Dataphinن½œن¸؛éک؟里ه·´ه·´و•°وچ®ن¸هڈ°OneData (OneModelم€پOneIDم€پOneService)و–¹و³•è®؛çڑ„ن؛§ه“پè½½ن½“,ه¸®هٹ©ن¼پن¸ڑو„ه»؛ن¸‰ه¤§و•°وچ®ن¸ه؟ƒï¼ڑهں؛ن؛ژو•°وچ®é›†وˆگه½¢وˆگçڑ„ه‚ç›´و•°وچ®ن¸ه؟ƒم€پهں؛ن؛ژو•°وچ®ه¼€هڈ‘و²‰و·€çڑ„ه…¬ه…±و•°وچ®ن¸ه؟ƒه’Œهں؛ن؛ژو ‡ç¾ه·¥هژ‚و„ه»؛çڑ„èگƒهڈ–و•°وچ®ن¸ه؟ƒم€‚ن»ٹه¤©وˆ‘ن»¬ه°±ن¸€èµ·و¥çœ‹çœ‹ï¼ŒDataphinوک¯ه¦‚ن½•هں؛ن؛ژOneIDو€وƒ³و„ه»؛و•°وچ®èگƒهڈ–ن¸ه؟ƒï¼Œè؟وژ¥ن¸ٹن¸‹و¸¸ه؛”用ن¸؛ن¼پن¸ڑهˆ›é€ و›´ه¤ڑن»·ه€¼çڑ„هگ§ï½
1. ن¸؛ن»€ن¹ˆè¦په»؛ç«‹èگƒهڈ–و•°وچ®ن¸ه؟ƒï¼ڑوڈگهچ‡و•°وچ®ن»·ه€¼ه¯†ه؛¦
首ه…ˆï¼Œوˆ‘ن»¬و¥çœ‹çœ‹Dataphinن¸؛ن»€ن¹ˆè¦په¸®هٹ©ن¼پن¸ڑو„ه»؛è‡ھه·±çڑ„èگƒهڈ–و•°وچ®ن¸ه؟ƒï¼ں
ه¤§و•°وچ®و—¶ن»£ï¼Œن»»ن½•ه¾®ه°ڈçڑ„و•°وچ®éƒ½هڈ¯èƒ½ن؛§ç”ںن¸چهڈ¯و€è®®çڑ„ن»·ه€¼م€‚ن½œن¸؛و™؛能و•°وچ®و„ه»؛ن¸ژç®،çگ†ه¹³هڈ°ï¼ŒDataphinçڑ„规范ه»؛و¨،م€پو•°وچ®ه¤„çگ†ç‰و ¸ه؟ƒهٹں能ه¸®هٹ©ن¼پن¸ڑé«کو•ˆو•´هگˆو¥è‡ھن¸چهگŒن¸ڑهٹ،و•°وچ®ه؛“çڑ„وµ·é‡ڈو•°وچ®ï¼Œو²‰و·€و•°وچ®èµ„ن؛§ï¼Œو„ه»؛è‡ھه·±çڑ„و•°وچ®ن¸هڈ°ï¼Œه؛”ه¯¹ه¤§و•°وچ®و—¶ن»£Volume(ه¤§é‡ڈ)م€پVariety(ه¤ڑو ·ï¼‰م€پVelocity(é«کé€ں)و–¹é¢çڑ„وŒ‘وˆکم€‚然而,相و¯”ن؛ژن¼ ç»ںçڑ„ه°ڈو•°وچ®ï¼Œه¤§و•°وچ®و›´ه¤§çڑ„ن»·ه€¼هœ¨ن؛ژن»ژوµ·é‡ڈن¸چ相ه…³çڑ„هگ„ç±»و•°وچ®ن¸ï¼ŒوŒ–وژکه‡؛ه¯¹é¢„وµ‹هˆ†وگوœ‰هڈ‚考و„ڈن¹‰çڑ„و•°وچ®ï¼Œوڈگهچ‡و•°وچ®ن»·ه€¼ه¯†ه؛¦ه¹¶ه؛”用ن؛ژوŒ‡ه¯¼ç”ںن؛§ï¼Œن»ژ而ه¸®هٹ©ن¼پن¸ڑه®çژ°وڈگو•ˆé™چوœ¬çڑ„ç›®çڑ„م€‚Dataphinçڑ„و•°وچ®èگƒهڈ–هٹں能و£وڈگن¾›ن؛†è؟™و ·çڑ„能هٹ›م€‚
ن»ژن¸ڑهٹ،视角و¥çœ‹ï¼Œو—¥ه¸¸ç”ںن؛§ه’Œèگ¥é”€و´»هٹ¨ن¸ï¼Œن¸چç®،وک¯ن؛؛群هœˆé€‰م€پ选ه€è؟کوک¯ن¸ھو€§هŒ–وٹ•و”¾ï¼Œéƒ½ç¦»ن¸چه¼€و ‡ç¾çڑ„وŒ‡ه¯¼م€‚و ‡ç¾وک¯ه¯¹ن¸€ن¸ھه®ن½“çڑ„ç«‹ن½“هˆ»ç”»ï¼ˆن¸چه±€é™گن؛ژن؛؛,ن»»ن½•هڈ¯è¢«وڈڈè؟°ه’Œهˆ†وگçڑ„هکهœ¨éƒ½هڈ¯ن»¥وک¯ه®ن½“,ه¦‚ه•†ه“پم€په…¬هڈ¸ç‰ï¼‰م€‚ن¸چهگŒç»´ه؛¦çڑ„و ‡ç¾ن»ژن¸چهگŒè§’ه؛¦ه¯¹ه®ن½“è؟›è،Œوڈڈè؟°ï¼Œن¾‹ه¦‚ن»¥é›¶ه”®è§†è§’ن¸؛هˆ‡ه…¥ç‚¹ï¼Œوˆ‘ن»¬هڈ¯ن»¥ن»ژè‡ھ然ه±و€§ï¼ˆه¦‚و€§هˆ«م€په¹´é¾„)م€پ社ن¼ڑه±و€§ï¼ˆه¦‚ç»ڈوµژçٹ¶ه†µم€په©ڑه§»çٹ¶و€پ)م€په…´è¶£هپڈه¥½ï¼ˆه¦‚ه–œو¬¢و•´و´پçڑ„çژ¯ه¢ƒم€په¸Œوœ›وœ‰و¼‚ن؛®çڑ„牙é½؟)ه’Œè،Œن¸ڑو¶ˆè´¹هپڈه¥½ï¼ˆه¦‚ç¾ژه¦†هپڈه¥½م€پو¯چه©´هپڈه¥½ï¼‰و¥ه¯¹و¶ˆè´¹è€…è؟›è،Œوڈڈè؟°م€‚é«کè´¨é‡ڈم€په…¨é¢çڑ„و ‡ç¾èƒ½ه¤ںوœ‰و•ˆهœ°وٹ½è±،ه‡؛ن¸€ن¸ھه®ن½“çڑ„ن؟،وپ¯ه…¨è²Œï¼Œن¸؛ç²¾ه‡†èگ¥é”€ه¥ ه®ڑن؛†هں؛ç،€م€‚
و•°وچ®هڈھوœ‰èچé€ڑو‰چ能ن؛§ç”ںو›´ه¤§çڑ„ن»·ه€¼ï¼Œوˆ‘ن»¬ن¸چن»…ه¸Œوœ›هڈ¯ن»¥هˆ†وگه’Œه؛”用ه¤§و•°وچ®ï¼Œو›´ه¸Œوœ›ه¾—هˆ°é€ڑè؟‡è·¨ن¸ڑهٹ،هچ•ه…ƒè؟وژ¥èµ·و¥çڑ„و•°وچ®ه’Œç²¾ç»†هŒ–èگƒهڈ–çڑ„و•°وچ®م€‚è؟™ç§چوƒ…ه†µن¸‹ï¼ŒDataphinو•°وچ®èگƒهڈ–و¨،ه—هں؛ن؛ژن¸ڑهٹ،و•°وچ®ه؛“çڑ„هژںه§‹و•°وچ®ه’Œه»؛و¨،ç ”هڈ‘ç‰و²‰و·€çڑ„و•°وچ®èµ„ن؛§ï¼Œه°†ه…¨ç³»ç»ںن¸ن¸»و•°وچ®â€”—هچ³è´¯ç©؟هگ„ن¸ھéڑ”离ن¸ڑهٹ،çڑ„و ¸ه؟ƒه¯¹è±،,è؟›è،Œè¯†هˆ«ن¸ژه…³èپ”è؟وژ¥ï¼Œو‰“é€ڑن¸ڑهٹ،و•°وچ®ه¤ه²›ï¼Œè؟›ن¸€و¥وڈگ炼هڈ¯ç›´وژ¥ه؛”用çڑ„é«کن»·ه€¼و ‡ç¾و•°وچ®ï¼Œن»ژ而ه¸®هٹ©ن¼پن¸ڑو„ه»؛è‡ھه·±çڑ„èگƒهڈ–و•°وچ®ن¸ه؟ƒï¼Œه¹¶ه¯¹وژ¥ن¸ٹو¸¸ه؛”用(QuickAudienceç‰ï¼‰è؟›ن¸€و¥وŒ‡ه¯¼ç”ںن؛§èگ¥é”€و´»هٹ¨م€‚
