- 浏览: 72425 次
- 性别:

- 来自: 北京
-

最新评论
-
guooo:
很深入,似懂非懂的,有待进一步深入
JAVA分布式事务原理及应用 -
beritha:
,讲的非常好
Oracle执行计划详解
index skip scan的基本介绍。
表employees (sex,
employee_id, address) ,有一个组合索引(sex, employee_id).
在索引跳跃的情况下,我们可以逻辑上把他们看成两个索引,一个是(男,employee_id),一个是(女,employee_id).
select * from employees where employee_id=1;
发出这个查询后,oracle
先进入sex为男的入口,查找employee_id=1的条目。再进入sex为女的入口,查找employee_id=1的条目。
ORACLE官方说,在前导列唯一值较少的情况下,才会用到index skip can。这个其实好理解,就是入口要少。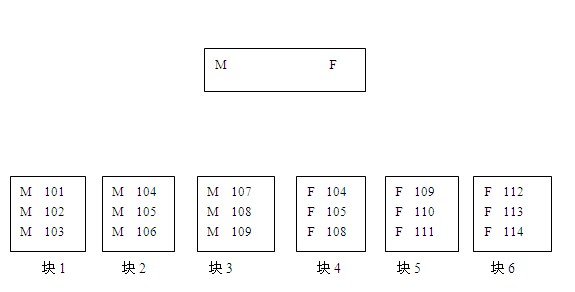
事实上.jpg
看上面的这幅图。
我有个疑问,就是ORACLE是通过什么样的扫描方式找到所需要的块的,假如我现在要查找employee_id是109的记录,从图可以看出来,109的记录存在与块3和块5上。但是ORACLE能通过skip scan定位到这两个块呢?几种可能。
1)先找到入口M,然后从第一个块扫起,扫到第三个块的时候发现了109,停止扫描。然后找到入口F,从块4扫起,扫描到块5的时候发现了109,由于索引已经是有序的了,后面的不用再扫了。
2)先找到入口M,然后把包含M的块都扫描一下,过滤出109的记录。找到入口F,然后把包含F的块都扫描一下,过滤出109的记录
3)通过根节点和分支节点的信息,非常精准的一下子定位到这两个块上。
到底是那一种呢?
看下面的实验
。
SQL> create table wxh_tbd as select * from dba_objects;
表已创建。
SQL> update wxh_tbd set object_id=1 where object_id in
2 (select object_id from (select min(object_id) object_id ,owner from wxh_tbd group by owner));
已更新18行。
SQL> commit;
提交完成。
SQL> update wxh_tbd set object_id=100000000 where object_id in
2 (select object_id from (select max(object_id) object_id ,owner from wxh_tbd group by owner));
已更新18行。
SQL> commit;
SQL> create index t on wxh_tbd(owner,object_id);
索引已创建。
我
的这个测试库里一共有18个schema,通过上面的步骤,我们做到了每个schema下面有一个最小的object_id
即1,一个最大的object_id即100000000.通过以下两个语句的逻辑读我们就可以知道,ORACLE到底是通过三种方式里的哪种来定位块
了。
select /*+ index_ffs(wxh_tbd) */ count(*) from wxh_tbd where object_id=1;
select count(*) from wxh_tbd where object_id=1;
select count(*) from wxh_tbd where object_id=100000000;
实验1)看看如果是采用的index fast scan大概需要多少逻辑读。(这种情况下的逻辑读与上面提到的方法三应该差别不大)
SQL> set autotrace trace stat
SQL> select /*+ index_ffs(wxh_tbd) */ count(*) from wxh_tbd where object_id=1;
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
156 consistent gets
实验2)object_id为1的时候SQL> select count(*) from wxh_tbd where object_id=1;
执行计划
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 5 | 19 (0)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=1)
filter("OBJECT_ID"=1)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
14 consistent gets
实验3)看看object_id为100000000的时候的逻辑读。
SQL> select count(*) from wxh_tbd where object_id=100000000;
执行计划
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 5 | 19 (0)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=100000000)
filter("OBJECT_ID"=100000000)
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
14 consistent gets
如果ORACLE采用的是上面假想的方式1扫描数据块,那么实验2的逻辑读应该远小于实验3的逻辑读。实验2和实验3的逻辑读是相等的。这种可能性排除
如果ORACLE采用的是上面假想的方式2扫描数据块,那么实验2和实验3的逻辑读应该都大约等于index fast full san的逻辑读。可以是从实验结果来看,远不相等。
如果ORACLE采用的是上面假想的方式3扫描数据块,那么实验2和实验3的逻辑读应该相等或接近,我们的实验完全符合。
因此可以得出结论,ORACLE可以在SKIP SCAN中,选择相应的入口后,可以根据某种结构(根块?分支块?页块?)精确定位到记录的叶子块。从中找出符合条件的记录。
还拿这个图为例,如果要查找employee_id为109的条目,ORACLE进入到入口M后,直接就可以定位到块3.而不需要扫描块1和块2.进入到入口F后,直接就可以定位到块5,而不需要扫描块4和块6.
