作者:向师富 转自:阿里巴巴数据中台官网[https://dp.alibaba.com](https://dp.alibaba.com/)
**概述**
数据抽取是指从源数据抽取所需要的数据, 是构建数据中台的第一步。 数据源一般是关系型数据库,近几年,随着移动互联网的蓬勃发展,出现了其他类型的数据源,典型的如网站浏览日期、APP浏览日志、IoT设备日志
从技术实现方式来讲,从关系型数据库获取数据,可以细分为全量抽取、增量抽取2种方式,两种方法分别适用于不用的业务场景
**增量抽取**
* 时间戳方式
用时间戳方式抽取增量数据很常见,业务系统在源表上新增一个时间戳字段,创建、修改表记录时,同时修改时间戳字段的值。 抽取任务运行时,进行全表扫描,通过比较抽取任务的业务时间、时间戳字段来决定抽取哪些数据。
此种数据同步方式,在准确率方面有两个弊端:
1、只能获取最新的状态,无法捕获过程变更信息,比如电商购物场景,如果客户下单后很快支付,隔天抽取增量数据时,只能获取最新的支付状态,下单时的状态有可能已经丢失。针对此种问题,需要根据业务需求来综合判定是否需要回溯状态。
2、会丢失已经被delete的记录。如果在业务系统中,将记录物理删除。也就无法进行增量抽取。一般情况下,要求业务系统不删除记录,只对记录进行打标。
业务系统维护时间戳
如果使用了Oracle、DB2等传统关系型数据库,需要业务系统维护时间戳字段,业务系统在更新业务数据时,在代码中更新时间戳字段。此种方法很常见,不过由于需要编码实现,工作量会变大,有可能会出现漏变更的情形
触发器维护时间戳
典型的关系型数据库,都支持触发器。当数据库记录有变更时,调用特定的函数,更新时间戳字段。典型的样例如下:
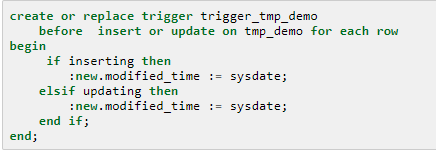
数据库维护时间戳
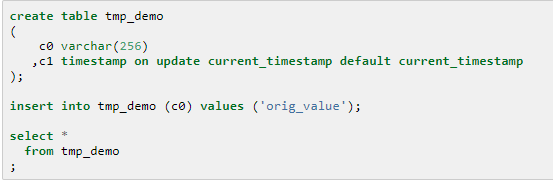
MySQL可以自动实现变更字段的维护,一定程度上减轻了开发工作量。 具体的实现样例如下:
创建记录
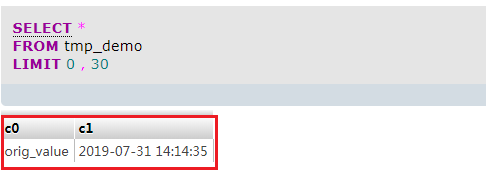
最终的结果如下:
更新记录
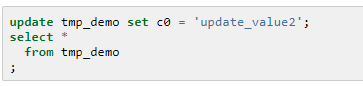
最终的结果如下,数据库自动变更了时间戳字段:
* 分析MySQL binlog日志
近几年,随着互联网的蓬勃发展,互联网公司一般使用MySQL作为主数据库,由于是开源数据库,很多公司都做了定制化开发。 其中一个很大的功能点是通过订阅MySQL binlog日志,实现了读写分离、主备实时同步,典型的示意图如下:
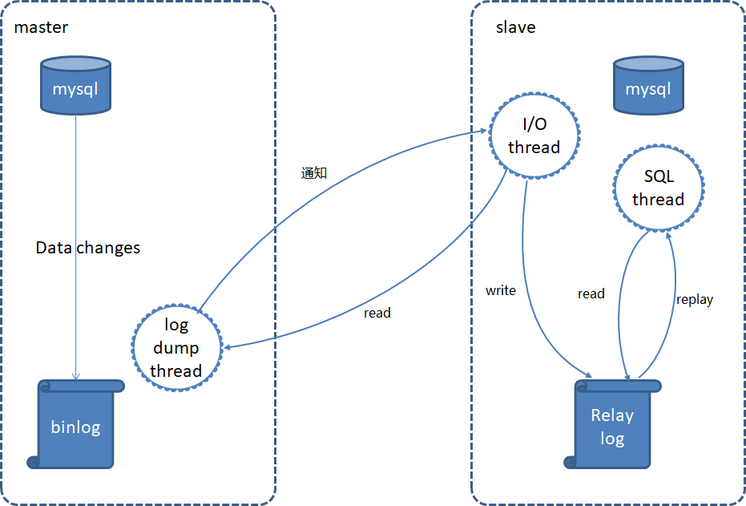
解析binlog日志,给数据同步带来了新的方法,将解析之后结果发送到Hive/MaxCompute等大数据平台,实现秒级延时的数据同步。
解析binlog日志增量同步方式技术很先进,有3个非常大的优点:
1.数据延时小。在阿里巴巴双11场景,在巨大的数据量之下,可以做到秒级延时;
2.不丢失数据,可以捕获数据delete的情形;
3.对业务表无额外要求,可以缺少时间戳字段;
当然,这种同步方式也有些缺点:
1.技术门槛很高。一般公司的技术储备不够,不足以自行完成整个系统搭建。目前国内也仅限于头部的互联网公司、大型的国企、央企。不过随着云计算的快速发展,在阿里云上开放了工具、服务,可以直接实现实时同步,经典的组合是MySQL、DTS、Datahub、MaxCompute;
