еӨ§ж¶ӣеӯҰй•ҝ
- жөҸи§Ҳ: 118705 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
дә‘ж –PPTдёӢиҪҪ | ејҖжәҗз•ҢеӨ§е’–йӣҶдҪ“зҺ°иә«пјҢејҖжәҗж•°жҚ®еә“дё“еңәйҮҚзӮ№еҶҚеӣһзңёпјҒ
йҳҝйҮҢдә‘ејҖжәҗж•°жҚ®еә“йЎ№зӣ®жңҖж–°еҸ‘еёғ
--------------
**йҳҝйҮҢе·ҙе·ҙйӣҶеӣўеүҜжҖ»иЈҒгҖҒйҳҝйҮҢдә‘жҷәиғҪж•°жҚ®еә“дәӢдёҡйғЁжҖ»иЈҒгҖҒй«ҳзә§з ”究е‘ҳжқҺйЈһйЈһпјҲйЈһеҲҖпјүгҖҒйҳҝйҮҢдә‘ж•°жҚ®еә“иө„ж·ұжҠҖжңҜ专家жҘјж–№й‘«пјҲй»„еҝ пјүд»ҘеҸҠйҳҝйҮҢдә‘ж•°жҚ®еә“жҠҖжңҜ专家еӮ…е®ҮпјҲйҪҗжңЁпјү**дёүдҪҚйҳҝйҮҢдә‘жҠҖжңҜ专家дёәеӨ§е®¶д»Ӣз»ҚдәҶжңҖж–°зҡ„йҳҝйҮҢдә‘ејҖжәҗж•°жҚ®еә“йЎ№зӣ®гҖӮ
### жқҺйЈһйЈһпјҡ
ж•°жҚ®еә“еңЁиҝҮеҺ»иҝҷд№ҲеӨҡе№ҙпјҢе°Өе…¶иҝ‘еҮ е№ҙеҸ‘еұ•еҰӮжӯӨиҝ…йҖҹзҡ„ж ёеҝғеҺҹеӣ д№ӢдёҖе°ұжҳҜејҖжәҗз”ҹжҖҒеҒҡеҮәдәҶеҫҲеӨ§иҙЎзҢ®гҖӮйҡҫд»ҘжғіиұЎеҰӮжһңжІЎжңүејҖжәҗзҡ„MySQLгҖҒPGгҖҒHBaseгҖҒMongoDBд»ҘеҸҠCassandraзӯүпјҢеҸӘжңүOracleгҖҒDB2гҖҒSQL ServerзӯүпјҢд»ҠеӨ©дё–з•ҢдјҡжҳҜд»Җд№Ҳж ·еӯҗпјҹйӮЈеҝ…然иҝҳжҳҜеҜЎеӨҙеһ„ж–ӯзҡ„еұҖйқўгҖӮеӣ дёәж ёеҝғзҡ„OLAPзі»з»ҹйҡҫд»Ҙе®һзҺ°пјҢйңҖиҰҒз»ҸиҝҮеӨ§йҮҸиҜ•й”ҷжүҚиғҪдёҚж–ӯе®Ңе–„гҖӮиҖҢејҖжәҗз”ҹжҖҒдёәж•°жҚ®еә“жҸҗдҫӣиҝҷж ·зҡ„дёҖдёӘе№іеҸ°пјҢеё®еҠ©ж•°жҚ®еә“еҝ«йҖҹиҝӯд»ЈпјҢдҪҝеҫ—ејҖжәҗж•°жҚ®еә“еҸҜд»ҘжҜ”иӮ©е•Ҷдёҡж•°жҚ®еә“зҡ„иғҪеҠӣгҖӮ
еҜ№дәҺйҳҝйҮҢиҖҢиЁҖпјҢAliSQLиҺ·еҫ—дәҶ2018е№ҙMySQLзҡ„зӨҫеҢәе…¬еҸёиҙЎзҢ®еҘ–пјҢиҝҷжҳҜеӣ дёәAliSQLеҒҡдәҶеӨ§йҮҸдјҳеҢ–пјҢжҜ”еҰӮе®һзҺ°дәҶSequenceгҖҒиЎЁзә§е№¶иЎҢеӨҚеҲ¶д»ҘеҸҠйҡҗејҸдё»й”®зӯүгҖӮиҖҢеҒҡиҝҷдәӣдјҳеҢ–зҡ„й©ұеҠЁеҠӣжҳҜйҳҝйҮҢеҶ…йғЁзҡ„дёҡеҠЎйңҖжұӮпјҢ并且еҜ№дәҺжҠҖжңҜзҡ„дјҳеҢ–еҗҺз»ӯе°ұдјҡиҙЎзҢ®еӣһејҖжәҗзӨҫеҢәгҖӮ

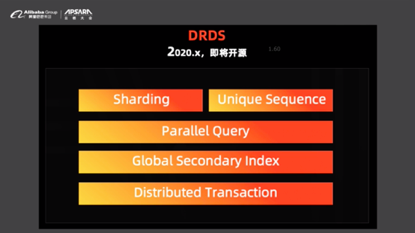
жңҖж–°еҸ‘еёғжҳҜи®©DRDSж”ҜжҢҒPOLARDBпјҢ并且еңЁ2020е№ҙзҡ„жҹҗдёӘж—¶й—ҙпјҢйҳҝйҮҢдә‘е°ҶдјҡејҖжәҗDRDSгҖӮDRDSе®Ңе…Ёз”ұйҳҝйҮҢиҮӘз ”пјҢе…¶дёӯеҢ…еҗ«дәҶShardingгҖҒUnique SequenceгҖҒParallel QueryгҖҒGlobal Secondry Indexд»ҘеҸҠDistributed TransactionгҖӮеёҢжңӣеӨ§е®¶иғҪеӨҹжӣҙеҠ е№ҝжіӣең°дҪҝз”ЁDRDSпјҢеҰӮжһңжңүжңәдјҡд№ҹиҙЎзҢ®жӣҙеӨҡзҡ„д»Јз ҒпјҢе°ҶDRDSеҒҡеҫ—жӣҙеҘҪгҖӮ
### жҘјж–№й‘«пјҡ
AliSQLйҖҡиҝҮж•ҲзҺҮгҖҒжҖ§иғҪгҖҒиҮӘдё»гҖҒзЁіе®ҡд»ҘеҸҠе®үе…Ёж–№йқўзҡ„дёҚж–ӯж”№иҝӣпјҢеёҢжңӣи®©дёҡеҠЎгҖҒиҝҗз»ҙгҖҒз ”еҸ‘е’ҢеҗҲдҪңдјҷдјҙйғҪиғҪеӨҹж„ҹи§үжӣҙвҖңзҲҪвҖқгҖӮ

еҹәдәҺиҝҷдёӘжҖқи·ҜпјҢйҳҝйҮҢдә‘еңЁдёҖе№ҙеҚҠд№ӢеүҚе°ұе°Ҷдё»иҰҒзІҫеҠӣжҠ•е…ҘеҲ°MySQL 8.0дёҠйқўпјҢиҝҷжҳҜеӣ дёәMySQL 8.0жӣҙиғҪеӨҹж»Ўи¶ід»ҘдёҠзӣ®ж ҮгҖӮMySQL 8.0е…·жңүAutomic DDLгҖҒInstant Add ColumnгҖҒWindow Functionе’ҢTemp Engineзҡ„иғҪеҠӣгҖӮиҖҢAliSQLеңЁMySQLзҡ„еҹәзЎҖд№ӢдёҠиҝҳеҒҡдәҶжӣҙеӨҡзҡ„дјҳеҢ–пјҢжҜ”еҰӮж”ҜжҢҒдәҶTDEеҠ еҜҶе’ҢSM4еӣҪеҜҶз®—жі•пјҢ并且йҮҚж–°и®ҫи®ЎдәҶзәҝзЁӢжұ пјҢAliSQL Clusterж”ҜжҢҒдёүиҠӮзӮ№е№¶иғҪеҒҡеҲ°RTOдёә0зӯүгҖӮ

