- жөҸи§Ҳ: 3572839 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: жқӯе·һ
-

ж–Үз« еҲҶзұ»
- е…ЁйғЁеҚҡе®ў (1491)
- Hibernate (28)
- spring (37)
- struts2 (19)
- jsp (12)
- servlet (2)
- mysql (24)
- tomcat (3)
- weblogic (1)
- ajax (36)
- jquery (47)
- html (43)
- JS (32)
- ibatis (0)
- DWR (3)
- EXTJS (43)
- Linux (15)
- Maven (3)
- python (8)
- е…¶д»– (8)
- JAVASE (6)
- java javase string (0)
- JAVA иҜӯжі• (3)
- juddiv3 (15)
- Mule (1)
- jquery easyui (2)
- mule esb (1)
- java (644)
- log4j (4)
- weka (12)
- android (257)
- web services (4)
- PHP (1)
- з®—жі• (18)
- ж•°жҚ®з»“жһ„ з®—жі• (7)
- ж•°жҚ®жҢ–жҺҳ (4)
- жңҹеҲҠ (6)
- йқўиҜ• (5)
- C++ (1)
- и®әж–Ү (10)
- е·ҘдҪң (1)
- ж•°жҚ®з»“жһ„ (6)
- JAVAй…ҚзҪ® (1)
- JAVAеһғеңҫеӣһ收 (2)
- SVM (13)
- web st (1)
- jvm (7)
- weka libsvm (1)
- wekaеұҲдјҹ (1)
- job (2)
- жҺ’еәҸ з®—жі• йқўиҜ• (3)
- spss (2)
- жҗңзҙўеј•ж“Һ (6)
- java зҲ¬иҷ« (6)
- еҲҶеёғејҸ (1)
- data ming (1)
- eclipse (6)
- жӯЈеҲҷиЎЁиҫҫејҸ (1)
- еҲҶиҜҚеҷЁ (2)
- еј еӯқзҘҘ (1)
- solr (3)
- nutch (1)
- зҲ¬иҷ« (4)
- lucene (3)
- зӢ—ж—Ҙзҡ„и…ҫи®Ҝ (1)
- жҲ‘зҡ„收и—ҸзҪ‘еқҖ (13)
- зҪ‘з»ң (1)
- java ж•°жҚ®з»“жһ„ (22)
- ACM (7)
- jboss (0)
- еӨ§зәё (10)
- maven2 (0)
- elipse (0)
- SVNдҪҝз”Ё (2)
- office (1)
- .net (14)
- extjs4 (2)
- zhaopin (0)
- C (2)
- spring mvc (5)
- JPA (9)
- iphone (3)
- css (3)
- еүҚз«ҜжЎҶжһ¶ (2)
- jui (1)
- dwz (1)
- joomla (1)
- im (1)
- web (2)
- 1 (0)
- 移еҠЁUI (1)
- пҪҠпҪҒпҪ–пҪҒ (1)
- jsoup (1)
- з®ЎзҗҶжЁЎжқҝ (2)
- javajava (1)
- kali (7)
- еҚ•зүҮжңә (1)
- еөҢе…ҘејҸ (1)
- mybatis (2)
- layui (7)
- asp (12)
- asp.net (1)
- sql (1)
- c# (4)
- andorid (1)
- ең°д»· (1)
- yihuo (1)
- oracle (1)
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 96)
- жҲ‘зҡ„й—®зӯ” ( 19)
еӯҳжЎЈеҲҶзұ»
- 2022-11 ( 1)
- 2022-04 ( 1)
- 2020-07 ( 1)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
endualпјҡ
https://blog.csdn.net/chenxbxh2 ...
IE6 bug -
ice86rainпјҡ
дҪ еҘҪпјҢESи·‘иө·жқҘдәҶеҗ—пјҹжҲ‘зҡ„еңЁtomcatеҗҜеҠЁж—¶еҚЎеңЁиҝҷйҮҢHibe ...
ESжһ¶жһ„жҠҖжңҜд»Ӣз»Қ -
TopLongManпјҡ
...
java public ,protect,friendly,privateзҡ„ж–№жі•жқғйҷҗпјҲиҪ¬пјү -
иҙқеЎ”ZQпјҡ
javaе®һзҺ°ж“ҚдҪңwordдёӯзҡ„иЎЁж јеҶ…е®№пјҢз”ЁжҸ’件е®һзҺ°зҡ„иҜқпјҢеҸҜд»ҘиҜ•иҜ• ...
java иҜ»еҸ– doc poiиҜ»еҸ–wordдёӯзҡ„иЎЁж ј(иҪ¬) -
ysj570440569пјҡ
MavenеӨҡжЁЎеқ—spring + springMVC + JP ...
Spring+SpringMVC+JPA
В
жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳйӣҶй”ҰдёҺBit-mapиҜҰи§Ј
еҚҒдёғйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺBit-mapиҜҰи§Ј
дҪңиҖ…пјҡе°ҸжЎҘжөҒж°ҙпјҢredfox66пјҢJulyгҖӮ
ж–Үз« жҖ§иҙЁпјҡж•ҙзҗҶгҖӮ
еүҚиЁҖ
В В В жң¬еҚҡе®ўеҶ…жӣҫз»Ҹж•ҙзҗҶиҝҮжңүе…іжө·йҮҸж•°жҚ®еӨ„зҗҶзҡ„10йҒ“йқўиҜ•йўҳпјҲеҚҒйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺеҚҒдёӘж–№жі•еӨ§жҖ»з»“ пјүпјҢжӯӨж¬ЎйҷӨдәҶйҮҚеӨҚдәҶд№ӢеүҚзҡ„10йҒ“йқўиҜ•йўҳд№ӢеҗҺпјҢйҮҚж–°еӨҡж•ҙзҗҶдәҶ7йҒ“гҖӮд»…дҪңеҗ„дҪҚеҸӮиҖғпјҢдёҚдҪңе®ғз”ЁгҖӮ
В В В еҗҢж—¶пјҢзЁӢеәҸе‘ҳзј–зЁӢиүәжңҜзі»еҲ— е°ҶйҮҚж–°ејҖе§ӢеҲӣдҪңпјҢ第еҚҒдёҖз« д»ҘеҗҺзҡ„йғЁеҲҶйўҳзӣ®жқҘжәҗе°ҶеҸ–иҮӘдёӢж–Үдёӯзҡ„17йҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶзҡ„йқўиҜ•йўҳгҖӮеӣ дёәпјҢжҲ‘们и§үеҫ—пјҢдёӢж–Үзҡ„жҜҸдёҖйҒ“йқўиҜ•йўҳйғҪеҖјеҫ—йҮҚж–°жҖқиҖғпјҢйҮҚж–°ж·ұ究дёҺеӯҰд№ гҖӮеҶҚиҖ…пјҢзј–зЁӢиүәжңҜзі»еҲ—зҡ„еүҚеҚҒз« д№ҹжҳҜиҝҷд№ҲжқҘзҡ„гҖӮиӢҘжӮЁжңүд»»дҪ•й—®йўҳжҲ–е»әи®®пјҢж¬ўиҝҺдёҚеҗқжҢҮжӯЈгҖӮи°ўи°ўгҖӮ
第дёҖйғЁеҲҶгҖҒеҚҒдә”йҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳ
1. з»ҷе®ҡaгҖҒbдёӨдёӘж–Ү件пјҢеҗ„еӯҳж”ҫ50дәҝдёӘurlпјҢжҜҸдёӘurlеҗ„еҚ 64еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶жҳҜ4GпјҢи®©дҪ жүҫеҮәaгҖҒbж–Ү件е…ұеҗҢзҡ„urlпјҹ
В В В ж–№жЎҲ1пјҡеҸҜд»Ҙдј°и®ЎжҜҸдёӘж–Ү件е®үзҡ„еӨ§е°Ҹдёә50GГ—64=320GпјҢиҝңиҝңеӨ§дәҺеҶ…еӯҳйҷҗеҲ¶зҡ„4GгҖӮжүҖд»ҘдёҚеҸҜиғҪе°Ҷе…¶е®Ңе…ЁеҠ иҪҪеҲ°еҶ…еӯҳдёӯеӨ„зҗҶгҖӮиҖғиҷ‘йҮҮеҸ–еҲҶиҖҢжІ»д№Ӣзҡ„ж–№жі•гҖӮ
- йҒҚеҺҶж–Ү件aпјҢеҜ№жҜҸдёӘurlжұӮеҸ–
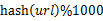 пјҢ然еҗҺж №жҚ®жүҖеҸ–еҫ—зҡ„еҖје°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000дёӘе°Ҹж–Ү件пјҲи®°дёә
пјҢ然еҗҺж №жҚ®жүҖеҸ–еҫ—зҡ„еҖје°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000дёӘе°Ҹж–Ү件пјҲи®°дёә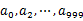 пјүдёӯгҖӮиҝҷж ·жҜҸдёӘе°Ҹж–Ү件зҡ„еӨ§зәҰдёә300MгҖӮ
