е§ІжґЫе≠¶йХњ
- жµПиІИ: 119898 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еМЧдЇђ
-

з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
AIеК†жМБзЪДйШњйЗМдЇСй£Ю姩姲жХ∞жНЃеє≥еП∞жКАжЬѓжП≠зІШ
иѓіеИ∞йШњйЗМеЈіеЈіе§ІжХ∞жНЃпЉМдЄНеЊЧдЄНжПРеИ∞зЪДжШѓ10еєіеЙНзОЛеЭЪеНЪе£ЂзОЗйҐЖеїЇжЮДзЪДй£Ю姩姲жХ∞жНЃеє≥еП∞пЉМеНБеєіз£®дЄАеЙСпЉМдїК姩й£Ю姩姲жХ∞жНЃеє≥еП∞еЈ≤жШѓйШњйЗМеЈіеЈі10еєіе§Іеє≥еП∞еїЇиЃЊжЬАдљ≥еЃЮиЈµзЪДзїУжЩґпЉМжШѓйШњйЗМе§ІжХ∞жНЃзФЯдЇІзЪДеЯЇзЯ≥гАВй£Ю姩姲жХ∞жНЃеє≥еП∞еЬ®йШњйЗМеЈіеЈійЫЖеЫҐеЖЕжѓП姩жЬЙжХ∞дЄЗеРНжХ∞жНЃеТМзЃЧж≥ХеЉАеПСеЈ•з®ЛеЄИеЬ®дљњзФ®пЉМжЙњиљљдЇЖйШњйЗМ99%зЪДжХ∞жНЃдЄЪеК°жЮДеїЇгАВеРМжЧґдєЯеЈ≤зїПеєњж≥ЫеЇФзФ®дЇОеЯОеЄВе§ІиДСгАБжХ∞е≠ЧжФњеЇЬгАБзФµеКЫгАБйЗСиЮНгАБжЦ∞йЫґеФЃгАБжЩЇиГљеИґйА†гАБжЩЇжЕІеЖЬдЄЪз≠ЙеРДйҐЖеЯЯзЪДе§ІжХ∞жНЃеїЇиЃЊгАВ

еЬ®2015еєізЪДжЧґеАЩпЉМжИСдїђеЉАеІЛеЕ≥ж≥®еИ∞жХ∞жНЃзЪДжµЈйЗПеҐЮйХњеѓєз≥їзїЯеЄ¶жЭ•дЇЖиґКжЭ•иґКйЂШзЪДи¶Бж±ВпЉМйЪПзЭАжЈ±еЇ¶е≠¶дє†зЪДйЬАж±ВеҐЮйХњпЉМжХ∞жНЃеТМжХ∞жНЃеѓєеЇФзЪДе§ДзРЖиГљеКЫжШѓеИґзЇ¶дЇЇеЈ•жЩЇиГљеПСе±ХзЪДеЕ≥йФЃйЧЃйҐШпЉМжИСдїђеЬ®зїЩеЃҐжИЈиБКеИ∞дЄАдЄ™жСЖеЬ®жѓПдЄ™CIO/CTOйЭҐеЙНзЪДзО∞еЃЮйЧЃйҐШвАФвАФе¶ВжЮЬжХ∞жНЃеҐЮйХњ10еАНпЉМеЇФиѓ•жАОдєИеКЮпЉЯеЫЊдЄ≠жХ∞е≠Че§ІеЃґзЬЛеЊЧйЭЮеЄЄжЄЕжЩ∞пЉМйЭЮеЄЄзЃАеНХзЪДжЛНзЂЛжЈШз≥їзїЯиГМеРОжШѓPBзЪДжХ∞жНЃеЬ®еБЪжФѓжТСпЉМйШњйЗМе∞ПиЬЬеЃҐжЬНз≥їзїЯжЬЙ20дЄ™PBпЉМе§ІеЃґжѓП姩еЬ®жЈШеЃЭдЄКжЧ•еЄЄдљњзФ®зЪДдЄ™жАІеМЦжО®иНРз≥їзїЯпЉМеРОеП∞и¶БиґЕињЗ100дЄ™PBзЪДжХ∞жНЃжЭ•жФѓжТСеРОеП∞зЪДеЖ≥з≠ЦпЉМ10еАНеИ∞100еАНзЪДжХ∞жНЃеҐЮйХњжШѓйЭЮеЄЄеЄЄиІБзЪДгАВдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМ10еАНзЪДжХ∞жНЃеҐЮйХњйАЪеЄЄжДПеС≥зЭАдїАдєИйЧЃйҐШпЉЯ
зђђдЄАпЉМжДПеС≥зЭА10еАНжИРжЬђзЪДеҐЮйХњпЉМе¶ВжЮЬиАГиЩСеИ∞еҐЮйХњдЄНжШѓеЭЗеМАзЪДпЉМдЉЪжЬЙж≥Ґе≥∞еТМж≥Ґи∞ЈпЉМеПѓиГљйЬАи¶Б30еАНеЉєжАІи¶Бж±ВпЉЫзђђдЇМпЉМеЃЮйЩЕдЄКеЫ†дЄЇдЇЇеЈ•жЩЇиГљзЪДеЕіиµЈпЉМдЇМзїізїУжЮДжАІзЪДеЕ≥з≥їеЮЛжХ∞жНЃжМБзї≠жАІеҐЮйХњзЪДеРМжЧґпЉМеЄ¶жЭ•зЪДжШѓйЭЮзїУжЮДеМЦжХ∞жНЃпЉМињЩзІНжМБзї≠зЪДжХ∞жНЃеҐЮйХњйЗМйЭҐпЉМдЄАеНКзЪДеҐЮйХњжЭ•иЗ™дЇОињЩзІНйЭЮзїУжЮДеМЦжХ∞жНЃпЉМжИСдїђйЩ§дЇЖиГље§Яе§ДзРЖе•љињЩзІНдЇМзїізЪДжХ∞жНЃеМЦдєЛеРОпЉМжИСдїђе¶ВдљХжЭ•еБЪе•ље§ЪзІНжХ∞жНЃиЮНеРИзЪДиЃ°зЃЧпЉЯзђђдЄЙпЉМйШњйЗМжЬЙдЄАдЄ™еЇЮе§ІзЪДдЄ≠еП∞еЫҐйШЯпЉМе¶ВжЮЬиѓіжИСдїђзЪДжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжИСдїђзЪДеЫҐйШЯжШѓдЄНжШѓеҐЮйХњдЇЖ10еАНпЉЯе¶ВжЮЬиѓіжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжХ∞жНЃзЪДеЕ≥з≥їе§НжЭВеЇ¶дєЯиґЕињЗдЇЖ10еАНпЉМйВ£дєИдЇЇеЈ•зЪДжИРжЬђжШѓдЄНжШѓдєЯиґЕињЗдЇЖ10еАНдї•дЄКпЉМжИСдїђзЪДй£Ю姩еє≥еП∞еЬ®2015еєіеРОе∞±жШѓеЫізїХињЩдЄЙдЄ™еЕ≥йФЃжАІзЪДйЧЃйҐШжЭ•еБЪеЈ•дљЬзЪДгАВ
еОЯеИЫжКАжЬѓдЉШеМЦ + з≥їзїЯиЮНеРИ
=============
ељУйШњйЗМеЈіеЈізЪДе§ІжХ∞жНЃиµ∞ињЗ10дЄЗеП∞иІДж®°зЪДжЧґеАЩпЉМжИСдїђеЈ≤зїПиµ∞еЕ•еИ∞жКАжЬѓзЪДжЧ†дЇЇеМЇпЉМињЩж†ЈзЪДжМСжИШзїЭе§Іе§ЪжХ∞еЕђеПЄдЄНдЄАеЃЪиГљйБЗеИ∞пЉМдљЖжШѓеѓєдЇОйШњйЗМеЈіеЈіињЩж†ЈзЪДдљУйЗПжЭ•иЃ≤пЉМињЩдЄ™жМСжИШжШѓдЄАзЫіжСЖеЬ®жИСдїђйЭҐеЙНзЪДгАВ
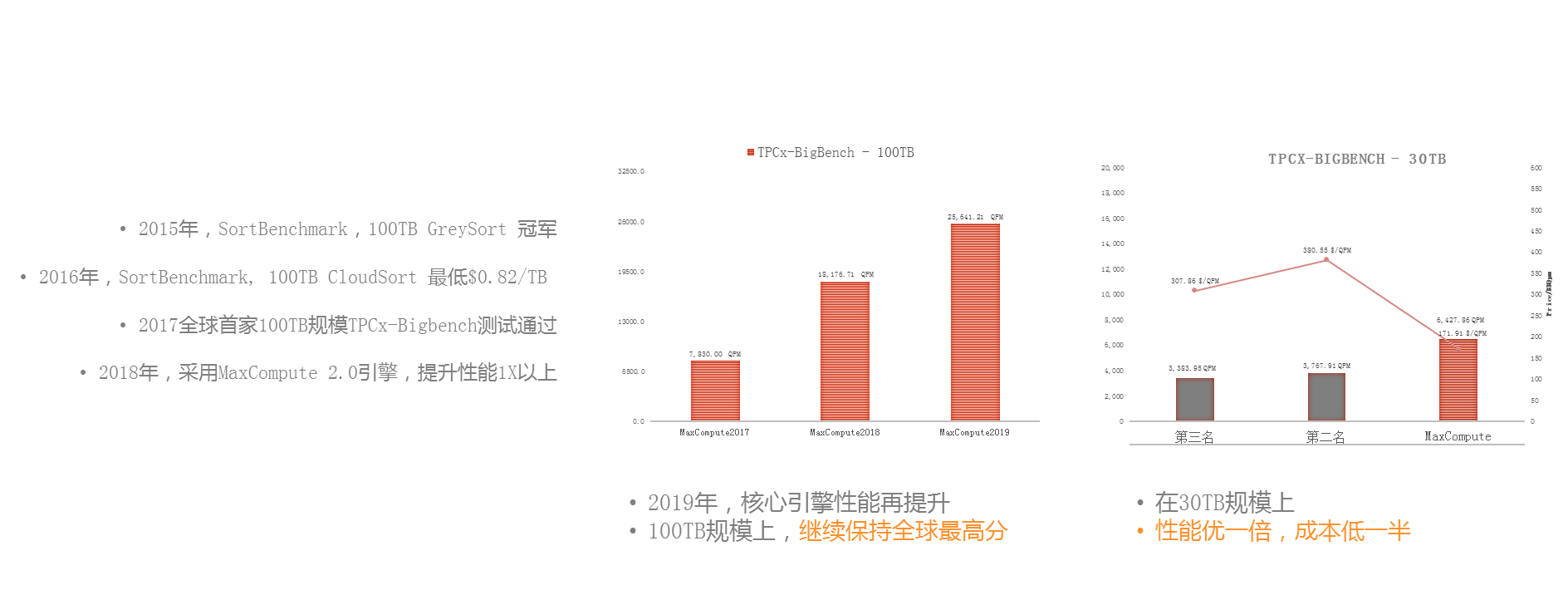
е§ІеЃґеПѓдї•зЬЛеИ∞пЉМ2015еєізЪДжЧґеАЩпЉМжИСдїђжХідЄ™зЪДдљУз≥їеїЇзЂЛиµЈжЭ•дєЛеРОпЉМе∞±еЉАеІЛеБЪеРДзІНеРДж†ЈзЪДBenchmarkпЉМжѓФе¶В2015еєі100TBзЪДSortingпЉМ2016еєіжИСдїђеБЪCloudSortпЉМеОїзЬЛжАІдїЈжѓФпЉМ2017еєіжИСдїђйАЙжЛ©дЇЖBigbenchгАВе¶ВеЫЊжШѓжИСдїђжЬАжЦ∞еПСеЄГзЪДжХ∞жНЃпЉМеЬ®2017гАБ2018еТМ2019еєіпЉМжѓПеєійГљжЬЙдЄАеАНзЪДжАІиГљжПРеНЗпЉМеРМжЧґжИСдїђеЬ®30TBзЪДиІДж®°дЄКжѓФзђђдЇМеРНзЪДдЇІеУБжЬЙдЄАеАНзЪДжАІиГљеҐЮйХњпЉМеєґдЄФжЬЙдЄАеНКзЪДжИРжЬђиКВзЬБпЉМињЩжШѓжИСдїђзЪДиЃ°зЃЧеКЫжМБзї≠дЄКеНЗзЪДдЉШеМЦиґЛеКњгАВ
йВ£дєИпЉМиЃ°зЃЧеКЫжМБзї≠еНЗзЇІжШѓе¶ВдљХеБЪеИ∞зЪДпЉЯе¶ВеЫЊжШѓжИСдїђзїПеЄЄзФ®еИ∞зЪДз≥їзїЯеНЗзЇІзЪДдЄЙиІТзРЖиЃЇпЉМжЬАеЇХе±ВзЪДиЃ°зЃЧж®°еЮЛжШѓйЂШжХИзЪДзЃЧе≠Ре±ВеТМе≠ШеВ®е±ВпЉМињЩжШѓйЭЮеЄЄеЇХе±ВзЪДеЯЇз°АдЉШеМЦпЉМеЊАдЄКйЭҐи¶БжЙЊеИ∞жЬАдЉШзЪДжЙІи°МиЃ°еИТпЉМдєЯе∞±жШѓзЃЧе≠РзїДеРИпЉМеЖНеЊАдЄКжШѓжЦ∞зЪДжЦєеРСпЉМеН≥жАОдєИеБЪеИ∞еК®жАБи∞ГжХідЄОиЗ™е≠¶дє†зЪДи∞ГдЉШгАВ
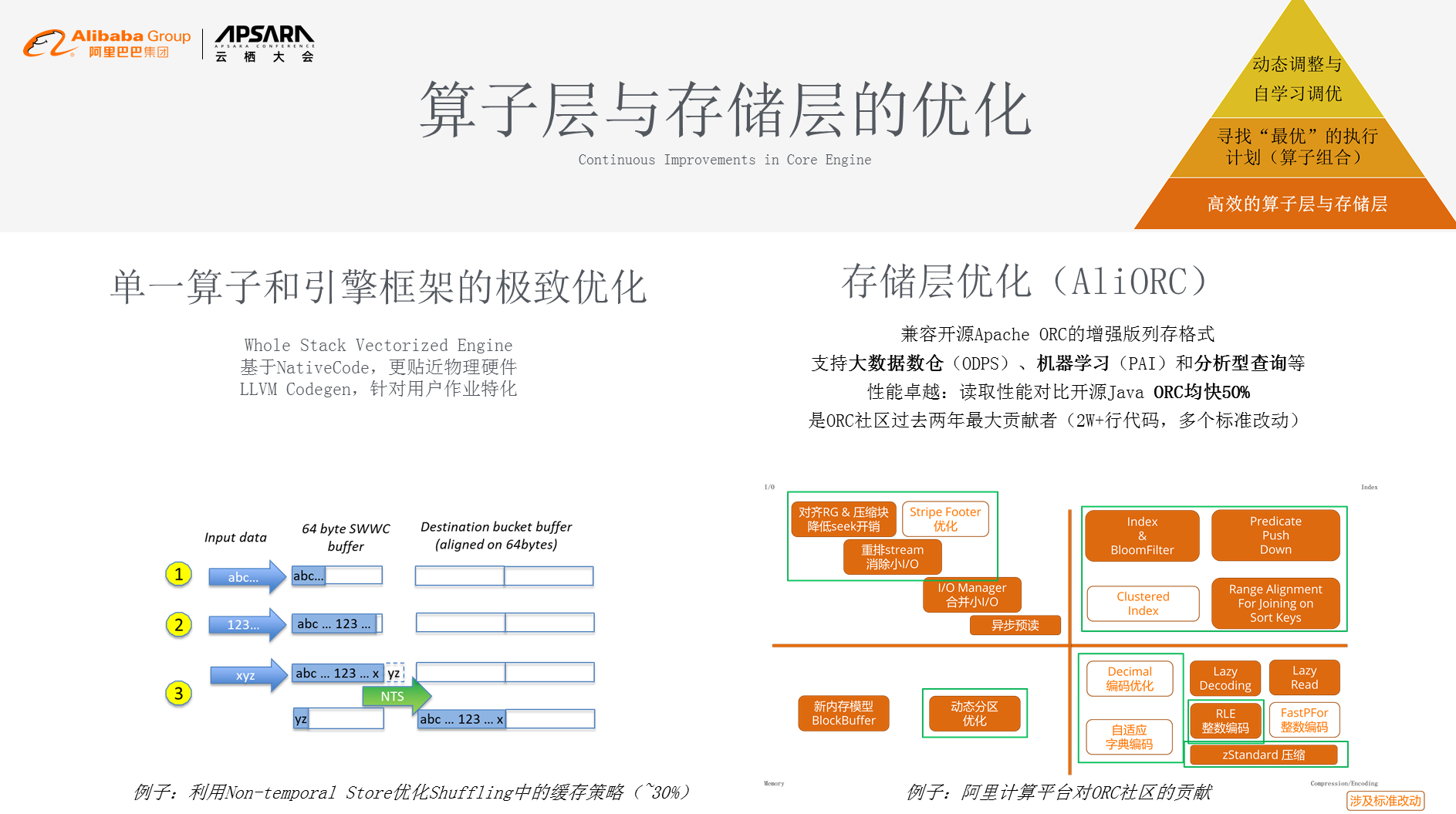
жИСдїђеЕИжЭ•зЬЛеНХдЄАзЃЧе≠РеТМеЉХжУОж°ЖжЮґзЪДжЮБиЗідЉШеМЦпЉМжИСдїђзФ®зЪДжШѓжѓФиЊГйЪЊеЖЩйЪЊзїіжК§зЪДж°ЖжЮґпЉМдљЖжШѓеЫ†дЄЇеЃГжѓФиЊГиііињСзЙ©зРЖз°ђдїґпЉМжЙАдї•еЄ¶жЭ•дЇЖжЫіжЮБиЗізЪДжАІиГљињљж±ВгАВеѓєдЇОеЊИе§Ъз≥їзїЯжЭ•иѓіеПѓиГљ5%зЪДжАІиГљжПРеНЗеєґдЄНеЕ≥йФЃпЉМдљЖеѓєдЇОй£Ю姩жКАжЬѓеє≥еП∞жЭ•иЃ≤пЉМ5%зЪДжАІиГљжПРеНЗе∞±жШѓ5еНГеП∞зЪДиІДж®°пЉМе§Іж¶Ве∞±жШѓ2пљЮ3дЇњзЪДжИРжЬђгАВе¶ВеЫЊеБЪдЇЖдЄАдЄ™зЃАеНХзЪДе∞ПдЊЛе≠РеБЪеНХдЄАзЃЧе≠РзЪДжЮБиЗідЉШеМЦпЉМеЬ®shuffleе≠РеЬЇжЩѓдЄ≠пЉМеИ©зФ®Non-temporal StoreдЉШеМЦshufflingдЄ≠зЪДзЉУе≠Шз≠ЦзХ•пЉМеЬ®ињЩж†ЈзЪДз≠ЦзХ•дЄКжЬЙ30%зЪДжАІиГљжПРеНЗгАВ
йЩ§дЇЖиЃ°зЃЧж®°еЭЧпЉМеЃГињШжЬЙе≠ШеВ®ж®°еЭЧпЉМе≠ШеВ®еИЖдЄЇ4дЄ™и±°йЩРгАВдЄАеЫЫи±°йЩРжШѓе≠ШеВ®жХ∞жНЃжЬђиЇЂзЪДеОЛзЉ©иГљеКЫпЉМжХ∞жНЃеҐЮйХњжЬАзЫіжО•зЪДжИРжЬђе∞±жШѓе≠ШеВ®жИРжЬђзЪДдЄКеНЗпЉМжИСдїђжАОдєИеБЪжЫіе•љзЪДеОЛзЉ©еТМзЉЦз†Бдї•еПКindexingпЉЯињЩжШѓдЄАеЫЫи±°йЩРеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉЫдЇМдЄЙи±°йЩРжШѓеЬ®жАІиГљиКВзЬБдЄКеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉМжИСдїђе≠ШеВ®е±ВеЕґеЃЮжШѓеЯЇдЇОеЉАжЇРORCзЪДж†ЗеЗЖпЉМжИСдїђеЬ®дЄКйЭҐеБЪдЇЖйЭЮеЄЄе§ЪзЪДжФєињЫеТМдЉШеМЦпЉМеЕґдЄ≠зЩљж°ЖйЗМйЭҐйГљжЬЙйЭЮеЄЄе§ЪзЪДж†ЗеЗЖжФєеК®пЉМжИСдїђиѓїеПЦжАІиГљеѓєжѓФеЉАжЇРJava ORC еЭЗењЂ 50%пЉМжИСдїђжШѓORCз§ЊеМЇињЗеОїдЄ§еєіжЬАе§Іиі°зМЃиАЕпЉМиі°зМЃдЇЖ2W+и°Мдї£з†БпЉМињЩжШѓжИСдїђеЬ®зЃЧе≠Ре±ВеТМе≠ШеВ®е±ВзЪДдЉШеМЦпЉМињЩжШѓжЬАеЇХе±ВзЪДжЮґжЮДгАВ