MySQLе®ҳж–№зүҲжң¬д№ҹжңүзәҝзЁӢжұ пјҢиҖҢAliSQLзәҝзЁӢжұ зҡ„еҢәеҲ«еңЁдәҺиҝһжҺҘж•°еҸҜд»ҘиҫҫеҲ°2дёҮпјҢ并且иғҪдҝқжҢҒйқһеёёе№ізЁізҡ„иҫ“еҮәгҖӮйҰ–е…ҲпјҢAliSQLдёҘж јжҺ§еҲ¶дәҶзәҝзЁӢж•°жқҘжҸҗеҚҮдәҶCPUж•ҲзҺҮпјҢеҒҡеҲ°дәҶй«ҳжҖ§иғҪгҖӮе…¶ж¬ЎпјҢAliSQLеҸҜд»ҘдёҖй”®йҡҸж—¶еҲҮжҚўеҗҜз”ЁзәҝзЁӢжұ пјҢиҖҢж— йңҖйҮҚеҗҜе®һдҫӢгҖӮжңҖеҗҺпјҢAliSQLиғҪеӨҹеҢәеҲҶж“ҚдҪңзұ»еһӢ并е®һзҺ°жҷәиғҪдјҳе…Ҳзә§жҺ’йҳҹпјҢ并йҖӮз”ЁдәҺжүҖжңүдёҡеҠЎеңәжҷҜгҖӮжҖ»д№ӢпјҢAliSQLзҡ„зәҝзЁӢжұ жҳҜе®Ңе…ЁйҮҚж–°е®һзҺ°зҡ„пјҢ并且жҖ§иғҪд№ҹдјҡи¶…еҮәжңҹжңӣгҖӮ
AliSQL ClusterеҸҜд»ҘжҖ»з»“еҮәвҖңдёүй«ҳвҖқпјҢеҚій«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёе’Ңй«ҳжҖ§иғҪгҖӮAliSQL Clusterе…·жңү99.99%зҡ„еҸҜз”ЁжҖ§пјҢдәӢеҠЎж•°жҚ®е…·жңүејәдёҖиҮҙжҖ§пјҢ并且дҪҝз”ЁдәҶPaxosжҷәиғҪ并иЎҢеҸ‘еҢ…е®һзҺ°й«ҳж•ҲеҗҢжӯҘгҖӮиҝҷж ·зҡ„вҖңдёүй«ҳвҖқдҪҝеҫ—дёҡеҠЎгҖҒиҝҗз»ҙе’Ңз ”еҸ‘йғҪжӣҙвҖңзҲҪвҖқгҖӮ
SQL OutlineжҳҜеңЁж•°жҚ®еә“зүҲжң¬еҚҮзә§гҖҒеўһеҮҸзҙўеј•гҖҒз»ҹи®ЎдҝЎжҒҜд»ҘеҸҠзЁӢеәҸеӣәеҢ–ж—¶жқҘ收йӣҶе’Ңзј–иҫ‘SQLе…ій”®и·ҜдҝЎжҒҜпјҢ并用жҢҒд№…еҢ–HintеӣәеҢ–жү§иЎҢи·Ҝеҫ„зҡ„гҖӮ
AliSQLеҹәдәҺMySQLеҒҡдәҶеҫҲеӨҡжҖ§иғҪзҡ„еўһејәпјҢе®һзҺ°дәҶеҜ№иұЎз»ҹи®ЎпјҢ并жҸҗдҫӣдәҶе®Ңе–„зҡ„жҢҮж Үе’ҢеӨҡзә§з»ҙеәҰгҖӮжҜ”еҰӮзҙўеј•гҖҒSQLз»ҹи®ЎдҝЎжҒҜйғҪиғҪеӨҹдёҖзӣ®дәҶ然пјҢеӣ жӯӨеҸҜд»ҘеҠ йҖҹеҜ№дёҡеҠЎзҡ„е“Қеә”гҖӮиҝҷд№ҹиҜҙжҳҺеңЁдёҠдә‘д№ӢеҗҺпјҢеҰӮжһңжғіиҰҒжңҚеҠЎеҘҪдёҡеҠЎпјҢиҝҳжңүеҫҲеӨҡе·ҘдҪңйңҖиҰҒеҒҡгҖӮ
AliSQLеңЁ5.6зүҲжң¬ж—¶еҒҡдәҶејҖжәҗпјҢз»ҸиҝҮжҖ»з»“д№ӢеҗҺеҸ‘зҺ°и®©е®ҳж–№еҗҲ并AliSQL 5.6иҝҷжқЎи·Ҝиө°дёҚйҖҡпјҢеӣ жӯӨд№ҹе°ҶеҜ№дәҺAliSQL 8.0иҝӣиЎҢејҖжәҗгҖӮеңЁејҖжәҗ8.0зүҲжң¬зҡ„ж—¶еҖҷдјҡеҗёж”¶5.6зүҲжң¬зҡ„з»ҸйӘҢпјҢжғіеҠһжі•жӣҙй«ҳж•Ҳең°з»ҙжҠӨAliSQLејҖжәҗйЎ№зӣ®гҖӮ
### еӮ…е®Үпјҡ
еңЁйҳҝйҮҢе·ҙе·ҙдёҡеҠЎдёӯпјҢDRDSе’ҢMySQLжҳҜзӣёдә’й…ҚеҗҲпјҢиҚЈиҫұдёҺе…ұзҡ„е…ізі»гҖӮDRDSжҳҜйҳҝйҮҢдә‘жҸҗдҫӣзҡ„дёҖдёӘжңҚеҠЎпјҢе…Ёз§°жҳҜеҲҶеёғејҸе…ізі»еһӢж•°жҚ®еә“жңҚеҠЎгҖӮDRDSеҠҹиғҪжңҖз®ҖеҚ•жҰӮжӢ¬е°ұжҳҜеҲҶеә“еҲҶиЎЁпјҢз”ЁжҲ·еҸҜд»Ҙд»ҺDRDSжҺҘеҸЈдёҠеҲӣе»әдёҖдёӘиЎЁпјҢеҸӘйңҖиҰҒеңЁе»әиЎЁж—¶жҢҮе®ҡеҲҶеә“еҲҶиЎЁзҡ„ж–№ејҸпјҢеү©дёӢзҡ„е·ҘдҪңз”ұDRDSжҗһе®ҡпјҢз”ЁжҲ·еҸҜд»ҘеғҸж“ҚдҪңжҷ®йҖҡиЎЁдёҖж ·ж“ҚдҪңDRDSпјҢдёҡеҠЎеұӮж— йңҖеҶҚеҒҡеҲҶеёғејҸзӣёе…ізҡ„иҖғиҷ‘гҖӮйҷӨжӯӨд№ӢеӨ–пјҢDRDSиҝҳжҸҗдҫӣдәҶиҜ»еҶҷеҲҶзҰ»гҖҒеј№жҖ§жү©е®№зӯүиғҪеҠӣгҖӮ
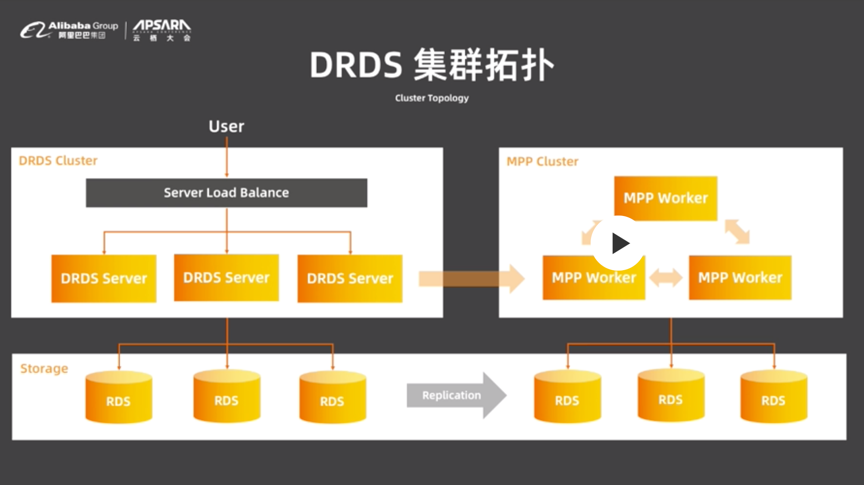
дёӢеӣҫжҳҜе…ёеһӢзҡ„DRDSйғЁзҪІжӢ“жү‘пјҢеӣҫе·Ұдҫ§еҲҶдёәдёӨеұӮпјҢServerеұӮеҢ…еҗ«еӨҡдёӘж— зҠ¶жҖҒзҡ„DRDSиҠӮзӮ№пјҢDRDSиҠӮзӮ№еҗ‘Load BalancerжұҮжҠҘеҝғи·іпјҢеҰӮжһңеҮәзҺ°е®•жңәпјҢLoad Balancerе°ұдјҡе°ҶжөҒйҮҸиҝҒ移еҲ°е…¶д»–иҠӮзӮ№дёҠпјҢдҝқиҜҒйӣҶзҫӨй«ҳеҸҜз”ЁгҖӮеӯҳеӮЁеұӮеҸҜиғҪдҪҝз”ЁRDSгҖҒPOLARDBз”ҡиҮіеҲ—ејҸеӯҳеӮЁгҖӮжҖ»дҪ“жқҘиҜҙпјҢжҹҘиҜўдјҡеңЁServerеұӮиў«иҪ¬еҢ–жҲҗжү§иЎҢи®ЎеҲ’пјҢеңЁеӯҳеӮЁеұӮе…·дҪ“жү§иЎҢ并иҝ”еӣһз»ҷз”ЁжҲ·гҖӮеӣҫеҸідҫ§жҳҜDRDSзҡ„еҲҶжһҗеһӢеҸӘиҜ»е®һдҫӢпјҢйҮҢйқўеҢ…еҗ«еӨҡдёӘMPP WorkerгҖӮеҜ№дәҺеӨҚжқӮSQLпјҢеҚ•еҸ°жңәеҷЁеҸҜиғҪж— жі•е®ҢжҲҗи®Ўз®—пјҢжӯӨж—¶е°ұдјҡе°ҶSQLзҡ„жү§иЎҢи®ЎеҲ’еҸ‘еҫҖMPPйӣҶзҫӨжқҘи®Ўз®—пјҢ并且дёҚдјҡеҜ№дё»еә“дә§з”ҹеҪұе“ҚгҖӮ
DRDSзҡ„жһ¶жһ„жј”иҝӣз»ҸеҺҶеҫҲй•ҝзҡ„иҝҮзЁӢпјҢжңҖејҖе§ӢеҸӘжғізқҖеҰӮдҪ•е°ҶеҲҶеә“еҲҶиЎЁеҒҡеҲ°жһҒиҮҙгҖӮйҡҸзқҖDRDSдёҠдә‘пјҢдјҒдёҡзә§еңәжҷҜжӣҙеҠ дё°еҜҢпјҢйҒҮеҲ°дәҶи¶ҠжқҘи¶ҠеӨҚжқӮзҡ„SQLпјҢйңҖжұӮжҺЁеҠЁзқҖDRDSжһ¶жһ„зҡ„йҮҚжһ„гҖӮеҰӮд»Ҡзҡ„DRDSжһ¶жһ„жңҖеҲҶдёәдәҶзҪ‘з»ңгҖҒдјҳеҢ–еҷЁе’Ңжү§иЎҢеҷЁгҖӮ
SQLиҝӣе…ҘDRDSйҰ–е…Ҳдјҡз»ҸиҝҮParserеҸҳжҲҗASTпјҢд№ӢеҗҺз»ҸиҝҮValidatorиҝӣиЎҢйӘҢиҜҒпјҢйҖҡиҝҮйӘҢиҜҒд№ӢеҗҺиҪ¬еҢ–жҲҗжңҖжңҙзҙ зҡ„йҖ»иҫ‘жү§иЎҢи®ЎеҲ’пјҢеңЁз»ҸиҝҮSQL Rewriterе’ҢPlan EnumeratorеҸҳдёәжңҖдјҳзҡ„зү©зҗҶжү§иЎҢи®ЎеҲ’пјҢ并дәӨз»ҷExecutorиҝӣиЎҢжү§иЎҢгҖӮ
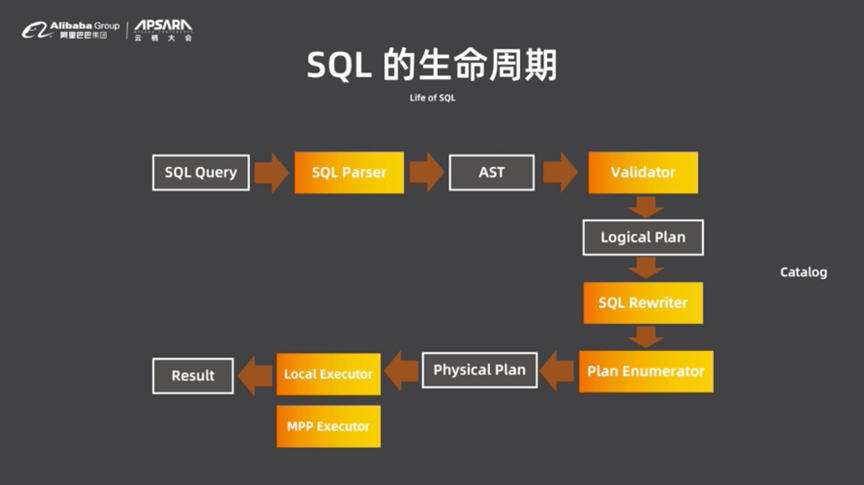
еҜ№дәҺжҹҘиҜўдјҳеҢ–еҷЁиҖҢиЁҖпјҢSQL RewriterдјҡеҜ№йҖ»иҫ‘жү§иЎҢи®ЎеҲ’иҝӣиЎҢж”№еҶҷпјҢе®ғжҳҜеҹәдәҺеҗҜеҸ‘ејҸ规еҲҷзҡ„дјҳеҢ–еҷЁпјҢд№ҹиў«з§°дёәRBOгҖӮSQL Rewriterдјҡе®һзҺ°еӯҗжҹҘиҜўзҡ„еҺ»е…іиҒ”еҢ–пјҢ并еҒҡз®—еӯҗTransposeпјҢиҖҢдёәдәҶе®һзҺ°жһҒиҮҙдёӢжҺЁпјҢSQL RewriterиҝҳеҒҡдәҶJoin ClusteringгҖӮ
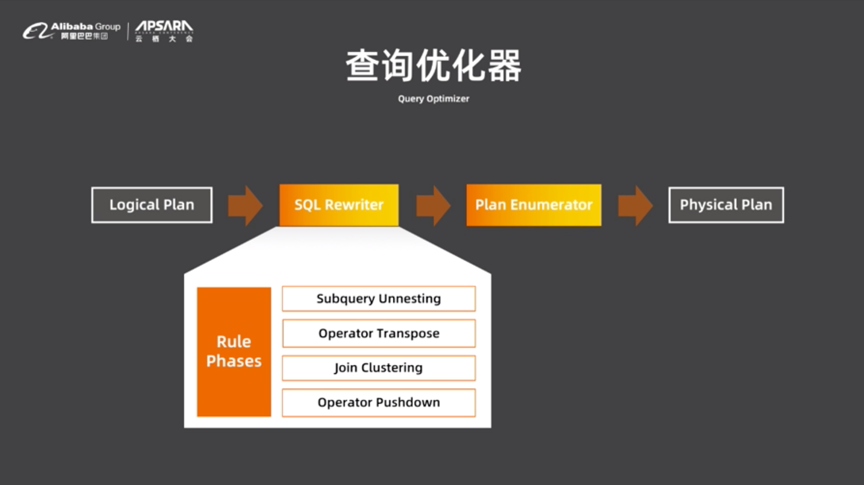
жҹҘиҜўдјҳеҢ–еҷЁзҡ„第дәҢжӯҘжҳҜPlan EnumeratorеҒҡзҡ„зү©зҗҶдјҳеҢ–пјҢдё»иҰҒиҙҹиҙЈJoint Recorderе’Ңз®—жі•йҖүжӢ©гҖӮDRDSйҮҮз”Ёзҡ„жңҖдёәйҖҡз”Ёзҡ„Volcano/CascadesдјҳеҢ–еҷЁпјҢз»ҸиҝҮиҝҷдёҖиҝҮзЁӢдјҡжӢҝеҲ°зҗҶи®әжңҖдјҳзҡ„зү©зҗҶжү§иЎҢи®ЎеҲ’гҖӮ
DRDSжҹҘиҜўдјҳеҢ–еҷЁзҡ„дјҳеҢ–иҝҮзЁӢжҳҜеҹәдәҺд»Јд»·зҡ„пјҢиҖҢд»Јд»·жңҖеҲқи®Ўз®—жқҘиҮӘдәҺз»ҹи®ЎдҝЎжҒҜпјҢиҝҷдәӣз»ҹи®ЎдҝЎжҒҜе°Ҷдјҡ计算代价并еёҰе…Ҙз®—еӯҗCost ModelдёӯиҝӣиҖҢи®Ўз®—жү§иЎҢи®ЎеҲ’зҡ„жҖ»дҪ“д»Јд»·гҖӮ
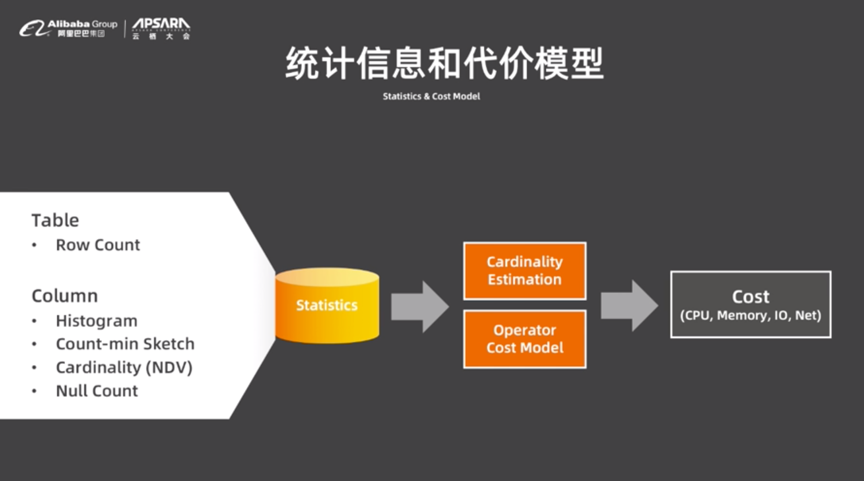
жҹҘиҜўдјҳеҢ–ж— жі•зһ¬й—ҙе®ҢжҲҗпјҢеӣ жӯӨйңҖиҰҒз®ЎзҗҶжү§иЎҢи®ЎеҲ’пјҢеҸҜд»Ҙе°Ҷжү§иЎҢи®ЎеҲ’еӯҳеӮЁдёӢжқҘеҠ д»ҘеӨҚз”ЁпјҢжҸҗеҚҮдјҳеҢ–йҖҹеәҰгҖӮDRDSдҪҝз”ЁдәҶеҹәдәҺChunkзҡ„жү§иЎҢеҷЁпјҢдҪҝеҫ—жҜҸдёӘз®—еӯҗдёҖж¬ЎжҖ§дә§еҮәдёҖжү№ж•°жҚ®гҖӮеңЁChunkйҮҢйқўж•°жҚ®жҢүеҲ—еӯҳеӮЁпјҢеҲҶжһҗйҖҹеәҰжӣҙеҝ«пјҢи®Ўз®—ж•ҲзҺҮжӣҙй«ҳгҖӮParallel QueryйғЁеҲҶдјҡеҗҜеҠЁеӨҡдёӘWorkerиҝӣзЁӢ并еҜ№з»“жһңеҠ д»ҘжұҮжҖ»гҖӮ
并иЎҢеӨ„зҗҶ--MySQLеҸ‘еұ•зҡ„и¶ӢеҠҝеҸҠдёӯеӣҪжң¬ең°еә”з”Ёе®һи·ө
-------------------------
дёӯеӣҪи®Ўз®—жңәиЎҢдёҡеҚҸдјҡејҖжәҗж•°жҚ®еә“专委дјҡдјҡй•ҝпјҢжһҒж•°дә‘иҲҹCEOе‘ЁеҪҰдјҹдёәеӨ§е®¶еҲҶдә«дәҶMySQLзҡ„еҹәзЎҖжһ¶жһ„е’ҢArkDBзҡ„并иЎҢеҢ–е®һи·өгҖӮ
#### MySQLеҹәзЎҖжһ¶жһ„
MySQL Serverеј•ж“Һзҡ„еҘҪеӨ„еңЁдәҺеӨ§е®¶еҸҜд»ҘеҹәдәҺжӯӨе®һзҺ°иҮӘе·ұзҡ„ж•°жҚ®еә“гҖӮзӣ®еүҚпјҢMySQLе·Із»ҸеҸ‘еёғдәҶ8.0зүҲжң¬пјҢеҸҜд»ҘзңӢеҲ°иҝҷд№ҲеӨҡе№ҙMySQLе®ҳж–№е…¶е®һдёҖзӣҙеңЁиҝӣжӯҘгҖӮMySQLеңЁе№¶иЎҢе’ҢжҸҗй«ҳйҖҹеәҰж–№йқўеҒҡдәҶеҫҲеӨҡе·ҘдҪңгҖӮеңЁеј•ж“Һж–№йқўпјҢжңҖејҖе§ӢMySQLдҪҝз”Ёзҡ„жҳҜMyISAMпјҢзҺ°еңЁй»ҳи®ӨжҳҜInnoDBпјҢиҝҷжҳҜеӣ дёәMyISAMзҡ„并иЎҢеӨ„зҗҶиғҪеҠӣдёҚеӨҹеҘҪпјҢиҖҢInnoDBе®һзҺ°дәҶиЎҢзә§й”ҒпјҢиҝҳж”ҜжҢҒдәҶMVCCпјҢеўһеҠ дәҶ并иЎҢиҜ»еҶҷзҡ„иғҪеҠӣгҖӮеңЁеј•ж“ҺеұӮйқўпјҢд»ҺMyISAMиҝҮжёЎеҲ°InnoDBжҳҜдёҖдёӘе·ЁеӨ§зҡ„иҝӣжӯҘгҖӮ
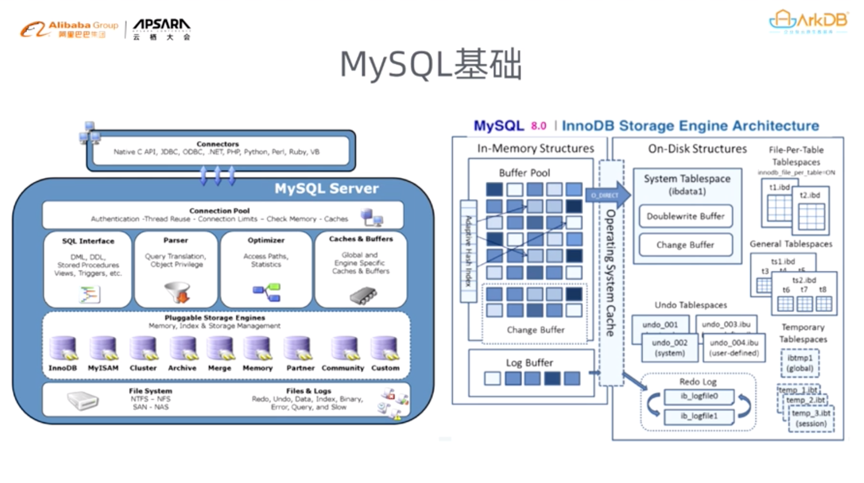
#### InnoDBзҡ„еҸ‘еұ•
InnoDBд№ҹеңЁMySQL 5.6гҖҒ5.7гҖҒ8.0зҡ„жј”иҝӣиҝҮзЁӢдёӯеҸ‘з”ҹдәҶеҫҲеӨ§еҸҳеҢ–гҖӮInnoDBжңҖж—©йҮҮз”Ёе…ұдә«иЎЁз©әй—ҙпјҢдёҖе ҶиЎЁж”ҫеңЁдёҖдёӘж–Ү件йҮҢпјҢж•ҲзҺҮжһҒе·®гҖӮеҗҺжқҘInnoDBйҮҮз”ЁзӢ¬з«ӢиЎЁз©әй—ҙпјҢдёҖдёӘиЎЁж”ҫеңЁдёҖдёӘж–Ү件йҮҢпјҢеҶҚеҗҺжқҘжј”еҸҳеҲ°дёҖдёӘиЎЁеҲҶжҲҗеӨҡдёӘж–Ү件гҖӮиҝҷж ·зҡ„еҸҳеҢ–жҳҜеёҢжңӣжҸҗеҚҮж•°жҚ®зҡ„еӨ„зҗҶйҖҹеәҰгҖӮиҖҢеҲ°зҺ°еңЁдёәжӯўпјҢMySQL 8.0иҝҳжҳҜиҗҪеңЁеҚ•еҸ°жңҚеҠЎеҷЁдёҠпјҢеҸӘиғҪеҲ©з”ЁеҚ•еҸ°жңәеҷЁзҡ„и®Ўз®—е’ҢеӯҳеӮЁеҠҹиғҪгҖӮ
зҺ°еңЁпјҢMySQLзҡ„иҝӣжӯҘе…¶е®һе°ұжҳҜInnoDBзҡ„иҝӣжӯҘпјҢиҝҷеңЁдёҖдәӣеҸӮж•°зҡ„еҸҳеҢ–дёҠжңүжүҖдҪ“зҺ°гҖӮжӯӨеӨ–пјҢInno DBд№ҹеҜ№UndoиҝӣиЎҢдәҶдјҳеҢ–пјҢ5.7д№ӢеүҚibdataж–Ү件дёӯеҢ…еҗ«Undoж®өпјҢеҜјиҮҙж–Ү件з©әй—ҙж— жі•еӣһ收гҖӮ5.7зүҲжң¬д№ӢеҗҺпјҢUndoж®өд»Һibdataж–Ү件дёӯзӢ¬з«ӢеҮәжқҘпјҢе°ұеҸҜд»Ҙе®һзҺ°е№¶иЎҢиҜ»еҶҷгҖӮ
еҫҲеӨҡе№ҙзҡ„ж—¶й—ҙпјҢMySQLжү©еұ•йғҪжҳҜеҹәдәҺReplicationзҡ„гҖӮзҺ°еңЁпјҢMySQLе®ҳж–№д№ҹеҒҡдәҶйӣҶзҫӨеҢ–зҡ„еӨ„зҗҶгҖӮ5.6д№ӢеүҚжҳҜеҚ•зәҝзЁӢеӨҚеҲ¶пјҢ5.7зүҲжң¬дёӯеўһеҠ ж”ҜжҢҒWrite Setзә§еҲ«зҡ„并иЎҢеӨҚеҲ¶гҖӮ
жҖ»з»“иҖҢиЁҖпјҢMySQLж•°жҚ®еә“иҮӘиә«д№ҹеңЁдёҚж–ӯиҝӣжӯҘпјҢеҲ°еҰӮд»ҠMySQL 8.0зүҲжң¬е·Із»ҸеҒҡеҫ—еҫҲдёҚй”ҷдәҶпјҢиғҪеӨҹж”ҜжҢҒеӨҚжқӮжҹҘиҜўе№¶дё”ж•ҲзҺҮдёҚй”ҷгҖӮ
#### 并иЎҢеҢ–еңЁArkDBзҡ„е®һи·ө
иҷҪ然MySQLе®ҳж–№иҝ‘еҮ е№ҙеҫҲеҠӘеҠӣпјҢдҪҶжҳҜдҫқж—§еӯҳеңЁдёҖдәӣдёҚи¶ід№ӢеӨ„пјҢеӣ жӯӨArkDBд№ҹеёҢжңӣиғҪеӨҹеҹәдәҺMySQLеҒҡеҮәдёҖдәӣиҙЎзҢ®гҖӮArkDBеңЁMySQLзҡ„еҹәзЎҖдёҠеҒҡдәҶеӨ§йҮҸ并иЎҢеҢ–е®һи·өгҖӮеңЁеј•ж“ҺеұӮпјҢArkDBе®һзҺ°дәҶи®Ўз®—е’ҢеӯҳеӮЁеҲҶзҰ»пјҢйҖҡиҝҮеҲҶеёғејҸеӯҳеӮЁе®һзҺ°дәҶ并иЎҢиҜ»еҶҷдјҳеҢ–гҖӮеңЁйӣҶзҫӨеұӮпјҢArkDBе®һзҺ°дәҶиҮӘйҖӮеә”еӨҡзәҝзЁӢзү©зҗҶеӨҚеҲ¶пјҢжһҒеӨ§ең°жҸҗеҚҮдәҶж•°жҚ®еӨҚеҲ¶ж•ҲзҺҮгҖӮеңЁжҺҘе…ҘеұӮпјҢArkDBе®һзҺ°дәҶеҜ№з§°ејҸдёӯй—ҙ件йӣҶзҫӨи·Ҝз”ұпјҢжҳҜжҺҘе…ҘеұӮжҲҗдёәж— зҠ¶жҖҒзҡ„пјҢиғҪеӨҹжүҝжӢ…еӨ§и§„жЁЎзҡ„и®ҝй—®еә”з”ЁгҖӮеңЁй«ҳеҸҜз”Ёж–№йқўпјҢArkDBе®һзҺ°дәҶеҺ»дёӯеҝғеҢ–еҲҶеёғејҸе“Ёе…өе®ҲжҠӨйӣҶзҫӨгҖӮеңЁиҝҒ移еұӮпјҢArkDBе®һзҺ°дәҶеӨҡжәҗз«ҜеӨҡйҖҡйҒ“еӨҡз»“жһ„е®һж—¶еҗҢжӯҘпјҢеҸҜд»Ҙе®һзҺ°зІҫзЎ®еҲ°иЎҢзә§зҡ„иҝҗиЎҢгҖӮ
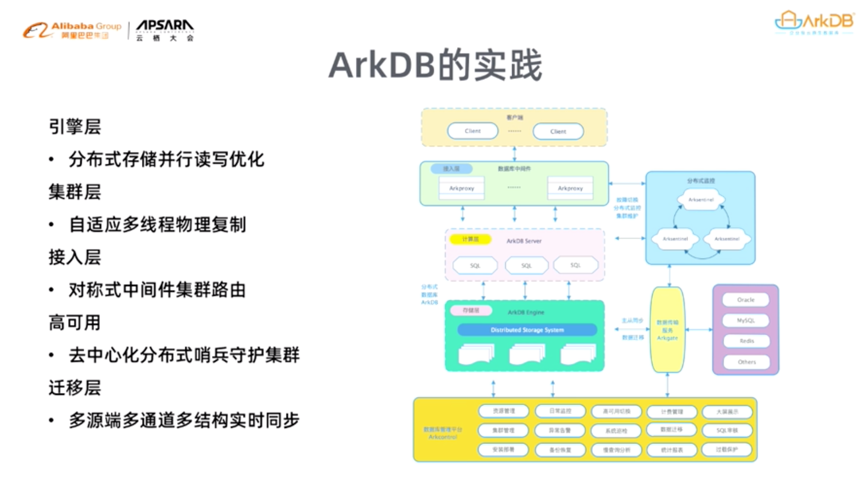
ArkDBеңЁеј•ж“ҺеұӮж—ўеҹәдәҺзҙўеј•ж ‘еӯҳеӮЁж•°жҚ®пјҢеҸҲе°Ҷж•°жҚ®еҲҶзүҮең°еӯҳеӮЁеңЁзҙўеј•з»“жһ„дёӯгҖӮеҹәдәҺеҲҶеёғејҸеӯҳеӮЁе®һзҺ°дәҶ并иЎҢиҜ»еҶҷдјҳеҢ–пјҢеҹәдәҺзҙўеј•з»“жһ„е®һзҺ°ж•°жҚ®е№¶иЎҢеҲҶзүҮпјҢеҹәдәҺеҜ№иұЎеӯҳеӮЁе®һзҺ°е№¶еҸ‘иҜ»еҶҷж”ҜжҢҒпјҢеҹәдәҺеҲҶеёғејҸеӯҳеӮЁж”ҜжҢҒдәҶеӨҡеүҜжң¬е’Ңеҝ«з…§еӨҮд»ҪгҖӮArkDBеңЁйӣҶзҫӨеұӮе®һзҺ°дәҶиҮӘйҖӮеә”еӨҡзәҝзЁӢзү©зҗҶеӨҚеҲ¶гҖҒзү©зҗҶж—Ҙеҝ—зҡ„еӨҡзәҝзЁӢиҜ»еҶҷпјҢ并еҹәдәҺд»Һеә“зҡ„еӨҡзүҲжң¬жҺ§еҲ¶е®һзҺ°дәҶеӨҡиҠӮзӮ№ж— й”ҒеҗҢжӯҘгҖӮArkDBеңЁиҝҒ移еұӮе……еҲҶеҲ©з”ЁдәҶеҗ„з§Қ并иЎҢж–№ејҸпјҢд»ҺеүҚз«ҜеӨҡжәҗз«ҜпјҢеҲ°еӨҡйҖҡйҒ“еӨ„зҗҶе®һзҺ°дәҶеңЁж•°жҚ®жү“йҖҡиҝҮзЁӢдёӯе°ҪйҮҸжҸҗеҚҮж•ҲзҺҮе’Ңдј иҫ“йҖҹеәҰгҖӮ
PostgreSQL 12 иҝҺжқҘж–°жңәйҒҮ
-------------------
PostgresдёӯеӣҪзӨҫеҢәпјҢеӨӘйҳіеЎ”科жҠҖеҲӣе§ӢдәәиөөжҢҜе№ідёәеӨ§е®¶еҲҶдә«дәҶPostgreSQL 12еёҰжқҘзҡ„ж–°жңәйҒҮгҖӮ
зӣ®еүҚпјҢPostgreSQL 12зҡ„ејҖеҸ‘йҖҹеәҰйқһеёёеҝ«пјҢд»Ҡе№ҙ5жңҲд»ҪеҸ‘еёғBeta 1зүҲжң¬пјҢ6жңҲд»ҪеҸ‘еёғBeta 2зүҲжң¬пјҢ8жңҲд»ҪеҸ‘еёғBeta 3зүҲжң¬пјҢ9жңҲд»ҪеҸ‘еёғBeta 4зүҲжң¬пјҢ并且жңүеҸҜиғҪжҲҗдёәдәҶжңҖеҗҺдёҖдёӘBetaзүҲжң¬пјҢиҝҷж„Ҹе‘ізқҖPostgreSQL 12еҚіе°ҶжӯЈејҸеҸ‘еёғгҖӮиҷҪ然жҜҸдёӘBetaзүҲжң¬еҜ№еӨ§е®¶иҖҢиЁҖеҸҜиғҪеҸӘжҳҜдёҖдёӘе°ҸзүҲжң¬пјҢдҪҶеҜ№дәҺPostgreSQLзӨҫеҢәиҖҢиЁҖпјҢеҚҙж„Ҹе‘ізқҖеӨ§йҮҸдҝ®ж”№пјҢжҜ”еҰӮеңЁPostgreSQL 12зҡ„Beta 3зүҲжң¬дёӯдҝ®ж”№дәҶ2дёӘе®үе…Ёissue并且дҝ®ж”№дәҶ40дёӘе°ҸBugгҖӮжҲӘжӯўеҲ°зӣ®еүҚпјҢPostgreSQL 12зҡ„BetaзүҲжң¬жҖ»е…ұеҒҡдәҶ161йЎ№дҝ®ж”№пјҢж•ҙдҪ“иҖҢиЁҖдҝ®ж”№йқһеёёеӨ§пјҢеҫҲеӨҡжҠҖжңҜзҡ„дҝ®ж”№е’Ңе®Ңе–„е°ҶдёәPostgreSQLеёҰжқҘеҫҲеӨ§зҡ„жҸҗеҚҮгҖӮиҖҢдё”еңЁжңӘжқҘпјҢPostgreSQLеҹәжң¬дёҠжҜҸдёӘеӯЈеәҰйғҪдјҡжҺЁеҮәдёҖдёӘе°ҸзүҲжң¬пјҢжҜҸе№ҙеҸ‘еёғдёҖдёӘеӨ§зүҲжң¬гҖӮ
еҰӮд»ҠPostgreSQLзӯүејҖжәҗж•°жҚ®еә“жӯЈеңЁйқўеҜ№ж–°зҡ„жңәйҒҮпјҢйҷӨдәҶж•°жҚ®еә“йўҶеҹҹзҡ„еӣҪдә§еҢ–д№Ӣи·ҜпјҢдё–з•Ңеҗ„ең°ж–№йғҪејҖе§ӢдәҶвҖңеҺ»IOEвҖқгҖӮиҖҢеӣҙз»•PostgreSQLеҸҜд»ҘеҒҡеҫҲеӨҡеҲӣж–°пјҢдјҒдёҡеҸҜд»ҘеҹәдәҺPostgreSQLејҖеҸ‘дә§е“ҒпјҢз”ҡиҮіе°ҶPostgreSQLе’ҢеҗҺеҸ°дә§е“Ғжү“еҢ…й”Җе”®еҲ°еӣҪеӨ–пјҢејҖеҸ‘иҖ…иҝҳеҸҜд»ҘеҹәдәҺPostgreSQLејҖеҸ‘ж–°зҡ„ж•°жҚ®еә“гҖӮиҖҢеҜ№дәҺеӨӘйҳіеЎ”иҝҷж ·зҡ„е…¬еҸёпјҢд№ҹеҸҜд»ҘжӣҙеҘҪең°жҸҗдҫӣPostgreSQLжҠҖжңҜжңҚеҠЎгҖӮ
д№ӢжүҖд»ҘйҖүжӢ©PostgreSQLпјҢйҰ–е…ҲжҳҜеӣ дёәе®ғеҺҶеҸІжӮ д№…гҖӮPostgreSQLеңЁдә’иҒ”зҪ‘дә§з”ҹд№ӢеүҚе°ұе·Із»ҸеӯҳеңЁдәҶпјҢе…¶еҲӣе§ӢдәәMichael StonebrakerиҺ·еҫ—дәҶеӣҫзҒөеҘ–гҖӮд»ҺDB-Enginesзҡ„ж•°жҚ®жқҘзңӢпјҢPostgreSQLеңЁдёҖи·ҜйЈҷеҚҮгҖӮ并且PostgreSQLе’ҢSQL Serverзӯүдё»жөҒж•°жҚ®еә“еҗҢе®—еҗҢжәҗпјҢйғҪжҳҜд»ҺIngresиЎҚз”ҹеҮәжқҘзҡ„гҖӮ
д»ҺжҠҖжңҜзҡ„и§’еәҰжқҘзңӢпјҢPostgreSQLд№ҹе…·жңүеҫҲеӨҡзҡ„дјҳзӮ№гҖӮ第дёҖзӮ№е°ұжҳҜ并иЎҢпјҢиҝҷдёҖиғҪеҠӣеңЁPostgreSQL 10ж—¶ејҖе§ӢжҲҗзҶҹпјҢеңЁPostgreSQL 11ж—¶еҸ‘жҢҘеҫ—ж·Ӣжј“е°ҪиҮҙгҖӮPostgreSQLзҡ„并иЎҢиғҪеҠӣдё»иҰҒдҪ“зҺ°еңЁе№¶иЎҢжү«жҸҸгҖҒ并иЎҢиҝһжҺҘд»ҘеҸҠ并иЎҢAppendдёүдёӘж–№йқўгҖӮ第дәҢзӮ№жҳҜзЁіе®ҡжҖ§пјҢд»ҺзүҲжң¬иҝӯд»Јзҡ„иҝҮзЁӢеҸҜд»ҘзңӢеҮәпјҢPostgreSQLжҳҜз»ҸиҝҮеҚғй”ӨзҷҫзӮјзҡ„гҖӮ第дёүзӮ№жҳҜе®үе…ЁпјҢеӨ§е®¶еҸҜиғҪеҜ№дәҺејҖжәҗж•°жҚ®еә“зҡ„е®үе…ЁжҖ§еӯҳеңЁдёҖдәӣиҜҜи§ЈпјҢе…¶е®һPostgreSQLжҳҜйқһеёёе®үе…Ёзҡ„пјҢе®ғжҸҗдҫӣдәҶи®ӨиҜҒж–№ејҸгҖҒйҖҡйҒ“еҠ еҜҶе’Ңж•°жҚ®еҠ еҜҶдёҖеҘ—е®Ңж•ҙзҡ„е®үе…ЁжңәеҲ¶пјҢеҹәжң¬еҸҜд»Ҙи®ӨдёәOracleжңүеӨҡе®үе…ЁпјҢPostgreSQLе°ұжңүеӨҡе®үе…ЁгҖӮ第еӣӣзӮ№жҳҜеҠҹиғҪејәеӨ§пјҢPostgreSQLеңЁеҠҹиғҪдёҠиҝҳжңүи¶…иҝҮOracleзҡ„ең°ж–№пјҢжҜ”еҰӮзҙўеј•жӣҙдё°еҜҢгҖҒи®Ўж—¶еҠҹиғҪжӣҙејәеӨ§гҖҒеҲҶеёғејҸж•°д»“еҠҹиғҪжӣҙеҠ жҲҗзҶҹгҖӮ
жӯӨеӨ–пјҢд№ӢжүҖд»ҘиҜҙPostgreSQLдјҡжңүеҫҲеӨ§жңәйҒҮзҡ„еҸҰеӨ–дёҖдёӘеҺҹеӣ е°ұжҳҜе®ғзҡ„ејҖжәҗеҚҸи®®пјҢеӨ§е®¶еҸҜд»ҘйҡҸж„ҸдҪҝз”ЁгҖҒжӢ·иҙқгҖҒеҲҶеҸ‘пјҢиҖҢдё”еҸҜд»ҘйҡҸдҫҝдҝ®ж”№пјҢжІЎжңүд»»дҪ•зүҲжқғйЈҺйҷ©е’Ңдё“еҲ©йЈҺйҷ©гҖӮеӣ жӯӨпјҢеҰӮд»ҠеҫҲеӨҡж•°жҚ®еә“йғҪжҳҜеҹәдәҺPostgreSQLпјҢд№ҹжӯЈжҳҜеӣ дёәе®ғзҡ„ејҖж”ҫеҚҸи®®е’ҢејҖж”ҫзӯ–з•ҘпјҢжҸҗдҫӣдәҶеҫҲеӨ§зҡ„е•ҶжңәгҖӮ
е®һи·өе·Із»ҸиҜҒжҳҺпјҢеҹәдәҺPostgreSQLдёҚд»…иҜһз”ҹеҮәеҫҲеӨҡе…¬еҸёпјҢд№ҹиҜһз”ҹеҮәеҫҲеӨҡзҡ„дә§е“ҒпјҢжҜ”еҰӮзӢ¬и§’е…Ҫе…¬еҸёGreenplumгҖӮжӯӨеӨ–пјҢPostgreSQLе…·жңүејәеӨ§зҡ„з”ҹжҖҒеңҲпјҢеӣҪйҷ…зӨҫеҢәзҡ„еҮқиҒҡеҠӣе’ҢејҖеҸ‘иғҪеҠӣиғҪеӨҹзўҫеҺӢдёҖеҲҮпјҢPostgreSQLйҮҮз”Ёзҡ„жҳҜејҖж”ҫејҸдҪ“зі»з»“жһ„пјҢд№ҹе°ұжҳҜжҸ’件结жһ„пјҢејҖеҸ‘еҗҺеҸҜд»ҘеҫҲе®№жҳ“ең°еҸҚйҰҲзӨҫеҢәгҖӮиҖҢдё”PostgreSQLзҡ„д»Јз Ғе’ҢиҙЎзҢ®зҡ„иҙЁйҮҸйғҪйқһеёёй«ҳгҖӮ
ејҖжәҗж•°жҚ®еә“еңЁе№іе®ү科жҠҖзҡ„еә”з”Ёе®һи·ө
---------------
е№іе®үдә‘ж•°жҚ®еә“еҸҠеӯҳеӮЁдә§е“ҒеӣўйҳҹжҖ»з»ҸзҗҶжұӘжҙӢдёәеӨ§е®¶еҲҶдә«дәҶе№іе®ү科жҠҖзҡ„ејҖжәҗж•°жҚ®еә“йҖүеһӢеҺҹеҲҷд»ҘеҸҠеә”з”Ёе®һи·өгҖӮ
#### дёәдҪ•дҪҝз”ЁејҖжәҗж•°жҚ®еә“
дҪңдёәдёҖдёӘз®ЎзҗҶзқҖж•°дёҮдәҝиө„дә§зҡ„йҮ‘иһҚзҺӢеӣҪпјҢе№іе®үдёәдҪ•иҰҒеј•е…ҘејҖжәҗж•°жҚ®еә“пјҹе…¶е®һпјҢжҠҖжңҜж°ёиҝңжҳҜжңҚеҠЎдәҺдёҡеҠЎе’ҢеңәжҷҜзҡ„гҖӮе№іе®үеңЁ2013е№ҙеҒҡе®Ң银иЎҢж–°ж ёеҝғзҡ„вҖңжҚўеҝғжүӢжңҜвҖқд№ӢеҗҺпјҢејҖе§ӢиҖғиҷ‘еҗ‘дә’иҒ”зҪ‘гҖҒж•°еӯ—еҢ–иҪ¬еһӢгҖӮеңЁиҝҷдёҖиҝҮзЁӢдёӯпјҢдёҖж–№йқўйңҖиҰҒй«ҳжҖ§иғҪгҖҒй«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёзҡ„зі»з»ҹжһ¶жһ„пјҢеҸҰдёҖж–№йқўйңҖиҰҒеҝ«йҖҹең°жҚ•жҚүеёӮеңәйңҖжұӮпјҢ并еҝ«йҖҹиҪ¬жҚўдёәITйңҖжұӮејҖеҸ‘еҮәдә§е“ҒпјҢеҶҚжҠ•е…ҘеёӮеңәиҝӣиЎҢйӘҢиҜҒгҖӮеҰӮжһңдҪҝз”Ёдј з»ҹзҡ„е•Ҷдёҡж•°жҚ®еә“пјҢеңЁж•ҸжҚ·ең°жҚ•жҚүеёӮеңәйңҖжұӮд№ӢеҗҺеҝ«йҖҹе°Ҷдә§е“ҒжҺЁеҮәеёӮеңәж–№йқўе°ұжҳҫеҫ—жҚүиҘҹи§ҒиӮҳпјҢиҝҷжҳҜе№іе®үеј•е…ҘејҖжәҗж•°жҚ®еә“зҡ„еҺҹеӣ д№ӢдёҖгҖӮ
еңЁж•ҸжҚ·ж–№йқўпјҢеҫ®жңҚеҠЎи§ЈеҶідәҶеҚ•дҪ“жһ¶жһ„зҡ„еҫҲеӨҡй—®йўҳгҖӮ第дёҖзӮ№пјҢеҚ•дҪ“жһ¶жһ„зүөдёҖеҸ‘иҖҢеҠЁе…Ёиә«пјҢдҝ®ж”№йЈҺйҷ©еҫҲеӨ§пјҢејҖеҸ‘е’ҢжөӢиҜ•е‘ЁжңҹеҫҲй•ҝпјҢж–°еҠҹиғҪзҡ„дёҠзәҝйҖҹеәҰеҫҲж…ўгҖӮ第дәҢзӮ№пјҢеңЁеҚ•дҪ“жһ¶жһ„дёӯпјҢдёәдәҶжү©е®№жҹҗдёӘ组件жҲ–жЁЎеқ—йңҖиҰҒеҜ№ж•ҙдёӘзі»з»ҹиҝӣиЎҢжү©е®№пјҢиҝҷжҳҜдёҖз§ҚжөӘиҙ№пјҢиҖҢеҫ®жңҚеҠЎжһ¶жһ„еҲҷеҸҜд»Ҙй’ҲеҜ№жҹҗдёҖдёӘжңҚеҠЎиҝӣиЎҢжү©е®№гҖӮ第дёүзӮ№пјҢеҫ®жңҚеҠЎеҸҜд»Ҙж»Ўи¶ідёҚеҗҢжҠҖжңҜж ҲејҖеҸ‘дәәе‘ҳзҡ„йңҖиҰҒпјҢдёҚеҗҢеӣўйҳҹеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„жҠҖжңҜж ҲиҝӣиЎҢејҖеҸ‘гҖӮ
еҰӮд»ҠпјҢдёҖз§Қж•°жҚ®еә“йҡҫд»ҘйҖӮеә”жүҖжңүдёҡеҠЎеңәжҷҜзҡ„йңҖиҰҒпјҢйңҖиҰҒдҫқйқ ж··еҗҲжҢҒд№…еҢ–ж•°жҚ®еә“жқҘи§ЈеҶідёҚеҗҢж•°жҚ®еӯҳеӮЁйңҖжұӮгҖӮOne For Allж—¶д»Је·Із»ҸиҝҮеҺ»пјҢж•°жҚ®еә“еҚідҫҝеҒҡеҲ°вҖңеӨ§иҖҢе…ЁвҖқпјҢд№ҹйҡҫд»Ҙж¶өзӣ–жүҖжңүеңәжҷҜпјҢзҺ°еңЁиҰҒеҒҡзҡ„жҳҜвҖңBest FitвҖқпјҢй’ҲеҜ№жҹҗдёҖз§ҚдёҡеҠЎе’ҢиҙҹиҪҪпјҢдҪҝз”ЁжңҖйҖӮеҗҲзҡ„ж•°жҚ®еә“гҖӮжӯӨеӨ–пјҢдј з»ҹзҡ„е•Ҷдёҡж•°жҚ®еә“иҝҮдәҺжІүйҮҚпјҢиҖҢејҖжәҗж•°жҚ®еә“еҲҷйқһеёёиҪ»йҮҸгҖӮиҝҷдәӣд№ҹжҳҜеј•е…Ҙе’ҢжҺЁе№ҝејҖжәҗж•°жҚ®еә“зҡ„еҺҹеӣ гҖӮжӯӨеӨ–пјҢеҚідҫҝдҪҝз”ЁејҖжәҗж•°жҚ®еә“пјҢд№ҹеҫҲйҡҫж»Ўи¶іжүҖжңүдёҡеҠЎзҡ„йңҖжұӮпјҢйңҖиҰҒиғҪеӨҹеҹәдәҺејҖжәҗж•°жҚ®еә“иҝӣиЎҢдәҢж¬ЎејҖеҸ‘пјҢиҖҢиҝҷд№ҹжҳҜе•Ҷдёҡж•°жҚ®еә“ж— жі•е®һзҺ°зҡ„гҖӮ
#### ејҖжәҗ并дёҚж„Ҹе‘ізқҖе…Қиҙ№
еј•е…ҘејҖжәҗж•°жҚ®еә“жҳҜеҝ…然и¶ӢеҠҝпјҢдҪҶејҖжәҗ并дёҚж„Ҹе‘ізқҖе…Қиҙ№гҖӮиҷҪ然LicenseжҳҜе…Қиҙ№зҡ„пјҢдҪҶиҝҳйңҖиҰҒд»ҳеҮәе…¶д»–жҲҗжң¬гҖӮжҺҢжҸЎејҖжәҗжҠҖжңҜйңҖиҰҒдёҖдёӘиҝҮзЁӢпјҢйңҖиҰҒеӯҰд№ жҲҗжң¬пјӣд»Һе•ҶдёҡеҢ–дә§е“ҒеҲ°ејҖжәҗж•°жҚ®еә“зҡ„иҝҒ移йңҖиҰҒиҝҒ移жҲҗжң¬пјӣиҝҒ移е®ҢжҲҗд№ӢеҗҺиҝҳеҸҜиғҪдјҡеўһеҠ иҝҗз»ҙжҲҗжң¬д»ҘеҸҠйЈҺйҷ©пјҢиҝҷдәӣжҲҗжң¬йғҪйңҖиҰҒеңЁеј•е…ҘејҖжәҗж•°жҚ®еә“зҡ„ж—¶еҖҷиҖғиҷ‘гҖӮ
