncodingпјҢеңЁblockеҶ…йғЁд№ҹеҸҜд»ҘйҖҡиҝҮзҙўеј•иҝӣиЎҢеҝ«йҖҹжҹҘиҜўпјҢseekжҖ§иғҪжңүдәҶиҫғеӨ§жҸҗй«ҳгҖӮIndexable Delta EncodingеҺҹзҗҶеҰӮеӣҫжүҖзӨәпјҡ

йҖҡиҝҮIndexable Delta EncodingпјҢ HFileзҡ„йҡҸжңәseekжҖ§иғҪзӣёеҜ№дәҺдҪҝз”Ёд№ӢеүҚзҝ»дәҶдёҖеҖҚпјҢд»Ҙ64K blockдёәдҫӢпјҢйҡҸжңәseekжҖ§иғҪеҹәжң¬дёҺдёҚеҒҡencodingзӣёиҝ‘пјҲе…¶д»–encodingз®—жі•дјҡжңүдёҖе®ҡжҖ§иғҪжҚҹеӨұпјүгҖӮеңЁе…Ёcacheе‘Ҫдёӯзҡ„йҡҸжңәGetеңәжҷҜдёӢпјҢзӣёеҜ№дәҺDiff encoding RTдёӢйҷҚ50%гҖӮ
#### е…¶д»–
зӣёжҜ”зӨҫеҢәзүҲHBaseпјҢLindormиҝҳжңүеӨҡиҫҫеҮ еҚҒйЎ№зҡ„жҖ§иғҪдјҳеҢ–е’ҢйҮҚжһ„пјҢеј•е…ҘдәҶдј—еӨҡж–°жҠҖжңҜпјҢз”ұдәҺзҜҮе№…жңүйҷҗпјҢиҝҷйҮҢеҸӘиғҪеҲ—дёҫдёҖйғЁеҲҶпјҢе…¶д»–зҡ„ж ёеҝғжҠҖжңҜпјҢжҜ”еҰӮпјҡ
> CCSMapВ
> иҮӘеҠЁи§„йҒҝж•…йҡңиҠӮзӮ№зҡ„并еҸ‘дёүеүҜжң¬ж—Ҙеҝ—еҚҸи®® (Quorum-based write)В
> й«ҳж•Ҳзҡ„жү№йҮҸз»„жҸҗдәӨ(Group Commit)В
> ж— зўҺзүҮзҡ„й«ҳжҖ§иғҪзј“еӯҳвҖ”Shared BucketCacheВ
> Memstore BloomfilterВ
> йқўеҗ‘иҜ»еҶҷзҡ„й«ҳж•Ҳж•°жҚ®з»“жһ„В
> GC-InvisibleеҶ…еӯҳз®ЎзҗҶВ
> еңЁзәҝи®Ўз®—дёҺзҰ»зәҝдҪңдёҡжһ¶жһ„еҲҶзҰ»В
> JDK/ж“ҚдҪңзі»з»ҹж·ұеәҰдјҳеҢ–В
> FPGA offloading CompactionВ
> з”ЁжҲ·жҖҒTCPеҠ йҖҹВ
> вҖҰвҖҰ
дё°еҜҢзҡ„жҹҘиҜўжЁЎеһӢпјҢйҷҚдҪҺејҖеҸ‘й—Ёж§ӣ
--------------
еҺҹз”ҹзҡ„HBaseеҸӘж”ҜжҢҒKVз»“жһ„зҡ„жҹҘиҜўпјҢиҷҪ然з®ҖеҚ•пјҢдҪҶжҳҜеңЁйқўеҜ№еҗ„йЎ№дёҡеҠЎзҡ„еӨҚжқӮйңҖжұӮж—¶пјҢжҳҫзҡ„жңүзӮ№еҠӣдёҚд»ҺеҝғгҖӮеӣ жӯӨпјҢеңЁLindormдёӯпјҢжҲ‘们й’ҲеҜ№дёҚеҗҢдёҡеҠЎзҡ„зү№зӮ№пјҢз ”еҸ‘дәҶеӨҡз§ҚжҹҘиҜўжЁЎеһӢпјҢйҖҡиҝҮжӣҙйқ иҝ‘еңәжҷҜзҡ„APIе’Ңзҙўеј•и®ҫи®ЎпјҢйҷҚдҪҺејҖеҸ‘й—Ёж§ӣгҖӮ
#### WideColumn жЁЎеһӢпјҲеҺҹз”ҹHBase APIпјү
WideColumnжҳҜдёҖз§ҚдёҺHBaseе®Ңе…ЁдёҖиҮҙзҡ„и®ҝй—®жЁЎеһӢе’Ңж•°жҚ®з»“жһ„пјҢд»ҺиҖҢдҪҝеҫ—LindromиғҪ100%е…је®№HBaseзҡ„APIгҖӮз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮLindormжҸҗдҫӣзҡ„й«ҳжҖ§иғҪеҺҹз”ҹе®ўжҲ·з«Ҝдёӯзҡ„WideColumn APIи®ҝй—®LindormпјҢд№ҹеҸҜд»ҘйҖҡиҝҮalihbase-connectorиҝҷдёӘжҸ’件пјҢдҪҝз”ЁHBaseе®ўжҲ·з«ҜеҸҠAPI(ж— йңҖд»»дҪ•д»Јз Ғж”№йҖ )зӣҙжҺҘи®ҝй—®LindormгҖӮ
еҗҢж—¶пјҢLindormдҪҝз”ЁдәҶиҪ»е®ўжҲ·з«Ҝзҡ„и®ҫи®ЎпјҢе°ҶеӨ§йҮҸж•°жҚ®и·Ҝз”ұгҖҒжү№йҮҸеҲҶеҸ‘гҖҒи¶…ж—¶гҖҒйҮҚиҜ•зӯүйҖ»иҫ‘дёӢжІүеҲ°жңҚеҠЎз«ҜпјҢ并еңЁзҪ‘з»ңдј иҫ“еұӮеҒҡдәҶеӨ§йҮҸзҡ„дјҳеҢ–пјҢдҪҝеҫ—еә”з”Ёз«Ҝзҡ„CPUж¶ҲиҖ—еҸҜд»ҘеӨ§еӨ§иҠӮзңҒгҖӮеғҸдёӢиЎЁдёӯпјҢзӣёжҜ”дәҺHBaseпјҢдҪҝз”ЁLindormеҗҺзҡ„еә”з”Ёдҫ§CPUдҪҝз”Ёж•ҲзҺҮжҸҗеҚҮ60%пјҢзҪ‘з»ңеёҰе®Ҫж•ҲзҺҮжҸҗеҚҮ25%гҖӮ
жіЁпјҡиЎЁдёӯзҡ„е®ўжҲ·з«ҜCPUд»ЈиЎЁHBase/Lindormе®ўжҲ·з«Ҝж¶ҲиҖ—зҡ„CPUиө„жәҗпјҢи¶Ҡе°Ҹи¶ҠеҘҪгҖӮ
еңЁHBaseеҺҹз”ҹAPIдёҠпјҢжҲ‘们иҝҳзӢ¬е®¶ж”ҜжҢҒдәҶй«ҳжҖ§иғҪдәҢзә§зҙўеј•пјҢз”ЁжҲ·еҸҜд»ҘдҪҝз”ЁHBaseеҺҹз”ҹAPIеҶҷе…Ҙж•°жҚ®иҝҮзЁӢдёӯпјҢзҙўеј•ж•°жҚ®йҖҸжҳҺең°еҶҷе…Ҙзҙўеј•иЎЁгҖӮеңЁжҹҘиҜўиҝҮзЁӢдёӯпјҢжҠҠеҸҜиғҪе…ЁиЎЁжү«зҡ„Scan + FilterеӨ§жҹҘиҜўпјҢеҸҳжҲҗеҸҜд»Ҙе…ҲеҺ»жҹҘиҜўзҙўеј•иЎЁпјҢеӨ§еӨ§жҸҗй«ҳдәҶжҹҘиҜўжҖ§иғҪгҖӮе…ідәҺй«ҳжҖ§иғҪеҺҹз”ҹдәҢзә§зҙўеј•пјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғпјҡ
[https://help.aliyun.com/document\_detail/144577.html](https://help.aliyun.com/document_detail/144577.html)
