**摘要:**2019云栖大会大数据 & AI专场,阿里巴巴资深技术专家王峰带来“Ververica Platform-阿里巴巴全新Flink企业版揭秘”的演讲。本文主要从Ververica由来开始谈起,着重讲了Ververica Platform的四个核心插件App Manager、Libra Service、Stream Ledger、Gemini,以及阿里巴巴实时计算云原生版本相关特性及典型应用场景。
[直播回放请点击](https://yunqi.youku.com/2019/hangzhou/review?spm=a2c4e.11165380.1395223.1)
以下是精彩视频内容整理:
随着人工智能时代的降临,数据量的爆发,在典型的大数据业务场景下数据业务最通用的做法是:选用批处理的技术处理全量数据,采用流式计算处理实时增量数据。2017年基于Flink开发的实时计算产品正式服务于阿里巴巴集团内部,并从搜索和推荐两大场景开始应用。目前阿里巴巴及下属所有子公司,都采用实时计算产品来处理所有的实时业务。
Ververica 是如何诞生的?
-----------------
众所周知,Apache Flink是业界非常流行的流计算引擎,最早诞生于欧洲,是柏林大学的研究型项目。后来由项目的发起人创办了DataArtisans公司并根据该研究项目孵化出 Flink,并于2014年将 Flink 捐赠给 Apache基金会。

同年,阿里巴巴开始关注Flink。由于搜索有很多业务场景非常依赖大数据和实时数据处理,而Flink在架构设计上,作为全流式的执行引擎,数据处理效率非常高。于是阿里巴巴内部开始着手研究Flink,并看好Flink将会成为新一代计算引擎,加速大数据计算的未来发展。
经过一年努力,阿里内部对Flink的开源版本做了很多深度优化与改进,使其能够适应阿里巴巴超大规模的业务场景,包括搜索、推荐等核心的业务场景。2016年,第一次将Flink推到双11场景使用,构建了搜索、推荐的全实时链路(包括在线学习、模型预测等),形成了一套完整的闭环。2017年,阿里巴巴全线上线了基于Flink实时计算产品,服务于阿里巴巴的搜索、推荐等核心场景以及广告、数据和所有部门的实时在线业务,比如:阿里巴巴双11全天各种多维的数据统计,交易额大屏幕的全球直播等全部都是由基于Flink的实时计算产品来支持。

在此基础之上,2018年,我们首次在阿里云公有云推出基于Flink的实时计算服务,开始支持各行各业的企业客户。阿里巴巴对Flink的认可度在逐渐增加,Flink也证明了在实时计算的业务中的巨大潜力。自此,阿里巴巴加大了对Flink的投入并加速推进Flink社区的发展。2019年1月,阿里巴巴收购了DataArtisans并创建了新企业品牌Ververica,以上即为Flink的企业品牌Ververica的由来。
在开源这块,相信大家都非常了解每个大的开源项目背后都有一个企业品牌,随着整合的逐步完善,德国的Flink创始团队与中国阿里巴巴的实时计算团队也开始密切合作。与此同时,我们也在持续推动Flink社区的发展。1月初,阿里巴巴将内部维护的Flink分支Blink贡献给整个Flink开源社区,目前阿里巴巴对Flink社区贡献的代码已超过100万行。并且,两个团队密切配合在商业化上进行联合作战,推出全新的Flink企业版——Ververica Platform。
