接下来再做一个测试,将并行和串行的循环次数设置为100,即将上例的main函数中:
for(int i = 0; i < 10000;i++)
更改为:
for(int i = 0; i < 100;i++)
然后分别运行10次,其结果如下表所示:
|
次数
|
串行
|
并行
|
|
1
|
0.00285003
|
0.007350087
|
|
2
|
0.00288031
|
0.00385478
|
|
3
|
0.0028603
|
0.00231841
|
|
4
|
0.00275407
|
0.0092762
|
|
5
|
0.00280949
|
0.00980167
|
|
6
|
0.00281462
|
0.00538499
|
|
7
|
0.00286081
|
0.00538858
|
|
8
|
0.00281103
|
0.00424682
|
|
9
|
0.00281309
|
0.00892829
|
|
10
|
0.00280026
|
0.00370494
|
|
平均值
|
0.002825401
|
0.006025477
|
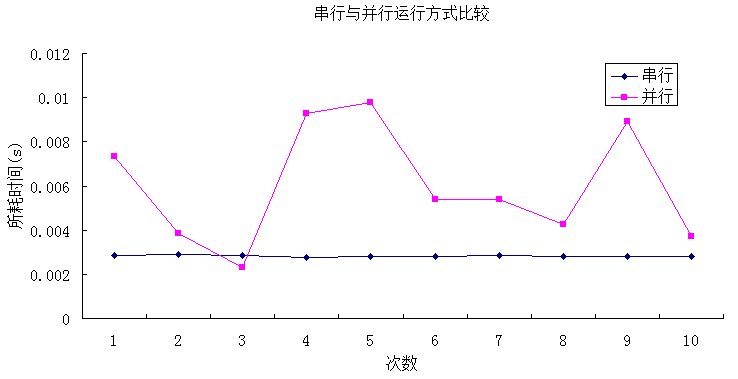
从上面的分析结果可见,在循环100次的时候,只有极少数情况下并行计算比串行计算所需的时间要少,许多情况下并行需要更多的时间,这与我们设计并行程序的初衷是截然相反的。出现这种情况的原因之一就是,在分发并行的时候,系统也是需要消耗资源的,如果用于并行分发所耗的时间大于并行计算中节约的时间,那么这种情况下的并行计算就显得毫无意义,正如上例中的测试。所以,在并行计算中,并不是所有的并行计算都比串行计算要节约时间,具体要看并行的任务是否值得去做并行计算。还有一个重要的原因就是每次并行的线程数目,由于计算机CPU同时支持的并行线程有限,不可能指定并行100次,
CPU在同一时刻就能运行100个线程。另外,由于这个比较程序的计算量非常小,很容易受到系统中其他因素的影响而导致计算结果的不稳定,所以,建议在进行测试时,尽量将计算量稍微调大一点,同时每次测试时应尽量保证运行环境相近,以减少系统中其他程序对测试结果的干扰。
下面用一个例子更能说明并行数目与程序运行效率间的关系,设置并形体中的计算量都一样,每次只是并行的次数不同,具体代码如下:
//File: Test02.cpp
#include "stdafx.h"
#include<omp.h>
#include<iostream>
using namespace std;
//循环测试函数
void test02()
{
for(inti=0;i<5000000;i++)
{
for(intj=0;j<1000;j++);
}
}
int main()
{
cout<<"这是一个新的并行测试程序!\n";
cout<<"请输入并行次数:\n";
intN=1;
cin>>N;
cout<<"开始进行计算...\n";
doublestart = omp_get_wtime( );//获取起始时间
#pragmaomp parallel for
for(inti = 0; i < N; i++)
{
test02();
}
doubleend = omp_get_wtime( );//获取结束时间
cout<<"计算耗时为:"<<end -start<<"\n";
cin>>end;
return0;
}
在近似的测试环境中分别对并行1次(相对于串行)、2次、3次等参数进行测试,其结果如下表:
|
N
|
计算耗时(s)
|
N
|
计算耗时(s)
|
|
1
|
13.3731
|
12
|
27.526
|
|
2
|
13.343