#### TableServiceжЁЎеһӢ(SQLгҖҒдәҢзә§зҙўеј•)
HBaseдёӯеҸӘж”ҜжҢҒRowkeyиҝҷдёҖз§Қзҙўеј•ж–№ејҸпјҢеҜ№дәҺеӨҡеӯ—ж®өжҹҘиҜўж—¶пјҢйҖҡеёёж•ҲзҺҮдҪҺдёӢгҖӮдёәжӯӨпјҢз”ЁжҲ·йңҖиҰҒз»ҙжҠӨеӨҡдёӘиЎЁжқҘж»Ўи¶ідёҚеҗҢеңәжҷҜзҡ„жҹҘиҜўйңҖжұӮпјҢиҝҷеңЁдёҖе®ҡзЁӢеәҰдёҠж—ўеўһеҠ дәҶеә”з”Ёзҡ„ејҖеҸ‘еӨҚжқӮжҖ§пјҢд№ҹдёҚиғҪеҫҲе®ҢзҫҺең°дҝқиҜҒж•°жҚ®дёҖиҮҙжҖ§е’ҢеҶҷе…Ҙж•ҲзҺҮгҖӮ并且HBaseдёӯеҸӘжҸҗдҫӣдәҶKV APIпјҢеҸӘиғҪеҒҡPutгҖҒGetгҖҒScanзӯүз®ҖеҚ•APIж“ҚдҪңпјҢд№ҹжІЎжңүж•°жҚ®зұ»еһӢпјҢжүҖжңүзҡ„ж•°жҚ®йғҪеҝ…йЎ»з”ЁжҲ·иҮӘе·ұиҪ¬жҚўе’ҢеӮЁеӯҳгҖӮеҜ№дәҺд№ жғҜдәҶSQLиҜӯиЁҖзҡ„ејҖеҸ‘иҖ…жқҘиҜҙпјҢе…Ҙй—Ёзҡ„й—Ёж§ӣйқһеёёй«ҳпјҢиҖҢдё”е®№жҳ“еҮәй”ҷгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёҖз—ӣзӮ№пјҢйҷҚдҪҺз”ЁжҲ·дҪҝз”Ёй—Ёж§ӣпјҢжҸҗй«ҳејҖеҸ‘ж•ҲзҺҮпјҢеңЁLindormдёӯжҲ‘们еўһеҠ дәҶTableServiceжЁЎеһӢпјҢе…¶жҸҗдҫӣдё°еҜҢзҡ„ж•°жҚ®зұ»еһӢгҖҒз»“жһ„еҢ–жҹҘиҜўиЎЁиҫҫAPIпјҢ并еҺҹз”ҹж”ҜжҢҒSQLи®ҝй—®е’Ңе…ЁеұҖдәҢзә§зҙўеј•пјҢи§ЈеҶідәҶдј—еӨҡзҡ„жҠҖжңҜжҢ‘жҲҳпјҢеӨ§е№…йҷҚдҪҺжҷ®йҖҡз”ЁжҲ·зҡ„ејҖеҸ‘й—Ёж§ӣгҖӮйҖҡиҝҮSQLе’ҢSQL likeзҡ„APIпјҢз”ЁжҲ·еҸҜд»Ҙж–№дҫҝең°еғҸдҪҝз”Ёе…ізі»ж•°жҚ®еә“йӮЈж ·дҪҝз”ЁLindormгҖӮдёӢйқўжҳҜдёҖдёӘLindorm SQLзҡ„з®ҖеҚ•зӨәдҫӢгҖӮ
\*иҜ·е·ҰеҸіж»‘еҠЁйҳ…и§Ҳ
```
-- дё»иЎЁе’Ңзҙўеј•DDL
create table shop_item_relation (
shop_id varchar,
item_id varchar,
status varchar
constraint primary key(shop_id, item_id)) ;
create index idx1 on shop_item_relation (item_id) include (ALL); -- еҜ№з¬¬дәҢеҲ—дё»й”®е»әзҙўеј•пјҢеҶ—дҪҷжүҖжңүеҲ—
create index idx2 on shop_item_relation (shop_id, status) include (ALL); -- еӨҡеҲ—зҙўеј•пјҢеҶ—дҪҷжүҖжңүеҲ—
-- еҶҷе…Ҙж•°жҚ®пјҢдјҡеҗҢжӯҘжӣҙж–°2дёӘзҙўеј•
upsert into shop_item_relation values('shop1', 'item1', 'active');
upsert into shop_item_relation values('shop1', 'item2', 'invalid');
-- ж №жҚ®WHEREеӯҗеҸҘиҮӘеҠЁйҖүжӢ©еҗҲйҖӮзҡ„зҙўеј•жү§иЎҢжҹҘиҜў
select * from shop_item_relation where item_id = 'item2'; -- е‘Ҫдёӯidx1
select * from shop_item_relation where shop_id = 'shop1' and status = 'invalid'; -- е‘Ҫдёӯidx2
```

зӣёжҜ”дәҺе…ізі»ж•°жҚ®еә“зҡ„SQLпјҢLindormдёҚе…·еӨҮеӨҡиЎҢдәӢеҠЎе’ҢеӨҚжқӮеҲҶжһҗ(еҰӮJoinгҖҒGroupby)зҡ„иғҪеҠӣпјҢиҝҷд№ҹжҳҜдёӨиҖ…д№Ӣй—ҙзҡ„е®ҡдҪҚе·®ејӮгҖӮ
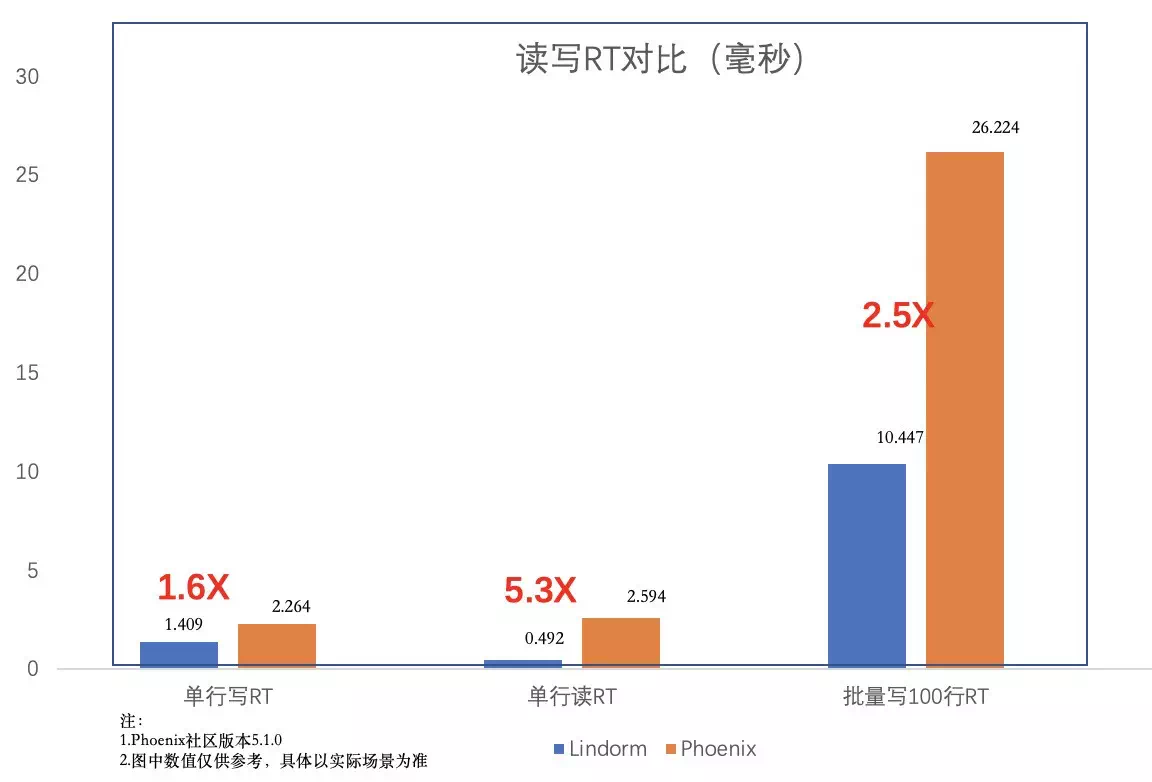
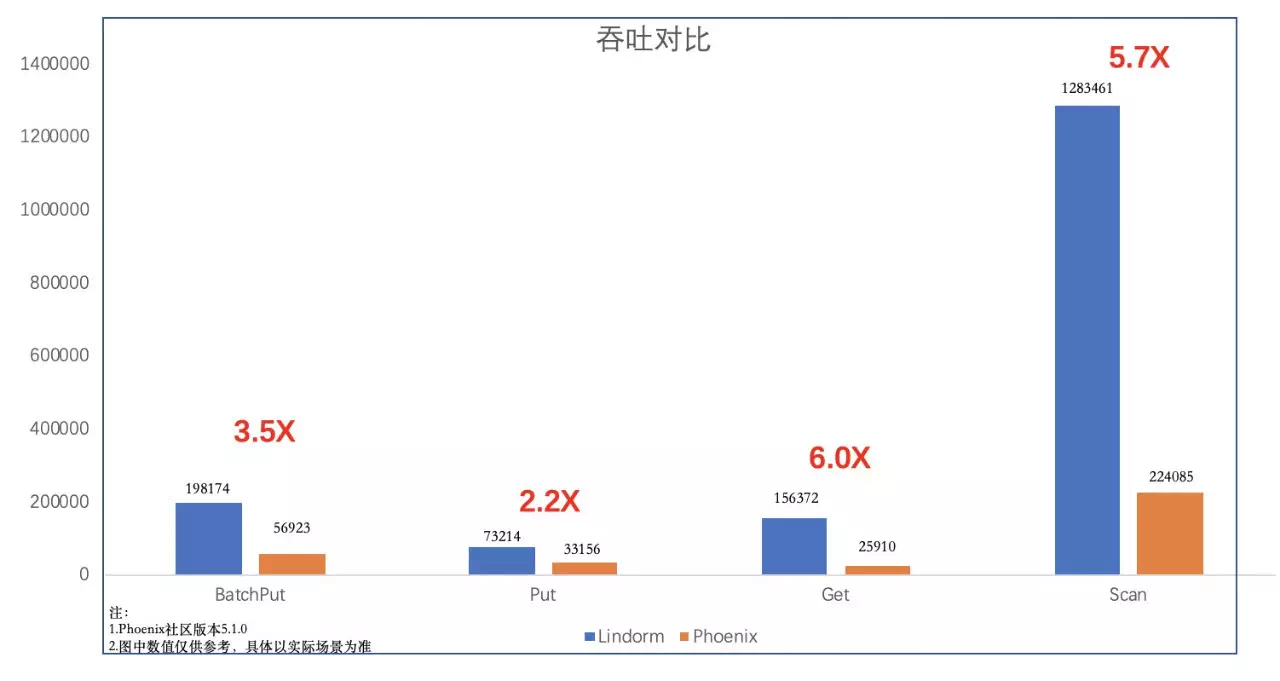
зӣёжҜ”дәҺHBaseдёҠPhoenix组件жҸҗдҫӣзҡ„дәҢзә§зҙўеј•пјҢLindormзҡ„дәҢзә§зҙўеј•еңЁеҠҹиғҪгҖҒжҖ§иғҪгҖҒзЁіе®ҡжҖ§дёҠиҝңиҝңи¶…иҝҮPhoenixпјҢдёӢеӣҫжҳҜдёҖдёӘз®ҖеҚ•зҡ„жҖ§иғҪеҜ№жҜ”гҖӮ


жіЁпјҡиҜҘжЁЎеһӢе·Із»ҸеңЁйҳҝйҮҢдә‘HBaseеўһејәзүҲдёҠеҶ…жөӢпјҢж„ҹе…ҙи¶Јзҡ„з”ЁжҲ·еҸҜд»ҘиҒ”зі»дә‘HBaseзӯ”з–‘й’үй’үеҸ·жҲ–иҖ…еңЁйҳҝйҮҢдә‘дёҠеҸ‘иө·е·ҘеҚ•е’ЁиҜўгҖӮ
#### FeedStreamжЁЎеһӢ
зҺ°д»Јдә’иҒ”зҪ‘жһ¶жһ„дёӯпјҢж¶ҲжҒҜйҳҹеҲ—жүҝжӢ…дәҶйқһеёёйҮҚиҰҒзҡ„иҒҢиҙЈпјҢеҸҜд»ҘжһҒеӨ§зҡ„жҸҗеҚҮж ёеҝғзі»з»ҹзҡ„жҖ§иғҪе’ҢзЁіе®ҡжҖ§гҖӮе…¶е…ёеһӢзҡ„еә”з”ЁеңәжҷҜжңүеҢ…жӢ¬зі»з»ҹи§ЈиҖҰпјҢеүҠеі°йҷҗжөҒпјҢж—Ҙеҝ—йҮҮйӣҶпјҢжңҖз»ҲдёҖиҮҙдҝқиҜҒпјҢеҲҶеҸ‘жҺЁйҖҒзӯүзӯүгҖӮ
еёёи§Ғзҡ„ж¶ҲжҒҜйҳҹеҲ—еҢ…жӢ¬RabbitMqпјҢKafkaд»ҘеҸҠRocketMqзӯүзӯүгҖӮиҝҷдәӣж•°жҚ®еә“е°Ҫз®Ўд»Һжһ¶жһ„е’ҢдҪҝз”Ёж–№ејҸе’ҢжҖ§иғҪдёҠз•ҘжңүдёҚеҗҢпјҢдҪҶе…¶еҹәжң¬дҪҝз”ЁеңәжҷҜйғҪзӣёеҜ№жҺҘиҝ‘гҖӮ然иҖҢпјҢдј з»ҹзҡ„ж¶ҲжҒҜйҳҹеҲ—并йқһе®ҢзҫҺпјҢе…¶еңЁж¶ҲжҒҜжҺЁйҖҒпјҢfeedжөҒзӯүеңәжҷҜеӯҳеңЁд»ҘдёӢй—®йўҳпјҡ
> еӯҳеӮЁпјҡдёҚйҖӮеҗҲй•ҝжңҹдҝқеӯҳж•°жҚ®пјҢйҖҡеёёиҝҮжңҹж—¶й—ҙйғҪеңЁеӨ©зә§В
> еҲ йҷӨиғҪеҠӣпјҡдёҚж”ҜжҢҒеҲ йҷӨжҢҮе®ҡж•°жҚ®entryВ
> жҹҘиҜўиғҪеҠӣпјҡдёҚж”ҜжҢҒиҫғдёәеӨҚжқӮзҡ„жҹҘиҜўе’ҢиҝҮж»ӨжқЎд»¶В
> дёҖиҮҙжҖ§е’ҢжҖ§иғҪйҡҫд»ҘеҗҢж—¶дҝқиҜҒпјҡзұ»дјјдәҺKafkaд№Ӣзұ»зҡ„ж•°жҚ®еә“жӣҙйҮҚеҗһеҗҗпјҢдёәдәҶжҸҗй«ҳжҖ§иғҪеӯҳеңЁдәҶжҹҗдәӣзҠ¶еҶөдёӢдёўж•°жҚ®зҡ„еҸҜиғҪпјҢиҖҢдәӢеҠЎеӨ„зҗҶиғҪеҠӣиҫғеҘҪзҡ„ж¶ҲжҒҜйҳҹеҲ—еҗһеҗҗеҸҲиҫғдёәеҸ—йҷҗгҖӮВ
> Partitionеҝ«йҖҹжӢ“еұ•иғҪеҠӣпјҡйҖҡеёёдёҖдёӘTopcдёӢзҡ„partitionж•°зӣ®йғҪжҳҜеӣәе®ҡпјҢдёҚж”ҜжҢҒеҝ«йҖҹжү©еұ•гҖӮВ
