一、Spark系统概述
===========
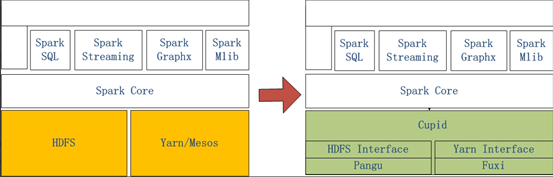
左侧是原生Spark的架构图,右边Spark on MaxCompute运行在阿里云自研的Cupid的平台之上,该平台可以原生支持开源社区Yarn所支持的计算框架,如Spark等。
二、Spark运行在客户端的配置和使用
===================
**2.1打开链接下载客户端到本地**
[http://odps-repo.oss-cn-hangzhou.aliyuncs.com/spark/2.3.0-odps0.30.0/spark-2.3.0-odps0.30.0.tar.gz?spm=a2c4g.11186623.2.12.666a4b69yO8Qur&file=spark-2.3.0-odps0.30.0.tar.gz](https://yq.aliyun.com/go/articleRenderRedirect?url=http%3A%2F%2Fodps-repo.oss-cn-hangzhou.aliyuncs.com%2Fspark%2F2.3.0-odps0.30.0%2Fspark-2.3.0-odps0.30.0.tar.gz%3Fspm%3Da2c4g.11186623.2.12.666a4b69yO8Qur%26amp%3Bfile%3Dspark-2.3.0-odps0.30.0.tar.gz)
**2.2将文件上传的ECS上**
**2.3将文件解压**
```
tar -zxvf spark-2.3.0-odps0.30.0.tar.gz
```

**2.4配置Spark-default.conf**
```
# spark-defaults.conf
# 一般来说默认的template只需要再填上MaxCompute相关的账号信息就可以使用Spark
spark.hadoop.odps.project.name =
spark.hadoop.odps.access.id =
spark.hadoop.odps.access.key =
# 其他的配置保持自带值一般就可以了
spark.hadoop.odps.end.point = http://service.cn.maxcompute.aliyun.com/api
spark.hadoop.odps.runtime.end.point = http://service.cn.maxcompute.aliyun-inc.com/api
spark.sql.catalogImplementation=odps
spark.hadoop.odps.task.major.version = cupid_v2
spark.hadoop.odps.cupid.container.image.enable = true
spark.hadoop.odps.cupid.container.vm.engine.type = hyper
```

**2.5在github上下载对应代码**
[https://github.com/aliyun/MaxCompute-Spark](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Faliyun%2FMaxCompute-Spark)
**2.5将代码上传到ECS上进行解压**
```
unzip MaxCompute-Spark-master.zip
```

**2.6将代码打包成jar包(确保安装Maven)**
```
cd MaxCompute-Spark-master/spark-2.x
mvn clean package
```

**2.7查看jar包,并进行运行**
```
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
MaxCompute-Spark-master/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
```

