еӨ§ж¶ӣеӯҰй•ҝ
- жөҸи§Ҳ: 122119 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
и¶…еӨ§и§„жЁЎе•Ҷз”Ё K8s еңәжҷҜдёӢпјҢйҳҝйҮҢе·ҙе·ҙеҰӮдҪ•еҠЁжҖҒи§ЈеҶіе®№еҷЁиө„жәҗзҡ„жҢүйңҖеҲҶй…Қй—®йўҳпјҹ
еј•иЁҖ
==
дёҚзҹҘйҒ“еӨ§е®¶жңүжІЎжңүиҝҮиҝҷж ·зҡ„з»ҸеҺҶпјҡеҪ“жҲ‘们жӢҘжңүдәҶдёҖеҘ— Kubernetes йӣҶзҫӨпјҢ然еҗҺејҖе§ӢйғЁзҪІеә”з”Ёзҡ„ж—¶еҖҷпјҢжҲ‘们еә”иҜҘз»ҷе®№еҷЁеҲҶй…ҚеӨҡе°‘иө„жәҗе‘ўпјҹ
иҝҷеҫҲйҡҫиҜҙгҖӮз”ұдәҺ Kubernetes иҮӘе·ұзҡ„жңәеҲ¶пјҢжҲ‘们еҸҜд»ҘзҗҶи§Је®№еҷЁзҡ„иө„жәҗе®һиҙЁдёҠжҳҜдёҖдёӘйқҷжҖҒзҡ„й…ҚзҪ®гҖӮ
* еҰӮжһңжҲ‘еҸ‘зҺ°иө„жәҗдёҚи¶іпјҢдёәдәҶеҲҶй…Қз»ҷе®№еҷЁжӣҙеӨҡиө„жәҗпјҢжҲ‘们йңҖиҰҒйҮҚе»ә Podпјӣ
* еҰӮжһңеҲҶй…ҚеҶ—дҪҷзҡ„иө„жәҗпјҢйӮЈд№ҲжҲ‘们зҡ„ worker node иҠӮзӮ№дјјд№ҺеҸҲйғЁзҪІдёҚдәҶеӨҡе°‘е®№еҷЁгҖӮ
иҜ•й—®пјҢжҲ‘们иғҪеҒҡеҲ°е®№еҷЁиө„жәҗзҡ„жҢүйңҖеҲҶй…Қеҗ—пјҹжҺҘдёӢжқҘпјҢжҲ‘们е°ҶеңЁжң¬ж¬ЎеҲҶдә«дёӯе’ҢеӨ§е®¶дёҖиө·иҝӣиЎҢжҺўи®ЁиҝҷдёӘй—®йўҳзҡ„зӯ”жЎҲгҖӮ
з”ҹдә§зҺҜеўғдёӯзҡ„зңҹе®һжҢ‘жҲҳ
==========
йҰ–е…ҲиҜ·е…Ғи®ёжҲ‘д»¬ж №жҚ®жҲ‘们зҡ„е®һйҷ…жғ…еҶөжҠӣеҮәжҲ‘们е®һйҷ…з”ҹдә§зҺҜеўғзҡ„жҢ‘жҲҳгҖӮжҲ–и®ёеӨ§е®¶иҝҳи®°еҫ— 2018 е№ҙзҡ„еӨ©зҢ«еҸҢ 11пјҢиҝҷдёҖеӨ©зҡ„жҖ»жҲҗдәӨйўқиҫҫеҲ°дәҶ 2135 дәҝгҖӮз”ұжӯӨдёҖж–‘еҸҜзӘҘе…Ёиұ№пјҢиғҪеӨҹж”Ҝж’‘еҰӮжӯӨеәһеӨ§и§„жЁЎзҡ„дәӨжҳ“йҮҸиғҢеҗҺзҡ„зі»з»ҹпјҢе…¶еә”з”Ёз§Қзұ»е’Ңж•°йҮҸеә”иҜҘжҳҜжҖҺж ·зҡ„дёҖз§Қ规模гҖӮ
еңЁиҝҷз§Қ规模дёӢпјҢжҲ‘们常常еҗ¬еҲ°зҡ„е®№еҷЁи°ғеәҰпјҢеҰӮпјҡе®№еҷЁзј–жҺ’пјҢиҙҹиҪҪеқҮиЎЎпјҢйӣҶзҫӨжү©зј©е®№пјҢйӣҶзҫӨеҚҮзә§пјҢеә”з”ЁеҸ‘еёғпјҢеә”з”ЁзҒ°еәҰзӯүзӯүиҝҷдәӣиҜҚпјҢеңЁиў«вҖңи¶…еӨ§и§„жЁЎйӣҶзҫӨвҖқиҝҷдёӘиҜҚдҝ®йҘ°еҗҺпјҢйғҪдёҚеҶҚжҳҜ件容жҳ“еӨ„зҗҶзҡ„дәӢжғ…гҖӮ规模жң¬иә«д№ҹе°ұжҳҜжҲ‘们жңҖеӨ§зҡ„жҢ‘жҲҳгҖӮеҰӮдҪ•иҝҗиҗҘе’Ңз®ЎзҗҶеҘҪиҝҷд№ҲдёҖдёӘеәһеӨ§зҡ„зі»з»ҹпјҢ并йҒөеҫӘдёҡз•Ң dev-ops е®Јдј зҡ„йӮЈж ·ж•ҲжһңпјҢзҠ№еҰӮи®©еӨ§иұЎеҺ»и·іиҲһгҖӮдҪҶжҳҜ马иҖҒеёҲжӣҫиҜҙиҝҮпјҢеӨ§иұЎе°ұиҜҘе№ІеӨ§иұЎиҜҘе№Ізҡ„дәӢжғ…пјҢдёәд»Җд№ҲиҰҒеҺ»и·іиҲһе‘ўгҖӮ
Kubernetes зҡ„её®еҠ©
==============
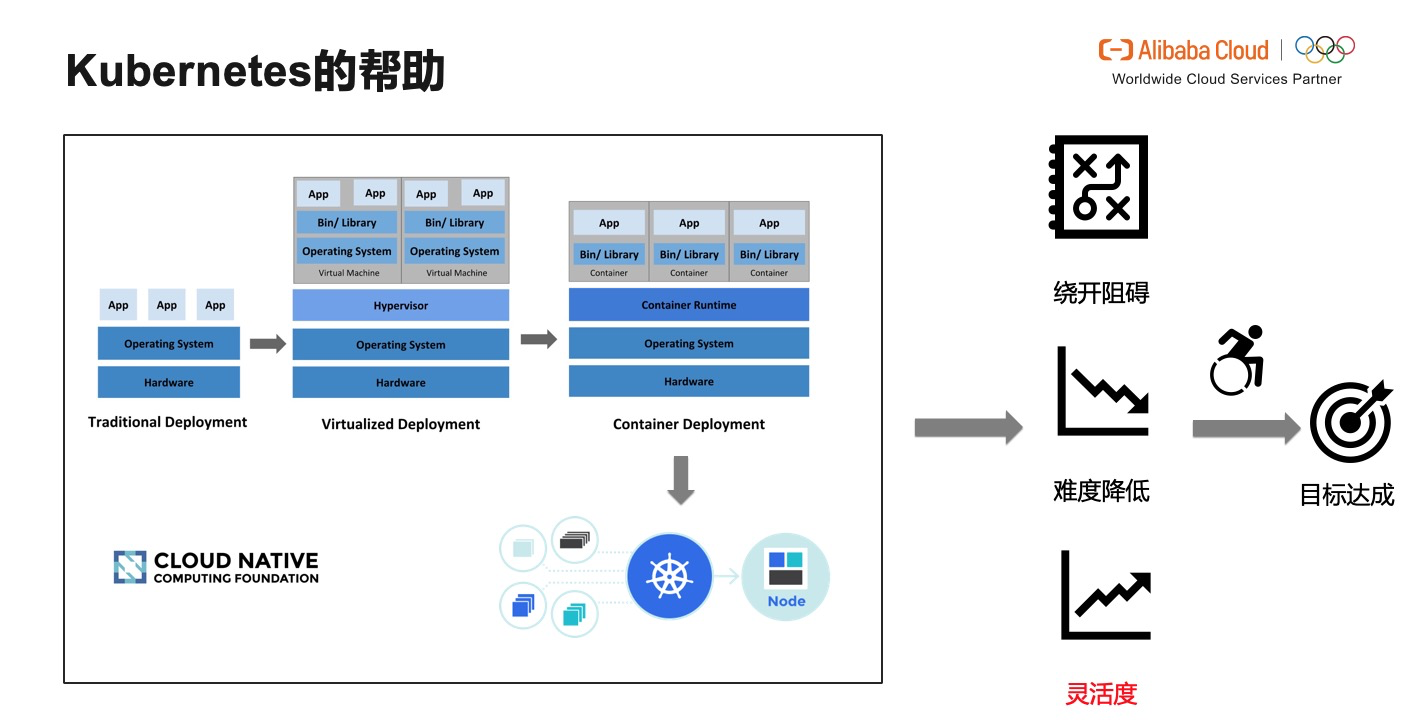
еӨ§иұЎжҳҜеҗҰеҸҜд»Ҙи·іиҲһпјҢеёҰзқҖиҝҷдёӘй—®йўҳпјҢжҲ‘们йңҖиҰҒд»Һж·ҳе®қгҖҒеӨ©зҢ«зӯү APP иғҢеҗҺзі»з»ҹиҜҙиө·гҖӮ
иҝҷеҘ—дә’иҒ”зҪ‘зі»з»ҹеә”з”ЁйғЁзҪІеӨ§иҮҙеҸҜеҲҶдёәдёүдёӘйҳ¶ж®өпјҢдј з»ҹйғЁзҪІпјҢиҷҡжӢҹжңәйғЁзҪІе’Ңе®№еҷЁйғЁзҪІгҖӮзӣёжҜ”дәҺдј з»ҹйғЁзҪІпјҢиҷҡжӢҹжңәйғЁзҪІжңүдәҶжӣҙеҘҪзҡ„йҡ”зҰ»жҖ§е’Ңе®үе…ЁжҖ§пјҢдҪҶжҳҜеңЁжҖ§иғҪдёҠдёҚеҸҜйҒҝе…Қзҡ„дә§з”ҹдәҶеӨ§йҮҸжҚҹиҖ—гҖӮиҖҢе®№еҷЁйғЁзҪІеҸҲеңЁиҷҡжӢҹжңәйғЁзҪІе®һзҺ°йҡ”зҰ»е’Ңе®үе…Ёзҡ„иғҢжҷҜдёӢпјҢжҸҗеҮәдәҶжӣҙиҪ»йҮҸеҢ–зҡ„и§ЈеҶіж–№жЎҲгҖӮжҲ‘们зҡ„зі»з»ҹд№ҹжҳҜжІҝзқҖиҝҷд№ҲдёҖжқЎдё»иҲӘйҒ“дёҠиҝҗиЎҢзҡ„гҖӮеҒҮи®ҫеә•еұӮзі»з»ҹеҘҪжҜ”дёҖиүҳе·ЁиҪ®пјҢйқўеҜ№е·ЁйҮҸзҡ„йӣҶиЈ…з®ұ---е®№еҷЁпјҢжҲ‘们йңҖиҰҒдёҖдёӘдјҳз§Җзҡ„иҲ№й•ҝпјҢеҜ№е®ғ们иҝӣиЎҢи°ғеәҰзј–жҺ’пјҢи®©зі»з»ҹиҝҷиүҳеӨ§иҲ№еҸҜд»ҘйҒҝејҖеұӮеұӮйҷ©йҳ»пјҢж“ҚдҪңйҡҫеәҰйҷҚдҪҺпјҢдё”е…·еӨҮжӣҙеӨҡзҒөжҙ»жҖ§пјҢжңҖз»ҲиҫҫжҲҗиҲӘиЎҢзҡ„зӣ®зҡ„гҖӮ
зҗҶжғідёҺзҺ°е®һ
=====
еңЁејҖе§Ӣд№ӢеҲқпјҢжғіеҲ°е®№еҷЁеҢ–е’Ң Kubernetes зҡ„еҗ„з§ҚзҫҺеҘҪеңәжҷҜпјҢжҲ‘们зҗҶжғідёӯзҡ„е®№еҷЁзј–жҺ’ж•Ҳжһңеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ
* д»Һе®№пјҡжҲ‘们зҡ„е·ҘзЁӢеёҲжӣҙеҠ д»Һе®№зҡ„йқўеҜ№еӨҚжқӮзҡ„жҢ‘жҲҳпјҢдёҚеҶҚзңүеӨҙзҙ§й”ҒиҖҢжҳҜжӣҙеӨҡ笑容е’ҢиҮӘдҝЎпјӣ
* дјҳйӣ…пјҡжҜҸдёҖж¬ЎзәҝдёҠеҸҳжӣҙж“ҚдҪңйғҪеҸҜд»ҘеғҸе“ҒзқҖзәўй…’дёҖж ·ж°”е®ҡзҘһй—ІпјҢдјҳйӣ…ең°жҢүдёӢжү§иЎҢзҡ„еӣһиҪҰй”®пјӣ
* жңүеәҸпјҡд»ҺејҖеҸ‘еҲ°жөӢиҜ•пјҢеҶҚеҲ°зҒ°еәҰеҸ‘еёғпјҢдёҖж°”е‘өжҲҗпјҢиЎҢдә‘жөҒж°ҙпјӣ
* зЁіе®ҡпјҡзі»з»ҹеҒҘеЈ®жҖ§иүҜеҘҪпјҢд»»е°”дёңиҘҝеҚ—еҢ—йЈҺпјҢжҲ‘们系з»ҹеІҝ然дёҚеҠЁгҖӮе…Ёе№ҙзі»з»ҹеҸҜз”ЁжҖ§ N еӨҡдёӘ 9пјӣ
* й«ҳж•ҲпјҡиҠӮзәҰеҮәжӣҙеӨҡдәәеҠӣпјҢе®һзҺ°вҖңеҝ«д№җе·ҘдҪңпјҢи®Өзңҹз”ҹжҙ»вҖқгҖӮ
然иҖҢзҗҶжғіеҫҲдё°ж»ЎпјҢзҺ°е®һеҫҲйӘЁж„ҹгҖӮиҝҺжҺҘжҲ‘们зҡ„еҚҙжҳҜжқӮд№ұе’ҢеҪўжҖҒеҗ„ејӮзҡ„зӘҳиҝ«гҖӮ
жқӮд№ұпјҢжҳҜеӣ дёәдҪңдёәдёҖдёӘејӮеҶӣзӘҒиө·зҡ„ж–°еһӢжҠҖжңҜж ҲпјҢеҫҲеӨҡй…ҚеҘ—е·Ҙе…·е’Ңе·ҘдҪңжөҒзҡ„е»әи®ҫеӨ„дәҺеҲқзә§йҳ¶ж®өгҖӮDemo зүҲжң¬дёӯиҝҗиЎҢиүҜеҘҪзҡ„е·Ҙе…·пјҢеңЁзңҹе®һеңәжҷҜдёӢеӨ§и§„жЁЎй“әејҖпјҢеҗ„з§Қйҡҗи—Ҹзҡ„й—®йўҳе°ұдјҡжҡҙйңІж— йҒ—пјҢеұӮеҮәдёҚз©·гҖӮд»ҺејҖеҸ‘еҲ°иҝҗз»ҙпјҢжүҖжңүзҡ„е·ҘдҪңдәәе‘ҳйғҪеңЁеҗ„з§Қиў«еҠЁең°з–ІдәҺеҘ”е‘ҪгҖӮеҸҰеӨ–пјҢвҖңеӨ§и§„жЁЎй“әејҖвҖқиҝҳж„Ҹе‘ізқҖпјҢиҰҒзӣҙжҺҘйқўеҜ№еҪўжҖҒеҗ„ејӮзҡ„з”ҹдә§зҺҜеўғпјҡејӮжһ„й…ҚзҪ®зҡ„жңәеҷЁгҖҒеӨҚжқӮзҡ„йңҖжұӮпјҢз”ҡиҮіжҳҜйҖӮй…Қз”ЁжҲ·зҡ„ж—ўеҫҖзҡ„дҪҝз”Ёд№ жғҜзӯүзӯүгҖӮ

йҷӨдәҶи®©дәәеҝғеҠӣдәӨзҳҒзҡ„ж··д№ұпјҢзі»з»ҹиҝҳйқўдёҙзқҖеә”з”Ёе®№еҷЁзҡ„еҗ„з§Қеҙ©жәғй—®йўҳпјҡеҶ…еӯҳдёҚи¶іеҜјиҮҙзҡ„ OOMпјҢCPU quota еҲҶй…ҚеӨӘе°‘пјҢеҜјиҮҙиҝӣзЁӢиў« throttleпјҢиҝҳжңүеёҰе®ҪдёҚи¶іпјҢе“Қеә”时延еӨ§е№…дёҠеҚҮ...з”ҡиҮіжҳҜдәӨжҳ“йҮҸеңЁйқўеҜ№и®ҝй—®й«ҳеі°ж—¶еҖҷз”ұдәҺзі»з»ҹдёҚз»ҷеҠӣеҜјиҮҙзҡ„ж–ӯеҙ–ејҸдёӢи·ҢзӯүзӯүгҖӮиҝҷдәӣйғҪдҪҝжҲ‘们еңЁеӨ§и§„жЁЎе•Ҷз”Ё Kubernetes еңәжҷҜдёӯз§ҜзҙҜйқһеёёеӨҡзҡ„з»ҸйӘҢгҖӮ
зӣҙйқўй—®йўҳ
====
зЁіе®ҡжҖ§
---
й—®йўҳжҖ»иҰҒиҝӣиЎҢйқўеҜ№зҡ„гҖӮжӯЈеҰӮжҹҗдҪҚй«ҳдәәиҜҙиҝҮпјҡеҰӮжһңж„ҹи§үе“ӘйҮҢдёҚеӨӘеҜ№пјҢйӮЈд№ҲиӮҜе®ҡжңүдәӣең°ж–№еҮәй—®йўҳдәҶгҖӮдәҺжҳҜжҲ‘们е°ұиҰҒеү–жһҗпјҢй—®йўҳ究з«ҹеҮәеңЁе“ӘйҮҢгҖӮй’ҲеҜ№дәҺеҶ…еӯҳзҡ„ OOMпјҢCPU иө„жәҗиў« throttleпјҢжҲ‘们еҸҜд»ҘжҺЁж–ӯжҲ‘们з»ҷдёҺе®№еҷЁеҲҶй…Қзҡ„еҲқе§Ӣиө„жәҗдёҚи¶ігҖӮ
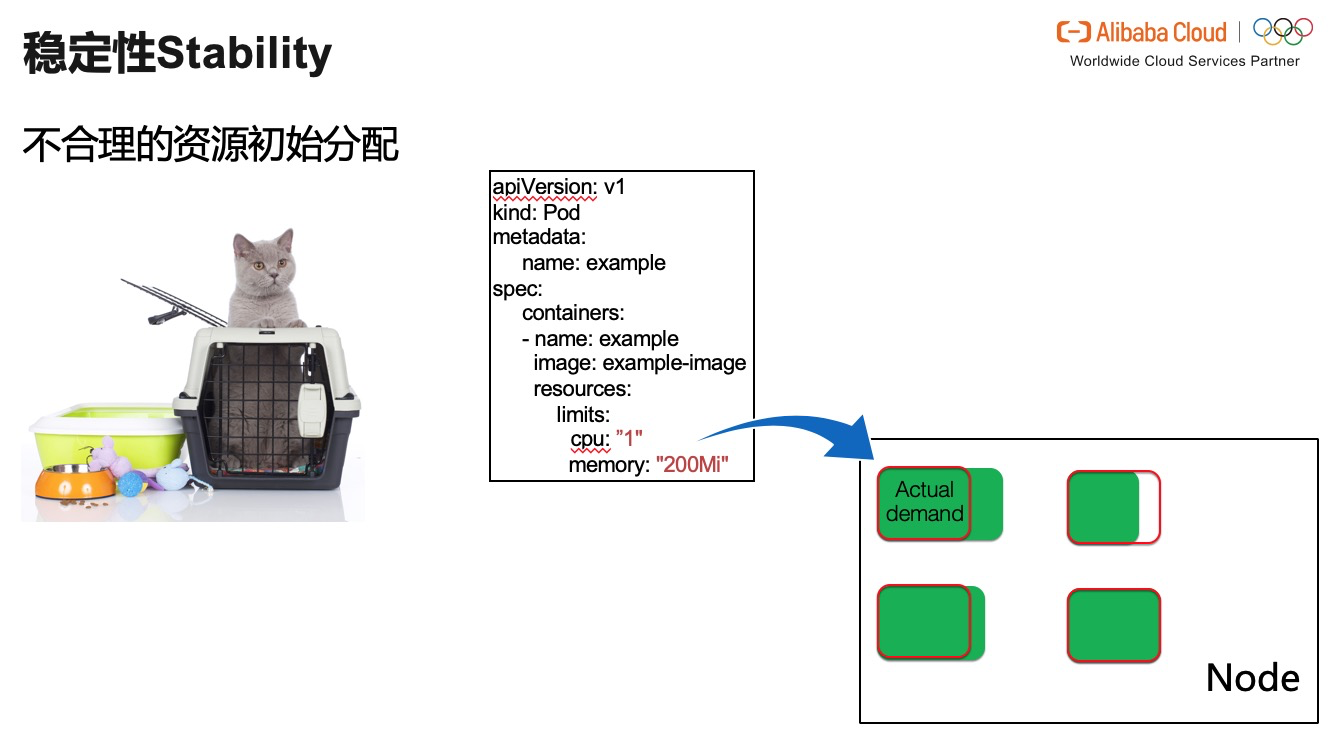
иө„жәҗдёҚи¶іе°ұеҠҝеҝ…йҖ жҲҗж•ҙдёӘеә”з”ЁжңҚеҠЎзЁіе®ҡжҖ§дёӢйҷҚгҖӮдҫӢеҰӮдёҠеӣҫзҡ„еңәжҷҜпјҡиҷҪ然жҳҜеҗҢдёҖз§Қеә”з”Ёзҡ„еүҜжң¬пјҢжҲ–и®ёжҳҜз”ұдәҺиҙҹиҪҪеқҮиЎЎдёҚеӨҹејәеӨ§пјҢжҲ–иҖ…жҳҜз”ұдәҺеә”з”ЁиҮӘиә«зҡ„еҺҹеӣ пјҢз”ҡиҮіжҳҜз”ұдәҺжңәеҷЁжң¬иә«жҳҜејӮжһ„зҡ„пјҢзӣёеҗҢж•°еҖјзҡ„иө„жәҗпјҢеҸҜиғҪеҜ№дәҺеҗҢдёҖз§Қеә”з”Ёзҡ„дёҚеҗҢеүҜжң¬е№¶е…·жңүзӣёзӯүзҡ„д»·еҖје’Ңж„Ҹд№үгҖӮеңЁж•°еҖјдёҠ他们зңӢдјјеҲҶй…ҚдәҶзӣёеҗҢзҡ„иө„жәҗпјҢ然иҖҢеңЁе®һйҷ…иҙҹиҪҪе·ҘдҪңж—¶пјҢжһҒжңүеҸҜиғҪеҮәзҺ°зҡ„зҺ°иұЎжҳҜиӮҘзҳҰдёҚеқҮзҡ„гҖӮ
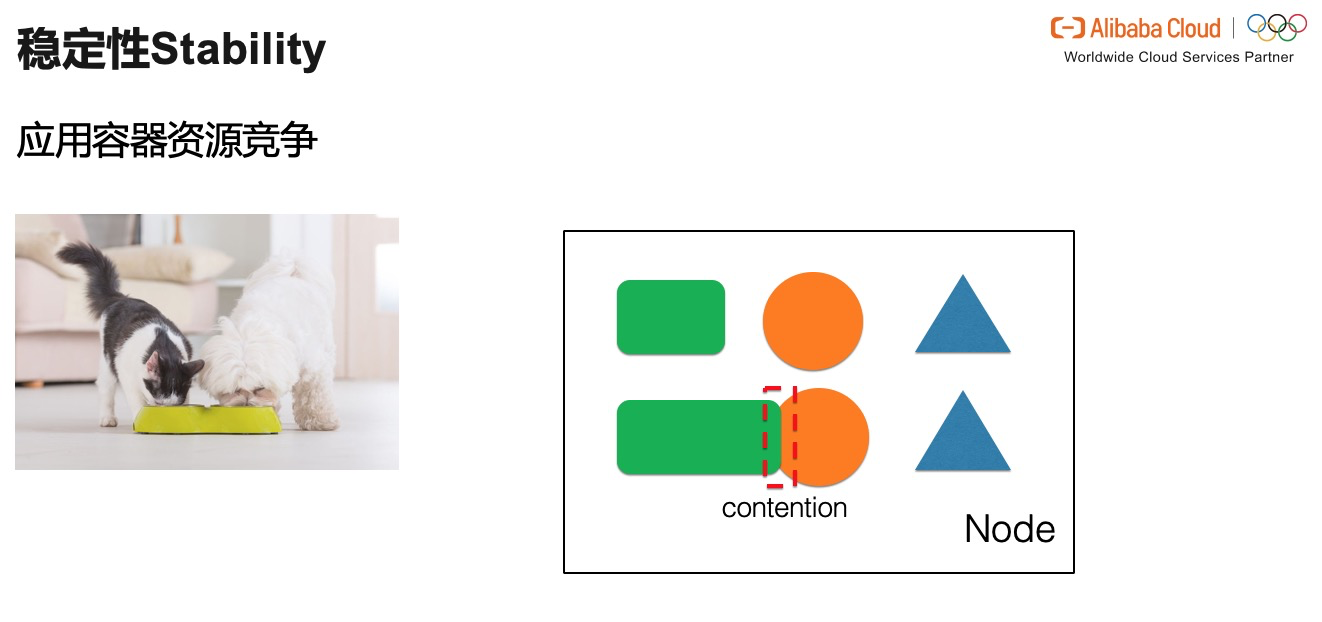
иҖҢеңЁиө„жәҗ overcommit зҡ„еңәжҷҜдёӢпјҢеә”з”ЁеңЁж•ҙдёӘиҠӮзӮ№иө„жәҗдёҚи¶іпјҢжҲ–жҳҜеңЁжүҖеңЁзҡ„ CPU share pool иө„жәҗдёҚи¶іж—¶пјҢд№ҹдјҡеҮәзҺ°дёҘйҮҚзҡ„иө„жәҗз«һдәүе…ізі»гҖӮиө„жәҗз«һдәүжҳҜеҜ№еә”з”ЁзЁіе®ҡжҖ§жңҖеӨ§зҡ„еЁҒиғҒд№ӢдёҖгҖӮжүҖд»ҘжҲ‘们иҰҒе°ҪеҠӣеңЁз”ҹдә§зҺҜеўғдёӯжё…йҷӨжүҖжңүзҡ„еЁҒиғҒгҖӮ
жҲ‘们йғҪзҹҘйҒ“зЁіе®ҡжҖ§жҳҜ件еҫҲйҮҚиҰҒзҡ„дәӢжғ…пјҢе°Өе…¶еҜ№дәҺжҺҢжҺ§дёҠзҷҫдёҮе®№еҷЁз”ҹжқҖеӨ§жқғзҡ„дёҖзәҝз ”еҸ‘дәәе‘ҳгҖӮжҲ–и®ёдёҚз»Ҹеҝғзҡ„дёҖдёӘж“ҚдҪңе°ұжңүеҸҜиғҪйҖ жҲҗеҪұе“Қйқўе·ЁеӨ§зҡ„з”ҹдә§дәӢж•…гҖӮ
еӣ жӯӨпјҢжҲ‘们д№ҹжҢүз…§дёҖиҲ¬жөҒзЁӢеҒҡдәҶзі»з»ҹйў„йҳІе’Ңе…ңеә•е·ҘдҪңгҖӮ
* еңЁйў„йҳІз»ҙеәҰпјҢжҲ‘们еҸҜд»ҘиҝӣиЎҢе…Ёй“ҫи·Ҝзҡ„еҺӢеҠӣжөӢиҜ•пјҢ并且жҸҗеүҚйҖҡиҝҮ科еӯҰзҡ„жүӢж®өйў„еҲӨеә”з”ЁйңҖиҰҒзҡ„еүҜжң¬ж•°е’Ңиө„жәҗйҮҸгҖӮеҰӮжһңжІЎжі•еҮҶзЎ®йў„з®—иө„жәҗпјҢйӮЈе°ұеҸӘйҮҮз”ЁеҶ—дҪҷеҲҶй…Қиө„жәҗзҡ„ж–№ејҸдәҶгҖӮ
* еңЁе…ңеә•з»ҙеәҰпјҢжҲ‘们еҸҜд»ҘеңЁеӨ§и§„жЁЎи®ҝй—®жөҒйҮҸжҠөиҫҫеҗҺпјҢеҜ№дёҚзҙ§иҰҒзҡ„дёҡеҠЎеҒҡжңҚеҠЎйҷҚзә§е№¶еҗҢж—¶еҜ№дё»иҰҒеә”з”ЁиҝӣиЎҢдёҙж—¶жү©е®№гҖӮ
дҪҶжҳҜеҜ№дәҺйҷЎз„¶еўһеҠ еҮ еҲҶй’ҹзҡ„зӘҒеўһжөҒйҮҸпјҢиҝҷд№ҲеӨҡз»„еҗҲжӢізҡ„иҠұиҙ№дёҚиҸІпјҢдјјд№ҺжңүдәӣдёҚеҲ’з®—гҖӮжҲ–и®ёжҲ‘们еҸҜд»ҘжҸҗеҮәдёҖдәӣи§ЈеҶіж–№жЎҲпјҢиҫҫеҲ°жҲ‘们зҡ„йў„жңҹгҖӮ
иө„жәҗеҲ©з”ЁзҺҮ
-----
еӣһйЎҫдёҖдёӢжҲ‘们зҡ„еә”з”ЁйғЁзҪІжғ…еҶөпјҡиҠӮзӮ№дёҠзҡ„е®№еҷЁдёҖиҲ¬еҲҶеұһеӨҡз§Қеә”з”ЁпјҢиҝҷдәӣеә”з”Ёжң¬иә«дёҚдёҖе®ҡпјҢд№ҹдёҖиҲ¬дёҚдјҡеҗҢж—¶еӨ„дәҺи®ҝй—®зҡ„й«ҳеі°гҖӮеҜ№дәҺж··еҗҲйғЁзҪІеә”з”Ёзҡ„е®ҝдё»жңәпјҢеҰӮжһңиғҪйғҪй”ҷеі°еҲҶй…ҚдёҠйқўиҝҗиЎҢе®№еҷЁзҡ„иө„жәҗжҲ–и®ёжӣҙ科еӯҰгҖӮ

еә”з”Ёзҡ„иө„жәҗйңҖжұӮеҸҜиғҪе°ұеғҸжңҲдә®дёҖж ·жңүйҳҙжҷҙеңҶзјәпјҢжңүе‘ЁжңҹеҸҳеҢ–гҖӮдҫӢеҰӮеңЁзәҝдёҡеҠЎпјҢе°Өе…¶жҳҜдәӨжҳ“дёҡеҠЎпјҢе®ғ们еңЁиө„жәҗдҪҝз”ЁдёҠе‘ҲзҺ°дёҖе®ҡзҡ„е‘ЁжңҹжҖ§пјҢдҫӢеҰӮпјҡеңЁеҮҢжҷЁгҖҒдёҠеҚҲж—¶пјҢе®ғзҡ„дҪҝз”ЁйҮҸ并дёҚжҳҜеҫҲй«ҳпјҢиҖҢеңЁеҚҲй—ҙгҖҒдёӢеҚҲж—¶дјҡжҜ”иҫғй«ҳгҖӮ
жү“дёӘжҜ”ж–№пјҡеҜ№дәҺ A еә”з”Ёзҡ„йҮҚиҰҒж—¶еҲ»пјҢеҜ№дәҺ B еә”з”ЁеҸҜиғҪдёҚйӮЈд№ҲйҮҚиҰҒпјҢйҖӮеҪ“жү“еҺӢ B еә”з”ЁпјҢи…ҫжҢӘеҮәиө„жәҗз»ҷ A еә”з”ЁпјҢиҝҷжҳҜдёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮиҝҷеҗ¬иө·жқҘжңүзӮ№еғҸжҳҜеҲҶж—¶еӨҚз”Ёзҡ„ж„ҹи§үгҖӮдҪҶжҳҜеҰӮжһңжҲ‘们жҢүз…§жөҒйҮҸеі°еҖјж—¶зҡ„йңҖжұӮй…ҚзҪ®иө„жәҗе°ұдјҡдә§з”ҹеӨ§йҮҸзҡ„жөӘиҙ№гҖӮ

йҷӨдәҶеҜ№дәҺе®һж—¶жҖ§иҰҒжұӮеҫҲй«ҳзҡ„еңЁзәҝеә”з”ЁеӨ–пјҢжҲ‘们иҝҳжңүзҰ»зәҝеә”з”Ёе’Ңе®һж—¶и®Ўз®—еә”з”ЁзӯүпјҡзҰ»зәҝи®Ўз®—еҜ№дәҺ CPU гҖҒMemory жҲ–зҪ‘з»ңиө„жәҗзҡ„дҪҝз”Ёд»ҘеҸҠж—¶й—ҙдёҚйӮЈд№Ҳж•Ҹж„ҹпјҢжүҖд»ҘеңЁд»»дҪ•ж—¶й—ҙж®өе®ғйғҪеҸҜд»ҘиҝҗиЎҢпјӣе®һж—¶и®Ўз®—пјҢеҸҜиғҪеҜ№дәҺж—¶й—ҙж•Ҹж„ҹжҖ§е°ұдјҡеҫҲй«ҳгҖӮ
ж—©жңҹпјҢжҲ‘们дёҡеҠЎжҳҜеңЁдёҚеҗҢзҡ„иҠӮзӮ№жҢүз…§еә”з”Ёзҡ„зұ»еһӢзӢ¬з«ӢиҝӣиЎҢйғЁзҪІгҖӮд»ҺдёҠйқўиҝҷеј еӣҫжқҘзңӢпјҢеҰӮжһңе®ғ们иҝӣиЎҢеҲҶж—¶еӨҚз”Ёиө„жәҗпјҢй’ҲеҜ№е®һж—¶жҖ§иҝҷдёӘйңҖжұӮеұӮйқўпјҢжҲ‘们дјҡеҸ‘зҺ°е®ғе®һйҷ…зҡ„жңҖеӨ§дҪҝз”ЁйҮҸдёҚжҳҜ 2+2+1=5пјҢиҖҢжҳҜжҹҗдёҖж—¶еҲ»йҮҚиҰҒзҙ§жҖҘеә”з”ЁйңҖжұӮйҮҸзҡ„жңҖеӨ§еҖјпјҢд№ҹе°ұжҳҜ 3 гҖӮеҰӮжһңжҲ‘们иғҪеӨҹж•°жҚ®зӣ‘жөӢеҲ°жҜҸдёӘеә”з”Ёзҡ„зңҹе®һдҪҝз”ЁйҮҸпјҢз»ҷе®ғеҲҶй…ҚеҗҲзҗҶеҖјпјҢйӮЈд№Ҳе°ұиғҪдә§з”ҹиө„жәҗеҲ©з”ЁзҺҮжҸҗеҚҮзҡ„е®һйҷ…ж•ҲжһңгҖӮ