#### еҰӮдҪ•йҖүжӢ©ејҖжәҗж•°жҚ®еә“
йҰ–е…ҲиҰҒзңӢдёҡеҠЎеңәжҷҜпјҢеӣ дёәжҠҖжңҜжҳҜжңҚеҠЎдәҺдёҡеҠЎеңәжҷҜйңҖжұӮзҡ„гҖӮеҶҚзңӢжҳҜеҗҰжңүеҗҲйҖӮзҡ„жӣҝд»Јж–№жЎҲпјҢжҜ”еҰӮPostgreSQLе°ұжҳҜOracleжҜ”иҫғеҗҲйҖӮзҡ„жӣҝд»Јж–№жЎҲгҖӮиҝҳиҰҒиҖғиҷ‘зҺ°жңүејҖеҸ‘дәәе‘ҳзҡ„жҠҖиғҪпјҢеҗҰеҲҷдјҡйқһеёёз—ӣиӢҰгҖӮжӯӨеӨ–пјҢйңҖиҰҒиҖғиҷ‘зҺ°жңүж•°жҚ®еә“зҡ„иҙҹиҪҪжЁЎејҸгҖҒејҖжәҗзӨҫеҢәзҡ„жҙ»и·ғеәҰгҖҒеёӮеңәд»Ҫйўқд»ҘеҸҠиЎҢдёҡзҹҘеҗҚеәҰгҖӮеҸҰеӨ–иҝҳйңҖиҰҒе…іжіЁејҖеҸ‘иҜӯиЁҖе’Ңж•°жҚ®еә“зұ»еһӢпјҢйңҖиҰҒдёҺеӣўйҳҹеҸҠдёҡеҠЎеңәжҷҜйҖӮй…ҚгҖӮд№ҹйңҖиҰҒе…іжіЁж•°жҚ®еә“жҠҖжңҜзҡ„еҸ‘еұ•и¶ӢеҠҝпјҢжҜ”еҰӮеӯҳеӮЁе’Ңи®Ўз®—еҲҶзҰ»гҖҒдә‘еҺҹз”ҹгҖҒеҲҶеёғејҸзӯүгҖӮжңҖеҗҺдёҖзӮ№е°ұжҳҜдёҚиҰҒдҪҝз”ЁеӨӘеӨҡејҖжәҗдә§е“ҒпјҢжҜҸзұ»йҖүжӢ©дёҖз§ҚеҚіеҸҜгҖӮ
#### ејҖжәҗж•°жҚ®еә“еј•е…Ҙе’Ңеә”з”Ёзӯ–з•Ҙ
еј•е…Ҙе’Ңеә”з”ЁејҖжәҗж•°жҚ®еә“д№ҹжңүдёҖдәӣзӯ–з•ҘпјҡеҢәеҲ«зҺ°жңүе’Ңж–°е»әзҡ„зі»з»ҹпјҢйҖүжӢ©дёҚеҗҢзӯ–з•ҘпјҢеҸҜд»ҘйҷҚдҪҺиҝҒ移йЈҺйҷ©е’ҢжҲҗжң¬гҖӮе°Ҷж•°жҚ®еә“иҝӣиЎҢеҲҶзұ»пјҢе…Ҳд»ҺдёҚйҮҚиҰҒзҡ„еә“ејҖе§ӢиҝҒ移пјҢз§ҜзҙҜз»ҸйӘҢпјҢжңҖе°ҸеҢ–йЈҺйҷ©гҖӮеҲ’еҲҶдёҚеҗҢзҡ„дёҡеҠЎжқЎзәҝпјҢе…Ҳд»ҺиҰҒжұӮдёҚй«ҳзҡ„дёҡеҠЎжқЎзәҝдёӢжүӢгҖӮе®һзҺ°ж•°жҚ®еә“дә§е“Ғеј•е…ҘиҝҮзЁӢдёӯзҡ„OwnerжңәеҲ¶пјҢеҒҡеҲ°вҖңжңҜдёҡжңүдё“ж”»вҖқгҖӮеҲ¶е®ҡж•°жҚ®еә“жһ¶жһ„гҖҒиҝҗиҗҘе’ҢејҖеҸ‘зҡ„жҢҮеҚ—жүӢеҶҢгҖӮиҝҳйңҖиҰҒеҜ№иҝҗиҗҘгҖҒејҖеҸ‘е’ҢDBAиҝӣиЎҢеҹ№и®ӯгҖӮй’ҲеҜ№йҒҮеҲ°зҡ„й—®йўҳжҢҒз»ӯиҝӣиЎҢжһ¶жһ„дјҳеҢ–пјҢз§ҜзҙҜејҖеҸ‘е’ҢиҝҗиҗҘз»ҸйӘҢгҖӮиҝҳйңҖиҰҒйҖҡиҝҮеӯҰд№ жәҗд»Јз ҒжқҘеҝ«йҖҹиҝҪиёӘеҲ°ж №жң¬еҺҹеӣ пјҢ并йҳІжӯўй—®йўҳзҡ„еҶҚж¬ЎеҮәзҺ°гҖӮеҰӮжһңзҺ°жңүеҠҹиғҪж»Ўи¶ідёҚдәҶдёҡеҠЎйңҖжұӮпјҢеҸҜд»Ҙз»„е»әз ”еҸ‘еӣўйҳҹиҝӣиЎҢдәҢж¬ЎејҖеҸ‘гҖӮжңҖеҗҺдёҖзӮ№е°ұжҳҜжӢҘжҠұејҖжәҗзӨҫеҢәпјҢе»әз«ӢиҮӘе·ұзҡ„з”ҹжҖҒпјҢе®һзҺ°дёҺејҖжәҗзӨҫеҢәзҡ„иүҜеҘҪдә’еҠЁпјҢиҝӣиҖҢе®һзҺ°еҸҢиөўгҖӮ
#### ж•°жҚ®еә“йҖүеһӢзӯ–з•Ҙ
еңЁе…ізі»еһӢж•°жҚ®еә“ж–№йқўпјҢеӣ дёәе№іе®үеұһдәҺйҮ‘иһҚе…¬еҸёпјҢжүҖд»ҘеҸӘиҰҒж¶үеҸҠеҲ°иө„йҮ‘дәӨжҳ“йғҪйңҖиҰҒжһҒй«ҳзҡ„ж•°жҚ®е®үе…ЁжҖ§е’ҢдёҖиҮҙжҖ§д»ҘеҸҠ7\*24е°Ҹж—¶дёҚй—ҙж–ӯзҡ„жңҚеҠЎгҖӮдёҚж¶үеҸҠиө„йҮ‘дәӨжҳ“зҡ„еҲҷеҸҜд»Ҙж №жҚ®е…·дҪ“дёҡеҠЎеңәжҷҜйҖүжӢ©гҖӮеңЁеҲҶеёғејҸе…ізі»еһӢж•°жҚ®еә“ж–№йқўпјҢжңүдёӨз§Қж•°жҚ®еә“йҖүеһӢвҖ”вҖ”иҮӘз ”зҡ„PDRSе’ҢејҖжәҗзҡ„TiDBгҖӮ
#### ејҖжәҗж•°жҚ®еә“жҺЁе№ҝжҲҗжһң
зҺ°еңЁе№іе®үжҖ»е…ұжңүе°Ҷиҝ‘дёүдёҮдёӘж•°жҚ®еә“е®һдҫӢпјҢе…¶дёӯOracleеҚ жҜ”йқһеёёдҪҺпјҢRedisжңҖеӨҡпјҢPostgreSQLж¬ЎеӨҡпјҢд№ҹжңүдёҖдәӣMongoDBе’ҢMySQLе®һдҫӢгҖӮ
#### еҸ‘еұ•и·Ҝеҫ„
жҖ»з»“иҖҢиЁҖпјҢж•°жҚ®еә“зҡ„еҸ‘еұ•и·Ҝеҫ„жңӘжқҘе°Ҷдјҡж”ҜжҢҒе®№еҷЁеҢ–йғЁзҪІпјҢе’ҢK8SжӣҙеҘҪең°з»“еҗҲпјҢз”ҡиҮіе®һзҺ°ServerlessеҢ–пјҢд№ҹдјҡеҮәзҺ°жӣҙеӨҡзҡ„иҮӘз ”ж•°жҚ®еә“е’ҢеҹәдәҺејҖжәҗж•°жҚ®еә“з ”еҸ‘ж–°зҡ„еҠҹиғҪгҖӮжңҖеҗҺдёҖзӮ№пјҢе°ұжҳҜеңЁдә‘дёҠеҸҜд»Ҙ收йӣҶеӨ§йҮҸиҝҗз»ҙж•°жҚ®пјҢиҝӣиҖҢе®һзҺ°AIOpsгҖӮ
дј з»ҹж•°жҚ®еә“еҲ°ејҖжәҗж•°жҚ®еә“иҝҒ移зҡ„е·Ҙе…·еҢ–жөҒзЁӢ
-------------------
иҝӘжҖқжқ°DSGе…¬еҸёеҲӣе§ӢдәәгҖҒжҖ»иЈҒйҹ©е®ҸеқӨдёәеӨ§е®¶еҲҶдә«дәҶдј з»ҹж•°жҚ®еә“еҲ°ејҖжәҗж•°жҚ®еә“иҝҒ移зҡ„е·Ҙе…·еҢ–жөҒзЁӢгҖӮ
зҺ°еңЁе·Із»ҸеҲ°дәҶж•°жҚ®еә“еҺҶеҸІзҡ„дёҖдёӘжӢҗзӮ№пјҢеҗ„дёӘдјҒдёҡзә·зә·д»Һй«ҳд»·еҖјзҡ„е•Ҷдёҡж•°жҚ®еә“иө°еҗ‘иҮӘз”ұзҡ„ејҖжәҗж•°жҚ®еә“пјҢ并且混еҗҲжһ¶жһ„ж—¶д»Је·Із»ҸжқҘдёҙпјҢеҗ„з§Қж•°жҚ®жӯЈеңЁеҝ«йҖҹең°жөҒеҠЁгҖӮ
DSGйңҖиҰҒжңҚеҠЎдәҺеҗ„з§ҚиЎҢдёҡзҡ„е®ўжҲ·пјҢиҖҢ他们зҡ„зі»з»ҹеҚғе·®дёҮеҲ«гҖӮDSGжӢҘжңүе®Ңе…ЁиҮӘз ”зҡ„жҠҖжңҜпјҢеӣ жӯӨиғҪеӨҹеҝ«йҖҹи·ҹиҝӣеҗ„з§ҚжҠҖжңҜзҡ„еҸҳеҢ–гҖӮDSGзҡ„ж ёеҝғжҠҖжңҜдјҳеҠҝеңЁдәҺеҮ д№ҺиғҪеӨҹж¶өзӣ–жүҖжңүдё»жөҒж•°жҚ®еә“ж—Ҙеҝ—зҡ„е®һж—¶еҲҶжһҗжҠҖжңҜпјҢ并且еҲӣйҖ дәҶдёҖз§Қз»ҹдёҖзҡ„ж•°жҚ®еә“ж•°жҚ®иЎЁиҫҫиҜӯиЁҖпјҢеӣ жӯӨDSGеҸҜд»ҘдҪҝз”Ёиҫғе°‘зҡ„з ”еҸ‘иө„жәҗеҲӣйҖ еҫҲеӨ§зҡ„д»·еҖјгҖӮзӣ®еүҚеҜ№дәҺдёӯеӣҪиҖҢиЁҖпјҢеңЁж•°жҚ®еә“ж–№йқўжңүе·ЁеӨ§зҡ„еҺӢеҠӣе’ҢйңҖжұӮпјҢжӯЈеӣ жӯӨжүҚй©ұеҠЁзқҖж•°жҚ®еә“жҠҖжңҜиө°еҗ‘жһҒиҮҙгҖӮйҳҝйҮҢеҰӮжӯӨпјҢDSGд№ҹеҰӮжӯӨгҖӮ
DSGе…·жңүејәеӨ§зҡ„ж•°жҚ®еӨ„зҗҶе’ҢеӨҚеҲ¶иғҪеҠӣпјҢеҜ№дәҺOracleзҡ„иҝҒ移иҖҢиЁҖпјҢжңәйҒҮеңЁдәҺPostgreSQLпјҢе®һи·өд№ҹиҜҒжҳҺдәҶPostgreSQLгҖӮеҗ„дёӘдјҒдёҡйғҪйңҖиҰҒеҒҡиҝҒ移пјҢиҖҢеҜ№дәҺе·ҘзЁӢдәәе‘ҳиҖҢиЁҖпјҢеҸҜд»ҘиҜҙвҖңе…өиҙөзҘһйҖҹвҖқпјҢеӣ жӯӨDSGе’ҢйҳҝйҮҢеҗҲдҪңеҜ№Oracleзҡ„иҝҒ移方法и®әеҒҡдәҶж•ҙдҪ“жўізҗҶгҖӮOracleиҝҒ移зҡ„е®ўжҲ·з—ӣзӮ№дё»иҰҒжңү6зӮ№пјҡ
> пҒ¬ жәҗж•°жҚ®еә“еҜ№иұЎе…ізі»гҖҒдҫқиө–е…ізі»еӨҚжқӮпјӣВ
> пҒ¬ ж•°жҚ®еә“е’Ңеә”з”Ёж”№йҖ е·ҘдҪңйҮҸдёҚжҳҺзЎ®пјӣВ
> пҒ¬ зӣ®ж Үеә“и§„ж јдёҚжҳҺзЎ®пјӣВ
> пҒ¬ иҝҒ移еүІжҺҘдёҡеҠЎеҒңжңәж—¶й—ҙзҹӯпјӣВ
> пҒ¬ йңҖиҰҒеҗҢжӯҘиҝӣиЎҢж•°жҚ®еҜ№жҜ”йӘҢиҜҒпјӣВ
> пҒ¬ йңҖиҰҒж•°жҚ®еӣһжөҒдҝқиҜҒе®үе…Ёе’Ңеә”з”ЁеӣһеҲҮгҖӮ
еҜ№дәҺOracleиҝҒ移зҡ„и§ЈеҶіж–№жЎҲиҖҢиЁҖпјҢйҰ–е…ҲиҰҒйҖҡиҝҮйҮҮйӣҶе’ҢиҜ„дј°жҸҗеүҚеҸ‘зҺ°е®ҡдҪҚй—®йўҳпјҢдёҚжҳҜеңЁиҝҒ移зҡ„ж—¶еҖҷжүҚеҸ‘зҺ°й—®йўҳпјҢиҖҢеә”иҜҘжҳҜеңЁиҝҒ移д№ӢеүҚпјҢе°ұе®ҢжҲҗеҜ№ж•°жҚ®еә“еҜ№иұЎе…ізі»д»ҘеҸҠеә”з”Ёе’Ңеә“д№Ӣй—ҙе…ізі»зҡ„жўізҗҶпјҢеҸ‘зҺ°еҸҜиғҪеӯҳеңЁзҡ„й—®йўҳ并дҪңеҮә规еҲ’гҖӮе…¶ж¬ЎиҰҒеҒҡиҮӘеҠЁе…је®№жҖ§иҜҶеҲ«е’ҢиҪ¬жҚўпјҢиҮӘеҠЁең°еҸ‘зҺ°дёҚе…је®№зҡ„еҜ№иұЎпјҢ并иҮӘеҠЁжўізҗҶж•°жҚ®еә“еҜ№иұЎд№Ӣй—ҙзҡ„е…ізі»пјҢд»ҺеӨҙеҲ°е°ҫиҮӘеҠЁең°з”ҹжҲҗе®Ңж•ҙзҡ„иҝҒ移жҠҘе‘ҠгҖӮиҝҷж ·дёҖжқҘпјҢз”ЁжҲ·е°ұиғҪеӨҹзҹҘйҒ“иҮӘе·ұеә”иҜҘиҙҹиҙЈд»Җд№ҲпјҢDSGеә”иҜҘиҙҹиҙЈд»Җд№ҲгҖӮжңҖеҗҺиҝҳеҸҜд»Ҙе®һзҺ°й«ҳж•ҲдҪҺе№Іжү°зҡ„еўһйҮҸеҗҢжӯҘе’Ңж•°жҚ®е®һж—¶еҜ№жҜ”пјҢDSGеҸҜд»Ҙеё®еҠ©е®ўжҲ·д»ҘжҜҸе°Ҹж—¶300GеҲ°500Gзҡ„йҖҹеәҰиҝӣиЎҢж•°жҚ®еә“иҝҒ移пјҢ并е®һзҺ°еҝ«йҖҹйӘҢиҜҒгҖӮ
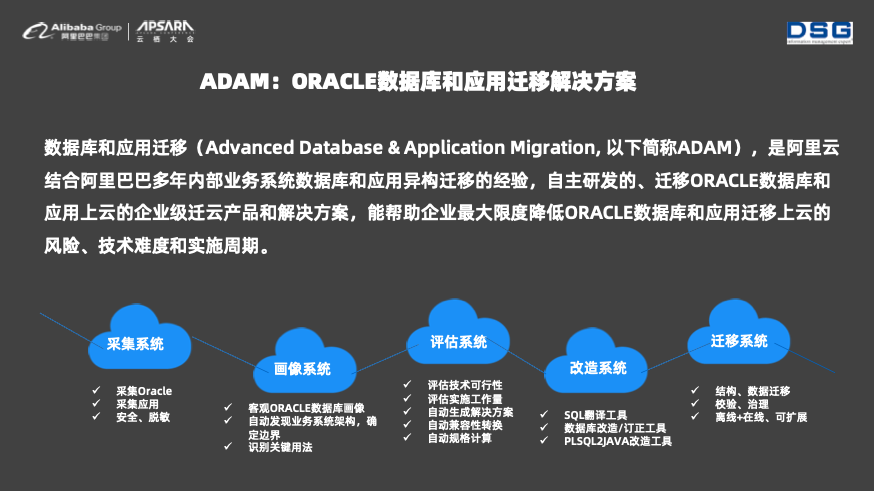
йҳҝйҮҢжҺЁеҮәдәҶADAMи®ЎеҲ’пјҢе°Ҷж•ҙдёӘж•°жҚ®еә“е’Ңеә”з”ЁиҝҒ移зҡ„жөҒзЁӢйғҪе®ҡд№үеҫ—йқһеёёжё…жҷ°гҖӮADAMжҸҗдҫӣдәҶеҠҹиғҪејәеӨ§зҡ„йҮҮйӣҶгҖҒз”»еғҸгҖҒиҜ„дј°гҖҒж”№йҖ д»ҘеҸҠиҝҒ移系з»ҹгҖӮADAMзҡ„жҷәиғҪз”»еғҸзі»з»ҹиғҪеӨҹдёәз”ЁжҲ·е®ўи§Ӯең°иҝӣиЎҢOracleж•°жҚ®еә“з”»еғҸпјҢеҲҶжһҗе…¶зү№жҖ§гҖҒжҖ§иғҪгҖҒе®№йҮҸд»ҘеҸҠеӨ–йғЁдҫқиө–зӯү并д»ҘеӣҫеҪўеҢ–ж–№ејҸеұ•зҺ°еҮәжқҘгҖӮADAMзҡ„жҷәиғҪиҜ„дј°зі»з»ҹиғҪеӨҹеҲҶжһҗж•°жҚ®еә“еҜ№иұЎд»ҘеҸҠSQLзҡ„е…је®№жҖ§пјҢиҜҶеҲ«йЈҺйҷ©SQLпјҢе°ҶPLSQLиҪ¬жҲҗJavaд»ҘеҸҠиҮӘеҠЁеҜ№ж•°жҚ®еә“еҜ№иұЎиҝӣиЎҢе…је®№жҖ§иҪ¬жҚўгҖӮADAMзҡ„жҷәиғҪж”№йҖ зі»з»ҹеҲҷдјҡдёәз”ЁжҲ·жҸҗдҫӣдёҖдёӘж•°жҚ®еә“жҠҘе‘ҠпјҢ并йҖҡиҝҮд»ҝзңҹдёәз”ЁжҲ·жҸҗдҫӣж•°жҚ®еә“ж”№йҖ е»әи®®гҖӮ
еҪ“ADAMзҡ„е·ҘдҪңе®ҢжҲҗд№ӢеҗҺпјҢDSGе°ұиҙҹиҙЈжү“йҖҡж•°жҚ®иҝҒ移зҡ„жңҖеҗҺдёҖе…¬йҮҢдәҶгҖӮDSGжҸҗдҫӣдәҶдёҖдёӘйқһеёёејәеӨ§гҖҒе®Ңж•ҙзҡ„ж•°жҚ®еә“иҝҒ移е·Ҙе…·пјҢе®һзҺ°дәҶд»ҘADAMиҝҒ移计еҲ’дёәж ёеҝғзҡ„е®Ңж•ҙж–№жі•и®әпјҢжү“йҖҡдәҶж•°жҚ®иҝҒ移зҡ„жңҖеҗҺдёҖе…¬йҮҢгҖӮDSGеҸҜд»Ҙе®һзҺ°еңәжҷҜеҢ–гҖҒиҮӘеҠЁеҢ–гҖҒжөҒзЁӢеҢ–зҡ„ж•°жҚ®е…ЁйҮҸиҝҒ移гҖҒеўһйҮҸиҝҒ移гҖҒж•°жҚ®ж ЎйӘҢгҖҒж•°жҚ®дҝ®жӯЈзӯүпјҢеё®еҠ©з”ЁжҲ·иҪ»жқҫгҖҒй«ҳж•Ҳең°иҝҒ移еҲ°дә‘дёҠжҲ–иҖ…POLARDBдёҖдҪ“жңәзӯүгҖӮ
DSGе’ҢADAMзҡ„ж ёеҝғиғҪеҠӣз»“еҗҲиө·жқҘе°ұиғҪеӨҹеҪўжҲҗOracleиҝҒ移жҷәиғҪе…Ёй“ҫи·Ҝи§ЈеҶіж–№жЎҲпјҢ并且еңЁеӣҪеҶ…зҡ„еҫҲеӨҡе®ўжҲ·дјҒдёҡдёӯе·Із»ҸиҗҪең°гҖӮиҝҷд№ҲеӨҡе№ҙжқҘпјҢDSGдёҖзӣҙеңЁж·ұиҖ•ж•°жҚ®иҝҒ移方йқўзҡ„еә•еұӮжҠҖжңҜгҖӮиҖҢдё”DSG for ADAMж·ұеәҰйӣҶжҲҗдәҶйҳҝйҮҢдә‘зҡ„жҠҖжңҜпјҢе®һзҺ°дәҶж•°жҚ®иҝҒ移гҖҒж•°жҚ®жҜ”еҜ№зӯүиҝҮзЁӢзҡ„еҸҜи§ҶеҢ–гҖӮжӯӨеӨ–пјҢDSG for ADAMж•°жҚ®еә“иҝҒ移方жЎҲеҜ№дәҺжӯЈеёёдёҡеҠЎзҡ„е№Іжү°жһҒе°ҸпјҢ并且еҸҜд»ҘеңЁдёӯй—ҙзҠ¶жҖҒгҖҒдә‘дёҠдә‘дёӢзҺҜеўғдёӯйғЁзҪІгҖӮдёәдәҶжү“ж¶Ҳе®ўжҲ·еҜ№дәҺж•°жҚ®еә“иҝҒ移зҡ„з–‘иҷ‘пјҢDSGиҝҳжҸҗдҫӣдәҶе®Ңе–„зҡ„ж•°жҚ®еӣһжөҒеҠҹиғҪгҖӮ
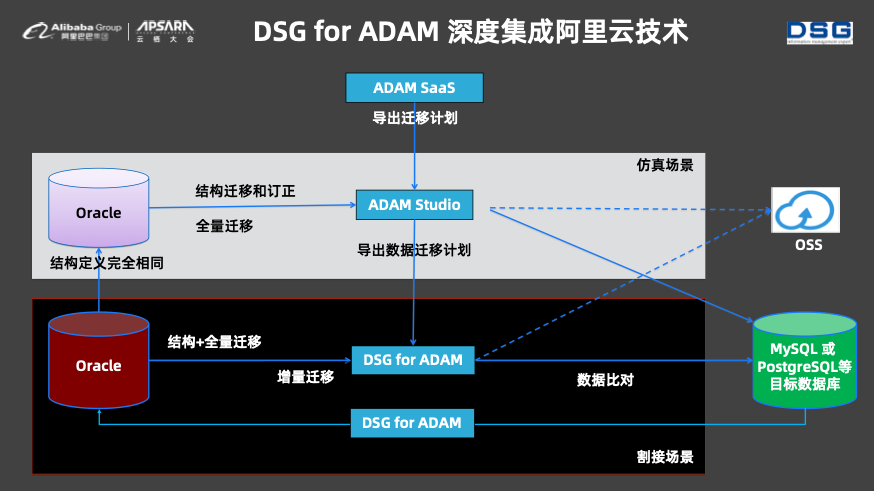
DSGжӢҘжңүзңҹжӯЈзҡ„еә•еұӮжҠҖжңҜпјҢеӣ жӯӨеҸҜд»Ҙе’ҢйҳҝйҮҢдә‘дёҖиө·жҺЁеҮәжӣҙеӨҡзҡ„дә§е“Ғе’Ңзӣёе…ізҡ„жңҚеҠЎпјҢжҜ”еҰӮеҠ е…ҘETLеҠҹиғҪеўһејәOracleиҝҒ移еӨ§и„‘пјҢж”ҜжҢҒblob to oidзӯүжӣҙеӨҡзұ»еһӢж–№жЎҲпјҢејӮжһ„еңЁзәҝDDLиҪ¬жҚўиғҪеҠӣпјҢеҠ ејәиҝҒ移жҢҮеҜјиҜ„дј°иғҪеҠӣпјҢж”ҜжҢҒPOLARDBгҖҒADBзӯүжӣҙеӨҡе…Ёж–°зҡ„зӣ®ж Үж•°жҚ®еә“зӯүгҖӮ
DSGзӣёдҝЎжңӘжқҘжҳҜејҖжәҗе’ҢPostgreSQLзҡ„ж—¶д»ЈпјҢOracleиў«еҸ–д»Јзҡ„йҖҹеәҰеҸҜиғҪйқһеёёеҝ«гҖӮиҖҢдё”еӣҪ家д№ҹжҸҗеҮәдәҶиҪҜ件еӣҪдә§еҢ–зҡ„иҰҒжұӮпјҢPostgreSQLдёәж ёеҝғзҡ„ж•°жҚ®еә“еҫҲеҸҜиғҪжҳҜдёҖдёӘзӘҒз ҙеҸЈпјҢеӣ жӯӨеҜ№дәҺдҝЎжҒҜжһ¶жһ„зҡ„з®ЎзҗҶдәәе‘ҳиҖҢиЁҖеә”иҜҘжҠ“зҙ§иЎҢеҠЁгҖӮ
ж•°жҚ®иҝҒ移иғҪеҠӣеҸӘжҳҜDSGзҡ„дёҖйғЁеҲҶпјҢDSGеңЁж•°жҚ®еӨҮд»ҪгҖҒе®№зҒҫгҖҒйӣҶжҲҗе’ҢжұҮйӣҶзӯүж–№йқўд№ҹйқһеёёејәеӨ§пјҢDSGиғҪеӨҹйҖӮеә”еҗ„з§Қеҗ„ж ·зҡ„ејӮжһ„ж•°жҚ®еә“пјҢ并且еҸҜд»ҘеңЁж•°жҚ®йҮҮйӣҶе’Ңе®һж–ҪиҝҮзЁӢдёӯиҝӣиЎҢиҪ¬жҚўпјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·иҺ·еҫ—ж•°жҚ®иҝҒ移зҡ„иҮӘз”ұгҖӮ
дј з»ҹж•°жҚ®еә“DBAеҲ°ејҖжәҗзҡ„жҠҖиғҪе’ҢеҝғзҗҶеҲҮжҚў
-------------------
дә‘е’ҢжҒ©еўЁеҲӣе§ӢдәәпјҢACOUGзӣ–еӣҪејәд»ҺеӨ©йҒ“й…¬еӢӨгҖҒи®ӨиҜҶж—¶й—ҙе’ҢеӨ§йҒ“иҮіз®ҖдёүдёӘж–№йқўеҲҶдә«дәҶDBAзҡ„еӯҰд№ жҺўзҙўд№Ӣи·ҜгҖӮ
зҺ°еңЁжҳҜдёҖдёӘвҖңзӣёеҗ‘иҖҢиЎҢвҖқзҡ„ж—¶д»ЈпјҢж— и®әеӨ§е®¶еҰӮдҪ•и®Ёи®әOracleпјҢдҪҶжҳҜжІЎжңүдёҖдёӘж•°жҚ®еә“ж•ўиҜҙиҮӘе·ұи¶…иҝҮдәҶOracleпјҢиҖҢйғҪеңЁеӯҰд№ е’ҢиҝҪиө¶Oracleзҡ„зү№жҖ§гҖӮдҪңдёәжҠҖжңҜдәәпјҢж— и®әжӣҫз»ҸзҶҹжӮүд»Җд№ҲжҠҖжңҜпјҢеңЁиҝҷдёӘеҝ«йҖҹеҸҳйқ©зҡ„ж—¶д»ЈпјҢйғҪдјҡйқўдёҙеӯҰд№ зҡ„жҢ‘жҲҳпјҢйғҪдјҡж„ҹеҲ°з„Ұиҷ‘гҖӮеҰӮд»ҠпјҢйҡҸзқҖж•°жҚ®еә“жҠҖжңҜзҡ„йЈһйҖҹеҸ‘еұ•пјҢDBAеә”иҜҘиҝӣиЎҢвҖңжҲҳз•ҘиҪ¬з§»вҖқгҖӮ
#### еӨ©йҒ“й…¬еӢӨ
ж— и®әеҜ№дәҺзЁӢеәҸе‘ҳиҝҳжҳҜDBAиҖҢиЁҖпјҢеӯҰд№ ж–№жі•еҸҜд»ҘеҲҶдёә6жӯҘгҖӮ第дёҖзӮ№е°ұжҳҜжү“еҘҪең°еҹәпјҢвҖңдёәеұұд№қд»һпјҢе§ӢдәҺеһ’еңҹвҖқпјҢеӯҰд№ д»»дҪ•жҠҖжңҜе°ҶеҹәзЎҖжү“зүўйғҪжҳҜеүҚжҸҗпјҢиҝҷж ·жүҚиғҪзҒөжҙ»иҝҗз”ЁиҝҷдәӣжҠҖжңҜи§ЈеҶізҺ°е®һдёӯйҒҮеҲ°зҡ„еӣ°йҡҫгҖӮ第дәҢзӮ№жҳҜеӯҰдјҡжҖқиҖғпјҢеҫҲеӨҡдәәиҷҪ然еӯҰд№ дәҶеҫҲеӨҡзҹҘиҜҶпјҢдҪҶжҳҜжІЎжңүзӢ¬з«ӢжҖқиҖғзҡ„ж„ҸиҜҶпјҢеңЁеӯҰд№ иҝҮзЁӢдёӯдёҖе®ҡиҰҒеӯҰдјҡиҮӘе·ұи®ҫй—®гҖҒиҮӘе·ұи§Јзӯ”пјҢиҝҷж ·зҡ„еҺҶзЁӢеҸҜд»ҘдҝғиҝӣиҮӘе·ұжҲҗй•ҝгҖӮ第дёүзӮ№жҳҜжҺҢжҸЎж–№жі•пјҢжҖ»жңүдёҖз§Қж–№жі•еҸҜд»Ҙеё®еҠ©дҪ еҠ еҝ«еӯҰд№ йҖҹеәҰпјҢе…¶дёӯжңҖз»ҸжөҺзҡ„ж–№жі•е°ұжҳҜвҖңз”ұзӮ№еҸҠйқўпјҢз”ұжө…е…Ҙж·ұвҖқпјҢжҠ“дҪҸйҒҮеҲ°зҡ„д»»дҪ•дёҖдёӘй—®йўҳпјҢж·ұ究еҲ°жәҗз ҒеұӮпјҢиҝҷж ·з”ұзҹҘиҜҶзӮ№еҲ°зәҝеҶҚеҲ°йқўиҝһеңЁдёҖиө·гҖӮ第еӣӣзӮ№жҳҜе…»жҲҗд№ жғҜпјҢеҜ№дәҺDBAиҖҢиЁҖпјҢдёҘи°ЁжҳҜйқһеёёйҮҚиҰҒзҡ„пјҢд»»дҪ•дёҖдёӘз–ҸеҝҪйғҪеҸҜиғҪеҜјиҮҙзҒҫйҡҫгҖӮ第дә”зӮ№жҳҜе®һи·өдҝ®жӯЈпјҢжңҖжңүеҠ©дәҺдёӘдәәжҲҗй•ҝзҡ„жҳҜй«ҳеҺӢзҺҜеўғпјҢйҖҡиҝҮе®һи·өжқҘйӘҢиҜҒзҹҘиҜҶдҪ“зі»гҖӮжңҖеҗҺдёҖзӮ№е°ұжҳҜиҮ»дәҺиҮіе–„пјҢиө°иҝҮеҚғеұұдёҮж°ҙпјҢжңҖеҗҺеҫ—д»ҘвҖңи§Ғеҫ®зҹҘи‘—пјҢеӨ§йҒ“иҮіз®ҖвҖқпјҢеҸҜд»ҘиҪ»иҖҢжҳ“дёҫең°и§ЈеҶіеӣ°жү°еҲ«дәәе·Ід№…зҡ„й—®йўҳгҖӮ
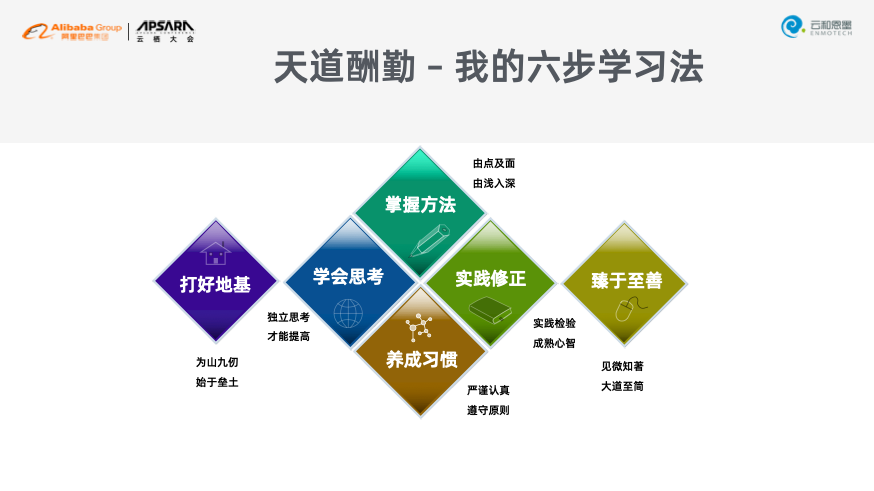
жҖ»з»“дәҶдёҖдёӘеӯҰд№ е…¬ејҸпјҡ**е…ҙи¶Ј+еӢӨеҘӢ+еқҡжҢҒ+ж–№жі•вүҲжҲҗеҠҹгҖӮ**йҰ–е…ҲжҳҜе…ҙи¶ЈпјҢе…ҙи¶ЈжҳҜжңҖеҘҪзҡ„иҖҒеёҲпјҢйҷӨдәҶз—ҙиҝ·дәҺжҠҖжңҜзҡ„дәәпјҢеӨ§йғЁеҲҶдәәеңЁж·ұе…ҘеӯҰд№ ж—¶йғҪдјҡж„ҹеҲ°жһҜзҮҘгҖӮеӣ жӯӨеңЁеӯҰд№ ж—¶пјҢжңҖеҘҪзҡ„ж–№ејҸжҳҜжүҫеҲ°е…ҙи¶ЈпјҢ然еҗҺеҹ№е…»гҖҒе‘өжҠӨе…ҙи¶ЈпјҢйҒҮеҲ°жҢ«жҠҳгҖҒжү“еҮ»ж—¶дёҚиҰҒж”ҫејғгҖӮе…¶ж¬ЎжҳҜеӢӨеҘӢпјҢжүҖжңүеҒҡеҮәеҚ“и¶ҠжҲҗз»©зҡ„дәәйғҪжҳҜеӢӨеҘӢзҡ„гҖӮ第дёүзӮ№е°ұжҳҜеқҡжҢҒдёҚжҮҲпјҢдёҚиҰҒйў‘з№Ғең°и°ғж•ҙж–№еҗ‘гҖӮ第еӣӣзӮ№е°ұжҳҜжүҫеҲ°йҖӮеҗҲзҡ„ж–№жі•гҖӮжңүдәҶиҝҷдәӣжқЎд»¶е°ұзәҰзӯүдәҺжҲҗеҠҹпјҢеҚідҪҝдёҚдёҖе®ҡзңҹжӯЈиғҪеӨҹеҒҡеҲ°дё–дәәзңӢеҲ°зҡ„жҲҗеҠҹпјҢдҪҶеҸҜд»Ҙж— ж„§дәҺеҝғгҖӮ
еңЁиҝҷдёӘж—¶д»ЈпјҢеӯҰд№ зҡ„йҖҹеәҰж…ўе°ұжҳҜйҖҖжӯҘгҖӮеҰӮд»Ҡзҡ„ж•°жҚ®еә“дё–з•ҢеҸҜд»ҘиҜҙжҳҜзҷҫиҠұйҪҗж”ҫпјҢзӣ®еүҚе…Ёдё–з•Ңжңүи¶…иҝҮ400з§Қж•°жҚ®еә“пјҢеҸҜд»ҘеҲҶдёәе…ізі»еһӢе’Ңйқһе…ізі»еһӢпјҢиҝҳеҸҜд»ҘеҲҶдёәж“ҚдҪңеһӢе’ҢеҲҶжһҗеһӢпјҢиҝҷж ·дёҖжЁӘдёҖзәөеҸҜд»ҘеҲҶдёәеӣӣеӨ§зұ»пјҢиҖҢиҝӣиҖҢеҸҜд»Ҙз»ҶеҲҶжҲҗе°Ҹзұ»гҖӮд»ҠеӨ©пјҢеӣҪдә§ж•°жҚ®еә“д№ҹжӯЈеңЁеҙӣиө·пјҢиҝҷжҳҜж•°жҚ®еә“дәәжңҖеҘҪзҡ„ж—¶д»ЈгҖӮ
#### и®ӨиҜҶж—¶й—ҙ
иҝҗз”Ёж–№жі•жқҘеҠ йҖҹеӯҰд№ пјҢйҰ–е…ҲиҰҒд»Һж—¶й—ҙејҖе§ӢгҖӮе…¶е®һеңЁз ”究数жҚ®еә“ж—¶пјҢжңҖйҮҚиҰҒзҡ„дёҖ件дәӢжғ…е°ұжҳҜиҖғиҷ‘ж•°жҚ®еә“еҰӮдҪ•и®Ўз®—ж—¶й—ҙгҖӮж•°жҚ®еә“зҡ„д»»дҪ•ж—¶й—ҙйғҪйңҖиҰҒеәҰйҮҸпјҢиҖҢеңЁеҲҶеёғејҸзҺҜеўғйҮҢйқўжӣҙйңҖиҰҒе…іжіЁж—¶й—ҙгҖӮж•°жҚ®еә“дёӯйҖҡеёёеӣӣз§Қи®Ўж—¶ж–№ејҸпјҢйҖ»иҫ‘зҡ„гҖҒзү©зҗҶзҡ„гҖҒж··еҗҲзҡ„пјҢиҝҳжңүе…ЁеұҖз»ҹдёҖж—¶й’ҹTSOгҖӮж•°жҚ®еә“йңҖиҰҒи®Ўж—¶зҡ„еҺҹеӣ жңүеҫҲеӨҡпјҢеҰӮдәӢеҠЎйңҖиҰҒжҺ’еәҸпјҢMVCCйңҖиҰҒйқ ж—¶й—ҙжҺ§еҲ¶зӯүпјҢжүҖд»Ҙж—¶й—ҙеҝ…дёҚеҸҜе°‘гҖӮ
Oracleж•°жҚ®еә“жҳҜжҖҺд№Ҳи®Ўж—¶зҡ„е‘ўпјҹе…¶е®һOracleж•°жҚ®еә“дҫқйқ SMON\_SCN\_TIMEиЎЁи®Ўж—¶пјҢз»қеӨ§еӨҡж•°Oracleдҝ®еӨҚе®ҢеҗҜеҠЁж—¶йғҪдјҡеҮәзҺ°зӣёе…ій”ҷиҜҜгҖӮOracleе»әз«ӢдәҶзү©зҗҶж—¶й—ҙе’ҢUnix Timeзҡ„еҜ№з…§иЎЁпјҢеӣ жӯӨеңЁж•°жҚ®еә“еҮәж•…йҡңзҡ„ж—¶еҖҷпјҢиҝҷеј иЎЁеӨ§жҰӮзҺҮдјҡеҸ‘з”ҹдёҚдёҖиҮҙгҖӮеҶҚиҝӣдёҖжӯҘпјҢж•°жҚ®еә“еҰӮдҪ•е’Ңж“ҚдҪңзі»з»ҹжү“дәӨйҒ“зҡ„е‘ўпјҹйҖҡиҝҮи·ҹиёӘOracleиҝӣзЁӢе°ұдјҡеҸ‘зҺ°пјҢе®ғдјҡйҖҡиҝҮgettimeofdayжқҘиҺ·еҸ–ж—¶й—ҙгҖӮ
MySQLеҸҲжҳҜжҖҺд№Ҳи®Ўж—¶зҡ„е‘ўпјҹMySQLжҸҗдҫӣдәҶеҫҲеӨҡеҮҪж•°жқҘиҪ¬жҚўUnix TimeгҖӮеҰӮжһңеӨ§е®¶е…іжіЁMySQL BinlogпјҢе°ұдјҡеҸ‘зҺ°MySQLзҡ„ж—Ҙеҝ—йҮҢйқўжңүеӨ§йҮҸTimestampпјҢиҝҷдәӣе°ұжҳҜUnix TimeпјҢиҝҷжҳҜеӣ дёәMySQLеңЁдёӢйқўеј•з”ЁдәҶnowеҮҪж•°гҖӮMySQLжҳҜејҖжәҗзҡ„пјҢеӣ жӯӨжғіиҰҒдәҶи§Је·®ејӮеҸӘйңҖиҰҒжү“ејҖжәҗз Ғе°ұеҸҜд»ҘпјҢеӣ жӯӨд»ҺOracleиҪ¬еҗ‘MySQLжҳҜеҫҲе®№жҳ“зҡ„гҖӮMySQLдҪҝз”Ёеӯ—иҠӮеӯҳеӮЁTimestampпјҢиҖҢOracleеҲҷжҳҜе°ҶSCNдҪңдёәж•°жҚ®еә“еҶ…йғЁж—¶й’ҹгҖӮ
еңЁPostgreSQLйҮҢйқўпјҢUnix Timeж— еӨ„дёҚеңЁгҖӮжңүи¶Јзҡ„жҳҜеңЁPostgreSQLж–ҮжЎЈдёӯеҶҷйҒ“е®ғжүҖжңүзҡ„ж—¶й—ҙи®Ўз®—йғҪжҳҜдҪҝз”Ёе„’з•ҘеҺҶжі•и®Ўз®—зҡ„пјҢиҝҷдёӘеҺҶжі•д»Һе…¬е…ғеүҚ4713е№ҙејҖе§Ӣи®Ўж—¶пјҢзҗҶи®әдёҠеҸҜд»Ҙи®Ўз®—еҲ°жңӘжқҘд»»дҪ•дёҖеӨ©гҖӮ
#### еӨ§йҒ“иҮіз®Җ
жҺҘи§Ұж–°жҠҖжңҜж—¶пјҢеҝғзҗҶжҒҗжғ§жҳҜжңҖеӨ§зҡ„йҡңзўҚгҖӮеҪ“дҪ е…ӢжңҚдәҶеҝғзҗҶжҒҗжғ§е°ұиғңеҲ©дәҶгҖӮдә‘е’ҢжҒ©еўЁжңҖж—©з ”з©¶дәҶж•°жҚ®еә“жҳҜжҖҺд№ҲеҲқе§ӢеҢ–е’ҢеҗҜеҠЁиө·жқҘзҡ„пјҢдәҺжҳҜе°ұи·ҹиёӘе®ғпјҢжңҖеҗҺеҸ‘зҺ°OracleжҳҜйҖҡиҝҮеҲқе§ӢеҢ–иЎЁзҡ„еј•еҜјеҗҜеҠЁиө·жқҘзҡ„гҖӮиҝҷеј иЎЁжҢҮеҗ‘дәҶblock file 377пјҢеҗҺз»ӯеҶҚж·ұе…ҘжҺўзҙўиҜ»еҸ–зҡ„ж–Ү件ең°еқҖгҖӮдҪҶжҳҜе…¶е®һеңЁжңҖејҖе§Ӣзҡ„ж—¶еҖҷе°ұиғҪеӨҹзңӢеҮәиҜ»еҸ–зҡ„ж–Ү件ең°еқҖпјҢиҝҷиҜҙжҳҺеҰӮжһңжҲ‘们иғҪеӨҹи·іеҮәжҖқз»ҙжғҜжҖ§е№¶жҲҳиғңеҝғзҗҶжҒҗжғ§пјҢе°ұиғҪеӨҹжҲҳиғңеӣ°йҡҫгҖӮ
зҗҶжғідёӯзҡ„ж·ұе…Ҙжө…еҮәжҳҜдёҖз§Қз»ҸеҺҶеҚғйҡҫдёҮйҷ©гҖҒеі°еӣһи·ҜиҪ¬д№ӢеҗҺпјҢзңӢеұұиҝҳжҳҜеұұзҡ„е№іж·ЎгҖӮжңүж—¶еҖҷиғҪж„ҹеҸ—еҲ°дјҡеҝғд№Ӣж„ҸжҳҜйқһеёёйҡҫиғҪе®қиҙөзҡ„пјҢиҝҗз”Ёд№ӢеҰҷпјҢеӯҳд№ҺдёҖеҝғгҖӮжҲ‘们еә”иҜҘиҠұеҠӣж°”еҺ»з§ҜзҙҜгҖҒж·ұе…ҘгҖҒжҖқиҖғпјҢ然еҗҺжүҚиғҪдёҫйҮҚиӢҘиҪ»гҖӮ
[еҺҹж–Үй“ҫжҺҘ](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/722263%3Futm_content%3Dg_1000083045)
жң¬ж–Үдёәдә‘ж –зӨҫеҢәеҺҹеҲӣеҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
--------------
**йҳҝйҮҢе·ҙе·ҙйӣҶеӣўеүҜжҖ»иЈҒгҖҒйҳҝйҮҢдә‘жҷәиғҪж•°жҚ®еә“дәӢдёҡйғЁжҖ»иЈҒгҖҒй«ҳзә§з ”究е‘ҳжқҺйЈһйЈһпјҲйЈһеҲҖпјүгҖҒйҳҝйҮҢдә‘ж•°жҚ®еә“иө„ж·ұжҠҖжңҜ专家жҘјж–№й‘«пјҲй»„еҝ пјүд»ҘеҸҠйҳҝйҮҢдә‘ж•°жҚ®еә“жҠҖжңҜ专家еӮ…е®ҮпјҲйҪҗжңЁпјү**дёүдҪҚйҳҝйҮҢдә‘жҠҖжңҜ专家дёәеӨ§е®¶д»Ӣз»ҚдәҶжңҖж–°зҡ„йҳҝйҮҢдә‘ејҖжәҗж•°жҚ®еә“йЎ№зӣ®гҖӮ
### жқҺйЈһйЈһпјҡ
ж•°жҚ®еә“еңЁиҝҮеҺ»иҝҷд№ҲеӨҡе№ҙпјҢе°Өе…¶иҝ‘еҮ е№ҙеҸ‘еұ•еҰӮжӯӨиҝ…йҖҹзҡ„ж ёеҝғеҺҹеӣ д№ӢдёҖе°ұжҳҜејҖжәҗз”ҹжҖҒеҒҡеҮәдәҶеҫҲеӨ§иҙЎзҢ®гҖӮйҡҫд»ҘжғіиұЎеҰӮжһңжІЎжңүејҖжәҗзҡ„MySQLгҖҒPGгҖҒHBaseгҖҒMongoDBд»ҘеҸҠCassandraзӯүпјҢеҸӘжңүOracleгҖҒDB2гҖҒSQL ServerзӯүпјҢд»ҠеӨ©дё–з•ҢдјҡжҳҜд»Җд№Ҳж ·еӯҗпјҹйӮЈеҝ…然иҝҳжҳҜеҜЎеӨҙеһ„ж–ӯзҡ„еұҖйқўгҖӮеӣ дёәж ёеҝғзҡ„OLAPзі»з»ҹйҡҫд»Ҙе®һзҺ°пјҢйңҖиҰҒз»ҸиҝҮеӨ§йҮҸиҜ•й”ҷжүҚиғҪдёҚж–ӯе®Ңе–„гҖӮиҖҢејҖжәҗз”ҹжҖҒдёәж•°жҚ®еә“жҸҗдҫӣиҝҷж ·зҡ„дёҖдёӘе№іеҸ°пјҢеё®еҠ©ж•°жҚ®еә“еҝ«йҖҹиҝӯд»ЈпјҢдҪҝеҫ—ејҖжәҗж•°жҚ®еә“еҸҜд»ҘжҜ”иӮ©е•Ҷдёҡж•°жҚ®еә“зҡ„иғҪеҠӣгҖӮ
еҜ№дәҺйҳҝйҮҢиҖҢиЁҖпјҢAliSQLиҺ·еҫ—дәҶ2018е№ҙMySQLзҡ„зӨҫеҢәе…¬еҸёиҙЎзҢ®еҘ–пјҢиҝҷжҳҜеӣ дёәAliSQLеҒҡдәҶеӨ§йҮҸдјҳеҢ–пјҢжҜ”еҰӮе®һзҺ°дәҶSequenceгҖҒиЎЁзә§е№¶иЎҢеӨҚеҲ¶д»ҘеҸҠйҡҗејҸдё»й”®зӯүгҖӮиҖҢеҒҡиҝҷдәӣдјҳеҢ–зҡ„й©ұеҠЁеҠӣжҳҜйҳҝйҮҢеҶ…йғЁзҡ„дёҡеҠЎйңҖжұӮпјҢ并且еҜ№дәҺжҠҖжңҜзҡ„дјҳеҢ–еҗҺз»ӯе°ұдјҡиҙЎзҢ®еӣһејҖжәҗзӨҫеҢәгҖӮ

