- жµПиІИ: 161191 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еєњеЈЮ
-

жЦЗзЂ†еИЖз±ї
- еЕ®йГ®еНЪеЃҐ (84)
- javascript (4)
- (0)
- oracle 11g (8)
- ubuntu11 (2)
- oracle (36)
- ubuntu (2)
- spring3 (1)
- ж≥®иІ£ (1)
- java (10)
- hibernate (11)
- annotation (4)
- javaеЉВеЄЄ (4)
- js (3)
- struts (2)
- html (2)
- Tomcat (2)
- WebServices (1)
- е≠Чзђ¶йЫЖ (1)
- sql (10)
- 糥еЉХ (1)
- зЃЧж≥Х (2)
- plsql (5)
- зЉЦз†Б (1)
- apache (1)
- е§Здїљ (1)
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2012-04 ( 3)
- 2012-03 ( 4)
- 2012-02 ( 2)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
linchixiongпЉЪ
е≠¶дє†дЇЖпЉМеЊИжЬЙзФ®пЉБ~
Hibernate properties
дЄАпЉО 糥еЉХдїЛзїН
¬†1.1¬† 糥еЉХзЪДеИЫеїЇ иѓ≠ж≥Х пЉЪ ¬†
CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>
       ON <schema>.<table_name>
          
 (<column_name> | <expression> ASC | DESC,
   
       
  <column_name> | <expression> ASC | DESC,...)
    
TABLESPACE <tablespace_name>
    
STORAGE <storage_settings>
    
LOGGING | NOLOGGING
   
COMPUTE STATISTICS
    
NOCOMPRESS | COMPRESS<nn>
    
NOSORT | REVERSE
    
PARTITION | GLOBAL PARTITION<partition_setting>
 
зЫЄеЕ≥иѓіжШО
1пЉЙ¬†
UNIQUE | BITMAP
пЉЪжМЗеЃЪUNIQUE
дЄЇеФѓдЄАеАЉзіҐеЉХпЉМ
BITMAP
дЄЇдљНеی糥еЉХпЉМ
зЬБзХ•дЄЇB-Tree
糥еЉХгАВ
2пЉЙ
<column_name> | <expression> ASC | DESC
пЉЪеПѓдї•еѓєе§ЪеИЧињЫи°МиБФеРИ糥еЉХпЉМељУдЄЇexpression
жЧґеН≥
вАЬ
еЯЇдЇОеЗљжХ∞зЪД糥еЉХ
вАЭ
3пЉЙ
TABLESPACE
пЉЪжМЗеЃЪе≠ШжԌ糥еЉХзЪДи°®з©ЇйЧі
(糥еЉХеТМеОЯи°®дЄНеЬ®дЄАдЄ™и°®з©ЇйЧіжЧґжХИзОЗжЫійЂШ
)
4пЉЙ
STORAGE
пЉЪеПѓињЫдЄАж≠•иЃЊзљЃи°®з©ЇйЧізЪДе≠ШеВ®еПВжХ∞
5пЉЙ
LOGGING | NOLOGGING
пЉЪжШѓеж僺糥еЉХдЇІзФЯйЗНеБЪжЧ•ењЧ(
еѓєе§Іи°®е∞љйЗПдљњзФ®
NOLOGGING
жЭ•еЗПе∞СеН†зФ®з©ЇйЧіеєґжПРйЂШжХИзОЗ
)
6пЉЙ
COMPUTE STATISTICS
пЉЪеИЫеїЇжЦ∞糥еЉХжЧґжФґйЫЖзїЯиЃ°дњ°жБѓ
7пЉЙ
NOCOMPRESS | COMPRESS<nn>
пЉЪжШѓеР¶дљњзФ®вАЬ
йФЃеОЛзЉ©
вАЭ(
дљњзФ®йФЃеОЛзЉ©еПѓдї•еИ†йЩ§дЄАдЄ™йФЃеИЧдЄ≠еЗЇзО∞зЪДйЗНе§НеАЉ
)
8пЉЙ
NOSORT | REVERSE
пЉЪNOSORT
и°®з§ЇдЄОи°®дЄ≠зЫЄеРМзЪДй°ЇеЇПеИЫ忯糥еЉХпЉМ
REVERSE
и°®з§ЇзЫЄеПНй°ЇеЇПе≠Ше®糥еЉХеАЉ
9пЉЙ
PARTITION | NOPARTITION
пЉЪеПѓдї•еЬ®
еИЖеМЇи°®
еТМжЬ™еИЖеМЇи°®дЄКеѓєеИЫеїЇзЪД糥еЉХињЫи°МеИЖеМЇ
 
 
1. 2 ¬†зіҐеЉХзЙєзВєпЉЪ ¬†
зђђдЄА пЉМйАЪињЗеИЫеїЇеФѓдЄАжАІзіҐеЉХпЉМеПѓдї•дњЭиѓБжХ∞жНЃеЇУи°®дЄ≠жѓПдЄАи°МжХ∞жНЃзЪДеФѓдЄАжАІгАВ¬†
зђђдЇМ пЉМеПѓдї•е§Іе§ІеК†ењЂжХ∞жНЃзЪДж£А糥йАЯеЇ¶пЉМињЩдєЯжШѓеИЫ忯糥еЉХзЪДжЬАдЄїи¶БзЪДеОЯеЫ†гАВ¬†
зђђдЄЙ пЉМеПѓдї•еК†йАЯи°®еТМи°®дєЛйЧізЪДињЮжО•пЉМзЙєеИЂжШѓеЬ®еЃЮзО∞жХ∞жНЃзЪДеПВиАГеЃМжХіжАІжЦєйЭҐзЙєеИЂжЬЙжДПдєЙгАВ¬†
зђђеЫЫ пЉМеЬ®дљњзФ®еИЖзїДеТМжОТеЇПе≠РеП•ињЫи°МжХ∞жНЃж£А糥жЧґпЉМеРМж†ЈеПѓдї•жШЊиСЧеЗПе∞Сжߕ胥дЄ≠еИЖзїДеТМжОТеЇПзЪДжЧґйЧігАВ¬†
зђђдЇФ пЉМйАЪињЗдљњзԮ糥еЉХпЉМеПѓдї•еЬ®жߕ胥зЪДињЗз®ЛдЄ≠пЉМдљњзФ®дЉШеМЦйЪРиЧПеЩ®пЉМжПРйЂШз≥їзїЯзЪДжАІиГљгАВ¬†
 
 
1. 3 ¬†зіҐеЉХдЄНиґ≥пЉЪ
зђђдЄА пЉМеИЫ忯糥еЉХеТМзїіжʧ糥еЉХи¶БиАЧиієжЧґйЧіпЉМињЩзІНжЧґйЧійЪПзЭАжХ∞жНЃйЗПзЪДеҐЮеК†иАМеҐЮеК†гАВ¬†
зђђдЇМ пЉМ糥еЉХйЬАи¶БеН†зЙ©зРЖз©ЇйЧіпЉМйЩ§дЇЖжХ∞жНЃи°®еН†жХ∞жНЃз©ЇйЧідєЛе§ЦпЉМжѓПдЄА䪙糥еЉХињШи¶БеН†дЄАеЃЪзЪДзЙ©зРЖз©ЇйЧіпЉМе¶ВжЮЬи¶БеїЇзЂЛиБЪз∞З糥еЉХпЉМйВ£дєИйЬАи¶БзЪДз©ЇйЧіе∞±дЉЪжЫіе§ІгАВ¬†
зђђдЄЙ пЉМељУеѓєи°®дЄ≠зЪДжХ∞жНЃињЫи°МеҐЮеК†гАБеИ†йЩ§еТМдњЃжФєзЪДжЧґеАЩпЉМ糥еЉХдєЯи¶БеК®жАБзЪДзїіжК§пЉМињЩж†Је∞±йЩНдљОдЇЖжХ∞жНЃзЪДзїіжК§йАЯеЇ¶гАВ¬†
 
 
1. 4 ¬†еЇФ胕忯糥еЉХеИЧзЪДзЙєзВєпЉЪ
1пЉЙ еЬ®зїПеЄЄйЬАи¶БжРЬ糥зЪДеИЧдЄКпЉМеПѓдї•еК†ењЂжРЬ糥зЪДйАЯеЇ¶пЉЫ¬†
2пЉЙ еЬ®дљЬдЄЇдЄїйФЃзЪДеИЧдЄКпЉМеЉЇеИґиѓ•еИЧзЪДеФѓдЄАжАІеТМзїДзїЗи°®дЄ≠жХ∞жНЃзЪДжОТеИЧзїУжЮДпЉЫ¬†
3пЉЙ еЬ®зїПеЄЄзФ®еЬ®ињЮжО•зЪДеИЧдЄКпЉМињЩдЇЫеИЧдЄїи¶БжШѓдЄАдЇЫе§ЦйФЃпЉМеПѓдї•еК†ењЂињЮжО•зЪДйАЯеЇ¶пЉЫ¬†
4пЉЙ еЬ®зїПеЄЄйЬАи¶Бж†єжНЃиМГеЫіињЫи°МжРЬ糥зЪДеИЧдЄКеИЫ忯糥еЉХпЉМеۆ䪯糥еЉХеЈ≤зїПжОТеЇПпЉМеЕґжМЗеЃЪзЪДиМГеЫіжШѓињЮзї≠зЪДпЉЫ¬†
5пЉЙ еЬ®зїПеЄЄйЬАи¶БжОТеЇПзЪДеИЧдЄКеИЫ忯糥еЉХпЉМеۆ䪯糥еЉХеЈ≤зїПжОТеЇПпЉМињЩж†Јжߕ胥еПѓдї•еИ©зԮ糥еЉХзЪДжОТеЇПпЉМеК†ењЂжОТеЇПжߕ胥жЧґйЧіпЉЫ¬†
6пЉЙ еЬ®зїПеЄЄдљњзФ®еЬ®WHERE е≠РеП•дЄ≠зЪДеИЧдЄКйЭҐеИЫ忯糥еЉХпЉМеК†ењЂжЭ°дїґзЪДеИ§жЦ≠йАЯеЇ¶гАВ¬†
 
 
1. 5 ¬†дЄНеЇФ胕忯糥еЉХеИЧзЪДзЙєзВєпЉЪ
зђђдЄА пЉМеѓєдЇОйВ£дЇЫеЬ®жߕ胥дЄ≠еЊИе∞СдљњзФ®жИЦиАЕеПВиАГзЪДеИЧдЄНеЇФиѓ•еИЫ忯糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМжЧҐзДґињЩдЇЫеИЧеЊИе∞СдљњзФ®еИ∞пЉМеЫ†ж≠§жЬЙ糥еЉХжИЦиАЕж׆糥еЉХпЉМеєґдЄНиГљжПРйЂШжߕ胥йАЯеЇ¶гАВзЫЄеПНпЉМзФ±дЇОеҐЮеК†дЇЖ糥еЉХпЉМеПНиАМйЩНдљОдЇЖз≥їзїЯзЪДзїіжК§йАЯеЇ¶еТМеҐЮе§ІдЇЖз©ЇйЧійЬАж±ВгАВ¬†
зђђдЇМ пЉМеѓєдЇОйВ£дЇЫеП™жЬЙеЊИе∞СжХ∞жНЃеАЉзЪДеИЧдєЯдЄНеЇФиѓ•еҐЮеʆ糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМзФ±дЇОињЩдЇЫеИЧзЪДеПЦеАЉеЊИе∞СпЉМдЊЛе¶ВдЇЇдЇЛи°®зЪДжАІеИЂеИЧпЉМеЬ®жߕ胥зЪДзїУжЮЬдЄ≠пЉМзїУжЮЬйЫЖзЪДжХ∞жНЃи°МеН†дЇЖи°®дЄ≠жХ∞жНЃи°МзЪДеЊИе§ІжѓФдЊЛпЉМеН≥йЬАи¶БеЬ®и°®дЄ≠жРЬ糥зЪДжХ∞жНЃи°МзЪДжѓФдЊЛеЊИе§ІгАВеҐЮеʆ糥еЉХпЉМеєґдЄНиГљжШОжШЊеК†ењЂж£А糥йАЯеЇ¶гАВ¬†
зђђдЄЙ пЉМеѓєдЇОйВ£дЇЫеЃЪдєЙдЄЇ blob жХ∞жНЃз±їеЮЛзЪДеИЧдЄНеЇФиѓ•еҐЮеʆ糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМињЩдЇЫеИЧзЪДжХ∞жНЃйЗПи¶БдєИзЫЄељУе§ІпЉМи¶БдєИеПЦеАЉеЊИе∞СгАВ¬†
зђђеЫЫ пЉМељУдњЃжФєжАІиГљињЬињЬе§ІдЇОж£А糥жАІиГљжЧґпЉМдЄНеЇФиѓ•еИЫ忯糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМдњЃжФєжАІиГљеТМж£А糥жАІиГљжШѓдЇТзЫЄзЯЫзЫЊзЪДгАВељУеҐЮеʆ糥еЉХжЧґпЉМдЉЪжПРйЂШж£А糥жАІиГљпЉМдљЖжШѓдЉЪйЩНдљОдњЃжФєжАІиГљгАВељУеЗПе∞С糥еЉХжЧґпЉМдЉЪжПРйЂШдњЃжФєжАІиГљпЉМйЩНдљОж£А糥жАІиГљгАВеЫ†ж≠§пЉМељУдњЃжФєжАІиГљињЬињЬе§ІдЇОж£А糥жАІиГљжЧґпЉМдЄНеЇФиѓ•еИЫ忯糥еЉХгАВ¬†
 