дљЖжШѓдїОеП¶е§ЦдЄАдЄ™е±ВйЭҐдЄКжЭ•иЃ≤пЉМеНХдЄАзЪДзЃЧе≠РеТМйГ®еИЖзЪДзЃЧе≠РзїДеРИеЊИйЪЊжї°иґ≥йГ®еИЖзЪДеЬЇжЩѓйЬАж±ВпЉМжЙАдї•жИСдїђе∞±жПРеИ∞зБµжіїзЪДзЃЧе≠РзїДеРИгАВдЄЊеЗ†дЄ™жХ∞е≠ЧпЉМжИСдїђеЬ®JoinдЄКжЬЙ4зІНж®°еЉПпЉМжЬЙ3зІНShufflingж®°еЉПжПРдЊЫпЉМжЬЙ3зІНдљЬдЄЪињРи°Мж®°еЉПпЉМжЬЙе§ЪзІНз°ђдїґжФѓжМБеТМе§ЪзІНе≠ШеВ®дїЛиі®жФѓжМБгАВеЫЊеП≥жШѓжАОж†ЈеОїеК®жАБеИ§еИЂJoinж®°еЉПпЉМдљњеЊЧињРзЃЧжХИзОЗжЫійЂШгАВйАЪињЗињЩзІНеК®жАБзЪДзЃЧе≠РзїДеРИпЉМжШѓжИСдїђдЉШеМЦзЪДзђђдЇМдЄ™зїіеЇ¶гАВ
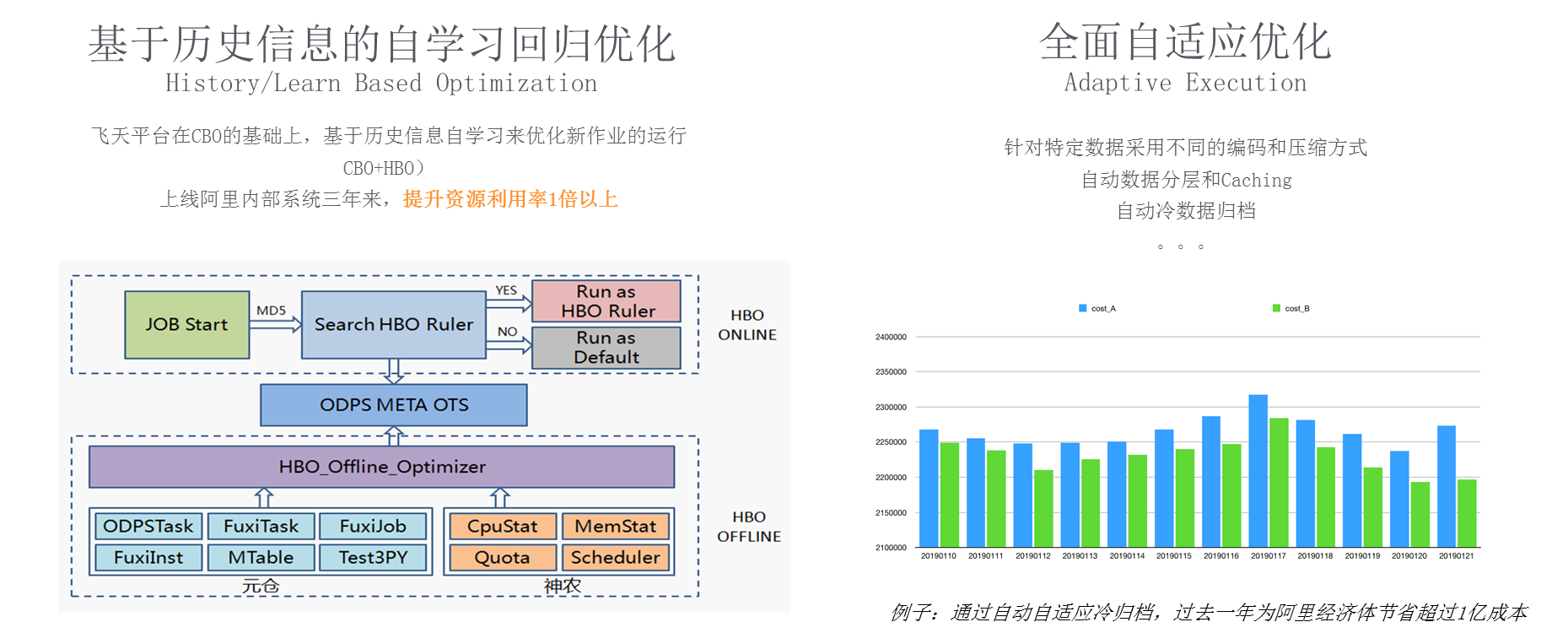
дїОеЉХжУОдЉШеМЦеИ∞иЗ™е≠¶дє†и∞ГдЉШжШѓжИСдїђеЬ®жЬАињС1еєіе§ЪзЪДжЧґйЧійЗМиК±з≤ЊеКЫжѓФиЊГе§ЪзЪДпЉМжИСдїђеЬ®иАГиЩСе¶ВдљХзФ®дЇЇеЈ•жЩЇиГљеПКиЗ™е≠¶дє†жКАжЬѓжЭ•еБЪе§ІжХ∞жНЃз≥їзїЯпЉМе§ІеЃґеПѓдї•жГ≥и±°е≠¶й™СиЗ™и°Миљ¶пЉМеИЪеЉАеІЛй™СеЊЧдЄНе•љпЉМйАЯеЇ¶жѓФиЊГжЕҐзФЪиЗ≥жЬЙзЪДжЧґеАЩдЉЪжСФеАТпЉМйАЪињЗжЕҐжЕҐзЪДе≠¶дє†пЉМдЇЇзЪДиГљеКЫдЉЪиґКжЭ•иґКе•љгАВеѓєдЇОдЄАдЄ™з≥їзїЯиАМи®АпЉМжИСдїђжШѓеР¶еПѓдї•зФ®еРМж†ЈзЪДжЦєеЉПжЭ•еБЪпЉЯељУдЄАдЄ™еЕ®жЦ∞зЪДдљЬдЄЪжПРдЇ§еИ∞ињЩдЄ™з≥їзїЯжЧґпЉМз≥їзїЯеѓєдљЬдЄЪзЪДдЉШеМЦжШѓжѓФиЊГдњЭеЃИзЪДпЉМжѓФе¶Вз®НеЊЃе§ЪзїЩдЄАзВєиµДжЇРпЉМйВ£дєИжИСйАЙжЛ©зЪДжЙІи°МиЃ°еИТдЉЪзЫЄеѓєжѓФиЊГдњЭеЃИдЄАзВєпЉМдљњеЊЧиЗ≥е∞СиГље§ЯиЈСињЗеОїпЉМељУиЈСињЗдєЛеРОе∞±иГље§ЯжРЬйЫЖеИ∞дњ°жБѓеТМзїПй™МпЉМйАЪињЗињЩдЇЫзїПй™МеЖНеПНеУЇеОїдЉШеМЦжХ∞жНЃпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™еЯЇдЇОеОЖеП≤дњ°жБѓзЪДиЗ™е≠¶дє†еЫЮељТдЉШеМЦпЉМеЇХе±ВжШѓе¶ВеЫЊзЪДжЮґжЮДеЫЊпЉМжИСдїђжККеОЖеП≤дњ°жБѓжФЊеЬ®OFFLINE systemеОїеБЪеРДзІНеРДж†ЈзЪДзїЯиЃ°еИЖжЮРпЉМељУдљЬдЄЪжЭ•дЇЖдєЛеРОжИСдїђжККињЩдЇЫдњ°жБѓеПНеУЇеИ∞з≥їзїЯдєЛдЄ≠еОїпЉМиЃ©з≥їзїЯињЫи°МиЗ™е≠¶дє†гАВйАЪеЄЄжГЕеЖµдЄЛпЉМдЄАдЄ™зЫЄдЉЉзЪДдљЬдЄЪе§Іж¶ВиЈСдЇЖ3еИ∞4жђ°зЪДжЧґеАЩпЉМињЫеЕ•еИ∞дЄАдЄ™зЫЄеѓєжѓФиЊГдЉШзЪДињЗз®ЛпЉМдЉШжМЗзЪДжШѓдљЬдЄЪињРи°МжЧґйЧіеТМз≥їзїЯиµДжЇРиКВзЬБгАВињЩе•Чз≥їзїЯе§Іж¶ВеЬ®йШњйЗМеЖЕйГ®3еєіеЙНдЄКзЇњзЪДпЉМжИСдїђйАЪињЗињЩж†ЈзЪДз≥їзїЯжККйШњйЗМзЪДж∞ідљНзЇњдїО40%жПРеНЗеИ∞70%дї•дЄКгАВ
еП¶е§ЦеЫЊдЄ≠еП≥дЊІдєЯжШѓдЄАдЄ™иЗ™е≠¶дє†зЪДдЊЛе≠РпЉМжИСдїђжАОдєИеМЇеИЖзГ≠жХ∞жНЃеТМеЖЈжХ∞жНЃпЉМдєЛеЙНеПѓдї•иЃ©зФ®жИЈиЗ™еЈ±еОїsetпЉМеПѓдї•зФ®дЄАдЄ™жЩЃйАЪзЪДconfigurationеОїйЕНзљЃпЉМеРОжЭ•еПСзО∞жИСдїђйЗЗзФ®еК®жАБзЪДж†єжНЃдљЬдЄЪжЦєеЉПжЭ•еБЪпЉМжХИжЮЬдЉЪжЫіе•љпЉМињЩдЄ™жКАжЬѓжШѓеОїеєідЄКзЇњзЪДпЉМеОїеєідЄЇйШњйЗМиКВзЇ¶дЇЖ1дЇњ+дЇЇж∞СеЄБгАВдїОдї•дЄКеЗ†дЄ™дЊЛе≠РдЄКжЭ•иЃ≤еЉХжУОе±ВйЭҐеТМе≠ШеВ®е±ВйЭҐеБЪзЪДжЮБиЗіжАІиГљдЉШеМЦпЉМжАІиГљдЉШеМЦеПИеЄ¶жЭ•дЇЖзФ®жИЈжИРжЬђзЪДйЩНдљОпЉМеЬ®2019еєі9жЬИ1еПЈпЉМй£Ю姩姲жХ∞жНЃеє≥еП∞зЪДжХідљУе≠ШеВ®жИРжЬђйЩНдљОдЇЖ30%пЉМеРМжЧґжИСдїђеПСеЄГдЇЖеЯЇдЇОеОЯзФЯиЃ°зЃЧзЪДжЦ∞иІДж†ЉпЉМеПѓдї•еЃЮзО∞жЬАйЂШ70%зЪДжИРжЬђиКВзЬБгАВ
дї•дЄКйГљжШѓеЬ®еЉХжУОе±ВйЭҐзЪДдЉШеМЦпЉМйЪПзЭАAIзЪДжЩЃжГ†дЉШеМЦпЉМAIзЪДеЉАеПСдЇЇеСШдЉЪиґКжЭ•иґКе§ЪпЉМзФЪиЗ≥еЊИе§ЪдЇЇйГљдЄН姙еЕЈе§Здї£з†БзЪДиГљеКЫпЉМйШњйЗМеЖЕйГ®жЬЙ10дЄЗеРНеСШеЈ•пЉМжѓП姩жЬЙиґЕињЗ1дЄЗдЄ™еСШеЈ•еЬ®й£Ю姩姲жХ∞жНЃеє≥еП∞дЄКеБЪеЉАеПСпЉМдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМдЄНдїЕз≥їзїЯзЪДдЉШеМЦжШѓйЗНи¶БзЪДпЉМеє≥еП∞еТМеЉАеПСеє≥еП∞зЪДдЉШеМЦдєЯжШѓйЭЮеЄЄеЕ≥йФЃзЪДгАВ
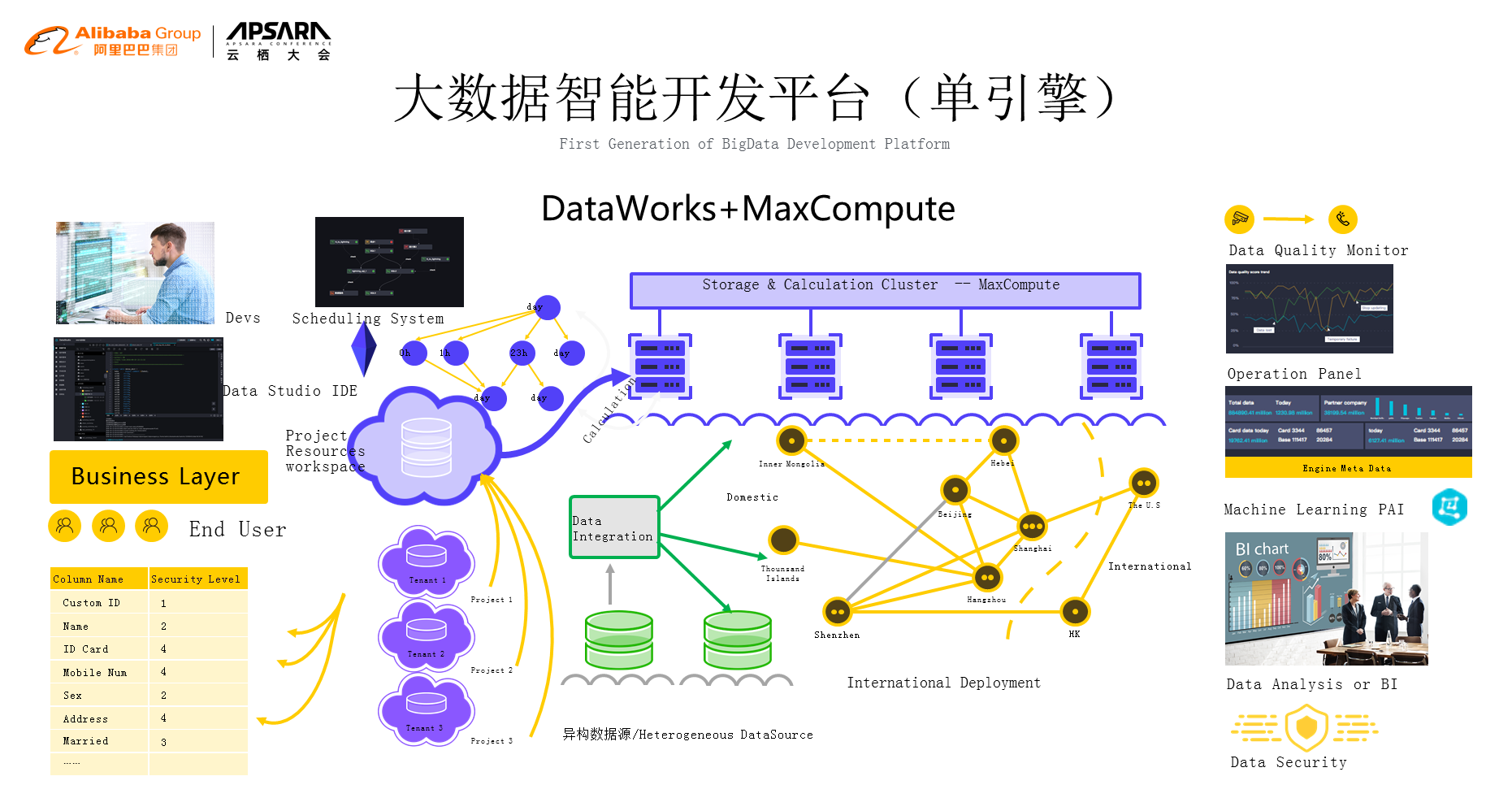
иЃ°зЃЧеЉХжУОеѓєе§ІеЃґжЭ•иѓізЬЛдЄНиІБжСЄдЄНзЭАпЉМжИСдїђи¶БеОїзФ®еЃГиВѓеЃЪеЄМжЬЫзФ®жЬАзЃАеНХзЪДжЦєеЉПпЉМеЕИжЭ•зЬЛдЄАдЄЛMaxcomputeиЃ°зЃЧеЉХжУОгАВй¶ЦеЕИжИСдїђйЬАи¶БжЬЙзФ®жИЈпЉМзФ®жИЈжАОдєИжЭ•дљњзФ®пЉЯйЬАи¶БиµДжЇРйЪФз¶їпЉМдєЯе∞±жШѓиѓіжѓПдЄ™зФ®жИЈеЬ®з≥їзїЯдЄКйЭҐдљњзФ®зЪДжЧґеАЩдЉЪеѓєеЇФзЭАиі¶еПЈпЉМиі¶еПЈдЉЪеѓєеЇФзЭАжЭГйЩРпЉМињЩж†Је∞±жККжХіе•ЧдЄЬи•њдЄ≤иБФиµЈжЭ•гАВдїК姩жИСзЪДзФ®жИЈжАОдєИзФ®пЉЯзФ®еУ™дЇЫйГ®еИЖпЉЯињЩжШѓзђђдЄАйГ®еИЖгАВзђђдЇМйГ®еИЖжШѓеЉАеПСпЉМеЉАеПСжЬЙIDEпЉМIDEзФ®жЭ•еЖЩдї£з†БпЉМеЖЩеЃМдї£з†БдєЛеРОжПРдЇ§пЉМжПРдЇ§дєЛеРОе≠ШеЬ®дЄАдЄ™и∞ГеЇ¶зЪДйЧЃйҐШпЉМињЩдєИе§ЪзЪДиµДжЇРдїїеК°й°ЇеЇПжШѓдїАдєИпЉЯи∞БеЕИи∞БеРОпЉМеЗЇдЇЖйЧЃйҐШи¶БдЄНи¶БдЄ≠жЦ≠пЉМињЩдЇЫйГљзФ±и∞ГеЇ¶з≥їзїЯжЭ•зЃ°пЉМжИСдїђзЪДињЩдЇЫдїїеК°е∞±жЬЙеПѓиГљеЬ®дЄНеРМзЪДеЬ∞жЦєжЭ•ињРи°МпЉМеПѓдї•йАЪињЗжХ∞жНЃйЫЖжИРжККеЃГжЛЙеИ∞дЄНеРМзЪДеМЇеЯЯпЉМиЃ©ињЩдЇЫжХ∞жНЃиГље§ЯеЬ®жХідЄ™зЪДеє≥еП∞дЄКиЈСиµЈжЭ•пЉМжИСдїђжЙАжЬЙзЪДдїїеК°иЈСиµЈжЭ•дєЛеРОжИСдїђйЬАи¶БжЬЙдЄАдЄ™зЫСжОІпЉМеРМжЧґжИСдїђзЪДoperationдєЯйЬАи¶БиЗ™еК®еМЦгАБињРзїіеМЦпЉМеЖНеЊАдЄЛжИСдїђдЉЪињЫи°МжХ∞жНЃзЪДеИЖжЮРжИЦиАЕBIжК•и°®дєЛз±їзЪДпЉМжИСдїђдєЯдЄНиГље§ЯењШиЃ∞machine learningдєЯжШѓеЬ®жИСдїђзЪДеє≥еП∞дЄКйЫЖжИРиµЈжЭ•зЪДгАВжЬАеРОпЉМжЬАйЗНи¶БзЪДе∞±жШѓжХ∞жНЃеЃЙеЕ®пЉМињЩдЄАеЭЧжХідЄ™дЄЬи•њжЮДиµЈдЄАдЄ™е§ІжХ∞жНЃеЉХжУОзЪДе§Цж≤њ+е§ІжХ∞жНЃеЉХжУОжЬђиЇЂпЉМињЩдЄАе•ЧжИСдїђзІ∞дєЛдЄЇеНХеЉХжУОзЪДеЃМе§Зе§ІжХ∞жНЃз≥їзїЯпЉМињЩдЄАе•Чз≥їзїЯжИСдїђеЬ®2017еєізЪДжЧґеАЩе∞±еЕЈе§ЗдЇЖгАВ