жңҖж–°еҸ‘еёғжҳҜи®©DRDSж”ҜжҢҒPOLARDBпјҢ并且еңЁ2020е№ҙзҡ„жҹҗдёӘж—¶й—ҙпјҢйҳҝйҮҢдә‘е°ҶдјҡејҖжәҗDRDSгҖӮDRDSе®Ңе…Ёз”ұйҳҝйҮҢиҮӘз ”пјҢе…¶дёӯеҢ…еҗ«дәҶShardingгҖҒUnique SequenceгҖҒParallel QueryгҖҒGlobal Secondry Indexд»ҘеҸҠDistributed TransactionгҖӮеёҢжңӣеӨ§е®¶иғҪеӨҹжӣҙеҠ е№ҝжіӣең°дҪҝз”ЁDRDSпјҢеҰӮжһңжңүжңәдјҡд№ҹиҙЎзҢ®жӣҙеӨҡзҡ„д»Јз ҒпјҢе°ҶDRDSеҒҡеҫ—жӣҙеҘҪгҖӮ

### жҘјж–№й‘«пјҡ
AliSQLйҖҡиҝҮж•ҲзҺҮгҖҒжҖ§иғҪгҖҒиҮӘдё»гҖҒзЁіе®ҡд»ҘеҸҠе®үе…Ёж–№йқўзҡ„дёҚж–ӯж”№иҝӣпјҢеёҢжңӣи®©дёҡеҠЎгҖҒиҝҗз»ҙгҖҒз ”еҸ‘е’ҢеҗҲдҪңдјҷдјҙйғҪиғҪеӨҹж„ҹи§үжӣҙвҖңзҲҪвҖқгҖӮ

