hzbook
- 浏览: 264052 次
- 性别:

- 来自: 北京
-

最新评论
-
hzbook:
Devin.Chenzx 写道书中的源代码 和网址现在不能访问 ...
软件管道规则 -
Devin.Chenzx:
书中的源代码 和网址现在不能访问!你们那里有备份么?
软件管道规则 -
hzbook:
fxllong123456 写道加入了Ext4.0的新特性? ...
ExtJS Web应用程序开发指南(第2版)(针对Ext JS 4.0更新) -
fxllong123456:
加入了Ext4.0的新特性? 在哪里能买到啊
ExtJS Web应用程序开发指南(第2版)(针对Ext JS 4.0更新) -
gundumw100:
感觉这本书<Android应用开发揭秘>很垃圾的. ...
移动开发参考书之Android篇
手工打造目标PE的步骤
为了熟悉程序流程,先通过手工方式打造这一补丁。目的是使用最原始的不经过加工(如免重定位、动态加载技术)的程序,在尽量不改变目标PE结构的前提下,实现将代码附加到.text节中、将数据附加到.data节中、将导入表附加到.rdata中,以实施补丁。
首先,从目标PE中获取如下参数:目标PE的节空闲长度。由于导入表需要单独的空间,所以目标PE至少要有两个节。这样可以把补丁代码和数据放到一个节中,而导入表等其他常量则放到另外一个节中。
其次,计算补丁程序的代码节和数据节的大小,并判断目标PE是否有单独的节空间。
然后,计算补丁程序与目标PE总的导入表所需要的空间,并判断目标PE是否有单独的节空间。
最后,修正代码及相关参数。
打完补丁以后的目标程序大致结构见图14-1。
14.3.1 基本思路
为了能将补丁程序插入到目标PE的空闲空间里,需要重点处理以下几种数据:数据段、代码段和常量段。此次手工补丁的基本思路如下:首先,从目标PE中获取如下参数:目标PE的节空闲长度。由于导入表需要单独的空间,所以目标PE至少要有两个节。这样可以把补丁代码和数据放到一个节中,而导入表等其他常量则放到另外一个节中。
其次,计算补丁程序的代码节和数据节的大小,并判断目标PE是否有单独的节空间。
然后,计算补丁程序与目标PE总的导入表所需要的空间,并判断目标PE是否有单独的节空间。
最后,修正代码及相关参数。
打完补丁以后的目标程序大致结构见图14-1。

图14-1 在节的空闲空间补丁
如图所示,依据同类数据放到相同类别的数据所在节中的基本原则,补丁代码嵌入到.text节,导入表及相关结构嵌入到.rdata节,而数据则嵌入到.data节。下面分别来看对各类数据的手工处理过程。
14.3.2 对代码段的处理
附加代码的最佳方法是将代码附加到某一位置,然后修改入口地址,使其指向该位置。当运行完附加代码后,还要回到原代码处执行。这时候需要在附加代码的最后添加一条跳转指令,该指令常用的有两种,一个是EB,另外一个是E9;但EB属于近跳转,在某些大型的程序中,当附加代码和原代码距离超过一个字节时,该指令就无能为力了,所以,这里选用E9指令,后跟一个双字的有符号偏移量。总体来说,对代码段的处理包括以下两部分:
- 将代码附加到目标PE的某个位置
- 修正代码中的地址
1) 代码中哪些地址是需要修正的?即要明晰字节码与指令之间的关系。
2) 在毫无意义的字节码序列中,如何确定哪些字节码是描述地址的。
3) 找到这些地址后,如何修正它们。
以下将围绕上述三个问题进行详细描述。
1.获取指令码与字节码的对应关系
在本书的学习过程中,经常会碰到将指令翻译为字节码,将字节码翻译为指令这样的任务。那么,有没有一种办法能够查找到汇编语言中的指令与字节码之间的对应关系呢?下面将使用一个简单的程序生成字节码,并通过dasm程序反编译后获取指令与字节码之间的对应关系。如代码清单14-3所示,该程序生成了一个用以描述字节码与汇编指令之间关系的文件comset.bin;通过反汇编程序反汇编该文件,即可得到字节码与汇编指令之间一对一的关系。
代码清单14-3 测试字节码与汇编指令之间的关系(chapter14\ makeComFile.asm)
1 ;------------------------
2 ; 生成comset.bin文件,测试字节对应的指令
3 ; 作者:戚利
4 ; 开发日期:2010.6.2
5 ;------------------------
6 .386
7 .model flat,stdcall
8 option casemap:none
9
10 include windows.inc
11 include user32.inc
12 includelib user32.lib
13 include kernel32.inc
14 includelib kernel32.lib
15
16 ;数据段
17 .data
18 szText db 'Sucess!',0
19 szFile db 'c:\comset.bin',0 ;生成的文件
20 szBinary db 00,00,00,00,00,90h,90h
21 hFile dd ?
22 dwSize db 0ffh
23 dwWritten dd ?