 
1.6 
йЩРеȴ糥еЉХ
йЩРеȴ糥еЉХжШѓдЄАдЇЫж≤°жЬЙзїПй™МзЪДеЉАеПСдЇЇеСШзїПеЄЄзКѓзЪДйФЩиѓѓдєЛдЄАгАВеЬ®SQL
дЄ≠жЬЙеЊИе§ЪйЩЈйШ±дЉЪдљњдЄАдЇЫ糥еЉХжЧ†ж≥ХдљњзФ®гАВдЄЛйЭҐиЃ®иЃЇдЄАдЇЫеЄЄиІБзЪДйЧЃйҐШпЉЪ
  
 
1.6.1  
дљњзФ®дЄНз≠ЙдЇОжУНдљЬзђ¶пЉИ<>
гАБ
!=
пЉЙ
      
  
 
дЄЛйЭҐзЪДжߕ胥еН≥дљњеЬ®cust_rating
еИЧжЬЙдЄА䪙糥еЉХпЉМжߕ胥иѓ≠еП•дїНзДґжЙІи°МдЄАжђ°еЕ®и°®жЙЂжППгАВ
     
   select cust_Id,cust_name from customers where  cust_rating <> 'aa';        
жККдЄКйЭҐзЪДиѓ≠еП•жФєжИРе¶ВдЄЛзЪДжߕ胥иѓ≠еП•пЉМињЩж†ЈпЉМеЬ®йЗЗзФ®еЯЇдЇОиІДеИЩзЪДдЉШеМЦеЩ®иАМдЄНжШѓеЯЇдЇОдї£дїЈзЪДдЉШеМЦеЩ®пЉИжЫіжЩЇиГљпЉЙжЧґпЉМе∞ЖдЉЪдљњзԮ糥еЉХгАВ¬†¬†¬†¬†¬†¬†¬†¬†
  select cust_Id,cust_name from customers where cust_rating < 'aa' or cust_rating > 'aa';
¬†¬†зЙєеИЂж≥®жДПпЉЪйАЪињЗжККдЄНз≠ЙдЇОжУНдљЬзђ¶жФєжИР
OR
жЭ°дїґпЉМе∞±еПѓдї•дљњзԮ糥еЉХпЉМдї•йБњеЕНеЕ®и°®жЙЂжППгАВ
  
 
1.6.
2¬†дљњзФ®
IS NULL 
жИЦ
IS NOT NULL
¬†¬†¬†дљњзФ®
IS NULL 
жИЦ
IS NOT NULL
еРМж†ЈдЉЪйЩРеȴ糥еЉХзЪДдљњзФ®
гАВеЫ†дЄЇ
NULL
еАЉеєґж≤°жЬЙ襀еЃЪдєЙгАВеЬ®
SQL
иѓ≠еП•дЄ≠дљњзФ®
NULL
дЉЪжЬЙеЊИе§ЪзЪДйЇїзГ¶гАВеЫ†ж≠§еїЇиЃЃеЉАеПСдЇЇеСШеЬ®еїЇи°®жЧґпЉМжККйЬАи¶Б糥еЉХзЪДеИЧиЃЊжИР¬†
NOT NULL
гАВе¶ВжЮЬ襀糥еЉХзЪДеИЧеЬ®жЯРдЇЫи°МдЄ≠е≠ШеЬ®
NULL
еАЉпЉМе∞±дЄНдЉЪдљњзФ®ињЩ䪙糥еЉХпЉИйЩ§йЭЮ糥еЉХжШѓдЄАдЄ™дљНеی糥еЉХпЉМеЕ≥дЇОдљНеی糥еЉХеЬ®з®НеРОеЬ®иѓ¶зїЖиЃ®иЃЇпЉЙгАВ
   
1.6
.3¬†дљњзФ®еЗљжХ∞
¬†¬†¬†е¶ВжЮЬдЄНдљњзФ®еЯЇдЇОеЗљжХ∞зЪД糥еЉХпЉМйВ£дєИеЬ®SQL
иѓ≠еП•зЪД
WHERE
е≠РеП•дЄ≠еѓєе≠Шеܮ糥еЉХзЪДеИЧдљњзФ®еЗљжХ∞жЧґпЉМдЉЪдљњдЉШеМЦеЩ®ењљзХ•жОЙињЩдЇЫ糥еЉХгАВ¬†
¬† дЄЛйЭҐзЪДжߕ胥дЄНдЉЪдљњзԮ糥еЉХпЉИеП™и¶БеЃГдЄНжШѓеЯЇдЇОеЗљжХ∞зЪД糥еЉХпЉЙ
 select empno,ename,deptno from emp  where  trunc(hiredate)='01-MAY-81';
¬†¬†¬†жККдЄКйЭҐзЪДиѓ≠еП•жФєжИРдЄЛйЭҐзЪДиѓ≠еП•пЉМињЩж†Је∞±еПѓдї•йАЪињЗ糥еЉХињЫи°МжЯ•жЙЊгАВ
select empno,ename,deptno from emp where  hiredate<(to_date('01-MAY-81')+0.9999);
 
 1.6
.4¬†жѓФиЊГдЄНеМєйЕНзЪДжХ∞жНЃз±їеЮЛ¬†¬†¬†¬†¬†¬†¬†
дєЯжШѓжѓФиЊГйЪЊдЇОеПСзО∞зЪДжАІиГљйЧЃйҐШдєЛдЄАгАВ¬†ж≥®жДПдЄЛйЭҐжߕ胥зЪДдЊЛе≠РпЉМaccount_number
жШѓдЄАдЄ™
VARCHAR2
з±їеЮЛ
,
еЬ®
account_number
е≠ЧжЃµдЄКжЬЙ糥еЉХгАВ
дЄЛйЭҐзЪДиѓ≠еП•е∞ЖжЙІи°МеЕ®и°®жЙЂжПП пЉЪ
 
select bank_name,address,city,state,zip from banks where account_number = 990354;
 
OracleеПѓдї•иЗ™еК®жКК
where
е≠РеП•еПШжИР
to_number(account_number)=990354
пЉМињЩж†Је∞±йЩРеИґдЇЖ糥еЉХ
зЪДдљњзФ®
,
жФєжИРдЄЛйЭҐзЪДжߕ胥е∞±еПѓдї•дљњзԮ糥еЉХпЉЪ
 select bank_name,address,city,state,zip from banks where account_number ='990354';
зЙєеИЂж≥®жДПпЉЪ дЄНеМєйЕНзЪДжХ∞жНЃз±їеЮЛдєЛйЧіжѓФиЊГдЉЪиЃ©Oracle иЗ™еК®йЩРеȴ糥еЉХзЪДдљњзФ® , еН≥дЊњеѓєињЩдЄ™жߕ胥жЙІи°М Explain¬†Plan дєЯдЄНиГљиЃ©жВ®жШОзЩљдЄЇдїАдєИеБЪдЇЖдЄАжђ° вАЬ еЕ®и°®жЙЂжПП вАЭ гАВ
 
 
1.
7
¬†жߕ胥
糥еЉХ
жߕ胥DBA_INDEXES
иІЖеЫЊеПѓеЊЧеИ∞и°®дЄ≠жЙАжЬЙ糥еЉХзЪДеИЧи°®пЉМж≥®жДПеП™иГљйАЪињЗ
USER_INDEXES
зЪДжЦєж≥ХжЭ•ж£А糥殰еЉП
(schema)
зЪД糥еЉХгАВиЃњйЧЃ
USER_IND_COLUMNS
иІЖеЫЊеПѓеЊЧеИ∞дЄАдЄ™зїЩеЃЪи°®дЄ≠襀糥еЉХзЪДзЙєеЃЪеИЧгАВ
1.
8
 
зїДеРИ糥еЉХ
ељУжЯР䪙糥еЉХеМЕеРЂжЬЙе§ЪдЄ™еЈ≤糥еЉХзЪДеИЧжЧґпЉМзІ∞ињЩ䪙糥еЉХдЄЇ
зїДеРИпЉИconcatented
пЉЙ糥еЉХ
гАВеЬ®¬†Oracle9i
еЉХеЕ•иЈ≥иЈГеЉПжЙЂжППзЪД糥еЉХиЃњйЧЃжЦєж≥ХдєЛеЙНпЉМжߕ胥еП™иГљеЬ®жЬЙйЩРжЭ°дїґдЄЛдљњзԮ胕糥еЉХгАВжѓФе¶ВпЉЪи°®
emp
жЬЙдЄАдЄ™зїДеРИ糥еЉХйФЃпЉМ胕糥еЉХеМЕеРЂдЇЖ
empno
гАБ¬†
ename
еТМ
deptno
гАВеЬ®
Oracle9i
дєЛеЙНйЩ§йЭЮеЬ®
where
дєЛеП•дЄ≠еѓєзђђдЄАеИЧпЉИ
empno
пЉЙжМЗеЃЪдЄАдЄ™еАЉпЉМеР¶еИЩе∞±дЄНиГљдљњзФ®ињЩ䪙糥еЉХйФЃињЫи°МдЄАжђ°иМГеЫіжЙЂжППгАВ
  
¬†зЙєеИЂж≥®жДПпЉЪеЬ®Oracle9i
дєЛеЙНпЉМеП™жЬЙеЬ®дљњзФ®еИ∞糥еЉХзЪДеЙН僊糥еЉХжЧґжЙНеПѓдї•дљњзФ®зїДеРИ糥еЉХпЉБ
 
1.
9
 ORACLE ROWID
йАЪињЗжѓПдЄ™и°МзЪДROWID
пЉМ糥еЉХ
Oracle
жПРдЊЫдЇЖиЃњйЧЃеНХи°МжХ∞жНЃзЪДиГљеКЫгАВ
ROWID
еЕґеЃЮе∞±жШѓзЫіжО•жМЗеРСеНХзЛђи°МзЪДзЇњиЈѓеЫЊгАВе¶ВжЮЬжГ≥ж£АжЯ•йЗНе§НеАЉжИЦжШѓеЕґдїЦеѓє
ROWID
жЬђиЇЂзЪДеЉХзФ®пЉМеПѓдї•еЬ®дїїдљХи°®дЄ≠дљњзФ®еТМжМЗеЃЪ
rowid
еИЧгАВ
 
1.10 
йАЙжЛ©жАІ
¬†¬†¬†дљњзФ®USER_INDEXES
иІЖеЫЊпЉМиѓ•иІЖеЫЊдЄ≠жШЊз§ЇдЇЖдЄАдЄ™
distinct_keys
еИЧгАВжѓФиЊГдЄАдЄЛеФѓдЄАйФЃзЪДжХ∞йЗПеТМи°®дЄ≠зЪДи°МжХ∞пЉМе∞±еПѓдї•еИ§жЦ≠糥еЉХзЪДйАЙжЛ©жАІгАВйАЙжЛ©жАІиґКйЂШпЉМ糥еЉХињФеЫЮзЪДжХ∞жНЃе∞±иґКе∞СгАВ
1.11 
зЊ§йЫЖеЫ†е≠Р(Clustering¬†Factor)
¬†¬†Clustering¬†FactorдљНдЇО
USER_INDEXES
иІЖеЫЊдЄ≠гАВиѓ•еИЧеПНжШ†дЇЖжХ∞жНЃзЫЄеѓєдЇОеЈ≤
еїЇ
糥еЉХзЪДеИЧжШѓеР¶жШЊеЊЧжЬЙеЇПгАВе¶ВжЮЬClustering¬†Factor
еИЧзЪДеАЉжО•ињСдЇО糥еЉХдЄ≠зЪДж†СеПґеЭЧ
(leaf block)
зЪДжХ∞зЫЃпЉМи°®дЄ≠зЪДжХ∞жНЃе∞±иґКжЬЙеЇПгАВе¶ВжЮЬеЃГзЪДеАЉжО•ињСдЇОи°®дЄ≠зЪДи°МжХ∞пЉМеИЩи°®дЄ≠зЪДжХ∞жНЃе∞±дЄНжШѓеЊИжЬЙеЇПгАВ
1.12 
дЇМеЕГйЂШеЇ¶(Binary¬†height)
¬†¬†зіҐеЉХзЪДдЇМеЕГйЂШеЇ¶еѓєжККROWID
ињФеЫЮзїЩзФ®жИЈињЫз®ЛжЧґжЙАи¶Бж±ВзЪД
I/O
йЗПиµЈеИ∞еЕ≥йФЃдљЬзФ®гАВеЬ®еѓєдЄА䪙糥еЉХињЫи°МеИЖжЮРеРОпЉМеПѓдї•йАЪињЗжߕ胥
DBA_INDEXES
зЪД
B- level
еИЧжЯ•зЬЛеЃГзЪДдЇМеЕГйЂШеЇ¶
гАВдЇМеЕГйЂШеЇ¶дЄїи¶БйЪПзЭАи°®зЪДе§Іе∞Пдї•еПК襀糥еЉХзЪДеИЧдЄ≠еАЉзЪДиМГеЫізЪДзЛ≠з™Дз®ЛеЇ¶иАМеПШеМЦгАВ糥еЉХдЄКе¶ВжЮЬжЬЙе§ІйЗП襀еИ†йЩ§зЪДи°МпЉМеЃГзЪДдЇМеЕГйЂШеЇ¶дєЯдЉЪеҐЮеК†гАВжЫіжЦ∞糥еЉХеИЧдєЯз±їдЉЉдЇОеИ†йЩ§жУНдљЬпЉМеЫ†дЄЇеЃГеҐЮеК†дЇЖеЈ≤еИ†йЩ§йФЃзЪДжХ∞зЫЃгАВ
йЗН忯糥еЉХеПѓиГљдЉЪйЩНдљОдЇМеЕГйЂШеЇ¶
гАВ
1.13
¬†ењЂйАЯеЕ®е±АжЙЂжПП
  