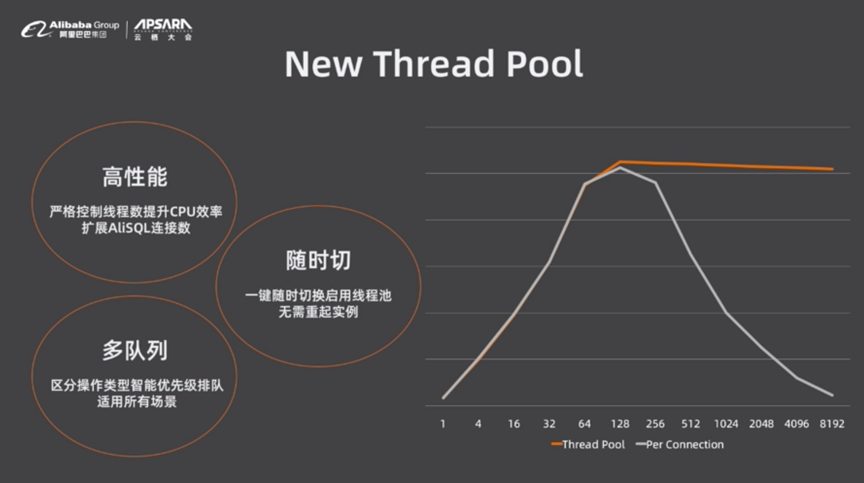
еҹәдәҺиҝҷдёӘжҖқи·ҜпјҢйҳҝйҮҢдә‘еңЁдёҖе№ҙеҚҠд№ӢеүҚе°ұе°Ҷдё»иҰҒзІҫеҠӣжҠ•е…ҘеҲ°MySQL 8.0дёҠйқўпјҢиҝҷжҳҜеӣ дёәMySQL 8.0жӣҙиғҪеӨҹж»Ўи¶ід»ҘдёҠзӣ®ж ҮгҖӮMySQL 8.0е…·жңүAutomic DDLгҖҒInstant Add ColumnгҖҒWindow Functionе’ҢTemp Engineзҡ„иғҪеҠӣгҖӮиҖҢAliSQLеңЁMySQLзҡ„еҹәзЎҖд№ӢдёҠиҝҳеҒҡдәҶжӣҙеӨҡзҡ„дјҳеҢ–пјҢжҜ”еҰӮж”ҜжҢҒдәҶTDEеҠ еҜҶе’ҢSM4еӣҪеҜҶз®—жі•пјҢ并且йҮҚж–°и®ҫи®ЎдәҶзәҝзЁӢжұ пјҢAliSQL Clusterж”ҜжҢҒдёүиҠӮзӮ№е№¶иғҪеҒҡеҲ°RTOдёә0зӯүгҖӮ

MySQLе®ҳж–№зүҲжң¬д№ҹжңүзәҝзЁӢжұ пјҢиҖҢAliSQLзәҝзЁӢжұ зҡ„еҢәеҲ«еңЁдәҺиҝһжҺҘж•°еҸҜд»ҘиҫҫеҲ°2дёҮпјҢ并且иғҪдҝқжҢҒйқһеёёе№ізЁізҡ„иҫ“еҮәгҖӮйҰ–е…ҲпјҢAliSQLдёҘж јжҺ§еҲ¶дәҶзәҝзЁӢж•°жқҘжҸҗеҚҮдәҶCPUж•ҲзҺҮпјҢеҒҡеҲ°дәҶй«ҳжҖ§иғҪгҖӮе…¶ж¬ЎпјҢAliSQLеҸҜд»ҘдёҖй”®йҡҸж—¶еҲҮжҚўеҗҜз”ЁзәҝзЁӢжұ пјҢиҖҢж— йңҖйҮҚеҗҜе®һдҫӢгҖӮжңҖеҗҺпјҢAliSQLиғҪеӨҹеҢәеҲҶж“ҚдҪңзұ»еһӢ并е®һзҺ°жҷәиғҪдјҳе…Ҳзә§жҺ’йҳҹпјҢ并йҖӮз”ЁдәҺжүҖжңүдёҡеҠЎеңәжҷҜгҖӮжҖ»д№ӢпјҢAliSQLзҡ„зәҝзЁӢжұ жҳҜе®Ңе…ЁйҮҚж–°е®һзҺ°зҡ„пјҢ并且жҖ§иғҪд№ҹдјҡи¶…еҮәжңҹжңӣгҖӮ

AliSQL ClusterеҸҜд»ҘжҖ»з»“еҮәвҖңдёүй«ҳвҖқпјҢеҚій«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёе’Ңй«ҳжҖ§иғҪгҖӮAliSQL Clusterе…·жңү99.99%зҡ„еҸҜз”ЁжҖ§пјҢдәӢеҠЎж•°жҚ®е…·жңүејәдёҖиҮҙжҖ§пјҢ并且дҪҝз”ЁдәҶPaxosжҷәиғҪ并иЎҢеҸ‘еҢ…е®һзҺ°й«ҳж•ҲеҗҢжӯҘгҖӮиҝҷж ·зҡ„вҖңдёүй«ҳвҖқдҪҝеҫ—дёҡеҠЎгҖҒиҝҗз»ҙе’Ңз ”еҸ‘йғҪжӣҙвҖңзҲҪвҖқгҖӮ
SQL OutlineжҳҜеңЁж•°жҚ®еә“зүҲжң¬еҚҮзә§гҖҒеўһеҮҸзҙўеј•гҖҒз»ҹи®ЎдҝЎжҒҜд»ҘеҸҠзЁӢеәҸеӣәеҢ–ж—¶жқҘ收йӣҶе’Ңзј–иҫ‘SQLе…ій”®и·ҜдҝЎжҒҜпјҢ并用жҢҒд№…еҢ–HintеӣәеҢ–жү§иЎҢи·Ҝеҫ„зҡ„гҖӮ
AliSQLеҹәдәҺMySQLеҒҡдәҶеҫҲеӨҡжҖ§иғҪзҡ„еўһејәпјҢе®һзҺ°дәҶеҜ№иұЎз»ҹи®ЎпјҢ并жҸҗдҫӣдәҶе®Ңе–„зҡ„жҢҮж Үе’ҢеӨҡзә§з»ҙеәҰгҖӮжҜ”еҰӮзҙўеј•гҖҒSQLз»ҹи®ЎдҝЎжҒҜйғҪиғҪеӨҹдёҖзӣ®дәҶ然пјҢеӣ жӯӨеҸҜд»ҘеҠ йҖҹеҜ№дёҡеҠЎзҡ„е“Қеә”гҖӮиҝҷд№ҹиҜҙжҳҺеңЁдёҠдә‘д№ӢеҗҺпјҢеҰӮжһңжғіиҰҒжңҚеҠЎеҘҪдёҡеҠЎпјҢиҝҳжңүеҫҲеӨҡе·ҘдҪңйңҖиҰҒеҒҡгҖӮ

AliSQLеңЁ5.6зүҲжң¬ж—¶еҒҡдәҶејҖжәҗпјҢз»ҸиҝҮжҖ»з»“д№ӢеҗҺеҸ‘зҺ°и®©е®ҳж–№еҗҲ并AliSQL 5.6иҝҷжқЎи·Ҝиө°дёҚйҖҡпјҢеӣ жӯӨд№ҹе°ҶеҜ№дәҺAliSQL 8.0иҝӣиЎҢејҖжәҗгҖӮеңЁејҖжәҗ8.0зүҲжң¬зҡ„ж—¶еҖҷдјҡеҗёж”¶5.6зүҲжң¬зҡ„з»ҸйӘҢпјҢжғіеҠһжі•жӣҙй«ҳж•Ҳең°з»ҙжҠӨAliSQLејҖжәҗйЎ№зӣ®гҖӮ
### еӮ…е®Үпјҡ
еңЁйҳҝйҮҢе·ҙе·ҙдёҡеҠЎдёӯпјҢDRDSе’ҢMySQLжҳҜзӣёдә’й…ҚеҗҲпјҢиҚЈиҫұдёҺе…ұзҡ„е…ізі»гҖӮDRDSжҳҜйҳҝйҮҢдә‘жҸҗдҫӣзҡ„дёҖдёӘжңҚеҠЎпјҢе…Ёз§°жҳҜеҲҶеёғејҸе…ізі»еһӢж•°жҚ®еә“жңҚеҠЎгҖӮDRDSеҠҹиғҪжңҖз®ҖеҚ•жҰӮжӢ¬е°ұжҳҜеҲҶеә“еҲҶиЎЁпјҢз”ЁжҲ·еҸҜд»Ҙд»ҺDRDSжҺҘеҸЈдёҠеҲӣе»әдёҖдёӘиЎЁпјҢеҸӘйңҖиҰҒеңЁе»әиЎЁж—¶жҢҮе®ҡеҲҶеә“еҲҶиЎЁзҡ„ж–№ејҸпјҢеү©дёӢзҡ„е·ҘдҪңз”ұDRDSжҗһе®ҡпјҢз”ЁжҲ·еҸҜд»ҘеғҸж“ҚдҪңжҷ®йҖҡиЎЁдёҖж ·ж“ҚдҪңDRDSпјҢдёҡеҠЎеұӮж— йңҖеҶҚеҒҡеҲҶеёғејҸзӣёе…ізҡ„иҖғиҷ‘гҖӮйҷӨжӯӨд№ӢеӨ–пјҢDRDSиҝҳжҸҗдҫӣдәҶиҜ»еҶҷеҲҶзҰ»гҖҒеј№жҖ§жү©е®№зӯүиғҪеҠӣгҖӮ
дёӢеӣҫжҳҜе…ёеһӢзҡ„DRDSйғЁзҪІжӢ“жү‘пјҢеӣҫе·Ұдҫ§еҲҶдёәдёӨеұӮпјҢServerеұӮеҢ…еҗ«еӨҡдёӘж— зҠ¶жҖҒзҡ„DRDSиҠӮзӮ№пјҢDRDSиҠӮзӮ№еҗ‘Load BalancerжұҮжҠҘеҝғи·іпјҢеҰӮжһңеҮәзҺ°е®•жңәпјҢLoad Balancerе°ұдјҡе°ҶжөҒйҮҸиҝҒ移еҲ°е…¶д»–иҠӮзӮ№дёҠпјҢдҝқиҜҒйӣҶзҫӨй«ҳеҸҜз”ЁгҖӮеӯҳеӮЁеұӮеҸҜиғҪдҪҝз”ЁRDSгҖҒPOLARDBз”ҡиҮіеҲ—ејҸеӯҳеӮЁгҖӮжҖ»дҪ“жқҘиҜҙпјҢжҹҘиҜўдјҡеңЁServerеұӮиў«иҪ¬еҢ–жҲҗжү§иЎҢи®ЎеҲ’пјҢеңЁеӯҳеӮЁеұӮе…·дҪ“жү§иЎҢ并иҝ”еӣһз»ҷз”ЁжҲ·гҖӮеӣҫеҸідҫ§жҳҜDRDSзҡ„еҲҶжһҗеһӢеҸӘиҜ»е®һдҫӢпјҢйҮҢйқўеҢ…еҗ«еӨҡдёӘMPP WorkerгҖӮеҜ№дәҺеӨҚжқӮSQLпјҢеҚ•еҸ°жңәеҷЁеҸҜиғҪж— жі•е®ҢжҲҗи®Ўз®—пјҢжӯӨж—¶е°ұдјҡе°ҶSQLзҡ„жү§иЎҢи®ЎеҲ’еҸ‘еҫҖMPPйӣҶзҫӨжқҘи®Ўз®—пјҢ并且дёҚдјҡеҜ№дё»еә“дә§з”ҹеҪұе“ҚгҖӮ

DRDSзҡ„жһ¶жһ„жј”иҝӣз»ҸеҺҶеҫҲй•ҝзҡ„иҝҮзЁӢпјҢжңҖејҖе§ӢеҸӘжғізқҖеҰӮдҪ•е°ҶеҲҶеә“еҲҶиЎЁеҒҡеҲ°жһҒиҮҙгҖӮйҡҸзқҖDRDSдёҠдә‘пјҢдјҒдёҡзә§еңәжҷҜжӣҙеҠ дё°еҜҢпјҢйҒҮеҲ°дәҶи¶ҠжқҘи¶ҠеӨҚжқӮзҡ„SQLпјҢйңҖжұӮжҺЁеҠЁзқҖDRDSжһ¶жһ„зҡ„йҮҚжһ„гҖӮеҰӮд»Ҡзҡ„DRDSжһ¶жһ„жңҖеҲҶдёәдәҶзҪ‘з»ңгҖҒдјҳеҢ–еҷЁе’Ңжү§иЎҢеҷЁгҖӮ
SQLиҝӣе…ҘDRDSйҰ–е…Ҳдјҡз»ҸиҝҮParserеҸҳжҲҗASTпјҢд№ӢеҗҺз»ҸиҝҮValidatorиҝӣиЎҢйӘҢиҜҒпјҢйҖҡиҝҮйӘҢиҜҒд№ӢеҗҺиҪ¬еҢ–жҲҗжңҖжңҙзҙ зҡ„йҖ»иҫ‘жү§иЎҢи®ЎеҲ’пјҢеңЁз»ҸиҝҮSQL Rewriterе’ҢPlan EnumeratorеҸҳдёәжңҖдјҳзҡ„зү©зҗҶжү§иЎҢи®ЎеҲ’пјҢ并дәӨз»ҷExecutorиҝӣиЎҢжү§иЎҢгҖӮ

еҜ№дәҺжҹҘиҜўдјҳеҢ–еҷЁиҖҢиЁҖпјҢSQL RewriterдјҡеҜ№йҖ»иҫ‘жү§иЎҢи®ЎеҲ’иҝӣиЎҢж”№еҶҷпјҢе®ғжҳҜеҹәдәҺеҗҜеҸ‘ејҸ规еҲҷзҡ„дјҳеҢ–еҷЁпјҢд№ҹиў«з§°дёәRBOгҖӮSQL Rewriterдјҡе®һзҺ°еӯҗжҹҘиҜўзҡ„еҺ»е…іиҒ”еҢ–пјҢ并еҒҡз®—еӯҗTransposeпјҢиҖҢдёәдәҶе®һзҺ°жһҒиҮҙдёӢжҺЁпјҢSQL RewriterиҝҳеҒҡдәҶJoin ClusteringгҖӮ

жҹҘиҜўдјҳеҢ–еҷЁзҡ„第дәҢжӯҘжҳҜPlan EnumeratorеҒҡзҡ„зү©зҗҶдјҳеҢ–пјҢдё»иҰҒиҙҹиҙЈJoint Recorderе’Ңз®—жі•йҖүжӢ©гҖӮDRDSйҮҮз”Ёзҡ„жңҖдёәйҖҡз”Ёзҡ„Volcano/CascadesдјҳеҢ–еҷЁпјҢз»ҸиҝҮиҝҷдёҖиҝҮзЁӢдјҡжӢҝеҲ°зҗҶи®әжңҖдјҳзҡ„зү©зҗҶжү§иЎҢи®ЎеҲ’гҖӮ
DRDSжҹҘиҜўдјҳеҢ–еҷЁзҡ„дјҳеҢ–иҝҮзЁӢжҳҜеҹәдәҺд»Јд»·зҡ„пјҢиҖҢд»Јд»·жңҖеҲқи®Ўз®—жқҘиҮӘдәҺз»ҹи®ЎдҝЎжҒҜпјҢиҝҷдәӣз»ҹи®ЎдҝЎжҒҜе°Ҷдјҡ计算代价并еёҰе…Ҙз®—еӯҗCost ModelдёӯиҝӣиҖҢи®Ўз®—жү§иЎҢи®ЎеҲ’зҡ„жҖ»дҪ“д»Јд»·гҖӮ

жҹҘиҜўдјҳеҢ–ж— жі•зһ¬й—ҙе®ҢжҲҗпјҢеӣ жӯӨйңҖиҰҒз®ЎзҗҶжү§иЎҢи®ЎеҲ’пјҢеҸҜд»Ҙе°Ҷжү§иЎҢи®ЎеҲ’еӯҳеӮЁдёӢжқҘеҠ д»ҘеӨҚз”ЁпјҢжҸҗеҚҮдјҳеҢ–йҖҹеәҰгҖӮDRDSдҪҝз”ЁдәҶеҹәдәҺChunkзҡ„жү§иЎҢеҷЁпјҢдҪҝеҫ—жҜҸдёӘз®—еӯҗдёҖж¬ЎжҖ§дә§еҮәдёҖжү№ж•°жҚ®гҖӮеңЁChunkйҮҢйқўж•°жҚ®жҢүеҲ—еӯҳеӮЁпјҢеҲҶжһҗйҖҹеәҰжӣҙеҝ«пјҢи®Ўз®—ж•ҲзҺҮжӣҙй«ҳгҖӮParallel QueryйғЁеҲҶдјҡеҗҜеҠЁеӨҡдёӘWorkerиҝӣзЁӢ并еҜ№з»“жһңеҠ д»ҘжұҮжҖ»гҖӮ
并иЎҢеӨ„зҗҶ--MySQLеҸ‘еұ•зҡ„и¶ӢеҠҝеҸҠдёӯеӣҪжң¬ең°еә”з”Ёе®һи·ө
-------------------------
дёӯеӣҪи®Ўз®—жңәиЎҢдёҡеҚҸдјҡејҖжәҗж•°жҚ®еә“专委дјҡдјҡй•ҝпјҢжһҒж•°дә‘иҲҹCEOе‘ЁеҪҰдјҹдёәеӨ§е®¶еҲҶдә«дәҶMySQLзҡ„еҹәзЎҖжһ¶жһ„е’ҢArkDBзҡ„并иЎҢеҢ–е®һи·өгҖӮ
#### MySQLеҹәзЎҖжһ¶жһ„
MySQL Serverеј•ж“Һзҡ„еҘҪеӨ„еңЁдәҺеӨ§е®¶еҸҜд»ҘеҹәдәҺжӯӨе®һзҺ°иҮӘе·ұзҡ„ж•°жҚ®еә“гҖӮзӣ®еүҚпјҢMySQLе·Із»ҸеҸ‘еёғдәҶ8.0зүҲжң¬пјҢеҸҜд»ҘзңӢеҲ°иҝҷд№ҲеӨҡе№ҙMySQLе®ҳж–№е…¶е®һдёҖзӣҙеңЁиҝӣжӯҘгҖӮMySQLеңЁе№¶иЎҢе’ҢжҸҗй«ҳйҖҹеәҰж–№йқўеҒҡдәҶеҫҲеӨҡе·ҘдҪңгҖӮеңЁеј•ж“Һж–№йқўпјҢжңҖејҖе§ӢMySQLдҪҝз”Ёзҡ„жҳҜMyISAMпјҢзҺ°еңЁй»ҳи®ӨжҳҜInnoDBпјҢиҝҷжҳҜеӣ дёәMyISAMзҡ„并иЎҢеӨ„зҗҶиғҪеҠӣдёҚеӨҹеҘҪпјҢиҖҢInnoDBе®һзҺ°дәҶиЎҢзә§й”ҒпјҢиҝҳж”ҜжҢҒдәҶMVCCпјҢеўһеҠ дәҶ并иЎҢиҜ»еҶҷзҡ„иғҪеҠӣгҖӮеңЁеј•ж“ҺеұӮйқўпјҢд»ҺMyISAMиҝҮжёЎеҲ°InnoDBжҳҜдёҖдёӘе·ЁеӨ§зҡ„иҝӣжӯҘгҖӮ

#### InnoDBзҡ„еҸ‘еұ•
InnoDBд№ҹеңЁMySQL 5.6гҖҒ5.7гҖҒ8.0зҡ„жј”иҝӣиҝҮзЁӢдёӯеҸ‘з”ҹдәҶеҫҲеӨ§еҸҳеҢ–гҖӮInnoDBжңҖж—©йҮҮз”Ёе…ұдә«иЎЁз©әй—ҙпјҢдёҖе ҶиЎЁж”ҫеңЁдёҖдёӘж–Ү件йҮҢпјҢж•ҲзҺҮжһҒе·®гҖӮеҗҺжқҘInnoDBйҮҮз”ЁзӢ¬з«ӢиЎЁз©әй—ҙпјҢдёҖдёӘиЎЁж”ҫеңЁдёҖдёӘж–Ү件йҮҢпјҢеҶҚеҗҺжқҘжј”еҸҳеҲ°дёҖдёӘиЎЁеҲҶжҲҗеӨҡдёӘж–Ү件гҖӮиҝҷж ·зҡ„еҸҳеҢ–жҳҜеёҢжңӣжҸҗеҚҮж•°жҚ®зҡ„еӨ„зҗҶйҖҹеәҰгҖӮиҖҢеҲ°зҺ°еңЁдёәжӯўпјҢMySQL 8.0иҝҳжҳҜиҗҪеңЁеҚ•еҸ°жңҚеҠЎеҷЁдёҠпјҢеҸӘиғҪеҲ©з”ЁеҚ•еҸ°жңәеҷЁзҡ„и®Ўз®—е’ҢеӯҳеӮЁеҠҹиғҪгҖӮ
зҺ°еңЁпјҢMySQLзҡ„иҝӣжӯҘе…¶е®һе°ұжҳҜInnoDBзҡ„иҝӣжӯҘпјҢиҝҷеңЁдёҖдәӣеҸӮж•°зҡ„еҸҳеҢ–дёҠжңүжүҖдҪ“зҺ°гҖӮжӯӨеӨ–пјҢInno DBд№ҹеҜ№UndoиҝӣиЎҢдәҶдјҳеҢ–пјҢ5.7д№ӢеүҚibdataж–Ү件дёӯеҢ…еҗ«Undoж®өпјҢеҜјиҮҙж–Ү件з©әй—ҙж— жі•еӣһ收гҖӮ5.7зүҲжң¬д№ӢеҗҺпјҢUndoж®өд»Һibdataж–Ү件дёӯзӢ¬з«ӢеҮәжқҘпјҢе°ұеҸҜд»Ҙе®һзҺ°е№¶иЎҢиҜ»еҶҷгҖӮ
еҫҲеӨҡе№ҙзҡ„ж—¶й—ҙпјҢMySQLжү©еұ•йғҪжҳҜеҹәдәҺReplicationзҡ„гҖӮзҺ°еңЁпјҢMySQLе®ҳж–№д№ҹеҒҡдәҶйӣҶзҫӨеҢ–зҡ„еӨ„зҗҶгҖӮ5.6д№ӢеүҚжҳҜеҚ•зәҝзЁӢеӨҚеҲ¶пјҢ5.7зүҲжң¬дёӯеўһеҠ ж”ҜжҢҒWrite Setзә§еҲ«зҡ„并иЎҢеӨҚеҲ¶гҖӮ
жҖ»з»“иҖҢиЁҖпјҢMySQLж•°жҚ®еә“иҮӘиә«д№ҹеңЁдёҚж–ӯиҝӣжӯҘпјҢеҲ°еҰӮд»ҠMySQL 8.0зүҲжң¬е·Із»ҸеҒҡеҫ—еҫҲдёҚй”ҷдәҶпјҢиғҪеӨҹж”ҜжҢҒеӨҚжқӮжҹҘиҜўе№¶дё”ж•ҲзҺҮдёҚй”ҷгҖӮ
#### 并иЎҢеҢ–еңЁArkDBзҡ„е®һи·ө
иҷҪ然MySQLе®ҳж–№иҝ‘еҮ е№ҙеҫҲеҠӘеҠӣпјҢдҪҶжҳҜдҫқж—§еӯҳеңЁдёҖдәӣдёҚи¶ід№ӢеӨ„пјҢеӣ жӯӨArkDBд№ҹеёҢжңӣиғҪеӨҹеҹәдәҺMySQLеҒҡеҮәдёҖдәӣиҙЎзҢ®гҖӮArkDBеңЁMySQLзҡ„еҹәзЎҖдёҠеҒҡдәҶеӨ§йҮҸ并иЎҢеҢ–е®һи·өгҖӮеңЁеј•ж“ҺеұӮпјҢArkDBе®һзҺ°дәҶи®Ўз®—е’ҢеӯҳеӮЁеҲҶзҰ»пјҢйҖҡиҝҮеҲҶеёғејҸеӯҳеӮЁе®һзҺ°дәҶ并иЎҢиҜ»еҶҷдјҳеҢ–гҖӮеңЁйӣҶзҫӨеұӮпјҢArkDBе®һзҺ°дәҶиҮӘйҖӮеә”еӨҡзәҝзЁӢзү©зҗҶеӨҚеҲ¶пјҢжһҒеӨ§ең°жҸҗеҚҮдәҶж•°жҚ®еӨҚеҲ¶ж•ҲзҺҮгҖӮеңЁжҺҘе…ҘеұӮпјҢArkDBе®һзҺ°дәҶеҜ№з§°ејҸдёӯй—ҙ件йӣҶзҫӨи·Ҝз”ұпјҢжҳҜжҺҘе…ҘеұӮжҲҗдёәж— зҠ¶жҖҒзҡ„пјҢиғҪеӨҹжүҝжӢ…еӨ§и§„жЁЎзҡ„и®ҝй—®еә”з”ЁгҖӮеңЁй«ҳеҸҜз”Ёж–№йқўпјҢArkDBе®һзҺ°дәҶеҺ»дёӯеҝғеҢ–еҲҶеёғејҸе“Ёе…өе®ҲжҠӨйӣҶзҫӨгҖӮеңЁиҝҒ移еұӮпјҢArkDBе®һзҺ°дәҶеӨҡжәҗз«ҜеӨҡйҖҡйҒ“еӨҡз»“жһ„е®һж—¶еҗҢжӯҘпјҢеҸҜд»Ҙе®һзҺ°зІҫзЎ®еҲ°иЎҢзә§зҡ„иҝҗиЎҢгҖӮ

