本文是基于本人对MaxCompute产品的学习进度,再结合开发者社区里面的一些问题,进而整理成文。希望对大家有所帮助。
问题一、如何查看information\_schema的tables?
在使用ODPS建表时,有可能会建出几千张表,那我们寻找需要的表时就需要知道表名称,可以在数据地图中查看表,也可以使用Pyodps批量获取表名称。
具体可参考文档:[https://help.aliyun.com/document\_detail/90412.html](https://help.aliyun.com/document_detail/90412.html)
问题二、不小心drop删除表可以恢复吗?
不可以。在客户端和IDE中drop表是一个不可逆操作。表操作要谨慎。
问题三、在哪里可以看到所有执行的SQL?
通过Information\_Schema元数据的TASKS\_HISTORY明细来查,元数据服务Information\_Schema已经全面开放,大家可以使用此服务查询项目内关键对象的元数据信息,在元数据之外,也提供了包括作业运行、数据上下传使用历史的行为数据。
具体可参考官方文档操作:[https://help.aliyun.com/document\_detail/135432.html](https://help.aliyun.com/document_detail/135432.html)
问题四、创建project报错OPDS操作错误OPDS-0410051,怎么解决?
下为报错截图
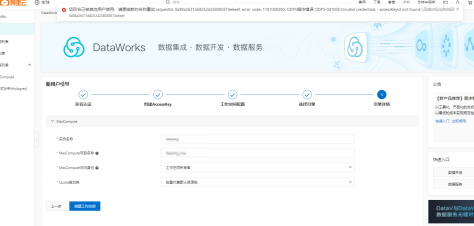
此错误报错信息可以理解为AK信息错误。解决方法是重新生成AK信息,重新绑定AK信息。
问题五、MaxCompute SQL注释如何多行注释?
多行注释为Ctrl + /
官方文档中有详细代码快捷键和DataStudio快捷键整理。请参考官方文档:
代码编辑器常用快捷键:[https://help.aliyun.com/document\_detail/68602.html](https://help.aliyun.com/document_detail/68602.html)
DataStudio快捷键:[https://help.aliyun.com/document\_detail/89931.html](https://help.aliyun.com/document_detail/89931.html)
问题六、MaxCompute数据导出,提供了哪几种方法?
可以选择通过DataHub实时数据通道和Tunnel批量数据通道两种途径进出MaxCompute系统。
具体可参考:[https://help.aliyun.com/document\_detail/51656.html](https://help.aliyun.com/document_detail/51656.html)
问题七、MaxCompute中如何把表的A列中,包含“123456”or “678910”or“45678”全部查询出来?
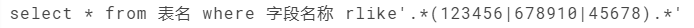
问题八、查询数据时报了这个错误:Semanticanalysisexception-INTtypeisnotenabled incurrentmode,int类型为什么不能用呢?
使用int类型需要打开setodps.sql.type.system.odps2=true。默认支持的是bigint,如果没有特别的需求的话,只用bigint就可以了。
问题九、如何查看MaxCompute每个分区存储的数据大小?

比如desct1partition(ds="20190820");
问题十、2019杭州.云栖大会精彩回顾
[https://yunqi.youku.com/](https://yunqi.youku.com/)
可以回顾0926PM“大数据&AI峰会”专场,了解大数据和人工智能最新技术核心内容。
[原文链接](https://yq.aliyun.com/articles/719868?utm_content=g_1000082808)
本文为云栖社区原创内容,未经允许不得转载。
分享到:





相关推荐
### 大数据之路选择Hadoop还是MaxCompute? #### 一、Hadoop与MaxCompute概述 ##### 1.1 Hadoop介绍与发展历程 Hadoop是由Apache软件基金会开发的一个开源分布式计算平台,采用Java语言编写,旨在支持大规模数据...
