
十步优化SQL Server中的数据访问
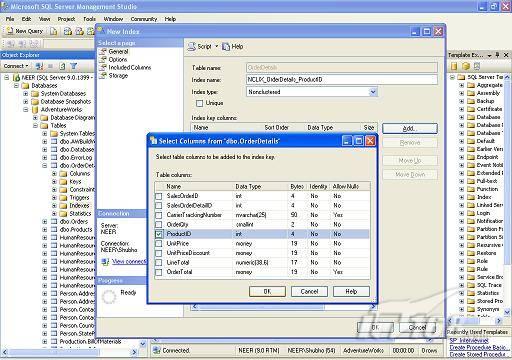
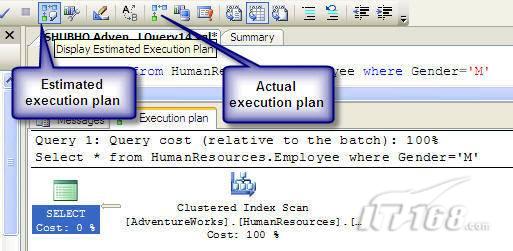
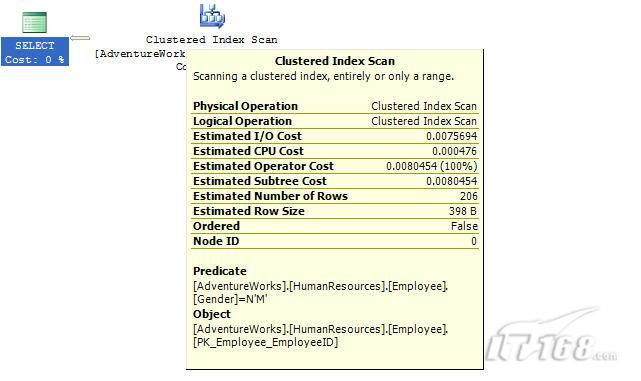
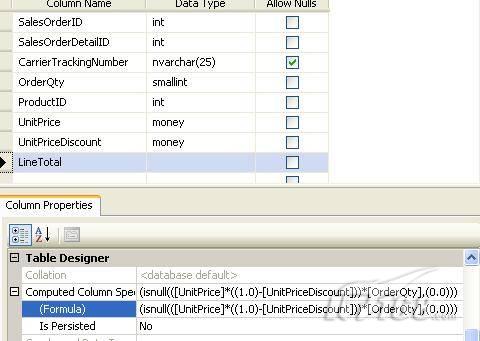
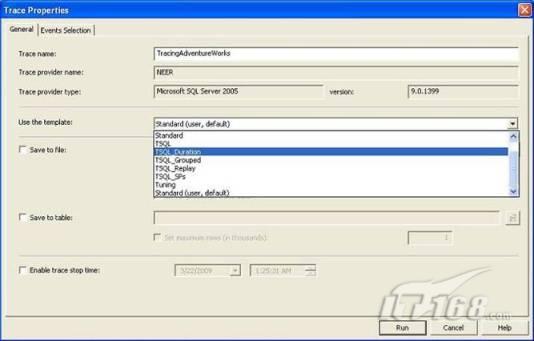
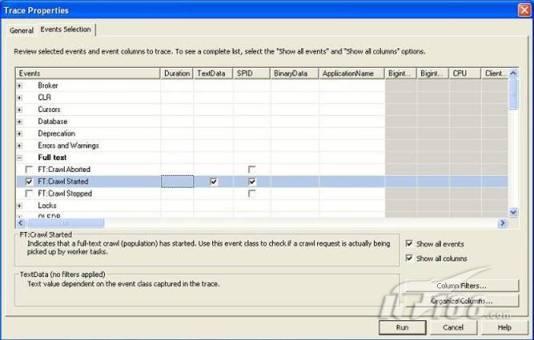
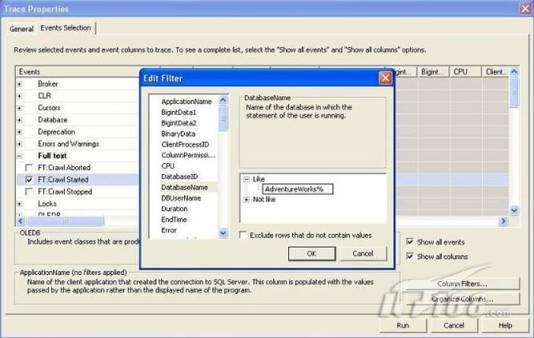
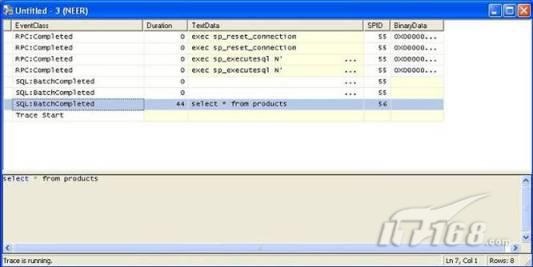
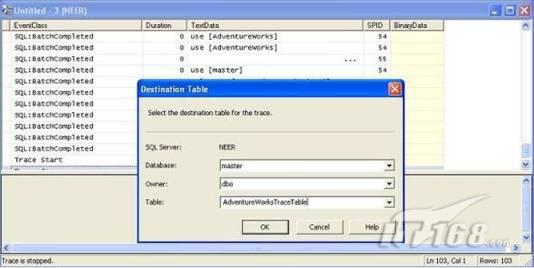
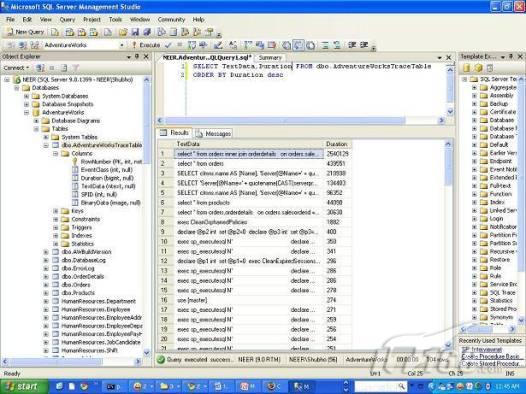
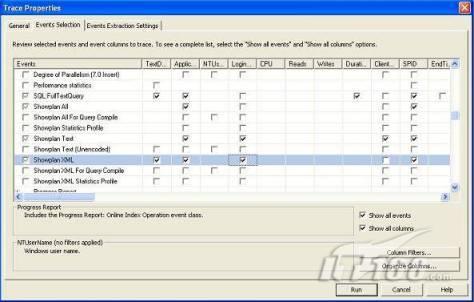
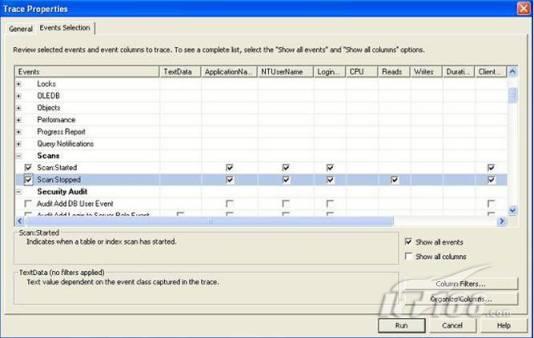
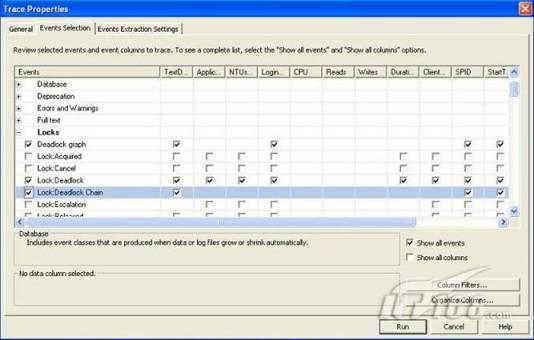
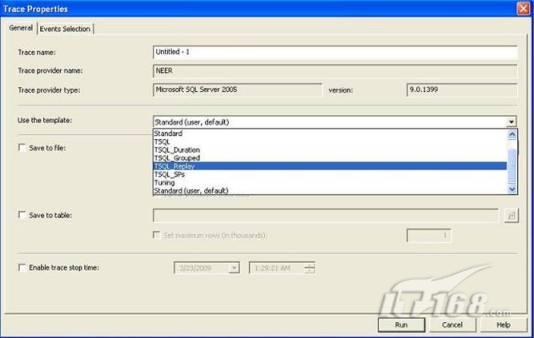
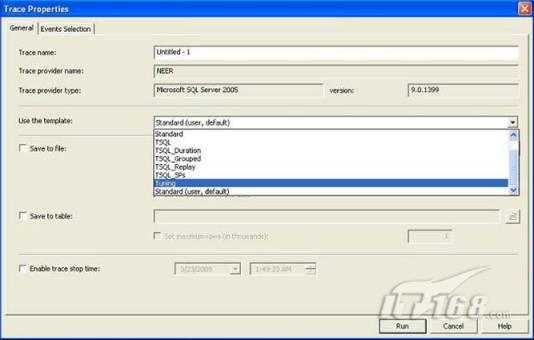
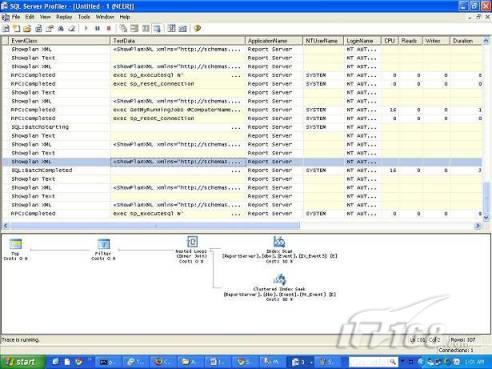
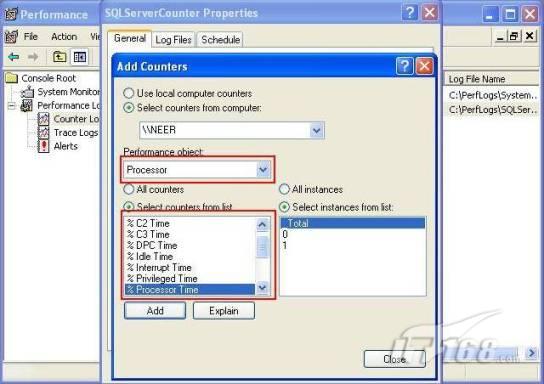
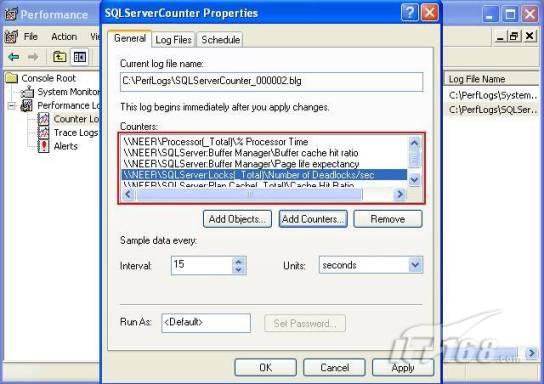
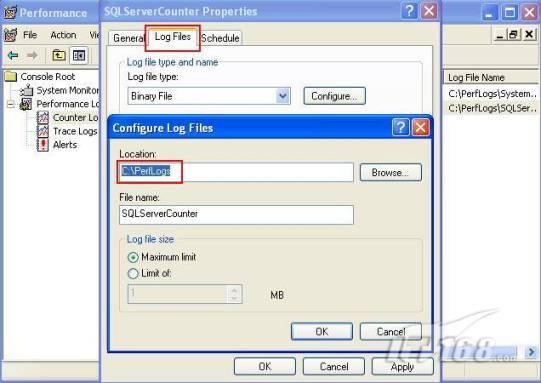
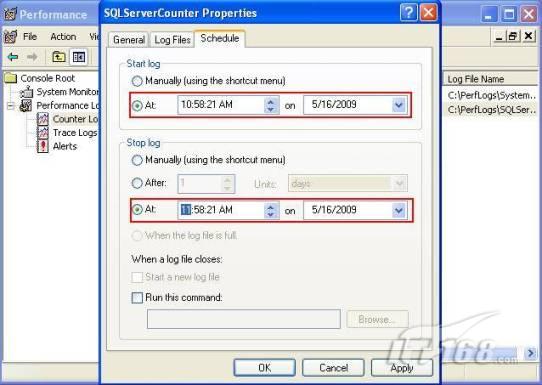
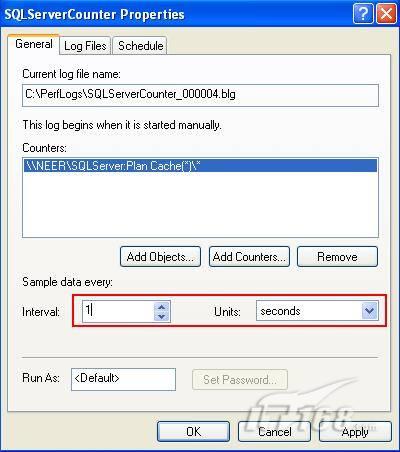
故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性能表现不错,但随着注册用户的增多,访问速度开始变慢,一些用户开始发来邮件表示抗议,事情变得越来越糟,为了留住用户,你开始着手调查访问变慢的原因。 经过紧张的调查,你发现问题出在数据库上,当应用程序尝试访问/更新数据时,数据库执行得相当慢,再次深入调查数据库后,你发现数据库表增长得很大,有些表甚至有上千万行数据,测试团队开始在生产数据库上测试,发现订单提交过程需要花5分钟时间,但在网站上线前的测试中,提交一次订单只需要2/3秒。 类似这种故事在世界各个角落每天都会上演,几乎每个开发人员在其开发生涯中都会遇到这种事情,我也曾多次遇到这种情况,因此我希望将我解决这种问题的经验和大家分享。 如果你正身处这种项目,逃避不是办法,只有勇敢地去面对现实。首先,我认为你的应用程序中一定没有写数据访问程序,我将在这个系列的文章中介绍如何编写最佳的数据访问程序,以及如何优化现有的数据访问程序。 范围 在正式开始之前,有必要澄清一下本系列文章的写作边界,我想谈的是“事务性(OLTP)SQL Server数据库中的数据访问性能优化”,但文中介绍的这些技巧也可以用于其它数据库平台。 同时,我介绍的这些技巧主要是面向程序开发人员的,虽然DBA也是优化数据库的一支主要力量,但DBA使用的优化方法不在我的讨论范围之内。 当一个基于数据库的应用程序运行起来很慢时,90%的可能都是由于数据访问程序的问题,要么是没有优化,要么是没有按最佳方法编写代码,因此你需要审查和优化你的数据访问/处理程序。 我将会谈到10个步骤来优化数据访问程序,先从最基本的索引说起吧! 第一步:应用正确的索引 我之所以先从索引谈起是因为采用正确的索引会使生产系统的性能得到质的提升,另一个原因是创建或修改索引是在数据库上进行的,不会涉及到修改程序,并可以立即见到成效。 我们还是温习一下索引的基础知识吧,我相信你已经知道什么是索引了,但我见到很多人都还不是很明白,我先给大家将一个故事吧。 很久以前,在一个古城的的大图书馆中珍藏有成千上万本书籍,但书架上的书没有按任何顺序摆放,因此每当有人询问某本书时,图书管理员只有挨个寻找,每一次都要花费大量的时间。 [这就好比数据表没有主键一样,搜索表中的数据时,数据库引擎必须进行全表扫描,效率极其低下。] 更糟的是图书馆的图书越来越多,图书管理员的工作变得异常痛苦,有一天来了一个聪明的小伙子,他看到图书管理员的痛苦工作后,想出了一个办法,他建议将每本书都编上号,然后按编号放到书架上,如果有人指定了图书编号,那么图书管理员很快就可以找到它的位置了。 [给图书编号就象给表创建主键一样,创建主键时,会创建聚集索引树,表中的所有行会在文件系统上根据主键值进行物理排序,当查询表中任一行时,数据库首先使用聚集索引树找到对应的数据页(就象首先找到书架一样),然后在数据页中根据主键键值找到目标行(就象找到书架上的书一样)。] 于是图书管理员开始给图书编号,然后根据编号将书放到书架上,为此他花了整整一天时间,但最后经过测试,他发现找书的效率大大提高了。 [在一个表上只能创建一个聚集索引,就象书只能按一种规则摆放一样。] 但问题并未完全解决,因为很多人记不住书的编号,只记得书的名字,图书管理员无赖又只有扫描所有的图书编号挨个寻找,但这次他只花了20分钟,以前未给图书编号时要花2-3小时,但与根据图书编号查找图书相比,时间还是太长了,因此他向那个聪明的小伙子求助。 [这就好像你给Product表增加了主键ProductID,但除此之外没有建立其它索引,当使用Product Name进行检索时,数据库引擎又只要进行全表扫描,逐个寻找了。] 聪明的小伙告诉图书管理员,之前已经创建好了图书编号,现在只需要再创建一个索引或目录,将图书名称和对应的编号一起存储起来,但这一次是按图书名称进行排序,如果有人想找“Database Management System”一书,你只需要跳到“D”开头的目录,然后按照编号就可以找到图书了。 于是图书管理员兴奋地花了几个小时创建了一个“图书名称”目录,经过测试,现在找一本书的时间缩短到1分钟了(其中30秒用于从“图书名称”目录中查找编号,另外根据编号查找图书用了30秒)。 图书管理员开始了新的思考,读者可能还会根据图书的其它属性来找书,如作者,于是他用同样的办法为作者也创建了目录,现在可以根据图书编号,书名和作者在1分钟内查找任何图书了,图书管理员的工作变得轻松了,故事也到此结束。 到此,我相信你已经完全理解了索引的真正含义。假设我们有一个Products表,创建了一个聚集索引(根据表的主键自动创建的),我们还需要在ProductName列上创建一个非聚集索引,创建非聚集索引时,数据库引擎会为非聚集索引自动创建一个索引树(就象故事中的“图书名称”目录一样),产品名称会存储在索引页中,每个索引页包括一定范围的产品名称和它们对应的主键键值,当使用产品名称进行检索时,数据库引擎首先会根据产品名称查找非聚集索引树查出主键键值,然后使用主键键值查找聚集索引树找到最终的产品。 