еҜ№дәҺз”өе•Ҷеә”з”ЁпјҢеҜ№дәҺйҮҮз”ЁдәҶйҮҚйҮҸзә§ Java жЎҶжһ¶е’Ңзӣёе…іжҠҖжңҜж Ҳзҡ„ Web еә”з”ЁпјҢзҹӯж—¶й—ҙеҶ… HPA жҲ–иҖ… VPA йғҪдёҚжҳҜ件容жҳ“зҡ„дәӢжғ…гҖӮ
е…ҲиҜҙ HPAпјҢжҲ‘们жҲ–и®ёеҸҜд»Ҙз§’зә§жӢүиө·дәҶ PodпјҢеҲӣе»әж–°зҡ„е®№еҷЁпјҢ然иҖҢжӢүиө·зҡ„е®№еҷЁжҳҜеҗҰзңҹзҡ„еҸҜз”Ёе‘ўгҖӮд»ҺеҲӣе»әеҲ°еҸҜз”ЁпјҢеҸҜиғҪйңҖиҰҒжҜ”иҫғд№…зҡ„ж—¶й—ҙпјҢеҜ№дәҺеӨ§дҝғе’ҢжҠўиҙӯз§’жқҖ-иҝҷз§Қи®ҝй—®йҮҸвҖңжҙӘеі°вҖқеҸҜиғҪд»…з»ҙжҢҒеҮ еҲҶй’ҹжҲ–иҖ…еҚҒеҮ еҲҶй’ҹзҡ„е®һйҷ…еңәжҷҜпјҢеҰӮжһңжҲ‘们зӯүеҲ° HPA зҡ„еүҜжң¬е…ЁйғЁеҸҜз”ЁпјҢеҸҜиғҪеёӮеңәжҙ»еҠЁж—©е·Із»Ҹз»“жқҹдәҶгҖӮ
иҮідәҺзӨҫеҢәзӣ®еүҚзҡ„ VPA еңәжҷҜпјҢеҲ жҺүж—§ PodпјҢеҲӣе»әж–° PodпјҢиҝҷж ·зҡ„йҖ»иҫ‘жӣҙйҡҫжҺҘеҸ—гҖӮжүҖд»Ҙз»јеҗҲиҖғиҷ‘пјҢжҲ‘们йңҖиҰҒдёҖдёӘжӣҙе®һйҷ…зҡ„и§ЈеҶіж–№жЎҲејҘиЎҘ HPA е’Ң VPA зҡ„еңЁиҝҷдёҖеҚ•жңәиө„жәҗи°ғеәҰзҡ„з©әзјәгҖӮ
и§ЈеҶіж–№жЎҲ
====
дәӨд»ҳж ҮеҮҶ
----
жҲ‘们йҰ–е…ҲиҰҒеҜ№и§ЈеҶіж–№жЎҲи®ҫе®ҡдёҖдёӘеҸҜд»ҘдәӨд»ҳзҡ„ж ҮеҮҶйӮЈе°ұжҳҜвҖ”вҖ” вҖңж—ўиҰҒзЁіе®ҡжҖ§пјҢд№ҹиҰҒеҲ©з”ЁзҺҮпјҢиҝҳиҰҒиҮӘеҠЁеҢ–е®һж–ҪпјҢеҪ“然еҰӮжһңиғҪеӨҹжҷәиғҪеҢ–йӮЈе°ұжӣҙеҘҪвҖқпјҢ然еҗҺеҶҚдәӨд»ҳж ҮеҮҶиҝӣиЎҢз»ҶеҢ–пјҡ
* е®үе…ЁзЁіе®ҡпјҡе·Ҙе…·жң¬иә«й«ҳеҸҜз”ЁгҖӮжүҖз”Ёзҡ„з®—жі•е’Ңе®һж–ҪжүӢж®өеҝ…йЎ»еҒҡеҲ°еҸҜжҺ§пјӣ
* дёҡеҠЎе®№еҷЁжҢүйңҖеҲҶй…Қиө„жәҗпјҡеҸҜд»ҘеҸҠж—¶ж №жҚ®дёҡеҠЎе®һж—¶иө„жәҗж¶ҲиҖ—еҜ№дёҚеӨӘд№…иҝңзҡ„е°ҶжқҘиҝӣиЎҢиө„жәҗж¶ҲиҖ—йў„жөӢпјҢи®©з”ЁжҲ·жҳҺзҷҪдёҡеҠЎжҺҘдёӢжқҘеҜ№дәҺиө„жәҗзҡ„зңҹе®һйңҖжұӮпјӣ
* е·Ҙе…·жң¬иә«иө„жәҗејҖй”Җе°Ҹпјҡе·Ҙе…·жң¬иә«иө„жәҗзҡ„ж¶ҲиҖ—иҰҒе°ҪеҸҜиғҪе°ҸпјҢдёҚиҰҒжҲҗдёәиҝҗз»ҙзҡ„иҙҹжӢ…пјӣ
* ж“ҚдҪңж–№дҫҝпјҢжү©еұ•жҖ§ејәпјҡиғҪеҒҡеҲ°ж— йңҖжҺҘеҸ—еҹ№и®ӯеҚіеҸҜзҺ©иҪ¬иҝҷдёӘе·Ҙе…·пјҢеҪ“然е·Ҙе…·иҝҳиҰҒе…·жңүиүҜеҘҪжү©еұ•жҖ§пјҢдҫӣз”ЁжҲ· DIYпјӣ
* еҝ«йҖҹеҸ‘зҺ° & еҸҠж—¶е“Қеә”пјҡе®һж—¶жҖ§пјҢд№ҹе°ұжҳҜжңҖйҮҚиҰҒзҡ„зү№иҙЁпјҢиҝҷд№ҹжҳҜе’ҢHPAжҲ–иҖ…VPAеңЁи§ЈеҶіиө„жәҗи°ғеәҰй—®йўҳж–№ејҸдёҚеҗҢзҡ„ең°ж–№гҖӮ
и®ҫи®ЎдёҺе®һзҺ°
-----
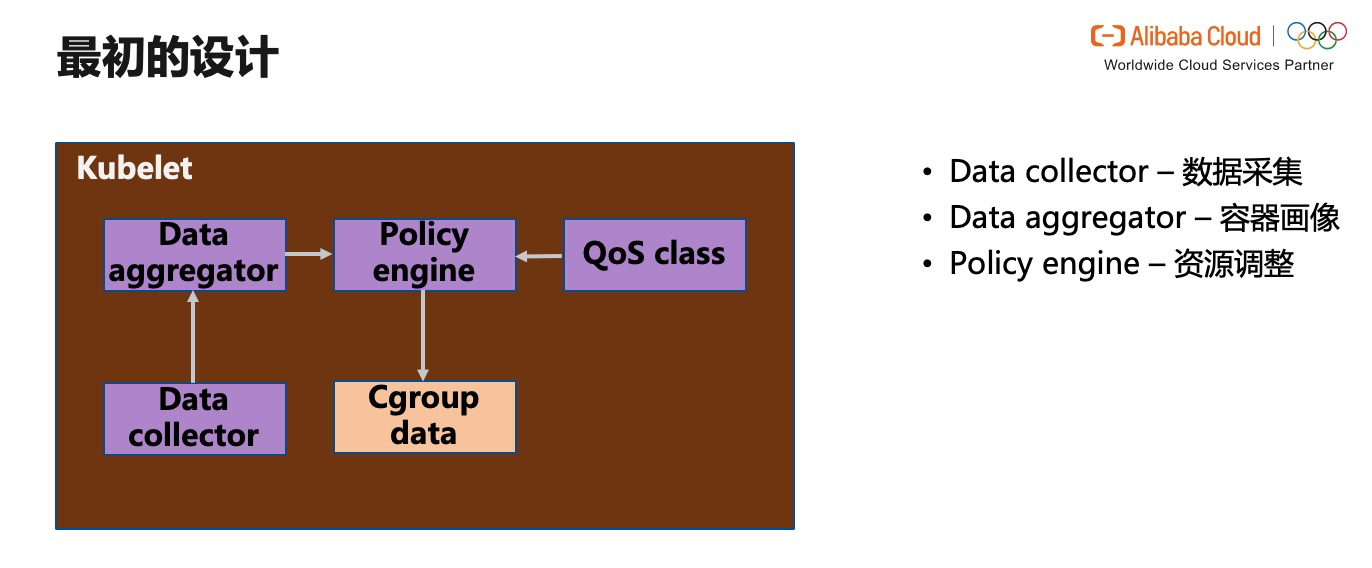
дёҠеӣҫжҳҜжҲ‘们жңҖеҲқзҡ„е·Ҙе…·жөҒзЁӢи®ҫи®ЎпјҡеҪ“дёҖдёӘеә”з”ЁйқўдёҙеҫҲй«ҳзҡ„дёҡеҠЎи®ҝй—®йңҖжұӮж—¶пјҢдҪ“зҺ°еңЁ CPUгҖҒMemory жҲ–е…¶д»–иө„жәҗзұ»еһӢйңҖжұӮйҮҸеҸҳеӨ§пјҢжҲ‘д»¬ж №жҚ® Data Collector йҮҮйӣҶзҡ„е®һж—¶еҹәзЎҖж•°жҚ®пјҢеҲ©з”Ё Data Aggregator з”ҹжҲҗжҹҗдёӘе®№еҷЁжҲ–ж•ҙдёӘеә”з”Ёзҡ„з”»еғҸпјҢеҶҚе°Ҷз”»еғҸеҸҚйҰҲз»ҷ Policy engineгҖӮ Policy engine дјҡзһ¬ж—¶еҝ«йҖҹдҝ®ж”№е®№еҷЁ Cgroup ж–Ү件зӣ®еҪ•дёӢзҡ„зҡ„еҸӮж•°гҖӮ
жҲ‘们жңҖж—©зҡ„жһ¶жһ„е’ҢжҲ‘们зҡ„жғіжі•дёҖж ·жңҙе®һпјҢеңЁ kubelet иҝӣиЎҢдәҶдҫөе…ҘејҸзҡ„дҝ®ж”№гҖӮиҷҪ然жҲ‘们еҸӘжҳҜеҠ дәҶеҮ дёӘжҺҘеҸЈпјҢдҪҶжҳҜиҝҷз§Қж–№ејҸзЎ®е®һдёҚеӨҹдјҳйӣ…гҖӮжҜҸж¬Ў kubenrnetes еҚҮзә§пјҢеҜ№дәҺ Policy engine зӣёе…із»„件еҚҮзә§д№ҹжңүдёҖе®ҡзҡ„жҢ‘жҲҳгҖӮ
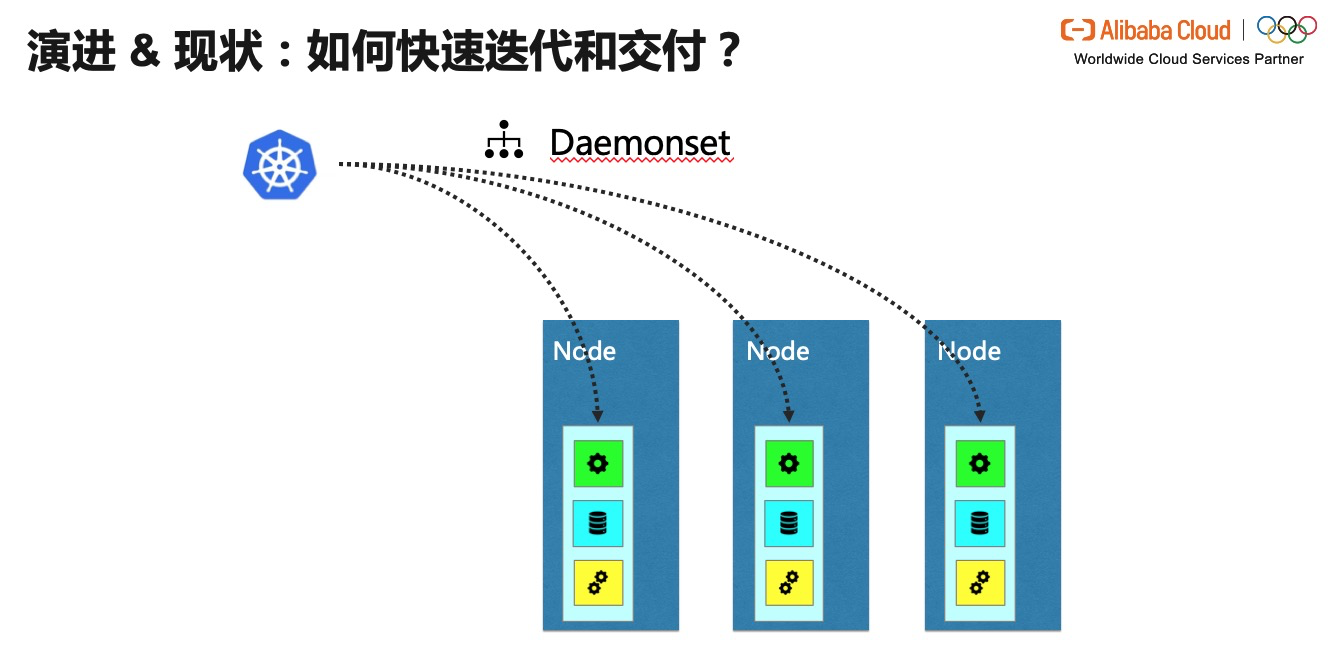
дёәдәҶеҒҡеҲ°еҝ«йҖҹиҝӯ代并е’Ң Kubelet и§ЈиҖҰпјҢжҲ‘们еҜ№дәҺе®һзҺ°ж–№ејҸиҝӣиЎҢдәҶж–°зҡ„жј”иҝӣгҖӮйӮЈе°ұжҳҜе°Ҷе…ій”®еә”з”Ёе®№еҷЁеҢ–гҖӮиҝҷж ·еҸҜд»ҘиҫҫеҲ°д»ҘдёӢеҠҹж•Ҳпјҡ
* дёҚдҫөе…Ҙдҝ®ж”№ K8s ж ёеҝғ组件пјӣ
* ж–№дҫҝиҝӯд»Ј&еҸ‘еёғпјӣ
* еҖҹеҠ©дәҺ Kubernetes зӣёе…ізҡ„ QoS Class жңәеҲ¶пјҢе®№еҷЁзҡ„иө„жәҗй…ҚзҪ®пјҢиө„жәҗејҖй”ҖеҸҜжҺ§гҖӮ
еҪ“然еңЁеҗҺз»ӯжј”иҝӣдёӯпјҢжҲ‘们д№ҹеңЁе°қиҜ•е’Ң HPAпјҢVPA иҝӣиЎҢжү“йҖҡпјҢжҜ•з«ҹиҝҷдәӣе’Ң Policy engine еӯҳеңЁзқҖдә’иЎҘзҡ„е…ізі»гҖӮеӣ жӯӨжҲ‘们жһ¶жһ„иҝӣдёҖжӯҘжј”иҝӣжҲҗеҰӮдёӢжғ…еҪўгҖӮеҪ“ Policy engine еңЁеӨ„зҗҶдёҖдәӣжӣҙеӨҡеӨҚжқӮеңәжҷҜжҗһеҲ°ж— еҠӣж—¶пјҢдёҠжҠҘдәӢ件让дёӯеҝғз«ҜеҒҡеҮәжӣҙе…ЁеұҖзҡ„еҶізӯ–гҖӮж°ҙе№іжү©е®№жҲ–жҳҜеһӮзӣҙеўһеҠ иө„жәҗгҖӮ
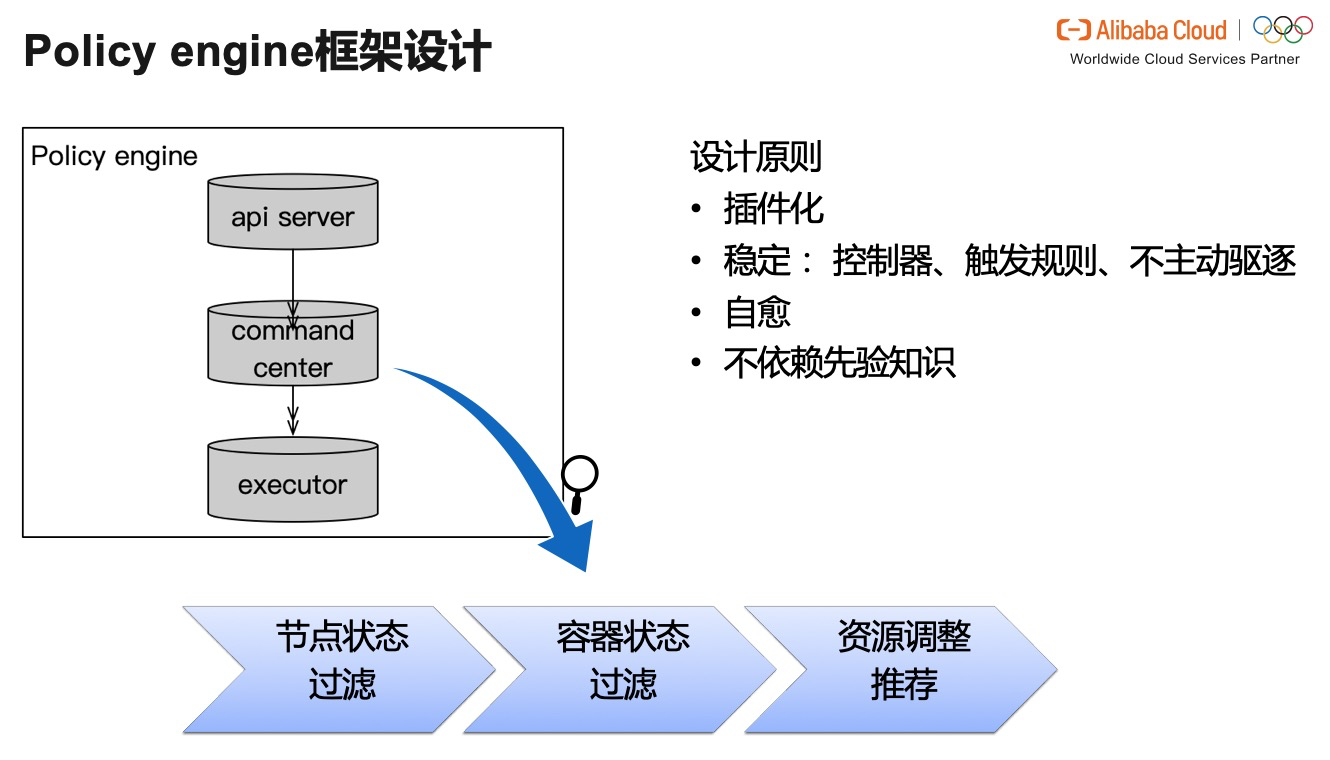
дёӢйқўжҲ‘们具дҪ“и®Ёи®әдёҖдёӢ Policy engine зҡ„и®ҫи®ЎгҖӮPolicy engine жҳҜеҚ•жңәиҠӮзӮ№дёҠиҝӣиЎҢжҷәиғҪи°ғеәҰ并жү§иЎҢ Pod иө„жәҗи°ғж•ҙзҡ„ж ёеҝғ组件гҖӮе®ғдё»иҰҒеҢ…жӢ¬ api serverпјҢжҢҮжҢҘдёӯеҝғ command center е’Ңжү§иЎҢеұӮ executorгҖӮ
* е…¶дёӯ api server з”ЁдәҺжңҚеҠЎеӨ–з•ҢеҜ№дәҺ policy engine иҝҗиЎҢзҠ¶жҖҒзҡ„жҹҘиҜўе’Ңи®ҫзҪ®зҡ„иҜ·жұӮпјӣ
* command center ж №жҚ®е®һж—¶зҡ„е®№еҷЁз”»еғҸе’Ңзү©зҗҶжңәжң¬иә«зҡ„иҙҹиҪҪд»ҘеҸҠиө„жәҗдҪҝз”Ёжғ…еҶөпјҢдҪңеҮә Pod иө„жәҗи°ғж•ҙзҡ„еҶізӯ–пјӣ
* Executor еҶҚж №жҚ® command center зҡ„еҶізӯ–пјҢеҜ№е®№еҷЁзҡ„иө„жәҗйҷҗеҲ¶иҝӣиЎҢи°ғж•ҙгҖӮеҗҢж—¶пјҢexecutor д№ҹжҠҠжҜҸж¬Ўи°ғж•ҙзҡ„ revision info жҢҒд№…еҢ–пјҢд»ҘдҫҝеҸ‘з”ҹж•…йҡңж—¶еҸҜд»Ҙеӣһж»ҡгҖӮ
жҢҮжҢҘдёӯеҝғе®ҡжңҹд»Һ data aggregator иҺ·еҸ–е®№еҷЁзҡ„е®һж—¶з”»еғҸпјҢеҢ…жӢ¬иҒҡеҗҲзҡ„з»ҹи®Ўж•°жҚ®е’Ңйў„жөӢж•°жҚ®пјҢйҰ–е…ҲеҲӨж–ӯиҠӮзӮ№зҠ¶жҖҒпјҢдҫӢеҰӮиҠӮзӮ№зЈҒзӣҳејӮеёёпјҢжҲ–иҖ…зҪ‘з»ңдёҚйҖҡпјҢиЎЁзӨәиҜҘиҠӮзӮ№е·Із»ҸеҸ‘з”ҹејӮеёёпјҢйңҖиҰҒдҝқжҠӨзҺ°еңәпјҢдёҚеҶҚеҜ№PodиҝӣиЎҢиө„жәҗи°ғж•ҙпјҢд»Ҙе…ҚйҖ жҲҗзі»з»ҹйңҮиҚЎпјҢеҪұе“Қиҝҗз»ҙе’Ңи°ғиҜ•гҖӮеҰӮжһңиҠӮзӮ№зҠ¶жҖҒжӯЈеёёпјҢжҢҮжҢҘдёӯеҝғдјҡзӯ–з•Ҙ规еҲҷпјҢеҜ№е®№еҷЁж•°жҚ®иҝӣиЎҢеҶҚж¬ЎиҝҮж»ӨгҖӮжҜ”еҰӮе®№еҷЁ CPU зҺҮйЈҷй«ҳпјҢжҲ–иҖ…е®№еҷЁзҡ„е“Қеә”ж—¶й—ҙи¶…иҝҮе®үе…ЁйҳҲеҖјгҖӮеҰӮжһңжқЎд»¶ж»Ўи¶іпјҢеҲҷеҜ№ж»Ўи¶іжқЎд»¶зҡ„е®№еҷЁйӣҶеҗҲз»ҷеҮәиө„жәҗи°ғж•ҙе»әи®®пјҢдј йҖ’з»ҷexecutorгҖӮ
еңЁжһ¶жһ„и®ҫи®ЎдёҠпјҢжҲ‘们йҒөеҫӘдәҶд»ҘдёӢеҺҹеҲҷпјҡ
* жҸ’件еҢ–пјҡжүҖжңүзҡ„规еҲҷе’Ңзӯ–з•Ҙиў«и®ҫи®ЎдёәеҸҜд»ҘйҖҡиҝҮй…ҚзҪ®ж–Ү件жқҘдҝ®ж”№пјҢе°ҪйҮҸдёҺж ёеҝғжҺ§еҲ¶жөҒзЁӢзҡ„д»Јз Ғи§ЈиҖҰпјҢдёҺ data collector е’Ң data aggregator зӯү其他组件зҡ„жӣҙж–°е’ҢеҸ‘еёғи§ЈиҖҰпјҢжҸҗеҚҮеҸҜжү©еұ•жҖ§пјӣ
* зЁіе®ҡпјҢиҝҷеҢ…жӢ¬д»ҘдёӢеҮ дёӘж–№йқўпјҡ
* жҺ§еҲ¶еҷЁзЁіе®ҡжҖ§гҖӮжҢҮжҢҘдёӯеҝғзҡ„еҶізӯ–д»ҘдёҚеҪұе“ҚеҚ•жңәд№ғиҮіе…ЁеұҖзЁіе®ҡжҖ§дёәеүҚжҸҗпјҢеҢ…жӢ¬е®№еҷЁзҡ„жҖ§иғҪзЁіе®ҡе’Ңиө„жәҗеҲҶй…ҚзЁіе®ҡгҖӮдҫӢеҰӮпјҢзӣ®еүҚжҜҸдёӘжҺ§еҲ¶еҷЁд»…иҙҹиҙЈдёҖз§Қ cgroup иө„жәҗзҡ„жҺ§еҲ¶пјҢеҚіеңЁеҗҢдёҖж—¶й—ҙзӘ—еҸЈеҶ…пјҢPolicy engine дёҚеҗҢж—¶и°ғж•ҙеӨҡз§Қиө„жәҗпјҢд»Ҙе…ҚйҖ жҲҗиө„жәҗеҲҶй…ҚйңҮиҚЎпјҢе№Іжү°и°ғж•ҙж•Ҳжһңпјӣ
* и§ҰеҸ‘规еҲҷзЁіе®ҡжҖ§гҖӮдҫӢеҰӮпјҢжҹҗдёҖжқЎи§„еҲҷзҡ„еҺҹе§Ӣи§ҰеҸ‘жқЎд»¶дёәе®№еҷЁзҡ„жҖ§иғҪжҢҮж Үи¶…еҮәе®үе…ЁйҳҲеҖјпјҢдҪҶжҳҜдёәйҒҝе…ҚжҺ§еҲ¶еҠЁдҪңиў«жҹҗдёҖзӘҒеҸ‘еі°еҖји§ҰеҸ‘иҖҢеҜјиҮҙйңҮиҚЎпјҢжҲ‘们жҠҠи§ҰеҸ‘规еҲҷе®ҡеҲ¶дёәпјҡиҝҮеҺ»дёҖж®өж—¶й—ҙзӘ—еҸЈеҶ…жҖ§иғҪжҢҮж Үзҡ„дҪҺзҷҫеҲҶдҪҚи¶…еҮәе®үе…ЁйҳҲеҖјпјӣеҰӮжһң规еҲҷж»Ўи¶іпјҢиҜҙжҳҺиҝҷж®өж—¶й—ҙеҶ…з»қеӨ§йғЁеҲҶзҡ„жҖ§иғҪжҢҮж ҮеҖјйғҪе·Із»Ҹи¶…еҮәдәҶе®үе…ЁйҳҲеҖјпјҢе°ұйңҖиҰҒи§ҰеҸ‘жҺ§еҲ¶еҠЁдҪңдәҶпјӣ
* еҸҰеӨ–пјҢдёҺзӨҫеҢәзүҲВ Vertical-Pod-Autoscaler дёҚеҗҢпјҢPolicy engine дёҚдё»еҠЁй©ұйҖҗи…ҫжҢӘе®№еҷЁпјҢиҖҢжҳҜзӣҙжҺҘдҝ®ж”№е®№еҷЁзҡ„ cgroup ж–Ү件пјӣ
* иҮӘж„Ҳпјҡиө„жәҗи°ғж•ҙзӯүеҠЁдҪңзҡ„жү§иЎҢеҸҜиғҪдјҡдә§з”ҹдёҖдәӣејӮеёёпјҢжҲ‘们еңЁжҜҸдёӘжҺ§еҲ¶еҷЁеҶ…йғҪеҠ е…ҘдәҶиҮӘж„Ҳеӣһж»ҡжңәеҲ¶пјҢдҝқиҜҒж•ҙдёӘзі»з»ҹзҡ„зЁіе®ҡжҖ§пјӣ
* дёҚдҫқиө–еә”з”Ёе…ҲйӘҢзҹҘиҜҶпјҡдёәжүҖжңүдёҚеҗҢзҡ„еә”з”ЁеҲҶеҲ«иҝӣиЎҢеҺӢжөӢгҖҒе®ҡеҲ¶зӯ–з•ҘпјҢжҲ–иҖ…жҸҗеүҚеҜ№еҸҜиғҪжҺ’йғЁеңЁдёҖиө·зҡ„еә”з”ЁиҝӣиЎҢеҺӢжөӢпјҢдјҡеҜјиҮҙе·ЁеӨ§ејҖй”ҖпјҢеҸҜжү©еұ•жҖ§йҷҚдҪҺгҖӮжҲ‘们зҡ„зӯ–з•ҘеңЁи®ҫи®ЎдёҠе°ҪеҸҜиғҪйҖҡз”ЁпјҢе°ҪйҮҸйҮҮз”ЁдёҚдҫқиө–дәҺе…·дҪ“е№іеҸ°гҖҒж“ҚдҪңзі»з»ҹгҖҒеә”з”Ёзҡ„жҢҮж Үе’ҢжҺ§еҲ¶зӯ–з•ҘгҖӮ
еңЁиө„жәҗи°ғж•ҙж–№йқўпјҢCgroup ж”ҜжҢҒжҲ‘们еҜ№еҗ„дёӘе®№еҷЁзҡ„ CPUгҖҒеҶ…еӯҳгҖҒзҪ‘з»ңе’ҢзЈҒзӣҳ IO еёҰе®Ҫиө„жәҗиҝӣиЎҢйҡ”зҰ»е’ҢйҷҗеҲ¶пјҢзӣ®еүҚжҲ‘们主иҰҒеҜ№е®№еҷЁзҡ„ CPU иө„жәҗиҝӣиЎҢи°ғж•ҙпјҢеҗҢж—¶еңЁжөӢиҜ•дёӯжҺўзҙўеңЁж—¶еҲҶеӨҚз”Ёзҡ„еңәжҷҜдёӢеҠЁжҖҒи°ғж•ҙ memory limit е’Ң swap usage иҖҢйҒҝе…Қ OOM зҡ„еҸҜиЎҢжҖ§пјӣеңЁжңӘжқҘжҲ‘们е°Ҷж”ҜжҢҒеҜ№е®№еҷЁзҡ„зҪ‘з»ңе’ҢзЈҒзӣҳ IO зҡ„еҠЁжҖҒи°ғж•ҙгҖӮ
и°ғж•ҙж•Ҳжһң
----
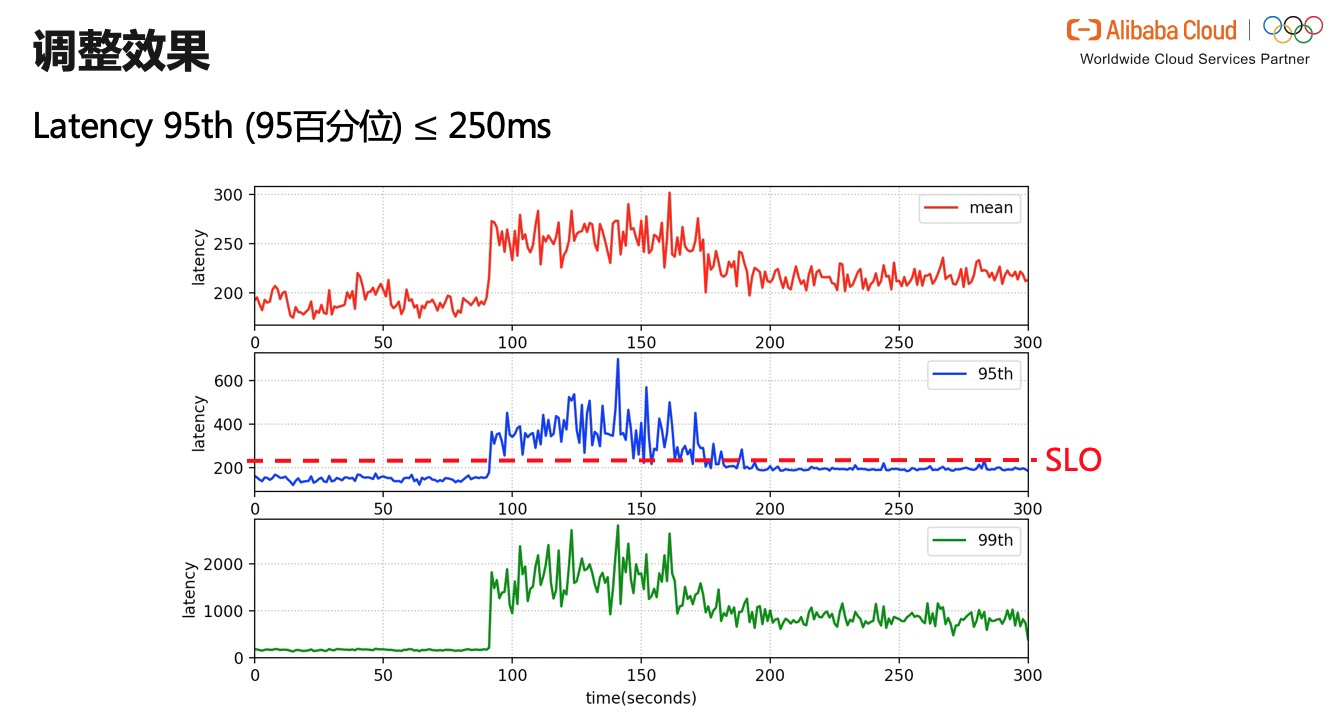
дёҠеӣҫеұ•зӨәдәҶжҲ‘们еңЁжөӢиҜ•йӣҶзҫӨеҫ—еҲ°зҡ„дёҖдәӣе®һйӘҢз»“жһңгҖӮжҲ‘们жҠҠй«ҳдјҳе…Ҳзә§зҡ„еңЁзәҝеә”з”Ёе’ҢдҪҺдјҳе…Ҳзә§зҡ„зҰ»зәҝеә”з”Ёж··еҗҲйғЁзҪІеңЁжөӢиҜ•йӣҶзҫӨйҮҢгҖӮSLO жҳҜ 250msпјҢжҲ‘们еёҢжңӣеңЁзәҝеә”з”Ёзҡ„ latency зҡ„ 95 зҷҫеҲҶдҪҚеҖјдҪҺдәҺйҳҲеҖј 250msгҖӮ
еңЁе®һйӘҢз»“жһңдёӯеҸҜд»ҘзңӢеҲ°пјҡ
* еңЁеӨ§зәҰ90sеүҚпјҢеңЁзәҝеә”з”Ёзҡ„иҙҹиҪҪеҫҲдҪҺпјӣlatency зҡ„еқҮеҖје’ҢзҷҫеҲҶдҪҚйғҪеңЁ 250ms д»ҘдёӢпјӣ
* еҲ°дәҶВ 90sеҗҺпјҢжҲ‘们з»ҷеңЁзәҝеә”з”ЁеҠ еҺӢпјҢжөҒйҮҸеўһеҠ пјҢиҙҹиҪҪд№ҹеҚҮй«ҳпјҢеҜјиҮҙеңЁзәҝеә”з”Ё latency зҡ„ 95 зҷҫеҲҶдҪҚеҖји¶…иҝҮдәҶ SLOпјӣ
* еңЁеӨ§зәҰ 150s е·ҰеҸіпјҢжҲ‘们зҡ„е°ҸжӯҘеҝ«и·‘жҺ§еҲ¶зӯ–з•Ҙиў«и§ҰеҸ‘пјҢжёҗиҝӣејҸең° throttle дёҺеңЁзәҝеә”з”ЁеҸ‘з”ҹиө„жәҗз«һдәүзҡ„зҰ»зәҝеә”з”Ёпјӣ
* еҲ°дәҶеӨ§зәҰ 200s е·ҰеҸіпјҢеңЁзәҝеә”з”Ёзҡ„жҖ§иғҪжҒўеӨҚжӯЈеёёпјҢlatency зҡ„ 95 зҷҫеҲҶдҪҚеӣһиҗҪеҲ° SLO д»ҘдёӢгҖӮ
иҝҷиҜҙжҳҺдәҶжҲ‘们зҡ„жҺ§еҲ¶зӯ–з•Ҙзҡ„жңүж•ҲжҖ§гҖӮ
з»ҸйӘҢе’Ңж•ҷи®ӯ
=====
дёӢйқўжҲ‘们жҖ»з»“дёҖдёӢеңЁж•ҙдёӘйЎ№зӣ®зҡ„иҝӣиЎҢиҝҮзЁӢдёӯпјҢжҲ‘们收иҺ·зҡ„дёҖдәӣз»ҸйӘҢе’Ңж•ҷи®ӯпјҢеёҢжңӣиҝҷдәӣз»ҸйӘҢж•ҷи®ӯиғҪеӨҹеҜ№йҒҮеҲ°зұ»дјјй—®йўҳе’ҢеңәжҷҜзҡ„дәәжңүжүҖеё®еҠ©гҖӮ
1. йҒҝејҖзЎ¬зј–з ҒпјҢ组件еҫ®жңҚеҠЎеҢ–пјҢдёҚд»…дҫҝдәҺеҝ«йҖҹжј”иҝӣе’Ңиҝӯд»ЈпјҢиҝҳжңүеҲ©дәҺзҶ”ж–ӯејӮеёёжңҚеҠЎгҖӮ