24 ;代码段
25 .code
26 start:
27 invoke CreateFile,addr szFile,GENERIC_WRITE,\
28 FILE_SHARE_READ,\
29 0,CREATE_ALWAYS,FILE_ATTRIBUTE_NORMAL,0
30 mov hFile,eax
31 .repeat
32 mov al,dwSize
33 mov byte ptr [szBinary],al
34 invoke WriteFile,hFile,addr szBinary,7,addr dwWritten,NULL
35 dec dwSize
36 .break .if dwSize==0
37 .until FALSE
38 invoke CloseHandle,hFile
39 invoke MessageBox,NULL,offset szText,NULL,MB_OK
40 invoke ExitProcess,NULL
41 end start
该程序的基本思路是构造从00~ff之间的所有指令码的指令+操作数,指令与指令之间操作数的长度为6个字节,最后两个字节是指令nop对应的90h。
运行后生成comset.bin字节码集合,使用dasm反编译,会生成如下结构的指令码与字节码之间的对应关系。通过这些对应关系,我们很容易就知道了哪个字节码翻译成汇编指令以后会是什么。
:00000000 FF00 inc dword ptr [eax]
:00000002 000000 BYTE 3 DUP(0)
:00000005 90 nop
:00000006 90 nop
:00000007 FE00 inc byte ptr [eax]
:00000009 000000 BYTE 3 DUP(0)
:0000000C 90 nop
:0000000D 90 nop
:0000000E FD std
:0000000F 00000000 BYTE 4 DUP(0)
:00000013 90 nop
:00000014 90 nop
:00000015 FC cld
:00000016 00000000 BYTE 4 DUP(0)
:0000001A 90 nop
:0000001B 90 nop
:0000001C FB sti
:0000001D 00000000 BYTE 4 DUP(0)
:00000021 90 nop
:00000022 90 nop
:00000023 FA cli
:00000024 00000000 BYTE 4 DUP(0)
……
通过以上方法可以得知,在00~ff字节码中,被翻译为跳转指令的一共有3个,它们分别是(加黑部分):
:0000008C EB00 jmp 0000008E
:0000008E 90 nop
:00000093 EA000000009090 jmp 9090:00000000
:0000009A E900000000 jmp 0000009F
:0000009F 90 nop
:000000A1 E800000000 call 000000A6
:000000A6 90 nop
扩展学习 两种最常用的跳转指令EB和E9
(1)EB指令
该指令为段内跳转指令,其后跟一个字节的偏移,其反汇编的代码为:
EB xx JMP SHORT DWORD PTR [$+xx]
其中偏移xx是有符号数。
偏移为负数的例子:比如偏移=A0,最高位为1,它就是一个负数,跳转方向是往前跳。去掉最高位后取反加1得到的是偏移量。
10100000(去符号位)=0100000(取反)=1011111(加1)
=1100000(转十六进制)=60h
从指令EB A0的下一条指令开始往前找60h个字节,就是要跳转到的位置。
在大范围跳转指令中,EB通常跳转不到指定位置,所以要使用操作数大一些的偏移来完成流程的转向。通常使用E9指令,后面还会看到大量使用FF 25指令的例子。
(2)E9指令
E9是段间相对转移指令,后面跟的是相对当前指令的下一条指令的地址的偏移量,目标地址的计算公式为:
该指令中的偏移值+本转移指令的下一条指令的地址
看一个例子:
00401000 E9370F0800 JMP 00481F3C
00401005 ...
因为在Win32下E9指令占5个字节,所以:
偏移量=目标地址-(转移指令所在地址+5)
=00481f3c-(00401000+5)=00080f37
输入时LSB(最低有效位)在前,MSB(最高有效位)在后就可以了。为了完成补丁代码结束以后向目标PE入口地址的跳转,这里将源代码稍做修改,增加了最后的E9跳转指令。
invoke RegCreateKey,HKEY_LOCAL_MACHINE,addr sz1,addr @hKey
invoke RegSetValueEx,@hKey,addr sz2,NULL,\
REG_SZ,addr sz3,27h
invoke RegCloseKey,@hKey
jmpToStart db 0E9h,0F0h,0FFh,0FFh,0FFh
那么E9指令后的操作数如何计算呢?看下面的例子:
0040102A . E8 1D000000 CALL <JMP.&advapi32.RegSetValueExA>
0040102F > FF35 5E304000 PUSH DWORD PTR DS:[40305E]
00401035 . E8 06000000 CALL <JMP.&advapi32.RegCloseKey>
0040103A .^ E9 F0FFFFFF JMP patch.0040102F
0040103F . C3 RETN
