皮尔逊相关系数理解有两个角度
其一, 按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数
Z分数一般代表正态分布中, 数据偏离中心点的距离.等于变量减掉平均数再除以标准差.(就是高考的标准分类似的处理)
标准差则等于变量减掉平均数的平方和,再除以样本数,最后再开方.
所以, 根据这个最朴素的理解,我们可以将公式依次精简为:
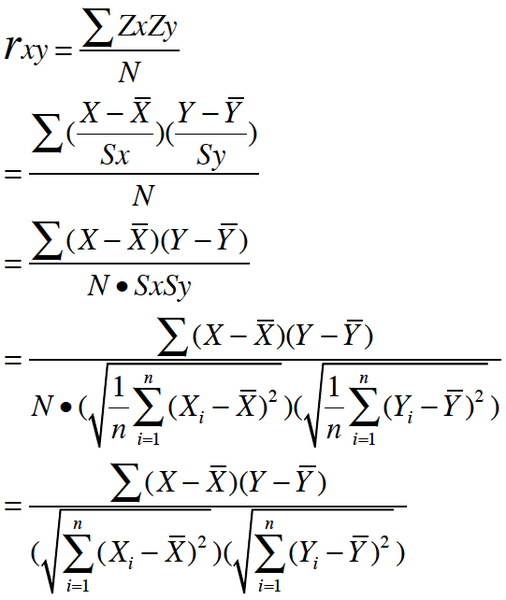
其二, 按照大学的线性数学水平来理解, 它比较复杂一点,可以看做是两组数据的向量夹角的余弦.
皮尔逊相关的约束条件
从以上解释, 也可以理解皮尔逊相关的约束条件:
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性.
先举个手算的例子
使用维基中的例子:
例如,假设五个国家的国民生产总值分别是1、2、3、5、8(单位10亿美元),又假设这五个国家的贫困比例分别是11%、12%、13%、15%、18%。
创建2个向量.(R语言)
x<-c(1,2,3,5,8)
y<-c(0.11,0.12,0.13,0.15,0.18)
按照维基的例子,应计算出相关系数为1出来.我们看看如何一步一步计算出来的.
x的平均数是:3.8
y的平均数是0.138
所以,
sum((x-mean(x))*(y-mean(y)))=0.308
用大白话来写就是:
(1-3.8)*(0.11-0.138)=0.0784
(2-3.8)*(0.12-0.138)=0.0324
(3-3.8)*(0.13-0.138)=0.0064
(5-3.8)*(0.15-0.138)=0.0144
(8-3.8)*(0.18-0.138)=0.1764
0.0784+0.0324+0.0064+0.0144+0.1764=0.308
同理, 分号下面的,分别是:
sum((x-mean(x))^2)=30.8
sum((y-mean(y))^2)= 0.00308
用大白话来写,分别是:
(1-3.8)^2=7.84 #平方
(2-3.8)^2=3.24 #平方
(3-3.8)^2=0.64 #平方
(5-3.8)^2=1.44 #平方
(8-3.8)^2=17.64 #平方
7.84+3.24+0.64+1.44+17.64=30.8
同理,求得:
sum((y-mean(y))^2)= 0.00308
然后再开平方根,分别是:
30.8^0.5=5.549775
0.00308^0.5=0.05549775
用分子除以分母,就计算出最终结果:
0.308/(5.549775*0.05549775)=1
假设有100人, 一组数据是年龄,平均年龄是35岁,标准差是5岁;另一组数据是发帖数量,平均帖子数量是45份post,标准差是8份帖子.
假设这两组都是正态分布.我们来求这两者的皮尔逊相关系数,R脚本如下:
> x<-rnorm(n=100,mean=35,sd=5) #创建一组平均数为35,标准差为5,样本数为100的随机数
> y<-rnorm(n=100,mean=45,sd=8) #创建一组平均数为45,标准差为8,样本数为100的随机数
> cor.test(x,y,method="pearson") #计算这两组数的相关,并进行T检验
然后R输出结果为:
Pearson's product-moment correlation
data: x and y
t = -0.0269, df = 98, p-value = 0.9786
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.1990316 0.1938019
sample estimates:
cor
-0.002719791
当然,这里是随机数.也可以用非随机的验证一下计算.
皮尔逊相关系数用于网站开发
直接将R与Ruby关联起来
调用很简单,仿照上述例子:
cor(x,y)
就输出系数结果了.
有这么几个库可以参考:
https://github.com/alexgutteridge/rsruby
https://github.com/davidrichards/stat...
https://github.com/jtprince/simpler
说明, 以上为ruby调用库. pythone程序员可以参考: Rpy (http://rpy.sourceforge.net/)
简单的相关系数的分类
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
ps : 这个网站开发者不要再次发明轮子,本来用markdown语法写作很爽,结果又不得不花时间来改动.请考虑尽快支持Markdown语法.