|
13
|
28.9753
|
|
3
|
13.2072
|
14
|
28.0228
|
|
4
|
13.7742
|
15
|
29.4308
|
|
5
|
13.5256
|
16
|
28.5016
|
|
6
|
14.0692
|
17
|
41.1712
|
|
7
|
14.4321
|
18
|
41.3934
|
|
8
|
15.2443
|
24
|
47.6976
|
|
9
|
27.5141
|
25
|
55.7176
|
|
10
|
28.201
|
32
|
60.9475
|
|
11
|
29.0979
|
33
|
69.7519
|
计算时间与并行次数之间的关系如下图所示:
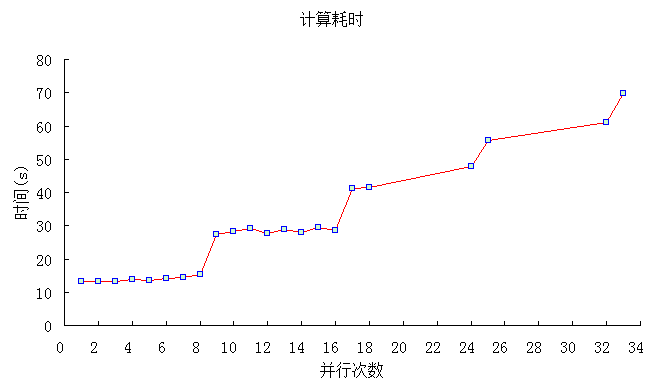
从以上分析结果可知,在并形体中计算量相同的情况下,在计算机CPU物理线程数目以内的并行次数可以得到更好的效果。这也可以很好的解释并行中线程数目设置的限制问题,如当设置9个并行线程时,由于计算机最多只支持8个线程,那第9个线程理所当然就不能和前面8个线程处于同一起跑线,它只能排在这8个线程的后面。假定第1到第8个线程是处于第一排,这一排的8个线程将会同时起步运行,而第9个到第16个处于第二排,它们则要在第一排后面起步,依次类推。每一时刻,都只会有8个线程在进行计算,而并行的结束是以所有的线程运行结束为标志,因此,最后那个线程(或者说最慢的那个线程)将决定并行结束的时间,所以线程越多,那么排队就越长,并行结束的时间相应就会增长。当然,具体一队中有多少个循环,可以通过schedule来设定,关于schedule后面将会详细介绍。
当然,上面的分析是基于并形体中计算量相同的前提,但有些情况下并形体的计算量与并行次数有着密切关系,譬如说总计算量一定的情况下,任何设置合理的并行次数对整个程序的运行起着至关重要的作用。如下例子,并行计算的总计算量一定,即如果设置并行次数越多,则并形体中的计算量越小。代码如下:
//File: Test03.cpp
#include "stdafx.h"
#include<omp.h>
#include<iostream>
using namespace std;
//循环测试函数
void test03(int space)
{
for(inti=0;i<space;i++)
{
for(intj=0;j<1000;j++);
}
}
int main()
{
inttotal=36288000;
cout<<"在总计算量一定的情况下测试程序!\n";
cout<<"请输入并行次数:\n";
intN=1;
cin>>N;
intspace =total/N;
cout<<"开始进行计算...\n";
doublestart = omp_get_wtime( );//获取起始时间
#pragmaomp parallel for
for(inti = 0; i < N; i++)
{
test03(space);
}
doubleend = omp_get_wtime( );//获取结束时间
cout<<"计算耗时为:"<<end -start<<"\n";
cin>>end;
return0;
}
分别设置并行次数从1到42进行测试,测试结果如下表所示:
|
N
|
计算耗时
|
N
|
计算耗时
|
N
|
计算耗时
|
N
|
计算耗时
|
|
1
|
96.9828
|
14
|
14.3488
|
27
|
14.9022
|
40
|
12.8593
|
|
2
|
47.2697
|
15
|
13.7259
|
28
|
14.3302
|
41
|
14.7085
|
|
3
|