дїО
Oracle7.3еРОе∞±еПѓдї•дљњзФ®ењЂйАЯеЕ®е±АжЙЂжПП
(Fast Full Scan)
ињЩдЄ™йАЙй°єгАВињЩдЄ™йАЙй°єеЕБиЃЄ
Oracle
жЙІи°МдЄАдЄ™еЕ®е±А糥еЉХжЙЂжППжУНдљЬгАВењЂйАЯеЕ®е±АжЙЂжППиѓїеПЦ
B-
ж†С糥еЉХдЄКжЙАжЬЙж†СеПґеЭЧгАВеИЭеІЛеМЦжЦЗдїґдЄ≠зЪД¬†
DB_FILE_MULTIBLOCK_READ_COUNT
еПВжХ∞еПѓдї•жОІеИґеРМж״襀胿еПЦзЪДеЭЧзЪДжХ∞зЫЃгАВ
1.14
¬†иЈ≥иЈГеЉПжЙЂжПП
¬†¬†дїОOracle9i
еЉАеІЛпЉМ糥еЉХиЈ≥иЈГеЉПжЙЂжППзЙєжАІеПѓдї•еЕБиЃЄдЉШеМЦеЩ®дљњзФ®зїДеРИ糥еЉХпЉМеН≥䌜糥еЉХзЪДеЙНеѓЉеИЧж≤°жЬЙеЗЇзО∞еЬ®
WHERE
е≠РеП•дЄ≠гАВ糥еЉХиЈ≥иЈГеЉПжЙЂжППжѓФеŮ糥еЉХжЙЂжПП
и¶БењЂзЪДе§ЪгАВ
дЄЛйЭҐзЪД
жѓФиЊГдїЦдїђзЪДеМЇеИЂ
пЉЪ
SQL> set timing on
SQL> create index TT_index on TT(teamid,areacode);
糥еЉХеЈ≤еИЫеїЇгАВ
еЈ≤зФ®жЧґйЧі:¬†¬†00:¬†02:¬†03.93
SQL> select count(areacode) from tt;
COUNT(AREACODE)
---------------
 7230369
еЈ≤зФ®жЧґйЧі:¬†¬†00:¬†00:¬†08.31
SQL> select  /*+ index(tt TT_index )*/  count(areacode) from tt;
COUNT(AREACODE)
---------------
7230369
еЈ≤зФ®жЧґйЧі:¬†¬†00:¬†00:¬†07.37
1.15
¬†зіҐеЉХзЪДз±їеЮЛ
- B-ж†С糥еЉХ¬†¬†¬† ¬†
- дљНеی糥еЉХ¬† ¬†
- HASH糥еЉХ¬† ¬†¬†
- 糥еЉХзЉЦжОТи°®¬†¬†
- еПНиљђйԁ糥еЉХ
- еЯЇдЇОеЗљжХ∞зЪД糥еЉХ
- еИЖе̯糥еЉХ
- жЬђеЬ∞еТМеЕ®е±А糥еЉХ
 
 
 
 
 
дЇМпЉО¬†зіҐеЉХеИЖз±ї
OracleжПРдЊЫдЇЖе§ІйЗП糥еЉХйАЙй°єгАВзЯ•йБУеЬ®зїЩеЃЪжЭ°дїґдЄЛдљњзФ®еУ™дЄ™йАЙй°єеѓєдЇОдЄАдЄ™еЇФзФ®з®ЛеЇПзЪДжАІиГљжЭ•иѓійЭЮеЄЄйЗНи¶БгАВдЄАдЄ™йФЩиѓѓзЪДйАЙжЛ©еПѓиГљдЉЪеЉХеПСж≠їйФБпЉМеєґеѓЉиЗіжХ∞жНЃеЇУжАІиГљжА•еЙІдЄЛйЩНжИЦињЫз®ЛзїИж≠ҐгАВиАМе¶ВжЮЬеБЪеЗЇж≠£з°ЃзЪДйАЙжЛ©пЉМеИЩеПѓдї•еРИзРЖдљњзФ®иµДжЇРпЉМдљњйВ£дЇЫеЈ≤зїПињРи°МдЇЖеЗ†дЄ™е∞ПжЧґзФЪиЗ≥еdž姩зЪДињЫз®ЛеЬ®еЗ†еИЖйТЯеЊЧдї•еЃМжИРпЉМињЩж†ЈдЉЪдљњжВ®зЂЛеИїжИРдЄЇдЄАдљНиЛ±йЫДгАВ
дЄЛйЭҐ
е∞±е∞ЖзЃАеНХзЪДиЃ®иЃЇжѓП䪙糥еЉХйАЙй°єгАВ
дЄЛйЭҐиЃ®иЃЇзЪД糥еЉХз±їеЮЛпЉЪ
Bж†С糥еЉХ
(йїШиЃ§з±їеЮЛ
)
дљНеی糥еЉХ
HASH糥еЉХ
糥еЉХзїДзїЗ谮糥еЉХ
еПНиљђйФЃ(reverse¬†key)
糥еЉХ
еЯЇдЇОеЗљжХ∞зЪД糥еЉХ
еИЖе̯糥еЉХ(
жЬђеЬ∞еТМеЕ®е±А糥еЉХ
)
дљНеЫЊињЮжΕ糥еЉХ
2.1¬†¬†Bж†С糥еЉХ
 
(йїШиЃ§з±їеЮЛ
)
 
Bж†С糥еЉХеЬ®
Oracle
дЄ≠жШѓдЄАдЄ™йАЪзԮ糥еЉХгАВеЬ®еИЫ忯糥еЉХжЧґеЃГе∞±жШѓйїШиЃ§зЪД糥еЉХз±їеЮЛ
гАВ
B
ж†С糥еЉХеПѓдї•жШѓдЄАдЄ™еИЧзЪД
(
зЃАеНХ
)
糥еЉХпЉМдєЯеПѓдї•жШѓзїДеРИ
/
е§НеРИ
(
е§ЪдЄ™еИЧ
)
зЪД糥еЉХгАВ
B
ж†С糥еЉХжЬАе§ЪеПѓдї•еМЕжЛђ
32
еИЧ
гАВ
еЬ®
дЄЛеЫЊ
зЪДдЊЛе≠РдЄ≠пЉМB
ж†С糥еЉХдљНдЇОйЫЗеСШи°®зЪД
last_name
еИЧдЄКгАВињЩ䪙糥еЉХзЪДдЇМеЕГйЂШеЇ¶дЄЇ
3
пЉЫжО•дЄЛжЭ•пЉМ
Oracle
дЉЪз©њињЗдЄ§дЄ™ж†СжЮЭеЭЧ
(branch block)
пЉМеИ∞иЊЊеМЕеРЂжЬЙ
ROWID
зЪДж†СеПґеЭЧгАВеЬ®жѓПдЄ™ж†СжЮЭеЭЧдЄ≠пЉМж†СжЮЭи°МеМЕеРЂйУЊдЄ≠дЄЛдЄАдЄ™еЭЧзЪД
ID
еПЈгАВ
ж†СеПґеЭЧеМЕеРЂ
дЇЖ
糥еЉХеАЉ
гАБ
ROWID
пЉМдї•еПКжМЗеРСеЙНдЄАдЄ™еТМеРОдЄАдЄ™ж†СеПґеЭЧзЪД
жМЗйТИ
гАВOracle
еПѓдї•дїОдЄ§дЄ™жЦєеРСйБНеОЖињЩдЄ™дЇМеПЙж†СгАВ
B
ж†С糥еЉХдњЭе≠ШдЇЖеܮ糥еЉХеИЧдЄКжЬЙеАЉзЪДжѓПдЄ™жХ∞жНЃи°МзЪД
ROWID
еАЉгАВ
OracleдЄНдЉЪ僺糥еЉХеИЧдЄКеМЕеРЂ
NULL
еАЉзЪДи°МињЫи°М糥еЉХ
гАВе¶ВжЮЬ糥еЉХжШѓе§ЪдЄ™еИЧзЪДзїДеРИ糥еЉХпЉМиАМеЕґдЄ≠еИЧдЄКеМЕеРЂNULL
еАЉпЉМињЩдЄАи°Ме∞±дЉЪе§ДдЇОеМЕеРЂ
NULL
еАЉзЪД糥еЉХеИЧдЄ≠пЉМдЄФе∞Ж襀е§ДзРЖдЄЇз©Ї
(
иІЖдЄЇ
NULL)
гАВ
жКАеЈІ
пЉЪ
糥еЉХеИЧзЪДеАЉйГље≠ШеВ®еܮ糥еЉХдЄ≠гАВеЫ†ж≠§пЉМеПѓдї•еїЇзЂЛдЄАдЄ™зїДеРИ
(
е§НеРИ
)
糥еЉХпЉМињЩдЇЫ糥еЉХеПѓдї•зЫіжО•жї°иґ≥жߕ胥пЉМиАМдЄНзФ®иЃњйЧЃи°®гАВињЩе∞±дЄНзФ®дїОи°®дЄ≠ж£А糥жХ∞жНЃпЉМдїОиАМеЗПе∞СдЇЖ
I/O
йЗПгАВ
B-tree
¬†зЙєзВє
пЉЪ
- йАВеРИдЄОе§ІйЗПзЪДеҐЮгАБеИ†гАБжФєпЉИOLTP пЉЙ
- дЄНиГљзФ®еМЕеРЂOR жУНдљЬзђ¶зЪДжߕ胥пЉЫ
- йАВеРИйЂШеЯЇжХ∞зЪДеИЧпЉИеФѓдЄАеАЉе§ЪпЉЙ
- еЕЄеЮЛзЪДж†СзКґзїУжЮДпЉЫ
- жѓПдЄ™зїУзВєйГљжШѓжХ∞жНЃеЭЧпЉЫ
- е§Іе§ЪйГљжШѓзЙ©зРЖдЄКдЄАе±ВгАБдЄ§е±ВжИЦдЄЙе±ВдЄНеЃЪпЉМйАїиЊСдЄКдЄЙе±ВпЉЫ
- еПґе≠РеЭЧжХ∞жНЃжШѓжОТеЇПзЪДпЉМдїОеЈ¶еРСеП≥йАТеҐЮпЉЫ
- еЬ®еИЖжФѓеЭЧеТМж†єеЭЧдЄ≠жФЊзЪДж؃糥еЉХзЪДиМГеЫіпЉЫ
 