E9指令操作数是有方向的偏移量,如果是往后跳,则将当前位置和要跳转的位置间的间隔字节个数(该间隔包含E9指令本身)减1,然后取反;如果是往前跳,则直接用当前位置和要跳转的位置间的间隔(含E9指令本身)字节个数即可。
如上加黑部分所示“JMP patch.0040102F”,该示例为前跳,要跳转的位置是0040102Fh。计算该位置的指令到E9指令的字节码个数为16,二进制表示00000010h,减1以后得到的结果为0000000Fh;将0000000Fh取反得到的结果是FFFFFFF0h,该结果即为E9指令的偏移。
下面计算HelloWorld.exe中的跳转偏移。从E9指令到目标文件的最初起始指令大小为63h,减1以后为62h(即0000 0000 0000 0000 0000 0000 0110 0010),取反结果为1111 1111 1111 1111 1111 1111 1001 1101,写成十六进制为FF FF FF 9Dh。
2.判断程序代码中的操作数是地址
这个不是特别容易,至少笔者是这么认为的。比如压栈指令push,压双字的指令字节码为68,但压入的是值还是RVA很难判断,因为这个压栈操作需要结合具体的函数进行分析才能得出结论。这里采用的办法是:根据后面操作数的具体值进行模糊推测。方法是取出指令的操作数,然后比较该值与数据所在段的范围;如果落在该范围内,则直接认为这是一个RVA。类似的代码如下:mov eax,dwPatchImageBase ;补丁基地址:040000h
add eax,dwPatchMemDataStart ;补丁数据段起始地址:003000h
mov @value1,eax
.repeat
mov bx,word ptr [edi]
.if bx==05FFh
;取其后的一个字 FF 05 43 02 04 00
mov ebx,dword ptr [edi+2]
mov @value,ebx
mov eax,@value ;计算RVA中距离数据段起始的偏移量@off
sub eax,@value1
mov @off,eax
and ebx,0ffff0000h
;判断该双字是否以ImageBase开始
mov edx,dwPatchImageBase
and edx,0FFFF0000h
.if ebx==edx
3.修正代码中的RVA
代码中有许多对数据段变量进行操作的指令,由于在进行数据合并时更改了数据段中某些变量的位置,所以,指令中这些涉及数据段变量的操作数必须得到修正。应该说,对程序而言这是一件很难的工作。但补丁程序是由开发者自己编写的,知道在编码时使用了哪些带地址的操作数的指令,相对来说再修正代码就容易多了。本实例将只对以下指令后的操作数进行修正:0040101F . 68 2E304000 PUSH patch.0040302E
00401024 . FF35 5E304000 PUSH DWORD PTR DS:[40305E]
0040102A . E8 3B000000 CALL <JMP.&advapi32.RegSetValueExA>
0040102F . FF35 5E304000 PUSH DWORD PTR DS:[40305E]
00401035 . E8 24000000 CALL <JMP.&advapi32.RegCloseKey>
0040103A . A3 5E304000 MOV DWORD PTR DS:[40305E],EAX
0040103F . B8 00304000 MOV EAX,patch.00403000
00401044 . 0305 5E304000 ADD EAX,DWORD PTR DS:[40305E]
0040104A . FF05 5E304000 INC DWORD PTR DS:[40305E]
00401050 . 8305 5E304000 02 ADD DWORD PTR DS:[40305E],2
0040187E $- FF25 50204000 JMP DWORD PTR DS:[<&user32.wsprintfA>]
具体包括:
- A3指令 (传值指令mov @hKey,eax)
- B8指令 (传值指令mov eax,offset sz1)
- 03 05指令(加法指令 add eax,@hKey)
- FF 05指令(加1指令 inc @hKey)
- 68指令 (段内压栈指令 push dword ptr ds:[xxxx])
- FF 25 指令(跨段的跳转指令 jmp dword ptr ds:[xxxx])
- FF 35 指令(跨段的压栈指令 push dword ptr ds:[xxxx])
00000400 6A 00 6A 00 68 00 30 40 00 6A 00 E8 08 00 00 00 j.j.h.0@.j.....
00000410 6A 00 E8 07 00 00 00 CC FF 25 08 20 40 00 FF 25 j.....%. @.%
00000420 00 20 40 00
从0424h处开始的是新代码,代码中凡是地址的操作数均做了修正(以下加边框的部分)。加黑部分E9 9D FF FF FF 则是跳转到原代码处的指令。
68 69 30 40 00 68 0B 30 40 00 68 02 . @.hi0@.h.0@.h.
00000430 00 00 80 E8 32 00 00 00 6A 27 68 42 30 40 00 6A ..2...j'hB0@.j
00000440 01 6A 00 68 39 30 40 00 FF 35 69 30 40 00 E8 1D .j.h90@.5i0@..
00000450 00 00 00 FF 35 69 30 40 00 E8 06 00 00 00 E9 9D ...5i0@.....
