一、需求场景分析
在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘关系,从而分析出数据的上下游依赖关系。
本文将介绍如何去根据MaxCompute InformationSchema中作业ID的输入输出表来分析出某张表的血缘关系。
二、方案设计思路
MaxCompute Information\_Schema提供了访问表的作业明细数据tasks\_history,该表中有作业ID、input\_tables、output\_tables字段记录表的上下游依赖关系。根据这三个字段统计分析出表的血缘关系
1、根据某1天的作业历史,通过获取tasks\_history表里的input\_tables、output\_tables、作业ID字段的详细信息,然后分析统计一定时间内的各个表的上下游依赖关系。
2、根据表上下游依赖推测出血缘关系。
三、方案实现方法
参考示例一:
(1)根据作业ID查询某表上下游依赖SQL处理如下:
```
select
t2.input_table,
t1.inst_id,
replace(replace(t1.output_tables,"[",""),"]","") as output_table
from information_schema.tasks_history t1
left join
(
select
---去除表开始和结尾的[ ]
trans_array(1,",",inst_id,
replace(replace(input_tables,"[",""),"]","")) as (inst_id,input_table)
from information_schema.tasks_history where ds = 20190902
)t2
on t1.inst_id = t2.inst_id
where (replace(replace(t1.output_tables,"[",""),"]","")) <> ""
order by t2.input_table limit 1000;
```

结果如下图所示:

(2)根据结果可以分析得出每张表张表的输入表输出表以及连接的作业ID,即每张表的血缘关系。
血缘关系位图如下图所示:
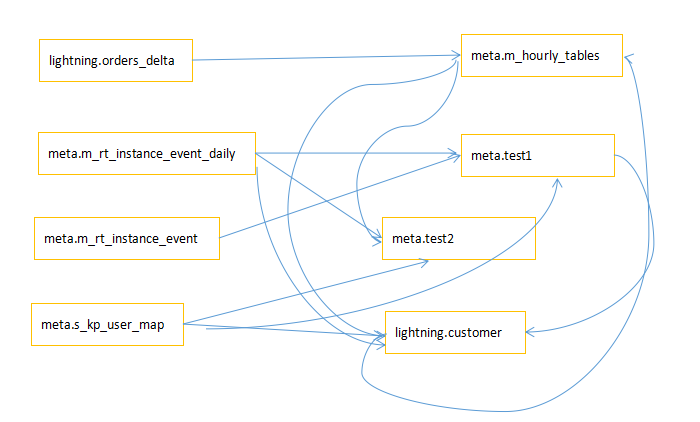
中间连线为作业ID,连线起始为输入表,箭头所指方向为输出表。
参考示例二:
以下方式是通过设置分区,结合DataWorks去分析血缘关系:
(1)设计存储结果表Schema
```
CREATE TABLE IF NOT EXISTS dim_meta_tasks_history_a
(
stat_date STRING COMMENT '统计日期',
project_name STRING COMMENT '项目名称',
task_id STRING COMMENT '作业ID',
start_time STRING COMMENT '开始时间',
end_time STRING COMMENT '结束时间',
input_table STRING COMMENT '输入表',
output_table STRING COMMENT '输出表',
etl_date STRING COMMENT 'ETL运行时间'
);
```

(2)关键解析sql
```
SELECT
'${yesterday}' AS stat_date
,'project_name' AS project_name
,a.inst_id AS task_id
,start_time AS start_time
,end_time AS end_time
,a.input_table AS input_table
,a.output_table AS output_table
,GETDATE() AS etl_date
FROM (
SELECT
t2.input_table
,t1.inst_id
,replace(replace(t1.input_tables,"[",""),"]","") AS output_table
,start_time
,end_time
FROM (
SELECT
*
,ROW_NUMBER() OVER(PARTITION BY output_tables ORDER BY end_time DESC) AS rows
FROM information_schema.tasks_history
WHERE operation_text LIKE 'INSERT OVERWRITE TABLE%'
AND (
start_time >= TO_DATE('${yesterday}','yyyy-mm-dd')
and
end_time <= DATEADD(TO_DATE('${yesterday}','yyyy-mm-dd'),8,'hh')
)
AND(replace(replace(output_tables,"[",""),"]",""))<>""
AND ds = CONCAT(SUBSTR('${yesterday}',1,4),SUBSTR('${yesterday}',6,2),SUBSTR('${yesterday}',9,2))
)t1
LEFT JOIN(
SELECT TRANS_ARRAY(1,",",inst_id,replace(replace(input_tables,"[",""),"]","")) AS (inst_id,input_table)
FROM information_schema.tasks_history
WHERE ds = CONCAT(SUBSTR('${yesterday}',1,4),SUBSTR('${yesterday}',6,2),SUBSTR('${yesterday}',9,2))
)t2
ON t1.inst_id = t2.inst_id
where t1.rows = 1
) a
WHERE a.input_table is not null
;
```

