一、测试环境
1、测试服务器状况
共涉及4台测试服务器:
压力测试服务器
Web服务器
MongoDB服务器
MySQL服务器。
机器配置为:
CPU:Intel(R) Core(TM)2 Duo CPU E7200 @ 2.53GHz
RAM:8G DDR2 667
磁盘:SATA
操作系统:Redhat 5.5
1. 压力测试服务器
安装Webbench 1.5,通过Webbench来压Web服务器。
2. Web服务器
Nginx 0.8.54 + PHP 5.3.3 (php-fpm),安装有Mongodb和HandlerSocket的php驱动。
Mongodb的php驱动为:mongodb-mongo-php-driver-1.1.1-19-gc584231.tar.gz
HandlerSocket的php驱动为:php-handlersocket-0.0.7.tar.gz
通过Php程序来调用Mongodb和HandlerSocket。
3. MongoDB服务器
MongoDB版本:1.6.5
4. MySQL服务器
MySQL版本:5.1.53
HandlerSocket版本:1.0.6-60-gf51e061
MySQL存储引擎:Innodb,调整了innodb的Thread Pool Size为2G
2、测试程序和测试数据提取
1. 为了避免打开连接和Http服务器成为瓶颈,在测试程序里设置为每1000个请求公用同一个连接,同时设置为每个页面请求执行1000次数据请求。
2. 测试的数据,包括QPS、CPU、IO等方面的数据,从操作系统提供的命令(如vmstat、iostat等)或者Mongodb、Mysql提供的命令(如mongostat、mysqladmin等)来获取。
二、测试结果
1、100万条记录
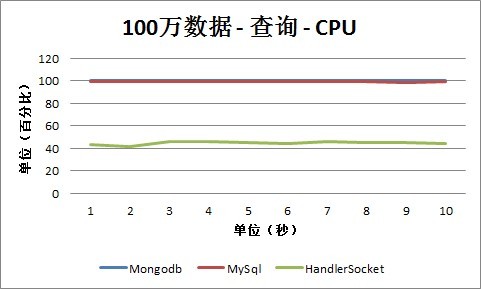
1. 查询
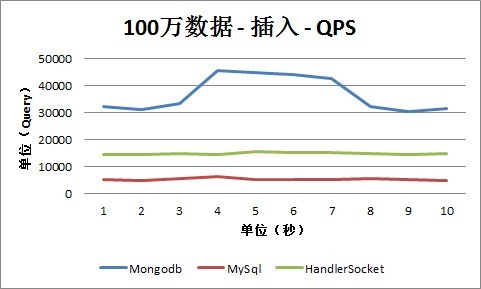
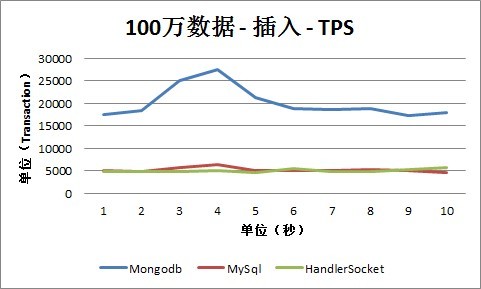
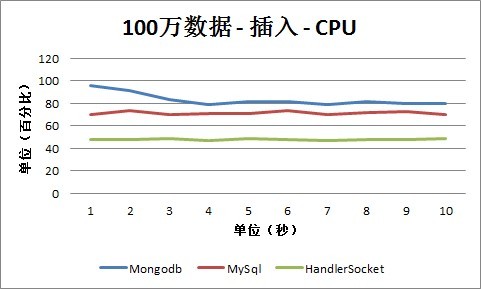
2. 插入
2、1000万条记录
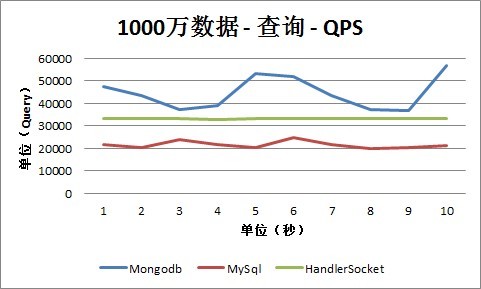
1. 查询

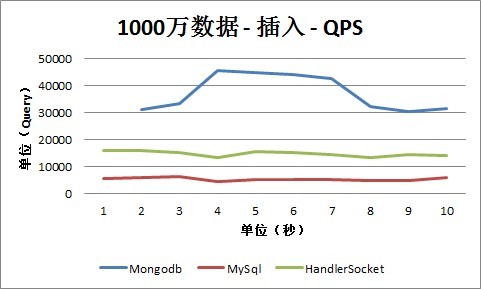