Ververica Platform的技术架构如何,能够解决哪些应用场景,下面将详细讲解。
Ververica Platform 介绍
---------------------
Ververica Platform是阿里巴巴推出的全新企业版,它仍然坚持以Apache Flink 的社区版本为内核,同时能够兼容各种企业级插件,在整个基于Flink的实时计算解决方案上对应用性、稳定性、性能、可运维性等方面提供企业级的增值服务。
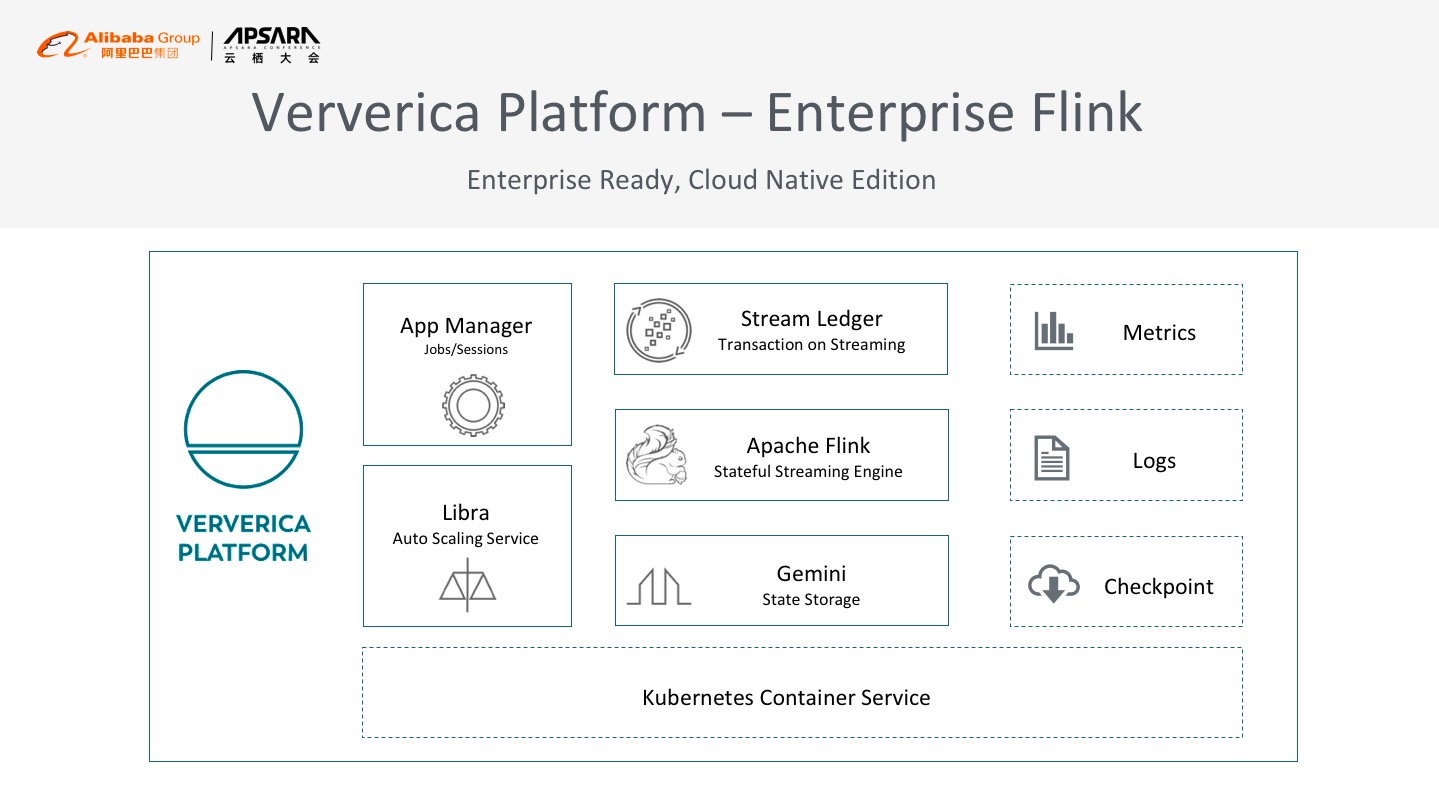
首先,Ververica Platform是一个企业级的开放软件,支持客户将其部署在生产环境中,对接已有的周边生态系统如日志、Metrics、存储等。最初在设计Ververica Platform时就将其定位为完全云原生的方案,系统组件和核心组件都以支持微服务方式部署到Kubernetes上,用户可以非常方便的将Ververica Platform和自己的在线服务或其他数据服务做云原生的混布。
### Ververica Platform 计算引擎
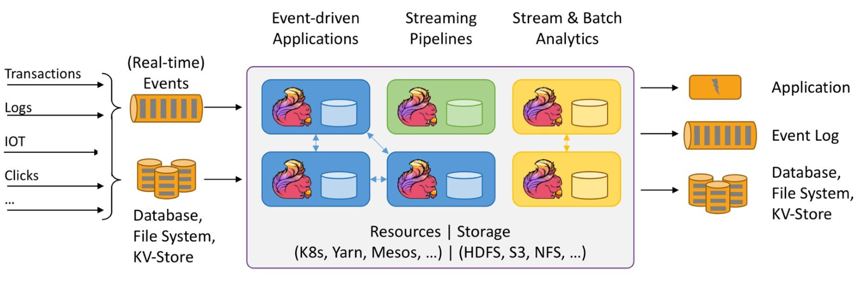
Ververica Platform使用Apache Flink作为其核心的计算引擎,保证和社区的完全兼容。上图为Apache Flink最新演进的架构图。Apache Flink的本质是一款有状态的流式计算引擎,可以连接各种各样的存储,通过ETL计算、数据分析等将数据结果导入到另外的存储中。作为流式计算,Flink的时效性非常好,可以在高吞吐量的同时达到亚秒级延时。Flink不仅能够连接消息队列等无限数据流的数据源,也可以连接文件系统、数据库表、KV存储等有限的数据集,所以Flink也在基于流式计算的优势上逐渐朝着批流融合的方向发展,有希望成为一种新的批流合一的全能计算引擎。
所以Ververica Platform将会依赖社区的力量,采用Flink社区的主流版本作为内核,所有的增值服务、各种优化都会通过嵌入的方式来实现,为用户提供一个开放透明的计算引擎。以下将详细介绍Ververica Platform的核心插件。
### Ververica Platform – App Manager
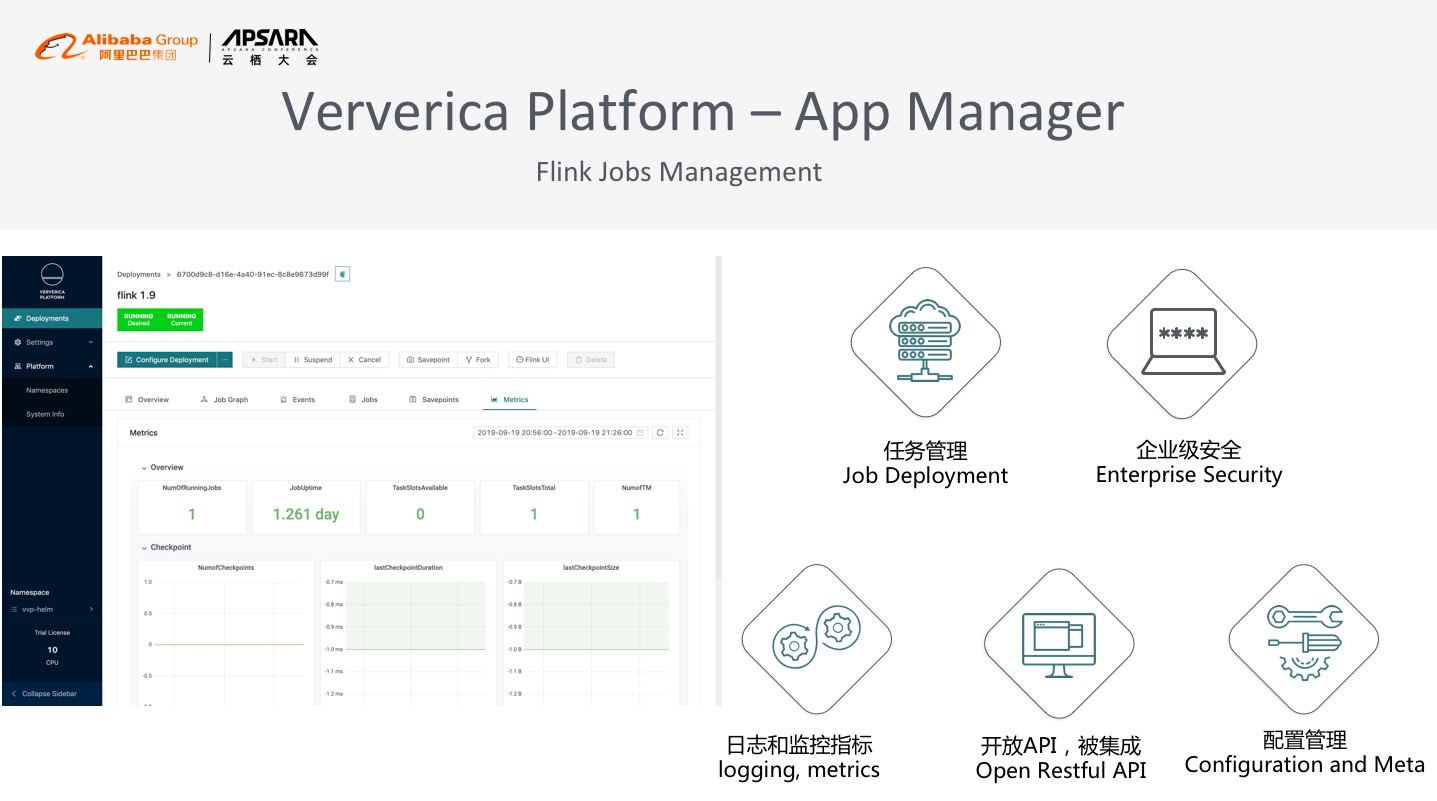
Ververica Platform在应用上的企业级插件叫APP Manager,是管理Flink全生命周期的工具。Flink作为计算引擎,在易用性方面可以采用多种优化来帮助用户更高效地使用Flink系统。比如,整个Job生命周期的管理,从Job的开发、配置,到提交上线、停止重启等基本的运维功能可以通过APP Manager封装出一套完整的工具链来完成,同时提供包括日志的采集收集、运行Metrics的收集展现等功能,方便用户对任务进行debug。此外,企业级安全也是非常重要的feature,尤其是企业应用时存在多租户部署的需求,因此APP Manager也提供了Rollbase权限管理、OpenID授权系统。同时,我们非常注重开放性和被集成的能力,所以APP Manager还提供了完善的API,使用户能非常方便的将Ververica Platform企业级软件集成到自己已有的大数据平台之中。