下图显示了一个索引树的结构 图 1 索引树结构 它叫做B+树(或平衡树),中间节点包含值的范围,指引SQL引擎应该在哪里去查找特定的索引值,叶子节点包含真正的索引值,如果这是一个聚集索引树,叶子节点就是物理数据页,如果这是一个非聚集索引树,叶子节点包含索引值和聚集索引键(数据库引擎使用它在聚集索引树中查找对应的行)。 通常,在索引树中查找目标值,然后跳到真实的行,这个过程是花不了什么时间的,因此索引一般会提高数据检索速度。下面的步骤将有助于你正确应用索引。 确保每个表都有主键 这样可以确保每个表都有聚集索引(表在磁盘上的物理存储是按照主键顺序排列的),使用主键检索表中的数据,或在主键字段上进行排序,或在where子句中指定任意范围的主键键值时,其速度都是非常快的。 在下面这些列上创建非聚集索引: 1)搜索时经常使用到的; 2)用于连接其它表的; 3)用于外键字段的; 4)高选中性的; 5)ORDER BY子句使用到的; 6)XML类型。 下面是一个创建索引的例子: 也可以使用SQL Server管理工作台在表上创建索引,如图2所示。 图 2 使用SQL Server管理工作台创建索引 第二步:创建适当的覆盖索引 假设你在Sales表(SelesID,SalesDate,SalesPersonID,ProductID,Qty)的外键列(ProductID)上创建了一个索引,假设ProductID列是一个高选中性列,那么任何在where子句中使用索引列(ProductID)的select查询都会更快,如果在外键上没有创建索引,将会发生全部扫描,但还有办法可以进一步提升查询性能。 假设Sales表有10,000行记录,下面的SQL语句选中400行(总行数的4%): 我们来看看这条SQL语句在SQL执行引擎中是如何执行的: 1)Sales表在ProductID列上有一个非聚集索引,因此它查找非聚集索引树找出ProductID=112的记录; 2)包含ProductID = 112记录的索引页也包括所有的聚集索引键(所有的主键键值,即SalesID); 3)针对每一个主键(这里是400),SQL Server引擎查找聚集索引树找出真实的行在对应页面中的位置; SQL Server引擎从对应的行查找SalesDate和SalesPersonID列的值。 在上面的步骤中,对ProductID = 112的每个主键记录(这里是400),SQL Server引擎要搜索400次聚集索引树以检索查询中指定的其它列(SalesDate,SalesPersonID)。 如果非聚集索引页中包括了聚集索引键和其它两列(SalesDate,,SalesPersonID)的值,SQL Server引擎可能不会执行上面的第3和4步,直接从非聚集索引树查找ProductID列速度还会快一些,直接从索引页读取这三列的数值。 幸运的是,有一种方法实现了这个功能,它被称为“覆盖索引”,在表列上创建覆盖索引时,需要指定哪些额外的列值需要和聚集索引键值(主键)一起存储在索引页中。下面是在Sales 表ProductID列上创建覆盖索引的例子: 应该在那些select查询中常使用到的列上创建覆盖索引,但覆盖索引中包括过多的列也不行,因为覆盖索引列的值是存储在内存中的,这样会消耗过多内存,引发性能下降。 创建覆盖索引时使用数据库调整顾问 我们知道,当SQL出问题时,SQL Server引擎中的优化器根据下列因素自动生成不同的查询计划: 1)数据量 2)统计数据 3)索引变化 4)TSQL中的参数值 5)服务器负载 这就意味着,对于特定的SQL,即使表和索引结构是一样的,但在生产服务器和在测试服务器上产生的执行计划可能会不一样,这也意味着在测试服务器上创建的索引可以提高应用程序的性能,但在生产服务器上创建同样的索引却未必会提高应用程序的性能。因为测试环境中的执行计划利用了新创建的索引,但在生产环境中执行计划可能不会利用新创建的索引(例如,一个非聚集索引列在生产环境中不是一个高选中性列,但在测试环境中可能就不一样)。 因此我们在创建索引时,要知道执行计划是否会真正利用它,但我们怎么才能知道呢?答案就是在测试服务器上模拟生产环境负载,然后创建合适的索引并进行测试,如果这样测试发现索引可以提高性能,那么它在生产环境也就更可能提高应用程序的性能了。 虽然要模拟一个真实的负载比较困难,但目前已经有很多工具可以帮助我们。 使用SQL profiler跟踪生产服务器,尽管不建议在生产环境中使用SQL profiler,但有时没有办法,要诊断性能问题关键所在,必须得用,在http://msdn.microsoft.com/en-us/library/ms181091.aspx有SQL profiler的使用方法。 使用SQL profiler创建的跟踪文件,在测试服务器上利用数据库调整顾问创建一个类似的负载,大多数时候,调整顾问会给出一些可以立即使用的索引建议,在http://msdn.microsoft.com/en-us/library/ms166575.aspx有调整顾问的详细介绍。 第三步:整理索引碎片 你可能已经创建好了索引,并且所有索引都在工作,但性能却仍然不好,那很可能是产生了索引碎片,你需要进行索引碎片整理。 什么是索引碎片? 由于表上有过度地插入、修改和删除操作,索引页被分成多块就形成了索引碎片,如果索引碎片严重,那扫描索引的时间就会变长,甚至导致索引不可用,因此数据检索操作就慢下来了。 有两种类型的索引碎片:内部碎片和外部碎片。 内部碎片:为了有效的利用内存,使内存产生更少的碎片,要对内存分页,内存以页为单位来使用,最后一页往往装不满,于是形成了内部碎片。 外部碎片:为了共享要分段,在段的换入换出时形成外部碎片,比如5K的段换出后,有一个4k的段进来放到原来5k的地方,于是形成1k的外部碎片。 如何知道是否发生了索引碎片? 执行下面的SQL语句就知道了(下面的语句可以在SQL Server 2005及后续版本中运行,用你的数据库名替换掉这里的AdventureWorks): 执行后显示AdventureWorks数据库的索引碎片信息。 图 3 索引碎片信息 使用下面的规则分析结果,你就可以找出哪里发生了索引碎片: 1)ExternalFragmentation的值>10表示对应的索引发生了外部碎片; 2)InternalFragmentation的值<75表示对应的索引发生了内部碎片。 如何整理索引碎片? 有两种整理索引碎片的方法: 1)重组有碎片的索引:执行下面的命令 ALTER INDEX ALL ON TableName REORGANIZE 2)重建索引:执行下面的命令 ALTER INDEX ALL ON TableName REBUILD WITH (FILLFACTOR=90,ONLINE=ON) 也可以使用索引名代替这里的“ALL”关键字重组或重建单个索引,也可以使用SQL Server管理工作台进行索引碎片的整理。 图 4 使用SQL Server管理工作台整理索引碎片 什么时候用重组,什么时候用重建呢? 