пјүдёӯгҖӮиҝҷж ·жҜҸдёӘе°Ҹж–Ү件зҡ„еӨ§зәҰдёә300MгҖӮ - йҒҚеҺҶж–Ү件bпјҢйҮҮеҸ–е’ҢaзӣёеҗҢзҡ„ж–№ејҸе°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000е°Ҹж–Ү件дёӯпјҲи®°дёә
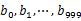 пјүгҖӮиҝҷж ·еӨ„зҗҶеҗҺпјҢжүҖжңүеҸҜиғҪзӣёеҗҢзҡ„urlйғҪеңЁеҜ№еә”зҡ„е°Ҹж–Ү件пјҲ
пјүгҖӮиҝҷж ·еӨ„зҗҶеҗҺпјҢжүҖжңүеҸҜиғҪзӣёеҗҢзҡ„urlйғҪеңЁеҜ№еә”зҡ„е°Ҹж–Ү件пјҲ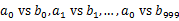 пјүдёӯпјҢдёҚеҜ№еә”зҡ„е°Ҹж–Ү件дёҚеҸҜиғҪжңүзӣёеҗҢзҡ„urlгҖӮ然еҗҺжҲ‘们еҸӘиҰҒжұӮеҮә1000еҜ№е°Ҹж–Ү件дёӯзӣёеҗҢзҡ„urlеҚіеҸҜгҖӮ
пјүдёӯпјҢдёҚеҜ№еә”зҡ„е°Ҹж–Ү件дёҚеҸҜиғҪжңүзӣёеҗҢзҡ„urlгҖӮ然еҗҺжҲ‘们еҸӘиҰҒжұӮеҮә1000еҜ№е°Ҹж–Ү件дёӯзӣёеҗҢзҡ„urlеҚіеҸҜгҖӮ - жұӮжҜҸеҜ№е°Ҹж–Ү件дёӯзӣёеҗҢзҡ„urlж—¶пјҢеҸҜд»ҘжҠҠе…¶дёӯдёҖдёӘе°Ҹж–Ү件зҡ„urlеӯҳеӮЁеҲ°hash_setдёӯгҖӮ然еҗҺйҒҚеҺҶеҸҰдёҖдёӘе°Ҹж–Ү件зҡ„жҜҸдёӘurlпјҢзңӢе…¶жҳҜеҗҰеңЁеҲҡжүҚжһ„е»әзҡ„hash_setдёӯпјҢеҰӮжһңжҳҜпјҢйӮЈд№Ҳе°ұжҳҜе…ұеҗҢзҡ„urlпјҢеӯҳеҲ°ж–Ү件йҮҢйқўе°ұеҸҜд»ҘдәҶгҖӮ
В В В ж–№жЎҲ2пјҡеҰӮжһңе…Ғи®ёжңүдёҖе®ҡзҡ„й”ҷиҜҜзҺҮпјҢеҸҜд»ҘдҪҝз”ЁBloom filterпјҢ4GеҶ…еӯҳеӨ§жҰӮеҸҜд»ҘиЎЁзӨә340дәҝbitгҖӮе°Ҷе…¶дёӯдёҖдёӘж–Ү件дёӯзҡ„urlдҪҝз”ЁBloom filterжҳ е°„дёәиҝҷ340дәҝbitпјҢ然еҗҺжҢЁдёӘиҜ»еҸ–еҸҰеӨ–дёҖдёӘж–Ү件зҡ„urlпјҢжЈҖжҹҘжҳҜеҗҰдёҺBloom filterпјҢеҰӮжһңжҳҜпјҢйӮЈд№ҲиҜҘurlеә”иҜҘжҳҜе…ұеҗҢзҡ„urlпјҲжіЁж„ҸдјҡжңүдёҖе®ҡзҡ„й”ҷиҜҜзҺҮпјүгҖӮ
В В В иҜ»иҖ…еҸҚйҰҲ @crowgnsпјҡ
- hashеҗҺиҰҒеҲӨж–ӯжҜҸдёӘж–Ү件еӨ§е°ҸпјҢеҰӮжһңhashеҲҶзҡ„дёҚеқҮиЎЎжңүж–Ү件иҫғеӨ§пјҢиҝҳеә”继з»ӯhashеҲҶж–Ү件пјҢжҚўдёӘhash算法第дәҢж¬ЎеҶҚеҲҶиҫғеӨ§зҡ„ж–Ү件пјҢдёҖзӣҙеҲҶеҲ°жІЎжңүиҫғеӨ§зҡ„ж–Ү件дёәжӯўгҖӮиҝҷж ·ж–Ү件ж ҮеҸ·еҸҜд»Ҙз”ЁA1-2иЎЁзӨәпјҲ第дёҖж¬Ўhashзј–еҸ·дёә1пјҢж–Ү件иҫғеӨ§жүҖд»ҘеҸӮеҠ 第дәҢж¬ЎhashпјҢзј–еҸ·дёә2пјү
- з”ұ дәҺ1еӯҳеңЁпјҢ第дёҖж¬ЎhashеҰӮжһңжңүеӨ§ж–Ү件пјҢдёҚиғҪз”ЁзӣҙжҺҘsetзҡ„ж–№жі•гҖӮе»әи®®еҜ№жҜҸдёӘж–Ү件йғҪе…Ҳз”Ёеӯ—з¬ҰдёІиҮӘ然йЎәеәҸжҺ’еәҸпјҢ然еҗҺе…·жңүзӣёеҗҢhashзј–еҸ·зҡ„пјҲеҰӮйғҪжҳҜ1-3пјҢ иҖҢдёҚиғҪaзј–еҸ·жҳҜ1пјҢbзј–еҸ·жҳҜ1-1е’Ң1-2пјүпјҢеҸҜд»ҘзӣҙжҺҘд»ҺеӨҙеҲ°е°ҫжҜ”иҫғдёҖйҒҚгҖӮеҜ№дәҺеұӮзә§дёҚдёҖиҮҙзҡ„пјҢеҰӮa1пјҢbжңү1-1пјҢ1-2-1пјҢ1-2-2пјҢеұӮзә§жө…зҡ„иҰҒе’Ң еұӮзә§ж·ұзҡ„жҜҸдёӘж–Ү件йғҪжҜ”иҫғдёҖж¬ЎпјҢжүҚиғҪзЎ®и®ӨжҜҸдёӘзӣёеҗҢзҡ„uriгҖӮ
2. жңү10дёӘж–Ү件пјҢжҜҸдёӘж–Ү件1GпјҢжҜҸдёӘж–Ү件зҡ„жҜҸдёҖиЎҢеӯҳж”ҫзҡ„йғҪжҳҜз”ЁжҲ·зҡ„queryпјҢжҜҸдёӘж–Ү件зҡ„queryйғҪеҸҜиғҪйҮҚеӨҚгҖӮиҰҒжұӮдҪ жҢүз…§queryзҡ„йў‘еәҰжҺ’еәҸгҖӮ
ж–№жЎҲ1пјҡ
- йЎәеәҸиҜ»еҸ–10дёӘж–Ү件пјҢжҢүз…§hash(query)%10зҡ„з»“жһңе°ҶqueryеҶҷе…ҘеҲ°еҸҰеӨ–10дёӘж–Ү件пјҲи®°дёә
 пјүдёӯгҖӮиҝҷж ·ж–°з”ҹжҲҗзҡ„ж–Ү件жҜҸдёӘзҡ„еӨ§е°ҸеӨ§зәҰд№ҹ1GпјҲеҒҮи®ҫhashеҮҪж•°жҳҜйҡҸжңәзҡ„пјүгҖӮ
пјүдёӯгҖӮиҝҷж ·ж–°з”ҹжҲҗзҡ„ж–Ү件жҜҸдёӘзҡ„еӨ§е°ҸеӨ§зәҰд№ҹ1GпјҲеҒҮи®ҫhashеҮҪж•°жҳҜйҡҸжңәзҡ„пјүгҖӮ - жүҫдёҖеҸ°еҶ…еӯҳеңЁ2Gе·ҰеҸізҡ„жңәеҷЁпјҢдҫқж¬ЎеҜ№
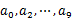 з”Ёhash_map(query, query_count)жқҘз»ҹи®ЎжҜҸдёӘqueryеҮәзҺ°зҡ„ж¬Ўж•°гҖӮеҲ©з”Ёеҝ«йҖҹ/е Ҷ/еҪ’并жҺ’еәҸжҢүз…§еҮәзҺ°ж¬Ўж•°иҝӣиЎҢжҺ’еәҸгҖӮе°ҶжҺ’еәҸеҘҪзҡ„queryе’ҢеҜ№еә”зҡ„query_coutиҫ“еҮәеҲ°ж–Ү件дёӯгҖӮиҝҷж ·еҫ—еҲ°дәҶ10дёӘжҺ’еҘҪеәҸзҡ„ж–Ү件пјҲи®°дёә
з”Ёhash_map(query, query_count)жқҘз»ҹи®ЎжҜҸдёӘqueryеҮәзҺ°зҡ„ж¬Ўж•°гҖӮеҲ©з”Ёеҝ«йҖҹ/е Ҷ/еҪ’并жҺ’еәҸжҢүз…§еҮәзҺ°ж¬Ўж•°иҝӣиЎҢжҺ’еәҸгҖӮе°ҶжҺ’еәҸеҘҪзҡ„queryе’ҢеҜ№еә”зҡ„query_coutиҫ“еҮәеҲ°ж–Ү件дёӯгҖӮиҝҷж ·еҫ—еҲ°дәҶ10дёӘжҺ’еҘҪеәҸзҡ„ж–Ү件пјҲи®°дёә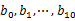 пјүгҖӮ
пјүгҖӮ - еҜ№
 иҝҷ10дёӘж–Ү件иҝӣиЎҢеҪ’并жҺ’еәҸпјҲеҶ…жҺ’еәҸдёҺеӨ–жҺ’еәҸзӣёз»“еҗҲпјүгҖӮ
иҝҷ10дёӘж–Ү件иҝӣиЎҢеҪ’并жҺ’еәҸпјҲеҶ…жҺ’еәҸдёҺеӨ–жҺ’еәҸзӣёз»“еҗҲпјүгҖӮ
ж–№жЎҲ2пјҡ
В В В дёҖиҲ¬queryзҡ„жҖ»йҮҸжҳҜжңүйҷҗзҡ„пјҢеҸӘжҳҜйҮҚеӨҚзҡ„ж¬Ўж•°жҜ”иҫғеӨҡиҖҢе·ІпјҢеҸҜиғҪеҜ№дәҺжүҖжңүзҡ„queryпјҢдёҖж¬ЎжҖ§е°ұеҸҜд»ҘеҠ е…ҘеҲ°еҶ…еӯҳдәҶгҖӮиҝҷж ·пјҢжҲ‘们е°ұеҸҜд»ҘйҮҮз”Ёtrieж ‘/hash_mapзӯүзӣҙжҺҘжқҘз»ҹи®ЎжҜҸдёӘqueryеҮәзҺ°зҡ„ж¬Ўж•°пјҢ然еҗҺжҢүеҮәзҺ°ж¬Ўж•°еҒҡеҝ«йҖҹ/е Ҷ/еҪ’并жҺ’еәҸе°ұеҸҜд»ҘдәҶ
В В В пјҲиҜ»иҖ…еҸҚйҰҲ @еә—е°ҸдәҢпјҡеҺҹж–Ү第дәҢдёӘдҫӢеӯҗдёӯпјҡвҖңжүҫдёҖеҸ°еҶ…еӯҳеңЁ2Gе·ҰеҸізҡ„жңәеҷЁпјҢдҫқж¬ЎеҜ№з”Ёhash_map(query, query_count)жқҘз»ҹи®ЎжҜҸдёӘqueryеҮәзҺ°зҡ„ж¬Ўж•°гҖӮвҖқз”ұдәҺqueryдјҡйҮҚеӨҚпјҢдҪңдёәkeyзҡ„иҜқпјҢеә”иҜҘдҪҝз”Ёhash_multimap гҖӮhash_map дёҚе…Ғи®ёkeyйҮҚеӨҚ гҖӮжӯӨеҸҚйҰҲжҳҜеҗҰжӯЈзЎ®пјҢеҫ…ж—ҘеҗҺиҖғиҜҒпјүгҖӮ
ж–№жЎҲ3пјҡ
В В В дёҺж–№жЎҲ1зұ»дјјпјҢдҪҶеңЁеҒҡе®ҢhashпјҢеҲҶжҲҗеӨҡдёӘж–Ү件еҗҺпјҢеҸҜд»ҘдәӨз»ҷеӨҡдёӘж–Ү件жқҘеӨ„зҗҶпјҢйҮҮз”ЁеҲҶеёғејҸзҡ„жһ¶жһ„жқҘеӨ„зҗҶпјҲжҜ”еҰӮMapReduceпјүпјҢжңҖеҗҺеҶҚиҝӣиЎҢеҗҲ并гҖӮ