### Ververica Platform – Libra Service

Libra Service是提供智能运维能力的企业级插件。大数据的系统运行中运维是其中的重要部分,尤其是规模扩大的场景中。常规情况下运行Flink Job,基本上是开发人员写完代码后要配各种各样的参数,对于Flink的运维人员来讲,需要知道这个Job是干什么的、支持什么样的业务、峰值是什么情况、大概的数据规模是什么样子,根据自己的经验进行调整,并且经过多次迭代后才能够将一个任务调好。在任务较少的情况下,还可以通过运维人员人肉维护,但如果出现上千个Job,甚至阿里巴巴内部上万个Flink Job的场景,这是Flink社区版本无法帮助解决的,所以Ververica Platform提供了一套智能运维插件,类似于AI Ops,智能运维插件能够帮助用户推算出一个Job需要多少个TMs,每个TM需要配置多少个Slots,每个TM的JVM参数如何配置以及一个Job的并发度如何配置等。
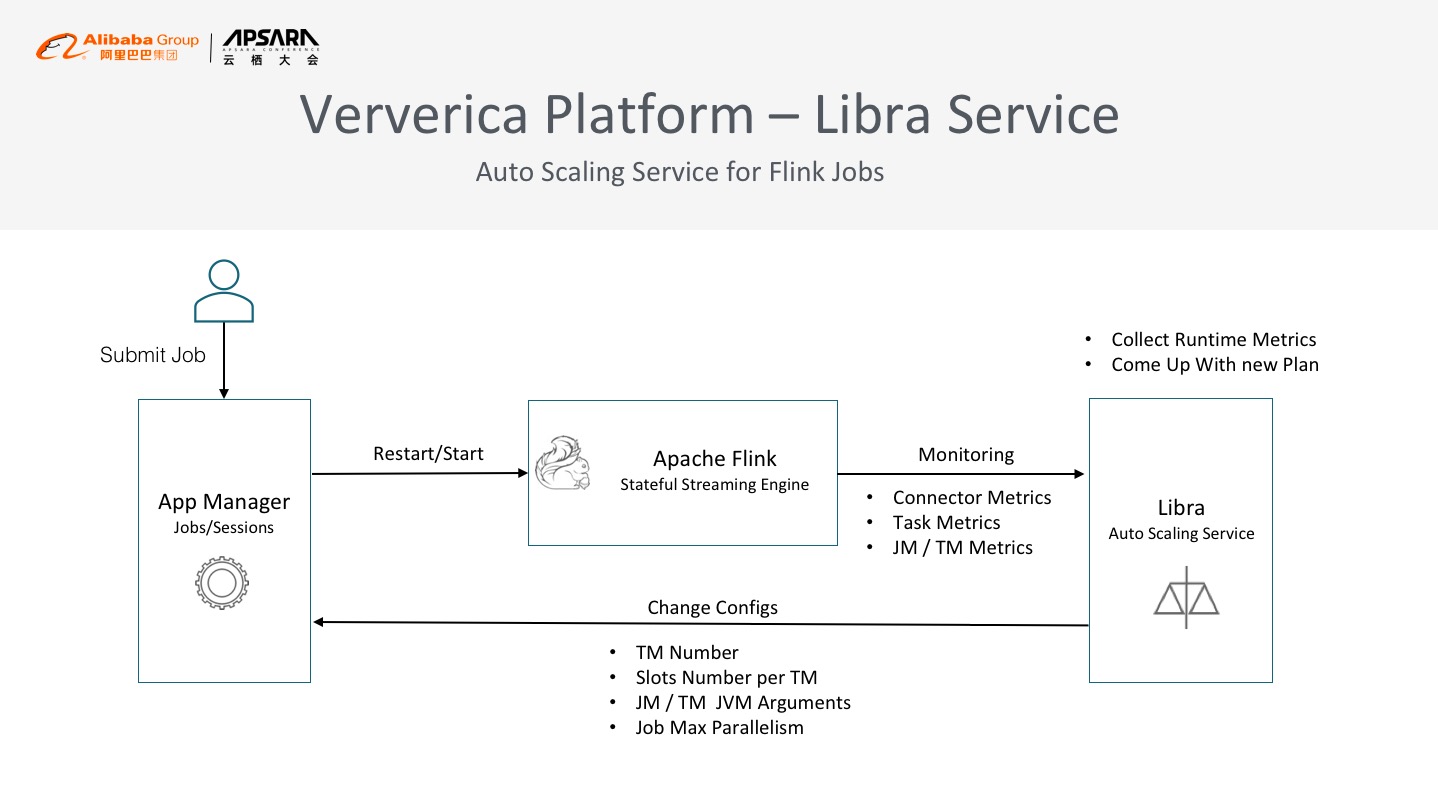
上图为Libra Service的基本设计思路,这是一个非常经典的智能AI Ops设计方案,可以看到用户正常通过APP Manager会提交一个Job,Job在Kubernetes集群启动之后,Libra Service会监控所有在Kubernetes集群上面运行的Flink Job,实时采集所有的Metrics,包括Task的Metrics是否延迟、吞吐、buffer等运行信息,Job Manager和Task Manager的GC情况,JVM各种运行的数据指标等等。相当于自动采集作业的各种指标特征,利用算法推算出现在的Job运行是否健康。比如部分Job在持续地延迟运行或利用了大量资源但其实是在空跑等不健康状态,当Job处于不健康状态时,通过算法推算出合理的计划,比如延迟了要扩容,浪费资源可能要缩容,然后通知App Manager去修改整个Job的配置,让Job重启适应新的配置来达到稳定高效节省资源的效果,这就是弹性扩缩容插件Libra Service,是智能运维的AI Ops。
### Ververica Platform – Stream Ledger
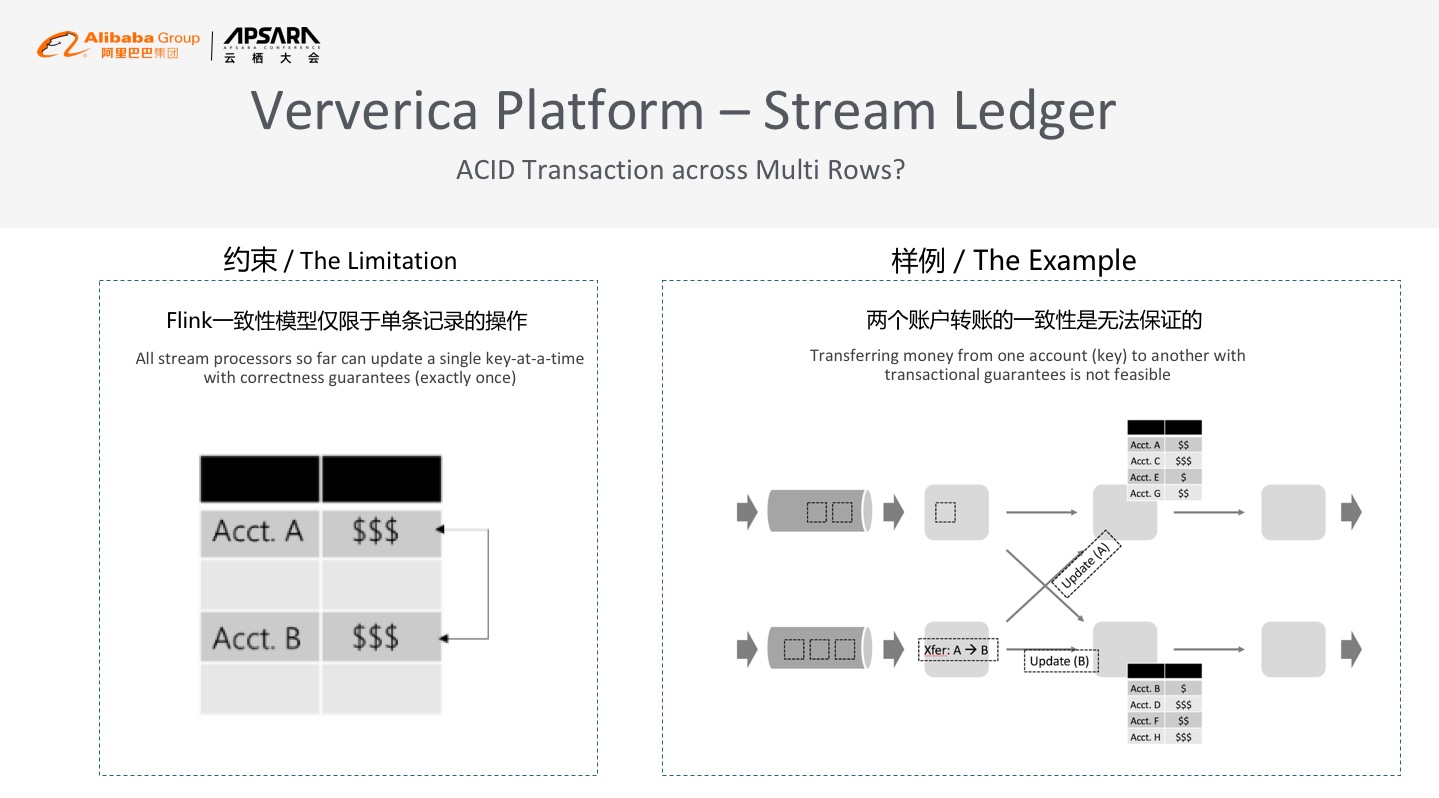
Flink提供了非常完整的一致性语义,也支持强一致性的语义,保证数据一条不丢、一条不少,这个是可以支持计费等金融级非常苛刻的条件,但有一个约束即整个正确性只能够保证单条的记录,比如2个账户要转账就保证不了,因为只能够保证对A的操作绝对正确,对B的操作绝对正确,但是对A的10块钱转给B,这个完整的事务原生的Flink是没有办法保证的。
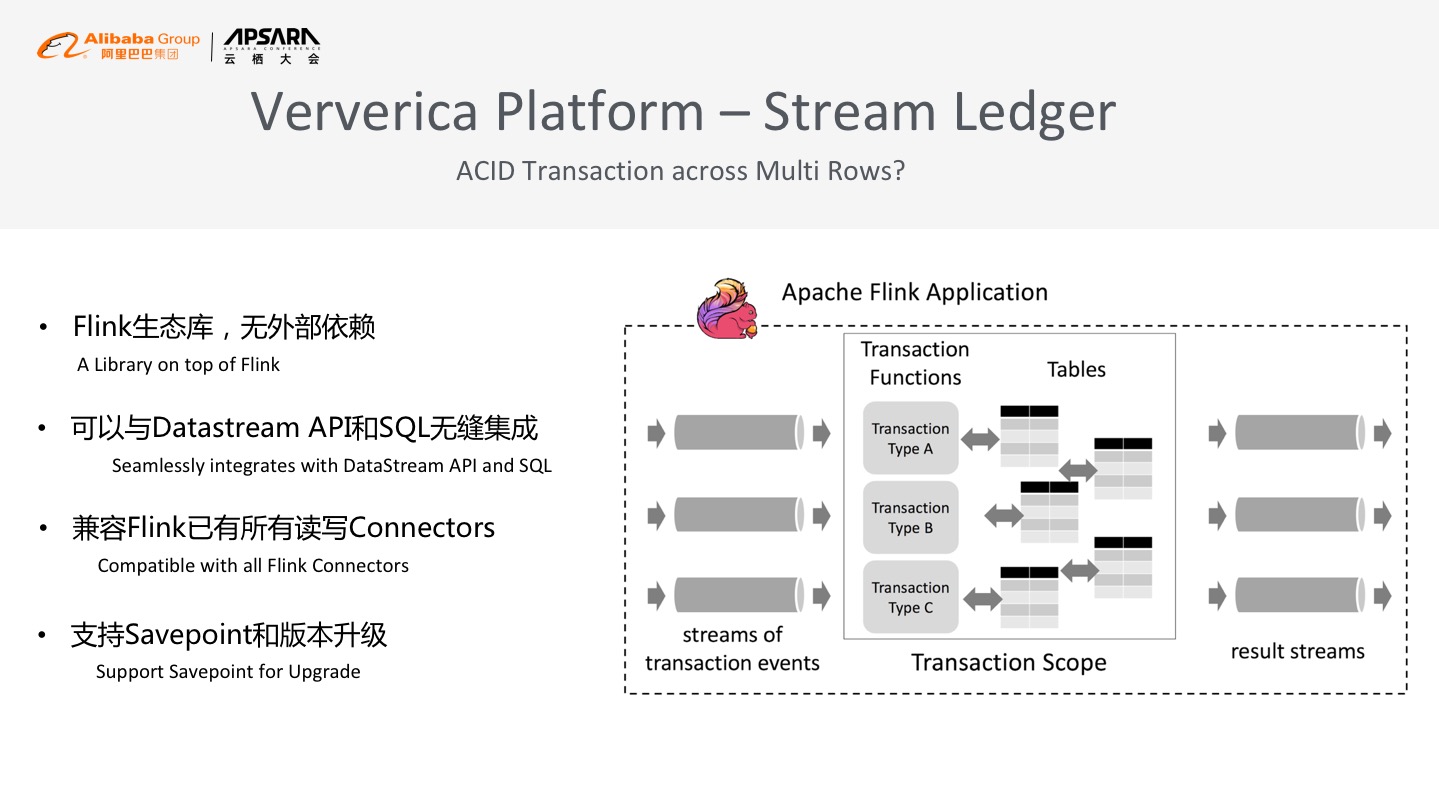
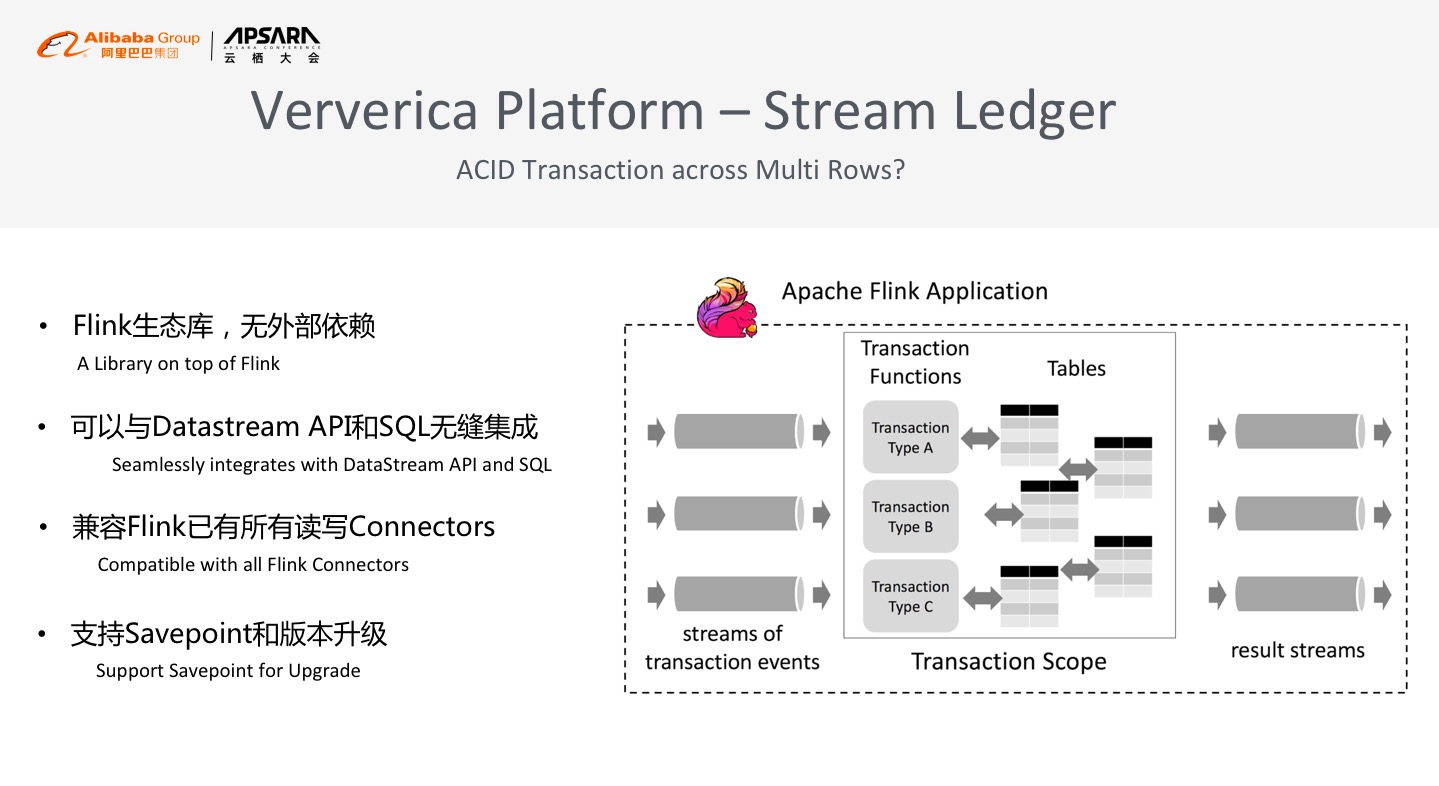