2018еєізЪДжЧґеАЩжИСдїђеБЪдїАдєИпЉЯ2018еєіжИСдїђеЬ®еНХеЉХжУОзЪДеЯЇз°АдЄКеѓєжО•еИ∞е§ЪеЉХжУОпЉМжИСдїђжХідЄ™еЉАеПСйУЊиЈѓи¶БиЃ©еЃГйЧ≠зОѓеМЦпЉМжХ∞жНЃйЫЖжИРеПѓдї•жККжХ∞жНЃеЬ®дЄНеРМзЪДжХ∞жНЃжЇРдєЛйЧіињЫи°МжЛЦеК®пЉМжИСдїђжККжХ∞жНЃеЉАеПСеЃМдєЛеРОпЉМдЉ†зїЯзЪДжЦєеЉПжШѓеЖНзФ®жХ∞жНЃеЉХжУОжККеЃГжЛЦиµ∞пЉМиАМжИСдїђеБЪзЪДдЇЛжГЕжШѓеЄМжЬЫињЩдЄ™жХ∞жНЃжШѓдЇСдЄКзЪДжЬНеК°пЉМињЩдЄ™жЬНеК°иГље§ЯзЫіжО•еѓєзФ®жИЈжПРдЊЫжГ≥и¶БзЪДжХ∞жНЃпЉМиАМдЄНйЬАи¶БжККжХ∞жНЃжХідЄ™жЛЦиµ∞пЉМеЫ†дЄЇжХ∞жНЃеЬ®дЉ†иЊУињЗз®ЛдЄ≠жЬЙе≠ШеВ®зЪДжґИиАЧгАБзљСзїЬзЪДжґИиАЧеТМдЄАиЗіжАІжґИиАЧпЉМжЙАжЬЙзЪДињЩдЇЫдЄЬи•њйГљеЬ®жґИиАЧзФ®жИЈзЪДжИРжЬђпЉМжИСдїђеЄМжЬЫйАЪињЗжХ∞жНЃжЬНеК°иЃ©зФ®жИЈжЛњеИ∞дїЦжГ≥и¶БзЪДдЄЬи•њгАВеЖНеЊАдЄЛпЉМе¶ВжЮЬжХ∞жНЃжЬНеК°дєЛдЄКињШжЬЙиЗ™еЃЪдєЙзЪДеЇФзФ®пЉМзФ®жИЈињШйЬАи¶БеОїеїЇдЄАдЄ™жЬЇжИњпЉМжР≠дЄАдЄ™webжЬНеК°пЉМзДґеРОжККжХ∞жНЃжЛњињЗжЭ•пЉМињЩж†ЈдєЯеЊИйЇїзГ¶пЉМжЙАдї•жИСдїђжПРдЊЫдЄАдЄ™жЙШзЃ°зЪДwebеЇФзФ®зЪДдЇСдЄКеЉАеПСеє≥еП∞пЉМиГље§ЯиЃ©зФ®жИЈзЫіжО•зЬЛеИ∞жЙАжЬЙзЪДжХ∞жНЃжЬНеК°пЉМеЬ®ињЩдЄ™жЦєеРСдЄКжЭ•иѓіпЉМжИСдїђе∞±еПѓдї•жЮДеїЇдїїжДПзЪДжХ∞жНЃжЩЇиГљиІ£еЖ≥жЦєж°ИгАВ
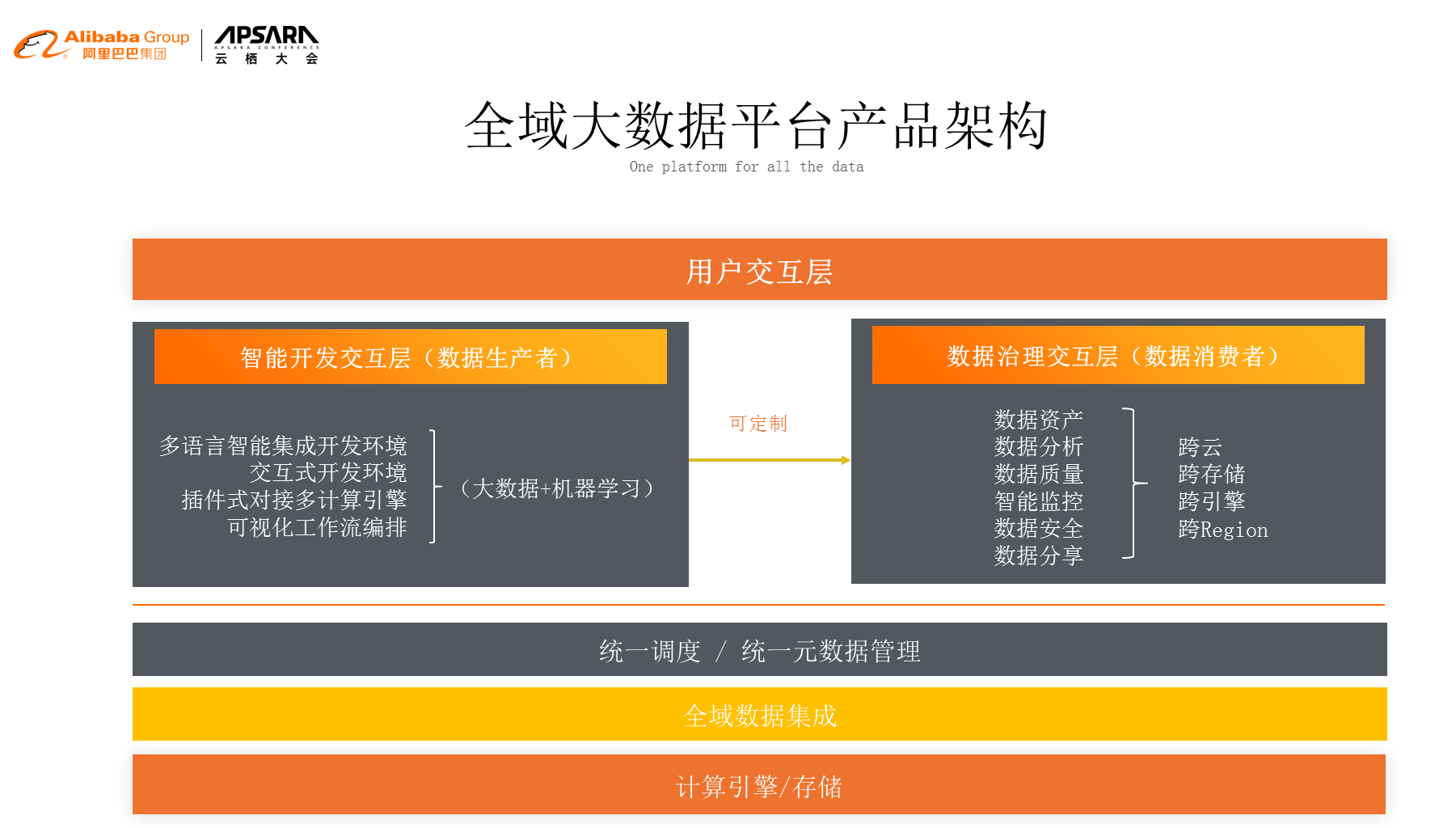
еИ∞2019еєіпЉМжИСдїђдЉЪжККзРЖењµеЖНжЛУе±ХдЄАе±ВпЉМй¶ЦеЕИеѓєдЇОзФ®жИЈжЭ•иѓіжШѓзФ®жИЈдЇ§дЇТе±ВпЉМдљЖжШѓзФ®жИЈзЪДдЇ§дЇТе±ВдЄНдїЕдїЕжШѓеЉАеПСпЉМжЙАдї•жИСдїђдЉЪжККзФ®жИЈеИЖжИРдЄ§з±їпЉМдЄАйГ®еИЖеПЂеБЪжХ∞жНЃзЪДзФЯдЇІиАЕпЉМдєЯе∞±жШѓеЖЩдїїеК°гАБеЖЩи∞ГеЇ¶гАБињРзїіз≠ЙпЉМињЩдЇЫжШѓжХ∞жНЃзЪДзФЯдЇІиАЕпЉМжХ∞жНЃзЪДзФЯдЇІиАЕеБЪе•љзЪДдЄЬи•њзїЩи∞БеСҐпЉЯзїЩжХ∞жНЃзЪДжґИиієиАЕпЉМжИСдїђзЪДжХ∞жНЃеИЖжХ£еЬ®еРДдЄ™еЬ∞жЦєпЉМжЙАжЬЙзЪДдЄЬи•њйГљдЉЪеЬ®ж≤їзРЖзЪДдЇ§дЇТе±ВеѓєжХ∞жНЃзЪДжґИиієиАЕжПРдЊЫжЬНеК°пЉМињЩж†ЈжИСдїђе∞±еЬ®дЄАдЄ™жЦ∞зЪДиІТеЇ¶жЭ•иѓ†йЗКй£Ю姩姲жХ∞жНЃеє≥еП∞гАВйЩ§дЇЖеЉХжУОе≠ШеВ®дї•е§ЦпЉМжИСдїђжЬЙеЕ®еЯЯзЪДжХ∞жНЃйЫЖжИРињЫи°МжЛЙеК®пЉМзїЯдЄАзЪДи∞ГеЇ¶еПѓдї•еЬ®дЄНеРМзЪДеЉХжУОдєЛйЧіжЭ•еИЗжНҐеНПеРМеЈ•дљЬпЉМеРМжЧґжИСдїђжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМеЬ®ињЩдєЛдЄКжИСдїђеѓєжХ∞жНЃзЪДзФЯдЇІиАЕеТМжХ∞жНЃзЪДжґИиієиАЕдєЯйГљињЫи°МдЇЖзЫЄеЇФзЪДжФѓжМБпЉМйВ£дєИињЩдЄ™жХідљУе∞±жШѓеЕ®еЯЯзЪДе§ІжХ∞жНЃеє≥еП∞дЇІеУБжЮґжЮДгАВ
дЇСеОЯзФЯеє≥еП∞еИ∞еЕ®еЯЯдЇСжХ∞дїУ
===========
жИСдїђжХідЄ™еє≥еП∞йГљжШѓдЇСеОЯзФЯзЪДпЉМдЇСеОЯзФЯжЬЙеУ™дЇЫжКАжЬѓеСҐпЉЯ
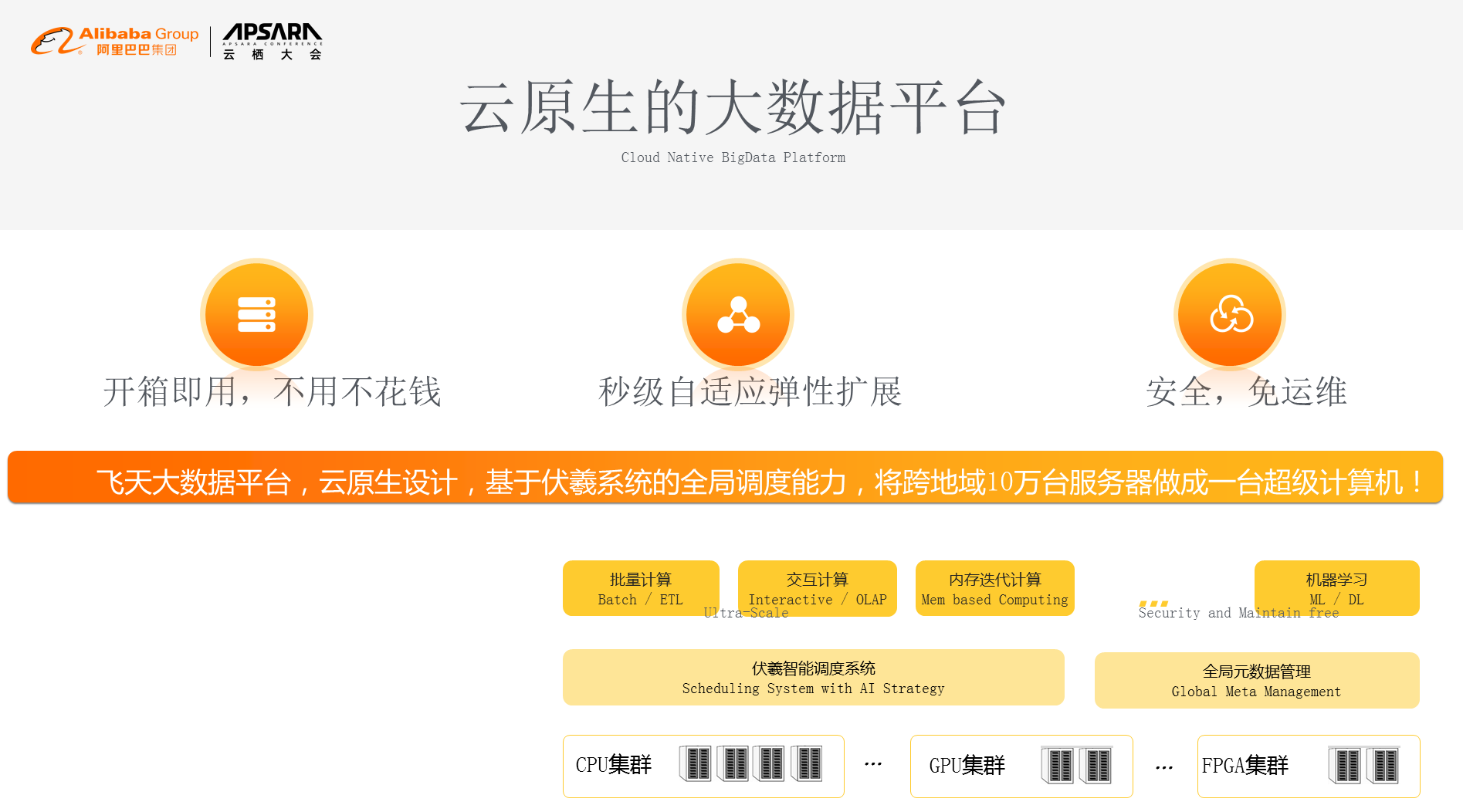
й£Ю姩姲жХ∞жНЃеє≥еП∞еЬ®10еєіеЙНе∞±еЭЪжМБдЇСеОЯзФЯзЪДжХ∞жНЃпЉМдЇСеОЯзФЯжДПеС≥зЭАдЄЙдїґдЇЛжГЕпЉМзђђдЄАеЉАзЃ±еН≥зФ®гАБдЄНзФ®дЄНиК±йТ±пЉМињЩдЄ™еТМдЉ†зїЯзЪДдє∞з°ђдїґжЦєеЉПжЬЙйЭЮеЄЄе§ІзЪДдЄНеРМпЉЫзђђдЇМжИСдїђеЕЈе§ЗдЇЖзІТзЇІиЗ™йАВеЇФзЪДеЉєжАІжЙ©е±ХпЉМзФ®е§Ъе∞Сдє∞е§Ъе∞СпЉЫзђђдЄЙеЫ†дЄЇжШѓдЇСдЄКзЪДж°ЖжЮґпЉМжИСдїђеЊИе§ЪињРзїіеТМеЃЙеЕ®зЪДдЄЬи•њзФ±дЇСиЗ™еК®жЭ•еЃМжИРдЇЖпЉМжЙАдї•жШѓеЃЙеЕ®еЕНињРзїізЪДгАВдїОз≥їзїЯжЮґжЮДдЄКиЃ≤пЉМй£Ю姩姲жХ∞жНЃеМЕжЛђдЉ†зїЯзЪДCPUгАБGPUйЫЖзЊ§пЉМдї•еПКеє≥е§іеУ•иКѓзЙЗйЫЖзЊ§пЉМеЖНеЊАдЄКжШѓжИСдїђзЪДдЉПзЊ≤жЩЇиГљи∞ГеЇ¶з≥їзїЯеТМеЕГжХ∞жНЃз≥їзїЯпЉМеЖНеЊАдЄКжИСдїђжПРдЊЫдЇЖе§ЪзІНиЃ°зЃЧиГљеКЫпЉМжИСдїђжЬАйЗНи¶БзЪДзЫЃж†Зе∞±жШѓйАЪињЗдЇСеОЯзФЯиЃЊиЃ°жКК10дЄЗеП∞еЬ®зЙ©зРЖдЄКеИЖеЄГеЬ®дЄНеРМеЬ∞еЯЯзЪДжЬНеК°еЩ®иЃ©зФ®жИЈиІЙеЊЧеГПдЄАеП∞иЃ°зЃЧжЬЇгАВжИСдїђдїК姩еЈ≤зїПиЊЊеИ∞дЇЖ10еєіеЙНзЪДиЃЊиЃ°и¶Бж±ВпЉМеЕЈе§ЗдЇЖжЫіеЉЇзЪДжЬНеК°жЙ©е±ХиГљеКЫпЉМиГље§ЯжФѓжТС5еИ∞10еєізЪДжХ∞жНЃињЫж≠•зЪДеПСе±ХгАВ
жИСдїђеЕЕеИЖеИ©зФ®дЇСеОЯзФЯиЃЊиЃ°зЪДзРЖењµпЉМжФѓжМБе§ІжХ∞жНЃеТМжЬЇеЩ®е≠¶дє†зЪДењЂйАЯе§ІиІДж®°еЉєжАІиіЯиљљйЬАж±ВгАВжИСдїђжФѓжТС0пљЮ100еАНзЪДеЉєжАІжЙ©еЃєиГљеКЫпЉМеОїеєіеЉАеІЛпЉМеПМеНБдЄА60%зЪДжХ∞жНЃе§ДзРЖйЗПжЭ•иЗ™дЇОе§ІжХ∞жНЃеє≥еП∞зЪДе§ДзРЖиГљеКЫпЉМељУеПМ11еЈЕе≥∞жЭ•зЪДжЧґеАЩпЉМжИСдїђжККе§ІжХ∞жНЃзЪДиµДжЇРеЉєеЫЮжЭ•иЃ©зїЩеЬ®зЇњз≥їзїЯеОїе§ДзРЖйЧЃйҐШгАВдїОеП¶е§ЦдЄАдЄ™иІТеЇ¶жЭ•иЃ≤пЉМжИСдїђеЕЈе§ЗеЉєжАІиГљеКЫпЉМзЫЄжѓФзЙ©зРЖзЪДIDCж®°еЉПпЉМжИСдїђжЬЙ80%жИРжЬђзЪДиКВзЬБпЉМжМЙдљЬдЄЪзЪДиЃ°иієж®°еЉПпЉМжИСдїђжПРдЊЫзІТзЇІеЉєжАІдЉЄзЉ©зЪДеРМжЧґпЉМдЄНдљњзФ®дЄНжФґиієгАВзЫЄжѓФиЗ™еїЇIDCпЉМзїЉеРИжИРжЬђеП™жЬЙ1/5гАВйЩ§дЇЖеЭЪжМБеОЯзФЯдєЛе§ЦпЉМжИСдїђжЬАињСеПСзО∞пЉМйЪПзЭАдЇЇеЈ•жЩЇиГљзЪДеПСе±ХпЉМиѓ≠йЯ≥иІЖеЫЊзЪДжХ∞жНЃиґКжЭ•иґКе§ЪдЇЖпЉМе§ДзРЖзЪДиГљеКЫе∞±и¶БеК†еЉЇпЉМжИСдїђи¶БдїОдЇМзїізЪДе§ІжХ∞жНЃеє≥еП∞еПШжИРеЕ®еЯЯзЪДжХ∞жНЃеє≥еП∞гАВ
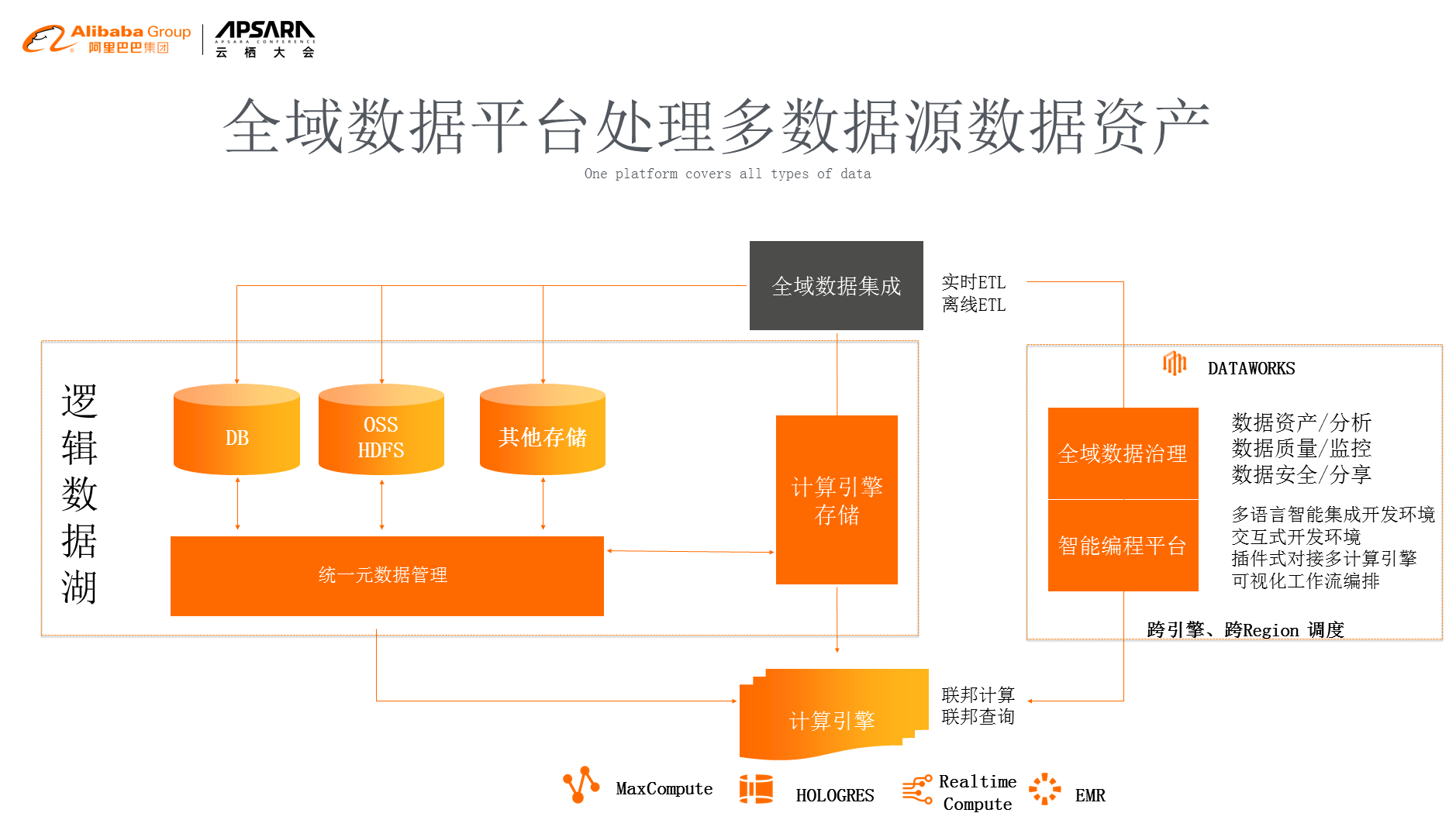
е¶ВеЫЊжЙАз§ЇпЉМдЄЪзХМжЬЙдЄАдЄ™жѓФиЊГзБЂзЪДж¶ВењµеПЂжХ∞жНЃжєЦпЉМжИСдїђи¶БжККеЃҐжИЈе§ЪзІНе§Ъж†ЈзЪДжХ∞жНЃжЛњеИ∞дЄАиµЈжЭ•ињЫи°МзїЯдЄАзЪДжߕ胥еТМзЃ°зРЖгАВдљЖжШѓеѓєдЇОзЬЯж≠£зЪДдЉБдЄЪзЇІжЬНеК°еЃЮиЈµпЉМжИСдїђзЬЛеИ∞дЄАдЇЫйЧЃйҐШпЉМй¶ЦеЕИжХ∞жНЃзЪДжЭ•жЇРеѓєдЇОеЃҐжИЈжЭ•иѓіжШѓдЄНеПѓжОІзЪДпЉМдєЯжШѓе§ЪзІНе§Ъж†ЈзЪДпЉМиАМдЄФеЊИе§Із®ЛеЇ¶дЄКж≤°жЬЙеКЮж≥ХжККжЙАжЬЙзЪДжХ∞жНЃзїЯдЄАзФ®дЄАзІНз≥їзїЯеТМеЉХжУОжЭ•зЃ°зРЖиµЈжЭ•пЉМеЬ®ињЩзІНжГЕеЖµдЄЛжИСдїђйЬАи¶БжЫіе§ІзЪДиГљеКЫжШѓдїАдєИеСҐпЉЯжИСдїђдїК姩йАЪињЗдЄНеРМзЪДжХ∞жНЃжЇРпЉМеПѓдї•ињЫи°МзїЯдЄАзЪДиЃ°зЃЧеТМзїЯдЄАзЪДжߕ胥еТМеИЖжЮРпЉМзїЯдЄАзЪДзЃ°зРЖпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™жЫіжЦ∞зЪДж¶ВењµеПЂйАїиЊСжХ∞жНЃжєЦпЉМеѓєдЇОзФ®жИЈжЭ•иѓіпЉМдЄНйЬАи¶БжККдїЦзЪДжХ∞жНЃињЫи°МзЙ©зРЖдЄКзЪДжРђињБпЉМдљЖжШѓжИСдїђдЄАж†ЈиГље§ЯињЫи°МиБФйВ¶иЃ°зЃЧеТМжߕ胥пЉМињЩе∞±жШѓжИСдїђиЃ≤зЪДйАїиЊСжХ∞жНЃжєЦзЪДж†ЄењГзРЖењµгАВ
дЄЇдЇЖжФѓжТСињЩдїґдЇЛжГЕпЉМжИСдїђдЉЪжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖз≥їзїЯеТМи∞ГеЇ¶з≥їзїЯпЉМиГље§ЯиЃ©дЄНеРМзЪДиЃ°зЃЧеЉХжУОеНПеРМиµЈжЭ•еЈ•дљЬпЉМжЬАеРОжККжЙАжЬЙзЪДеЈ•дљЬж±ЗиБЪеИ∞еЕ®еЯЯжХ∞жНЃж≤їзРЖдЄКйЭҐпЉМеєґдЄФжПРдЊЫзїЩжХ∞жНЃеЉАеПСиАЕдЄАдЄ™зЉЦз®Леє≥еП∞пЉМиЃ©дїЦиГље§ЯзЫіжО•зЪДдЇІзФЯжХ∞жНЃпЉМжИЦиАЕжШѓеОїеЃЪеИґиЗ™еЈ±зЪДеЇФзФ®гАВйВ£дєИпЉМйАЪињЗињЩж†ЈзЪДжЦєеЉПпЉМжИСдїђжККеОЯжЭ•зЪДеНХзїіеЇ¶е§ІжХ∞жНЃеє≥еП∞еОїеБЪе§ІжХ∞жНЃе§ДзРЖпЉМжЛУе±ХеИ∞дЄАдЄ™еЕ®еЯЯзЪДжХ∞жНЃж≤їзРЖпЉМињЩдЄ™жХ∞жНЃеЕґеЃЮеПѓдї•еМЕеРЂзЃАеНХзЪДе§ІжХ∞жНЃзЪДпЉМдєЯеПѓдї•еМЕеРЂжХ∞жНЃеЇУзЪДпЉМзФЪиЗ≥жШѓдЄАдЇЫOSSзЪДfileпЉМињЩдЇЫжИСдїђеЬ®жХідЄ™зЪДеє≥еП∞йЗМйЭҐйГљдЉЪеК†дї•е§ДзРЖгАВ
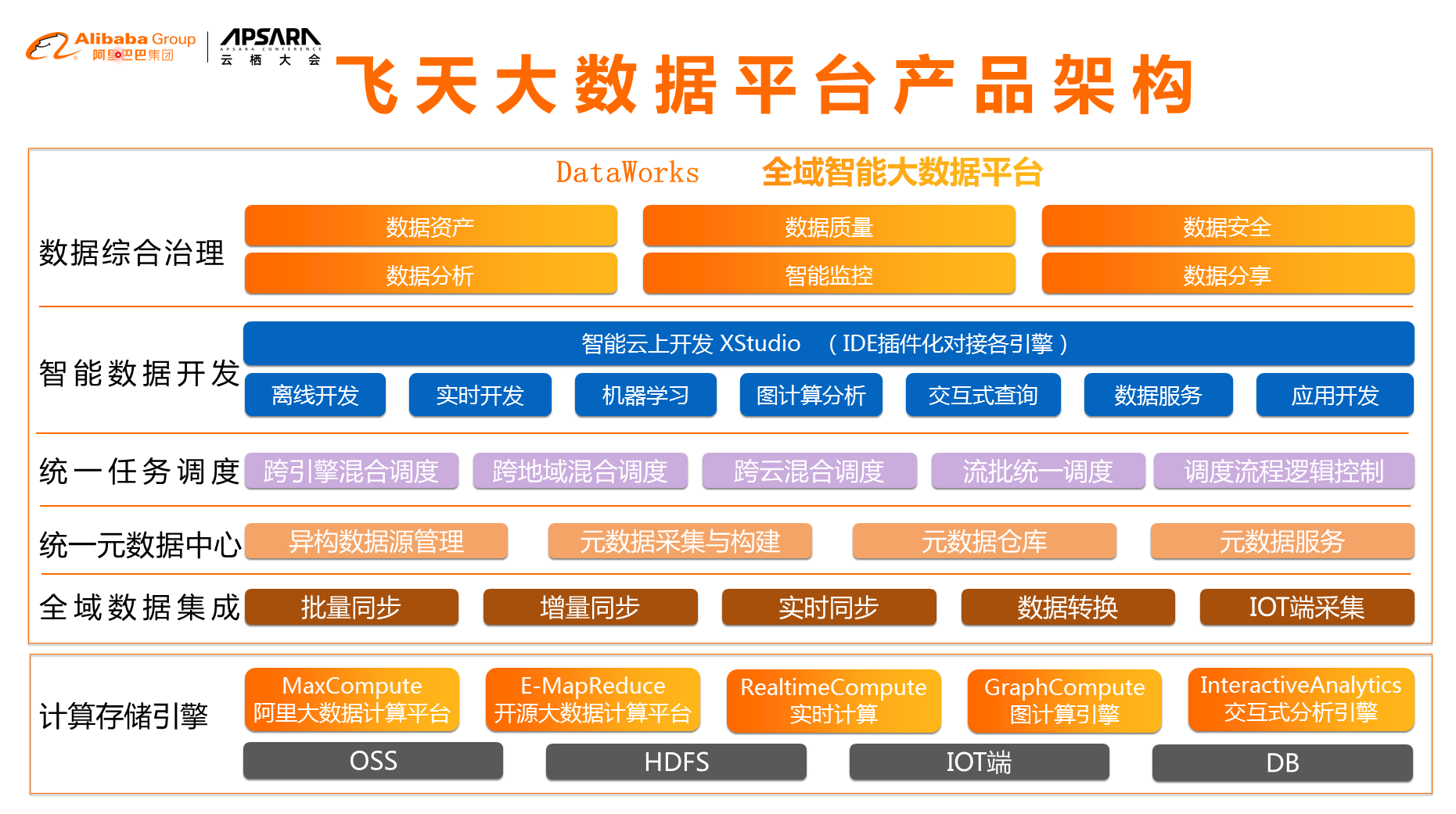
е¶ВеЫЊдЄЇй£Ю姩姲жХ∞жНЃзЪДдЇІеУБжЮґжЮДпЉМдЄЛйЭҐжШѓе≠ШеВ®иЃ°зЃЧеЉХжУОпЉМеПѓдї•зЬЛеИ∞жИСдїђйЩ§дЇЖиЃ°зЃЧеЉХжУОиЗ™еЄ¶зЪДе≠ШеВ®дєЛе§ЦињШжЬЙеЕґеЃГеЉАжФЊзЪДOSSпЉМињШжЬЙIOTзЂѓйЗЗйЫЖзЪДжХ∞жНЃеТМжХ∞жНЃеЇУзЪДжХ∞жНЃпЉМжЙАжЬЙжХ∞жНЃињЫи°МеЕ®еЯЯжХ∞жНЃйЫЖжИРпЉМйЫЖжИРеРОињЫи°МзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМзїЯдЄАзЪДжЈЈеРИдїїеК°и∞ГеЇ¶пЉМеЖНеЊАдЄКжШѓеЉАеПСе±ВеТМжХ∞жНЃзїЉеРИж≤їзРЖе±ВпЉМйАЪињЗињЩзІНжЦєеЉПпЉМжИСдїђзЂЛдљУеМЦзЪДжККжХідЄ™е§ІжХ∞жНЃеЬИиµЈжЭ•зЃ°зРЖгАВ
е§ІжХ∞жНЃдЄОAI еПМзФЯз≥їзїЯ
===========
жПРеИ∞дЇЖе§ІжХ∞жНЃжИСдїђиВѓеЃЪдЉЪжГ≥еИ∞AIпЉМAIеТМе§ІжХ∞жНЃжШѓеПМзФЯзЪДпЉМеѓєдЇОAIжЭ•иѓіеЃГжШѓйЬАи¶Бе§ІжХ∞жНЃжЭ•empowerзЪДпЉМдєЯе∞±иѓіbigdata for AIгАВдЄЛйЭҐеПѓдї•йАЪињЗдЄАдЄ™demoжЭ•зЬЛжИСдїђжАОдєИжЭ•еБЪињЩдїґдЇЛжГЕгАВеѓєдЇОAIзЪДеЉАеПСеЈ•з®ЛеЄИжЭ•иѓіпЉМдїЦдїђжѓФиЊГеЄЄзФ®зЪДжЦєеЉПжШѓзФ®дЇ§дЇТеЉПзЪДnotebookжЭ•ињЫи°МAIзЪДеЉАеПСпЉМеЫ†дЄЇеЃГжѓФиЊГзЫіиІВпЉМдљЖжШѓе¶ВдљХжККе§ІжХ∞жНЃдєЯињЫи°МдЇ§дЇТеЉПеЉАеПСпЉМеєґдЄФеТМAIжЭ•зїСеЃЪпЉМдЄЛйЭҐжЭ•зЬЛдЄАдЄЛињЩдЄ™зЃАеНХзЪДдЊЛе≠РгАВ
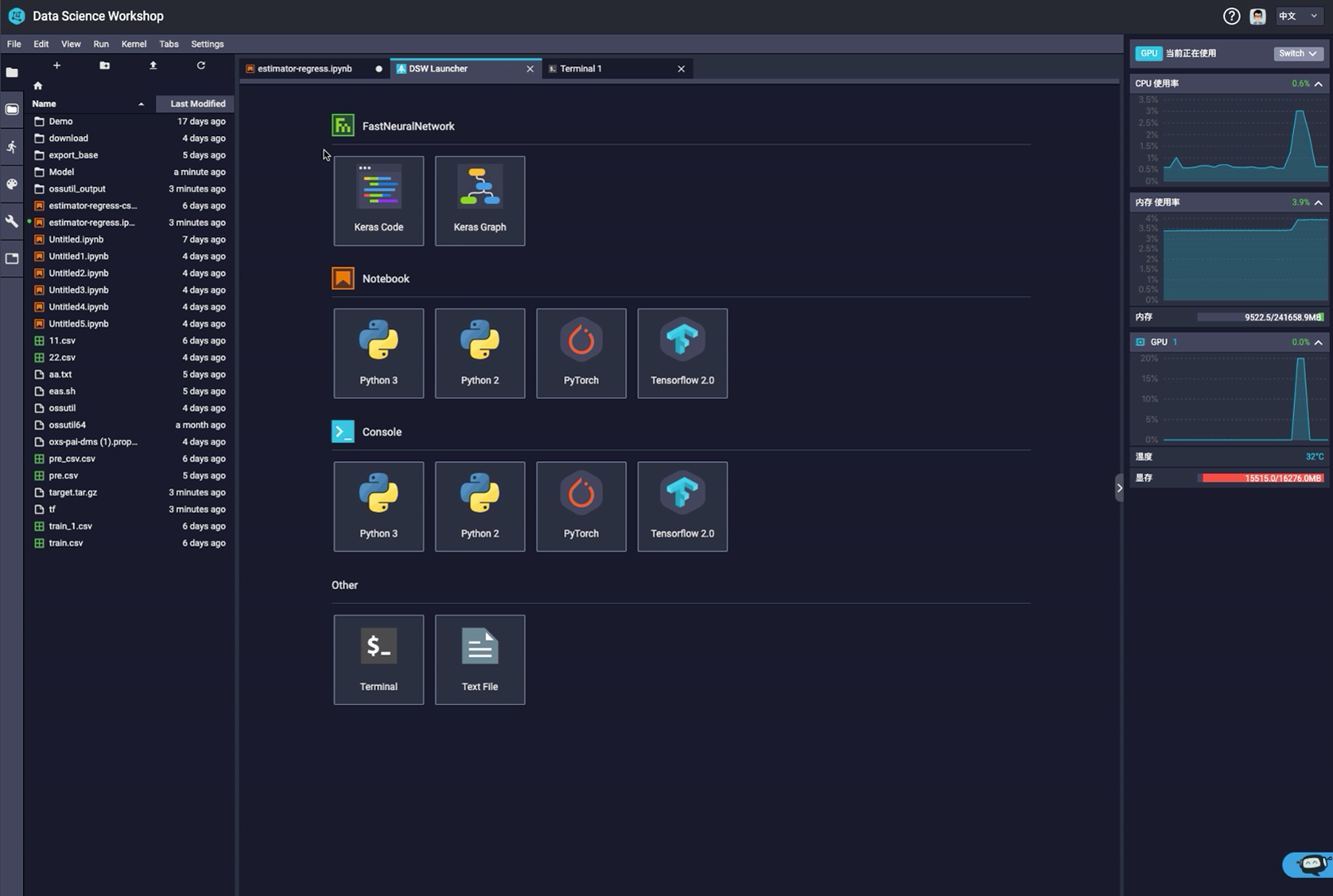
е¶ВеЫЊжШѓжИСдїђDSWзЪДеє≥еП∞пЉМжИСдїђеПѓдї•зЫіжО•зЪДзФ®дЄАдЄ™magicеСљдї§пЉМconnectеИ∞зО∞е≠ШзЪДmaxcomputeйЫЖзЊ§пЉМеєґдЄФйАЙжЛ©projectеРОпЉМеПѓдї•зЫіжО•иЊУеЕ•sqlиѓ≠еП•пЉМињЩдЇЫйГљжШѓжЩЇиГљзЪДгАВзДґеРОжИСдїђеОїжЙІи°МпЉМзїУжЮЬеЗЇжЭ•дєЛеРОжИСдїђеПѓдї•еѓєfeatureињЫи°МзЫЄеЇФзЪДеИЖжЮРпЉМеМЕжЛђеПѓдї•еОїжФєеПШињЩдЇЫfeatureзЪДж®™зЇµеЭРж†ЗеБЪеЗЇдЄНеРМзЪДchartsпЉМеРМжЧґжИСдїђзФЪиЗ≥еПѓдї•жККзФЯжИРзЪДзїУжЮЬзЫіжО•webеИ∞excelжЦєеЉПињЫи°МзЉЦиЊСеТМе§ДзРЖпЉМе§ДзРЖеЃМдєЛеРОжИСдїђеЖНжККжХ∞жНЃжЛЙеЫЮжЭ•пЉМдєЯеПѓдї•еИЗжНҐеИ∞GPUжИЦиАЕCPUињЫи°МжЈ±еЇ¶е≠¶дє†еТМиЃ≠зїГпЉМиЃ≠зїГеЃМдЇЖдєЛеРОпЉМжИСдїђдЉЪжККжХідЄ™зЪДдї£з†БеПШжИРдЄАдЄ™ж®°еЮЛпЉМжИСдїђдЉЪжККињЩдЄ™ж®°еЮЛеѓЉеЕ•еИ∞дЄАдЄ™зЫЄеЇФзЪДеЬ∞жЦєдєЛеРОжПРдЊЫдЄАдЄ™WebжЬНеК°пЉМињЩдЄ™жЬНеК°дєЯе∞±жШѓжИСдїђзЪДеЬ®зЇњжО®зРЖжЬНеК°гАВжХіе•ЧжµБз®ЛеБЪеЃМдєЛеРОпЉМзФЪиЗ≥жИСдїђеПѓдї•еЖНжО•жХ∞жНЃеЇФзФ®пЉМеПѓдї•еЬ®жЙШзЃ°зЪДWEBдЄКжЮДеїЇпЉМињЩе∞±жШѓе§ІжХ∞жНЃеє≥еП∞зїЩAIжПРдЊЫжХ∞жНЃеТМзЃЧеКЫгАВ