(3)任务依赖关系
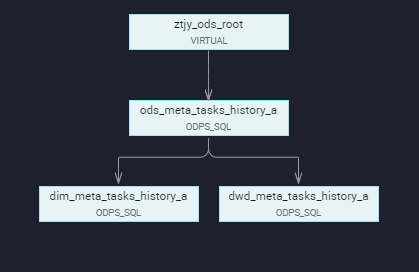
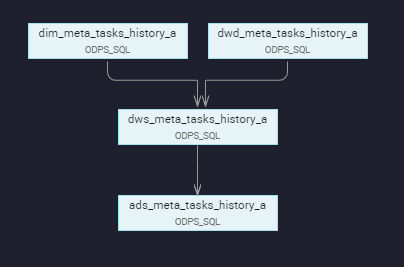
(4)最终血缘关系

以上血缘关系的分析是根据自己的思路实践去完成。真实的业务场景需要大家一起去验证。所以希望大家有需要的可以根据自己的业务需求去做相应的sql修改。如果有发现处理不当的地方希望多多指教。我在做相应的调整。
[原文链接](https://yq.aliyun.com/articles/738779?utm_content=g_1000095333)
本文为阿里云内容,未经允许不得转载。
分享到:





相关推荐
基于Python实现字段级血缘分析项目源码.zip基于Python实现字段级血缘分析项目源码.zip基于Python实现字段级血缘分析项目源码.zip基于Python实现字段级血缘分析项目源码.zip基于Python实现字段级血缘分析项目源码.zip...
理解表血缘关系对于数据仓库和大数据环境的数据流分析尤其重要。 3. **数据库血缘分析**:这是一个数据管理过程,旨在跟踪数据从源头到目标的整个生命周期。这包括数据的创建、处理、转换和消费。通过血缘分析,...
【作品名称】:基于Python 实现AI技术的数据内容血缘关系分析技术 【适用人群】:适用于希望学习不同技术领域的小白或进阶学习者。可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【项目介绍】:...
【作品名称】:基于 Java通过hive-sql分析字段的血缘关系 【适用人群】:适用于希望学习不同技术领域的小白或进阶学习者。可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【项目介绍】:通过hive-...
“血缘关系”是“博爱”或“悲伤”的性别中立术语。 最初,血缘关系包括M个男性成员和F个女性成员。 每周随机选择一个成员,选择一个新成员,该成员的性别始终与进行选择的成员相同。 这种进化模型与经典的Pólya...
基于图数据库的元数据血缘关系分析技术研究与实践.docx
在本项目中,源码着重于对HQL集合进行静态分析,这意味着它不会实际执行HQL查询,而是通过分析查询语句的结构来推断血缘关系。这种分析方法有助于提前发现可能的错误,例如未定义的表或字段,或者不正确的JOIN条件。...
梳理Informatic的元数据,理清ETL背后的数据加工流水线基础数据,基于SQL析可以获取目标表依赖的源表和映射,然后基于映射可以追溯到相应的会话、工作集、工作流,完成整个数据加工链的血缘
在血缘关系图谱的实现中,X6允许用户添加、删除节点和边,进行拖动、旋转等操作。它的高性能和灵活性使其在处理大规模数据时也能保持流畅。 3. **JsPlumb**: JsPlumb是一个用于HTML元素连接的JavaScript库,虽然...
本demo在Vue框架下,采用d3第三方库,对数据进行血缘分析,形成数据血缘分析图
阿里云MaxCompute助力众安保险...MaxCompute提供了强大的数据处理能力、数据安全功能、低成本的计算平台、扩展性强、数据质量监控、元数据管理、血缘关系分析、数据服务等功能,能够满足企业对数据处理和分析的需求。
// 获取id字段的血缘 LineageNode idNode = Delegate.getDelegate().getLineage(hql, "id"); // 获取name字段的血缘 LineageNode nameNode = Delegate.getDelegate().getLineage(hql, "name"); // 打印血缘 ...
在数据仓库建设中,经常会使用到数据血缘追中方面的功能,本项目实现了对hql集合进行静态分析,获取hql对应的血缘图(表血缘 + 字段血缘) 项目升级内容 删除hive-exec与hadoop-common的maven依赖,使得项目更加的轻...
MaxCompute提供的数据服务功能十分丰富,包括数据监控、数据同步、任务调度、预警系统、元数据管理、数据门户、自助取数、血缘关系分析、服务API以及计算存储管理等。这些工具使得数据的存储、处理、分析和应用变得...
传统的数据血缘分析方法可能无法满足这种复杂环境下的需求,因此,本文提出了一种基于代理重签名技术的细粒度卷烟营销数据血缘安全分析方法。代理重签名是一种公钥密码学协议,它允许一个代理在不泄露原始签名者私钥...
【作品名称】:基于 Java 简单的表级别血缘分析工具 【适用人群】:适用于希望学习不同技术领域的小白或进阶学习者。可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【项目介绍】:简单的表级别血缘...
为了进行Hive血缘关系分析,通常需要借助一些专业工具,如Apache Atlas、Data Governance Suite等,它们能自动收集和展示Hive的血缘信息,方便数据分析师和数据工程师进行管理和监控。 总的来说,Hive的血缘关系...
此血缘图实现了以下功能: 1、支持节点跨级连线 2、支持正反向连线(任意连线)3、节点层级清晰 4、支持放大、缩小功能 5、支持拖拽节点功能 6、连线为箭头连线 7、连线上可以加文字标注 8、节点内容清晰明了 9、...