- жµПиІИ: 113120 жђ°
- жАІеИЂ:

- жЭ•иЗ™: зП†жµЈ
-

жЦЗзЂ†еИЖз±ї
- еЕ®йГ®еНЪеЃҐ (83)
- иБМеЬЇзФµељ±20йГ® (1)
- жИРеКЯзЪДеЕ≥йФЃеЬ®дЇОињРдљЬ (1)
- ж≤°жЬЙиАРењГеОїз≠ЙеЊЕжИРеКЯзЪДеИ∞жЭ•пЉМеП™е•љзФ®дЄАзФЯзЪДиАРењГеОїйݥ僺姱賕 (1)
- з©ЈдЇЇжЬАзЉЇе∞СзЪДжШѓдїАдєИ (1)
- HTMLзЙєжЃКе≠Чзђ¶и°® (1)
- JavaеЖЕе≠Шж≥ДйЬ≤зЪДзРЖиІ£дЄОиІ£еЖ≥ (1)
- з®ЛеЇПеСШжШѓдЄНжШѓеП™еЬ®дєОиЗ™еЈ±зЪДдЄАдЇ©дЄЙеИЖеЬ∞ (1)
- зїЖиКВдЉШеМЦжПРеНЗиµДжЇРеИ©зФ®зОЗ (1)
- зФ®Resin 3.1.2еИЖжЮРз≥їзїЯжАІиГљзУґйҐИ (1)
- е¶ВдљХжЙНзЃЧжОМжП°Java (1)
- oracle еИЖй°µsqlиѓ≠еП• (1)
- JDK 7 дЄ≠зЪД Fork/Join ж®°еЉП (1)
- Servlet 3.0 еЃЮжИШпЉЪеЉВж≠• Servlet дЄО Comet й£Ож†ЉеЇФзФ®з®ЛеЇП (1)
- иІВеѓЯиАЕж®°еЉП(Observer Pattern)зЪДдЊЛе≠Р (1)
- JAVA IOжАїзїУ (1)
- 2011еєі10жЬИзЉЦз®Лиѓ≠и®АжОТи°Мж¶ЬпЉЪJavaдЇЇж∞ФжМБзї≠иµ∞дљО (1)
- 2011еєі8жЬИзЉЦз®Лиѓ≠и®АжОТи°Мж¶ЬпЉЪF#й¶Цжђ°ињЫеЕ•еЙН20 (1)
- еЙНзЂѓеЉАеПСеПВиАГиµДжЇР (1)
- и£ЕйАЉзКѓжШѓжАОж†ЈзїГжИРзЪД--зЬЛзЬЛдљ†и£ЕйАЉдЇЖж≤°жЬЙ (1)
- Cз®ЛеЇПеСШи£ЕйАЉжМЗеНЧ (1)
- йЂШзЇІз®ЛеЇПеСШи£ЕйАЉжМЗеНЧ (1)
- 21жЭ°з≤ЊйАЪз®ЛеЇПеСШи£ЕйАЉжКАжЬѓ (1)
- гАРз®ЛеЇПеСШењЕзЬЛгАСдљ†ињШи£ЕйАЉдєИпЉЯињШзЙЫйАЉеСҐпЉЯ (1)
- Javaз®ЛеЇПеСШдљњзФ®GrailsзЪДеНБе§ІдЉШеКњ (1)
- жИСжШѓжАОдєИдЇЖпЉМжАїжДЯ襀䯯зۃ楥 (1)
- JAVAиЗ™еЃЪдєЙж†Зз≠Њ (1)
- JAVAзЙИжЬђйЧЃйҐШ bad version number in class file зЪДиІ£еЖ≥жЦєж≥Х (1)
- е≠¶дє†JavaењЕй°їзЯ•йБУзЪДеЯЇжЬђж¶Вењµ (1)
- javaиОЈеПЦwindowsз≥їзїЯдњ°жБѓпЉИCPU (1)
- еЖЕе≠Ш (1)
- жЦЗдїґз≥їзїЯ (1)
- з°ђзЫШе§Іе∞ПпЉЙ (1)
- JavaеЖЕе≠Шж≥ДйЬ≤дЄОжЇҐеЗЇзЪДеМЇеИЂ (1)
- JavaзЪДresultsetдЄО.netзЪДdataset жЬЙдїАдєИеМЇеИЂ? (1)
- javaз±їеЃЪжЧґеЩ®TimerеТМTimerTaskзЪДдљњзФ®еЃЮдЊЛеПКеЖЕйГ®з±ї (1)
- дЇЖиІ£дїАдєИжШѓж°ЖжЮґгАБжЮДдїґдЄОиЃЊиЃ°ж®°еЉП (1)
- lucene2.9 дЄ≠жЦЗеИЖиѓНе≠¶дє†еТМSmartChineseAnalyzerзЪДзФ®ж≥Х (1)
- JavaдїАдєИжШѓйЭҐеРСеѓєи±°еТМйЭҐеРСеѓєи±°зЙєжАІ (1)
- Tomcat 7еРѓеК®еЉВеЄЄ:java.lang.IllegalArgumentException: taglib definition not consistent with specification version (0)
- Struts2дЄ≠дљњзФ®FreeMarkerеЕЕељУи°®зО∞е±В (1)
- 7дЄ™жФєеПШдЄЦзХМзЪДJavaй°єзЫЃ (1)
- jqueryдЄ≠пЉМhtmlгАБvalдЄОtextдЄЙиАЕе±ЮжАІеПЦеАЉзЪДиБФз≥їдЄОеМЇеИЂ (1)
- дЄАдЄ™зЃАеНХзЪДйЭҐиѓХйҐШпЉИjavaпЉЙ (1)
- Tomcat (1)
- HibernateзЪДдЉШзВє (1)
- JavaеЖЕе≠ШзЫЄеЕ≥зЪДеЗ†дЄ™йЕНзљЃ (1)
- ињЫи°МBPMеїЇиЃЊзЪДеНБе§Іж≠•й™§ (1)
- дЄ≠жђІи°М-иЗ™жЙЊзЪДйЇїзГ¶ (1)
- еОїеєідЄ≠еЫљ12зЬБеЕђиЈѓжФґиієйЂШиЊЊ1025дЇњпЉМдЄЇдљХињШеПЂдЇПпЉЯ (1)
- иБМеЬЇдЄ≠дЄНеПѓжЈ±дЇ§зЪДдЇФзІНдЇЇ (1)
- дЄ≠еЫљITеЈ•дљЬиАЕ35е≤БеРОзЪДеПСе±ХеЗЇиЈѓи∞ГжЯ•жК•еСК(1) (1)
- дЄ≠еЫљITеЈ•дљЬиАЕ35е≤БеРОзЪДеПСе±ХеЗЇиЈѓи∞ГжЯ•жК•еСК(2) (1)
- дЄ≠еЫљITеЈ•дљЬиАЕ35е≤БеРОзЪДеПСе±ХеЗЇиЈѓи∞ГжЯ•жК•еСК(3) (1)
- дЄ≠еЫљITеЈ•дљЬиАЕ35е≤БеРОзЪДеПСе±ХеЗЇиЈѓи∞ГжЯ•жК•еСК(4) (1)
- жЮґжЮДе≠¶дє†зђФиЃ∞вАФAmazon (1)
- Windows 8иГМеРОжХ∞е≠ЧпЉЪжФѓжМБ2зІНжЮґжЮД7зІНз®ЛеЇПиѓ≠и®А (1)
- иѓіе•љзЪДCacheеСҐ (1)
- 10 000е∞ПжЧґзЪДж†ЗеЗЖ----жШѓеР¶жЬЙеЕИ姩зЪДжЙНиГљ (1)
- javaз®ЛеЇПеСШйЬАи¶БзїГе∞±зЪДе≠§зЛђдєЭеЙС (1)
- дЄ≠еЫљз®ЛеЇПеСШзЪДзЬЯеЃЮеЖЩзЕІпЉБжВ≤еУА¬Ј¬Ј¬Ј¬Ј (1)
- е¶ВдљХжККObjectеѓєи±°иљђжНҐдЄЇXML (1)
- JavaзЪДеЫЫзІНеЉХзФ® (1)
- javaдЄ≠byteиљђжНҐintжЧґдЄЇдљХдЄО0xffињЫи°МдЄОињРзЃЧ (1)
- java еЖЩжЦЗдїґжЧґе¶ВдљХж≠£з°ЃиЊУеЕ•жНҐи°Ме≠Чзђ¶. (1)
- JavaжЬНеК°ж°ЖжЮґDubbo (1)
- жЈ±еЕ•еИЖжЮР Java I/O зЪДеЈ•дљЬжЬЇеИґ (1)
- жО®иНРеНБдЄ™жЬАе•љзЪДJavaжАІиГљжХЕйЪЬжОТйЩ§еЈ•еЕЈ (1)
- жґИзБ≠з®ЛеЇПеСШйЬАи¶БзЩЊеєіеРЧпЉЯ (1)
- иЛєжЮЬеПИжНЯ姱дЇЖдЄАдљНйЂШзЃ°еЕ®зРГеЃЙеЕ®йГ®йЧ®VP John Theriault (1)
- дЄ≠е§ЃжГЕжК•е±АCIAйАЪињЗFacebookз≠Йз§ЊдЇ§е™ТдљУеѓєеЕ®зРГеЃЮжЦљзљСзїЬзЫСиІЖ (1)
- Java дЄ≠зЪДfinallyдљ†зЯ•е§Ъе∞СпЉЯ (1)
- Java 7 NIO.2 еЃЮзО∞жЦЗдїґз≥їзїЯзЫСиІЖ (1)
- javaдЄ≠зЪДеЉХзФ®еИ∞еЇХжШѓдЉ†еАЉињШжШѓдЉ†еЭАпЉЯ (1)
- дљЬдЄЇз®ЛеЇПеСШпЉМйЪЊйБУжИСдїђдЄНеЇФиѓ•иЗ™и±™еРЧ (1)
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2011-11 ( 9)
- 2011-10 ( 74)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
iamstruts2пЉЪ
CyclicActionеЬ®jdk7дЄ≠襀CANCELжОЙдЇЖ
JDK 7 дЄ≠зЪД Fork/Join ж®°еЉП -
еЇЈдєРзЛВиК±пЉЪ
дЇЖдЄНиµЈ
дљЬдЄЇз®ЛеЇПеСШпЉМйЪЊйБУжИСдїђдЄНеЇФиѓ•иЗ™и±™еРЧ -
йїОжШОзЪДжЫЩеЕЙпЉЪ
дЄАеЃЪжШѓдЉ†еАЉпЉБеЉХзФ®з±їеЮЛдЉ†зЪДжШѓеЬ∞еЭАзЪДеЙѓжЬђпЉМеАЉз±їеЮЛдЉ†зЪДе≠ШеВ®еНХеЕГеЖЕеЃєзЪД ...
javaдЄ≠зЪДеЉХзФ®еИ∞еЇХжШѓдЉ†еАЉињШжШѓдЉ†еЭАпЉЯ -
Berson_ChengпЉЪ
еЙНеЗ†дЄ™ж†єжЬђе∞±жШѓдЄЇдЇЖдљ†жЙАи∞УзЪДзРЖиЃЇиАМжЮДйА†еЗЇжЭ•зЪДпЉМж†єжЬђе∞±ж≤°дїАдєИзФ®гАВе∞§ ...
Java дЄ≠зЪДfinallyдљ†зЯ•е§Ъе∞СпЉЯ -
ayxtlztds24пЉЪ
еЖЩзЪДзЬЯе•љеХК
дљЬдЄЇз®ЛеЇПеСШпЉМйЪЊйБУжИСдїђдЄНеЇФиѓ•иЗ™и±™еРЧ
зїЖиКВдЉШеМЦжПРеНЗиµДжЇРеИ©зФ®зОЗ
- еНЪеЃҐеИЖз±їпЉЪ
- зїЖиКВдЉШеМЦжПРеНЗиµДжЇРеИ©зФ®зОЗ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ињЩйЗМйАЪињЗдїЛзїНеѓєдЇОжЈШеЃЭеЉАжФЊеє≥еП∞еЯЇз°АиЃЊзљЃдєЛдЄАзЪД TOPAnalyzer зЪДдї£з†БдЉШеМЦпЉМжЭ•и∞ИдЄАдЄЛеѓєдЇОжµЈйЗПжХ∞жНЃе§ДзРЖзЪД Java еЇФзФ®еПѓдї•еЕ±дЇЂзЪДдЄАдЇЫзїЖиКВиЃЊиЃ°пЉИдЄАдЄ™з≥їзїЯиГље§ЯжЙњеПЧзЪДе§ДзРЖйЗПзЇІеИЂеЊАеЊАеПЦеЖ≥дЇОзїЖиКВпЉМдЄАдЄ™з≥їзїЯиГље§ЯжФѓжМБзЪДдЄЪеʰ嚥жАБеЊАеЊАеПЦеЖ≥дЇОиЃЊиЃ°зЫЃж†ЗпЉЙгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЕИдїЛзїНдЄАдЄЛжХідЄ™ TOPAnalyzer зЪДиГМжЩѓпЉМзЫЃж†ЗеТМеИЭеІЛиЃЊиЃ°пЉМдЄЇеРОйЭҐзЪДжЉФеПШеБЪдЄАзВєйУЇеЮЂгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЉАжФЊеє≥еП∞дїОеЖЕйГ®еЉАжФЊеИ∞ж≠£еЉПеѓєе§ЦеЉАжФЊпЉМйАРж≠•дїОжѓП姩еЗ†еНГдЄЗзЪДжЬНеК°и∞ГзФ®йЗПеПСе±ХеИ∞дЇЖдЄКдЇњеИ∞зО∞еЬ®зЪД 15 дЇњпЉМеЉАжФЊзЪДжЬНеК°дєЯдїОеЗ†еНБдЄ™еИ∞дЇЖеЗ†зЩЊдЄ™пЉМеЇФзФ®жО•еЕ•дїОеЗ†зЩЊдЄ™еҐЮеК†еИ∞дЇЖеЗ†еНБдЄЗдЄ™гАВж≠§жЧґпЉМеѓєдЇОеОЯеІЛжЬНеК°иЃњйЧЃжХ∞жНЃзЪДеИЖжЮРйЬАж±Ве∞±еЗЄзО∞еЗЇжЭ•пЉЪ
1пЉО¬† еЇФзФ®зїіеЇ¶еИЖжЮРпЉИеЇФзФ®зЪДж≠£еЄЄдЄЪеК°и∞ГзФ®и°МдЄЇеТМеЉВеЄЄи∞ГзФ®и°МдЄЇеИЖжЮРпЉЙ
2пЉО¬† жЬНеК°зїіеЇ¶еИЖжЮРпЉИжЬНеК° RT, жАїйЗПпЉМжИРеКЯ姱賕зОЗпЉМдЄЪеК°йФЩиѓѓеПКе≠РйФЩиѓѓз≠ЙпЉЙ
3пЉО¬† еє≥еП∞зїіеЇ¶еИЖжЮРпЉИеє≥еП∞жґИиАЧжЧґйЧіпЉМеє≥еП∞жОИжЭГз≠ЙдЄЪеК°зїЯиЃ°еИЖжЮРпЉМеє≥еП∞йФЩиѓѓеИЖжЮРпЉМеє≥еП∞з≥їзїЯеБ•еЇЈжМЗж†ЗеИЖжЮРз≠ЙпЉЙ
4пЉО¬† дЄЪеК°зїіеЇ¶еИЖжЮРпЉИзФ®жИЈпЉМеЇФзФ®пЉМжЬНеК°дєЛйЧіеЕ≥з≥їеИЖжЮРпЉМеЇФзФ®ељТз±їеИЖжЮРпЉМжЬНеК°ељТз±їеИЖжЮРз≠ЙпЉЙ
дЄКйЭҐеП™жШѓдЄАйГ®еИЖпЉМдїОдЄКйЭҐзЪДйЬАж±ВжЭ•зЬЛйЬАи¶БдЄАдЄ™з≥їзїЯиГље§ЯзБµжіїзЪДињРи°МжЬЯйЕНзљЃеИЖжЮРз≠ЦзХ•пЉМеѓєжµЈйЗПжХ∞жНЃдљЬеН≥жЧґеИЖжЮРпЉМе∞ЖжО•ињЗзФ®дЇОеСКи≠¶пЉМзЫСжОІпЉМдЄЪеК°еИЖжЮРгАВ
 