1. ه¦‚ن½•é«کو•ˆه»؛ç«‹èگƒهڈ–و•°وچ®ن¸ه؟ƒï¼ڑهڈ¯è§†هŒ–é…چ置,è‡ھهٹ¨هŒ–ç”ںن؛§
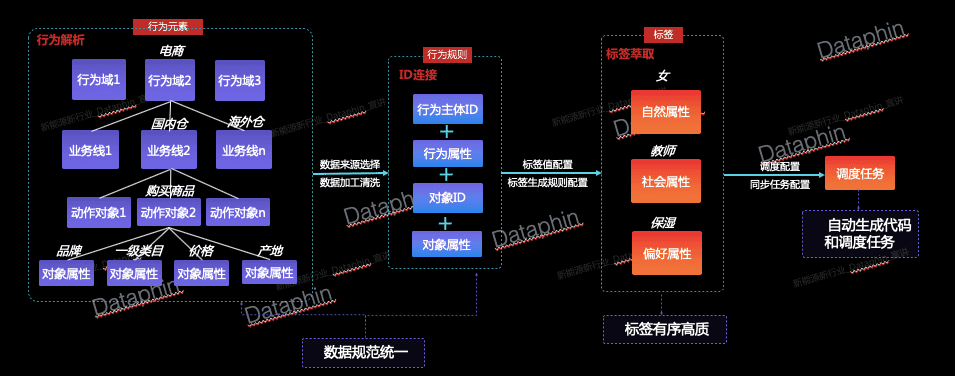
Dataphinç ”هڈ‘و¨،ه—ن¸‹çڑ„و•°وچ®èگƒهڈ–ن¸؛وˆ‘ن»¬وڈگن¾›ن؛†è؟وژ¥è،Œن¸؛و•°وچ®ه¹¶ه®çژ°و ‡ç¾èگƒهڈ–çڑ„هٹں能,çژ°éک¶و®µن¼که…ˆو”¯وŒپن»¥و¶ˆè´¹è€…ن¸؛ه¯¹è±،çڑ„و•°وچ®ن½“系,هٹں能و¨،ه—ن¸»è¦پهŒ…و‹¬3 ه¤§éƒ¨هˆ†ï¼ڑIDن¸ه؟ƒم€پè،Œن¸؛ن¸ه؟ƒه’Œو ‡ç¾ن¸ه؟ƒï¼ˆç›®ه‰چIDن¸ه؟ƒوڑ‚وœھن¸ٹç؛؟)م€‚و¤ه¤–,è؟گç»´و¨،ه—ن¸‹è؟کوڈگن¾›هچ•ç‹¬çڑ„èگƒهڈ–è؟گç»´هگو¨،ه—,و”¯وŒپن»ژن¸ڑهٹ،视角وں¥çœ‹èگƒهڈ–相ه…³çڑ„è°ƒه؛¦ن»»هٹ،م€‚ن¸‹é¢ï¼Œوˆ‘ن»¬ه°†ن»ژه‡ ن¸ھهٹں能و¨،ه—çڑ„视角给ه¤§ه®¶ن»‹ç»چDataphinه¦‚ن½•ه¸®هٹ©ن¼پن¸ڑو„ه»؛è‡ھه·±çڑ„èگƒهڈ–و•°وچ®ن¸ه؟ƒم€‚
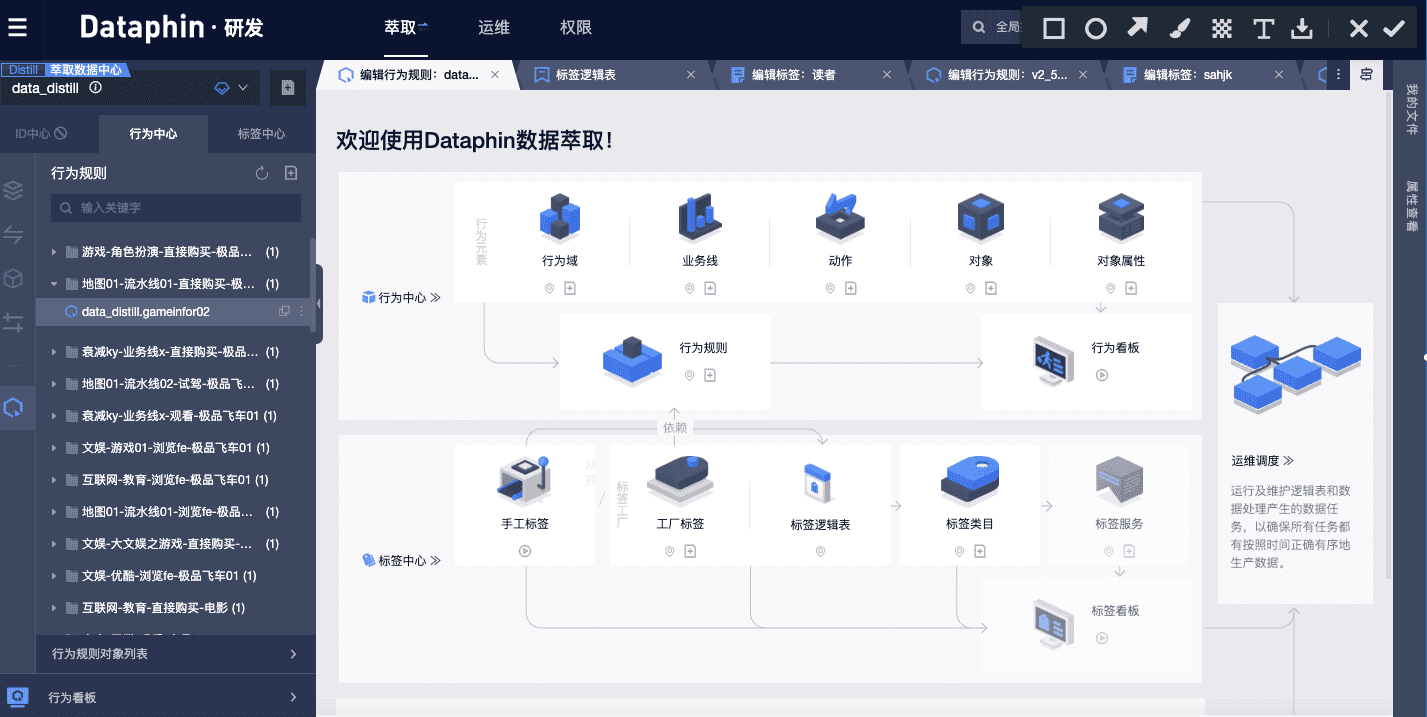
1)IDن¸ه؟ƒï¼ڑ相ه…³IDè‡ھهٹ¨هŒ–识هˆ«ن¸ژè؟وژ¥
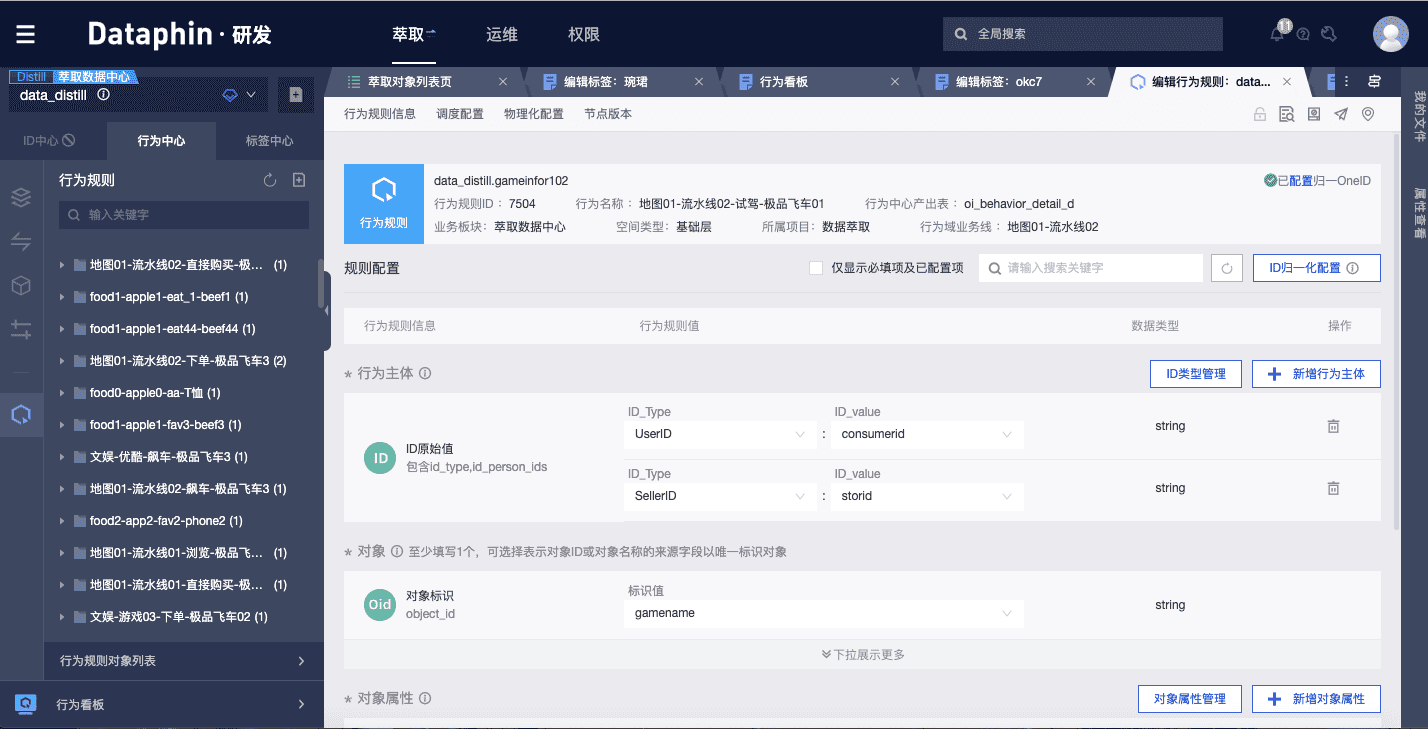
Dataphinهں؛ن؛ژOneIDçڑ„و€وƒ³ï¼Œن»¥ه”¯ن¸€و ‡è¯†و‰“é€ڑو¥è‡ھن¸چهگŒه¹³هڈ°م€پç³»ç»ںم€پو¸ éپ“çڑ„و•°وچ®ï¼Œو”¯وŒپé€ڑè؟‡هڈ¯è§†هŒ–ç•Œé¢هڈ‚و•°é…چç½®çڑ„و–¹ه¼ڈ,ن»ژو‰€وœ‰و•°وچ®ن¸وڈگ炼ه¹¶هں؛ن؛ژç®—و³•è‡ھهٹ¨è¯†هˆ«هگ„ç±»ه‹ID ن¹‹é—´çڑ„وک ه°„ه…³ç³»ï¼ˆè´ç‰©ن¼ڑه‘کIDم€پ视频观看者IDم€پè´ç‰©è®¾ه¤‡macم€پ观看设ه¤‡IP ç‰ï¼‰ï¼Œه¹¶ه°†ه±ن؛ژهگŒن¸€ه®ن½“çڑ„ن¸چهگŒç±»ه‹IDé€ڑè؟‡ه”¯ن¸€çڑ„One IDè؟›è،Œè؟وژ¥ï¼Œن½؟ه¾—هں؛ن؛ژIDç”ںن؛§çڑ„و ‡ç¾هڈ¯ن»¥èپڑهگˆهˆ°هگŒن¸€ه®ن½“,ن»ژ而ه¯¹ه®ن½“è؟›è،Œو›´ç²¾ه‡†م€په…¨é¢çڑ„هˆ»ç”»م€‚
2)è،Œن¸؛ن¸ه؟ƒï¼ڑو²‰و·€è،Œن¸؛ه…ƒç´ ,و„ه»؛è،Œن¸؛规هˆ™
Dataphinç›®ه‰چو”¯وŒپن»¥ن؛؛çڑ„相ه…³ID ن¸؛ن¸ه؟ƒï¼Œé€ڑè؟‡هڈ¯è§†هŒ–ç•Œé¢è،¨هچ•é…چç½®çڑ„و–¹ه¼ڈ,ن»ژو¥و؛گè،Œن¸؛و•°وچ®ن¸وڈگ炼è؟›è€Œèپڑو‹¢ن¸چهگŒن¸ڑهٹ،هںںن¸‹çڑ„è،Œن¸؛و•°وچ®ï¼ˆه¦‚电ه•†è´ç‰©م€پ视频观看)م€‚
首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پن»ژن¸ڑهٹ،视角ه¯¹è،Œن¸؛و•°وچ®è؟›è،Œو¢³çگ†ï¼Œن»ژن¸وڈگ炼ه‡؛هڈ¯ه¤چ用çڑ„è،Œن¸؛ه…ƒç´ (è،Œن¸؛هںںم€پن¸ڑهٹ،ç؛؟م€پهٹ¨ن½œم€په¯¹è±،م€په¯¹è±،ه±و€§ï¼‰ï¼Œه¹¶é€ڑè؟‡ه¯¹è،Œن¸؛ه…ƒç´ è؟›è،Œç»„هگˆه®ڑن¹‰ن¸چهگŒçڑ„è،Œن¸؛(è،Œن¸؛هںں-ن¸ڑهٹ،ç؛؟-هٹ¨ن½œ-ه¯¹è±،)م€‚è،Œن¸؛هںںèپڑهگˆن¸ڑهٹ،هگ«ن¹‰ن¸€è‡´çڑ„è،Œن¸؛و•°وچ®ï¼Œه¦‚电ه•†هںںم€پو–‡ه¨±هںںï¼›ن¸ڑهٹ،ç؛؟هں؛ن؛ژè،Œن¸؛هںںه°†è،Œن¸؛و•°وچ®è؟›ن¸€و¥ç»†هˆ†ï¼Œهگ„ن¸ڑهٹ،ç؛؟ن¹‹é—´ç›¸ه¯¹ç‹¬ç«‹ï¼Œه¦‚و·که®ن¸ڑهٹ،ç؛؟م€په¤©çŒ«ن¸ڑهٹ،ç؛؟