00000460 FF FF FF C3 FF 25 18 20 40 00 FF 25 10 20 40 00 %. @.%. @.
00000470 FF 25 14 20 40 00 %. @.
下面谈谈如何进行地址修正。例如,第一个地址原始值为0040305Eh,因为数据段的地址是在原数据的后面,即距离原数据的偏移为:
数据当前位置减去数据原来位置:
0000300Bh-00003000h=0Bh
地址进行修正的时候加上这个偏移量即可。如例子中的第一个地址:
0040305Eh+0Bh=00403069h
所以说,确定了数据在内存中的地址以后再对代码中的地址进行修正就很容易了。
14.3.3 对导入表的处理
要想操作导入表,必须知道导入表所在节的相关信息,所以,首先要找到导入表所在的节。导入表所在的节的确定方法如下:步骤1 通过数据目录表获取导入表的RVA。
步骤2 通过该RVA与每个节的起始、结束RVA对比。
步骤3 确定导入表落在哪个节内。
知道了导入表的在哪个节里,与这个节有关的其他信息,比如,节在文件中的的起始地址、节在内存中的起始地址、节的实际尺寸等参数,就可以从节表项的结构中获取到了,相关代码如下:
mov esi,_lpFileHead
assume esi:ptr IMAGE_DOS_HEADER
add esi,[esi].e_lfanew
assume esi:ptr IMAGE_NT_HEADERS
mov edi,_dwRVA
mov edx,esi
add edx,sizeof IMAGE_NT_HEADERS
assume edx:ptr IMAGE_SECTION_HEADER
movzx ecx,[esi].FileHeader.NumberOfSections
;遍历节表
.repeat
mov eax,[edx].VirtualAddress
add eax,[edx].SizeOfRawData ;计算该节结束RVA
.if (edi>=[edx].VirtualAddress)&&(edi<eax)
mov eax,[edx].PointerToRawData
jmp @F
.endif
add edx,sizeof IMAGE_SECTION_HEADER
.untilcxz
为了将补丁导入表数据插入到目标PE中,首先要知道在补丁代码中一共调用了多少个动态链接库,以及每个动态链接库所引入的函数个数,这些信息可以从导入表中获取到。
现在,假设补丁程序中用到的所有函数在目标代码段的导入表中都没有。所以,只要确定了动态链接库的个数,确定了每个动态链接库中调用函数的个数,新导入表的大小也就确定了。剩下的工作就是确定新导入表的位置和相关数据结构中RVA地址的修正了。
特别注意 原有的IAT一定不能破坏,否则会导致原指令中许多语句(那些涉及地址访问的语句)需要修改,这可是个大工程,相信你不会愿意那么做的。
破坏IAT结构的唯一办法就是把新增加的IA放到其他空闲的空间中。这样,才能保证原有调用的RVA不被破坏。那么,新增加的IA放到哪里去呢?
由于两个PE文件的导入表要放到一起,所以目标文件中的导入表必须移位;如果不移位置,新加入的补丁导入表会破坏后面的数据。基本想法是将目标文件中描述导入表的几个IMAGE_IMPORT_DESCRIPTOR数组原样移走,而代替原位置的将是补丁程序的IAT数据,以及由originalFirstThunk指向的结构数组数据。目标文件导入表加上补丁文件导入表将被移动到节的末尾。所以,两个导入表的IMAGE_IMPORT_DESCRIPTOR数组总和即为判断空间是否足够用的数值。
如果补丁程序调用的函数比较多,采用上述方法也会出现问题,主要是用来存放补丁程序导入表相关的两个结构无法在目标导入表的空间里容纳下,这时候可以采用第二种策略,即将两个相关结构放到其他空闲空间中。在示例程序中,采取第一种策略,大家可以自己通过程序实现第二种策略,以提高程序的兼容性。以下是大致的步骤。
步骤1 求补丁程序的动态链接库个数dwDll。
通过遍历导入表,直到发现最后一个全0结构即可获得动态链接库个数。相关代码见清单14-4。其中返回值eax中存放了动态链接库的个数,而ebx为调用函数的个数。
代码清单14-4 获取PE文件的导入表调用的函数个数(chapter14\bind.asm的_getImportFunctions函数)
1 ;---------------------------------
2 ; 获取PE文件的导入表调用的函数个数
3 ;---------------------------------
4 _getImportFunctions proc _lpFile
5 local @szBuffer[1024]:byte
6 local @szSectionName[16]:byte
7 local _lpPeHead
8 local @dwDlls,@dwFuns,@dwFunctions
9
10 pushad
11 mov edi,_lpFile
12 assume edi:ptr IMAGE_DOS_HEADER
13 add edi,[edi].e_lfanew ;调整esi指针指向PE文件头
14 assume edi:ptr IMAGE_NT_HEADERS
15 mov eax,[edi].OptionalHeader.DataDirectory[8].VirtualAddress
16 .if !eax
17 jmp @F
18 .endif
19 invoke _RVAToOffset,_lpFile,eax
20 add eax,_lpFile
21 mov edi,eax ;计算引入表所在文件偏移位置
22 assume edi:ptr IMAGE_IMPORT_DESCRIPTOR
23 invoke _getRVASectionName,_lpFile,[edi].OriginalFirstThunk
24
25 mov @dwFuns,0
26 mov @dwFunctions,0
27 mov @dwDlls,0
28
29 .while [edi].OriginalFirstThunk || [edi].TimeDateStamp ||\
30 [edi].ForwarderChain || [edi].Name1 || [edi].FirstThunk
31 mov @dwFuns,0
32 invoke _RVAToOffset,_lpFile,[edi].Name1
33 add eax,_lpFile
34
35 ;获取IMAGE_THUNK_DATA列表到ebx
36 .if [edi].OriginalFirstThunk
37 mov eax,[edi].OriginalFirstThunk
38 .else
39 mov eax,[edi].FirstThunk
40 .endif
41 invoke _RVAToOffset,_lpFile,eax