当对应索引的外部碎片值介于10-15之间,内部碎片值介于60-75之间时使用重组,其它情况就应该使用重建。 值得注意的是重建索引时,索引对应的表会被锁定,但重组不会锁表,因此在生产系统中,对大表重建索引要慎重,因为在大表上创建索引可能会花几个小时,幸运的是,从SQL Server 2005开始,微软提出了一个解决办法,在重建索引时,将ONLINE选项设置为ON,这样可以保证重建索引时表仍然可以正常使用。 虽然索引可以提高查询速度,但如果你的数据库是一个事务型数据库,大多数时候都是更新操作,更新数据也就意味着要更新索引,这个时候就要兼顾查询和更新操作了,因为在OLTP数据库表上创建过多的索引会降低整体数据库性能。 我给大家一个建议:如果你的数据库是事务型的,平均每个表上不能超过5个索引,如果你的数据库是数据仓库型,平均每个表可以创建10个索引都没问题。 在前面我们介绍了如何正确使用索引,调整索引是见效最快的性能调优方法,但一般而言,调整索引只会提高查询性能。除此之外,我们还可以调整数据访问代码和TSQL,本文就介绍如何以最优的方法重构数据访问代码和TSQL。 第四步:将TSQL代码从应用程序迁移到数据库中 也许你不喜欢我的这个建议,你或你的团队可能已经有一个默认的潜规则,那就是使用ORM(Object Relational Mapping,即对象关系映射)生成所有SQL,并将SQL放在应用程序中,但如果你要优化数据访问性能,或需要调试应用程序性能问题,我建议你将SQL代码移植到数据库上(使用存储过程,视图,函数和触发器),原因如下: 1、使用存储过程,视图,函数和触发器实现应用程序中SQL代码的功能有助于减少应用程序中SQL复制的弊端,因为现在只在一个地方集中处理SQL,为以后的代码复用打下了良好的基础。 2、使用数据库对象实现所有的TSQL有助于分析TSQL的性能问题,同时有助于你集中管理TSQL代码。 3、将TS QL移植到数据库上去后,可以更好地重构TSQL代码,以利用数据库的高级索引特性。此外,应用程序中没了SQL代码也将更加简洁。 虽然这一步可能不会象前三步那样立竿见影,但做这一步的主要目的是为后面的优化步骤打下基础。如果在你的应用程序中使用ORM(如NHibernate)实现了数据访问例行程序,在测试或开发环境中你可能发现它们工作得很好,但在生产数据库上却可能遇到问题,这时你可能需要反思基于ORM的数据访问逻辑,利用TSQL对象实现数据访问例行程序是一种好办法,这样做有更多的机会从数据库角度来优化性能。 我向你保证,如果你花1-2人月来完成迁移,那以后肯定不止节约1-2人年的的成本。 OK!假设你已经照我的做的了,完全将TSQL迁移到数据库上去了,下面就进入正题吧! 第五步:识别低效TSQL,采用最佳实践重构和应用TSQL 由于每个程序员的能力和习惯都不一样,他们编写的TSQL可能风格各异,部分代码可能不是最佳实现,对于水平一般的程序员可能首先想到的是编写TSQL实现需求,至于性能问题日后再说,因此在开发和测试时可能发现不了问题。 也有一些人知道最佳实践,但在编写代码时由于种种原因没有采用最佳实践,等到用户发飙的那天才乖乖地重新埋头思考最佳实践。 我觉得还是有必要介绍一下具有都有哪些最佳实践。 1、在查询中不要使用“select *” (1)检索不必要的列会带来额外的系统开销,有句话叫做“该省的则省”; (2)数据库不能利用“覆盖索引”的优点,因此查询缓慢。 2、在select清单中避免不必要的列,在连接条件中避免不必要的表 (1)在select查询中如有不必要的列,会带来额外的系统开销,特别是LOB类型的列; (2)在连接条件中包含不必要的表会强制数据库引擎检索和匹配不需要的数据,增加了查询执行时间。 3、不要在子查询中使用count()求和执行存在性检查 (1)不要使用 使用 代替; (2)当你使用count()时,SQL Server不知道你要做的是存在性检查,它会计算所有匹配的值,要么会执行全表扫描,要么会扫描最小的非聚集索引; (3)当你使用EXISTS时,SQL Server知道你要执行存在性检查,当它发现第一个匹配的值时,就会返回TRUE,并停止查询。类似的应用还有使用IN或ANY代替count()。 4、避免使用两个不同类型的列进行表的连接 (1)当连接两个不同类型的列时,其中一个列必须转换成另一个列的类型,级别低的会被转换成高级别的类型,转换操作会消耗一定的系统资源; (2)如果你使用两个不同类型的列来连接表,其中一个列原本可以使用索引,但经过转换后,优化器就不会使用它的索引了。例如: 在这个例子中,SQL Server会将int列转换为float类型,因为int比float类型的级别低,large_table.int_column上的索引就不会被使用,但smalltable.float_column上的索引可以正常使用。 5、避免死锁 (1)在你的存储过程和触发器中访问同一个表时总是以相同的顺序; (2)事务应经可能地缩短,在一个事务中应尽可能减少涉及到的数据量; (3)永远不要在事务中等待用户输入。 6、使用“基于规则的方法”而不是使用“程序化方法”编写TSQL (1)数据库引擎专门为基于规则的SQL进行了优化,因此处理大型结果集时应尽量避免使用程序化的方法(使用游标或UDF[User Defined Functions]处理返回的结果集) ; (2)如何摆脱程序化的SQL呢?有以下方法: - 使用内联子查询替换用户定义函数; - 使用相关联的子查询替换基于游标的代码; - 如果确实需要程序化代码,至少应该使用表变量代替游标导航和处理结果集。 7、避免使用count(*)获得表的记录数 (1)为了获得表中的记录数,我们通常使用下面的SQL语句: 这条语句会执行全表扫描才能获得行数。 (2)但下面的SQL语句不会执行全表扫描一样可以获得行数: 8、避免使用动态SQL 除非迫不得已,应尽量避免使用动态SQL,因为: (1)动态SQL难以调试和故障诊断; (2)如果用户向动态SQL提供了输入,那么可能存在SQL注入风险。 9、避免使用临时表 (1)除非却有需要,否则应尽量避免使用临时表,相反,可以使用表变量代替; (2)大多数时候(99%),表变量驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,因此临时表上的操作需要跨数据库通信,速度自然慢。 10、使用全文搜索搜索文本数据,取代like搜索 全文搜索始终优于like搜索: (1)全文搜索让你可以实现like不能完成的复杂搜索,如搜索一个单词或一个短语,搜索一个与另一个单词或短语相近的单词或短语,或者是搜索同义词; (2)实现全文搜索比实现like搜索更容易(特别是复杂的搜索); 11、使用union实现or操作 (1)在查询中尽量不要使用or,使用union合并两个不同的查询结果集,这样查询性能会更好; (2)如果不是必须要不同的结果集,使用union all效果会更好,因为它不会对结果集排序。 