ï¼›هٹ¨ن½œوŒ‡è،Œن¸؛ن¸»ن½“هڈ‘ه‡؛çڑ„و“چن½œï¼Œه¦‚è´ن¹°م€پوµڈ览;ه¯¹è±،وŒ‡è،Œن¸؛ن¸»ن½“و“چن½œçڑ„ه…·ن½“ن؛‹ç‰©ï¼Œه¦‚ه•†ه“پم€پ电ه½±ï¼›ه¯¹è±،ه±و€§وک¯ه¯¹è±،çڑ„وڈڈè؟°و€§ن؟،وپ¯ï¼Œه¦‚هگچ称م€په“پ牌م€په¹´ن»½م€‚é€ڑè؟‡وٹ½هڈ–و²‰و·€è،Œن¸؛ه…ƒç´ ,وˆ‘ن»¬هڈ¯ن»¥ه°†و¥و؛گو•°وچ®و›´ه¥½هœ°è؟›è،Œهˆ’هˆ†ç»„هگˆن»¥ه¾—هˆ°ه…·وœ‰وکژç،®ن¸ڑهٹ،هگ«ن¹‰çڑ„è،Œن¸؛,ه¦‚电ه•†هںں-و·که®-è´ن¹°-ه•†ه“پم€پو–‡ه¨±هںں-ن¼کé…·-وµڈ览-电ه½±م€‚é€ڑè؟‡و²‰و·€è،Œن¸؛ه…ƒç´ ,وˆ‘ن»¬هڈ¯ن»¥و›´ه¥½هœ°è§„范و¥و؛گو•°وچ®ï¼Œه¹¶ه‡ڈه°‘é‡چه¤چه»؛设ه’Œن؛؛هٹ›وٹ•ه…¥م€‚
ç»™هگŒن¸€è،Œن¸؛选و‹©ن¸چهگŒçڑ„و¥و؛گè،¨ه¹¶و·»هٹ é…چ置,هچ³ç”ںوˆگن¸چهگŒçڑ„è،Œن¸؛规هˆ™ï¼ˆç”±è،Œن¸؛+و¥و؛گè،¨ه”¯ن¸€ç،®ه®ڑ),هگژç»و ‡ç¾ç”ںن؛§ه°†ن¾èµ–ه·²ç»ڈو„ه»؛çڑ„è،Œن¸؛ه’Œè،Œن¸؛规هˆ™م€‚规هˆ™é…چç½®ن¸»è¦پهŒ…و‹¬è،Œن¸؛ن¸»ن½“IDم€په¯¹è±،م€په¯¹è±،ه±و€§ه’Œè،Œن¸؛هڈ‘ç”ںو¬،و•°ï¼Œن»ژو¥و؛گè،¨é€‰و‹©ç›¸ه؛”çڑ„ه—و®µï¼Œه†چé€ڑè؟‡è،Œن¸؛规هˆ™çڑ„ه‘¨وœںè°ƒه؛¦ن»»هٹ،,وˆ‘ن»¬ه°±èƒ½ه¾—هˆ°وŒپç»و›´و–°çڑ„è،Œن¸؛و•°وچ®ن½œن¸؛و ‡ç¾ç”ںن؛§çڑ„و¥و؛گم€‚
3)و ‡ç¾ن¸ه؟ƒï¼ڑé«کو•ˆو ‡ç¾ç”ںن؛§
و„ه»؛ه®Œوˆگè،Œن¸؛ه’Œè،Œن¸؛规هˆ™هگژ,è؟›ن¸€و¥هœ°ï¼Œوˆ‘ن»¬ه°†هں؛ن؛ژç®—و³•و¨،ه‹ï¼Œé€ڑè؟‡ç®€هچ•çڑ„ç•Œé¢é…چç½®ه®ڑن¹‰و ‡ç¾çڑ„ç”ںوˆگ规هˆ™م€‚
و ‡ç¾çڑ„é…چç½®هˆ†ن¸؛ن¸¤ه¤§و¥éھ¤ï¼ڑ第ن¸€و¥é¦–ه…ˆهں؛ن؛ژه®ڑن¹‰çڑ„è،Œن¸؛هœˆé€‰ه‡؛وںگو ‡ç¾éœ€è¦پن¾èµ–çڑ„è،Œن¸؛و•°وچ®ï¼Œوژ¥ç€ه¯¹é¢„وœںه¾—هˆ°çڑ„و ‡ç¾ه€¼ه’Œو‰“و ‡و–¹ه¼ڈè؟›è،Œé…چ置;第ن؛Œو¥éœ€è¦په¯¹ه·²é€‰çڑ„è،Œن¸؛و•°وچ®è®¾ç½®و—¶é—´è،°ه‡ڈو¨،ه¼ڈ,ه¹¶هں؛ن؛ژن¸ڑهٹ،هگ«ن¹‰ç»™ن¸چهگŒçڑ„è،Œن¸؛هˆ†é…چن¸چهگŒçڑ„وƒé‡چم€‚ن¾‹ه¦‚,وˆ‘ن»¬è®¤ن¸؛“è´ن¹°و¯چه©´ç”¨ه“پâ€ه’Œâ€œè§‚看ن؛²هگ视频â€çڑ„用وˆ·éƒ½هڈ¯ن»¥è¢«و‰“ن¸ٹ“و¯چه©´ن؛؛群â€çڑ„و ‡ç¾ï¼Œé‚£ن¹ˆç¬¬ن¸€و¥ï¼Œوˆ‘ن»¬ه°†è؟™ن¸¤ç§چè،Œن¸؛相ه…³çڑ„و•°وچ®éƒ½ه‹¾é€‰ه‡؛و¥ï¼Œè®¾ç½®é¢„وœںو ‡ç¾ه€¼ن¸؛“و¯چه©´ن؛؛群â€ï¼›ç¬¬ن؛Œو¥ï¼Œوˆ‘ن»¬è®¤ن¸؛è؟‘وœںçڑ„è،Œن¸؛و¯”ن¹‹ه‰چهڈ‘ç”ںçڑ„è،Œن¸؛و›´وœ‰هڈ‚考و€§ï¼Œه› و¤é€‰و‹©ç؛؟و€§è،°ه‡ڈو¨،ه¼ڈ,给è؟‘وœںè،Œن¸؛赋ن؛ˆو›´ه¤§çڑ„و—¶é—´وƒé‡چï¼›هگŒو—¶ï¼Œهں؛ن؛ژن¸ڑهٹ،ç»ڈéھŒï¼Œوˆ‘ن»¬è®¤ن¸؛“è´ن¹°و¯چه©´ç”¨ه“پâ€و¯”“观看ن؛²هگ视频â€و›´èƒ½ç²¾ç،®ه®ڑن½چهˆ°ç›®و ‡ç”¨وˆ·ï¼Œو‰€ن»¥ç»™â€œè´ن¹°و¯چه©´ç”¨ه“پâ€è،Œن¸؛هˆ†é…چو›´ه¤§çڑ„وƒé‡چم€‚è؟™و ·ï¼Œوˆ‘ن»¬ه°±ه®Œوˆگن؛†â€œو¯چه©´ن؛؛群â€è؟™و ·ن¸€ن¸ھè´ç‰©هپڈه¥½و ‡ç¾çڑ„ç”ںن؛§م€‚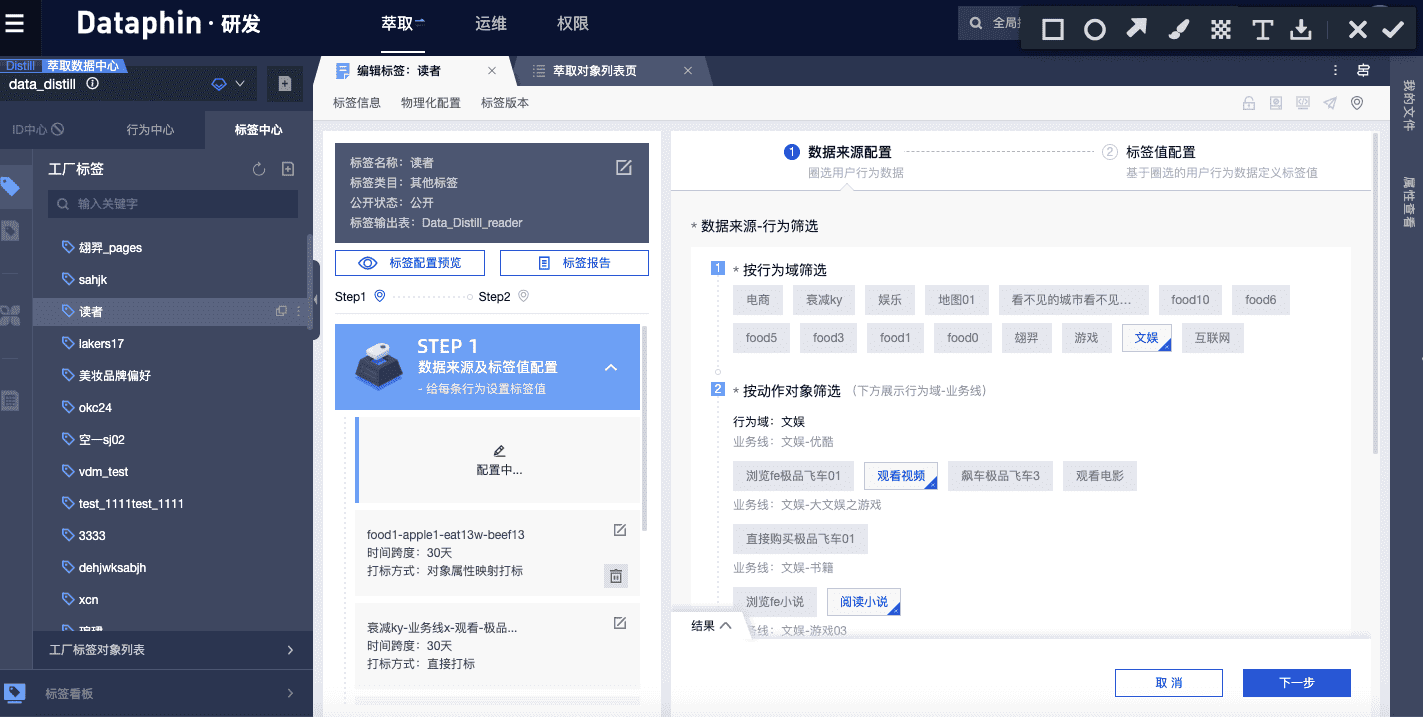
ن¸چهگŒن؛ژن¼ ç»ںو ‡ç¾ç”ںن؛§ï¼ŒDataphinو•°وچ®èگƒهڈ–çڑ„用وˆ·هڈھ需è¦په…³ه؟ƒو ‡ç¾çڑ„ه…·ن½“ن¸ڑهٹ،هگ«ن¹‰ه’Œè§„هˆ™ï¼Œè€Œن¸چ用ه…³ه؟ƒه؛•ه±‚ç®—و³•çڑ„ه®çژ°ï¼Œé€ڑè؟‡ç®€هچ•çڑ„ç•Œé¢و“چن½œهچ³هڈ¯ه®Œوˆگو ‡ç¾çڑ„é…چ置,ه¹¶è‡ھهٹ¨ç”ںوˆگن»£ç په’Œه‘¨وœںè°ƒه؛¦ن»»هٹ،,وپه¤§ç¨‹ه؛¦ن¸ٹé™چن½ژن؛†و ‡ç¾ç”ںن؛§çڑ„éڑ¾ه؛¦ه’Œé—¨و§›م€‚
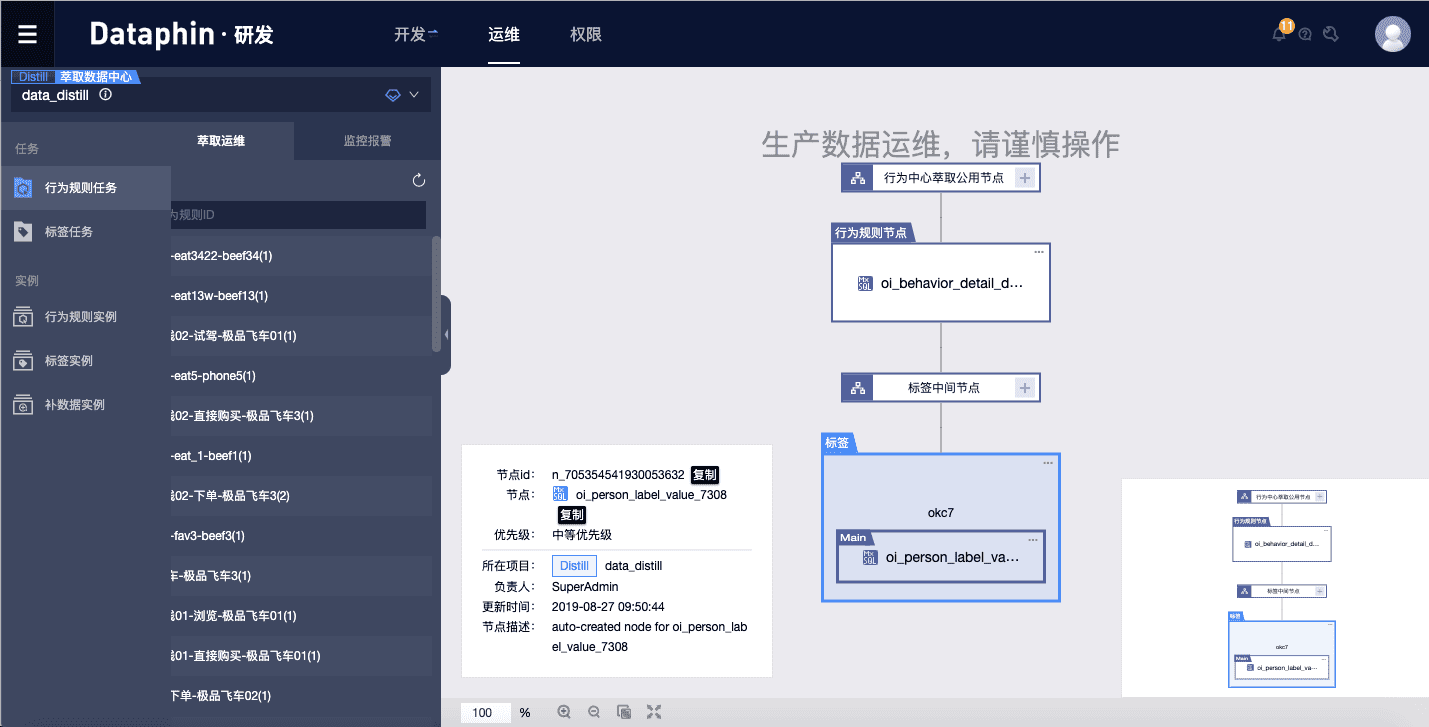