е§ІжХ∞жНЃеТМAIжШѓеПМзФЯз≥їзїЯпЉМAIжШѓдЄАдЄ™еЈ•еЕЈе±ВпЉМеПѓдї•дЉШеМЦжЙАжЬЙзЪДдЇЛжГЕгАВжИСдїђеЄМжЬЫй£Ю姩зЪДе§ІжХ∞жНЃеє≥еП∞иГље§ЯиµЛиГљзїЩAIгАВжИСдїђеЬ®жЬАеЉАеІЛзЪДжЧґеАЩеЄМжЬЫbuildдЄАдЄ™еПѓзФ®зЪДз≥їзїЯпЉМиГље§ЯйЭҐдЄіеПМ11зЪДеЉєжАІиіЯиљљдїНзДґжШѓеПѓзФ®зЪДгАВйАЪињЗињЩдЇЫеєізЪДеК™еКЫпЉМжИСдїђињљж±ВжЮБиЗізЪДжАІиГљпЉМжИСдїђиГље§ЯжЙУз†іжХ∞жНЃзЪДеҐЮйХњеТМжИРжЬђеҐЮйХњзЪДзЇњжАІеЕ≥з≥їпЉМжИСдїђдєЯеЄМжЬЫеЃГжШѓдЄАдЄ™жЩЇиГљзЪДпЉМжИСдїђеЄМжЬЫжЫіе§ЪзЪДжХ∞жНЃеЉАеПСеЈ•з®ЛеЄИжЭ•жФѓжМБеЃГпЉМжИСдїђйЬАи¶БжЫіе§НжЭВзЪДдЇЇеКЫжКХеЕ•жЭ•зРЖиІ£дїЦпЉМжИСдїђеЄМжЬЫжЬЙжЫіеЉЇзЪДе§ІжХ∞жНЃжЭ•дЉШеМЦе§ІжХ∞жНЃз≥їзїЯгАВ

жИСдїђжПРеЗЇдЄАдЄ™ж¶ВењµеПЂAuto Data WarehouseпЉМжИСдїђеЄМжЬЫйАЪињЗжЩЇиГљеМЦзЪДжЦєеЉПжККе§ІжХ∞жНЃеБЪеЊЧжЫіиБ™жШОгАВжХідљУдЄКеПѓдї•еИЖжИР3дЄ™йШґжЃµпЉЪ
* зђђдЄАйШґжЃµжШѓиЃ°зЃЧе±ВйЭҐеТМжХИзОЗе±ВйЭҐпЉМжИСдїђе∞ЭиѓХеѓїжЙЊиЃ°зЃЧзЪДзђђдЄАе±ВеОЯзРЖпЉМжИСдїђеОїжЙЊзЩЊдЄЗеИ∞еНГдЄЗзЇІеИЂйЗМйЭҐзЪДеУ™дЇЫдљЬдЄЪжШѓзЫЄдЉЉзЪДпЉМеЫ†ж≠§еПѓдї•еРИеєґпЉМйАЪињЗињЩзІНжЦєеЉПжЭ•иКВзЬБжИРжЬђпЉМињШжЬЙељУдљ†жЬЙеНГдЄЗзЇІеИЂзЪДи°®дєЛеРОпЉМз©ґзЂЯеУ™дЇЫ谮忯糥еЉХеЕ®е±АжШѓжЬАдЉШзЪДпЉМдї•еПКжИСдїђжАОдєИеОїеБЪеЖЈзГ≠зЪДжХ∞жНЃеИЖе±ВеТМеБЪиЗ™йАВеЇФзЉЦз†БгАВ
* зђђдЇМйШґжЃµжШѓиµДжЇРиІДеИТпЉМAIеТМAuto Data WarehouseеПѓдї•еЄЃеК©жИСдїђеБЪжЫіе•љзЪДиµДжЇРдЉШеМЦпЉМеМЕжЛђжИСдїђжЬЙ3зІНзЪДжЙІи°МдљЬдЄЪж®°еЉПпЉМеУ™дЄАзІНж®°еЉПжЫіе•љпЉМжШѓеПѓдї•йАЪињЗе≠¶дє†зЪДжЦєеЉПе≠¶еЗЇжЭ•зЪДпЉМињШжЬЙеМЕжЛђдљЬдЄЪзЪДињРи°МйҐДжµЛеТМиЗ™еК®йҐДжК•и≠¶пЉМињЩе•Чз≥їзїЯдњЭиѓБдЇЖе§ІеЃґзЬЛеЊЧеИ∞жИЦиАЕзЬЛдЄНеИ∞зЪДйШњйЗМеЕ≥йФЃдљЬдЄЪзЪДж†ЄењГпЉМжѓФе¶ВжѓПињЗдЄАжЃµжЧґйЧіе§ІеЃґдЉЪеИЈдЄАдЄЛиКЭйЇїдњ°зФ®еИЖпЉМжѓП姩жЧ©дЄКдєЭзВєйШњйЗМзЪДеХЖжИЈз≥їзїЯдЉЪеТМдЄЛжЄЄз≥їзїЯеБЪзїУзЃЧпЉМеТМе§Ѓи°МеБЪзїУзЃЧпЉМињЩдЇЫеЯЇзЇњжШѓзФ±еНГзЩЊдЄ™дљЬдЄЪзїДжИРзЪДдЄАжЭ°зЇњпЉМдїОжѓП姩жЧ©дЄКеЗМжЩ®еЉАеІЛињРи°МеИ∞жЧ©дЄКеЕЂзВєиЈСеЃМпЉМз≥їзїЯеЫ†дЄЇеРДзІНеРДж†ЈзЪДеОЯеЫ†дЉЪеЗЇзО∞еРДзІНзЪДзКґеЖµпЉМеПѓиГљдЄ™еИЂзЪДжЬЇеЩ®дЉЪеЃХжЬЇгАВжИСдїђеБЪдЇЖдЄАдЄ™иЗ™еК®йҐДжµЛз≥їзїЯпЉМеОїйҐДжµЛињЩдЄ™з≥їзїЯжШѓеР¶иГље§ЯеЬ®еЕ≥йФЃжЧґйЧізВєдЄКеЃМжИРпЉМе¶ВжЮЬдЄНиГље§ЯеЃМжИРпЉМдЉЪжККжЫіе§ЪзЪДиµДжЇРеК†ињЫжЭ•пЉМдњЭиѓБеЕ≥йФЃдљЬдЄЪзЪДеЃМжИРгАВињЩдЇЫз≥їзїЯдњЭиѓБдЇЖжИСдїђе§ІеЃґжЧ•еЄЄзЬЛдЄНиІБзЪДеЕ≥йФЃжХ∞жНЃзЪДжµБиљђпЉМдї•еПКеПМеНБдЄАз≠ЙйЗНи¶БзЪДиµДжЇРеЉєжАІгАВ
* зђђдЄЙйШґжЃµжШѓжЩЇиГљеїЇж®°пЉМељУжХ∞жНЃињЫжЭ•дєЛеРОеТМйЗМйЭҐеЈ≤жЬЙзЪДжХ∞жНЃз©ґзЂЯжЬЙе§Ъе∞СзЪДйЗНеП†пЉЯињЩдЇЫжХ∞жНЃжЬЙе§Ъе∞СзЪДеЕ≥иБФпЉЯељУжХ∞жНЃжШѓеЗ†зЩЊеЉ†и°®жЧґпЉМжРЮDBAжЙЛеЈ•зЪДжЦєеЉПеПѓдї•и∞ГдЉШзЪДпЉМзО∞еЬ®йШњйЗМеЖЕйГ®зЪДз≥їзїЯжЬЙиґЕињЗеНГдЄЗзЇІеИЂзЪДи°®пЉМжИСдїђжЬЙйЭЮеЄЄе•љзЪДеЉАеПСдЇЇеСШзРЖиІ£и°®йЗМйЭҐеЃМеЕ®зЪДйАїиЊСеЕ≥з≥їгАВињЩдЇЫиЗ™еК®и∞ГдЉШеТМиЗ™еК®еїЇж®°иГље§ЯеЄЃеК©жИСдїђеЬ®ињЩдЇЫжЦєйЭҐеБЪдЄАдЇЫиЊЕеК©жАІзЪДеЈ•дљЬгАВ
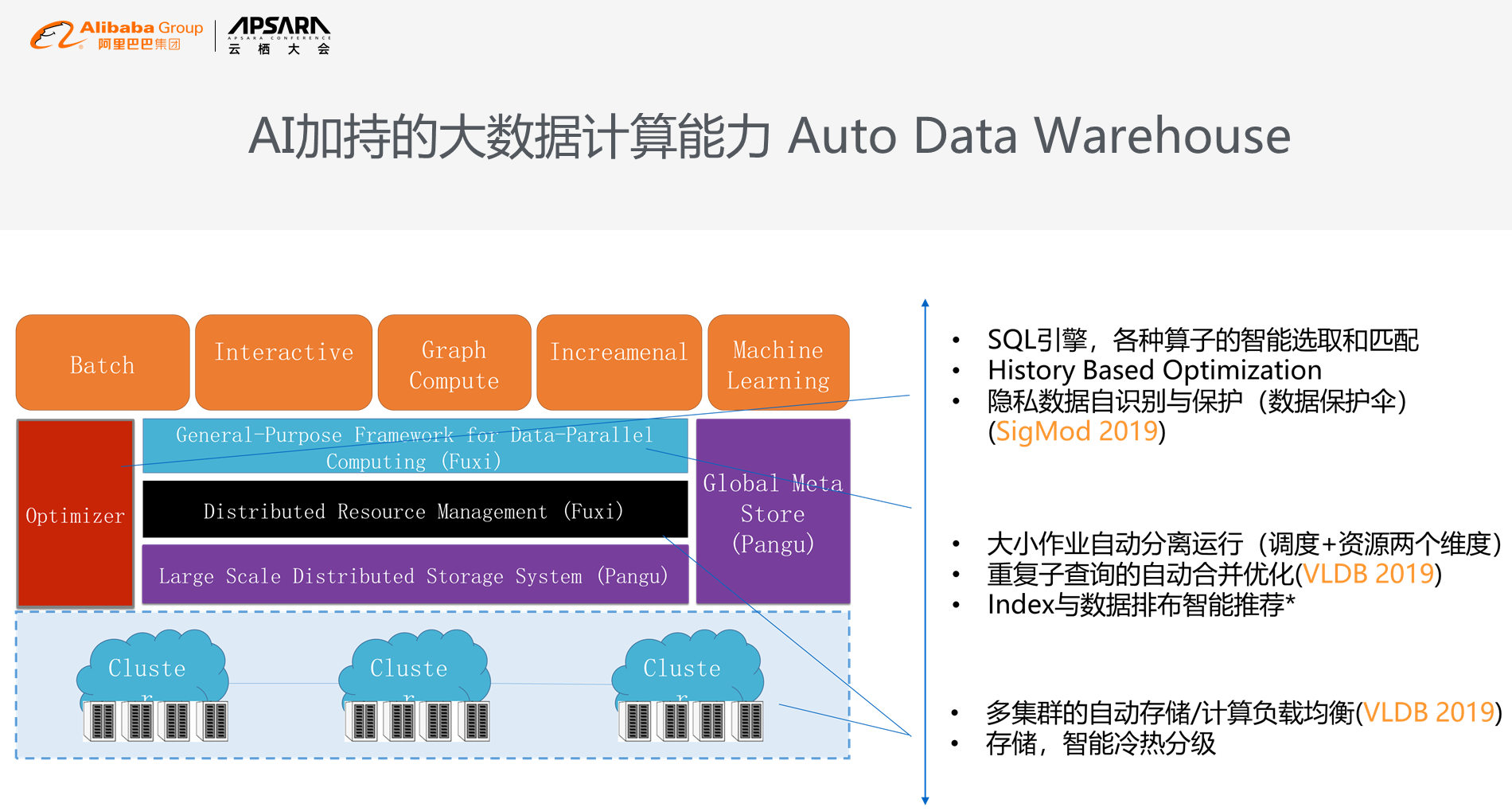
ињЩжШѓAuto Data Warehouseз≥їзїЯжЮґжЮДеЫЊпЉМдїОе§ЪйЫЖзЊ§зЪДиіЯиљљеЭЗи°°еИ∞иЗ™еК®еЖЈе≠ШпЉМеИ∞дЄ≠йЧізЪДйЪР嚥дљЬдЄЪдЉШеМЦпЉМеЖНеИ∞дЄКе±ВзЪДйЪРзІБжХ∞жНЃиЗ™еК®иѓЖеИЂпЉМињЩжШѓжИСдїђеТМиЪВиЪБдЄАиµЈеЉАеПСзЪДжКАжЬѓпЉМељУйЪРзІБзЪДжХ∞жНЃиЗ™еК®жШЊз§ЇеИ∞е±ПеєХдЄКжЭ•пЉМз≥їзїЯдЉЪиЗ™еК®ж£АжµЛеєґжЙУз†БгАВжИСдїђеЕґдЄ≠зЪДдЄЙй°єжКАжЬѓпЉМеМЕжЛђиЗ™еК®йЪРзІБдњЭжК§пЉМеМЕжЛђйЗНе§Не≠Ржߕ胥иЗ™еК®еРИеєґдЉШеМЦпЉМеМЕжЛђе§ЪйЫЖзЊ§зЪДиЗ™еК®еЃєзБЊпЉМжИСдїђжЬЙ3зѓЗpaperеПСи°®пЉМе§ІеЃґжЬЙеЕіиґ£зЪДиѓЭеПѓдї•еОїзљСзЂЩдЄКиѓїдЄАдЄЛзЫЄеЕ≥зЪДиЃЇжЦЗгАВ
[еОЯжЦЗйУЊжО•](https://yq.aliyun.com/articles/723228?utm_content=g_1000085633)
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ

еЬ®2015еєізЪДжЧґеАЩпЉМжИСдїђеЉАеІЛеЕ≥ж≥®еИ∞жХ∞жНЃзЪДжµЈйЗПеҐЮйХњеѓєз≥їзїЯеЄ¶жЭ•дЇЖиґКжЭ•иґКйЂШзЪДи¶Бж±ВпЉМйЪПзЭАжЈ±еЇ¶е≠¶дє†зЪДйЬАж±ВеҐЮйХњпЉМжХ∞жНЃеТМжХ∞жНЃеѓєеЇФзЪДе§ДзРЖиГљеКЫжШѓеИґзЇ¶дЇЇеЈ•жЩЇиГљеПСе±ХзЪДеЕ≥йФЃйЧЃйҐШпЉМжИСдїђеЬ®зїЩеЃҐжИЈиБКеИ∞дЄАдЄ™жСЖеЬ®жѓПдЄ™CIO/CTOйЭҐеЙНзЪДзО∞еЃЮйЧЃйҐШвАФвАФе¶ВжЮЬжХ∞жНЃеҐЮйХњ10еАНпЉМеЇФиѓ•жАОдєИеКЮпЉЯеЫЊдЄ≠жХ∞е≠Че§ІеЃґзЬЛеЊЧйЭЮеЄЄжЄЕжЩ∞пЉМйЭЮеЄЄзЃАеНХзЪДжЛНзЂЛжЈШз≥їзїЯиГМеРОжШѓPBзЪДжХ∞жНЃеЬ®еБЪжФѓжТСпЉМйШњйЗМе∞ПиЬЬеЃҐжЬНз≥їзїЯжЬЙ20дЄ™PBпЉМе§ІеЃґжѓП姩еЬ®жЈШеЃЭдЄКжЧ•еЄЄдљњзФ®зЪДдЄ™жАІеМЦжО®иНРз≥їзїЯпЉМеРОеП∞и¶БиґЕињЗ100дЄ™PBзЪДжХ∞жНЃжЭ•жФѓжТСеРОеП∞зЪДеЖ≥з≠ЦпЉМ10еАНеИ∞100еАНзЪДжХ∞жНЃеҐЮйХњжШѓйЭЮеЄЄеЄЄиІБзЪДгАВдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМ10еАНзЪДжХ∞жНЃеҐЮйХњйАЪеЄЄжДПеС≥зЭАдїАдєИйЧЃйҐШпЉЯ
зђђдЄАпЉМжДПеС≥зЭА10еАНжИРжЬђзЪДеҐЮйХњпЉМе¶ВжЮЬиАГиЩСеИ∞еҐЮйХњдЄНжШѓеЭЗеМАзЪДпЉМдЉЪжЬЙж≥Ґе≥∞еТМж≥Ґи∞ЈпЉМеПѓиГљйЬАи¶Б30еАНеЉєжАІи¶Бж±ВпЉЫзђђдЇМпЉМеЃЮйЩЕдЄКеЫ†дЄЇдЇЇеЈ•жЩЇиГљзЪДеЕіиµЈпЉМдЇМзїізїУжЮДжАІзЪДеЕ≥з≥їеЮЛжХ∞жНЃжМБзї≠жАІеҐЮйХњзЪДеРМжЧґпЉМеЄ¶жЭ•зЪДжШѓйЭЮзїУжЮДеМЦжХ∞жНЃпЉМињЩзІНжМБзї≠зЪДжХ∞жНЃеҐЮйХњйЗМйЭҐпЉМдЄАеНКзЪДеҐЮйХњжЭ•иЗ™дЇОињЩзІНйЭЮзїУжЮДеМЦжХ∞жНЃпЉМжИСдїђйЩ§дЇЖиГље§Яе§ДзРЖе•љињЩзІНдЇМзїізЪДжХ∞жНЃеМЦдєЛеРОпЉМжИСдїђе¶ВдљХжЭ•еБЪе•ље§ЪзІНжХ∞жНЃиЮНеРИзЪДиЃ°зЃЧпЉЯзђђдЄЙпЉМйШњйЗМжЬЙдЄАдЄ™еЇЮе§ІзЪДдЄ≠еП∞еЫҐйШЯпЉМе¶ВжЮЬиѓіжИСдїђзЪДжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжИСдїђзЪДеЫҐйШЯжШѓдЄНжШѓеҐЮйХњдЇЖ10еАНпЉЯе¶ВжЮЬиѓіжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжХ∞жНЃзЪДеЕ≥з≥їе§НжЭВеЇ¶дєЯиґЕињЗдЇЖ10еАНпЉМйВ£дєИдЇЇеЈ•зЪДжИРжЬђжШѓдЄНжШѓдєЯиґЕињЗдЇЖ10еАНдї•дЄКпЉМжИСдїђзЪДй£Ю姩еє≥еП∞еЬ®2015еєіеРОе∞±жШѓеЫізїХињЩдЄЙдЄ™еЕ≥йФЃжАІзЪДйЧЃйҐШжЭ•еБЪеЈ•дљЬзЪДгАВ
еОЯеИЫжКАжЬѓдЉШеМЦ + з≥їзїЯиЮНеРИ
=============
ељУйШњйЗМеЈіеЈізЪДе§ІжХ∞жНЃиµ∞ињЗ10дЄЗеП∞иІДж®°зЪДжЧґеАЩпЉМжИСдїђеЈ≤зїПиµ∞еЕ•еИ∞жКАжЬѓзЪДжЧ†дЇЇеМЇпЉМињЩж†ЈзЪДжМСжИШзїЭе§Іе§ЪжХ∞еЕђеПЄдЄНдЄАеЃЪиГљйБЗеИ∞пЉМдљЖжШѓеѓєдЇОйШњйЗМеЈіеЈіињЩж†ЈзЪДдљУйЗПжЭ•иЃ≤пЉМињЩдЄ™жМСжИШжШѓдЄАзЫіжСЖеЬ®жИСдїђйЭҐеЙНзЪДгАВ

е§ІеЃґеПѓдї•зЬЛеИ∞пЉМ2015еєізЪДжЧґеАЩпЉМжИСдїђжХідЄ™зЪДдљУз≥їеїЇзЂЛиµЈжЭ•дєЛеРОпЉМе∞±еЉАеІЛеБЪеРДзІНеРДж†ЈзЪДBenchmarkпЉМжѓФе¶В2015еєі100TBзЪДSortingпЉМ2016еєіжИСдїђеБЪCloudSortпЉМеОїзЬЛжАІдїЈжѓФпЉМ2017еєіжИСдїђйАЙжЛ©дЇЖBigbenchгАВе¶ВеЫЊжШѓжИСдїђжЬАжЦ∞еПСеЄГзЪДжХ∞жНЃпЉМеЬ®2017гАБ2018еТМ2019еєіпЉМжѓПеєійГљжЬЙдЄАеАНзЪДжАІиГљжПРеНЗпЉМеРМжЧґжИСдїђеЬ®30TBзЪДиІДж®°дЄКжѓФзђђдЇМеРНзЪДдЇІеУБжЬЙдЄАеАНзЪДжАІиГљеҐЮйХњпЉМеєґдЄФжЬЙдЄАеНКзЪДжИРжЬђиКВзЬБпЉМињЩжШѓжИСдїђзЪДиЃ°зЃЧеКЫжМБзї≠дЄКеНЗзЪДдЉШеМЦиґЛеКњгАВ

йВ£дєИпЉМиЃ°зЃЧеКЫжМБзї≠еНЗзЇІжШѓе¶ВдљХеБЪеИ∞зЪДпЉЯе¶ВеЫЊжШѓжИСдїђзїПеЄЄзФ®еИ∞зЪДз≥їзїЯеНЗзЇІзЪДдЄЙиІТзРЖиЃЇпЉМжЬАеЇХе±ВзЪДиЃ°зЃЧж®°еЮЛжШѓйЂШжХИзЪДзЃЧе≠Ре±ВеТМе≠ШеВ®е±ВпЉМињЩжШѓйЭЮеЄЄеЇХе±ВзЪДеЯЇз°АдЉШеМЦпЉМеЊАдЄКйЭҐи¶БжЙЊеИ∞жЬАдЉШзЪДжЙІи°МиЃ°еИТпЉМдєЯе∞±жШѓзЃЧе≠РзїДеРИпЉМеЖНеЊАдЄКжШѓжЦ∞зЪДжЦєеРСпЉМеН≥жАОдєИеБЪеИ∞еК®жАБи∞ГжХідЄОиЗ™е≠¶дє†зЪДи∞ГдЉШгАВ

жИСдїђеЕИжЭ•зЬЛеНХдЄАзЃЧе≠РеТМеЉХжУОж°ЖжЮґзЪДжЮБиЗідЉШеМЦпЉМжИСдїђзФ®зЪДжШѓжѓФиЊГйЪЊеЖЩйЪЊзїіжК§зЪДж°ЖжЮґпЉМдљЖжШѓеЫ†дЄЇеЃГжѓФиЊГиііињСзЙ©зРЖз°ђдїґпЉМжЙАдї•еЄ¶жЭ•дЇЖжЫіжЮБиЗізЪДжАІиГљињљж±ВгАВеѓєдЇОеЊИе§Ъз≥їзїЯжЭ•иѓіеПѓиГљ5%зЪДжАІиГљжПРеНЗеєґдЄНеЕ≥йФЃпЉМдљЖеѓєдЇОй£Ю姩жКАжЬѓеє≥еП∞жЭ•иЃ≤пЉМ5%зЪДжАІиГљжПРеНЗе∞±жШѓ5еНГеП∞зЪДиІДж®°пЉМе§Іж¶Ве∞±жШѓ2пљЮ3дЇњзЪДжИРжЬђгАВе¶ВеЫЊеБЪдЇЖдЄАдЄ™зЃАеНХзЪДе∞ПдЊЛе≠РеБЪеНХдЄАзЃЧе≠РзЪДжЮБиЗідЉШеМЦпЉМеЬ®shuffleе≠РеЬЇжЩѓдЄ≠пЉМеИ©зФ®Non-temporal StoreдЉШеМЦshufflingдЄ≠зЪДзЉУе≠Шз≠ЦзХ•пЉМеЬ®ињЩж†ЈзЪДз≠ЦзХ•дЄКжЬЙ30%зЪДжАІиГљжПРеНЗгАВ
йЩ§дЇЖиЃ°зЃЧж®°еЭЧпЉМеЃГињШжЬЙе≠ШеВ®ж®°еЭЧпЉМе≠ШеВ®еИЖдЄЇ4дЄ™и±°йЩРгАВдЄАеЫЫи±°йЩРжШѓе≠ШеВ®жХ∞жНЃжЬђиЇЂзЪДеОЛзЉ©иГљеКЫпЉМжХ∞жНЃеҐЮйХњжЬАзЫіжО•зЪДжИРжЬђе∞±жШѓе≠ШеВ®жИРжЬђзЪДдЄКеНЗпЉМжИСдїђжАОдєИеБЪжЫіе•љзЪДеОЛзЉ©еТМзЉЦз†Бдї•еПКindexingпЉЯињЩжШѓдЄАеЫЫи±°йЩРеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉЫдЇМдЄЙи±°йЩРжШѓеЬ®жАІиГљиКВзЬБдЄКеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉМжИСдїђе≠ШеВ®е±ВеЕґеЃЮжШѓеЯЇдЇОеЉАжЇРORCзЪДж†ЗеЗЖпЉМжИСдїђеЬ®дЄКйЭҐеБЪдЇЖйЭЮеЄЄе§ЪзЪДжФєињЫеТМдЉШеМЦпЉМеЕґдЄ≠зЩљж°ЖйЗМйЭҐйГљжЬЙйЭЮеЄЄе§ЪзЪДж†ЗеЗЖжФєеК®пЉМжИСдїђиѓїеПЦжАІиГљеѓєжѓФеЉАжЇРJava ORC еЭЗењЂ 50%пЉМжИСдїђжШѓORCз§ЊеМЇињЗеОїдЄ§еєіжЬАе§Іиі°зМЃиАЕпЉМиі°зМЃдЇЖ2W+и°Мдї£з†БпЉМињЩжШѓжИСдїђеЬ®зЃЧе≠Ре±ВеТМе≠ШеВ®е±ВзЪДдЉШеМЦпЉМињЩжШѓжЬАеЇХе±ВзЪДжЮґжЮДгАВ

дљЖжШѓдїОеП¶е§ЦдЄАдЄ™е±ВйЭҐдЄКжЭ•иЃ≤пЉМеНХдЄАзЪДзЃЧе≠РеТМйГ®еИЖзЪДзЃЧе≠РзїДеРИеЊИйЪЊжї°иґ≥йГ®еИЖзЪДеЬЇжЩѓйЬАж±ВпЉМжЙАдї•жИСдїђе∞±жПРеИ∞зБµжіїзЪДзЃЧе≠РзїДеРИгАВдЄЊеЗ†дЄ™жХ∞е≠ЧпЉМжИСдїђеЬ®JoinдЄКжЬЙ4зІНж®°еЉПпЉМжЬЙ3зІНShufflingж®°еЉПжПРдЊЫпЉМжЬЙ3зІНдљЬдЄЪињРи°Мж®°еЉПпЉМжЬЙе§ЪзІНз°ђдїґжФѓжМБеТМе§ЪзІНе≠ШеВ®дїЛиі®жФѓжМБгАВеЫЊеП≥жШѓжАОж†ЈеОїеК®жАБеИ§еИЂJoinж®°еЉПпЉМдљњеЊЧињРзЃЧжХИзОЗжЫійЂШгАВйАЪињЗињЩзІНеК®жАБзЪДзЃЧе≠РзїДеРИпЉМжШѓжИСдїђдЉШеМЦзЪДзђђдЇМдЄ™зїіеЇ¶гАВ

дїОеЉХжУОдЉШеМЦеИ∞иЗ™е≠¶дє†и∞ГдЉШжШѓжИСдїђеЬ®жЬАињС1еєіе§ЪзЪДжЧґйЧійЗМиК±з≤ЊеКЫжѓФиЊГе§ЪзЪДпЉМжИСдїђеЬ®иАГиЩСе¶ВдљХзФ®дЇЇеЈ•жЩЇиГљеПКиЗ™е≠¶дє†жКАжЬѓжЭ•еБЪе§ІжХ∞жНЃз≥їзїЯпЉМе§ІеЃґеПѓдї•жГ≥и±°е≠¶й™СиЗ™и°Миљ¶пЉМеИЪеЉАеІЛй™СеЊЧдЄНе•љпЉМйАЯеЇ¶жѓФиЊГжЕҐзФЪиЗ≥жЬЙзЪДжЧґеАЩдЉЪжСФеАТпЉМйАЪињЗжЕҐжЕҐзЪДе≠¶дє†пЉМдЇЇзЪДиГљеКЫдЉЪиґКжЭ•иґКе•љгАВеѓєдЇОдЄАдЄ™з≥їзїЯиАМи®АпЉМжИСдїђжШѓеР¶еПѓдї•зФ®еРМж†ЈзЪДжЦєеЉПжЭ•еБЪпЉЯељУдЄАдЄ™еЕ®жЦ∞зЪДдљЬдЄЪжПРдЇ§еИ∞ињЩдЄ™з≥їзїЯжЧґпЉМз≥їзїЯеѓєдљЬдЄЪзЪДдЉШеМЦжШѓжѓФиЊГдњЭеЃИзЪДпЉМжѓФе¶Вз®НеЊЃе§ЪзїЩдЄАзВєиµДжЇРпЉМйВ£дєИжИСйАЙжЛ©зЪДжЙІи°МиЃ°еИТдЉЪзЫЄеѓєжѓФиЊГдњЭеЃИдЄАзВєпЉМдљњеЊЧиЗ≥е∞СиГље§ЯиЈСињЗеОїпЉМељУиЈСињЗдєЛеРОе∞±иГље§ЯжРЬйЫЖеИ∞дњ°жБѓеТМзїПй™МпЉМйАЪињЗињЩдЇЫзїПй™МеЖНеПНеУЇеОїдЉШеМЦжХ∞жНЃпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™еЯЇдЇОеОЖеП≤дњ°жБѓзЪДиЗ™е≠¶дє†еЫЮељТдЉШеМЦпЉМеЇХе±ВжШѓе¶ВеЫЊзЪДжЮґжЮДеЫЊпЉМжИСдїђжККеОЖеП≤дњ°жБѓжФЊеЬ®OFFLINE systemеОїеБЪеРДзІНеРДж†ЈзЪДзїЯиЃ°еИЖжЮРпЉМељУдљЬдЄЪжЭ•дЇЖдєЛеРОжИСдїђжККињЩдЇЫдњ°жБѓеПНеУЇеИ∞з≥їзїЯдєЛдЄ≠еОїпЉМиЃ©з≥їзїЯињЫи°МиЗ™е≠¶дє†гАВйАЪеЄЄжГЕеЖµдЄЛпЉМдЄАдЄ™зЫЄдЉЉзЪДдљЬдЄЪе§Іж¶ВиЈСдЇЖ3еИ∞4жђ°зЪДжЧґеАЩпЉМињЫеЕ•еИ∞дЄАдЄ™зЫЄеѓєжѓФиЊГдЉШзЪДињЗз®ЛпЉМдЉШжМЗзЪДжШѓдљЬдЄЪињРи°МжЧґйЧіеТМз≥їзїЯиµДжЇРиКВзЬБгАВињЩе•Чз≥їзїЯе§Іж¶ВеЬ®йШњйЗМеЖЕйГ®3еєіеЙНдЄКзЇњзЪДпЉМжИСдїђйАЪињЗињЩж†ЈзЪДз≥їзїЯжККйШњйЗМзЪДж∞ідљНзЇњдїО40%жПРеНЗеИ∞70%дї•дЄКгАВ
еП¶е§ЦеЫЊдЄ≠еП≥дЊІдєЯжШѓдЄАдЄ™иЗ™е≠¶дє†зЪДдЊЛе≠РпЉМжИСдїђжАОдєИеМЇеИЖзГ≠жХ∞жНЃеТМеЖЈжХ∞жНЃпЉМдєЛеЙНеПѓдї•иЃ©зФ®жИЈиЗ™еЈ±еОїsetпЉМеПѓдї•зФ®дЄАдЄ™жЩЃйАЪзЪДconfigurationеОїйЕНзљЃпЉМеРОжЭ•еПСзО∞жИСдїђйЗЗзФ®еК®жАБзЪДж†єжНЃдљЬдЄЪжЦєеЉПжЭ•еБЪпЉМжХИжЮЬдЉЪжЫіе•љпЉМињЩдЄ™жКАжЬѓжШѓеОїеєідЄКзЇњзЪДпЉМеОїеєідЄЇйШњйЗМиКВзЇ¶дЇЖ1дЇњ+дЇЇж∞СеЄБгАВдїОдї•дЄКеЗ†дЄ™дЊЛе≠РдЄКжЭ•иЃ≤еЉХжУОе±ВйЭҐеТМе≠ШеВ®е±ВйЭҐеБЪзЪДжЮБиЗіжАІиГљдЉШеМЦпЉМжАІиГљдЉШеМЦеПИеЄ¶жЭ•дЇЖзФ®жИЈжИРжЬђзЪДйЩНдљОпЉМеЬ®2019еєі9жЬИ1еПЈпЉМй£Ю姩姲жХ∞жНЃеє≥еП∞зЪДжХідљУе≠ШеВ®жИРжЬђйЩНдљОдЇЖ30%пЉМеРМжЧґжИСдїђеПСеЄГдЇЖеЯЇдЇОеОЯзФЯиЃ°зЃЧзЪДжЦ∞иІДж†ЉпЉМеПѓдї•еЃЮзО∞жЬАйЂШ70%зЪДжИРжЬђиКВзЬБгАВ
дї•дЄКйГљжШѓеЬ®еЉХжУОе±ВйЭҐзЪДдЉШеМЦпЉМйЪПзЭАAIзЪДжЩЃжГ†дЉШеМЦпЉМAIзЪДеЉАеПСдЇЇеСШдЉЪиґКжЭ•иґКе§ЪпЉМзФЪиЗ≥еЊИе§ЪдЇЇйГљдЄН姙еЕЈе§Здї£з†БзЪДиГљеКЫпЉМйШњйЗМеЖЕйГ®жЬЙ10дЄЗеРНеСШеЈ•пЉМжѓП姩жЬЙиґЕињЗ1дЄЗдЄ™еСШеЈ•еЬ®й£Ю姩姲жХ∞жНЃеє≥еП∞дЄКеБЪеЉАеПСпЉМдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМдЄНдїЕз≥їзїЯзЪДдЉШеМЦжШѓйЗНи¶БзЪДпЉМеє≥еП∞еТМеЉАеПСеє≥еП∞зЪДдЉШеМЦдєЯжШѓйЭЮеЄЄеЕ≥йФЃзЪДгАВ

иЃ°зЃЧеЉХжУОеѓєе§ІеЃґжЭ•иѓізЬЛдЄНиІБжСЄдЄНзЭАпЉМжИСдїђи¶БеОїзФ®еЃГиВѓеЃЪеЄМжЬЫзФ®жЬАзЃАеНХзЪДжЦєеЉПпЉМеЕИжЭ•зЬЛдЄАдЄЛMaxcomputeиЃ°зЃЧеЉХжУОгАВй¶ЦеЕИжИСдїђйЬАи¶БжЬЙзФ®жИЈпЉМзФ®жИЈжАОдєИжЭ•дљњзФ®пЉЯйЬАи¶БиµДжЇРйЪФз¶їпЉМдєЯе∞±жШѓиѓіжѓПдЄ™зФ®жИЈеЬ®з≥їзїЯдЄКйЭҐдљњзФ®зЪДжЧґеАЩдЉЪеѓєеЇФзЭАиі¶еПЈпЉМиі¶еПЈдЉЪеѓєеЇФзЭАжЭГйЩРпЉМињЩж†Је∞±жККжХіе•ЧдЄЬи•њдЄ≤иБФиµЈжЭ•гАВдїК姩жИСзЪДзФ®жИЈжАОдєИзФ®пЉЯзФ®еУ™дЇЫйГ®еИЖпЉЯињЩжШѓзђђдЄАйГ®еИЖгАВзђђдЇМйГ®еИЖжШѓеЉАеПСпЉМеЉАеПСжЬЙIDEпЉМIDEзФ®жЭ•еЖЩдї£з†БпЉМеЖЩеЃМдї£з†БдєЛеРОжПРдЇ§пЉМжПРдЇ§дєЛеРОе≠ШеЬ®дЄАдЄ™и∞ГеЇ¶зЪДйЧЃйҐШпЉМињЩдєИе§ЪзЪДиµДжЇРдїїеК°й°ЇеЇПжШѓдїАдєИпЉЯи∞БеЕИи∞БеРОпЉМеЗЇдЇЖйЧЃйҐШи¶БдЄНи¶БдЄ≠жЦ≠пЉМињЩдЇЫйГљзФ±и∞ГеЇ¶з≥їзїЯжЭ•зЃ°пЉМжИСдїђзЪДињЩдЇЫдїїеК°е∞±жЬЙеПѓиГљеЬ®дЄНеРМзЪДеЬ∞жЦєжЭ•ињРи°МпЉМеПѓдї•йАЪињЗжХ∞жНЃйЫЖжИРжККеЃГжЛЙеИ∞дЄНеРМзЪДеМЇеЯЯпЉМиЃ©ињЩдЇЫжХ∞жНЃиГље§ЯеЬ®жХідЄ™зЪДеє≥еП∞дЄКиЈСиµЈжЭ•пЉМжИСдїђжЙАжЬЙзЪДдїїеК°иЈСиµЈжЭ•дєЛеРОжИСдїђйЬАи¶БжЬЙдЄАдЄ™зЫСжОІпЉМеРМжЧґжИСдїђзЪДoperationдєЯйЬАи¶БиЗ™еК®еМЦгАБињРзїіеМЦпЉМеЖНеЊАдЄЛжИСдїђдЉЪињЫи°МжХ∞жНЃзЪДеИЖжЮРжИЦиАЕBIжК•и°®дєЛз±їзЪДпЉМжИСдїђдєЯдЄНиГље§ЯењШиЃ∞machine learningдєЯжШѓеЬ®жИСдїђзЪДеє≥еП∞дЄКйЫЖжИРиµЈжЭ•зЪДгАВжЬАеРОпЉМжЬАйЗНи¶БзЪДе∞±жШѓжХ∞жНЃеЃЙеЕ®пЉМињЩдЄАеЭЧжХідЄ™дЄЬи•њжЮДиµЈдЄАдЄ™е§ІжХ∞жНЃеЉХжУОзЪДе§Цж≤њ+е§ІжХ∞жНЃеЉХжУОжЬђиЇЂпЉМињЩдЄАе•ЧжИСдїђзІ∞дєЛдЄЇеНХеЉХжУОзЪДеЃМе§Зе§ІжХ∞жНЃз≥їзїЯпЉМињЩдЄАе•Чз≥їзїЯжИСдїђеЬ®2017еєізЪДжЧґеАЩе∞±еЕЈе§ЗдЇЖгАВ

2018еєізЪДжЧґеАЩжИСдїђеБЪдїАдєИпЉЯ2018еєіжИСдїђеЬ®еНХеЉХжУОзЪДеЯЇз°АдЄКеѓєжО•еИ∞е§ЪеЉХжУОпЉМжИСдїђжХідЄ™еЉАеПСйУЊиЈѓи¶БиЃ©еЃГйЧ≠зОѓеМЦпЉМжХ∞жНЃйЫЖжИРеПѓдї•жККжХ∞жНЃеЬ®дЄНеРМзЪДжХ∞жНЃжЇРдєЛйЧіињЫи°МжЛЦеК®пЉМжИСдїђжККжХ∞жНЃеЉАеПСеЃМдєЛеРОпЉМдЉ†зїЯзЪДжЦєеЉПжШѓеЖНзФ®жХ∞жНЃеЉХжУОжККеЃГжЛЦиµ∞пЉМиАМжИСдїђеБЪзЪДдЇЛжГЕжШѓеЄМжЬЫињЩдЄ™жХ∞жНЃжШѓдЇСдЄКзЪДжЬНеК°пЉМињЩдЄ™жЬНеК°иГље§ЯзЫіжО•еѓєзФ®жИЈжПРдЊЫжГ≥и¶БзЪДжХ∞жНЃпЉМиАМдЄНйЬАи¶БжККжХ∞жНЃжХідЄ™жЛЦиµ∞пЉМеЫ†дЄЇжХ∞жНЃеЬ®дЉ†иЊУињЗз®ЛдЄ≠жЬЙе≠ШеВ®зЪДжґИиАЧгАБзљСзїЬзЪДжґИиАЧеТМдЄАиЗіжАІжґИиАЧпЉМжЙАжЬЙзЪДињЩдЇЫдЄЬи•њйГљеЬ®жґИиАЧзФ®жИЈзЪДжИРжЬђпЉМжИСдїђеЄМжЬЫйАЪињЗжХ∞жНЃжЬНеК°иЃ©зФ®жИЈжЛњеИ∞дїЦжГ≥и¶БзЪДдЄЬи•њгАВеЖНеЊАдЄЛпЉМе¶ВжЮЬжХ∞жНЃжЬНеК°дєЛдЄКињШжЬЙиЗ™еЃЪдєЙзЪДеЇФзФ®пЉМзФ®жИЈињШйЬАи¶БеОїеїЇдЄАдЄ™жЬЇжИњпЉМжР≠дЄАдЄ™webжЬНеК°пЉМзДґеРОжККжХ∞жНЃжЛњињЗжЭ•пЉМињЩж†ЈдєЯеЊИйЇїзГ¶пЉМжЙАдї•жИСдїђжПРдЊЫдЄАдЄ™жЙШзЃ°зЪДwebеЇФзФ®зЪДдЇСдЄКеЉАеПСеє≥еП∞пЉМиГље§ЯиЃ©зФ®жИЈзЫіжО•зЬЛеИ∞жЙАжЬЙзЪДжХ∞жНЃжЬНеК°пЉМеЬ®ињЩдЄ™жЦєеРСдЄКжЭ•иѓіпЉМжИСдїђе∞±еПѓдї•жЮДеїЇдїїжДПзЪДжХ∞жНЃжЩЇиГљиІ£еЖ≥жЦєж°ИгАВ