2.资源成本比较高,要求有一个系统实时接收业务库的binlog日志,一直处于运行状态,占用资源较多
3.业务表中需要有主键,以便进行数据排序
* 分析Oracle Redo Log日志
Oracle是功能非常强大的数据库,通过Oracle GoldenGate实时解析Redo Log日志,并将解析后的结果发布到指定的系统
**全量抽取**
全量抽取是将数据源中的表或视图的数据原封不动的从数据库中抽取出来,并写入到Hive、MaxCompute等大数据平台中,有点类似于业务库之间的数据迁移。
全量同步比较简单,常用于小数据量的离线同步场景。不过这种同步方法,也有两个弊端,与增量离线同步一模一样:
1.只能获取最新的状态
2.会丢失已经被delete的记录
**业务库表同步策略**
* 同步架构图
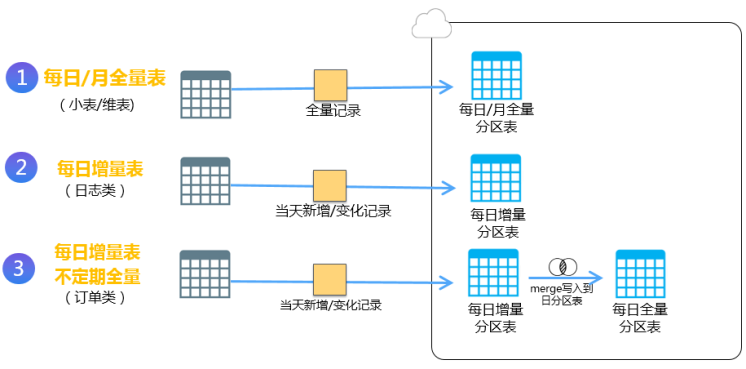
从业务视角,可以将离线数据表同步细分为4个场景,总体架构图表如下:
原则上,在数据上云这个环节,建议只进行数据镜像同步。不进行业务相关的数据转换工作。从ETL策略转变为ELT,出发点有3个:
1.机器成本。在库外进行转换,需要额外的机器,带来新的成本;
2.沟通成本。 业务系统的开发人员,也是数据中台的用户,这些技术人员对原始的业务库表很熟悉,如果进行了额外的转换,他们需要额外的学习其他工具、产品;
3.执行效率。库外的转换机器性能,一般会低于MaxCompute、Hadoop集群,增加了执行时间;
同步过程中,建议全表所有字段上云,减少后期变更成本
* 小数据量表
来源数据每日全量更新,采用数据库直连方式全量抽取,写入每日/每月全量分区表。
* 日志型表
原始日志增量抽取到每日增量表,按天增量存储。因为日志数据表现为只会有新增不会有修改的情况,因此不需要保存全量表。
* 大数据量表
数据库直连方式通过业务时间戳抽取增量数据到今日增量分区表,再将今日增量分区表merge前一日全量分区表,写入今日全量分区表。
* 小时/分钟增量表/不定期全量
来源数据更新频率较高,达到分钟/小时级别,从源数据库通过时间戳抽取增量数据到小时/分钟增量分区表,将N个小时/分钟增量分区表merge入每日增量分区表,再将今日增量分区表merge前一日全量分区表,写入今日全量分区表。
更多内容详见阿里巴巴数据中台官网 [https://dp.alibaba.com](https://dp.alibaba.com/)
阿里巴巴数据中台团队,致力于输出阿里云数据智能的最佳实践,助力每个企业建设自己的数据中台,进而共同实现新时代下的智能商业!
阿里巴巴数据中台解决方案,核心产品:
Dataphin,以阿里巴巴大数据核心方法论OneData为内核驱动,提供一站式数据构建与管理能力;
Quick BI,集阿里巴巴数据分析经验沉淀,提供一站式数据分析与展现能力;
Quick Audience,集阿里巴巴消费者洞察及营销经验,提供一站式人群圈选、洞察及营销投放能力,连接阿里巴巴商业,实现用户增长。
[原文链接](https://yq.aliyun.com/articles/721965?utm_content=g_1000085051)
本文为云栖社区原创内容,未经允许不得转载。
分享到:





相关推荐
### Kettle增量抽取数据知识点详解 #### 一、Kettle简介与重要性 Pentaho Data Integration (PDI),也称为Kettle,是一款开源的数据集成工具,被广泛应用于数据清洗、转换以及ETL(Extract, Transform, Load)过程...