12、为大对象使用延迟加载策略 (1)在不同的表中存储大对象(如VARCHAR(MAX),Image,Text等),然后在主表中存储这些大对象的引用; (2)在查询中检索所有主表数据,如果需要载入大对象,按需从大对象表中检索大对象。 13、使用VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX) (1)在SQL Server 2000中,一行的大小不能超过800字节,这是受SQL Server内部页面大小8KB的限制造成的,为了在单列中存储更多的数据,你需要使用TEXT,NTEXT或IMAGE数据类型(BLOB); (2)这些和存储在相同表中的其它数据不一样,这些页面以B-Tree结构排列,这些数据不能作为存储过程或函数中的变量,也不能用于字符串函数,如REPLACE,CHARINDEX或SUBSTRING,大多数时候你必须使用READTEXT,WRITETEXT和UPDATETEXT; (3)为了解决这个问题,在SQL Server 2005中增加了VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX),这些数据类型可以容纳和BLOB相同数量的数据(2GB),和其它数据类型使用相同的数据页; (4)当MAX数据类型中的数据超过8KB时,使用溢出页(在ROW_OVERFLOW分配单元中)指向源数据页,源数据页仍然在IN_ROW分配单元中。 14、在用户定义函数中使用下列最佳实践 不要在你的存储过程,触发器,函数和批处理中重复调用函数,例如,在许多时候,你需要获得字符串变量的长度,无论如何都不要重复调用LEN函数,只调用一次即可,将结果存储在一个变量中,以后就可以直接使用了。 15、在存储过程中使用下列最佳实践 (1)不要使用SP_xxx作为命名约定,它会导致额外的搜索,增加I/O(因为系统存储过程的名字就是以SP_开头的),同时这么做还会增加与系统存储过程名称冲突的几率; (2)将Nocount设置为On避免额外的网络开销; (3)当索引结构发生变化时,在EXECUTE语句中(第一次)使用WITH RECOMPILE子句,以便存储过程可以利用最新创建的索引; (4)使用默认的参数值更易于调试。 16、在触发器中使用下列最佳实践 (1)最好不要使用触发器,触发一个触发器,执行一个触发器事件本身就是一个耗费资源的过程; (2)如果能够使用约束实现的,尽量不要使用触发器; (3)不要为不同的触发事件(Insert,Update和Delete)使用相同的触发器; (4)不要在触发器中使用事务型代码。 17、在视图中使用下列最佳实践 (1)为重新使用复杂的TSQL块使用视图,并开启索引视图; (2)如果你不想让用户意外修改表结构,使用视图时加上SCHEMABINDING选项; (3)如果只从单个表中检索数据,就不需要使用视图了,如果在这种情况下使用视图反倒会增加系统开销,一般视图会涉及多个表时才有用。 18、在事务中使用下列最佳实践 (1)SQL Server 2005之前,在BEGIN TRANSACTION之后,每个子查询修改语句时,必须检查@@ERROR的值,如果值不等于0,那么最后的语句可能会导致一个错误,如果发生任何错误,事务必须回滚。从SQL Server 2005开始,Try..Catch..代码块可以处理TSQL中的事务,因此在事务型代码中最好加上Try…Catch…; (2)避免使用嵌套事务,使用@@TRANCOUNT变量检查事务是否需要启动(为了避免嵌套事务); (3)尽可能晚启动事务,提交和回滚事务要尽可能快,以减少资源锁定时间。 要完全列举最佳实践不是本文的初衷,当你了解了这些技巧后就应该拿来使用,否则了解了也没有价值。此外,你还需要评审和监视数据访问代码是否遵循下列标准和最佳实践。 如何分析和识别你的TSQL中改进的范围? 理想情况下,大家都想预防疾病,而不是等病发了去治疗。但实际上这个愿望根本无法实现,即使你的团队成员全都是专家级人物,我也知道你有进行评审,但代码仍然一团糟,因此需要知道如何治疗疾病一样重要。 首先需要知道如何诊断性能问题,诊断就得分析TSQL,找出瓶颈,然后重构,要找出瓶颈就得先学会分析执行计划。 理解查询执行计划 当你将SQL语句发给SQL Server引擎后,SQL Server首先要确定最合理的执行方法,查询优化器会使用很多信息,如数据分布统计,索引结构,元数据和其它信息,分析多种可能的执行计划,最后选择一个最佳的执行计划。 可以使用SQL Server Management Studio预览和分析执行计划,写好SQL语句后,点击SQL Server Management Studio上的评估执行计划按钮查看执行计划,如图1所示。 图 1 在Management Studio中评估执行计划 在执行计划图中的每个图标代表计划中的一个行为(操作),应从右到左阅读执行计划,每个行为都一个相对于总体执行成本(100%)的成本百分比。 在上面的执行计划图中,右边的那个图标表示在HumanResources表上的一个“聚集索引扫描”操作(阅读表中所有主键索引值),需要100%的总体查询执行成本,图中左边那个图标表示一个select操作,它只需要0%的总体查询执行成本。 下面是一些比较重要的图标及其对应的操作: 图 2 常见的重要图标及对应的操作 注意执行计划中的查询成本,如果说成本等于100%,那很可能在批处理中就只有这个查询,如果在一个查询窗口中有多个查询同时执行,那它们肯定有各自的成本百分比(小于100%)。 如果想知道执行计划中每个操作详细情况,将鼠标指针移到对应的图标上即可,你会看到类似于下面的这样一个窗口。 图 3 查看执行计划中行为(操作)的详细信息 这个窗口提供了详细的评估信息,上图显示了聚集索引扫描的详细信息,它要查找AdventureWorks数据库HumanResources方案下Employee表中 Gender = ‘M’的行,它也显示了评估的I/O,CPU成本。 查看执行计划时,我们应该获得什么信息 当你的查询很慢时,你就应该看看预估的执行计划(当然也可以查看真实的执行计划),找出耗时最多的操作,注意观察以下成本通常较高的操作: 1、表扫描(Table Scan) 当表没有聚集索引时就会发生,这时只要创建聚集索引或重整索引一般都可以解决问题。 2、聚集索引扫描(Clustered Index Scan) 有时可以认为等同于表扫描,当某列上的非聚集索引无效时会发生,这时只要创建一个非聚集索引就ok了。 3、哈希连接(Hash Join) 当连接两个表的列没有被索引时会发生,只需在这些列上创建索引即可。 4、嵌套循环(Nested Loops) 当非聚集索引不包括select查询清单的列时会发生,只需要创建覆盖索引问题即可解决。 5、RID查找(RID Lookup) 当你有一个非聚集索引,但相同的表上却没有聚集索引时会发生,此时数据库引擎会使用行ID查找真实的行,这时一个代价高的操作,这时只要在该表上创建聚集索引即可。 TSQL重构真实的故事 只有解决了实际的问题后,知识才转变为价值。