еИ∞2019еєіпЉМжИСдїђдЉЪжККзРЖењµеЖНжЛУе±ХдЄАе±ВпЉМй¶ЦеЕИеѓєдЇОзФ®жИЈжЭ•иѓіжШѓзФ®жИЈдЇ§дЇТе±ВпЉМдљЖжШѓзФ®жИЈзЪДдЇ§дЇТе±ВдЄНдїЕдїЕжШѓеЉАеПСпЉМжЙАдї•жИСдїђдЉЪжККзФ®жИЈеИЖжИРдЄ§з±їпЉМдЄАйГ®еИЖеПЂеБЪжХ∞жНЃзЪДзФЯдЇІиАЕпЉМдєЯе∞±жШѓеЖЩдїїеК°гАБеЖЩи∞ГеЇ¶гАБињРзїіз≠ЙпЉМињЩдЇЫжШѓжХ∞жНЃзЪДзФЯдЇІиАЕпЉМжХ∞жНЃзЪДзФЯдЇІиАЕеБЪе•љзЪДдЄЬи•њзїЩи∞БеСҐпЉЯзїЩжХ∞жНЃзЪДжґИиієиАЕпЉМжИСдїђзЪДжХ∞жНЃеИЖжХ£еЬ®еРДдЄ™еЬ∞жЦєпЉМжЙАжЬЙзЪДдЄЬи•њйГљдЉЪеЬ®ж≤їзРЖзЪДдЇ§дЇТе±ВеѓєжХ∞жНЃзЪДжґИиієиАЕжПРдЊЫжЬНеК°пЉМињЩж†ЈжИСдїђе∞±еЬ®дЄАдЄ™жЦ∞зЪДиІТеЇ¶жЭ•иѓ†йЗКй£Ю姩姲жХ∞жНЃеє≥еП∞гАВйЩ§дЇЖеЉХжУОе≠ШеВ®дї•е§ЦпЉМжИСдїђжЬЙеЕ®еЯЯзЪДжХ∞жНЃйЫЖжИРињЫи°МжЛЙеК®пЉМзїЯдЄАзЪДи∞ГеЇ¶еПѓдї•еЬ®дЄНеРМзЪДеЉХжУОдєЛйЧіжЭ•еИЗжНҐеНПеРМеЈ•дљЬпЉМеРМжЧґжИСдїђжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМеЬ®ињЩдєЛдЄКжИСдїђеѓєжХ∞жНЃзЪДзФЯдЇІиАЕеТМжХ∞жНЃзЪДжґИиієиАЕдєЯйГљињЫи°МдЇЖзЫЄеЇФзЪДжФѓжМБпЉМйВ£дєИињЩдЄ™жХідљУе∞±жШѓеЕ®еЯЯзЪДе§ІжХ∞жНЃеє≥еП∞дЇІеУБжЮґжЮДгАВ
дЇСеОЯзФЯеє≥еП∞еИ∞еЕ®еЯЯдЇСжХ∞дїУ
===========
жИСдїђжХідЄ™еє≥еП∞йГљжШѓдЇСеОЯзФЯзЪДпЉМдЇСеОЯзФЯжЬЙеУ™дЇЫжКАжЬѓеСҐпЉЯ

й£Ю姩姲жХ∞жНЃеє≥еП∞еЬ®10еєіеЙНе∞±еЭЪжМБдЇСеОЯзФЯзЪДжХ∞жНЃпЉМдЇСеОЯзФЯжДПеС≥зЭАдЄЙдїґдЇЛжГЕпЉМзђђдЄАеЉАзЃ±еН≥зФ®гАБдЄНзФ®дЄНиК±йТ±пЉМињЩдЄ™еТМдЉ†зїЯзЪДдє∞з°ђдїґжЦєеЉПжЬЙйЭЮеЄЄе§ІзЪДдЄНеРМпЉЫзђђдЇМжИСдїђеЕЈе§ЗдЇЖзІТзЇІиЗ™йАВеЇФзЪДеЉєжАІжЙ©е±ХпЉМзФ®е§Ъе∞Сдє∞е§Ъе∞СпЉЫзђђдЄЙеЫ†дЄЇжШѓдЇСдЄКзЪДж°ЖжЮґпЉМжИСдїђеЊИе§ЪињРзїіеТМеЃЙеЕ®зЪДдЄЬи•њзФ±дЇСиЗ™еК®жЭ•еЃМжИРдЇЖпЉМжЙАдї•жШѓеЃЙеЕ®еЕНињРзїізЪДгАВдїОз≥їзїЯжЮґжЮДдЄКиЃ≤пЉМй£Ю姩姲жХ∞жНЃеМЕжЛђдЉ†зїЯзЪДCPUгАБGPUйЫЖзЊ§пЉМдї•еПКеє≥е§іеУ•иКѓзЙЗйЫЖзЊ§пЉМеЖНеЊАдЄКжШѓжИСдїђзЪДдЉПзЊ≤жЩЇиГљи∞ГеЇ¶з≥їзїЯеТМеЕГжХ∞жНЃз≥їзїЯпЉМеЖНеЊАдЄКжИСдїђжПРдЊЫдЇЖе§ЪзІНиЃ°зЃЧиГљеКЫпЉМжИСдїђжЬАйЗНи¶БзЪДзЫЃж†Зе∞±жШѓйАЪињЗдЇСеОЯзФЯиЃЊиЃ°жКК10дЄЗеП∞еЬ®зЙ©зРЖдЄКеИЖеЄГеЬ®дЄНеРМеЬ∞еЯЯзЪДжЬНеК°еЩ®иЃ©зФ®жИЈиІЙеЊЧеГПдЄАеП∞иЃ°зЃЧжЬЇгАВжИСдїђдїК姩еЈ≤зїПиЊЊеИ∞дЇЖ10еєіеЙНзЪДиЃЊиЃ°и¶Бж±ВпЉМеЕЈе§ЗдЇЖжЫіеЉЇзЪДжЬНеК°жЙ©е±ХиГљеКЫпЉМиГље§ЯжФѓжТС5еИ∞10еєізЪДжХ∞жНЃињЫж≠•зЪДеПСе±ХгАВ
жИСдїђеЕЕеИЖеИ©зФ®дЇСеОЯзФЯиЃЊиЃ°зЪДзРЖењµпЉМжФѓжМБе§ІжХ∞жНЃеТМжЬЇеЩ®е≠¶дє†зЪДењЂйАЯе§ІиІДж®°еЉєжАІиіЯиљљйЬАж±ВгАВжИСдїђжФѓжТС0пљЮ100еАНзЪДеЉєжАІжЙ©еЃєиГљеКЫпЉМеОїеєіеЉАеІЛпЉМеПМеНБдЄА60%зЪДжХ∞жНЃе§ДзРЖйЗПжЭ•иЗ™дЇОе§ІжХ∞жНЃеє≥еП∞зЪДе§ДзРЖиГљеКЫпЉМељУеПМ11еЈЕе≥∞жЭ•зЪДжЧґеАЩпЉМжИСдїђжККе§ІжХ∞жНЃзЪДиµДжЇРеЉєеЫЮжЭ•иЃ©зїЩеЬ®зЇњз≥їзїЯеОїе§ДзРЖйЧЃйҐШгАВдїОеП¶е§ЦдЄАдЄ™иІТеЇ¶жЭ•иЃ≤пЉМжИСдїђеЕЈе§ЗеЉєжАІиГљеКЫпЉМзЫЄжѓФзЙ©зРЖзЪДIDCж®°еЉПпЉМжИСдїђжЬЙ80%жИРжЬђзЪДиКВзЬБпЉМжМЙдљЬдЄЪзЪДиЃ°иієж®°еЉПпЉМжИСдїђжПРдЊЫзІТзЇІеЉєжАІдЉЄзЉ©зЪДеРМжЧґпЉМдЄНдљњзФ®дЄНжФґиієгАВзЫЄжѓФиЗ™еїЇIDCпЉМзїЉеРИжИРжЬђеП™жЬЙ1/5гАВйЩ§дЇЖеЭЪжМБеОЯзФЯдєЛе§ЦпЉМжИСдїђжЬАињСеПСзО∞пЉМйЪПзЭАдЇЇеЈ•жЩЇиГљзЪДеПСе±ХпЉМиѓ≠йЯ≥иІЖеЫЊзЪДжХ∞жНЃиґКжЭ•иґКе§ЪдЇЖпЉМе§ДзРЖзЪДиГљеКЫе∞±и¶БеК†еЉЇпЉМжИСдїђи¶БдїОдЇМзїізЪДе§ІжХ∞жНЃеє≥еП∞еПШжИРеЕ®еЯЯзЪДжХ∞жНЃеє≥еП∞гАВ

е¶ВеЫЊжЙАз§ЇпЉМдЄЪзХМжЬЙдЄАдЄ™жѓФиЊГзБЂзЪДж¶ВењµеПЂжХ∞жНЃжєЦпЉМжИСдїђи¶БжККеЃҐжИЈе§ЪзІНе§Ъж†ЈзЪДжХ∞жНЃжЛњеИ∞дЄАиµЈжЭ•ињЫи°МзїЯдЄАзЪДжߕ胥еТМзЃ°зРЖгАВдљЖжШѓеѓєдЇОзЬЯж≠£зЪДдЉБдЄЪзЇІжЬНеК°еЃЮиЈµпЉМжИСдїђзЬЛеИ∞дЄАдЇЫйЧЃйҐШпЉМй¶ЦеЕИжХ∞жНЃзЪДжЭ•жЇРеѓєдЇОеЃҐжИЈжЭ•иѓіжШѓдЄНеПѓжОІзЪДпЉМдєЯжШѓе§ЪзІНе§Ъж†ЈзЪДпЉМиАМдЄФеЊИе§Із®ЛеЇ¶дЄКж≤°жЬЙеКЮж≥ХжККжЙАжЬЙзЪДжХ∞жНЃзїЯдЄАзФ®дЄАзІНз≥їзїЯеТМеЉХжУОжЭ•зЃ°зРЖиµЈжЭ•пЉМеЬ®ињЩзІНжГЕеЖµдЄЛжИСдїђйЬАи¶БжЫіе§ІзЪДиГљеКЫжШѓдїАдєИеСҐпЉЯжИСдїђдїК姩йАЪињЗдЄНеРМзЪДжХ∞жНЃжЇРпЉМеПѓдї•ињЫи°МзїЯдЄАзЪДиЃ°зЃЧеТМзїЯдЄАзЪДжߕ胥еТМеИЖжЮРпЉМзїЯдЄАзЪДзЃ°зРЖпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™жЫіжЦ∞зЪДж¶ВењµеПЂйАїиЊСжХ∞жНЃжєЦпЉМеѓєдЇОзФ®жИЈжЭ•иѓіпЉМдЄНйЬАи¶БжККдїЦзЪДжХ∞жНЃињЫи°МзЙ©зРЖдЄКзЪДжРђињБпЉМдљЖжШѓжИСдїђдЄАж†ЈиГље§ЯињЫи°МиБФйВ¶иЃ°зЃЧеТМжߕ胥пЉМињЩе∞±жШѓжИСдїђиЃ≤зЪДйАїиЊСжХ∞жНЃжєЦзЪДж†ЄењГзРЖењµгАВ
дЄЇдЇЖжФѓжТСињЩдїґдЇЛжГЕпЉМжИСдїђдЉЪжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖз≥їзїЯеТМи∞ГеЇ¶з≥їзїЯпЉМиГље§ЯиЃ©дЄНеРМзЪДиЃ°зЃЧеЉХжУОеНПеРМиµЈжЭ•еЈ•дљЬпЉМжЬАеРОжККжЙАжЬЙзЪДеЈ•дљЬж±ЗиБЪеИ∞еЕ®еЯЯжХ∞жНЃж≤їзРЖдЄКйЭҐпЉМеєґдЄФжПРдЊЫзїЩжХ∞жНЃеЉАеПСиАЕдЄАдЄ™зЉЦз®Леє≥еП∞пЉМиЃ©дїЦиГље§ЯзЫіжО•зЪДдЇІзФЯжХ∞жНЃпЉМжИЦиАЕжШѓеОїеЃЪеИґиЗ™еЈ±зЪДеЇФзФ®гАВйВ£дєИпЉМйАЪињЗињЩж†ЈзЪДжЦєеЉПпЉМжИСдїђжККеОЯжЭ•зЪДеНХзїіеЇ¶е§ІжХ∞жНЃеє≥еП∞еОїеБЪе§ІжХ∞жНЃе§ДзРЖпЉМжЛУе±ХеИ∞дЄАдЄ™еЕ®еЯЯзЪДжХ∞жНЃж≤їзРЖпЉМињЩдЄ™жХ∞жНЃеЕґеЃЮеПѓдї•еМЕеРЂзЃАеНХзЪДе§ІжХ∞жНЃзЪДпЉМдєЯеПѓдї•еМЕеРЂжХ∞жНЃеЇУзЪДпЉМзФЪиЗ≥жШѓдЄАдЇЫOSSзЪДfileпЉМињЩдЇЫжИСдїђеЬ®жХідЄ™зЪДеє≥еП∞йЗМйЭҐйГљдЉЪеК†дї•е§ДзРЖгАВ

е¶ВеЫЊдЄЇй£Ю姩姲жХ∞жНЃзЪДдЇІеУБжЮґжЮДпЉМдЄЛйЭҐжШѓе≠ШеВ®иЃ°зЃЧеЉХжУОпЉМеПѓдї•зЬЛеИ∞жИСдїђйЩ§дЇЖиЃ°зЃЧеЉХжУОиЗ™еЄ¶зЪДе≠ШеВ®дєЛе§ЦињШжЬЙеЕґеЃГеЉАжФЊзЪДOSSпЉМињШжЬЙIOTзЂѓйЗЗйЫЖзЪДжХ∞жНЃеТМжХ∞жНЃеЇУзЪДжХ∞жНЃпЉМжЙАжЬЙжХ∞жНЃињЫи°МеЕ®еЯЯжХ∞жНЃйЫЖжИРпЉМйЫЖжИРеРОињЫи°МзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМзїЯдЄАзЪДжЈЈеРИдїїеК°и∞ГеЇ¶пЉМеЖНеЊАдЄКжШѓеЉАеПСе±ВеТМжХ∞жНЃзїЉеРИж≤їзРЖе±ВпЉМйАЪињЗињЩзІНжЦєеЉПпЉМжИСдїђзЂЛдљУеМЦзЪДжККжХідЄ™е§ІжХ∞жНЃеЬИиµЈжЭ•зЃ°зРЖгАВ
е§ІжХ∞жНЃдЄОAI еПМзФЯз≥їзїЯ
===========
жПРеИ∞дЇЖе§ІжХ∞жНЃжИСдїђиВѓеЃЪдЉЪжГ≥еИ∞AIпЉМAIеТМе§ІжХ∞жНЃжШѓеПМзФЯзЪДпЉМеѓєдЇОAIжЭ•иѓіеЃГжШѓйЬАи¶Бе§ІжХ∞жНЃжЭ•empowerзЪДпЉМдєЯе∞±иѓіbigdata for AIгАВдЄЛйЭҐеПѓдї•йАЪињЗдЄАдЄ™demoжЭ•зЬЛжИСдїђжАОдєИжЭ•еБЪињЩдїґдЇЛжГЕгАВеѓєдЇОAIзЪДеЉАеПСеЈ•з®ЛеЄИжЭ•иѓіпЉМдїЦдїђжѓФиЊГеЄЄзФ®зЪДжЦєеЉПжШѓзФ®дЇ§дЇТеЉПзЪДnotebookжЭ•ињЫи°МAIзЪДеЉАеПСпЉМеЫ†дЄЇеЃГжѓФиЊГзЫіиІВпЉМдљЖжШѓе¶ВдљХжККе§ІжХ∞жНЃдєЯињЫи°МдЇ§дЇТеЉПеЉАеПСпЉМеєґдЄФеТМAIжЭ•зїСеЃЪпЉМдЄЛйЭҐжЭ•зЬЛдЄАдЄЛињЩдЄ™зЃАеНХзЪДдЊЛе≠РгАВ

е¶ВеЫЊжШѓжИСдїђDSWзЪДеє≥еП∞пЉМжИСдїђеПѓдї•зЫіжО•зЪДзФ®дЄАдЄ™magicеСљдї§пЉМconnectеИ∞зО∞е≠ШзЪДmaxcomputeйЫЖзЊ§пЉМеєґдЄФйАЙжЛ©projectеРОпЉМеПѓдї•зЫіжО•иЊУеЕ•sqlиѓ≠еП•пЉМињЩдЇЫйГљжШѓжЩЇиГљзЪДгАВзДґеРОжИСдїђеОїжЙІи°МпЉМзїУжЮЬеЗЇжЭ•дєЛеРОжИСдїђеПѓдї•еѓєfeatureињЫи°МзЫЄеЇФзЪДеИЖжЮРпЉМеМЕжЛђеПѓдї•еОїжФєеПШињЩдЇЫfeatureзЪДж®™зЇµеЭРж†ЗеБЪеЗЇдЄНеРМзЪДchartsпЉМеРМжЧґжИСдїђзФЪиЗ≥еПѓдї•жККзФЯжИРзЪДзїУжЮЬзЫіжО•webеИ∞excelжЦєеЉПињЫи°МзЉЦиЊСеТМе§ДзРЖпЉМе§ДзРЖеЃМдєЛеРОжИСдїђеЖНжККжХ∞жНЃжЛЙеЫЮжЭ•пЉМдєЯеПѓдї•еИЗжНҐеИ∞GPUжИЦиАЕCPUињЫи°МжЈ±еЇ¶е≠¶дє†еТМиЃ≠зїГпЉМиЃ≠зїГеЃМдЇЖдєЛеРОпЉМжИСдїђдЉЪжККжХідЄ™зЪДдї£з†БеПШжИРдЄАдЄ™ж®°еЮЛпЉМжИСдїђдЉЪжККињЩдЄ™ж®°еЮЛеѓЉеЕ•еИ∞дЄАдЄ™зЫЄеЇФзЪДеЬ∞жЦєдєЛеРОжПРдЊЫдЄАдЄ™WebжЬНеК°пЉМињЩдЄ™жЬНеК°дєЯе∞±жШѓжИСдїђзЪДеЬ®зЇњжО®зРЖжЬНеК°гАВжХіе•ЧжµБз®ЛеБЪеЃМдєЛеРОпЉМзФЪиЗ≥жИСдїђеПѓдї•еЖНжО•жХ∞жНЃеЇФзФ®пЉМеПѓдї•еЬ®жЙШзЃ°зЪДWEBдЄКжЮДеїЇпЉМињЩе∞±жШѓе§ІжХ∞жНЃеє≥еП∞зїЩAIжПРдЊЫжХ∞жНЃеТМзЃЧеКЫгАВ

е§ІжХ∞жНЃеТМAIжШѓеПМзФЯз≥їзїЯпЉМAIжШѓдЄАдЄ™еЈ•еЕЈе±ВпЉМеПѓдї•дЉШеМЦжЙАжЬЙзЪДдЇЛжГЕгАВжИСдїђеЄМжЬЫй£Ю姩зЪДе§ІжХ∞жНЃеє≥еП∞иГље§ЯиµЛиГљзїЩAIгАВжИСдїђеЬ®жЬАеЉАеІЛзЪДжЧґеАЩеЄМжЬЫbuildдЄАдЄ™еПѓзФ®зЪДз≥їзїЯпЉМиГље§ЯйЭҐдЄіеПМ11зЪДеЉєжАІиіЯиљљдїНзДґжШѓеПѓзФ®зЪДгАВйАЪињЗињЩдЇЫеєізЪДеК™еКЫпЉМжИСдїђињљж±ВжЮБиЗізЪДжАІиГљпЉМжИСдїђиГље§ЯжЙУз†іжХ∞жНЃзЪДеҐЮйХњеТМжИРжЬђеҐЮйХњзЪДзЇњжАІеЕ≥з≥їпЉМжИСдїђдєЯеЄМжЬЫеЃГжШѓдЄАдЄ™жЩЇиГљзЪДпЉМжИСдїђеЄМжЬЫжЫіе§ЪзЪДжХ∞жНЃеЉАеПСеЈ•з®ЛеЄИжЭ•жФѓжМБеЃГпЉМжИСдїђйЬАи¶БжЫіе§НжЭВзЪДдЇЇеКЫжКХеЕ•жЭ•зРЖиІ£дїЦпЉМжИСдїђеЄМжЬЫжЬЙжЫіеЉЇзЪДе§ІжХ∞жНЃжЭ•дЉШеМЦе§ІжХ∞жНЃз≥їзїЯгАВ