ArkDBеңЁеј•ж“ҺеұӮж—ўеҹәдәҺзҙўеј•ж ‘еӯҳеӮЁж•°жҚ®пјҢеҸҲе°Ҷж•°жҚ®еҲҶзүҮең°еӯҳеӮЁеңЁзҙўеј•з»“жһ„дёӯгҖӮеҹәдәҺеҲҶеёғејҸеӯҳеӮЁе®һзҺ°дәҶ并иЎҢиҜ»еҶҷдјҳеҢ–пјҢеҹәдәҺзҙўеј•з»“жһ„е®һзҺ°ж•°жҚ®е№¶иЎҢеҲҶзүҮпјҢеҹәдәҺеҜ№иұЎеӯҳеӮЁе®һзҺ°е№¶еҸ‘иҜ»еҶҷж”ҜжҢҒпјҢеҹәдәҺеҲҶеёғејҸеӯҳеӮЁж”ҜжҢҒдәҶеӨҡеүҜжң¬е’Ңеҝ«з…§еӨҮд»ҪгҖӮArkDBеңЁйӣҶзҫӨеұӮе®һзҺ°дәҶиҮӘйҖӮеә”еӨҡзәҝзЁӢзү©зҗҶеӨҚеҲ¶гҖҒзү©зҗҶж—Ҙеҝ—зҡ„еӨҡзәҝзЁӢиҜ»еҶҷпјҢ并еҹәдәҺд»Һеә“зҡ„еӨҡзүҲжң¬жҺ§еҲ¶е®һзҺ°дәҶеӨҡиҠӮзӮ№ж— й”ҒеҗҢжӯҘгҖӮArkDBеңЁиҝҒ移еұӮе……еҲҶеҲ©з”ЁдәҶеҗ„з§Қ并иЎҢж–№ејҸпјҢд»ҺеүҚз«ҜеӨҡжәҗз«ҜпјҢеҲ°еӨҡйҖҡйҒ“еӨ„зҗҶе®һзҺ°дәҶеңЁж•°жҚ®жү“йҖҡиҝҮзЁӢдёӯе°ҪйҮҸжҸҗеҚҮж•ҲзҺҮе’Ңдј иҫ“йҖҹеәҰгҖӮ
PostgreSQL 12 иҝҺжқҘж–°жңәйҒҮ
-------------------
PostgresдёӯеӣҪзӨҫеҢәпјҢеӨӘйҳіеЎ”科жҠҖеҲӣе§ӢдәәиөөжҢҜе№ідёәеӨ§е®¶еҲҶдә«дәҶPostgreSQL 12еёҰжқҘзҡ„ж–°жңәйҒҮгҖӮ
зӣ®еүҚпјҢPostgreSQL 12зҡ„ејҖеҸ‘йҖҹеәҰйқһеёёеҝ«пјҢд»Ҡе№ҙ5жңҲд»ҪеҸ‘еёғBeta 1зүҲжң¬пјҢ6жңҲд»ҪеҸ‘еёғBeta 2зүҲжң¬пјҢ8жңҲд»ҪеҸ‘еёғBeta 3зүҲжң¬пјҢ9жңҲд»ҪеҸ‘еёғBeta 4зүҲжң¬пјҢ并且жңүеҸҜиғҪжҲҗдёәдәҶжңҖеҗҺдёҖдёӘBetaзүҲжң¬пјҢиҝҷж„Ҹе‘ізқҖPostgreSQL 12еҚіе°ҶжӯЈејҸеҸ‘еёғгҖӮиҷҪ然жҜҸдёӘBetaзүҲжң¬еҜ№еӨ§е®¶иҖҢиЁҖеҸҜиғҪеҸӘжҳҜдёҖдёӘе°ҸзүҲжң¬пјҢдҪҶеҜ№дәҺPostgreSQLзӨҫеҢәиҖҢиЁҖпјҢеҚҙж„Ҹе‘ізқҖеӨ§йҮҸдҝ®ж”№пјҢжҜ”еҰӮеңЁPostgreSQL 12зҡ„Beta 3зүҲжң¬дёӯдҝ®ж”№дәҶ2дёӘе®үе…Ёissue并且дҝ®ж”№дәҶ40дёӘе°ҸBugгҖӮжҲӘжӯўеҲ°зӣ®еүҚпјҢPostgreSQL 12зҡ„BetaзүҲжң¬жҖ»е…ұеҒҡдәҶ161йЎ№дҝ®ж”№пјҢж•ҙдҪ“иҖҢиЁҖдҝ®ж”№йқһеёёеӨ§пјҢеҫҲеӨҡжҠҖжңҜзҡ„дҝ®ж”№е’Ңе®Ңе–„е°ҶдёәPostgreSQLеёҰжқҘеҫҲеӨ§зҡ„жҸҗеҚҮгҖӮиҖҢдё”еңЁжңӘжқҘпјҢPostgreSQLеҹәжң¬дёҠжҜҸдёӘеӯЈеәҰйғҪдјҡжҺЁеҮәдёҖдёӘе°ҸзүҲжң¬пјҢжҜҸе№ҙеҸ‘еёғдёҖдёӘеӨ§зүҲжң¬гҖӮ

еҰӮд»ҠPostgreSQLзӯүејҖжәҗж•°жҚ®еә“жӯЈеңЁйқўеҜ№ж–°зҡ„жңәйҒҮпјҢйҷӨдәҶж•°жҚ®еә“йўҶеҹҹзҡ„еӣҪдә§еҢ–д№Ӣи·ҜпјҢдё–з•Ңеҗ„ең°ж–№йғҪејҖе§ӢдәҶвҖңеҺ»IOEвҖқгҖӮиҖҢеӣҙз»•PostgreSQLеҸҜд»ҘеҒҡеҫҲеӨҡеҲӣж–°пјҢдјҒдёҡеҸҜд»ҘеҹәдәҺPostgreSQLејҖеҸ‘дә§е“ҒпјҢз”ҡиҮіе°ҶPostgreSQLе’ҢеҗҺеҸ°дә§е“Ғжү“еҢ…й”Җе”®еҲ°еӣҪеӨ–пјҢејҖеҸ‘иҖ…иҝҳеҸҜд»ҘеҹәдәҺPostgreSQLејҖеҸ‘ж–°зҡ„ж•°жҚ®еә“гҖӮиҖҢеҜ№дәҺеӨӘйҳіеЎ”иҝҷж ·зҡ„е…¬еҸёпјҢд№ҹеҸҜд»ҘжӣҙеҘҪең°жҸҗдҫӣPostgreSQLжҠҖжңҜжңҚеҠЎгҖӮ
д№ӢжүҖд»ҘйҖүжӢ©PostgreSQLпјҢйҰ–е…ҲжҳҜеӣ дёәе®ғеҺҶеҸІжӮ д№…гҖӮPostgreSQLеңЁдә’иҒ”зҪ‘дә§з”ҹд№ӢеүҚе°ұе·Із»ҸеӯҳеңЁдәҶпјҢе…¶еҲӣе§ӢдәәMichael StonebrakerиҺ·еҫ—дәҶеӣҫзҒөеҘ–гҖӮд»ҺDB-Enginesзҡ„ж•°жҚ®жқҘзңӢпјҢPostgreSQLеңЁдёҖи·ҜйЈҷеҚҮгҖӮ并且PostgreSQLе’ҢSQL Serverзӯүдё»жөҒж•°жҚ®еә“еҗҢе®—еҗҢжәҗпјҢйғҪжҳҜд»ҺIngresиЎҚз”ҹеҮәжқҘзҡ„гҖӮ
д»ҺжҠҖжңҜзҡ„и§’еәҰжқҘзңӢпјҢPostgreSQLд№ҹе…·жңүеҫҲеӨҡзҡ„дјҳзӮ№гҖӮ第дёҖзӮ№е°ұжҳҜ并иЎҢпјҢиҝҷдёҖиғҪеҠӣеңЁPostgreSQL 10ж—¶ејҖе§ӢжҲҗзҶҹпјҢеңЁPostgreSQL 11ж—¶еҸ‘жҢҘеҫ—ж·Ӣжј“е°ҪиҮҙгҖӮPostgreSQLзҡ„并иЎҢиғҪеҠӣдё»иҰҒдҪ“зҺ°еңЁе№¶иЎҢжү«жҸҸгҖҒ并иЎҢиҝһжҺҘд»ҘеҸҠ并иЎҢAppendдёүдёӘж–№йқўгҖӮ第дәҢзӮ№жҳҜзЁіе®ҡжҖ§пјҢд»ҺзүҲжң¬иҝӯд»Јзҡ„иҝҮзЁӢеҸҜд»ҘзңӢеҮәпјҢPostgreSQLжҳҜз»ҸиҝҮеҚғй”ӨзҷҫзӮјзҡ„гҖӮ第дёүзӮ№жҳҜе®үе…ЁпјҢеӨ§е®¶еҸҜиғҪеҜ№дәҺејҖжәҗж•°жҚ®еә“зҡ„е®үе…ЁжҖ§еӯҳеңЁдёҖдәӣиҜҜи§ЈпјҢе…¶е®һPostgreSQLжҳҜйқһеёёе®үе…Ёзҡ„пјҢе®ғжҸҗдҫӣдәҶи®ӨиҜҒж–№ејҸгҖҒйҖҡйҒ“еҠ еҜҶе’Ңж•°жҚ®еҠ еҜҶдёҖеҘ—е®Ңж•ҙзҡ„е®үе…ЁжңәеҲ¶пјҢеҹәжң¬еҸҜд»Ҙи®ӨдёәOracleжңүеӨҡе®үе…ЁпјҢPostgreSQLе°ұжңүеӨҡе®үе…ЁгҖӮ第еӣӣзӮ№жҳҜеҠҹиғҪејәеӨ§пјҢPostgreSQLеңЁеҠҹиғҪдёҠиҝҳжңүи¶…иҝҮOracleзҡ„ең°ж–№пјҢжҜ”еҰӮзҙўеј•жӣҙдё°еҜҢгҖҒи®Ўж—¶еҠҹиғҪжӣҙејәеӨ§гҖҒеҲҶеёғејҸж•°д»“еҠҹиғҪжӣҙеҠ жҲҗзҶҹгҖӮ
жӯӨеӨ–пјҢд№ӢжүҖд»ҘиҜҙPostgreSQLдјҡжңүеҫҲеӨ§жңәйҒҮзҡ„еҸҰеӨ–дёҖдёӘеҺҹеӣ е°ұжҳҜе®ғзҡ„ејҖжәҗеҚҸи®®пјҢеӨ§е®¶еҸҜд»ҘйҡҸж„ҸдҪҝз”ЁгҖҒжӢ·иҙқгҖҒеҲҶеҸ‘пјҢиҖҢдё”еҸҜд»ҘйҡҸдҫҝдҝ®ж”№пјҢжІЎжңүд»»дҪ•зүҲжқғйЈҺйҷ©е’Ңдё“еҲ©йЈҺйҷ©гҖӮеӣ жӯӨпјҢеҰӮд»ҠеҫҲеӨҡж•°жҚ®еә“йғҪжҳҜеҹәдәҺPostgreSQLпјҢд№ҹжӯЈжҳҜеӣ дёәе®ғзҡ„ејҖж”ҫеҚҸи®®е’ҢејҖж”ҫзӯ–з•ҘпјҢжҸҗдҫӣдәҶеҫҲеӨ§зҡ„е•ҶжңәгҖӮ
е®һи·өе·Із»ҸиҜҒжҳҺпјҢеҹәдәҺPostgreSQLдёҚд»…иҜһз”ҹеҮәеҫҲеӨҡе…¬еҸёпјҢд№ҹиҜһз”ҹеҮәеҫҲеӨҡзҡ„дә§е“ҒпјҢжҜ”еҰӮзӢ¬и§’е…Ҫе…¬еҸёGreenplumгҖӮжӯӨеӨ–пјҢPostgreSQLе…·жңүејәеӨ§зҡ„з”ҹжҖҒеңҲпјҢеӣҪйҷ…зӨҫеҢәзҡ„еҮқиҒҡеҠӣе’ҢејҖеҸ‘иғҪеҠӣиғҪеӨҹзўҫеҺӢдёҖеҲҮпјҢPostgreSQLйҮҮз”Ёзҡ„жҳҜејҖж”ҫејҸдҪ“зі»з»“жһ„пјҢд№ҹе°ұжҳҜжҸ’件结жһ„пјҢејҖеҸ‘еҗҺеҸҜд»ҘеҫҲе®№жҳ“ең°еҸҚйҰҲзӨҫеҢәгҖӮиҖҢдё”PostgreSQLзҡ„д»Јз Ғе’ҢиҙЎзҢ®зҡ„иҙЁйҮҸйғҪйқһеёёй«ҳгҖӮ
ејҖжәҗж•°жҚ®еә“еңЁе№іе®ү科жҠҖзҡ„еә”з”Ёе®һи·ө
---------------
е№іе®үдә‘ж•°жҚ®еә“еҸҠеӯҳеӮЁдә§е“ҒеӣўйҳҹжҖ»з»ҸзҗҶжұӘжҙӢдёәеӨ§е®¶еҲҶдә«дәҶе№іе®ү科жҠҖзҡ„ејҖжәҗж•°жҚ®еә“йҖүеһӢеҺҹеҲҷд»ҘеҸҠеә”з”Ёе®һи·өгҖӮ
#### дёәдҪ•дҪҝз”ЁејҖжәҗж•°жҚ®еә“
дҪңдёәдёҖдёӘз®ЎзҗҶзқҖж•°дёҮдәҝиө„дә§зҡ„йҮ‘иһҚзҺӢеӣҪпјҢе№іе®үдёәдҪ•иҰҒеј•е…ҘејҖжәҗж•°жҚ®еә“пјҹе…¶е®һпјҢжҠҖжңҜж°ёиҝңжҳҜжңҚеҠЎдәҺдёҡеҠЎе’ҢеңәжҷҜзҡ„гҖӮе№іе®үеңЁ2013е№ҙеҒҡе®Ң银иЎҢж–°ж ёеҝғзҡ„вҖңжҚўеҝғжүӢжңҜвҖқд№ӢеҗҺпјҢејҖе§ӢиҖғиҷ‘еҗ‘дә’иҒ”зҪ‘гҖҒж•°еӯ—еҢ–иҪ¬еһӢгҖӮеңЁиҝҷдёҖиҝҮзЁӢдёӯпјҢдёҖж–№йқўйңҖиҰҒй«ҳжҖ§иғҪгҖҒй«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёзҡ„зі»з»ҹжһ¶жһ„пјҢеҸҰдёҖж–№йқўйңҖиҰҒеҝ«йҖҹең°жҚ•жҚүеёӮеңәйңҖжұӮпјҢ并еҝ«йҖҹиҪ¬жҚўдёәITйңҖжұӮејҖеҸ‘еҮәдә§е“ҒпјҢеҶҚжҠ•е…ҘеёӮеңәиҝӣиЎҢйӘҢиҜҒгҖӮеҰӮжһңдҪҝз”Ёдј з»ҹзҡ„е•Ҷдёҡж•°жҚ®еә“пјҢеңЁж•ҸжҚ·ең°жҚ•жҚүеёӮеңәйңҖжұӮд№ӢеҗҺеҝ«йҖҹе°Ҷдә§е“ҒжҺЁеҮәеёӮеңәж–№йқўе°ұжҳҫеҫ—жҚүиҘҹи§ҒиӮҳпјҢиҝҷжҳҜе№іе®үеј•е…ҘејҖжәҗж•°жҚ®еә“зҡ„еҺҹеӣ д№ӢдёҖгҖӮ
еңЁж•ҸжҚ·ж–№йқўпјҢеҫ®жңҚеҠЎи§ЈеҶідәҶеҚ•дҪ“жһ¶жһ„зҡ„еҫҲеӨҡй—®йўҳгҖӮ第дёҖзӮ№пјҢеҚ•дҪ“жһ¶жһ„зүөдёҖеҸ‘иҖҢеҠЁе…Ёиә«пјҢдҝ®ж”№йЈҺйҷ©еҫҲеӨ§пјҢејҖеҸ‘е’ҢжөӢиҜ•е‘ЁжңҹеҫҲй•ҝпјҢж–°еҠҹиғҪзҡ„дёҠзәҝйҖҹеәҰеҫҲж…ўгҖӮ第дәҢзӮ№пјҢеңЁеҚ•дҪ“жһ¶жһ„дёӯпјҢдёәдәҶжү©е®№жҹҗдёӘ组件жҲ–жЁЎеқ—йңҖиҰҒеҜ№ж•ҙдёӘзі»з»ҹиҝӣиЎҢжү©е®№пјҢиҝҷжҳҜдёҖз§ҚжөӘиҙ№пјҢиҖҢеҫ®жңҚеҠЎжһ¶жһ„еҲҷеҸҜд»Ҙй’ҲеҜ№жҹҗдёҖдёӘжңҚеҠЎиҝӣиЎҢжү©е®№гҖӮ第дёүзӮ№пјҢеҫ®жңҚеҠЎеҸҜд»Ҙж»Ўи¶ідёҚеҗҢжҠҖжңҜж ҲејҖеҸ‘дәәе‘ҳзҡ„йңҖиҰҒпјҢдёҚеҗҢеӣўйҳҹеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„жҠҖжңҜж ҲиҝӣиЎҢејҖеҸ‘гҖӮ
еҰӮд»ҠпјҢдёҖз§Қж•°жҚ®еә“йҡҫд»ҘйҖӮеә”жүҖжңүдёҡеҠЎеңәжҷҜзҡ„йңҖиҰҒпјҢйңҖиҰҒдҫқйқ ж··еҗҲжҢҒд№…еҢ–ж•°жҚ®еә“жқҘи§ЈеҶідёҚеҗҢж•°жҚ®еӯҳеӮЁйңҖжұӮгҖӮOne For Allж—¶д»Је·Із»ҸиҝҮеҺ»пјҢж•°жҚ®еә“еҚідҫҝеҒҡеҲ°вҖңеӨ§иҖҢе…ЁвҖқпјҢд№ҹйҡҫд»Ҙж¶өзӣ–жүҖжңүеңәжҷҜпјҢзҺ°еңЁиҰҒеҒҡзҡ„жҳҜвҖңBest FitвҖқпјҢй’ҲеҜ№жҹҗдёҖз§ҚдёҡеҠЎе’ҢиҙҹиҪҪпјҢдҪҝз”ЁжңҖйҖӮеҗҲзҡ„ж•°жҚ®еә“гҖӮжӯӨеӨ–пјҢдј з»ҹзҡ„е•Ҷдёҡж•°жҚ®еә“иҝҮдәҺжІүйҮҚпјҢиҖҢејҖжәҗж•°жҚ®еә“еҲҷйқһеёёиҪ»йҮҸгҖӮиҝҷдәӣд№ҹжҳҜеј•е…Ҙе’ҢжҺЁе№ҝејҖжәҗж•°жҚ®еә“зҡ„еҺҹеӣ гҖӮжӯӨеӨ–пјҢеҚідҫҝдҪҝз”ЁејҖжәҗж•°жҚ®еә“пјҢд№ҹеҫҲйҡҫж»Ўи¶іжүҖжңүдёҡеҠЎзҡ„йңҖжұӮпјҢйңҖиҰҒиғҪеӨҹеҹәдәҺејҖжәҗж•°жҚ®еә“иҝӣиЎҢдәҢж¬ЎејҖеҸ‘пјҢиҖҢиҝҷд№ҹжҳҜе•Ҷдёҡж•°жҚ®еә“ж— жі•е®һзҺ°зҡ„гҖӮ
#### ејҖжәҗ并дёҚж„Ҹе‘ізқҖе…Қиҙ№
еј•е…ҘејҖжәҗж•°жҚ®еә“жҳҜеҝ…然и¶ӢеҠҝпјҢдҪҶејҖжәҗ并дёҚж„Ҹе‘ізқҖе…Қиҙ№гҖӮиҷҪ然LicenseжҳҜе…Қиҙ№зҡ„пјҢдҪҶиҝҳйңҖиҰҒд»ҳеҮәе…¶д»–жҲҗжң¬гҖӮжҺҢжҸЎејҖжәҗжҠҖжңҜйңҖиҰҒдёҖдёӘиҝҮзЁӢпјҢйңҖиҰҒеӯҰд№ жҲҗжң¬пјӣд»Һе•ҶдёҡеҢ–дә§е“ҒеҲ°ејҖжәҗж•°жҚ®еә“зҡ„иҝҒ移йңҖиҰҒиҝҒ移жҲҗжң¬пјӣиҝҒ移е®ҢжҲҗд№ӢеҗҺиҝҳеҸҜиғҪдјҡеўһеҠ иҝҗз»ҙжҲҗжң¬д»ҘеҸҠйЈҺйҷ©пјҢиҝҷдәӣжҲҗжң¬йғҪйңҖиҰҒеңЁеј•е…ҘејҖжәҗж•°жҚ®еә“зҡ„ж—¶еҖҷиҖғиҷ‘гҖӮ
#### еҰӮдҪ•йҖүжӢ©ејҖжәҗж•°жҚ®еә“
йҰ–е…ҲиҰҒзңӢдёҡеҠЎеңәжҷҜпјҢеӣ дёәжҠҖжңҜжҳҜжңҚеҠЎдәҺдёҡеҠЎеңәжҷҜйңҖжұӮзҡ„гҖӮеҶҚзңӢжҳҜеҗҰжңүеҗҲйҖӮзҡ„жӣҝд»Јж–№жЎҲпјҢжҜ”еҰӮPostgreSQLе°ұжҳҜOracleжҜ”иҫғеҗҲйҖӮзҡ„жӣҝд»Јж–№жЎҲгҖӮиҝҳиҰҒиҖғиҷ‘зҺ°жңүејҖеҸ‘дәәе‘ҳзҡ„жҠҖиғҪпјҢеҗҰеҲҷдјҡйқһеёёз—ӣиӢҰгҖӮжӯӨеӨ–пјҢйңҖиҰҒиҖғиҷ‘зҺ°жңүж•°жҚ®еә“зҡ„иҙҹиҪҪжЁЎејҸгҖҒејҖжәҗзӨҫеҢәзҡ„жҙ»и·ғеәҰгҖҒеёӮеңәд»Ҫйўқд»ҘеҸҠиЎҢдёҡзҹҘеҗҚеәҰгҖӮеҸҰеӨ–иҝҳйңҖиҰҒе…іжіЁејҖеҸ‘иҜӯиЁҖе’Ңж•°жҚ®еә“зұ»еһӢпјҢйңҖиҰҒдёҺеӣўйҳҹеҸҠдёҡеҠЎеңәжҷҜйҖӮй…ҚгҖӮд№ҹйңҖиҰҒе…іжіЁж•°жҚ®еә“жҠҖжңҜзҡ„еҸ‘еұ•и¶ӢеҠҝпјҢжҜ”еҰӮеӯҳеӮЁе’Ңи®Ўз®—еҲҶзҰ»гҖҒдә‘еҺҹз”ҹгҖҒеҲҶеёғејҸзӯүгҖӮжңҖеҗҺдёҖзӮ№е°ұжҳҜдёҚиҰҒдҪҝз”ЁеӨӘеӨҡејҖжәҗдә§е“ҒпјҢжҜҸзұ»йҖүжӢ©дёҖз§ҚеҚіеҸҜгҖӮ
#### ејҖжәҗж•°жҚ®еә“еј•е…Ҙе’Ңеә”з”Ёзӯ–з•Ҙ
еј•е…Ҙе’Ңеә”з”ЁејҖжәҗж•°жҚ®еә“д№ҹжңүдёҖдәӣзӯ–з•ҘпјҡеҢәеҲ«зҺ°жңүе’Ңж–°е»әзҡ„зі»з»ҹпјҢйҖүжӢ©дёҚеҗҢзӯ–з•ҘпјҢеҸҜд»ҘйҷҚдҪҺиҝҒ移йЈҺйҷ©е’ҢжҲҗжң¬гҖӮе°Ҷж•°жҚ®еә“иҝӣиЎҢеҲҶзұ»пјҢе…Ҳд»ҺдёҚйҮҚиҰҒзҡ„еә“ејҖе§ӢиҝҒ移пјҢз§ҜзҙҜз»ҸйӘҢпјҢжңҖе°ҸеҢ–йЈҺйҷ©гҖӮеҲ’еҲҶдёҚеҗҢзҡ„дёҡеҠЎжқЎзәҝпјҢе…Ҳд»ҺиҰҒжұӮдёҚй«ҳзҡ„дёҡеҠЎжқЎзәҝдёӢжүӢгҖӮе®һзҺ°ж•°жҚ®еә“дә§е“Ғеј•е…ҘиҝҮзЁӢдёӯзҡ„OwnerжңәеҲ¶пјҢеҒҡеҲ°вҖңжңҜдёҡжңүдё“ж”»вҖқгҖӮеҲ¶е®ҡж•°жҚ®еә“жһ¶жһ„гҖҒиҝҗиҗҘе’ҢејҖеҸ‘зҡ„жҢҮеҚ—жүӢеҶҢгҖӮиҝҳйңҖиҰҒеҜ№иҝҗиҗҘгҖҒејҖеҸ‘е’ҢDBAиҝӣиЎҢеҹ№и®ӯгҖӮй’ҲеҜ№йҒҮеҲ°зҡ„й—®йўҳжҢҒз»ӯиҝӣиЎҢжһ¶жһ„дјҳеҢ–пјҢз§ҜзҙҜејҖеҸ‘е’ҢиҝҗиҗҘз»ҸйӘҢгҖӮиҝҳйңҖиҰҒйҖҡиҝҮеӯҰд№ жәҗд»Јз ҒжқҘеҝ«йҖҹиҝҪиёӘеҲ°ж №жң¬еҺҹеӣ пјҢ并йҳІжӯўй—®йўҳзҡ„еҶҚж¬ЎеҮәзҺ°гҖӮеҰӮжһңзҺ°жңүеҠҹиғҪж»Ўи¶ідёҚдәҶдёҡеҠЎйңҖжұӮпјҢеҸҜд»Ҙз»„е»әз ”еҸ‘еӣўйҳҹиҝӣиЎҢдәҢж¬ЎејҖеҸ‘гҖӮжңҖеҗҺдёҖзӮ№е°ұжҳҜжӢҘжҠұејҖжәҗзӨҫеҢәпјҢе»әз«ӢиҮӘе·ұзҡ„з”ҹжҖҒпјҢе®һзҺ°дёҺејҖжәҗзӨҫеҢәзҡ„иүҜеҘҪдә’еҠЁпјҢиҝӣиҖҢе®һзҺ°еҸҢиөўгҖӮ
#### ж•°жҚ®еә“йҖүеһӢзӯ–з•Ҙ
еңЁе…ізі»еһӢж•°жҚ®еә“ж–№йқўпјҢеӣ дёәе№іе®үеұһдәҺйҮ‘иһҚе…¬еҸёпјҢжүҖд»ҘеҸӘиҰҒж¶үеҸҠеҲ°иө„йҮ‘дәӨжҳ“йғҪйңҖиҰҒжһҒй«ҳзҡ„ж•°жҚ®е®үе…ЁжҖ§е’ҢдёҖиҮҙжҖ§д»ҘеҸҠ7\*24е°Ҹж—¶дёҚй—ҙж–ӯзҡ„жңҚеҠЎгҖӮдёҚж¶үеҸҠиө„йҮ‘дәӨжҳ“зҡ„еҲҷеҸҜд»Ҙж №жҚ®е…·дҪ“дёҡеҠЎеңәжҷҜйҖүжӢ©гҖӮеңЁеҲҶеёғејҸе…ізі»еһӢж•°жҚ®еә“ж–№йқўпјҢжңүдёӨз§Қж•°жҚ®еә“йҖүеһӢвҖ”вҖ”иҮӘз ”зҡ„PDRSе’ҢејҖжәҗзҡ„TiDBгҖӮ
#### ејҖжәҗж•°жҚ®еә“жҺЁе№ҝжҲҗжһң
зҺ°еңЁе№іе®үжҖ»е…ұжңүе°Ҷиҝ‘дёүдёҮдёӘж•°жҚ®еә“е®һдҫӢпјҢе…¶дёӯOracleеҚ жҜ”йқһеёёдҪҺпјҢRedisжңҖеӨҡпјҢPostgreSQLж¬ЎеӨҡпјҢд№ҹжңүдёҖдәӣMongoDBе’ҢMySQLе®һдҫӢгҖӮ
#### еҸ‘еұ•и·Ҝеҫ„
жҖ»з»“иҖҢиЁҖпјҢж•°жҚ®еә“зҡ„еҸ‘еұ•и·Ҝеҫ„жңӘжқҘе°Ҷдјҡж”ҜжҢҒе®№еҷЁеҢ–йғЁзҪІпјҢе’ҢK8SжӣҙеҘҪең°з»“еҗҲпјҢз”ҡиҮіе®һзҺ°ServerlessеҢ–пјҢд№ҹдјҡеҮәзҺ°жӣҙеӨҡзҡ„иҮӘз ”ж•°жҚ®еә“е’ҢеҹәдәҺејҖжәҗж•°жҚ®еә“з ”еҸ‘ж–°зҡ„еҠҹиғҪгҖӮжңҖеҗҺдёҖзӮ№пјҢе°ұжҳҜеңЁдә‘дёҠеҸҜд»Ҙ收йӣҶеӨ§йҮҸиҝҗз»ҙж•°жҚ®пјҢиҝӣиҖҢе®һзҺ°AIOpsгҖӮ
дј з»ҹж•°жҚ®еә“еҲ°ејҖжәҗж•°жҚ®еә“иҝҒ移зҡ„е·Ҙе…·еҢ–жөҒзЁӢ
-------------------
иҝӘжҖқжқ°DSGе…¬еҸёеҲӣе§ӢдәәгҖҒжҖ»иЈҒйҹ©е®ҸеқӨдёәеӨ§е®¶еҲҶдә«дәҶдј з»ҹж•°жҚ®еә“еҲ°ејҖжәҗж•°жҚ®еә“иҝҒ移зҡ„е·Ҙе…·еҢ–жөҒзЁӢгҖӮ
зҺ°еңЁе·Із»ҸеҲ°дәҶж•°жҚ®еә“еҺҶеҸІзҡ„дёҖдёӘжӢҗзӮ№пјҢеҗ„дёӘдјҒдёҡзә·зә·д»Һй«ҳд»·еҖјзҡ„е•Ҷдёҡж•°жҚ®еә“иө°еҗ‘иҮӘз”ұзҡ„ејҖжәҗж•°жҚ®еә“пјҢ并且混еҗҲжһ¶жһ„ж—¶д»Је·Із»ҸжқҘдёҙпјҢеҗ„з§Қж•°жҚ®жӯЈеңЁеҝ«йҖҹең°жөҒеҠЁгҖӮ
DSGйңҖиҰҒжңҚеҠЎдәҺеҗ„з§ҚиЎҢдёҡзҡ„е®ўжҲ·пјҢиҖҢ他们зҡ„зі»з»ҹеҚғе·®дёҮеҲ«гҖӮDSGжӢҘжңүе®Ңе…ЁиҮӘз ”зҡ„жҠҖжңҜпјҢеӣ жӯӨиғҪеӨҹеҝ«йҖҹи·ҹиҝӣеҗ„з§ҚжҠҖжңҜзҡ„еҸҳеҢ–гҖӮDSGзҡ„ж ёеҝғжҠҖжңҜдјҳеҠҝеңЁдәҺеҮ д№ҺиғҪеӨҹж¶өзӣ–жүҖжңүдё»жөҒж•°жҚ®еә“ж—Ҙеҝ—зҡ„е®һж—¶еҲҶжһҗжҠҖжңҜпјҢ并且еҲӣйҖ дәҶдёҖз§Қз»ҹдёҖзҡ„ж•°жҚ®еә“ж•°жҚ®иЎЁиҫҫиҜӯиЁҖпјҢеӣ жӯӨDSGеҸҜд»ҘдҪҝз”Ёиҫғе°‘зҡ„з ”еҸ‘иө„жәҗеҲӣйҖ еҫҲеӨ§зҡ„д»·еҖјгҖӮзӣ®еүҚеҜ№дәҺдёӯеӣҪиҖҢиЁҖпјҢеңЁж•°жҚ®еә“ж–№йқўжңүе·ЁеӨ§зҡ„еҺӢеҠӣе’ҢйңҖжұӮпјҢжӯЈеӣ жӯӨжүҚй©ұеҠЁзқҖж•°жҚ®еә“жҠҖжңҜиө°еҗ‘жһҒиҮҙгҖӮйҳҝйҮҢеҰӮжӯӨпјҢDSGд№ҹеҰӮжӯӨгҖӮ
DSGе…·жңүејәеӨ§зҡ„ж•°жҚ®еӨ„зҗҶе’ҢеӨҚеҲ¶иғҪеҠӣпјҢеҜ№дәҺOracleзҡ„иҝҒ移иҖҢиЁҖпјҢжңәйҒҮеңЁдәҺPostgreSQLпјҢе®һи·өд№ҹиҜҒжҳҺдәҶPostgreSQLгҖӮеҗ„дёӘдјҒдёҡйғҪйңҖиҰҒеҒҡиҝҒ移пјҢиҖҢеҜ№дәҺе·ҘзЁӢдәәе‘ҳиҖҢиЁҖпјҢеҸҜд»ҘиҜҙвҖңе…өиҙөзҘһйҖҹвҖқпјҢеӣ жӯӨDSGе’ҢйҳҝйҮҢеҗҲдҪңеҜ№Oracleзҡ„иҝҒ移方法и®әеҒҡдәҶж•ҙдҪ“жўізҗҶгҖӮOracleиҝҒ移зҡ„е®ўжҲ·з—ӣзӮ№дё»иҰҒжңү6зӮ№пјҡ
> пҒ¬ жәҗж•°жҚ®еә“еҜ№иұЎе…ізі»гҖҒдҫқиө–е…ізі»еӨҚжқӮпјӣВ
> пҒ¬ ж•°жҚ®еә“е’Ңеә”з”Ёж”№йҖ е·ҘдҪңйҮҸдёҚжҳҺзЎ®пјӣВ
> пҒ¬ зӣ®ж Үеә“и§„ж јдёҚжҳҺзЎ®пјӣВ
> пҒ¬ иҝҒ移еүІжҺҘдёҡеҠЎеҒңжңәж—¶й—ҙзҹӯпјӣВ
> пҒ¬ йңҖиҰҒеҗҢжӯҘиҝӣиЎҢж•°жҚ®еҜ№жҜ”йӘҢиҜҒпјӣВ
> пҒ¬ йңҖиҰҒж•°жҚ®еӣһжөҒдҝқиҜҒе®үе…Ёе’Ңеә”з”ЁеӣһеҲҮгҖӮ
еҜ№дәҺOracleиҝҒ移зҡ„и§ЈеҶіж–№жЎҲиҖҢиЁҖпјҢйҰ–е…ҲиҰҒйҖҡиҝҮйҮҮйӣҶе’ҢиҜ„дј°жҸҗеүҚеҸ‘зҺ°е®ҡдҪҚй—®йўҳпјҢдёҚжҳҜеңЁиҝҒ移зҡ„ж—¶еҖҷжүҚеҸ‘зҺ°й—®йўҳпјҢиҖҢеә”иҜҘжҳҜеңЁиҝҒ移д№ӢеүҚпјҢе°ұе®ҢжҲҗеҜ№ж•°жҚ®еә“еҜ№иұЎе…ізі»д»ҘеҸҠеә”з”Ёе’Ңеә“д№Ӣй—ҙе…ізі»зҡ„жўізҗҶпјҢеҸ‘зҺ°еҸҜиғҪеӯҳеңЁзҡ„й—®йўҳ并дҪңеҮә规еҲ’гҖӮе…¶ж¬ЎиҰҒеҒҡиҮӘеҠЁе…је®№жҖ§иҜҶеҲ«е’ҢиҪ¬жҚўпјҢиҮӘеҠЁең°еҸ‘зҺ°дёҚе…је®№зҡ„еҜ№иұЎпјҢ并иҮӘеҠЁжўізҗҶж•°жҚ®еә“еҜ№иұЎд№Ӣй—ҙзҡ„е…ізі»пјҢд»ҺеӨҙеҲ°е°ҫиҮӘеҠЁең°з”ҹжҲҗе®Ңж•ҙзҡ„иҝҒ移жҠҘе‘ҠгҖӮиҝҷж ·дёҖжқҘпјҢз”ЁжҲ·е°ұиғҪеӨҹзҹҘйҒ“иҮӘе·ұеә”иҜҘиҙҹиҙЈд»Җд№ҲпјҢDSGеә”иҜҘиҙҹиҙЈд»Җд№ҲгҖӮжңҖеҗҺиҝҳеҸҜд»Ҙе®һзҺ°й«ҳж•ҲдҪҺе№Іжү°зҡ„еўһйҮҸеҗҢжӯҘе’Ңж•°жҚ®е®һж—¶еҜ№жҜ”пјҢDSGеҸҜд»Ҙеё®еҠ©е®ўжҲ·д»ҘжҜҸе°Ҹж—¶300GеҲ°500Gзҡ„йҖҹеәҰиҝӣиЎҢж•°жҚ®еә“иҝҒ移пјҢ并е®һзҺ°еҝ«йҖҹйӘҢиҜҒгҖӮ
йҳҝйҮҢжҺЁеҮәдәҶADAMи®ЎеҲ’пјҢе°Ҷж•ҙдёӘж•°жҚ®еә“е’Ңеә”з”ЁиҝҒ移зҡ„жөҒзЁӢйғҪе®ҡд№үеҫ—йқһеёёжё…жҷ°гҖӮADAMжҸҗдҫӣдәҶеҠҹиғҪејәеӨ§зҡ„йҮҮйӣҶгҖҒз”»еғҸгҖҒиҜ„дј°гҖҒж”№йҖ д»ҘеҸҠиҝҒ移系з»ҹгҖӮADAMзҡ„жҷәиғҪз”»еғҸзі»з»ҹиғҪеӨҹдёәз”ЁжҲ·е®ўи§Ӯең°иҝӣиЎҢOracleж•°жҚ®еә“з”»еғҸпјҢеҲҶжһҗе…¶зү№жҖ§гҖҒжҖ§иғҪгҖҒе®№йҮҸд»ҘеҸҠеӨ–йғЁдҫқиө–зӯү并д»ҘеӣҫеҪўеҢ–ж–№ејҸеұ•зҺ°еҮәжқҘгҖӮADAMзҡ„жҷәиғҪиҜ„дј°зі»з»ҹиғҪеӨҹеҲҶжһҗж•°жҚ®еә“еҜ№иұЎд»ҘеҸҠSQLзҡ„е…је®№жҖ§пјҢиҜҶеҲ«йЈҺйҷ©SQLпјҢе°ҶPLSQLиҪ¬жҲҗJavaд»ҘеҸҠиҮӘеҠЁеҜ№ж•°жҚ®еә“еҜ№иұЎиҝӣиЎҢе…је®№жҖ§иҪ¬жҚўгҖӮADAMзҡ„жҷәиғҪж”№йҖ зі»з»ҹеҲҷдјҡдёәз”ЁжҲ·жҸҗдҫӣдёҖдёӘж•°жҚ®еә“жҠҘе‘ҠпјҢ并йҖҡиҝҮд»ҝзңҹдёәз”ЁжҲ·жҸҗдҫӣж•°жҚ®еә“ж”№йҖ е»әи®®гҖӮ