2.2¬†¬†дљНеی糥еЉХ
дљНеی糥еЉХйЭЮеЄЄйАВеРИдЇОеЖ≥з≠ЦжФѓжМБз≥їзїЯ(Decision¬†Support¬†System
пЉМ
DSS)
еТМжХ∞жНЃдїУеЇУ
пЉМеЃГдїђдЄНеЇФиѓ•зФ®дЇОйАЪињЗдЇЛеК°е§ДзРЖеЇФзФ®з®ЛеЇПиЃњйЧЃзЪДи°®гАВеЃГдїђеПѓдї•дљњзФ®иЊГе∞СеИ∞дЄ≠з≠ЙеЯЇжХ∞(
дЄНеРМеАЉзЪДжХ∞йЗП
)
зЪДеИЧиЃњйЧЃйЭЮеЄЄе§ІзЪДи°®гАВе∞љзЃ°дљНеی糥еЉХжЬАе§ЪеПѓиЊЊ
30
дЄ™еИЧпЉМдљЖйАЪеЄЄеЃГдїђйГљеП™зФ®дЇОе∞СйЗПзЪДеИЧгАВ
дЊЛе¶ВпЉМжВ®зЪДи°®еПѓиГљеМЕеРЂдЄАдЄ™зІ∞дЄЇSex
зЪДеИЧпЉМеЃГжЬЙдЄ§дЄ™еПѓиГљеАЉпЉЪзФЈеТМе•≥гАВињЩдЄ™еЯЇжХ∞еП™дЄЇ
2
пЉМе¶ВжЮЬзФ®жИЈйҐСзєБеЬ∞ж†єжНЃ
Sex
еИЧзЪДеАЉжߕ胥胕谮пЉМињЩе∞±жШѓдљНеی糥еЉХзЪДеЯЇеИЧгАВељУдЄАдЄ™и°®еЖЕеМЕеРЂдЇЖе§ЪдЄ™дљНеی糥еЉХжЧґпЉМжВ®еПѓдї•дљУдЉЪеИ∞дљНеی糥еЉХзЪДзЬЯж≠£е®БеКЫгАВе¶ВжЮЬжЬЙе§ЪдЄ™еПѓзФ®зЪДдљНеی糥еЉХпЉМ
Oracle
е∞±еПѓдї•еРИеєґдїОжѓПдЄ™дљНеی糥еЉХеЊЧеИ∞зЪДзїУжЮЬйЫЖпЉМењЂйАЯеИ†йЩ§дЄНењЕи¶БзЪДжХ∞жНЃгАВ
Bitmap
t¬†зЙєзВє
пЉЪ
- йАВеРИдЄОеЖ≥з≠ЦжФѓжМБз≥їзїЯпЉЫ
- еБЪUPDATE дї£дїЈйЭЮеЄЄйЂШпЉЫ
- йЭЮеЄЄйАВеРИOR жУНдљЬзђ¶зЪДжߕ胥пЉЫ
- еЯЇжХ∞жѓФиЊГе∞СзЪДжЧґеАЩжЙНиГљеїЇдљНеی糥еЉХпЉЫ
жКАеЈІпЉЪ
еѓєдЇОжЬЙиЊГдљОеЯЇжХ∞зЪДеИЧйЬАи¶БдљњзФ®дљНеی糥еЉХгАВжАІеИЂеИЧе∞±жШѓињЩж†ЈдЄАдЄ™дЊЛе≠РпЉМеЃГжЬЙдЄ§дЄ™еПѓиГљеАЉпЉЪзФЈжИЦе•≥(
еЯЇжХ∞дїЕдЄЇ
2)
гАВ
дљНеЫЊеѓєдЇОдљОеЯЇжХ∞(
е∞СйЗПзЪДдЄНеРМеАЉ
)
еИЧжЭ•иѓійЭЮеЄЄењЂ
пЉМињЩжШѓеۆ䪯糥еЉХзЪДе∞ЇеѓЄзЫЄеѓєдЇОB
ж†С糥еЉХжЭ•иѓіе∞ПдЇЖеЊИе§ЪгАВеЫ†дЄЇињЩдЇЫ糥еЉХжШѓдљОеЯЇжХ∞зЪД
B
ж†С糥еЉХпЉМжЙАдї•йЭЮеЄЄе∞ПпЉМеЫ†ж≠§жВ®еПѓдї•зїПеЄЄж£А糥谮дЄ≠иґЕињЗеНКжХ∞зЪДи°МпЉМеєґдЄФдїНдљњзФ®дљНеی糥еЉХгАВ
ељУе§Іе§ЪжХ∞жЭ°зЫЃдЄНдЉЪеРСдљНеЫЊжЈїеК†жЦ∞зЪДеАЉжЧґпЉМдљНеی糥еЉХеЬ®жЙєе§ДзРЖ(
еНХзФ®жИЈ
)
жУНдљЬдЄ≠еК†иљљи°®
(
жПТеЕ•жУНдљЬ
)
жЦєйЭҐйАЪеЄЄи¶БжѓФ
B
ж†СеБЪеЊЧе•љгАВељУе§ЪдЄ™дЉЪиѓЭеРМжЧґеРСи°®дЄ≠жПТеЕ•и°МжЧґдЄНеЇФиѓ•дљњзФ®дљНеی糥еЉХпЉМеЬ®е§Іе§ЪжХ∞дЇЛеК°е§ДзРЖеЇФзФ®з®ЛеЇПдЄ≠йГљдЉЪеПСзФЯињЩзІНжГЕеЖµгАВ
з§ЇдЊЛ
дЄЛйЭҐжЭ•зЬЛдЄАдЄ™з§ЇдЊЛи°®PARTICIPANT
пЉМиѓ•и°®еМЕеРЂдЇЖжЭ•иЗ™дЄ™дЇЇзЪДи∞ГжЯ•жХ∞жНЃгАВеИЧ
Age_Code
гАБ
Income_Level
гАБ
Education_Level
еТМ
Marital_Status
йГљеМЕжЛђдЇЖеРДиЗ™зЪДдљНеی糥еЉХгАВ
дЄЛеЫЊ
жШЊз§ЇдЇЖжѓПдЄ™зЫіжЦєеЫЊдЄ≠зЪДжХ∞жНЃеє≥и°°жГЕеЖµпЉМдї•еПКеѓєиЃњйЧЃжѓПдЄ™дљНеی糥еЉХзЪДжߕ胥зЪДжЙІи°МиЈѓеЊДгАВеЫЊдЄ≠зЪДжЙІи°МиЈѓеЊДжШЊз§ЇдЇЖжЬЙе§Ъе∞СдЄ™дљНеی糥еЉХ襀еРИеєґпЉМеПѓдї•зЬЛеЗЇжАІиГљеЊЧеИ∞дЇЖжШЊиСЧзЪДжПРйЂШгАВ
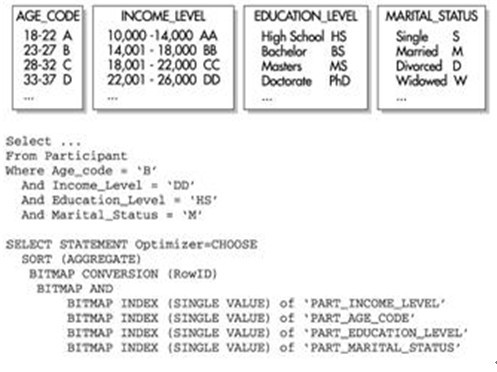
е¶В
дЄКеЫЊ
еЫЊжЙАз§ЇпЉМдЉШеМЦеЩ®дЊЭжђ°дљњзФ®4
дЄ™еНХзЛђзЪДдљНеی糥еЉХпЉМињЩдЇЫ糥еЉХзЪДеИЧеЬ®
WHERE
е≠РеП•дЄ≠襀еЉХзФ®гАВжѓПдЄ™дљНеЫЊиЃ∞ељХжМЗйТИ
(
дЊЛе¶В
0
жИЦ
1)
пЉМзФ®дЇОжМЗз§Їи°®дЄ≠зЪДеУ™дЇЫи°МеМЕеРЂдљНеЫЊдЄ≠зЪДеЈ≤зЯ•еАЉгАВжЬЙдЇЖињЩдЇЫдњ°жБѓеРОпЉМ
Oracle
е∞±жЙІи°М
BITMAP AND
жУНдљЬдї•жЯ•жЙЊе∞ЖдїОжЙАжЬЙ
4
дЄ™дљНеЫЊдЄ≠ињФеЫЮеУ™дЇЫи°МгАВиѓ•еАЉзДґеРО襀蚐жНҐдЄЇ
ROWID
еАЉпЉМеєґдЄФжߕ胥翲зї≠еЃМжИРеЙ©дљЩзЪДе§ДзРЖеЈ•дљЬгАВ
ж≥®жДПпЉМжЙАжЬЙ4
дЄ™еИЧйГљжЬЙйЭЮеЄЄдљОзЪДеЯЇжХ∞пЉМдљњзԮ糥еЉХеПѓдї•йЭЮеЄЄењЂйАЯеЬ∞ињФеЫЮеМєйЕНзЪДи°МгАВ
жКАеЈІпЉЪ
еЬ®дЄАдЄ™жߕ胥дЄ≠еРИеєґе§ЪдЄ™дљНеی糥еЉХеРОпЉМеПѓдї•дљњжАІиГљжШЊиСЧжПРйЂШгАВдљНеی糥еЉХдљњзФ®еЫЇеЃЪйХњеЇ¶зЪДжХ∞жНЃз±їеЮЛи¶БжѓФеПѓеПШйХњеЇ¶зЪДжХ∞жНЃз±їеЮЛе•љгАВиЊГе§Іе∞ЇеѓЄзЪДеЭЧдєЯдЉЪжПРйЂШеѓєдљНеی糥еЉХзЪДе≠ШеВ®еТМиѓїеПЦжАІиГљгАВ
дЄЛйЭҐзЪДжߕ胥еПѓж،积糥еЉХз±їеЮЛгАВ
SQL> select index_name, index_type from user_indexes;
INDEX_NAME         INDEX_TYPE
------------------------------ ----------------------
TT_INDEX            NORMAL
IX_CUSTADDR_TP    NORMAL
Bж†С糥еЉХ
дљЬдЄЇNORMAL
еИЧеЗЇпЉЫиАМ
дљНеی糥еЉХ
зЪДз±їеЮЛеАЉдЄЇ
BITMAP
гАВ
жКАеЈІпЉЪ
е¶ВжЮЬи¶Бжߕ胥дљНеی糥еЉХеИЧи°®пЉМеПѓдї•еЬ®USER¬†_INDEXES
иІЖеЫЊдЄ≠жߕ胥
index_type
еИЧгАВ
еїЇиЃЃдЄНи¶БеЬ®дЄАдЇЫиБФжЬЇдЇЛеК°е§ДзРЖ(OLTP)
еЇФзФ®з®ЛеЇПдЄ≠дљњзФ®дљНеی糥еЉХ
гАВB
ж†С糥еЉХзЪД糥еЉХеАЉдЄ≠еМЕеРЂ
ROWID
пЉМињЩж†Ј
Oracle
е∞±еПѓдї•еЬ®и°МзЇІеИЂдЄКйФБеЃЪ糥еЉХгАВдљНеی糥еЉХе≠ШеВ®дЄЇеОЛзЉ©зЪД糥еЉХеАЉпЉМеЕґдЄ≠еМЕеРЂдЇЖдЄАеЃЪиМГеЫізЪД
ROWID
пЉМеЫ†ж≠§
Oracle
ењЕй°їйТИеѓєдЄАдЄ™зїЩеЃЪеАЉйФБеЃЪжЙАжЬЙиМГеЫіеЖЕзЪД
ROWID
гАВињЩзІНйФБеЃЪз±їеЮЛеПѓиГљеЬ®жЯРдЇЫ
DML
иѓ≠еП•дЄ≠йА†жИРж≠їйФБгАВ
SELECT
иѓ≠еП•дЄНдЉЪеПЧеИ∞ињЩзІНйФБеЃЪйЧЃйҐШзЪДељ±еУНгАВ
дљНеی糥еЉХ
зЪДдљњзФ®
йЩРеИґ
пЉЪ
- еЯЇдЇОиІДеИЩзЪДдЉШеМЦеЩ®дЄНдЉЪиАГиЩСдљНеی糥еЉХгАВ
- ељУжЙІи°МALTER¬†TABLE иѓ≠еП•еєґдњЃжФєеМЕеРЂжЬЙдљНеی糥еЉХзЪДеИЧжЧґпЉМдЉЪдљњдљНеی糥еЉХ姱жХИгАВ
- дљНеی糥еЉХдЄНеМЕеРЂдїїдљХеИЧжХ∞жНЃпЉМеєґдЄФдЄНиГљзФ®дЇОдїїдљХз±їеЮЛзЪДеЃМжХіжАІж£АжЯ•гАВ
- дљНеی糥еЉХдЄНиÚ襀е£∞жШОдЄЇеФѓдЄА糥еЉХгАВ
- дљНеی糥еЉХзЪДжЬАе§ІйХњеЇ¶дЄЇ30 гАВ
жКАеЈІпЉЪ
дЄНи¶БеЬ®зєБйЗНзЪДOLTP
зОѓеҐГдЄ≠дљњзФ®дљНеی糥еЉХ
2.3¬†¬†HASH糥еЉХ
дљњзФ®HASH
糥еЉХењЕй°їи¶БдљњзФ®
HASH
йЫЖзЊ§
гАВеїЇзЂЛдЄАдЄ™йЫЖзЊ§жИЦHASH
йЫЖзЊ§зЪДеРМжЧґпЉМдєЯе∞±еЃЪдєЙдЇЖдЄАдЄ™йЫЖзЊ§йФЃгАВињЩдЄ™йФЃеСКиѓЙ
Oracle