42 add eax,_lpFile
43 mov ebx,eax
44 .while dword ptr [ebx]
45 inc @dwFuns
46 inc @dwFunctions
47 .if dword ptr [ebx] & IMAGE_ORDINAL_FLAG32 ;按序号导入
48 mov eax,dword ptr [ebx]
49 and eax,0ffffh
50 .else ;按名称导入
51 invoke _RVAToOffset,_lpFile,dword ptr [ebx]
52 add eax,_lpFile
53 assume eax:ptr IMAGE_IMPORT_BY_NAME
54 movzx ecx,[eax].Hint
55 assume eax:nothing
56 .endif
57 add ebx,4
58 .endw
59 mov eax,@dwFuns
60 mov ebx,@dwDlls
61 mov dword ptr dwFunctions[ebx*4],eax
62 mov dword ptr dwFunctions[ebx*4+4],0
63 inc @dwDlls
64 add edi,sizeof IMAGE_IMPORT_DESCRIPTOR
65 .endw
66 mov ebx,@dwDlls
67 mov dword ptr dwFunctions[ebx*4],0
68 @@:
69 assume edi:nothing
70 popad
71 mov eax,@dwDlls
72 mov ebx,@dwFunctions
73 ret
74 _getImportFunctions endp
步骤2 求补丁程序每个动态链接库对应的函数的个数。
导入表IMAGE_IMPORT_DESCRIPTOR的结构中有一个FirstThunk指针,这个指针指向的数组中有该动态链接库的个数dwFunctions。
程序设计时,可以构造一个“个数,个数,个数,0”的数组,用来记录每个DLL中调用的函数个数。
步骤3 计算新导入表增加的大小。
有了以上信息,新导入表比最初的导入表增加的大小就可以计算出来:
①(所有的函数个数+动态链接库个数)*4=新IAT项大小
②(所有的函数个数+动态链接库个数)*4=新originalFirstThunk表项大小
③(目标文件动态链接库个数+补丁文件动态链接库个数)*sizeof IMAGE_IMPORT_DESCRIPTOR=新增加的导入表项大小
④补丁函数名和动态链接库的字符串部分
1)将①和②两项的和与目标文件导入表数组的大小比较,如果前者小于后者,则满足条件,可以继续进行,否则提示空间不足。
2)将③和④两项的数值之和与找到的连续空闲空间相比较,如果前者小于后者,则满足条件,可以继续进行,否则提示空间不足。
步骤4 找到目标导入表所处的节,算出该节的剩余空间。如果大于步骤3后两项算出的结果之和,则可以继续进行;否则提示导入表部分空间不足,退出。
步骤5 关于导入表及相关数据结构的位置。
将目标文件偏移0610处(即目标文件导入表)开始的3ch字节复制到导入表所在节的空闲空间中(文件偏移0692h),然后修改目标文件中数据目录中导入表的RVA为00002092h,经过这样修改的PE依旧可以运行,而无需改动其他位置的数据。
步骤6 在新的导入表后追加补丁代码的导入表数据。
00000690 54 20 00 00 00 00 00 00 00 00 00 00 6A 20 T ..........j
000006A0 00 00 08 20 00 00 4C 20 00 00 00 00 00 00 00 00 ... ..L ........
000006B0 00 00 84 20 00 00 00 20 00 00 38 20 00 00 00 00 .. ... ..8 ....
000006C0 00 00 00 00 00 00 78 20 00 00 00 20 00 00 00 00 ......x ... ....
000006D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000006E0 00 00 ..
黑体部分会根据最终导入表其他相关数据的存放位置作修改。
步骤7 将导入表相关的函数名与动态链接库的名字附加到新导入表的后面,如下所示:
000006E0 80 01 52 65 67 43 6C 6F 73 65 4B 65 79 00 .RegCloseKey.
000006F0 83 01 52 65 67 43 72 65 61 74 65 4B 65 79 41 00 .RegCreateKeyA.
00000700 AE 01 52 65 67 53 65 74 56 61 6C 75 65 45 78 41 .RegSetValueExA
00000710 00 00 61 64 76 61 70 69 33 32 2E 64 6C 6C 00 00 ..advapi32.dll..
步骤8 将导入表涉及的IAT,以及由originalFirstThunk指向的数据结构数组分别存放到目标文件的原始导入表位置,即610h开始的位置。
- IAT存放在原始导入表的起始位置0610h。
- 由originalFirstThunk指向的数据结构数组存放在紧接下来的空间中0620h。
00000610 F0 20 00 00 00 21 00 00 E2 20 00 00 00 00 00 00 ...!.. ......
00000620 F0 20 00 00 00 21 00 00 E2 20 00 00 00 00 00 00 ...!.. ......
步骤9 修正参数。
对参数的修正包括以下三步:
1)数据目录表中将导入表的RVA更改为00002092h,大小设置为50h。
2)导入表所在的节.rdata大小设置为0120h。
3)修正导入表的内容,以及IAT内容和originalFirstThunk指向的数据结构数组中相关的RVA值(如下黑体部分)。
00000690 54 20 00 00 00 00 00 00 00 00 00 00 6A 20 T ..........j
000006A0 00 00 08 20 00 00 4C 20 00 00 00 00 00 00 00 00 ... ..L ........
000006B0 00 00 84 20 00 00 00 20 00 00 20 20 00 00 00 00 .. ... .. ....
000006C0 00 00 00 00 00 00 12 21 00 00 10 20 00 00 00 00 .......!... ....
000006D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000006E0 00 00 ..