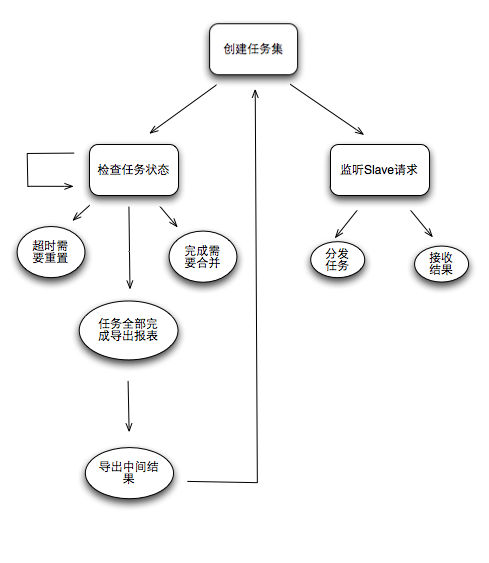
дЄЛеЫЊжШѓжЬАеОЯеІЛзЪДиЃЊиЃ°еЫЊпЉМеЊИзЃАеНХпЉМдљЖињШжШѓжЬЙдЇЫжГ≥ж≥ХеЬ®йЗМйЭҐпЉЪ
 

 
Master пЉЪзЃ°зРЖдїїеК°пЉИеИЖжЮРдїїеК°пЉЙпЉМеРИеєґзїУжЮЬпЉИ Reduce пЉЙпЉМиЊУеЗЇзїУжЮЬпЉИеЕ®йЗПзїЯиЃ°пЉМеҐЮйЗПзЙЗжЃµзїЯиЃ°пЉЙ
Slave пЉЪ Require Job + Do Job + Return Result пЉМйЪПжДПеК†еЕ•пЉМйААеЗЇйЫЖзЊ§гАВ
Job пЉЪ (Input + Analysis Rule + Output) зЪДеЃЪдєЙгАВ
 
еЗ†дЄ™иЃЊиЃ°зВєпЉЪ
1.¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еРОеП∞з≥їзїЯдїїеК°еИЖйЕНпЉЪжЧ†иіЯиљљеИЖйЕНзЃЧж≥ХпЉМйЗЗзФ®зїЖеМЦдїїеК°пЉЛеЈ•дљЬиАЕжМЙйЬАиЗ™еПЦпЉЛз≤ЧжЪізЃАеНХдїїеК°йЗНзљЃз≠ЦзХ•гАВ
2.¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† Slave дЄО Master йЗЗзФ®еНХеРСйАЪдњ°пЉМдЊњдЇОеЃєйЗПжЙ©еЕЕеТМзЉ©еЗПгАВ
3.¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† Job иЗ™жППињ∞жАІпЉМдїОдїїеК°жХ∞жНЃжЭ•жЇРпЉМеИЖжЮРиІДеИЩпЉМзїУжЮЬиЊУеЗЇйГљеЃЪдєЙеЬ®дїїеК°дЄ≠пЉМдљњеЊЧ Slave йАВзФ®дЄОеРДзІНеИЖжЮРдїїеК°пЉМдЄАдЄ™йЫЖзЊ§еИЖжЮРе§ЪзІНжЧ•ењЧпЉМе§ЪдЄ™йЫЖзЊ§еЕ±дЇЂ Slave гАВ
4.¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† жХ∞жНЃе≠ШеВ®жЧ†дЄЪеК°жАІпЉИжДПеС≥зЭАе≠ШеВ®зЪДжЧґеАЩдЄНеЃЪдєЙдїїдљХдЄЪеК°еРЂдєЙпЉЙпЉМеИЖжЮРиІДеИЩеМЕеРЂдЄЪеК°еРЂдєЙпЉИеЬ®жЙІи°МеИЖжЮРзЪДжЧґеАЩеСКзЯ•дЄНеРМеИЧжШѓдїАдєИеРЂдєЙпЉМжАОдєИзїЯиЃ°еТМиЃ°зЃЧпЉЙпЉМдЉШеКњеЬ®дЇОеПѓжЙ©е±ХпЉМеК£еКњеЬ®дЇОеЕ®йЗПжЙЂжППжЧ•ењЧпЉИжЧ†йҐДеЕИ糥еЉХеЃЪдєЙпЉЙгАВ
5.¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† йАПжШОеМЦжХідЄ™йЫЖзЊ§ињРи°МзКґеЖµпЉМдњЭиѓБзЃАеНХз≤ЧжЪізЪДжЦєеЉПдЄЛиГље§ЯењЂйАЯеЃЪдљНеЗЇиКВзВєйЧЃйҐШжИЦиАЕдїїеК°йЧЃйҐШгАВпЉИиЩљзДґж≤°жЬЙењГиЈ≥пЉМдљЖжШѓжѓПдЄ™иКВзВєзЪДеЈ•дљЬйГљдЉЪиЊУеЗЇдњ°жБѓпЉМйАЪињЗе§ЦйГ®жФґйЫЖжЦєеЉПењЂйАЯеЃЪдљНйЧЃйҐШпЉМйШ≤ж≠ҐйЫЖзЊ§дЄЇдЇЖзЫСжОІиА¶еРИдЄНеИ©дЇОжЙ©е±ХпЉЙ
6.¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† Master еНХзВєйЗЗзФ®еЖЈе§ЗжЦєеЉПиІ£еЖ≥гАВеНХзВєдЄНеПѓжАХпЉМеПѓжАХзЪДж؃䪥姱зО∞еЬЇеТМйЗНеРѓжИЦйЗНйАЙ Master еС®жЬЯйХњгАВеЫ†ж≠§йЗЗзФ®еИЖжЮРжХ∞жНЃеТМдїїеК°дњ°жБѓзЃАеНХеС®жЬЯжАІе§ЦйГ®е≠ШеВ®зЪДжЦєеЉПе∞ЖзО∞еЬЇдњЭе≠ШдЄОе§ЦйГ®пЉИдњ°жБѓе∞љйЗПе∞СпЉМдњЭиѓБжБҐе§НжЧґењЂйАЯпЉЙпЉМеП¶дЄАжЦєйЭҐйЗЗзФ®е§ЦйГ®з≥їзїЯйАЪзЯ•жЦєеЉПдњЃжФє Slave йЫЖзЊ§ MasterIP пЉМдЇЇеЈ•ењЂйАЯеИЗжНҐеИ∞еЖЈе§ЗгАВ
 