жИСдїђжПРеЗЇдЄАдЄ™ж¶ВењµеПЂAuto Data WarehouseпЉМжИСдїђеЄМжЬЫйАЪињЗжЩЇиГљеМЦзЪДжЦєеЉПжККе§ІжХ∞жНЃеБЪеЊЧжЫіиБ™жШОгАВжХідљУдЄКеПѓдї•еИЖжИР3дЄ™йШґжЃµпЉЪ
* зђђдЄАйШґжЃµжШѓиЃ°зЃЧе±ВйЭҐеТМжХИзОЗе±ВйЭҐпЉМжИСдїђе∞ЭиѓХеѓїжЙЊиЃ°зЃЧзЪДзђђдЄАе±ВеОЯзРЖпЉМжИСдїђеОїжЙЊзЩЊдЄЗеИ∞еНГдЄЗзЇІеИЂйЗМйЭҐзЪДеУ™дЇЫдљЬдЄЪжШѓзЫЄдЉЉзЪДпЉМеЫ†ж≠§еПѓдї•еРИеєґпЉМйАЪињЗињЩзІНжЦєеЉПжЭ•иКВзЬБжИРжЬђпЉМињШжЬЙељУдљ†жЬЙеНГдЄЗзЇІеИЂзЪДи°®дєЛеРОпЉМз©ґзЂЯеУ™дЇЫ谮忯糥еЉХеЕ®е±АжШѓжЬАдЉШзЪДпЉМдї•еПКжИСдїђжАОдєИеОїеБЪеЖЈзГ≠зЪДжХ∞жНЃеИЖе±ВеТМеБЪиЗ™йАВеЇФзЉЦз†БгАВ
* зђђдЇМйШґжЃµжШѓиµДжЇРиІДеИТпЉМAIеТМAuto Data WarehouseеПѓдї•еЄЃеК©жИСдїђеБЪжЫіе•љзЪДиµДжЇРдЉШеМЦпЉМеМЕжЛђжИСдїђжЬЙ3зІНзЪДжЙІи°МдљЬдЄЪж®°еЉПпЉМеУ™дЄАзІНж®°еЉПжЫіе•љпЉМжШѓеПѓдї•йАЪињЗе≠¶дє†зЪДжЦєеЉПе≠¶еЗЇжЭ•зЪДпЉМињШжЬЙеМЕжЛђдљЬдЄЪзЪДињРи°МйҐДжµЛеТМиЗ™еК®йҐДжК•и≠¶пЉМињЩе•Чз≥їзїЯдњЭиѓБдЇЖе§ІеЃґзЬЛеЊЧеИ∞жИЦиАЕзЬЛдЄНеИ∞зЪДйШњйЗМеЕ≥йФЃдљЬдЄЪзЪДж†ЄењГпЉМжѓФе¶ВжѓПињЗдЄАжЃµжЧґйЧіе§ІеЃґдЉЪеИЈдЄАдЄЛиКЭйЇїдњ°зФ®еИЖпЉМжѓП姩жЧ©дЄКдєЭзВєйШњйЗМзЪДеХЖжИЈз≥їзїЯдЉЪеТМдЄЛжЄЄз≥їзїЯеБЪзїУзЃЧпЉМеТМе§Ѓи°МеБЪзїУзЃЧпЉМињЩдЇЫеЯЇзЇњжШѓзФ±еНГзЩЊдЄ™дљЬдЄЪзїДжИРзЪДдЄАжЭ°зЇњпЉМдїОжѓП姩жЧ©дЄКеЗМжЩ®еЉАеІЛињРи°МеИ∞жЧ©дЄКеЕЂзВєиЈСеЃМпЉМз≥їзїЯеЫ†дЄЇеРДзІНеРДж†ЈзЪДеОЯеЫ†дЉЪеЗЇзО∞еРДзІНзЪДзКґеЖµпЉМеПѓиГљдЄ™еИЂзЪДжЬЇеЩ®дЉЪеЃХжЬЇгАВжИСдїђеБЪдЇЖдЄАдЄ™иЗ™еК®йҐДжµЛз≥їзїЯпЉМеОїйҐДжµЛињЩдЄ™з≥їзїЯжШѓеР¶иГље§ЯеЬ®еЕ≥йФЃжЧґйЧізВєдЄКеЃМжИРпЉМе¶ВжЮЬдЄНиГље§ЯеЃМжИРпЉМдЉЪжККжЫіе§ЪзЪДиµДжЇРеК†ињЫжЭ•пЉМдњЭиѓБеЕ≥йФЃдљЬдЄЪзЪДеЃМжИРгАВињЩдЇЫз≥їзїЯдњЭиѓБдЇЖжИСдїђе§ІеЃґжЧ•еЄЄзЬЛдЄНиІБзЪДеЕ≥йФЃжХ∞жНЃзЪДжµБиљђпЉМдї•еПКеПМеНБдЄАз≠ЙйЗНи¶БзЪДиµДжЇРеЉєжАІгАВ
* зђђдЄЙйШґжЃµжШѓжЩЇиГљеїЇж®°пЉМељУжХ∞жНЃињЫжЭ•дєЛеРОеТМйЗМйЭҐеЈ≤жЬЙзЪДжХ∞жНЃз©ґзЂЯжЬЙе§Ъе∞СзЪДйЗНеП†пЉЯињЩдЇЫжХ∞жНЃжЬЙе§Ъе∞СзЪДеЕ≥иБФпЉЯељУжХ∞жНЃжШѓеЗ†зЩЊеЉ†и°®жЧґпЉМжРЮDBAжЙЛеЈ•зЪДжЦєеЉПеПѓдї•и∞ГдЉШзЪДпЉМзО∞еЬ®йШњйЗМеЖЕйГ®зЪДз≥їзїЯжЬЙиґЕињЗеНГдЄЗзЇІеИЂзЪДи°®пЉМжИСдїђжЬЙйЭЮеЄЄе•љзЪДеЉАеПСдЇЇеСШзРЖиІ£и°®йЗМйЭҐеЃМеЕ®зЪДйАїиЊСеЕ≥з≥їгАВињЩдЇЫиЗ™еК®и∞ГдЉШеТМиЗ™еК®еїЇж®°иГље§ЯеЄЃеК©жИСдїђеЬ®ињЩдЇЫжЦєйЭҐеБЪдЄАдЇЫиЊЕеК©жАІзЪДеЈ•дљЬгАВ

ињЩжШѓAuto Data Warehouseз≥їзїЯжЮґжЮДеЫЊпЉМдїОе§ЪйЫЖзЊ§зЪДиіЯиљљеЭЗи°°еИ∞иЗ™еК®еЖЈе≠ШпЉМеИ∞дЄ≠йЧізЪДйЪР嚥дљЬдЄЪдЉШеМЦпЉМеЖНеИ∞дЄКе±ВзЪДйЪРзІБжХ∞жНЃиЗ™еК®иѓЖеИЂпЉМињЩжШѓжИСдїђеТМиЪВиЪБдЄАиµЈеЉАеПСзЪДжКАжЬѓпЉМељУйЪРзІБзЪДжХ∞жНЃиЗ™еК®жШЊз§ЇеИ∞е±ПеєХдЄКжЭ•пЉМз≥їзїЯдЉЪиЗ™еК®ж£АжµЛеєґжЙУз†БгАВжИСдїђеЕґдЄ≠зЪДдЄЙй°єжКАжЬѓпЉМеМЕжЛђиЗ™еК®йЪРзІБдњЭжК§пЉМеМЕжЛђйЗНе§Не≠Ржߕ胥иЗ™еК®еРИеєґдЉШеМЦпЉМеМЕжЛђе§ЪйЫЖзЊ§зЪДиЗ™еК®еЃєзБЊпЉМжИСдїђжЬЙ3зѓЗpaperеПСи°®пЉМе§ІеЃґжЬЙеЕіиґ£зЪДиѓЭеПѓдї•еОїзљСзЂЩдЄКиѓїдЄАдЄЛзЫЄеЕ≥зЪДиЃЇжЦЗгАВ
[еОЯжЦЗйУЊжО•](https://yq.aliyun.com/articles/723228?utm_content=g_1000085633)
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ
еИЖдЇЂеИ∞пЉЪ