2. 插入
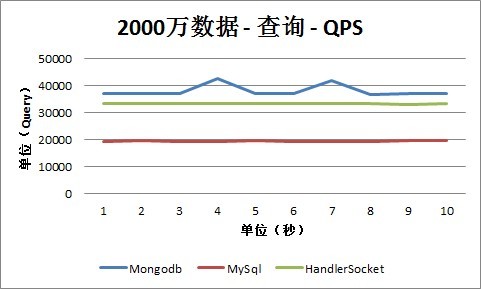
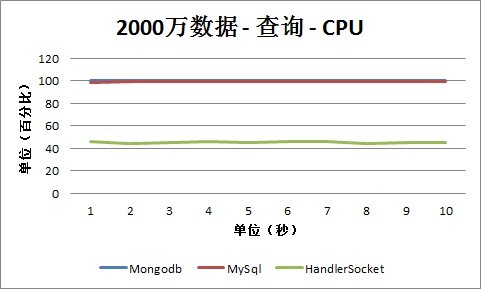
3、2000万条记录
1. 查询
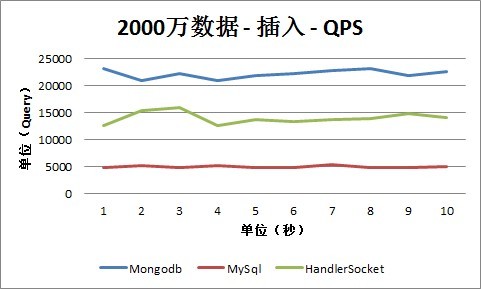
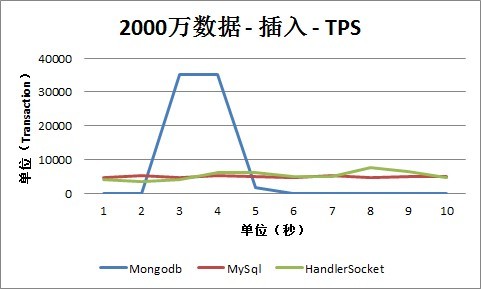
2. 插入
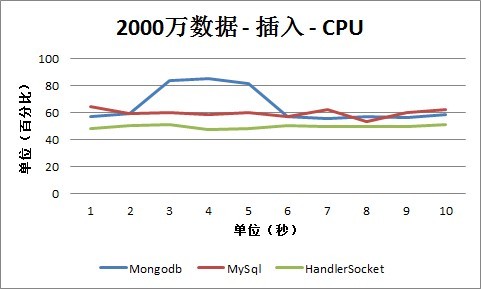
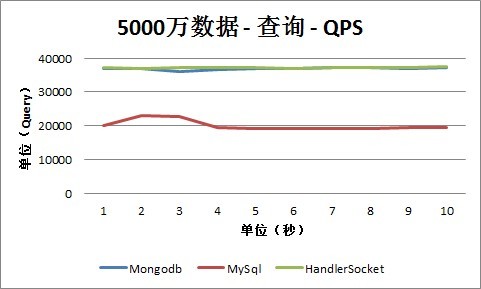
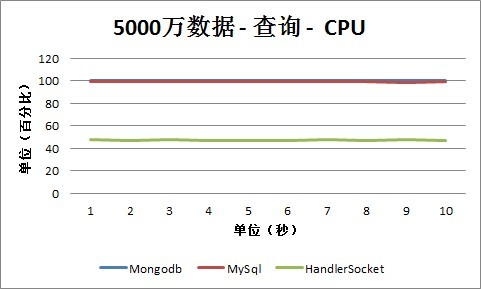
4、5000万条记录
1. 查询
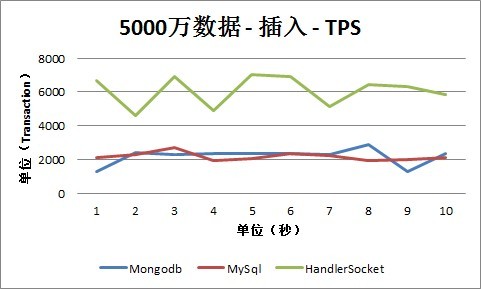
2. 插入

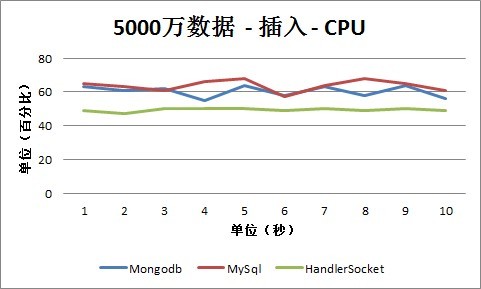
三、测试分析总结
1、 I/O读写情况
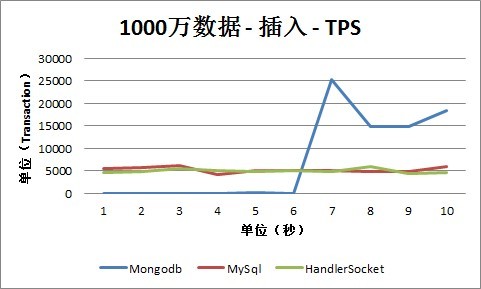
从插入情况下的TPS数据可以看出, MySQL、HandlerSocket和Mongodb的数据有比较明显的差别,这主要跟他们的内部实现和测试方式有关系。
测试场景下MySQL采用的是单条Insert的方式,所以可以看出QPS数和TPS数是基本一致的,也就是每个Insert操作,都对应有一次I/O写入操作。可以从MySQL数据库本身做一些优化,这次测试没有覆盖到这种场景。
HandlerSocket内部采用的是Bulk Insert操作,所以,可以看出QPS数明显大于TPS数,批量的插入操作明显提高了整体性能。
Mongodb内部采用合并操作的方式,采用数据先存放到内存中,然后再Flush到磁盘上的方式。所以,从测试数据可以看出,TPS曲线坡度非常大:有时候TPS是零,这时候是还放到内存中,还没有Flush到磁盘上;有时候TPS非常高,同时这时候CPU也非常高,几乎是100%,这时候是在做Flush到磁盘的操作。基于此种机制,以后会再做一些更细化的优化和测试,因为这样有可能会存在几种问题:
第一, 可能会导致某个时间段IO和CPU的压力非常大,甚至达到峰值,这种情况下,服务的整体健康状态将面临着一些挑战。