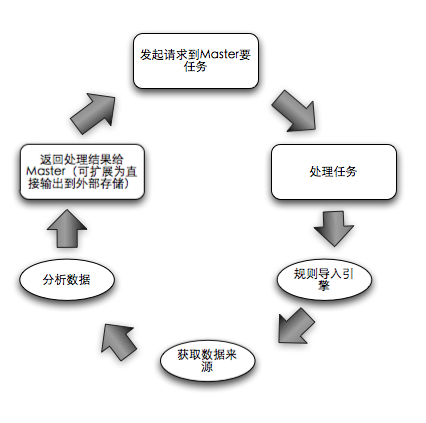
Master зЪДзФЯжіїиљ®ињєпЉЪ
 
 
 
Slave зЪДзФЯжіїиљ®ињєпЉЪ
 
 
жЬЙдЇЇдЉЪиІЙеЊЧињЩзО©жДПеДњзЃАеНХпЉМз≥їзїЯе∞±жШѓзЃАеНХпЉЛйАПжШОжЙНдЉЪйЂШжХИпЉМеЊАеЊАе∞±жШѓеЫ†дЄЇз≥їзїЯе§НжЭВжЙНдЉЪеЄ¶жЭ•жЫіе§ЪзЬЛдЉЉеЊИйЂШжЈ±зЪДиЃЊиЃ°пЉМжЬАзїИжЧ†йЭЮжШѓжКШиЕЊдЇЖиЗ™еЈ±пЉМиЛ¶дЇЖдЄАзЇњгАВеЇЯиѓЭдЄНе§ЪиѓіпЉМиГМжЩѓдїЛзїНеЃМдЇЖпЉМеЉАеІЛиЃ≤еЕЈдљУзЪДжЉФеПШињЗз®ЛгАВ
жХ∞жНЃйЗПпЉЪ 2 еНГдЄЗ √† 1 дЇњ √† 8 дЇњ √† 15 дЇњгАВжК•и°®иЊУеЗЇзїУжЮЬпЉЪ 10 дїљйЕНзљЃ √† 30 дїљ √† 60 дїљ √† 100 дїљгАВзїЯиЃ°еРОзЪДжХ∞жНЃйЗПпЉЪ 10k √† 10M √† 9G гАВзїЯиЃ°еС®жЬЯзЪДи¶Бж±ВпЉЪ 1 姩 √† 5 еИЖйТЯ √† 3 еИЖйТЯ √† 1 еИЖеНКгАВ
дїОдЄКйЭҐињЩдЇЫжХ∞жНЃеПѓдї•зЯ•йБУдїОзљСзїЬеТМз£БзЫШ IO пЉМеИ∞еЖЕе≠ШпЉМеИ∞ CPU йГљдЉЪзїПеОЖеЊИе§ІзЪДиАГй™МпЉМзФ±дЇО Master жШѓзЇµеРСжЙ©е±ХзЪДпЉМеЫ†ж≠§дЉШеМЦ Master жИРдЄЇжѓПдЄ™жХ∞жНЃиЈ≥еК®зЪДењЕзДґи¶Бж±ВгАВзФ±дЇОжШѓзФ® Java еЖЩзЪДпЉМеЫ†ж≠§еЖЕе≠ШеѓєдЇОжХідљУеИЖжЮРзЪДељ±еУНжЫіеК†дЄ•йЗНпЉМ GC зЪДеБЬй°њзЫіжО•еПѓдї•дљњеЊЧз≥їзїЯжМВжОЙпЉИеЫ†дЄЇжХ∞жНЃеЬ®дЄНжЦ≠жµБеЕ•еЖЕе≠ШпЉЙгАВ
 
дЉШеМЦињЗз®ЛпЉЪ
 
зЇµеРСз≥їзїЯзЪДеЈ•дљЬзЪДеИЖжЛЕпЉЪ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† дїО Master зЪДзФЯжіїиљ®ињєеПѓдї•зЬЛеИ∞пЉМеЃГиіЯиНЈжЬАе§ІзЪДдЄАж≠•е∞±жШѓи¶БеОїиіЯиі£ Reduce пЉМжЧ†иЃЇе¶ВдљХйГљйЬАи¶БдЇ§зїЩдЄАдЄ™еНХиКВзВєжЭ•еЃМжИРжЙАжЬЙзЪД Reduce пЉМдљЖеєґдЄНи°®з§ЇеѓєдЇОе§ЪдЄ™ Slave зЪДжЙАжЬЙзЪД Reduce йГљйЬАи¶Б Master жЭ•еБЪгАВжЬЙеРМе≠¶зїЩињЗеїЇиЃЃиѓіиЃ© Master еЖНеОїеИЖйЕНзїЩдЄНеРМзЪД Slave еОїеБЪ Slave дєЛйЧізЪД Reduce пЉМдљЖдЄАжЧ¶еЉХеЕ• Master еѓє Slave зЪДйАЪдњ°еТМзЃ°зРЖпЉМињЩе∞±еЫЮеИ∞дЇЖе§НжЭВзЪДиАБиЈѓгАВеЫ†ж≠§ињЩйЗМзФ®жЬАзЃАеНХзЪДжЦєеЉПпЉМдЄАдЄ™жЬЇеЩ®еПѓдї•йГ®зљ≤е§ЪдЄ™ Slave пЉМдЄАдЄ™ Slave еПѓдї•дЄАжђ°иОЈеПЦе§ЪдЄ™ Job пЉМжЙІи°МеЃМжѓХеРОжЬђеЬ∞еРИеєґеЖНж±ЗжК•зїЩ Master гАВпЉИдЉШеКњпЉЪ Master еЬ® Job еРИеєґжЙАдЇІзФЯзЪДеЖЕе≠ШжґИиАЧеПѓдї•еЗПиљїпЉМеЫ†дЄЇињЩжШѓзїЯиЃ°пЉМжЙАдї•еРИеєґеРОжХ∞жНЃйЗПдЄАеЃЪе§ІеєЕдЄЛйЩНпЉМж≠§жЧґ Master еРИеєґиґКе∞СзЪД Job жХ∞йЗПпЉМеЖЕе≠ШжґИиАЧиґКе∞ПпЉЙпЉМеЫ†ж≠§ Slave зЪДзФЯжіїиљ®ињєеПШеМЦдЇЖдЄАзВєпЉЪ
 
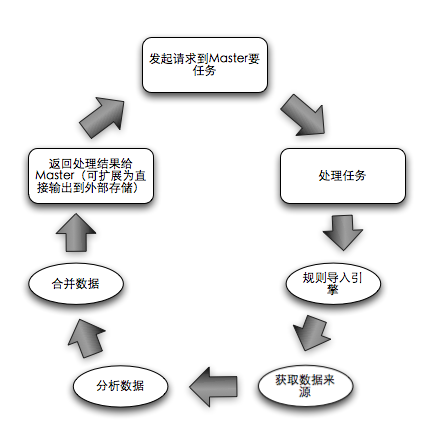
 
 
 