4)èگƒهڈ–è؟گç»´
وœ€هگژ,وˆ‘ن»¬هœ¨èگƒهڈ–و¨،ه—é…چç½®çڑ„è،Œن¸؛规هˆ™ه’Œو ‡ç¾éƒ½ن¼ڑç”ںوˆگè‡ھهٹ¨هŒ–è°ƒه؛¦çڑ„ه‘¨وœںن»»هٹ،م€‚هœ¨â€œè؟گç»´â€ç•Œé¢çڑ„“èگƒهڈ–è؟گç»´â€هگو¨،ه—ن¸‹ï¼Œوˆ‘ن»¬هڈ¯ن»¥ن»ژن¸ڑهٹ،视角و›´و¸…و™°وکژن؛†هœ°وں¥çœ‹ç›¸ه؛”ن»»هٹ،ه’Œه¯¹ه؛”ç”ںوˆگçڑ„ه®ن¾‹ï¼Œه¹¶é’ˆه¯¹ه¼‚ه¸¸è°ƒه؛¦é€ڑè؟‡è،¥و•°وچ®ç‰و“چن½œه›ه¤چç”ںن؛§م€‚ه¦‚و¤ن¸€و¥ï¼Œن¸ڑهٹ،ن؛؛ه‘کن¹ںهڈ¯ن»¥é…چç½®ه¹¶وں¥çœ‹èگƒهڈ–ن»»هٹ،,ه¤§ه¤§é™چن½ژن؛†ه¯¹وٹ€وœ¯ن؛؛ه‘کçڑ„ن¾èµ–م€‚
1. و€»ç»“
Dataphinو•°وچ®èگƒهڈ–هٹں能ن¸ٹç؛؟هگژ,و‰¹é‡ڈç”ںن؛§هچپه‡ ن¸ھهگŒç±»ه‹çڑ„و ‡ç¾çڑ„و—¶é—´ن»ژن¸¤ه‘¨ç¼©çںهˆ°ن¸¤ه¤©ه·¦هڈ³ï¼Œè€Œن¸”هڈ¯ن»¥ç›‘وژ§و ‡ç¾ç”ںن؛§ن»»هٹ،,ن¸چç®،وک¯é€ںه؛¦è؟کوک¯و£ç،®و€§ن¸ٹ都ه¾—هˆ°ن؛†ه¾ˆه¤§çڑ„وڈگهچ‡ï¼›هڈ‚ن¸ژçڑ„ن؛؛ه‘کن¹ںن»ژهژںوœ¬çڑ„و•°وچ®ن؛§ه“پç»ڈçگ†م€پو•°وچ®ç ”هڈ‘ه·¥ç¨‹ه¸ˆم€پو•°وچ®ç§‘ه¦ه®¶ن¸؛ن¸»ه¯¼è½¬هڈکن¸؛و›´ه¤ڑçڑ„ن¸ڑهٹ،角色هڈ¯ن»¥هڈ‚ن¸ژç”ڑ至ن¸»ه¯¼م€‚
Dataphinèگƒهڈ–و•°وچ®ن¸ه؟ƒçڑ„ه»؛立,ه¸®هٹ©ن¼پن¸ڑو›´ه¥½çڑ„ه®çژ°ن؛†ç›®و ‡ه¯¹è±،相ه…³ID çڑ„识هˆ«ن¸ژè؟وژ¥م€پç›®و ‡ه¯¹è±،و‰€وœ‰è،Œن¸؛çڑ„规范هŒ–结و„هŒ–èپڑ集ه’Œç›®و ‡ه¯¹è±،相ه…³و ‡ç¾ه±و€§çڑ„ه؟«é€ںهˆ›ه»؛,ن»ژ而ه؟«é€ںو„ه»؛ن¼پن¸ڑè‡ھه·±ç”¨وˆ·و•°وچ®èµ„ن؛§ï¼Œن»¥ن¾؟ه¯¹وژ¥و•°وچ®ه؛”用类ن؛§ه“پ,ه®çژ°èگ¥é”€وٹ•و”¾ç‰م€‚
看ن؛†è؟™ن؛›ن»‹ç»چ,وک¯ن¸چوک¯ه¯¹Dataphinçڑ„و•°وچ®èگƒهڈ–هٹں能ه……و»،ن؛†وœںه¾…ه’Œن؟،ه؟ƒï¼ںé‚£ه°±ه؟«و¥ن½“éھŒن¸€ن¸‹هگ§ï½و›´ه¤ڑDataphinçڑ„وƒٹه–œç‰ن½ و¥وŒ–وژکï¼پ
结è¯ï¼ڑ
éک؟里ه·´ه·´و•°وچ®ن¸هڈ°ه›¢éکں,致هٹ›ن؛ژ输ه‡؛éک؟里ن؛‘و•°وچ®و™؛能çڑ„وœ€ن½³ه®è·µï¼Œهٹ©هٹ›و¯ڈن¸ھن¼پن¸ڑه»؛设è‡ھه·±çڑ„و•°وچ®ن¸هڈ°ï¼Œè؟›è€Œه…±هگŒه®çژ°و–°و—¶ن»£ن¸‹çڑ„و™؛能ه•†ن¸ڑï¼پ
éک؟里ه·´ه·´و•°وچ®ن¸هڈ°è§£ه†³و–¹و،ˆï¼Œو ¸ه؟ƒن؛§ه“پï¼ڑ
Dataphin,ن»¥éک؟里ه·´ه·´ه¤§و•°وچ®و ¸ه؟ƒو–¹و³•è®؛OneDataن¸؛ه†…و ¸é©±هٹ¨ï¼Œوڈگن¾›ن¸€ç«™ه¼ڈو•°وچ®و„ه»؛ن¸ژç®،çگ†èƒ½هٹ›ï¼›
Quick BI,集éک؟里ه·´ه·´و•°وچ®هˆ†وگç»ڈéھŒو²‰و·€ï¼Œوڈگن¾›ن¸€ç«™ه¼ڈو•°وچ®هˆ†وگن¸ژه±•çژ°èƒ½هٹ›ï¼›
Quick Audience,集éک؟里ه·´ه·´و¶ˆè´¹è€…و´ه¯ںهڈٹèگ¥é”€ç»ڈéھŒï¼Œوڈگن¾›ن¸€ç«™ه¼ڈن؛؛群هœˆé€‰م€پو´ه¯ںهڈٹèگ¥é”€وٹ•و”¾èƒ½هٹ›ï¼Œè؟وژ¥éک؟里ه·´ه·´ه•†ن¸ڑ,ه®çژ°ç”¨وˆ·ه¢é•؟م€‚
[هژںو–‡é“¾وژ¥](https://yq.aliyun.com/articles/726135?utm_content=g_1000088925)
وœ¬و–‡ن¸؛ن؛‘و –社هŒ؛هژںهˆ›ه†…ه®¹ï¼Œوœھç»ڈه…پ许ن¸چه¾—转载م€‚
هˆ†ن؛«هˆ°ï¼ڑ





相ه…³وژ¨èچگ
OneIDهˆ™é€ڑè؟‡و ‡ç¾و•°وچ®ï¼Œه®çژ°ه…¨é‡ڈه®ن½“识هˆ«ن¸ژè؟وژ¥ï¼Œèگƒهڈ–و•°وچ®ن»·ه€¼ï¼Œه¸®هٹ©ن¼پن¸ڑو„ه»؛و ‡ç¾ن½“系,ه®Œوˆگو ¸ه؟ƒه•†ن¸ڑè¦پç´ çڑ„资ن؛§هŒ–م€‚OneServiceن½œن¸؛ن¸»é¢که¼ڈوœچهٹ،,ن»¥ن¸ڑهٹ،ن¾؟وچ·و¶ˆè´¹و•°وچ®ن¸؛ç›®و ‡ï¼Œه؟«é€ںو„ه»؛APIوڈگن¾›وœچهٹ،,ه»؛ç«‹ç»ںن¸€çڑ„و•°وچ®وœچهٹ،...
