
简介
Apache Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
消息保存多久呢?其实可配置的
log.retention.hours=48 #数据最多保存48小时
log.retention.bytes=1073741824 #数据最多1G
而rabbitmq就不同,它的消费组消费之前,会建立队列queue,消息进来会扔到队列里。如果没有队列,就不会收到消息;同样,队列的消息如果不消费并确认删除,就永远存在(当然也有参数设置过期时间ttl,会自动删除)。
Kafka架构
它的架构包括以下组件:
话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。
生产者(Producer):是能够发布消息到话题的任何对象。
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
注意:同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
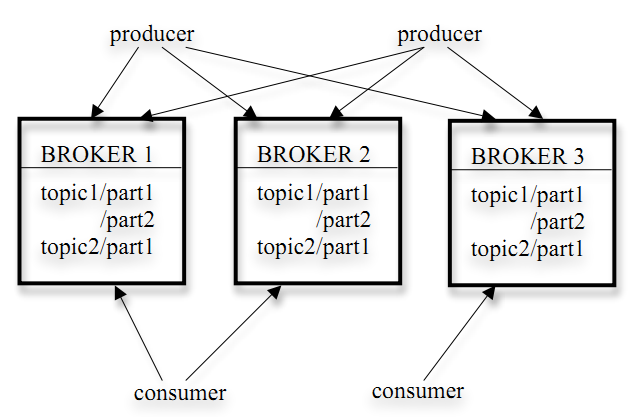
Kafka存储策略
1)kafka以topic来进行消息管理,每个topic包含多个partition,每个partition对应一个逻辑log,有多个segment组成。
2)每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3)每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
4)发布者发到某个topic的消息会被均匀的分布到多个partition上(或根据用户指定的路由规则进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
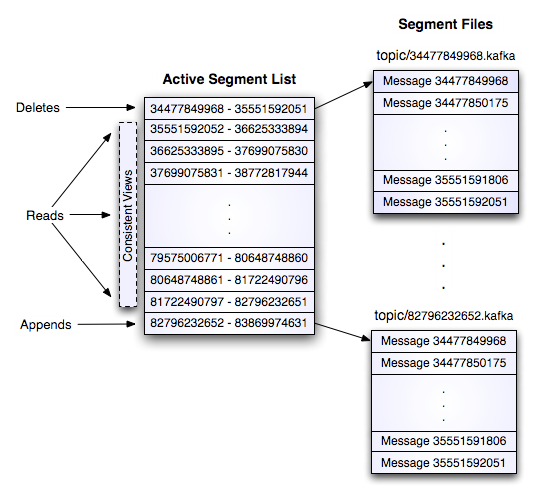
Kafka数据保留策略
1)N天前的删除。
2)保留最近的多少Size数据。
Kafka broker
与其它消息系统不同,Kafka broker是无状态的。这意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,broker完全不管(有offset managerbroker管理)。
- 从代理删除消息变得很棘手,因为代理并不知道消费者是否已经使用了该消息。Kafka创新性地解决了这个问题,它将一个简单的基于时间的SLA应用于保留策略。当消息在代理中超过一定时间后,将会被自动删除。
- 这种创新设计有很大的好处,消费者可以故意倒回到老的偏移量再次消费数据。这违反了队列的常见约定,但被证明是许多消费者的基本特征。
以下摘抄自kafka官方文档:
Kafka Design
目标
1) 高吞吐量来支持高容量的事件流处理
2) 支持从离线系统加载数据
3) 低延迟的消息系统
持久化
1) 依赖文件系统,持久化到本地
2) 数据持久化到log
效率
1) 解决”small IO problem“:
使用”message set“组合消息。
server使用”chunks of messages“写到log。
consumer一次获取大的消息块。
2)解决”byte copying“:
在producer、broker和consumer之间使用统一的binary message format。
使用系统的page cache。
使用sendfile传输log,避免拷贝。
端到端的批量压缩(End-to-end Batch Compression)
Kafka支持GZIP和Snappy压缩协议。
复制(Replication)
1)一个partition的复制个数(replication factor)包括这个partition的leader本身。
2)所有对partition的读和写都通过leader。
3)Followers通过pull获取leader上log(message和offset)
4)如果一个follower挂掉、卡住或者同步太慢,leader会把这个follower从”in sync replicas“(ISR)列表中删除。
5)当所有的”in sync replicas“的follower把一个消息写入到自己的log中时,这个消息才被认为是”committed“的。
6)如果针对某个partition的所有复制节点都挂了,Kafka默认选择最先复活的那个节点作为leader(这个节点不一定在ISR里)。
Leader选举
Kafka在Zookeeper中为每一个partition动态的维护了一个ISR,这个ISR里的所有replica都跟上了leader,只有ISR里的成员才能有被选为leader的可能(unclean.leader.election.enable=false)。
在这种模式下,对于f+1个副本,一个Kafka topic能在保证不丢失已经commit消息的前提下容忍f个副本的失败,在大多数使用场景下,这种模式是十分有利的。事实上,为了容忍f个副本的失败,“少数服从多数”的方式和ISR在commit前需要等待的副本的数量是一样的,但是ISR需要的总的副本的个数几乎是“少数服从多数”的方式的一半。
The Producer
发送确认
通过request.required.acks来设置,选择是否等待消息commit(是否等待所有的”in sync replicas“都成功复制了数据)
Producer可以通过acks参数指定最少需要多少个Replica确认收到该消息才视为该消息发送成功。acks的默认值是1,即Leader收到该消息后立即告诉Producer收到该消息,此时如果在ISR中的消息复制完该消息前Leader宕机,那该条消息会丢失。
推荐的做法是,将acks设置为all或者-1,此时只有ISR中的所有Replica都收到该数据(也即该消息被Commit),Leader才会告诉Producer该消息发送成功,从而保证不会有未知的数据丢失。
负载均衡
1)producer可以自定义发送到哪个partition的路由规则。默认路由规则:hash(key)%numPartitions,如果key为null则随机选择一个partition。
2)自定义路由:如果key是一个user id,可以把同一个user的消息发送到同一个partition,这时consumer就可以从同一个partition读取同一个user的消息。
异步批量发送
批量发送:配置不多于固定消息数目一起发送并且等待时间小于一个固定延迟的数据。
The Consumer
consumer控制消息的读取。
Push vs Pull
1) producer push data to broker,consumer pull data from broker
2) consumer pull的优点:consumer自己控制消息的读取速度和数量。
3) consumer pull的缺点:如果broker没有数据,则可能要pull多次忙等待,Kafka可以配置consumer long pull一直等到有数据。
Consumer Position
1) 大部分消息系统由broker记录哪些消息被消费了,但Kafka不是。
2) Kafka由consumer控制消息的消费,consumer甚至可以回到一个old offset的位置再次消费消息。
Consumer group
每一个consumer实例都属于一个consumer group。