жµБз®ЛдЄ≠йЧіжХ∞жНЃдЉШеМЦпЉЪ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ињЩйЗМдЄЊдЄ§дЄ™дЊЛе≠РжЭ•иѓіжШОеѓєдЇОе§ДзРЖдЄ≠дЄ≠йЧіжХ∞жНЃдЉШеМЦзЪДжДПдєЙгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЬ®зїЯиЃ°еИЖжЮРдЄ≠еЊАеЊАдЉЪжЬЙеѓєеИЖжЮРеРОзЪДжХ∞жНЃеБЪеЖНжђ°е§ДзРЖзЪДйЬАж±ВпЉМдЊЛе¶ВдЄАдЄ™ API жК•и°®йЗМйЭҐдЉЪжЬЙ API иЃњйЧЃжАїйЗПпЉМ API иЃњйЧЃжИРеКЯжХ∞пЉМеРМжЧґдЉЪи¶БжЬЙ API зЪДжИРеКЯзОЗпЉМињЩдЄ™жХ∞жНЃжЬАжЧ©иЃЊиЃ°зЪДжЧґеАЩеТМжЩЃйАЪзЪД MapReduce е≠ЧжЃµдЄАж†Је§ДзРЖпЉМиЃ°зЃЧеТМе≠ШеВ®еЬ®жѓПдЄАи°МжХ∞жНЃеИЖжЮРзЪДжЧґеАЩйГљеБЪпЉМдљЖеЕґеЃЮињЩз±їжХ∞жНЃеП™жЬЙеЬ®жЬАеРОиЊУеЗЇзЪДжЧґеАЩжЙНжЬЙзїЯиЃ°еТМе≠ШеВ®дїЈеАЉпЉМеЫ†дЄЇињЩдЇЫжХ∞жНЃйГљеПѓдї•йАЪињЗеЈ≤жЬЙжХ∞жНЃиЃ°зЃЧеЊЧеИ∞пЉМиАМдЄ≠йЧіеПНе§НеБЪиЃ°зЃЧеЬ®е≠ШеВ®еТМиЃ°зЃЧдЄКйГљжШѓдЄАзІНжµ™иієпЉМеЫ†ж≠§еѓєдЇОињЩзІНзЙєжЃКзЪД Lazy е§ДзРЖе≠ЧжЃµпЉМдЄ≠йЧідЄНиЃ°зЃЧдєЯдЄНе≠ШеВ®пЉМеЬ®еС®жЬЯиЊУеЗЇжЧґеБЪдЄАжђ°еИЖжЮРпЉМйЩНдљОдЇЖиЃ°зЃЧеТМе≠ШеВ®зЪДеОЛеКЫгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еѓєдЇО MapReduce дЄ≠зЪД Key е≠ШеВ®зЪДеОЛзЉ©гАВзФ±дЇОеЊИе§ЪзїЯиЃ°зЪД Key жШѓеЊИе§ЪдЄЪеК°жХ∞жНЃзЪДзїДеРИпЉМдЊЛе¶В APPAPIUser зЪДзїЯиЃ°жК•и°®пЉМеЃГзЪД Key е∞±жШѓдЄЙдЄ™е≠ЧжЃµзЪДдЄ≤иБФпЉЪ taobao.user.getвАФ12132342вАФfangweng пЉМињЩжЧґеАЩе§ІйЗПзЪД Key дЉЪеН†зФ®еЖЕе≠ШпЉМиАМ Key зЪДзЫЃзЪДе∞±жШѓдЇІзФЯињЩдЄ™дЄЪеК°зїЯиЃ°дЄ≠зЪДеФѓдЄАж†ЗиѓЖпЉМеЫ†ж≠§иАГиЩСињЩдЇЫ API зЪДеРНзІ∞з≠Йз≠ЙжШѓеР¶еПѓдї•жЫњжНҐжИРеФѓдЄАзЪДзЯ≠еЖЕеЃєе∞±еПѓдї•еЗПе∞СеЖЕе≠ШеН†зФ®гАВињЗз®ЛдЄ≠е∞±дЄНе§ЪиѓідЇЖпЉМжЬАеРОеЬ®еИЖжЮРеЩ®йЗМйЭҐеЃЮзО∞дЇЖдЄ§зІНз≠ЦзХ•пЉЪ
1.¬†¬†¬†¬† дЄНеПѓйАЖжХ∞е≠ЧжСШи¶БйЗЗж†ЈгАВ
жЬЙзВєз±їдЉЉдЄОзЯ≠ињЮжО•иљђжНҐзЪДжЦєеЉПпЉМеѓєжХ∞жНЃеБЪ Md5 жХ∞е≠ЧжСШи¶БпЉМиОЈеЊЧ 16 дЄ™ byte пЉМзДґеРОж†єжНЃеОЛзЉ©йЕНзљЃжЭ•йЗЗж†Ј 16 дЄ™ byte йГ®еИЖпЉМзФ®еПѓиІБе≠Чзђ¶еЃЪдєЙеЗЇ 64 ињЫеИґжЭ•ж†ЗиѓЖињЩдЇЫйЗЗж†ЈпЉМжЬАеРО嚥жИРиЊГзЯ≠зЪДе≠Чзђ¶дЄ≤гАВ
зФ±дЇО Slave жШѓжХ∞жНЃеИЖжЮРиАЕпЉМеЫ†ж≠§зФ® Slave зЪД CPU жЭ•жНҐ Master зЪДеЖЕе≠ШпЉМе∞ЖдЄ≠йЧізїУжЮЬзФ®дЄНеПѓйАЖзЪДзЯ≠е≠Чзђ¶дЄ≤жЦєеЉПи°®з§ЇгАВеЉ±зВєпЉЪељУжЬАеРОеИЖжЮРеЗЇжЭ•зЪДжХ∞жНЃйЗПиґКе§ІпЉМйЗЗж†Ј md5 еРОзЪДжХ∞жНЃиґКе∞СпЉМиґКеЃєжШУдЇІзФЯеЖ≤з™БпЉМеѓЉиЗізїЯиЃ°дЄНеЗЖз°ЃгАВ
 
2.¬†¬†¬†¬† жПРдЊЫйЬАи¶БеОЛзЉ©зЪДдЄЪеК°жХ∞жНЃеИЧи°®гАВ
дЄЪеК°жЦєжПРдЊЫжЧ•ењЧдЄ≠йЬАи¶БжЫњжНҐзЪДеИЧеЃЪдєЙеПКдЄАзїДеЃЪдєЙеЖЕеЃєгАВзЃАеНХжЭ•иѓіпЉМељУжЧ•ењЧжЯРдЄАеИЧеσ俕襀жЮЪдЄЊпЉМйВ£дєИе∞±жДПеС≥иАЕињЩдЄАеИЧеσ俕襀зЃАеНХзЪДжЫњжНҐжИРзЯ≠ж†ЗиѓЖгАВдЊЛе¶ВйЕНзљЃ APIName ињЩеИЧеЬ®еИЖжЮРзФЯжИР key зЪДжЧґеАЩеσ俕襀жЫњжНҐпЉМеєґдЄФжПРдЊЫдЇЖ 500 е§ЪдЄ™ api зЪДеРНзІ∞жЦЗдїґиљљеЕ•еИ∞еЖЕе≠ШдЄ≠пЉМйВ£дєИжѓПжђ° api еЬ®зФЯжИР key зЪДжЧґеАЩе∞±дЉЪ襀жЫњжНҐжОЙеРНзІ∞зїДеРИеЬ® key дЄ≠пЉМе§Іе§ІзЉ©зЯ≠ key гАВйВ£дЄЇдїАдєИи¶БжПРдЊЫињЩдЇЫ api зЪДеРНзІ∞еСҐпЉЯй¶ЦеЕИеИЖжЮРзФЯжИР key еЬ® Slave пЉМжШѓеИЖеЄГеЉПзЪДпЉМе¶ВжЮЬйЗЗзФ®иЗ™е≠¶дє†зЪДж®°еЉПпЉМеКњењЕи¶БеЉХеЕ•йЫЖдЄ≠еЉПеФѓдЄА糥еЉХзФЯжИРеЩ®пЉМеЕґжђ°ињШи¶БеБЪе•љиґ≥е§ЯзЪДеєґеПСжОІеИґпЉМеП¶дЄАжЦєйЭҐдєЯдЉЪзФ±еєґеПСжОІеИґеЄ¶жЭ•жАІиГљжНЯиАЧгАВињЩзІНж®°еЉПиЩљзДґеЊИеОЯеІЛпЉМдљЖдЄНдЉЪељ±еУНзїЯиЃ°зїУжЮЬзЪДеЗЖз°ЃжАІпЉМеЫ†ж≠§еЬ®еИЖжЮРеЩ®дЄ≠襀䚜зФ®пЉМињЩдЄ™еИЧи°®дЉЪйЪПзЭАдїїеК°иІДеИЩжѓПжђ°еПСйАБеИ∞ Slave дЄ≠пЉМдњЭиѓБжЙАжЬЙиКВзВєеИЖжЮРзїУжЮЬзЪДдЄАиЗіжАІгАВ
 