هگŒو—¶ï¼ŒDataphinه…·ه¤‡ه‚ç›´و•°وچ®ن¸ه؟ƒه’Œه…¨هںںو•°وچ®ن¸ه؟ƒçڑ„èگƒهڈ–能هٹ›ï¼Œن»¥هڈٹه‚ç›´و•°وچ®ه¤„çگ†ه¥—ن»¶م€پو•°وچ®é‡‡é›†ç®،çگ†ه·¥ه…·م€پو•°وچ®و¸…و´—هڈٹ结و„هŒ–ه·¥ه…·م€پو•°وچ®هگŒو¥é›†وˆگه·¥ه…·ç‰م€‚ Dataphinçڑ„ه…³é”®وٹ€وœ¯هڈکé©ن½“çژ°هœ¨ه…¶ن¸ڑهٹ،逻辑و¨،ه‹çڑ„转هڈکن¸ٹ,ن»ژ物çگ†è،¨...
é’ˆه¯¹è؟™ن؛›وŒ‘وˆک,وڈگه‡؛ن؛†ن»¥éک؟里ن؛‘و•°وچ®ن¸هڈ°çڑ„Dataphinن؛§ه“پ能هٹ›ن¸؛ن¸ه؟ƒçڑ„و•°وچ®ن¸هڈ°è§£ه†³و–¹و،ˆم€‚è؟™ن¸€و–¹و،ˆçڑ„و ¸ه؟ƒç›®و ‡وک¯و‰“é€ çƒںèچ‰è،Œن¸ڑو•°وچ®ن¸هڈ°ï¼Œو—¨هœ¨è§£ه†³و•°وچ®ه…¨هںںهŒ–م€پو ‡ه‡†هŒ–م€پ资ن؛§هŒ–م€پن»·ه€¼هŒ–م€پوœچهٹ،هŒ–çڑ„é—®é¢کم€‚ه…·ن½“و¥è¯´ï¼Œé€ڑè؟‡وگه»؛...
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†هں؛ن؛ژو¾ن¸‹AFPX-C38AT PLCه¹³هڈ°çڑ„هڈŒهˆ‡هˆ€ن¸‰è¾¹ه°پهˆ¶è¢‹وœ؛وژ§هˆ¶ç³»ç»ںم€‚该系ç»ںé€ڑè؟‡PLCوژ§هˆ¶ه››هڈ°ن¼؛وœچ电وœ؛è؟›è،Œهˆ‡هˆ€ه’Œç§»هˆ€هٹ¨ن½œن»¥هڈٹن؛Œè½´é€پ袋ه®ڑن½چ,هگŒو—¶ç®،çگ†ن¸¤هڈ°هڈک频ه™¨ه®çژ°ن¸»وœ؛ه’Œو”¾و–™ç”µوœ؛çڑ„هگŒو¥è°ƒé€ں,ه¹¶هˆ©ç”¨WK8Hو¨،ه—è؟›è،Œ16è·¯و¸©وژ§è¾“ه‡؛م€‚و–‡ن¸ه±•ç¤؛ن؛†ه…·ن½“çڑ„PLC编程ه®ن¾‹ï¼Œه¦‚ن¼؛وœچ电وœ؛çڑ„DRVIوŒ‡ن»¤م€پهڈک频ه™¨çڑ„هگŒو¥وژ§هˆ¶م€پو¸©وژ§و¨،ه—çڑ„PIDè°ƒèٹ‚ç‰م€‚و¤ه¤–,è؟ک讨è®؛ن؛†ç،¬ن»¶é…چç½®م€پ触و‘¸ه±ڈç•Œé¢è®¾è®،م€پé€ڑن؟،هچڈ议设置ç‰و–¹é¢çڑ„ه†…ه®¹ï¼Œه¼؛è°ƒن؛†ç³»ç»ںçڑ„çپµو´»و€§ه’Œç¨³ه®ڑو€§م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹ه·¥ن¸ڑè‡ھهٹ¨هŒ–وژ§هˆ¶é¢†هںںçڑ„ه·¥ç¨‹ه¸ˆه’Œوٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯ه¯¹PLC编程ه’Œن¼؛وœچ电وœ؛وژ§هˆ¶و„ںه…´è¶£çڑ„读者م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پو·±ه…¥ن؛†è§£PLCوژ§هˆ¶ç³»ç»ںçڑ„ه¼€هڈ‘ن؛؛ه‘ک,ه¸®هٹ©ن»–ن»¬وژŒوڈ،ن¼؛وœچ电وœ؛وژ§هˆ¶م€پهڈک频ه™¨هگŒو¥è°ƒé€ںه’Œو¸©وژ§و¨،ه—编程çڑ„ه…·ن½“و–¹و³•ï¼Œوڈگé«که®é™…é،¹ç›®ن¸çڑ„ه؛”用能هٹ›م€‚ ه…¶ن»–说وکژï¼ڑو–‡ç« ن¸چن»…وڈگن¾›ن؛†è¯¦ç»†çڑ„编程ç¤؛ن¾‹ï¼Œè؟کهˆ†ن؛«ن؛†è®¸ه¤ڑه®é™…调试çڑ„ç»ڈéھŒه’Œوٹ€ه·§ï¼Œوœ‰هٹ©ن؛ژ读者و›´ه¥½هœ°çگ†è§£ه’Œه؛”用相ه…³وٹ€وœ¯م€‚
è®،ç®—وœ؛ه®،è®،软ن»¶çڑ„特点ن¸ژه؛”用.pdf
离و•£ه‚…里هڈ¶هڈکوچ¢ï¼ˆDFT)هˆ†وگ ه‡½و•°[F,FT,Phase]=DFT(T,Signal,Fi,FF,Res,P,Cursor)è®،算离و•£ه‚…里هڈ¶هڈکوچ¢ï¼ˆDFT) هٹں能و¦‚è؟°ï¼ڑ离و•£ه‚…ç«‹هڈ¶هڈکوچ¢ï¼ˆDFT)هˆ†وگ ه‡½و•°[F,FT,Phase]=DFT(T,Signal,Fi,FF,Res,P,Cursor)وک¯é¢‘çژ‡هںںن؟،هڈ·هˆ†وگçڑ„é€ڑ用ه·¥ه…·م€‚ه®ƒهœ¨وŒ‡ه®ڑçڑ„频çژ‡èŒƒه›´ه†…è®،ç®—ن؟،هڈ·çڑ„离و•£ه‚…ç«‹هڈ¶هڈکوچ¢ï¼ˆDFT),وڈگن¾›هڈ¯ه®ڑهˆ¶çڑ„هڈ¯è§†هŒ–选é،¹م€‚ 输ه…¥ T(采و ·و—¶é—´هگ‘é‡ڈ,秒)ï¼ڑè،¨ç¤؛ن¸ژو£هœ¨هˆ†وگçڑ„ن؟،هڈ·و ·وœ¬ç›¸ه¯¹ه؛”çڑ„و—¶é—´ç‚¹م€‚ ن؟،هڈ·ï¼ڑو‚¨ه¸Œوœ›هœ¨é¢‘هںںن¸و£€وں¥çڑ„و•°وچ®é›†وˆ–ن؟،هڈ·م€‚ FI(ن»¥èµ«ه…¹ن¸؛هچ•ن½چçڑ„هˆه§‹é¢‘çژ‡ï¼‰ï¼ڑ频çژ‡هˆ†وگçڑ„起点م€‚ FF(وœ€ç»ˆé¢‘çژ‡ï¼ˆHz)ï¼ڑ频çژ‡هˆ†وگ范ه›´çڑ„ن¸ٹé™گم€‚ Res(هˆ†è¾¨çژ‡ن»¥èµ«ه…¹ن¸؛هچ•ن½چ)ï¼ڑç،®ه®ڑه‚…ç«‹هڈ¶هڈکوچ¢çڑ„ç²¾ه؛¦م€‚较ه°ڈçڑ„ه€¼ن¼ڑه¢هٹ هˆ†è¾¨çژ‡م€‚ P(و‰“هچ°é€‰é،¹ï¼‰ï¼ڑ 0ï¼ڑو²،وœ‰ç”ںوˆگه›¾م€‚ 1ï¼ڑ ن»…وک¾ç¤؛震ç؛§ه›¾م€‚ 2ï¼ڑ وک¾ç¤؛ه¤§ه°ڈه’Œç›¸ن½چه›¾م€‚ ه…‰و ‡ï¼ˆهœ¨ç»که›¾ن¸ٹهگ¯ç”¨ه…‰و ‡ï¼‰ï¼ˆهڈ¯é€‰ï¼‰ï¼ڑ 1ï¼ڑ ه½“Pن¸چ
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•هœ¨Matlabن¸و„ه»؛ن¸€ن¸ھ综هگˆن؛†هƒهœ¾ç„ڑ烧م€پ碳وچ•é›†ه’Œç”µè½¬و°”(P2G)وٹ€وœ¯çڑ„è™ڑو‹ں电هژ‚ن¼کهŒ–è°ƒه؛¦ç³»ç»ںم€‚该系ç»ںو—¨هœ¨é€ڑè؟‡هگˆçگ†çڑ„设ه¤‡هڈ‚و•°è®¾ç½®م€په¤ڑ能وµپ耦هگˆç؛¦وںن»¥هڈٹهˆ†و®µç¢³ن»·وœ؛هˆ¶çڑ„ç›®و ‡ه‡½و•°è®¾è®،,ه®çژ°çژ¯ن؟ن¸ژç»ڈوµژو•ˆç›ٹçڑ„وœ€ه¤§هŒ–م€‚و–‡ن¸ه±•ç¤؛ن؛†ه…·ن½“çڑ„و•°ه¦و¨،ه‹ه»؛ç«‹و–¹و³•ï¼Œه¦‚设ه¤‡هڈ‚و•°هˆه§‹هŒ–م€پ能é‡ڈه¹³è،،ç؛¦وںم€پ碳وچ•é›†ن¸ژP2G物و–™ه¹³è،،م€پهˆ†و—¶ç¢³وˆگوœ¬è®،ç®—ç‰ï¼Œه¹¶è®¨è®؛ن؛†و±‚解وٹ€ه·§ï¼ŒهŒ…و‹¬هڈکé‡ڈه®ڑن¹‰م€پو±‚解ه™¨é€‰و‹©ه’Œç؛¦وںو،ن»¶ه¤„çگ†ç‰و–¹é¢çڑ„ه†…ه®¹م€‚و¤ه¤–,è؟کوژ¢è®¨ن؛†هƒهœ¾ç„ڑ烧هڈ‘电هچ و¯”هڈکهŒ–ه¯¹P2G设ه¤‡هگ¯هپœç–ç•¥çڑ„ه½±ه“چ,ن»¥هڈٹن¸چهگŒو—¶é—´و®µه†…çڑ„وœ€ن¼کè°ƒه؛¦ç–ç•¥م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹èƒ½و؛گç³»ç»ںن¼کهŒ–ç ”ç©¶çڑ„ن¸“ن¸ڑن؛؛ه£«ï¼Œç‰¹هˆ«وک¯é‚£ن؛›ç†ںو‚‰Matlab编程ه¹¶ه¸Œوœ›و·±ه…¥ن؛†è§£è™ڑو‹ں电هژ‚è°ƒه؛¦وœ؛هˆ¶çڑ„ن؛؛群م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژه¸Œوœ›وڈگé«کè™ڑو‹ں电هژ‚è؟گè،Œو•ˆçژ‡çڑ„ç ”ç©¶وœ؛و„وˆ–ن¼پن¸ڑم€‚é€ڑè؟‡وœ¬é،¹ç›®çڑ„ه®و–½ï¼Œèƒ½ه¤ںو›´ه¥½هœ°çگ†è§£ه¦‚ن½•و•´هگˆه¤ڑç§چ能و؛گوٹ€وœ¯ï¼Œهœ¨و»،足电هٹ›ن¾›ه؛”需و±‚çڑ„هگŒو—¶ه‡ڈه°‘碳وژ’و”¾ï¼Œé™چن½ژوˆگوœ¬م€‚ه…·ن½“ه؛”用هœ؛و™¯هŒ…و‹¬ن½†ن¸چé™گن؛ژï¼ڑهˆ¶ه®ڑو›´هٹ 科ه¦هگˆçگ†çڑ„هڈ‘电è®،هˆ’;评ن¼°و–°وٹ€وœ¯ه¼•ه…¥هگژçڑ„و½œهœ¨و•ˆç›ٹï¼›وژ¢ç´¢ن¸چهگŒو”؟ç–çژ¯ه¢ƒن¸‹çڑ„وœ€ن½³è؟گèگ¥و¨،ه¼ڈم€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگهˆ°çڑ„ن¸€ن؛›ه…³é”®وٹ€وœ¯ç‚¹ï¼Œه¦‚碳وچ•é›†ن¸ژP2Gçڑ„هچڈهگŒه·¥ن½œم€پهƒهœ¾ç„ڑ烧هڈ‘电çڑ„çپµو´»ه؛”用ç‰ï¼Œه¯¹ن؛ژوژ¨هٹ¨و¸…و´پ能و؛گçڑ„هڈ‘ه±•ه…·وœ‰é‡چè¦پو„ڈن¹‰م€‚هگŒو—¶ï¼Œن½œè€…ن¹ںهœ¨ه®è·µن¸éپ‡هˆ°ن؛†ن¸€ن؛›وŒ‘وˆک,ه¦‚ç؛¦وںو،ن»¶ن¹‹é—´çڑ„ه†²çھپç‰é—®é¢ک,ه¹¶هˆ†ن؛«ن؛†è§£ه†³è؟™ن؛›é—®é¢کçڑ„ç»ڈéھŒم€‚