因此Ververica Platform提供了一套分布式的跨行跨机器事务解决方案。Stream Ledger是基于Flink Datastream API生态的Library,可以实现高性能的跨行分布式事务处理能力,这套Library完全基于Flink内部API,没有任何外部依赖,可以与Datastream API和SQL无缝集成,能够兼容Flink已有的所有读写Connectors,所以Steam Ledger是一个轻量的分布式事务处理方案,也是为金融级场景提供的分布式事务处理能力的解决方案。
### Ververica Platform – Gemini
最后一个插件是状态存储插件。在流式计算中,Flink天然支持内置状态存储管理,不需要依赖外部的存储就可以把实时的数据统计等工作完成。正常做报表统计时都有count、sum、average等参数,这些计数器就是状态数据,随着计算量的增加,状态数据可能会越来越大以至于内存可能无法承担,所以需要一套内置的状态存储来存储这些状态。大家都知道在计算系统中,一旦有存储IO访问,性能瓶颈则很有可能是在存储IO上,所以需要优化状态存储的访问。
Flink内置了两种状态存储,一种是基于Java Heap的State Backend状态存储插件,另一种是基于RocksDB的状态存储插件。基于Java Heap的性能非常好,因为是完全基于JVM内存的,并且没有序列化反序列化。但它的局限在于Java的方案内存容量会是瓶颈,因为Java对内存的利用率非常低,不如序列化高。经过测试,在物理数据超过几百兆之后,内存的使用率超过几个G就不能够扩大数据量了,所以系统非常不稳定。业界很多公司都是在用RocksDB来做,这是非常优秀的开源KV存储,但因为是基于C++写的,所以和Flink的集成上还有很多不方便的地方,同时RocksDB也不是为Flink设计的,所以Flink在很多状态的数据结构设计上没有办法进行优化。我们希望针对Flink的状态存储来做一套自己的存储插件,可以提供更强大的功能,同时也兼容社区的协议,所以Gemini应运而生。Gemini是完全存储计算分离的设计,它和RocksDB有很大的不同,同时它也可以利用本地SSD做二级缓存来加速访问,尤其是在Flink出现故障,一个Task失败,重新拉起一个进程时,它可以远程的从HDFS上直接拉起状态,下载时间会大幅降低,提升了整个Flink SLB体验,包括它在设计的时候采用了Java,和Flink系统间的整合也会更好。
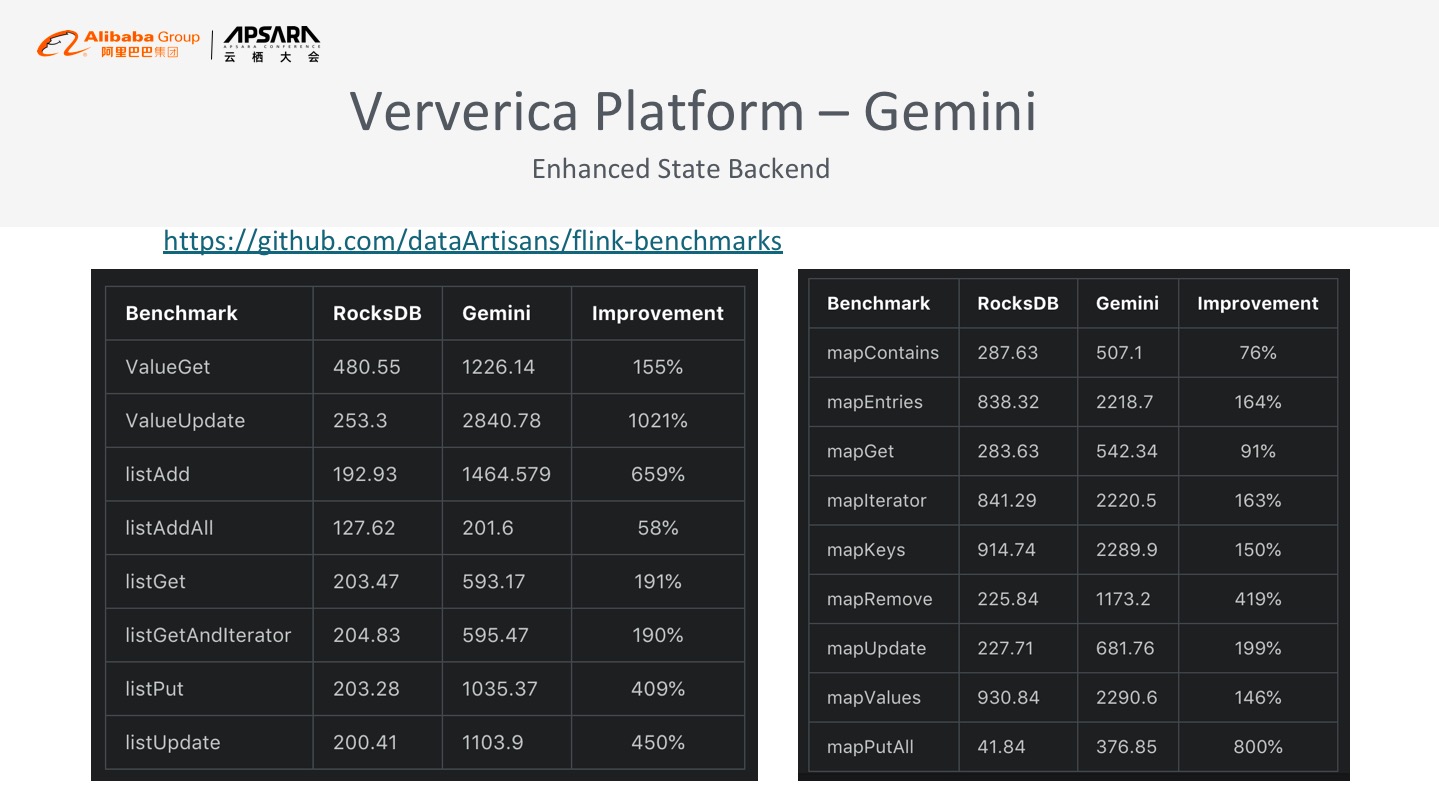
这是整个Ververica Platform Gemini Store和RocksDB的Benchmark的性能数据,我们可以看到Flink在常用的KV state、List state、Map state等性能上都有非常明显的提升,具体的数据大家可以自行查看。这个项目也是我们在整个Ververica Platform做性能优化中效果最明显的插件。
阿里巴巴实时计算云原生版本
-------------
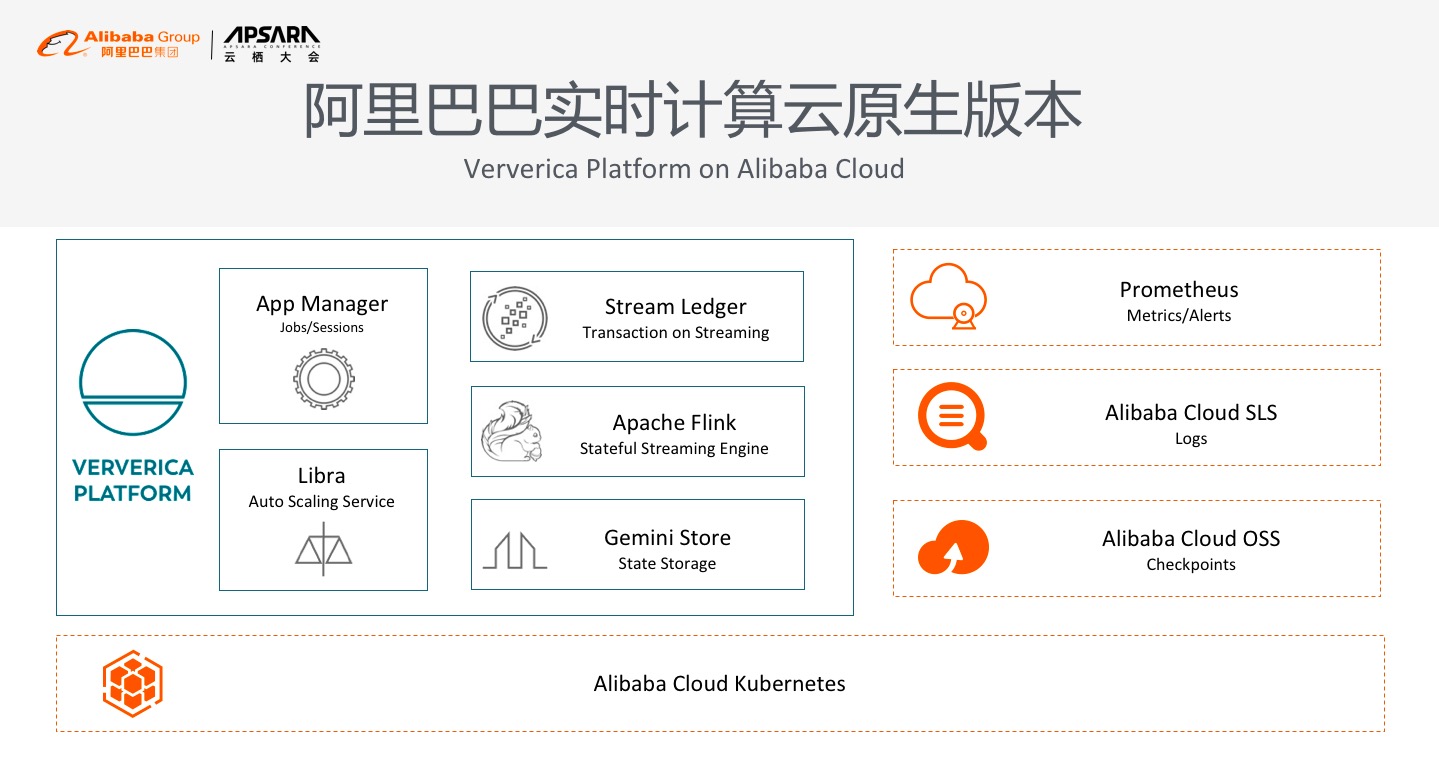