зЙєжЃКеМЦе§ДзРЖзЙєжЃКзЪДжµБз®ЛпЉЪ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЬ® Master зЪДзФЯжіїиљ®ињєдЄ≠еПѓдї•зЬЛеЗЇпЉМељ±еУНдЄАиљЃиЊУеЗЇжЧґйЧіеТМеЖЕе≠ШдљњзФ®зЪДеМЕжЛђеИЖжЮРеРИеєґжХ∞жНЃзїУжЮЬпЉМеѓЉеЗЇжК•и°®еТМеѓЉеЗЇдЄ≠йЧізїУжЮЬгАВеЬ®жХ∞жНЃдЄКеНЗеИ∞ 1 дЇњзЪДжЧґеАЩпЉМ Slave еТМ Master дєЛйЧіжХ∞жНЃйАЪдњ°дї•еПК Master зЪДдЄ≠йЧізїУжЮЬз£БзЫШеМЦзЪДињЗз®ЛдЄ≠йГљйЗЗзФ®дЇЖеОЛзЉ©зЪДжЦєеЉПжЭ•еЗПе∞СжХ∞жНЃдЇ§дЇТеѓє IO зЉУеЖ≤зЪДељ±еУНпЉМдљЖдЄАзЫіиАГиЩСжШѓеР¶ињШеПѓдї•еЖНеОЛ涮дЄАзВєгАВй¶ЦеЕИеѓЉеЗЇдЄ≠йЧізїУжЮЬзЪДжЧґеАЩжЬАеИЭйЗЗзФ®зЃАеНХзЪД Object еЇПеИЧеМЦеѓЉеЗЇпЉМдїОеЖЕе≠ШдљњзФ®пЉМе§ЦйГ®жХ∞жНЃе§Іе∞ПпЉМиЊУеЗЇжЧґйЧідЄКжЭ•иѓійГљжЬЙдЄНе∞СзЪДжґИиАЧпЉМдїФзїЖзЬЛдЇЖдЄАдЄЛдЄ≠йЧізїУжЮЬжШѓ Map<String,Map<String,Obj>> пЉМеЕґеЃЮжЬАеРОдЄАдЄ™ Obj жЧ†йЭЮеП™жЬЙдЄ§зІНз±їеЮЛ Double еТМ String пЉМжЧҐзДґињЩж†ЈпЉМеЇПеИЧеМЦеЃМеЕ®еПѓдї•зЃАеНХжЭ•дљЬпЉМеЫ†ж≠§зЫіжО•еЊИзЃАеНХзЪДеЃЮзО∞дЇЖз±їдЉЉ Json зЃАеМЦзЙИзЪДеЇПеИЧеМЦпЉМдїОеЇПеИЧеМЦйАЯеЇ¶пЉМеЖЕе≠ШеН†зФ®еЗПе∞СдЄКпЉМе§ЦйГ®з£БзЫШе≠ШеВ®йГљжЬЙдЇЖжЮБе§ІзЪДжПРйЂШпЉМе§ЦйГ®з£БзЫШе≠ШеВ®иґКе∞ПпЉМжЙАжґИиАЧзЪД IO еТМињЗз®ЛдЄ≠йЬАи¶БзЪДдЄіжЧґеЖЕе≠ШйГљдЉЪдЄЛйЩНпЉМеЇПеИЧеМЦйАЯеЇ¶еК†ењЂпЉМйВ£дєИеЖЕе≠ШдЄ≠зЪДжХ∞жНЃе∞±дЉЪ襀е∞љењЂйЗКжФЊгАВжАїдљУдЄКжЭ•иѓіе∞±жШѓзЙєжЃКеМЦе§ДзРЖдЇЖеПѓдї•зЙєжЃКеМЦеѓєеЊЕзЪДжµБз®ЛпЉМжПРйЂШдЇЖиµДжЇРеИ©зФ®зОЗгАВпЉИеРМжЧґдЄ≠йЧізїУжЮЬеЬ®еЙНжЬЯдЉШеМЦйШґжЃµзЪДдљЬзФ®е∞±жШѓдЄЇдЇЖе§ЗдїљпЉМеЫ†ж≠§дЄНйЬАи¶БжѓПдЄ™еС®жЬЯйГљеБЪпЉМељУжЧґеБЪжИРеПѓйЕНзљЃзЪДеС®жЬЯеАЉиЊУеЗЇпЉЙ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЖНжО•зЭАжЭ•и∞ИдЄАдЄЛдЄ≠йЧізїУжЮЬеРИеєґжЧґеАЩеѓєдЇОеЖЕе≠ШдљњзФ®зЪДдЉШеМЦгАВ Master дЉЪдїОе§ЪдЄ™ Slave еЊЧеИ∞е§ЪдЄ™ Map<Key,Map<Key,Value>> пЉМеРИеєґињЗз®Ле∞±жШѓеѓєе§ЪдЄ™ Map е∞ЖзђђдЄАзЇІ Key зЫЄеРМзЪДжХ∞жНЃеБЪжХіеРИпЉМдЊЛе¶ВзђђдЄАзЇІ Key зЪДдЄАдЄ™еАЉжШѓ API иЃњйЧЃжАїйЗПпЉМйВ£дєИеЃГеѓєеЇФзЪД Map дЄ≠е∞±жШѓдЄНеРМзЪД api еРНзІ∞еТМжАїйЗПзЪДзїЯиЃ°пЉМиАМе§ЪдЄ™ Map зЫіжО•еРИеєґе∞±жШѓе∞ЖдЄАзЇІ key пЉИ API иЃњйЧЃжАїйЗПпЉЙдЄЛзЪД Map жХ∞жНЃеРИеєґиµЈжЭ•пЉИеРМж†ЈзЪД api жАїйЗПзЫЄеК†жЬАеРОдњЭе≠ШдЄАдїљпЉЙгАВжЬАзЃАеНХзЪДеБЪж≥Хе∞±жШѓе§ЪдЄ™ Map<Key,Map<Key,Value>> йАТељТзЪДжЭ•еРИеєґпЉМдљЖе¶ВжЮЬи¶БиКВзЬБеЖЕе≠ШеТМиЃ°зЃЧеПѓдї•жЬЙдЄ§дЄ™е∞ПжФєињЫпЉМй¶ЦеЕИйАЙжЛ©еЕґдЄ≠дЄАдЄ™дљЬдЄЇжЬАзїИзЪДзїУжЮЬйЫЖеРИпЉИйБњеЕНзФ≥иѓЈжЦ∞з©ЇйЧіпЉМдєЯйБњеЕН蚁胥ињЩдЄ™ Map зЪДжХ∞жНЃпЉЙпЉМеЕґжђ°жѓПдЄАжђ°йАТељТжЧґеАЩпЉМе∞ЖеРИеєґеРОзЪДеРОйЭҐзЪД Map дЄ≠жХ∞жНЃзІїеЗЇпЉИеЗПе∞СеРОзї≠жЧ†зФ®зЪДеЊ™зОѓеѓєжѓФпЉМеРМжЧґдєЯиКВзЬБз©ЇйЧіпЉЙгАВзЬЛдЉЉе∞ПжФєеК®пЉМдљЖжХИжЮЬеЊИдЄНйФЩгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЖНи∞ИдЄАдЄЛеЬ®иЊУеЗЇзїУжЮЬжЧґеАЩзЪДеЖЕе≠ШиКВзЬБгАВеЬ®иЊУеЗЇзїУжЮЬзЪДжЧґеАЩпЉМжШѓеЯЇдЇОеЖЕе≠ШдЄ≠дЄАдїљ Map<Key,Map<Key,Value>> жЭ•жЮДеїЇзЪДгАВеЕґеЃЮе∞ЖдЉ†зїЯзЪД MapReduce зЪД KV зїУжЮЬе¶ВдљХиљђжНҐжИРдЄЇдЉ†зїЯзЪД Report пЉМеП™йЬАи¶БзЬЛзЬЛ Sql дЄ≠зЪД Group иЃЊиЃ°пЉМе∞Же§ЪдЄ™ KV йАЪињЗ Group by key пЉМе∞±еПѓдї•еЊЧеИ∞дЉ†зїЯжДПдєЙдЄКзЪД Key пЉМ Value пЉМ Value пЉМ Value гАВдЊЛе¶ВпЉЪ KV еПѓдї•жШѓ <apiName,apiTotalCount>,<apiName,apiResponse>,<apiName,apiFailCount> пЉМе¶ВжЮЬ Group by apiName пЉМйВ£дєИе∞±еПѓдї•еЊЧеИ∞ apiName,apiTotalCount,apiResponse,apiFailCount зЪДжК•и°®и°МзїУжЮЬгАВињЩзІНељТжАїзЪДжЦєеЉПеПѓдї•з±їдЉЉе°Ђе≠ЧжЄЄжИПпЉМеЫ†дЄЇжИСдїђзїУжЮЬжШѓ KV пЉМжЙАдї•ињЩдЄ™е°Ђе≠ЧжЄЄжИПйїШиЃ§дїОеИЧеЉАеІЛе°ЂеЖЩпЉМйБНеОЖжЙАжЬЙзЪД KV дї•еРОе∞±еПѓдї•еЃМжХізЪДеЊЧеИ∞дЄАдЄ™е§ІзЪДзЯ©йШµеєґжМЙзЕІи°МиЊУеЗЇпЉМдљЖдї£дїЈжШѓ KV ж≤°жЬЙйБНеОЖеЃМжИРдї•еЙНпЉМжЧ†ж≥ХиЊУеЗЇгАВеЫ†ж≠§иАГиЩСжШѓеР¶еПѓдї•жМЙзЕІи°МжЭ•е°ЂеЖЩпЉМзДґеРОжѓПдЄАи°Ме°ЂеЖЩеЃМжѓХдєЛеРОзЫіжО•иЊУеЗЇпЉМиКВзЬБзФ≥иѓЈеЖЕе≠ШгАВжМЙи°Ме°ЂеЖЩжЬАе§ІзЪДйЧЃйҐШе∞±жШѓе¶ВдљХеЬ®еѓє KV дЄ≠еЈ≤зїПе§ДзРЖињЗзЪДжХ∞жНЃжЙУдЄКж†ЗиѓЖпЉМдЄНи¶БйЗНе§Не§ДзРЖгАВпЉИдЄАзІНжЦєеЉПеЉХеЕ•е§ЦйГ®е≠ШеВ®жЭ•ж†ЗиѓЖињЩдЄ™еАЉеЈ≤зїП襀е§ДзРЖињЗпЉМеЫ†дЄЇињЩдЇЫ KV дЄНеПѓдї•з±їдЉЉеРИеєґзЪДжЧґеАЩеИ†йЩ§пЉМеРОзї≠ињШдЉЪзїІзї≠и¶БзФ®пЉМеП¶дЄАзІНжЦєеЉПе∞±жШѓеЃМеЕ®е§ЗдїљдЄАдїљжХ∞жНЃпЉМеРИеєґеЃМжИРеРОе∞±еИ†йЩ§пЉЙпЉМдљЖжЬђжЭ•е∞±жШѓдЄЇдЇЖиКВзЇ¶еЖЕе≠ШзЪДпЉМеЉХеЕ•жЫіе§ЪзЪДе≠ШеВ®пЉМе∞±еТМзЫЃж†ЗжЬЙжВЦдЇЖгАВеЫ†ж≠§еБЪдЇЖдЄАдЄ™иЃ°зЃЧжНҐе≠ШеВ®зЪДеБЪж≥ХпЉМдЊЛе¶Ве°ЂеЕЕжЧґиљЃиЃ≠зЪДй°ЇеЇПдЄЇпЉЪ K1V1 пЉМ K2V2 пЉМ K3V3 пЉМеИ∞ K2V2 йБНеОЖзЪДжЧґеАЩпЉМеИ§жЦ≠жШѓеР¶и¶Бе§ДзРЖељУеЙНињЩдЄ™жХ∞жНЃпЉМе∞±еП™и¶БеИ§жЦ≠ињЩдЄ™ K жШѓеР¶еЬ® K1 йЗМйЭҐеЗЇзО∞ињЗпЉМиАМеИ∞ K3V3 йБНеОЖзЪДжЧґеАЩпЉМеИ§жЦ≠жШѓеР¶и¶Бе§ДзРЖпЉМе∞±иљЃиѓҐ K1K2 жШѓеР¶е≠ШеЬ®ињЩдЄ™ K пЉМзФ±дЇОйГљжШѓ Map зїУжЮДпЉМеЫ†ж≠§ињЩзІНжЯ•жЙЊзЪДжґИиАЧеЊИе∞ПпЉМзФ±ж≠§жФєдЄЇи°Ме°ЂеЖЩпЉМйАРи°МиЊУеЗЇгАВ
 