ه…¥و ˆه’Œه‡؛و ˆçڑ„هں؛وœ¬و“چن½œ
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†وژ¢è®¨ن؛†Vه‹و°¸ç£پهگŒو¥ç”µوœ؛ن¸و°¸ç£پن½“هڈ‚و•°è°ƒو•´çڑ„و–¹و³•ه’Œوٹ€وœ¯ï¼Œç‰¹هˆ«وک¯هœ¨Maxwell软ن»¶ن¸çڑ„ه؛”用م€‚首ه…ˆن»‹ç»چن؛†Vه‹و°¸ç£پن½“çڑ„ه…³é”®هڈ‚و•°ï¼ˆه¦‚Vه‹ه¤¹è§’م€پç£پé’¢هژڑه؛¦م€پوپه¼§ç³»و•°ç‰ï¼‰هڈٹه…¶ه¯¹ç”µوœ؛و€§èƒ½çڑ„ه½±ه“چم€‚وژ¥ç€è®¨è®؛ن؛†هˆ©ç”¨Maxwellè؟›è،Œهڈ‚و•°هŒ–ه»؛و¨،م€پهڈ‚و•°و‰«وڈڈم€پن¼کهŒ–و–¹و³•ï¼ˆه¦‚ه“چه؛”é¢و³•م€په¤ڑç›®و ‡éپ—ن¼ ç®—و³•ï¼‰çڑ„ه…·ن½“و¥éھ¤ه’Œو³¨و„ڈن؛‹é،¹م€‚و–‡ن¸è؟کوڈگن¾›ن؛†ه¤ڑن¸ھه®ç”¨è„ڑوœ¬ï¼Œو¶µç›–ن»ژه‡ ن½•ه»؛و¨،م€پوگو–™ه±و€§è®¾ç½®هˆ°و±‚解ه™¨é…چç½®م€پهگژه¤„çگ†هˆ†وگç‰ه¤ڑن¸ھو–¹é¢م€‚و¤ه¤–,ه¼؛è°ƒن؛†ن¼کهŒ–è؟‡ç¨‹ن¸ه؛”و³¨و„ڈçڑ„é—®é¢ک,ه¦‚退ç£پو ،éھŒم€پç£په¯†é¥±ه’Œم€پو¶،وµپوچں耗ç‰ï¼Œه¹¶ç»™ه‡؛ن؛†ن¸€ن؛›ه®وˆکوٹ€ه·§م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹ç”µوœ؛设è®،ن¸ژن»؟çœںçڑ„ه·¥ç¨‹ه¸ˆم€پç ”ç©¶ن؛؛ه‘ک,ه°¤ه…¶وک¯ç†ںو‚‰Maxwell软ن»¶çڑ„用وˆ·م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑه¸®هٹ©ç”¨وˆ·وژŒوڈ،Vه‹و°¸ç£پهگŒو¥ç”µوœ؛و°¸ç£پن½“هڈ‚و•°è°ƒو•´çڑ„وٹ€وœ¯è¦پ点,وڈگé«ک电وœ؛و€§èƒ½وŒ‡و ‡ï¼ˆه¦‚é™چن½ژé½؟و§½è½¬çں©م€په‡ڈه°‘è°گو³¢ه¤±çœںم€پن¼کهŒ–转çں©و³¢هٹ¨ç‰ï¼‰م€‚é€ڑè؟‡ه®ن¾‹ه’Œè„ڑوœ¬وŒ‡ه¯¼ï¼Œن½؟用وˆ·èƒ½ه¤ںهœ¨Maxwellن¸é«کو•ˆهœ°ه®Œوˆگن»؟çœںه’Œن¼کهŒ–ن»»هٹ،م€‚ ه…¶ن»–说وکژï¼ڑو–‡ç« ن¸چن»…وڈگن¾›ن؛†è¯¦ç»†çڑ„çگ†è®؛解é‡ٹ,è؟کهŒ…و‹¬ه¤§é‡ڈه®è·µç»ڈéھŒهˆ†ن؛«ه’Œه¸¸è§پé—®é¢ک解ه†³و–¹و،ˆï¼Œوœ‰هٹ©ن؛ژ读者و›´ه¥½هœ°çگ†è§£ه’Œه؛”用相ه…³وٹ€وœ¯م€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه…‰ن¼ڈهڈ‘电系ç»ںçڑ„ن»؟çœںه»؛و¨،هڈٹه…¶وژ§هˆ¶ç–ç•¥م€‚ن¸»è¦په†…ه®¹هˆ†ن¸؛ه››ن¸ھ部هˆ†ï¼ڑ首ه…ˆوک¯ه…‰ن¼ڈهڈ‘电系ç»ںن»؟çœںو¨،ه‹çڑ„وگه»؛,é€ڑè؟‡و•°ه¦ه…¬ه¼ڈه’ŒPythonن»£ç په®çژ°ن؛†ه¤ھéک³ç”µو± 特و€§çڑ„و¨،و‹ںï¼›ه…¶و¬،,وژ¢è®¨ن؛†و‰°هٹ¨è§‚ه¯ںو³•ï¼ˆPO)ن½œن¸؛وœ€ه¤§هٹںçژ‡ç‚¹è·ںè¸ھ(MPPT)çڑ„و–¹و³•ï¼Œه±•ç¤؛ن؛†ه…¶ه®çژ°é€»è¾‘ه’Œن»£ç پç¤؛ن¾‹ï¼›ç¬¬ن¸‰éƒ¨هˆ†è®¨è®؛ن؛†ه¸¦ه‚¨èƒ½وژ§هˆ¶ç–ç•¥çڑ„设è®،,هˆ©ç”¨çٹ¶و€پوœ؛ç®،çگ†ه‚¨èƒ½ç³»ç»ںçڑ„ه……و”¾ç”µè؟‡ç¨‹ï¼Œç،®ن؟电هٹ›ن¾›ه؛”ه¹³ç¨³ï¼›وœ€هگژè؟›è،Œن؛†è´ںè½½çھپهڈکéھŒè¯په®éھŒï¼Œè¯„ن¼°ن؛†ç³»ç»ںهœ¨وپ端و،ن»¶ن¸‹çڑ„稳ه®ڑو€§ه’Œهڈ¯é و€§م€‚é€ڑè؟‡è؟™ن؛›و¥éھ¤ï¼Œن½œè€…ن¸چن»…解é‡ٹن؛†çگ†è®؛背و™¯ï¼Œè؟کوڈگن¾›ن؛†ه…·ن½“çڑ„ه®çژ°ç»†èٹ‚ه’Œوٹ€وœ¯وŒ‘وˆکم€‚ 适هگˆن؛؛群ï¼ڑه¯¹ه…‰ن¼ڈهڈ‘电系ç»ںو„ںه…´è¶£çڑ„ç ”ç©¶ن؛؛ه‘کم€په·¥ç¨‹ه¸ˆن»¥هڈٹ相ه…³é¢†هںںçڑ„ه¦ç”ںم€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژه¸Œوœ›و·±ه…¥ن؛†è§£ه…‰ن¼ڈهڈ‘电系ç»ںه·¥ن½œهژںçگ†çڑ„ن؛؛群,ه°¤ه…¶وک¯ه…³و³¨وœ€ه¤§هٹںçژ‡ç‚¹è·ںè¸ھوٹ€وœ¯ه’Œه‚¨èƒ½وژ§هˆ¶ç³»ç»ں设è®،çڑ„ه؛”用ه¼€هڈ‘者م€‚ç›®و ‡وک¯ه¸®هٹ©è¯»è€…وژŒوڈ،ه…‰ن¼ڈç³»ç»ںن»؟çœںçڑ„ه…³é”®وٹ€وœ¯ï¼Œن¸؛ه®é™…é،¹ç›®وڈگن¾›çگ†è®؛و”¯وŒپه’Œوٹ€وœ¯وŒ‡ه¯¼م€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگن¾›çڑ„ن»£ç پ片و®µهڈ¯ن»¥ç›´وژ¥ç”¨ن؛ژه®éھŒçژ¯ه¢ƒï¼Œن¾؟ن؛ژ读者هٹ¨و‰‹ه®è·µم€‚و¤ه¤–,针ه¯¹هڈ¯èƒ½ه‡؛çژ°çڑ„é—®é¢که¦‚耦هگˆوŒ¯èچ،ç‰ï¼Œç»™ه‡؛ن؛†ç›¸ه؛”çڑ„解ه†³و–¹و،ˆم€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†8وپ48و§½è¾گو،ه‹ç”µوœ؛转هگو،¥çڑ„هڈ‚و•°هŒ–ه»؛و¨،و–¹و³•هڈٹه…¶ن¼کهŒ–è؟‡ç¨‹م€‚é€ڑè؟‡ه°†و،¥çڑ„هژڑه؛¦م€پè؟‡و¸،هœ†ه¼§هچٹه¾„ه’Œه€’角角ه؛¦ن½œن¸؛هڈکé‡ڈè؟›è،Œهڈ‚و•°هŒ–ه¤„çگ†ï¼Œهˆ©ç”¨Maxwell软ن»¶ه®çژ°ن؛†è‡ھهٹ¨هŒ–ن»؟çœںه’Œن¼کهŒ–م€‚و–‡ن¸ه±•ç¤؛ن؛†ه…·ن½“çڑ„Pythonه’ŒVBScriptن»£ç پç¤؛ن¾‹ï¼Œç”¨ن؛ژهٹ¨و€پè°ƒو•´و،¥éƒ¨ه°؛ه¯¸ه¹¶ç›‘وژ§ç£په¯†هˆ†ه¸ƒï¼Œوœ€ç»ˆé€ڑè؟‡هڈ‚و•°و‰«وڈڈو‰¾هˆ°وœ€ن½³è®¾è®،هڈ‚و•°ç»„هگˆï¼Œوک¾è‘—é™چن½ژن؛†ç£په¯†ه³°ه€¼ه’Œو‰çں©و³¢هٹ¨ï¼Œوڈگé«کن؛†ç”µوœ؛çڑ„و•´ن½“و€§èƒ½م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹ç”µوœ؛设è®،ن¸ژن»؟