> зү©зҗҶйҳҹеҲ—/йҖ»иҫ‘йҳҹеҲ—пјҡйҖҡеёёеҸӘж”ҜжҢҒе°‘йҮҸзү©зҗҶйҳҹеҲ—(еҰӮжҜҸдёӘpartitionеҸҜд»ҘзңӢжҲҗдёҖдёӘйҳҹеҲ—)пјҢиҖҢдёҡеҠЎйңҖиҰҒзҡ„еңЁзү©зҗҶйҳҹеҲ—зҡ„еҹәзЎҖдёҠжЁЎжӢҹеҮәйҖ»иҫ‘йҳҹеҲ—пјҢеҰӮIMзі»з»ҹдёӯдёәжҜҸдёӘз”ЁжҲ·з»ҙжҠӨдёҖдёӘйҖ»иҫ‘дёҠзҡ„ж¶ҲжҒҜйҳҹеҲ—пјҢз”ЁжҲ·еҫҖеҫҖйңҖиҰҒеҫҲеӨҡйўқеӨ–зҡ„ејҖеҸ‘е·ҘдҪңгҖӮ
й’ҲеҜ№дёҠиҝ°йңҖжұӮпјҢLindormжҺЁеҮәдәҶйҳҹеҲ—жЁЎеһӢFeedStreamServiceпјҢиғҪеӨҹи§ЈеҶіжө·йҮҸз”ЁжҲ·дёӢзҡ„ж¶ҲжҒҜеҗҢжӯҘпјҢи®ҫеӨҮйҖҡзҹҘпјҢиҮӘеўһIDеҲҶй…Қзӯүй—®йўҳгҖӮ

FeedStreamжЁЎеһӢеңЁд»Ҡе№ҙжүӢжңәж·ҳе®қж¶ҲжҒҜзі»з»ҹдёӯжү®жј”дәҶйҮҚиҰҒи§’иүІпјҢи§ЈеҶідәҶжүӢжңәж·ҳе®қж¶ҲжҒҜжҺЁйҖҒдҝқеәҸпјҢе№ӮзӯүзӯүйҡҫйўҳгҖӮеңЁд»Ҡе№ҙеҸҢеҚҒдёҖдёӯпјҢжүӢж·ҳзҡ„зӣ–жҘје’ҢеӣһиЎҖеӨ§зәўеҢ…жҺЁйҖҒйғҪжңүLindormзҡ„иә«еҪұгҖӮжүӢж·ҳж¶ҲжҒҜзҡ„жҺЁйҖҒдёӯпјҢеі°еҖји¶…иҝҮдәҶ100w/sпјҢеҒҡеҲ°дәҶеҲҶй’ҹзә§жҺЁйҖҒе…ЁзҪ‘з”ЁжҲ·гҖӮ

жіЁпјҡиҜҘжЁЎеһӢе·Із»ҸеңЁйҳҝйҮҢдә‘HBaseеўһејәзүҲдёҠеҶ…жөӢпјҢж„ҹе…ҙи¶Јзҡ„з”ЁжҲ·еҸҜд»ҘиҒ”зі»дә‘HBaseзӯ”з–‘й’үй’үеҸ·жҲ–иҖ…еңЁйҳҝйҮҢдә‘дёҠеҸ‘иө·е·ҘеҚ•е’ЁиҜўгҖӮ
е…Ёж–Үзҙўеј•жЁЎеһӢ
------
иҷҪ然Lindormдёӯзҡ„TableServiceжЁЎеһӢжҸҗдҫӣдәҶж•°жҚ®зұ»еһӢе’ҢдәҢзә§зҙўеј•гҖӮдҪҶжҳҜпјҢеңЁйқўеҜ№еҗ„з§ҚеӨҚжқӮжқЎд»¶жҹҘиҜўе’Ңе…Ёж–Үзҙўеј•зҡ„йңҖжұӮдёӢпјҢиҝҳжҳҜжҳҫеҫ—еҠӣдёҚд»ҺеҝғпјҢиҖҢSolrе’ҢESжҳҜдјҳз§Җзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺгҖӮ
дҪҝз”ЁLindorm+Solr/ESпјҢеҸҜд»ҘжңҖеӨ§йҷҗеәҰеҸ‘жҢҘLindormе’ҢSolr/ESеҗ„иҮӘзҡ„дјҳзӮ№пјҢд»ҺиҖҢдҪҝеҫ—жҲ‘们еҸҜд»Ҙжһ„е»әеӨҚжқӮзҡ„еӨ§ж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўжңҚеҠЎгҖӮLindormеҶ…зҪ®дәҶеӨ–йғЁзҙўеј•еҗҢжӯҘ组件пјҢиғҪеӨҹиҮӘеҠЁең°е°ҶеҶҷе…ҘLindormзҡ„ж•°жҚ®еҗҢжӯҘеҲ°еӨ–йғЁзҙўеј•з»„件еҰӮSolrжҲ–иҖ…ESдёӯгҖӮиҝҷз§ҚжЁЎеһӢйқһеёёйҖӮеҗҲйңҖиҰҒдҝқеӯҳеӨ§йҮҸж•°жҚ®пјҢиҖҢжҹҘиҜўжқЎд»¶зҡ„еӯ—ж®өж•°жҚ®д»…еҚ еҺҹж•°жҚ®зҡ„дёҖе°ҸйғЁеҲҶпјҢ并且йңҖиҰҒеҗ„з§ҚжқЎд»¶з»„еҗҲжҹҘиҜўзҡ„дёҡеҠЎпјҢдҫӢеҰӮпјҡ
> еёёи§Ғзү©жөҒдёҡеҠЎеңәжҷҜпјҢйңҖиҰҒеӯҳеӮЁеӨ§йҮҸиҪЁиҝ№зү©жөҒдҝЎжҒҜпјҢ并йңҖж №жҚ®еӨҡдёӘеӯ—ж®өд»»ж„Ҹз»„еҗҲжҹҘиҜўжқЎд»¶В
> дәӨйҖҡзӣ‘жҺ§дёҡеҠЎеңәжҷҜпјҢдҝқеӯҳеӨ§йҮҸиҝҮиҪҰи®°еҪ•пјҢеҗҢж—¶дјҡж №жҚ®иҪҰиҫҶдҝЎжҒҜд»»ж„ҸжқЎд»¶з»„еҗҲжЈҖзҙўеҮәж„ҹе…ҙи¶Јзҡ„и®°еҪ•В
> еҗ„з§ҚзҪ‘з«ҷдјҡе‘ҳгҖҒе•Ҷе“ҒдҝЎжҒҜжЈҖзҙўеңәжҷҜпјҢдёҖиҲ¬дҝқеӯҳеӨ§йҮҸзҡ„е•Ҷе“Ғ/дјҡе‘ҳдҝЎжҒҜпјҢ并йңҖиҰҒж №жҚ®е°‘йҮҸжқЎд»¶иҝӣиЎҢеӨҚжқӮдё”д»»ж„Ҹзҡ„жҹҘиҜўпјҢд»Ҙж»Ўи¶ізҪ‘з«ҷз”ЁжҲ·д»»ж„ҸжҗңзҙўйңҖжұӮзӯүгҖӮ
е…Ёж–Үзҙўеј•жЁЎеһӢе·Із»ҸеңЁйҳҝйҮҢдә‘дёҠзәҝпјҢж”ҜжҢҒSolr/ESеӨ–йғЁзҙўеј•гҖӮзӣ®еүҚпјҢзҙўеј•зҡ„жҹҘиҜўз”ЁжҲ·иҝҳйңҖиҰҒзӣҙжҺҘжҹҘиҜўSolr/ESеҶҚжқҘеҸҚжҹҘLindormпјҢеҗҺз»ӯжҲ‘们дјҡз”ЁTableServiceзҡ„иҜӯжі•жҠҠжҹҘиҜўеӨ–йғЁзҙўеј•зҡ„иҝҮзЁӢеҢ…иЈ…иө·жқҘпјҢз”ЁжҲ·е…ЁзЁӢеҸӘйңҖиҰҒе’ҢLindormдәӨдә’пјҢеҚіеҸҜиҺ·еҫ—е…Ёж–Үзҙўеј•зҡ„иғҪеҠӣгҖӮ
#### жӣҙеӨҡжЁЎеһӢеңЁи·ҜдёҠ
йҷӨдәҶдёҠиҝ°иҝҷдәӣжЁЎеһӢпјҢжҲ‘们иҝҳдјҡж №жҚ®дёҡеҠЎзҡ„йңҖжұӮе’Ңз—ӣзӮ№пјҢејҖеҸ‘жӣҙеӨҡз®ҖеҚ•жҳ“з”Ёзҡ„жЁЎеһӢпјҢж–№дҫҝз”ЁжҲ·дҪҝз”ЁпјҢйҷҚдҪҺдҪҝз”Ёй—Ёж§ӣгҖӮеғҸж—¶еәҸжЁЎеһӢпјҢеӣҫжЁЎеһӢзӯүпјҢйғҪе·Із»ҸеңЁи·ҜдёҠпјҢ敬иҜ·жңҹеҫ…гҖӮ
йӣ¶е№Ійў„гҖҒз§’жҒўеӨҚзҡ„й«ҳеҸҜз”ЁиғҪеҠӣ
-------------
д»ҺдёҖдёӘе©ҙе„ҝжҲҗй•ҝдёәйқ’е№ҙпјҢйҳҝйҮҢHBaseж‘”иҝҮеҫҲеӨҡж¬ЎпјҢз”ҡиҮіеӨҙз ҙиЎҖжөҒпјҢжҲ‘们еңЁе®ўжҲ·зҡ„дҝЎд»»д№ӢдёӢе№ёиҝҗзҡ„жҲҗй•ҝгҖӮеңЁ9е№ҙзҡ„йҳҝйҮҢеә”з”ЁиҝҮзЁӢдёӯпјҢжҲ‘们з§ҜзҙҜдәҶеӨ§йҮҸзҡ„й«ҳеҸҜз”ЁжҠҖжңҜпјҢиҖҢиҝҷдәӣжҠҖжңҜпјҢйғҪеә”з”ЁеҲ°дәҶHBaseеўһејәзүҲдёӯгҖӮ
