- 浏览: 41649 次
- 性别:

- 来自: 深圳
-

最新评论
-
Wuaner:
体积小巧,文字却很清晰,不错的版本。谢谢lz分享!
Hadoop权威指南(第二版)pdf中文版 -
laserdance:
command type python3.2
在Linux下安装Python
MapReduce工作机制
1. 剖析MapReduce的工作运行机制

2. 失败
Tasktracker失败:
失败检测机制,是通过心跳进行检测。主要有:
(1) 超时:mapred.tasktracker.expiry.interval属性设置,单位毫秒
(2) 黑名单机制:失败任务数远远高于集群的平均失败任务数。
失败处理机制:
(1) 从等待任务调度的tasktracker池中移除
(2) 未完成的作业,重新运行和调度
(3) 黑名单中的tasktracker通过重启从jobtracker中移出。
JobTracker失败:
最严重的一种,目前Hadoop没有处理jobtracker失败的机制(单点故障)
3. 作业的调度
早期版本:先进先出算法(FIFO)
随后:加入设置作业优先级的功能(mapred.job.priority属性、JobClient的setJobPriority())
不支持抢占(FIFO算法决定)
默认调度器:FIFO;用户调度器:Fair Scheduler、Capacity Scheduler
Fair Scheduler(公平调度器)
目的:让每个用户公平的共享集群能力
特点:
(1) 支持抢占
(2) 短的作业将在合理的时间内完成
使用方式:
属于后续模块,需要专门调整
需要将其JAR文件放在Hadoop的类路径(从Hadoop的contrib/fairscheduler目录复制到lib目录)
设置mapred.jobtracker.taskScheduler属性:mapred.jobtracker.taskScheduler= org.apache.hadoop.mapred.FairScheduler
Capacity Scheduler
针对多用户的调度
允许用户或组织为每个用户或组织模拟一个独立的使用FIFO Scheduling的MapReduce集群。
4. Shuffle和排序
Shuffle:将map输出作为输入传给reducer(系统执行排序的过程)
MapReduce的核心部分,属于不断被优化和改进的代码库的一部分。
Map端:
环形内存缓冲区:
100MB:io.sort.mb 阀值:io.sort.spill.percent80% mapred.local.dir : 作业特定子目录
超过阀值则写入磁盘。如果写入过程中缓冲区填满,则堵塞直到写磁盘完成。
io.sort.factor:一次最多合并多少流,默认10
压缩:mapred.compress.map.output
Tracker.http.threads:针对每个tasktracker,而不是针对每个map任务槽,默认40;在运行大型作业的大型集群上,可以根据需要而增加。
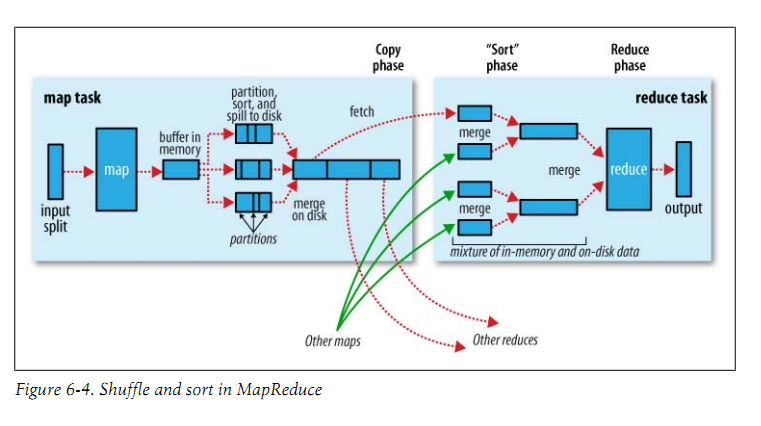
Reduce端
Map输出文件位于运行map任务的tasktracker的本地磁盘;reduce输出并不这样
复制阶段(copyphase):mapred.reduce.parallel.copies ,默认5;设置多少并行获取map输出
排序、合并、合并印子、合并的次数
配置的调优:重要章节
1、给shuffle过程尽量多提供内存空间(猜测原因:避免写入磁盘、提高性能???)。所以,map和reduce应尽量少用内存
2、运行map任务和reduce任务的JVM,其内存大小在mapred.child.java.opts属性设置,应该尽量大。
