lastthelast
- 浏览: 22471 次
- 性别:

- 来自: 上海
-

最近访客 更多访客>>
最新评论
-
lastthelast:
未闻花铭 写道 private void initialPoo ...
Java操作Redis -
未闻花铭:
private void initialPool() ...
Java操作Redis -
tianma630:
失败乃成功之母 还是有点道理的
人一生下来就是不断的在犯错
Linux下高可用集群方案很多,本文介绍的是性价比比较高的一种: 使用Heartbeat 2.0配置Linux高可用性集群。
一、 准备工作
你首先需要两台电脑,这两台电脑并不需要有相同的硬件(或者内存大小等),但如果相同的话,当某个部件出现故障时会容易处理得多。 接下来您需要决定如何部署。你的集群是通过Heartbeat 软件产生在两台电脑之间心跳信号来建立的。为了传输心跳信号,需要在节点之间存在一条或多条介质通路(串口线通过modem电线,以太网通过交叉线,等等)。 现在可以开始配置硬件了。既然想要获得高可用性(HA),那么您很可能希望避免单点失效。在本例中,可能是您的null modem线/串口,或者网卡(NIC)/ 交叉线。因此便需要决定是否希望为每个节点添加第二条串口null modem连线或者第二条NIC/交叉线连接。我使用一个串口和一块额外的网卡来作为heartbeat的通路,这是因为我只有一条null modem线和一块多余的网卡,并且认为有两种介质类型传输heartbeat信号比较好。 硬件配置完成之后,便需要安装操作系统以及配置网络(我在本文中使用的是RedHat)。假设您有两块网卡,那么有一块应该配置用于常规网络用途,另一块作为集群节点之间的专用网络连接(通过交叉线)。例如,假设集群节点有如表-1下的IP地址:
表-1集群节点的IP地址

输入如下命令检查您的配置:
ifconfig
这将显示您的网卡及其配置。也可以使用命令“netstat –nr”来获得网络路由信息。 如果一切正常,接下来要确定可以来两个节点之间通过所有接口ping通对方。 如果使用了串口,便需要检测其连接情况。把一个节点作为接收者,输入命令:
cat </dev/ttyS0
在另一个节点上,输入:
echo hello >/dev/ttyS0
应该可以在接收节点上看到该文本。如果正常的话交换这两个节点的角色再作一次,否则有可能是使用了错误的设备文件。现在就开始动手搭建和配置一个简单的高性能计算集群系统。关闭不需要的服务:
初始方案是使用两台PC(系统的具体结构如图-1所示),CPU为Pentium D 805,内存为 512MB,用1000Mbps交换机连接,整个硬件环境可以说是再普通不过了。操作系统采用的是Red Hat Enterprise Linux 5.0,该方法对于红旗Linux、Fedora Linux和SuSE等发布版本均可实现。
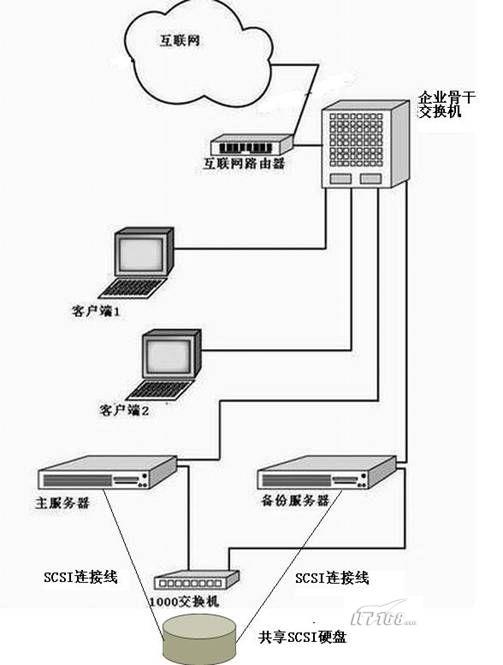
图-1系统的物理结构
二、下载安装软件包
接下来便可以安装Heartbeat软件。可以从如下位置得到: http://linux-ha.org/download Heartbeat软件包。在网站上也有RPM安装包,您也可以选择从源代码编译。取得源代码tar文件或者安装source RPM包,将其解包到某个文件夹。在源代码树的顶端,输入"./ConfigureMe configure", 之后输入"make"和"make install"。
如果使用RPM安装包的话需要包括如下软件包: ipfail,Stonith,Ldirectord。
ipfail的功能直接包含在heartbeat里面,是一个能够在探知服务IP失效了便立即将服务IP抓取来用的功能。
Stonith是为了要在任何server停止时,确保剩下的server不会被正在运作的server所影响,可以选择性强制停止一些server的解决方案。可能会使用在例如共享数据的情况之下。
Ldirector是一个负载平衡的服务器。
安装命令:
也可以使用yum命令在线安装,这样做不需要考虑依赖包所带来的麻烦。命令:
yum install heartbeat
1、 配置主服务器的heartbeat
在启用Heartbeat之前,安装后要配置三个文件(如没有可手动建立):ha.cf、haresources、authkeys。这三个配置文件需要在/etc/ha.d目录下面,但是默认是没有这三个文件的,可以到官网上下这三个文件,也可以在源码包里找这三个文件,在源码目录下的DOC子目录里。
1 配置ha.cf
第一个是ha.cf该文件位于在安装后创建的/etc/ha.d目录中。该文件中包括为Heartbeat使用何种介质通路和如何配置他们的信息。在源代码目录中的ha.cf文件包含了您可以使用的全部选项,详述如下:
serial /dev/ttyS0
使用串口heartbeat-如果不使用串口heartbeat,则必须使用其他的介质,如bcast(以太网)heartbeat。用适当的设备文件代替/dev/ttyS0。
watchdog /dev/watchdog
该选项是可选配置。通过Watchdog 功能可以获得提供最少功能的系统,该系统不提供heartbeat,可以在持续一份钟的不正常状态后重新启动。该功能有助于避免一台机器在被认定已经死亡之后恢复heartbeat的情况。如果这种情况发生并且磁盘挂载因故障而迁移(fail over),便有可能有两个节点同时挂载一块磁盘。如果要使用这项功能,则除了这行之外,也需要加载“softdog”内核模块,并创建相应的设备文件。方法是使用命令“insmod softdog”加载模块。然后输入“grep misc /proc/devices”并记住得到的数字(应该是10)。然后输入”cat /proc/misc | grep watchdog”并记住输出的数字(应该是130)。根据以上得到的信息可以创建设备文件,“mknod /dev/watchdog c 10 130”。
bcast eth1
表示在eth1接口上使用广播heartbeat(将eth1替换为eth0,eth2,或者您使用的任何接口)。
keepalive 2
设定heartbeat之间的时间间隔为2秒。
warntime 10
在日志中发出“late heartbeat“警告之前等待的时间,单位为秒。
deadtime 30
在30秒后宣布节点死亡。
initdead 120
在某些配置下,重启后网络需要一些时间才能正常工作。这个单独的”deadtime”选项可以处理这种情况。它的取值至少应该为通常deadtime的两倍。
baud 19200
波特率,串口通信的速度。
udpport 694
使用端口694进行bcast和ucast通信。这是默认的,并且在IANA官方注册的端口号。
auto_failback on