分享到:




相关推荐
Pearson相关系数,也称为皮尔逊积矩相关系数,是衡量两个连续变量之间线性关系强度和方向的指标。它的取值范围在-1到1之间,1表示完全正相关,-1表示完全负相关,0表示没有线性关系。 在面板数据中,我们通常处理的...
《Pearson相关系数简介》的学习教案主要介绍了统计学中的一个重要概念——Pearson相关系数,它用于衡量两个变量间线性的相关程度。相关性是描述事物间联系的一种方式,例如医学中身高与体重、体温与脉搏等之间的关系...
在数据分析和统计学中,Pearson相关系数是一种衡量两个变量之间线性关系强度和方向的指标。在面板数据(Panel Data)分析中,这种系数尤其重要,因为它可以帮助研究者理解不同观测单位(如时间序列或个体)之间的...
"Pearson 相关系数在数据分析和统计学中的应用" Pearson 相关系数是一种常用的统计分析方法,用于度量两个变量之间的相关程度。该方法由 Karl Pearson 于 19 世纪 80 年代提出,广泛应用于自然科学领域中。 模型...
同时输出Pearson和Spearman相关系数 实现功能 左下角为Pearso n系数,右上角为Spearman系数 显示p值(括号内为p值) 标注显著性:*、 **、***分别代表在10%、5%和1%的水平上显著 导出格式为rtf,可以用w ord直接打开...
Pearson相关系数(Pearson correlation coefficient)也是一种常用的相关系数,用于度量两个变量之间的线性关系强弱。 Pearson相关系数的计算方法是将两个变量的标准化后,计算它们的协方差除以它们的标准差的乘积。...
可能有人做相关系数分析时,需要将pearson和spearman相关系数同时输出 到一张表格中,并且标识出星星,网上给出了很多方案,但都过于复杂,不太适合新手,于 是乎,我封装了一个stata命令,叫pscorr,取名规则为...
在这个主题中,"面板数据Pearson相关系数stata操作的代码"涉及到的是如何在Stata软件中计算面板数据的Pearson相关系数。Stata是一款广泛使用的统计分析软件,因其用户友好的界面和强大的命令行功能而受到研究人员的...
Pearson 相关系数代码实现了该系数的计算,通过 Python 语言编写,使用了 multiply 函数计算两个列表的元素乘积之和,cal_pearson 函数计算 Pearson 相关系数。该代码使用 x 和 y 两个列表作为输入,计算出 Pearson ...
Pearson相关系数简介分析PPT教案.pptx
Pearson相关系数简介资料PPT教案.pptx
在1999年发表于浙江师大学报自然科学版的文章《维电负性——Pearson—Pauling悖论的重新估价和解析》中,钱清华和叶素芳两位作者对电负性这一无机化学中的重要概念进行了深入探讨,特别是在Pearson—Pauling悖论的...
【基于BP神经网络及Pearson相关系数的风机发电机轴承温升故障诊断研究】 在风力发电领域,确保设备高效稳定运行至关重要。风机发电机轴承温升故障是直接影响风力发电效率和设备寿命的主要问题之一。传统的故障预警...
Pearson相关系数是衡量线性相关性的指标,数值范围在-1到1之间,1表示完全正相关,-1表示完全负相关,0表示没有线性关系。Spearman相关等级系数则考察变量间的等级关系,同样在-1到1之间,用于处理非正态分布的数据...
"Pearson相关系数"是一种衡量两个变量之间线性关系强度和方向的统计指标,这里用于计算每个IMF分量与原始信号之间的相关性。如果相关系数接近1,表示IMF与原始信号高度相关;如果接近-1,则表示两者有强烈的负相关;...
Python LC Loan贷款数据集 文本字符串预处理转换 方差阈值 pearson相关系数柱状图 2D 3D 散点图统计图 热力图 导出csv png jupyter notebook numpy pandas matplotlib 数据分析 数据挖掘 统计分析 id member_id loan...
计算三大相关性系数(pearson、spearman、kendall)copula函数族检验
标题 "Pearson_气象_PM2.5_相关性分析_" 指出的主题是通过Pearson相关性分析来研究气象变量与PM2.5(细颗粒物)浓度之间的关系。这种分析方法常用于量化两个连续变量间的线性关联程度。在环境科学中,了解气象条件...
本文将详细介绍一种常用的相关系数——Pearson(皮尔逊)相关系数,并通过实例演示其在MATLAB中的实现方法。 #### 二、相关系数的基本概念 相关系数是用来量化两个变量之间线性关系强度的统计量。它可以帮助我们...