е¶ВдљХеЬ®йЫЖзЊ§дЄКе≠ШеВ®и°®гАВеЬ®е≠ШеВ®жХ∞жНЃжЧґпЉМжЙАжЬЙдЄОињЩдЄ™йЫЖзЊ§йФЃзЫЄеЕ≥зЪДи°МйÚ襀е≠ШеВ®еЬ®дЄАдЄ™жХ∞жНЃеЇУеЭЧдЄКгАВе¶ВжЮЬжХ∞жНЃйГље≠ШеВ®еЬ®еРМдЄАдЄ™жХ∞жНЃеЇУеЭЧдЄКпЉМеєґдЄФе∞Ж
HASH
糥еЉХдљЬдЄЇ
WHERE
е≠РеП•дЄ≠зЪДз°ЃеИЗеМєйЕНпЉМ
Oracle
е∞±еПѓдї•йАЪињЗжЙІи°МдЄАдЄ™
HASH
еЗљжХ∞еТМ
I/O
жЭ•иЃњйЧЃжХ∞жНЃ
вАФвАФ
иАМйАЪињЗдљњзФ®дЄАдЄ™дЇМеЕГйЂШеЇ¶дЄЇ
4
зЪД
B
ж†С糥еЉХжЭ•иЃњйЧЃжХ∞жНЃпЉМеИЩйЬАи¶БеЬ®ж£А糥жХ∞жНЃжЧґдљњзФ®
4
дЄ™
I/O
гАВе¶В
дЄЛеЫЊ
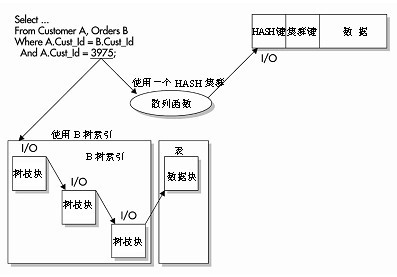
жЙАз§ЇпЉМеЕґдЄ≠зЪДжߕ胥жШѓдЄАдЄ™з≠ЙдїЈжߕ胥пЉМзФ®дЇОеМєйЕНHASH
еИЧеТМз°ЃеИЗзЪДеАЉгАВ
Oracle
еПѓдї•ењЂйАЯдљњзФ®иѓ•еАЉпЉМеЯЇдЇО
HASH
еЗљжХ∞з°ЃеЃЪи°МзЪДзЙ©зРЖе≠ШеВ®дљНзљЃгАВ
HASH糥еЉХеПѓиГљжШѓиЃњйЧЃжХ∞жНЃеЇУдЄ≠жХ∞жНЃзЪДжЬАењЂжЦєж≥ХпЉМдљЖеЃГдєЯжЬЙиЗ™иЇЂзЪДзЉЇзВє
гАВйЫЖзЊ§йФЃдЄКдЄНеРМеАЉзЪДжХ∞зЫЃењЕй°їеЬ®еИЫеїЇHASH
йЫЖзЊ§дєЛеЙНе∞±и¶БзЯ•йБУгАВйЬАи¶БеЬ®еИЫеїЇ
HASH
йЫЖзЊ§зЪДжЧґеАЩжМЗеЃЪињЩдЄ™еАЉгАВдљОдЉ∞дЇЖйЫЖзЊ§йФЃзЪДдЄНеРМеАЉзЪДжХ∞е≠ЧеПѓиГљдЉЪйА†жИРйЫЖзЊ§зЪДеЖ≤з™Б
(
дЄ§дЄ™йЫЖзЊ§зЪДйФЃеАЉжЛ•жЬЙзЫЄеРМзЪД
HASH
еАЉ
)
гАВињЩзІНеЖ≤з™БжШѓйЭЮеЄЄжґИиАЧиµДжЇРзЪДгАВеЖ≤з™БдЉЪйА†жИРзФ®жЭ•е≠ШеВ®йҐЭе§Ци°МзЪДзЉУеЖ≤жЇҐеЗЇпЉМзДґеРОйА†жИРйҐЭе§ЦзЪД
I/O
гАВе¶ВжЮЬдЄНеРМ
HASH
еАЉзЪДжХ∞зЫЃеЈ≤зїП襀дљОдЉ∞пЉМжВ®е∞±ењЕй°їеЬ®йЗНеїЇињЩдЄ™йЫЖзЊ§дєЛеРОжФєеПШињЩдЄ™еАЉгАВ
ALTER¬†CLUSTERеСљдї§дЄНиГљжФєеПШ
HASH
йФЃзЪДжХ∞зЫЃгАВ
HASH
йЫЖзЊ§ињШеПѓиГљжµ™иієз©ЇйЧі
гАВе¶ВжЮЬжЧ†ж≥Хз°ЃеЃЪйЬАи¶Бе§Ъе∞Сз©ЇйЧіжЭ•зїіжК§жЯРдЄ™йЫЖзЊ§йФЃдЄКзЪДжЙАжЬЙи°МпЉМе∞±еПѓиГљйА†жИРз©ЇйЧізЪДжµ™иієгАВе¶ВжЮЬ
дЄНиГљдЄЇйЫЖзЊ§зЪДжЬ™жЭ•еҐЮйХњеИЖйЕНе•љйЩДеК†зЪДз©ЇйЧі
пЉМHASH
йЫЖзЊ§еПѓиГље∞±
дЄНжШѓжЬАе•љзЪДйАЙжЛ©
гАВ
е¶ВжЮЬеЇФзФ®з®ЛеЇПзїПеЄЄеЬ®йЫЖзЊ§и°®дЄКињЫи°МеЕ®и°®жЙЂжПП
пЉМHASH
йЫЖзЊ§еПѓиГљдєЯ
дЄНжШѓжЬАе•љзЪДйАЙжЛ©
гАВзФ±дЇОйЬАи¶БдЄЇжЬ™жЭ•зЪДеҐЮйХњеИЖйЕНе•љйЫЖзЊ§зЪДеЙ©дљЩз©ЇйЧійЗПпЉМеЕ®и°®жЙЂжППеПѓиГљйЭЮеЄЄжґИиАЧиµДжЇРгАВ
еЬ®еЃЮзО∞HASH
йЫЖзЊ§дєЛеЙНдЄАеЃЪи¶Бе∞ПењГгАВжВ®йЬАи¶БеЕ®йЭҐеЬ∞иІВеѓЯеЇФзФ®з®ЛеЇПпЉМдњЭиѓБеЬ®еЃЮзО∞ињЩдЄ™йАЙй°єдєЛеЙНеЈ≤зїПдЇЖиІ£еЕ≥дЇОи°®еТМжХ∞жНЃзЪДе§ІйЗПдњ°жБѓгАВ
йАЪеЄЄпЉМHASH
еѓєдЇОдЄАдЇЫеМЕеРЂжЬЙеЇПеАЉзЪДйЭЩжАБжХ∞жНЃйЭЮеЄЄжЬЙжХИгАВ
жКАеЈІпЉЪ
HASH糥еЉХеЬ®жЬЙйЩРеИґжЭ°дїґ
(
йЬАи¶БжМЗеЃЪдЄАдЄ™з°ЃеЃЪзЪДеАЉиАМдЄНжШѓдЄАдЄ™еАЉиМГеЫі
)
зЪДжГЕеЖµдЄЛйЭЮеЄЄжЬЙзФ®гАВ
2.4¬†¬†зіҐеЉХзїДзїЗи°®
糥еЉХзїДзїЗи°®дЉЪжККи°®зЪДе≠ШеВ®зїУжЮДжФєжИРB
ж†СзїУжЮДпЉМдї•и°®зЪДдЄїйФЃињЫи°МжОТеЇПгАВињЩзІНзЙєжЃКзЪДи°®еТМеЕґдїЦз±їеЮЛзЪДи°®дЄАж†ЈпЉМеПѓдї•еЬ®и°®дЄКжЙІи°МжЙАжЬЙзЪД
DML
еТМ
DDL
иѓ≠еП•гАВ
зФ±дЇОи°®зЪДзЙєжЃКзїУжЮДпЉМROWID
еєґж≤°жЬЙ襀еЕ≥иБФеИ∞и°®зЪДи°МдЄКгАВ
еѓєдЇОдЄАдЇЫжґЙеПКз≤Њз°ЃеМєйЕНеТМиМГеЫіжРЬ糥зЪДиѓ≠еП•пЉМ糥еЉХзїДзїЗи°®жПРдЊЫдЇЖдЄАзІНеЯЇдЇОйФЃзЪДењЂйАЯжХ∞жНЃиЃњйЧЃжЬЇеИґгАВ
еЯЇдЇОдЄїйФЃеАЉзЪДUPDATE
еТМ
DELETE
иѓ≠еП•зЪДжАІиГљдєЯеРМж†ЈеЊЧдї•жПРйЂШпЉМ
ињЩжШѓеЫ†дЄЇи°МеЬ®зЙ©зРЖдЄКжЬЙеЇПгАВзФ±дЇОйФЃеИЧзЪДеАЉеЬ®и°®еТМ糥еЉХдЄ≠йГљж≤°жЬЙйЗНе§НпЉМ
е≠ШеВ®жЙАйЬАи¶БзЪДз©ЇйЧідєЯйЪПдєЛеЗПе∞СгАВ
е¶ВжЮЬдЄНдЉЪйҐСзєБеЬ∞ж†єжНЃдЄїйФЃеИЧжߕ胥жХ∞жНЃпЉМеИЩйЬАи¶Беܮ糥еЉХзїДзїЗи°®дЄ≠зЪДеЕґдїЦеИЧдЄКеИЫеїЇдЇМ篲糥еЉХгАВдЄНдЉЪйҐСзєБж†єжНЃдЄїйФЃжߕ胥谮зЪДеЇФзФ®з®ЛеЇПдЄНдЉЪдЇЖиІ£еИ∞дљњзԮ糥еЉХзїДзїЗи°®зЪДеЕ®йГ®дЉШзВєгАВ
еѓєдЇОжАїжШѓйАЪињЗеѓєдЄїйФЃзЪДз≤Њз°ЃеМєйЕНжИЦиМГеЫіжЙЂжППињЫи°МиЃњйЧЃзЪДи°®пЉМе∞±йЬАи¶БиАГиЩСдљњзԮ糥еЉХзїДзїЗи°®гАВ
жКАеЈІпЉЪ
еПѓдї•еܮ糥еЉХзїДзїЗи°®дЄКеїЇзЂЛдЇМ篲糥еЉХгАВ
2.5¬†¬†еПНиљђйԁ糥еЉХ
ељУиљљеЕ•дЄАдЇЫжЬЙеЇПжХ∞жНЃжЧґпЉМ糥еЉХиВѓеЃЪдЉЪзҐ∞еИ∞дЄОI/O
зЫЄеЕ≥зЪДдЄАдЇЫзУґйҐИгАВеЬ®жХ∞жНЃиљљеЕ•жЬЯйЧіпЉМжЯРйГ®еИЖ糥еЉХеТМз£БзЫШиВѓеЃЪдЉЪжѓФеЕґдїЦйГ®еИЖдљњзФ®йҐСзєБеЊЧе§ЪгАВдЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМеПѓдї•жКК糥еЉХи°®з©ЇйЧіе≠ШжФЊеЬ®иГље§ЯжКК
жЦЗдїґзЙ©зРЖеИЖеЙ≤еЬ®е§ЪдЄ™з£БзЫШдЄКзЪДз£БзЫШдљУз≥їзїУжЮДдЄК
гАВ
дЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМOracle
ињШжПРдЊЫдЇЖдЄАзІНеПНиљђйԁ糥еЉХзЪДжЦєж≥ХгАВе¶ВжЮЬжХ∞жНЃдї•еПНиљђйԁ糥еЉХе≠ШеВ®пЉМињЩдЇЫжХ∞жНЃзЪДеАЉе∞±дЉЪдЄОеОЯеЕИе≠ШеВ®зЪДжХ∞еАЉзЫЄеПНгАВињЩж†ЈпЉМжХ∞жНЃ
1234
гАБ
1235
еТМ
1236
е∞±иҐЂе≠ШеВ®жИР
4321
гАБ
5321
еТМ
6321
гАВ
зїУжЮЬе∞±ж؃糥еЉХдЉЪдЄЇжѓПжђ°жЦ∞жПТеЕ•зЪДи°МжЫіжЦ∞дЄНеРМзЪД糥еЉХеЭЧгАВ
жКАеЈІпЉЪ
е¶ВжЮЬжВ®зЪДз£БзЫШеЃєйЗПжЬЙйЩРпЉМеРМжЧґињШи¶БжЙІи°Ме§ІйЗПзЪДжЬЙеЇПиљљеЕ•пЉМе∞±еПѓдї•дљњзФ®еПНиљђйԁ糥еЉХгАВ
дЄНеПѓдї•е∞ЖеПНиљђйԁ糥еЉХдЄОдљНеی糥еЉХжИЦ糥еЉХзїДзїЗи°®зїУеРИдљњзФ®гАВ
еЫ†дЄЇ
дЄНиГљеѓєдљНеی糥еЉХеТМ糥еЉХзїДзїЗи°®ињЫи°МеПНиљђйФЃе§ДзРЖгАВ
2.6¬†¬†еЯЇдЇОеЗљжХ∞зЪД糥еЉХ
еПѓдї•еЬ®и°®дЄ≠еИЫеїЇеЯЇдЇОеЗљжХ∞зЪД糥еЉХгАВе¶ВжЮЬж≤°жЬЙеЯЇдЇОеЗљжХ∞зЪД糥еЉХпЉМдїїдљХеЬ®еИЧдЄКжЙІи°МдЇЖеЗљжХ∞зЪДжߕ胥йГљдЄНиГљдљњзФ®ињЩдЄ™еИЧзЪД糥еЉХгАВдЊЛе¶ВпЉМдЄЛйЭҐзЪДжߕ胥е∞±дЄНиГљдљњзФ®JOB
еИЧдЄКзЪД糥еЉХпЉМйЩ§йЭЮеЃГжШѓеЯЇдЇОеЗљжХ∞зЪД糥еЉХпЉЪ
select *
 