3. жңүдёҖдёӘ1GеӨ§е°Ҹзҡ„дёҖдёӘж–Ү件пјҢйҮҢйқўжҜҸдёҖиЎҢжҳҜдёҖдёӘиҜҚпјҢиҜҚзҡ„еӨ§е°ҸдёҚи¶…иҝҮ16еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶еӨ§е°ҸжҳҜ1MгҖӮиҝ”еӣһйў‘ж•°жңҖй«ҳзҡ„100дёӘиҜҚгҖӮ
В В В ж–№жЎҲ1пјҡйЎәеәҸиҜ»ж–Ү件дёӯпјҢеҜ№дәҺжҜҸдёӘиҜҚxпјҢеҸ– пјҢ然еҗҺжҢүз…§иҜҘеҖјеӯҳеҲ°5000дёӘе°Ҹж–Ү件пјҲи®°дёә
пјҢ然еҗҺжҢүз…§иҜҘеҖјеӯҳеҲ°5000дёӘе°Ҹж–Ү件пјҲи®°дёә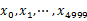 пјү
дёӯгҖӮиҝҷж ·жҜҸдёӘж–Ү件еӨ§жҰӮжҳҜ200kе·ҰеҸігҖӮеҰӮжһңе…¶дёӯзҡ„жңүзҡ„ж–Ү件超иҝҮдәҶ1MеӨ§е°ҸпјҢиҝҳеҸҜд»ҘжҢүз…§зұ»дјјзҡ„方法继з»ӯеҫҖдёӢеҲҶпјҢзӣҙеҲ°еҲҶи§Јеҫ—еҲ°зҡ„е°Ҹж–Ү件зҡ„еӨ§е°ҸйғҪдёҚи¶…иҝҮ1MгҖӮеҜ№
жҜҸдёӘе°Ҹж–Ү件пјҢз»ҹи®ЎжҜҸдёӘж–Ү件дёӯеҮәзҺ°зҡ„иҜҚд»ҘеҸҠзӣёеә”зҡ„йў‘зҺҮпјҲеҸҜд»ҘйҮҮз”Ёtrieж ‘/hash_mapзӯүпјүпјҢ并еҸ–еҮәеҮәзҺ°йў‘зҺҮжңҖеӨ§зҡ„100дёӘиҜҚпјҲеҸҜд»Ҙз”Ёеҗ«100дёӘз»“зӮ№
зҡ„жңҖе°Ҹе ҶпјүпјҢ并жҠҠ100иҜҚеҸҠзӣёеә”зҡ„йў‘зҺҮеӯҳе…Ҙж–Ү件пјҢиҝҷж ·еҸҲеҫ—еҲ°дәҶ5000дёӘж–Ү件гҖӮдёӢдёҖжӯҘе°ұжҳҜжҠҠиҝҷ5000дёӘж–Ү件иҝӣиЎҢеҪ’并пјҲзұ»дјјдёҺеҪ’并жҺ’еәҸпјүзҡ„иҝҮзЁӢдәҶгҖӮ
пјү
дёӯгҖӮиҝҷж ·жҜҸдёӘж–Ү件еӨ§жҰӮжҳҜ200kе·ҰеҸігҖӮеҰӮжһңе…¶дёӯзҡ„жңүзҡ„ж–Ү件超иҝҮдәҶ1MеӨ§е°ҸпјҢиҝҳеҸҜд»ҘжҢүз…§зұ»дјјзҡ„方法继з»ӯеҫҖдёӢеҲҶпјҢзӣҙеҲ°еҲҶи§Јеҫ—еҲ°зҡ„е°Ҹж–Ү件зҡ„еӨ§е°ҸйғҪдёҚи¶…иҝҮ1MгҖӮеҜ№
жҜҸдёӘе°Ҹж–Ү件пјҢз»ҹи®ЎжҜҸдёӘж–Ү件дёӯеҮәзҺ°зҡ„иҜҚд»ҘеҸҠзӣёеә”зҡ„йў‘зҺҮпјҲеҸҜд»ҘйҮҮз”Ёtrieж ‘/hash_mapзӯүпјүпјҢ并еҸ–еҮәеҮәзҺ°йў‘зҺҮжңҖеӨ§зҡ„100дёӘиҜҚпјҲеҸҜд»Ҙз”Ёеҗ«100дёӘз»“зӮ№
зҡ„жңҖе°Ҹе ҶпјүпјҢ并жҠҠ100иҜҚеҸҠзӣёеә”зҡ„йў‘зҺҮеӯҳе…Ҙж–Ү件пјҢиҝҷж ·еҸҲеҫ—еҲ°дәҶ5000дёӘж–Ү件гҖӮдёӢдёҖжӯҘе°ұжҳҜжҠҠиҝҷ5000дёӘж–Ү件иҝӣиЎҢеҪ’并пјҲзұ»дјјдёҺеҪ’并жҺ’еәҸпјүзҡ„иҝҮзЁӢдәҶгҖӮ
4. жө·йҮҸж—Ҙеҝ—ж•°жҚ®пјҢжҸҗеҸ–еҮәжҹҗж—Ҙи®ҝй—®зҷҫеәҰж¬Ўж•°жңҖеӨҡзҡ„йӮЈдёӘIPгҖӮ
В В В ж–№жЎҲ1пјҡйҰ–е…ҲжҳҜиҝҷдёҖеӨ©пјҢ并且жҳҜи®ҝй—®зҷҫеәҰзҡ„ж—Ҙеҝ—дёӯзҡ„IPеҸ–еҮәжқҘпјҢйҖҗдёӘеҶҷе…ҘеҲ°дёҖдёӘеӨ§ж–Ү件дёӯгҖӮжіЁж„ҸеҲ°IPжҳҜ32дҪҚзҡ„пјҢжңҖеӨҡжңү2^32дёӘIPгҖӮеҗҢж ·еҸҜд»ҘйҮҮз”Ёжҳ е°„зҡ„ ж–№жі•пјҢжҜ”еҰӮжЁЎ1000пјҢжҠҠж•ҙдёӘеӨ§ж–Ү件жҳ е°„дёә1000дёӘе°Ҹж–Ү件пјҢеҶҚжүҫеҮәжҜҸдёӘе°Ҹж–ҮдёӯеҮәзҺ°йў‘зҺҮжңҖеӨ§зҡ„IPпјҲеҸҜд»ҘйҮҮз”Ёhash_mapиҝӣиЎҢйў‘зҺҮз»ҹи®ЎпјҢ然еҗҺеҶҚжүҫеҮәйў‘ зҺҮжңҖеӨ§зҡ„еҮ дёӘпјүеҸҠзӣёеә”зҡ„йў‘зҺҮгҖӮ然еҗҺеҶҚеңЁиҝҷ1000дёӘжңҖеӨ§зҡ„IPдёӯпјҢжүҫеҮәйӮЈдёӘйў‘зҺҮжңҖеӨ§зҡ„IPпјҢеҚідёәжүҖжұӮгҖӮ
5. еңЁ2.5дәҝдёӘж•ҙж•°дёӯжүҫеҮәдёҚйҮҚеӨҚзҡ„ж•ҙж•°пјҢеҶ…еӯҳдёҚи¶ід»Ҙе®№зәіиҝҷ2.5дәҝдёӘж•ҙж•°гҖӮ
В В В ж–№жЎҲ1пјҡйҮҮз”Ё2-BitmapпјҲжҜҸдёӘж•°еҲҶй…Қ2bitпјҢ00иЎЁзӨәдёҚеӯҳеңЁпјҢ01иЎЁзӨәеҮәзҺ°дёҖж¬ЎпјҢ10иЎЁзӨәеӨҡж¬ЎпјҢ11ж— ж„Ҹд№үпјүиҝӣиЎҢпјҢе…ұйңҖеҶ…еӯҳ2^32*2bit=1GBеҶ…еӯҳпјҢиҝҳеҸҜд»ҘжҺҘеҸ—гҖӮ然еҗҺжү«жҸҸиҝҷ2.5дәҝдёӘж•ҙж•°пјҢжҹҘзңӢBitmapдёӯзӣёеҜ№еә”дҪҚпјҢеҰӮжһңжҳҜ00еҸҳ01пјҢ01еҸҳ10пјҢ10дҝқжҢҒдёҚеҸҳгҖӮжүҖжҸҸе®ҢдәӢеҗҺпјҢжҹҘзңӢbitmapпјҢжҠҠеҜ№еә”дҪҚжҳҜ01зҡ„ж•ҙж•°иҫ“еҮәеҚіеҸҜгҖӮ
В В В ж–№жЎҲ2пјҡд№ҹеҸҜйҮҮз”ЁдёҠйўҳзұ»дјјзҡ„ж–№жі•пјҢиҝӣиЎҢеҲ’еҲҶе°Ҹж–Ү件зҡ„ж–№жі•гҖӮ然еҗҺеңЁе°Ҹж–Ү件дёӯжүҫеҮәдёҚйҮҚеӨҚзҡ„ж•ҙж•°пјҢ并жҺ’еәҸгҖӮ然еҗҺеҶҚиҝӣиЎҢеҪ’并пјҢжіЁж„ҸеҺ»йҷӨйҮҚеӨҚзҡ„е…ғзҙ гҖӮ
6. жө·йҮҸж•°жҚ®еҲҶеёғеңЁ100еҸ°з”өи„‘дёӯпјҢжғідёӘеҠһжі•й«ҳж•Ҳз»ҹи®ЎеҮәиҝҷжү№ж•°жҚ®зҡ„TOP10гҖӮ
ж–№жЎҲ1пјҡ
- еңЁ жҜҸеҸ°з”өи„‘дёҠжұӮеҮәTOP10пјҢеҸҜд»ҘйҮҮз”ЁеҢ…еҗ«10дёӘе…ғзҙ зҡ„е Ҷе®ҢжҲҗпјҲTOP10е°ҸпјҢз”ЁжңҖеӨ§е ҶпјҢTOP10еӨ§пјҢз”ЁжңҖе°Ҹе ҶпјүгҖӮжҜ”еҰӮжұӮTOP10еӨ§пјҢжҲ‘们йҰ–е…ҲеҸ–еүҚ10 дёӘе…ғзҙ и°ғж•ҙжҲҗжңҖе°Ҹе ҶпјҢеҰӮжһңеҸ‘зҺ°пјҢ然еҗҺжү«жҸҸеҗҺйқўзҡ„ж•°жҚ®пјҢ并дёҺе ҶйЎ¶е…ғзҙ жҜ”иҫғпјҢеҰӮжһңжҜ”е ҶйЎ¶е…ғзҙ еӨ§пјҢйӮЈд№Ҳз”ЁиҜҘе…ғзҙ жӣҝжҚўе ҶйЎ¶пјҢ然еҗҺеҶҚи°ғж•ҙдёәжңҖе°Ҹе ҶгҖӮжңҖеҗҺе Ҷдёӯзҡ„е…ғзҙ е°ұ жҳҜTOP10еӨ§гҖӮ
- жұӮеҮәжҜҸеҸ°з”өи„‘дёҠзҡ„TOP10еҗҺпјҢ然еҗҺжҠҠиҝҷ100еҸ°з”өи„‘дёҠзҡ„TOP10з»„еҗҲиө·жқҘпјҢе…ұ1000дёӘж•°жҚ®пјҢеҶҚеҲ©з”ЁдёҠйқўзұ»дјјзҡ„ж–№жі•жұӮеҮәTOP10е°ұеҸҜд»ҘдәҶгҖӮ
пјҲжӣҙеӨҡеҸҜд»ҘеҸӮиҖғпјҡ第дёүз« гҖҒеҜ»жүҫжңҖе°Ҹзҡ„kдёӘж•° пјҢд»ҘеҸҠ第дёүз« з»ӯгҖҒTop Kз®—жі•й—®йўҳ зҡ„е®һзҺ° пјү
В В В иҜ»иҖ…еҸҚйҰҲ @QinLeopard пјҡ
第6йўҳзҡ„ж–№жі•дёӯпјҢжҳҜдёҚжҳҜдёҚиғҪдҝқиҜҒжҜҸдёӘз”өи„‘дёҠзҡ„еүҚеҚҒжқЎпјҢиӮҜе®ҡеҢ…еҗ«жңҖеҗҺйў‘зҺҮжңҖй«ҳзҡ„еүҚеҚҒжқЎе‘ўпјҹ
жҜ”еҰӮиҜҙ第дёҖдёӘж–Ү件дёӯпјҡA(4), B(5), C(6), D(3)
第дәҢдёӘж–Ү件дёӯпјҡA(4),B(5),C(3),D(6)
第дёүдёӘж–Ү件дёӯ: A(6), B(5), C(4), D(3)
еҰӮжһңиҰҒйҖүTop(1), йҖүеҮәжқҘзҡ„з»“жһңжҳҜAпјҢдҪҶз»“жһңеә”иҜҘжҳҜBгҖӮ
