在高并发的系统中,我们常采用多数据库分散放置、读写分离、细粒度的隔离级别设定等策略来提高系统的性能。DataRabbit3.3 以及以上版本对这三种策略都给予了内置的支持。
(1)数据库分散放置:对于较大型的系统,在设计数据库时,我们可以根据业务范围将其设计为多个数据库,而不是一个,然后将这些数据库部署在不同的物理服务器上,以分担负载。当然,如果已经设计好的数据库,也可以采用水平分区或垂直分区的方式来达到类似的效果。
(2)读写分离:在高性能的系统中,这是最常采用的策略。在SqlServer中,可以采用事务型的订阅/发布模型来实现这种策略。在这种策略中,有一个Master DB 和多个(或一个)Slave DB,其中所有的Slave DB是只读的,而Master DB支持读写,当Master DB中的数据发生变化时,所有Slave DB会自动与其同步(可能会有稍微的延迟)。
(3)细粒度的隔离级别:比如,对于某些要求不高的查询可以采用ReadUncommitted的隔离级别来读取数据。
DataRabbit.Application.TransactionScopeFactoryProvider<TSourceKey,TSlaveSuitKey> 类可以支持数据库分散放置和读写分离。它支持【1套主/N套从】数据库实例。 【一套】表示支持一个系统运行的不可或缺的相互协作的多个数据库。
TransactionScopeFactoryProvider类图结构如下所示:
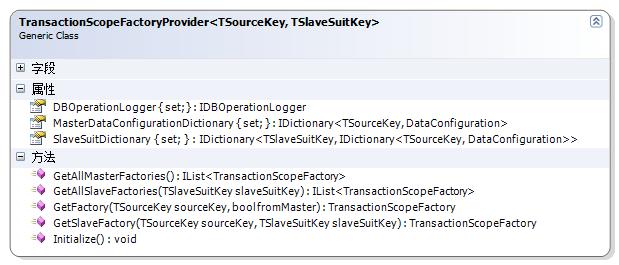
其中泛型参数TSourceKey是用来表示数据源标志的类型,比如我们可以用字符串来为每个数据库(数据源)命名,那么TSourceKey便可使用string类型。
泛型参数TSlaveSuitKey是用来表示每套从库的【套标志】的类型,比如,我们每套Slave库中包含5个数据库(这与Master中的5个是一一对应的),而我们可以提供比如3套Slave库以支持超大负载的数据读取,于是我们就要为这三套Slave库加以不同的标志以区分。
其中有用于注入Master DB数据库连接信息的Dictionary属性:MasterDataConfigurationDictionary,键便是TSourceKey类型,是每个数据源的标志,其值是用于封装数据库连接信息的DataConfiguration,这个类大家已经很熟悉了。而SlaveSuitDictionary用于注入多套从库的数据库连接信息。当然你已经知道,MasterDataConfigurationDictionary和SlaveSuitDictionary中每一套的项是一一对应的。还有一个小技巧,如果你现在的系统还不够大,但是以后会采用倒读写分离策略,那么暂时你可以将Master和Slave配置为指向同一个数据库,这是没有问题的,等系统做大了以上,需要Slave的支持时,只要修改一下配置即可。
DBOperationLogger属性用于记录数据库的所有操作和访问产生的异常信息。如果不设置,则表示不记录这些信息,关于DBOperationLogger的介绍,可以参考这里。
接下来我们再看GetFactory方法:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->TransactionScopeFactoryGetFactory(TSourceKeysourceKey,boolfromMaster);
其第一个参数表示要访问哪个数据库,第二个参数表示是要访问Master库还是Slave库。我们要注意到,当系统采用多套从库时,GetFactory()方法会随机的返回某套从库的TransactionScopeFactory,从而达到自动负载均衡的目的。当然你也可以通过GetSlaveFactory()方法来返回指定标志的某套从库的TransactionScopeFactory。
如此,我们可以这样来使用读写分离机制 -- 比如,我们有一个任务只是读取数据库,而不会有任何修改行为,那么就从Slave库中读取:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->IList<Student>list=null;
TransactionScopeFactoryfactory=this.transactionScopeFactoryProvider.GetFactory(DBSourceType.Basic,false);
using(TransactionScopescope=factory.NewTransactionScope(false))
{
IOrmAccesser<Student>accesser=scope.NewOrmAccesser<Student>();
list=accesser.GetAll();
scope.Commit();
}
returnlist;
这个例子中,我们用一个枚举DBSourceType来标志多个数据源,例子从标志位Basic的数据源的Slave库中读取所有的Student列表信息。
接下来,我们来看对隔离级别的支持。
还是使用上面的这个例子,假设我们的业务允许读取Student列表可以为脏读,那么可以降低读取的隔离级别(默认为ReadCommitted):
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->IList<Student>list=null;
TransactionScopeFactoryfactory=this.transactionScopeFactoryProvider.GetFactory(DBSourceType.Basic,false);
using(TransactionScopescope=factory.NewTransactionScope(false, IsolationLevel.ReadUncommitted))
{
IOrmAccesser<Student>accesser=scope.NewOrmAccesser<Student>();
list=accesser.GetAll();
scope.Commit();
}
returnlist;
IsolationLevel定义如下:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->publicenumIsolationLevel
{
ReadUncommitted=0,
ReadCommitted,
RepeatableRead,
Serializable
}
DataRabbit3.3及以上版本对上述策略都给予了充分的支持,你可以下载最新版本试试。
关于DataRabbit的更多信息目录,参见这里。
分享到:





相关推荐
Sharding-JDBC是阿里巴巴开源的一款轻量级Java框架,主要用于解决大数据量场景下的数据库分库分表问题,同时也支持读写分离,以提高系统的并发处理能力和数据存储能力。在这个“Sharding-JDBC实现读写分离demo”中,...