该选项是必须配置的。对于那些熟悉Tru64 Unix的人来说,heartbeat的工作方式类似于“favored member“模式。在failover之前,haresources文件中列出的主节点掌握所有的资源,之后从节点接管这些资源。当 auto_failback设置为on时,一旦主节点重新恢复联机,将从从节点取回所有资源。若该选项设置为off,主节点便不能重新获得资源。该选项与废弃的nice_failback选项类似。如果要从一个nice_failback设置为off的集群升级到这个或更新的版本,需要特别注意一些事项以防止flash cut。请参阅FAQ中关于如何处理这类情况的章节。
node primary.mydomain.com
该选项是必须配置的。集群中机器的主机名,与“uname –n”的输出相同。
node backup.mydomain.com
该选项是必须配置的。同上。
respawn <userid> <cmd>
该选项是可选配置的:列出将要执行和监控的命令。例如:要执行ccm守护进程,则要添加如下的内容:
respawn hacluster /usr/lib/heartbeat/ccm
使得Heartbeat以userid(在本例中为hacluster)的身份来执行该进程并监视该进程的执行情况,如果其死亡便重启之。对于 ipfail,则应该是:
respawn hacluster /usr/lib/heartbeat/ipfail
注意:如果结束进程的退出代码为100,则不会重启该进程。
2 配置haresources
配置好ha.cf文件之后,便是haresources文件。该文件列出集群所提供的服务以及服务的默认所有者。 注意:两个集群节点上的该文件必须相同。集群的IP地址是该选项是必须配置的,不能在haresources文件以外配置该地址, haresources文件用于指定双机系统的主节点、集群IP、子网掩码、广播地址以及启动的服务等。其配置语句格式如下:
node-name network-config <resource-group>
其中node-name指定双机系统的主节点,取值必须匹配ha.cf文件中node选项设置的主机名中的一个,node选项设置的另一个主机名成为从节点。network-config用于网络设置,包括指定集群IP、子网掩码、广播地址等。resource-group用于设置heartbeat启动的服务,该服务最终由双机系统通过集群IP对外提供。在本文中我们假设要配置的HA服务为Apache和Samba。
在haresources文件中需要如下内容:
primary.mydomain.com 192.168.85.3 httpd smb
该行指定在启动时,节点linuxha1得到IP地址192.168.85.3,并启动Apache和Samba。在停止时,Heartbeat将首先停止smb,然后停止Apache,最后释放IP地址192.168.85.3。这里假设命令“uname –n”的输出为“primary.mydomain.com”-如果输出为“primary”,便应使用“primary”。
正确配置好haresources文件之后,将ha.cf和haresource拷贝到/etc/ha.d目录。
3 配置Authkeys
需要配置的第三个文件authkeys决定了您的认证密钥。共有三种认证方式:crc,md5,和sha1。您可能会问:“我应该用哪个方法呢?”简而言之: 如果您的Heartbeat运行于安全网络之上,如本例中的交叉线,可以使用crc,从资源的角度来看,这是代价最低的方法。如果网络并不安全,但您也希望降低CPU使用,则使用md5。最后,如果您想得到最好的认证,而不考虑CPU使用情况,则使用sha1,它在三者之中最难破解。
文件格式如下:
auth <number>
<number> <authmethod> [<authkey>]
因此,对于sha1,示例的/etc/ha.d/authkeys可能是
auth 1
1 sha1 key-for-sha1-any-text-you-want
对于md5,只要将上面内容中的sha1换成md5就可以了。 对于crc,可作如下配置:
auth 2
2 crc
不论您在关键字auth后面指定的是什么索引值,在后面必须要作为键值再次出现。如果您指定“auth 4”,则在后面一定要有一行的内容为“4 <signaturetype>”。
确保该文件的访问权限是安全的,如600。
4、配置备份服务器的heartbeat
依次安装主服务器上的rpm软件包到备份服务器的heartbeat。然后使用ssh命令把主服务器配置文件传输到备份服务器。
#scp -r /etc/ha.d backupnode:/etc/ha.d
Backupnode是备份服务器的ip地址。
5、设置主服务器和备份服务器时间同步
虽然Heartbeat不要求在两个服务器上使系统钟同步主要和备份服务器,但是系统时钟应该在的几十秒之内,否则在高可用性服务的环境下会产生故障。 在在两个系统启动Heartbeat之前,你应该人工检查并且放置系统时间(使用date命令)。 关于一种更好的长期的解决的方法你应该在两个系统上使用NTP软件同步钟。
6、启动主服务器的Heartbeat
在启动主服务器的Heartbeat,使用命令:
#/etc/init.d/heartbeat start
或者
#service heartbeat start
可以使用命令查看日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
primary.mydomain.com heartbeat[2886]: WARN: node backup.mydomain.com: is dead
表示备份服务器死机的警告,原因是备份服务器的Heartbeat还没有启动。
主服务器的web服务应该被heartbeat启动,同时heartbeat为主节点设置IP地址192.168.100.10。使用ifconfig eth0:0可以看到如下信息:
同时/dev/sdb1,应该被挂接。使用df -h,可以看到的信息包含下面的行:
/dev/sdb1 485M 8.1M 452M 2% /ha
7、 启动备份服务器的Heartbeat
启动主服务器的Heartbeat,使用命令:
#/etc/init.d/heartbeat start
或者
#service heartbeat start
可以使用命令查看日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
backup heartbeat[4656]: info: No local resources [/usr/lib/heartbeat/
ResourceManager listkeys backup.mydomain.com]
backup.mydomain.com heartbeat[4656]: info: Resource acquisition completed.