第二, 如果服务器重启,可能会出现数据丢失的情况,内存中的数据还没有Flush到磁盘的会丢失。当然这种情况是两面性的,因为采用这种方式,从测试结果也可以看出,整体的写入性能比MySQL和HandlerSocket都高,这是一种取舍,就看具体业务是否可以接受这样的以高性能换取数据可靠性,有些业务可能是可以接受的,比如Feed。
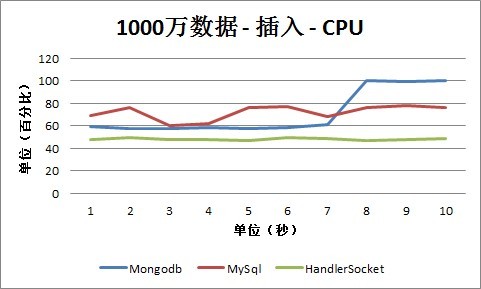
2、 CPU占用情况
从查询情况下的CPU数据可以看出,MySQL和Mongodb几乎都接近100%,而HandlerSocket由于省去了各种Sql Parser和相关的操作,CPU占用率保持在40%-60%之间,在一个比较合理的范围内。
从插入情况下的CPU数据可以看出,HandlerSocket的CPU占用率还是保持在40%-60%之间,低于MySQL和Mongodb。MySQL和Mongodb大部分情况保持在50%-90%之间。
3、 QPS情况
从查询情况下的QPS数据可以看出,HandlerSocket和Mongodb的查询性能几乎差不多,都达到3万以上,并且随着数据量的增长,性能没有回落,还是保持在3万以上。目前只是最大测试到5000万数据的情况,更高的数值这次测试还没有覆盖到。而MySQL的性能相比之下则差一些,一般在18000到25000之间。当然这次没有太多的针对MySQL做优化,只是增大了innodb_thread_pool大小和每次分配的数据块的大小,如果针对MySQL做优化,可能能同时提高HandlerSocket和MySQL的性能。
从插入情况下的QPS数据可以看出,Mongodb明显占有比较大的优势,这根之前说的它的实现方式有关。随着数据量的增长,QPS都相应的在减少,这方面,MySQL的幅度最大,数据量到达5000万以上时,MySQL的插入性能为2000-3000,而HandlerSocket能保持在1万以上,Mongodb为2万以上。
转自: http://www.cnblogs.com/inrie/archive/2011/02/22/1961415.html
分享到:




相关推荐
#### 四、MongoDB、HandlerSocket和MySQL性能测试及其结果分析 ##### **测试环境** 为了全面评估这三个系统的性能差异,测试在相同的硬件环境下进行。测试硬件包括多台配备高速SSD硬盘和高性能CPU的服务器。 ####...