这几天因为工作需要,学习研究了一下spring-boot。spring-boot+mybatis+druid+读写分离+swagger进行一个整合,做了一个demo。自己已经充分测试,过程中也踩了不少的坑。
### 构建高性能Web之路——MySQL读写分离实战 #### 一、概述 在现代Web应用开发中,数据库性能往往是制约应用性能的关键因素之一。为了提高数据库系统的整体性能,一种常见的做法是实施读写分离策略。本文将详细...
Sharding-JDBC是阿里巴巴开源的一款轻量级Java框架,它可以在不改变业务代码的前提下,帮助我们快速实现数据库的读写分离。在这个“使用sharding-jdbc快速实现自动读写分离-demo源码”中,我们将探讨如何利用...
为了提高系统的响应速度以及数据处理能力,一种常用的技术手段就是采用**读写分离**的方式。读写分离的基本原理是将数据库的读取操作与写入操作分开处理,通常的做法是设置一个主数据库负责写操作,而一个或多个从...
标题中的“一款ef-core下高性能、轻量级针对分表分库读写分离的解决方案”指的是一种在Entity Framework Core(简称ef-core)框架下的数据库管理工具或库,旨在优化数据库性能并实现读写分离。Entity Framework Core...
Seconds_Behind_Master 是一个用于监控从服务器与主服务器之间复制延迟的指标,如果这个值较大,可能意味着从服务器的数据不是实时更新的,可能会对读写分离的效率产生影响。 在MySQL Proxy的场景下,我们通常会...
Sharding-JDBC是一款轻量级的Java框架,它无需额外的中间件,可以直接嵌入到现有应用中,实现数据库的读写分离和分库分表功能。它的核心设计理念是"以数据库为中心",提供了一种透明化的数据访问层,使得应用程序...
7. **性能优化**:轻量级框架往往关注性能,例如通过缓存查询结果、延迟加载关联数据等方式来提高运行效率。 8. **代码可维护性**:轻量级框架通常注重代码的简洁性和可维护性,遵循一定的设计模式,如单一职责原则...
数据读写分离是一种在大型分布式系统中常见的数据库优化策略,主要目的是提高系统的性能和可用性。在本资料中,我们探讨的主题是“行业分类-设备装置-数据读写分离机制的实现方法和装置”,这表明内容可能涉及具体的...
在现代企业级应用开发中,数据管理是至关重要的部分,特别是在高并发、大数据量的场景下,为了提高系统的性能和稳定性,通常会采用读写分离的数据库架构。本实例将探讨如何利用Spring Boot和MyBatis框架实现多数据源...
spring-boot2+mybatis+druid+读写分离+swagger2进行一个整合,做了一个demo。自己已经充分测试,过程中也踩了不少的坑。 前两天刚上传一个demo。事物有点问题,非常抱歉。建议大家选择spring-boot 2.0版本以上,jdk8...
docker_compose搭建shardingSphereProxyMysql主从读写分离
MyBatis是一个轻量级的持久层框架,它将SQL语句与Java代码解耦,使得数据库操作更灵活。Druid则是一个高性能的数据库连接池,支持监控、拦截器等功能,有助于优化数据库访问性能。 读写分离的目的是将对数据库的读...
Sharding-JDBC是一款开源的分布式JDBC层框架,它可以提供分库分表、读写分离、分布式主键、数据分片等功能。读写分离是一种数据库扩展方案,通过将写操作和读操作分开到不同的服务器来提高性能,让主服务器专门负责...
本项目将这些框架进行了整合,并进行了数据库读写分离的配置,以提高系统的稳定性和性能。 首先,Spring框架作为基础,提供了强大的依赖注入(Dependency Injection,DI)和面向切面编程(Aspect-Oriented ...
在数据库设计与应用领域,“读写分离”是一种常见的架构模式,它通过将数据读取操作和写入操作分配到不同的数据库服务器上来提高系统的整体性能。这种模式尤其适用于那些“读多写少”的应用场景。 #### 二、读写...
Java分布式数据源分库分表、读写分离是大型互联网系统中常见的数据库优化策略,用于应对高并发、大数据量的场景。`j360-datasource` 是一个专为解决这些问题而设计的应用层框架。它允许开发者在不改变原有业务逻辑的...
Oracle数据库的读写分离是一种优化策略,用于提升大型系统中数据处理能力,通过将读操作与写操作分离到不同的数据库实例上,实现高并发场景下的性能优化。在本配置文档中,我们将关注如何利用Mycat中间键实现Oracle ...
本项目“Springboot-mybatis读写分离”正是基于SpringBoot和Mybatis框架实现这一功能的示例代码,适用于个人的Docker环境进行测试。以下是关于这个主题的详细知识点: 1. **SpringBoot**: SpringBoot是由Pivotal...