表示备份服务器没有可以使用的资源,原因是备份服务器的现在是闲置状态,它只监听主服务器心跳,直到主服务器失效。
8、 查看主服务器日志信息
可以使用命令查看日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
可以使用tcpdump命令查看心跳广播是否到达两个服务器节点。
#tcpdump -i all -n -p udp port 694
9、 停止主服务器的Heartbeat
停止主服务器的Heartbeat,使用命令:
#/etc/init.d/heartbeat stop
或者
#service heartbeat stop
此时可以使用命令查看备份服务器日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
在这个过程中,使用ping命令进行不间断监测,可以发现集群IP地址一直处于可通状态,并没有产生任何阻塞或延迟,所以,在关闭处于激活状态的 heartbeat的情况下,双机系统可以实现无缝切换。但是在另外一些情况下,比如网络故障、主机关机或重启等,如果该主机的heartbeat处于激活状态,则不能实现双机的无缝切换,切换过程需要有一定的延迟,使用ping命令可以发现集群IP地址暂时无法使用。
10、 配置ipfail
ipfail插件的用途是检测网络故障,并作出合理的反应,如果需要的话使集群资源failover。为了实现这样的功能ipfail使用ping节点或者ping节点组,这些节点在集群中作为“哑”节点出现。如果HA节点间可以相互通信ipfail便可以可靠地检测到其中一个网络连接失效的情况,并作出补救。
配置ipfail的步骤如下:
a.选择好的候选ping节点
这步很重要。你的选择越好,则得到的HA集群便越强壮。选择固定的交换机路由器等是一个好主意。不要选择HA集群中的任一个成员,也不要选择其他人的工作站。选择能反映您HA节点的连接状况的ping节点也很重要。如果您要监视两个接口的连接情况,明智的做法是为每个接口选择一个只对该接口可用的ping 节点。
b.设置auto_failback为on或者off
只有当Heartbeat被配置为非legacy时ipfail才会起作用。在ha.cf文件中,如下将auto_failback设置为on或者 off:
auto_failback on
或者
auto_failback off
c.配置ha.cf使之启动ipfail。
向ha.cf中增加如下一行(假设您在编译时的PREFIX为/usr):
respawn hacluster /usr/lib/heartbeat/ipfail
d.向ha.cf中加入ping节点:
ping pnode1 pnode2 pnodeN
将pnode1,pnode2,…pnodeN等替换为您ping节点的IP地址。
确保向集群中各个成员的ha.cf中加入以上相同的配置指令。
e. 修改Heartbeat配置文件
如果修改了配置文件etc/ha.d/ authkeys或者 /etc/ha.d/ha.cf后要使用下面的命令重新加载服务。
#/etc/init.d/heartbeat reload
或者
#service heartbeat reload
三、配置Stonith
Stonith 即shoot the other node in the head使Heartbeat软件包的一部分,该组件允许系统自动地复位一个失败的服务器使用连接到一个健康的服务器的遥远电源设备。Stonith设备是一种能够自动关闭电源来响应软件命令的设备。图-1是Heartbeat与配置Stonith示例。

图 -1 Heartbeat与配置Stonith示例
Stonith设备清单如下表-1:

查看当前支持Stonith设备清单的命令:
#/usr/sbin/stonith -L
查看当前支持Stonith设备其他情况的命令
例如查看rps10的设备配置的命令:
# /usr/sbin/stonith -l -t rps10 test
命令输出:
所以在rps10设备在/etc/ha.d/ha.cf 配置文件中的格式如下:
STONITH_host backupserver rps10 /dev/ttyS0 primaryserver.mydomain.com 0
四、 配置内核看门狗支持Heartbeat
1 Linux下watchdog的工作原理
Watchdog在实现上可以是硬件电路也可以是软件定时器,能够在系统出现故障时自动重新启动系统。在Linux 内核下, watchdog的基本工作原理是:当watchdog启动后(即/dev/watchdog 设备被打开后),如果在某一设定的时间间隔内/dev/watchdog没有被执行写操作, 硬件watchdog电路或软件定时器就会重新启动系统。
/dev/watchdog 是一个主设备号为10, 从设备号130的字符设备节点。 Linux内核不仅为各种不同类型的watchdog硬件电路提供了驱动,还提供了一个基于定时器的纯软件watchdog驱动。 驱动源码位于内核源码树drivers\char\watchdog\目录下。
2 硬件与软件watchdog的区别
硬件watchdog必须有硬件电路支持, 设备节点/dev/watchdog对应着真实的物理设备, 不同类型的硬件watchdog设备由相应的硬件驱动管理。软件watchdog由一内核模块softdog.ko 通过定时器机制实现,/dev/watchdog并不对应着真实的物理设备,只是为应用提供了一个与操作硬件watchdog相同的接口。
硬件watchdog比软件watchdog有更好的可靠性。 软件watchdog基于内核的定时器实现,当内核或中断出现异常时,软件watchdog将会失效。而硬件watchdog由自身的硬件电路控制, 独立于内核。无论当前系统状态如何,硬件watchdog在设定的时间间隔内没有被执行写操作,仍会重新启动系统。
一些硬件watchdog卡如WDT501P 以及一些Berkshire卡还可以监测系统温度,提供了 /dev/temperature接口。 对于应用程序而言, 操作软件、硬件watchdog的方式基本相同:打开设备/dev/watchdog, 在重启时间间隔内对/dev/watchdog执行写操作。即软件、硬件watchdog对应用程序而言基本是透明的。
在任一时刻, 只能有一个watchdog驱动模块被加载,管理/dev/watchdog 设备节点。如果系统没有硬件watchdog电路,可以加载软件watchdog驱动softdog.ko。
3 Linux内核中关于watchdog的配置
在/usr/src/linux目录运行命令:makemenu config
确保在下面的菜单已经启用Software Watchdog选项

图 2 编译内核支持Software Watchdog选项
4 加载模块
#insmod softdog
说明:watchdog能让系统在出现故障1分钟后重启该机器。这个功能可以帮助服务器在确实停止心跳后能够重新恢复心跳。 如果使用该特性,则在内核中装入"softdog"内核模块,用来生成实际的设备文件,输入"insmod softdog"加载模块。 输入"grep misc /proc/devices"(应为10),输入"cat /proc/misc | grep watchdog"(应为130)。 生成设备文件:"mknod /dev/watchdog c 10 130" 。
5 测试软件狗
编辑文件 /etc/ha.d/ha.cf
如掉下面一行的注释号:
watchdog /dev/watchdog
重新启动Heartbeat
#service heartbeat restart
使用命令杀掉heartbeat进程
killall -9 heartbeat
此时日志文件中应当出现一行:
Softdog: WDT device closed unexpectedly. WDT will not stop!
表示软件狗生效。另外使用命令lsmod可以看到软件狗已经加载。如图3 。

6 删除软件狗的方法
使用命令可以从内核中删除软件狗:
#modprobe -r softdog
五、测试Heartbeat配置
在你把你的Heartbeat的高可用性服务器放到生产中之前,这里是对试图的一些事情:
1. 在主服务器上拔去电源线
在备份服务器上的Heartbeat应该从主要的服务器发现heartbeat若干数据包损失,并且开始故障转移。 使用Stonith,备份服务器应该把电源关闭或者复位到主要的服务器。 在备份服务器上的Heartbeat然后应该运行适当的资源脚本(当Stonith事件有“清除”时或者完成)拿资源的所有权。 在备份服务器上的Heartbeat也应该发送ARP广播通知顾客或者网络设备MAC地址因为资源IP地址已变化。
2. 测试hb_standby命令的行为
使用在主要的服务器上的hb_standby命令把资源强迫到迁移到备份服务器。 然后再一次在备份服务器上使用命令来把资源往回强迫迁移到主服务器. ipfail如果hb_standby命令不适当地工作,也将不适当地工作。
3. 拔去在主服务器上的网络电缆
使用ipfail可以检测到网络联系失败,并且应该被发现到备份服务器,并且资源和IP别名迁移到备份服务器。
4. 在两个服务器之间删除所有heartbeat路径
当你在两个服务器之间删除所有heartbeat路径时,什么会发生? 如果你使用Stonith,备份服务器将假定主要的服务器已死去,开始一个Stonith事件,而接管资源。
5. 在主要的服务器( 使用命令:killall - 9 heartbeat )上杀死heartbeat 守护进程
当你使用IP别名到提供资源到顾客计算机时,Stonith是尤其重要的。 备份服务器必须Stonith或者在试图假定资源的所有权避免裂痕脑条件之前复位主服务器。
6. 重新引导两个服务器
六、配置Mon
1 什么是Mon
mon是针对linux开发的工具,但众所周知在sorlaris下他也可以工作。因为客户和服务端都是由perl语言书写,因此在轻便性上不会有问题。