当我们检查应用程序性能时,发现一个存储过程比我们预期的执行得慢得多,在生产数据库中检索一个月的销售数据居然要50秒,下面就是这个存储过程的执行语句: exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009,’Cap’ Tom受命来优化这个存储过程,下面是这个存储过程的代码: 分析索引 首先,Tom想到了审查这个存储过程使用到的表的索引,很快他发现下面两列的索引无故丢失了: OrderDetails.ProductID OrderDetails.SalesOrderID 他在这两个列上创建了非聚集索引,然后再执行存储过程: exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009 with recompile 性能有所改变,但仍然低于预期(这次花了35秒),注意这里的with recompile子句告诉SQL Server引擎重新编译存储过程,重新生成执行计划,以利用新创建的索引。 分析查询执行计划 Tom接下来查看了SQL Server Management Studio中的执行计划,通过分析,他找到了某些重要的线索: 1、发生了一次表扫描,即使该表已经正确设置了索引,而表扫描占据了总体查询执行时间的30%; 2、发生了一个嵌套循环连接。 Tom想知道是否有索引碎片,因为所有索引配置都是正确的,通过TSQL他知道了有两个索引都产生了碎片,很快他重组了这两个索引,于是表扫描消失了,现在执行存储过程的时间减少到25秒了。 为了消除嵌套循环连接,他又在表上创建了覆盖索引,时间进一步减少到23秒。 实施最佳实践 Tom发现有个UDF有问题,代码如下: 在计算订单总金额时看起来代码很程序化,Tom决定在UDF的SQL中使用内联SQL。 dbo.ufnGetLineTotal(SalesOrderDetailID) Total -- 旧代码 (CurrentProductRate-CurrentDiscount)*OrderQty Total -- 新代码 执行时间一下子减少到14秒了。 在select查询清单中放弃不必要的Text列 为了进一步提升性能,Tom决定检查一下select查询清单中使用的列,很快他发现有一个Products.DetailedDescription列是Text类型,通过对应用程序代码的走查,Tom发现其实这一列的数据并不会立即用到,于是他将这一列从select查询清单中取消掉,时间一下子从14秒减少到6秒,于是Tom决定使用一个存储过程应用延迟加载策略加载这个Text列。 最后Tom还是不死心,认为6秒也无法接受,于是他再次仔细检查了SQL代码,他发现了一个like子句,经过反复研究他认为这个like搜索完全可以用全文搜索替换,最后他用全文搜索替换了like搜索,时间一下子降低到1秒,至此Tom认为调优应该暂时结束了。 小结 看起来我们介绍了好多种优化数据访问的技巧,但大家要知道优化数据访问是一个无止境的过程,同样大家要相信一个信念,无论你的系统多么庞大,多么复杂,只要灵活运用我们所介绍的这些技巧,你一样可以驯服它们。下一篇将介绍高级索引和反范式化。 经过索引优化,重构TSQL后你的数据库还存在性能问题吗?完全有可能,这时必须得找另外的方法才行。SQL Server在索引方面还提供了某些高级特性,可能你还从未使用过,利用高级索引会显著地改善系统性能,本文将从高级索引技术谈起,另外还将介绍反范式化技术。 第六步:应用高级索引 实施计算列并在这些列上创建索引 你可能曾经写过从数据库查询一个结果集的应用程序代码,对结果集中每一行进行计算生成最终显示输出的信息。例如,你可能有一个查询从数据库检索订单信息,在应用程序代码中你可能已经通过对产品和销售量执行算术操作计算出了总的订单价格,但为什么你不在数据库中执行这些操作呢? 请看下面这张图,你可以通过指定一个公式将一个数据库表列作为计算列,你的TSQL在查询清单中包括这个计算列,SQL引擎将会应用这个公式计算出这一列的值,在执行查询时,数据库引擎将会计算订单总价,并为计算列返回结果。 图 1 计算列 使用计算列你可以将计算工作全部交给后端执行,但如果表的行数太多可能计算性能也不高,如果计算列出现在Select查询的where子句中情况会更糟,在这种情况下,为了匹配where子句指定的值,数据库引擎不得不计算表中所有行中计算列的值,这是一个低效的过程,因为它总是需要全表扫描或全聚集索引扫描。 因此问题就来了,如何提高计算列的性能呢?解决办法是在计算列上创建索引,当计算列上有索引后,SQL Server会提前计算结果,然后在结果之上构建索引。此外,当对应列(计算列依赖的列)的值更新时,计算列上的索引值也会更新。因此,在执行查询时,数据库引擎不会为结果集中的每一行都执行一次计算公式,相反,通过索引可直接获得计算列预先计算出的值,因此在计算列上创建一个索引将会加快查询速度。 提示:如果你想在计算列上创建索引,必须确保计算列上的公式不能包括任何“非确定的”函数,例如getdate()就是一个非确定的函数,因为每次调用它,它返回的值都是不一样的。 创建索引视图 你是否知道可以在视图上创建索引?OK,不知道没关系,看了我的介绍你就明白了。 为什么要使用视图? 大家都知道,视图本身不存储任何数据,只是一条编译的select语句。数据库会为视图生成一个执行计划,视图是可以重复使用的,因为执行计划也可以重复使用。 视图本身不会带来性能的提升,我曾经以为它会“记住”查询结果,但后来我才知道它除了是一个编译了的查询外,其它什么都不是,视图根本记不住查询结果,我敢打赌好多刚接触SQL的人都会有这个错误的想法。 但是现在我要告诉你一个方法让视图记住查询结果,其实非常简单,就是在视图上创建索引就可以了。 如果你在视图上应用了索引,视图就成为索引视图,对于一个索引视图,数据库引擎处理SQL,并在数据文件中存储结果,和聚集表类似,当基础表中的数据发生变化时,SQL Server会自动维护索引,因此当你在索引视图上查询时,数据库引擎简单地从索引中查找值,速度当然就很快了,因此在视图上创建索引可以明显加快查询速度。 但请注意,天下没有免费的午餐,创建索引视图可以提升性能,当基础表中的数据发生变化时,数据库引擎也会更新索引,因此,当视图要处理很多行,且要求和,当数据和基础表不经常发生变化时,就应该考虑创建索引视图。 如何创建索引视图? 1)创建/修改视图时指定SCHEMABINDING选项: 2)在视图上创建一个唯一的聚集索引; 3)视需要在视图上创建一个非聚集索引。 不是所有视图上都可以创建索引,在视图上创建索引存在以下限制: 1)创建视图时使用了SCHEMABINDING选项,这种情况下,数据库引擎不允许你改变表的基础结构; 2)视图不能包含任何非确定性函数,DISTINCT子句和子查询; 3)视图中的底层表必须由聚集索引(主键)。 如果你发现你的应用程序中使用的TSQL是用视图实现的,但存在性能问题,那此时给视图加上索引可能会带来性能的提升。 