- 浏览: 214883 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (124)
- 一段耗CPU的随机生成字符串的代码,why? (1)
- 生活如何才能不匆忙? (1)
- Null Object设计模式 (1)
- 珍爱生命,远离java (1)
- Oracle强杀进程,解决表锁死等问题 (1)
- java发送消息到RTX提醒 (1)
- 以HTTP形式获取图片流并写入另一个图片 (1)
- struts2获取Session和request方法 (1)
- 洛克菲勒.第一封:起点不决定终点 (1)
- tomcat的OutOfMemoryError解决方法 (1)
- REST和SOAP:谁更好,或者都好? (1)
- 35款免费的Javascript、Flash Web图表组件 (1)
- 盘点:三十五个非主流开源数据库 (1)
- Lucene并发连接实现 - ConcurrentLuceneConnection (1)
- 能大大提升工作效率和时间效率的9个重要习惯 (1)
- 读周鸿祎的《乔布斯的拿来主义》后感 (1)
- 表变量与临时表的优缺点 (1)
- Visual C++线程同步技术剖析 (转载) (1)
- 海量数据处理专题1——Bloom Filter (1)
- 海量数据处理专题2——Hash (1)
- 海量数据处理专题3——Bit-map (1)
- 海量数据处理专题4——堆 (1)
- 海量数据处理专题5——双层桶划分 (1)
- 海量数据处理专题6——数据库索引及优化 (1)
- 海量数据处理专题7——倒排索引(搜索引擎之基石) (1)
- 如何让优化你在搜索引擎上的形象 (1)
- 20个专业的SEO网站分析工具 (1)
- 杯具了,武汉开出国内首张个人网店税单:征税430余万 (1)
- java关键字的实现原理 (1)
- 关于Class类的成员函数与Java反射机制,坦言Synchronize的本质 (1)
- iBATIS的一对多关联查询 (1)
- 详解spring 依赖注入的作用 (1)
- 为什么要用JSP做显示而不用servlet? (1)
- 解决:java webservice调用net 参数返回NULL (1)
- Lucene搜索 关键字高亮 (1)
- Java常用类 Object类简单用法和深入 (1)
- 我在上海奋斗五年 从月薪3500到700万 (1)
- 每个Java初学者都应该搞懂的六个问题 (1)
- 强 奸数据库就这八步! (0)
- 数据库就这八步! (1)
- 什么才是最好处理中文方法 (1)
- JS实现简单的ajax访问Struts2的action类 (1)
- 跨域终极解决办法 (1)
- 由Map的复制问题引发对深复制和浅复制的思考 (1)
- Object类型转换为String类型的两种方式 (1)
- 写Java程序的三十个基本规则 (1)
- java计算时间差及某个时间段数据 (1)
- 推荐10个Java开源CMS系统 (1)
- 折半插入排序java实现 (1)
- 什么是程序员的优秀品质? (1)
- JDK Proxy AOP实现 (1)
- Java的最优化内存管理 (1)
- 100个Java经典例子 (1)
- java多态反射机制例子 (1)
- hashCode与equals的区别与联系 (1)
- 软件公司如何才能留住员工 (1)
- Java模拟操作系统进程调度算法—先来先服务、短作业优先、高响比优先 (1)
- 抛砖引玉 教你如何成为一名Java初级程序员 (1)
- 是什么成就了一名“高级”程序员? (1)
- 10分钟教会你Apache Shiro (1)
- Lucene排序 Payload的应用 (1)
- Lucene3.0之结果排序 (1)
- synchronized和java.util.concurrent.locks.Lock的异同 (1)
- 如何把Object对象转换为XML (1)
- 大流量网站的底层系统架构 (1)
- 程序员应该知道的100个vim命令 (1)
- 小编辑 Java 6 JVM参数选项大全(中文版) (1)
- 使用 Java Native Interface 的最佳实践 (1)
- 您适合从事Web前端开发行业吗? (1)
- 一个当了爹的程序员的自白 (1)
- Hibernate中设置MySQL的中文编码 (1)
- 雅虎声明称董事会运转良好 杨致远无需辞职 (1)
- IBM开源Java语言变种NetRexx (1)
- Tomcat VS Jetty (1)
- 正版office 2007 简体中文专业版(附正版序列号)高速下载正版office 2007 简体中文专业版 (1)
- java程序员应该知道的两种引用 (1)
- 基于Oracle 分布式数据库的查询优化 (1)
- JAVA设计模式 (1)
- java高并发-静态页面生成方案(1) (1)
- 程序员和编码员之间的区别 (1)
- 看看美国是如何解决开发人员的缺陷的 (1)
- ClassNotFoundException: org.springframework.web.util.IntrospectorCleanupListener (1)
- 开发模式 (0)
最新评论
-
泛黄秋颜:
大神你好,我最近在做云显示,奈何就是不会,能不能麻烦您发我一份 ...