жЬАеРОеЖНи∞ИдЄАдЄЛжЬАйЗНе§ізЪДдЉШеМЦпЉМеРИеєґи∞ГеЇ¶еПКз£БзЫШеЖЕе≠ШдЇТжНҐзЪДдЉШеМЦ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† дїО Master зЪДзФЯжіїиљ®ињєеПѓдї•зЬЛеИ∞пЉМеОЯжЭ•зЪДдЄїзЇњз®ЛиіЯиі£ж£АжЯ•е§ЦйГ®еИЖжЮРжХ∞жНЃзїУжЮЬзКґжАБпЉМеРИеєґжХ∞жНЃзїУжЮЬињЩдЄ™еЊ™зОѓпЉМиАГиЩСеИ∞жЬАзїИеРИеєґеРОжХ∞жНЃеП™жЬЙдЄАдЄ™дЄїеє≤пЉМеЫ†ж≠§йЗЗзФ®еНХзЇњз®ЛеРИеєґж®°еЉПжЭ•ињРдљЬпЉМиІБдЄЛеЫЊпЉЪ
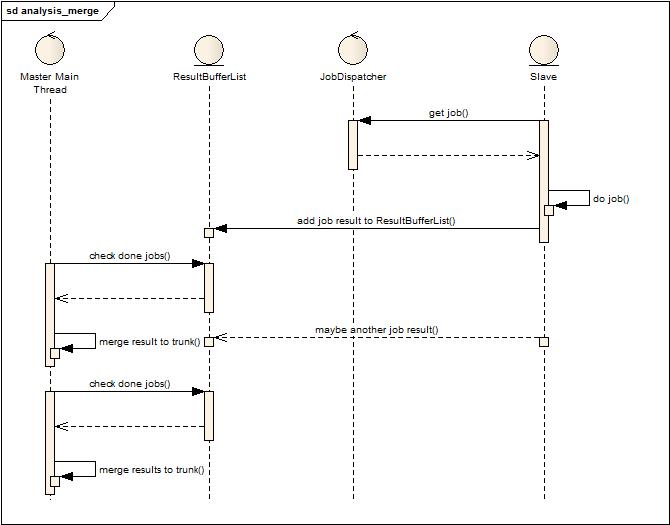
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ињЩеЉ†еЫЊе§ІиЗіжППињ∞дЇЖдЄАдЄЛе§ДзРЖжµБз®ЛпЉМ Slave йЪПжЧґйГљдЉЪе∞ЖеИЖжЮРеРОзЪДзїУжЮЬжМВеИ∞зїУжЮЬзЉУеЖ≤йШЯеИЧдЄКпЉМзДґеРОдЄїзЇњз®ЛиіЯиі£жЙєйЗП иОЈеПЦзїУжЮЬеєґдЄФеРИеєґгАВиЩљзДґжШѓжЙєйЗПиОЈеПЦпЉМдљЖжШѓдЄЇдЇЖиКВзЬБеЖЕе≠ШпЉМдєЯдЄНиГљз≠ЙеЊЕ姙дєЕпЉМеЫ†дЄЇжѓПдЄАзВєз≠ЙеЊЕе∞±жДПеС≥зЭАе§ІйЗПж≤°жЬЙеРИеєґзЪДжХ∞жНЃе∞ЖдЉЪе≠ШеЬ®дЄОеЖЕе≠ШдЄ≠пЉМдљЖеРИеєґзЪД姙йҐСзєБдєЯдЉЪ еѓЉиЗіеЬ®еРИеєґињЗз®ЛдЄ≠пЉМжЦ∞еК†еЕ•зЪДзїУжЮЬдЉЪз≠ЙеЊЕеЊИдєЕпЉМеѓЉиЗіеЖЕе≠ШеРГзіІгАВжИЦиЃЄињЩдЄ™жЧґеАЩдЉЪиАГиЩСпЉМдЄЇдїАдєИдЄНзЫіжО•зФ®е§ЪзЇњз®ЛжЭ•еРИеєґпЉМзЪДз°ЃпЉМе§ЪзЇњз®ЛеРИеєґеєґйЭЮдЄНеПѓи°МпЉМдљЖи¶БиАГиЩСе¶ВдљХ еЕЉй°ЊеИ∞дЄїеє≤еРИеєґзЪДеєґеПСжОІеИґпЉМеЫ†дЄЇе§ЪдЄ™зЇњз®ЛдЄНеПѓиГљеРМжЧґйГљеРИеєґеИ∞жХ∞жНЃдЄїеє≤дЄКпЉМзФ±ж≠§еЉХеЕ•дЇЖдЄЛйЭҐзЪДиЃЊиЃ°еЃЮзО∞пЉМеНКеєґи°Мж®°еЉПзЪДеРИеєґпЉЪ
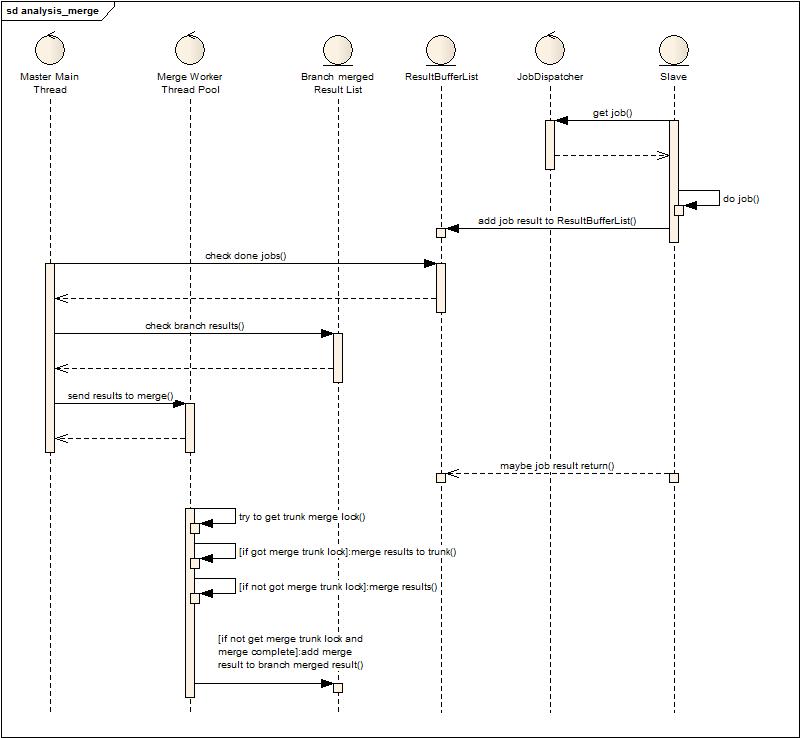
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† дїОдЄКеЫЊеПѓдї•еПСзО∞еҐЮеК†дЇЖдЄ§дЄ™иІТиЙ≤пЉЪ Merge Worker Thread Pool еТМ Branch merged ResultList пЉМ дЄОдЄКйЭҐиЃЊиЃ°зЪДеЈЃеИЂе∞±еЬ®дЇОдЄїзЇњз®ЛдЄНеЖНиіЯиі£еРИеєґжХ∞жНЃпЉМиАМжШѓжЙєйЗПзЪДиОЈеПЦжХ∞жНЃдЇ§зїЩеРИеєґзЇњз®Л汆жЭ•еРИеєґпЉМиАМеРИеєґзЇњз®Л汆дЄ≠зЪДеЈ•дљЬиАЕеЬ®еРИеєґзЪДињЗз®ЛдЄ≠дЉЪзЂЮдЇЙдЄїеє≤еРИеєґйФБпЉМжИРеКЯ иОЈеЊЧзЪДе∞±еТМдЄїеє≤еРИеєґпЉМдЄНжИРеКЯзЪДе∞±е∞ЖзїУжЮЬеРИеєґеРОжФЊеИ∞еИЖжФѓеРИеєґйШЯеИЧдЄКпЉМз≠ЙеЊЕдЄЛжђ°еРИеєґж״襀䪿еє≤еРИеєґжИЦиАЕеИЖжФѓеРИеєґиОЈеЊЧеЖНжђ°еРИеєґгАВињЩж†ЈжФєињЫеРОпЉМеПСзО∞зФ±дЇОжХ∞жНЃжМВеЬ®йШЯеИЧ ж≤°жЬЙеЊЧеИ∞еПКжЧґе§ДзРЖдЇІзФЯзЪДеЖЕе≠ШеОЛеКЫе§Іе§ІдЄЛйЩНпЉМеРМжЧґдєЯеЕЕеИЖеИ©зФ®дЇЖе§Ъж†ЄпЉМе§ЪзЇњз®Л涮еє≤дЇЖе§Ъж†ЄзЪДиЃ°зЃЧиГљеКЫпЉИзЇњз®Л汆姲е∞Пж†єжНЃ cpu ж†ЄжЭ•иЃЊзљЃзЪДе∞ПдЄАзВєпЉМйҐДзХЩдЄАзВєзїЩ GC зФ®пЉЙгАВињЩзІНиЃЊиЃ°дЄ≠ињШе§ЪдЇЖдЄАдЇЫе∞ПзЪДи∞ГдЉШйЕНзљЃпЉМдЊЛе¶ВжШѓеР¶еЕБ聪襀еРИеєґињЗзЪДжХ∞жНЃе§Ъ搰襀еЖНжђ°еРИеєґпЉИйШ≤ж≠ҐжЧ†зХПзЪДиЃ°зЃЧжґИиАЧпЉЙпЉМжѓПжђ°еєґи°МеРИеєґжЬАе∞ПзїУжЮЬжХ∞жШѓе§Ъе∞СпЉМз≠ЙеЊЕе†ЖзІѓеИ∞жЬАе∞ПзїУжЮЬжХ∞зЪДжЬАе§ІжЧґйЧіз≠Йз≠ЙгАВпЉИжЬЙеЕіиґ£зЬЛдї£з†БпЉЙ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† иЗ≥дЄКйЭҐзЪДдЉШеМЦдЄЇж≠ҐпЉМжДЯиІЙеРИеєґињЩеЭЧеЈ≤зїП襀涮еє≤дЇЖпЉМдљЖеИЖжЮРжЧ•ењЧжХ∞жНЃзЪД еҐЮе§ЪпЉМеѓєеПКжЧґжАІи¶Бж±ВзЪДеК†еЉЇпЉМдљњеЊЧжИСеПИи¶БйЗНжЦ∞еЃ°иІЖжШѓеР¶ињШжЬЙиГљеКЫзїІзї≠涮еЗЇињЩдЄ™жµБз®ЛзЪДж∞ідїљгАВеЫ†ж≠§жЬЙдЇЖдЄАдЄ™е§ІиГЖзЪДжГ≥ж≥ХпЉМз£БзЫШжНҐеЖЕе≠ШгАВеЫ†дЄЇеЬ®и∞ГеЇ¶еРИеєґдЄКеЈ≤зїПжЙЊдЄНеИ∞жЫі е§ЪеПѓдї•дЉШеМЦзЪДзВєдЇЖпЉМдљЖжШѓжЬЙдЄАзВєињШеПѓдї•иАГиЩСпЉМе∞±жШѓдЄїеє≤зЪДйВ£зВєжХ∞жНЃжШѓеР¶и¶Биіѓз©њдЇОжХідЄ™еРИеєґеС®жЬЯпЉМиАМдЄФдЄїеє≤зЪДжХ∞жНЃйЪПзЭАеҐЮйЗПеИЖжЮРдЄНжЦ≠еҐЮе§ІпЉИеЬ®жЬАињСињЩжђ°дЉШеМЦзЪДињЗз®ЛдЄ≠дєЯ е∞±жШѓеПСзО∞ GC зЪДйҐСзєБеѓЉиЗіеРИеєґйАЯеЇ¶дЄЛйЩНпЉМеРИеєґйАЯеЇ¶дЄЛйЩНеѓЉиЗіеЖЕе≠ШдЄ≠дЄіжЧґжХ∞жНЃдњЭе≠ШзЪДжЧґйЧідєЕпЉМеПНињЗжЭ•еПИељ±еУН GC пЉМжЬАеРОеПШжИРдЇЖжБґжАІеЊ™зОѓпЉЙгАВе∞љзЃ°иІЙеЊЧйЭ†и∞±пЉМдљЖдЄНжµЛиѓХдЄНеЊЧиАМзЯ•гАВдЇОжШѓеЊЧеИ∞дЇЖдї•дЄЛзЪДиЃЊиЃ°еТМеЃЮзО∞пЉЪ
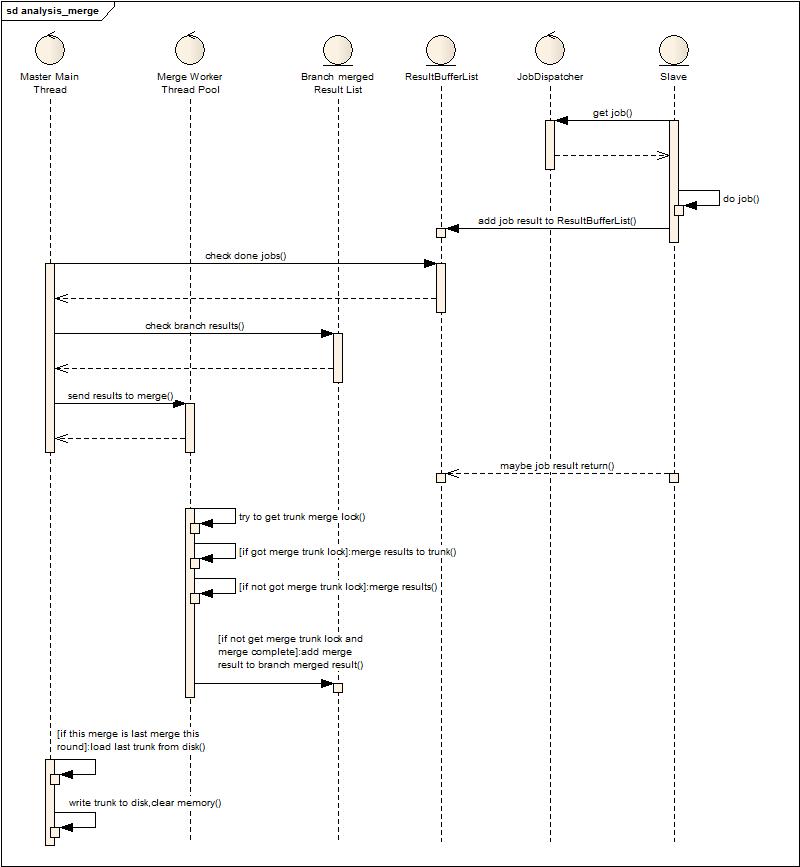
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ињЩдЄ™жµБз®ЛеПСзО∞еТМзђђдЇМдЄ™жµБз®Ле∞±е§ЪдЇЖжЬАеРОдЄ§дЄ™ж≠•й™§пЉМеИ§жЦ≠жШѓеР¶жШѓжЬАеРОзЪДдЄАжђ°еРИеєґпЉМе¶ВжЮЬжШѓиљљеЕ•з£БзЫШжХ∞жНЃпЉМзДґеРОеРИеєґпЉМеРИеєґеЃМеРОе∞ЖдЄїеє≤иЊУеЗЇеИ∞з£БзЫШпЉМжЄЕз©ЇдЄїеє≤еЖЕе≠ШгАВпЉИж≠§жЧґеПСзО∞еѓЉеЗЇдЄ≠йЧізїУжЮЬеОЯжЭ•дЄНжШѓжѓПжђ°ењЕй°їзЪДпЉМдљЖжШѓињЩзІНж®°еЉПдЄЛеНіжИРдЄЇжѓПжђ°ењЕй°їзЪДдЇЖпЉЙ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ињЩдЄ™жФєеК®зЪДдЉШеКњеЬ®дїАдєИеЬ∞жЦєпЉЯдЊЛе¶ВдЄАдЄ™еИЖжЮРеС®жЬЯжШѓ 2 еИЖйТЯпЉМйВ£дєИеЬ® 2 еИЖйТЯеЖЕпЉМдЄїеє≤еЇЮе§ІзЪДжХ∞ж́襀е§ЦзљЃеИ∞з£БзЫШпЉМеЖЕе≠Ше§ІйЗПз©ЇйЧ≤пЉМжЮБе§ІжПРйЂШдЇЖељУеЙНжЧґйЧізЙЗзїУжЮЬеРИеєґзЪДжХИзОЗпЉИ GC е∞СдЇЖпЉЙгАВзЉЇзВєжШѓдїАдєИпЉЯдЉЪеЬ®жѓПдЄ™еС®жЬЯдЇІзФЯдЄ§жђ°з£БзЫШе§ІйЗПзЪДиѓїеЖЩпЉМдљЖйЕНеРИдЄКдЉШеМЦињЗзЪДдЄ≠йЧізїУжЮЬиљљеЕ•иљљеЗЇпЉИеЙНйЭҐзЪДзІБжЬЙеЇПеИЧеМЦпЉЙдЉЪйАВељУзЉУеТМгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† зФ±дЇОзЇњдЄЛжЧ†ж≥Хж®°жЛЯпЉМе∞±е∞ЭиѓХзЭАзЇњдЄКжµЛиѓХпЉМеПСзО∞ GC еЗПе∞СпЉМеРИеєґињЗз®ЛеК†йАЯиЊЊеИ∞йҐДжЬЯпЉМдљЖжШѓжѓПиљЃзЪДз£БзЫШеТМеЖЕе≠ШзЪДжНҐеЕ•жНҐеЗЇзФ±дЇОдєЯиЃ∞еЕ•еЬ®дЄАиљЃеИЖжЮРжЧґйЧідєЛеЖЕпЉМжѓПиљЃеЖЩеЗЇжЬАе§ІжЧґеАЩ 70m жХ∞жНЃпЉМйЬАи¶БжґИиАЧ 10 е§ЪзІТпЉМзФЪиЗ≥ 20 зІТпЉМиѓїеЕ•жЬАе§ІйЬАи¶Б 10s пЉМињЩдЄ™жЧґйЧіе¶ВжЮЬзЃЧеЬ®и¶Бж±ВдЄАиљЃдЄ§еИЖйТЯеЖЕпЉМйВ£дєЯжШѓдЄНеПѓжО•еПЧзЪДпЉЙпЉМйЗНжЦ∞еЃ°иІЖжШѓеР¶жЬЙзЦПжЉПзЪД зїЖиКВгАВй¶ЦеЕИиљљеЕ•жШѓеР¶еПѓдї•еЉВж≠•пЉМе¶ВжЮЬеПѓдї•еЉВж≠•пЉМиАМдЄНжШѓеЬ®жЬАеРОдЄАиљЃжЙНиљљеЕ•пЉМйВ£дєИе∞±дЄНдЉЪзЇ≥еЕ•еИ∞еИЖжЮРеС®жЬЯдЄ≠пЉМеЫ†ж≠§йЕНзљЃдЇЖдЄАдЄ™еПѓдї•и∞ГжХізЪДжѓФдЊЛеАЉпЉМељУдїїеК°еЃМжИРеИ∞иЊЊжИЦиАЕ иґЕињЗињЩдЄ™жѓФдЊЛеАЉзЪДжЧґеАЩпЉМе∞ЖеЉАеІЛеєґи°МиљљеЕ•жХ∞жНЃпЉМжЬАеРОдЄАиљЃз≠ЙеИ∞еЉВж≠•иљљеЕ•еРОеЉАеІЛеИЖжЮРпЉМеПСзО∞жЮЬзДґеПѓи°МпЉМеЫ†ж≠§ињЩдЄ™жЧґй׳襀жОТйЩ§еЬ®еС®жЬЯдєЛе§ЦпЉИиЩљзДґдєЯеЄ¶жЭ•дЇЖдЄАзВєеЖЕе≠ШжґИ иАЧпЉЙгАВзДґеРОеЖНиАГиЩСиЊУеЗЇжШѓеР¶еПѓдї•еЉВж≠•пЉМдї•еЙНиЊУеЗЇдЄНеПѓдї•еЉВж≠•зЪДеОЯеЫ†жШѓињЩдїљжХ∞жНЃжШѓдЄЛдЄАиљЃеИЖжЮРзЪДдЄїеє≤пЉМе¶ВжЮЬеЉВж≠•иЊУеЗЇпЉМдЄЛдЄАиљЃжХ∞жНЃеЉАеІЛе§ДзРЖпЉМеЊИйЪЊдњЭиѓБдЄЛдЄАиљЃзЪДзђђдЄАдЄ™ дїїеК°жШѓеР¶дЉЪеЉХеПСжХ∞жНЃдњЃжФєпЉМеѓЉиЗіеєґеПСйЧЃйҐШпЉМжЙАдї•дЄАзЫійФБеЃЪдЄїеє≤иЊУеЗЇпЉМзЫіеИ∞еЃМжИРеЖНеЉАеІЛпЉМдљЖзО∞еЬ®жѓПжђ°еРИеєґйГљжШѓз©ЇдЄїеє≤еЉАеІЛзЪДпЉМеЫ†ж≠§иЊУеЗЇеЃМеЕ®еПѓдї•еЉВж≠•пЉМдЄїеє≤еПѓдї•зЂЛеИїжЄЕ з©ЇпЉМињЫеЕ•дЄЛдЄАиљЃеРИеєґпЉМеП™и¶БеЬ®дЄЛдЄАдЄ™еС®жЬЯеЉАеІЛиљљеЕ•дЄїеє≤еЙНеЉВж≠•еѓЉеЗЇдЄїеє≤еЃМжИРеН≥еПѓпЉМињЩдЄ™жЧґйЧіжШѓеЊИйХњзЪДпЉМеЃМеЕ®еПѓдї•жККжОІпЉМеЫ†ж≠§иЊУеЗЇдєЯеПѓдї•еПШжИРеЉВж≠•пЉМдЄНзЇ≥еЕ•еИЖжЮРеС®жЬЯгАВ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† иЗ≥ж≠§еЃМжИРдЇЖжЙАжЬЙзЪДдЉШеМЦпЉМеИЖжЮРеЩ®йЂШе≥∞жЬЯзЪДжМЗж†ЗеПСзФЯдЇЖжФєеПШпЉЪдЄАиљЃеИЖжЮРдїО 2 еИЖйТЯеЈ¶еП≥йЩНдљОеИ∞дЇЖ 1 еИЖ 10 зІТпЉМ JVM зЪД O еМЇеЬ®еРИеєґињЗз®ЛдЄ≠дїО 50 пЉН 80 зЪДеН†зФ®зОЗдЄЛйЩНеИ∞ 20 пЉН 60 зЪДеН†зФ®зОЗпЉМ GC жђ°жХ∞жШОжШЊе§ІеєЕеЗПе∞СгАВ
 