简单来说Heartbeat用来实现心跳和高可用性,Mon用来监控服务 。
2 Mon方案
图 4 是基于集群监视的Mon方案

图 5 是Mon检查每个集群节点MIB的过程

3 首先自行搜尋以下的 Perl 模块
安装命令:
4 下载安装fping
Ping命令大概是网管员最常用的命令了,使用Ping可以监测网络的通断、设备是否宕机,遗憾的是每次只能针对一台设备。在一个拥有20余台服务器和80多个可网管交换机的局域网内,Ping上一遍是很艰难的事情,而运行在Linux下的 Fping(http://www.fping.com)可以轻松完成这一工作。Fping 命令与Ping命令非常相似,使用ICMP回应请求和应答来确定系统的可达性。它提供了一些Ping没有的特殊功能,比如,Fping可以在命令行上指定主机名或IP地址的列表、可以处理一个包含主机名或IP地址清单的文件。Fping并不是发送一个请求到单一目标(Ping的做法),而是用循环的方法发送ICMP请求到每个目标。另外,Fping可以用于脚本编程中。
5 下载安装Mon
建立Mon报告目录和Mon报告文件
内容如下:
#vi /etc/mon/mon.cf
内容如下:
不要写跟随他们的箭和数字; 他们仅仅出现在这里说明参数。
说明如下:
[ 1 ]警报脚本的路径。
[ 2 ]监视器脚本的路径。
[ 3 ]报告文件的路径。
[ 4 ]→事件的最大限度数字在报告中节省。
[ 5 ]→启用宕机的日志记录成为可能。
[ 6 ]→报告到宕机事件。
[ 7 ]被分配到一组的丛群节点的列表。
[ 8 ]→在每个主机之后要求空的行。
[ 9 ]→监视组观看所有节点。
[ 10 ]→称为服务任何事物你想要。
[ 11 ] fping的工作频率。
[ 12 ]→使用fping.monitor脚本。
[ 13 ]→针对语法输入:perldoc Time::Period
[ 14 ]→当节点之一断开时。
[ 15 ]→当节点之一连接时。
[ 16 ]→每小时仅仅发送警报的电子邮件一次。
Vi /etc/services,添加两行:
mon 2583/tcp # MON
mon 2583/udp # MON traps
6 通过手工运行fping.monitor和mail.alert脚本的测试
脚本命令如下:
上面的报告IP地址为209.100.100.2以58.10个秒响应fping。
如果这脚本不适当地工作,你能需要告诉Perl找到fping的工具。编辑fping.monitor文件:
my $CMD = "/usr/local/sbin/fping -e -r $RETRIES -t $TIMEOUT";
要测试电子邮件警报,输入:
#echo "Testing 123" | /usr/lib/mon/alert.d/mail.alert alert@domain.com
alert@domain.com 是电子邮件的发送地址。
7 使用调试方式时开始Mon测试
#/usr/lib/mon/mon -d
正常输出如下:
PID 8211 (clusternodes/cluster-ping-check) exited with [0]
Mon发送的电子邮件警报如下:
Subject: ALERT clusternodes/process-check: localhost:ntpd,ypbind
Summary output : localhost:ntpd,ypbind
Group : clusternodes
Service : process-check
Time noticed : <Time and Date>
Secs until next alert :
Members : localhost
Detailed text (if any) follows:
-------------------------------
localhost:ntpd Count=0 Min=0 Max=0
localhost:ypbind Count=0 Min=0 Max=0
到此为止简单介绍了使用Heartbeat 2.0配置Linux高可用性集群的从部署到监视完整过程。
一、 准备工作
你首先需要两台电脑,这两台电脑并不需要有相同的硬件(或者内存大小等),但如果相同的话,当某个部件出现故障时会容易处理得多。 接下来您需要决定如何部署。你的集群是通过Heartbeat 软件产生在两台电脑之间心跳信号来建立的。为了传输心跳信号,需要在节点之间存在一条或多条介质通路(串口线通过modem电线,以太网通过交叉线,等等)。 现在可以开始配置硬件了。既然想要获得高可用性(HA),那么您很可能希望避免单点失效。在本例中,可能是您的null modem线/串口,或者网卡(NIC)/ 交叉线。因此便需要决定是否希望为每个节点添加第二条串口null modem连线或者第二条NIC/交叉线连接。我使用一个串口和一块额外的网卡来作为heartbeat的通路,这是因为我只有一条null modem线和一块多余的网卡,并且认为有两种介质类型传输heartbeat信号比较好。 硬件配置完成之后,便需要安装操作系统以及配置网络(我在本文中使用的是RedHat)。假设您有两块网卡,那么有一块应该配置用于常规网络用途,另一块作为集群节点之间的专用网络连接(通过交叉线)。例如,假设集群节点有如表-1下的IP地址:
表-1集群节点的IP地址
输入如下命令检查您的配置:
ifconfig
这将显示您的网卡及其配置。也可以使用命令“netstat –nr”来获得网络路由信息。 如果一切正常,接下来要确定可以来两个节点之间通过所有接口ping通对方。 如果使用了串口,便需要检测其连接情况。把一个节点作为接收者,输入命令:
cat </dev/ttyS0
在另一个节点上,输入:
echo hello >/dev/ttyS0
应该可以在接收节点上看到该文本。如果正常的话交换这两个节点的角色再作一次,否则有可能是使用了错误的设备文件。现在就开始动手搭建和配置一个简单的高性能计算集群系统。关闭不需要的服务:
| /sbin/chkconfig acpid off /sbin/chkconfig anacron off /sbin/chkconfig apmd off /sbin/chkconfig auditd off /sbin/chkconfig autofs off /sbin/chkconfig bluetooth off /sbin/chkconfig cpuspeed off /sbin/chkconfig cups off /sbin/chkconfig gpm off /sbin/chkconfig haldaemon off /sbin/chkconfig iptables off /sbin/chkconfig isdn off /sbin/chkconfig kudzu off /sbin/chkconfig mDNSResponder off /sbin/chkconfig mdmonitor off /sbin/chkconfig messagebus off /sbin/chkconfig netfs off /sbin/chkconfig nfslock off /sbin/chkconfig nifd off /sbin/chkconfig pcmcia off /sbin/chkconfig portmap off /sbin/chkconfig rhnsd off /sbin/chkconfig rpcgssd off /sbin/chkconfig rpcidmapd off /sbin/chkconfig sendmail off /sbin/chkconfig xfs off |
初始方案是使用两台PC(系统的具体结构如图-1所示),CPU为Pentium D 805,内存为 512MB,用1000Mbps交换机连接,整个硬件环境可以说是再普通不过了。操作系统采用的是Red Hat Enterprise Linux 5.0,该方法对于红旗Linux、Fedora Linux和SuSE等发布版本均可实现。
图-1系统的物理结构
二、下载安装软件包
接下来便可以安装Heartbeat软件。可以从如下位置得到: http://linux-ha.org/download Heartbeat软件包。在网站上也有RPM安装包,您也可以选择从源代码编译。取得源代码tar文件或者安装source RPM包,将其解包到某个文件夹。在源代码树的顶端,输入"./ConfigureMe configure", 之后输入"make"和"make install"。
如果使用RPM安装包的话需要包括如下软件包: ipfail,Stonith,Ldirectord。
ipfail的功能直接包含在heartbeat里面,是一个能够在探知服务IP失效了便立即将服务IP抓取来用的功能。
Stonith是为了要在任何server停止时,确保剩下的server不会被正在运作的server所影响,可以选择性强制停止一些server的解决方案。可能会使用在例如共享数据的情况之下。
Ldirector是一个负载平衡的服务器。
安装命令:
| #rpm -ivh heartbeat-pils-*.rpm |
| #rpm -ivh hearbeat-stonith-*.rpm |
| #rpm -ivh hearbeat-*i386.rpm |
也可以使用yum命令在线安装,这样做不需要考虑依赖包所带来的麻烦。命令:
yum install heartbeat
1、 配置主服务器的heartbeat
在启用Heartbeat之前,安装后要配置三个文件(如没有可手动建立):ha.cf、haresources、authkeys。这三个配置文件需要在/etc/ha.d目录下面,但是默认是没有这三个文件的,可以到官网上下这三个文件,也可以在源码包里找这三个文件,在源码目录下的DOC子目录里。
1 配置ha.cf