3、在map端,可以通过避免多次溢出写磁盘来获取最佳性能
4、在reduce端,中间的数据全部驻留在内存时,就能获得最佳性能。
整个调优的思路是:减少磁盘读写(使用内存)、减少数据大小(压缩)
5. 任务的执行
推测执行:
提取为可能出错的任务建立一个备份任务,做好预案。
进行冗余,牺牲性能作为代价。
解决方式:在集群上关闭此选项,但根据个别作业需要再开启。
问题:推测执行选项是对整个集群还是作业???
答案:可以针对某个map和reduece开启,有两个选项
mapred.map.tasks.speculative.execution
mapred.reduce.tasks.speculative.execution
任务JVM重用:
对短时间执行的任务,启用JVM重用,避免启动JVM(1秒左右)的消耗。
mapred.job.reuse.jvm.num.tasks:指定给定作业每个JVM运行的任务的最大数,默认为1
-1则表示同一作业的任务都可以共享同一个JVM
JobConf中的setNumTaskToExecutePerJvm()来设置。
这个设置是针对作业粒度的。
重用是指JVM空闲后可以被分配给其他任务使用。
另一个好处:各个任务之间状态共享;共享数据;
跳过坏记录:
处理坏记录的最佳位置在于mapper和reducer代码。
skipping mode:
出现失败,报告给tasktracker,重新执行后,跳过该记录。
只有在任务失败两次后才会启用skippingmode
流程如下:
(1) 任务失败
(2) 任务失败
(3) 开启skipping mode。任务失败,但是失败记录由tasktracker保存
(4) 仍然启用skipping mode。任务继续运行,但跳过上一次尝试中失败的坏记录。
缺点:每次都只能检测一条坏记录,所以对多条坏记录的话,这个就是个灾难。。。。。
可以通过设置taskattempt的最多次数来设置:mapred.map.max.attemps mapred.reduce.max.attemps
坏记录保存在:_logs/skip
Hadoop fs –text 诊断
任务执行环境:
1、 Mapper和reducer中提供一个 configure() 方法实现。
2、 Streaming环境变量
3、 任务附属文件
防止文件覆盖
将任务写到特定的临时文件夹({mapred.output.dir}/_temporary/${mapred.task.id}),任务完成后,将该目录中的内容复制到作业的输出目录(${mapred.output.dir})。
Hadoop提供了方式便于程序开发使用:
检索mapred.work.output.dir检索
调用FileOutputFormat的getWorkOutputPath()静态方法得到表示工作目录的Path对象。
-------------------------------------------------------------------------------------------------------------------
作者:CNZQS|JesseZhang 个人博客:CNZQS(http://www.cnzqs.com)
版权声明:除非注明,文章均为原创,可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明
--------------------------------------------------------------------------------------------------------------------