from emp
 
where UPPER(job) = 'MGR';
дЄЛйЭҐзЪДжߕ胥䚜зФ®JOB
еИЧдЄКзЪД糥еЉХпЉМдљЖжШѓеЃГе∞ЖдЄНдЉЪињФеЫЮ
JOB
еИЧеЕЈжЬЙ
Mgr
жИЦ
mgr
еАЉзЪДи°МпЉЪ
select *
 
from emp
 
where job = 'MGR';
еПѓдї•еИЫеїЇињЩж†ЈзЪД糥еЉХпЉМеЕБ聪糥еЉХиЃњйЧЃжФѓжМБеЯЇдЇОеЗљжХ∞зЪДеИЧжИЦжХ∞жНЃгАВеПѓдї•еѓєеИЧи°®иЊЊеЉПUPPER(job)
еИЫ忯糥еЉХпЉМиАМдЄНжШѓзЫіжО•еЬ®
JOB
еИЧдЄКеїЇзЂЛ糥еЉХ
пЉМе¶В
пЉЪ
create index EMP$UPPER_JOB on
 
emp(UPPER(job));
е∞љзЃ°еЯЇдЇОеЗљжХ∞зЪД糥еЉХйЭЮеЄЄжЬЙзФ®пЉМдљЖеЬ®еїЇзЂЛеЃГдїђдєЛеЙНењЕй°їеЕИиАГиЩСдЄЛйЭҐдЄАдЇЫйЧЃйҐШпЉЪ
иГљйЩРеИґеЬ®ињЩдЄ™еИЧдЄКдљњзФ®зЪДеЗљжХ∞еРЧпЉЯе¶ВжЮЬиГљпЉМиГљйЩРеИґжЙАжЬЙеЬ®ињЩдЄ™еИЧдЄКжЙІи°МзЪДжЙАжЬЙеЗљжХ∞еРЧ
жШѓеР¶жЬЙиґ≥е§ЯеЇФдїШйҐЭе§Ц糥еЉХзЪДе≠ШеВ®з©ЇйЧіпЉЯ
еЬ®жѓПеИЧдЄКеҐЮеК†зЪД糥еЉХжХ∞йЗПдЉЪеѓєйТИеѓєиѓ•и°®жЙІи°МзЪДDML
иѓ≠еП•зЪДжАІиГљеЄ¶жЭ•дљХзІНељ±еУНпЉЯ
еЯЇдЇОеЗљжХ∞зЪД糥еЉХйЭЮеЄЄжЬЙзФ®пЉМдљЖеЬ®еЃЮзО∞жЧґењЕй°їе∞ПењГгАВеЬ®и°®дЄКеИЫеїЇзЪД糥еЉХиґКе§ЪпЉМINSERT
гАБ
UPDATE
еТМ
DELETE
иѓ≠еП•зЪДжЙІи°Ме∞±дЉЪиК±иієиґКе§ЪзЪДжЧґйЧігАВ
ж≥®жДПпЉЪ
еѓєдЇОдЉШеМЦеЩ®жЙАдљњзФ®зЪДеЯЇдЇОеЗљжХ∞зЪД糥еЉХжЭ•иѓіпЉМ
ењЕй°їжККеИЭеІЛеПВжХ∞QUERY¬†_REWRITE¬†_¬†ENABLED
иЃЊеЃЪдЄЇ
TRUE
гАВ
з§ЇдЊЛпЉЪ
select 
 
count(*)
 
from 
 
sample
 
where ratio(balance,limit) >.5;
Elapsed time: 20.1 minutes
create index ratio_idx1 on
 
sample (ratio(balance, limit));
select  count(*)
 
from  sample
 
where ratio(balance,limit) >.5;
Elapsed time: 7 seconds!!!
2.7¬†¬†еИЖе̯糥еЉХ
еИЖе̯糥еЉХе∞±жШѓзЃАеНХеЬ∞жККдЄА䪙糥еЉХеИЖжИРе§ЪдЄ™зЙЗжЦ≠гАВйАЪињЗжККдЄА䪙糥еЉХеИЖжИРе§ЪдЄ™зЙЗжЦ≠пЉМеПѓдї•иЃњйЧЃжЫіе∞ПзЪДзЙЗжЦ≠(
дєЯжЫіењЂ
)
пЉМеєґдЄФеПѓдї•жККињЩдЇЫзЙЗжЦ≠еИЖеИЂе≠ШжФЊеЬ®дЄНеРМзЪДз£БзЫШй©±еК®еЩ®дЄК
(
йБњеЕН
I/O
йЧЃйҐШ
)
гАВ
Bж†СеТМдљНеی糥еЉХйГљеσ俕襀еИЖеМЇпЉМиАМ
HASH
糥еЉХдЄНеσ俕襀еИЖеМЇ
гАВеПѓдї•жЬЙе•љеЗ†зІНеИЖеМЇжЦєж≥ХпЉЪ
谮襀еИЖеМЇиАМ糥еЉХжܙ襀еИЖеМЇ
пЉЫ
и°®жܙ襀еИЖеМЇиАМ糥еЉХ襀еИЖеМЇ
пЉЫ
и°®еТМ糥еЉХйÚ襀еИЖеМЇ
гАВдЄНзЃ°йЗЗзФ®еУ™зІНжЦєж≥ХпЉМ
йГљењЕй°їдљњзФ®еЯЇдЇОжИРжЬђзЪДдЉШеМЦеЩ®
гАВеИЖеМЇиГље§ЯжПРдЊЫжЫіе§ЪеПѓдї•жПРйЂШжАІиГљеТМеПѓзїіжК§жАІзЪДеПѓиГљжАІ
жЬЙдЄ§зІНз±їеЮЛзЪДеИЖе̯糥еЉХпЉЪ
жЬђеЬ∞еИЖе̯糥еЉХ
еТМ
еЕ®е±АеИЖе̯糥еЉХ
гАВжѓПдЄ™з±їеЮЛйГљжЬЙдЄ§дЄ™е≠Рз±їеЮЛпЉМжЬЙеЙНзЉА糥еЉХеТМжЧ†еЙНзЉА糥еЉХгАВи°®еРДеИЧдЄКзЪД糥еЉХеПѓдї•жЬЙеРДзІНз±їеЮЛ糥еЉХзЪДзїДеРИгАВ
е¶ВжЮЬдљњзФ®дЇЖдљНеی糥еЉХпЉМе∞±ењЕй°їжШѓжЬђеЬ∞糥еЉХ
гАВжКК糥еЉХеИЖеМЇжЬАдЄїи¶БзЪДеОЯеЫ†жШѓеПѓдї•еЗПе∞СжЙАйЬАиѓїеПЦзЪД糥еЉХзЪДе§Іе∞ПпЉМеП¶е§ЦжККеИЖеМЇжФЊеЬ®дЄНеРМзЪДи°®з©ЇйЧідЄ≠еПѓдї•жПРйЂШеИЖеМЇзЪДеПѓзФ®жАІеТМеПѓйЭ†жАІгАВ
еЬ®дљњзФ®еИЖеМЇеРОзЪДи°®еТМ糥еЉХжЧґпЉМOracle
ињШжФѓжМБеєґи°Мжߕ胥еТМеєґи°М
DML
гАВињЩж†Је∞±еПѓдї•еРМжЧґжЙІи°Ме§ЪдЄ™ињЫз®ЛпЉМдїОиАМеК†ењЂе§ДзРЖињЩжЭ°иѓ≠еП•гАВ
2.7.
1.жЬђеЬ∞еИЖе̯糥еЉХ
(
йАЪеЄЄдљњзФ®зЪД糥еЉХ
)
еПѓдї•дљњзФ®дЄОи°®зЫЄеРМзЪДеИЖеМЇйФЃеТМиМГеЫізХМйЩРжЭ•еѓєжЬђеЬ∞糥еЉХеИЖеМЇгАВжѓПдЄ™жЬђеЬ∞糥еЉХзЪДеИЖеМЇеП™еМЕеРЂдЇЖеЃГжЙАеЕ≥иБФзЪДи°®еИЖеМЇзЪДйФЃеТМROWID
гАВжЬђеЬ∞糥еЉХеПѓдї•жШѓ
B
ж†СжИЦдљНеی糥еЉХгАВе¶ВжЮЬжШѓ
B
ж†С糥еЉХпЉМеЃГеПѓдї•жШѓеФѓдЄАжИЦдЄНеФѓдЄАзЪД糥еЉХгАВ
ињЩзІНз±їеЮЛзЪД糥еЉХжФѓжМБеИЖеМЇзЛђзЂЛжАІпЉМињЩе∞±жДПеС≥зЭАеѓєдЇОеНХзЛђзЪДеИЖеМЇпЉМеПѓдї•ињЫи°МеҐЮеК†гАБжИ™еПЦгАБеИ†йЩ§гАБеИЖеЙ≤гАБиД±жЬЇз≠Йе§ДзРЖпЉМиАМдЄНзФ®еРМжЧґеИ†йЩ§жИЦйЗН忯糥еЉХгАВ
OracleиЗ™еК®зїіжК§ињЩдЇЫжЬђеЬ∞糥еЉХгАВ
жЬђеЬ∞糥еЉХеИЖеМЇињШеσ俕襀еНХзЛђйЗНеїЇпЉМиАМеЕґдїЦеИЖеМЇдЄНдЉЪеПЧеИ∞ељ±еУНгАВ
2.7.1.1 
жЬЙеЙНзЉАзЪД糥еЉХ
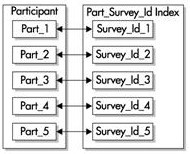
жЬЙеЙНзЉАзЪД糥еЉХеМЕеРЂдЇЖжЭ•иЗ™еИЖеМЇйФЃзЪДйФЃпЉМеєґжККеЃГдїђдљЬ䪯糥еЉХзЪДеЙНеѓЉгАВдЊЛе¶ВпЉМиЃ©жИСдїђеЖНжђ°еЫЮй°Њparticipant
и°®гАВеЬ®еИЫеїЇиѓ•и°®еРОпЉМдљњзФ®
survey_id
еТМ
survey_date
ињЩдЄ§дЄ™еИЧињЫи°МиМГеЫіеИЖеМЇпЉМзДґеРОеЬ®
survey_id
еИЧдЄКеїЇзЂЛдЄАдЄ™жЬЙеЙНзЉАзЪДжЬђеЬ∞糥еЉХпЉМе¶В
дЄЛеЫЊ
жЙАз§ЇгАВињЩ䪙糥еЉХзЪДжЙАжЬЙеИЖеМЇйÚ襀з≠ЙдїЈеИТеИЖпЉМе∞±ж؃胳糥еЉХзЪДеИЖеМЇйГљдљњзФ®и°®зЪДзЫЄеРМиМГеЫізХМйЩРжЭ•еИЫеїЇгАВ
жКАеЈІпЉЪ
жЬђеЬ∞зЪДжЬЙеЙНзЉА糥еЉХеПѓдї•иЃ©Oracle
ењЂйАЯеЙФйЩ§дЄАдЇЫдЄНењЕи¶БзЪДеИЖеМЇгАВдєЯе∞±жШѓиѓіж≤°жЬЙеМЕеРЂ
WHERE
жЭ°дїґе≠РеП•дЄ≠дїїдљХеАЉзЪДеИЖеМЇе∞ЖдЄНдЉЪ襀聜йЧЃпЉМињЩж†ЈдєЯжПРйЂШдЇЖиѓ≠еП•зЪДжАІиГљгАВ
2.7.1.2 
жЧ†еЙНзЉАзЪД糥еЉХ
жЧ†еЙНзЉАзЪД糥еЉХеєґж≤°жЬЙжККеИЖеМЇйФЃзЪДеЙНеѓЉеИЧдљЬ䪯糥еЉХзЪДеЙНеѓЉеИЧгАВиЛ•дљњзФ®жЬЙеРМж†ЈеИЖеМЇйФЃ(survey_id
еТМ
survey_date)
зЪДзЫЄеРМеИЖеМЇи°®пЉМеїЇзЂЛеЬ®
survey_date
еИЧдЄКзЪД糥еЉХе∞±жШѓдЄАдЄ™жЬђеЬ∞зЪДжЧ†еЙНзЉА糥еЉХпЉМе¶В
дЄЛеЫЊ
жЙАз§ЇгАВеПѓдї•еЬ®и°®зЪДдїїдЄАеИЧдЄКеИЫеїЇжЬђеЬ∞жЧ†еЙНзЉА糥еЉХпЉМдљЖ糥еЉХзЪДжѓПдЄ™еИЖеМЇеП™еМЕеРЂи°®зЪДзЫЄеЇФеИЖеМЇзЪДйФЃеАЉгАВ
    
                     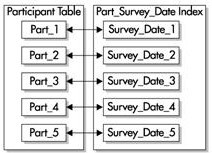
 
е¶ВжЮЬи¶БжККжЧ†еЙНзЉАзЪД糥еЉХиЃЊдЄЇеФѓдЄА糥еЉХпЉМињЩ䪙糥еЉХе∞±ењЕй°їеМЕеРЂеИЖеМЇйФЃзЪДе≠РйЫЖгАВеЬ®ињЩдЄ™дЊЛе≠РдЄ≠пЉМжИСдїђењЕй°їжККеМЕеРЂsurvey
еТМ
(
жИЦ
)survey_id
зЪДеИЧињЫи°МзїДеРИ
(
еП™и¶Б
survey_id
дЄНж؃糥еЉХзЪДзђђдЄАеИЧпЉМеЃГе∞±жШѓдЄАдЄ™жЬЙеЙНзЉАзЪД糥еЉХ
)
гАВ
жКАеЈІпЉЪ
еѓєдЇОдЄАдЄ™еФѓдЄАзЪДжЧ†еЙНзЉА糥еЉХпЉМеЃГењЕй°їеМЕеРЂеИЖеМЇйФЃзЪДе≠РйЫЖгАВ
2.7.
2.
 