- 2019-11-06 14:59
- жµПиІИ 272
- иѓДиЃЇ(0)
- еИЖз±ї:йЭЮжКАжЬѓ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
еЬ®2019еєідЇСж†Це§ІдЉЪзЪДе§ІжХ∞жНЃ&AIдЄУеЬЇдЄКпЉМйШњйЗМдЇСжЩЇиГљиЃ°зЃЧеє≥еП∞дЇЛдЄЪйГ®зЪДз†Фз©ґеСШеЕ≥жґЫеПКиµДжЈ±дЄУеЃґеЊРжЩЯжЈ±еЕ•иІ£жЮРдЇЖгАКAIеК†жМБзЪДйШњйЗМдЇСй£Ю姩姲жХ∞жНЃеє≥еП∞жКАжЬѓжП≠зІШгАЛзЪДдЄїйҐШжЉФиЃ≤гАВжЬђйГ®еИЖдЄїи¶БеИЖдЄЇдЄЙдЄ™йЗНзВєйГ®еИЖињЫи°МйШРињ∞пЉЪ 1. **еОЯеИЫжКАжЬѓ...
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЯЇдЇОжЭЊдЄЛAFPX-C38AT PLCеє≥еП∞зЪДеПМеИЗеИАдЄЙиЊєе∞БеИґиҐЛжЬЇжОІеИґз≥їзїЯгАВиѓ•з≥їзїЯйАЪињЗPLCжОІеИґеЫЫеП∞дЉЇжЬНзФµжЬЇињЫи°МеИЗеИАеТМзІїеИАеК®дљЬдї•еПКдЇМиљійАБиҐЛеЃЪдљНпЉМеРМжЧґзЃ°зРЖдЄ§еП∞еПШйҐСеЩ®еЃЮзО∞дЄїжЬЇеТМжФЊжЦЩзФµжЬЇзЪДеРМж≠•и∞ГйАЯпЉМеєґеИ©зФ®WK8Hж®°еЭЧињЫи°М16иЈѓжЄ©жОІиЊУеЗЇгАВжЦЗдЄ≠е±Хз§ЇдЇЖеЕЈдљУзЪДPLCзЉЦз®ЛеЃЮдЊЛпЉМе¶ВдЉЇжЬНзФµжЬЇзЪДDRVIжМЗдї§гАБеПШйҐСеЩ®зЪДеРМж≠•жОІеИґгАБжЄ©жОІж®°еЭЧзЪДPIDи∞ГиКВз≠ЙгАВж≠§е§ЦпЉМињШиЃ®иЃЇдЇЖз°ђдїґйЕНзљЃгАБиІ¶жСЄе±ПзХМйЭҐиЃЊиЃ°гАБйАЪдњ°еНПиЃЃиЃЊзљЃз≠ЙжЦєйЭҐзЪДеЖЕеЃєпЉМеЉЇи∞ГдЇЖз≥їзїЯзЪДзБµжіїжАІеТМз®≥еЃЪжАІгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛеЈ•дЄЪиЗ™еК®еМЦжОІеИґйҐЖеЯЯзЪДеЈ•з®ЛеЄИеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓеѓєPLCзЉЦз®ЛеТМдЉЇжЬНзФµжЬЇжОІеИґжДЯеЕіиґ£зЪДиѓїиАЕгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БжЈ±еЕ•дЇЖиІ£PLCжОІеИґз≥їзїЯзЪДеЉАеПСдЇЇеСШпЉМеЄЃеК©дїЦдїђжОМжП°дЉЇжЬНзФµжЬЇжОІеИґгАБеПШйҐСеЩ®еРМж≠•и∞ГйАЯеТМжЄ©жОІж®°еЭЧзЉЦз®ЛзЪДеЕЈдљУжЦєж≥ХпЉМжПРйЂШеЃЮйЩЕй°єзЫЃдЄ≠зЪДеЇФзФ®иГљеКЫгАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†дЄНдїЕжПРдЊЫдЇЖиѓ¶зїЖзЪДзЉЦз®Лз§ЇдЊЛпЉМињШеИЖдЇЂдЇЖиЃЄе§ЪеЃЮйЩЕи∞ГиѓХзЪДзїПй™МеТМжКАеЈІпЉМжЬЙеК©дЇОиѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®зЫЄеЕ≥жКАжЬѓгАВ
иЃ°зЃЧжЬЇеЃ°иЃ°иљѓдїґзЪДзЙєзВєдЄОеЇФзФ®.pdf
з¶їжХ£еВЕйЗМеПґеПШжНҐпЉИDFTпЉЙеИЖжЮР еЗљжХ∞[FпЉМFTпЉМPhase]=DFTпЉИTпЉМSignalпЉМFiпЉМFFпЉМResпЉМPпЉМCursorпЉЙиЃ°зЃЧз¶їжХ£еВЕйЗМеПґеПШжНҐпЉИDFTпЉЙ еКЯиГљж¶Вињ∞пЉЪз¶їжХ£еВЕзЂЛеПґеПШжНҐпЉИDFTпЉЙеИЖжЮР еЗљжХ∞[FпЉМFTпЉМPhase]=DFTпЉИTпЉМSignalпЉМFiпЉМFFпЉМResпЉМPпЉМCursorпЉЙжШѓйҐСзОЗеЯЯдњ°еПЈеИЖжЮРзЪДйАЪзФ®еЈ•еЕЈгАВеЃГеЬ®жМЗеЃЪзЪДйҐСзОЗиМГеЫіеЖЕиЃ°зЃЧдњ°еПЈзЪДз¶їжХ£еВЕзЂЛеПґеПШжНҐпЉИDFTпЉЙпЉМжПРдЊЫеПѓеЃЪеИґзЪДеПѓиІЖеМЦйАЙй°єгАВ иЊУеЕ• TпЉИйЗЗж†ЈжЧґйЧіеРСйЗПпЉМзІТпЉЙпЉЪи°®з§ЇдЄОж≠£еЬ®еИЖжЮРзЪДдњ°еПЈж†ЈжЬђзЫЄеѓєеЇФзЪДжЧґйЧізВєгАВ дњ°еПЈпЉЪжВ®еЄМжЬЫеЬ®йҐСеЯЯдЄ≠ж£АжЯ•зЪДжХ∞жНЃйЫЖжИЦдњ°еПЈгАВ FIпЉИдї•иµЂеЕєдЄЇеНХдљНзЪДеИЭеІЛйҐСзОЗпЉЙпЉЪйҐСзОЗеИЖжЮРзЪДиµЈзВєгАВ FFпЉИжЬАзїИйҐСзОЗпЉИHzпЉЙпЉЪйҐСзОЗеИЖжЮРиМГеЫізЪДдЄКйЩРгАВ ResпЉИеИЖиЊ®зОЗдї•иµЂеЕєдЄЇеНХдљНпЉЙпЉЪз°ЃеЃЪеВЕзЂЛеПґеПШжНҐзЪДз≤ЊеЇ¶гАВиЊГе∞ПзЪДеАЉдЉЪеҐЮеК†еИЖиЊ®зОЗгАВ PпЉИжЙУеН∞йАЙй°єпЉЙпЉЪ 0пЉЪж≤°жЬЙзФЯжИРеЫЊгАВ 1пЉЪ дїЕжШЊз§ЇйЬЗзЇІеЫЊгАВ 2пЉЪ жШЊз§Їе§Іе∞ПеТМзЫЄдљНеЫЊгАВ еЕЙж†ЗпЉИеЬ®зїШеЫЊдЄКеРѓзФ®еЕЙж†ЗпЉЙпЉИеПѓйАЙпЉЙпЉЪ 1пЉЪ ељУPдЄН
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХеЬ®MatlabдЄ≠жЮДеїЇдЄАдЄ™зїЉеРИдЇЖеЮГеЬЊзДЪзГІгАБзҐ≥жНХйЫЖеТМзФµиљђж∞ФпЉИP2GпЉЙжКАжЬѓзЪДиЩЪжЛЯзФµеОВдЉШеМЦи∞ГеЇ¶з≥їзїЯгАВиѓ•з≥їзїЯжЧ®еЬ®йАЪињЗеРИзРЖзЪДиЃЊе§ЗеПВжХ∞иЃЊзљЃгАБе§ЪиГљжµБиА¶еРИзЇ¶жЭЯдї•еПКеИЖжЃµзҐ≥дїЈжЬЇеИґзЪДзЫЃж†ЗеЗљжХ∞иЃЊиЃ°пЉМеЃЮзО∞зОѓдњЭдЄОзїПжµОжХИзЫКзЪДжЬАе§ІеМЦгАВжЦЗдЄ≠е±Хз§ЇдЇЖеЕЈдљУзЪДжХ∞е≠¶ж®°еЮЛеїЇзЂЛжЦєж≥ХпЉМе¶ВиЃЊе§ЗеПВжХ∞еИЭеІЛеМЦгАБиГљйЗПеє≥и°°зЇ¶жЭЯгАБзҐ≥жНХйЫЖдЄОP2GзЙ©жЦЩеє≥и°°гАБеИЖжЧґзҐ≥жИРжЬђиЃ°зЃЧз≠ЙпЉМеєґиЃ®иЃЇдЇЖж±ВиІ£жКАеЈІпЉМеМЕжЛђеПШйЗПеЃЪдєЙгАБж±ВиІ£еЩ®йАЙжЛ©еТМзЇ¶жЭЯжЭ°дїґе§ДзРЖз≠ЙжЦєйЭҐзЪДеЖЕеЃєгАВж≠§е§ЦпЉМињШжОҐиЃ®дЇЖеЮГеЬЊзДЪзГІеПСзФµеН†жѓФеПШеМЦеѓєP2GиЃЊе§ЗеРѓеБЬз≠ЦзХ•зЪДељ±еУНпЉМдї•еПКдЄНеРМжЧґйЧіжЃµеЖЕзЪДжЬАдЉШи∞ГеЇ¶з≠ЦзХ•гАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛиГљжЇРз≥їзїЯдЉШеМЦз†Фз©ґзЪДдЄУдЄЪдЇЇе£ЂпЉМзЙєеИЂжШѓйВ£дЇЫзЖЯжВЙMatlabзЉЦз®ЛеєґеЄМжЬЫжЈ±еЕ•дЇЖиІ£иЩЪжЛЯзФµеОВи∞ГеЇ¶жЬЇеИґзЪДдЇЇзЊ§гАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОеЄМжЬЫжПРйЂШиЩЪжЛЯзФµеОВињРи°МжХИзОЗзЪДз†Фз©ґжЬЇжЮДжИЦдЉБдЄЪгАВйАЪињЗжЬђй°єзЫЃзЪДеЃЮжЦљпЉМиГље§ЯжЫіе•љеЬ∞зРЖиІ£е¶ВдљХжХіеРИе§ЪзІНиГљжЇРжКАжЬѓпЉМеЬ®жї°иґ≥зФµеКЫдЊЫеЇФйЬАж±ВзЪДеРМжЧґеЗПе∞СзҐ≥жОТжФЊпЉМйЩНдљОжИРжЬђгАВеЕЈдљУеЇФзФ®еЬЇжЩѓеМЕжЛђдљЖдЄНйЩРдЇОпЉЪеИґеЃЪжЫіеК†зІСе≠¶еРИзРЖзЪДеПСзФµиЃ°еИТпЉЫиѓДдЉ∞жЦ∞жКАжЬѓеЉХеЕ•еРОзЪДжљЬеЬ®жХИзЫКпЉЫжΥ糥дЄНеРМжФњз≠ЦзОѓеҐГдЄЛзЪДжЬАдљ≥ињРиР•ж®°еЉПгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРеИ∞зЪДдЄАдЇЫеЕ≥йФЃжКАжЬѓзВєпЉМе¶ВзҐ≥жНХйЫЖдЄОP2GзЪДеНПеРМеЈ•дљЬгАБеЮГеЬЊзДЪзГІеПСзФµзЪДзБµжіїеЇФзФ®з≠ЙпЉМеѓєдЇОжО®еК®жЄЕжіБиГљжЇРзЪДеПСе±ХеЕЈжЬЙйЗНи¶БжДПдєЙгАВеРМжЧґпЉМдљЬиАЕдєЯеЬ®еЃЮиЈµдЄ≠йБЗеИ∞дЇЖдЄАдЇЫжМСжИШпЉМе¶ВзЇ¶жЭЯжЭ°дїґдєЛйЧізЪДеЖ≤з™Бз≠ЙйЧЃйҐШпЉМеєґеИЖдЇЂдЇЖиІ£еЖ≥ињЩдЇЫйЧЃйҐШзЪДзїПй™МгАВ
еЕ•ж†ИеТМеЗЇж†ИзЪДеЯЇжЬђжУНдљЬ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖжОҐиЃ®дЇЖVеЮЛж∞Єз£БеРМж≠•зФµжЬЇдЄ≠ж∞Єз£БдљУеПВжХ∞и∞ГжХізЪДжЦєж≥ХеТМжКАжЬѓпЉМзЙєеИЂжШѓеЬ®MaxwellиљѓдїґдЄ≠зЪДеЇФзФ®гАВй¶ЦеЕИдїЛзїНдЇЖVеЮЛж∞Єз£БдљУзЪДеЕ≥йФЃеПВжХ∞пЉИе¶ВVеЮЛе§єиІТгАБз£БйТҐеОЪеЇ¶гАБжЮБеЉІз≥їжХ∞з≠ЙпЉЙеПКеЕґеѓєзФµжЬЇжАІиГљзЪДељ±еУНгАВжО•зЭАиЃ®иЃЇдЇЖеИ©зФ®MaxwellињЫи°МеПВжХ∞еМЦеїЇж®°гАБеПВжХ∞жЙЂжППгАБдЉШеМЦжЦєж≥ХпЉИе¶ВеУНеЇФйЭҐж≥ХгАБе§ЪзЫЃж†ЗйБЧдЉ†зЃЧж≥ХпЉЙзЪДеЕЈдљУж≠•й™§еТМж≥®жДПдЇЛй°єгАВжЦЗдЄ≠ињШжПРдЊЫдЇЖе§ЪдЄ™еЃЮзФ®иДЪжЬђпЉМжґµзЫЦдїОеЗ†дљХеїЇж®°гАБжЭРжЦЩе±ЮжАІиЃЊзљЃеИ∞ж±ВиІ£еЩ®йЕНзљЃгАБеРОе§ДзРЖеИЖжЮРз≠Йе§ЪдЄ™жЦєйЭҐгАВж≠§е§ЦпЉМеЉЇи∞ГдЇЖдЉШеМЦињЗз®ЛдЄ≠еЇФж≥®жДПзЪДйЧЃйҐШпЉМе¶ВйААз£Бж†°й™МгАБз£БеѓЖй•±еТМгАБжґ°жµБжНЯиАЧз≠ЙпЉМеєґзїЩеЗЇдЇЖдЄАдЇЫеЃЮжИШжКАеЈІгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛзФµжЬЇиЃЊиЃ°дЄОдїњзЬЯзЪДеЈ•з®ЛеЄИгАБз†Фз©ґдЇЇеСШпЉМе∞§еЕґжШѓзЖЯжВЙMaxwellиљѓдїґзЪДзФ®жИЈгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪеЄЃеК©зФ®жИЈжОМжП°VеЮЛж∞Єз£БеРМж≠•зФµжЬЇж∞Єз£БдљУеПВжХ∞и∞ГжХізЪДжКАжЬѓи¶БзВєпЉМжПРйЂШзФµжЬЇжАІиГљжМЗж†ЗпЉИе¶ВйЩНдљОйљњжІљиљђзЯ©гАБеЗПе∞Си∞Рж≥Ґе§±зЬЯгАБдЉШеМЦиљђзЯ©ж≥ҐеК®з≠ЙпЉЙгАВйАЪињЗеЃЮдЊЛеТМиДЪжЬђжМЗеѓЉпЉМдљњзФ®жИЈиГље§ЯеЬ®MaxwellдЄ≠йЂШжХИеЬ∞еЃМжИРдїњзЬЯеТМдЉШеМЦдїїеК°гАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†дЄНдїЕжПРдЊЫдЇЖиѓ¶зїЖзЪДзРЖиЃЇиІ£йЗКпЉМињШеМЕжЛђе§ІйЗПеЃЮиЈµзїПй™МеИЖдЇЂеТМеЄЄиІБйЧЃйҐШиІ£еЖ≥жЦєж°ИпЉМжЬЙеК©дЇОиѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®зЫЄеЕ≥жКАжЬѓгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЕЙдЉПеПСзФµз≥їзїЯзЪДдїњзЬЯеїЇж®°еПКеЕґжОІеИґз≠ЦзХ•гАВдЄїи¶БеЖЕеЃєеИЖдЄЇеЫЫдЄ™йГ®еИЖпЉЪй¶ЦеЕИжШѓеЕЙдЉПеПСзФµз≥їзїЯдїњзЬЯж®°еЮЛзЪДжР≠еїЇпЉМйАЪињЗжХ∞е≠¶еЕђеЉПеТМPythonдї£з†БеЃЮзО∞дЇЖ姙йШ≥зԵ汆зЙєжАІзЪДж®°жЛЯпЉЫеЕґжђ°пЉМжОҐиЃ®дЇЖжЙ∞еК®иІВеѓЯж≥ХпЉИPOпЉЙдљЬдЄЇжЬАе§ІеКЯзОЗзВєиЈЯиЄ™пЉИMPPTпЉЙзЪДжЦєж≥ХпЉМе±Хз§ЇдЇЖеЕґеЃЮзО∞йАїиЊСеТМдї£з†Бз§ЇдЊЛпЉЫзђђдЄЙйГ®еИЖиЃ®иЃЇдЇЖеЄ¶еВ®иГљжОІеИґз≠ЦзХ•зЪДиЃЊиЃ°пЉМеИ©зФ®зКґжАБжЬЇзЃ°зРЖеВ®иГљз≥їзїЯзЪДеЕЕжФЊзФµињЗз®ЛпЉМз°ЃдњЭзФµеКЫдЊЫеЇФеє≥з®≥пЉЫжЬАеРОињЫи°МдЇЖиіЯиљљз™БеПШй™МиѓБеЃЮй™МпЉМиѓДдЉ∞дЇЖз≥їзїЯеЬ®жЮБзЂѓжЭ°дїґдЄЛзЪДз®≥еЃЪжАІеТМеПѓйЭ†жАІгАВйАЪињЗињЩдЇЫж≠•й™§пЉМдљЬиАЕдЄНдїЕиІ£йЗКдЇЖзРЖиЃЇиГМжЩѓпЉМињШжПРдЊЫдЇЖеЕЈдљУзЪДеЃЮзО∞зїЖиКВеТМжКАжЬѓжМСжИШгАВ йАВеРИдЇЇзЊ§пЉЪеѓєеЕЙдЉПеПСзФµз≥їзїЯжДЯеЕіиґ£зЪДз†Фз©ґдЇЇеСШгАБеЈ•з®ЛеЄИдї•еПКзЫЄеЕ≥йҐЖеЯЯзЪДе≠¶зФЯгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОеЄМжЬЫжЈ±еЕ•дЇЖиІ£еЕЙдЉПеПСзФµз≥їзїЯеЈ•дљЬеОЯзРЖзЪДдЇЇзЊ§пЉМе∞§еЕґжШѓеЕ≥ж≥®жЬАе§ІеКЯзОЗзВєиЈЯиЄ™жКАжЬѓеТМеВ®иГљжОІеИґз≥їзїЯиЃЊиЃ°зЪДеЇФзФ®еЉАеПСиАЕгАВзЫЃж†ЗжШѓеЄЃеК©иѓїиАЕжОМжП°еЕЙдЉПз≥їзїЯдїњзЬЯзЪДеЕ≥йФЃжКАжЬѓпЉМдЄЇеЃЮйЩЕй°єзЫЃжПРдЊЫзРЖиЃЇжФѓжМБеТМжКАжЬѓжМЗеѓЉгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРдЊЫзЪДдї£з†БзЙЗжЃµеПѓдї•зЫіжО•зФ®дЇОеЃЮй™МзОѓеҐГпЉМдЊњдЇОиѓїиАЕеК®жЙЛеЃЮиЈµгАВж≠§е§ЦпЉМйТИеѓєеПѓиГљеЗЇзО∞зЪДйЧЃйҐШе¶ВиА¶еРИжМѓиН°з≠ЙпЉМзїЩеЗЇдЇЖзЫЄеЇФзЪДиІ£еЖ≥жЦєж°ИгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖ8жЮБ48жІљиЊРжЭ°еЮЛзФµжЬЇиљђе≠Рж°•зЪДеПВжХ∞еМЦеїЇж®°жЦєж≥ХеПКеЕґдЉШеМЦињЗз®ЛгАВйАЪињЗе∞Жж°•зЪДеОЪеЇ¶гАБињЗжЄ°еЬЖеЉІеНКеЊДеТМеАТиІТиІТеЇ¶дљЬдЄЇеПШйЗПињЫи°МеПВжХ∞еМЦе§ДзРЖпЉМеИ©зФ®MaxwellиљѓдїґеЃЮзО∞дЇЖиЗ™еК®еМЦдїњзЬЯеТМдЉШеМЦгАВжЦЗдЄ≠е±Хз§ЇдЇЖеЕЈдљУзЪДPythonеТМVBScriptдї£з†Бз§ЇдЊЛпЉМзФ®дЇОеК®жАБи∞ГжХіж°•йГ®е∞ЇеѓЄеєґзЫСжОІз£БеѓЖеИЖеЄГпЉМжЬАзїИйАЪињЗеПВжХ∞жЙЂжППжЙЊеИ∞жЬАдљ≥иЃЊиЃ°еПВжХ∞зїДеРИпЉМжШЊиСЧйЩНдљОдЇЖз£БеѓЖе≥∞еАЉеТМжЙ≠зЯ©ж≥ҐеК®пЉМжПРйЂШдЇЖзФµжЬЇзЪДжХідљУжАІиГљгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛзФµжЬЇиЃЊиЃ°дЄОдїњзЬЯзЪДеЈ•з®ЛеЄИеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓзЖЯжВЙMaxwellиљѓдїґзЪДзФ®жИЈгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БдЉШеМЦзФµжЬЇиљђе≠Рж°•зїУжЮДзЪДиЃЊиЃ°й°єзЫЃпЉМжЧ®еЬ®жПРйЂШзФµжЬЇжАІиГљпЉМйЩНдљОз£БеѓЖе≥∞еАЉеТМжЙ≠зЯ©ж≥ҐеК®пЉМз°ЃдњЭжЬЇжҐ∞еЉЇеЇ¶зЪДеРМжЧґжПРеНЗзФµз£БжАІиГљгАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†жПРдЊЫдЇЖиѓ¶зїЖзЪДдї£з†Бз§ЇдЊЛеТМжУНдљЬж≠•й™§пЉМеЄЃеК©иѓїиАЕењЂйАЯжОМжП°еПВжХ∞еМЦеїЇж®°жКАеЈІпЉМеєґеЉЇи∞ГдЇЖзљСж†ЉиЃЊзљЃеТМе§ЪеПВжХ∞иБФеК®дЉШеМЦзЪДйЗНи¶БжАІгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖзФ®дЇОй£ОзФµи∞ГйҐСеєґзљСз≥їзїЯзЪД4жЬЇ2еМЇж®°еЮЛпЉМиѓ•ж®°еЮЛиГље§ЯеЬ®зЯ≠жЧґйЧіеЖЕеЃМжИРйХњжЧґйЧіиЈ®еЇ¶зЪДдїњзЬЯпЉМжЮБе§ІжПРйЂШдЇЖзІСз†ФеТМеЈ•з®ЛеИЖжЮРзЪДжХИзОЗгАВжЦЗдЄ≠еЕЈдљУйШРињ∞дЇЖж®°еЮЛзЪДзїУжЮДзЙєзВєпЉМеМЕжЛђдЄ§дЄ™еМЇеЯЯеЖЕзЪДеПСзФµжЬЇзїДеИЖеЄГгАБињЮжО•жЦєеЉПдї•еПКй£ОзФµеЬЇзЪДиЩЪжЛЯжГѓйЗПжОІеИґжЬЇеИґгАВж≠§е§ЦпЉМжЦЗзЂ†жЈ±еЕ•иІ£жЮРдЇЖеЫЫзІНPSSпЉИзФµеКЫз≥їзїЯз®≥еЃЪеЩ®пЉЙж®°еЉПзЪДеЈ•дљЬеОЯзРЖеПКеЕґеЬ®дЄНеРМеЈ•еЖµдЄЛзЪДи°®зО∞пЉМзЙєеИЂжШѓйТИеѓєй£ОзФµжО•еЕ•еЄ¶жЭ•зЪДдљОйҐСжМѓиН°йЧЃйҐШињЫи°МдЇЖиЃ®иЃЇгАВйАЪињЗеЃЮдЊЛе±Хз§ЇдЇЖPSSж®°еЉПеѓєз≥їзїЯз®≥еЃЪжАІзЪДжШЊиСЧжПРеНЗжХИжЮЬпЉМеєґеИЖдЇЂдЇЖдЄАдЇЫеЃЮзФ®зЪДи∞ГеПВжКАеЈІгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛзФµеКЫз≥їзїЯдїњзЬЯгАБй£ОзФµеєґзљСз†Фз©ґзЪДдЄУдЄЪжКАжЬѓдЇЇеСШеПКйЂШж†°зЫЄеЕ≥дЄУдЄЪеЄИзФЯгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БињЫи°Ме§ІиІДж®°й£ОзФµи∞ГйҐСеєґзљСз≥їзїЯдїњзЬЯзЪДеЬЇеРИпЉМжЧ®еЬ®еЄЃеК©з†Фз©ґдЇЇеСШжЫіе•љеЬ∞зРЖиІ£еТМиІ£еЖ≥й£ОзФµжО•еЕ•еѓєзФµзљСз®≥еЃЪжАІзЪДељ±еУНпЉМдЉШеМЦй£ОзФµеєґзљСеПЛе•љеЇ¶гАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†дЄНдїЕжПРдЊЫдЇЖзРЖиЃЇеИЖжЮРпЉМињШеМЕжЛђеЕЈдљУзЪДPythonеТМMatlabдї£з†Бз§ЇдЊЛпЉМдЊњдЇОиѓїиАЕзРЖиІ£еТМеЃЮиЈµгАВеРМжЧґеЉЇи∞ГдЇЖеЬ®йЂШй£ОзФµжЄЧйАПзОЗжЭ°дїґдЄЛйАЙжЛ©еРИйАВPSSж®°еЉПзЪДйЗНи¶БжАІгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХдљњзФ®LabVIEWзЪДExcelеЈ•еЕЈеМЕжЭ•йЂШжХИзФЯжИРеЄ¶жЬЙзЙєеЃЪж†ЉеЉПзЪДжµЛиѓХжК•еСКгАВй¶ЦеЕИпЉМеЗЖе§ЗдЄАдЄ™Excelж®°жЭњжЦЗдїґпЉМиЃЊзљЃе•љи°®е§іж†ЈеЉПгАБеЕђеПЄLOGOеТМеРИеєґеНХеЕГж†ЉпЉМеєґзФ®зЙєжЃКж†ЗиЃ∞еН†дљНгАВзДґеРОпЉМйАЪињЗLabVIEWдї£з†БињЫи°МExcelжУНдљЬпЉМе¶ВеИЭеІЛеМЦExcelеЇФзФ®гАБжЙУеЉАеТМе§НеИґж®°жЭњжЦЗдїґгАБеЖЩеЕ•жµЛиѓХжХ∞жНЃгАБиЃЊзљЃжЭ°дїґж†ЉеЉПгАБи∞ГжХіеИЧеЃљдї•еПКдњЭе≠ШеТМеЕ≥йЧ≠жЦЗдїґгАВжЦЗдЄ≠еЉЇи∞ГдЇЖдљњзФ®дЇМзїіжХ∞зїДжЙєйЗПеЖЩеЕ•жХ∞жНЃгАБжЭ°дїґж†ЉеЉПиЃЊзљЃиґЕж†ЗжХ∞жНЃж†ЗзЇҐгАБз≤Њз°ЃжОІеИґеИЧеЃљгАБйБњеЕНжЦЗдїґи¶ЖзЫЦз≠ЙйЧЃйҐШгАВж≠§е§ЦпЉМињШжПРеИ∞дЇЖдЄАдЇЫеЄЄиІБйЧЃйҐШеПКеЕґиІ£еЖ≥жЦєж°ИпЉМе¶ВExcelињЫз®ЛеН°ж≠їгАБжХ∞жНЃйФЩдљНз≠ЙгАВжЬАзїИпЉМйАЪињЗињЩдЇЫжЦєж≥ХеПѓдї•е∞ЖеОЯжЬђе§НжЭВзЪДжК•еСКзФЯжИРињЗз®Ле§ІеєЕзЃАеМЦпЉМжПРйЂШеЈ•дљЬжХИзОЗгАВ йАВеРИдЇЇзЊ§пЉЪзЖЯжВЙLabVIEWзЉЦз®ЛзЪДеЈ•з®ЛеЄИеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓдїОдЇЛиЗ™еК®еМЦжµЛиѓХеТМжХ∞жНЃеИЖжЮРеЈ•дљЬзЪДдЇЇеСШгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БйҐСзєБзФЯжИРж†ЉеЉПдЄАиЗізЪДжµЛиѓХжК•еСКзЪДеЬЇжЩѓпЉМе¶Вж±љиљ¶зФµе≠РжµЛиѓХгАБзОѓеҐГзЫСжµЛз≠ЙйҐЖеЯЯгАВзЫЃж†ЗжШѓйАЪињЗLabVIEWзЪДExcelеЈ•еЕЈеМЕеЃЮзО∞иЗ™еК®еМЦгАБйЂШжХИзЪДжК•еСКзФЯжИРпЉМиКВзЬБжЧґйЧіеТМз≤ЊеКЫгАВ йШЕиѓїеїЇиЃЃпЉЪиѓїиАЕеПѓдї•йАЪињЗжЬђжЦЗе≠¶дє†е¶ВдљХеИ©зФ®LabVIEWзЪДExcelеЈ•еЕЈеМЕењЂйАЯзФЯжИРеЄ¶ж†ЉеЉПзЪДжµЛиѓХжК•еСКпЉМжОМжП°еЕ≥йФЃжКАжЬѓеТМжЬАдљ≥еЃЮиЈµпЉМдїОиАМжПРеНЗеЈ•дљЬжХИзОЗгАВеРМжЧґпЉМеЬ®еЃЮиЈµдЄ≠еЇФж≥®жДПж®°жЭњзЪДиЃЊиЃ°еТМдї£з†БзЪДдЉШеМЦпЉМдї•еЇФеѓєеРДзІНе§НжЭВзЪДйЬАж±ВеПШеМЦгАВ
main (4).ipynb
иЃ°зЃЧжЬЇжХ∞е≠¶еЯЇз°А(дЄЛ).pdf
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХеИ©зФ®MATLABеЃЮзО∞еЯЇдЇОе§ЪжЩЇиГљдљУз≥їзїЯдЄАиЗіжАІзЃЧж≥ХзЪДзФµеКЫз≥їзїЯеИЖеЄГеЉПзїПжµОи∞ГеЇ¶з≠ЦзХ•гАВй¶ЦеЕИпЉМйАЪињЗжЮДеїЇйВїжО•зЯ©йШµзФЯжИРеЗљжХ∞пЉМе§ДзРЖзФµзљСжЛУжЙСзїУжЮДпЉМз°ЃдњЭжѓПдЄ™иКВзВєиГље§Яж≠£з°ЃиОЈеПЦйВїе±Едњ°жБѓгАВжО•зЭАпЉМеЃЪдєЙеПСзФµжЬЇжИРжЬђеЗљжХ∞еТМиіЯиНЈжХИзФ®еЗљжХ∞пЉМе∞ЖдЄ§иАЕзїЯдЄАдЄЇдЇМжђ°еЗљжХ∞嚥еЉПпЉМдї•дЊњжЫіе•љеЬ∞еЕЉй°ЊеПСзФµдЊІеТМзФ®зФµдЊІзЪДзїПжµОжАІгАВзДґеРОпЉМйЗНзВєе±Хз§ЇдЇЖж†ЄењГзЪДдЄАиЗіжАІињ≠дї£зЃЧж≥ХпЉМйАЪињЗжЛЙжЩЃжЛЙжЦѓзЯ©йШµеЃЮзО∞дњ°жБѓжЙ©жХ£пЉМдљњеПСзФµжЬЇеТМиіЯиНЈдєЛйЧізЪДеҐЮйЗПжИРжЬђеТМжХИзЫКйАРж≠•иґЛдЇОдЄАиЗігАВж≠§е§ЦпЉМжЦЗдЄ≠ињШжПРдЊЫдЇЖеЕЈдљУзЪДжµЛиѓХж°ИдЊЛпЉМеМЕжЛђ10еП∞еПСзФµжЬЇеТМ19дЄ™жЯФжАІиіЯиНЈзїДжИРзЪДз≥їзїЯпЉМе±Хз§ЇдЇЖзЃЧж≥ХзЪДйЂШжХИжАІеТМй≤Бж£ТжАІгАВжЬАеРОпЉМеЉЇи∞ГдЇЖйАЪдњ°жЛУжЙСиЃЊиЃ°еѓєжФґжХЫйАЯеЇ¶зЪДељ±еУНпЉМеєґеИЖдЇЂдЇЖдЄАдЇЫи∞ГиѓХзїПй™МеТМжљЬеЬ®зЪДеЇФзФ®еЙНжЩѓгАВ йАВеРИдЇЇзЊ§пЉЪзФµеКЫз≥їзїЯз†Фз©ґдЇЇеСШгАБиЗ™еК®еМЦжОІеИґеЈ•з®ЛеЄИгАБMATLABеЉАеПСиАЕдї•еПКеѓєеИЖеЄГеЉПдЉШеМЦзЃЧж≥ХжДЯеЕіиґ£зЪДе≠¶иАЕгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОзФµеКЫз≥їзїЯзїПжµОи∞ГеЇ¶зЪДз†Фз©ґдЄОеЉАеПСпЉМжЧ®еЬ®жПРйЂШи∞ГеЇ¶жХИзОЗгАБйЩНдљОжИРжЬђзЪДеРМжЧґдњЭйЪЬз≥їзїЯзЪДз®≥еЃЪжАІгАВйАЪињЗеИЖеЄГеЉПзЃЧж≥ХжЫњдї£дЉ†зїЯзЪДйЫЖдЄ≠еЉПи∞ГеЇ¶жЦєеЉПпЉМеҐЮеЉЇз≥їзїЯзЪДйЪРзІБдњЭжК§иГљеКЫеТМиЃ°зЃЧжХИзОЗгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРдЊЫзЪДMATLABдї£з†БдЄНдїЕеПѓзФ®дЇОе≠¶жЬѓз†Фз©ґпЉМињШеПѓдї•ињЫдЄАж≠•еЇФзФ®дЇОеЃЮйЩЕеЈ•з®Лй°єзЫЃдЄ≠пЉМзЙєеИЂжШѓеЬ®еРЂжЬЙе§ІйЗПжЦ∞иГљжЇРжО•еЕ•зЪДзО∞дї£зФµеКЫз≥їзїЯдЄ≠пЉМе±ХзО∞еЗЇжЫіе§ІзЪДдЉШеКњгАВ
иЃ°зЃЧжЬЇжХ∞жОІи£ЕзљЃиѓЊдїґ.pdf
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖRRTпЉИењЂйАЯжЙ©е±ХйЪПжЬЇж†СпЉЙиЈѓеЊДиІДеИТзЃЧж≥ХзЪДе§ЪдЄ™дЉШеМЦжЦєж≥ХеПКеЕґеЕЈдљУеЃЮзО∞гАВй¶ЦеЕИжМЗеЗЇеОЯеІЛRRTе≠ШеЬ®зЪДзЉЇйЩЈпЉМе¶ВиЈѓеЊДиі®йЗПеЈЃгАБиЃ°зЃЧжЧґйЧійХњз≠ЙйЧЃйҐШгАВзДґеРОжПРеЗЇдЇЖдЄАз≥їеИЧжФєињЫжО™жЦљпЉМеМЕжЛђзЫЃж†ЗеБПеРСйЗЗж†ЈгАБиЗ™йАВеЇФж≠•йХњжОІеИґгАБиЈѓеЊДеє≥жїСе§ДзРЖдї•еПКж§≠еЬЖзЇ¶жЭЯйЗЗж†Јз≠ЙгАВжѓПдЄ™жФєињЫйГљйЩДжЬЙеЕЈдљУзЪДPythonдї£з†БзЙЗжЃµпЉМеєґиІ£йЗКдЇЖеЕґеЃЮзО∞жАЭиЈѓеТМжКАжЬѓзїЖиКВгАВж≠§е§ЦпЉМжЦЗдЄ≠ињШиЃ®иЃЇдЇЖдЄНеРМжФєињЫжЦєж°ИдєЛйЧізЪДеНПеРМдљњзФ®жХИжЮЬпЉМеЉЇи∞ГдЇЖеЃЮйЩЕеЇФзФ®дЄ≠зЪДж≥®жДПдЇЛй°єгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛжЬЇеЩ®дЇЇиЈѓеЊДиІДеИТз†Фз©ґзЪДжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓжЬЙдЄАеЃЪзЉЦз®ЛеЯЇз°АеєґеЄМжЬЫжЈ±еЕ•дЇЖиІ£RRTзЃЧж≥ХдЉШеМЦзЪДдЇЇзЊ§гАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОеРДзІНйЬАи¶БйЂШжХИиЈѓеЊДиІДеИТзЪДеЇФзФ®еЬЇеРИпЉМе¶ВдїУеВ®жЬЇеЩ®дЇЇгАБжЧ†дЇЇжЬЇйБњйЪЬгАБжЬЇжҐ∞иЗВињРеК®иІДеИТз≠ЙгАВдЄїи¶БзЫЃж†ЗжШѓжПРйЂШиЈѓеЊДиІДеИТзЪДйАЯеЇ¶еТМиі®йЗПпЉМеРМжЧґеЗПе∞СиЃ°зЃЧиµДжЇРжґИиАЧгАВ еЕґдїЦиѓіжШОпЉЪе∞љзЃ°ињЩдЇЫжФєињЫжШЊиСЧжПРеНЗдЇЖRRTзЪДи°®зО∞пЉМдљЖеЬ®еЃЮйЩЕйГ®зљ≤жЧґдїНйЬАиАГиЩСдЉ†жДЯеЩ®еЩ™е£∞еТМз≥їзїЯеїґињЯз≠ЙеЫ†зі†зЪДељ±еУНгАВдљЬиАЕеИЖдЇЂдЇЖиЃЄе§ЪдЄ™дЇЇеЃЮиЈµзїПй™МпЉМдЄЇиѓїиАЕжПРдЊЫдЇЖеЃЭиіµзЪДеПВиАГгАВ
иЃ°зЃЧжЬЇиѓХйҐШеЃЮдЊЛеИЖжЮР.pdf
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеИ©зФ®дЄЙиП±FX3Uз≥їеИЧPLCжЮДеїЇиЗ™еК®йЧ®з¶Бз≥їзїЯзЪДеЕ®ињЗз®ЛгАВй¶ЦеЕИйШРињ∞дЇЖз°ђдїґйЕНзљЃжЦєж°ИпЉМеМЕжЛђйАЙзФ®дЄЙиП±FX3U-32MTдљЬдЄЇдЄїжОІеИґеЩ®пЉМйЕНе§Зе§ЪзІНдЉ†жДЯеЩ®е¶ВзЇҐе§Цеѓєе∞ДгАБеЬ∞з£Бдї•еПКйШ≤е§єдЉ†жДЯеЩ®з≠ЙпЉМеєґйЗЗзФ®йАВељУзЪДжЙІи°МжЬЇжЮДињЫи°МйЧ®зЪДеЉАйЧ≠жОІеИґгАВжО•зЭАжЈ±еЕ•иІ£жЮРдЇЖ楃嚥еЫЊйАїиЊСзЪДиЃЊиЃ°пЉМжґµзЫЦеЯЇжЬђеЉАйЧ≠йАїиЊСгАБеЃЙеЕ®еЫЮиЈѓиЃЊиЃ°гАБжї§ж≥Ґе§ДзРЖз≠ЙжЦєйЭҐзЪДеЖЕеЃєгАВжЦЗдЄ≠зЙєеИЂеЉЇи∞ГдЇЖеЗ†дЄ™еЕ≥йФЃжКАжЬѓзВєпЉМе¶ВйАЪињЗеЃЪжЧґеЩ®жОІеИґйЧ®зЪДеЉАеРѓжЧґйЧіеТМйШ≤е§єдњЭжК§жО™жЦљпЉМиІ£еЖ≥дЇЖзЇҐе§ЦдЉ†жДЯеЩ®иѓѓиІ¶еПСзЪДйЧЃйҐШпЉМеєґеЉХеЕ•дЇЖGX Works2ж®°жЛЯеЩ®зФ®дЇОз®ЛеЇПи∞ГиѓХгАВж≠§е§ЦпЉМињШиЃ®иЃЇдЇЖе¶ВдљХйАЪињЗRS485йАЪдњ°жО•еП£еЃЮзО∞иЇЂдїљй™МиѓБж®°еЭЧзЪДиБФзљСеКЯиГљеПКеЕґжХЕйЪЬиљђзІїжЬЇеИґгАВжЬАеРОпЉМдљЬиАЕеИЖдЇЂдЇЖдЄАдЇЫеЃЮзФ®зЪДзїПй™МжХЩиЃ≠пЉМдЊЛе¶ВйБњеЕНдњ°еПЈеє≤жЙ∞зЪДжЦєж≥ХеТМз°ЃдњЭз≥їзїЯз®≥еЃЪжАІзЪДеЖЧдљЩиЃЊиЃ°гАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛиЗ™еК®еМЦжОІеИґйҐЖеЯЯзЪДеЈ•з®ЛеЄИеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓеѓєPLCзЉЦз®ЛжЬЙдЄАеЃЪеЯЇз°АзЪДдЇЇзЊ§гАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БжЮДеїЇйЂШжХИеПѓйЭ†зЪДиЗ™еК®йЧ®з¶Бз≥їзїЯзЪДеЬЇеРИпЉМжЧ®еЬ®жПРйЂШйЧ®з¶Бз≥їзїЯзЪДеЃЙеЕ®жАІгАБеПѓйЭ†жАІеТМжЩЇиГљеМЦж∞іеє≥гАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРеИ∞зЪДеЕЈдљУж°ИдЊЛеТМиІ£еЖ≥жЦєж°ИеПѓдї•дЄЇз±їдЉЉй°єзЫЃзЪДеЃЮжЦљжПРдЊЫеЃЭиіµзЪДеПВиАГдїЈеАЉгАВеРМжЧґпЉМдљЬиАЕињШжПРдЊЫдЇЖиЃЄе§Ъи∞ГиѓХжКАеЈІеТМж≥®жДПдЇЛй°єпЉМжЬЙеК©дЇОиѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®жЙАе≠¶зЯ•иѓЖгАВ