步骤10 修改以后的PE文件分析。
使用PEInfo对修改完数据和导入表信息的新的PE文件HelloWorld_1.exe进行测试,查看导入表是否可以被正确识别,如下所示:
文件名:D:\masm32\source\chapter11\HelloWorld_1.exe
-----------------------------------------
运行平台: 0x014c
节的数量: 3
文件属性: 0x010f
建议装入基地址: 0x00400000
文件执行入口(RVA地址): 0x1000
-------------------------------------------------------------------------------
节名称 未对齐前长度 内存中的偏移(对齐后) 文件中对齐后的长度 文件中的偏移 节的属性
-------------------------------------------------------------------------------
.text 00000024 00001000 00000200 00000400 60000020
.rdata 00000120 00002000 00000200 00000600 40000040
.data 0000000b 00003000 00000200 00000800 c0000040
----------------------------------
导入表所处的节:.rdata
--------------------------------------------
导入库:user32.dll
-----------------------------
OriginalFirstThunk 00002054
TimeDateStamp 00000000
ForwarderChain 00000000
FirstThunk 00002008
-----------------------------
00000413 MessageBoxA
导入库:kernel32.dll
-----------------------------
OriginalFirstThunk 0000204c
TimeDateStamp 00000000
ForwarderChain 00000000
FirstThunk 00002000
-----------------------------
00000128 ExitProcess
导入库:advapi32.dll
-----------------------------
OriginalFirstThunk 00002020
TimeDateStamp 00000000
ForwarderChain 00000000
FirstThunk 00002010
-----------------------------
00000387 RegCreateKeyA
00000430 RegSetValueExA
00000384 RegCloseKey
未发现该文件有导出函数
未发现该文件有重定位信息
如上黑体所示,PEInfo已可正确识别修改后的PE文件的导入表信息,文件也可执行。接下来的工作是附加和补丁数据。
14.3.4 对数据段的处理
对数据段的处理包括目标数据段识别以及空间计算。因为补丁程序是开发者自己编写的,所以每个节的真实大小,都在节表项的IMAGE_SECTION_HEADER.VirtualSize字段中被记录下来,其他来源的PE文件则无法通过数据结构中的该字段获取真实大小(因为即使用户更改了这一部分内容,装载器也不会发现错误!大家可以自己来做这个实验)。构造以后的数据段增加了补丁的数据。首先,从源中获取补丁数据段大小dstDataSize,从目标数据段中获取剩余空间(数据段文件对齐后的大小减去数据段真实的大小)。理论上讲,如果剩余空间大于补丁的数据段大小,那么对数据段的修改就被认为是可行的;但通常获取的目标数据段真实大小是假的。所以,数据段剩余空间的最好的判断方法是:
先定位可存放数据的节。方法是查找目标文件的节,其属性为C0000040h,该节的属性一般为可读、可写,并包含初始化数据。只需要判断字段IMAGE_SECTION_HEADER. Characteristics标识字段的第6、30、31位均为1,即认定该节是存放数据的节。
找到该节以后,查找该节在文件中的起始位置startAddress,以及文件对齐后的长度fLen。
从本节的最后一个位置起往前查找连续的全0字符,并记录长度。如果长度能达到我们的要求,就可以认为数据段的剩余空间是足够存放补丁程序数据的。
这种判断方法会存在一些安全隐患,比如,目标PE文件的数据段中有一些连续的初始化为0的数据,通过这种方法找到的空间大小可能会比实际的大。从而在整合补丁数据的时候将数据覆盖到目标PE的正常数据区,导致目标PE文件运行出现问题。在实际操作中将忽略这个安全因素,而直接记录下这个比较重要的值,即在目标文件中存放补丁数据的起始地址(文件中的),其他数据的插入方法类似。
附加数据起始位置=startAddress+fLen-dstDataSize+1
接下来,使用上面的思路编写程序,以测试多个PE文件的数据段。以第2章的pe.asm作为基础程序框架,在函数_openFile中加入代码清单14-5所示的代码。
代码清单14-5 判断PE文件数据段是否能容纳补丁代码的数据 (chapter14\bind.asm的_openFile函数部分代码)
1 ;获取补丁文件数据段的大小
2 invoke getDataSize,@lpMemory
3 mov dwPatchDataSize,eax
4
5 .if eax==0 ;未找到存放数据的节
6 invoke _appendInfo,addr szErr110
7 .else
8 invoke wsprintf,addr szBuffer,addr szOut11,eax
9 invoke _appendInfo,addr szBuffer
10 .endif
11
12
13
14 ;获取补丁文件数据段在内存中的起始位置
15 invoke getDataStart,@lpMemory