В В В @JulyпјҡжҲ‘жғіпјҢиҝҷдҪҚиҜ»иҖ…еҸҜиғҪжІЎжңүжҳҺзЎ®жҸҗи®®гҖӮжң¬йўҳзӣ®дёӯзҡ„TOP10жҳҜжҢҮжңҖеӨ§зҡ„10дёӘж•° пјҢиҖҢдёҚжҳҜжҢҮеҮәзҺ°йў‘зҺҮжңҖеӨҡзҡ„10дёӘж•°гҖӮдҪҶеҰӮжһңиҜҙпјҢзҺ°еңЁжңүеҸҰеӨ–дёҖжҸҗпјҢиҰҒдҪ жұӮйў‘зҺҮжңҖеӨҡзҡ„ 10дёӘпјҢзӣёеҪ“дәҺжұӮи®ҝй—®ж¬Ўж•°жңҖеӨҡзҡ„10дёӘIPең°еқҖйӮЈйҒ“йўҳпјҢеҚіжҳҜжң¬ж–ҮдёӯдёҠйқўзҡ„第4 йўҳгҖӮзү№жӯӨиҜҙжҳҺгҖӮ
7. жҖҺд№ҲеңЁжө·йҮҸж•°жҚ®дёӯжүҫеҮәйҮҚеӨҚж¬Ўж•°жңҖеӨҡзҡ„дёҖдёӘпјҹ
В В В ж–№жЎҲ1пјҡе…ҲеҒҡhashпјҢ然еҗҺжұӮжЁЎжҳ е°„дёәе°Ҹж–Ү件пјҢжұӮеҮәжҜҸдёӘе°Ҹж–Ү件дёӯйҮҚеӨҚж¬Ўж•°жңҖеӨҡзҡ„дёҖдёӘпјҢ并记еҪ•йҮҚеӨҚж¬Ўж•°гҖӮ然еҗҺжүҫеҮәдёҠдёҖжӯҘжұӮеҮәзҡ„ж•°жҚ®дёӯйҮҚеӨҚж¬Ўж•°жңҖеӨҡзҡ„дёҖдёӘе°ұжҳҜжүҖжұӮпјҲе…·дҪ“еҸӮиҖғеүҚйқўзҡ„йўҳпјүгҖӮ
8. дёҠеҚғдёҮжҲ–дёҠдәҝж•°жҚ®пјҲжңүйҮҚеӨҚпјүпјҢз»ҹи®Ўе…¶дёӯеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„й’ұNдёӘж•°жҚ®гҖӮ
В В В ж–№жЎҲ1пјҡдёҠеҚғдёҮжҲ–дёҠдәҝзҡ„ж•°жҚ®пјҢзҺ°еңЁзҡ„жңәеҷЁзҡ„еҶ…еӯҳеә”иҜҘиғҪеӯҳдёӢгҖӮжүҖд»ҘиҖғиҷ‘йҮҮз”Ёhash_map/жҗңзҙўдәҢеҸүж ‘/зәўй»‘ж ‘зӯүжқҘиҝӣиЎҢз»ҹи®Ўж¬Ўж•°гҖӮ然еҗҺе°ұжҳҜеҸ–еҮәеүҚNдёӘеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„ж•°жҚ®дәҶпјҢеҸҜд»Ҙ用第6йўҳжҸҗеҲ°зҡ„е ҶжңәеҲ¶е®ҢжҲҗгҖӮ
9. 1000дёҮеӯ—з¬ҰдёІпјҢе…¶дёӯжңүдәӣжҳҜйҮҚеӨҚзҡ„пјҢйңҖиҰҒжҠҠйҮҚеӨҚзҡ„е…ЁйғЁеҺ»жҺүпјҢдҝқз•ҷжІЎжңүйҮҚеӨҚзҡ„еӯ—з¬ҰдёІгҖӮиҜ·жҖҺд№Ҳи®ҫи®Ўе’Ңе®һзҺ°пјҹ
В В В ж–№жЎҲ1пјҡиҝҷйўҳз”Ёtrieж ‘жҜ”иҫғеҗҲйҖӮпјҢhash_mapд№ҹеә”иҜҘиғҪиЎҢгҖӮ
10. дёҖдёӘж–Үжң¬ж–Ү件пјҢеӨ§зәҰжңүдёҖдёҮиЎҢпјҢжҜҸиЎҢдёҖдёӘиҜҚпјҢиҰҒжұӮз»ҹи®ЎеҮәе…¶дёӯжңҖйў‘з№ҒеҮәзҺ°зҡ„еүҚ10дёӘиҜҚпјҢиҜ·з»ҷеҮәжҖқжғіпјҢз»ҷеҮәж—¶й—ҙеӨҚжқӮеәҰеҲҶжһҗгҖӮ
В В В ж–№жЎҲ1пјҡиҝҷйўҳжҳҜиҖғиҷ‘ж—¶й—ҙж•ҲзҺҮгҖӮз”Ёtrieж ‘з»ҹи®ЎжҜҸдёӘиҜҚеҮәзҺ°зҡ„ж¬Ўж•°пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜO(n*le)пјҲleиЎЁзӨәеҚ•иҜҚзҡ„е№іеҮҶй•ҝеәҰпјүгҖӮ然еҗҺжҳҜжүҫеҮәеҮәзҺ°жңҖйў‘з№Ғзҡ„еүҚ10 дёӘиҜҚпјҢеҸҜд»Ҙз”Ёе ҶжқҘе®һзҺ°пјҢеүҚйқўзҡ„йўҳдёӯе·Із»Ҹи®ІеҲ°дәҶпјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜO(n*lg10)гҖӮжүҖд»ҘжҖ»зҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢжҳҜO(n*le)дёҺO(n*lg10)дёӯиҫғеӨ§зҡ„е“ӘдёҖ дёӘгҖӮ
11. дёҖдёӘж–Үжң¬ж–Ү件пјҢжүҫеҮәеүҚ10дёӘз»ҸеёёеҮәзҺ°зҡ„иҜҚпјҢдҪҶиҝҷж¬Ўж–Ү件жҜ”иҫғй•ҝпјҢиҜҙжҳҜдёҠдәҝиЎҢжҲ–еҚҒдәҝиЎҢпјҢжҖ»д№Ӣж— жі•дёҖж¬ЎиҜ»е…ҘеҶ…еӯҳпјҢй—®жңҖдјҳи§ЈгҖӮ
В В В ж–№жЎҲ1пјҡйҰ–е…Ҳж №жҚ®з”Ёhash并жұӮжЁЎпјҢе°Ҷж–Ү件еҲҶи§ЈдёәеӨҡдёӘе°Ҹж–Ү件пјҢеҜ№дәҺеҚ•дёӘж–Ү件еҲ©з”ЁдёҠйўҳзҡ„ж–№жі•жұӮеҮәжҜҸдёӘж–Ү件件дёӯ10дёӘжңҖеёёеҮәзҺ°зҡ„иҜҚгҖӮ然еҗҺеҶҚиҝӣиЎҢеҪ’并еӨ„зҗҶпјҢжүҫеҮәжңҖз»Ҳзҡ„10дёӘжңҖеёёеҮәзҺ°зҡ„иҜҚгҖӮ
12. 100wдёӘж•°дёӯжүҫеҮәжңҖеӨ§зҡ„100дёӘж•°гҖӮ
- В В В ж–№жЎҲ1пјҡеңЁеүҚйқўзҡ„йўҳдёӯпјҢжҲ‘们已з»ҸжҸҗеҲ°дәҶпјҢз”ЁдёҖдёӘеҗ«100дёӘе…ғзҙ зҡ„жңҖе°Ҹе Ҷе®ҢжҲҗгҖӮеӨҚжқӮеәҰдёәO(100w*lg100)гҖӮ
- В В В ж–№жЎҲ2пјҡйҮҮз”Ёеҝ«йҖҹжҺ’еәҸзҡ„жҖқжғіпјҢжҜҸж¬ЎеҲҶеүІд№ӢеҗҺеҸӘиҖғиҷ‘жҜ”иҪҙеӨ§зҡ„дёҖйғЁеҲҶпјҢзҹҘйҒ“жҜ”иҪҙеӨ§зҡ„дёҖйғЁеҲҶеңЁжҜ”100еӨҡзҡ„ж—¶еҖҷпјҢйҮҮз”Ёдј з»ҹжҺ’еәҸз®—жі•жҺ’еәҸпјҢеҸ–еүҚ100дёӘгҖӮеӨҚжқӮеәҰдёәO(100w*100)гҖӮ
- В В В ж–№жЎҲ3пјҡйҮҮз”ЁеұҖйғЁж·ҳжұ°жі•гҖӮйҖүеҸ–еүҚ100дёӘе…ғзҙ пјҢ并жҺ’еәҸпјҢи®°дёәеәҸеҲ—LгҖӮ然еҗҺдёҖж¬Ўжү«жҸҸеү©дҪҷзҡ„е…ғзҙ xпјҢдёҺжҺ’еҘҪеәҸзҡ„100дёӘе…ғзҙ дёӯжңҖе°Ҹзҡ„е…ғзҙ жҜ”пјҢеҰӮжһңжҜ”иҝҷдёӘжңҖе°Ҹзҡ„ иҰҒеӨ§пјҢйӮЈд№ҲжҠҠиҝҷдёӘжңҖе°Ҹзҡ„е…ғзҙ еҲ йҷӨпјҢ并жҠҠxеҲ©з”ЁжҸ’е…ҘжҺ’еәҸзҡ„жҖқжғіпјҢжҸ’е…ҘеҲ°еәҸеҲ—LдёӯгҖӮдҫқж¬ЎеҫӘзҺҜпјҢзҹҘйҒ“жү«жҸҸдәҶжүҖжңүзҡ„е…ғзҙ гҖӮеӨҚжқӮеәҰдёәO(100w*100)гҖӮ
13. еҜ»жүҫзғӯй—ЁжҹҘиҜўпјҡ
жҗң зҙўеј•ж“ҺдјҡйҖҡиҝҮж—Ҙеҝ—ж–Ү件жҠҠз”ЁжҲ·жҜҸж¬ЎжЈҖзҙўдҪҝз”Ёзҡ„жүҖжңүжЈҖзҙўдёІйғҪи®°еҪ•дёӢжқҘпјҢжҜҸдёӘжҹҘиҜўдёІзҡ„й•ҝеәҰдёә1-255еӯ—иҠӮгҖӮеҒҮи®ҫзӣ®еүҚжңүдёҖеҚғдёҮдёӘи®°еҪ•пјҢиҝҷдәӣжҹҘиҜўдёІзҡ„йҮҚеӨҚиҜ»жҜ”иҫғ й«ҳпјҢиҷҪ然жҖ»ж•°жҳҜ1еҚғдёҮпјҢдҪҶжҳҜеҰӮжһңеҺ»йҷӨйҮҚеӨҚе’ҢпјҢдёҚи¶…иҝҮ3зҷҫдёҮдёӘгҖӮдёҖдёӘжҹҘиҜўдёІзҡ„йҮҚеӨҚеәҰи¶Ҡй«ҳпјҢиҜҙжҳҺжҹҘиҜўе®ғзҡ„з”ЁжҲ·и¶ҠеӨҡпјҢд№ҹе°ұи¶Ҡзғӯй—ЁгҖӮиҜ·дҪ з»ҹи®ЎжңҖзғӯй—Ёзҡ„10дёӘжҹҘиҜў дёІпјҢиҰҒжұӮдҪҝз”Ёзҡ„еҶ…еӯҳдёҚиғҪи¶…иҝҮ1GгҖӮ
(1) иҜ·жҸҸиҝ°дҪ и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„жҖқи·Ҝпјӣ
(2) иҜ·з»ҷеҮәдё»иҰҒзҡ„еӨ„зҗҶжөҒзЁӢпјҢз®—жі•пјҢд»ҘеҸҠз®—жі•зҡ„еӨҚжқӮеәҰгҖӮ
В В В ж–№жЎҲ1пјҡйҮҮз”Ёtrieж ‘пјҢе…ій”®еӯ—еҹҹеӯҳиҜҘжҹҘиҜўдёІеҮәзҺ°зҡ„ж¬Ўж•°пјҢжІЎжңүеҮәзҺ°дёә0гҖӮжңҖеҗҺз”Ё10дёӘе…ғзҙ зҡ„жңҖе°ҸжҺЁжқҘеҜ№еҮәзҺ°йў‘зҺҮиҝӣиЎҢжҺ’еәҸгҖӮ
В В В е…ідәҺжӯӨй—®йўҳзҡ„иҜҰз»Ҷи§Јзӯ”пјҢиҜ·еҸӮиҖғжӯӨж–Үзҡ„第3.1иҠӮпјҡ第дёүз« з»ӯгҖҒTop Kз®—жі•й—®йўҳзҡ„е®һзҺ° гҖӮ
14. дёҖе…ұжңүNдёӘжңәеҷЁпјҢжҜҸдёӘжңәеҷЁдёҠжңүNдёӘж•°гҖӮжҜҸдёӘжңәеҷЁжңҖеӨҡеӯҳO(N)дёӘ数并еҜ№е®ғ们ж“ҚдҪңгҖӮеҰӮдҪ•жүҫеҲ°N^2дёӘж•°дёӯзҡ„дёӯж•°пјҹ