MySQL通过HandlerSocket插件提供了API访问接口,在我们的基准测试中,普通的R510服务器单实例Percona/XtraDB达到了72W+QPS(纯读),如果采用更强劲的CPU增加更多的网卡,理论上可以获得更高的性能。而同等条件下Mem
# 【spring-ai-bedrock-converse-1.0.0-M7.jar中文文档.zip】 中包含: 中文文档:【spring-ai-bedrock-converse-1.0.0-M7-javadoc-API文档-中文(简体)版.zip】 jar包下载地址:【spring-ai-bedrock-converse-1.0.0-M7.jar下载地址(官方地址+国内镜像地址).txt】 Maven依赖:【spring-ai-bedrock-converse-1.0.0-M7.jar Maven依赖信息(可用于项目pom.xml).txt】 Gradle依赖:【spring-ai-bedrock-converse-1.0.0-M7.jar Gradle依赖信息(可用于项目build.gradle).txt】 源代码下载地址:【spring-ai-bedrock-converse-1.0.0-M7-sources.jar下载地址(官方地址+国内镜像地址).txt】 # 本文件关键字: spring-ai-bedrock-converse-1.0.0-M7.jar中文文档.zip,java,spring-ai-bedrock-converse-1.0.0-M7.jar,org.springframework.ai,spring-ai-bedrock-converse,1.0.0-M7,org.springframework.ai.bedrock.converse,jar包,Maven,第三方jar包,组件,开源组件,第三方组件,Gradle,springframework,spring,ai,bedrock,converse,中文API文档,手册,开发手册,使用手册,参考手册 # 使用方法: 解压 【spring-ai-bedrock-converse-1
房地产 -可视化管理课件.ppt
# 【tokenizers-***.jar***文档.zip】 中包含: ***文档:【tokenizers-***-javadoc-API文档-中文(简体)版.zip】 jar包下载地址:【tokenizers-***.jar下载地址(官方地址+国内镜像地址).txt】 Maven依赖:【tokenizers-***.jar Maven依赖信息(可用于项目pom.xml).txt】 Gradle依赖:【tokenizers-***.jar Gradle依赖信息(可用于项目build.gradle).txt】 源代码下载地址:【tokenizers-***-sources.jar下载地址(官方地址+国内镜像地址).txt】 # 本文件关键字: tokenizers-***.jar***文档.zip,java,tokenizers-***.jar,ai.djl.huggingface,tokenizers,***,ai.djl.engine.rust,jar包,Maven,第三方jar包,组件,开源组件,第三方组件,Gradle,djl,huggingface,中文API文档,手册,开发手册,使用手册,参考手册 # 使用方法: 解压 【tokenizers-***.jar***文档.zip】,再解压其中的 【tokenizers-***-javadoc-API文档-中文(简体)版.zip】,双击 【index.html】 文件,即可用浏览器打开、进行查看。 # 特殊说明: ·本文档为人性化翻译,精心制作,请放心使用。 ·只翻译了该翻译的内容,如:注释、说明、描述、用法讲解 等; ·不该翻译的内容保持原样,如:类名、方法名、包名、类型、关键字、代码 等。 # 温馨提示: (1)为了防止解压后路径太长导致浏览器无法打开,推荐在解压时选择“解压到当前文件夹”(放心,自带文件夹,文件不会散落一地); (2)有时,一套Java组件会有多个jar,所以在下载前,请仔细阅读本篇描述,以确保这就是你需要的文件; # Maven依赖: ``` <dependency> <groupId>ai.djl.huggingface</groupId> <artifactId>tokenizers</artifactId> <version>***</version> </dependency> ``` # Gradle依赖: ``` Gradle: implementation group: 'ai.djl.huggingface', name: 'tokenizers', version: '***' Gradle (Short): implementation 'ai.djl.huggingface:tokenizers:***' Gradle (Kotlin): implementation("ai.djl.huggingface:tokenizers:***") ``` # 含有的 Java package(包): ``` ai.djl.engine.rust ai.djl.engine.rust.zoo ai.djl.huggingface.tokenizers