在本例中,我们选择“表输入”控件,因为我们需要从一个数据库表中抽取数据。双击“表输入”控件,打开配置选项,新建一个数据库连接,输入数据库相关信息,并测试连接,成功返回 OK。 1.2 配置数据库连接 在配置...
【标题】"Kettle实现多表数据全量抽取"涉及的主要知识点是Kettle(Pentaho Data Integration,简称PDI)工具在数据处理中的应用,尤其是如何进行多表数据的同步与更新。Kettle是一款开源的数据集成工具,以其强大的...
本教程将详细介绍如何使用Kettle实现多表数据的全量抽取。 首先,我们要理解"全量抽取"的概念。全量抽取是指从源系统中提取所有数据,不考虑数据是否已经存在于目标系统中。这种策略适用于首次构建数据仓库或者在源...
增量抽取是从源系统中提取自上次抽取以来发生改变的新数据或更新数据,而不是每次全量抽取所有数据,这样可以显著提高效率并减少网络和存储资源的消耗。在这个案例中,我们不依赖时间戳,可能需要用到其他的追踪机制...
ETL,即提取(Extract)、转换(Transform)和加载...总的来说,全量与增量策略的选择取决于业务需求、数据规模、系统性能以及可用资源。在实际应用中,往往需要根据具体情况灵活组合使用,以实现最优的数据处理效果。
触发器方式需要在数据库表上建立触发器(插入、更新、删除),一旦表数据发生变化,触发器就会将变化的数据写入临时表中,随后ETL线程从临时表中抽取数据。这种方法的优点在于性能较好,ETL处理简单,能快速加载数据...
kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 ...
### Informatica全量与按时间戳增量更新抽取详解 #### 一、概述 在数据仓库领域,ETL(Extract, Transform, Load)是一项至关重要的任务,它负责将来自不同源系统的数据提取出来,经过清洗、转换等处理后,加载到...
【通用全量抽取】是一种常见的数据处理操作,用于从源数据库获取所有数据并将其加载到目标数据库或数据存储系统中。在这个场景中,我们使用的工具是Kettle,它是一个强大的ETL(Extract, Transform, Load)平台,由...
增量抽取机制的选择直接影响到数据仓库的性能和维护成本。 #### 四、常见的数据增量抽取机制 根据不同的应用场景和技术要求,数据增量抽取机制有很多种实现方式,常见的包括但不限于以下几种: 1. **时间戳方法**...
1. **增量抽取数据的基本概念** 增量抽取是ETL过程中的一种优化策略,只处理自上次抽取以来发生更改的数据,而不是每次都全量处理所有数据。这种策略显著提高了效率,减少了对源系统和目标系统的压力,并节省了存储...
选择合适的增量抽取方法需要考虑源系统的特性、数据量大小以及业务需求等因素。通过合理设计和实施,数据增量抽取可以有效提升数据仓库的响应速度,降低运营成本,为企业决策提供更加及时准确的数据支持。
20210511_kettle抽取mysql增量到ES中.zip20210511_kettle抽取mysql增量到ES中.zip20210511_kettle抽取mysql增量到ES中.zip20210511_kettle抽取mysql增量到ES中.zip20210511_kettle抽取mysql增量到ES中.zip20210511_...
kettle数据清洗抽取,全量对比记录,包含列转行,增加序列,字段拆分,对比记录
数据抽取是从数据源中抽取数据的过程。实际应用中,数据源采用较多的是关系数据库。 从数据库中抽取数据一般有一下几种方式。 1、全量抽取 全量抽取类似于数据迁移或复制,它将数据源中的表或视图的数据原封不动的从...
增量数据抽取是数据挖掘和大数据处理中的关键技术,它主要用于跟踪数据库中的变化,以便高效地获取新数据或更新数据,而不必每次都重新处理整个数据库。在本例中,我们将讨论一种适用于SQL Server数据库系统的增量...
ODI 通过 LogMiner 从 Oracle 数据库中抽取增量数据 本文主要介绍了使用 ODI 通过 LogMiner 技术从 Oracle 数据库中抽取增量数据的方法。ODI 提供了三种知识模块来抽取数据库中的增量数据:Simple、Consistent 和 ...
总结,Informatica 的增量更新功能提供了灵活的数据处理策略,无论是基于时间戳还是数据比对,都能有效地处理大量数据的变更,提高数据处理效率。在实际应用中,根据业务需求和数据特性,选择合适的增量更新方法是至...
在数据处理过程中,增量抽取是一项重要的技术,尤其是在大数据场景下,能够有效减少不必要的数据处理,提高效率。 增量抽取是指仅处理自上次抽取以来发生更改的数据,而不是重新处理整个数据集。这种策略对于保持...