Java实现标签云 -
Zhang_amao:
我的QQ邮箱1101232017@qq.com
Java实现标签云 -
Zhang_amao:
您好, 我现在也在研究这一领域,特别需要java版本来生成中文 ...
Java实现标签云 -
moon198654:
Technoboy 写道引用
总结
本文介绍了目前 Java ...
Tomcat VS Jetty -
mengxiangzhou:
dfvdf
Java模拟操作系统进程调度算法—先来先服务、短作业优先、高响比优先
Lucene3.0之结果排序(原理篇)
传统上,人们将信息检索系统返回结果的排序称为"相关排序" ( relevance ranking) ,隐含其中各条目的顺序反映结果和查询的相关程度。
1、 基本排序原理
① 向量空间模型
Gerald Salton 等在 30 多年前提出的"向量空间模型" ( Vector Space Model, VSM) [Salton and Lesk,1968, Salton,1971]。该模型的基础是如下假设:文档 d和查询 q的相关性可以由它们包含的共有词汇情况来刻画。
经典的 TF*IDF词项权重的计算公式:
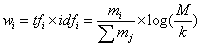
给定某种权重的定量设计,求文档和查询的相关性就变成了求 d 和 q 向量的
某种距离,最常用的是余弦( cos)距离
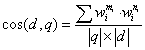
② 链接分析 PageRank原理
链接分析技术主要基于两个假设: 1)一个网页被多次引用,则它可能是很重要的,如果被重要的网页引用,说明自身也是重要的,网页的重要性在网页之间可以传递。
2)随机冲浪模型:认为假定用户一开始随机地访问网页集合中的一个网页,然和跟随网页的链接向前浏览网页,不会退浏览,那么浏览下一个网页的概率是被浏览网页的量化的重要程度值。
按照以上的用户行为模型,每个网页可能被访问到的次数越多就越重要,这样的"可能被访问的次数"也就定义为网页的权值, PageRank值。如何计算这个权值呢? PageRank采用以下公式进行计算:
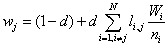
其中wj代表第 j个网页的权值;lij只取 0、 1值,代表从网页 i到网页 j是否存在链接;ni代表网页 i有多少个连向其它网页的链接; d代表"随机冲浪"中沿着链接访问网页的平均次数。选择合适的初始数值,递归的使用上述公式,即可得到理想的网页权值。
2、 Lucene排序计算公式
Lucene的排序公式如下:
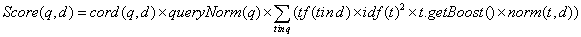
1)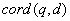 ,协调因子,表示文档(
d)中
Term(t)出现的百分比,也就是计算查询条件(
q)中不同
Term(t),以及在文档中出现的数量之和,两者的数量之比。通常在文档中出现查询
Term种类越多,分值越高。
,协调因子,表示文档(
d)中
Term(t)出现的百分比,也就是计算查询条件(
q)中不同
Term(t),以及在文档中出现的数量之和,两者的数量之比。通常在文档中出现查询
Term种类越多,分值越高。
2)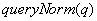 ,调节因子,不影响索引排序情况,只在检索时使用,主要是用来让排序结果在不同的查询条件之间可以比较。这个条件是在搜索时候计算。数值是根据每一个查询项权重的平方和计算得到。计算公式如下:
,调节因子,不影响索引排序情况,只在检索时使用,主要是用来让排序结果在不同的查询条件之间可以比较。这个条件是在搜索时候计算。数值是根据每一个查询项权重的平方和计算得到。计算公式如下:
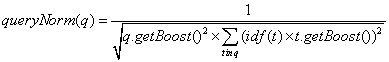
3) 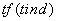 ,文档频率,表示查询词中,每个
Term在对应的结果文档中
(d)中出现的次数。查询词出现的次数越多,表示出现频率越高,文档的检索得分就越高。为了避免获得更大的相关性函数,实际中,使用次数的平方跟作为文档频率
tf的值,避免数值过度放大。
,文档频率,表示查询词中,每个
Term在对应的结果文档中
(d)中出现的次数。查询词出现的次数越多,表示出现频率越高,文档的检索得分就越高。为了避免获得更大的相关性函数,实际中,使用次数的平方跟作为文档频率
tf的值,避免数值过度放大。
4) 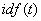 ,逆文档频率,检索匹配文档数量的反向函数。按照信息理论,文档出现的次数越少,每一篇文档的信息量就会越大。所以匹配的文档数越少,得分就越高。而索引库中文档总数越多,找到一篇目标文档难度越大,相应的信息量也会比较大。
,逆文档频率,检索匹配文档数量的反向函数。按照信息理论,文档出现的次数越少,每一篇文档的信息量就会越大。所以匹配的文档数越少,得分就越高。而索引库中文档总数越多,找到一篇目标文档难度越大,相应的信息量也会比较大。