第一个是ha.cf该文件位于在安装后创建的/etc/ha.d目录中。该文件中包括为Heartbeat使用何种介质通路和如何配置他们的信息。在源代码目录中的ha.cf文件包含了您可以使用的全部选项,详述如下:
serial /dev/ttyS0
使用串口heartbeat-如果不使用串口heartbeat,则必须使用其他的介质,如bcast(以太网)heartbeat。用适当的设备文件代替/dev/ttyS0。
watchdog /dev/watchdog
该选项是可选配置。通过Watchdog 功能可以获得提供最少功能的系统,该系统不提供heartbeat,可以在持续一份钟的不正常状态后重新启动。该功能有助于避免一台机器在被认定已经死亡之后恢复heartbeat的情况。如果这种情况发生并且磁盘挂载因故障而迁移(fail over),便有可能有两个节点同时挂载一块磁盘。如果要使用这项功能,则除了这行之外,也需要加载“softdog”内核模块,并创建相应的设备文件。方法是使用命令“insmod softdog”加载模块。然后输入“grep misc /proc/devices”并记住得到的数字(应该是10)。然后输入”cat /proc/misc | grep watchdog”并记住输出的数字(应该是130)。根据以上得到的信息可以创建设备文件,“mknod /dev/watchdog c 10 130”。
bcast eth1
表示在eth1接口上使用广播heartbeat(将eth1替换为eth0,eth2,或者您使用的任何接口)。
keepalive 2
设定heartbeat之间的时间间隔为2秒。
warntime 10
在日志中发出“late heartbeat“警告之前等待的时间,单位为秒。
deadtime 30
在30秒后宣布节点死亡。
initdead 120
在某些配置下,重启后网络需要一些时间才能正常工作。这个单独的”deadtime”选项可以处理这种情况。它的取值至少应该为通常deadtime的两倍。
baud 19200
波特率,串口通信的速度。
udpport 694
使用端口694进行bcast和ucast通信。这是默认的,并且在IANA官方注册的端口号。
auto_failback on
该选项是必须配置的。对于那些熟悉Tru64 Unix的人来说,heartbeat的工作方式类似于“favored member“模式。在failover之前,haresources文件中列出的主节点掌握所有的资源,之后从节点接管这些资源。当 auto_failback设置为on时,一旦主节点重新恢复联机,将从从节点取回所有资源。若该选项设置为off,主节点便不能重新获得资源。该选项与废弃的nice_failback选项类似。如果要从一个nice_failback设置为off的集群升级到这个或更新的版本,需要特别注意一些事项以防止flash cut。请参阅FAQ中关于如何处理这类情况的章节。
node primary.mydomain.com
该选项是必须配置的。集群中机器的主机名,与“uname –n”的输出相同。
node backup.mydomain.com
该选项是必须配置的。同上。
respawn <userid> <cmd>
该选项是可选配置的:列出将要执行和监控的命令。例如:要执行ccm守护进程,则要添加如下的内容:
respawn hacluster /usr/lib/heartbeat/ccm
使得Heartbeat以userid(在本例中为hacluster)的身份来执行该进程并监视该进程的执行情况,如果其死亡便重启之。对于 ipfail,则应该是:
respawn hacluster /usr/lib/heartbeat/ipfail
注意:如果结束进程的退出代码为100,则不会重启该进程。
2 配置haresources
配置好ha.cf文件之后,便是haresources文件。该文件列出集群所提供的服务以及服务的默认所有者。 注意:两个集群节点上的该文件必须相同。集群的IP地址是该选项是必须配置的,不能在haresources文件以外配置该地址, haresources文件用于指定双机系统的主节点、集群IP、子网掩码、广播地址以及启动的服务等。其配置语句格式如下:
node-name network-config <resource-group>
其中node-name指定双机系统的主节点,取值必须匹配ha.cf文件中node选项设置的主机名中的一个,node选项设置的另一个主机名成为从节点。network-config用于网络设置,包括指定集群IP、子网掩码、广播地址等。resource-group用于设置heartbeat启动的服务,该服务最终由双机系统通过集群IP对外提供。在本文中我们假设要配置的HA服务为Apache和Samba。
在haresources文件中需要如下内容:
primary.mydomain.com 192.168.85.3 httpd smb
该行指定在启动时,节点linuxha1得到IP地址192.168.85.3,并启动Apache和Samba。在停止时,Heartbeat将首先停止smb,然后停止Apache,最后释放IP地址192.168.85.3。这里假设命令“uname –n”的输出为“primary.mydomain.com”-如果输出为“primary”,便应使用“primary”。
正确配置好haresources文件之后,将ha.cf和haresource拷贝到/etc/ha.d目录。
3 配置Authkeys
需要配置的第三个文件authkeys决定了您的认证密钥。共有三种认证方式:crc,md5,和sha1。您可能会问:“我应该用哪个方法呢?”简而言之: 如果您的Heartbeat运行于安全网络之上,如本例中的交叉线,可以使用crc,从资源的角度来看,这是代价最低的方法。如果网络并不安全,但您也希望降低CPU使用,则使用md5。最后,如果您想得到最好的认证,而不考虑CPU使用情况,则使用sha1,它在三者之中最难破解。
文件格式如下:
auth <number>
<number> <authmethod> [<authkey>]
因此,对于sha1,示例的/etc/ha.d/authkeys可能是
auth 1
1 sha1 key-for-sha1-any-text-you-want
对于md5,只要将上面内容中的sha1换成md5就可以了。 对于crc,可作如下配置:
auth 2
2 crc
不论您在关键字auth后面指定的是什么索引值,在后面必须要作为键值再次出现。如果您指定“auth 4”,则在后面一定要有一行的内容为“4 <signaturetype>”。
确保该文件的访问权限是安全的,如600。
4、配置备份服务器的heartbeat
依次安装主服务器上的rpm软件包到备份服务器的heartbeat。然后使用ssh命令把主服务器配置文件传输到备份服务器。
#scp -r /etc/ha.d backupnode:/etc/ha.d
Backupnode是备份服务器的ip地址。
5、设置主服务器和备份服务器时间同步
虽然Heartbeat不要求在两个服务器上使系统钟同步主要和备份服务器,但是系统时钟应该在的几十秒之内,否则在高可用性服务的环境下会产生故障。 在在两个系统启动Heartbeat之前,你应该人工检查并且放置系统时间(使用date命令)。 关于一种更好的长期的解决的方法你应该在两个系统上使用NTP软件同步钟。
6、启动主服务器的Heartbeat
在启动主服务器的Heartbeat,使用命令:
#/etc/init.d/heartbeat start
或者
#service heartbeat start
可以使用命令查看日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
primary.mydomain.com heartbeat[2886]: WARN: node backup.mydomain.com: is dead
表示备份服务器死机的警告,原因是备份服务器的Heartbeat还没有启动。
主服务器的web服务应该被heartbeat启动,同时heartbeat为主节点设置IP地址192.168.100.10。使用ifconfig eth0:0可以看到如下信息:
| eth0:0 Link encap:Ethernet HWaddr 00:0C:29:D8:FD:EB inet addr:192.168.100.10 Bcast:192.168.100.15 Mask:255.255.255.240 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:14970 errors:0 dropped:0 overruns:0 frame:0 TX packets:14977 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:100 RX bytes:3624073 (3.4 Mb) TX bytes:3626223 (3.4 Mb) Interrupt:19 Base address:0x10a0 |
同时/dev/sdb1,应该被挂接。使用df -h,可以看到的信息包含下面的行:
/dev/sdb1 485M 8.1M 452M 2% /ha
7、 启动备份服务器的Heartbeat
启动主服务器的Heartbeat,使用命令:
#/etc/init.d/heartbeat start
或者
#service heartbeat start
可以使用命令查看日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
backup heartbeat[4656]: info: No local resources [/usr/lib/heartbeat/
ResourceManager listkeys backup.mydomain.com]
backup.mydomain.com heartbeat[4656]: info: Resource acquisition completed.
