1.缘起:
从IMultiTree到IAgileMultiTree,一切进展得都不错。但是,还有改进的地方。多叉树的一个优点在于,根据指定的节点能够非常迅速地找到其所有的子节点。但是缺点在于,根据节点值的ID定位到目标节点不够快,因为需要对所有的节点进行遍历操作。当节点非常多、层次非常深时,这种定位操作可能会严重的影响效率。
我设计了层级结构缓存ESBasic.ObjectManagement.Cache.IHiberarchyCache来加速这种根据节点值ID定位节点的访问。所谓“层级结构”,就是类似我们在IMultiTree章节缘起中介绍的那个多叉树式的组织结构。
使用IHiberarchyCache可以使两种操作都足够快:一是根据ID找到目标对象,另一种是根据ID找到其所有下级对象。
IHiberarchyCache融合了IAgileMultiTree和Dictionary两种对象容器的优势,以达到对层级结构的高效缓存。
层级结构缓存的形象示意图如下:
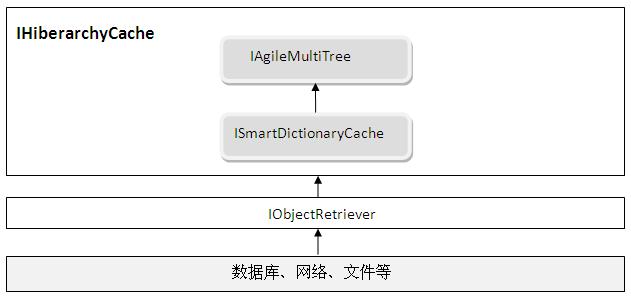
从示意图可以看到,IHiberarchyCache内部是借助IAgileMultiTree和ISmartDictionaryCache来实现的。
2.适用场合:
如果你在使用IAgileMultiTree的同时,经常需要根据节点值ID来定位节点,而且希望这种定位非常迅速,那么你可以改用IHiberarchyCache。
3.设计思想与实现
所有希望能够存储在IHiberarchyCache中的节点值必须实现IHiberarchyVal接口,该接口从IMTreeVal继承,其定义如下:
<!--<br/ /><br/ />Code highlighting produced by Actipro CodeHighlighter (freeware)<br/ />http://www.CodeHighlighter.com/<br/ /><br/ />--> publicinterfaceIHiberarchyVal:IMTreeVal
{
stringSequenceCode{get;}
}
其相比于IMTreeVal增加了一个SequenceCode属性,以表明节点值在多叉树中的具体位置。
最初的IMultiTree对节点值是否有SequenceCode并没有任何要求,也就是说没有SequenceCode特性也可以正常使用IMultiTree。接着,IAgileMultiTree将SequenceCode作为一个设计参数纳入到核心机制中。到现在IHiberarchyCache,SequenceCode已经是节点值必须实现的一个属性了,否则,IHiberarchyCache将无法正常工作。这是一个逐渐强化SequenceCode作用的过程。
接下来我们来看IHiberarchyCache接口的定义:
<!--<br/ /><br/ />Code highlighting produced by Actipro CodeHighlighter (freeware)<br/ />http://www.CodeHighlighter.com/<br/ /><br/ />--> publicinterfaceIHiberarchyCache<TVal>whereTVal:IHiberarchyVal
{
///<summary>
///RootID设置根节点的ID。
///</summary>
stringRootID{set;}
///<summary>
///SequenceCodeSplitter节点路径(序列号)的分割符。
///</summary>
charSequenceCodeSplitter{get;set;}
IObjectRetriever<string,TVal>ObjectRetriever{set;}
intCount{get;}
voidInitialize();
///<summary>
///Get如果目标对象在缓存中不存在,则通过ObjectRetriever去提取。
///</summary>
TValGet(stringid);
///<summary>
///HaveContained缓存中是否一经包含了目标对象。
///</summary>
boolHaveContained(stringid);
///<summary>
///GetAllKeyListCopy获取所有ID的列表的拷贝。
///</summary>
IList<string>GetAllKeyListCopy();
///<summary>
///GetAllValListCopy获取所有的节点值列表的拷贝。
///</summary>
IList<TVal>GetAllValListCopy();
///<summary>
///GetChildrenOf获取parentID的所有孩子节点的节点值列表。
///</summary>
IList<TVal>GetChildrenOf(stringparentID);
///<summary>
///GetChildrenCount获取parentID直接下级的个数。
///</summary>
intGetChildrenCount(stringparentID);
///<summary>
///CreateHiberarchyTree返回表示层级信息的最单纯的数据结构。
///注意:返回的Tree实际上与内部的AgileMultiTree是引用的根节点是同一个节点。
///</summary>
MultiTree<TVal>CreateHiberarchyTree();
///<summary>
///GetNodesOnDepthIndex获取某一深度的所有节点。Root的深度索引为0
///</summary>
IList<TVal>GetNodesOnDepthIndex(intdepthIndex);
///<summary>
///GetNodesOnDepthIndex获取所属parentID体系下并且深度为depthIndex的所有节点。Root的深度索引为0