5) 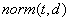 ,长度因子,每个索引词汇在域中的总体长度决定的,这个参数在索引建立时确定。数值根据文档中实际具有的索引项个数确定。检索词长度在文档总长度中占的比例越大,长度因子的数值也越大。
,长度因子,每个索引词汇在域中的总体长度决定的,这个参数在索引建立时确定。数值根据文档中实际具有的索引项个数确定。检索词长度在文档总长度中占的比例越大,长度因子的数值也越大。


Lucene3.0之结果排序(操作篇)
1、 Lucene相关排序流程

2、 Lucene相关类
① Query类:一个抽象类, Lucene检索结果最终评分的总控制中心。其它评分有关的类和对象都是由 Query类来管理和生产。
② Weight类接口:定义 Query权重计算的一个实现接口,可以被重用。 Weight类可以用来生成 Scorer类,也可以解析评分的详细信息,另外还定义了获取 Query权值的方法。
③ Scorer类: Lucene评分机制的核心类。类的定义是抽象类,提供的一些抽象基本的计分功能方法提供所有的评分类实现,同时还定义了评分的详细解析方法, Scorer类内部有一个 Similarity对象,用来指明计算公式。
④ Scorer类: Lucene相似度计算的核心抽象类。 Similarity类主要处理评分计算,系统缺省使用类 DefaultSimilarity类对象
3、 排序控制
使用 Sort对象定制排序,通过改变文档 Boost值来改变排序结果以及使用自定义的 Similarity方法更改排序
4、 文档 Boost加权排序
① Boost是指索引建立过程中,给整篇文档或者文档的某一特定域设定的权值因子,在检索时,优先返回分数高的。
Document和 Field两重 Boosting参数。通过 Document对象的 setBoost()方法和 Field对象的 setBoost()方法。不同在于前者对文档中每一个域都修改了参数,而后者只针对指定域进行修改。
文档加权 =Document-boosting*Field-boosting,默认情况下为 1,一般不做修改。
② Sort对象检索排序
Sort使用时通过实例化对象作为参数,通过 Searcher类的 search接口来实现。 Sort支持的排序功能以文档当中的域为单位,通过这种方法,可以实现一个或者多个不同域的多形式的值排序。
实际使用排序对象 Sort进行排序。主要有两种模式,一种是以字符串表示文档域的名称作为参数指定域排序,一种是直接以排序域的包装域的包装类作为参数进行排序。
Sort对象使用比较简单,只需要在对文档索引进行检索时,在检索器的 Search方法中带 Sort对象作为参数即可。
1) Sort对象相关性排序
按照相关性排序时最基本的结果排序方法,使用 Sort对象无参数构造函数完成的排序效果相当于 Lucene默认的按相关性降序排序。
2) Sort对象文档编号排序
某些应用场合需要对所有符合匹配度的结果,按照文档内部编号排序输出。使用 Sort对象的静态实例 Sort.INDEXORDER来实现
3) Sort对象独立域排序
在检索过程中,把检索结果按照某一个特定域排 序,非常重要。在使用搜索引擎过程中,有时会选择使用时间排序,而在搜索引擎库中,检索词完全是另外一个域的内容,与时间没有任何关系。这种应用中,检索 关键词的匹配仍然是首要因素,匹配太低或者不匹配的文档直接不必处理,而匹配的文档则需进一步排序输出。
指定的排序域并没有进行特别限制,可以是检索词的关联域,也可以是文档中的任意其它域。
4) Sort对象联合域排序
多个文档域联合排序时,需要注意文档域的添加次序。排序的结果先按照第一个域排序,然后第二个域作为次要关键字排序。开发时,需要根据自己的需要选择合适的次序。
5) Sort对象逆向排序
Sort(field,true)或者 Sort(field,false)实现升降序排序。
Lucene3.0之结果排序(示例篇)
这个例子是根据《开发自己的搜索引擎: Lucene2.0+Heritrix 》中的例子改的,由于原书中是使用 Lucene2.0 ,所以代码有部分改动。
package sortApp;
import java.io.File;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class SortTest {
public static void makeItem(IndexWriter writer, String bookNumber,
String bookName, String publishDate) throws Exception {
writer.setUseCompoundFile(false);
Document doc = new Document();
Field f1 = new Field("bookNumber", bookNumber, Field.Store.YES,
Field.Index.NOT_ANALYZED);