表示备份服务器没有可以使用的资源,原因是备份服务器的现在是闲置状态,它只监听主服务器心跳,直到主服务器失效。
8、 查看主服务器日志信息
可以使用命令查看日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
| primary heartbeat[2886]: info: Heartbeat restart on node backup.mydomain.com |
| primary heartbeat[2886]: info: Link backup.mydomain.com:eth2 up. |
| primary heartbeat[2886]: info: Node backup.mydomain.com: status up |
| primary heartbeat: info: Running /etc/ha.d/rc.d/status status |
| primary heartbeat: info: Running /etc/ha.d/rc.d/ifstat ifstat |
| primary heartbeat[2886]: info: Node backup.mydomain.com: status active |
| primary heartbeat: info: Running /etc/ha.d/rc.d/status status |
可以使用tcpdump命令查看心跳广播是否到达两个服务器节点。
#tcpdump -i all -n -p udp port 694
9、 停止主服务器的Heartbeat
停止主服务器的Heartbeat,使用命令:
#/etc/init.d/heartbeat stop
或者
#service heartbeat stop
此时可以使用命令查看备份服务器日志文件:
#tail -f /var/log/messages
此时会发现出现如下信息:
| backup.mydomain.com heartbeat[5725]: WARN: node primary.mydomain.com: is dead |
| backup.mydomain.com heartbeat[5725]: info: Link primary.mydomain.com:eth1dead. |
| backup.mydomain.com heartbeat: info: Running /etc/ha.d/rc.d/status status |
| backup.mydomain.com heartbeat: info: Running /etc/ha.d/rc.d/ifstat ifstat |
| backup.mydomain.com heartbeat: info: Taking over resource group test |
| *** /etc/ha.d/resource.d/test called with status |
| backup.mydomain.com heartbeat: info: Acquiring resource group: |
| primary.mydomain. |
| com test |
| backup.mydomain.com heartbeat: info: Running /etc/ha.d/resource.d/test start |
| *** /etc/ha.d/resource.d/test called with start |
| backup.mydomain.com heartbeat: info: mach_down takeover complete. |
在这个过程中,使用ping命令进行不间断监测,可以发现集群IP地址一直处于可通状态,并没有产生任何阻塞或延迟,所以,在关闭处于激活状态的 heartbeat的情况下,双机系统可以实现无缝切换。但是在另外一些情况下,比如网络故障、主机关机或重启等,如果该主机的heartbeat处于激活状态,则不能实现双机的无缝切换,切换过程需要有一定的延迟,使用ping命令可以发现集群IP地址暂时无法使用。
10、 配置ipfail
ipfail插件的用途是检测网络故障,并作出合理的反应,如果需要的话使集群资源failover。为了实现这样的功能ipfail使用ping节点或者ping节点组,这些节点在集群中作为“哑”节点出现。如果HA节点间可以相互通信ipfail便可以可靠地检测到其中一个网络连接失效的情况,并作出补救。
配置ipfail的步骤如下:
a.选择好的候选ping节点
这步很重要。你的选择越好,则得到的HA集群便越强壮。选择固定的交换机路由器等是一个好主意。不要选择HA集群中的任一个成员,也不要选择其他人的工作站。选择能反映您HA节点的连接状况的ping节点也很重要。如果您要监视两个接口的连接情况,明智的做法是为每个接口选择一个只对该接口可用的ping 节点。
b.设置auto_failback为on或者off
只有当Heartbeat被配置为非legacy时ipfail才会起作用。在ha.cf文件中,如下将auto_failback设置为on或者 off:
auto_failback on
或者
auto_failback off
c.配置ha.cf使之启动ipfail。
向ha.cf中增加如下一行(假设您在编译时的PREFIX为/usr):
respawn hacluster /usr/lib/heartbeat/ipfail
d.向ha.cf中加入ping节点:
ping pnode1 pnode2 pnodeN
将pnode1,pnode2,…pnodeN等替换为您ping节点的IP地址。
确保向集群中各个成员的ha.cf中加入以上相同的配置指令。
e. 修改Heartbeat配置文件
如果修改了配置文件etc/ha.d/ authkeys或者 /etc/ha.d/ha.cf后要使用下面的命令重新加载服务。
#/etc/init.d/heartbeat reload
或者
#service heartbeat reload
三、配置Stonith
Stonith 即shoot the other node in the head使Heartbeat软件包的一部分,该组件允许系统自动地复位一个失败的服务器使用连接到一个健康的服务器的遥远电源设备。Stonith设备是一种能够自动关闭电源来响应软件命令的设备。图-1是Heartbeat与配置Stonith示例。
图 -1 Heartbeat与配置Stonith示例
Stonith设备清单如下表-1:
查看当前支持Stonith设备清单的命令:
#/usr/sbin/stonith -L
查看当前支持Stonith设备其他情况的命令
例如查看rps10的设备配置的命令:
# /usr/sbin/stonith -l -t rps10 test
命令输出:
| STONITH: Cannot open /etc/ha.d/rpc.cfg |
| STONITH: Invalid config file for rps10 device. |
| STONITH: Config file syntax: <serial_device> <server> <outlet> [ <server> |
| <outlet> [...] ] |
| All tokens are white-space delimited. |
| Blank lines and lines beginning with # are ignored |
所以在rps10设备在/etc/ha.d/ha.cf 配置文件中的格式如下:
STONITH_host backupserver rps10 /dev/ttyS0 primaryserver.mydomain.com 0
四、 配置内核看门狗支持Heartbeat
1 Linux下watchdog的工作原理
Watchdog在实现上可以是硬件电路也可以是软件定时器,能够在系统出现故障时自动重新启动系统。在Linux 内核下, watchdog的基本工作原理是:当watchdog启动后(即/dev/watchdog 设备被打开后),如果在某一设定的时间间隔内/dev/watchdog没有被执行写操作, 硬件watchdog电路或软件定时器就会重新启动系统。
/dev/watchdog 是一个主设备号为10, 从设备号130的字符设备节点。 Linux内核不仅为各种不同类型的watchdog硬件电路提供了驱动,还提供了一个基于定时器的纯软件watchdog驱动。 驱动源码位于内核源码树drivers\char\watchdog\目录下。
2 硬件与软件watchdog的区别