В В В ж–№жЎҲ1пјҡе…ҲеӨ§дҪ“дј°и®ЎдёҖдёӢиҝҷдәӣж•°зҡ„иҢғеӣҙпјҢжҜ”еҰӮиҝҷйҮҢеҒҮи®ҫиҝҷдәӣж•°йғҪжҳҜ32дҪҚж— з¬ҰеҸ·ж•ҙж•°пјҲе…ұжңү2^32дёӘпјүгҖӮжҲ‘们жҠҠ0еҲ°2^32-1зҡ„ж•ҙж•°еҲ’еҲҶдёәNдёӘиҢғеӣҙж®өпјҢжҜҸдёӘ ж®өеҢ…еҗ«пјҲ2^32пјү/NдёӘж•ҙж•°гҖӮжҜ”еҰӮпјҢ第дёҖдёӘж®өдҪҚ0еҲ°2^32/N-1пјҢ第дәҢж®өдёәпјҲ2^32пјү/NеҲ°пјҲ2^32пјү/N-1пјҢвҖҰпјҢ第NдёӘж®өдёәпјҲ2^32пјү пјҲN-1пјү/NеҲ°2^32-1гҖӮ然еҗҺпјҢжү«жҸҸжҜҸдёӘжңәеҷЁдёҠзҡ„NдёӘж•°пјҢжҠҠеұһдәҺ第дёҖдёӘеҢәж®өзҡ„ж•°ж”ҫеҲ°з¬¬дёҖдёӘжңәеҷЁдёҠпјҢеұһдәҺ第дәҢдёӘеҢәж®өзҡ„ж•°ж”ҫеҲ°з¬¬дәҢдёӘжңәеҷЁдёҠпјҢвҖҰпјҢеұһдәҺ第 NдёӘеҢәж®өзҡ„ж•°ж”ҫеҲ°з¬¬NдёӘжңәеҷЁдёҠгҖӮжіЁж„ҸиҝҷдёӘиҝҮзЁӢжҜҸдёӘжңәеҷЁдёҠеӯҳеӮЁзҡ„ж•°еә”иҜҘжҳҜO(N)зҡ„гҖӮдёӢйқўжҲ‘们дҫқж¬Ўз»ҹи®ЎжҜҸдёӘжңәеҷЁдёҠж•°зҡ„дёӘж•°пјҢдёҖж¬ЎзҙҜеҠ пјҢзӣҙеҲ°жүҫеҲ°з¬¬kдёӘжңәеҷЁпјҢ еңЁиҜҘжңәеҷЁдёҠзҙҜеҠ зҡ„ж•°еӨ§дәҺжҲ–зӯүдәҺпјҲN^2пјү/2пјҢиҖҢеңЁз¬¬k-1дёӘжңәеҷЁдёҠзҡ„зҙҜеҠ ж•°е°ҸдәҺпјҲN^2пјү/2пјҢ并жҠҠиҝҷдёӘж•°и®°дёәxгҖӮйӮЈд№ҲжҲ‘们иҰҒжүҫзҡ„дёӯдҪҚж•°еңЁз¬¬kдёӘжңәеҷЁ дёӯпјҢжҺ’еңЁз¬¬пјҲN^2пјү/2-xдҪҚгҖӮ然еҗҺжҲ‘们еҜ№з¬¬kдёӘжңәеҷЁзҡ„ж•°жҺ’еәҸпјҢ并жүҫеҮә第пјҲN^2пјү/2-xдёӘж•°пјҢеҚідёәжүҖжұӮзҡ„дёӯдҪҚж•°зҡ„еӨҚжқӮеәҰжҳҜOпјҲN^2пјүзҡ„гҖӮ
В В В ж–№жЎҲ2пјҡе…ҲеҜ№жҜҸеҸ°жңәеҷЁдёҠзҡ„ж•°иҝӣиЎҢжҺ’еәҸгҖӮжҺ’еҘҪеәҸеҗҺпјҢжҲ‘们йҮҮз”ЁеҪ’并жҺ’еәҸзҡ„жҖқжғіпјҢе°ҶиҝҷNдёӘжңәеҷЁдёҠзҡ„ж•°еҪ’并иө·жқҘеҫ—еҲ°жңҖз»Ҳзҡ„жҺ’еәҸгҖӮжүҫеҲ°з¬¬пјҲN^2пјү/2дёӘдҫҝжҳҜжүҖжұӮгҖӮеӨҚжқӮеәҰжҳҜOпјҲN^2*lgN^2пјүзҡ„гҖӮ
15. жңҖеӨ§й—ҙйҡҷй—®йўҳ
з»ҷе®ҡnдёӘе®һж•°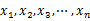 пјҢжұӮзқҖnдёӘе®һж•°еңЁе®һиҪҙдёҠеҗ‘йҮҸ2дёӘж•°д№Ӣй—ҙзҡ„жңҖеӨ§е·®еҖјпјҢиҰҒжұӮзәҝжҖ§зҡ„ж—¶й—ҙз®—жі•гҖӮ
пјҢжұӮзқҖnдёӘе®һж•°еңЁе®һиҪҙдёҠеҗ‘йҮҸ2дёӘж•°д№Ӣй—ҙзҡ„жңҖеӨ§е·®еҖјпјҢиҰҒжұӮзәҝжҖ§зҡ„ж—¶й—ҙз®—жі•гҖӮ
ж–№жЎҲ1пјҡжңҖе…ҲжғіеҲ°зҡ„ж–№жі•е°ұжҳҜе…ҲеҜ№иҝҷnдёӘж•°жҚ®иҝӣиЎҢжҺ’еәҸпјҢ然еҗҺдёҖйҒҚжү«жҸҸеҚіеҸҜзЎ®е®ҡзӣёйӮ»зҡ„жңҖеӨ§й—ҙйҡҷгҖӮдҪҶиҜҘж–№жі•дёҚиғҪж»Ўи¶ізәҝжҖ§ж—¶й—ҙзҡ„иҰҒжұӮгҖӮж•…йҮҮеҸ–еҰӮдёӢж–№жі•пјҡ
- жүҫеҲ°nдёӘж•°жҚ®дёӯжңҖеӨ§е’ҢжңҖе°Ҹж•°жҚ®maxе’ҢminгҖӮ
- з”Ёn-2дёӘзӮ№зӯүеҲҶеҢәй—ҙ[min, max]пјҢеҚіе°Ҷ[min, max]зӯүеҲҶдёәn-1дёӘеҢәй—ҙпјҲеүҚй—ӯеҗҺејҖеҢәй—ҙпјүпјҢе°ҶиҝҷдәӣеҢәй—ҙзңӢдҪңжЎ¶пјҢзј–еҸ·дёә
 пјҢдё”жЎ¶i зҡ„дёҠз•Ңе’ҢжЎ¶i+1зҡ„дёӢеұҠзӣёеҗҢпјҢеҚіжҜҸдёӘжЎ¶зҡ„еӨ§е°ҸзӣёеҗҢгҖӮжҜҸдёӘжЎ¶зҡ„еӨ§е°Ҹдёәпјҡ
пјҢдё”жЎ¶i зҡ„дёҠз•Ңе’ҢжЎ¶i+1зҡ„дёӢеұҠзӣёеҗҢпјҢеҚіжҜҸдёӘжЎ¶зҡ„еӨ§е°ҸзӣёеҗҢгҖӮжҜҸдёӘжЎ¶зҡ„еӨ§е°Ҹдёәпјҡ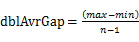 гҖӮе®һйҷ…дёҠпјҢиҝҷдәӣжЎ¶зҡ„иҫ№з•Ңжһ„жҲҗдәҶдёҖдёӘзӯүе·®ж•°еҲ—пјҲйҰ–йЎ№дёәminпјҢе…¬е·®дёә
гҖӮе®һйҷ…дёҠпјҢиҝҷдәӣжЎ¶зҡ„иҫ№з•Ңжһ„жҲҗдәҶдёҖдёӘзӯүе·®ж•°еҲ—пјҲйҰ–йЎ№дёәminпјҢе…¬е·®дёә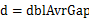 пјүпјҢдё”и®Өдёәе°Ҷminж”ҫе…Ҙ第дёҖдёӘжЎ¶пјҢе°Ҷmaxж”ҫе…Ҙ第n-1дёӘжЎ¶гҖӮ
пјүпјҢдё”и®Өдёәе°Ҷminж”ҫе…Ҙ第дёҖдёӘжЎ¶пјҢе°Ҷmaxж”ҫе…Ҙ第n-1дёӘжЎ¶гҖӮ - е°ҶnдёӘж•°ж”ҫе…Ҙn-1дёӘжЎ¶дёӯпјҡе°ҶжҜҸдёӘе…ғзҙ x[i] еҲҶй…ҚеҲ°жҹҗдёӘжЎ¶пјҲзј–еҸ·дёәindexпјүпјҢе…¶дёӯ
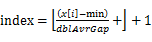 пјҢ并жұӮеҮәеҲҶеҲ°жҜҸдёӘжЎ¶зҡ„жңҖеӨ§жңҖе°Ҹж•°жҚ®гҖӮ
пјҢ并жұӮеҮәеҲҶеҲ°жҜҸдёӘжЎ¶зҡ„жңҖеӨ§жңҖе°Ҹж•°жҚ®гҖӮ - жңҖ еӨ§й—ҙйҡҷпјҡйҷӨжңҖеӨ§жңҖе°Ҹж•°жҚ®maxе’Ңminд»ҘеӨ–зҡ„n-2дёӘж•°жҚ®ж”ҫе…Ҙn-1дёӘжЎ¶дёӯпјҢз”ұжҠҪеұүеҺҹзҗҶеҸҜзҹҘиҮіе°‘жңүдёҖдёӘжЎ¶жҳҜз©әзҡ„пјҢеҸҲеӣ дёәжҜҸдёӘжЎ¶зҡ„еӨ§е°ҸзӣёеҗҢпјҢжүҖд»ҘжңҖеӨ§й—ҙйҡҷдёҚ дјҡеңЁеҗҢдёҖжЎ¶дёӯеҮәзҺ°пјҢдёҖе®ҡжҳҜжҹҗдёӘжЎ¶зҡ„дёҠз•Ңе’Ңж°”еҖҷжҹҗдёӘжЎ¶зҡ„дёӢз•Ңд№Ӣй—ҙйҡҷпјҢдё”иҜҘйҮҸзӯ’д№Ӣй—ҙзҡ„жЎ¶пјҲеҚідҫҝеҘҪеңЁиҜҘиҝһдёӘдҫҝеҘҪд№Ӣй—ҙзҡ„жЎ¶пјүдёҖе®ҡжҳҜз©әжЎ¶гҖӮд№ҹе°ұжҳҜиҜҙпјҢжңҖеӨ§й—ҙйҡҷеңЁжЎ¶i зҡ„дёҠз•Ңе’ҢжЎ¶jзҡ„дёӢз•Ңд№Ӣй—ҙдә§з”ҹj>=i+1гҖӮдёҖйҒҚжү«жҸҸеҚіеҸҜе®ҢжҲҗгҖӮ
16. е°ҶеӨҡдёӘйӣҶеҗҲеҗҲ并жҲҗжІЎжңүдәӨйӣҶзҡ„йӣҶеҗҲ
В В В з»ҷе®ҡдёҖдёӘеӯ—з¬ҰдёІзҡ„йӣҶеҗҲпјҢж јејҸеҰӮпјҡ гҖӮиҰҒжұӮе°Ҷе…¶дёӯдәӨйӣҶдёҚдёәз©әзҡ„йӣҶеҗҲеҗҲ并пјҢиҰҒжұӮеҗҲ并е®ҢжҲҗзҡ„йӣҶеҗҲд№Ӣй—ҙж— дәӨйӣҶпјҢдҫӢеҰӮдёҠдҫӢеә”иҫ“еҮә
гҖӮиҰҒжұӮе°Ҷе…¶дёӯдәӨйӣҶдёҚдёәз©әзҡ„йӣҶеҗҲеҗҲ并пјҢиҰҒжұӮеҗҲ并е®ҢжҲҗзҡ„йӣҶеҗҲд№Ӣй—ҙж— дәӨйӣҶпјҢдҫӢеҰӮдёҠдҫӢеә”иҫ“еҮә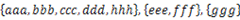 гҖӮ
гҖӮ
(1) иҜ·жҸҸиҝ°дҪ и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„жҖқи·Ҝпјӣ
(2) з»ҷеҮәдё»иҰҒзҡ„еӨ„зҗҶжөҒзЁӢпјҢз®—жі•пјҢд»ҘеҸҠз®—жі•зҡ„еӨҚжқӮеәҰпјӣ
(3) иҜ·жҸҸиҝ°еҸҜиғҪзҡ„ж”№иҝӣгҖӮ
В В В ж–№жЎҲ1пјҡйҮҮ用并жҹҘйӣҶгҖӮйҰ–е…ҲжүҖжңүзҡ„еӯ—з¬ҰдёІйғҪеңЁеҚ•зӢ¬зҡ„并жҹҘйӣҶдёӯгҖӮ然еҗҺдҫқжү«жҸҸжҜҸдёӘйӣҶеҗҲпјҢйЎәеәҸеҗҲ并е°ҶдёӨдёӘзӣёйӮ»е…ғзҙ еҗҲ并гҖӮдҫӢеҰӮпјҢеҜ№дәҺ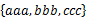 пјҢ