жАїзїУпЉЪ
1.¬†¬†¬†¬† еИ©зФ®еПѓж®™еРСжЙ©е±ХзЪДз≥їзїЯжЭ•еИЖжЛЕзЇµеРСжЙ©е±Хз≥їзїЯзЪДеЈ•дљЬгАВ
2.¬†¬†¬†¬† жµБз®ЛдЄ≠дЄ≠йЧіжХ∞жНЃзЪДдЉШеМЦе§ДзРЖгАВ
3.¬†¬†¬†¬† зЙєжЃКеМЦе§ДзРЖеПѓдї•зЙєжЃКе§ДзРЖзЪДжµБз®ЛгАВ
4.¬†¬†¬†¬† дїОжХідљУжµБз®ЛдЄКиАГиЩСдЄНеРМз≠ЦзХ•зЪДжґИиАЧпЉМжПРйЂШжХідљУе§ДзРЖиГљеКЫгАВ
5.¬†¬†¬†¬† иµДжЇРзЪДењЂзФ®ењЂжФЊпЉМжПРйЂШеРМдЄАз±їиµДжЇРеИ©зФ®зОЗгАВ
6.¬†¬†¬†¬† дЄНеРМйШґжЃµдЄНеРМиµДжЇРзЪДдЇТжНҐпЉМжПРйЂШдЄНеРМиµДжЇРзЪДеИ©зФ®зОЗгАВ
 