еЕ®е±АеИЖе̯糥еЉХ
еЕ®е±АеИЖе̯糥еЉХеЬ®дЄА䪙糥еЉХеИЖеМЇдЄ≠еМЕеРЂжЭ•иЗ™е§ЪдЄ™и°®еИЖеМЇзЪДйФЃгАВдЄАдЄ™еЕ®е±АеИЖе̯糥еЉХзЪДеИЖеМЇйФЃжШѓеИЖеМЇи°®дЄ≠дЄНеРМзЪДжИЦжМЗеЃЪдЄАдЄ™иМГеЫізЪДеАЉгАВеЬ®еИЫеїЇеЕ®е±АеИЖе̯糥еЉХжЧґпЉМењЕй°їеЃЪдєЙеИЖеМЇйФЃзЪДиМГеЫіеТМеАЉгАВ
еЕ®е±А糥еЉХеП™иГљжШѓB
ж†С糥еЉХ
гАВ
OracleеЬ®йїШиЃ§жГЕеЖµдЄЛдЄНдЉЪзїіжК§еЕ®е±АеИЖе̯糥еЉХгАВе¶ВжЮЬдЄАдЄ™еИЖе̯襀жИ™еПЦгАБеҐЮеК†гАБеИЖеЙ≤гАБеИ†йЩ§з≠ЙпЉМе∞±ењЕй°їйЗНеїЇеЕ®е±АеИЖе̯糥еЉХ
пЉМйЩ§йЭЮеЬ®дњЃжФєи°®жЧґжМЗеЃЪALTER¬†TABLE
еСљдї§зЪД
UPDATE GLOBAL INDEXES
е≠РеП•гАВ
2.7.2.1 
жЬЙеЙНзЉАзЪД糥еЉХ
йАЪеЄЄпЉМеЕ®е±АжЬЙеЙНзЉА糥еЉХеЬ®еЇХе±Ви°®дЄ≠ж≤°жЬЙзїПињЗеѓєз≠ЙеИЖеМЇгАВж≤°жЬЙдїАдєИеЫ†зі†иГљйЩРеȴ糥еЉХзЪДеѓєз≠ЙеИЖеМЇпЉМдљЖOracle
еЬ®зФЯжИРжߕ胥聰еИТжИЦжЙІи°МеИЖеМЇзїіжК§жУНдљЬжЧґпЉМеєґдЄНдЉЪеЕЕеИЖеИ©зФ®еѓєз≠ЙеИЖеМЇгАВе¶ВжЮЬ糥еЉХ襀僺з≠ЙеИЖеМЇпЉМе∞±ењЕй°їжККеЃГеИЫеїЇдЄЇдЄАдЄ™жЬђеЬ∞糥еЉХпЉМињЩж†Ј
Oracle
еПѓдї•зїіжК§ињЩ䪙糥еЉХпЉМеєґдљњзФ®еЃГжЭ•еИ†йЩ§дЄНењЕи¶БзЪДеИЖеМЇпЉМе¶В
дЄЛеЫЊ
жЙАз§ЇгАВеЬ®иѓ•еЫЊзЪД3
䪙糥еЉХеИЖеМЇдЄ≠пЉМжѓПдЄ™еИЖеМЇйГљеМЕеРЂжМЗеРСе§ЪдЄ™и°®еИЖеМЇдЄ≠и°МзЪД糥еЉХжЭ°зЫЃгАВ
         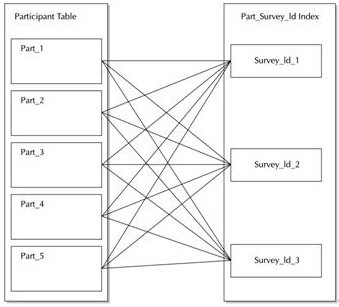
                       
       
¬†¬†еИЖеМЇзЪДгАБеЕ®е±АжЬЙеЙНзЉА糥еЉХ
жКАеЈІ
пЉЪ
е¶ВжЮЬдЄАдЄ™еЕ®е±А糥еЉХе∞Ж襀僺з≠ЙеИЖеМЇпЉМе∞±ењЕй°їжККеЃГеИЫеїЇдЄЇдЄАдЄ™жЬђеЬ∞糥еЉХпЉМињЩж†ЈOracle
еПѓдї•зїіжК§ињЩ䪙糥еЉХпЉМеєґдљњзФ®еЃГжЭ•еИ†йЩ§дЄНењЕи¶БзЪДеИЖеМЇгАВ
2.7.2.2 
жЧ†еЙНзЉАзЪД糥еЉХ
OracleдЄНжФѓжМБжЧ†еЙНзЉАзЪДеЕ®е±А糥еЉХгАВ
2.8¬†¬†дљНеЫЊињЮжΕ糥еЉХ
дљНеЫЊињЮжΕ糥еЉХжШѓеЯЇдЇОдЄ§дЄ™и°®зЪДињЮжО•зЪДдљНеی糥еЉХпЉМеЬ®жХ∞жНЃдїУеЇУзОѓеҐГдЄ≠дљњзФ®ињЩзІН糥еЉХжФєињЫињЮжО•зїіеЇ¶и°®еТМдЇЛеЃЮи°®зЪДжߕ胥зЪДжАІиГљгАВеИЫеїЇдљНеЫЊињЮжΕ糥еЉХжЧґпЉМж†ЗеЗЖжЦєж≥ХжШѓињЮжΕ糥еЉХдЄ≠еЄЄзФ®зЪДзїіеЇ¶и°®еТМдЇЛеЃЮи°®гАВељУзФ®жИЈеЬ®дЄАжђ°жߕ胥дЄ≠зїУеРИжߕ胥дЇЛеЃЮи°®еТМзїіеЇ¶и°®жЧґпЉМе∞±дЄНйЬАи¶БжЙІи°МињЮжО•пЉМеЫ†дЄЇеЬ®дљНеЫЊињЮжΕ糥еЉХдЄ≠еЈ≤зїПжЬЙеПѓзФ®зЪДињЮжО•зїУжЮЬгАВйАЪињЗеОЛзЉ©дљНеЫЊињЮжΕ糥еЉХдЄ≠зЪДROWID
ињЫдЄАж≠•жФєињЫжАІиГљпЉМеєґдЄФеЗПе∞СиЃњйЧЃжХ∞жНЃжЙАйЬАзЪД
I/O
жХ∞йЗПгАВ
еИЫеїЇдљНеЫЊињЮжΕ糥еЉХжЧґпЉМжМЗеЃЪжґЙеПКзЪДдЄ§дЄ™и°®гАВзЫЄеЇФзЪДиѓ≠ж≥ХеЇФиѓ•йБµеЊ™е¶ВдЄЛж®°еЉПпЉЪ
create bitmap index FACT_DIM_COL_IDX
 
on FACT(DIM.Descr_Col)
 
from FACT, DIM
where FACT.JoinCol = DIM.JoinCol;
дљНеЫЊињЮжО•зЪДиѓ≠ж≥ХжѓФиЊГзЙєеИЂпЉМеЕґдЄ≠еМЕеРЂFROM
е≠РеП•еТМ
WHERE
е≠РеП•пЉМеєґдЄФеЉХзФ®дЄ§дЄ™еНХзЛђзЪДи°®гАВ糥еЉХеИЧйАЪеЄЄжШѓзїіеЇ¶и°®дЄ≠зЪДжППињ∞еИЧ
вАФвАФ
е∞±жШѓиѓіпЉМе¶ВжЮЬзїіеЇ¶жШѓ
CUSTOMER
пЉМеєґдЄФеЃГзЪДдЄїйФЃжШѓ
CUSTOMER_ID
пЉМеИЩйАЪ媪糥еЉХ
Customer_Name
ињЩж†ЈзЪДеИЧгАВе¶ВжЮЬдЇЛеЃЮи°®еРНдЄЇ
SALES
пЉМеПѓдї•дљњзФ®е¶ВдЄЛзЪДеСљдї§еИЫ忯糥еЉХпЉЪ
create
 
bitmap
 
index
 
SALES_CUST_NAME_IDX
on  SALES(CUSTOMER.Customer_Name)
  
from SALES, CUSTOMER
where  SALES.Customer_ID=CUSTOMER.Customer_ID;
е¶ВжЮЬзФ®жИЈжО•дЄЛжЭ•дљњзФ®жМЗеЃЪCustomer_Name
еИЧеАЉзЪД
WHERE
е≠РеП•жߕ胥
SALES
еТМ
CUSTOMER
и°®пЉМдЉШеМЦеЩ®е∞±еПѓдї•дљњзФ®дљНеЫЊињЮжΕ糥еЉХењЂйАЯињФеЫЮеМєйЕНињЮжО•жЭ°дїґеТМ
Customer_Name
жЭ°дїґзЪДи°МгАВ
дљНеЫЊињЮжΕ糥еЉХзЪДдљњзФ®дЄАиИђдЉЪеПЧеИ∞йЩРеИґ
пЉЪ
1пЉЙ еП™еσ俕糥еЉХзїіеЇ¶и°®дЄ≠зЪДеИЧгАВ
2пЉЙ зФ®дЇОињЮжО•зЪДеИЧењЕй°їжШѓзїіеЇ¶и°®дЄ≠зЪДдЄїйФЃжИЦеФѓдЄАзЇ¶жЭЯпЉЫе¶ВжЮЬжШѓе§НеРИдЄїйФЃпЉМеИЩењЕй°їдљњзФ®ињЮжО•дЄ≠зЪДжѓПдЄАеИЧгАВ
3пЉЙ дЄНеσ俕僺糥еЉХзїДзїЗи°®еИЫеїЇдљНеЫЊињЮжΕ糥еЉХпЉМеєґдЄФйАВзФ®дЇОеЄЄиІДдљНеی糥еЉХзЪДйЩРеИґдєЯйАВзФ®дЇОдљНеЫЊињЮжΕ糥еЉХгАВ¬†
 
 
     