发表评论

-
Hadoop正式发布1.0版本
2011-12-30 23:46 1013作者:JesseZhang (CNZQS|JesseZh ... -
hadoop运行报错: java.lang.ClassNotFoundException解决方法
2011-12-11 23:10 2444作者:JesseZhang (CNZQS|JesseZh ... -
网友分享的《Hadoop实战》中文版 pdf
2011-12-08 20:50 2130作者:JesseZhang (CNZQS ... -
《权威指南》笔记十 管理Hadoop
2011-12-07 00:29 1666作者:JesseZhang (CNZQS|JesseZh ... -
《权威指南》笔记九 构建Hadoop集群
2011-12-05 22:03 1623作者:JesseZhang (CNZQS|JesseZh ... -
《权威指南》笔记八 MapReduce的特性
2011-12-05 00:25 1525作者:JesseZhang (CNZQS|JesseZh ... -
《权威指南》笔记七 MapReduce的类型和格式
2011-12-04 00:30 1753作者:JesseZhang (CNZQS|JesseZh ... -
Google三大论文中文版 pdf
2011-11-30 11:43 1920作者:JesseZhang (CNZQS|Jess ... -
Hadoop的五个典型应用场景
2011-11-08 11:18 1718本文为转载,原始地址为:http://blog.nosq ... -
Hadoop权威指南(第二版)pdf中文版
2011-11-03 11:29 2906今天终于找到 hadoop权威指南第二版的中文pdf版本 ... -
利用Ant构建Hadoop高效开发环境
2011-10-23 23:10 949最近Hadoop的研究中,都是利用Mockito ... -
chp5_MapReduce应用开发_20111011
2011-10-16 16:43 966MapReduce应用开发 1. ... -
hadoop的应用(摘自itpub论坛)
2011-09-23 22:44 1106在itpub的hadoop论坛中看到一则hadoop的应用说明 ... -
Hadoop的Namenode的容灾处理
2011-08-17 21:48 1671Hadoop的namenode是关键节点,虽然业务尽量单一,减 ... -
HDFS系统学习笔记
2011-08-14 23:19 1079HDFS系统 1. 读� ... -
hadoop开发环境配置(伪分布)
2011-08-14 10:44 1029Hadoop开发环境 安装插件 0.20.0 ... -
Hadoop安装总结
2011-08-13 13:07 891Hadoop安装总结 安装JDK 1 ... -
Hadoop及子项目介绍
2011-08-13 12:26 1555Hadoop及子项目介绍 H ... -
Google的三大基石
2011-07-20 13:58 1100Google的三大基石,也是云计算的几个重点论文的来源: ...
相关推荐
CCNAS_Chp3_PTActA_AAA.pka章节作业满分,加油自己配置
《C++编程实践:从Chp4_code.rar解密编程艺术》 在计算机科学的世界里,C++是一种强大且广泛应用的编程语言,以其高效、灵活和面向对象的特性深受程序员喜爱。当我们打开"Chp4_code.rar"这个压缩包,我们即将踏上一...
chp6_多媒体存储.ppt
chp6_多媒体文件格式与流媒体技术.ppt
实验的最后步骤是检查所有配置的结果,确保所有设备的AAA认证机制都能正常工作,提供安全的网络访问环境。通过这些实践,学生能够深入理解网络安全中AAA认证的重要性,以及如何在实际环境中配置和验证不同类型的AAA...
本文将深入探讨7z格式的特性,以及如何处理一个特定的7z压缩文件“CHP014_SH.7z”。 首先,了解7z压缩格式的基本特性是非常重要的。作为一种开源的压缩格式,7z由7-Zip这一免费且功能强大的压缩工具所支持。它不仅...
pta_chp5_78.py
有限质点法的练习4,丁承先向量式结构力学
chp5_MPEG视像.ppt
java练习题chp6 Key Point ●封装/数据隐藏 ●继承的基本语法 ●访问修饰符 ●对象创建过程 ●super 关键字 ●方法覆盖 ●多态的基本语法和使用 ●instanceof●多态用在参数和返回值上
6. **结果输出**:最后,源代码可能会包含可视化或数据输出部分,用于展示和分析计算结果,例如位移、速度、加速度的图形或数值。 通过运行并分析“chp5_ex2.m”文件,学习者可以更好地理解质点法的计算流程,如何...
chp4_数字图像编码.ppt
chp3_数字声音编码.ppt
chp2_数据无损压缩.ppt
chp1_多媒体技术概要.ppt
+Chp10_学生数据读写.cpp
chp5_上海市行政区划图制作.doc
6. **后处理**:计算并显示应力、应变、位移等结果,可能通过图形化工具(如`plot`函数)展示在平面上。 向量式有限元方法的一个主要优势在于它可以减少存储需求和计算时间,因为矩阵运算可以更有效地进行。此外,...
C语言课件(王曙燕)chp3_算法和基本程序设计.ppt
文件名"chp2_2.m"暗示这是一个MATLAB脚本,用于进行相关的仿真计算。在这样的脚本中,可能会包括以下几个步骤: 1. **信号生成**:创建代表信号的数学模型,如正弦波、脉冲序列等。 2. **噪声添加**:模拟实际环境...