йҰ–е…ҲжҹҘзңӢaaaе’ҢbbbжҳҜеҗҰеңЁеҗҢдёҖдёӘ并жҹҘйӣҶдёӯпјҢеҰӮжһңдёҚеңЁпјҢйӮЈд№ҲжҠҠе®ғ们жүҖеңЁзҡ„并жҹҘйӣҶеҗҲ并пјҢ然еҗҺеҶҚзңӢbbbе’ҢcccжҳҜеҗҰеңЁеҗҢдёҖдёӘ并жҹҘйӣҶдёӯпјҢеҰӮжһңдёҚеңЁпјҢйӮЈд№Ҳд№ҹжҠҠ
е®ғ们жүҖеңЁзҡ„并жҹҘйӣҶеҗҲ并гҖӮжҺҘдёӢжқҘеҶҚжү«жҸҸе…¶д»–зҡ„йӣҶеҗҲпјҢеҪ“жүҖжңүзҡ„йӣҶеҗҲйғҪжү«жҸҸе®ҢдәҶпјҢ并жҹҘйӣҶд»ЈиЎЁзҡ„йӣҶеҗҲдҫҝжҳҜжүҖжұӮгҖӮеӨҚжқӮеәҰеә”иҜҘжҳҜO(NlgN)зҡ„гҖӮж”№иҝӣзҡ„иҜқпјҢйҰ–е…ҲеҸҜд»Ҙ
и®°еҪ•жҜҸдёӘиҠӮзӮ№зҡ„ж №з»“зӮ№пјҢж”№иҝӣжҹҘиҜўгҖӮеҗҲ并зҡ„ж—¶еҖҷпјҢеҸҜд»ҘжҠҠеӨ§зҡ„е’Ңе°Ҹзҡ„иҝӣиЎҢеҗҲпјҢиҝҷж ·д№ҹеҮҸе°‘еӨҚжқӮеәҰгҖӮ
пјҢ
йҰ–е…ҲжҹҘзңӢaaaе’ҢbbbжҳҜеҗҰеңЁеҗҢдёҖдёӘ并жҹҘйӣҶдёӯпјҢеҰӮжһңдёҚеңЁпјҢйӮЈд№ҲжҠҠе®ғ们жүҖеңЁзҡ„并жҹҘйӣҶеҗҲ并пјҢ然еҗҺеҶҚзңӢbbbе’ҢcccжҳҜеҗҰеңЁеҗҢдёҖдёӘ并жҹҘйӣҶдёӯпјҢеҰӮжһңдёҚеңЁпјҢйӮЈд№Ҳд№ҹжҠҠ
е®ғ们жүҖеңЁзҡ„并жҹҘйӣҶеҗҲ并гҖӮжҺҘдёӢжқҘеҶҚжү«жҸҸе…¶д»–зҡ„йӣҶеҗҲпјҢеҪ“жүҖжңүзҡ„йӣҶеҗҲйғҪжү«жҸҸе®ҢдәҶпјҢ并жҹҘйӣҶд»ЈиЎЁзҡ„йӣҶеҗҲдҫҝжҳҜжүҖжұӮгҖӮеӨҚжқӮеәҰеә”иҜҘжҳҜO(NlgN)зҡ„гҖӮж”№иҝӣзҡ„иҜқпјҢйҰ–е…ҲеҸҜд»Ҙ
и®°еҪ•жҜҸдёӘиҠӮзӮ№зҡ„ж №з»“зӮ№пјҢж”№иҝӣжҹҘиҜўгҖӮеҗҲ并зҡ„ж—¶еҖҷпјҢеҸҜд»ҘжҠҠеӨ§зҡ„е’Ңе°Ҹзҡ„иҝӣиЎҢеҗҲпјҢиҝҷж ·д№ҹеҮҸе°‘еӨҚжқӮеәҰгҖӮ
17. жңҖеӨ§еӯҗеәҸеҲ—дёҺжңҖеӨ§еӯҗзҹ©йҳөй—®йўҳ
ж•°з»„зҡ„жңҖеӨ§еӯҗеәҸеҲ—й—®йўҳпјҡз»ҷе®ҡдёҖдёӘж•°з»„пјҢе…¶дёӯе…ғзҙ жңүжӯЈпјҢд№ҹжңүиҙҹпјҢжүҫеҮәе…¶дёӯдёҖдёӘиҝһз»ӯеӯҗеәҸеҲ—пјҢдҪҝе’ҢжңҖеӨ§гҖӮ
В В В ж–№жЎҲ1пјҡиҝҷдёӘй—®йўҳеҸҜд»ҘеҠЁжҖҒ规еҲ’зҡ„жҖқжғіи§ЈеҶігҖӮи®ҫb[i]иЎЁзӨәд»Ҙ第iдёӘе…ғзҙ a[i]з»“е°ҫзҡ„жңҖеӨ§еӯҗеәҸеҲ—пјҢйӮЈд№Ҳжҳҫ然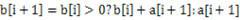 гҖӮеҹәдәҺиҝҷдёҖзӮ№еҸҜд»ҘеҫҲеҝ«з”Ёд»Јз Ғе®һзҺ°гҖӮ
гҖӮеҹәдәҺиҝҷдёҖзӮ№еҸҜд»ҘеҫҲеҝ«з”Ёд»Јз Ғе®һзҺ°гҖӮ
жңҖеӨ§еӯҗзҹ©йҳөй—®йўҳпјҡз»ҷе®ҡдёҖдёӘзҹ©йҳөпјҲдәҢз»ҙж•°з»„пјүпјҢе…¶дёӯж•°жҚ®жңүеӨ§жңүе°ҸпјҢиҜ·жүҫдёҖдёӘеӯҗзҹ©йҳөпјҢдҪҝеҫ—еӯҗзҹ©йҳөзҡ„е’ҢжңҖеӨ§пјҢ并иҫ“еҮәиҝҷдёӘе’ҢгҖӮ
В В В ж–№жЎҲ2пјҡеҸҜд»ҘйҮҮз”ЁдёҺжңҖеӨ§еӯҗеәҸеҲ—зұ»дјјзҡ„жҖқжғіжқҘи§ЈеҶігҖӮеҰӮжһңжҲ‘们确е®ҡдәҶйҖүжӢ©з¬¬iеҲ—е’Ң第jеҲ—д№Ӣй—ҙзҡ„е…ғзҙ пјҢйӮЈд№ҲеңЁиҝҷдёӘиҢғеӣҙеҶ…пјҢе…¶е®һе°ұжҳҜдёҖдёӘжңҖеӨ§еӯҗеәҸеҲ—й—®йўҳгҖӮеҰӮдҪ•зЎ®е®ҡ第iеҲ—е’Ң第jеҲ—еҸҜд»ҘиҜҚз”Ёжҡҙжҗңзҡ„ж–№жі•иҝӣиЎҢгҖӮ
В
第дәҢйғЁеҲҶгҖҒжө·йҮҸж•°жҚ®еӨ„зҗҶд№ӢBti-mapиҜҰи§Ј
В В В Bloom Filterе·ІеңЁдёҠдёҖзҜҮж–Үз« жө·йҮҸж•°жҚ®еӨ„зҗҶд№ӢBloom FilterиҜҰи§Ј дёӯдәҲд»ҘиҜҰз»Ҷйҳҗиҝ°пјҢжң¬ж–ҮжҺҘдёӢжқҘзқҖйҮҚйҳҗиҝ°Bit-mapгҖӮжңүд»»дҪ•й—®йўҳпјҢж¬ўиҝҺдёҚеҗқжҢҮжӯЈгҖӮ
д»Җд№ҲжҳҜBit-map
В В В жүҖи°“зҡ„Bit-mapе°ұжҳҜз”ЁдёҖдёӘbitдҪҚжқҘж Үи®°жҹҗдёӘе…ғзҙ еҜ№еә”зҡ„ValueпјҢ иҖҢKeyеҚіжҳҜиҜҘе…ғзҙ гҖӮз”ұдәҺйҮҮз”ЁдәҶBitдёәеҚ•дҪҚжқҘеӯҳеӮЁж•°жҚ®пјҢеӣ жӯӨеңЁеӯҳеӮЁз©әй—ҙж–№йқўпјҢеҸҜд»ҘеӨ§еӨ§иҠӮзңҒгҖӮ
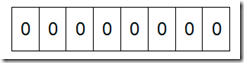
В В В еҰӮжһңиҜҙдәҶиҝҷд№ҲеӨҡиҝҳжІЎжҳҺзҷҪд»Җд№ҲжҳҜBit-mapпјҢйӮЈд№ҲжҲ‘们жқҘзңӢдёҖдёӘе…·дҪ“зҡ„дҫӢеӯҗпјҢеҒҮи®ҫжҲ‘们иҰҒеҜ№0-7еҶ…зҡ„5дёӘе…ғзҙ (4,7,2,5,3)жҺ’еәҸпјҲиҝҷйҮҢеҒҮи®ҫиҝҷдәӣе…ғ зҙ жІЎжңүйҮҚеӨҚпјүгҖӮйӮЈд№ҲжҲ‘们е°ұеҸҜд»ҘйҮҮз”ЁBit-mapзҡ„ж–№жі•жқҘиҫҫеҲ°жҺ’еәҸзҡ„зӣ®зҡ„гҖӮиҰҒиЎЁзӨә8дёӘж•°пјҢжҲ‘们е°ұеҸӘйңҖиҰҒ8дёӘBitпјҲ1BytesпјүпјҢйҰ–е…ҲжҲ‘们ејҖиҫҹ 1Byteзҡ„з©әй—ҙпјҢе°Ҷиҝҷдәӣз©әй—ҙзҡ„жүҖжңүBitдҪҚйғҪзҪ®дёә0(еҰӮдёӢеӣҫпјҡ)
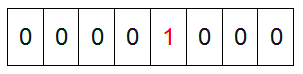
   然еҗҺйҒҚеҺҶиҝҷ5дёӘе…ғзҙ пјҢйҰ–е…Ҳ第дёҖдёӘе…ғзҙ жҳҜ4пјҢйӮЈд№Ҳе°ұжҠҠ4еҜ№еә”зҡ„дҪҚзҪ®дёә1пјҲеҸҜд»Ҙиҝҷж ·ж“ҚдҪң p+(i/8)|(0Г—01<<(i%8)) еҪ“然дәҶиҝҷйҮҢзҡ„ж“ҚдҪңж¶үеҸҠеҲ°Big-endingе’ҢLittle-endingзҡ„жғ…еҶөпјҢиҝҷйҮҢй»ҳи®ӨдёәBig-endingпјү,еӣ дёәжҳҜд»Һйӣ¶ејҖе§Ӣзҡ„пјҢжүҖд»ҘиҰҒжҠҠ第дә”дҪҚ зҪ®дёәдёҖпјҲеҰӮдёӢеӣҫпјүпјҡ
В В В В В
然еҗҺеҶҚеӨ„зҗҶ第дәҢдёӘе…ғзҙ 7пјҢе°Ҷ第八дҪҚзҪ®дёә1,пјҢжҺҘзқҖеҶҚеӨ„зҗҶ第дёүдёӘе…ғзҙ пјҢдёҖзӣҙеҲ°жңҖеҗҺеӨ„зҗҶе®ҢжүҖжңүзҡ„е…ғзҙ пјҢе°Ҷзӣёеә”зҡ„дҪҚзҪ®дёә1пјҢиҝҷж—¶еҖҷзҡ„еҶ…еӯҳзҡ„BitдҪҚзҡ„зҠ¶жҖҒеҰӮдёӢпјҡ
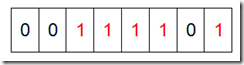
然еҗҺжҲ‘们зҺ°еңЁйҒҚеҺҶдёҖйҒҚBitеҢәеҹҹпјҢе°ҶиҜҘдҪҚжҳҜдёҖзҡ„дҪҚзҡ„зј–еҸ·иҫ“еҮәпјҲ2пјҢ3пјҢ4пјҢ5пјҢ7пјүпјҢиҝҷж ·е°ұиҫҫеҲ°дәҶжҺ’еәҸзҡ„зӣ®зҡ„гҖӮдёӢйқўзҡ„д»Јз Ғз»ҷеҮәдәҶдёҖдёӘBitMapзҡ„з”Ёжі•пјҡжҺ’еәҸгҖӮ
- //е®ҡд№үжҜҸдёӘByteдёӯжңү8дёӘBitдҪҚ В В
- #includeВ пјңmemory.hпјһ В В
- #defineВ BYTESIZEВ 8 В В
- void В SetBit( char В *p,В int В posi)В В
- {В В
- В В В В for ( int В i=0;В iВ пјңВ (posi/BYTESIZE);В i++)В В
- В В В В {В В
- В В В В В В В В p++;В В
- В В В В }В В
- В В
- В В В В *pВ =В *p|(0x01пјңпјң(posi%BYTESIZE));//е°ҶиҜҘBitдҪҚиөӢеҖј1 В В