#### MTTRдјҳеҢ–
HBaseжҳҜеҸӮз…§Gooogleи‘—еҗҚи®әж–ҮBigTableзҡ„ејҖжәҗе®һзҺ°пјҢе…¶дёӯжңҖж ёеҝғзү№зӮ№жҳҜж•°жҚ®жҢҒд№…еҢ–еӯҳеӮЁдәҺеә•еұӮзҡ„еҲҶеёғејҸж–Ү件系з»ҹHDFSпјҢйҖҡиҝҮHDFSеҜ№ж•°жҚ®зҡ„еӨҡеүҜжң¬з»ҙжҠӨжқҘдҝқйҡңж•ҙдёӘзі»з»ҹзҡ„й«ҳеҸҜйқ жҖ§пјҢиҖҢHBaseиҮӘиә«дёҚйңҖиҰҒеҺ»е…іеҝғж•°жҚ®зҡ„еӨҡеүҜжң¬еҸҠе…¶дёҖиҮҙжҖ§пјҢиҝҷжңүеҠ©дәҺж•ҙдҪ“е·ҘзЁӢзҡ„з®ҖеҢ–пјҢдҪҶд№ҹеј•е…ҘдәҶ"жңҚеҠЎеҚ•зӮ№"зҡ„зјәйҷ·пјҢеҚіеҜ№дәҺзЎ®е®ҡзҡ„ж•°жҚ®зҡ„иҜ»еҶҷжңҚеҠЎеҸӘжңүеҸ‘з”ҹеӣәе®ҡзҡ„жҹҗдёӘиҠӮзӮ№жңҚеҠЎеҷЁпјҢиҝҷж„Ҹе‘ізқҖеҪ“дёҖдёӘиҠӮзӮ№е®•жңәеҗҺпјҢж•°жҚ®йңҖиҰҒйҖҡиҝҮйҮҚж”ҫLogжҒўеӨҚеҶ…еӯҳзҠ¶жҖҒпјҢ并且йҮҚж–°жҙҫеҸ‘з»ҷж–°зҡ„иҠӮзӮ№еҠ иҪҪеҗҺпјҢжүҚиғҪжҒўеӨҚжңҚеҠЎгҖӮ
еҪ“йӣҶзҫӨ规模иҫғеӨ§ж—¶пјҢHBaseеҚ•зӮ№ж•…йҡңеҗҺжҒўеӨҚж—¶й—ҙеҸҜиғҪдјҡиҫҫеҲ°10-20еҲҶй’ҹпјҢеӨ§и§„жЁЎйӣҶзҫӨе®•жңәзҡ„жҒўеӨҚж—¶й—ҙеҸҜиғҪйңҖиҰҒеҘҪеҮ дёӘе°Ҹж—¶пјҒиҖҢеңЁLindormеҶ…ж ёдёӯпјҢжҲ‘们еҜ№MTTRпјҲе№іеқҮж•…йҡңжҒўеӨҚж—¶й—ҙпјүеҒҡдәҶдёҖзі»еҲ—зҡ„дјҳеҢ–пјҢеҢ…жӢ¬ж•…йҡңжҒўеӨҚж—¶е…ҲдёҠзәҝregionгҖҒ并иЎҢreplayгҖҒеҮҸе°‘е°Ҹж–Ү件дә§з”ҹзӯүдј—еӨҡжҠҖжңҜгҖӮе°Ҷж•…йҡңжҒўеӨҚйҖҹеәҰжҸҗеҚҮ10еҖҚд»ҘдёҠпјҒеҹәжң¬дёҠжҺҘиҝ‘дәҶHBaseи®ҫи®Ўзҡ„зҗҶи®әеҖјгҖӮ
#### еҸҜи°ғзҡ„еӨҡдёҖиҮҙжҖ§
еңЁеҺҹжқҘзҡ„HBaseжһ¶жһ„дёӯпјҢжҜҸдёӘregionеҸӘиғҪеңЁдёҖдёӘRegionServerдёӯдёҠзәҝпјҢеҰӮжһңиҝҷдёӘregion serverе®•жңәпјҢregionйңҖиҰҒз»ҸеҺҶRe-assginпјҢWALжҢүregionеҲҮеҲҶпјҢWALж•°жҚ®еӣһж”ҫзӯүжӯҘйӘӨеҗҺпјҢжүҚиғҪжҒўеӨҚиҜ»еҶҷгҖӮ
иҝҷдёӘжҒўеӨҚж—¶й—ҙеҸҜиғҪйңҖиҰҒж•°еҲҶй’ҹпјҢеҜ№дәҺжҹҗдәӣй«ҳиҰҒжұӮзҡ„дёҡеҠЎжқҘиҜҙпјҢиҝҷжҳҜдёҖдёӘж— жі•и§ЈеҶізҡ„з—ӣзӮ№гҖӮеҸҰеӨ–пјҢиҷҪ然HBaseдёӯжңүдё»еӨҮеҗҢжӯҘпјҢдҪҶж•…йҡңдёӢеҸӘиғҪйӣҶзҫӨзІ’еәҰзҡ„жүӢеҠЁеҲҮжҚўпјҢ并且主е’ҢеӨҮзҡ„ж•°жҚ®еҸӘиғҪеҒҡеҲ°жңҖз»ҲдёҖиҮҙжҖ§пјҢиҖҢжңүдёҖдәӣдёҡеҠЎеҸӘиғҪжҺҘеҸ—ејәдёҖиҮҙпјҢHBaseеңЁиҝҷзӮ№дёҠжңӣе°ҳиҺ«еҸҠгҖӮ
LindormеҶ…йғЁе®һзҺ°дәҶдёҖз§ҚеҹәдәҺShared Logзҡ„дёҖиҮҙжҖ§еҚҸи®®пјҢйҖҡиҝҮеҲҶеҢәеӨҡеүҜжң¬жңәеҲ¶иҫҫеҲ°ж•…йҡңдёӢзҡ„жңҚеҠЎиҮӘеҠЁеҝ«йҖҹжҒўеӨҚзҡ„иғҪеҠӣпјҢе®ҢзҫҺйҖӮй…ҚдәҶеӯҳеӮЁеҲҶзҰ»зҡ„жһ¶жһ„, еҲ©з”ЁеҗҢдёҖеҘ—дҪ“зі»еҚіеҸҜж”ҜжҢҒејәдёҖиҮҙиҜӯд№үпјҢеҸҲеҸҜд»ҘйҖүжӢ©еңЁзүәзүІдёҖиҮҙжҖ§зҡ„еүҚжҸҗжҚўеҸ–жӣҙдҪізҡ„жҖ§иғҪе’ҢеҸҜз”ЁжҖ§пјҢе®һзҺ°еӨҡжҙ»пјҢй«ҳеҸҜз”ЁзӯүеӨҡз§ҚиғҪеҠӣгҖӮ
еңЁиҝҷеҘ—жһ¶жһ„дёӢпјҢLindormжӢҘжңүдәҶд»ҘдёӢеҮ дёӘдёҖиҮҙжҖ§зә§еҲ«пјҢз”ЁжҲ·еҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎиҮӘз”ұйҖүжӢ©дёҖиҮҙжҖ§зә§еҲ«пјҡ

жіЁпјҡиҜҘеҠҹиғҪжҡӮж—¶жңӘеңЁйҳҝйҮҢдә‘HBaseеўһејәзүҲдёҠеҜ№еӨ–ејҖж”ҫ
#### е®ўжҲ·з«Ҝй«ҳеҸҜз”ЁеҲҮжҚў
иҷҪ然иҜҙзӣ®еүҚHBaseеҸҜд»Ҙз»„жҲҗдё»еӨҮпјҢдҪҶжҳҜзӣ®еүҚеёӮйқўдёҠжІЎжңүдёҖдёӘй«ҳж•Ҳең°е®ўжҲ·з«ҜеҲҮжҚўи®ҝй—®ж–№жЎҲгҖӮHBaseзҡ„е®ўжҲ·з«ҜеҸӘиғҪи®ҝй—®еӣәе®ҡең°еқҖзҡ„HBaseйӣҶзҫӨгҖӮеҰӮжһңдё»йӣҶзҫӨеҸ‘з”ҹж•…йҡңпјҢз”ЁжҲ·йңҖиҰҒеҒңжӯўHBaseе®ўжҲ·з«ҜпјҢдҝ®ж”№HBaseзҡ„й…ҚзҪ®еҗҺйҮҚеҗҜпјҢжүҚиғҪиҝһжҺҘеӨҮйӣҶзҫӨи®ҝй—®гҖӮжҲ–иҖ…з”ЁжҲ·еңЁдёҡеҠЎдҫ§еҝ…йЎ»и®ҫи®ЎдёҖеҘ—еӨҚжқӮең°и®ҝй—®йҖ»иҫ‘жқҘе®һзҺ°дё»еӨҮйӣҶзҫӨзҡ„и®ҝй—®гҖӮ
йҳҝйҮҢHBaseж”№йҖ дәҶHBaseе®ўжҲ·з«ҜпјҢжөҒйҮҸзҡ„еҲҮжҚўеҸ‘з”ҹеңЁе®ўжҲ·з«ҜеҶ…йғЁпјҢйҖҡиҝҮй«ҳеҸҜз”Ёзҡ„йҖҡйҒ“е°ҶеҲҮжҚўе‘Ҫд»ӨеҸ‘йҖҒз»ҷе®ўжҲ·з«ҜпјҢе®ўжҲ·з«Ҝдјҡе…ій—ӯж—§зҡ„й“ҫжҺҘпјҢжү“ејҖдёҺеӨҮйӣҶзҫӨзҡ„й“ҫжҺҘпјҢ然еҗҺйҮҚиҜ•иҜ·жұӮгҖӮ

еҰӮжһңйңҖиҰҒдҪҝз”ЁжӯӨйЎ№еҠҹиғҪпјҢиҜ·еҸӮиҖғй«ҳеҸҜз”Ёеё®еҠ©ж–ҮжЎЈпјҡ
[https://help.aliyun.com/document\_detail/140940.html](https://help.aliyun.com/document_detail/140940.html)
дә‘еҺҹз”ҹпјҢжӣҙдҪҺдҪҝз”ЁжҲҗжң¬
----------
Lindormд»Һз«ӢйЎ№д№ӢеҲқе°ұиҖғиҷ‘еҲ°дёҠдә‘пјҢеҗ„з§Қи®ҫи®Ўд№ҹиғҪе°ҪйҮҸеӨҚз”Ёдә‘дёҠеҹәзЎҖи®ҫж–ҪпјҢдёәдә‘зҡ„зҺҜеўғдё“й—ЁдјҳеҢ–гҖӮжҜ”еҰӮеңЁдә‘дёҠпјҢжҲ‘们йҷӨдәҶж”ҜжҢҒдә‘зӣҳд№ӢеӨ–пјҢжҲ‘们иҝҳж”ҜжҢҒе°Ҷж•°жҚ®еӯҳеӮЁеңЁOSSиҝҷз§ҚдҪҺжҲҗжң¬зҡ„еҜ№иұЎеӯҳеӮЁдёӯеҮҸе°‘жҲҗжң¬гҖӮжҲ‘们иҝҳй’ҲеҜ№ECSйғЁзҪІеҒҡдәҶдёҚе°‘дјҳеҢ–пјҢйҖӮй…Қе°ҸеҶ…еӯҳи§„ж јжңәеһӢпјҢеҠ ејәйғЁзҪІеј№жҖ§пјҢдёҖеҲҮдёәдәҶдә‘еҺҹз”ҹпјҢдёәдәҶиҠӮзңҒе®ўжҲ·жҲҗжң¬гҖӮ