2. е°ҪеҸҜиғҪдёҚиҰҒи°ғз”Ёзұ»еә“дёӯиҝҳжҳҜ alpha жҲ–иҖ… beta зү№жҖ§зҡ„жҺҘеҸЈгҖӮ дҫӢеҰӮжҲ‘们жӣҫз»ҸзӣҙжҺҘи°ғз”Ё CRI жҺҘеҸЈиҜ»еҸ–е®№еҷЁзҡ„дёҖдәӣдҝЎжҒҜпјҢжҲ–иҖ…еҒҡдёҖдәӣжӣҙж–°ж“ҚдҪңпјҢдҪҶжҳҜйҡҸзқҖжҺҘеҸЈеӯ—ж®өжҲ–иҖ…ж–№жі•зҡ„дҝ®ж”№пјҢе…ұе»әжңүдәӣеҠҹиғҪе°ұдјҡеҸҳеҫ—дёҚеҸҜз”ЁпјҢжҲ–и®ёжңүж—¶еҖҷпјҢи°ғз”ЁдёҚзЁіе®ҡзҡ„жҺҘеҸЈиҝҳдёҚеҰӮзӣҙжҺҘиҺ·еҸ–жҹҗдёӘеә”з”Ёзҡ„жү“еҚ°дҝЎжҒҜеҸҜиғҪжӣҙйқ и°ұгҖӮ
3. еҹәдәҺ QoS зҡ„иө„жәҗеҠЁжҖҒи°ғж•ҙж–№йқўпјҡеҰӮжҲ‘们д№ӢеүҚжүҖи®ІпјҢйҳҝйҮҢйӣҶеӣўеҶ…йғЁжңүдёҠдёҮдёӘеә”з”ЁпјҢеә”з”Ёд№Ӣй—ҙзҡ„и°ғз”Ёй“ҫзӣёеҪ“еӨҚжқӮгҖӮеә”з”Ё A зҡ„е®№еҷЁжҖ§иғҪеҸ‘з”ҹејӮеёёпјҢдёҚдёҖе®ҡйғҪжҳҜеңЁеҚ•жңәиҠӮзӮ№дёҠзҡ„иө„жәҗдёҚи¶іжҲ–иҖ…иө„жәҗз«һдәүеҜјиҮҙпјҢиҖҢеҫҲжңүеҸҜиғҪжҳҜе®ғдёӢжёёзҡ„еә”з”Ё BгҖҒеә”з”Ё CпјҢжҲ–иҖ…ж•°жҚ®еә“гҖҒcache зҡ„и®ҝ问延иҝҹеҜјиҮҙзҡ„гҖӮз”ұдәҺеҚ•жңәиҠӮзӮ№дёҠиҝҷз§ҚдҝЎжҒҜзҡ„еұҖйҷҗжҖ§пјҢеҹәдәҺеҚ•жңәиҠӮзӮ№дҝЎжҒҜзҡ„иө„жәҗи°ғж•ҙпјҢеҸӘиғҪйҮҮз”ЁвҖңе°ҪеҠӣиҖҢдёәвҖқпјҢд№ҹе°ұжҳҜ best effort зҡ„зӯ–з•ҘдәҶгҖӮеңЁжңӘжқҘпјҢжҲ‘们计еҲ’жү“йҖҡеҚ•жңәиҠӮзӮ№е’Ңдёӯеҝғз«Ҝзҡ„иө„жәҗи°ғжҺ§й“ҫи·ҜпјҢз”ұдёӯеҝғз«Ҝз»јеҗҲеҚ•жңәиҠӮзӮ№дёҠжҠҘзҡ„жҖ§иғҪдҝЎжҒҜе’Ңиө„жәҗи°ғж•ҙиҜ·жұӮпјҢз»ҹдёҖиҝӣиЎҢиө„жәҗзҡ„йҮҚж–°еҲҶй…ҚпјҢжҲ–иҖ…е®№еҷЁзҡ„йҮҚж–°зј–жҺ’пјҢжҲ–иҖ…и§ҰеҸ‘ HPAпјҢд»ҺиҖҢеҪўжҲҗдёҖдёӘйӣҶзҫӨзә§еҲ«зҡ„й—ӯзҺҜзҡ„жҷәиғҪиө„жәҗи°ғжҺ§й“ҫи·ҜпјҢиҝҷе°ҶдјҡеӨ§еӨ§жҸҗй«ҳж•ҙдёӘйӣҶзҫӨз»ҙеәҰзҡ„зЁіе®ҡжҖ§е’Ңз»јеҗҲиө„жәҗеҲ©з”ЁзҺҮгҖӮ
4. иө„жәҗv.s.жҖ§иғҪжЁЎеһӢпјҡеҸҜиғҪжңүдәәе·Із»ҸжіЁж„ҸеҲ°пјҢжҲ‘们зҡ„и°ғж•ҙзӯ–з•ҘйҮҢпјҢ并没жңүжҳҺжҳҫең°жҸҗеҮәдёәе®№еҷЁе»әз«ӢвҖңиө„жәҗv.s.жҖ§иғҪвҖқзҡ„жЁЎеһӢгҖӮиҝҷз§ҚжЁЎеһӢеңЁеӯҰжңҜи®әж–ҮйҮҢйқһеёёеёёи§ҒпјҢдёҖиҲ¬жҳҜеҜ№иў«жөӢзҡ„еҮ з§Қеә”з”ЁиҝӣиЎҢдәҶзҰ»зәҝеҺӢжөӢжҲ–иҖ…еңЁзәҝеҺӢжөӢпјҢж”№еҸҳеә”з”Ёзҡ„иө„жәҗеҲҶй…ҚпјҢжөӢйҮҸеә”з”Ёзҡ„жҖ§иғҪжҢҮж ҮпјҢеҫ—еҲ°жҖ§иғҪйҡҸиө„жәҗеҸҳеҢ–зҡ„жӣІзәҝпјҢжңҖз»Ҳз”ЁеңЁе®һж—¶зҡ„иө„жәҗи°ғжҺ§з®—жі•дёӯгҖӮеңЁеә”з”Ёж•°йҮҸжҜ”иҫғе°‘пјҢи°ғз”Ёй“ҫжҜ”иҫғз®ҖеҚ•пјҢйӣҶзҫӨйҮҢзҡ„зү©зҗҶжңә硬件й…ҚзҪ®д№ҹжҜ”иҫғе°‘зҡ„жғ…еҶөдёӢпјҢиҝҷз§ҚеҹәдәҺеҺӢжөӢзҡ„ж–№жі•еҸҜд»Ҙз©·дёҫеҲ°жүҖжңүеҸҜиғҪзҡ„жғ…еҶөпјҢжүҫеҲ°жңҖдјҳжҲ–иҖ…ж¬Ўдјҳзҡ„иө„жәҗи°ғж•ҙж–№жЎҲпјҢд»ҺиҖҢеҫ—еҲ°жҜ”иҫғеҘҪзҡ„жҖ§иғҪгҖӮдҪҶжҳҜеңЁйҳҝйҮҢйӣҶеӣўзҡ„еңәжҷҜдёӢпјҢжҲ‘们жңүдёҠдёҮдёӘеә”з”ЁпјҢеҫҲеӨҡйҮҚзӮ№еә”з”Ёзҡ„зүҲжң¬еҸ‘еёғд№ҹйқһеёёйў‘з№ҒпјҢеҫҖеҫҖж–°зүҲжң¬еҸ‘еёғеҗҺпјҢж—§зҡ„еҺӢжөӢж•°жҚ®пјҢжҲ–иҖ…иҜҙиө„жәҗжҖ§иғҪжЁЎеһӢпјҢе°ұдёҚйҖӮз”ЁдәҶгҖӮеҸҰеӨ–пјҢжҲ‘们зҡ„йӣҶзҫӨеҫҲеӨҡжҳҜејӮжһ„йӣҶзҫӨпјҢеңЁжҹҗдёҖз§Қзү©зҗҶжңәдёҠжөӢиҜ•еҫ—еҲ°зҡ„жҖ§иғҪж•°жҚ®пјҢеңЁеҸҰдёҖеҸ°дёҚеҗҢеһӢеҸ·зҡ„зү©зҗҶжңәдёҠе°ұдёҚдјҡеӨҚзҺ°гҖӮиҝҷдәӣйғҪеҜ№жҲ‘们зӣҙжҺҘеә”з”ЁеӯҰжңҜи®әж–ҮйҮҢзҡ„иө„жәҗи°ғжҺ§з®—жі•еёҰжқҘдәҶйҡңзўҚгҖӮжүҖд»ҘпјҢй’ҲеҜ№йҳҝйҮҢйӣҶеӣўеҶ…йғЁзҡ„еңәжҷҜпјҢжҲ‘们йҮҮз”ЁдәҶиҝҷж ·зҡ„зӯ–з•ҘпјҡдёҚеҜ№еә”з”ЁиҝӣиЎҢзҰ»зәҝеҺӢжөӢпјҢиҺ·еҸ–жҳҫзӨәзҡ„иө„жәҗжҖ§иғҪжЁЎеһӢгҖӮиҖҢжҳҜе»әз«Ӣе®һж—¶зҡ„еҠЁжҖҒе®№еҷЁз”»еғҸпјҢз”ЁиҝҮеҺ»дёҖж®өж—¶й—ҙзӘ—еҸЈеҶ…е®№еҷЁиө„жәҗдҪҝз”Ёжғ…еҶөзҡ„з»ҹи®Ўж•°жҚ®дҪңдёәеҜ№жңӘжқҘдёҖе°Ҹж®өж—¶й—ҙеҶ…зҡ„йў„жөӢпјҢ并且еҠЁжҖҒжӣҙж–°пјӣжңҖеҗҺеҹәдәҺиҝҷдёӘеҠЁжҖҒзҡ„е®№еҷЁз”»еғҸпјҢжү§иЎҢе°ҸжӯҘеҝ«и·‘зҡ„иө„жәҗи°ғж•ҙзӯ–з•ҘпјҢиҫ№иө°иҫ№зңӢпјҢе°ҪеҠӣиҖҢдёәгҖӮ
жҖ»з»“дёҺеұ•жңӣ
=====
жҖ»з»“иө·жқҘпјҢжҲ‘们зҡ„е·ҘдҪңдё»иҰҒе®һзҺ°дәҶд»ҘдёӢеҮ ж–№йқўзҡ„收зӣҠпјҡ
* йҖҡиҝҮеҲҶж—¶еӨҚз”Ёд»ҘеҸҠе°ҶдёҚеҗҢдјҳе…Ҳзә§зҡ„е®№еҷЁпјҲд№ҹе°ұжҳҜеңЁзәҝе’ҢзҰ»зәҝд»»еҠЎпјүж··еҗҲйғЁзҪІпјҢ并且йҖҡиҝҮеҜ№е®№еҷЁиө„жәҗйҷҗеҲ¶зҡ„еҠЁжҖҒи°ғж•ҙпјҢдҝқиҜҒдәҶеңЁзәҝеә”з”ЁеңЁдёҚеҗҢиҙҹиҪҪжғ…еҶөдёӢйғҪиғҪеҫ—еҲ°и¶іеӨҹзҡ„иө„жәҗпјҢд»ҺиҖҢжҸҗй«ҳйӣҶзҫӨзҡ„з»јеҗҲиө„жәҗеҲ©з”ЁзҺҮгҖӮ
* йҖҡиҝҮеҜ№еҚ•жңәиҠӮзӮ№дёҠзҡ„е®№еҷЁиө„жәҗзҡ„жҷәиғҪеҠЁжҖҒи°ғж•ҙпјҢйҷҚдҪҺдәҶеә”з”Ёд№Ӣй—ҙзҡ„жҖ§иғҪе№Іжү°пјҢдҝқйҡңй«ҳдјҳе…Ҳзә§еә”з”Ёзҡ„жҖ§иғҪзЁіе®ҡжҖ§
* еҗ„з§Қиө„жәҗи°ғж•ҙзӯ–з•ҘйҖҡиҝҮ Daemonset йғЁзҪІпјҢеҸҜд»ҘиҮӘеҠЁең°гҖҒжҷәиғҪең°еңЁиҠӮзӮ№дёҠиҝҗиЎҢпјҢеҮҸе°‘дәәе·Ҙе№Ійў„пјҢйҷҚдҪҺдәҶиҝҗз»ҙзҡ„дәәеҠӣжҲҗжң¬гҖӮ
еұ•жңӣжңӘжқҘпјҢжҲ‘们еёҢжңӣеңЁд»ҘдёӢеҮ дёӘж–№йқўеҠ ејәе’Ңжү©еұ•жҲ‘们зҡ„е·ҘдҪңпјҡ
* й—ӯзҺҜжҺ§еҲ¶й“ҫи·ҜпјҡеүҚйқўе·Із»ҸжҸҗеҲ°пјҢеҚ•жңәиҠӮзӮ№дёҠз”ұдәҺзјәд№Ҹе…ЁеұҖдҝЎжҒҜпјҢеҜ№дәҺиө„жәҗзҡ„и°ғж•ҙжңүе…¶еұҖйҷҗжҖ§пјҢеҸӘиғҪе°ҪеҠӣиҖҢдёәгҖӮжңӘжқҘпјҢжҲ‘们еёҢжңӣиғҪеӨҹжү“йҖҡдёҺ HPA е’Ң VPA зҡ„йҖҡи·ҜпјҢдҪҝеҚ•жңәиҠӮзӮ№е’Ңдёӯеҝғз«ҜиҒ”еҠЁиҝӣиЎҢиө„жәҗи°ғж•ҙпјҢжңҖеӨ§еҢ–еј№жҖ§дјёзј©зҡ„收зӣҠгҖӮ
* е®№еҷЁйҮҚж–°зј–жҺ’пјҡеҚідҪҝжҳҜеҗҢдёҖдёӘеә”з”ЁпјҢдёҚеҗҢе®№еҷЁзҡ„иҙҹиҪҪе’ҢжүҖеӨ„зҡ„зү©зҗҶзҺҜеўғд№ҹжҳҜеҠЁжҖҒеҸҳеҢ–зҡ„пјҢеҚ•жңәдёҠи°ғж•ҙ pod зҡ„иө„жәҗпјҢдёҚдёҖе®ҡиғҪеӨҹж»Ўи¶іеҠЁжҖҒзҡ„йңҖжұӮгҖӮжҲ‘们еёҢжңӣеҚ•жңәдёҠе®һж—¶е®№еҷЁз”»еғҸпјҢиғҪеӨҹдёәдёӯеҝғз«ҜжҸҗдҫӣжӣҙеӨҡзҡ„жңүж•ҲдҝЎжҒҜпјҢеё®еҠ©дёӯеҝғз«Ҝзҡ„и°ғеәҰеҷЁдҪңеҮәжӣҙеҠ жҷәиғҪзҡ„е®№еҷЁйҮҚзј–жҺ’еҶізӯ–гҖӮ
* зӯ–з•ҘжҷәиғҪеҢ–пјҡжҲ‘们зҺ°еңЁзҡ„иө„жәҗи°ғж•ҙзӯ–з•Ҙд»Қ然жҜ”иҫғзІ—зІ’еәҰпјҢеҸҜд»Ҙи°ғж•ҙзҡ„иө„жәҗд№ҹжҜ”иҫғжңүйҷҗпјӣеҗҺз»ӯжҲ‘们еёҢжңӣи®©иө„жәҗи°ғж•ҙзӯ–з•ҘжӣҙеҠ жҷәиғҪеҢ–пјҢ并且иҖғиҷ‘еҲ°жӣҙеӨҡзҡ„иө„жәҗпјҢжҜ”еҰӮеҜ№зЈҒзӣҳе’ҢзҪ‘з»ңIOеёҰе®Ҫзҡ„и°ғж•ҙпјҢжҸҗй«ҳиө„жәҗи°ғж•ҙзҡ„жңүж•ҲжҖ§гҖӮ
* е®№еҷЁз”»еғҸзІҫз»ҶеҢ–пјҡзӣ®еүҚзҡ„е®№еҷЁз”»еғҸд№ҹжҜ”иҫғзІ—зіҷпјҢд»…д»…дҫқйқ з»ҹи®Ўж•°жҚ®е’ҢзәҝжҖ§йў„жөӢпјӣеҲ»з”»е®№еҷЁжҖ§иғҪзҡ„жҢҮж Үз§Қзұ»д№ҹжҜ”иҫғеұҖйҷҗгҖӮжҲ‘们еёҢжңӣжүҫеҲ°жӣҙеҠ зІҫзЎ®зҡ„гҖҒйҖҡз”Ёзҡ„гҖҒеҸҚжҳ е®№еҷЁжҖ§иғҪзҡ„жҢҮж ҮпјҢд»ҘдҫҝжӣҙеҠ зІҫз»Ҷең°еҲ»з”»е®№еҷЁеҪ“еүҚзҡ„зҠ¶жҖҒе’ҢеҜ№дёҚеҗҢиө„жәҗзҡ„йңҖжұӮзЁӢеәҰгҖӮ
* жҹҘжүҫе№Іжү°жәҗпјҡжҲ‘们еёҢжңӣиғҪжүҫеҲ°еңЁеҚ•жңәиҠӮзӮ№дёҠжүҫеҲ°иЎҢд№Ӣжңүж•Ҳзҡ„ж–№жЎҲпјҢжқҘзІҫеҮҶе®ҡдҪҚеә”з”ЁжҖ§иғҪеҸ—жҚҹж—¶зҡ„е№Іжү°жәҗпјӣиҝҷеҜ№зӯ–з•ҘжҷәиғҪеҢ–д№ҹжңүеҫҲеӨ§ж„Ҹд№үгҖӮ
Q & A
=====
**Q1пјҡ**зӣҙжҺҘдҝ®ж”№ cgroup е®№еҷЁдёҖе®ҡдјҡиҺ·еҫ—иө„жәҗеҗ—пјҹ
**A1пјҡ**е®№еҷЁжҠҖжңҜйҡ”зҰ»зҡ„жҠҖжңҜеҹәзЎҖе°ұжҳҜ cgroup еұӮйқўгҖӮеңЁе®ҝдё»жңәи…ҫеҮәи¶іеӨҹиө„жәҗзҡ„жғ…еҶөдёӢпјҢз»ҷ cgroup и®ҫзҪ®жӣҙеӨ§зҡ„еҖјеҸҜд»ҘиҺ·еҸ–жӣҙеӨҡзҡ„иө„жәҗгҖӮеҗҢзҗҶпјҢеҜ№дәҺдёҖиҲ¬дјҳе…Ҳзә§дёҚй«ҳзҡ„еә”з”ЁпјҢи®ҫзҪ®иҫғдҪҺзҡ„ cgroup иө„жәҗеҖје°ұдјҡиҫҫеҲ°жҠ‘еҲ¶е®№еҷЁиҝҗиЎҢзҡ„ж•ҲжһңгҖӮ
**Q2пјҡ**еә•еұӮжҳҜеҰӮдҪ•еҢәеҲҶеңЁзәҝе’ҢзҰ»зәҝдјҳе…Ҳзә§зҡ„пјҹ
**A2пјҡ**еә•еұӮжҳҜж— жі•иҮӘеҠЁиҺ·еҸ–и°ҒжҳҜеңЁзәҝпјҢи°ҒжҳҜзҰ»зәҝпјҢжҲ–иҖ…и°Ғзҡ„дјҳе…Ҳзә§й«ҳпјҢи°Ғзҡ„дјҳе…Ҳзә§дҪҺзҡ„гҖӮиҝҷдёӘжҲ‘们еҸҜд»ҘйҖҡиҝҮеҗ„з§Қ Kubernetes жҸҗдҫӣзҡ„жү©еұ•е®һзҺ°гҖӮжңҖз®ҖеҚ•зҡ„жҳҜйҖҡиҝҮ labelпјҢAnnotation ж ҮиҜҶгҖӮеҪ“然йҖҡиҝҮжү©еұ• QoS class д№ҹжҳҜдёҖз§ҚжҖқи·ҜгҖӮзӨҫеҢәзүҲжң¬зҡ„ QoS classи®ҫзҪ®еӨӘиҝҮдәҺдҝқе®ҲпјҢз»ҷдәҲз”ЁжҲ·еҸ‘жҢҘзҡ„з©әй—ҙдёҚеӨ§гҖӮжҲ‘们йҖҡиҝҮиҝҷдәӣж–№йқўд№ҹиҝӣиЎҢдәҶеўһејәгҖӮеңЁеҗҲйҖӮзҡ„ж—¶еҖҷжҲ–и®ёдјҡжҺЁеҗ‘зӨҫеҢәгҖӮиҮӘеҠЁж„ҹзҹҘжҳҜдёӘж–№еҗ‘пјҢж„ҹзҹҘи°ҒжҳҜе№Іжү°жәҗпјҢж„ҹзҹҘи°ҒжҳҜжҹҗз§Қиө„жәҗеһӢеә”з”ЁпјҢиҝҷеқ—жҲ‘们иҝҳеңЁз ”еҸ‘дёӯгҖӮеҒҡеҲ°зңҹжӯЈзҡ„еҠЁжҖҒпјҢиӮҜе®ҡжҳҜе…·еӨҮиҮӘеҠЁж„ҹзҹҘзҡ„жҷәиғҪзі»з»ҹгҖӮ
**Q3пјҡ**вҖңдёҺзӨҫеҢәзүҲВ Vertical-Pod-Autoscaler дёҚеҗҢпјҢPolicy engine дёҚдё»еҠЁй©ұйҖҗи…ҫжҢӘе®№еҷЁпјҢиҖҢжҳҜзӣҙжҺҘдҝ®ж”№е®№еҷЁзҡ„ cgroup ж–Ү件вҖқпјҢжғій—®дёҖдёӢпјҢдёҚдё»еҠЁй©ұйҖҗзҡ„иҜқпјҢеҰӮжһң Node зҡ„иө„жәҗиҫҫеҲ°дёҠзәҝдәҶдјҡжҖҺд№ҲеӨ„зҗҶпјҹ
**A3пјҡ**иҝҷжҳҜдёҖдёӘеҘҪй—®йўҳгҖӮйҰ–е…ҲиҝҷйҮҢиҰҒе…ҲеҢәеҲҶжҳҜе“Әз§Қиө„жәҗпјҢеҰӮжһңжҳҜ CPU еһӢзҡ„пјҢжҲ‘们еҸҜд»Ҙи°ғж•ҙдҪҺдјҳе…Ҳзә§е®№еҷЁзҡ„ cgroup дёӢ cpu quota зҡ„еҖјпјҢйҰ–е…ҲжҠ‘еҲ¶дҪҺдјҳе…Ҳзә§зҡ„е®№еҷЁеҜ№дәҺ CPU зҡ„дәүжҠўгҖӮ然еҗҺеҶҚйҖӮеҪ“дёҠи°ғй«ҳдјҳе…Ҳзә§е®№еҷЁзҡ„зӣёе…іиө„жәҗеҖјгҖӮеҰӮжһңжҳҜеҶ…еӯҳеһӢиө„жәҗпјҢиҝҷдёӘдёҚиғҪзӣҙжҺҘеҺ»зј©е°ҸдҪҺдјҳе…Ҳзә§е®№еҷЁзҡ„ cgroup еҖјпјҢеҗҰеҲҷдјҡйҖ жҲҗ OOMпјҢеҜ№дәҺеӯҰд№ еҶ…еӯҳеһӢиө„жәҗзҡ„и°ғж•ҙпјҢжҲ‘们дјҡеңЁе…¶д»–еҲҶдә«дёӯ继з»ӯи®Ёи®әгҖӮиҝҷдёӘжҠҖжңҜжҜ”иҫғзү№ж®ҠгҖӮ
**Q4пјҡ**еҸӘдҝ®ж”№ cgroupпјҢжҖҺд№ҲдҝқиҜҒ K8s еҜ№еҚ•дёӘзү©зҗҶжңәиғҪеӨҹеҲҶй…ҚжӣҙеӨҡзҡ„е®№еҷЁпјҹ
**A4пјҡ**ж–Үеӯ—зӣҙж’ӯжңүдәҶдёҖе®ҡиҜҙжҳҺпјҢе®№еҷЁзҡ„иө„жәҗж¶ҲиҖ—并йқһжҳҜдёҖжҲҗдёҚеҸҳзҡ„пјҢеҫҲеӨҡж—¶еҖҷе®ғ们зҡ„иө„жәҗж¶ҲиҖ—е‘ҲзҺ°жҪ®жұҗзҺ°иұЎпјҢзӣёеҗҢзҡ„иө„жәҗжқЎд»¶дёӢйғЁзҪІжӣҙеӨҡеә”з”ЁпјҢе®ҢжҲҗжӣҙеӨҡдҪңдёҡе°ұжҳҜиҫҫеҲ°иө„жәҗеҲ©з”Ёзҡ„жңҖеӨ§еҢ–зҡ„ж•ҲжһңгҖӮиө„жәҗеҮәзҺ°и¶…еҚ–жүҚжҳҜжҲ‘们иҝҷдёӘдё»йўҳи®Ёи®әзҡ„жңҖеӨ§д»·еҖјгҖӮ
**Q5пјҡ**д№ҹе°ұжҳҜиҜҙпјҢдҪҺдјҳе…Ҳзә§зҡ„е®№еҷЁпјҢrequest и®ҫзҪ®зҡ„жҜ” limit е°ҸеҫҲеӨҡпјҢ然еҗҺдҪ 们еҶҚеҠЁжҖҒзҡ„и°ғж•ҙ cgroupпјҹ
**A5пјҡ**еңЁзҺ°жңү QoS еңәжҷҜдёӢпјҢдҪ еҸҜд»ҘзҗҶи§Јиў«и°ғж•ҙзҡ„ Pod йғҪжҳҜ burstable зҡ„гҖӮдҪҶжҳҜжҲ‘们并дёҚжҳҜзӣҙжҺҘи°ғж•ҙ Pod е…ғж•°жҚ®зҡ„ limit зҡ„еҖјпјҢиҖҢжҳҜи°ғж•ҙ limit еңЁ cgroup еҸҚжҳ зҡ„еҖјпјҢиҝҷдёӘеҖјеңЁиө„жәҗз«һдәүзј“е’Ңзҡ„ж—¶еҖҷиҝҳдјҡиў«и°ғж•ҙеӣһеҺ»зҡ„гҖӮжҲ‘们并дёҚе»әи®®еҚ•жңәзҡ„ cgroup ж•°жҚ®е’Ң etcd зҡ„дёӯеҝғж•°жҚ®еүІиЈӮеӨӘд№…гҖӮеҰӮжһңй•ҝжңҹеҒҸзҰ»пјҢжҲ‘们дјҡеғҸ VPA еҸ‘еҮәиӯҰжҠҘпјҢиҒ”еҠЁ VPA еҒҡи°ғж•ҙгҖӮеҪ“然еңЁе®№еҷЁиҝҗиЎҢзҡ„й«ҳеі°жңҹпјҢд»»дҪ•йҮҚе»әе®№еҷЁзҡ„ж“ҚдҪңйғҪжҳҜдёҚжҳҺжҷәзҡ„гҖӮ
**Q6пјҡ**ж•ҙдҪ“зҡ„зҗҶи§Је°ұжҳҜдҪ 们ејҖе§Ӣе°ұи®©зү©зҗҶжңәи¶…й…ҚдәҶдёҖе®ҡжҜ”дҫӢзҡ„ podпјҢ然еҗҺйҖҡиҝҮзӯ–з•ҘеҠЁжҖҒи°ғж•ҙе®№еҷЁзҡ„ cgroup еҖјпјҹ
**A6пјҡ**еҰӮжһңиө„жәҗе®Ңе…ЁжҳҜеҜҢи¶іеҶ—дҪҷзҡ„пјҢиҝҷдёӘеҠЁжҖҒи°ғж•ҙд№ҹжңүдёҖе®ҡж„Ҹд№үгҖӮе°ұжҳҜ并йқһиө„жәҗз”Ёж»ЎеңәжҷҜдёӢпјҢй«ҳдјҳе…Ҳзә§еә”з”Ёдјҡиў«е№Іжү°пјҢе®һйҷ…дёҠпјҢеҪ“дё»жңәзҡ„ CPU иҫҫеҲ°дёҖе®ҡжҜ”дҫӢпјҢжү“дёӘжҜ”ж–№дҫӢеҰӮ 50%пјҢеә”з”Ёзҡ„时延е°ұеҸҳеӨ§гҖӮдёәдәҶе®Ңе…ЁзЎ®дҝқй«ҳдјҳе…Ҳзә§еә”з”Ёзҡ„ SLOпјҢзүәзүІдҪҺдјҳе…Ҳзә§зҡ„ CPU жӯЈеёёиҝҗиЎҢд№ҹжҳҜжңүд»·еҖјзҡ„гҖӮ
**Q7:**Policy engine жңүжІЎжңүиҖғиҷ‘ејҖжәҗпјҹ
**A7пјҡ**жңүи®ЎеҲ’иҝӣиЎҢејҖжәҗпјҢPolicy engine жӣҙеӨҡзҡ„жҳҜе’ҢиҮӘиә«зҡ„еә”з”ЁеұһжҖ§зӣёе…іпјҢз”өе•Ҷеә”з”ЁжҲ–иҖ…еӨ§ж•°жҚ®еӨ„зҗҶеә”з”Ёзҡ„зӯ–з•ҘйғҪжҳҜдёҚзӣёеҗҢзҡ„пјҢжҲ‘们ејҖжәҗдјҡйҰ–е…ҲејҖжәҗжЎҶжһ¶е’Ңйҷ„еёҰдёҖдәӣз®ҖеҚ•зҡ„зӯ–з•ҘпјҢжӣҙеӨҡзҡ„зӯ–з•ҘеҸҜд»Ҙз”ЁжҲ·иҮӘе®ҡд№үгҖӮ
**Q8пјҡ**жҲ‘д№ӢеүҚйҒҮеҲ°зҡ„еӨ§йғЁеҲҶеә”з”ЁйғҪж— жі•жӯЈзЎ®ж„ҹзҹҘ cgroup зҡ„й…ҚзҪ®пјҢеӣ жӯӨеҫҲеӨҡжғ…еҶөйғҪйңҖиҰҒеңЁеҗҜеҠЁеҸӮж•°йҮҢйқўж №жҚ® cpu жҲ–иҖ… mem и®ҫзҪ®еҸӮж•°пјҢйӮЈд№Ҳд№ҹе°ұжҳҜиҜҙеҚідҪҝж”№еҸҳдәҶ cgroup еҜ№дәҺ他们жқҘиҜҙйғҪж— ж•ҲпјҢйӮЈд№ҲдҪҝз”ЁеңәжҷҜд№ҹе°ұжңүйҷҗдәҶ
**A8пјҡ**йҷҗеҲ¶е®№еҷЁзҡ„иө„жәҗдҪҝз”ЁиҝҷдёӘиҝҳжҳҜжңүд»·еҖјзҡ„гҖӮйҷҗеҲ¶дҪҺдјҳе…Ҳзә§еә”з”Ёжң¬иә«д№ҹеҸҜд»ҘжҸҗеҚҮй«ҳдјҳе…Ҳзә§еә”з”Ёзҡ„ SLOпјҢиҷҪ然ж•ҲжһңжІЎжңүйӮЈд№ҲжҳҺжҳҫгҖӮзЁіе®ҡжҖ§зҡ„иҖғйҮҸеҗҢж ·д№ҹеҫҲйҮҚиҰҒгҖӮ
**Q9:**Policy engine зӣ®еүҚеңЁйҳҝйҮҢзҡ„дҪҝз”ЁеҰӮдҪ•пјҹеңЁз”ҹдә§дёҠжңүеӨҡдёҠзҡ„规模дҪҝз”Ёиҝҷз§Қж–№ејҸиҝӣиЎҢеҠЁжҖҒи°ғж•ҙпјҹжҳҜеҗҰе’ҢзӨҫеҢәзҡ„ HPA VPA й…ҚеҗҲдҪҝз”Ёпјҹ
**A9:В **Policy engine еңЁйҳҝйҮҢжҹҗдәӣйӣҶзҫӨе·Із»ҸдҪҝз”ЁгҖӮиҮідәҺ规模жҡӮж—¶ж— жі•йҖҸжјҸгҖӮж¶үеҸҠеҲ°еҫҲеӨҡ组件д№Ӣй—ҙзҡ„иҒ”еҠЁпјҢзӨҫеҢәзҡ„ HPA е’Ң VPA зӣ®еүҚйғҪдёҚеӨӘиғҪж»Ўи¶іжҲ‘们зҡ„йңҖжұӮгҖӮеӣ жӯӨйҳҝйҮҢзҡ„ HPA е’Ң VPA йғҪжҳҜжҲ‘们иҮӘиЎҢејҖеҸ‘зҡ„пјҢдҪҶжҳҜе’ҢзӨҫеҢәзҡ„еҺҹзҗҶжҳҜдёҖиҮҙзҡ„гҖӮйҳҝйҮҢ HPA зҡ„ејҖжәҗеҸҜд»Ҙе…іжіЁ Openkruise зӨҫеҢәгҖӮVPA ејҖжәҗи®ЎеҲ’жҲ‘иҝҷйҮҢиҝҳжІЎжңүзЎ®еҲҮж¶ҲжҒҜгҖӮ
**Q10пјҡ**еҪ“еҚ•жңәиҠӮзӮ№иө„жәҗдёҚи¶ід»ҘжҸҗдҫӣе®№еҷЁжү©е®№ж—¶пјҢзӣ®еүҚжҳҜеҗҰеҸҜд»ҘиҝӣиЎҢ HPA жҲ– VPA жү©е®№е‘ўпјҹ
**A10пјҡ**еҚ•жңәиҠӮзӮ№дёҚи¶ізҡ„ж—¶еҖҷпјҢеә”з”ЁеҸҜд»ҘйҖҡиҝҮ HPA иҝӣиЎҢеўһеҠ еүҜжң¬еә”еҜ№гҖӮдҪҶжҳҜ VPA еҰӮжһңйҖүжӢ©еҺҹиҠӮзӮ№иҝӣиЎҢжӣҙж–°зҡ„иҜқпјҢжҳҜеӨұиҙҘзҡ„гҖӮеҸӘиғҪи°ғеәҰеҲ°е…¶д»–иө„жәҗдё°еҜҢзҡ„иҠӮзӮ№гҖӮеңЁжөҒйҮҸйҷЎеҚҮзҡ„еңәжҷҜдёӢпјҢйҮҚе»әе®№еҷЁжңӘеҝ…иғҪж»Ўи¶ійңҖжұӮпјҢеҫҲеҸҜиғҪеҜјиҮҙйӣӘеҙ©пјҢеҚійҮҚе»әиҝҮзЁӢдёӯпјҢж•ҙдёӘеә”з”Ёе…¶д»–жңӘеҚҮзә§зҡ„еүҜжң¬жҺҘеҸ—жӣҙеӨҡжөҒйҮҸпјҢOOM жҺүпјҢж–°еҗҜеҠЁзҡ„е®№еҷЁеҶҚзһ¬й—ҙиў« OOMпјҢжүҖд»ҘйҮҚеҗҜе®№еҷЁйңҖиҰҒж…ҺйҮҚгҖӮеҝ«йҖҹжү©е®№пјҲHPAпјүжҲ–иҖ…еҝ«йҖҹжҸҗеҚҮй«ҳдјҳе…Ҳзә§иө„жәҗпјҢжҠ‘еҲ¶дҪҺдјҳе…Ҳзә§е®№еҷЁиө„жәҗзҡ„ж–№ејҸж•ҲжһңжӣҙжҳҺжҳҫгҖӮ
жң¬ж–ҮдҪңиҖ…пјҡеј жҷ“е®ҮпјҲиЎ·жәҗпјүВ йҳҝйҮҢдә‘е®№еҷЁе№іеҸ°жҠҖжңҜ专家
[еҺҹж–Үй“ҫжҺҘ](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/719845%3Futm_content%3Dg_1000079633)
жң¬ж–Үдёәдә‘ж –зӨҫеҢәеҺҹеҲӣеҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
==
дёҚзҹҘйҒ“еӨ§е®¶жңүжІЎжңүиҝҮиҝҷж ·зҡ„з»ҸеҺҶпјҡеҪ“жҲ‘们жӢҘжңүдәҶдёҖеҘ— Kubernetes йӣҶзҫӨпјҢ然еҗҺејҖе§ӢйғЁзҪІеә”з”Ёзҡ„ж—¶еҖҷпјҢжҲ‘们еә”иҜҘз»ҷе®№еҷЁеҲҶй…ҚеӨҡе°‘иө„жәҗе‘ўпјҹ
иҝҷеҫҲйҡҫиҜҙгҖӮз”ұдәҺ Kubernetes иҮӘе·ұзҡ„жңәеҲ¶пјҢжҲ‘们еҸҜд»ҘзҗҶи§Је®№еҷЁзҡ„иө„жәҗе®һиҙЁдёҠжҳҜдёҖдёӘйқҷжҖҒзҡ„й…ҚзҪ®гҖӮ
* еҰӮжһңжҲ‘еҸ‘зҺ°иө„жәҗдёҚи¶іпјҢдёәдәҶеҲҶй…Қз»ҷе®№еҷЁжӣҙеӨҡиө„жәҗпјҢжҲ‘们йңҖиҰҒйҮҚе»ә Podпјӣ
* еҰӮжһңеҲҶй…ҚеҶ—дҪҷзҡ„иө„жәҗпјҢйӮЈд№ҲжҲ‘们зҡ„ worker node иҠӮзӮ№дјјд№ҺеҸҲйғЁзҪІдёҚдәҶеӨҡе°‘е®№еҷЁгҖӮ
иҜ•й—®пјҢжҲ‘们иғҪеҒҡеҲ°е®№еҷЁиө„жәҗзҡ„жҢүйңҖеҲҶй…Қеҗ—пјҹжҺҘдёӢжқҘпјҢжҲ‘们е°ҶеңЁжң¬ж¬ЎеҲҶдә«дёӯе’ҢеӨ§е®¶дёҖиө·иҝӣиЎҢжҺўи®ЁиҝҷдёӘй—®йўҳзҡ„зӯ”жЎҲгҖӮ
з”ҹдә§зҺҜеўғдёӯзҡ„зңҹе®һжҢ‘жҲҳ
==========
йҰ–е…ҲиҜ·е…Ғи®ёжҲ‘д»¬ж №жҚ®жҲ‘们зҡ„е®һйҷ…жғ…еҶөжҠӣеҮәжҲ‘们е®һйҷ…з”ҹдә§зҺҜеўғзҡ„жҢ‘жҲҳгҖӮжҲ–и®ёеӨ§е®¶иҝҳи®°еҫ— 2018 е№ҙзҡ„еӨ©зҢ«еҸҢ 11пјҢиҝҷдёҖеӨ©зҡ„жҖ»жҲҗдәӨйўқиҫҫеҲ°дәҶ 2135 дәҝгҖӮз”ұжӯӨдёҖж–‘еҸҜзӘҘе…Ёиұ№пјҢиғҪеӨҹж”Ҝж’‘еҰӮжӯӨеәһеӨ§и§„жЁЎзҡ„дәӨжҳ“йҮҸиғҢеҗҺзҡ„зі»з»ҹпјҢе…¶еә”з”Ёз§Қзұ»е’Ңж•°йҮҸеә”иҜҘжҳҜжҖҺж ·зҡ„дёҖз§Қ规模гҖӮ
еңЁиҝҷз§Қ规模дёӢпјҢжҲ‘们常常еҗ¬еҲ°зҡ„е®№еҷЁи°ғеәҰпјҢеҰӮпјҡе®№еҷЁзј–жҺ’пјҢиҙҹиҪҪеқҮиЎЎпјҢйӣҶзҫӨжү©зј©е®№пјҢйӣҶзҫӨеҚҮзә§пјҢеә”з”ЁеҸ‘еёғпјҢеә”з”ЁзҒ°еәҰзӯүзӯүиҝҷдәӣиҜҚпјҢеңЁиў«вҖңи¶…еӨ§и§„жЁЎйӣҶзҫӨвҖқиҝҷдёӘиҜҚдҝ®йҘ°еҗҺпјҢйғҪдёҚеҶҚжҳҜ件容жҳ“еӨ„зҗҶзҡ„дәӢжғ…гҖӮ规模жң¬иә«д№ҹе°ұжҳҜжҲ‘们жңҖеӨ§зҡ„жҢ‘жҲҳгҖӮеҰӮдҪ•иҝҗиҗҘе’Ңз®ЎзҗҶеҘҪиҝҷд№ҲдёҖдёӘеәһеӨ§зҡ„зі»з»ҹпјҢ并йҒөеҫӘдёҡз•Ң dev-ops е®Јдј зҡ„йӮЈж ·ж•ҲжһңпјҢзҠ№еҰӮи®©еӨ§иұЎеҺ»и·іиҲһгҖӮдҪҶжҳҜ马иҖҒеёҲжӣҫиҜҙиҝҮпјҢеӨ§иұЎе°ұиҜҘе№ІеӨ§иұЎиҜҘе№Ізҡ„дәӢжғ…пјҢдёәд»Җд№ҲиҰҒеҺ»и·іиҲһе‘ўгҖӮ
Kubernetes зҡ„её®еҠ©
==============

еӨ§иұЎжҳҜеҗҰеҸҜд»Ҙи·іиҲһпјҢеёҰзқҖиҝҷдёӘй—®йўҳпјҢжҲ‘们йңҖиҰҒд»Һж·ҳе®қгҖҒеӨ©зҢ«зӯү APP иғҢеҗҺзі»з»ҹиҜҙиө·гҖӮ
иҝҷеҘ—дә’иҒ”зҪ‘зі»з»ҹеә”з”ЁйғЁзҪІеӨ§иҮҙеҸҜеҲҶдёәдёүдёӘйҳ¶ж®өпјҢдј з»ҹйғЁзҪІпјҢиҷҡжӢҹжңәйғЁзҪІе’Ңе®№еҷЁйғЁзҪІгҖӮзӣёжҜ”дәҺдј з»ҹйғЁзҪІпјҢиҷҡжӢҹжңәйғЁзҪІжңүдәҶжӣҙеҘҪзҡ„йҡ”зҰ»жҖ§е’Ңе®үе…ЁжҖ§пјҢдҪҶжҳҜеңЁжҖ§иғҪдёҠдёҚеҸҜйҒҝе…Қзҡ„дә§з”ҹдәҶеӨ§йҮҸжҚҹиҖ—гҖӮиҖҢе®№еҷЁйғЁзҪІеҸҲеңЁиҷҡжӢҹжңәйғЁзҪІе®һзҺ°йҡ”зҰ»е’Ңе®үе…Ёзҡ„иғҢжҷҜдёӢпјҢжҸҗеҮәдәҶжӣҙиҪ»йҮҸеҢ–зҡ„и§ЈеҶіж–№жЎҲгҖӮжҲ‘们зҡ„зі»з»ҹд№ҹжҳҜжІҝзқҖиҝҷд№ҲдёҖжқЎдё»иҲӘйҒ“дёҠиҝҗиЎҢзҡ„гҖӮеҒҮи®ҫеә•еұӮзі»з»ҹеҘҪжҜ”дёҖиүҳе·ЁиҪ®пјҢйқўеҜ№е·ЁйҮҸзҡ„йӣҶиЈ…з®ұ---е®№еҷЁпјҢжҲ‘们йңҖиҰҒдёҖдёӘдјҳз§Җзҡ„иҲ№й•ҝпјҢеҜ№е®ғ们иҝӣиЎҢи°ғеәҰзј–жҺ’пјҢи®©зі»з»ҹиҝҷиүҳеӨ§иҲ№еҸҜд»ҘйҒҝејҖеұӮеұӮйҷ©йҳ»пјҢж“ҚдҪңйҡҫеәҰйҷҚдҪҺпјҢдё”е…·еӨҮжӣҙеӨҡзҒөжҙ»жҖ§пјҢжңҖз»ҲиҫҫжҲҗиҲӘиЎҢзҡ„зӣ®зҡ„гҖӮ
зҗҶжғідёҺзҺ°е®һ
=====
еңЁејҖе§Ӣд№ӢеҲқпјҢжғіеҲ°е®№еҷЁеҢ–е’Ң Kubernetes зҡ„еҗ„з§ҚзҫҺеҘҪеңәжҷҜпјҢжҲ‘们зҗҶжғідёӯзҡ„е®№еҷЁзј–жҺ’ж•Ҳжһңеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ
* д»Һе®№пјҡжҲ‘们зҡ„е·ҘзЁӢеёҲжӣҙеҠ д»Һе®№зҡ„йқўеҜ№еӨҚжқӮзҡ„жҢ‘жҲҳпјҢдёҚеҶҚзңүеӨҙзҙ§й”ҒиҖҢжҳҜжӣҙеӨҡ笑容е’ҢиҮӘдҝЎпјӣ
* дјҳйӣ…пјҡжҜҸдёҖж¬ЎзәҝдёҠеҸҳжӣҙж“ҚдҪңйғҪеҸҜд»ҘеғҸе“ҒзқҖзәўй…’дёҖж ·ж°”е®ҡзҘһй—ІпјҢдјҳйӣ…ең°жҢүдёӢжү§иЎҢзҡ„еӣһиҪҰй”®пјӣ
* жңүеәҸпјҡд»ҺејҖеҸ‘еҲ°жөӢиҜ•пјҢеҶҚеҲ°зҒ°еәҰеҸ‘еёғпјҢдёҖж°”е‘өжҲҗпјҢиЎҢдә‘жөҒж°ҙпјӣ
* зЁіе®ҡпјҡзі»з»ҹеҒҘеЈ®жҖ§иүҜеҘҪпјҢд»»е°”дёңиҘҝеҚ—еҢ—йЈҺпјҢжҲ‘们系з»ҹеІҝ然дёҚеҠЁгҖӮе…Ёе№ҙзі»з»ҹеҸҜз”ЁжҖ§ N еӨҡдёӘ 9пјӣ
* й«ҳж•ҲпјҡиҠӮзәҰеҮәжӣҙеӨҡдәәеҠӣпјҢе®һзҺ°вҖңеҝ«д№җе·ҘдҪңпјҢи®Өзңҹз”ҹжҙ»вҖқгҖӮ
然иҖҢзҗҶжғіеҫҲдё°ж»ЎпјҢзҺ°е®һеҫҲйӘЁж„ҹгҖӮиҝҺжҺҘжҲ‘们зҡ„еҚҙжҳҜжқӮд№ұе’ҢеҪўжҖҒеҗ„ејӮзҡ„зӘҳиҝ«гҖӮ
жқӮд№ұпјҢжҳҜеӣ дёәдҪңдёәдёҖдёӘејӮеҶӣзӘҒиө·зҡ„ж–°еһӢжҠҖжңҜж ҲпјҢеҫҲеӨҡй…ҚеҘ—е·Ҙе…·е’Ңе·ҘдҪңжөҒзҡ„е»әи®ҫеӨ„дәҺеҲқзә§йҳ¶ж®өгҖӮDemo зүҲжң¬дёӯиҝҗиЎҢиүҜеҘҪзҡ„е·Ҙе…·пјҢеңЁзңҹе®һеңәжҷҜдёӢеӨ§и§„жЁЎй“әејҖпјҢеҗ„з§Қйҡҗи—Ҹзҡ„й—®йўҳе°ұдјҡжҡҙйңІж— йҒ—пјҢеұӮеҮәдёҚз©·гҖӮд»ҺејҖеҸ‘еҲ°иҝҗз»ҙпјҢжүҖжңүзҡ„е·ҘдҪңдәәе‘ҳйғҪеңЁеҗ„з§Қиў«еҠЁең°з–ІдәҺеҘ”е‘ҪгҖӮеҸҰеӨ–пјҢвҖңеӨ§и§„жЁЎй“әејҖвҖқиҝҳж„Ҹе‘ізқҖпјҢиҰҒзӣҙжҺҘйқўеҜ№еҪўжҖҒеҗ„ејӮзҡ„з”ҹдә§зҺҜеўғпјҡејӮжһ„й…ҚзҪ®зҡ„жңәеҷЁгҖҒеӨҚжқӮзҡ„йңҖжұӮпјҢз”ҡиҮіжҳҜйҖӮй…Қз”ЁжҲ·зҡ„ж—ўеҫҖзҡ„дҪҝз”Ёд№ жғҜзӯүзӯүгҖӮ

йҷӨдәҶи®©дәәеҝғеҠӣдәӨзҳҒзҡ„ж··д№ұпјҢзі»з»ҹиҝҳйқўдёҙзқҖеә”з”Ёе®№еҷЁзҡ„еҗ„з§Қеҙ©жәғй—®йўҳпјҡеҶ…еӯҳдёҚи¶іеҜјиҮҙзҡ„ OOMпјҢCPU quota еҲҶй…ҚеӨӘе°‘пјҢеҜјиҮҙиҝӣзЁӢиў« throttleпјҢиҝҳжңүеёҰе®ҪдёҚи¶іпјҢе“Қеә”时延еӨ§е№…дёҠеҚҮ...з”ҡиҮіжҳҜдәӨжҳ“йҮҸеңЁйқўеҜ№и®ҝй—®й«ҳеі°ж—¶еҖҷз”ұдәҺзі»з»ҹдёҚз»ҷеҠӣеҜјиҮҙзҡ„ж–ӯеҙ–ејҸдёӢи·ҢзӯүзӯүгҖӮиҝҷдәӣйғҪдҪҝжҲ‘们еңЁеӨ§и§„жЁЎе•Ҷз”Ё Kubernetes еңәжҷҜдёӯз§ҜзҙҜйқһеёёеӨҡзҡ„з»ҸйӘҢгҖӮ
зӣҙйқўй—®йўҳ
====
зЁіе®ҡжҖ§
---
й—®йўҳжҖ»иҰҒиҝӣиЎҢйқўеҜ№зҡ„гҖӮжӯЈеҰӮжҹҗдҪҚй«ҳдәәиҜҙиҝҮпјҡеҰӮжһңж„ҹи§үе“ӘйҮҢдёҚеӨӘеҜ№пјҢйӮЈд№ҲиӮҜе®ҡжңүдәӣең°ж–№еҮәй—®йўҳдәҶгҖӮдәҺжҳҜжҲ‘们е°ұиҰҒеү–жһҗпјҢй—®йўҳ究з«ҹеҮәеңЁе“ӘйҮҢгҖӮй’ҲеҜ№дәҺеҶ…еӯҳзҡ„ OOMпјҢCPU иө„жәҗиў« throttleпјҢжҲ‘们еҸҜд»ҘжҺЁж–ӯжҲ‘们з»ҷдёҺе®№еҷЁеҲҶй…Қзҡ„еҲқе§Ӣиө„жәҗдёҚи¶ігҖӮ

иө„жәҗдёҚи¶іе°ұеҠҝеҝ…йҖ жҲҗж•ҙдёӘеә”з”ЁжңҚеҠЎзЁіе®ҡжҖ§дёӢйҷҚгҖӮдҫӢеҰӮдёҠеӣҫзҡ„еңәжҷҜпјҡиҷҪ然жҳҜеҗҢдёҖз§Қеә”з”Ёзҡ„еүҜжң¬пјҢжҲ–и®ёжҳҜз”ұдәҺиҙҹиҪҪеқҮиЎЎдёҚеӨҹејәеӨ§пјҢжҲ–иҖ…жҳҜз”ұдәҺеә”з”ЁиҮӘиә«зҡ„еҺҹеӣ пјҢз”ҡиҮіжҳҜз”ұдәҺжңәеҷЁжң¬иә«жҳҜејӮжһ„зҡ„пјҢзӣёеҗҢж•°еҖјзҡ„иө„жәҗпјҢеҸҜиғҪеҜ№дәҺеҗҢдёҖз§Қеә”з”Ёзҡ„дёҚеҗҢеүҜжң¬е№¶е…·жңүзӣёзӯүзҡ„д»·еҖје’Ңж„Ҹд№үгҖӮеңЁж•°еҖјдёҠ他们зңӢдјјеҲҶй…ҚдәҶзӣёеҗҢзҡ„иө„жәҗпјҢ然иҖҢеңЁе®һйҷ…иҙҹиҪҪе·ҘдҪңж—¶пјҢжһҒжңүеҸҜиғҪеҮәзҺ°зҡ„зҺ°иұЎжҳҜиӮҘзҳҰдёҚеқҮзҡ„гҖӮ

иҖҢеңЁиө„жәҗ overcommit зҡ„еңәжҷҜдёӢпјҢеә”з”ЁеңЁж•ҙдёӘиҠӮзӮ№иө„жәҗдёҚи¶іпјҢжҲ–жҳҜеңЁжүҖеңЁзҡ„ CPU share pool иө„жәҗдёҚи¶іж—¶пјҢд№ҹдјҡеҮәзҺ°дёҘйҮҚзҡ„иө„жәҗз«һдәүе…ізі»гҖӮиө„жәҗз«һдәүжҳҜеҜ№еә”з”ЁзЁіе®ҡжҖ§жңҖеӨ§зҡ„еЁҒиғҒд№ӢдёҖгҖӮжүҖд»ҘжҲ‘们иҰҒе°ҪеҠӣеңЁз”ҹдә§зҺҜеўғдёӯжё…йҷӨжүҖжңүзҡ„еЁҒиғҒгҖӮ