Field f2 = new Field("bookName", bookName, Field.Store.YES,
Field.Index.ANALYZED);
Field f3 = new Field("publishDate", publishDate, Field.Store.YES,
Field.Index.NOT_ANALYZED);
doc.add(f1);
doc.add(f2);
doc.add(f3);
writer.addDocument(doc);
}
public static void main(String[] args) {
String Index_Store_Path = "D:/index/1";
File file = new File(Index_Store_Path);
try {
Directory Index = FSDirectory.open(file);
IndexWriter writer = new IndexWriter(Index, new StandardAnalyzer(Version.LUCENE_CURRENT), true,
MaxFieldLength.LIMITED);
writer.setUseCompoundFile(false);
Document doc1 = new Document();
Field f11 = new Field("bookNumber", "0000001", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f12 = new Field("bookName", "
钢铁是怎样炼成的
", Field.Store.YES, Field.Index.ANALYZED);
Field f13 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc1.add(f11);
doc1.add(f12);
doc1.add(f13);
Document doc2 = new Document();
Field f21 = new Field("bookNumber", "0000002", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f22 = new Field("bookName", "
钢铁战士
", Field.Store.YES, Field.Index.ANALYZED);
Field f23 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc2.add(f21);
doc2.add(f22);
doc2.add(f23);
Document doc3 = new Document();
Field f31 = new Field("bookNumber", "0000003", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f32 = new Field("bookName", "
篱笆女人和狗
", Field.Store.YES, Field.Index.ANALYZED);
Field f33 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc3.add(f31);
doc3.add(f32);
doc3.add(f33);
Document doc4 = new Document();
Field f41 = new Field("bookNumber", "0000004", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f42 = new Field("bookName", "
女人是水做的
", Field.Store.YES, Field.Index.ANALYZED);
Field f43 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc4.add(f41);
doc4.add(f42);
doc4.add(f43);
Document doc5 = new Document();
Field f51 = new Field("bookNumber", "0000005", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f52 = new Field("bookName", "
英雄儿女
", Field.Store.YES, Field.Index.ANALYZED);
Field f53 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc5.add(f51);
doc5.add(f52);
doc5.add(f53);
Document doc6 = new Document();