еҪ“ADAMзҡ„е·ҘдҪңе®ҢжҲҗд№ӢеҗҺпјҢDSGе°ұиҙҹиҙЈжү“йҖҡж•°жҚ®иҝҒ移зҡ„жңҖеҗҺдёҖе…¬йҮҢдәҶгҖӮDSGжҸҗдҫӣдәҶдёҖдёӘйқһеёёејәеӨ§гҖҒе®Ңж•ҙзҡ„ж•°жҚ®еә“иҝҒ移е·Ҙе…·пјҢе®һзҺ°дәҶд»ҘADAMиҝҒ移计еҲ’дёәж ёеҝғзҡ„е®Ңж•ҙж–№жі•и®әпјҢжү“йҖҡдәҶж•°жҚ®иҝҒ移зҡ„жңҖеҗҺдёҖе…¬йҮҢгҖӮDSGеҸҜд»Ҙе®һзҺ°еңәжҷҜеҢ–гҖҒиҮӘеҠЁеҢ–гҖҒжөҒзЁӢеҢ–зҡ„ж•°жҚ®е…ЁйҮҸиҝҒ移гҖҒеўһйҮҸиҝҒ移гҖҒж•°жҚ®ж ЎйӘҢгҖҒж•°жҚ®дҝ®жӯЈзӯүпјҢеё®еҠ©з”ЁжҲ·иҪ»жқҫгҖҒй«ҳж•Ҳең°иҝҒ移еҲ°дә‘дёҠжҲ–иҖ…POLARDBдёҖдҪ“жңәзӯүгҖӮ
DSGе’ҢADAMзҡ„ж ёеҝғиғҪеҠӣз»“еҗҲиө·жқҘе°ұиғҪеӨҹеҪўжҲҗOracleиҝҒ移жҷәиғҪе…Ёй“ҫи·Ҝи§ЈеҶіж–№жЎҲпјҢ并且еңЁеӣҪеҶ…зҡ„еҫҲеӨҡе®ўжҲ·дјҒдёҡдёӯе·Із»ҸиҗҪең°гҖӮиҝҷд№ҲеӨҡе№ҙжқҘпјҢDSGдёҖзӣҙеңЁж·ұиҖ•ж•°жҚ®иҝҒ移方йқўзҡ„еә•еұӮжҠҖжңҜгҖӮиҖҢдё”DSG for ADAMж·ұеәҰйӣҶжҲҗдәҶйҳҝйҮҢдә‘зҡ„жҠҖжңҜпјҢе®һзҺ°дәҶж•°жҚ®иҝҒ移гҖҒж•°жҚ®жҜ”еҜ№зӯүиҝҮзЁӢзҡ„еҸҜи§ҶеҢ–гҖӮжӯӨеӨ–пјҢDSG for ADAMж•°жҚ®еә“иҝҒ移方жЎҲеҜ№дәҺжӯЈеёёдёҡеҠЎзҡ„е№Іжү°жһҒе°ҸпјҢ并且еҸҜд»ҘеңЁдёӯй—ҙзҠ¶жҖҒгҖҒдә‘дёҠдә‘дёӢзҺҜеўғдёӯйғЁзҪІгҖӮдёәдәҶжү“ж¶Ҳе®ўжҲ·еҜ№дәҺж•°жҚ®еә“иҝҒ移зҡ„з–‘иҷ‘пјҢDSGиҝҳжҸҗдҫӣдәҶе®Ңе–„зҡ„ж•°жҚ®еӣһжөҒеҠҹиғҪгҖӮ

DSGжӢҘжңүзңҹжӯЈзҡ„еә•еұӮжҠҖжңҜпјҢеӣ жӯӨеҸҜд»Ҙе’ҢйҳҝйҮҢдә‘дёҖиө·жҺЁеҮәжӣҙеӨҡзҡ„дә§е“Ғе’Ңзӣёе…ізҡ„жңҚеҠЎпјҢжҜ”еҰӮеҠ е…ҘETLеҠҹиғҪеўһејәOracleиҝҒ移еӨ§и„‘пјҢж”ҜжҢҒblob to oidзӯүжӣҙеӨҡзұ»еһӢж–№жЎҲпјҢејӮжһ„еңЁзәҝDDLиҪ¬жҚўиғҪеҠӣпјҢеҠ ејәиҝҒ移жҢҮеҜјиҜ„дј°иғҪеҠӣпјҢж”ҜжҢҒPOLARDBгҖҒADBзӯүжӣҙеӨҡе…Ёж–°зҡ„зӣ®ж Үж•°жҚ®еә“зӯүгҖӮ
DSGзӣёдҝЎжңӘжқҘжҳҜејҖжәҗе’ҢPostgreSQLзҡ„ж—¶д»ЈпјҢOracleиў«еҸ–д»Јзҡ„йҖҹеәҰеҸҜиғҪйқһеёёеҝ«гҖӮиҖҢдё”еӣҪ家д№ҹжҸҗеҮәдәҶиҪҜ件еӣҪдә§еҢ–зҡ„иҰҒжұӮпјҢPostgreSQLдёәж ёеҝғзҡ„ж•°жҚ®еә“еҫҲеҸҜиғҪжҳҜдёҖдёӘзӘҒз ҙеҸЈпјҢеӣ жӯӨеҜ№дәҺдҝЎжҒҜжһ¶жһ„зҡ„з®ЎзҗҶдәәе‘ҳиҖҢиЁҖеә”иҜҘжҠ“зҙ§иЎҢеҠЁгҖӮ
ж•°жҚ®иҝҒ移иғҪеҠӣеҸӘжҳҜDSGзҡ„дёҖйғЁеҲҶпјҢDSGеңЁж•°жҚ®еӨҮд»ҪгҖҒе®№зҒҫгҖҒйӣҶжҲҗе’ҢжұҮйӣҶзӯүж–№йқўд№ҹйқһеёёејәеӨ§пјҢDSGиғҪеӨҹйҖӮеә”еҗ„з§Қеҗ„ж ·зҡ„ејӮжһ„ж•°жҚ®еә“пјҢ并且еҸҜд»ҘеңЁж•°жҚ®йҮҮйӣҶе’Ңе®һж–ҪиҝҮзЁӢдёӯиҝӣиЎҢиҪ¬жҚўпјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·иҺ·еҫ—ж•°жҚ®иҝҒ移зҡ„иҮӘз”ұгҖӮ
дј з»ҹж•°жҚ®еә“DBAеҲ°ејҖжәҗзҡ„жҠҖиғҪе’ҢеҝғзҗҶеҲҮжҚў
-------------------
дә‘е’ҢжҒ©еўЁеҲӣе§ӢдәәпјҢACOUGзӣ–еӣҪејәд»ҺеӨ©йҒ“й…¬еӢӨгҖҒи®ӨиҜҶж—¶й—ҙе’ҢеӨ§йҒ“иҮіз®ҖдёүдёӘж–№йқўеҲҶдә«дәҶDBAзҡ„еӯҰд№ жҺўзҙўд№Ӣи·ҜгҖӮ
зҺ°еңЁжҳҜдёҖдёӘвҖңзӣёеҗ‘иҖҢиЎҢвҖқзҡ„ж—¶д»ЈпјҢж— и®әеӨ§е®¶еҰӮдҪ•и®Ёи®әOracleпјҢдҪҶжҳҜжІЎжңүдёҖдёӘж•°жҚ®еә“ж•ўиҜҙиҮӘе·ұи¶…иҝҮдәҶOracleпјҢиҖҢйғҪеңЁеӯҰд№ е’ҢиҝҪиө¶Oracleзҡ„зү№жҖ§гҖӮдҪңдёәжҠҖжңҜдәәпјҢж— и®әжӣҫз»ҸзҶҹжӮүд»Җд№ҲжҠҖжңҜпјҢеңЁиҝҷдёӘеҝ«йҖҹеҸҳйқ©зҡ„ж—¶д»ЈпјҢйғҪдјҡйқўдёҙеӯҰд№ зҡ„жҢ‘жҲҳпјҢйғҪдјҡж„ҹеҲ°з„Ұиҷ‘гҖӮеҰӮд»ҠпјҢйҡҸзқҖж•°жҚ®еә“жҠҖжңҜзҡ„йЈһйҖҹеҸ‘еұ•пјҢDBAеә”иҜҘиҝӣиЎҢвҖңжҲҳз•ҘиҪ¬з§»вҖқгҖӮ
#### еӨ©йҒ“й…¬еӢӨ
ж— и®әеҜ№дәҺзЁӢеәҸе‘ҳиҝҳжҳҜDBAиҖҢиЁҖпјҢеӯҰд№ ж–№жі•еҸҜд»ҘеҲҶдёә6жӯҘгҖӮ第дёҖзӮ№е°ұжҳҜжү“еҘҪең°еҹәпјҢвҖңдёәеұұд№қд»һпјҢе§ӢдәҺеһ’еңҹвҖқпјҢеӯҰд№ д»»дҪ•жҠҖжңҜе°ҶеҹәзЎҖжү“зүўйғҪжҳҜеүҚжҸҗпјҢиҝҷж ·жүҚиғҪзҒөжҙ»иҝҗз”ЁиҝҷдәӣжҠҖжңҜи§ЈеҶізҺ°е®һдёӯйҒҮеҲ°зҡ„еӣ°йҡҫгҖӮ第дәҢзӮ№жҳҜеӯҰдјҡжҖқиҖғпјҢеҫҲеӨҡдәәиҷҪ然еӯҰд№ дәҶеҫҲеӨҡзҹҘиҜҶпјҢдҪҶжҳҜжІЎжңүзӢ¬з«ӢжҖқиҖғзҡ„ж„ҸиҜҶпјҢеңЁеӯҰд№ иҝҮзЁӢдёӯдёҖе®ҡиҰҒеӯҰдјҡиҮӘе·ұи®ҫй—®гҖҒиҮӘе·ұи§Јзӯ”пјҢиҝҷж ·зҡ„еҺҶзЁӢеҸҜд»ҘдҝғиҝӣиҮӘе·ұжҲҗй•ҝгҖӮ第дёүзӮ№жҳҜжҺҢжҸЎж–№жі•пјҢжҖ»жңүдёҖз§Қж–№жі•еҸҜд»Ҙеё®еҠ©дҪ еҠ еҝ«еӯҰд№ йҖҹеәҰпјҢе…¶дёӯжңҖз»ҸжөҺзҡ„ж–№жі•е°ұжҳҜвҖңз”ұзӮ№еҸҠйқўпјҢз”ұжө…е…Ҙж·ұвҖқпјҢжҠ“дҪҸйҒҮеҲ°зҡ„д»»дҪ•дёҖдёӘй—®йўҳпјҢж·ұ究еҲ°жәҗз ҒеұӮпјҢиҝҷж ·з”ұзҹҘиҜҶзӮ№еҲ°зәҝеҶҚеҲ°йқўиҝһеңЁдёҖиө·гҖӮ第еӣӣзӮ№жҳҜе…»жҲҗд№ жғҜпјҢеҜ№дәҺDBAиҖҢиЁҖпјҢдёҘи°ЁжҳҜйқһеёёйҮҚиҰҒзҡ„пјҢд»»дҪ•дёҖдёӘз–ҸеҝҪйғҪеҸҜиғҪеҜјиҮҙзҒҫйҡҫгҖӮ第дә”зӮ№жҳҜе®һи·өдҝ®жӯЈпјҢжңҖжңүеҠ©дәҺдёӘдәәжҲҗй•ҝзҡ„жҳҜй«ҳеҺӢзҺҜеўғпјҢйҖҡиҝҮе®һи·өжқҘйӘҢиҜҒзҹҘиҜҶдҪ“зі»гҖӮжңҖеҗҺдёҖзӮ№е°ұжҳҜиҮ»дәҺиҮіе–„пјҢиө°иҝҮеҚғеұұдёҮж°ҙпјҢжңҖеҗҺеҫ—д»ҘвҖңи§Ғеҫ®зҹҘи‘—пјҢеӨ§йҒ“иҮіз®ҖвҖқпјҢеҸҜд»ҘиҪ»иҖҢжҳ“дёҫең°и§ЈеҶіеӣ°жү°еҲ«дәәе·Ід№…зҡ„й—®йўҳгҖӮ