ECS+дә‘зӣҳзҡ„жһҒиҮҙеј№жҖ§
зӣ®еүҚLindormеңЁдә‘дёҠзҡ„зүҲжң¬HBaseеўһејәзүҲеқҮйҮҮз”ЁECS+дә‘зӣҳйғЁзҪІпјҲйғЁеҲҶеӨ§е®ўжҲ·еҸҜиғҪйҮҮз”Ёжң¬ең°зӣҳпјүпјҢECS+дә‘зӣҳйғЁзҪІзҡ„еҪўжҖҒз»ҷLindormеёҰжқҘдәҶжһҒиҮҙзҡ„еј№жҖ§гҖӮ

жңҖејҖе§Ӣзҡ„ж—¶еҖҷпјҢHBaseеңЁйӣҶеӣўзҡ„йғЁзҪІеқҮйҮҮз”Ёзү©зҗҶжңәзҡ„еҪўејҸгҖӮжҜҸдёӘдёҡеҠЎдёҠзәҝеүҚпјҢйғҪеҝ…йЎ»е…Ҳ规еҲ’еҘҪжңәеҷЁж•°йҮҸе’ҢзЈҒзӣҳеӨ§е°ҸгҖӮеңЁзү©зҗҶжңәйғЁзҪІдёӢпјҢеҫҖеҫҖдјҡйҒҮеҲ°еҮ дёӘйҡҫд»Ҙи§ЈеҶізҡ„й—®йўҳпјҡ
> дёҡеҠЎеј№жҖ§йҡҫд»Ҙж»Ўи¶іпјҡеҪ“йҒҮеҲ°дёҡеҠЎзӘҒеҸ‘жөҒйҮҸй«ҳеі°жҲ–иҖ…ејӮеёёиҜ·жұӮж—¶пјҢеҫҲйҡҫеңЁзҹӯж—¶й—ҙеҶ…жүҫеҲ°ж–°зҡ„зү©зҗҶжңәжү©е®№гҖӮ
>
> еӯҳеӮЁе’Ңи®Ўз®—з»‘е®ҡпјҢзҒөжҙ»жҖ§е·®пјҡзү©зҗҶжңәдёҠCPUе’ҢзЈҒзӣҳзҡ„жҜ”дҫӢйғҪжҳҜдёҖе®ҡзҡ„пјҢдҪҶжҳҜжҜҸдёӘдёҡеҠЎзҡ„зү№зӮ№йғҪдёҚдёҖж ·пјҢйҮҮз”ЁдёҖж ·зҡ„зү©зҗҶжңәпјҢжңүдёҖдәӣдёҡеҠЎи®Ўз®—иө„жәҗдёҚеӨҹпјҢдҪҶеӯҳеӮЁиҝҮеү©пјҢиҖҢжңүдәӣдёҡеҠЎи®Ўз®—иө„жәҗиҝҮеү©пјҢиҖҢеӯҳеӮЁз“¶йўҲгҖӮзү№еҲ«жҳҜеңЁHBaseеј•е…Ҙж··еҗҲеӯҳеӮЁеҗҺпјҢHDDе’ҢSSDзҡ„жҜ”дҫӢйқһеёёйҡҫзЎ®е®ҡпјҢжңүдәӣй«ҳиҰҒжұӮзҡ„дёҡеҠЎеёёеёёдјҡжҠҠSSDз”Ёж»ЎиҖҢHDDжңүеү©дҪҷпјҢиҖҢдёҖдәӣжө·йҮҸзҡ„зҰ»зәҝеһӢдёҡеҠЎSSDзӣҳеҸҲж— жі•еҲ©з”ЁдёҠгҖӮ
>
> иҝҗз»ҙеҺӢеҠӣеӨ§пјҡдҪҝз”Ёзү©зҗҶжңәж—¶пјҢиҝҗз»ҙйңҖиҰҒж—¶еҲ»жіЁж„Ҹзү©зҗҶжңәжҳҜеҗҰиҝҮдҝқпјҢжҳҜеҗҰжңүзЈҒзӣҳеқҸпјҢзҪ‘еҚЎеқҸзӯү硬件故йҡңйңҖиҰҒеӨ„зҗҶпјҢзү©зҗҶжңәзҡ„жҠҘдҝ®жҳҜдёҖдёӘжј«й•ҝзҡ„иҝҮзЁӢпјҢеҗҢж—¶йңҖиҰҒеҒңжңәпјҢиҝҗз»ҙеҺӢеҠӣе·ЁеӨ§гҖӮеҜ№дәҺHBaseиҝҷз§Қжө·йҮҸеӯҳеӮЁдёҡеҠЎжқҘиҜҙпјҢжҜҸеӨ©еқҸеҮ еқ—зЈҒзӣҳжҳҜйқһеёёжӯЈеёёзҡ„дәӢжғ…гҖӮиҖҢеҪ“LindormйҮҮз”ЁдәҶECS+дә‘зӣҳйғЁзҪІеҗҺпјҢиҝҷдәӣй—®йўҳйғҪиҝҺеҲғиҖҢи§ЈгҖӮ
ECSжҸҗдҫӣдәҶдёҖдёӘиҝ‘дјјж— йҷҗзҡ„иө„жәҗжұ гҖӮеҪ“йқўеҜ№дёҡеҠЎзҡ„зҙ§жҖҘжү©е®№ж—¶пјҢжҲ‘们еҸӘйңҖеңЁиө„жәҗжұ дёӯз”іиҜ·ж–°зҡ„ECSжӢүиө·еҗҺпјҢеҚіеҸҜеҠ е…ҘйӣҶзҫӨпјҢж—¶й—ҙеңЁеҲҶй’ҹзә§еҲ«д№ӢеҶ…пјҢж— жғ§дёҡеҠЎжөҒйҮҸй«ҳеі°гҖӮй…ҚеҗҲдә‘зӣҳиҝҷж ·зҡ„еӯҳеӮЁи®Ўз®—еҲҶзҰ»жһ¶жһ„гҖӮжҲ‘们еҸҜд»ҘзҒөжҙ»ең°дёәеҗ„з§ҚдёҡеҠЎеҲҶй…ҚдёҚеҗҢзҡ„зЈҒзӣҳз©әй—ҙгҖӮ
еҪ“з©әй—ҙдёҚеӨҹж—¶пјҢеҸҜд»ҘзӣҙжҺҘеңЁзәҝжү©зј©е®№зЈҒзӣҳгҖӮеҗҢж—¶пјҢиҝҗз»ҙеҶҚд№ҹдёҚз”ЁиҖғиҷ‘硬件故йҡңпјҢеҪ“ECSжңүж•…йҡңж—¶пјҢECSеҸҜд»ҘеңЁеҸҰеӨ–дёҖеҸ°е®ҝдё»жңәдёҠжӢүиө·пјҢиҖҢдә‘зӣҳе®Ңе…ЁеҜ№дёҠеұӮеұҸи”ҪдәҶеқҸзӣҳзҡ„еӨ„зҗҶгҖӮжһҒиҮҙзҡ„еј№жҖ§еҗҢж ·еёҰжқҘдәҶжҲҗжң¬зҡ„дјҳеҢ–гҖӮжҲ‘们дёҚйңҖиҰҒдёәдёҡеҠЎйў„з•ҷеӨӘеӨҡзҡ„иө„жәҗпјҢеҗҢж—¶еҪ“дёҡеҠЎзҡ„еӨ§дҝғз»“жқҹеҗҺпјҢиғҪеӨҹеҝ«йҖҹең°зј©е®№йҷҚдҪҺжҲҗжң¬гҖӮ

#### дёҖдҪ“еҢ–еҶ·зғӯеҲҶзҰ»
еңЁжө·йҮҸеӨ§ж•°жҚ®еңәжҷҜдёӢпјҢдёҖеј иЎЁдёӯзҡ„йғЁеҲҶдёҡеҠЎж•°жҚ®йҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»д»…дҪңдёәеҪ’жЎЈж•°жҚ®жҲ–иҖ…и®ҝй—®йў‘зҺҮеҫҲдҪҺпјҢеҗҢж—¶иҝҷйғЁеҲҶеҺҶеҸІж•°жҚ®дҪ“йҮҸйқһеёёеӨ§пјҢжҜ”еҰӮи®ўеҚ•ж•°жҚ®жҲ–иҖ…зӣ‘жҺ§ж•°жҚ®пјҢйҷҚдҪҺиҝҷйғЁеҲҶж•°жҚ®зҡ„еӯҳеӮЁжҲҗжң¬е°ҶдјҡжһҒеӨ§зҡ„иҠӮзңҒдјҒдёҡзҡ„жҲҗжң¬гҖӮ
еҰӮдҪ•д»ҘжһҒз®Җзҡ„иҝҗз»ҙй…ҚзҪ®жҲҗжң¬е°ұиғҪдёәдјҒдёҡжһҒеӨ§йҷҚдҪҺеӯҳеӮЁжҲҗжң¬пјҢLindormеҶ·зғӯеҲҶзҰ»еҠҹиғҪеә”иҝҗиҖҢз”ҹгҖӮLindormдёәеҶ·ж•°жҚ®жҸҗдҫӣж–°зҡ„еӯҳеӮЁд»ӢиҙЁпјҢж–°зҡ„еӯҳеӮЁд»ӢиҙЁеӯҳеӮЁжҲҗжң¬д»…дёәй«ҳж•Ҳдә‘зӣҳзҡ„1/3гҖӮ