- 2011-11-15 13:00
- жµПиІИ 26077
- иѓДиЃЇ(0)
- еИЖз±ї:жХ∞жНЃеЇУ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
OracleеЕ≥дЇОжЧґйЧі/жЧ•жЬЯзЪДжУНдљЬ
2012-04-09 23:12 8751.жЧ•жЬЯжЧґйЧійЧійЪФжУНдљЬ гААгААељУеЙНжЧґйЧіеЗПеОї7еИЖйТЯзЪДжЧґйЧі гААгААs ... -
oracle жХ∞жНЃеЇУеҐЮйЗПе§Здїљ
2012-03-16 20:03 1189EXPеТМIMPжШѓOracleжПРдЊЫзЪДдЄАзІНйАїиЊСе§ЗдїљеЈ•еЕЈгАВйАїиЊСе§ЗдїљеИЫ ... -
oracle start with connect by зФ®ж≥Х
2012-02-19 23:58 1054oracle жПРдЊЫдЇЖstart with connect by ... -
OracleжХ∞жНЃеѓЉеЕ•еѓЉеЗЇimp/exp
2012-02-09 17:38 642OracleжХ∞жНЃеѓЉеЕ•еѓЉеЗЇimp/exp еКЯиГљпЉЪOracleжХ∞ ... -
жАІиГљзЫСжОІSQLиѓ≠еП•
2011-12-23 13:51 848еИЖжЮРи°® analyze table tablename co ... -
еЄЄзФ®SQLиѓ≠еП•
2011-12-23 13:50 1001жЯ•жЙЊжХ∞жНЃеЇУдЄ≠жЙАжЬЙе≠ЧжЃµ¬† дї•еѓєеЇФзЪДи°® select C.colu ... -
еЃЙи£ЕеИ∞жЬАеРОзЪДдЄ§дЄ™иДЪжЬђдљЬзФ®
2011-12-06 18:32 1067еЬ®linuxдЄЛеЃЙи£ЕOralceзЪДжЧґеАЩпЉМжЬАеРОдЉЪиЃ©дљ†дї•rootзЪДиЇЂ ... -
ORACLEдЄ≠дЄАдЄ™е≠Чзђ¶еН†е§Ъе∞Се≠ЧиКВ
2011-12-01 22:07 3899еЬ®oracleдЄ≠дЄАдЄ™е≠Чзђ¶зЙєеИЂжШѓдЄ≠жЦЗеН†еЗ†дЄ™е≠ЧиКВжШѓдЄНеРМзЪДгАВ жѓФе¶В ... -
жПРйЂШSQLжХИзОЗ
2011-12-01 00:13 1049¬† дЄЛйЭҐе∞±жЯРдЇЫSQL иѓ≠еП•зЪД where е≠РеП•зЉЦеЖЩдЄ≠йЬАи¶Бж≥®жДП ... -
вАЬexistsвАЭеТМвАЬinвАЭзЪДжХИзОЗйЧЃйҐШ
2011-11-30 23:49 1042жЬЙдЄ§дЄ™зЃАеНХдЊЛе≠РпЉМдї•иѓіжШО вАЬexistsвАЭеТМвАЬinвАЭзЪДжХИзОЗйЧЃйҐШ ... -
OracleеїЇзЂЛеЕ®жЦЗ糥еЉХиѓ¶иІ£
2011-11-30 20:42 14901.еЕ®жЦЗж£А糥еТМжЩЃйАЪж£А糥зЪДеМЇеИЂ дЄНдљњзФ®Oracle textеКЯ ... -
еЕ®жЦЗж£А糥CLOB
2011-11-30 12:00 1020¬†¬†¬† еїЇиЃЃдљњзФ®еЕ®жЦЗж£А糥(FULL TEXT SEARCH) ... -
вАЬOracleвАЭжХ∞жНЃеЇУзЪДвАЬеС®жХ∞иЃ°зЃЧвАЭ
2011-11-16 13:25 1015вАФвАФжЧ•жЬЯиЃ°зЃЧпЉМзЃЧзђђnеС®зЪДзђђдЄА姩еПКжЬАеРОдЄА姩жШѓеЗ†еПЈгАВ by key ... -
OracleдЄ≠TO_DATEж†ЉеЉП
2011-11-16 13:17 851TO_DATEж†ЉеЉП(дї•жЧґйЧі:2007-11-02¬†¬† 13:4 ... -
Oracle SQLдЄ≠зЪДIN еТМ EXSITSеМЇеИЂжАїзїУ
2011-11-15 11:06 1035IN з°ЃеЃЪзїЩеЃЪзЪДеАЉжШѓеР¶дЄОе≠Ржߕ胥жИЦеИЧи°®дЄ≠зЪДеАЉзЫЄеМєйЕНгАВ EX ... -
Oracle е≠Чзђ¶йЫЖзЪДжЯ•зЬЛеТМдњЃжФє
2011-11-14 23:09 972дЄАгАБдїАдєИжШѓOracleе≠Чзђ¶йЫЖ ... -
Oracle FlashbackжКАжЬѓжАїзїУ
2011-11-14 01:06 995Flashback жКАжЬѓжШѓдї•Undo segmentдЄ≠зЪДеЖЕеЃєдЄЇ ... -
oracleжЧ•ењЧељТж°£ж®°еЉПжФєеПШ
2011-11-14 00:15 1138еЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМдЄїи¶Бж ... -
е¶ВдљХжЬАе§Із®ЛеЇ¶зЪД жККи°®з©ЇйЧійЗМйЭҐзЪДжХ∞жНЃзїЩжКҐжХСеЗЇжЭ•
2011-11-03 16:18 1302дїК姩дЄАжЬЛеПЛйЧЃеИ∞дЄАдЄ™жѓФиЊГжЬЙжДПиѓЖзЪДйЧЃйҐШпЉЪ е¶ВжЮЬдЄАдЄ™и°®з©ЇйЧіпЉМеЕґдЄ≠дЄАдЄ™ ... -
oracle жАІиГљдЉШеМЦеїЇиЃЃе∞ПзїУ
2011-10-24 23:45 460еОЯеИЩдЄАпЉЪж≥®жДПWHEREе≠РеП•дЄ ...
зЫЄеЕ≥жО®иНР
жАїзЪДжЭ•иѓіпЉМOracle糥еЉХиѓ¶иІ£еПКSQLдЉШеМЦжШѓдЄАдЄ™жЈ±еЇ¶еєњеЇ¶еЕЉеЕЈзЪДдЄїйҐШпЉМйЬАи¶БзїУеРИеЃЮйЩЕжХ∞жНЃеЇУзїУжЮДеТМдЄЪеК°йЬАж±ВпЉМзБµжіїеЇФзФ®еРДзІН糥еЉХз±їеЮЛеТМдЉШеМЦз≠ЦзХ•пЉМдї•еЃЮзО∞жХ∞жНЃеЇУжАІиГљзЪДжЬАе§ІеМЦгАВйАЪињЗжЈ±еЕ•е≠¶дє†еТМеЃЮиЈµпЉМдљ†еПѓдї•жЫіе•љеЬ∞й©Њй©≠OracleжХ∞жНЃеЇУ...
жЬђзѓЗеЖЕеЃєе∞ЖжЈ±еЕ•иІ£жЮРOracle糥еЉХзЪДеЯЇжЬђж¶ВењµгАБеОЯзРЖдї•еПКз±їеЮЛгАВ й¶ЦеЕИпЉМ糥еЉХжШѓеПѓйАЙзЪДи°®еѓєи±°пЉМеЕґдЄїи¶БзЫЃзЪДжШѓжПРеНЗжߕ胥йАЯеЇ¶гАВе∞љзЃ°зіҐеЉХеПѓдї•жШЊиСЧжПРйЂШжХ∞жНЃж£А糥зЪДжХИзОЗпЉМдљЖеРМжЧґдєЯеН†зФ®йҐЭе§ЦзЪДе≠ШеВ®з©ЇйЧіпЉМеєґеПѓиГљељ±еУНжХ∞жНЃжПТеЕ•гАБжЫіжЦ∞еТМ...
Oracle糥еЉХжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠зФ®дЇОеК†йАЯжХ∞жНЃж£А糥зЪДеЕ≥йФЃжХ∞жНЃзїУжЮДпЉМе∞§еЕґеЬ®е§ДзРЖе§ІйЗПжХ∞жНЃжߕ胥жЧґпЉМеЕґжХИзОЗиЗ≥еЕ≥йЗНи¶БгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®OracleдЄ≠зЪДBж†С糥еЉХпЉМеМЕжЛђеЃГзЪДж¶ВењµгАБеИЫеїЇгАБеИ†йЩ§еТМдњЃжФєпЉМдї•еПКе¶ВдљХзРЖиІ£еЕґеЈ•дљЬеОЯзРЖгАВ й¶ЦеЕИпЉМ...
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖ OracleдЄ≠зЪДеРДзІН糥еЉХз±їеЮЛеПКеЕґдљњзФ®еЬЇжЩѓпЉМеМЕжЛђ B*Tree糥еЉХгАБдљНеی糥еЉХгАБ糥еЉХзїДзїЗи°®гАБйЩНеЇП糥еЉХгАБеПНеРСйԁ糥еЉХеТМеЯЇдЇОеЗљжХ∞зЪД糥еЉХгАВжѓПзІН糥еЉХзЪДдЉШзЉЇзВєгАБйАВзФ®еЬЇеРИеТМеИЫеїЇжЦєж≥ХеЭЗжЬЙиѓ¶зїЖдїЛзїНгАВжЦЗзЂ†ињШиЃ®иЃЇдЇЖ...
oracleжХ∞жНЃеЇУдЄ≠е¶ВдљХеїЇзЂЛ糥еЉХпЉМеїЇзЂЛ糥еЉХжЬЙдїАдєИдЉШеКњпЉМ糥еЉХиѓ•е¶ВдљХдљњзФ®
Oracle糥еЉХжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯOracleдЄ≠зФ®дЇОеК†йАЯжХ∞жНЃж£А糥зЪДйЗНи¶БеЈ•еЕЈгАВ糥еЉХзЪДж¶Вењµз±їдЉЉдЇОдє¶з±НзЪДзЫЃељХпЉМеЃГзЪДдЄїи¶БдљЬзФ®жШѓжПРйЂШжߕ胥йАЯеЇ¶пЉМзЙєеИЂжШѓеЬ®е§ДзРЖе§ІйЗПжХ∞жНЃзЪДи°®жЧґгАВOracle糥еЉХеИЖдЄЇйАїиЊСдЄКеТМзЙ©зРЖдЄКзЛђзЂЛзЪДеѓєи±°пЉМеИЫеїЇжИЦеИ†й٧糥еЉХ...
**Oracle糥еЉХиѓ¶иІ£** Oracle糥еЉХжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠зФ®дЇОжПРйЂШжߕ胥жХИзОЗзЪДйЗНи¶БжХ∞жНЃзїУжЮДгАВеЃГзЪДеЈ•дљЬеОЯзРЖз±їдЉЉдЇОдє¶з±НзЪДзЫЃељХпЉМеЕБиЃЄжХ∞жНЃеЇУз≥їзїЯењЂйАЯеЃЪдљНеИ∞жЙАйЬАзЪДжХ∞жНЃи°МпЉМиАМжЧ†йЬАжЙЂжППжХідЄ™и°®гАВ糥еЉХзЪДе≠ШеЬ®дљњеЊЧеѓєе§ІйЗПжХ∞жНЃзЪДжЯ•жЙЊгАБ...
ињЩдїљ"OracleзђФиЃ∞иѓ¶иІ£иµДжЦЩзФ®дЊЛ"жґµзЫЦдЇЖOracleжХ∞жНЃеЇУзЪДж†ЄењГж¶ВењµгАБеЃЙи£ЕйЕНзљЃгАБSQLиѓ≠и®АгАБи°®еТМ糥еЉХгАБе≠ШеВ®зїУжЮДгАБе§ЗдїљжБҐе§НгАБжАІиГљдЉШеМЦз≠Йе§ЪдЄ™жЦєйЭҐпЉМжШѓе≠¶дє†еТМжОМжП°OracleжХ∞жНЃеЇУзЪДеЃЭиіµиµДжЇРгАВ й¶ЦеЕИпЉМOracleжХ∞жНЃеЇУзЪДеЯЇз°АйГ®еИЖеМЕжЛђ...
### Oracle糥еЉХдЉШеМЦзЫЄеЕ≥зЯ•иѓЖзВєиѓ¶иІ£ #### дЄАгАБеЯЇжܐ糥еЉХж¶Вењµ еЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМ糥еЉХжШѓжПРйЂШжХ∞жНЃж£А糥йАЯеЇ¶зЪДйЗНи¶БеЈ•еЕЈгАВйАЪињЗжߕ胥`DBA_INDEXES`иІЖеЫЊпЉМеПѓдї•иОЈеПЦеИ∞ељУеЙНжХ∞жНЃеЇУдЄ≠жЙАжЬЙи°®зЪДжЙАжЬЙ糥еЉХдњ°жБѓгАВйЬАи¶Бж≥®жДПзЪДжШѓпЉМе¶ВжЮЬ...
### Oracle糥еЉХз±їеЮЛиѓ¶иІ£ #### дЄАгАБB\*Tree糥еЉХпЉЪжХ∞жНЃж£А糥зЪДеЯЇзЯ≥ еЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМB\*Tree糥еЉХжШѓжЬАеЄЄиІБзЪД糥еЉХзїУжЮДпЉМдєЯжШѓйїШиЃ§еИЫеїЇзЪД糥еЉХз±їеЮЛгАВеЃГеЯЇдЇОдЇМеПЙж†СеОЯзРЖпЉМзФ±еИЖжФѓеЭЧ(branch block)еТМеПґеЭЧ(leaf block)жЮДжИРпЉМ...
### Oracle糥еЉХиѓ¶иІ£ #### дЄАгАБ糥еЉХж¶ВењµдЄОдљЬзФ® **糥еЉХеЃЪдєЙ**пЉЪ糥еЉХжШѓеЬ®и°®зЪДдЄАдЄ™жИЦе§ЪдЄ™еИЧдЄКеИЫеїЇзЪДдЄАзІНжХ∞жНЃзїУжЮДпЉМеЃГзЪДдЄїи¶БзЫЃзЪДжШѓдЄЇдЇЖжПРйЂШжХ∞жНЃиЃњйЧЃзЪДйАЯеЇ¶гАВ糥еЉХе∞±еГПжШѓеЫЊдє¶зЪДзЫЃељХпЉМеПѓдї•еЄЃеК©зФ®жИЈењЂйАЯеЃЪдљНеИ∞жЙАйЬАзЪДжХ∞жНЃгАВ ...
### Oracle糥еЉХиѓ¶иІ£ еЬ®OracleжХ∞жНЃеЇУзЃ°зРЖдЄ≠пЉМ糥еЉХжШѓдЄАзІНйЗНи¶БзЪДжХ∞жНЃзїУжЮДпЉМеЃГиГљжШЊиСЧжПРеНЗжХ∞жНЃж£А糥зЪДйАЯеЇ¶гАВжЬђжЦЗе∞ЖдїОB-tree糥еЉХеЕ•жЙЛпЉМиѓ¶зїЖиІ£жЮРеЕґзїУжЮДдЄОзЙєжАІпЉМеєґзїУеРИеЕЈдљУзЪДеЫЊиІ£дЄОеЃЮдЊЛжЭ•еЄЃеК©иѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМжОМжП°Oracle糥еЉХ...
### OracleдЄ≠зЪД糥еЉХиѓ¶иІ£ #### дЄАгАБROWIDзЪДж¶Вењµ ROWIDжШѓдЄАзІНзЙєжЃКзЪДжХ∞жНЃз±їеЮЛпЉМзФ®дЇОе≠ШеВ®и°МеЬ®жХ∞жНЃжЦЗдїґдЄ≠зЪДеЕЈдљУдљНзљЃгАВеЃГжШѓдЄАдЄ™64дљНзЉЦз†БзЪДжХ∞жНЃпЉМзФ±е≠Чзђ¶`A-Z`гАБ`a-z`гАБ`0-9`гАБ`+`еТМ`/`зїДжИРгАВеЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМROWIDзФ®дЇО...
### Oracle糥еЉХдљњзФ®ж†ЈдЊЛиѓ¶иІ£ #### дЄАгАБ糥еЉХеєґи°МеИЫеїЇ еЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМеєґи°МеИЫ忯糥еЉХеПѓдї•жШЊиСЧжПРйЂШеИЫ忯糥еЉХзЪДйАЯеЇ¶пЉМе∞§еЕґжШѓеЬ®е§ДзРЖе§ІйЗПжХ∞жНЃжЧґгАВдЄЛйЭҐзЪДSQLиѓ≠еП•е±Хз§ЇдЇЖе¶ВдљХеєґи°МеИЫеїЇдЄА䪙糥еЉХпЉЪ ```sql CREATE INDEX IDX_GD...
#### дЄАгАБOracle糥еЉХж¶Вињ∞ 糥еЉХеЬ®жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠жЙЃжЉФзЭАжЮБеЕґйЗНи¶БзЪДиІТиЙ≤пЉМеЃГиГљжШЊиСЧжПРйЂШжߕ胥жАІиГљгАВеЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМ糥еЉХжШѓдЄАзІНзЙєжЃКзЪДжХ∞жНЃзїУжЮДпЉМзФ®дЇОењЂйАЯжЯ•жЙЊжХ∞жНЃеЇУи°®дЄ≠зЪДиЃ∞ељХгАВ糥еЉХеПѓдї•еїЇзЂЛеЬ®и°®зЪДдЄАдЄ™еИЧжИЦе§ЪдЄ™еИЧдЄК...
### Oracle еИЫеїЇеТМеИ†й٧糥еЉХиѓ¶иІ£ #### дЄАгАБOracle糥еЉХж¶Вињ∞ еЬ®OracleжХ∞жНЃеЇУдЄ≠пЉМ糥еЉХжШѓдЄАзІНйЗНи¶БзЪДжХ∞жНЃзїУжЮДпЉМзФ®дЇОжПРйЂШжХ∞жНЃж£А糥йАЯеЇ¶гАВйАЪињЗеИЫ忯糥еЉХпЉМеПѓдї•жШЊиСЧжПРеНЗжߕ胥жАІиГљпЉМе∞§еЕґжШѓеЬ®е§ДзРЖе§ІеЮЛжХ∞жНЃи°®жЧґжЫідЄЇжШОжШЊгАВ糥еЉХз±їдЉЉ...