为用户定义函数(UDF)创建索引 在用户定义函数上也可以创建索引,但不能直接在它上面创建索引,需要创建一个辅助的计算列,公式就使用用户定义函数,然后在这个计算列字段上创建索引。具体步骤如下: 1)首先创建一个确定性的函数(如果不存在的话),在函数定义中添加SCHEMABINDING选项,如: 2)在目标表上增加一个计算列,使用前面定义的函数作为该列的计算公式,如图2所示。 3)在计算列上创建索引 当你的查询中包括UDF时,如果在该UDF上创建了以计算列为基础的索引,特别是两个表或视图的连接条件中使用了UDF,性能都会有明显的改善。 在XML列上创建索引 在SQL Server(2005和后续版本)中,XML列是以二进制大对象(BLOB)形式存储的,可以使用XQuery进行查询,但如果没有索引,每次查询XML数据类型时都非常耗时,特别是大型XML实例,因为SQL Server在运行时需要分隔二进制大对象评估查询。为了提升XML数据类型上的查询性能,XML列可以索引,XML索引分为两类。 主XML索引 创建XML列上的主索引时,SQL Server会切碎XML内容,创建多个数据行,包括元素,属性名,路径,节点类型和值等,创建主索引让SQL Server更轻松地支持XQuery请求。下面是创建一个主XML索引的示例语法。 次要XML索引 虽然XML数据已经被切条,但SQL Server仍然要扫描所有切条的数据才能找到想要的结果,为了进一步提升性能,还需要在主XML索引之上创建次要XML索引。有三种次要XML索引。 1)“路径”(Path)次要XML索引:使用.exist()方法确定一个特定的路径是否存在时它很有用; 2)“值”(Value)次要XML索引:用于执行基于值的查询,但不知道完整的路径或路径包括通配符时; 3)“属性”(Secondary)次要XML索引:知道路径时检索属性的值。 下面是一个创建次要XML索引的示例: 请注意,上面讲的原则是基础,如果盲目地在表上创建索引,不一定会提升性能,因为有时在某些表的某些列上创建索引时,可能会致使插入和更新操作变慢,当这个表上有一个低选中性列时更是如此,同样,当表中的记录很少(如<500)时,如果在这样的表上创建索引反倒会使数据检索性能降低,因为对于小表而言,全表扫描反而会更快,因此在创建索引时应放聪明一点。 第七步:应用反范式化,使用历史表和预计算列 反范式化 如果你正在为一个OLTA(在线事务分析)系统设计数据库,主要指为只读查询优化过的数据仓库,你可以(和应该)在你的数据库中应用反范式化和索引,也就是说,某些数据可以跨多个表存储,但报告和数据分析查询在这种数据库上可能会更快。 但如果你正在为一个OLTP(联机事务处理)系统设计数据库,这样的数据库主要执行数据更新操作(包括插入/更新/删除),我建议你至少实施第一、二、三范式,这样数据冗余可以降到最低,数据存储也可以达到最小化,可管理性也会好一点。 无论我们在OLTP系统上是否应用范式,在数据库上总有大量的读操作(即select查询),当应用了所有优化技术后,如果发现数据检索操作仍然效率低下,此时,你可能需要考虑应用反范式设计了,但问题是如何应用反范式化,以及为什么应用反范式化会提升性能?让我们来看一个简单的例子,答案就在例子中。 假设我们有两个表OrderDetails(ID,ProductID,OrderQty) 和 Products(ID,ProductName)分别存储订单详细信息和产品信息,现在要查询某个客户订购的产品名称和它们的数量,查询SQL语句如下: 如果这两个都是大表,当你应用了所有优化技巧后,查询速度仍然很慢,这时可以考虑以下反范式化设计: 1)在OrderDetails表上添加一列ProductName,并填充好数据; 2)重写上面的SQL语句 注意在OrderDetails表上应用了反范式化后,不再需要连接Products表,因此在执行SQL时,SQL引擎不会执行两个表的连接操作,查询速度当然会快一些。 为了提高select操作性能,我们不得不做出一些牺牲,需要在两个地方(OrderDetails 和 Products表)存储相同的数据(ProductName),当我们插入或更新Products 表中的ProductName字段时,不得不同步更新OrderDetails表中的ProductName字段,此外,应用这种反范式化设计时会增加存储资源消耗。 因此在实施反范式化设计时,我们必须在数据冗余和查询操作性能之间进行权衡,同时在应用反范式化后,我们不得不重构某些插入和更新操作代码。有一个重要的原则需要遵守,那就是只有当你应用了所有其它优化技术都还不能将性能提升到理想情况时才使用反范式化。同时还需注意不能使用太多的反范式化设计,那样会使原本清晰的表结构设计变得越来模糊。 历史表 如果你的应用程序中有定期运行的数据检索操作(如报表),如果涉及到大表的检索,可以考虑定期将事务型规范化表中的数据复制到反范式化的单一的历史表中,如利用数据库的Job来完成这个任务,并对这个历史表建立合适的索引,那么周期性执行的数据检索操作可以迁移到这个历史表上,对单个历史表的查询性能肯定比连接多个事务表的查询速度要快得多。 例如,假设有一个连锁商店的月度报表需要3个小时才能执行完毕,你被派去优化这个报表,目的只有一个:最小化执行时间。那么你除了应用其它优化技巧外,还可以采取以下手段: 1)使用反范式化结构创建一个历史表,并对销售数据建立合适的索引; 2)在SQL Server上创建一个定期执行的操作,每隔24小时运行一次,在半夜往历史表中填充数据; 3)修改报表代码,从历史表获取数据。 创建定期执行的操作 按照下面的步骤在SQL Server中创建一个定期执行的操作,定期从事务表中提取数据填充到历史表中。 1)首先确保SQL Server代理服务处于运行状态; 2)在SQL Server配置管理器中展开SQL Server代理节点,在“作业”节点上创建一个新作业,在“常规”标签页中,输入作业名称和描述文字; 3)在“步骤”标签页中,点击“新建”按钮创建一个新的作业步骤,输入名字和TSQL代码,最后保存; 4)切换到“调度”标签页,点击“新建”按钮创建一个新调度计划; 5)最后保存调度计划。 在数据插入和更新中提前执行耗时的计算,简化查询 大多数情况下,你会看到你的应用程序是一个接一个地执行数据插入或更新操作,一次只涉及到一条记录,但数据检索操作可能同时涉及到多条记录。 如果你的查询中包括一个复杂的计算操作,毫无疑问这将导致整体的查询性能下降,你可以考虑下面的解决办法: 1)在表中创建额外的一列,包含计算的值; 2)为插入和更新事件创建一个触发器,使用相同的计算逻辑计算值,计算完成后更新到新建的列; 3)使用新创建的列替换查询中的计算逻辑。 实施完上述步骤后,插入和更新操作可能会更慢一点,因为每次插入和更新时触发器都会执行一下,但数据检索操作会比之前快得多,因为执行查询时,数据库引擎不会执行计算操作了。 小结 至此,我们已经应用了索引,重构TSQL,应用高级索引,反范式化,以及历史表加速数据检索速度,但性能优化是一个永无终点的过程,最下一篇文章中我们将会介绍如何诊断数据库性能问题。 