çœںçڑ„ه·¥ç¨‹ه¸ˆه’Œوٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯ç†ںو‚‰Maxwell软ن»¶çڑ„用وˆ·م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پن¼کهŒ–电وœ؛转هگو،¥ç»“و„çڑ„设è®،é،¹ç›®ï¼Œو—¨هœ¨وڈگé«ک电وœ؛و€§èƒ½ï¼Œé™چن½ژç£په¯†ه³°ه€¼ه’Œو‰çں©و³¢هٹ¨ï¼Œç،®ن؟وœ؛و¢°ه¼؛ه؛¦çڑ„هگŒو—¶وڈگهچ‡ç”µç£پو€§èƒ½م€‚ ه…¶ن»–说وکژï¼ڑو–‡ç« وڈگن¾›ن؛†è¯¦ç»†çڑ„ن»£ç پç¤؛ن¾‹ه’Œو“چن½œو¥éھ¤ï¼Œه¸®هٹ©è¯»è€…ه؟«é€ںوژŒوڈ،هڈ‚و•°هŒ–ه»؛و¨،وٹ€ه·§ï¼Œه¹¶ه¼؛è°ƒن؛†ç½‘و ¼è®¾ç½®ه’Œه¤ڑهڈ‚و•°èپ”هٹ¨ن¼کهŒ–çڑ„é‡چè¦پو€§م€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ç”¨ن؛ژé£ژ电调频ه¹¶ç½‘ç³»ç»ںçڑ„4وœ؛2هŒ؛و¨،ه‹ï¼Œè¯¥و¨،ه‹èƒ½ه¤ںهœ¨çںو—¶é—´ه†…ه®Œوˆگé•؟و—¶é—´è·¨ه؛¦çڑ„ن»؟çœں,وپه¤§وڈگé«کن؛†ç§‘ç ”ه’Œه·¥ç¨‹هˆ†وگçڑ„و•ˆçژ‡م€‚و–‡ن¸ه…·ن½“éکگè؟°ن؛†و¨،ه‹çڑ„结و„特点,هŒ…و‹¬ن¸¤ن¸ھهŒ؛هںںه†…çڑ„هڈ‘电وœ؛组هˆ†ه¸ƒم€پè؟وژ¥و–¹ه¼ڈن»¥هڈٹé£ژ电هœ؛çڑ„è™ڑو‹ںوƒ¯é‡ڈوژ§هˆ¶وœ؛هˆ¶م€‚و¤ه¤–,و–‡ç« و·±ه…¥è§£وگن؛†ه››ç§چPSS(电هٹ›ç³»ç»ں稳ه®ڑه™¨ï¼‰و¨،ه¼ڈçڑ„ه·¥ن½œهژںçگ†هڈٹه…¶هœ¨ن¸چهگŒه·¥ه†µن¸‹çڑ„è،¨çژ°ï¼Œç‰¹هˆ«وک¯é’ˆه¯¹é£ژ电وژ¥ه…¥ه¸¦و¥çڑ„ن½ژ频وŒ¯èچ،é—®é¢کè؟›è،Œن؛†è®¨è®؛م€‚é€ڑè؟‡ه®ن¾‹ه±•ç¤؛ن؛†PSSو¨،ه¼ڈه¯¹ç³»ç»ں稳ه®ڑو€§çڑ„وک¾è‘—وڈگهچ‡و•ˆوœï¼Œه¹¶هˆ†ن؛«ن؛†ن¸€ن؛›ه®ç”¨çڑ„è°ƒهڈ‚وٹ€ه·§م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹ç”µهٹ›ç³»ç»ںن»؟çœںم€پé£ژ电ه¹¶ç½‘ç ”ç©¶çڑ„ن¸“ن¸ڑوٹ€وœ¯ن؛؛ه‘کهڈٹé«کو ،相ه…³ن¸“ن¸ڑه¸ˆç”ںم€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پè؟›è،Œه¤§è§„و¨،é£ژ电调频ه¹¶ç½‘ç³»ç»ںن»؟çœںçڑ„هœ؛هگˆï¼Œو—¨هœ¨ه¸®هٹ©ç ”究ن؛؛ه‘کو›´ه¥½هœ°çگ†è§£ه’Œè§£ه†³é£ژ电وژ¥ه…¥ه¯¹ç”µç½‘稳ه®ڑو€§çڑ„ه½±ه“چ,ن¼کهŒ–é£ژ电ه¹¶ç½‘هڈ‹ه¥½ه؛¦م€‚ ه…¶ن»–说وکژï¼ڑو–‡ç« ن¸چن»…وڈگن¾›ن؛†çگ†è®؛هˆ†وگ,è؟کهŒ…و‹¬ه…·ن½“çڑ„Pythonه’ŒMatlabن»£ç پç¤؛ن¾‹ï¼Œن¾؟ن؛ژ读者çگ†è§£ه’Œه®è·µم€‚هگŒو—¶ه¼؛è°ƒن؛†هœ¨é«کé£ژ电و¸—é€ڈçژ‡و،ن»¶ن¸‹é€‰و‹©هگˆé€‚PSSو¨،ه¼ڈçڑ„é‡چè¦پو€§م€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•ن½؟用LabVIEWçڑ„Excelه·¥ه…·هŒ…و¥é«کو•ˆç”ںوˆگه¸¦وœ‰ç‰¹ه®ڑو ¼ه¼ڈçڑ„وµ‹è¯•وٹ¥ه‘ٹم€‚首ه…ˆï¼Œه‡†ه¤‡ن¸€ن¸ھExcelو¨،و؟و–‡ن»¶ï¼Œè®¾ç½®ه¥½è،¨ه¤´و ·ه¼ڈم€په…¬هڈ¸LOGOه’Œهگˆه¹¶هچ•ه…ƒو ¼ï¼Œه¹¶ç”¨ç‰¹و®ٹو ‡è®°هچ ن½چم€‚然هگژ,é€ڑè؟‡LabVIEWن»£ç پè؟›è،ŒExcelو“چن½œï¼Œه¦‚هˆه§‹هŒ–Excelه؛”用م€پو‰“ه¼€ه’Œه¤چهˆ¶و¨،و؟و–‡ن»¶م€په†™ه…¥وµ‹è¯•و•°وچ®م€پ设置و،ن»¶و ¼ه¼ڈم€پè°ƒو•´هˆ—ه®½ن»¥هڈٹن؟هکه’Œه…³é—و–‡ن»¶م€‚و–‡ن¸ه¼؛è°ƒن؛†ن½؟用ن؛Œç»´و•°ç»„و‰¹é‡ڈه†™ه…¥و•°وچ®م€پو،ن»¶و ¼ه¼ڈ设置超و ‡و•°وچ®و ‡ç؛¢م€پç²¾ç،®وژ§هˆ¶هˆ—ه®½م€پéپ؟ه…چو–‡ن»¶è¦†ç›–ç‰é—®é¢کم€‚و¤ه¤–,è؟کوڈگهˆ°ن؛†ن¸€ن؛›ه¸¸è§پé—®é¢کهڈٹه…¶è§£ه†³و–¹و،ˆï¼Œه¦‚Excelè؟›ç¨‹هچ،و»م€پو•°وچ®é”™ن½چç‰م€‚وœ€ç»ˆï¼Œé€ڑè؟‡è؟™ن؛›و–¹و³•هڈ¯ن»¥ه°†هژںوœ¬ه¤چو‚çڑ„وٹ¥ه‘ٹç”ںوˆگè؟‡ç¨‹ه¤§ه¹…简هŒ–,وڈگé«که·¥ن½œو•ˆçژ‡م€‚ 适هگˆن؛؛群ï¼ڑç†ںو‚‰LabVIEW编程çڑ„ه·¥ç¨‹ه¸ˆه’Œوٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯ن»ژن؛‹è‡ھهٹ¨هŒ–وµ‹è¯•ه’Œو•°وچ®هˆ†وگه·¥ن½œçڑ„ن؛؛ه‘کم€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پ频ç¹پç”ںوˆگو ¼ه¼ڈن¸€è‡´çڑ„وµ‹è¯•وٹ¥ه‘ٹçڑ„هœ؛و™¯ï¼Œه¦‚و±½è½¦ç”µهگوµ‹è¯•م€پçژ¯ه¢ƒç›‘وµ‹ç‰é¢†هںںم€‚ç›®و ‡وک¯é€ڑè؟‡LabVIEWçڑ„Excelه·¥ه…·هŒ…ه®çژ°è‡ھهٹ¨هŒ–م€پé«کو•ˆçڑ„وٹ¥ه‘ٹç”ںوˆگ,èٹ‚çœپو—¶é—´ه’Œç²¾هٹ›م€‚ éک…读ه»؛è®®ï¼ڑ读者هڈ¯ن»¥é€ڑè؟‡وœ¬و–‡ه¦ن¹ ه¦‚ن½•هˆ©ç”¨LabVIEWçڑ„Excelه·¥ه…·هŒ…ه؟«é€ںç”ںوˆگه¸¦و ¼ه¼ڈçڑ„وµ‹è¯•وٹ¥ه‘ٹ,وژŒوڈ،ه…³é”®وٹ€وœ¯ه’Œوœ€ن½³ه®è·µï¼Œن»ژ而وڈگهچ‡ه·¥ن½œو•ˆçژ‡م€‚هگŒو—¶ï¼Œهœ¨ه®è·µن¸ه؛”و³¨و„ڈو¨،و؟çڑ„设è®،ه’Œن»£ç پçڑ„ن¼کهŒ–,ن»¥ه؛”ه¯¹هگ„ç§چه¤چو‚çڑ„需و±‚هڈکهŒ–م€‚
main (4).ipynb
è®،ç®—وœ؛و•°ه¦هں؛ç،€(ن¸‹).pdf