еЕґеЃЮеЊИе§ЪзїЖиКВдєЯиЃЄзЬЛдЇЖдї£з†БжЙНдЉЪжЬЙжЫіжЈ±зЪДдљУдЉЪпЉМеИЖжЮРеЩ®еП™жШѓдЄАдЄ™еЕЄеЮЛзЪДжґИиАЧжАІж°ИдЊЛпЉМжѓПдЄАзВєжФєињЫйГљжШѓеЬ®жХ∞жНЃеТМдЄЪеК°й©±еК®дЄЛдЄНжЦ≠зЪДиАГй™МгАВдЊЛе¶ВзЇµеРСзЪД Master дєЯиЃЄзЬЯзЪДжЬЙдЄА姩е∞±еИ∞дЇЖеЃГзЪДжЮБйЩРпЉМйВ£дєИе∞±дЇ§зїЩ Slave е∞ЖжХ∞жНЃдЇІеЗЇеИ∞е§ЦйГ®е≠ШеВ®пЉМдЇ§зФ±еЕґдїЦз≥їзїЯжИЦиАЕеП¶дЄАдЄ™еИЖжЮРйЫЖзЊ§еОїеБЪдЇМжђ°еИЖжЮРгАВеѓєдЇОжµЈйЗПжХ∞жНЃзЪДе§ДзРЖжЭ•иѓійГљйЬАи¶БзїПеОЖеИЭжђ°з≠ЫйАЙпЉМеЖНжђ°еИЖжЮРпЉМе±Хз§ЇеЕ≥иБФеЗ†дЄ™йШґжЃµпЉМ Java зЪДеЇФзФ®жСЖиД±дЄНдЇЖеЖЕе≠ШзЇ¶жЭЯеЄ¶жЭ•еѓєиЃ°зЃЧзЪДељ±еУНпЉМеЫ†ж≠§е∞±и¶БиАГиЩСе•љиЗ™еЈ±зЪДй°ґеЬ®дїАдєИеЬ∞жЦєгАВдљЖдЉШеМЦдЄАеЃЪжШѓеЕ®е±АзЪДпЉМдЊЛе¶Вз£БзЫШжНҐеЖЕе≠ШпЉМз£БзЫШеЄ¶жЭ•зЪДжґИиАЧеЬ®жАїдљУдЄКжЭ•иѓіињШжШѓеПѓдї•жО•еПЧзЪДеМЦпЉМйВ£дєИе∞±еσ俕襀йЗЗзЇ≥пЉИељУзДґе¶ВжЮЬзФ®дЄК SSD жХИжЮЬдЉ∞иЃ°дЉЪжЫіе•љпЉЙгАВ
жЬАеРОињШжШѓжГ≥иѓізЪДжШѓпЉМеЊИе§ЪдЇЛжГЕжШѓзЃАеНХеБЪеИ∞е§НжЭВпЉМе§НжЭВеЖНеЫЮељТеИ∞зЃАеНХпЉМеѓєз≥їзїЯжПРеЗЇзЪДжМСжИШе∞±жШѓе¶ВдљХиГље§ЯзФ®жЬАзЫіжО•зЪДжЦєеЉПзЃАеНХзЪДжРЮеЃЪпЉМиАМдЄНжШѓеБЪдЄАдЄ™иЗГиВњдЊЭиµЦеЇЮе§ІзЪДз≥їзїЯпЉМзЃАеНХжЙНзЬЛзЪДжЄЕж•ЪпЉМзЬЛзЪДжЄЕж•ЪжЙНжЬЙжЬЇдЉЪдЄНжЦ≠жФєињЫгАВ
й°ґ
иЄ©


- 2011-10-10 09:39
- жµПиІИ 1316
- иѓДиЃЇ(2)
- еИЖз±ї:зЉЦз®Лиѓ≠и®А
- жЯ•зЬЛжЫіе§Ъ
иѓДиЃЇ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
### жПРеНЗиµДжЇРеИ©зФ®зОЗзЪДMapReduceж°ЖжЮґпЉЪHCE #### иГМжЩѓдЄОеК®жЬЇ йЪПзЭАе§ІжХ∞жНЃе§ДзРЖйЬАж±ВзЪДеҐЮйХњпЉМMapReduceдљЬдЄЇдЄАзІНдЄїжµБзЪДе§ІжХ∞жНЃе§ДзРЖж°Жж޴襀府ж≥ЫеЇФзФ®дЇОеРДзІНеЬЇжЩѓдЄ≠гАВзДґиАМпЉМеЬ®еЃЮйЩЕеЇФзФ®ињЗз®ЛдЄ≠пЉМдЇЇдїђеПСзО∞дЉ†зїЯзЪДMapReduceж°ЖжЮґе¶В...
CCEжШ†е∞ДжЦєеЉПдЉШеМЦпЉЪйТИеѓєиѓЇеЯЇдЇЪзЂЩзВєи¶ЖзЫЦеЖЬжЭСеМЇеЯЯпЉМйАЪињЗдЉШеМЦCCEиµДжЇРжШ†е∞ДжЦєеЉПпЉИдЇ§зїЗгАБйЭЮдЇ§зїЗпЉЙпЉМжПРеНЗRRCињЮжО•еїЇзЂЛжИРеКЯзОЗеТМжЧ†зЇњжО•йАЪзОЗгАВйЭЮдЇ§зїЗжЦєеЉПзЫЄжѓФдЇ§зїЗжЦєеЉПжЬЙжШЊиСЧжПРеНЗгАВ 5G AAUдЄ§жЙЗеМЇзїДзљСпЉЪдЄОдЄЙжЙЗеМЇзїДзљСзЫЄжѓФпЉМAAUдЄ§...
OpenNestingеЬ®ж≠§йҐЖеЯЯдєЯи°®зО∞еЗЇиЙ≤пЉМиГље§ЯењЂйАЯжЙЊеИ∞жЬАдЉШиІ£пЉМеЗПе∞Сз©ЇйЪЩпЉМжПРеНЗжХідљУеИ©зФ®зОЗгАВ дљЬдЄЇC++еЃЮзО∞зЪДиљѓдїґпЉМOpenNestingеЕЈе§ЗиЙѓе•љзЪДжАІиГљеТМеПѓжЙ©е±ХжАІгАВC++жШѓдЄАзІНеЇХе±ВзЉЦз®Лиѓ≠и®АпЉМеЕЈжЬЙжЙІи°МжХИзОЗйЂШгАБиµДжЇРзЃ°зРЖзБµжіїз≠ЙзЙєзВєпЉМдљњеЊЧ...
- **жПРйЂШиµДжЇРеИ©зФ®зОЗ**пЉЪйАЪињЗеЃЮжЦљжЈЈйГ®жКАжЬѓпЉМжШЊиСЧжПРеНЗжХ∞жНЃдЄ≠ењГзЪДиµДжЇРеИ©зФ®зОЗпЉМеЗПе∞СиµДжЇРжµ™иієгАВ - **йЩНдљОжИРжЬђ**пЉЪйАЪињЗдЉШеМЦиµДжЇРзЃ°зРЖпЉМеЗПе∞СдЄНењЕи¶БзЪДз°ђдїґжКХиµДеТМињРзїіеЉАжФѓпЉМдїОиАМйЩНдљОдЉБдЄЪзЪДжХідљУињРиР•жИРжЬђгАВ - **жПРеНЗз≥їзїЯз®≥еЃЪжАІ**...