16 mov dwPatchDataStart,eax
17
18 invoke wsprintf,addr szBuffer,addr szOut12,eax
19 invoke _appendInfo,addr szBuffer
20
21 ;获取目标文件数据段的大小
22 invoke getDataSize,@lpMemory1
23 mov dwDstDataSize,eax
24
25 invoke wsprintf,addr szBuffer,addr szOut13,eax
26 invoke _appendInfo,addr szBuffer
27
28 ;获取目标文件数据段在内存中的起始位置
29 invoke getDataStart,@lpMemory1
30 mov dwDstDataStart,eax
31
32 invoke wsprintf,addr szBuffer,addr szOut14,eax
33 invoke _appendInfo,addr szBuffer
34
35 ;获取目标文件数据段在文件中对齐后的大小
36 invoke getRawDataSize,@lpMemory1
37 mov dwDstRawDataSize,eax
38
39 invoke wsprintf,addr szBuffer,addr szOut15,eax
40 invoke _appendInfo,addr szBuffer
41
42 ;获取目标数据段在内存中的起始位置
43 invoke getDataStartInMem,@lpMemory1
44 mov dwDstMemDataStart,eax
45
46 invoke wsprintf,addr szBuffer,addr szOut17,eax
47 invoke _appendInfo,addr szBuffer
48
49
50 ;从本节的最后一个位置起往前查找连续的全0字符
51 mov eax,dwDstDataStart
52 add eax,dwDstRawDataSize ;定位到本节的最后一个字节
53 mov ecx,dwPatchDataSize
54 mov esi,@lpMemory1
55 add esi,eax
56 dec esi
57 .repeat
58 mov bl,byte ptr[esi]
59 .break .if bl!=0
60 dec esi
61 dec ecx
62 dec eax
63 .break .if ecx==0
64 .until FALSE
65 .if ecx==0 ;表示找到了连续可用的空间
66 mov @dwTemp1,eax
67 sub eax,dwPatchDataSize
68 mov dwStartAddressinDstDS,eax
69
70 mov @dwTemp,0
71
72 mov esi,@lpMemory1
73 mov eax,dwDstDataStart
74 add eax,dwDstRawDataSize ;定位到本节的最后一个字节
75 add esi,eax
76 dec esi
77 .repeat
78 mov bl,byte ptr [esi]
79 .break .if bl!=0
80 inc @dwTemp
81 dec esi
82 .until FALSE
83
84 invoke wsprintf,addr szBuffer,addr szOut16,@dwTemp,@dwTemp1
85 invoke _appendInfo,addr szBuffer
86 .else ;数据段空间不够
87 invoke _appendInfo,addr szErr11
88 .endif
89
90 invoke _appendInfo,addr szoutLine
从以上的代码中可以看出,退出补丁过程需要满足两个条件:
- 如果文件中不存在可存放数据的节,则退出,并提示未找到.data节。对应代码行1~7。
- 如果文件中连续的全0空间不够补丁数据大小,则退出,提示目标数据段空间不够。对应代码行50~88。
因为对0的计数是从节的最后一个字节开始的,所以合并以后的数据段的情况是:如果空闲空间很大,那么老数据和新数据之间可能会存在很多0。尽可能地把新数据放到离老数据相对较远的位置,这样也就最大限度地避免了某些以0初始化的老数据被覆盖的现象。如下所示:
00000800 48 65 6C 6C 6F 57 6F 72 6C 64 00 00 00 00 00 00 HelloWorld......
00000810 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000820 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
…… 很多0
00000980 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000990 00 00 00 00 00 00 00 00 00 00 00 00 00 00 53 4F ..............SO
000009a0 46 54 57 41 52 45 5C 4D 49 43 52 4F 53 4F 46 54 FTWARE\MICROSOFT
000009b0 5C 57 49 4E 44 4F 57 53 5C 43 55 52 52 45 4E 54 \WINDOWS\CURRENT
000009c0 56 45 52 53 49 4F 4E 5C 52 55 4E 00 4E 65 77 56 VERSION\RUN.NewV
000009d0 61 6C 75 65 00 64 3A 5C 6D 61 73 6D 33 32 5C 73 alue.d:\masm32\s
000009e0 6F 75 72 63 65 5C 63 68 61 70 74 65 72 35 5C 4C ource\chapter5\L
000009f0 6F 63 6B 54 72 61 79 2E 65 78 65 00 00 00 00 00 ockTray.exe.....