- В В В В return ;В В
- }В В
- В В
- void В BitMapSortDemo()В В
- {В В
- В В В В //дёәдәҶз®ҖеҚ•иө·и§ҒпјҢжҲ‘们дёҚиҖғиҷ‘иҙҹж•° В В
- В В В В int В num[]В =В {3,5,2,10,6,12,8,14,9};В В
- В В
- В В В В //BufferLenиҝҷдёӘеҖјжҳҜж №жҚ®еҫ…жҺ’еәҸзҡ„ж•°жҚ®дёӯжңҖеӨ§еҖјзЎ®е®ҡзҡ„ В В
- В В В В //еҫ…жҺ’еәҸдёӯзҡ„жңҖеӨ§еҖјжҳҜ14пјҢеӣ жӯӨеҸӘйңҖиҰҒ2дёӘBytes(16дёӘBit) В В
- В В В В //е°ұеҸҜд»ҘдәҶгҖӮ В В
- В В В В const В int В BufferLenВ =В 2;В В
- В В В В char В *pBufferВ =В new В char [BufferLen];В В
- В В
- В В В В //иҰҒе°ҶжүҖжңүзҡ„BitдҪҚзҪ®дёә0пјҢеҗҰеҲҷз»“жһңдёҚеҸҜйў„зҹҘгҖӮ В В
- В В В В memset(pBuffer,0,BufferLen);В В
- В В В В for ( int В i=0;iпјң9;i++)В В
- В В В В {В В
- В В В В В В В В //йҰ–е…Ҳе°Ҷзӣёеә”BitдҪҚдёҠзҪ®дёә1 В В
- В В В В В В В В SetBit(pBuffer,num[i]);В В
- В В В В }В В
- В В
- В В В В //иҫ“еҮәжҺ’еәҸз»“жһң В В
- В В В В for ( int В i=0;iпјңBufferLen;i++) //жҜҸж¬ЎеӨ„зҗҶдёҖдёӘеӯ—иҠӮ(Byte) В В
- В В В В {В В
- В В В В В В В В for ( int В j=0;jпјңBYTESIZE;j++) //еӨ„зҗҶиҜҘеӯ—иҠӮдёӯзҡ„жҜҸдёӘBitдҪҚ В В
- В В В В В В В В {В В
- В В В В В В В В В В В В //еҲӨж–ӯиҜҘдҪҚдёҠжҳҜеҗҰжҳҜ1пјҢиҝӣиЎҢиҫ“еҮәпјҢиҝҷйҮҢзҡ„еҲӨж–ӯжҜ”иҫғз¬ЁгҖӮ В В
- В В В В В В В В В В В В //йҰ–е…Ҳеҫ—еҲ°иҜҘ第jдҪҚзҡ„жҺ©з ҒпјҲ0x01пјңпјңjпјүпјҢе°ҶеҶ…еӯҳеҢәдёӯзҡ„ В В
- В В В В В В В В В В В В //дҪҚе’ҢжӯӨжҺ©з ҒдҪңдёҺж“ҚдҪңгҖӮжңҖеҗҺеҲӨж–ӯжҺ©з ҒжҳҜеҗҰе’ҢеӨ„зҗҶеҗҺзҡ„ В В
- В В В В В В В В В В В В //з»“жһңзӣёеҗҢ В В
- В В В В В В В В В В В В if ((*pBuffer&(0x01пјңпјңj))В ==В (0x01пјңпјңj))В В
- В В В В В В В В В В В В {В В
- В В В В В В В В В В В В В В В В printf("%dВ " ,i*BYTESIZEВ +В j);В В
- В В В В В В В В В В В В }В В
- В В В В В В В В }В В
- В В В В В В В В pBuffer++;В В
- В В В В }В В
- }В В
- В В
- int В _tmain( int В argc,В _TCHAR*В argv[])В В
- {В В
- В В В В BitMapSortDemo();В В
- В В В В return В 0;В В
- }В В
еҸҜиҝӣиЎҢж•°жҚ®зҡ„еҝ«йҖҹжҹҘжүҫпјҢеҲӨйҮҚпјҢеҲ йҷӨпјҢдёҖиҲ¬жқҘиҜҙж•°жҚ®иҢғеӣҙжҳҜintзҡ„10еҖҚд»ҘдёӢ
еҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№
дҪҝз”Ёbitж•°з»„жқҘиЎЁзӨәжҹҗдәӣе…ғзҙ жҳҜеҗҰеӯҳеңЁпјҢжҜ”еҰӮ8дҪҚз”өиҜқеҸ·з Ғ
жү©еұ•
Bloom filterеҸҜд»ҘзңӢеҒҡжҳҜеҜ№bit-mapзҡ„жү©еұ•пјҲе…ідәҺBloom filterпјҢиҜ·еҸӮи§Ғпјҡжө·йҮҸж•°жҚ®еӨ„зҗҶд№ӢBloom filter иҜҰи§Ј пјүгҖӮ
й—®йўҳе®һдҫӢ
1)е·ІзҹҘжҹҗдёӘж–Ү件еҶ…еҢ…еҗ«дёҖдәӣз”өиҜқеҸ·з ҒпјҢжҜҸдёӘеҸ·з Ғдёә8дҪҚж•°еӯ—пјҢз»ҹи®ЎдёҚеҗҢеҸ·з Ғзҡ„дёӘж•°гҖӮ
В В В 8дҪҚжңҖеӨҡ99 999 999пјҢеӨ§жҰӮйңҖиҰҒ99mдёӘbitпјҢеӨ§жҰӮ10еҮ mеӯ—иҠӮзҡ„еҶ…еӯҳеҚіеҸҜгҖӮ пјҲеҸҜд»ҘзҗҶи§Јдёәд»Һ0-99 999 999зҡ„ж•°еӯ—пјҢжҜҸдёӘж•°еӯ—еҜ№еә”дёҖдёӘBitдҪҚпјҢжүҖд»ҘеҸӘйңҖиҰҒ99MдёӘBit==1.2MBytesпјҢиҝҷж ·пјҢе°ұз”ЁдәҶе°Ҹе°Ҹзҡ„1.2Mе·ҰеҸізҡ„еҶ…еӯҳиЎЁзӨәдәҶжүҖжңүзҡ„8дҪҚж•°зҡ„ з”өиҜқпјү
2)2.5дәҝдёӘж•ҙж•°дёӯжүҫеҮәдёҚйҮҚеӨҚзҡ„ж•ҙж•°зҡ„дёӘж•°пјҢеҶ…еӯҳз©әй—ҙдёҚи¶ід»Ҙе®№зәіиҝҷ2.5дәҝдёӘж•ҙж•°гҖӮ
В В В е°Ҷbit-mapжү©еұ•дёҖдёӢпјҢз”Ё2bitиЎЁзӨәдёҖдёӘж•°еҚіеҸҜпјҢ0иЎЁзӨәжңӘеҮәзҺ°пјҢ1иЎЁзӨәеҮәзҺ°дёҖж¬ЎпјҢ2иЎЁзӨәеҮәзҺ°2ж¬ЎеҸҠд»ҘдёҠпјҢеңЁйҒҚеҺҶиҝҷдәӣж•°зҡ„ж—¶еҖҷпјҢеҰӮжһңеҜ№еә”дҪҚзҪ®зҡ„еҖјжҳҜ 0пјҢеҲҷе°Ҷе…¶зҪ®дёә1пјӣеҰӮжһңжҳҜ1пјҢе°Ҷе…¶зҪ®дёә2пјӣеҰӮжһңжҳҜ2пјҢеҲҷдҝқжҢҒдёҚеҸҳгҖӮжҲ–иҖ…жҲ‘们дёҚз”Ё2bitжқҘиҝӣиЎҢиЎЁзӨәпјҢжҲ‘们用дёӨдёӘbit-mapеҚіеҸҜжЁЎжӢҹе®һзҺ°иҝҷдёӘ2bit- mapпјҢйғҪжҳҜдёҖж ·зҡ„йҒ“зҗҶгҖӮ
еҸӮиҖғпјҡ
- http://www.cnblogs.com/youwang/archive/2010/07/20/1781431.html гҖӮ
- http://blog.redfox66.com/post/2010/09/26/mass-data-4-bitmap.aspx гҖӮ
е®ҢгҖӮ


- 2011-10-06 17:20
- жөҸи§Ҳ 1590
- иҜ„и®ә(0)
- еҲҶзұ»:зј–зЁӢиҜӯиЁҖ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
йқўиҜ•--зәҰиҲҚеӨ«й—®йўҳ
2012-08-29 19:37 1815д»ҘеүҚеңЁдёҖдёӘ笔иҜ•зҡ„ж—¶еҖҷи ... -
жҖқ科йқўиҜ•пјҲ2пјү
2012-08-29 19:31 2067жҖқ科жҳҜжңҖиҝ‘жҠ•зҡ„пјҢдёҖдёӘе ... -
зҪ‘жҳ“йқўиҜ•пјҲ1пјү
2012-08-29 19:16 1586зҪ‘жҳ“йқўиҜ•еә”иҜҘжҳҜеҺ»е№ҙ11жңҲд»Ҫзҡ„ж—¶еҖҷпјҢйӮЈдёӘж—¶еҖҷйҷӘеёҲе…„еҺ»жүҫе·ҘдҪңдәҶпјҢжҲ‘ ... -
жҺ’еәҸ1
2011-12-01 08:10 1511#include<stdio.h> int ma ...
зӣёе…іжҺЁиҚҗ
еңЁеӨ„зҗҶжө·йҮҸж•°жҚ®зҡ„й—®йўҳж—¶пјҢжҲ‘们йңҖиҰҒиҖғиҷ‘еҰӮдҪ•жңүж•Ҳең°еҲ©з”Ёжңүйҷҗзҡ„еҶ…еӯҳиө„жәҗпјҢд»ҘеҸҠеҰӮдҪ•и®ҫи®Ўй«ҳж•Ҳзҡ„з®—жі•жқҘйҷҚдҪҺж—¶й—ҙеӨҚжқӮеәҰгҖӮд»ҘдёӢжҳҜеҜ№з»ҷе®ҡйўҳзӣ®дёӯеҗ„дёӘй—®йўҳзҡ„иҜҰз»Ҷи§Јзӯ”пјҡ 1. **жүҫе…ұеҗҢURL**пјҡ - ж–№жЎҲ1пјҡдҪҝз”Ёе“ҲеёҢеҮҪж•°е°ҶURLеҲҶй…ҚеҲ°е°Ҹ...