Ververica Platform是企业级的引擎软件,能够部署到任何环境中,天然可以跑在Kubernetes上,所以为了方便提供实时计算的云计算服务,让阿里云的客户都能够方便的使用,我们已经把它适配到阿里云的云环境之中,和阿里云的系统实现了无缝的集成。将Flink的log放到阿里云的SLS上,可以利用SLS的log技术查询搜索Flink的log,所以我们将Flink Metrics对接到Prometheus生态中。我们也将Flink Checkpoint存储的状态数据对接到阿里云的OSS上,让已有的用户能够复用OSS系统。更重要的一点是整个阿里系统都是云原生的,Ververica Platform也完全运行在阿里云的容器服务平台之上,因此云原生也是Ververica Platform的特点之一。如果用户已经有自己的云原生集群或容器服务,可以尝试半托管模式,用户将提供集群给我们,我们就可以把整个软件部署到用户的集群上,包括已经存在的集群或新购买的集群,这种半托管方式能够给用户提供到此种服务,当然我们也会提供全托管模式,选择上比较灵活,这就是目前已经在公测的Ververica Platform云原生企业版。
Ververica Platform产品能够应用于哪些场景,帮助用户解决哪些问题想必是大家非常关心的,以下将详述。
### 应用场景1 - 实时数仓
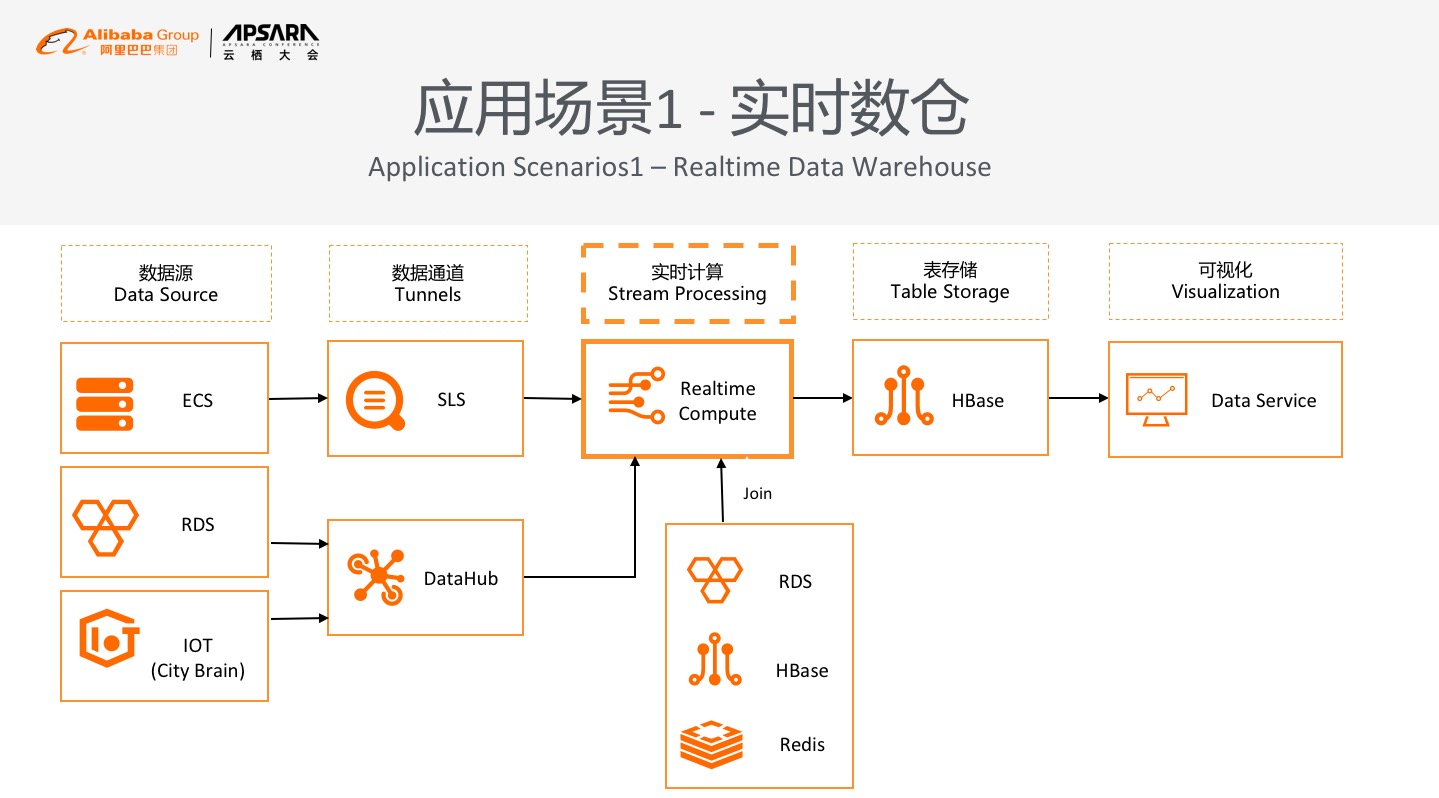
第一个场景是实时数仓,这也是在阿里巴巴内部用得最多的场景,在云上抽象为如图的模型,用户的数据来自于两处甚至是三处,第一部分来自于ECS日志,第二部分来自于RDS结构化数据,第三部分来自于IOT的设备。通过阿里云的SLS服务或者DataHub数据收集通道来收集用户数据,实时计算的产品可以实时订阅到上述数据,用Flink SQL对以上数据进行多维数据分析,产生实时的数据报表。这个过程中,除了有单流的数据处理还有多流数据的join,还可能和HBase、Redis、MySQL等数据库的数据有结合,其中可以运行复杂的SQL做经典数仓的处理,把数仓处理的结果实时写到在线的数据库比如HBase中,都是比较常用的用法。然后通过在线的数据服务在大屏幕中展现,这个场景在淘宝内部是非常经典的场景,双11的时候可以看到大屏幕上有各种数据的成交、统计、分布、排名等,最典型的就是GMA交易数据,比如今年1000多亿,明年2000多亿等等,数字是实时滚动、全球直播的,也是通过这套Flink的架构来实现的。现在对于云上的很多客户而言,实时数仓也是一个很大的应用场景。
### 应用场景2 - 实时风控
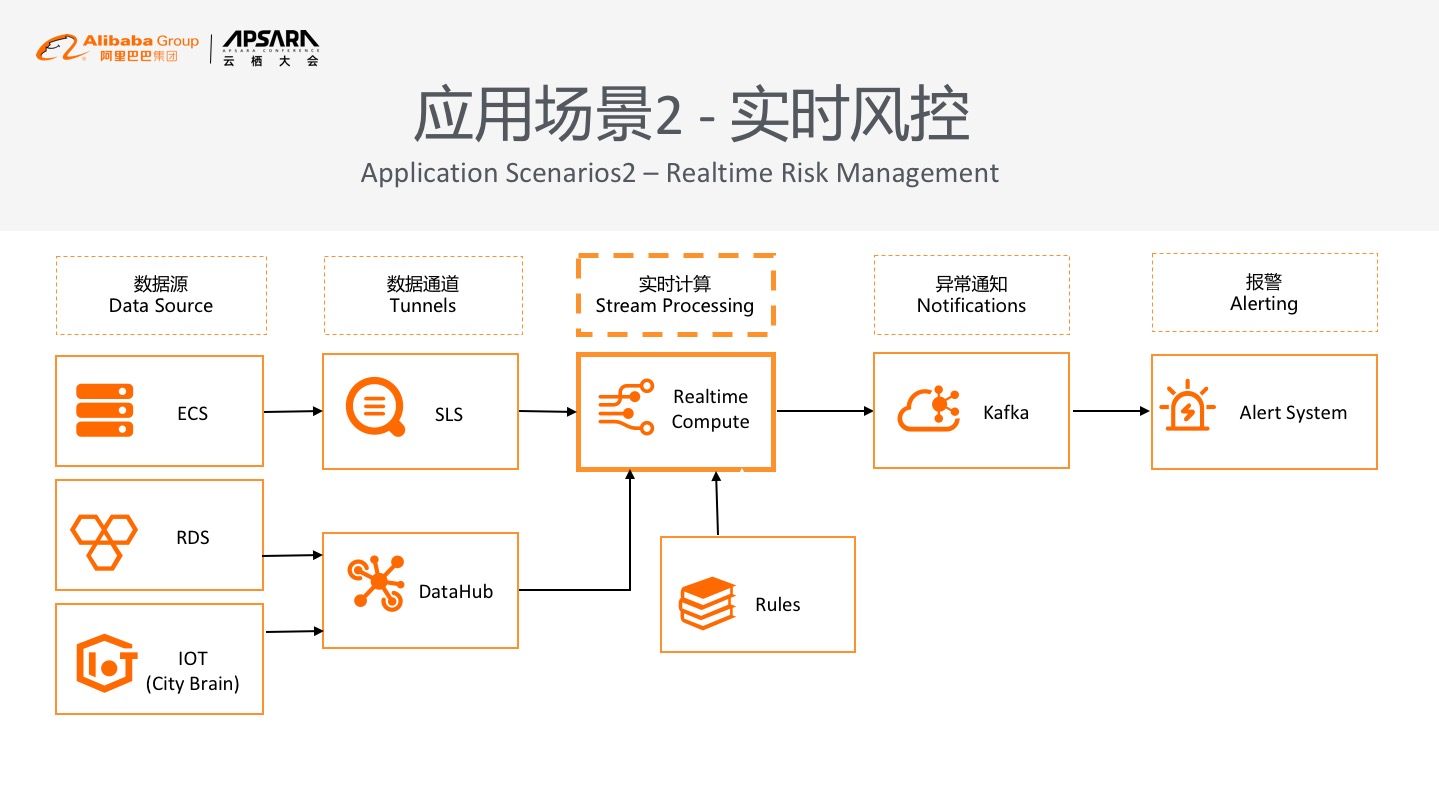
第二个实时场景就是实时监控、异常数据的报警等等。这也是现在非常主流的场景之一,其实数据源和实时数仓很像,基本上还是基于ECS的日志数据或数据库中的增量数据表的更新数据、IOT的数据等,工业会产生大量的数据,需要监测设备数据的异常。与实时数仓不同之处在于实时风控并不是采用SQL来做统计和分析,基本上会采用复杂时间处理,比如Flink CEP或业务方自己定制的风控库来对实时数据进行监测,这个监测可能基于业务的规则,也可能基于Bigdata on AI的方案。新的研究方向是在异常监测或者风控领域基于模型监控,离线或实时训练并在线加载这些模型进行实时检测,能够实时发现异常的事件,及时进行补救。通过Kafka集群到在线的报警系统来对接各种业务系统去报警,这也是能够秒级实时监测各种异常事件做风险控制的方式之一,在整个安防场景、金融场景都是非常常见的解决方案。