每一条消息只会被同一个consumer group里的一个consumer实例消费。
不同consumer group可以同时消费同一条消息。
Consumer Rebalance
Kafka consumer high level API:
Message Delivery Semantics
三种:
At most once—Messages may be lost but are never redelivered.
At least once—Messages are never lost but may be redelivered.
Exactly once—this is what people actually want, each message is delivered once and only once.
Producer:有个”acks“配置可以控制接收的leader的在什么情况下就回应producer消息写入成功。
Consumer:
* 读取消息,写log,处理消息。如果处理消息失败,log已经写入,则无法再次处理失败的消息,对应”At most once“。
* 读取消息,处理消息,写log。如果消息处理成功,写log失败,则消息会被处理两次,对应”At least once“。
* 读取消息,同时处理消息并把result和log同时写入。这样保证result和log同时更新或同时失败,对应”Exactly once“。
Kafka默认保证at-least-once delivery,容许用户实现at-most-once语义,exactly-once的实现取决于目的存储系统,kafka提供了读取offset,实现也没有问题。
Distribution
Consumer Offset Tracking
1)High-level consumer记录每个partition所消费的maximum offset,并定期commit到offset manager(broker)。
2)Simple consumer需要手动管理offset。现在的Simple consumer Java API只支持commit offset到zookeeper。
Consumers and Consumer Groups
1)consumer注册到zookeeper
2)属于同一个group的consumer(group id一样)平均分配partition,每个partition只会被一个consumer消费。
3)当broker或同一个group的其他consumer的状态发生变化的时候,consumer rebalance就会发生。
Zookeeper协调控制
1)管理broker与consumer的动态加入与离开。
2)触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一个consumer group内的多个consumer的订阅负载平衡。
3)维护消费关系及每个partition的消费信息。
日志压缩(Log Compaction)
1)针对一个topic的partition,压缩使得Kafka至少知道每个key对应的最后一个值。
2)压缩不会重排序消息。
3)消息的offset是不会变的。
4)消息的offset是顺序的。
5)压缩发送和接收能降低网络负载。
6)以压缩后的形式持久化到磁盘。
生产者代码示例:

import java.util.*; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; public class TestProducer { public static void main(String[] args) { long events = Long.parseLong(args[0]); Random rnd = new Random(); Properties props = new Properties(); props.put("metadata.broker.list", "broker1:9092,broker2:9092 "); props.put("serializer.class", "kafka.serializer.StringEncoder"); props.put("partitioner.class", "example.producer.SimplePartitioner"); props.put("request.required.acks", "1"); ProducerConfig config = new ProducerConfig(props); Producer<String, String> producer = new Producer<String, String>(config); for (long nEvents = 0; nEvents < events; nEvents++) { long runtime = new Date().getTime(); String ip = “192.168.2.” + rnd.nextInt(255); String msg = runtime + “,www.example.com,” + ip; KeyedMessage<String, String> data = new KeyedMessage<String, String>("page_visits", ip, msg); producer.send(data); } producer.close(); } }
Partitioning Code:
import kafka.producer.Partitioner; import kafka.utils.VerifiableProperties; public class SimplePartitioner implements Partitioner { public SimplePartitioner (VerifiableProperties props) { } public int partition(Object key, int a_numPartitions) { int partition = 0; String stringKey = (String) key; int offset = stringKey.lastIndexOf('.'); if (offset > 0) { partition = Integer.parseInt( stringKey.substring(offset+1)) % a_numPartitions; } return partition; } }
消费者代码示例:
import kafka.consumer.ConsumerConfig; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ConsumerGroupExample { private final ConsumerConnector consumer; private final String topic; private ExecutorService executor; public ConsumerGroupExample(String a_zookeeper, String a_groupId, String a_topic) { consumer = kafka.consumer.Consumer.createJavaConsumerConnector( createConsumerConfig(a_zookeeper, a_groupId)); this.topic = a_topic; } public void shutdown() { if (consumer != null) consumer.shutdown(); if (executor != null) executor.shutdown(); try { if (!executor.awaitTermination(5000, TimeUnit.MILLISECONDS)) { System.out.println("Timed out waiting for consumer threads to shut down, exiting uncleanly"); } } catch (InterruptedException e) { System.out.println("Interrupted during shutdown, exiting uncleanly"); } } public void run(int a_numThreads) { Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(topic, new Integer(a_numThreads)); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap); List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic); // now launch all the threads // executor = Executors.newFixedThreadPool(a_numThreads); // now create an object to consume the messages // int threadNumber = 0; for (final KafkaStream stream : streams) { executor.submit(new ConsumerTest(stream, threadNumber)); threadNumber++; } } private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) { Properties props = new Properties(); props.put("zookeeper.connect", a_zookeeper); props.put("group.id", a_groupId); props.put("zookeeper.session.timeout.ms", "400"); props.put("zookeeper.sync.time.ms", "200"); props.put("auto.commit.interval.ms", "1000"); return new ConsumerConfig(props); } public static void main(String[] args) { String zooKeeper = args[0]; String groupId = args[1]; String topic = args[2]; int threads = Integer.parseInt(args[3]); ConsumerGroupExample example = new ConsumerGroupExample(zooKeeper, groupId, topic); example.run(threads); try { Thread.sleep(10000); } catch (InterruptedException ie) { } example.shutdown(); } }
import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; public class ConsumerTest implements Runnable { private KafkaStream m_stream; private int m_threadNumber; public ConsumerTest(KafkaStream a_stream, int a_threadNumber) { m_threadNumber = a_threadNumber; m_stream = a_stream; } public void run() { ConsumerIterator<byte[], byte[]> it = m_stream.iterator(); while (it.hasNext()) System.out.println("Thread " + m_threadNumber + ": " + new String(it.next().message())); System.out.println("Shutting down Thread: " + m_threadNumber); } }
关于Consumer的一个细节说明:
topicCountMap.put(topic, new Integer(a_numThreads));
这里,如果提供的thread数目(a_numThreads)大于这个topic的partition的数目,有些thread会永远读不到消息。
如果如果提供的thread数目(a_numThreads)小于这个topic的partition的数目,有些thread会从多个partition读到消息。
如果一个线程从多个partition读取消息,无法保证的消息的顺序,只能保证从同一个partition读取到的消息是顺序的。
增加更多的进程/线程消费消息,会导致Kafka re-balance,可能会改变Partition和消费Thread的对应关系。
开发环境搭建:
https://cwiki.apache.org/confluence/display/KAFKA/Developer+Setup
一些example:
https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+Producer+Example
自己管理offset:
https://cwiki.apache.org/confluence/display/KAFKA/Committing+and+fetching+consumer+offsets+in+Kafka
参考:
Kafka深度解析:http://www.jasongj.com/2015/01/02/Kafka%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90/
https://kafka.apache.org/documentation.html
https://cwiki.apache.org/confluence/display/KAFKA/Index



相关推荐
### Kafka核心原理与实战 #### 一、Kafka概述与特点 Kafka是一款开源的分布式消息系统,由LinkedIn开发并在2011年开源,现在是Apache顶级项目。其主要设计目的是为了提供一种高吞吐量、低延迟的发布订阅模型,适用...