жҲ‘们йғҪзҹҘйҒ“зЁіе®ҡжҖ§жҳҜ件еҫҲйҮҚиҰҒзҡ„дәӢжғ…пјҢе°Өе…¶еҜ№дәҺжҺҢжҺ§дёҠзҷҫдёҮе®№еҷЁз”ҹжқҖеӨ§жқғзҡ„дёҖзәҝз ”еҸ‘дәәе‘ҳгҖӮжҲ–и®ёдёҚз»Ҹеҝғзҡ„дёҖдёӘж“ҚдҪңе°ұжңүеҸҜиғҪйҖ жҲҗеҪұе“Қйқўе·ЁеӨ§зҡ„з”ҹдә§дәӢж•…гҖӮ
еӣ жӯӨпјҢжҲ‘们д№ҹжҢүз…§дёҖиҲ¬жөҒзЁӢеҒҡдәҶзі»з»ҹйў„йҳІе’Ңе…ңеә•е·ҘдҪңгҖӮ
* еңЁйў„йҳІз»ҙеәҰпјҢжҲ‘们еҸҜд»ҘиҝӣиЎҢе…Ёй“ҫи·Ҝзҡ„еҺӢеҠӣжөӢиҜ•пјҢ并且жҸҗеүҚйҖҡиҝҮ科еӯҰзҡ„жүӢж®өйў„еҲӨеә”з”ЁйңҖиҰҒзҡ„еүҜжң¬ж•°е’Ңиө„жәҗйҮҸгҖӮеҰӮжһңжІЎжі•еҮҶзЎ®йў„з®—иө„жәҗпјҢйӮЈе°ұеҸӘйҮҮз”ЁеҶ—дҪҷеҲҶй…Қиө„жәҗзҡ„ж–№ејҸдәҶгҖӮ
* еңЁе…ңеә•з»ҙеәҰпјҢжҲ‘们еҸҜд»ҘеңЁеӨ§и§„жЁЎи®ҝй—®жөҒйҮҸжҠөиҫҫеҗҺпјҢеҜ№дёҚзҙ§иҰҒзҡ„дёҡеҠЎеҒҡжңҚеҠЎйҷҚзә§е№¶еҗҢж—¶еҜ№дё»иҰҒеә”з”ЁиҝӣиЎҢдёҙж—¶жү©е®№гҖӮ
дҪҶжҳҜеҜ№дәҺйҷЎз„¶еўһеҠ еҮ еҲҶй’ҹзҡ„зӘҒеўһжөҒйҮҸпјҢиҝҷд№ҲеӨҡз»„еҗҲжӢізҡ„иҠұиҙ№дёҚиҸІпјҢдјјд№ҺжңүдәӣдёҚеҲ’з®—гҖӮжҲ–и®ёжҲ‘们еҸҜд»ҘжҸҗеҮәдёҖдәӣи§ЈеҶіж–№жЎҲпјҢиҫҫеҲ°жҲ‘们зҡ„йў„жңҹгҖӮ
иө„жәҗеҲ©з”ЁзҺҮ
-----
еӣһйЎҫдёҖдёӢжҲ‘们зҡ„еә”з”ЁйғЁзҪІжғ…еҶөпјҡиҠӮзӮ№дёҠзҡ„е®№еҷЁдёҖиҲ¬еҲҶеұһеӨҡз§Қеә”з”ЁпјҢиҝҷдәӣеә”з”Ёжң¬иә«дёҚдёҖе®ҡпјҢд№ҹдёҖиҲ¬дёҚдјҡеҗҢж—¶еӨ„дәҺи®ҝй—®зҡ„й«ҳеі°гҖӮеҜ№дәҺж··еҗҲйғЁзҪІеә”з”Ёзҡ„е®ҝдё»жңәпјҢеҰӮжһңиғҪйғҪй”ҷеі°еҲҶй…ҚдёҠйқўиҝҗиЎҢе®№еҷЁзҡ„иө„жәҗжҲ–и®ёжӣҙ科еӯҰгҖӮ

еә”з”Ёзҡ„иө„жәҗйңҖжұӮеҸҜиғҪе°ұеғҸжңҲдә®дёҖж ·жңүйҳҙжҷҙеңҶзјәпјҢжңүе‘ЁжңҹеҸҳеҢ–гҖӮдҫӢеҰӮеңЁзәҝдёҡеҠЎпјҢе°Өе…¶жҳҜдәӨжҳ“дёҡеҠЎпјҢе®ғ们еңЁиө„жәҗдҪҝз”ЁдёҠе‘ҲзҺ°дёҖе®ҡзҡ„е‘ЁжңҹжҖ§пјҢдҫӢеҰӮпјҡеңЁеҮҢжҷЁгҖҒдёҠеҚҲж—¶пјҢе®ғзҡ„дҪҝз”ЁйҮҸ并дёҚжҳҜеҫҲй«ҳпјҢиҖҢеңЁеҚҲй—ҙгҖҒдёӢеҚҲж—¶дјҡжҜ”иҫғй«ҳгҖӮ
жү“дёӘжҜ”ж–№пјҡеҜ№дәҺ A еә”з”Ёзҡ„йҮҚиҰҒж—¶еҲ»пјҢеҜ№дәҺ B еә”з”ЁеҸҜиғҪдёҚйӮЈд№ҲйҮҚиҰҒпјҢйҖӮеҪ“жү“еҺӢ B еә”з”ЁпјҢи…ҫжҢӘеҮәиө„жәҗз»ҷ A еә”з”ЁпјҢиҝҷжҳҜдёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮиҝҷеҗ¬иө·жқҘжңүзӮ№еғҸжҳҜеҲҶж—¶еӨҚз”Ёзҡ„ж„ҹи§үгҖӮдҪҶжҳҜеҰӮжһңжҲ‘们жҢүз…§жөҒйҮҸеі°еҖјж—¶зҡ„йңҖжұӮй…ҚзҪ®иө„жәҗе°ұдјҡдә§з”ҹеӨ§йҮҸзҡ„жөӘиҙ№гҖӮ

йҷӨдәҶеҜ№дәҺе®һж—¶жҖ§иҰҒжұӮеҫҲй«ҳзҡ„еңЁзәҝеә”з”ЁеӨ–пјҢжҲ‘们иҝҳжңүзҰ»зәҝеә”з”Ёе’Ңе®һж—¶и®Ўз®—еә”з”ЁзӯүпјҡзҰ»зәҝи®Ўз®—еҜ№дәҺ CPU гҖҒMemory жҲ–зҪ‘з»ңиө„жәҗзҡ„дҪҝз”Ёд»ҘеҸҠж—¶й—ҙдёҚйӮЈд№Ҳж•Ҹж„ҹпјҢжүҖд»ҘеңЁд»»дҪ•ж—¶й—ҙж®өе®ғйғҪеҸҜд»ҘиҝҗиЎҢпјӣе®һж—¶и®Ўз®—пјҢеҸҜиғҪеҜ№дәҺж—¶й—ҙж•Ҹж„ҹжҖ§е°ұдјҡеҫҲй«ҳгҖӮ
ж—©жңҹпјҢжҲ‘们дёҡеҠЎжҳҜеңЁдёҚеҗҢзҡ„иҠӮзӮ№жҢүз…§еә”з”Ёзҡ„зұ»еһӢзӢ¬з«ӢиҝӣиЎҢйғЁзҪІгҖӮд»ҺдёҠйқўиҝҷеј еӣҫжқҘзңӢпјҢеҰӮжһңе®ғ们иҝӣиЎҢеҲҶж—¶еӨҚз”Ёиө„жәҗпјҢй’ҲеҜ№е®һж—¶жҖ§иҝҷдёӘйңҖжұӮеұӮйқўпјҢжҲ‘们дјҡеҸ‘зҺ°е®ғе®һйҷ…зҡ„жңҖеӨ§дҪҝз”ЁйҮҸдёҚжҳҜ 2+2+1=5пјҢиҖҢжҳҜжҹҗдёҖж—¶еҲ»йҮҚиҰҒзҙ§жҖҘеә”з”ЁйңҖжұӮйҮҸзҡ„жңҖеӨ§еҖјпјҢд№ҹе°ұжҳҜ 3 гҖӮеҰӮжһңжҲ‘们иғҪеӨҹж•°жҚ®зӣ‘жөӢеҲ°жҜҸдёӘеә”з”Ёзҡ„зңҹе®һдҪҝз”ЁйҮҸпјҢз»ҷе®ғеҲҶй…ҚеҗҲзҗҶеҖјпјҢйӮЈд№Ҳе°ұиғҪдә§з”ҹиө„жәҗеҲ©з”ЁзҺҮжҸҗеҚҮзҡ„е®һйҷ…ж•ҲжһңгҖӮ
еҜ№дәҺз”өе•Ҷеә”з”ЁпјҢеҜ№дәҺйҮҮз”ЁдәҶйҮҚйҮҸзә§ Java жЎҶжһ¶е’Ңзӣёе…іжҠҖжңҜж Ҳзҡ„ Web еә”з”ЁпјҢзҹӯж—¶й—ҙеҶ… HPA жҲ–иҖ… VPA йғҪдёҚжҳҜ件容жҳ“зҡ„дәӢжғ…гҖӮ
е…ҲиҜҙ HPAпјҢжҲ‘们жҲ–и®ёеҸҜд»Ҙз§’зә§жӢүиө·дәҶ PodпјҢеҲӣе»әж–°зҡ„е®№еҷЁпјҢ然иҖҢжӢүиө·зҡ„е®№еҷЁжҳҜеҗҰзңҹзҡ„еҸҜз”Ёе‘ўгҖӮд»ҺеҲӣе»әеҲ°еҸҜз”ЁпјҢеҸҜиғҪйңҖиҰҒжҜ”иҫғд№…зҡ„ж—¶й—ҙпјҢеҜ№дәҺеӨ§дҝғе’ҢжҠўиҙӯз§’жқҖ-иҝҷз§Қи®ҝй—®йҮҸвҖңжҙӘеі°вҖқеҸҜиғҪд»…з»ҙжҢҒеҮ еҲҶй’ҹжҲ–иҖ…еҚҒеҮ еҲҶй’ҹзҡ„е®һйҷ…еңәжҷҜпјҢеҰӮжһңжҲ‘们зӯүеҲ° HPA зҡ„еүҜжң¬е…ЁйғЁеҸҜз”ЁпјҢеҸҜиғҪеёӮеңәжҙ»еҠЁж—©е·Із»Ҹз»“жқҹдәҶгҖӮ
иҮідәҺзӨҫеҢәзӣ®еүҚзҡ„ VPA еңәжҷҜпјҢеҲ жҺүж—§ PodпјҢеҲӣе»әж–° PodпјҢиҝҷж ·зҡ„йҖ»иҫ‘жӣҙйҡҫжҺҘеҸ—гҖӮжүҖд»Ҙз»јеҗҲиҖғиҷ‘пјҢжҲ‘们йңҖиҰҒдёҖдёӘжӣҙе®һйҷ…зҡ„и§ЈеҶіж–№жЎҲејҘиЎҘ HPA е’Ң VPA зҡ„еңЁиҝҷдёҖеҚ•жңәиө„жәҗи°ғеәҰзҡ„з©әзјәгҖӮ
и§ЈеҶіж–№жЎҲ
====
дәӨд»ҳж ҮеҮҶ
----
жҲ‘们йҰ–е…ҲиҰҒеҜ№и§ЈеҶіж–№жЎҲи®ҫе®ҡдёҖдёӘеҸҜд»ҘдәӨд»ҳзҡ„ж ҮеҮҶйӮЈе°ұжҳҜвҖ”вҖ” вҖңж—ўиҰҒзЁіе®ҡжҖ§пјҢд№ҹиҰҒеҲ©з”ЁзҺҮпјҢиҝҳиҰҒиҮӘеҠЁеҢ–е®һж–ҪпјҢеҪ“然еҰӮжһңиғҪеӨҹжҷәиғҪеҢ–йӮЈе°ұжӣҙеҘҪвҖқпјҢ然еҗҺеҶҚдәӨд»ҳж ҮеҮҶиҝӣиЎҢз»ҶеҢ–пјҡ
* е®үе…ЁзЁіе®ҡпјҡе·Ҙе…·жң¬иә«й«ҳеҸҜз”ЁгҖӮжүҖз”Ёзҡ„з®—жі•е’Ңе®һж–ҪжүӢж®өеҝ…йЎ»еҒҡеҲ°еҸҜжҺ§пјӣ
* дёҡеҠЎе®№еҷЁжҢүйңҖеҲҶй…Қиө„жәҗпјҡеҸҜд»ҘеҸҠж—¶ж №жҚ®дёҡеҠЎе®һж—¶иө„жәҗж¶ҲиҖ—еҜ№дёҚеӨӘд№…иҝңзҡ„е°ҶжқҘиҝӣиЎҢиө„жәҗж¶ҲиҖ—йў„жөӢпјҢи®©з”ЁжҲ·жҳҺзҷҪдёҡеҠЎжҺҘдёӢжқҘеҜ№дәҺиө„жәҗзҡ„зңҹе®һйңҖжұӮпјӣ
* е·Ҙе…·жң¬иә«иө„жәҗејҖй”Җе°Ҹпјҡе·Ҙе…·жң¬иә«иө„жәҗзҡ„ж¶ҲиҖ—иҰҒе°ҪеҸҜиғҪе°ҸпјҢдёҚиҰҒжҲҗдёәиҝҗз»ҙзҡ„иҙҹжӢ…пјӣ
* ж“ҚдҪңж–№дҫҝпјҢжү©еұ•жҖ§ејәпјҡиғҪеҒҡеҲ°ж— йңҖжҺҘеҸ—еҹ№и®ӯеҚіеҸҜзҺ©иҪ¬иҝҷдёӘе·Ҙе…·пјҢеҪ“然е·Ҙе…·иҝҳиҰҒе…·жңүиүҜеҘҪжү©еұ•жҖ§пјҢдҫӣз”ЁжҲ· DIYпјӣ
* еҝ«йҖҹеҸ‘зҺ° & еҸҠж—¶е“Қеә”пјҡе®һж—¶жҖ§пјҢд№ҹе°ұжҳҜжңҖйҮҚиҰҒзҡ„зү№иҙЁпјҢиҝҷд№ҹжҳҜе’ҢHPAжҲ–иҖ…VPAеңЁи§ЈеҶіиө„жәҗи°ғеәҰй—®йўҳж–№ејҸдёҚеҗҢзҡ„ең°ж–№гҖӮ
и®ҫи®ЎдёҺе®һзҺ°
-----

дёҠеӣҫжҳҜжҲ‘们жңҖеҲқзҡ„е·Ҙе…·жөҒзЁӢи®ҫи®ЎпјҡеҪ“дёҖдёӘеә”з”ЁйқўдёҙеҫҲй«ҳзҡ„дёҡеҠЎи®ҝй—®йңҖжұӮж—¶пјҢдҪ“зҺ°еңЁ CPUгҖҒMemory жҲ–е…¶д»–иө„жәҗзұ»еһӢйңҖжұӮйҮҸеҸҳеӨ§пјҢжҲ‘д»¬ж №жҚ® Data Collector йҮҮйӣҶзҡ„е®һж—¶еҹәзЎҖж•°жҚ®пјҢеҲ©з”Ё Data Aggregator з”ҹжҲҗжҹҗдёӘе®№еҷЁжҲ–ж•ҙдёӘеә”з”Ёзҡ„з”»еғҸпјҢеҶҚе°Ҷз”»еғҸеҸҚйҰҲз»ҷ Policy engineгҖӮ Policy engine дјҡзһ¬ж—¶еҝ«йҖҹдҝ®ж”№е®№еҷЁ Cgroup ж–Ү件зӣ®еҪ•дёӢзҡ„зҡ„еҸӮж•°гҖӮ
жҲ‘们жңҖж—©зҡ„жһ¶жһ„е’ҢжҲ‘们зҡ„жғіжі•дёҖж ·жңҙе®һпјҢеңЁ kubelet иҝӣиЎҢдәҶдҫөе…ҘејҸзҡ„дҝ®ж”№гҖӮиҷҪ然жҲ‘们еҸӘжҳҜеҠ дәҶеҮ дёӘжҺҘеҸЈпјҢдҪҶжҳҜиҝҷз§Қж–№ејҸзЎ®е®һдёҚеӨҹдјҳйӣ…гҖӮжҜҸж¬Ў kubenrnetes еҚҮзә§пјҢеҜ№дәҺ Policy engine зӣёе…із»„件еҚҮзә§д№ҹжңүдёҖе®ҡзҡ„жҢ‘жҲҳгҖӮ

дёәдәҶеҒҡеҲ°еҝ«йҖҹиҝӯ代并е’Ң Kubelet и§ЈиҖҰпјҢжҲ‘们еҜ№дәҺе®һзҺ°ж–№ејҸиҝӣиЎҢдәҶж–°зҡ„жј”иҝӣгҖӮйӮЈе°ұжҳҜе°Ҷе…ій”®еә”з”Ёе®№еҷЁеҢ–гҖӮиҝҷж ·еҸҜд»ҘиҫҫеҲ°д»ҘдёӢеҠҹж•Ҳпјҡ
* дёҚдҫөе…Ҙдҝ®ж”№ K8s ж ёеҝғ组件пјӣ
* ж–№дҫҝиҝӯд»Ј&еҸ‘еёғпјӣ
* еҖҹеҠ©дәҺ Kubernetes зӣёе…ізҡ„ QoS Class жңәеҲ¶пјҢе®№еҷЁзҡ„иө„жәҗй…ҚзҪ®пјҢиө„жәҗејҖй”ҖеҸҜжҺ§гҖӮ
еҪ“然еңЁеҗҺз»ӯжј”иҝӣдёӯпјҢжҲ‘们д№ҹеңЁе°қиҜ•е’Ң HPAпјҢVPA иҝӣиЎҢжү“йҖҡпјҢжҜ•з«ҹиҝҷдәӣе’Ң Policy engine еӯҳеңЁзқҖдә’иЎҘзҡ„е…ізі»гҖӮеӣ жӯӨжҲ‘们жһ¶жһ„иҝӣдёҖжӯҘжј”иҝӣжҲҗеҰӮдёӢжғ…еҪўгҖӮеҪ“ Policy engine еңЁеӨ„зҗҶдёҖдәӣжӣҙеӨҡеӨҚжқӮеңәжҷҜжҗһеҲ°ж— еҠӣж—¶пјҢдёҠжҠҘдәӢ件让дёӯеҝғз«ҜеҒҡеҮәжӣҙе…ЁеұҖзҡ„еҶізӯ–гҖӮж°ҙе№іжү©е®№жҲ–жҳҜеһӮзӣҙеўһеҠ иө„жәҗгҖӮ

дёӢйқўжҲ‘们具дҪ“и®Ёи®әдёҖдёӢ Policy engine зҡ„и®ҫи®ЎгҖӮPolicy engine жҳҜеҚ•жңәиҠӮзӮ№дёҠиҝӣиЎҢжҷәиғҪи°ғеәҰ并жү§иЎҢ Pod иө„жәҗи°ғж•ҙзҡ„ж ёеҝғ组件гҖӮе®ғдё»иҰҒеҢ…жӢ¬ api serverпјҢжҢҮжҢҘдёӯеҝғ command center е’Ңжү§иЎҢеұӮ executorгҖӮ
* е…¶дёӯ api server з”ЁдәҺжңҚеҠЎеӨ–з•ҢеҜ№дәҺ policy engine иҝҗиЎҢзҠ¶жҖҒзҡ„жҹҘиҜўе’Ңи®ҫзҪ®зҡ„иҜ·жұӮпјӣ
* command center ж №жҚ®е®һж—¶зҡ„е®№еҷЁз”»еғҸе’Ңзү©зҗҶжңәжң¬иә«зҡ„иҙҹиҪҪд»ҘеҸҠиө„жәҗдҪҝз”Ёжғ…еҶөпјҢдҪңеҮә Pod иө„жәҗи°ғж•ҙзҡ„еҶізӯ–пјӣ
* Executor еҶҚж №жҚ® command center зҡ„еҶізӯ–пјҢеҜ№е®№еҷЁзҡ„иө„жәҗйҷҗеҲ¶иҝӣиЎҢи°ғж•ҙгҖӮеҗҢж—¶пјҢexecutor д№ҹжҠҠжҜҸж¬Ўи°ғж•ҙзҡ„ revision info жҢҒд№…еҢ–пјҢд»ҘдҫҝеҸ‘з”ҹж•…йҡңж—¶еҸҜд»Ҙеӣһж»ҡгҖӮ
жҢҮжҢҘдёӯеҝғе®ҡжңҹд»Һ data aggregator иҺ·еҸ–е®№еҷЁзҡ„е®һж—¶з”»еғҸпјҢеҢ…жӢ¬иҒҡеҗҲзҡ„з»ҹи®Ўж•°жҚ®е’Ңйў„жөӢж•°жҚ®пјҢйҰ–е…ҲеҲӨж–ӯиҠӮзӮ№зҠ¶жҖҒпјҢдҫӢеҰӮиҠӮзӮ№зЈҒзӣҳејӮеёёпјҢжҲ–иҖ…зҪ‘з»ңдёҚйҖҡпјҢиЎЁзӨәиҜҘиҠӮзӮ№е·Із»ҸеҸ‘з”ҹејӮеёёпјҢйңҖиҰҒдҝқжҠӨзҺ°еңәпјҢдёҚеҶҚеҜ№PodиҝӣиЎҢиө„жәҗи°ғж•ҙпјҢд»Ҙе…ҚйҖ жҲҗзі»з»ҹйңҮиҚЎпјҢеҪұе“Қиҝҗз»ҙе’Ңи°ғиҜ•гҖӮеҰӮжһңиҠӮзӮ№зҠ¶жҖҒжӯЈеёёпјҢжҢҮжҢҘдёӯеҝғдјҡзӯ–з•Ҙ规еҲҷпјҢеҜ№е®№еҷЁж•°жҚ®иҝӣиЎҢеҶҚж¬ЎиҝҮж»ӨгҖӮжҜ”еҰӮе®№еҷЁ CPU зҺҮйЈҷй«ҳпјҢжҲ–иҖ…е®№еҷЁзҡ„е“Қеә”ж—¶й—ҙи¶…иҝҮе®үе…ЁйҳҲеҖјгҖӮеҰӮжһңжқЎд»¶ж»Ўи¶іпјҢеҲҷеҜ№ж»Ўи¶іжқЎд»¶зҡ„е®№еҷЁйӣҶеҗҲз»ҷеҮәиө„жәҗи°ғж•ҙе»әи®®пјҢдј йҖ’з»ҷexecutorгҖӮ
еңЁжһ¶жһ„и®ҫи®ЎдёҠпјҢжҲ‘们йҒөеҫӘдәҶд»ҘдёӢеҺҹеҲҷпјҡ
* жҸ’件еҢ–пјҡжүҖжңүзҡ„规еҲҷе’Ңзӯ–з•Ҙиў«и®ҫи®ЎдёәеҸҜд»ҘйҖҡиҝҮй…ҚзҪ®ж–Ү件жқҘдҝ®ж”№пјҢе°ҪйҮҸдёҺж ёеҝғжҺ§еҲ¶жөҒзЁӢзҡ„д»Јз Ғи§ЈиҖҰпјҢдёҺ data collector е’Ң data aggregator зӯү其他组件зҡ„жӣҙж–°е’ҢеҸ‘еёғи§ЈиҖҰпјҢжҸҗеҚҮеҸҜжү©еұ•жҖ§пјӣ
* зЁіе®ҡпјҢиҝҷеҢ…жӢ¬д»ҘдёӢеҮ дёӘж–№йқўпјҡ
* жҺ§еҲ¶еҷЁзЁіе®ҡжҖ§гҖӮжҢҮжҢҘдёӯеҝғзҡ„еҶізӯ–д»ҘдёҚеҪұе“ҚеҚ•жңәд№ғиҮіе…ЁеұҖзЁіе®ҡжҖ§дёәеүҚжҸҗпјҢеҢ…жӢ¬е®№еҷЁзҡ„жҖ§иғҪзЁіе®ҡе’Ңиө„жәҗеҲҶй…ҚзЁіе®ҡгҖӮдҫӢеҰӮпјҢзӣ®еүҚжҜҸдёӘжҺ§еҲ¶еҷЁд»…иҙҹиҙЈдёҖз§Қ cgroup иө„жәҗзҡ„жҺ§еҲ¶пјҢеҚіеңЁеҗҢдёҖж—¶й—ҙзӘ—еҸЈеҶ…пјҢPolicy engine дёҚеҗҢж—¶и°ғж•ҙеӨҡз§Қиө„жәҗпјҢд»Ҙе…ҚйҖ жҲҗиө„жәҗеҲҶй…ҚйңҮиҚЎпјҢе№Іжү°и°ғж•ҙж•Ҳжһңпјӣ
* и§ҰеҸ‘规еҲҷзЁіе®ҡжҖ§гҖӮдҫӢеҰӮпјҢжҹҗдёҖжқЎи§„еҲҷзҡ„еҺҹе§Ӣи§ҰеҸ‘жқЎд»¶дёәе®№еҷЁзҡ„жҖ§иғҪжҢҮж Үи¶…еҮәе®үе…ЁйҳҲеҖјпјҢдҪҶжҳҜдёәйҒҝе…ҚжҺ§еҲ¶еҠЁдҪңиў«жҹҗдёҖзӘҒеҸ‘еі°еҖји§ҰеҸ‘иҖҢеҜјиҮҙйңҮиҚЎпјҢжҲ‘们жҠҠи§ҰеҸ‘规еҲҷе®ҡеҲ¶дёәпјҡиҝҮеҺ»дёҖж®өж—¶й—ҙзӘ—еҸЈеҶ…жҖ§иғҪжҢҮж Үзҡ„дҪҺзҷҫеҲҶдҪҚи¶…еҮәе®үе…ЁйҳҲеҖјпјӣеҰӮжһң规еҲҷж»Ўи¶іпјҢиҜҙжҳҺиҝҷж®өж—¶й—ҙеҶ…з»қеӨ§йғЁеҲҶзҡ„жҖ§иғҪжҢҮж ҮеҖјйғҪе·Із»Ҹи¶…еҮәдәҶе®үе…ЁйҳҲеҖјпјҢе°ұйңҖиҰҒи§ҰеҸ‘жҺ§еҲ¶еҠЁдҪңдәҶпјӣ
* еҸҰеӨ–пјҢдёҺзӨҫеҢәзүҲВ Vertical-Pod-Autoscaler дёҚеҗҢпјҢPolicy engine дёҚдё»еҠЁй©ұйҖҗи…ҫжҢӘе®№еҷЁпјҢиҖҢжҳҜзӣҙжҺҘдҝ®ж”№е®№еҷЁзҡ„ cgroup ж–Ү件пјӣ