三、Spark运行在DataWorks的配置和使用
=========================
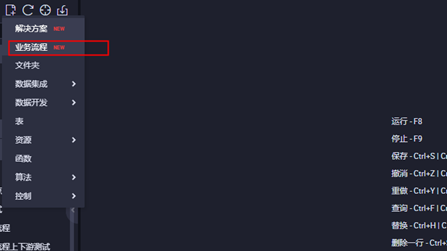
**3.1进入DataWorks控制台界面,点击业务流程**
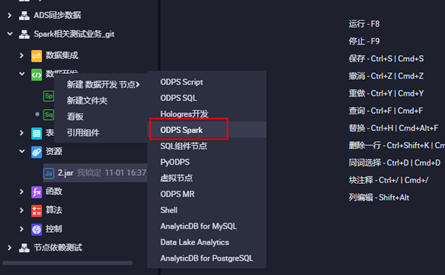
**3.2打开业务流程,创建ODPS Spark节点**
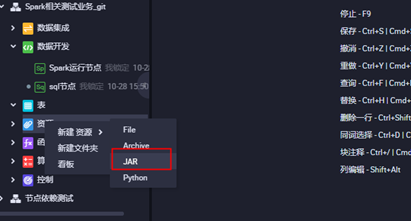
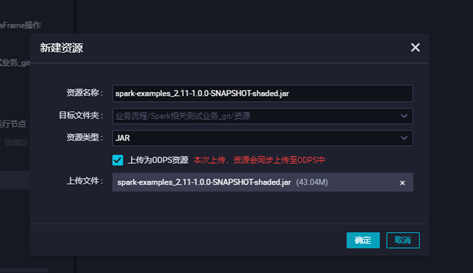
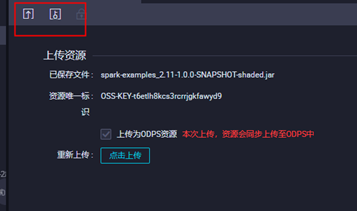
**3.3上传jar包资源,点击对应的jar包上传,并提交**
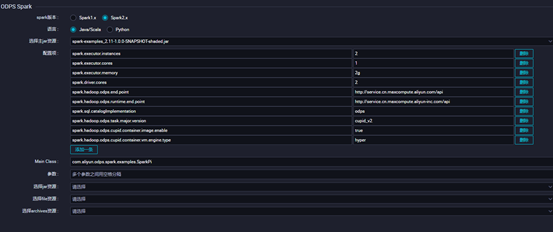
**3.4配置对应ODPS Spark的节点配置点击保存并提交,点击运行查看运行状态**
四、Spark在本地idea测试环境的使用
=====================
**4.1下载客户端与模板代码并解压**
客户端:
[http://odps-repo.oss-cn-hangzhou.aliyuncs.com/spark/2.3.0-odps0.30.0/spark-2.3.0-odps0.30.0.tar.gz?spm=a2c4g.11186623.2.12.666a4b69yO8Qur&file=spark-2.3.0-odps0.30.0.tar.gz](https://yq.aliyun.com/go/articleRenderRedirect?url=http%3A%2F%2Fodps-repo.oss-cn-hangzhou.aliyuncs.com%2Fspark%2F2.3.0-odps0.30.0%2Fspark-2.3.0-odps0.30.0.tar.gz%3Fspm%3Da2c4g.11186623.2.12.666a4b69yO8Qur%26amp%3Bfile%3Dspark-2.3.0-odps0.30.0.tar.gz)
模板代码:
[https://github.com/aliyun/MaxCompute-Spark](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Faliyun%2FMaxCompute-Spark)
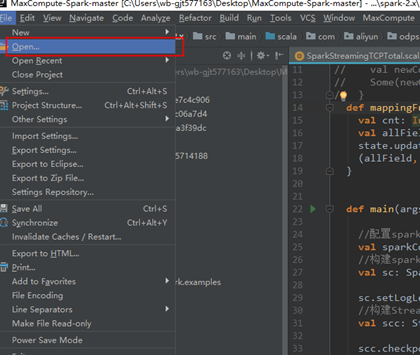
**4.2打开idea,点击Open选择模板代码**
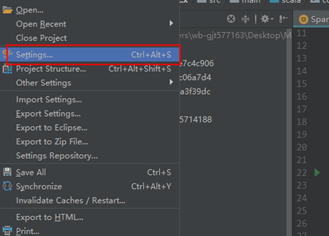
**4.2安装Scala插件**
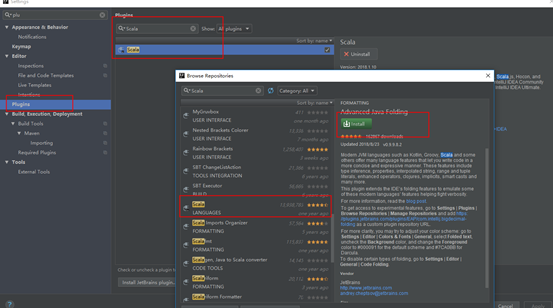
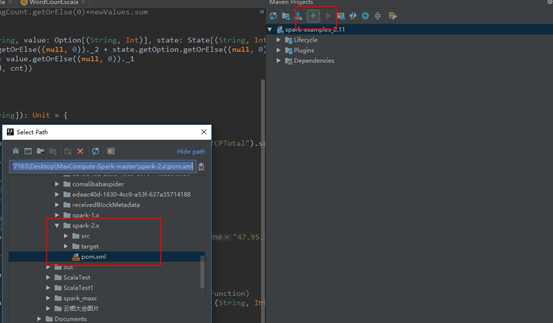
**4.3配置maven**
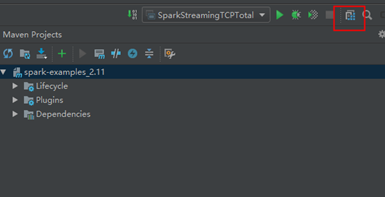
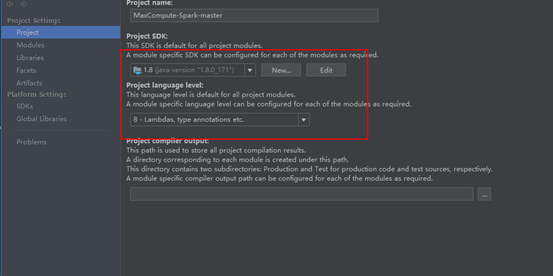
**4.4配置JDK和相关依赖**
分享到:





相关推荐
- **整体介绍**:MaxCompute支持多种数据处理方式,包括SQL查询、MapReduce计算等,并提供了丰富的功能,如数据导入导出、任务调度等。 - **发展历程**:MaxCompute最初由阿里巴巴集团内部开发,用于支持集团内部的...
用户可以通过Spark on MaxCompute来运行Spark作业,充分利用Spark的计算性能,同时利用MaxCompute的海量存储能力。这种结合提供了快速的数据探索和实验环境,适合数据科学家进行迭代分析。 三、MaxCompute与Kafka的...
* MaxCompute 提供了安全的数据平台,原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。 * 该安全数据平台支持 ACL+Policy+Label 细粒度授权,支持数据 KMS 加密,支持行为审计。 知识点 6: 生态...
MaxCompute 运行隔离是指在MaxCompute PaaS多租户架构中,使用进程隔离、lightweight VM、process isolation、untrusted worker、runtime isolation、language sandbox、untrusted code、java security manager、...
5. **运行环境标准化**:MaxCompute采用标准化的运行环境,包括统一的REST API、支持Kubernetes的部署方式等,使得不同的计算任务能够在相同的环境中执行,提高了整体的效率和灵活性。 #### 五、展望:大数据与云...
本项目支持在Spark运行环境中与阿里云的基础服务OSS、ODPS、LogService、ONS等进行交互。 构建和安装 git clone https://github.com/aliyun/aliyun-emapreduce-datasources.git cd aliyun-emapreduce-data...
另外,MaxCompute在性能优化方面也有所建树,例如编译器优化器会基于代价和历史运行信息进行优化,以提高计算效率。同时,MaxCompute支持了新一代大数据语言的引入,这些语言结合了命令式编程与声明式编程的优势,...
在易用性方面,MaxCompute提供了多种数据导入方案和分布式计算模型,如流计算、图计算和Batch计算,以及与Spark API、Beam API和Hive API等接口的兼容,构建了一个丰富的应用生态系统。 MaxCompute的研发目标在于...
MaxCompute2.0集成了NewSQL、Python和Java等多种编程语言,以及基于代价和历史运行信息的编译器优化器。 在资源管理方面,MaxCompute2.0实现了元数据管理、资源调度、任务调度、多级群协调和调度能力。它还支持索引...
4. **安全性**:原生的多租户系统,所有计算任务在安全沙箱中运行,支持细粒度的权限控制和数据加密。 5. **生态开放**:高度兼容Hive,支持Spark应用,Python生态,以及第三方BI工具。 **ADB(AnalyticDB)**是...
MaxCompute是阿里云推出的一种大规模数据处理服务,它在大数据领域扮演着重要的角色,尤其在淘系(淘宝、天猫等阿里巴巴旗下电商平台)的数据治理中,MaxCompute提供了强大的数据存储和计算能力。本篇将深入探讨...
综上所述,MaxCompute的公有云多租户设计在金融营销领域的应用,不仅提供了大数据处理的技术支撑,还通过严谨的安全机制和灵活的资源管理,确保了金融业务的稳定和高效运行。金融机构可以通过这种平台实现精细化运营...
Flighting工具则用于确保MaxCompute运行器的正确执行,防止快速迭代中的错误导致重大事故。它需要在不牺牲数据安全性的同时,有效地测试调度或可扩展性等方面的改进。然而,建立相同规模的测试集群会消耗大量资源,...
在MaxCompute 2.0中,它强调了兼容性、开放性和统一性,能够支持多种计算框架,如Spark、Hive和Elasticsearch等,构建起一个强大的生态。这一版本还引入了盘古作为分布式存储系统,伏羲作为分布式调度系统,增强了...
通常要求本科及以上学历,计算机、数学、统计学等相关专业,且需熟悉数据处理流程,具有相关开发语言(如Java、Python)和大数据平台(如Hadoop、Spark、Maxcompute)的实际操作经验。 14. **数据治理**: 熟悉...
机器学习PAI是构建在MaxCompute上的机器学习平台,用户可以在不迁移数据的情况下进行模型训练和预测。AnalyticDB是一款实时分析服务,与MaxCompute配合,实现从离线到在线的分析流程。 总结来说,大数据技术涵盖了...
- **不支持Spark增强应用**: MaxCompute本身提供了丰富的计算能力,但并不直接支持Spark框架的增强应用。 - **单租户使用模式**: MaxCompute采用单租户模式,每个用户或组织都有独立的计算资源。 - **规模有限...
然而,在Kubernetes集群中,日志分析和监控变得越来越复杂。因此,本文将探讨Kubernetes Ingress日志分析的最佳实践,帮助读者更好地理解和实现Kubernetes Ingress日志分析。 技术创新 在Kubernetes Ingress日志...