诊断数据库性能问题就象医生诊断病人病情一样,既要结合自己积累的经验,又要依靠科学的诊断报告,才能准确地判断问题的根源在哪里。前面三篇文章我们介绍了许多优化数据库性能的方法,固然掌握优化技巧很重要,但诊断数据库性能问题是优化的前提,本文就介绍一下如何诊断数据库性能问题。 第八步:使用SQL事件探查器和性能监控工具有效地诊断性能问题 在SQL Server应用领域SQL事件探查器可能是最著名的性能故障排除工具,大多数情况下,当得到一个性能问题报告后,一般首先启动它进行诊断。 你可能已经知道,SQL事件探查器是一个跟踪和监控SQL Server实例的图形化工具,主要用于分析和衡量在数据库服务器上执行的TSQL性能,你可以捕捉服务器实例上的每个事件,将其保存到文件或表中供以后分析。例如,如果生产数据库速度很慢,你可以使用SQL事件探查器查看哪些存储过程执行时耗时过多。 SQL事件探查器的基本用法 你可能已经知道如何使用它,那么你可以跳过这一小节,但我还是要重复一下,也许有许多新手阅读本文。 1)启动SQL事件探查器,连接到目标数据库实例,创建一个新跟踪,指定一个跟踪模板(跟踪模板预置了一些事件和用于跟踪的列),如图1所示; 图 1 选择跟踪模板 2)作为可选的一步,你还可以选择特定事件和列 图 2 选择跟踪过程要捕捉的事件 3)另外你还可以点击“组织列”按钮,在弹出的窗口中指定列的显示顺序,点击“列过滤器”按钮,在弹出的窗口中设置过滤器,例如,通过设置数据库的名称(在like文本框中),只跟踪特定的数据库,如果不设置过滤器,SQL事件探查器会捕捉所有的事件,跟踪的信息会非常多,要找出有用的关键信息就如大海捞针。 图 3 过滤器设置 4)运行事件探查器,等待捕捉事件 图 4 运行事件探查器 5)跟踪了足够的信息后,停掉事件探查器,将跟踪信息保存到一个文件中,或者保存到一个数据表中,如果保存到表中,需要指定表名,SQL Server会自动创建表中的字段。 图 5 将探查器跟踪数据保存到表中 6)执行下面的SQL查询语句找出执行代价较高的TSQL 图 6 查找成本最高的TSQL/存储过程 有效利用SQL事件探查器排除与性能相关的问题 SQL事件探查器除了可以用于找出执行成本最高的那些TSQL或存储过程外,还可以利用它许多强大的功能诊断和解决其它不同类型的问题。当你收到一个性能问题报告后,或者想提前诊断潜在的性能问题时都可以使用SQL事件探查器。下面是一些SQL事件探查器使用技巧,或许对你有帮助。 1)使用现有的模板,但需要时应创建你自己的模板 大多数时候现有的模板能够满足你的需求,但当诊断一个特殊类型的数据库性能问题时(如数据库发生死锁),你可能需要创建自己的模板,在这种情况下,你可以点击“文件”*“模板”*“新建模板”创建一个新模板,需要指定模板名、事件和列。当然也可以从现有的模板修改而来。 图 7 创建一个新模板 图 8 为新模板指定事件和列 2)捕捉表扫描(TableScan)和死锁(DeadLock)事件 没错,你可以使用SQL事件探查器监听这两个有趣的事件。 先假设一种情况,假设你已经在你的测试库上创建了合适的索引,经过测试后,现在你已经将索引应用到生产服务器上了,但由于某些不明原因,生产数据库的性能一直没达到预期的那样好,你推测执行查询时发生了表扫描,你希望有一种方法能够检测出是否真的发生了表扫描。 再假设另一种情况,假设你已经设置好了将错误邮件发送到一个指定的邮件地址,这样开发团队可以第一时间获得通知,并有足够的信息进行问题诊断。某一天,你突然收到一封邮件说数据库发生了死锁,并在邮件中包含了数据库级别的错误代码,你需要找出是哪个TSQL创造了死锁。 这时你可以打开SQL事件探查器,修改一个现有模板,使其可以捕捉表扫描和死锁事件,修改好后,启动事件探查器,运行你的应用程序,当再次发生表扫描和死锁事件时,事件探查器就可以捕捉到,利用跟踪信息就可以找出执行代价最高的TSQL。 注意:从SQL Server日志文件中可能也可以找到死锁事件记录,在某些时候,你可能需要结合SQL Server日志和跟踪信息才能找出引起数据库死锁的数据库对象和TSQL。 图 9 检测表扫描 图 10 检测死锁 3)创建重放跟踪 某些时候,为了解决生产数据库的性能问题,你需要在测试服务器上模拟一个生产环境,这样可以重演性能问题。使用SQL事件探查器的TSQL_Replay模板捕捉生产库上的事件,并将跟踪信息保存为一个.trace文件,然后在测试服务器上播放跟踪文件就可以重现性能问题是如何出现的了。 图 11 创建重放跟踪 4)创建优化跟踪 数据库调优顾问是一个伟大的工具,它可以给你提供很好的调优建议,但要真正从它那获得有用的建议,你需要模拟出与生产库一样的负载,也就是说,你需要在测试服务器上执行相同的TSQL,打开相同数量的并发连接,然后运行调优顾问。SQL事件探查器的Tuning模板可以捕捉到这类事件和列,使用Tuning模板运行事件探查器,捕捉跟踪信息并保存,通过调优顾问使用跟踪文件在测试服务器上创建相同的负载。 图 12 创建Tuning事件探查器跟踪 5)捕捉ShowPlan在事件探查器中包括SQL执行计划 有时相同的查询在测试服务器和生产服务器上的性能完全不一样,假设你遇到这种问题,你应该仔细查看一下生产数据库上TSQL的执行计划。但问题是现在不能在生产库上执行这个TSQL,因为它已经有严重的性能问题。这时SQL事件探查器可以派上用场,在跟踪属性中选中ShowPlan或ShowPlan XML,这样可以捕捉到SQL执行计划和TSQL文本,然后在测试服务器上执行相同的TSQL,并比较两者的执行计划。 图 13 指定捕捉执行计划 图 14 在事件探查器跟踪中的执行计划 使用性能监视工具(PerfMon)诊断性能问题 当你的数据库遇到性能问题时,大多数时候使用SQL事件探查器就能够诊断和找出引起性能问题的背后原因了,但有时SQL事件探查器并不是万能的。 例如,在生产库上使用SQL事件探查器分析查询执行时间时,对应的TSQL执行很慢(假设需要10秒),但同样的TSQL在测试服务器上执行时间却只要200毫秒,通过分析执行计划和数据列,发现它们都没有太大的差异,因此在生产库上肯定有其它问题,那该如何揪出这些问题呢? 此时性能监视工具(著名的PerfMon)可以帮你一把,它可以定期收集硬件和软件相关的统计数据,还有它是内置于Windows操作系统的一个免费的工具。 当你向SQL Server数据库发送一条TSQL语句,会产生许多相关的执行参与者,包括TSQL执行引擎,服务器缓存,SQL优化器,输出队列,CPU,磁盘I/O等,只要这些参与者任何一环执行节奏没有跟上,最终的查询执行时间就会变长,使用性能监视工具可以对这些参与者进行观察,以找出根本原因。 使用性能监视工具可以创建多个不同的性能计数器,通过图形界面分析计数器日志,此外还可以将性能计数器日志和SQL事件探查器跟踪信息结合起来分析。 性能监视器基本用法介绍 Windows内置了许多性能监视计数器,安装SQL Server时会添加一个SQL Server性能计数器,下面是创建一个性能计数器日志的过程。 