ai.djl.huggingface.tokenizers.jni ai.djl.huggingface.translator ai.djl.huggingface.zoo ``` # 含有的 Java class(类): ``` ai.djl.engine.rust.RsEngine ai.djl.engine.rust.RsEngineProvider ai.djl.engine.rust.RsModel ai.djl.engine.rust.RsNDArray ai.djl.engine.rust.RsNDArrayEx ai.djl.engine.rust.RsNDArrayIndexer ai.djl.engine.rust.RsNDManager ai.djl.engine.rust.RsSymbolBlock ai.djl.engine.rust.RustLibrary ai.djl.engine.rust.zoo.RsModelZoo ai.djl.engine.rust.zoo.RsZooProvider ai.djl.huggingface.tokenizers.Encoding ai.djl.huggingface.tokenizers.HuggingFaceTokenizer ai.djl.huggingface.tokenizers.HuggingFaceTokenizer.Builder ai.djl.hu
内容概要:本文详细介绍了如何使用MATLAB构建和应用BP神经网络预测模型。首先,通过读取Excel数据并进行预处理,如归一化处理,确保数据的一致性和有效性。接着,配置网络结构,选择合适的训练算法(如SCG),设置训练参数(如最大迭代次数、目标误差等)。然后,进行模型训练,并通过可视化窗口实时监控训练过程。训练完成后,利用测试集评估模型性能,计算均方误差(MSE)和相关系数(R²),并通过图表展示预测效果。最后,将训练好的模型保存以便后续调用,并提供了一个简单的预测函数,确保新数据能够正确地进行归一化和预测。 适合人群:具有一定MATLAB基础,从事数据分析、机器学习领域的研究人员和技术人员。 使用场景及目标:适用于需要对多维数据进行预测的任务,如电力负荷预测、金融数据分析等。主要目标是帮助用户快速搭建一个可用的BP神经网络预测系统,提高预测准确性。 其他说明:文中提供了完整的代码框架和详细的注释,便于理解和修改。同时,强调了数据预处理的重要性以及一些常见的注意事项,如数据量的要求、归一化的必要性等。
# 【tokenizers-***.jar***文档.zip】 中包含: ***文档:【tokenizers-***-javadoc-API文档-中文(简体)版.zip】 jar包下载地址:【tokenizers-***.jar下载地址(官方地址+国内镜像地址).txt】 Maven依赖:【tokenizers-***.jar Maven依赖信息(可用于项目pom.xml).txt】 Gradle依赖:【tokenizers-***.jar Gradle依赖信息(可用于项目build.gradle).txt】 源代码下载地址:【tokenizers-***-sources.jar下载地址(官方地址+国内镜像地址).txt】 # 本文件关键字: tokenizers-***.jar***文档.zip,java,tokenizers-***.jar,ai.djl.huggingface,tokenizers,***,ai.djl.engine.rust,jar包,Maven,第三方jar包,组件,开源组件,第三方组件,Gradle,djl,huggingface,中文API文档,手册,开发手册,使用手册,参考手册 # 使用方法: 解压 【tokenizers-***.jar***文档.zip】,再解压其中的 【tokenizers-***-javadoc-API文档-中文(简体)版.zip】,双击 【index.html】 文件,即可用浏览器打开、进行查看。 # 特殊说明: ·本文档为人性化翻译,精心制作,请放心使用。 ·只翻译了该翻译的内容,如:注释、说明、描述、用法讲解 等; ·不该翻译的内容保持原样,如:类名、方法名、包名、类型、关键字、代码 等。 # 温馨提示: (1)为了防止解压后路径太长导致浏览器无法打开,推荐在解压时选择“解压到当前文件夹”(放心,自带文件夹,文件不会散落一地); (2)有时,一套Java组件会有多个jar,所以在下载前,请仔细阅读本篇描述,以确保这就是你需要的文件; # Maven依赖: ``` <dependency> <groupId>ai.djl.huggingface</groupId> <artifactId>tokenizers</artifactId> <version>***</version> </dependency> ``` # Gradle依赖: ``` Gradle: implementation group: 'ai.djl.huggingface', name: 'tokenizers', version: '***' Gradle (Short): implementation 'ai.djl.huggingface:tokenizers:***' Gradle (Kotlin): implementation("ai.djl.huggingface:tokenizers:***") ``` # 含有的 Java package(包): ``` ai.djl.engine.rust ai.djl.engine.rust.zoo ai.djl.huggingface.tokenizers ai.djl.huggingface.tokenizers.jni ai.djl.huggingface.translator ai.djl.huggingface.zoo ``` # 含有的 Java class(类): ``` ai.djl.engine.rust.RsEngine ai.djl.engine.rust.RsEngineProvider ai.djl.engine.rust.RsModel ai.djl.engine.rust.RsNDArray ai.djl.engine.rust.RsNDArrayEx ai.djl.engine.rust.RsNDArrayIndexer ai.djl.engine.rust.RsNDManager ai.djl.engine.rust.RsSymbolBlock ai.djl.engine.rust.RustLibrary ai.djl.engine.rust.zoo.RsModelZoo ai.djl.engine.rust.zoo.RsZooProvider ai.djl.huggingface.tokenizers.Encoding ai.djl.huggingface.tokenizers.HuggingFaceTokenizer ai.djl.huggingface.tokenizers.HuggingFaceTokenizer.Builder ai.djl.hu
内容概要:本文探讨了电动汽车(EV)对IEEE 33节点电网的影响,特别是汽车负荷预测与节点潮流网损、压损计算。通过蒙特卡洛算法模拟电动汽车负荷的时空特性,研究了四种不同场景下电动汽车接入电网的影响。具体包括:负荷接入前后的网损与电压计算、不同节点接入时的变化、不同时段充电的影响以及不同负荷大小对电网的影响。通过这些分析,揭示了电动汽车充电行为对电网的具体影响机制,为未来的电网规划和优化提供了重要参考。 适合人群:从事电力系统研究的专业人士、电网规划工程师、电动汽车行业从业者、能源政策制定者。 使用场景及目标:①评估电动汽车大规模接入对现有电网基础设施的压力;②优化电动汽车充电设施的布局和运营策略;③为相关政策和技术标准的制定提供科学依据。 其他说明:文中提供的Python代码片段用于辅助理解和验证理论分析,实际应用中需要更复杂的模型和详细的电网参数。
房地产 -【万科经典-第五园】第五园产品推介会.ppt
稳压器件.SchLib
1
模拟符号.SCHLIB
内容概要:本文详细介绍了如何在Simulink中构建并仿真三相电压型逆变器的SPWM调制和电压单闭环控制系统。首先,搭建了由六个IGBT组成的三相全桥逆变电路,并设置了LC滤波器和1000V直流电源。接着,利用PWM Generator模块生成SPWM波形,设置载波频率为2kHz,调制波为50Hz工频正弦波。为了实现精确的电压控制,采用了abc/dq变换将三相电压信号转换到旋转坐标系,并通过锁相环(PLL)进行同步角度跟踪。电压闭环控制使用了带有抗饱和处理的PI调节器,确保输出电压稳定。此外,文中还讨论了标幺值处理方法及其优势,以及如何通过FFT分析验证输出波形的质量。 适用人群:电力电子工程师、自动化控制专业学生、从事逆变器研究的技术人员。 使用场景及目标:适用于希望深入了解三相电压型逆变器控制原理和技术实现的研究人员和工程师。主要目标是掌握SPWM调制技术和电压单闭环控制的设计与调试方法,提高系统的稳定性和效率。 其他说明:文中提供了详细的建模步骤和参数设置指南,帮助读者快速上手并在实践中不断优化模型性能。同时,强调了一些常见的调试技巧和注意事项,如载波频率的选择、积分器防饱和处理等。
【蓝桥杯EDA】客观题解析
房地产 -物业 苏州设备房管理标准.ppt
3
房地产 -2024H1房地产市场总结与展望(新房篇).docx
内容概要:本文详细介绍了利用LabVIEW与PLC进行自动化数据交互的技术方案,涵盖参数管理、TCP通信、串口扫描、数据转移等方面。首先,通过配置文件(INI)实现参数的自动加载与保存,确保参数修改不影响程序运行。其次,在TCP通信方面采用异步模式和心跳包设计,增强通信稳定性,并加入CRC16校验避免数据丢失。对于串口扫描,则通过VISA配置实现状态触发,确保进出站检测的准确性。最后,针对不同类型的数据转移提出具体方法,如TDMS文件存储策略,确保高效可靠的数据处理。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是熟悉LabVIEW和PLC编程的从业者。 使用场景及目标:适用于需要将LabVIEW作为上位机与PLC进行数据交互的工业生产线环境,旨在提高系统的自动化程度、稳定性和易维护性。 其他说明:文中提供了多个实用代码片段和注意事项,帮助读者更好地理解和应用相关技术。
d65689da7ed20e21882a634f8f5ce6c9_faad2735d293907fb32f7c5837f7302a