14.3.5 修改前后PE文件对比
需要修正和迁移的数据基本都完成了,使用PEComp程序对比两个程序,运行界面如图14-2所示。从对比图可以看出,手工补丁后的HelloWorld_2.exe和补丁前的HelloWorld.exe的区别有三处:
1)文件头部分,程序入口地址做了修改,即字段IMAGE_OPTIONAL_HEADER32.AddressOfEntryPoint的值不一样。
2)数据目录表中对导入表的描述不一样。因为导入表已经被搬移了原来的位置,而原来的位置放置了新文件的数据结构(包括补丁IAT和补丁的originalFirstThunk指向的数据结构数组)。
3)三个节的长度不一样。前面已经讲过,数据节的长度不需要修正,程序可以照常运行。
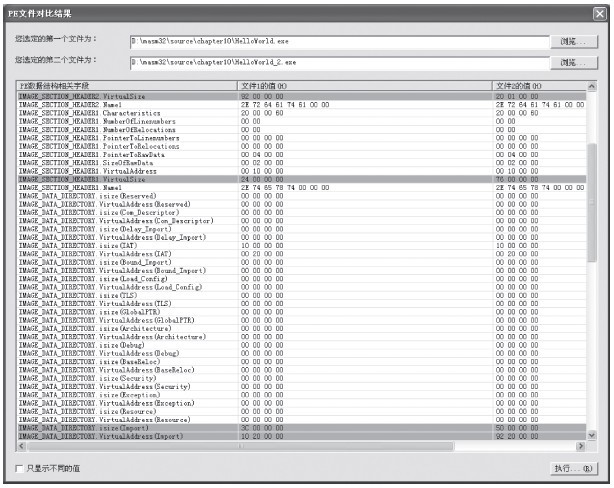
图14-2 手工补丁后的HelloWorld_2.exe与HelloWorld.exe对比
 本文节选自《Windows PE权威指南》(作者:戚利)
本文节选自《Windows PE权威指南》(作者:戚利)
全书共分为三大部分:第一部分简单介绍了学习本书需要搭建的工作环境和必须具备的工具,深入分析了PE文件头、导入表、导出表、重定位表、资源表、延迟导入表、线程局部存储、加载配置信息等核心技术的概念、原理及其编程方法,针对性地讲解了程序设计中的重定位、程序堆栈、动态加载等;第二部分讨论了PE头部的变形技术及静态附加补丁的技术,其中静态附加补丁技术重点讲解了如何在空闲空间、间隙、新节、最后一节等四种情况下打补丁和进行编码的方法;第三部分精心编写了多个大型而完整的PE应用案例,以PE补丁作为重要手段,通过对目标PE文件实施不同的补丁内容来实现不同的应用,详细展示了EXE捆绑器、软件安装自动化、EXE加锁器、EXE加密、PE病毒提示器以及PE病毒的实现过程和方法。
作者简介:戚利,资深安全技术专家和软件开发工程师,对Windows PE、Windows内核、计算机网络安全、协议分析和病毒技术有较为深入的研究,实践经验丰富。擅长汇编语言和Java技术,曾自主开发了一个RMI框架。活跃于国内著名的安全论坛看雪学院,乐于与大家分享自己的心得和体会,且有较高的知名度。此外,教学(副教授)经验也十分丰富,对读者的学习习惯和认知方式有一定的认识,这一点在本书的写作方式上得到了体现。
分享到:


发表评论

相关推荐
### 手工打造PE文件详解 #### 一、PE文件简介 PE(Portable Executable)文件格式是一种由微软设计的标准可执行文件格式,用于Windows操作系统中的可执行文件、动态链接库(DLLs)、某些类型的COM对象、驱动程序及...
根据pe格式更改其中内容使其最小化 其中包括pe格式中的关键字段的描述
### 手动打造PE文件详解 #### 一、引言 PE文件是现代Windows操作系统中极为重要的文件格式之一,广泛应用于各种类型的可执行文件、动态链接库等。深入理解PE文件不仅有助于提升软件开发能力,还能帮助我们在逆向...
全手工制作2004PE 之维护版.7z
5. **配置可选头**:根据目标PE文件的具体需求,填充`IMAGE_OPTIONAL_HEADER32`或`IMAGE_OPTIONAL_HEADER64`,包括代码段和数据段的位置、入口点地址、基地址等关键信息。 6. **设置数据目录表**:确定PE文件中需要...
Oracle 手工建库步骤详解 Oracle 手工建库步骤是创建 Oracle 数据库的基本步骤。本文将详细介绍手工建库的每个步骤,并解释每个步骤的重要性。 步骤 1:确定 Global Database Name 在创建数据库之前,需要确定 ...
再写手工打造可执行程序。一个文档,包含具体步骤
### 手工打造完美WinPE3.0的步骤详解 #### 一、制作WinPE3.0基础步骤 ##### 步骤1:准备文件 - 首先,需要从Windows 7安装光盘(或者镜像文件)中获取`sources\boot.wim`文件。 - 将该文件复制到`D:\winpe\sources...
本文将深入探讨"手工打造C#编译器"这一主题,这是一项极具挑战性的任务,需要对计算机语言理论、编译原理以及C#语言本身有深入的理解。 首先,我们要明白编译器的基本工作流程。一个编译器通常包含以下几个核心组件...
【贴片元件手工焊接步骤详解】 在电子制作和维修领域,手工焊接贴片元件是一项基本技能,特别是对于PCB(印刷电路板)的组装。以下是详细的贴片元件手工焊接步骤: 1. **清洁和固定PCB** - 在开始焊接之前,确保...
### Oracle手工创建数据库完整步骤详解 #### 系统环境配置 在进行Oracle数据库的手工创建之前,确保系统环境已正确设置。本示例基于以下环境: - **操作系统**:Windows 2000 Server - **数据库版本**:Oracle 9i...
手工盒子折纸的步骤教程
【手工打造摇摆LED钟】是一项充满挑战的DIY项目,它基于单片机技术和视觉暂留原理,创造了一个独特的动态显示时钟。这个时钟不仅具有显示时间的功能,还能展示欢迎信息,提供了正常运行、调分和调时三种状态。在设计...
### Oracle手工创建数据库完整步骤详解 #### 环境配置 在进行Oracle数据库的手工创建之前,需要确保系统环境已正确设置。根据题目中的描述,我们的操作系统为**Windows 2000 Server**,数据库版本为**Oracle 9i**,...
手工设计PCB的步骤.pptx
### Oracle手工创建数据库完整步骤详解 #### 一、前言 在Oracle数据库管理领域,手工创建数据库是一项重要的技能。本文将详细介绍如何在Windows 2000 Server环境下手动创建一个Oracle 9i数据库的完整步骤。这不仅...
以下是对“手工计算钢筋的步骤以及方法”的详细解析,旨在帮助建筑从业者掌握这一基本技能。 ### 钢筋计算的基本原理 钢筋计算主要基于两个原则:力学原理和规范要求。力学原理涉及材料力学和结构力学的基础知识,...
自己刚刚手工构建的一个简单的pe文件,希望对大家有帮助。
手工制作笔筒方法步骤教程.pdf