LindormеңЁеҗҢдёҖеј иЎЁйҮҢе®һзҺ°дәҶж•°жҚ®зҡ„еҶ·зғӯеҲҶзҰ»пјҢзі»з»ҹдјҡиҮӘеҠЁж №жҚ®з”ЁжҲ·и®ҫзҪ®зҡ„еҶ·зғӯеҲҶз•ҢзәҝиҮӘеҠЁе°ҶиЎЁдёӯзҡ„еҶ·ж•°жҚ®еҪ’жЎЈеҲ°еҶ·еӯҳеӮЁдёӯгҖӮеңЁз”ЁжҲ·зҡ„и®ҝй—®ж–№ејҸдёҠе’Ңжҷ®йҖҡиЎЁеҮ д№ҺжІЎжңүд»»дҪ•е·®ејӮпјҢеңЁжҹҘиҜўзҡ„иҝҮзЁӢдёӯпјҢз”ЁжҲ·еҸӘйңҖй…ҚзҪ®жҹҘиҜўHintжҲ–иҖ…TimeRangeпјҢзі»з»ҹж №жҚ®жқЎд»¶иҮӘеҠЁең°еҲӨж–ӯжҹҘиҜўеә”иҜҘиҗҪеңЁзғӯж•°жҚ®еҢәиҝҳжҳҜеҶ·ж•°жҚ®еҢәгҖӮеҜ№з”ЁжҲ·иҖҢиЁҖе§Ӣз»ҲжҳҜдёҖеј иЎЁпјҢеҜ№з”ЁжҲ·еҮ д№ҺеҒҡеҲ°е®Ңе…Ёзҡ„йҖҸжҳҺгҖӮиҜҰз»Ҷд»Ӣз»ҚиҜ·еҸӮиҖғпјҡ
[https://yq.aliyun.com/articles/718395](https://yq.aliyun.com/articles/718395)
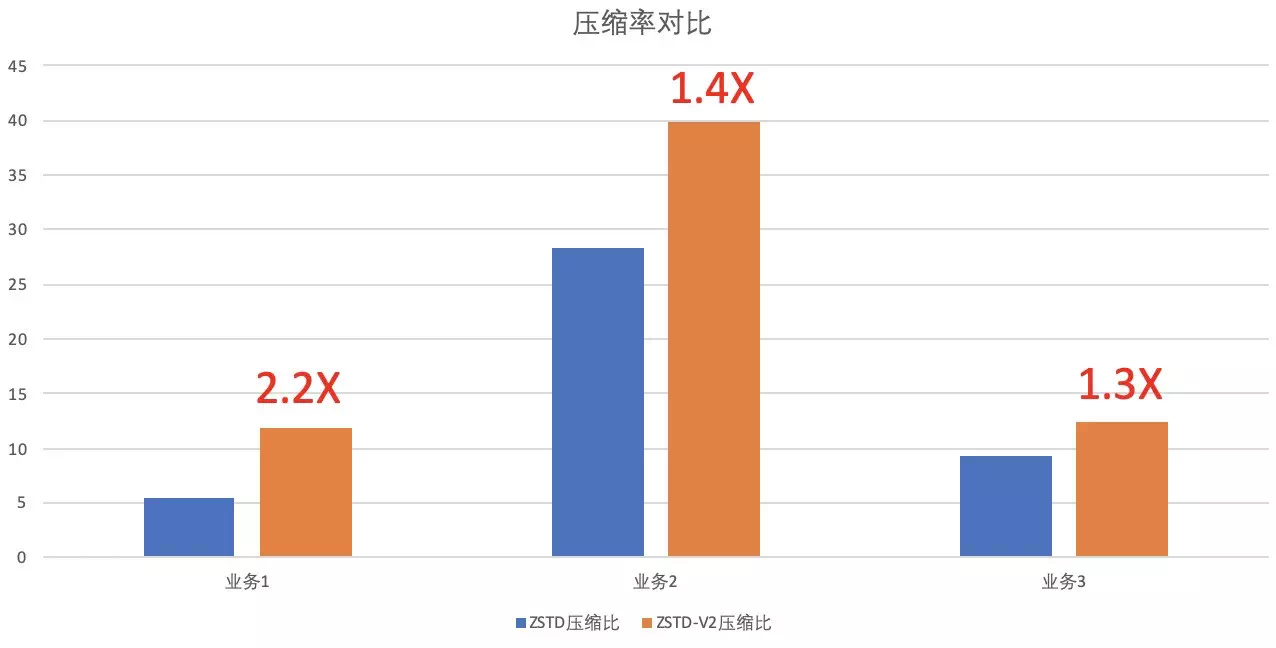
#### ZSTD-V2пјҢеҺӢзј©жҜ”еҶҚжҸҗеҚҮ100%
ж—©еңЁдёӨе№ҙеүҚпјҢжҲ‘们е°ұжҠҠйӣҶеӣўеҶ…зҡ„еӯҳеӮЁеҺӢзј©з®—жі•жӣҝжҚўжҲҗдәҶZSTDпјҢзӣёжҜ”еҺҹжқҘзҡ„SNAPPYз®—жі•пјҢиҺ·еҫ—дәҶйўқеӨ–25%зҡ„еҺӢ缩收зӣҠгҖӮд»Ҡе№ҙжҲ‘们еҜ№жӯӨиҝӣдёҖжӯҘдјҳеҢ–пјҢејҖеҸ‘е®һзҺ°дәҶж–°зҡ„ZSTD-v2з®—жі•пјҢе…¶еҜ№дәҺе°Ҹеқ—ж•°жҚ®зҡ„еҺӢзј©пјҢжҸҗеҮәдәҶдҪҝз”Ёйў„е…ҲйҮҮж ·ж•°жҚ®иҝӣиЎҢи®ӯз»ғеӯ—е…ёпјҢ然еҗҺз”Ёеӯ—е…ёиҝӣиЎҢеҠ йҖҹзҡ„ж–№жі•гҖӮ
жҲ‘们еҲ©з”ЁдәҶиҝҷдёҖж–°зҡ„еҠҹиғҪпјҢеңЁLindormжһ„е»әLDFileзҡ„ж—¶еҖҷпјҢе…ҲеҜ№ж•°жҚ®иҝӣиЎҢйҮҮж ·и®ӯз»ғпјҢжһ„е»әеӯ—е…ёпјҢ然еҗҺеңЁиҝӣиЎҢеҺӢзј©гҖӮеңЁдёҚеҗҢдёҡеҠЎзҡ„ж•°жҚ®жөӢиҜ•дёӯпјҢжҲ‘们жңҖй«ҳиҺ·еҫ—дәҶи¶…иҝҮеҺҹз”ҹZSTDз®—жі•100%зҡ„еҺӢзј©жҜ”пјҢиҝҷж„Ҹе‘ізқҖжҲ‘们еҸҜд»Ҙдёәе®ўжҲ·еҶҚиҠӮзңҒ50%зҡ„еӯҳеӮЁиҙ№з”ЁгҖӮ

#### HBase ServerlessзүҲпјҢе…Ҙй—ЁйҰ–йҖү
йҳҝйҮҢдә‘HBase Serverless зүҲжҳҜеҹәдәҺLindormеҶ…ж ёпјҢдҪҝз”ЁServerlessжһ¶жһ„жһ„е»әзҡ„дёҖеҘ—ж–°еһӢзҡ„HBase жңҚеҠЎгҖӮйҳҝйҮҢдә‘HBase ServerlessзүҲзңҹжӯЈжҠҠHBaseеҸҳжҲҗдәҶдёҖдёӘжңҚеҠЎпјҢз”ЁжҲ·ж— йңҖжҸҗеүҚ规еҲ’иө„жәҗпјҢйҖүжӢ©CPUпјҢеҶ…еӯҳиө„жәҗж•°йҮҸпјҢиҙӯд№°йӣҶзҫӨгҖӮеңЁеә”еҜ№дёҡеҠЎй«ҳеі°пјҢдёҡеҠЎз©әй—ҙеўһй•ҝж—¶пјҢд№ҹж— йңҖиҝӣиЎҢжү©е®№зӯүеӨҚжқӮиҝҗз»ҙж“ҚдҪңпјҢеңЁдёҡеҠЎдҪҺи°·ж—¶пјҢд№ҹж— йңҖжөӘиҙ№й—ІзҪ®иө„жәҗгҖӮ
еңЁдҪҝз”ЁиҝҮзЁӢдёӯпјҢз”ЁжҲ·еҸҜд»Ҙе®Ңе…Ёж №жҚ®еҪ“еүҚдёҡеҠЎйҮҸпјҢжҢүйңҖиҙӯд№°иҜ·жұӮйҮҸе’Ңз©әй—ҙиө„жәҗеҚіеҸҜгҖӮдҪҝз”ЁйҳҝйҮҢдә‘HBase ServerlessзүҲжң¬пјҢз”ЁжҲ·е°ұеҘҪеғҸеңЁдҪҝз”ЁдёҖдёӘж— йҷҗиө„жәҗзҡ„HBaseйӣҶзҫӨпјҢйҡҸж—¶ж»Ўи¶ідёҡеҠЎжөҒйҮҸзӘҒ然зҡ„еҸҳеҢ–пјҢиҖҢеҗҢж—¶еҸӘйңҖиҰҒж”Ҝд»ҳиҮӘе·ұзңҹжӯЈдҪҝз”Ёзҡ„йӮЈдёҖйғЁеҲҶиө„жәҗзҡ„й’ұгҖӮ

е…ідәҺHBase Serverlessзҡ„д»Ӣз»Қе’ҢдҪҝз”ЁпјҢеҸҜд»ҘеҸӮиҖғпјҡ
[https://developer.aliyun.com/article/719206](https://developer.aliyun.com/article/719206)
йқўеҗ‘еӨ§е®ўжҲ·зҡ„е®үе…Ёе’ҢеӨҡз§ҹжҲ·иғҪеҠӣ
--------------
Lindormеј•ж“ҺеҶ…зҪ®дәҶе®Ңж•ҙзҡ„з”ЁжҲ·еҗҚеҜҶз ҒдҪ“зі»пјҢжҸҗдҫӣеӨҡз§Қзә§еҲ«зҡ„жқғйҷҗжҺ§еҲ¶пјҢ并еҜ№жҜҸдёҖж¬ЎиҜ·жұӮйүҙжқғпјҢйҳІжӯўжңӘжҺҲжқғзҡ„ж•°жҚ®и®ҝй—®пјҢзЎ®дҝқз”ЁжҲ·ж•°жҚ®зҡ„и®ҝй—®е®үе…ЁгҖӮеҗҢж—¶пјҢй’ҲеҜ№дјҒдёҡзә§еӨ§е®ўжҲ·зҡ„иҜүжұӮпјҢLindormеҶ…зҪ®дәҶGroupпјҢQuotaйҷҗеҲ¶зӯүеӨҡз§ҹжҲ·йҡ”зҰ»еҠҹиғҪпјҢдҝқиҜҒдјҒдёҡдёӯеҗ„дёӘдёҡеҠЎеңЁдҪҝз”ЁеҗҢдёҖдёӘHBaseйӣҶзҫӨж—¶дёҚдјҡиў«зӣёдә’еҪұе“ҚпјҢе®үе…Ёй«ҳж•Ҳең°е…ұдә«еҗҢдёҖдёӘеӨ§ж•°жҚ®е№іеҸ°гҖӮ
#### з”ЁжҲ·е’ҢACLдҪ“зі»
LindormеҶ…ж ёжҸҗдҫӣдёҖеҘ—з®ҖеҚ•жҳ“з”Ёзҡ„з”ЁжҲ·и®ӨиҜҒе’ҢACLдҪ“зі»гҖӮз”ЁжҲ·зҡ„и®ӨиҜҒеҸӘйңҖиҰҒеңЁй…ҚзҪ®дёӯз®ҖеҚ•зҡ„еЎ«еҶҷз”ЁжҲ·еҗҚеҜҶз ҒеҚіеҸҜгҖӮз”ЁжҲ·зҡ„еҜҶз ҒеңЁжңҚеҠЎеҷЁз«ҜйқһжҳҺж–ҮеӯҳеӮЁпјҢ并且еңЁи®ӨиҜҒиҝҮзЁӢдёӯдёҚдјҡжҳҺж–Үдј иҫ“еҜҶз ҒпјҢеҚідҪҝйӘҢиҜҒиҝҮзЁӢзҡ„еҜҶж–Үиў«жӢҰжҲӘпјҢз”Ёд»Ҙи®ӨиҜҒзҡ„йҖҡдҝЎеҶ…е®№дёҚеҸҜйҮҚеӨҚдҪҝз”ЁпјҢж— жі•иў«дјӘйҖ гҖӮ
LindormдёӯжңүдёүдёӘжқғйҷҗеұӮзә§гҖӮGlobalпјҢNamespaceе’ҢTableгҖӮиҝҷдёүиҖ…жҳҜзӣёдә’иҰҶзӣ–зҡ„е…ізі»гҖӮжҜ”еҰӮз»ҷuser1иөӢдәҲдәҶGlobalзҡ„иҜ»еҶҷжқғйҷҗпјҢеҲҷд»–е°ұжӢҘжңүдәҶжүҖжңүnamespaceдёӢжүҖжңүTableзҡ„иҜ»еҶҷжқғйҷҗгҖӮеҰӮжһңз»ҷuser2иөӢдәҲдәҶNamespace1зҡ„иҜ»еҶҷжқғйҷҗпјҢйӮЈд№Ҳд»–дјҡиҮӘеҠЁжӢҘжңүNamespace1дёӯжүҖжңүиЎЁзҡ„иҜ»еҶҷжқғйҷҗгҖӮ