硬件watchdog必须有硬件电路支持, 设备节点/dev/watchdog对应着真实的物理设备, 不同类型的硬件watchdog设备由相应的硬件驱动管理。软件watchdog由一内核模块softdog.ko 通过定时器机制实现,/dev/watchdog并不对应着真实的物理设备,只是为应用提供了一个与操作硬件watchdog相同的接口。
硬件watchdog比软件watchdog有更好的可靠性。 软件watchdog基于内核的定时器实现,当内核或中断出现异常时,软件watchdog将会失效。而硬件watchdog由自身的硬件电路控制, 独立于内核。无论当前系统状态如何,硬件watchdog在设定的时间间隔内没有被执行写操作,仍会重新启动系统。
一些硬件watchdog卡如WDT501P 以及一些Berkshire卡还可以监测系统温度,提供了 /dev/temperature接口。 对于应用程序而言, 操作软件、硬件watchdog的方式基本相同:打开设备/dev/watchdog, 在重启时间间隔内对/dev/watchdog执行写操作。即软件、硬件watchdog对应用程序而言基本是透明的。
在任一时刻, 只能有一个watchdog驱动模块被加载,管理/dev/watchdog 设备节点。如果系统没有硬件watchdog电路,可以加载软件watchdog驱动softdog.ko。
3 Linux内核中关于watchdog的配置
在/usr/src/linux目录运行命令:makemenu config
确保在下面的菜单已经启用Software Watchdog选项
| Character Devices |
| Watchdog Cards ---> |
| [M] Software Watchdog (NEW) |
图 2 编译内核支持Software Watchdog选项
4 加载模块
#insmod softdog
说明:watchdog能让系统在出现故障1分钟后重启该机器。这个功能可以帮助服务器在确实停止心跳后能够重新恢复心跳。 如果使用该特性,则在内核中装入"softdog"内核模块,用来生成实际的设备文件,输入"insmod softdog"加载模块。 输入"grep misc /proc/devices"(应为10),输入"cat /proc/misc | grep watchdog"(应为130)。 生成设备文件:"mknod /dev/watchdog c 10 130" 。
5 测试软件狗
编辑文件 /etc/ha.d/ha.cf
如掉下面一行的注释号:
watchdog /dev/watchdog
重新启动Heartbeat
#service heartbeat restart
使用命令杀掉heartbeat进程
killall -9 heartbeat
此时日志文件中应当出现一行:
Softdog: WDT device closed unexpectedly. WDT will not stop!
表示软件狗生效。另外使用命令lsmod可以看到软件狗已经加载。如图3 。
6 删除软件狗的方法
使用命令可以从内核中删除软件狗:
#modprobe -r softdog
五、测试Heartbeat配置
在你把你的Heartbeat的高可用性服务器放到生产中之前,这里是对试图的一些事情:
1. 在主服务器上拔去电源线
在备份服务器上的Heartbeat应该从主要的服务器发现heartbeat若干数据包损失,并且开始故障转移。 使用Stonith,备份服务器应该把电源关闭或者复位到主要的服务器。 在备份服务器上的Heartbeat然后应该运行适当的资源脚本(当Stonith事件有“清除”时或者完成)拿资源的所有权。 在备份服务器上的Heartbeat也应该发送ARP广播通知顾客或者网络设备MAC地址因为资源IP地址已变化。
2. 测试hb_standby命令的行为
使用在主要的服务器上的hb_standby命令把资源强迫到迁移到备份服务器。 然后再一次在备份服务器上使用命令来把资源往回强迫迁移到主服务器. ipfail如果hb_standby命令不适当地工作,也将不适当地工作。
3. 拔去在主服务器上的网络电缆
使用ipfail可以检测到网络联系失败,并且应该被发现到备份服务器,并且资源和IP别名迁移到备份服务器。
4. 在两个服务器之间删除所有heartbeat路径
当你在两个服务器之间删除所有heartbeat路径时,什么会发生? 如果你使用Stonith,备份服务器将假定主要的服务器已死去,开始一个Stonith事件,而接管资源。
5. 在主要的服务器( 使用命令:killall - 9 heartbeat )上杀死heartbeat 守护进程
当你使用IP别名到提供资源到顾客计算机时,Stonith是尤其重要的。 备份服务器必须Stonith或者在试图假定资源的所有权避免裂痕脑条件之前复位主服务器。
6. 重新引导两个服务器
六、配置Mon
1 什么是Mon
mon是针对linux开发的工具,但众所周知在sorlaris下他也可以工作。因为客户和服务端都是由perl语言书写,因此在轻便性上不会有问题。
简单来说Heartbeat用来实现心跳和高可用性,Mon用来监控服务 。
2 Mon方案
图 4 是基于集群监视的Mon方案
图 5 是Mon检查每个集群节点MIB的过程
3 首先自行搜尋以下的 Perl 模块
- perl-Mon-0.11-2.2.el5.rf.noarch.rpm
- perl-Convert-BER-1.31.01-1.2.el5.rf.noarch.rpm
- perl-Net-Telnet-3.03-1.2.el5.rf.noarch.rpm
- perl-Time-HiRes-1.55-3.i386.rpm
- perl-Time-Period-1.20-2.el5.rf.noarch.rpm
安装命令:
- #perl -MCPAN -e shell
- cpan>install Time::Period
- cpan>install Time::HiRes
- cpan>install Convert::BER
- cpan>install Mon::Protocol
- cpan>install Mon::SNMP
- cpan>install Mon::Client
4 下载安装fping
Ping命令大概是网管员最常用的命令了,使用Ping可以监测网络的通断、设备是否宕机,遗憾的是每次只能针对一台设备。在一个拥有20余台服务器和80多个可网管交换机的局域网内,Ping上一遍是很艰难的事情,而运行在Linux下的 Fping(http://www.fping.com)可以轻松完成这一工作。Fping 命令与Ping命令非常相似,使用ICMP回应请求和应答来确定系统的可达性。它提供了一些Ping没有的特殊功能,比如,Fping可以在命令行上指定主机名或IP地址的列表、可以处理一个包含主机名或IP地址清单的文件。Fping并不是发送一个请求到单一目标(Ping的做法),而是用循环的方法发送ICMP请求到每个目标。另外,Fping可以用于脚本编程中。
- #wget http://www.kernel.org/pub/software/admin/mon/fping-2.2b1.tar.bz2
- #bunzip2 fping-2.2b1.tar.bz2
- #./configure
- #make
- #make check
- #make install
5 下载安装Mon
- #wget ftp://ftp.kernel.org/pub/software/admin/mon/mon-0.99.2.tar.gz
- #tar -xzf mon-0.99.2.tar.gz
- #cd mon-0.99.2
- #mkdir /etc/mon
- #cp auth.cf mon.cf /etc/mon
- #mkdir /usr/lib/mon
- #cp -r alert.d mon.d state.d mon /usr/lib/mon
建立Mon报告目录和Mon报告文件
- #mkdir /usr/lib/mon/log.d
- #vi /etc/mon/auth.cf
内容如下:
- disable: root
- dump: root
- enable: root
- get: root
- loadstate: root
- reset: root
- savestate: root
- set: root
- start: root
- stop: root
- term: root
#vi /etc/mon/mon.cf
内容如下:
不要写跟随他们的箭和数字; 他们仅仅出现在这里说明参数。
- alertdir = /usr/lib/mon/alert.d ← [1]
- mondir = /usr/lib/mon/mon.d ← [2]
- logdir = /usr/lib/mon/logs ← [3]
- histlength = 500 ← [4]