Field f61 = new Field("bookNumber", "0000006", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f62 = new Field("bookName", "
白毛女
", Field.Store.YES, Field.Index.ANALYZED);
Field f63 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc6.add(f61);
doc6.add(f62);
doc6.add(f63);
Document doc7 = new Document();
Field f71 = new Field("bookNumber", "0000007", Field.Store.YES, Field.Index.NOT_ANALYZED);
Field f72 = new Field("bookName", "
我的兄弟和女儿
", Field.Store.YES, Field.Index.ANALYZED);
Field f73 = new Field("publishDate", "1970-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED);
doc7.add(f71);
doc7.add(f72);
doc7.add(f73);
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.addDocument(doc3);
writer.addDocument(doc4);
writer.addDocument(doc5);
writer.addDocument(doc6);
writer.addDocument(doc7);
writer.optimize();
writer.close();
IndexSearcher searcher = new IndexSearcher(Index);
TermQuery q = new TermQuery(new Term("bookName", "
女
"));
ScoreDoc[] hits = searcher.search(q, null, 1000, Sort.RELEVANCE).scoreDocs;
for (int i = 0; i < hits.length; i++) {
Document hitDoc = searcher.doc(hits[i].doc);
System.out.print("
书名
:
");
System.out.println(hitDoc.get("bookName"));
System.out.print("
得分
:
");
System.out.println(hits[i].score);
System.out.print("
内部
ID
:
");
System.out.println(hits[i].doc);
System.out.print("
书号
:
");
System.out.println(hitDoc.get("bookNumber"));
System.out.print("
发行日期
:
");
System.out.println(hitDoc.get("publishDate"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
Sort 属性设为 RELEVANCE :

Sort 属性设为 INDEXORDE :

去除
Sort
参数后:



发表评论

相关推荐
【Lucene3.0查询类型详解】 在Lucene3.0中,查询处理是一个关键环节,涉及多种查询方式和理论模型。以下是对这些概念的详细解释: 1. **查询方式**: - **顺序查询**:是最简单的查询方式,直接遍历索引,效率较...
### Lucene 3.0 特性详析 #### 概述 Lucene 3.0,于2009年11月25日正式发布,标志着Lucene发展历程中的一个重大里程碑。相较于之前的版本,3.0进行了大幅度的革新与升级,不仅在API层面进行了诸多调整,还全面拥抱...
【Lucene3.0 使用教程】是针对Java开发者的一个指南,旨在教授如何利用Apache Lucene 3.0.1版本实现全文检索功能。Lucene是一个高性能、可伸缩的开源全文检索库,它提供了文本分析、索引创建、文档检索等核心功能。...
《Lucene 3.0 原理与代码分析完整版》是一本深入解析Lucene 3.0搜索引擎库的专业书籍。Lucene是Apache软件基金会的开源项目,它为Java开发者提供了一个高性能、全文检索的工具包,广泛应用于各种信息检索系统。这...
这里的"lucene3.0核心jar包"是 Lucene 的一个重要版本,发布于2009年,为当时的开发人员提供了构建全文搜索引擎的基础框架。 在 Lucene 3.0 中,以下几个关键知识点值得关注: 1. **索引结构**:Lucene 使用倒排...