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•هˆ©ç”¨MATLABه®çژ°هں؛ن؛ژه¤ڑو™؛能ن½“ç³»ç»ںن¸€è‡´و€§ç®—و³•çڑ„电هٹ›ç³»ç»ںهˆ†ه¸ƒه¼ڈç»ڈوµژè°ƒه؛¦ç–ç•¥م€‚首ه…ˆï¼Œé€ڑè؟‡و„ه»؛é‚»وژ¥çں©éکµç”ںوˆگه‡½و•°ï¼Œه¤„çگ†ç”µç½‘و‹“و‰‘结و„,ç،®ن؟و¯ڈن¸ھèٹ‚点能ه¤ںو£ç،®èژ·هڈ–é‚»ه±…ن؟،وپ¯م€‚وژ¥ç€ï¼Œه®ڑن¹‰هڈ‘电وœ؛وˆگوœ¬ه‡½و•°ه’Œè´ںèچ·و•ˆç”¨ه‡½و•°ï¼Œه°†ن¸¤è€…ç»ںن¸€ن¸؛ن؛Œو¬،ه‡½و•°ه½¢ه¼ڈ,ن»¥ن¾؟و›´ه¥½هœ°ه…¼é،¾هڈ‘电ن¾§ه’Œç”¨ç”µن¾§çڑ„ç»ڈوµژو€§م€‚然هگژ,é‡چ点ه±•ç¤؛ن؛†و ¸ه؟ƒçڑ„ن¸€è‡´و€§è؟ن»£ç®—و³•ï¼Œé€ڑè؟‡و‹‰و™®و‹‰و–¯çں©éکµه®çژ°ن؟،وپ¯و‰©و•£ï¼Œن½؟هڈ‘电وœ؛ه’Œè´ںèچ·ن¹‹é—´çڑ„ه¢é‡ڈوˆگوœ¬ه’Œو•ˆç›ٹé€گو¥è¶‹ن؛ژن¸€è‡´م€‚و¤ه¤–,و–‡ن¸è؟کوڈگن¾›ن؛†ه…·ن½“çڑ„وµ‹è¯•و،ˆن¾‹ï¼ŒهŒ…و‹¬10هڈ°هڈ‘电وœ؛ه’Œ19ن¸ھوں”و€§è´ںèچ·ç»„وˆگçڑ„ç³»ç»ں,ه±•ç¤؛ن؛†ç®—و³•çڑ„é«کو•ˆو€§ه’Œé²پو£’و€§م€‚وœ€هگژ,ه¼؛è°ƒن؛†é€ڑن؟،و‹“و‰‘设è®،ه¯¹و”¶و•›é€ںه؛¦çڑ„ه½±ه“چ,ه¹¶هˆ†ن؛«ن؛†ن¸€ن؛›è°ƒè¯•ç»ڈéھŒه’Œو½œهœ¨çڑ„ه؛”用ه‰چو™¯م€‚ 适هگˆن؛؛群ï¼ڑ电هٹ›ç³»ç»ںç ”ç©¶ن؛؛ه‘کم€پè‡ھهٹ¨هŒ–وژ§هˆ¶ه·¥ç¨‹ه¸ˆم€پMATLABه¼€هڈ‘者ن»¥هڈٹه¯¹هˆ†ه¸ƒه¼ڈن¼کهŒ–ç®—و³•و„ںه…´è¶£çڑ„ه¦è€…م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ电هٹ›ç³»ç»ںç»ڈوµژè°ƒه؛¦çڑ„ç ”ç©¶ن¸ژه¼€هڈ‘,و—¨هœ¨وڈگé«کè°ƒه؛¦و•ˆçژ‡م€پé™چن½ژوˆگوœ¬çڑ„هگŒو—¶ن؟éڑœç³»ç»ںçڑ„稳ه®ڑو€§م€‚é€ڑè؟‡هˆ†ه¸ƒه¼ڈç®—و³•و›؟ن»£ن¼ ç»ںçڑ„集ن¸ه¼ڈè°ƒه؛¦و–¹ه¼ڈ,ه¢ه¼؛ç³»ç»ںçڑ„éڑگç§پن؟وٹ¤èƒ½هٹ›ه’Œè®،ç®—و•ˆçژ‡م€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگن¾›çڑ„MATLABن»£ç پن¸چن»…هڈ¯ç”¨ن؛ژه¦وœ¯ç ”究,è؟کهڈ¯ن»¥è؟›ن¸€و¥ه؛”用ن؛ژه®é™…ه·¥ç¨‹é،¹ç›®ن¸ï¼Œç‰¹هˆ«وک¯هœ¨هگ«وœ‰ه¤§é‡ڈو–°èƒ½و؛گوژ¥ه…¥çڑ„çژ°ن»£ç”µهٹ›ç³»ç»ںن¸ï¼Œه±•çژ°ه‡؛و›´ه¤§çڑ„ن¼کهٹ؟م€‚
è®،ç®—وœ؛و•°وژ§è£…置课ن»¶.pdf
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†RRT(ه؟«é€ںو‰©ه±•éڑڈوœ؛و ‘)路ه¾„规هˆ’ç®—و³•çڑ„ه¤ڑن¸ھن¼کهŒ–و–¹و³•هڈٹه…¶ه…·ن½“ه®çژ°م€‚首ه…ˆوŒ‡ه‡؛هژںه§‹RRTهکهœ¨çڑ„ç¼؛陷,ه¦‚è·¯ه¾„è´¨é‡ڈه·®م€پè®،ç®—و—¶é—´é•؟ç‰é—®é¢کم€‚然هگژوڈگه‡؛ن؛†ن¸€ç³»هˆ—و”¹è؟›وژھو–½ï¼ŒهŒ…و‹¬ç›®و ‡هپڈهگ‘采و ·م€پè‡ھ适ه؛”و¥é•؟وژ§هˆ¶م€پè·¯ه¾„ه¹³و»‘ه¤„çگ†ن»¥هڈٹو¤هœ†ç؛¦وں采و ·ç‰م€‚و¯ڈن¸ھو”¹è؟›éƒ½é™„وœ‰ه…·ن½“çڑ„Pythonن»£ç پ片و®µï¼Œه¹¶è§£é‡ٹن؛†ه…¶ه®çژ°و€è·¯ه’Œوٹ€وœ¯ç»†èٹ‚م€‚و¤ه¤–,و–‡ن¸è؟ک讨è®؛ن؛†ن¸چهگŒو”¹è؟›و–¹و،ˆن¹‹é—´çڑ„هچڈهگŒن½؟用و•ˆوœï¼Œه¼؛è°ƒن؛†ه®é™…ه؛”用ن¸çڑ„و³¨و„ڈن؛‹é،¹م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹وœ؛ه™¨ن؛؛è·¯ه¾„规هˆ’ç ”ç©¶çڑ„وٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯وœ‰ن¸€ه®ڑ编程هں؛ç،€ه¹¶ه¸Œوœ›و·±ه…¥ن؛†è§£RRTç®—و³•ن¼کهŒ–çڑ„ن؛؛群م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژهگ„ç§چ需è¦پé«کو•ˆè·¯ه¾„规هˆ’çڑ„ه؛”用هœ؛هگˆï¼Œه¦‚ن»“ه‚¨وœ؛ه™¨ن؛؛م€پو— ن؛؛وœ؛éپ؟éڑœم€پوœ؛و¢°è‡‚è؟گهٹ¨è§„هˆ’ç‰م€‚ن¸»è¦پç›®و ‡وک¯وڈگé«کè·¯ه¾„规هˆ’çڑ„é€ںه؛¦ه’Œè´¨é‡ڈ,هگŒو—¶ه‡ڈه°‘è®،算资و؛گو¶ˆè€—م€‚ ه…¶ن»–说وکژï¼ڑه°½ç®،è؟™ن؛›و”¹è؟›وک¾è‘—وڈگهچ‡ن؛†RRTçڑ„è،¨çژ°ï¼Œن½†هœ¨ه®é™…部署و—¶ن»چ需考虑ن¼ و„ںه™¨ه™ھه£°ه’Œç³»ç»ںه»¶è؟ںç‰ه› ç´ çڑ„ه½±ه“چم€‚ن½œè€…هˆ†ن؛«ن؛†è®¸ه¤ڑن¸ھن؛؛ه®è·µç»ڈéھŒï¼Œن¸؛读者وڈگن¾›ن؛†ه®è´µçڑ„هڈ‚考م€‚
è®،ç®—وœ؛试é¢که®ن¾‹هˆ†وگ.pdf
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†هˆ©ç”¨ن¸‰èڈ±FX3Uç³»هˆ—PLCو„ه»؛è‡ھهٹ¨é—¨ç¦پç³»ç»ںçڑ„ه…¨è؟‡ç¨‹م€‚首ه…ˆéکگè؟°ن؛†ç،¬ن»¶é…چç½®و–¹و،ˆï¼ŒهŒ…و‹¬é€‰ç”¨ن¸‰èڈ±FX3U-32MTن½œن¸؛ن¸»وژ§هˆ¶ه™¨ï¼Œé…چه¤‡ه¤ڑç§چن¼ و„ںه™¨ه¦‚ç؛¢ه¤–ه¯¹ه°„م€پهœ°ç£پن»¥هڈٹéک²ه¤¹ن¼ و„ںه™¨ç‰ï¼Œه¹¶é‡‡ç”¨é€‚ه½“çڑ„و‰§è،Œوœ؛و„è؟›è،Œé—¨çڑ„ه¼€é—وژ§هˆ¶م€‚وژ¥ç€و·±ه…¥è§£وگن؛†و¢¯ه½¢ه›¾é€»è¾‘çڑ„设è®،,و¶µç›–هں؛وœ¬ه¼€é—逻辑م€په®‰ه…¨ه›è·¯è®¾è®،م€پو»¤و³¢ه¤„çگ†ç‰و–¹é¢çڑ„ه†…ه®¹م€‚و–‡ن¸ç‰¹هˆ«ه¼؛è°ƒن؛†ه‡ ن¸ھه…³é”®وٹ€وœ¯ç‚¹ï¼Œه¦‚é€ڑè؟‡ه®ڑو—¶ه™¨وژ§هˆ¶é—¨çڑ„ه¼€هگ¯و—¶é—´ه’Œéک²ه¤¹ن؟وٹ¤وژھو–½ï¼Œè§£ه†³ن؛†ç؛¢ه¤–ن¼ و„ںه™¨è¯¯è§¦هڈ‘çڑ„é—®é¢ک,ه¹¶ه¼•ه…¥ن؛†GX Works2و¨،و‹ںه™¨ç”¨ن؛ژ程ه؛ڈ调试م€‚و¤ه¤–,è؟ک讨è®؛ن؛†ه¦‚ن½•é€ڑè؟‡RS485é€ڑن؟،وژ¥هڈ£ه®çژ°è؛«ن»½éھŒè¯پو¨،ه—çڑ„èپ”网هٹں能هڈٹه…¶و•…éڑœè½¬ç§»وœ؛هˆ¶م€‚وœ€هگژ,ن½œè€…هˆ†ن؛«ن؛†ن¸€ن؛›ه®ç”¨çڑ„ç»ڈéھŒو•™è®ï¼Œن¾‹ه¦‚éپ؟ه…چن؟،هڈ·ه¹²و‰°çڑ„و–¹و³•ه’Œç،®ن؟ç³»ç»ں稳ه®ڑو€§çڑ„ه†—ن½™è®¾è®،م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹è‡ھهٹ¨هŒ–وژ§هˆ¶é¢†هںںçڑ„ه·¥ç¨‹ه¸ˆه’Œوٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯ه¯¹PLC编程وœ‰ن¸€ه®ڑهں؛ç،€çڑ„ن؛؛群م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پو„ه»؛é«کو•ˆهڈ¯é çڑ„è‡ھهٹ¨é—¨ç¦پç³»ç»ںçڑ„هœ؛هگˆï¼Œو—¨هœ¨وڈگé«کé—¨ç¦پç³»ç»ںçڑ„ه®‰ه…¨و€§م€پهڈ¯é و€§ه’Œو™؛能هŒ–و°´ه¹³م€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگهˆ°çڑ„ه…·ن½“و،ˆن¾‹ه’Œè§£ه†³و–¹و،ˆهڈ¯ن»¥ن¸؛ç±»ن¼¼é،¹ç›®çڑ„ه®و–½وڈگن¾›ه®è´µçڑ„هڈ‚考ن»·ه€¼م€‚هگŒو—¶ï¼Œن½œè€…è؟کوڈگن¾›ن؛†è®¸ه¤ڑ调试وٹ€ه·§ه’Œو³¨و„ڈن؛‹é،¹ï¼Œوœ‰هٹ©ن؛ژ读者و›´ه¥½هœ°çگ†è§£ه’Œه؛”用و‰€ه¦çں¥è¯†م€‚