31.8575
|
16
|
12.8605
|
29
|
14.0329
|
42
|
14.3195
|
|
4
|
23.5635
|
17
|
17.213
|
30
|
13.6062
|
50
|
14.2404
|
|
5
|
19.2746
|
18
|
16.551
|
31
|
13.1146
|
60
|
13.5563
|
|
6
|
16.7957
|
19
|
15.819
|
32
|
12.8218
|
80
|
12.8094
|
|
7
|
14.2741
|
20
|
14.9696
|
33
|
15.0214
|
100
|
13.2439
|
|
8
|
12.8982
|
21
|
14.3318
|
34
|
14.7972
|
200
|
12.8838
|
|
9
|
21.3869
|
22
|
13.8786
|
35
|
14.4498
|
400
|
12.8444
|
|
10
|
19.7044
|
23
|
13.3461
|
36
|
14.0154
|
1000
|
12.8158
|
|
11
|
17.9848
|
24
|
12.9017
|
37
|
13.7218
|
2000
|
12.7411
|
|
12
|
16.4976
|
25
|
15.9088
|
38
|
13.3481
|
|
|
|
13
|
14.5436
|
26
|
15.5088
|
39
|
13.0619
|
|
|
比较结果如下图所示:
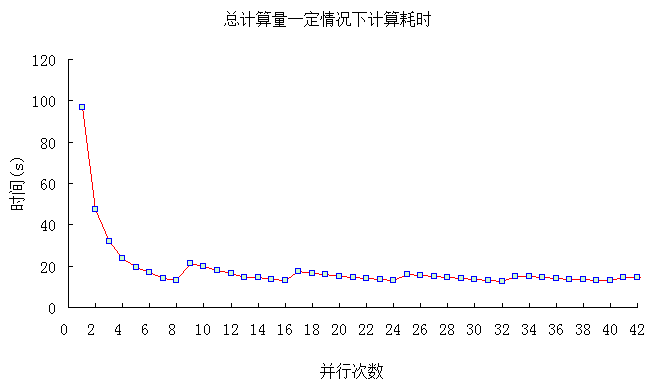
由上图中可以很明显的看出,当并行数目达到计算机CPU最多线程数目时(测试计算机上CPU支持8线程),其计算效率将达到比较好的效果。假定计算机支持的最多线程为n,并行数目在0~n之间,计算效率逐渐增加,达到n时效率极高,当增加到n+1个并行数目时,计算效率会骤降,但在n+1与2n之间,计算效率同样也会逐渐增加,当达到2n+1时,又会骤降,随着并行数目不断增加,该规律将会不断的重现。
所以,综合以上两个测试例子也不难发现,并非并行数目越多,其计算效率就越高,具体效率跟程序结构以及计算机有着密切的联系。
相关程序源码下载地址:
http://download.csdn.net/detail/xwebsite/3843187
分享到:




相关推荐
本文主要介绍了MATLAB的并行计算机制,并对其进行了实际测试,评估了parfor的工作效率。MATLAB提供了并行计算工具箱(Parallel Computing Toolbox),可以将一个MATLAB会话(session,即client)的计算工作分配到...
运行效率对比 运行结果会输出两次计算的时间和最终的平方和。你会注意到 OpenMP 并行化版本的运行时间明显少于单线程版本。这种加速效果在处理大规模数据时尤为显著,因为它能够充分利用多核处理器的优势,同时处理...
综上所述,电法勘探中并行数据采集与传统数据采集效率的比较研究,不仅展示了并行数据采集的技术优势,也为电法勘探领域的技术升级提供了重要的理论依据和实践指导。随着科技的不断进步,预计并行数据采集技术将在电...
3. Sun和Ni定律:这个定律考虑了存储器性能对并行系统加速比的影响。在处理大数据量时,存储器的访问速度可能成为系统性能的瓶颈。因此,增加处理器的同时,也需要改进存储系统,以保持系统的整体性能。 复习这些...
总结来说,FEKO6.2并行设置与提交任务的知识点包括但不限于:CADFEKO的启动与模型加载、并行计算环境的配置、多核或网络并行机选择与核数设定、以及并行计算的激活与仿真任务的提交。这些操作步骤对于提高FEKO软件的...