* иҮӘж„Ҳпјҡиө„жәҗи°ғж•ҙзӯүеҠЁдҪңзҡ„жү§иЎҢеҸҜиғҪдјҡдә§з”ҹдёҖдәӣејӮеёёпјҢжҲ‘们еңЁжҜҸдёӘжҺ§еҲ¶еҷЁеҶ…йғҪеҠ е…ҘдәҶиҮӘж„Ҳеӣһж»ҡжңәеҲ¶пјҢдҝқиҜҒж•ҙдёӘзі»з»ҹзҡ„зЁіе®ҡжҖ§пјӣ
* дёҚдҫқиө–еә”з”Ёе…ҲйӘҢзҹҘиҜҶпјҡдёәжүҖжңүдёҚеҗҢзҡ„еә”з”ЁеҲҶеҲ«иҝӣиЎҢеҺӢжөӢгҖҒе®ҡеҲ¶зӯ–з•ҘпјҢжҲ–иҖ…жҸҗеүҚеҜ№еҸҜиғҪжҺ’йғЁеңЁдёҖиө·зҡ„еә”з”ЁиҝӣиЎҢеҺӢжөӢпјҢдјҡеҜјиҮҙе·ЁеӨ§ејҖй”ҖпјҢеҸҜжү©еұ•жҖ§йҷҚдҪҺгҖӮжҲ‘们зҡ„зӯ–з•ҘеңЁи®ҫи®ЎдёҠе°ҪеҸҜиғҪйҖҡз”ЁпјҢе°ҪйҮҸйҮҮз”ЁдёҚдҫқиө–дәҺе…·дҪ“е№іеҸ°гҖҒж“ҚдҪңзі»з»ҹгҖҒеә”з”Ёзҡ„жҢҮж Үе’ҢжҺ§еҲ¶зӯ–з•ҘгҖӮ
еңЁиө„жәҗи°ғж•ҙж–№йқўпјҢCgroup ж”ҜжҢҒжҲ‘们еҜ№еҗ„дёӘе®№еҷЁзҡ„ CPUгҖҒеҶ…еӯҳгҖҒзҪ‘з»ңе’ҢзЈҒзӣҳ IO еёҰе®Ҫиө„жәҗиҝӣиЎҢйҡ”зҰ»е’ҢйҷҗеҲ¶пјҢзӣ®еүҚжҲ‘们主иҰҒеҜ№е®№еҷЁзҡ„ CPU иө„жәҗиҝӣиЎҢи°ғж•ҙпјҢеҗҢж—¶еңЁжөӢиҜ•дёӯжҺўзҙўеңЁж—¶еҲҶеӨҚз”Ёзҡ„еңәжҷҜдёӢеҠЁжҖҒи°ғж•ҙ memory limit е’Ң swap usage иҖҢйҒҝе…Қ OOM зҡ„еҸҜиЎҢжҖ§пјӣеңЁжңӘжқҘжҲ‘们е°Ҷж”ҜжҢҒеҜ№е®№еҷЁзҡ„зҪ‘з»ңе’ҢзЈҒзӣҳ IO зҡ„еҠЁжҖҒи°ғж•ҙгҖӮ
и°ғж•ҙж•Ҳжһң
----

дёҠеӣҫеұ•зӨәдәҶжҲ‘们еңЁжөӢиҜ•йӣҶзҫӨеҫ—еҲ°зҡ„дёҖдәӣе®һйӘҢз»“жһңгҖӮжҲ‘们жҠҠй«ҳдјҳе…Ҳзә§зҡ„еңЁзәҝеә”з”Ёе’ҢдҪҺдјҳе…Ҳзә§зҡ„зҰ»зәҝеә”з”Ёж··еҗҲйғЁзҪІеңЁжөӢиҜ•йӣҶзҫӨйҮҢгҖӮSLO жҳҜ 250msпјҢжҲ‘们еёҢжңӣеңЁзәҝеә”з”Ёзҡ„ latency зҡ„ 95 зҷҫеҲҶдҪҚеҖјдҪҺдәҺйҳҲеҖј 250msгҖӮ
еңЁе®һйӘҢз»“жһңдёӯеҸҜд»ҘзңӢеҲ°пјҡ
* еңЁеӨ§зәҰ90sеүҚпјҢеңЁзәҝеә”з”Ёзҡ„иҙҹиҪҪеҫҲдҪҺпјӣlatency зҡ„еқҮеҖје’ҢзҷҫеҲҶдҪҚйғҪеңЁ 250ms д»ҘдёӢпјӣ
* еҲ°дәҶВ 90sеҗҺпјҢжҲ‘们з»ҷеңЁзәҝеә”з”ЁеҠ еҺӢпјҢжөҒйҮҸеўһеҠ пјҢиҙҹиҪҪд№ҹеҚҮй«ҳпјҢеҜјиҮҙеңЁзәҝеә”з”Ё latency зҡ„ 95 зҷҫеҲҶдҪҚеҖји¶…иҝҮдәҶ SLOпјӣ
* еңЁеӨ§зәҰ 150s е·ҰеҸіпјҢжҲ‘们зҡ„е°ҸжӯҘеҝ«и·‘жҺ§еҲ¶зӯ–з•Ҙиў«и§ҰеҸ‘пјҢжёҗиҝӣејҸең° throttle дёҺеңЁзәҝеә”з”ЁеҸ‘з”ҹиө„жәҗз«һдәүзҡ„зҰ»зәҝеә”з”Ёпјӣ
* еҲ°дәҶеӨ§зәҰ 200s е·ҰеҸіпјҢеңЁзәҝеә”з”Ёзҡ„жҖ§иғҪжҒўеӨҚжӯЈеёёпјҢlatency зҡ„ 95 зҷҫеҲҶдҪҚеӣһиҗҪеҲ° SLO д»ҘдёӢгҖӮ
иҝҷиҜҙжҳҺдәҶжҲ‘们зҡ„жҺ§еҲ¶зӯ–з•Ҙзҡ„жңүж•ҲжҖ§гҖӮ
з»ҸйӘҢе’Ңж•ҷи®ӯ
=====
дёӢйқўжҲ‘们жҖ»з»“дёҖдёӢеңЁж•ҙдёӘйЎ№зӣ®зҡ„иҝӣиЎҢиҝҮзЁӢдёӯпјҢжҲ‘们收иҺ·зҡ„дёҖдәӣз»ҸйӘҢе’Ңж•ҷи®ӯпјҢеёҢжңӣиҝҷдәӣз»ҸйӘҢж•ҷи®ӯиғҪеӨҹеҜ№йҒҮеҲ°зұ»дјјй—®йўҳе’ҢеңәжҷҜзҡ„дәәжңүжүҖеё®еҠ©гҖӮ
1. йҒҝејҖзЎ¬зј–з ҒпјҢ组件еҫ®жңҚеҠЎеҢ–пјҢдёҚд»…дҫҝдәҺеҝ«йҖҹжј”иҝӣе’Ңиҝӯд»ЈпјҢиҝҳжңүеҲ©дәҺзҶ”ж–ӯејӮеёёжңҚеҠЎгҖӮ
2. е°ҪеҸҜиғҪдёҚиҰҒи°ғз”Ёзұ»еә“дёӯиҝҳжҳҜ alpha жҲ–иҖ… beta зү№жҖ§зҡ„жҺҘеҸЈгҖӮ дҫӢеҰӮжҲ‘们жӣҫз»ҸзӣҙжҺҘи°ғз”Ё CRI жҺҘеҸЈиҜ»еҸ–е®№еҷЁзҡ„дёҖдәӣдҝЎжҒҜпјҢжҲ–иҖ…еҒҡдёҖдәӣжӣҙж–°ж“ҚдҪңпјҢдҪҶжҳҜйҡҸзқҖжҺҘеҸЈеӯ—ж®өжҲ–иҖ…ж–№жі•зҡ„дҝ®ж”№пјҢе…ұе»әжңүдәӣеҠҹиғҪе°ұдјҡеҸҳеҫ—дёҚеҸҜз”ЁпјҢжҲ–и®ёжңүж—¶еҖҷпјҢи°ғз”ЁдёҚзЁіе®ҡзҡ„жҺҘеҸЈиҝҳдёҚеҰӮзӣҙжҺҘиҺ·еҸ–жҹҗдёӘеә”з”Ёзҡ„жү“еҚ°дҝЎжҒҜеҸҜиғҪжӣҙйқ и°ұгҖӮ
3. еҹәдәҺ QoS зҡ„иө„жәҗеҠЁжҖҒи°ғж•ҙж–№йқўпјҡеҰӮжҲ‘们д№ӢеүҚжүҖи®ІпјҢйҳҝйҮҢйӣҶеӣўеҶ…йғЁжңүдёҠдёҮдёӘеә”з”ЁпјҢеә”з”Ёд№Ӣй—ҙзҡ„и°ғз”Ёй“ҫзӣёеҪ“еӨҚжқӮгҖӮеә”з”Ё A зҡ„е®№еҷЁжҖ§иғҪеҸ‘з”ҹејӮеёёпјҢдёҚдёҖе®ҡйғҪжҳҜеңЁеҚ•жңәиҠӮзӮ№дёҠзҡ„иө„жәҗдёҚи¶іжҲ–иҖ…иө„жәҗз«һдәүеҜјиҮҙпјҢиҖҢеҫҲжңүеҸҜиғҪжҳҜе®ғдёӢжёёзҡ„еә”з”Ё BгҖҒеә”з”Ё CпјҢжҲ–иҖ…ж•°жҚ®еә“гҖҒcache зҡ„и®ҝ问延иҝҹеҜјиҮҙзҡ„гҖӮз”ұдәҺеҚ•жңәиҠӮзӮ№дёҠиҝҷз§ҚдҝЎжҒҜзҡ„еұҖйҷҗжҖ§пјҢеҹәдәҺеҚ•жңәиҠӮзӮ№дҝЎжҒҜзҡ„иө„жәҗи°ғж•ҙпјҢеҸӘиғҪйҮҮз”ЁвҖңе°ҪеҠӣиҖҢдёәвҖқпјҢд№ҹе°ұжҳҜ best effort зҡ„зӯ–з•ҘдәҶгҖӮеңЁжңӘжқҘпјҢжҲ‘们计еҲ’жү“йҖҡеҚ•жңәиҠӮзӮ№е’Ңдёӯеҝғз«Ҝзҡ„иө„жәҗи°ғжҺ§й“ҫи·ҜпјҢз”ұдёӯеҝғз«Ҝз»јеҗҲеҚ•жңәиҠӮзӮ№дёҠжҠҘзҡ„жҖ§иғҪдҝЎжҒҜе’Ңиө„жәҗи°ғж•ҙиҜ·жұӮпјҢз»ҹдёҖиҝӣиЎҢиө„жәҗзҡ„йҮҚж–°еҲҶй…ҚпјҢжҲ–иҖ…е®№еҷЁзҡ„йҮҚж–°зј–жҺ’пјҢжҲ–иҖ…и§ҰеҸ‘ HPAпјҢд»ҺиҖҢеҪўжҲҗдёҖдёӘйӣҶзҫӨзә§еҲ«зҡ„й—ӯзҺҜзҡ„жҷәиғҪиө„жәҗи°ғжҺ§й“ҫи·ҜпјҢиҝҷе°ҶдјҡеӨ§еӨ§жҸҗй«ҳж•ҙдёӘйӣҶзҫӨз»ҙеәҰзҡ„зЁіе®ҡжҖ§е’Ңз»јеҗҲиө„жәҗеҲ©з”ЁзҺҮгҖӮ
4. иө„жәҗv.s.жҖ§иғҪжЁЎеһӢпјҡеҸҜиғҪжңүдәәе·Із»ҸжіЁж„ҸеҲ°пјҢжҲ‘们зҡ„и°ғж•ҙзӯ–з•ҘйҮҢпјҢ并没жңүжҳҺжҳҫең°жҸҗеҮәдёәе®№еҷЁе»әз«ӢвҖңиө„жәҗv.s.жҖ§иғҪвҖқзҡ„жЁЎеһӢгҖӮиҝҷз§ҚжЁЎеһӢеңЁеӯҰжңҜи®әж–ҮйҮҢйқһеёёеёёи§ҒпјҢдёҖиҲ¬жҳҜеҜ№иў«жөӢзҡ„еҮ з§Қеә”з”ЁиҝӣиЎҢдәҶзҰ»зәҝеҺӢжөӢжҲ–иҖ…еңЁзәҝеҺӢжөӢпјҢж”№еҸҳеә”з”Ёзҡ„иө„жәҗеҲҶй…ҚпјҢжөӢйҮҸеә”з”Ёзҡ„жҖ§иғҪжҢҮж ҮпјҢеҫ—еҲ°жҖ§иғҪйҡҸиө„жәҗеҸҳеҢ–зҡ„жӣІзәҝпјҢжңҖз»Ҳз”ЁеңЁе®һж—¶зҡ„иө„жәҗи°ғжҺ§з®—жі•дёӯгҖӮеңЁеә”з”Ёж•°йҮҸжҜ”иҫғе°‘пјҢи°ғз”Ёй“ҫжҜ”иҫғз®ҖеҚ•пјҢйӣҶзҫӨйҮҢзҡ„зү©зҗҶжңә硬件й…ҚзҪ®д№ҹжҜ”иҫғе°‘зҡ„жғ…еҶөдёӢпјҢиҝҷз§ҚеҹәдәҺеҺӢжөӢзҡ„ж–№жі•еҸҜд»Ҙз©·дёҫеҲ°жүҖжңүеҸҜиғҪзҡ„жғ…еҶөпјҢжүҫеҲ°жңҖдјҳжҲ–иҖ…ж¬Ўдјҳзҡ„иө„жәҗи°ғж•ҙж–№жЎҲпјҢд»ҺиҖҢеҫ—еҲ°жҜ”иҫғеҘҪзҡ„жҖ§иғҪгҖӮдҪҶжҳҜеңЁйҳҝйҮҢйӣҶеӣўзҡ„еңәжҷҜдёӢпјҢжҲ‘们жңүдёҠдёҮдёӘеә”з”ЁпјҢеҫҲеӨҡйҮҚзӮ№еә”з”Ёзҡ„зүҲжң¬еҸ‘еёғд№ҹйқһеёёйў‘з№ҒпјҢеҫҖеҫҖж–°зүҲжң¬еҸ‘еёғеҗҺпјҢж—§зҡ„еҺӢжөӢж•°жҚ®пјҢжҲ–иҖ…иҜҙиө„жәҗжҖ§иғҪжЁЎеһӢпјҢе°ұдёҚйҖӮз”ЁдәҶгҖӮеҸҰеӨ–пјҢжҲ‘们зҡ„йӣҶзҫӨеҫҲеӨҡжҳҜејӮжһ„йӣҶзҫӨпјҢеңЁжҹҗдёҖз§Қзү©зҗҶжңәдёҠжөӢиҜ•еҫ—еҲ°зҡ„жҖ§иғҪж•°жҚ®пјҢеңЁеҸҰдёҖеҸ°дёҚеҗҢеһӢеҸ·зҡ„зү©зҗҶжңәдёҠе°ұдёҚдјҡеӨҚзҺ°гҖӮиҝҷдәӣйғҪеҜ№жҲ‘们зӣҙжҺҘеә”з”ЁеӯҰжңҜи®әж–ҮйҮҢзҡ„иө„жәҗи°ғжҺ§з®—жі•еёҰжқҘдәҶйҡңзўҚгҖӮжүҖд»ҘпјҢй’ҲеҜ№йҳҝйҮҢйӣҶеӣўеҶ…йғЁзҡ„еңәжҷҜпјҢжҲ‘们йҮҮз”ЁдәҶиҝҷж ·зҡ„зӯ–з•ҘпјҡдёҚеҜ№еә”з”ЁиҝӣиЎҢзҰ»зәҝеҺӢжөӢпјҢиҺ·еҸ–жҳҫзӨәзҡ„иө„жәҗжҖ§иғҪжЁЎеһӢгҖӮиҖҢжҳҜе»әз«Ӣе®һж—¶зҡ„еҠЁжҖҒе®№еҷЁз”»еғҸпјҢз”ЁиҝҮеҺ»дёҖж®өж—¶й—ҙзӘ—еҸЈеҶ…е®№еҷЁиө„жәҗдҪҝз”Ёжғ…еҶөзҡ„з»ҹи®Ўж•°жҚ®дҪңдёәеҜ№жңӘжқҘдёҖе°Ҹж®өж—¶й—ҙеҶ…зҡ„йў„жөӢпјҢ并且еҠЁжҖҒжӣҙж–°пјӣжңҖеҗҺеҹәдәҺиҝҷдёӘеҠЁжҖҒзҡ„е®№еҷЁз”»еғҸпјҢжү§иЎҢе°ҸжӯҘеҝ«и·‘зҡ„иө„жәҗи°ғж•ҙзӯ–з•ҘпјҢиҫ№иө°иҫ№зңӢпјҢе°ҪеҠӣиҖҢдёәгҖӮ
жҖ»з»“дёҺеұ•жңӣ
=====
жҖ»з»“иө·жқҘпјҢжҲ‘们зҡ„е·ҘдҪңдё»иҰҒе®һзҺ°дәҶд»ҘдёӢеҮ ж–№йқўзҡ„收зӣҠпјҡ
* йҖҡиҝҮеҲҶж—¶еӨҚз”Ёд»ҘеҸҠе°ҶдёҚеҗҢдјҳе…Ҳзә§зҡ„е®№еҷЁпјҲд№ҹе°ұжҳҜеңЁзәҝе’ҢзҰ»зәҝд»»еҠЎпјүж··еҗҲйғЁзҪІпјҢ并且йҖҡиҝҮеҜ№е®№еҷЁиө„жәҗйҷҗеҲ¶зҡ„еҠЁжҖҒи°ғж•ҙпјҢдҝқиҜҒдәҶеңЁзәҝеә”з”ЁеңЁдёҚеҗҢиҙҹиҪҪжғ…еҶөдёӢйғҪиғҪеҫ—еҲ°и¶іеӨҹзҡ„иө„жәҗпјҢд»ҺиҖҢжҸҗй«ҳйӣҶзҫӨзҡ„з»јеҗҲиө„жәҗеҲ©з”ЁзҺҮгҖӮ
* йҖҡиҝҮеҜ№еҚ•жңәиҠӮзӮ№дёҠзҡ„е®№еҷЁиө„жәҗзҡ„жҷәиғҪеҠЁжҖҒи°ғж•ҙпјҢйҷҚдҪҺдәҶеә”з”Ёд№Ӣй—ҙзҡ„жҖ§иғҪе№Іжү°пјҢдҝқйҡңй«ҳдјҳе…Ҳзә§еә”з”Ёзҡ„жҖ§иғҪзЁіе®ҡжҖ§
* еҗ„з§Қиө„жәҗи°ғж•ҙзӯ–з•ҘйҖҡиҝҮ Daemonset йғЁзҪІпјҢеҸҜд»ҘиҮӘеҠЁең°гҖҒжҷәиғҪең°еңЁиҠӮзӮ№дёҠиҝҗиЎҢпјҢеҮҸе°‘дәәе·Ҙе№Ійў„пјҢйҷҚдҪҺдәҶиҝҗз»ҙзҡ„дәәеҠӣжҲҗжң¬гҖӮ
еұ•жңӣжңӘжқҘпјҢжҲ‘们еёҢжңӣеңЁд»ҘдёӢеҮ дёӘж–№йқўеҠ ејәе’Ңжү©еұ•жҲ‘们зҡ„е·ҘдҪңпјҡ
* й—ӯзҺҜжҺ§еҲ¶й“ҫи·ҜпјҡеүҚйқўе·Із»ҸжҸҗеҲ°пјҢеҚ•жңәиҠӮзӮ№дёҠз”ұдәҺзјәд№Ҹе…ЁеұҖдҝЎжҒҜпјҢеҜ№дәҺиө„жәҗзҡ„и°ғж•ҙжңүе…¶еұҖйҷҗжҖ§пјҢеҸӘиғҪе°ҪеҠӣиҖҢдёәгҖӮжңӘжқҘпјҢжҲ‘们еёҢжңӣиғҪеӨҹжү“йҖҡдёҺ HPA е’Ң VPA зҡ„йҖҡи·ҜпјҢдҪҝеҚ•жңәиҠӮзӮ№е’Ңдёӯеҝғз«ҜиҒ”еҠЁиҝӣиЎҢиө„жәҗи°ғж•ҙпјҢжңҖеӨ§еҢ–еј№жҖ§дјёзј©зҡ„收зӣҠгҖӮ
* е®№еҷЁйҮҚж–°зј–жҺ’пјҡеҚідҪҝжҳҜеҗҢдёҖдёӘеә”з”ЁпјҢдёҚеҗҢе®№еҷЁзҡ„иҙҹиҪҪе’ҢжүҖеӨ„зҡ„зү©зҗҶзҺҜеўғд№ҹжҳҜеҠЁжҖҒеҸҳеҢ–зҡ„пјҢеҚ•жңәдёҠи°ғж•ҙ pod зҡ„иө„жәҗпјҢдёҚдёҖе®ҡиғҪеӨҹж»Ўи¶іеҠЁжҖҒзҡ„йңҖжұӮгҖӮжҲ‘们еёҢжңӣеҚ•жңәдёҠе®һж—¶е®№еҷЁз”»еғҸпјҢиғҪеӨҹдёәдёӯеҝғз«ҜжҸҗдҫӣжӣҙеӨҡзҡ„жңүж•ҲдҝЎжҒҜпјҢеё®еҠ©дёӯеҝғз«Ҝзҡ„и°ғеәҰеҷЁдҪңеҮәжӣҙеҠ жҷәиғҪзҡ„е®№еҷЁйҮҚзј–жҺ’еҶізӯ–гҖӮ
* зӯ–з•ҘжҷәиғҪеҢ–пјҡжҲ‘们зҺ°еңЁзҡ„иө„жәҗи°ғж•ҙзӯ–з•Ҙд»Қ然жҜ”иҫғзІ—зІ’еәҰпјҢеҸҜд»Ҙи°ғж•ҙзҡ„иө„жәҗд№ҹжҜ”иҫғжңүйҷҗпјӣеҗҺз»ӯжҲ‘们еёҢжңӣи®©иө„жәҗи°ғж•ҙзӯ–з•ҘжӣҙеҠ жҷәиғҪеҢ–пјҢ并且иҖғиҷ‘еҲ°жӣҙеӨҡзҡ„иө„жәҗпјҢжҜ”еҰӮеҜ№зЈҒзӣҳе’ҢзҪ‘з»ңIOеёҰе®Ҫзҡ„и°ғж•ҙпјҢжҸҗй«ҳиө„жәҗи°ғж•ҙзҡ„жңүж•ҲжҖ§гҖӮ
* е®№еҷЁз”»еғҸзІҫз»ҶеҢ–пјҡзӣ®еүҚзҡ„е®№еҷЁз”»еғҸд№ҹжҜ”иҫғзІ—зіҷпјҢд»…д»…дҫқйқ з»ҹи®Ўж•°жҚ®е’ҢзәҝжҖ§йў„жөӢпјӣеҲ»з”»е®№еҷЁжҖ§иғҪзҡ„жҢҮж Үз§Қзұ»д№ҹжҜ”иҫғеұҖйҷҗгҖӮжҲ‘们еёҢжңӣжүҫеҲ°жӣҙеҠ зІҫзЎ®зҡ„гҖҒйҖҡз”Ёзҡ„гҖҒеҸҚжҳ е®№еҷЁжҖ§иғҪзҡ„жҢҮж ҮпјҢд»ҘдҫҝжӣҙеҠ зІҫз»Ҷең°еҲ»з”»е®№еҷЁеҪ“еүҚзҡ„зҠ¶жҖҒе’ҢеҜ№дёҚеҗҢиө„жәҗзҡ„йңҖжұӮзЁӢеәҰгҖӮ
* жҹҘжүҫе№Іжү°жәҗпјҡжҲ‘们еёҢжңӣиғҪжүҫеҲ°еңЁеҚ•жңәиҠӮзӮ№дёҠжүҫеҲ°иЎҢд№Ӣжңүж•Ҳзҡ„ж–№жЎҲпјҢжқҘзІҫеҮҶе®ҡдҪҚеә”з”ЁжҖ§иғҪеҸ—жҚҹж—¶зҡ„е№Іжү°жәҗпјӣиҝҷеҜ№зӯ–з•ҘжҷәиғҪеҢ–д№ҹжңүеҫҲеӨ§ж„Ҹд№үгҖӮ
Q & A
=====