### 应用场景3 - 在线机器学习
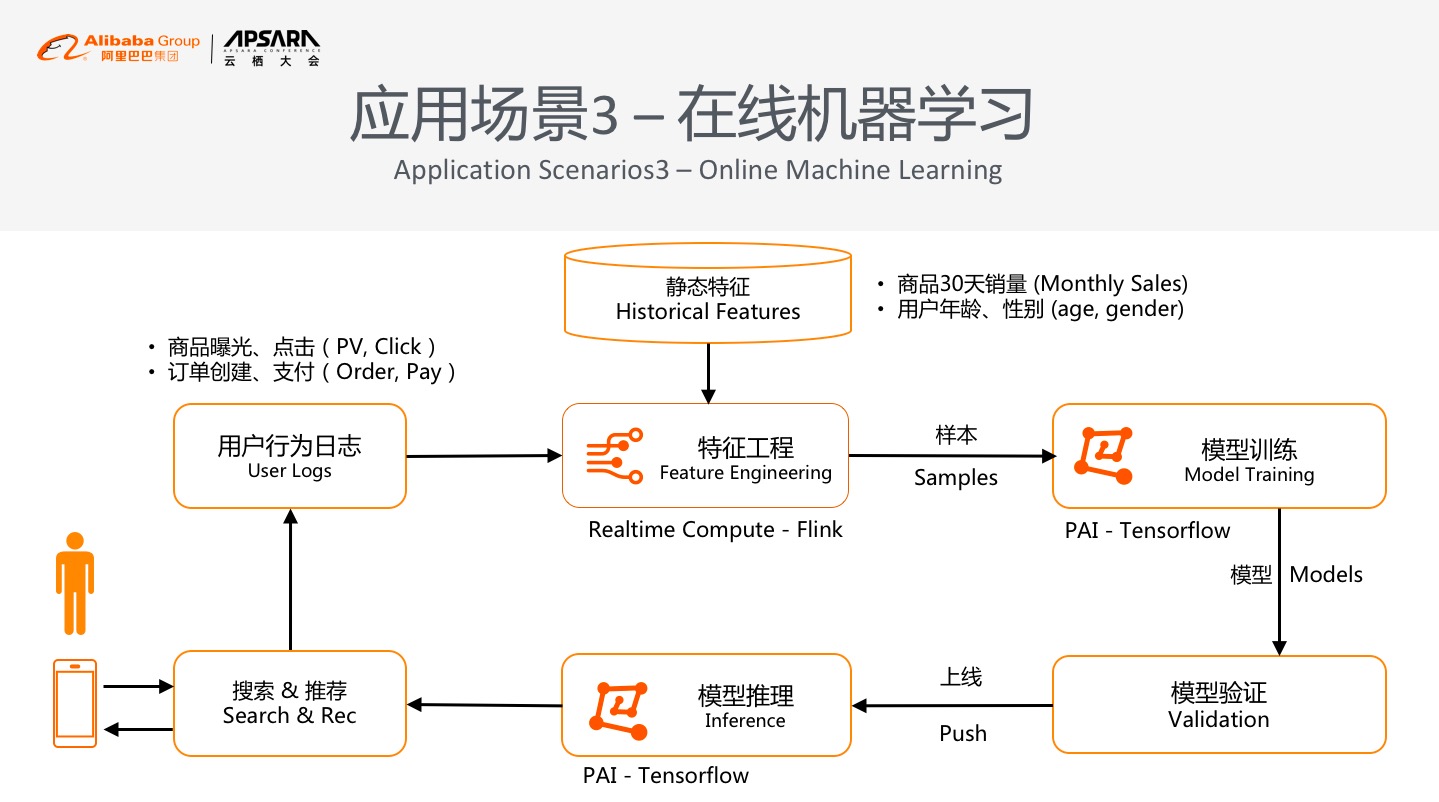
第三个场景是成长最快的在线机器学习。在线机器学习是阿里多年的研究方向之一,也是Flink首先应用在阿里巴巴搜索事业部搜索推荐业务部场景的原因。在线机器学习是搜索推荐广告中非常火的方向,机器学习不仅是离线数据模型来做训练,甚至能够形成一个完全的实时化闭环方案,通过用户在天猫、淘宝上产生的大量的点击、交易,相关数据都会通过日志系统实时收集,之后传入实时计算中计算,我们称之为特征工程。对用户的数据如用户的订单等做数据清洗,数据特征的弥补、计算,甚至和离线特征做一些结合。部分数据,如30天销量、用户年龄等数据并非实时变化,是需要长时间的统计得到,我们把实时特征、离线特征全部都做了拼接之后就是多维数据的join,最终能够得出实时样本。我们通过流式得到实时样本之后就能够在后面对接流式来做机器学习的训练,可以通过PAI等类似的机器学习产品来做实时或者准实时的模型训练,训练完之后产生的模型有一套完整的验证机制,验证完整的模型Validation之后才能推上线,再用新模型提供个性化的搜索和推荐,从而驱动用户产生新的点击,再去进行模型的更新,进而形成一套完整的闭环。这是Bigdata+AI的一个典型场景,从数据处理、数据训练,再到数据预测、用户点击形成反馈等,形成完整生产线。这也是Flink做实时计算和在线的流式计算与在线机器学习的训练形成一套完整闭环的经典方案,这套方案也是淘宝天猫真实的在线搜索推荐解决方案。
目前我们有很多客户都在采用这种新的方案来提升他们的点击,尤其是社交媒体类的公司都在尝试这个新的解决方案。
最后,回到社区,阿里巴巴收购完DataArtisans之后成立了新的企业品牌Ververica,我们希望除了商业化品牌的统一、提供的增值服务之外,还希望能够继续扩大社区规模,服务好更多社区的用户,推动社区繁荣发展。所以阿里巴巴也投入了很大的精力来支持整个 Flink 社区的发展,尤其是在中国,我们已经在北京、上海、深圳等连续办了非常多的Flnik社区Meetup,包括去年年底举办的首届Flink Forward China大会,今年将继续举办第二届。去年大会的规模是1000人,今年希望能够达到2000人,希望[中国比较主流的互联网公司](https://yq.aliyun.com/articles/720732?spm=a2c4e.11155435.0.0.33483312ab3as7)都能参与其中,分享他们对Flink应用的经验,我们也会联合Flink创始团队一起,讲Flink的新特性、发布以及方向上的展示。欢迎更多对Flink有兴趣的同学一起来参与大会,交流探讨。
[原文链接](https://yq.aliyun.com/articles/724113?utm_content=g_1000084564)