- dtlogging = yes ← [5]
- dtlogfile = /usr/lib/mon/logs/dtlog ← [6]
- hostgroup clusternodes clnode1 clnode2 clnode3 ← [7]
- ← [8]
- watch clusternodes ← [9]
- service cluster-ping-check [10]
- interval 5s [11]
- monitor fping.monitor [12]
- period wd ...{Sa-Su} [13]
- alert mail.alert alert@domain.com ← [14]
- upalert mail.alert alert@domain.com ← [15]
- alertevery 1h ← [16]
说明如下:
[ 1 ]警报脚本的路径。
[ 2 ]监视器脚本的路径。
[ 3 ]报告文件的路径。
[ 4 ]→事件的最大限度数字在报告中节省。
[ 5 ]→启用宕机的日志记录成为可能。
[ 6 ]→报告到宕机事件。
[ 7 ]被分配到一组的丛群节点的列表。
[ 8 ]→在每个主机之后要求空的行。
[ 9 ]→监视组观看所有节点。
[ 10 ]→称为服务任何事物你想要。
[ 11 ] fping的工作频率。
[ 12 ]→使用fping.monitor脚本。
[ 13 ]→针对语法输入:perldoc Time::Period
[ 14 ]→当节点之一断开时。
[ 15 ]→当节点之一连接时。
[ 16 ]→每小时仅仅发送警报的电子邮件一次。
Vi /etc/services,添加两行:
mon 2583/tcp # MON
mon 2583/udp # MON traps
6 通过手工运行fping.monitor和mail.alert脚本的测试
脚本命令如下:
- #/usr/lib/mon/mon.d/fping.monitor clnode1
- 输出如下:
- start time: <current date>
- end time : <current date>
- duration : 0 seconds
- --------------------------------------------------------
- reachable hosts rtt
- -------------------------------------------------------
- 209.100.100.2 58.10 ms
上面的报告IP地址为209.100.100.2以58.10个秒响应fping。
如果这脚本不适当地工作,你能需要告诉Perl找到fping的工具。编辑fping.monitor文件:
my $CMD = "/usr/local/sbin/fping -e -r $RETRIES -t $TIMEOUT";
要测试电子邮件警报,输入:
#echo "Testing 123" | /usr/lib/mon/alert.d/mail.alert alert@domain.com
alert@domain.com 是电子邮件的发送地址。
7 使用调试方式时开始Mon测试
#/usr/lib/mon/mon -d
正常输出如下:
PID 8211 (clusternodes/cluster-ping-check) exited with [0]
Mon发送的电子邮件警报如下:
Subject: ALERT clusternodes/process-check: localhost:ntpd,ypbind
Summary output : localhost:ntpd,ypbind
Group : clusternodes
Service : process-check
Time noticed : <Time and Date>
Secs until next alert :
Members : localhost
Detailed text (if any) follows:
-------------------------------
localhost:ntpd Count=0 Min=0 Max=0
localhost:ypbind Count=0 Min=0 Max=0
到此为止简单介绍了使用Heartbeat 2.0配置Linux高可用性集群的从部署到监视完整过程。
分享到:


发表评论

相关推荐
利用VMware 实验基于heartbeat 的Debian Linux 高可用性集群服务
### VMware实验基于heartbeat的Debian Linux高可用性集群服务 #### 高可用性集群(HA Cluster)概述 在IT行业中,高可用性集群(HA Cluster)是一种关键的技术,用于确保服务的连续性和可靠性,特别是在面临单点故障的...
在 Linux 平台下,高可用集群方案有很多,本文介绍的是性价比比较高的一种,即使用 Heartbeat 2.0 配置 Linux 高可用性集群。高可用性(HA)集群是指可以避免单点失效的计算机集群系统,即使某个节点出现故障,集群...
本主题将详细探讨如何在CentOS 7操作系统中利用HeartBeat软件来配置高可用性集群,以及VIP(Virtual IP)的角色和作用。HeartBeat是一款用于监控和管理集群服务的工具,它能在主服务器出现故障时自动将服务切换到...
总之,Heartbeat 是构建基于 Linux 的高可用性集群的重要工具之一。无论是 Heartbeat 1.x 还是 2.0 版本,都为中/高级 Linux 系统管理员、企业 IT 决策者和方案架构师提供了强大的技术支持,帮助他们在服务器出现...
本篇文档主要介绍了使用Heartbeat 2.0在两台Linux服务器之间配置高可用性集群的步骤和注意事项。 首先,构建高可用性集群需要两台计算机,它们的硬件配置不必完全相同,但为了方便故障处理,保持一致是有益的。集群...
Heartbeat 是一个 Linux 高可用集群软件包,目前支持两个结点(主/从模式),实现串行线、UDP 广播、UDP 多播等心跳传输方式,以及 IP 地址接管和资源管理机制。Heartbeat 集群软件实现了两种类型的心跳:环形...
因此,本文将详细介绍如何使用Heartbeat工具来搭建MySQL高可用性集群,以确保数据服务的连续性和可靠性。 #### 二、Heartbeat与MySQL高可用性集群 Heartbeat是一款开源软件包,用于实现Linux系统的集群管理。它能够...
在RHEL5中,Heartbeat被用于构建高可用性集群,实现对共享资源的管理和故障恢复。 **步骤 1:安装Heartbeat** 在搭建高可用集群时,首先要在所有参与集群的节点上安装Heartbeat软件包。这通常通过执行yum install ...
### 高可用性Linux集群实现 #### 摘要 随着互联网技术的飞速发展以及人们对服务质量要求的不断提高,单一服务器已经难以满足当前业务需求。为了确保服务的连续性和稳定性,构建高可用性(High Availability,简称HA...
高可用性(High Availability,简称HA)是IT系统的重要组成部分,特别是在对业务连续性要求极高的领域。 首先,书中详细阐述了高可用性的背景。在数字化时代,企业对IT系统的依赖程度日益加深,任何服务中断都可能...
**LVS** (Linux Virtual Server) 是一种基于Linux内核的负载均衡技术,可以用来创建高性能、高可用性的服务器集群。LVS支持多种负载均衡算法,如轮询(Round Robin)、最小连接数(Least Connections)等,可以根据...
本文主要讨论了基于 Linux 的高可用集群系统的设计与实现,旨在满足关键业务对服务器高可用性的要求。以下是本文的知识点总结: 一、高可用集群系统的重要性 * 高可用集群系统是指能够提供 7×24 小时不间断服务的...
本文主要探讨在Linux系统下,特别是Red Hat和Novell的发行版中,如何构建高可用性集群环境。 **一、高可用性概念** 1. **集群节点定义**:集群由多个互相协作的服务器节点组成,每个节点都可以提供服务。 2. **...
"基于DRBD的Linux高可用集群" Linux高可用集群的重要性 随着医院电子病历系统(E MR...基于DRBD的Linux高可用集群可以提供高可用性和数据安全性,解决了传统高可用集群的缺点,为医院信息化工作提供了可靠的解决方案。
本文首先介绍了高可用集群技术的概念和实现方法,接着分析了基于 Linux 平台使用廉价的 COTS 硬件和开放的 Heartbeat 软件构建高可用集群的过程。 高可用集群技术是指将多个服务器节点组合成一个集群,使得集群可以...