**Q1пјҡ**зӣҙжҺҘдҝ®ж”№ cgroup е®№еҷЁдёҖе®ҡдјҡиҺ·еҫ—иө„жәҗеҗ—пјҹ
**A1пјҡ**е®№еҷЁжҠҖжңҜйҡ”зҰ»зҡ„жҠҖжңҜеҹәзЎҖе°ұжҳҜ cgroup еұӮйқўгҖӮеңЁе®ҝдё»жңәи…ҫеҮәи¶іеӨҹиө„жәҗзҡ„жғ…еҶөдёӢпјҢз»ҷ cgroup и®ҫзҪ®жӣҙеӨ§зҡ„еҖјеҸҜд»ҘиҺ·еҸ–жӣҙеӨҡзҡ„иө„жәҗгҖӮеҗҢзҗҶпјҢеҜ№дәҺдёҖиҲ¬дјҳе…Ҳзә§дёҚй«ҳзҡ„еә”з”ЁпјҢи®ҫзҪ®иҫғдҪҺзҡ„ cgroup иө„жәҗеҖје°ұдјҡиҫҫеҲ°жҠ‘еҲ¶е®№еҷЁиҝҗиЎҢзҡ„ж•ҲжһңгҖӮ
**Q2пјҡ**еә•еұӮжҳҜеҰӮдҪ•еҢәеҲҶеңЁзәҝе’ҢзҰ»зәҝдјҳе…Ҳзә§зҡ„пјҹ
**A2пјҡ**еә•еұӮжҳҜж— жі•иҮӘеҠЁиҺ·еҸ–и°ҒжҳҜеңЁзәҝпјҢи°ҒжҳҜзҰ»зәҝпјҢжҲ–иҖ…и°Ғзҡ„дјҳе…Ҳзә§й«ҳпјҢи°Ғзҡ„дјҳе…Ҳзә§дҪҺзҡ„гҖӮиҝҷдёӘжҲ‘们еҸҜд»ҘйҖҡиҝҮеҗ„з§Қ Kubernetes жҸҗдҫӣзҡ„жү©еұ•е®һзҺ°гҖӮжңҖз®ҖеҚ•зҡ„жҳҜйҖҡиҝҮ labelпјҢAnnotation ж ҮиҜҶгҖӮеҪ“然йҖҡиҝҮжү©еұ• QoS class д№ҹжҳҜдёҖз§ҚжҖқи·ҜгҖӮзӨҫеҢәзүҲжң¬зҡ„ QoS classи®ҫзҪ®еӨӘиҝҮдәҺдҝқе®ҲпјҢз»ҷдәҲз”ЁжҲ·еҸ‘жҢҘзҡ„з©әй—ҙдёҚеӨ§гҖӮжҲ‘们йҖҡиҝҮиҝҷдәӣж–№йқўд№ҹиҝӣиЎҢдәҶеўһејәгҖӮеңЁеҗҲйҖӮзҡ„ж—¶еҖҷжҲ–и®ёдјҡжҺЁеҗ‘зӨҫеҢәгҖӮиҮӘеҠЁж„ҹзҹҘжҳҜдёӘж–№еҗ‘пјҢж„ҹзҹҘи°ҒжҳҜе№Іжү°жәҗпјҢж„ҹзҹҘи°ҒжҳҜжҹҗз§Қиө„жәҗеһӢеә”з”ЁпјҢиҝҷеқ—жҲ‘们иҝҳеңЁз ”еҸ‘дёӯгҖӮеҒҡеҲ°зңҹжӯЈзҡ„еҠЁжҖҒпјҢиӮҜе®ҡжҳҜе…·еӨҮиҮӘеҠЁж„ҹзҹҘзҡ„жҷәиғҪзі»з»ҹгҖӮ
**Q3пјҡ**вҖңдёҺзӨҫеҢәзүҲВ Vertical-Pod-Autoscaler дёҚеҗҢпјҢPolicy engine дёҚдё»еҠЁй©ұйҖҗи…ҫжҢӘе®№еҷЁпјҢиҖҢжҳҜзӣҙжҺҘдҝ®ж”№е®№еҷЁзҡ„ cgroup ж–Ү件вҖқпјҢжғій—®дёҖдёӢпјҢдёҚдё»еҠЁй©ұйҖҗзҡ„иҜқпјҢеҰӮжһң Node зҡ„иө„жәҗиҫҫеҲ°дёҠзәҝдәҶдјҡжҖҺд№ҲеӨ„зҗҶпјҹ
**A3пјҡ**иҝҷжҳҜдёҖдёӘеҘҪй—®йўҳгҖӮйҰ–е…ҲиҝҷйҮҢиҰҒе…ҲеҢәеҲҶжҳҜе“Әз§Қиө„жәҗпјҢеҰӮжһңжҳҜ CPU еһӢзҡ„пјҢжҲ‘们еҸҜд»Ҙи°ғж•ҙдҪҺдјҳе…Ҳзә§е®№еҷЁзҡ„ cgroup дёӢ cpu quota зҡ„еҖјпјҢйҰ–е…ҲжҠ‘еҲ¶дҪҺдјҳе…Ҳзә§зҡ„е®№еҷЁеҜ№дәҺ CPU зҡ„дәүжҠўгҖӮ然еҗҺеҶҚйҖӮеҪ“дёҠи°ғй«ҳдјҳе…Ҳзә§е®№еҷЁзҡ„зӣёе…іиө„жәҗеҖјгҖӮеҰӮжһңжҳҜеҶ…еӯҳеһӢиө„жәҗпјҢиҝҷдёӘдёҚиғҪзӣҙжҺҘеҺ»зј©е°ҸдҪҺдјҳе…Ҳзә§е®№еҷЁзҡ„ cgroup еҖјпјҢеҗҰеҲҷдјҡйҖ жҲҗ OOMпјҢеҜ№дәҺеӯҰд№ еҶ…еӯҳеһӢиө„жәҗзҡ„и°ғж•ҙпјҢжҲ‘们дјҡеңЁе…¶д»–еҲҶдә«дёӯ继з»ӯи®Ёи®әгҖӮиҝҷдёӘжҠҖжңҜжҜ”иҫғзү№ж®ҠгҖӮ
**Q4пјҡ**еҸӘдҝ®ж”№ cgroupпјҢжҖҺд№ҲдҝқиҜҒ K8s еҜ№еҚ•дёӘзү©зҗҶжңәиғҪеӨҹеҲҶй…ҚжӣҙеӨҡзҡ„е®№еҷЁпјҹ
**A4пјҡ**ж–Үеӯ—зӣҙж’ӯжңүдәҶдёҖе®ҡиҜҙжҳҺпјҢе®№еҷЁзҡ„иө„жәҗж¶ҲиҖ—并йқһжҳҜдёҖжҲҗдёҚеҸҳзҡ„пјҢеҫҲеӨҡж—¶еҖҷе®ғ们зҡ„иө„жәҗж¶ҲиҖ—е‘ҲзҺ°жҪ®жұҗзҺ°иұЎпјҢзӣёеҗҢзҡ„иө„жәҗжқЎд»¶дёӢйғЁзҪІжӣҙеӨҡеә”з”ЁпјҢе®ҢжҲҗжӣҙеӨҡдҪңдёҡе°ұжҳҜиҫҫеҲ°иө„жәҗеҲ©з”Ёзҡ„жңҖеӨ§еҢ–зҡ„ж•ҲжһңгҖӮиө„жәҗеҮәзҺ°и¶…еҚ–жүҚжҳҜжҲ‘们иҝҷдёӘдё»йўҳи®Ёи®әзҡ„жңҖеӨ§д»·еҖјгҖӮ
**Q5пјҡ**д№ҹе°ұжҳҜиҜҙпјҢдҪҺдјҳе…Ҳзә§зҡ„е®№еҷЁпјҢrequest и®ҫзҪ®зҡ„жҜ” limit е°ҸеҫҲеӨҡпјҢ然еҗҺдҪ 们еҶҚеҠЁжҖҒзҡ„и°ғж•ҙ cgroupпјҹ
**A5пјҡ**еңЁзҺ°жңү QoS еңәжҷҜдёӢпјҢдҪ еҸҜд»ҘзҗҶи§Јиў«и°ғж•ҙзҡ„ Pod йғҪжҳҜ burstable зҡ„гҖӮдҪҶжҳҜжҲ‘们并дёҚжҳҜзӣҙжҺҘи°ғж•ҙ Pod е…ғж•°жҚ®зҡ„ limit зҡ„еҖјпјҢиҖҢжҳҜи°ғж•ҙ limit еңЁ cgroup еҸҚжҳ зҡ„еҖјпјҢиҝҷдёӘеҖјеңЁиө„жәҗз«һдәүзј“е’Ңзҡ„ж—¶еҖҷиҝҳдјҡиў«и°ғж•ҙеӣһеҺ»зҡ„гҖӮжҲ‘们并дёҚе»әи®®еҚ•жңәзҡ„ cgroup ж•°жҚ®е’Ң etcd зҡ„дёӯеҝғж•°жҚ®еүІиЈӮеӨӘд№…гҖӮеҰӮжһңй•ҝжңҹеҒҸзҰ»пјҢжҲ‘们дјҡеғҸ VPA еҸ‘еҮәиӯҰжҠҘпјҢиҒ”еҠЁ VPA еҒҡи°ғж•ҙгҖӮеҪ“然еңЁе®№еҷЁиҝҗиЎҢзҡ„й«ҳеі°жңҹпјҢд»»дҪ•йҮҚе»әе®№еҷЁзҡ„ж“ҚдҪңйғҪжҳҜдёҚжҳҺжҷәзҡ„гҖӮ
**Q6пјҡ**ж•ҙдҪ“зҡ„зҗҶи§Је°ұжҳҜдҪ 们ејҖе§Ӣе°ұи®©зү©зҗҶжңәи¶…й…ҚдәҶдёҖе®ҡжҜ”дҫӢзҡ„ podпјҢ然еҗҺйҖҡиҝҮзӯ–з•ҘеҠЁжҖҒи°ғж•ҙе®№еҷЁзҡ„ cgroup еҖјпјҹ
**A6пјҡ**еҰӮжһңиө„жәҗе®Ңе…ЁжҳҜеҜҢи¶іеҶ—дҪҷзҡ„пјҢиҝҷдёӘеҠЁжҖҒи°ғж•ҙд№ҹжңүдёҖе®ҡж„Ҹд№үгҖӮе°ұжҳҜ并йқһиө„жәҗз”Ёж»ЎеңәжҷҜдёӢпјҢй«ҳдјҳе…Ҳзә§еә”з”Ёдјҡиў«е№Іжү°пјҢе®һйҷ…дёҠпјҢеҪ“дё»жңәзҡ„ CPU иҫҫеҲ°дёҖе®ҡжҜ”дҫӢпјҢжү“дёӘжҜ”ж–№дҫӢеҰӮ 50%пјҢеә”з”Ёзҡ„时延е°ұеҸҳеӨ§гҖӮдёәдәҶе®Ңе…ЁзЎ®дҝқй«ҳдјҳе…Ҳзә§еә”з”Ёзҡ„ SLOпјҢзүәзүІдҪҺдјҳе…Ҳзә§зҡ„ CPU жӯЈеёёиҝҗиЎҢд№ҹжҳҜжңүд»·еҖјзҡ„гҖӮ
**Q7:**Policy engine жңүжІЎжңүиҖғиҷ‘ејҖжәҗпјҹ
**A7пјҡ**жңүи®ЎеҲ’иҝӣиЎҢејҖжәҗпјҢPolicy engine жӣҙеӨҡзҡ„жҳҜе’ҢиҮӘиә«зҡ„еә”з”ЁеұһжҖ§зӣёе…іпјҢз”өе•Ҷеә”з”ЁжҲ–иҖ…еӨ§ж•°жҚ®еӨ„зҗҶеә”з”Ёзҡ„зӯ–з•ҘйғҪжҳҜдёҚзӣёеҗҢзҡ„пјҢжҲ‘们ејҖжәҗдјҡйҰ–е…ҲејҖжәҗжЎҶжһ¶е’Ңйҷ„еёҰдёҖдәӣз®ҖеҚ•зҡ„зӯ–з•ҘпјҢжӣҙеӨҡзҡ„зӯ–з•ҘеҸҜд»Ҙз”ЁжҲ·иҮӘе®ҡд№үгҖӮ
**Q8пјҡ**жҲ‘д№ӢеүҚйҒҮеҲ°зҡ„еӨ§йғЁеҲҶеә”з”ЁйғҪж— жі•жӯЈзЎ®ж„ҹзҹҘ cgroup зҡ„й…ҚзҪ®пјҢеӣ жӯӨеҫҲеӨҡжғ…еҶөйғҪйңҖиҰҒеңЁеҗҜеҠЁеҸӮж•°йҮҢйқўж №жҚ® cpu жҲ–иҖ… mem и®ҫзҪ®еҸӮж•°пјҢйӮЈд№Ҳд№ҹе°ұжҳҜиҜҙеҚідҪҝж”№еҸҳдәҶ cgroup еҜ№дәҺ他们жқҘиҜҙйғҪж— ж•ҲпјҢйӮЈд№ҲдҪҝз”ЁеңәжҷҜд№ҹе°ұжңүйҷҗдәҶ
**A8пјҡ**йҷҗеҲ¶е®№еҷЁзҡ„иө„жәҗдҪҝз”ЁиҝҷдёӘиҝҳжҳҜжңүд»·еҖјзҡ„гҖӮйҷҗеҲ¶дҪҺдјҳе…Ҳзә§еә”з”Ёжң¬иә«д№ҹеҸҜд»ҘжҸҗеҚҮй«ҳдјҳе…Ҳзә§еә”з”Ёзҡ„ SLOпјҢиҷҪ然ж•ҲжһңжІЎжңүйӮЈд№ҲжҳҺжҳҫгҖӮзЁіе®ҡжҖ§зҡ„иҖғйҮҸеҗҢж ·д№ҹеҫҲйҮҚиҰҒгҖӮ
**Q9:**Policy engine зӣ®еүҚеңЁйҳҝйҮҢзҡ„дҪҝз”ЁеҰӮдҪ•пјҹеңЁз”ҹдә§дёҠжңүеӨҡдёҠзҡ„规模дҪҝз”Ёиҝҷз§Қж–№ејҸиҝӣиЎҢеҠЁжҖҒи°ғж•ҙпјҹжҳҜеҗҰе’ҢзӨҫеҢәзҡ„ HPA VPA й…ҚеҗҲдҪҝз”Ёпјҹ
**A9:В **Policy engine еңЁйҳҝйҮҢжҹҗдәӣйӣҶзҫӨе·Із»ҸдҪҝз”ЁгҖӮиҮідәҺ规模жҡӮж—¶ж— жі•йҖҸжјҸгҖӮж¶үеҸҠеҲ°еҫҲеӨҡ组件д№Ӣй—ҙзҡ„иҒ”еҠЁпјҢзӨҫеҢәзҡ„ HPA е’Ң VPA зӣ®еүҚйғҪдёҚеӨӘиғҪж»Ўи¶іжҲ‘们зҡ„йңҖжұӮгҖӮеӣ жӯӨйҳҝйҮҢзҡ„ HPA е’Ң VPA йғҪжҳҜжҲ‘们иҮӘиЎҢејҖеҸ‘зҡ„пјҢдҪҶжҳҜе’ҢзӨҫеҢәзҡ„еҺҹзҗҶжҳҜдёҖиҮҙзҡ„гҖӮйҳҝйҮҢ HPA зҡ„ејҖжәҗеҸҜд»Ҙе…іжіЁ Openkruise зӨҫеҢәгҖӮVPA ејҖжәҗи®ЎеҲ’жҲ‘иҝҷйҮҢиҝҳжІЎжңүзЎ®еҲҮж¶ҲжҒҜгҖӮ
**Q10пјҡ**еҪ“еҚ•жңәиҠӮзӮ№иө„жәҗдёҚи¶ід»ҘжҸҗдҫӣе®№еҷЁжү©е®№ж—¶пјҢзӣ®еүҚжҳҜеҗҰеҸҜд»ҘиҝӣиЎҢ HPA жҲ– VPA жү©е®№е‘ўпјҹ
**A10пјҡ**еҚ•жңәиҠӮзӮ№дёҚи¶ізҡ„ж—¶еҖҷпјҢеә”з”ЁеҸҜд»ҘйҖҡиҝҮ HPA иҝӣиЎҢеўһеҠ еүҜжң¬еә”еҜ№гҖӮдҪҶжҳҜ VPA еҰӮжһңйҖүжӢ©еҺҹиҠӮзӮ№иҝӣиЎҢжӣҙж–°зҡ„иҜқпјҢжҳҜеӨұиҙҘзҡ„гҖӮеҸӘиғҪи°ғеәҰеҲ°е…¶д»–иө„жәҗдё°еҜҢзҡ„иҠӮзӮ№гҖӮеңЁжөҒйҮҸйҷЎеҚҮзҡ„еңәжҷҜдёӢпјҢйҮҚе»әе®№еҷЁжңӘеҝ…иғҪж»Ўи¶ійңҖжұӮпјҢеҫҲеҸҜиғҪеҜјиҮҙйӣӘеҙ©пјҢеҚійҮҚе»әиҝҮзЁӢдёӯпјҢж•ҙдёӘеә”з”Ёе…¶д»–жңӘеҚҮзә§зҡ„еүҜжң¬жҺҘеҸ—жӣҙеӨҡжөҒйҮҸпјҢOOM жҺүпјҢж–°еҗҜеҠЁзҡ„е®№еҷЁеҶҚзһ¬й—ҙиў« OOMпјҢжүҖд»ҘйҮҚеҗҜе®№еҷЁйңҖиҰҒж…ҺйҮҚгҖӮеҝ«йҖҹжү©е®№пјҲHPAпјүжҲ–иҖ…еҝ«йҖҹжҸҗеҚҮй«ҳдјҳе…Ҳзә§иө„жәҗпјҢжҠ‘еҲ¶дҪҺдјҳе…Ҳзә§е®№еҷЁиө„жәҗзҡ„ж–№ејҸж•ҲжһңжӣҙжҳҺжҳҫгҖӮ
жң¬ж–ҮдҪңиҖ…пјҡеј жҷ“е®ҮпјҲиЎ·жәҗпјүВ йҳҝйҮҢдә‘е®№еҷЁе№іеҸ°жҠҖжңҜ专家
[еҺҹж–Үй“ҫжҺҘ](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/719845%3Futm_content%3Dg_1000079633)
жң¬ж–Үдёәдә‘ж –зӨҫеҢәеҺҹеҲӣеҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
еҲҶдә«еҲ°пјҡ


- 2019-10-15 14:48
- жөҸи§Ҳ 221
- иҜ„и®ә(0)
- еҲҶзұ»:йқһжҠҖжңҜ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҰӮдҪ•еҲ©з”ЁMatlabжһ„е»әгҖҒдјҳеҢ–е’Ңеә”з”ЁеҶізӯ–еҲҶзұ»ж ‘гҖӮйҰ–е…ҲпјҢи®Іи§ЈдәҶж•°жҚ®еҮҶеӨҮйҳ¶ж®өпјҢе°Ҷж•°жҚ®дёҺзЁӢеәҸеҲҶзҰ»пјҢзЎ®дҝқзҒөжҙ»жҖ§гҖӮжҺҘзқҖпјҢйҖҡиҝҮе…·дҪ“е®һдҫӢеұ•зӨәдәҶеҰӮдҪ•дҪҝз”ЁMatlabеҶ…зҪ®еҮҪж•°еҰӮfitctreeеҝ«йҖҹжһ„е»әеҶізӯ–ж ‘жЁЎеһӢпјҢ并йҖҡиҝҮеҸҜи§ҶеҢ–е·Ҙе…·зӣҙи§Ӯе‘ҲзҺ°еҶізӯ–ж ‘з»“жһ„гҖӮй’ҲеҜ№еҸҜиғҪеҮәзҺ°зҡ„иҝҮжӢҹеҗҲй—®йўҳпјҢжҸҗеҮәдәҶеҹәдәҺжҲҗжң¬еӨҚжқӮеәҰзҡ„еүӘжһқж–№жі•пјҢд»ҘжҸҗй«ҳжЁЎеһӢзҡ„жіӣеҢ–иғҪеҠӣгҖӮжӯӨеӨ–пјҢиҝҳеҲҶдә«дәҶдёҖдәӣе®һз”ЁжҠҖе·§пјҢеҰӮеӨ„зҗҶиҝһз»ӯзү№еҫҒгҖҒдҝқеӯҳжЁЎеһӢгҖҒ并иЎҢи®Ўз®—зӯүпјҢеё®еҠ©з”ЁжҲ·жӣҙеҘҪең°зҗҶи§Је’Ңеә”з”ЁеҶізӯ–ж ‘гҖӮ йҖӮеҗҲдәәзҫӨпјҡе…·жңүдёҖе®ҡзј–зЁӢеҹәзЎҖзҡ„ж•°жҚ®еҲҶжһҗеёҲгҖҒжңәеҷЁеӯҰд№ зҲұеҘҪиҖ…еҸҠз§‘з ”е·ҘдҪңиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒиҝӣиЎҢж•°жҚ®еҲҶзұ»д»»еҠЎзҡ„еңәжҷҜпјҢзү№еҲ«жҳҜеҪ“йңҖиҰҒи§ЈйҮҠжҖ§ејәзҡ„жЁЎеһӢж—¶гҖӮдё»иҰҒзӣ®ж ҮжҳҜж•ҷдјҡиҜ»иҖ…еҰӮдҪ•еңЁMatlabзҺҜеўғдёӯй«ҳж•Ҳең°жһ„е»әе’ҢдјҳеҢ–еҶізӯ–еҲҶзұ»ж ‘пјҢд»ҺиҖҢеә”з”ЁдәҺе®һйҷ…йЎ№зӣ®дёӯгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯдёҚд»…жҸҗдҫӣдәҶе®Ңж•ҙзҡ„д»Јз ҒзӨәдҫӢпјҢиҝҳејәи°ғдәҶд»Јз ҒжЁЎеқ—еҢ–зҡ„йҮҚиҰҒжҖ§пјҢдҫҝдәҺеҗҺз»ӯз»ҙжҠӨе’Ңжү©еұ•гҖӮеҗҢж—¶пјҢеҜ№дәҺеҲқеӯҰиҖ…жқҘиҜҙпјҢе»әи®®д»Һз®ҖеҚ•зҡ„йёўе°ҫиҠұж•°жҚ®йӣҶејҖе§Ӣз»ғд№ пјҢйҖҗжӯҘжҺҢжҸЎеҶізӯ–ж ‘зҡ„еҗ„йЎ№жҠҖиғҪгҖӮ
гҖҠиҗҘй”Җи°ғз ”гҖӢ第7з« -жҺўзҙўжҖ§и°ғз ”ж•°жҚ®йҮҮйӣҶ.pptx
Assignment1_search_final(1).ipynb
зҫҺеӣўдјҳжғ еҲёе°ҸзЁӢеәҸеёҰдёҫзүҢе°ҸдәәеёҰиҸңи°ұ+жөҒйҮҸдё»жЁЎејҸпјҢжҢәеӨҡеӨ–еҚ–е°ҸзЁӢеәҸзҡ„пјҢдҪҶжҳҜйғҪжІЎжңүжҗӯе»әж•ҷзЁӢ жҗӯе»әпјҡ 1гҖҒдёӢиҪҪжәҗз ҒпјҢеҺ»еҫ®дҝЎе…¬дј—е№іеҸ°жіЁеҶҢиҮӘе·ұзҡ„иҙҰеҸ· 2гҖҒи§ЈеҺӢеҲ°жЎҢйқў 3гҖҒжү“ејҖеҫ®дҝЎејҖеҸ‘иҖ…е·Ҙе…·ж·»еҠ е°ҸзЁӢеәҸ-жҠҠи§ЈеҺӢзҡ„жәҗз Ғж·»еҠ иҝӣеҺ»-appidж”№жҲҗиҮӘе·ұе°ҸзЁӢеәҸзҡ„ 4гҖҒеңЁpages/index/index.jsж–Ү件жҗңжөҒйҮҸдё»е№ҝе‘Ҡж”№жҲҗиҮӘе·ұзҡ„е№ҝе‘ҠID 5гҖҒеҲ°еҫ®дҝЎе…¬дј—е№іеҸ°зҷ»йҷҶиҮӘе·ұзҡ„е°ҸзЁӢеәҸ-ејҖеҸ‘з®ЎзҗҶ-ејҖеҸ‘и®ҫзҪ®-жңҚеҠЎеҷЁеҹҹеҗҚдҝ®ж”№жҲҗ
гҖҠи®Ўз®—жңәеҪ•е…ҘжҠҖжңҜгҖӢ第еҚҒе…«з« -еёёз”ЁеӨ–ж–Үиҫ“е…Ҙжі•.pptx
еҹәдәҺAndoridзҡ„и·ЁеұҸжӢ–еҠЁеә”з”Ёи®ҫи®Ўе®һзҺ°жәҗз ҒпјҢдё»иҰҒй’ҲеҜ№и®Ўз®—жңәзӣёе…ідё“дёҡзҡ„жӯЈеңЁеҒҡжҜ•и®ҫзҡ„еӯҰз”ҹе’ҢйңҖиҰҒйЎ№зӣ®е®һжҲҳз»ғд№ зҡ„еӯҰд№ иҖ…пјҢд№ҹеҸҜдҪңдёәиҜҫзЁӢи®ҫи®ЎгҖҒжңҹжң«еӨ§дҪңдёҡгҖӮ
гҖҠзҪ‘з«ҷе»әи®ҫдёҺз»ҙжҠӨгҖӢйЎ№зӣ®4-еңЁзәҝиҙӯзү©е•ҶеҹҺз”ЁжҲ·з®ЎзҗҶеҠҹиғҪ.pptx
еҢәеқ—й“ҫ_жҲҝеұӢиҪ¬з§ҹзі»з»ҹ_еҺ»дёӯеҝғеҢ–еӯҳеӮЁ_ж•°жҚ®йҳІзҜЎж”№_жҷәиғҪеҗҲзәҰ_S_1744435730
гҖҠи®Ўз®—жңәеә”з”ЁеҹәзЎҖе®һи®ӯжҢҮеҜјгҖӢе®һи®ӯдә”-Word-2010зҡ„ж–Үеӯ—зј–иҫ‘ж“ҚдҪң.pptx
гҖҠ移еҠЁйҖҡдҝЎ(第4зүҲ)гҖӢ第5з« -з»„зҪ‘жҠҖжңҜ.ppt
ABBжңәеҷЁдәәеҹәзЎҖ.pdf
гҖҠз»јеҗҲеёғзәҝж–Ҫе·ҘжҠҖжңҜгҖӢ第9з« -з»јеҗҲеёғзәҝе®һи®ӯжҢҮеҜј.ppt