本文为云栖社区原创内容,未经允许不得转载。
分享到:





相关推荐
在阿里巴巴的实践中,Flink的大规模持久化存储可以分为四个阶段:2016年,阿里巴巴开始使用Flink处理大规模数据流;2017年,阿里巴巴开始使用External State和Internal State来提高数据存储的可扩展性和可靠性;2018...
flink-core-1.8.1 flink-cdc-3.1.1基础依赖lib包 免费下载flink-core-1.8.1 flink-cdc-3.1.1基础依赖lib包 免费下载flink-core-1.8.1 flink-cdc-3.1.1基础依赖lib包 免费下载flink-core-1.8.1 flink-cdc-3.1.1基础...
ubuntu系统下部署完全分布式flink平台及与平台相关的zookeeper,kafka平台的安装部署过程及遇见的问题的解决方案
Ververica 是一个基于 Flink 的企业版平台,提供了 Workspace、Runtime、DataStream、TableAPI、Streaming JOB 等多种功能。Ververica 平台提供了统一的开发体验,帮助用户快速构建实时计算应用程序。 五、Flink on...
flink-streaming-platform-web系统是基于Apache Flink 封装的一个可视化的、轻量级的flink web客户端系统,用户只需在web 界面进行sql配置就能完成流计算任务。主要功能:包含任务配置、启/停任务、告警、日志等功能...
flink-connector-postgres-cdc-1.4.0.jar
包含翻译后的API文档:flink-connector-redis_2.10-1.1.5-javadoc-API文档-中文(简体)版.zip; Maven坐标:org.apache.flink:flink-connector-redis_2.10:1.1.5; 标签:apache、flink、connector、redis、中文文档...
文件名: flink-1.17.1-bin-scala_2.12.tgz 这是 Apache Flink 1.17.1 版本的二进制文件,专为 Scala 2.12 设计。Flink 是一种开源流处理框架,用于大规模数据处理和分析。这个版本包含了最新的功能和修复,提供了更...
包含翻译后的API文档:flink-table-planner-blink_2.11-1.12.7-javadoc-API文档-中文(简体)版.zip; Maven坐标:org.apache.flink:flink-table-planner-blink_2.11:1.12.7; 标签:apache、flink、table、planner、...
标题和描述中提到的"flink-1.19.0-bin-scala-2.12.tgz"和"flink-1.16.3-bin-scala-2.12.tgz"是Apache Flink的两个不同版本的二进制发行版。Flink是一个开源的流处理和批处理框架,它提供了低延迟、高吞吐量的数据...