жҖ»з»“дәҶдёҖдёӘеӯҰд№ е…¬ејҸпјҡ**е…ҙи¶Ј+еӢӨеҘӢ+еқҡжҢҒ+ж–№жі•вүҲжҲҗеҠҹгҖӮ**йҰ–е…ҲжҳҜе…ҙи¶ЈпјҢе…ҙи¶ЈжҳҜжңҖеҘҪзҡ„иҖҒеёҲпјҢйҷӨдәҶз—ҙиҝ·дәҺжҠҖжңҜзҡ„дәәпјҢеӨ§йғЁеҲҶдәәеңЁж·ұе…ҘеӯҰд№ ж—¶йғҪдјҡж„ҹеҲ°жһҜзҮҘгҖӮеӣ жӯӨеңЁеӯҰд№ ж—¶пјҢжңҖеҘҪзҡ„ж–№ејҸжҳҜжүҫеҲ°е…ҙи¶ЈпјҢ然еҗҺеҹ№е…»гҖҒе‘өжҠӨе…ҙи¶ЈпјҢйҒҮеҲ°жҢ«жҠҳгҖҒжү“еҮ»ж—¶дёҚиҰҒж”ҫејғгҖӮе…¶ж¬ЎжҳҜеӢӨеҘӢпјҢжүҖжңүеҒҡеҮәеҚ“и¶ҠжҲҗз»©зҡ„дәәйғҪжҳҜеӢӨеҘӢзҡ„гҖӮ第дёүзӮ№е°ұжҳҜеқҡжҢҒдёҚжҮҲпјҢдёҚиҰҒйў‘з№Ғең°и°ғж•ҙж–№еҗ‘гҖӮ第еӣӣзӮ№е°ұжҳҜжүҫеҲ°йҖӮеҗҲзҡ„ж–№жі•гҖӮжңүдәҶиҝҷдәӣжқЎд»¶е°ұзәҰзӯүдәҺжҲҗеҠҹпјҢеҚідҪҝдёҚдёҖе®ҡзңҹжӯЈиғҪеӨҹеҒҡеҲ°дё–дәәзңӢеҲ°зҡ„жҲҗеҠҹпјҢдҪҶеҸҜд»Ҙж— ж„§дәҺеҝғгҖӮ
еңЁиҝҷдёӘж—¶д»ЈпјҢеӯҰд№ зҡ„йҖҹеәҰж…ўе°ұжҳҜйҖҖжӯҘгҖӮеҰӮд»Ҡзҡ„ж•°жҚ®еә“дё–з•ҢеҸҜд»ҘиҜҙжҳҜзҷҫиҠұйҪҗж”ҫпјҢзӣ®еүҚе…Ёдё–з•Ңжңүи¶…иҝҮ400з§Қж•°жҚ®еә“пјҢеҸҜд»ҘеҲҶдёәе…ізі»еһӢе’Ңйқһе…ізі»еһӢпјҢиҝҳеҸҜд»ҘеҲҶдёәж“ҚдҪңеһӢе’ҢеҲҶжһҗеһӢпјҢиҝҷж ·дёҖжЁӘдёҖзәөеҸҜд»ҘеҲҶдёәеӣӣеӨ§зұ»пјҢиҖҢиҝӣиҖҢеҸҜд»Ҙз»ҶеҲҶжҲҗе°Ҹзұ»гҖӮд»ҠеӨ©пјҢеӣҪдә§ж•°жҚ®еә“д№ҹжӯЈеңЁеҙӣиө·пјҢиҝҷжҳҜж•°жҚ®еә“дәәжңҖеҘҪзҡ„ж—¶д»ЈгҖӮ
#### и®ӨиҜҶж—¶й—ҙ
иҝҗз”Ёж–№жі•жқҘеҠ йҖҹеӯҰд№ пјҢйҰ–е…ҲиҰҒд»Һж—¶й—ҙејҖе§ӢгҖӮе…¶е®һеңЁз ”究数жҚ®еә“ж—¶пјҢжңҖйҮҚиҰҒзҡ„дёҖ件дәӢжғ…е°ұжҳҜиҖғиҷ‘ж•°жҚ®еә“еҰӮдҪ•и®Ўз®—ж—¶й—ҙгҖӮж•°жҚ®еә“зҡ„д»»дҪ•ж—¶й—ҙйғҪйңҖиҰҒеәҰйҮҸпјҢиҖҢеңЁеҲҶеёғејҸзҺҜеўғйҮҢйқўжӣҙйңҖиҰҒе…іжіЁж—¶й—ҙгҖӮж•°жҚ®еә“дёӯйҖҡеёёеӣӣз§Қи®Ўж—¶ж–№ејҸпјҢйҖ»иҫ‘зҡ„гҖҒзү©зҗҶзҡ„гҖҒж··еҗҲзҡ„пјҢиҝҳжңүе…ЁеұҖз»ҹдёҖж—¶й’ҹTSOгҖӮж•°жҚ®еә“йңҖиҰҒи®Ўж—¶зҡ„еҺҹеӣ жңүеҫҲеӨҡпјҢеҰӮдәӢеҠЎйңҖиҰҒжҺ’еәҸпјҢMVCCйңҖиҰҒйқ ж—¶й—ҙжҺ§еҲ¶зӯүпјҢжүҖд»Ҙж—¶й—ҙеҝ…дёҚеҸҜе°‘гҖӮ
Oracleж•°жҚ®еә“жҳҜжҖҺд№Ҳи®Ўж—¶зҡ„е‘ўпјҹе…¶е®һOracleж•°жҚ®еә“дҫқйқ SMON\_SCN\_TIMEиЎЁи®Ўж—¶пјҢз»қеӨ§еӨҡж•°Oracleдҝ®еӨҚе®ҢеҗҜеҠЁж—¶йғҪдјҡеҮәзҺ°зӣёе…ій”ҷиҜҜгҖӮOracleе»әз«ӢдәҶзү©зҗҶж—¶й—ҙе’ҢUnix Timeзҡ„еҜ№з…§иЎЁпјҢеӣ жӯӨеңЁж•°жҚ®еә“еҮәж•…йҡңзҡ„ж—¶еҖҷпјҢиҝҷеј иЎЁеӨ§жҰӮзҺҮдјҡеҸ‘з”ҹдёҚдёҖиҮҙгҖӮеҶҚиҝӣдёҖжӯҘпјҢж•°жҚ®еә“еҰӮдҪ•е’Ңж“ҚдҪңзі»з»ҹжү“дәӨйҒ“зҡ„е‘ўпјҹйҖҡиҝҮи·ҹиёӘOracleиҝӣзЁӢе°ұдјҡеҸ‘зҺ°пјҢе®ғдјҡйҖҡиҝҮgettimeofdayжқҘиҺ·еҸ–ж—¶й—ҙгҖӮ
MySQLеҸҲжҳҜжҖҺд№Ҳи®Ўж—¶зҡ„е‘ўпјҹMySQLжҸҗдҫӣдәҶеҫҲеӨҡеҮҪж•°жқҘиҪ¬жҚўUnix TimeгҖӮеҰӮжһңеӨ§е®¶е…іжіЁMySQL BinlogпјҢе°ұдјҡеҸ‘зҺ°MySQLзҡ„ж—Ҙеҝ—йҮҢйқўжңүеӨ§йҮҸTimestampпјҢиҝҷдәӣе°ұжҳҜUnix TimeпјҢиҝҷжҳҜеӣ дёәMySQLеңЁдёӢйқўеј•з”ЁдәҶnowеҮҪж•°гҖӮMySQLжҳҜејҖжәҗзҡ„пјҢеӣ жӯӨжғіиҰҒдәҶи§Је·®ејӮеҸӘйңҖиҰҒжү“ејҖжәҗз Ғе°ұеҸҜд»ҘпјҢеӣ жӯӨд»ҺOracleиҪ¬еҗ‘MySQLжҳҜеҫҲе®№жҳ“зҡ„гҖӮMySQLдҪҝз”Ёеӯ—иҠӮеӯҳеӮЁTimestampпјҢиҖҢOracleеҲҷжҳҜе°ҶSCNдҪңдёәж•°жҚ®еә“еҶ…йғЁж—¶й’ҹгҖӮ
еңЁPostgreSQLйҮҢйқўпјҢUnix Timeж— еӨ„дёҚеңЁгҖӮжңүи¶Јзҡ„жҳҜеңЁPostgreSQLж–ҮжЎЈдёӯеҶҷйҒ“е®ғжүҖжңүзҡ„ж—¶й—ҙи®Ўз®—йғҪжҳҜдҪҝз”Ёе„’з•ҘеҺҶжі•и®Ўз®—зҡ„пјҢиҝҷдёӘеҺҶжі•д»Һе…¬е…ғеүҚ4713е№ҙејҖе§Ӣи®Ўж—¶пјҢзҗҶи®әдёҠеҸҜд»Ҙи®Ўз®—еҲ°жңӘжқҘд»»дҪ•дёҖеӨ©гҖӮ
#### еӨ§йҒ“иҮіз®Җ
жҺҘи§Ұж–°жҠҖжңҜж—¶пјҢеҝғзҗҶжҒҗжғ§жҳҜжңҖеӨ§зҡ„йҡңзўҚгҖӮеҪ“дҪ е…ӢжңҚдәҶеҝғзҗҶжҒҗжғ§е°ұиғңеҲ©дәҶгҖӮдә‘е’ҢжҒ©еўЁжңҖж—©з ”з©¶дәҶж•°жҚ®еә“жҳҜжҖҺд№ҲеҲқе§ӢеҢ–е’ҢеҗҜеҠЁиө·жқҘзҡ„пјҢдәҺжҳҜе°ұи·ҹиёӘе®ғпјҢжңҖеҗҺеҸ‘зҺ°OracleжҳҜйҖҡиҝҮеҲқе§ӢеҢ–иЎЁзҡ„еј•еҜјеҗҜеҠЁиө·жқҘзҡ„гҖӮиҝҷеј иЎЁжҢҮеҗ‘дәҶblock file 377пјҢеҗҺз»ӯеҶҚж·ұе…ҘжҺўзҙўиҜ»еҸ–зҡ„ж–Ү件ең°еқҖгҖӮдҪҶжҳҜе…¶е®һеңЁжңҖејҖе§Ӣзҡ„ж—¶еҖҷе°ұиғҪеӨҹзңӢеҮәиҜ»еҸ–зҡ„ж–Ү件ең°еқҖпјҢиҝҷиҜҙжҳҺеҰӮжһңжҲ‘们иғҪеӨҹи·іеҮәжҖқз»ҙжғҜжҖ§е№¶жҲҳиғңеҝғзҗҶжҒҗжғ§пјҢе°ұиғҪеӨҹжҲҳиғңеӣ°йҡҫгҖӮ
зҗҶжғідёӯзҡ„ж·ұе…Ҙжө…еҮәжҳҜдёҖз§Қз»ҸеҺҶеҚғйҡҫдёҮйҷ©гҖҒеі°еӣһи·ҜиҪ¬д№ӢеҗҺпјҢзңӢеұұиҝҳжҳҜеұұзҡ„е№іж·ЎгҖӮжңүж—¶еҖҷиғҪж„ҹеҸ—еҲ°дјҡеҝғд№Ӣж„ҸжҳҜйқһеёёйҡҫиғҪе®қиҙөзҡ„пјҢиҝҗз”Ёд№ӢеҰҷпјҢеӯҳд№ҺдёҖеҝғгҖӮжҲ‘们еә”иҜҘиҠұеҠӣж°”еҺ»з§ҜзҙҜгҖҒж·ұе…ҘгҖҒжҖқиҖғпјҢ然еҗҺжүҚиғҪдёҫйҮҚиӢҘиҪ»гҖӮ
[еҺҹж–Үй“ҫжҺҘ](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/722263%3Futm_content%3Dg_1000083045)
жң¬ж–Үдёәдә‘ж –зӨҫеҢәеҺҹеҲӣеҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
еҲҶдә«еҲ°пјҡ


- 2019-10-30 16:34
- жөҸи§Ҳ 414
- иҜ„и®ә(0)
- еҲҶзұ»:йқһжҠҖжңҜ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
гҖҗ2017е№ҙдә‘ж –еӨ§дјҡPPTгҖ‘жҳҜ2017е№ҙеәҰйҳҝйҮҢе·ҙе·ҙдё»еҠһзҡ„дёҖеңәйҮҚиҰҒ科жҠҖзӣӣдјҡзҡ„иө„ж–ҷйӣҶеҗҲпјҢдё»иҰҒеӣҙз»•вҖңдә‘ж –еӨ§дјҡвҖқиҝҷдёҖдё»йўҳеұ•ејҖгҖӮдә‘ж –еӨ§дјҡжҳҜз”ұйҳҝйҮҢдә‘дё»еҠһзҡ„е…ЁзҗғйЎ¶зә§з§‘жҠҖеӨ§дјҡпјҢжұҮиҒҡдәҶе…ЁзҗғйЎ¶е°–зҡ„科жҠҖдәәжүҚгҖҒдјҒдёҡеҸҠеҲӣж–°иҖ…пјҢж—ЁеңЁжҺўи®Ё...
еңЁжң¬ж¬ЎвҖңдә‘ж –еӨ§дјҡдәәе·ҘжҷәиғҪдё“еңәPPTвҖқдёӯпјҢ专家们ж·ұе…ҘжҺўи®ЁдәҶдәәе·ҘжҷәиғҪиҝҷдёҖеүҚжІҝ科жҠҖеңЁеҗ„иЎҢеҗ„дёҡзҡ„еә”з”ЁеҸҠе…¶жЁЎеһӢгҖӮдә‘ж –еӨ§дјҡдҪңдёәйҳҝйҮҢе·ҙе·ҙдё»еҠһзҡ„е…ЁзҗғйЎ¶зә§з§‘жҠҖзӣӣдјҡпјҢжұҮйӣҶдәҶдј—еӨҡдёҡз•ҢзІҫиӢұпјҢе…ұеҗҢеҲҶдә«жңҖж–°зҡ„жҠҖжңҜе’Ңз ”з©¶жҲҗжһңпјҢиҖҢдәәе·Ҙ...
2019жқӯе·һдә‘ж –еӨ§дјҡ70+д»ҪйЎ¶зә§еӨ§е’–жј”и®ІPPTеҲҶдә«пјҒhttps://yq.aliyun.com/articles/720857?spm=a2c4e.11153940.0.0.553ac88czBCeJf part2:https://download.csdn.net/download/kingreatwill/12461601
дә‘ж –еӨ§дјҡжҳҜйҳҝйҮҢдә‘дёҖе№ҙдёҖеәҰзҡ„ејҖеҸ‘иҖ…еӨ§дјҡпјҢ10 жңҲ 19 ж—ҘиҮі 22 ж—ҘпјҢ2021 дә‘ж –еӨ§дјҡе°ҶеңЁжқӯе·һдә‘ж –е°Ҹй•ҮдёҫеҠһгҖӮд»Ҡе№ҙдә‘ж –еӨ§дјҡд»ҘвҖңеүҚжІҝжҺўзҙўжғіиұЎеҠӣвҖқдёәдё»йўҳпјҢеӣһеҪ’зәҝдёӢ并е…Қиҙ№еҗ‘е…¬дј—ејҖж”ҫпјҢи®ҫзҪ®иҝ‘еҚғеңәдё»йўҳжј”и®Іе’ҢеӣӣдёҮе№ізұіз§‘жҠҖеұ•пјҢе°Ҷ...
йҖҒдёҠдёҖд»ҪйҮҚйҮҸзә§зҡ„е№Іиҙ§еӯҰд№ еҢ…еҗ«еӨҡдҪҚйЎ¶зә§еӨ§е’–е®Ңж•ҙзүҲPDFеҲҶдә«е…Қиҙ№ејҖж”ҫз»ҷеӨ§е®¶гҖӮ...жӯӨд»ҪеӯҰд№ еҢ…иҰҶзӣ–дәҶи®ёеӨҡзІҫеҪ©зҡ„и®әеқӣжҜ”еҰӮйҳҝйҮҢејҖжәҗеі°дјҡгҖҒеӨ§ж•°жҚ®еҲҶи®әеқӣгҖҒйҳҝйҮҢдә‘еӨ§ж•°жҚ®и®Ўз®—жңҚеҠЎMaxComputeдё“еңәSQLSERVERдё“еңәвҖҰвҖҰ
гҖҗдә‘ж –еӨ§дјҡйғЁеҲҶе…¬ејҖзҡ„PPTгҖ‘жҳҜдёҖж¬ЎжҠҖжңҜеҲҶдә«зӣӣе®ҙзҡ„зІҫеҪ©еӣһйЎҫпјҢ...йҖҡиҝҮдёӢиҪҪе№¶з ”з©¶дә‘ж –еӨ§дјҡNLPзҡ„PPTпјҢдёҚд»…еҸҜд»ҘдәҶи§ЈжңҖж–°зҡ„з ”з©¶еҠЁжҖҒпјҢиҝҳиғҪжҺҢжҸЎе®һйҷ…йЎ№зӣ®дёӯеҸҜиғҪз”ЁеҲ°зҡ„жҠҖжңҜж–№жі•пјҢеҜ№дәҺжҸҗеҚҮдёӘдәәжҲ–еӣўйҳҹеңЁNLPйўҶеҹҹзҡ„дё“дёҡиғҪеҠӣеӨ§жңүиЈЁзӣҠгҖӮ
2019жқӯе·һдә‘ж –еӨ§дјҡ70+д»ҪйЎ¶зә§еӨ§е’–жј”и®ІPPTеҲҶдә«пјҒhttps://yq.aliyun.com/articles/720857?spm=a2c4e.11153940.0.0.553ac88czBCeJf part1:https://download.csdn.net/download/kingreatwill/12461603
йҳҝйҮҢеӨ§ж•°жҚ®дё“еңә EBзә§еҲ«дҪ“йҮҸд№ӢдёӢзҡ„й«ҳж•Ҳж•°жҚ®иөӢиғҪ йҳҝйҮҢе·ҙе·ҙеӨ§ж•°жҚ®жҷәиғҪжҠҖжңҜ йҳҝйҮҢе·ҙе·ҙдәәе·ҘжҷәиғҪй©ұеҠЁеӨ§ж•°жҚ® йҳҝйҮҢе·ҙе·ҙж•°жҚ®иө„дә§з®ЎзҗҶ жҢ‘жҲҳеҸҢ11е®һж—¶ж•°жҚ®жҙӘеі°зҡ„жөҒи®Ўз®—е®һи·ө ж•°жҚ®й©ұеҠЁжҷәиғҪеҠ©еҠӣдјҒдёҡжҲҗй•ҝ йҳҝйҮҢе·ҙе·ҙе…Ёеҹҹж•°жҚ®е»әи®ҫ
### дә‘ж –еӨ§дјҡPPTзҹҘиҜҶзӮ№и§Јжһҗ #### дёҖгҖҒдә‘ж –еӨ§дјҡжҰӮиҝ° дә‘ж –еӨ§дјҡдҪңдёәйҳҝйҮҢе·ҙе·ҙйӣҶеӣўдё»еҠһзҡ„дёҖеңәеӨ§еһӢ科жҠҖзӣӣдјҡпјҢж—ЁеңЁеұ•зӨәдә‘и®Ўз®—гҖҒеӨ§ж•°жҚ®гҖҒдәәе·ҘжҷәиғҪзӯүеүҚжІҝжҠҖжңҜжҲҗжһңеҸҠе…¶еңЁеҗ„иЎҢеҗ„дёҡзҡ„еә”з”ЁжЎҲдҫӢгҖӮжң¬ж¬ЎеҲҶдә«дё»иҰҒеӣҙз»•вҖңCDNеҠ©жүӢвҖқиҝҷдёҖ...
2017дә‘ж –еӨ§дјҡзҡ„вҖңдә‘ж•°жҚ®еә“RedisзүҲзҡ„ејҖжәҗд№Ӣи·ҜвҖқпјҢжҠҖжңҜеҶ…е®№дёҚжҳҜзү№еҲ«ж·ұпјҢеҸҜд»ҘдҪңдёәдәҶи§Ј
иһҚеҗҲжҖ§еҸёжі•иЎҢж”ҝж–°дҪ“зі».pdf и§Ҷи§үеӨ§ж•°жҚ®жҷәиғҪи®Ўз®—е®һи·өвҖ”вҖ”д»Һе®һйӘҢе®ӨеҲ°зңҹе®һдё–з•Ң.pdf и§Ҷйў‘жңҚеҠЎзү№иүІи§ЈеҶіж–№жЎҲеҠ©еҠӣејҖеҸ‘иҖ…0зј–з Ғж•ҙеҗҲи§Ҷйў‘иғҪеҠӣ.pdf и§Ұж‘ёж—¶з©әзҡ„еҠӣйҮҸ....й«ҳеҫ·з»Ҹе…ёж•°жҚ®еә“е®һи·өжЎҲдҫӢеҲҶдә«.pdf й«ҳиЎҖеҺӢдә‘жңҚеҠЎз”ҹжҖҒзҡ„еҒҘеә·жўҰ.pdf
йҳҝйҮҢдә‘ж –еӨ§дјҡжҳҜе…Ёзҗғ科жҠҖз•Ңзҡ„дёҖеңәзӣӣдјҡпјҢжҜҸе№ҙйғҪдјҡиҒҡйӣҶдј—еӨҡжҠҖжңҜ专家е’ҢиЎҢдёҡйўҶеҜјиҖ…пјҢе…ұеҗҢжҺўи®ЁжңҖеүҚжІҝзҡ„科жҠҖи¶ӢеҠҝе’Ңеә”з”ЁгҖӮ2019е№ҙзҡ„еӨ§дјҡзү№еҲ«е…іжіЁдәҶдә‘еҺҹз”ҹгҖҒж•°жҚ®дёӯеҝғгҖҒеӨ§ж•°жҚ®гҖҒдәәе·ҘжҷәиғҪд»ҘеҸҠзү©иҒ”зҪ‘зӯүйўҶеҹҹпјҢиҝҷдәӣжҳҜеҪ“д»ҠдҝЎжҒҜжҠҖжңҜ...
д»Һж ҮйўҳгҖҠдј з»ҹж•°жҚ®еә“еҲ°ејҖжәҗж•°жҚ®еә“иҝҒ移е·Ҙе…·еҢ–жөҒзЁӢ.pdfгҖӢе’ҢжҸҸиҝ°гҖҠдј з»ҹж•°жҚ®еә“еҲ°ејҖжәҗж•°жҚ®еә“иҝҒ移е·Ҙе…·еҢ–жөҒзЁӢ.pdfгҖӢеҸҜд»ҘзңӢеҮәпјҢжң¬ж–ҮжЎЈдё»иҰҒи®Ёи®әзҡ„жҳҜе°Ҷдј з»ҹзҡ„ж•°жҚ®еә“зі»з»ҹиҝҒ移еҲ°ејҖжәҗж•°жҚ®еә“зі»з»ҹзҡ„иҝҮзЁӢпјҢ并且ж¶үеҸҠеҲ°е·Ҙе…·еҢ–зҡ„ж–№жі•гҖӮ...
жқӯе·һдә‘ж –еӨ§дјҡжҳҜйҳҝйҮҢйӣҶеӣўдёҖе№ҙдёҖеәҰзҡ„е…Ёз”ҹжҖҒ科жҠҖзӣӣдјҡгҖӮжӯӨж¬ЎеӨ§дјҡеҢ…еҗ«140еӨҡеңәжҠҖжңҜдё»йўҳи®әеқӣпјҢе…ұи®Ў800еӨҡдёӘдё»йўҳеҲҶдә«пјҢж¶өзӣ–дәәе·ҘжҷәиғҪгҖҒйҮ‘иһҚ科жҠҖгҖҒйҮҸеӯҗи®Ўз®—гҖҒз”ҹе‘Ҫ科еӯҰгҖҒIoTгҖҒж”ҝеҠЎгҖҒеӨҡеӘ’дҪ“гҖҒVRзӯү20еӨҡдёӘеүҚжІҝ科жҠҖйўҶеҹҹгҖӮ
гҖҗдә‘ж –гҖ‘вҖңеӨ©жІідәҢеҸ·вҖңзҡ„OpenStackејҖжәҗе®һи·өеҸҠдҪ“дјҡзҺ°еңәзҡ„PPT
2017дә‘ж –еӨ§дјҡдё»иҰҒеҶ…е®№
1-14 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - йҳҝйҮҢз”өе•Ҷдә‘д»Ӣз»ҚдёҺе®һи·ө 1-15 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - еҗҢзЁӢеёҰжӮЁдә‘з«Ҝзҝұзҝ” 1-16 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - з”өе•Ҷз«ҜеҲ°з«Ҝж•°жҚ®зІҫз»ҶеҢ–иҝҗиҗҘ 1-17 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - ж•°еӯ—иҗҘй”ҖеҠ©еҠӣдј з»ҹдјҒдёҡйҖҡеҫҖ...
1-7 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - вҖңеҹҹвҖқи§ҒжӣҙзҫҺеҘҪзҡ„жңӘжқҘпјҡеҹҹеҗҚзӯ‘жўҰдә’иҒ”зҪ‘+ 1-8 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - вҖңеҹҹвҖқзҪўдёҚиғҪпјҡеҲӣж–°ж”№еҸҳиЎҢдёҡ 1-9 - 2016жқӯе·һВ·дә‘ж –еӨ§дјҡ - вҖңеҹҹвҖқж„ҹпјҡеҹҹеҗҚжҠ•иө„д»Һе…Ҙй—ЁеҲ°зІҫйҖҡ 1-10 - 2016жқӯе·һВ·дә‘ж –...
гҖҗжҺЁиҚҗгҖ‘2021дә‘ж –еӨ§дјҡPPTеҗҲйӣҶжҳҜдёҖдёӘеҢ…еҗ«143д»ҪPPTзҡ„дё°еҜҢиө„жәҗеә“пјҢиҝҷдәӣPPTж¶өзӣ–дәҶ24дёӘдёҚеҗҢзҡ„дё»йўҳзұ»еҲ«пјҢж—ЁеңЁж·ұе…ҘжҺўи®ЁдёҺдҝЎжҒҜжҠҖжңҜзӣёе…ізҡ„еүҚжІҝи¶ӢеҠҝе’ҢзғӯзӮ№и®®йўҳгҖӮдә‘ж –еӨ§дјҡдҪңдёәе…ЁзҗғзҹҘеҗҚзҡ„科жҠҖзӣӣдјҡпјҢжҜҸе№ҙйғҪеҗёеј•зқҖдј—еӨҡдёҡз•Ң专家е’Ң...