ITеёёи§ҒйқўиҜ•йўҳ-жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳйӣҶй”ҰпјҢж №жҚ®е®һйҷ…зҡ„йқўиҜ•з»ҸйӘҢпјҢжҖ»з»“дәҶзҪ‘дёҠзҡ„йқўиҜ•йўҳзӣ®пјҢ并з»ҷеҮәдәҶиҜҰз»Ҷи§Јжһҗ
еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-002-еҫҒжңҚ99%зҡ„йқўиҜ•е®ҳзҡ„жө·йҮҸж•°жҚ®жҹҘиҜўдјҳеҢ–и§ЈйўҳжҖқи·Ҝ.mp4 еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-003-зғӮеӨ§иЎ—зҡ„HashMapеҰӮдҪ•и§ЈйўҳжүҚиғҪз§’жқҖйқўиҜ•е®ҳ-1.mp4 еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-003-зғӮеӨ§иЎ—зҡ„HashMapеҰӮдҪ•и§Јйўҳ...
еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-002-еҫҒжңҚ99%зҡ„йқўиҜ•е®ҳзҡ„жө·йҮҸж•°жҚ®жҹҘиҜўдјҳеҢ–и§ЈйўҳжҖқи·Ҝ.mp4 еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-003-зғӮеӨ§иЎ—зҡ„HashMapеҰӮдҪ•и§ЈйўҳжүҚиғҪз§’жқҖйқўиҜ•е®ҳ-1.mp4 еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-003-зғӮеӨ§иЎ—зҡ„HashMapеҰӮдҪ•и§Јйўҳ...
еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-002-еҫҒжңҚ99%зҡ„йқўиҜ•е®ҳзҡ„жө·йҮҸж•°жҚ®жҹҘиҜўдјҳеҢ–и§ЈйўҳжҖқи·Ҝ.mp4 еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-003-зғӮеӨ§иЎ—зҡ„HashMapеҰӮдҪ•и§ЈйўҳжүҚиғҪз§’жқҖйқўиҜ•е®ҳ-1.mp4 еӨ§еҺӮйқўиҜ•йўҳ第дёҖеӯЈ-йҳҝйҮҢзҜҮ-003-зғӮеӨ§иЎ—зҡ„HashMapеҰӮдҪ•и§Јйўҳ...
йқўиҜ•йўҳ ...ж•ҷдҪ еҰӮдҪ•иҝ…йҖҹз§’жқҖжҺүпјҡ99%зҡ„жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳ@.pdf 0.5MB еҫҲе…Ёйқўзҡ„иҪҜ件е·ҘзЁӢеёҲйқўиҜ•иө„ж–ҷ@.docx 0.0MB еёёи§Ғз®—жі•йқўиҜ•йўҳ@.docx 0.0MB зҷҫеәҰгҖҒи…ҫи®ҜгҖҒеӨҙжқЎгҖҒзҫҺеӣўзҡ„JavaйқўиҜ•йўҳзӣ®жҖ»з»“@.docx 3.0MB
#### дёҖгҖҒжө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳи§Јжһҗ **1гҖҒжө·йҮҸж—Ҙеҝ—ж•°жҚ®пјҢжҸҗеҸ–еҮәжҹҗж—Ҙи®ҝй—®зҷҫеәҰж¬Ўж•°жңҖеӨҡзҡ„йӮЈдёӘIP** - **й—®йўҳжҰӮиҝ°**: з»ҷе®ҡдёҖеӨ©еҶ…зҡ„жө·йҮҸж—Ҙеҝ—ж•°жҚ®пјҢд»ҺдёӯжүҫеҮәи®ҝй—®зҷҫеәҰж¬Ўж•°жңҖеӨҡзҡ„IPең°еқҖгҖӮ - **и§ЈеҶіж–№жЎҲ**: - **еҲқжӯҘжҖқи·Ҝ**: ...
жө·йҮҸж•°жҚ®еӨ„зҗҶ пјҒпјҒпјҒпјҒпјҒ
ж•ҙзҗҶзҡ„дёҖдәӣеёёи§Ғдә’иҒ”зҪ‘жө·йҮҸж•°жҚ®жҺ’еәҸйқўиҜ•йўҳгҖӮ
жө·йҮҸж•°жҚ®еӨ„зҗҶжҳҜдә’иҒ”зҪ‘е…¬еҸёжҠҖжңҜйқўиҜ•дёӯзҡ„дёҖдёӘйҮҚиҰҒзҺҜиҠӮпјҢе®ғдё»иҰҒиҖғеҜҹеә”иҒҳиҖ…еӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®йӣҶзҡ„иғҪеҠӣпјҢд»ҘеҸҠеҜ№еҗ„з§ҚеӯҳеӮЁгҖҒи®Ўз®—гҖҒжҺ’еәҸз®—жі•зҡ„зҗҶи§Је’Ңеә”з”ЁгҖӮд»ҘдёӢй’ҲеҜ№жҸҗдҫӣзҡ„ж–Ү件еҶ…е®№пјҢжҸҗзӮјеҮәзӣёе…ізҡ„зҹҘиҜҶзӮ№гҖӮ йҰ–е…ҲпјҢжө·йҮҸж•°жҚ®еӨ„зҗҶзҡ„...
### Elasticsearch йқўиҜ•йўҳи§Јжһҗ #### 1. Elasticsearch йӣҶзҫӨжһ¶жһ„дёҺи°ғдјҳжүӢж®ө - **йқўиҜ•е®ҳж„Ҹеӣҫ**пјҡдәҶи§Јеә”иҒҳиҖ…еңЁе…¶жүҖеңЁе…¬еҸёзҡ„ Elasticsearch дҪҝз”Ёжғ…еҶөгҖҒйҒҮеҲ°зҡ„й—®йўҳеҸҠе…¶и§ЈеҶіж–№жі•пјҢзү№еҲ«жҳҜжҳҜеҗҰжңүеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®зҡ„з»ҸйӘҢгҖӮ -...
жң¬ж–Үж•ҙзҗҶе’ҢеӨ§е®¶еҲҶдә«дёҖдәӣSQLж•°жҚ®еә“еҜ№дәҺжө·йҮҸж•°жҚ®йқўиҜ•йўҳеҸҠзӯ”жЎҲз»ҷеӨ§е®¶пјҢеҫҲдёҚй”ҷе“ҰпјҢе–ңж¬ўиҜ·ж”¶и—ҸдёҖдёӢгҖӮ
еҢ…еҗ«йқһеёёдё°еҜҢзҡ„JavaзҹҘиҜҶзӮ№е’Ңжө·йҮҸйқўиҜ•йўҳпјҢж•ҙзҗҶиҮӘвҖңзЁӢеәҸе‘ҳд№”жҲҲйҮҢвҖқпјҢж„ҹи°ўеҺҹдҪңиҖ…зҡ„иҫӣиӢҰд»ҳеҮәпјҢжң¬иө„жәҗдҪңдёәжҗ¬иҝҗпјҢжҳҜеӣ дёәеҺҹдҪңиҖ…зҡ„й“ҫжҺҘж— жі•и®ҝй—®дәҶпјҢиҮӘе·ұйҖҡиҝҮдёҖдәӣжүӢж®өиҫӣиӢҰдёӢиҪҪдёӢжқҘпјҢеёҢжңӣиғҪеё®еҲ°еӨ§е®¶пјҒ жҗңйӣҶдёҚжҳ“пјҢиҜ·дәҲд»ҘзӮ№ж»ҙ...
### еҚҒдёғйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺBit-mapиҜҰи§Ј #### 第дёҖйғЁеҲҶпјҡеҚҒдә”йҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳ **йўҳзӣ®дёҖ**пјҡз»ҷе®ҡaгҖҒbдёӨдёӘж–Ү件пјҢеҗ„еӯҳж”ҫ50дәҝдёӘURLпјҢжҜҸдёӘURLеҗ„еҚ 64еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶жҳҜ4GBпјҢи®©дҪ жүҫеҮәaгҖҒbж–Ү件е…ұеҗҢзҡ„URLгҖӮ - **...
### жө·йҮҸж•°жҚ®еӨ„зҗҶдёҺйқўиҜ•йўҳи§Јжһҗ #### 1. URL еҺ»йҮҚз®—жі• еңЁеӨ„зҗҶжө·йҮҸURLж—¶пјҢйңҖиҰҒй«ҳж•Ҳең°иҝӣиЎҢеҺ»йҮҚеӨ„зҗҶгҖӮдёҖз§Қеёёи§Ғзҡ„ж–№ејҸжҳҜйҖҡиҝҮе“ҲеёҢйӣҶ(hash set)жқҘе®һзҺ°гҖӮ - **ж–№жі•дёҖ**пјҡеҜ№дәҺжҜҸдёӘURLпјҢе°Ҷе…¶ж·»еҠ еҲ°дёҖдёӘе“ҲеёҢйӣҶдёӯгҖӮеҰӮжһңе“ҲеёҢ...
### жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺж–№жі•еӨ§жҖ»з»“ еңЁITиЎҢдёҡдёӯпјҢжө·йҮҸж•°жҚ®еӨ„зҗҶжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„йўҶеҹҹпјҢе®ғж¶үеҸҠеҲ°дәҶеҫҲеӨҡй«ҳж•Ҳзҡ„ж•°жҚ®еӯҳеӮЁгҖҒжЈҖзҙўд»ҘеҸҠеӨ„зҗҶжҠҖжңҜгҖӮжң¬ж–Үе°ҶеҹәдәҺз»ҷе®ҡзҡ„ж–Ү件еҶ…е®№пјҢеҜ№е…¶дёӯжҸҗеҸҠзҡ„дёҖдәӣе…ій”®зҹҘиҜҶзӮ№иҝӣиЎҢиҜҰз»Ҷзҡ„йҳҗиҝ°гҖӮ ...
дёҖиҲ¬иҖҢиЁҖпјҢж Үйўҳеҗ«жңүвҖңз§’жқҖвҖқпјҢвҖң99%вҖқпјҢвҖңеҸІдёҠжңҖе…Ё/жңҖејәвҖқзӯүиҜҚжұҮзҡ„еҫҖеҫҖйғҪи„ұдёҚдәҶе“—дј—еҸ–е® д№Ӣе«ҢпјҢдҪҶиҝӣдёҖжӯҘжқҘи®ІпјҢеҰӮжһңиҜ»иҖ…иҜ»зҪўжӯӨж–ҮпјҢеҚҙж— д»»дҪ•ж”¶иҺ·пјҢйӮЈд№ҲпјҢжҲ‘д№ҹ...еҚҒйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺеҚҒдёӘж–№жі•еӨ§жҖ»з»“зҡ„дёҖиҲ¬жҠҪиұЎжҖ§жҖ»з»“гҖӮ
в”ңв”Җ001-P7зЁӢеәҸе‘ҳйқўиҜ•иҝҷж ·и§Јйўҳж•°жҚ®еә“зҙўеј•-1.mp4в”ңв”Җ001-P7зЁӢеәҸе‘ҳйқўиҜ•иҝҷж ·и§Јйўҳж•°жҚ®еә“зҙўеј•-2.mp4в”ңв”Җ001-P7зЁӢеәҸе‘ҳйқўиҜ•иҝҷж ·и§Јйўҳж•°жҚ®еә“зҙўеј•-3.mp4в”ңв”Җ002-еҫҒжңҚ99%зҡ„йқўиҜ•е®ҳзҡ„жө·йҮҸж•°жҚ®жҹҘиҜўдјҳеҢ–и§ЈйўҳжҖқи·Ҝ.mp4в”ңв”Җ003-зғӮеӨ§иЎ—...