еҫҲдёҚй”ҷзҡ„дёҖеҘ—з«ҷзҫӨзі»з»ҹжәҗз Ғ,еҗҺеҸ°й…ҚзҪ®йҮҮйӣҶиҠӮзӮ№пјҢиҫ“е…Ҙзӣ®ж Үз«ҷең°еқҖеҚіеҸҜе…ЁиҮӘеҠЁжҷәиғҪиҪ¬жҚўиҮӘеҠЁе…Ёз«ҷйҮҮйӣҶ!ж”ҜжҢҒ httpsгҖҒж”ҜжҢҒ POST иҺ·еҸ–гҖҒж”ҜжҢҒжҗңзҙўгҖҒж”ҜжҢҒ cookieгҖҒж”ҜжҢҒд»ЈзҗҶгҖҒж”ҜжҢҒз ҙи§ЈйҳІзӣ—й“ҫгҖҒж”ҜжҢҒз ҙи§ЈйҳІйҮҮйӣҶ е…ЁиҮӘеҠЁеҲҶжһҗ,еҶ…еӨ–й“ҫжҺҘиҮӘеҠЁиҪ¬жҚўгҖҒеӣҫзүҮең°еқҖгҖҒcssгҖҒjsпјҢиҮӘеҠЁеҲҶжһҗ CSS еҶ…зҡ„еӣҫзүҮдҪҝеҫ—йЎөйқўйЈҺж јдёҚдёўеӨұ: е№ҝе‘Ҡж ҮзӯҫпјҢж–№дҫҝеңЁи§„еҲҷйҮҢзӣҙжҺҘжӣҝжҚўе№ҝе‘Ҡд»Јз Ғ ж”ҜжҢҒиҮӘе®ҡд№үж ҮзӯҫпјҢж ҮзӯҫеҸҜиҮӘе®ҡд№үеҶ…е®№гҖҒиҮӘз”ұжҲӘеҸ–гҖҒеҶ…е®№жӯЈеҲҷжҲӘеҸ–гҖӮеҸҜд»Ҙж”ҫеңЁжЁЎжқҝйҮҢпјҢд№ҹеҸҜд»ҘеңЁи§„еҲҷйҮҢжӣҝжҚў ж”ҜжҢҒиҮӘе®ҡд№үжЁЎжқҝпјҢеҸҜдҪҝз”Ёж Үзӯҫ diy дёӘжҖ§жЁЎжқҝпјҢзңҹжӯЈеҒҡеҲ°еҶ…е®№дёҠ移иҠұжҺҘжңЁ и°ғиҜ•жЁЎејҸпјҢеҸҜи§ӮеҜҹйҮҮйӣҶжҖ§иғҪпјҢдҫҝдәҺеҸ‘зҺ°е’Ңи§ЈеҶіеҗ„з§Қй”ҷиҜҜ еӨҡжқЎйҮҮйӣҶ规еҲҷдёҖй”®еҲҮжҚўпјҢж”ҜжҢҒеҜје…ҘеҜјеҮә еҶ…зҪ®ејәеӨ§жӣҝжҚўе’ҢиҝҮж»ӨеҠҹиғҪпјҢж ҮзӯҫиҝҮж»ӨгҖҒз«ҷеҶ…еӨ–иҝҮж»ӨгҖҒеӯ—з¬ҰдёІжӣҝжҚўгҖҒзӯүзӯү IP еұҸи”ҪеҠҹиғҪпјҢеұҸи”ҪжғіиҰҒеұҸи”Ҫ IP ең°еқҖи®©е®ғж— жі•и®ҝй—® ****й«ҳзә§еҠҹиғҪ*****В· url иҝҮж»ӨеҠҹиғҪпјҢеҸҜиҝҮж»ӨеұҸи”ҪдёҚйҮҮйӣҶжҢҮе®ҡй“ҫжҺҘВ· дјӘеҺҹеҲӣпјҢиҝ‘д№үиҜҚжӣҝжҚўжңүеҲ©дәҺ seoВ· дјӘйқҷжҖҒпјҢurl дјӘйқҷжҖҒеҢ–пјҢжңүеҲ©дәҺ seoВ· иҮӘеҠЁзј“еӯҳиҮӘеҠЁжӣҙж–°пјҢеҸҜи®ҫзҪ®зј“еӯҳж—¶й—ҙиҫҫеҲ°иҮӘеҠЁжӣҙж–°пјҢcss зј“еӯҳВ· ж”ҜжҢҒжј”зӨәжңүйҳҝдёүжәҗз Ғз®Җз№ҒдҪ“дә’иҪ¬В· д»ЈзҗҶ IPгҖҒдјӘйҖ IPгҖҒйҡҸжңә IPгҖҒдјӘйҖ user-agentгҖҒдјӘйҖ referer жқҘи·ҜгҖҒиҮӘе®ҡд№ү cookieпјҢд»Ҙдҫҝеә”еҜ№йҳІйҮҮйӣҶжҺӘж–ҪВ· url ең°еқҖеҠ еҜҶиҪ¬жҚўпјҢдёӘжҖ§еҢ– urlпјҢи®©дҪ зҡ„ url ең°еқҖдёҺдј—дёҚеҗҢВ· е…ій”®иҜҚеҶ…й“ҫеҠҹиғҪВ· иҝҳжңүжӣҙеӨҡеҠҹиғҪзӯүдҪ еҸ‘зҺ°вҖҰвҖҰ зЁӢеәҸдҪҝз”Ёйқһеёёз®ҖеҚ•пјҢд»…йңҖеңЁеҗҺеҸ°иҫ“е…ҘдёҖдёӘеҹҹеҗҚеҚіеҸҜе»әз«ҷпјҢдёҚйҷҗеӯҗеҹҹеҗҚпјҢз«ҷзҫӨеҲ©еҷЁпјҢж— жҺҲжқғпјҢж— з»‘е®ҡйҷҗеҲ¶пјҢдҪҝз”ЁеҗҺеҸ°еҠҹиғҪеҸҜеҜ№йЎөйқўиҝӣиЎҢиҮӘе®ҡд№үдҝ®ж”№пјҢеңЁзЁӢеәҸеҗҺеҸ°ејҖеҗҜз”ҹ жҲҗеҠҹиғҪпјҢеҸӘиҰҒи®ҝй—®йЎөйқўе°ұдјҡз”ҹжҲҗдёҖдёӘжң¬ең°ж–Ү件гҖӮеҪ“з”ЁжҲ·еҶҚж¬Ўи®ҝй—®зҡ„ж—¶еҖҷе°ұзӣҙжҺҘи®ҝй—®зҪ‘з«ҷжң¬ең°зҡ„йЎөйқўпјҢжүҖд»Ҙзӣ®ж Үз«ҷзӮ№ж— жі•и®ҝй—®дәҶд№ҹжІЎе…ізі»пјҢжҲ‘们зҡ„з«ҷзӮ№дҫқ然еҸҜд»Ҙи®ҝй—®пјҢ ж”ҜжҢҒдјӘйқҷжҖҒгҖҒдјӘеҺҹеҲӣгҖҒз”ҹжҲҗйқҷжҖҒж–Ү件гҖҒиҮӘе®ҡд№үжӣҝжҚўгҖҒе№ҝе‘Ҡз®ЎзҗҶгҖҒеҸӢжғ…й“ҫжҺҘз®ЎзҗҶгҖҒиҮӘеҠЁдёӢиҪҪ CSS еҶ…зҡ„еӣҫгҖӮ
гҖҗиҮӘ然иҜӯиЁҖеӨ„зҗҶгҖ‘ж–Үжң¬еҲҶзұ»ж–№жі•з»јиҝ°пјҡд»ҺеҹәзЎҖжЁЎеһӢеҲ°ж·ұеәҰеӯҰд№ зҡ„жғ…ж„ҹеҲҶжһҗзі»з»ҹи®ҫи®Ў
еҹәдәҺAndoridзҡ„дёӢжӢүжөҸи§Ҳеә”з”Ёи®ҫи®Ўе®һзҺ°жәҗз ҒпјҢдё»иҰҒй’ҲеҜ№и®Ўз®—жңәзӣёе…ідё“дёҡзҡ„жӯЈеңЁеҒҡжҜ•и®ҫзҡ„еӯҰз”ҹе’ҢйңҖиҰҒйЎ№зӣ®е®һжҲҳз»ғд№ зҡ„еӯҰд№ иҖ…пјҢд№ҹеҸҜдҪңдёәиҜҫзЁӢи®ҫи®ЎгҖҒжңҹжң«еӨ§дҪңдёҡгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶдёҖдёӘеҺҹеҲӣзҡ„P2жҸ’з”өејҸж··еҗҲеҠЁеҠӣзі»з»ҹSimulinkжЁЎеһӢпјҢиҜҘжЁЎеһӢеҹәдәҺйҖ»иҫ‘й—ЁйҷҗеҖјжҺ§еҲ¶зӯ–з•ҘпјҢж¶өзӣ–дәҶеӨҡдёӘе…ій”®жЁЎеқ—еҰӮе·ҘеҶөиҫ“е…ҘгҖҒй©ҫ驶е‘ҳжЁЎеһӢгҖҒеҸ‘еҠЁжңәжЁЎеһӢгҖҒз”өжңәжЁЎеһӢгҖҒеҲ¶еҠЁиғҪйҮҸеӣһ收模еһӢгҖҒиҪ¬зҹ©еҲҶй…ҚжЁЎеһӢгҖҒиҝҗиЎҢжЁЎејҸеҲҮжҚўжЁЎеһӢгҖҒжЎЈдҪҚеҲҮжҚўжЁЎеһӢд»ҘеҸҠзәөеҗ‘еҠЁеҠӣеӯҰжЁЎеһӢгҖӮжЁЎеһӢж”ҜжҢҒеӨҡз§Қж ҮеҮҶе·ҘеҶөпјҲWLTCгҖҒUDDSгҖҒEUDCгҖҒNEDCпјүе’ҢиҮӘе®ҡд№үе·ҘеҶөпјҢ并еұ•зӨәдәҶдё°еҜҢзҡ„д»ҝзңҹз»“жһңпјҢеҢ…жӢ¬еҸ‘еҠЁжңәе’Ңз”өжңәиҪ¬зҹ©еҸҳеҢ–гҖҒе·ҘдҪңжЁЎејҸеҲҮжҚўгҖҒжЎЈдҪҚеҸҳеҢ–гҖҒз”өжұ SOCеҸҳеҢ–гҖҒзҮғжІ№ж¶ҲиҖ—йҮҸгҖҒйҖҹеәҰи·ҹйҡҸе’ҢжңҖеӨ§зҲ¬еқЎеәҰзӯүгҖӮжӯӨеӨ–пјҢж–Үз« иҝҳж·ұе…ҘжҺўи®ЁдәҶйҖ»иҫ‘й—ЁйҷҗеҖјжҺ§еҲ¶зӯ–з•Ҙзҡ„е…·дҪ“е®һзҺ°еҸҠе…¶ж•ҲжһңпјҢжҸҗдҫӣдәҶиҜҰз»Ҷзҡ„д»Јз ҒзӨәдҫӢе’ҢжҠҖжңҜз»ҶиҠӮгҖӮ йҖӮеҗҲдәәзҫӨпјҡжұҪиҪҰе·ҘзЁӢдё“дёҡеӯҰз”ҹгҖҒз ”з©¶дәәе‘ҳгҖҒж··еҠЁжұҪиҪҰејҖеҸ‘иҖ…еҸҠзҲұеҘҪиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ з”ЁдәҺж•ҷеӯҰе’Ңз§‘з ”пјҢеё®еҠ©зҗҶи§Је’ҢжҺҢжҸЎP2ж··еҠЁзі»з»ҹзҡ„еҺҹзҗҶе’ҢжҺ§еҲ¶зӯ–з•Ҙпјӣв‘ЎдҪңдёәејҖеҸ‘е·Ҙе…·пјҢиҫ…еҠ©и®ҫи®Ўе’ҢдјҳеҢ–ж··еҠЁжұҪиҪҰжҺ§еҲ¶зі»з»ҹпјӣв‘ўжҸҗдҫӣд»ҝзңҹе№іеҸ°пјҢиҜ„дј°дёҚеҗҢе·ҘеҶөдёӢзҡ„ж··еҠЁзі»з»ҹжҖ§иғҪгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯдёҚд»…д»Ӣз»ҚдәҶжЁЎеһӢзҡ„ж•ҙдҪ“жһ¶жһ„е’Ңеҗ„жЁЎеқ—зҡ„еҠҹиғҪпјҢиҝҳеҲҶдә«дәҶи®ёеӨҡе®һз”Ёзҡ„и°ғиҜ•жҠҖе·§е’ҢдјҳеҢ–ж–№жі•пјҢдҪҝиҜ»иҖ…иғҪеӨҹжӣҙеҘҪең°зҗҶи§Је’Ңеә”з”ЁиҜҘжЁЎеһӢгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҹәдәҺADMMпјҲдәӨжӣҝж–№еҗ‘д№ҳеӯҗжі•пјүз®—жі•еңЁз”өеҠӣзі»з»ҹеҲҶеёғејҸи°ғеәҰдёӯзҡ„еә”з”ЁпјҢзү№еҲ«жҳҜ并иЎҢпјҲJacobiпјүе’ҢдёІиЎҢпјҲGauss-SeidelпјүдёӨз§ҚдёҚеҗҢжӣҙж–°жЁЎејҸзҡ„е®һзҺ°гҖӮж–ҮдёӯйҖҡиҝҮMATLABд»Јз Ғеұ•зӨәдәҶиҝҷдёӨз§ҚжЁЎејҸзҡ„е…·дҪ“е®һзҺ°ж–№жі•пјҢ并жҜ”иҫғдәҶе®ғ们зҡ„дјҳеҠЈгҖӮ并иЎҢжЁЎејҸйҖӮз”ЁдәҺеӨҡж ёи®Ўз®—зҺҜеўғпјҢиғҪеӨҹе……еҲҶеҲ©з”ЁзЎ¬д»¶иө„жәҗпјҢе°Ҫз®Ўиҝӯд»Јж¬Ўж•°иҫғеӨҡпјҢдҪҶжҖ»дҪ“и®Ўз®—ж—¶й—ҙиҫғзҹӯпјӣдёІиЎҢжЁЎејҸеҲҷз”ұдәҺвҖңжҺҘеҠӣејҸвҖқжӣҙж–°жңәеҲ¶пјҢйҖҡ常收ж•ӣжӣҙеҝ«пјҢдҪҶеңЁи®Ўз®—иө„жәҗжңүйҷҗзҡ„жғ…еҶөдёӢеҸҜиғҪдјҡеҪўжҲҗ瓶йўҲгҖӮжӯӨеӨ–пјҢж–Үз« иҝҳи®Ёи®әдәҶжғ©зҪҡзі»ж•°rhoзҡ„иҮӘйҖӮеә”и°ғж•ҙзӯ–з•Ҙд»ҘеҸҠеңЁз”ө-ж°”иҖҰеҗҲзі»з»ҹдјҳеҢ–дёӯзҡ„еә”з”Ёе®һдҫӢгҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢз”өеҠӣзі»з»ҹдјҳеҢ–гҖҒеҲҶеёғејҸи®Ўз®—з ”з©¶зҡ„дё“дёҡдәәеЈ«пјҢе°Өе…¶жҳҜжңүдёҖе®ҡMATLABзј–зЁӢеҹәзЎҖзҡ„з ”з©¶дәәе‘ҳе’ҢжҠҖжңҜдәәе‘ҳгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ зҗҶи§Је’Ңе®һзҺ°ADMMз®—жі•еңЁз”өеҠӣзі»з»ҹеҲҶеёғејҸи°ғеәҰдёӯзҡ„еә”з”Ёпјӣв‘ЎиҜ„估并иЎҢе’ҢдёІиЎҢжЁЎејҸеңЁдёҚеҗҢеә”з”ЁеңәжҷҜдёӢзҡ„жҖ§иғҪиЎЁзҺ°пјӣв‘ўжҺҢжҸЎжғ©зҪҡзі»ж•°rhoзҡ„иҮӘйҖӮеә”и°ғж•ҙжҠҖе·§пјҢжҸҗй«ҳ算法收ж•ӣйҖҹеәҰе’ҢзЁіе®ҡжҖ§гҖӮ е…¶д»–иҜҙжҳҺпјҡж–Үз« жҸҗдҫӣдәҶиҜҰз»Ҷзҡ„MATLABд»Јз ҒзӨәдҫӢпјҢеё®еҠ©иҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’Ңе®һи·өADMMз®—жі•гҖӮеҗҢж—¶пјҢејәи°ғдәҶеңЁе®һйҷ…е·ҘзЁӢеә”з”ЁдёӯйңҖиҰҒжіЁж„Ҹзҡ„е…ій”®жҠҖжңҜе’ҢдјҳеҢ–зӯ–з•ҘгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–Үж·ұе…Ҙз ”з©¶дәҶдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁзҡ„е·ҘдҪңеҺҹзҗҶгҖҒжҖ§иғҪдјҳеҠҝеҸҠе…¶е…·дҪ“е®һзҺ°гҖӮж–Үз« йҰ–е…Ҳд»Ӣз»ҚдәҶдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁзӣёиҫғдәҺдј з»ҹBuckеҸҳжҚўеҷЁзҡ„дјҳеҠҝпјҢеҢ…жӢ¬еҮҸе°Ҹиҫ“еҮәз”өжөҒе’Ңз”өеҺӢзә№жіўгҖҒйҷҚдҪҺејҖе…із®Ўе’ҢдәҢжһҒз®Ўзҡ„з”өжөҒеә”еҠӣгҖҒеҮҸе°Ҹиҫ“еҮәж»Өжіўз”өе®№е®№йҮҸзӯүгҖӮжҺҘзқҖпјҢж–Үз« иҜҰз»Ҷеұ•зӨәдәҶеҰӮдҪ•йҖҡиҝҮMATLAB/Simulinkе»әз«ӢиҜҘеҸҳжҚўеҷЁзҡ„д»ҝзңҹжЁЎеһӢпјҢеҢ…жӢ¬еҸӮж•°и®ҫзҪ®гҖҒз”өи·Ҝе…ғ件添еҠ гҖҒPWMдҝЎеҸ·з”ҹжҲҗеҸҠиҝһжҺҘгҖҒз”өеҺӢз”өжөҒжөӢйҮҸжЁЎеқ—зҡ„ж·»еҠ зӯүгҖӮжӯӨеӨ–пјҢиҝҳжҺўи®ЁдәҶPIDжҺ§еҲ¶еҷЁзҡ„и®ҫи®ЎдёҺе®һзҺ°пјҢйҖҡиҝҮзҗҶи®әеҲҶжһҗе’Ңд»ҝзңҹйӘҢиҜҒдәҶе…¶жңүж•ҲжҖ§гҖӮжңҖеҗҺпјҢж–Үз« йҖҡиҝҮеӨҡдёӘд»ҝзңҹе®һйӘҢйӘҢиҜҒдәҶдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁеңЁзә№жіўжҖ§иғҪгҖҒеҷЁд»¶еә”еҠӣзӯүж–№йқўзҡ„дјҳеҠҝпјҢ并еҲҶжһҗдәҶдёҚеҗҢжҺ§еҲ¶зӯ–з•Ҙзҡ„ж•ҲжһңпјҢеҰӮPгҖҒPIгҖҒPIDжҺ§еҲ¶зӯүгҖӮ йҖӮеҗҲдәәзҫӨпјҡе…·еӨҮдёҖе®ҡз”өеҠӣз”өеӯҗеҹәзЎҖпјҢеҜ№DC-DCеҸҳжҚўеҷЁзү№еҲ«жҳҜдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁж„ҹе…ҙи¶Јзҡ„е·ҘзЁӢеёҲе’ҢжҠҖжңҜдәәе‘ҳгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ зҗҶи§ЈдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁзҡ„е·ҘдҪңеҺҹзҗҶеҸҠе…¶зӣёеҜ№дәҺдј з»ҹBuckеҸҳжҚўеҷЁзҡ„дјҳеҠҝпјӣв‘ЎжҺҢжҸЎдҪҝз”ЁMATLAB/Simulinkжҗӯе»әдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁд»ҝзңҹжЁЎеһӢзҡ„ж–№жі•пјӣв‘ўеӯҰд№ PIDжҺ§еҲ¶еҷЁзҡ„и®ҫи®ЎдёҺе®һзҺ°пјҢдәҶи§Је…¶еңЁз”өжәҗзі»з»ҹдёӯзҡ„еә”з”Ёпјӣв‘ЈйҖҡиҝҮд»ҝзңҹе®һйӘҢйӘҢиҜҒдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁзҡ„жҖ§иғҪпјҢиҜ„дј°дёҚеҗҢжҺ§еҲ¶зӯ–з•Ҙзҡ„ж•ҲжһңгҖӮ е…¶д»–иҜҙжҳҺпјҡжң¬ж–ҮдёҚд»…жҸҗдҫӣдәҶиҜҰз»Ҷзҡ„зҗҶи®әеҲҶжһҗпјҢиҝҳз»ҷеҮәдәҶеӨ§йҮҸеҸҜиҝҗиЎҢзҡ„MATLABд»Јз ҒпјҢеё®еҠ©иҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’Ңе®һи·өдәӨй”ҷ并иҒ”BuckеҸҳжҚўеҷЁзҡ„и®ҫи®ЎдёҺе®һзҺ°гҖӮеҗҢж—¶пјҢйҖҡиҝҮеҜ№дёҚеҗҢжҺ§еҲ¶зӯ–з•Ҙзҡ„еҜ№жҜ”еҲҶжһҗпјҢдёәе®һйҷ…е·ҘзЁӢеә”з”ЁжҸҗдҫӣдәҶжңүд»·еҖјзҡ„еҸӮиҖғгҖӮ
гҖҠз»јеҗҲеёғзәҝж–Ҫе·ҘжҠҖжңҜгҖӢ第8з« -з»јеҗҲеёғзәҝе·ҘзЁӢжЎҲдҫӢ.ppt
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҹәдәҺSTM32F103C8T6зҡ„KеһӢзғӯз”өеҒ¶жё©еәҰжҺ§еҲ¶д»Әзҡ„и®ҫи®ЎдёҺе®һзҺ°гҖӮ硬件йғЁеҲҶж¶өзӣ–дәҶзғӯз”өеҒ¶йҮҮйӣҶз”өи·ҜгҖҒOLEDжҳҫзӨәжЁЎеқ—гҖҒиңӮйёЈеҷЁз”өи·ҜгҖҒйЈҺжүҮжҺ§еҲ¶з”өи·Ҝд»ҘеҸҠEEPROMеӯҳеӮЁжЁЎеқ—гҖӮиҪҜ件йғЁеҲҶеҲҷж¶үеҸҠADCй…ҚзҪ®гҖҒOLEDеҲ·ж–°гҖҒPIDжҺ§жё©з®—жі•гҖҒEEPROMеҸӮж•°еӯҳеӮЁгҖҒйЈҺжүҮPWMжҺ§еҲ¶зӯүеӨҡдёӘж–№йқўзҡ„е…·дҪ“е®һзҺ°гҖӮж–ҮдёӯдёҚд»…жҸҗдҫӣдәҶиҜҰз»Ҷзҡ„д»Јз ҒзӨәдҫӢпјҢиҝҳеҲҶдә«дәҶи®ёеӨҡи°ғиҜ•з»ҸйӘҢе’ҢжіЁж„ҸдәӢйЎ№пјҢеҰӮеҶ·з«ҜиЎҘеҒҝгҖҒDMAдј иҫ“дјҳеҢ–гҖҒI2Cж—¶й’ҹй…ҚзҪ®гҖҒPWMйў‘зҺҮйҖүжӢ©зӯүгҖӮ йҖӮеҗҲдәәзҫӨпјҡе…·жңүдёҖе®ҡеөҢе…ҘејҸзі»з»ҹејҖеҸ‘з»ҸйӘҢзҡ„е·ҘзЁӢеёҲе’ҢжҠҖжңҜзҲұеҘҪиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒиҝӣиЎҢжё©еәҰзӣ‘жөӢдёҺжҺ§еҲ¶зҡ„еә”з”ЁеңәжҷҜпјҢеҰӮе·ҘдёҡиҮӘеҠЁеҢ–гҖҒе®һйӘҢе®Өи®ҫеӨҮзӯүгҖӮзӣ®ж ҮжҳҜеё®еҠ©иҜ»иҖ…жҺҢжҸЎSTM32F103C8T6еңЁжё©еәҰжҺ§еҲ¶йўҶеҹҹзҡ„еә”з”ЁжҠҖе·§пјҢжҸҗеҚҮ硬件и®ҫи®Ўе’ҢиҪҜ件编зЁӢиғҪеҠӣгҖӮ е…¶д»–иҜҙжҳҺпјҡжң¬ж–ҮжҸҗдҫӣзҡ„е·ҘзЁӢж–Ү件еҢ…еҗ«Altium Designerзҡ„еҺҹзҗҶеӣҫPCBж–Ү件пјҢдҫҝдәҺдәҢж¬ЎејҖеҸ‘гҖӮжӯӨеӨ–пјҢж–ҮдёӯиҝҳжҸҗеҲ°дәҶдёҖдәӣжү©еұ•еҠҹиғҪпјҢеҰӮеҠ е…ҘModbusйҖҡдҝЎеҚҸи®®пјҢдҫӣжңүе…ҙи¶Јзҡ„иҜ»иҖ…иҝӣдёҖжӯҘжҺўзҙўгҖӮ