#### Groupйҡ”зҰ»
еҪ“еӨҡдёӘз”ЁжҲ·жҲ–иҖ…дёҡеҠЎеңЁдҪҝз”ЁеҗҢдёҖдёӘHBaseйӣҶзҫӨж—¶пјҢеҫҖеҫҖдјҡеӯҳеңЁиө„жәҗдәүжҠўзҡ„й—®йўҳгҖӮдёҖдәӣйҮҚиҰҒзҡ„еңЁзәҝдёҡеҠЎзҡ„иҜ»еҶҷпјҢеҸҜиғҪдјҡиў«зҰ»зәҝдёҡеҠЎжү№йҮҸиҜ»еҶҷжүҖеҪұе“ҚгҖӮиҖҢGroupеҠҹиғҪпјҢеҲҷжҳҜHBaseеўһејәзүҲпјҲLindormпјүжҸҗдҫӣзҡ„з”ЁжқҘи§ЈеҶіеӨҡз§ҹжҲ·йҡ”зҰ»й—®йўҳзҡ„еҠҹиғҪгҖӮ
йҖҡиҝҮжҠҠRegionServerеҲ’еҲҶеҲ°дёҚеҗҢзҡ„GroupеҲҶз»„пјҢжҜҸдёӘеҲҶз»„дёҠhostдёҚеҗҢзҡ„иЎЁпјҢд»ҺиҖҢиҫҫеҲ°иө„жәҗйҡ”зҰ»зҡ„зӣ®зҡ„гҖӮ

дҫӢеҰӮпјҢеңЁдёҠеӣҫдёӯпјҢжҲ‘们еҲӣе»әдәҶдёҖдёӘGroup1пјҢжҠҠRegionServer1е’ҢRegionServer2еҲ’еҲҶеҲ°Group1дёӯпјҢеҲӣе»әдәҶдёҖдёӘGroup2пјҢжҠҠRegionServer3е’ҢRegionServer4еҲ’еҲҶеҲ°Group2гҖӮеҗҢж—¶пјҢжҲ‘们жҠҠTable1е’ҢTable2д№ҹ移еҠЁеҲ°Group1еҲҶз»„гҖӮиҝҷж ·зҡ„иҜқпјҢTable1е’ҢTable2зҡ„жүҖжңүregionпјҢйғҪеҸӘдјҡеҲҶй…ҚеҲ°Group1дёӯзҡ„RegionServer1е’ҢRegionServer2иҝҷдёӨеҸ°жңәеҷЁдёҠгҖӮ
еҗҢж ·пјҢеұһдәҺGroup2зҡ„Table3е’ҢTable4зҡ„RegionеңЁеҲҶй…Қе’ҢbalanceиҝҮзЁӢдёӯпјҢд№ҹеҸӘдјҡиҗҪеңЁRegionServer3е’ҢRegionServer4дёҠгҖӮеӣ жӯӨпјҢз”ЁжҲ·еңЁиҜ·жұӮиҝҷдәӣиЎЁж—¶пјҢеҸ‘еҫҖTable1гҖҒTable2зҡ„иҜ·жұӮпјҢеҸӘдјҡз”ұRegionServer1е’ҢRegionServer2жңҚеҠЎпјҢиҖҢеҸ‘еҫҖTable3е’ҢTable4зҡ„иҜ·жұӮпјҢеҸӘдјҡз”ұRegionServer3е’ҢRegionServer4жңҚеҠЎпјҢд»ҺиҖҢиҫҫеҲ°иө„жәҗйҡ”зҰ»зҡ„зӣ®зҡ„
#### QuotaйҷҗжөҒ
LindormеҶ…ж ёдёӯеҶ…зҪ®дәҶдёҖеҘ—е®Ңж•ҙзҡ„QuotaдҪ“зі»пјҢжқҘеҜ№еҗ„дёӘз”ЁжҲ·зҡ„иө„жәҗдҪҝз”ЁеҒҡйҷҗеҲ¶гҖӮеҜ№дәҺжҜҸдёҖдёӘиҜ·жұӮпјҢLindormеҶ…ж ёйғҪжңүзІҫзЎ®зҡ„и®Ўз®—жүҖж¶ҲиҖ—зҡ„CUпјҲCapacity UnitпјүпјҢCUдјҡд»Ҙе®һйҷ…ж¶ҲиҖ—зҡ„иө„жәҗжқҘи®Ўз®—гҖӮ
жҜ”еҰӮз”ЁжҲ·дёҖдёӘScanиҜ·жұӮпјҢз”ұдәҺfilterзҡ„еӯҳеңЁпјҢиҷҪ然иҝ”еӣһзҡ„ж•°жҚ®еҫҲе°‘пјҢдҪҶеҸҜиғҪе·Із»ҸеңЁRegionServerе·Із»Ҹж¶ҲиҖ—еӨ§йҮҸзҡ„CPUе’ҢIOиө„жәҗжқҘиҝҮж»Өж•°жҚ®пјҢиҝҷдәӣзңҹе®һиө„жәҗзҡ„ж¶ҲиҖ—пјҢйғҪдјҡи®Ўз®—еңЁCUйҮҢгҖӮ
еңЁжҠҠLindormеҪ“еҒҡдёҖдёӘеӨ§ж•°жҚ®е№іеҸ°дҪҝз”Ёж—¶пјҢдјҒдёҡз®ЎзҗҶе‘ҳеҸҜд»Ҙе…Ҳз»ҷдёҚеҗҢдёҡеҠЎеҲҶй…ҚдёҚеҗҢзҡ„з”ЁжҲ·пјҢ然еҗҺйҖҡиҝҮQuotaзі»з»ҹйҷҗеҲ¶жҹҗдёӘз”ЁжҲ·жҜҸз§’зҡ„иҜ»CUдёҚиғҪи¶…иҝҮеӨҡе°‘пјҢжҲ–иҖ…жҖ»зҡ„CUдёҚиғҪи¶…иҝҮеӨҡе°‘пјҢд»ҺиҖҢйҷҗеҲ¶з”ЁжҲ·еҚ з”ЁиҝҮеӨҡзҡ„иө„жәҗпјҢеҪұе“Қе…¶д»–з”ЁжҲ·гҖӮеҗҢж—¶пјҢQuotaйҷҗжөҒд№ҹж”ҜжҢҒNamesapceзә§еҲ«е’ҢиЎЁзә§еҲ«йҷҗеҲ¶гҖӮ
жңҖеҗҺ
--
е…Ёж–°дёҖд»ЈNoSQLж•°жҚ®еә“LindormжҳҜйҳҝйҮҢе·ҙе·ҙHBase&Lindormеӣўйҳҹ9е№ҙд»ҘжқҘжҠҖжңҜз§ҜзҙҜзҡ„з»“жҷ¶пјҢLindormеңЁйқўеҗ‘жө·йҮҸж•°жҚ®еңәжҷҜжҸҗдҫӣдё–з•ҢйўҶе…Ҳзҡ„й«ҳжҖ§иғҪгҖҒеҸҜи·ЁеҹҹгҖҒеӨҡдёҖиҮҙгҖҒеӨҡжЁЎеһӢзҡ„ж··еҗҲеӯҳеӮЁеӨ„зҗҶиғҪеҠӣгҖӮеҜ№з„ҰдәҺеҗҢж—¶и§ЈеҶіеӨ§ж•°жҚ®(ж— йҷҗжү©еұ•гҖҒй«ҳеҗһеҗҗ)гҖҒеңЁзәҝжңҚеҠЎ(дҪҺ延时гҖҒй«ҳеҸҜз”Ё)гҖҒеӨҡеҠҹиғҪжҹҘиҜўзҡ„иҜүжұӮпјҢдёәз”ЁжҲ·жҸҗдҫӣж— зјқжү©еұ•гҖҒй«ҳеҗһеҗҗгҖҒжҢҒз»ӯеҸҜз”ЁгҖҒжҜ«з§’зә§зЁіе®ҡе“Қеә”гҖҒејәејұдёҖиҮҙеҸҜи°ғгҖҒдҪҺеӯҳеӮЁжҲҗжң¬гҖҒдё°еҜҢзҙўеј•зҡ„ж•°жҚ®е®һж—¶ж··еҗҲеӯҳеҸ–иғҪеҠӣгҖӮ
[еҺҹж–Үй“ҫжҺҘ](https://yq.aliyun.com/articles/738755?utm_content=g_1000096254)
жң¬ж–ҮдёәйҳҝйҮҢдә‘еҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
еҲҶдә«еҲ°пјҡ


- 2019-12-25 17:18
- жөҸи§Ҳ 444
- иҜ„и®ә(0)
- еҲҶзұ»:йқһжҠҖжңҜ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
еӣ жӯӨпјҢеҮәзҺ°дәҶ4RпјҲе…іиҒ”гҖҒеҸҚеә”гҖҒе…ізі»гҖҒеӣһжҠҘпјүгҖҒ4IпјҲдә’еҠЁгҖҒдёӘжҖ§еҢ–гҖҒж•ҙеҗҲгҖҒеҲ©зӣҠпјүе’Ң4VпјҲе·®ејӮеҢ–гҖҒеҠҹиғҪеҢ–гҖҒйҷ„еҠ д»·еҖјгҖҒе…ұйёЈпјүзӯүж–°жЁЎеһӢгҖӮ然иҖҢпјҢиҝҷдәӣжЁЎеһӢеҫҖеҫҖдё“жіЁдәҺзү№е®ҡзҡ„иҗҘй”Җзӯ–з•ҘпјҢиҖҢдёҚжҳҜжҸҗдҫӣе…Ёйқўзҡ„и§ЈеҶіж–№жЎҲгҖӮ 4Pе’Ң4CпјҲйЎҫе®ў...