首先,"alibaba-flink-connectors-flink-1.5.2-compatible"这一名称表明这是阿里巴巴针对Flink 1.5.2版本开发的一套兼容连接器。这意味着它经过了精心设计,确保在Flink 1.5.2的环境中可以稳定运行,同时提供了对...
包含翻译后的API文档:flink-streaming-java_2.11-1.13.2-javadoc-API文档-中文(简体)版.zip; Maven坐标:org.apache.flink:flink-streaming-java_2.11:1.13.2; 标签:apache、flink、streaming、java、中文文档、...
Flink Doris Connector(apache-doris-flink-connector-1.11_2.12-1.0.3-incubating-src.tar.gz) Flink Doris Connector Version:1.0.3 Flink Version:1.11 Scala Version:2.12 Apache Doris是一个现代MPP分析...
flink-1.14.4-scala_2.12 + CDH6.2.1 版 parcel 包, 包含 FLINK-1.14.4-BIN-SCALA_2.12-el7.parcel FLINK-1.14.4-BIN-SCALA_2.12-el7.parcel.sha manifest.json (以上三个文件放入 /opt/cloudera/parcel-repo/ 下...
flink-sql-connector-mysql-cdc-2.2.1.jar flink-connector-elasticsearch7-1.15.0.jar flink-1.15.0-bin-scala_2.12.tgz
适用于CDH5.2 - CDH6.3.2 的 flink版本,FLINK-1.14.3-BIN-SCALA_2.12.tar
包含翻译后的API文档:flink-table-planner-blink_2.11-1.13.2-javadoc-API文档-中文(简体)版.zip; Maven坐标:org.apache.flink:flink-table-planner-blink_2.11:1.13.2; 标签:apache、flink、table、planner、...
Apache Flink Community China 在文档中扮演了重要角色,这表明文档可能包含了Flink在阿里巴巴集团的应用和贡献。Apache Flink是一款开源的流处理框架,它支持事件驱动的数据处理,并具有低延迟、高吞吐量以及强大的...
由于jar包的下载速度很慢,我想也有很多下载慢的同学,分享下
Flink Doris Connector(apache-doris-flink-connector-1.14_2.12-1.0.3-incubating-src.tar.gz) Flink Doris Connector Version:1.0.3 Flink Version:1.14 Scala Version:2.12 Apache Doris是一个现代MPP...