本文研究了不同数量的CPU核心如何影响并行计算效率,并试图找到最佳的并行核数配置以提高计算效率。为了达到此目的,研究选择了STARCCM+软件作为CFD计算工具,并设定了五个不同的计算工况。工况1至工况5分别对应从...
LabVIEW(Laboratory Virtual Instrument Engineering Workbench)是美国国家仪器公司(NI)开发...通过学习和理解这个示例,开发者可以掌握如何在实际项目中应用事件结构来解决多任务并行的问题,提升程序的运行效率。
通过对本书的学习,读者不仅能够掌握并行计算的基础知识,还能够了解到如何将理论应用到实践中,如在高性能计算集群上运行复杂的应用程序,或在多核处理器的个人电脑上优化应用程序的性能。本书的翻译和出版,为广大...
并行程序设计环境和工具,如并行调试器、性能分析器和并行编译器,对优化并行代码和诊断问题至关重要。 并行计算的实践通常涉及硬件选择、算法转换、通信优化和性能调优等多个层面。随着计算需求的增长和高性能计算...
并行计算是现代计算机科学中的一个关键领域,特别是在高性能计算和大数据处理中。...通过学习和理解这些知识,开发者可以提高代码的运行效率,解决大规模数据处理的问题,为高性能计算和科学模拟等领域提供强大的工具。
本资源提供了完整的代码和数据,使用户可以直接运行,体验并行仿真的优势。以下将详细介绍MATLAB Simulink的并行仿真计算及其相关知识点。 1. MATLAB与Simulink简介: MATLAB是一款强大的数值计算软件,而Simulink...
并行计算是计算机科学领域的一个分支,它涉及到同时使用两个或多个计算资源解决计算问题。这种方法能显著减少解决...要充分掌握并行计算与性能评价的知识,需要深入学习和实践,以及对相关领域的最新研究成果保持关注。
在使用 ANSYS 并行计算设置方法之前,需要对系统进行配置。一般来说,系统已经设置好了,但如果您需要更多的信息,可以参考回答 5。 二、修改并行求解器脚本 在修改 ANSYS 输入文件之前,需要修改并行求解器脚本。...
并行编程技术是现代高性能计算领域中的核心概念,它能够充分利用多核处理器和分布式系统的能力,大幅提高计算效率。MPI(Message Passing Interface)是并行编程中广泛采用的一种标准通信库,尤其适用于大规模科学...
5. **性能分析与优化**:如何通过性能模型、基准测试和调优技术来评估并行系统的效率和可扩展性。 6. **并行计算应用**:可能会涉及到并行计算在科研、工程、云计算等多个领域的实际应用案例,如气候模拟、生物信息...
首先,理解并行与串行的概念是至关重要的。并行执行是指多个任务同时进行,可以充分利用多核处理器的计算能力,提高程序的运行效率。而串行执行则是按照一定的顺序逐个执行任务,这在某些情况下可能是必要的,比如当...
并行计算是现代计算机科学中的一个重要领域,它涉及到在多个处理器或计算机之间同时处理任务,以提高计算效率和解决问题的速度。在Linux操作系统下构建并行计算平台,不仅可以利用多核处理器的优势,还可以通过网络...
实验可能涉及矩阵乘法、求解线性方程组等典型问题,通过对比不同通信策略和进程数量对性能的影响,来深入理解MPI的效率和可扩展性。 "OpenMP多线程编程实验.doc"则会介绍如何利用OpenMP实现多线程并行计算,可能...
3. **并行度(Degree of Parallelism)**:指的是并行作业中同时运行的工作单元数量,它直接影响了作业的处理速度和资源利用率。 #### 三、并行作业设计原则 在设计并行作业时,应遵循以下原则以确保最佳性能: 1...