kafka原理文档1 kafka是一种高吞吐量、基于发布/订阅模式的消息队列系统。下面是kafka的原理文档,涵盖了kafka的架构、设计理念、消息模型、 Partition机制、日志策略、消息可靠性机制等方面。 一、kafka架构 ...
kafka原理优化及参数。 可恢复性 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 顺序保证 在...
运维,java开发,消息中间件,Kafka原理剖析及实战演练视频教程,刚刚买的
### Apache Kafka概述及原理 #### 一、Apache Kafka简介 Apache Kafka是一款开源的分布式流处理平台,由LinkedIn公司创建,并于2011年捐赠给Apache软件基金会,现已成为Apache顶级项目之一。Kafka主要用于构建实时...
Kafka是一款高性能、分布式的发布订阅消息系统,由LinkedIn开发并贡献给Apache软件基金会。它被设计成能够处理海量数据,提供高...理解并掌握Kafka的工作原理和使用方法,对于构建高效、可靠的数据处理系统至关重要。
自己花钱买的视频教程,做JAVA开发一定要学习的哦,即使没有在实际项目中使用过,也是面试时的敲门砖,一点都不了解的话,想进互联网企业怕是很困难的,放上来只想赚点积分,方便自己下载别的资源,来支持一个
### Kafka工作原理详解 #### 一、Kafka的角色与组件 Kafka作为一款分布式消息系统,在实际应用中涉及多种角色及组件,它们协同工作确保消息的高效传递。 1. **Broker**:Kafka集群的基本单元,一个Broker可以视为...
《深入理解Kafka:核心设计与实践原理》从Kafka的基础概念切入,循序渐进地转入对其内部原理的剖析。《深入理解Kafka:核心设计与实践原理》主要阐述了Kafka中生产者客户端、消费者客户端、主题与分区、日志存储、...
kafka是一个分步数据流平台,可以分布在单个服务器上,也可以分布在多个服务器上部署形成集群,提供了发布和订阅功能,使用者可以发送数据到kafka中,也可以从kafka中读出数据,kafka具有高吞吐,低延迟,高容错等...
《Kafka 消息队列(高清版)深入理解Kafka:核心设计与实践原理》是一本详尽探讨Apache Kafka的书籍,旨在帮助读者深入掌握Kafka的核心设计理念和实际操作技巧。Kafka是一个分布式流处理平台,广泛应用于大数据处理...
kafka架构原理 1、kafka架构原理简介 2、kafka架构原理深度解析 3、常见问题以及处理方案 4、各种消息中间件的对比 ps:可用于公司技术分享
《深入理解Kafka:核心设计与实践原理》是由朱忠华编著的一本关于Kafka的专业书籍,旨在帮助读者从基础知识到深入原理全面掌握Kafka。这本书以清晰易懂的文字和直观的图形辅助讲解,既适合初学者快速入门,也满足有...
Kafka高可用性实现原理 Kafka 作为一个分布式消息系统,具有高可用性和高吞吐量的特点。其高可用性实现原理可以从以下几个方面来分析: 1. 分布式系统架构 Kafka 的架构是基于分布式系统的,包括 Producer、...
kafka
### Kafka核心原理与实战 #### 一、Kafka简介与特点 Kafka是一款开源的分布式消息系统,由LinkedIn开发并在2011年开源,现在是Apache顶级项目。其主要设计目的是提供一种高吞吐量的实时消息处理系统,同时支持离线...
### Kafka核心原理与实战 #### 一、Kafka概述及特点 Kafka是一个高效、可扩展的分布式消息队列系统,广泛应用于实时数据管道、流处理等场景。它以其高吞吐量、低延迟和持久化的特性,在大数据领域占据着举足轻重的...
Kafka原理剖析及实战演练视频教程,高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理