///</summary>
IList<TVal>GetNodesOnDepthIndex(stringparentID,intdepthIndex);
}
RootID属性表明了根节点值的ID,IHiberarchyCache将会以该ID的节点值来初始化层级结构的根。
接下来的SequenceCodeSplitter、ObjectRetriever和Count属性的含义我们在前面介绍IMultiTree时已经详细介绍过了,这里就不再赘述。
以-Copy结尾的方法返回的都是对象集合的一个拷贝,在方法返回后,这个集合中的元素个数可以被修改,不会影响到IHiberarchyCache的内部缓存。
注意,GetChildrenOf方法返回的是TVal的IList,而不是MNode的IList。这是因为在IHiberarchyCache中,节点的概念已经被淡化了,它只是在IHiberarchyCache的内部实现时使用,用于加快类似获取某个元素的所有下级对象的访问。而外部根本不用在乎IHiberarchyCache内部的具体实现方式,所以不需要将MNode暴露出来。
而且,如果IHiberarchyCache的某个方法暴露出了MNode节点对象,则有可能产生危险,因为当用户获取了某MNode节点对象的引用后,就可以调用其AddChild方法手动向IHiberarchyCache内部多叉树中添加节点,而这个节点在内部的ISmartDictionaryCache缓存中并不存在,从而导致IHiberarchyCache内部的两个缓存的状态不一致。
CreateHiberarchyTree方法用于创建一个新的MultiTree,返回的MultiTree与IHiberarchyCache内部的多叉树拥有完全一样的结构。
GetNodesOnDepthIndex方法的含义与IMultiTree是完全一致的。
接下来我们将注意力转移到HiberarchyCache的具体实现上来。
正如示意图所展示的,HiberarchyCache内部使用了IAgileMultiTree和ISmartDictionaryCache,从而达到了我们在缘起部分希望达到的效果。但是图中还有一个细节我们应该注意到,那就是数据流的方向。我们看到,IAgileMultiTree的数据的来源是ISmartDictionaryCache,这意味着,如果目标对象在当前IHiberarchyCache实例中不存在,则会先通过IObjectRetriever将其加载到ISmartDictionaryCache中,然后IAgileMultiTree再从ISmartDictionaryCache中取出加载到多叉树中。那么,IAgileMultiTree是如何从ISmartDictionaryCache加载数据的了?是通过一个适配器,这个适配器叫做HiberarchyAgileNodePicker,其类图如下所示:
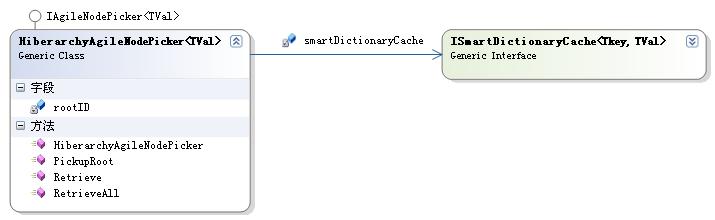
它将ISmartDictionaryCache适配为一个IAgileNodePicker对象给IAgileMultiTree使用。这一点我们可以从HiberarchyCache的Initialize方法的实现中一窥究竟。
关于HiberarchyCache的具体实现,其中的关键点罗列如下:
(1)关于线程安全的部分。由于内部仅有的两个容器ISmartDictionaryCache和IAgileMultiTree的实现都是线程安全的,所以HiberarchyCache本身也是线程安全的,而且不用做任何额外的处理。
(2)CreateHiberarchyTree方法返回的是内部多叉树的一个浅表拷贝。
(3)其它很多方法都是借助内部的IAgileMultiTree来完成的。
4. 使用时的注意事项
(1) IHiberarchyCache加速了根据节点值ID定位节点的查找访问,这是通过使用额外的内存空间为代价的,即典型的“以空间换时间”的例子。幸运的是,需要重复存储的只是节点值ID,而不是整个节点值对象,所以这个额外的内存开销并不是特别大。在大多数情况下,这个开销是值得的。
(2) 在介绍IMultiTree时,我们提到不要轻易调用其Count属性,因为每次调用都会进行一次递归统计动作,可能会影响性能。但是IHiberarchyCache的Count属性却可以非常快的返回,因为它直接返回了内部字典的Count属性,而不需要做额外的动作。
(3) IHiberarchyCache内部使用的两个缓存容器IAgileMultiTree和ISmartDictionaryCache,它们的状态是完全一致的。也就是说,如果一个对象存在于ISmartDictionaryCache中,那么在IAgileMultiTree中一定就能找到与之对应的节点,反之亦然。
(4) CreateHiberarchyTree方法返回的多叉树是只读的,这一点要特别注意。因为它只是IHiberarchyCache内部多叉树的一个浅表拷贝,所以对它的修改会导致IHiberarchyCache的内部状态不一致。通常,我使用CreateHiberarchyTree方法都是为了将返回的实例进行持久化存储的。
5.扩展
层级结构缓存IHiberarchyCache暂时没有任何扩展。
注:ESBasic源码可到http://esbasic.codeplex.com/下载。
ESBasic讨论:37677395
ESBasic开源前言
<script type="text/javascript">
if ($ != jQuery) {
$ = jQuery.noConflict();
}
</script>
分享到:





相关推荐
1. 部门管理( DepartManage):此模块用于创建、编辑和删除部门信息,同时可以设置部门间的层级关系,便于组织结构的管理和调整。 2. 员工管理:涵盖员工信息录入、修改、查询等功能,包括个人信息、岗位、薪资、...