之所以想搞明白这个,是因为最近遇到了一个这么的查询,当时非常惊讶,谓词都出现在了索引块里,怎么会用到skip scan.
SQL> select count(*) from wxh_tbd where owner>'SCOTT' and object_id=5;
执行计划
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 11 | 11 (10)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 11 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 11 | 11 (10)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER">'SCOTT' AND "OBJECT_ID"=5 AND "OWNER" IS NOT NULL)
filter("OBJECT_ID"=5)
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
如
果理解了上面的我所论述的,我相信理解这个就不困难了。上面的查询对于index skip scan 是非常适合的。如果是index
range的话,会扫描所有的首列大于'SCOTT'的索引,从中过滤掉object_id。而index
skip的话,只需要找到大于'SCOTT'的入口,然后精确的定位到object_id即可。


发表评论

-
Why Facebook Uses MySQL for Timeline
2011-12-16 22:28 723A little-known fact about Fac ... -
浅析Oracle中PGA和UGA两者间的区别
2011-09-30 12:01 1229初学Oracle时,你可能会� ... -
Oracle开发专题之:分析函数(OVER)
2011-09-27 15:17 714一、Oracle分析函数简介: 在日常的生产环境中,我们 ... -
oracle decode()
2011-09-23 17:27 759decode(条件,值1,翻译值1,值2,翻译值2,...值n ... -
dba_segments
2011-09-20 10:19 9871、desc dba_segments 名称 ... -
Oracle表空间管理
2011-09-20 10:18 10312010-01-05 08:54 129人阅读 ... -
关于oracle 中的dmt_lmt_mssm_assm之间的关系
2011-09-16 11:46 1633在了解dmt和lmt之前,先来简单的熟悉一下oracle数 ... -
如果查看Oracle数据块和操作系统块大小
2011-09-14 11:21 40511、 在命令窗口中执行: SQL& ... -
深入了解Oracle SCN(3)
2011-09-09 10:49 715示例 例子背景:oracle ... -
深入了解Oracle SCN(2)
2011-09-09 10:48 725SCN 号与 oracle ... -
深入了解Oracle SCN(1)
2011-09-09 10:46 701[说明] 本来在研究Backup and R ... -
DBWn基础
2011-09-08 11:00 762DBWn基础 Database Writer (DBWn ... -
Oracle 绑定变量详解
2011-09-02 17:26 614之前整理过一篇有关绑� ... -
OLTP和OLAP
2011-09-01 11:55 602联机事务处理(OLTP)和联机分析处理(OLAP)的不同,主要 ... -
Oracle的优化器(Optimizer) (CBO优化) 分享
2011-09-01 10:56 726Oracle的优化器(Optimizer) ... -
oracle中的exists 和not exists 用法详解
2011-08-31 17:25 712有两个简单例子,以说明 “exists”和“in”的效率问 ...
相关推荐
sql学习 07.INDEX SKIP SCAN.sql
MySQL 8.0.13开始支持 index skip scan 也即索引跳跃扫描。该优化方式支持那些SQL在不符合组合索引最左前缀的原则的情况,优化器依然能组使用组合索引。 talk is cheap ,show me the code 实践 使用官方文档的例子...