阿里云大数据平台Maxcompute操作工具客户端
基于 MaxCompute的大数据 BI 分析 本方案旨在解决大数据 BI 分析的技术创新问题,通过将业务数据和日志数据快速汇总到 ADB 后再通过 QuickBI 等工具进行可视化分析和展示。该方案适用于互联网、电商、游戏行业等...
9月4日MaxCompute直播课件下载。 了解更多MaxCompute产品和技术相关内容,可扫描二维码加入“MaxCompute开发者交流”钉钉群。
阿里云高级专家 戴谢宁在2017杭州云栖大会中做了题为《MaxCompute索引优化实践分享》的分享,就MaxCompute的数据模型,MaxCompute性能优化,应用实例 – 淘宝交易记录查询做了深入的分析。
9月18日MaxCompute直播课件下载。 了解更多MaxCompute产品和技术相关内容,可扫描二维码加入“MaxCompute开发者交流”钉钉群。
阿里大数据计算服务MaxCompute入门指南 MaxCompute是阿里云提供的一种大数据计算服务,允许用户快速处理大量数据。为帮助用户快速开始使用MaxCompute,本文档提供了详细的入门指南。 一、准备工作 在使用...
MaxCompute是阿里巴巴集团开发的云大数据计算平台,专为大规模数据仓库场景而设计。在【标题】中提到的“MaxCompute案例实践杭州峰会.pdf”文件中,主要讨论了MaxCompute的典型应用案例和架构,探讨了该平台在不同...
MaxCompute是阿里巴巴云推出的一种大规模数据处理服务,它专注于大数据的存储和计算,能够支持PB级别的数据处理。在大数据生态集成和开发工具方面,MaxCompute 2.0展现了其强大的兼容性和灵活性。 首先,MaxCompute...
阿里大数据计算服务MaxCompute是一款由阿里巴巴提供的分布式大数据处理平台,旨在为企业提供高效、稳定、低成本的数据存储和计算能力。在本工具指南中,主要讲解了如何使用MaxCompute的客户端工具来操作和管理...
本资源摘要信息涵盖了阿里大数据计算服务MaxCompute的入门指南,包括准备工作、创建项目空间、快速开始使用MaxCompute、加载MaxCompute项目空间到大数据开发平台、创建MaxCompute项目、使用MaxCompute客户端等内容。...
MaxCompute是阿里巴巴推出的一种大规模数据处理服务,原名为ODPS,专为TB至PB级别的海量数据仓库解决方案设计。它提供了一种快速、完全托管的服务,旨在简化大数据分析和计算过程,降低企业的运营成本,并确保数据的...
MaxCompute,原名ODPS,是阿里巴巴集团及阿里云的核心大数据计算服务,它是一个超大规模、低成本、高并发的分布式计算平台。此平台主要负责99%的数据存储和95%的计算任务,支撑了阿里巴巴内部包括阿里妈妈、天猫、...
### MaxCompute Tunnel 上传功能详解及典型问题场景分析 #### 一、MaxCompute Tunnel 上传功能概述 MaxCompute Tunnel 是一种高效的数据传输工具,主要用于将本地文件上传至MaxCompute表中。该工具提供了灵活的...
### MaxCompute数据开发实战——数据进入MaxCompute的多种方式 #### 概述 本文档旨在详细介绍如何通过不同的技术手段和工具实现数据从多种源头至MaxCompute的高效迁移,并结合具体的业务场景,展示整个数据处理...
本资料“MaxCompute的NewSQL演进之路”将探讨MaxCompute如何借鉴NewSQL的思想,以适应大数据时代的挑战。 MaxCompute作为一个批处理系统,其核心设计目标是处理PB级别的数据,并支持SQL查询。然而,随着业务需求的...
MaxCompute是阿里巴巴推出的大数据分析平台,它随着技术的进步和用户需求的增加,已经发展到2.0版本。在此过程中,MaxCompute不仅继承了传统数据库的强语义和强结构特点,同时也融入了NoSQL的横向扩展性和大数据处理...