ThinkPHP遵循PSR规范,鼓励使用命名空间和自动加载,开发者可以方便地引入和复用各种类库,提高代码的可维护性和可扩展性。 七、缓存管理 `Cache`目录涉及的是缓存管理,ThinkPHP提供了多种缓存驱动,如文件、...
**其他**:缓存、Session、Cookie、多语言、分页、上传、验证码、图像处理、文件处理、单元测试、扩展函数、类库、行为、Composer包、命令行、自动生成、目录结构、创建类库文件、生成类库映射文件、生成路由缓存、...
- **类库**:自定义类库。 - **行为驱动**:基于行为的驱动设计。 - **Composer包**:第三方库集成。 - **时间处理**:时间日期相关功能。 - **数据库迁移**:数据库结构变更管理。 - **工具**:辅助开发的工具类。 ...
- **Traits 引入**:利用 Traits 实现代码复用,避免多个类间的代码重复。 - **API 友好**:提供了丰富的 API 接口,方便开发者进行功能扩展。 #### 三、配置管理 - **配置格式**:支持多种配置格式,如数组、YAML...
- **快速搭建类框架**: 基于UI工厂提供的基础类库,快速构建项目的基础结构。 - **开发出第一个卡片单据**: 实现基本的数据展示和交互功能。 - **完善功能**: 逐步添加数据加载、增删改操作、前后台校验等功能。 - *...
- **目录结构**:清晰明了,便于管理和维护。 ##### 3. **架构** - **架构总览**:采用MVC模式,将应用程序分为模型(Model)、视图(View)和控制器(Controller)三个部分。 - **生命周期**:从用户请求到返回响应的...
在编程中,对path菜单控件的封装意味着开发者将这个控件的功能和交互逻辑打包成一个独立的模块或类库,以便在不同的项目中复用。这样做的好处包括代码重用、提高开发效率、减少错误和增强软件的可维护性。封装通常...
设计模式可以帮助提高代码的复用性、灵活性以及维护性。以下是对几种常见设计模式的总结。 #### 二、创建型模式 **1. 工厂模式(Factory)** - **定义**:提供创建对象的接口,通过工厂方法或抽象工厂的方式实现...
设计模式的概念源自于建筑学,被引入到软件工程领域后,极大地提升了代码的可读性、可维护性和复用性。在Java编程中,设计模式尤其重要,因为Java本身就是一种面向对象的语言,而设计模式主要应用于面向对象的设计。...
两种语言的混用,可以充分利用各自的优势,实现更好的代码复用和维护。 3. **网络请求与数据解析** 在`Services`目录下,可能会有负责网络请求的类或模块,使用AFNetworking或者Alamofire等第三方库。接收到的...
这包括使用ViewHolder减少视图复用的开销,使用CursorLoader进行数据加载,以及合理使用缓存策略等。 通过深入理解以上这些技术点,开发者不仅能实现一个仿ES界面的文件浏览器,还能掌握Android应用开发中的许多...
在iOS应用开发中,框架(Framework)是一种重要的组织代码的方式,它包含了一组相关的类库、资源和其他软件组件,用于解决特定类型的问题或提供特定功能。"自用iOS开发框架"是一个个人定制的框架,主要服务于iOS应用...
这种交互设计在移动应用中被广泛用于展示层级结构丰富的数据。 要实现这样的功能,开发者需要考虑以下几个关键点: 1. **自定义Adapter**:你需要为每个ListView创建自定义的Adapter,用于填充数据并处理点击事件...
设计模式是一种在特定软件开发环境下,为解决常见问题而总结出的可复用的解决方案。在TypeScript这种静态类型的强类型语言中,设计模式显得尤为重要,因为它能够帮助开发者编写更可维护、可扩展和可读性强的代码。...
"BCL (Base Class Library)"是.NET框架的基础类库。"bin packing"(装箱问题)是优化问题,旨在将物品装入最小数量的箱子。"binary"(二进制)是计算机的主要数字系统。"binding"(绑定)是将数据源连接到显示元素。...
在Android开发中,"BamboyBlur"是一个用于实现毛玻璃效果的工具类库。毛玻璃效果,又称模糊效果,通常被用在UI设计中,为背景元素添加一种半透明且朦胧的视觉感受,以此来突出前景内容,提升界面的整体美感。在...