жңҖеҘҪиҜ»зҡ„ж–°еӘ’дҪ“иҝҗиҗҘжүӢеҶҢ(дёҮеӯ—е№Іиҙ§).docx
дёҮеӯ—е№Іиҙ§пјҒ20йҒ“JavaйқўиҜ•йўҳпјҢзӣҙйҖҡеҝғд»Әoffer.docx
дёҮеӯ—е№Іиҙ§пјҒ20йҒ“C#йқўиҜ•йўҳпјҢзӣҙйҖҡеҝғд»Әoffer.docx
дёҮеӯ—е№Іиҙ§пјҡChatGPTзҡ„е·ҘдҪңеҺҹзҗҶ-2023-107йЎө_еҠ ж°ҙеҚ°.pdf
дёҮеӯ—е№Іиҙ§пјҡChatGPTзҡ„е·ҘдҪңеҺҹзҗҶ-2023-107йЎө 2023-5-23 14123 4.pdf
дёҮеӯ—е№Іиҙ§ 8760е°Ҹж—¶пјҢеҫ®дҝЎз”ҹжҖҒдёӢеҚғдёҮиҗҘ收еңЁзәҝж•ҷиӮІеҲӣдёҡйЎ№зӣ®зҡ„дёҖдёӘж·ұеәҰеӨҚзӣҳ.docx
4гҖҒиҜҙеҶҚеӨҡпјҢйғҪдёҚеҰӮдҪ дәІиҮӘзӨәиҢғ | йҳҝйҮҢж–ҮеҢ–жЎҲдҫӢ 5гҖҒеҚ«е“І:еӯҰдјҡиҝҷдәӣжӢӣиҒҳз§ҳжҠҖпјҢдҪ д№ҹиғҪжү“йҖ дёҖж”ҜйҳҝйҮҢй“ҒеҶӣ 6гҖҒйҳҝйҮҢвҖңжҸӘеӨҙеҸ‘вҖқиҜҰи§Ј:дёҖдёӘеҘҪзҡ„з®ЎзҗҶиҖ…пјҢеҝ…йЎ»жҳҜдёҖдёӘеҘҪзҡ„ж•ҷз»ғ 7гҖҒйҳҝйҮҢй“ҒеҶӣдё»её…дҝһжңқзҝҺ:зӣҜзӣ®ж ҮпјҢе°ұжҳҜиҝҪиҝҮзЁӢ 8гҖҒйҳҝйҮҢ...
ж·ұеәҰи§ЈиҜ» | йҳҝйҮҢдә‘ж–°дёҖд»Је…ізі»еһӢж•°жҚ®еә“ PolarDB 1 йҳҝйҮҢеңЁж•°жҚ®еә“жҷәиғҪдјҳеҢ–и·ҜдёҠпјҢеҒҡдәҶе“ӘдәӣжҺўзҙўдёҺе®һи·ө? 16 еҰӮдҪ•йҷҚдҪҺ 90%Java еһғеңҫеӣһ收时й—ҙ?д»ҘйҳҝйҮҢ HBase зҡ„ GC дјҳеҢ–е®һи·өдёәдҫӢ 37 еҰӮдҪ•жү“йҖ еҚғдёҮзә§ Feed жөҒзі»з»ҹ?йҳҝйҮҢж•°жҚ®еә“...
йҰ–е…ҲиҰҒи§ЈйҮҠзҡ„жҳҜпјҢChatGPT д»Һж №жң¬дёҠиҜҙжҖ»жҳҜиҜ•еӣҫеҜ№е®ғзӣ®еүҚеҫ—еҲ°зҡ„д»»дҪ•ж–Үжң¬иҝӣиЎҢ вҖңеҗҲзҗҶзҡ„延з»ӯвҖқпјҢиҝҷйҮҢзҡ„ вҖңеҗҲзҗҶвҖқ жҳҜжҢҮ вҖңеңЁзңӢеҲ°дәә们еңЁж•°еҚҒдәҝдёӘзҪ‘йЎөдёҠжүҖеҶҷзҡ„дёңиҘҝд№ӢеҗҺпјҢдәә们еҸҜиғҪдјҡжңҹжңӣжҹҗдәәеҶҷеҮәд»Җд№ҲвҖқгҖӮ еӣ жӯӨпјҢеҒҮи®ҫжҲ‘们已з»Ҹ...
дҫӣеә”е•ҶзҺ°еңәе®Ўж ёжҳҜзЎ®дҝқдә§е“ҒиҙЁйҮҸе’Ңдҫӣеә”й“ҫзЁіе®ҡзҡ„е…ій”®жӯҘйӘӨгҖӮеңЁITиЎҢдёҡдёӯпјҢе°Өе…¶еңЁзЎ¬д»¶еҲ¶йҖ гҖҒиҪҜ件ејҖеҸ‘е’ҢжңҚеҠЎжҸҗдҫӣе•Ҷзҡ„йҖүжӢ©дёҠпјҢеҜ№дҫӣеә”е•Ҷзҡ„зҺ°еңәе®Ўж ёеҗҢж ·иҮіе…ійҮҚиҰҒгҖӮжң¬ж–Үдё»иҰҒйҳҗиҝ°дәҶдҫӣеә”е•ҶзҺ°еңәе®Ўж ёзҡ„вҖңе…ӯеӨ§е…іжіЁзӮ№вҖқд»ҘеҸҠвҖңеӣӣйЎ№еҹәжң¬...
7 вҖ”ChatGPT еҶ…йғЁ 8 вҖ”ChatGPT зҡ„и®ӯз»ғ 9 вҖ”еҹәжң¬и®ӯз»ғд№ӢдёҠ 10 вҖ”жҳҜд»Җд№ҲзңҹжӯЈи®© ChatGPT е·ҘдҪңпјҹ 11 вҖ”ж„Ҹд№үз©әй—ҙе’ҢиҜӯд№үиҝҗеҠЁжі•еҲҷ 12 вҖ”иҜӯд№үиҜӯжі•е’Ңи®Ўз®—иҜӯиЁҖзҡ„еҠӣйҮҸ 13 вҖ”ChatGPTеҜ№дәҺжҷ®йҖҡдәәзҡ„еҪұе“Қе’ҢжңәдјҡжҳҜд»Җд№Ҳпјҹ 14вҖ”йӮЈд№Ҳ...
жҚ®зҹҘеҗҚиЎҢз ”жңәжһ„дј°з®—пјҢ2025 е№ҙе…Ёзҗғж ҮжіЁе·Ҙе…·зҡ„еёӮеңә规模е°ҶиҫҫеҲ° 16 дәҝзҫҺе…ғгҖӮ еӣҫеғҸж ҮжіЁжҳҜжҢҮеңЁеҺҹе§ӢеӣҫеғҸжү“дёҠж Үзӯҫзҡ„иЎҢдёәгҖӮеңЁи®ӯз»ғж·ұеәҰеӯҰд№ жЁЎеһӢеүҚпјҢйңҖиҰҒеҮҶеӨҮи¶ійҮҸзҡ„пјҢе·Іиў«ж ҮжіЁзҡ„ж ·жң¬з”ЁдәҺи®ӯз»ғгҖӮиҖҢеӣҫеғҸж ҮжіЁе°ұжҳҜж ·жң¬еҮҶеӨҮдёӯзҡ„дёҖдёӘ...
chatgptиө„ж–ҷ
е№Іиҙ§пҪңиҪҰеӨ–й—ЁжҠҠжүӢи®ҫи®ЎжҢҮеҜј_new.pdf
ChatGPTзҡ„еҮәзҺ°дёәжҷ®йҖҡдәәжҸҗдҫӣдәҶдёҺAIдәӨдә’зҡ„ж–°ж–№ејҸпјҢе®ғеҸҜд»Ҙз”ЁдәҺе®ўжңҚгҖҒж•ҷиӮІгҖҒеҲӣж„ҸеҶҷдҪңзӯүеӨҡдёӘйўҶеҹҹпјҢеҗҢж—¶д№ҹеёҰжқҘдәҶж•°жҚ®йҡҗз§ҒгҖҒдјҰзҗҶе’Ңе°ұдёҡзӯүж–№йқўзҡ„жҢ‘жҲҳгҖӮ 15. **ChatGPTеҲ°еә•еңЁеҒҡд»Җд№ҲпјҢдёәд»Җд№Ҳе®ғиғҪеҸ‘жҢҘдҪңз”Ёпјҹ** ChatGPTйҖҡиҝҮ...
еңЁдә’иҒ”зҪ‘ж—¶д»ЈпјҢиҝҷеӣӣдёӘе…ғзҙ зӣёдә’дәӨз»ҮпјҢеҪўжҲҗж–°зҡ„еўһй•ҝзӯ–з•Ҙпјҡ 1. дә§е“Ғ(Product)пјҡдёҚд»…иҰҒж»Ўи¶із”ЁжҲ·йңҖжұӮпјҢиҝҳйңҖиҰҒе…·еӨҮз—…жҜ’жҖ§пјҢеҚідә§е“ҒиҮӘиә«иғҪдҝғиҝӣз”ЁжҲ·й—ҙзҡ„дј ж’ӯпјҢеҰӮзӨҫдәӨеӘ’дҪ“зҡ„еҲҶдә«еҠҹиғҪгҖӮ 2. д»·ж ј(Price)пјҡдә’иҒ”зҪ‘дҪҝеҫ—д»·ж јзӯ–з•Ҙ...
"е№Іиҙ§пҪңжҺҘең°и®ҫи®ЎжҢҮеҜј.pdf" жң¬ж–ҮжЎЈеҜ№еә”зҡ„зҹҘиҜҶзӮ№еҢ…жӢ¬пјҡ 1. EMCи®ҫи®ЎжҢҮеҜјпјҡж–ҮжЎЈдёӯж¶үеҸҠеҲ°EMCзҡ„и®ҫи®ЎжҢҮеҜјпјҢеҢ…жӢ¬EMCзҡ„еҹәжң¬жҰӮеҝөгҖҒEMCи®ҫи®Ўзҡ„йҮҚиҰҒжҖ§гҖҒEMCи®ҫи®Ўзҡ„жӯҘйӘӨгҖҒEMCи®ҫи®Ўзҡ„е·Ҙе…·е’Ңж–№жі•зӯүгҖӮ 2. жҺҘең°и®ҫи®Ўпјҡж–ҮжЎЈдёӯи®Ёи®әдәҶжҺҘең°...