对于联合索引,INDEX SKIP SCAN 可以跳过某些列,当查询的条件在索引的后续列时非常有用。例如,如果有 `(column1, column2)` 的联合索引,而查询条件只涉及到 `column2`,数据库可以跳过 `column1`,直接在 `...
4.索引跳跃扫描(INDEX SKIP SCAN) 5.索引快速全扫描(INDEX FAST FULL SCAN) 索引唯一扫描(INDEX UNIQUE SCAN) 通过这种索引访问数据的特点是对于某个特定的值只返回一行数据,通常如果在查询谓语中使用UNIQE和...
假设`object_name`和`object_type`上有一个复合索引,且查询仅涉及`object_type`列,那么Oracle可能会采用INDEX SKIP SCAN来提高查询效率。 ### 6. SCAN DESCENDING(降序扫描) 当查询需要按照索引的逆序返回结果...
### Skip List 数据结构详解 #### 一、引言与背景 Skip list 是一种概率性数据结构,它在很多场景下可以替代平衡树作为首选的实现方法。与平衡树相比,Skip list 具有更简单的实现、更快的速度以及更低的空间消耗...
MySQL中的 Loose Index Scan 是一种查询优化策略,它与Oracle的Index Skip Scan类似,主要用于提高查询效率,特别是处理涉及`GROUP BY`和`DISTINCT`操作的复杂查询时。在InnoDB存储引擎中,由于索引组织表(IOT,...
至于"文本8"(text8),这是一个常用的小型文本数据集,由维基百科文章的前100万个字符组成,适合用于快速验证和实验不同的文本处理和机器学习算法。 总的来说,这个压缩包中的数据集和代码实现可以帮助我们了解和...
Oracle 9i 引入了一项名为索引跳跃扫描(Index Skip Scan)的创新特性,这一特性显著提升了针对特定查询场景的性能,尤其是在处理连接索引和多值索引的查询时。传统的索引通常依赖于查询语句中完全匹配索引的所有列...
skiplist模板类
然而,SIP协议本身存在一些局限性,例如对服务器的高度依赖导致的单点故障问题以及网络性能瓶颈。 为解决这些问题,P2P(Peer-to-Peer)技术被引入到SIP系统中,旨在构建一种去中心化的网络架构。P2P-SIP系统通过将...
ppt文档 详细介绍了skip list的算法和实现
跳表(Skip List)是一种高效的动态查找数据结构,它的设计灵感来源于随机化算法。在C++中实现跳表,可以利用其高效的插入、删除和查找操作,尤其适用于大规模数据的处理。下面我们将深入探讨跳表的基本原理、C++...
"word2vec Skip-Gram模型的简单实现" 指的是一个教程或项目,专注于演示如何在Python3环境下实现word2vec算法中的Skip-Gram模型。word2vec是一种流行的自然语言处理(NLP)工具,用于学习词汇的分布式表示,即词向量...
### Word2Vec与Skip-Gram模型详解 #### 一、Word2Vec与Embeddings概念解析 Word2Vec是一种从大规模文本语料库中无监督学习语义知识的模型,在自然语言处理(NLP)领域应用广泛。其核心在于能够通过学习文本数据,...
跳表(Skip List)是一种随机化的数据结构,用于高效地实现查找、插入和删除操作,其性能接近于平衡二叉搜索树,但实现起来更为简单。在Java编程中,跳表通常被用作数据库和搜索引擎中的索引结构,因为它的平均时间...
5. **INDEX SKIP SCAN**:在联合索引中,如果前几列的值相同,但后续列的值不同,数据库会跳过相同的前导列,直接找到不同值的记录。 6. **SCAN DESCENDING**:用于降序扫描,例如在ORDER BY子句中指定列的降序排列...
本文将详细介绍两种常用的词向量训练模型——CBOW(Continuous Bag of Words)和skip-gram,并讨论它们在Python中的实现以及分层softmax和负采样这两种优化学习算法。 **CBOW模型** CBOW模型是通过上下文预测目标词...
这个是跳表的头文件
当REPORT_DATE是分区条件且后面跟的都是唯一值时,理想的执行计划应该是Index Skip Scan,因为它能直接定位到具体的分区和相关的行,而避免了大量无谓的数据扫描。 - 但是,如果执行计划选择了Index Range Scan,它...