**Lucene 3.0 全文信息检索** Lucene 是一个由Apache软件基金会4 Jakarta项目组开发的开源全文检索引擎工具包。自1999年发布以来,Lucene 已经发展成为Java世界中最为广泛使用的全文检索库,为开发者提供了构建高...
总结,Lucene3.0是Java世界中不可或缺的全文检索工具,它的索引构建、查询处理和结果排序机制为我们提供了高效且灵活的搜索功能。通过深入学习其内部工作原理,结合具体的代码实践,开发者可以更好地利用Lucene3.0...
在本文中,我们将深入探讨Lucene 3.0版本,了解其核心概念、功能特性,并通过实例来展示如何使用这个强大的工具。 ### 1. Lucene 3.0核心概念 #### 1.1 文档与字段 在Lucene中,数据是以文档(Document)的形式...
**Lucene 3.0 入门实例** Lucene 是一个高性能、全文本搜索库,由 Apache 软件基金会开发。它提供了完整的搜索功能,包括索引、查询解析、排序以及高级的文本分析能力。在 Lucene 3.0 版本中,开发者可以利用其强大...
在"mysearch"项目中,可能包含了基于Lucene 3.0构建的搜索引擎实现,涵盖了索引创建、查询解析、结果展示等功能。开发者可以研究源代码,学习如何整合Lucene到实际项目中,以提高搜索效率和用户体验。 总结,Lucene...
**Lucene 3.0 入门实例及关键知识点** Lucene 是一个开源的全文搜索引擎库,由 Apache 软件基金会开发。它为开发者提供了在应用程序中实现文本搜索功能的强大工具。本实例主要针对 Lucene 3.0 版本,这个版本虽然...
4. 结果排序:根据相关性或其他指标对搜索结果进行排序。 5. 显示结果:将搜索结果以用户友好的方式呈现。 五、实战示例 在实际应用中,我们可以使用jQuery等JavaScript库在前端处理用户输入,发送请求到后端的...
**Lucene3.0文件搜索概述** Lucene是Apache软件基金会的一个开源全文搜索引擎库,它提供了高级的文本分析和索引功能,使开发者能够轻松地在应用中实现强大的搜索功能。在Lucene 3.0版本中,这个功能得到了进一步...
- `Sort`类如何控制搜索结果的排序方式。 六、工具应用 在实际项目中,我们可以利用Lucene提供的工具类,如`AnalyzerComparator`用于比较不同分析器的效果,`Benchmark`用于性能测试。 总结,Lucene 3.0为我们提供...
3. **结果排序**: Lucene支持多种评分机制,如TF-IDF(词频-逆文档频率),可以根据评分对搜索结果进行排序。 4. **优化索引**: 可以定期进行索引合并,以减少索引分段数量,提高搜索性能。 **源码分析** 由于...
**基于Lucene 3.0的书籍查询系统详解** Lucene是一个开源的全文搜索引擎库,由Apache软件基金会开发。在3.0版本中,Lucene提供了强大的文本分析、索引和搜索功能,使得开发者能够快速地构建自己的全文检索应用。本...
在Lucene 3.0版本中,主要包含了索引构建、查询解析、搜索执行以及结果排序等功能。这个版本在前代的基础上优化了性能,提升了稳定性,并且支持更多的查询类型。 二、搜索器源程序结构 Lucene的搜索器源程序通常由...
《Lucene 3.0 API CHM指南》 Lucene是一个高性能、全文本搜索库,由Apache软件基金会开发,广泛应用于各种搜索引擎和信息检索系统。本指南主要关注的是Lucene 3.0版本的API,这是一个强大的工具集,用于在Java环境...
Java Lucene 3.0的使用涉及到多个步骤,包括设置分析器(Analyzer)来处理不同语言的文本,创建索引(IndexWriter),查询索引(Searcher),以及对搜索结果进行评分和排序。同时,开发者还需要关注性能优化,例如...