1)在SQL事件探查器中启动性能监视工具(“工具”*“性能监视器”); 图 15 启动性能监视工具 2)点击“计数器日志”*“新建日志设置”创建一个新的性能计数器日志 图 16 创建一个性能计数器日志 指定日志文件名,点击“确定”。 图 17 为性能计数器日志指定名字 3)点击“添加计数器”按钮,选择一个需要的计数器 图 18 为性能计数器日志指定计数器 4)从列表中选择要监视的对象和对应的计数器,点击“关闭” 图 19 指定对象和对应的计数器 5)选择的计数器应显示在窗体中 图 20 指定计数器 6)点击“日志文件”标签,再点击“配置”按钮,指定日志文件保存位置,如果需要现在还可以修改日志文件名 图 21 指定性能计数器日志文件保存位置 7)点击“调度”标签,指定一个时间读取计数器性能,写入日志文件,也可以选择“手动”启动和停止计数器日志。 图 22 指定性能计数器日志运行时间 8)点击“常规”标签,指定收集计数器数据的间隔时间 图 23 设置计数器间隔采样时间 9)点击“确定”,选择刚刚创建的计数器日志,点击右键启动它。 图 24 启动性能计数器日志 10)为了查看日志数据,再次打开性能监视工具,点击查看日志图标(红色),在“源”标签上选中“日志文件”单选按钮,点击“添加”按钮添加一个日志文件。 图 25 查看性能计数器日志 11)默认情况下,在日志输出中只有三个计数器被选中,点击“数据”标签可以追加其它计数器。 图 26 查看日志数据时追加计数器 12)点击“确定”,返回图形化的性能计数器日志输出界面 图 27 查看性能计数器日志 关联性能计数器日志和SQL事件探查器跟踪信息进行深入的分析 通过SQL事件探查器可以找出哪些SQL执行时间过长,但它却不能给出导致执行时间过长的上下文信息,但性能监视工具可以提供独立组件的性能统计数据(即上下文信息),它们正好互补。 如果相同的查询在生产库和测试库上的执行时间差别过大,那说明测试服务器的负载,环境和查询执行上下文都和生产服务器不一样,因此需要一种方法来模拟生产服务器上的查询执行上下文,这时就需要结合SQL事件探查器的跟踪信息和性能监视工具的性能计数器日志。 将二者结合起来分析可以更容易找出性能问题的根本原因,例如,你可能发现在生产服务器上每次查询都需要10秒,CPU利用率达到了100%,这时就应该放下SQL调优,先调查一下为什么CPU利用率会上升到100%。 关联SQL事件探查器跟踪信息和性能计数器日志的步骤如下: 1)创建性能计数器日志,包括下列常见的性能计数器,指定“手动”方式启动和停止计数器日志: --网络接口\输出队列长度 --处理器\%处理器时间 --SQL Server:缓冲管理器\缓冲区缓存命中率 --SQL Server:缓冲管理器\页面生命周期 --SQL Server:SQL统计\批量请求数/秒 --SQL Server:SQL统计\SQL 编译 --SQL Server:SQL统计\SQL 重新编译/秒 创建好性能计数器日志,但不启动它。 2)使用SQL事件探查器TSQL Duration模板创建一个跟踪,添加“开始时间”和“结束时间”列跟踪,同时启动事件探查器跟踪和前一步创建的性能计数器日志; 3)跟踪到足够信息后,同时停掉SQL事件探查器跟踪和性能计数器日志,将SQL事件探查器跟踪信息保存为一个.trc文件; 4)关闭SQL事件探查器跟踪窗口,再使用事件探查器打开.trc文件,点击“文件”*“导入性能数据”关联性能计数器日志,此时会打开一个文件浏览器窗口,选择刚刚保存的性能计数器日志文件进行关联; 5)在打开的窗口中选择所有计数器,点击“确定”,你将会看到下图所示的界面,它同时显示SQL事件探查器的跟踪信息和性能计数器日志; 图 28 关联SQL事件探查器和性能监视工具输出 6)在事件探查器跟踪信息输出中选择一条TSQL,你将会看到一个红色竖条,这代表这条TSQL执行时相关计数器的统计数据位置,同样,点击性能计数器日志输出曲线中高于正常值的点,你会看到对应的TSQL在SQL事件探查器输出中也是突出显示的。 我相信你学会如何关联这两个工具的输出数据后,一定会觉得非常方便和有趣。 小结 诊断SQL Server性能问题的工具和技术有很多,例如查看SQL Server日志文件,利用调优顾问(DTA)获得调优建议,无论使用哪种工具,你都需要深入了解内部的细节原因,只有找出最根本的原因之后,解决性能问题才会得心应手。 本系列最后一篇将介绍如何优化数据文件和应用分区。 优化技巧主要是面向DBA的,但我认为即使是开发人员也应该掌握这些技巧,因为不是每个开发团队都配有专门的DBA的。 第九步:合理组织数据库文件组和文件 创建SQL Server数据库时,数据库服务器会自动在文件系统上创建一系列的文件,之后创建的每一个数据库对象实际上都是存储在这些文件中的。SQL Server有下面三种文件: 1).mdf文件 这是最主要的数据文件,每个数据库只能有一个主数据文件,所有系统对象都存储在主数据文件中,如果不创建次要数据文件,所有用户对象(用户创建的数据库对象)也都存储在主数据文件中。 2).ndf文件 这些都是次要数据文件,它们是可选的,它们存储的都是用户创建的对象。 3).ldf文件 这些是事务日志文件,数量从一到几个不等,它里面存储的是事务日志。 默认情况下,创建SQL Server数据库时会自动创建主数据文件和事务日志文件,当然也可以修改这两个文件的属性,如保存路径。 文件组 为了便于管理和获得更好的性能,数据文件通常都进行了合理的分组,创建一个新的SQL Server数据库时,会自动创建主文件组,主数据文件就包含在主文件组中,主文件组也被设为默认组,因此所有新创建的用户对象都自动存储在主文件组中(具体说就是存储在主数据文件中)。 如果你想将你的用户对象(表、视图、存储过程和函数等)存储在次要数据文件中,那需要: 1)创建一个新的文件组,并将其设为默认文件组; 2)创建一个新的数据文件(.ndf),将其归于第一步创建的新文件组中。 以后创建的对象就会全部存储在次要文件组中了。 注意:事务日志文件不属于任何文件组。 文件/文件组组织最佳实践 如果你的数据库不大,那么默认的文件/文件组应该就能满足你的需要,但如果你的数据库变得很大时(假设有1000MB),你可以(应该)对文件/文件组进行调整以获得更好的性能,调整文件/文件组的最佳实践内容如下: 1)主文件组必须完全独立,它里面应该只存储系统对象,所有的用户对象都不应该放在主文件组中。主文件组也不应该设为默认组,将系统对象和用户对象分开可以获得更好的性能; 2)如果有多块硬盘,可以将每个文件组中的每个文件分配到每块硬盘上,这样可以实现分布式磁盘I/O,大大提高数据读写速度; 3)将访问频繁的表及其索引放到一个单独的文件组中,这样读取表数据和索引都会更快; 4)将访问频繁的包含Text和Image数据类型的列的表放到一个单独的文件组中,最好将其中的Text和Image列数据放在一个独立的硬盘中,这样检索该表的非Text和Image列时速度就不会受Text和Image列的影响; 5)将事务日志文件放在一个独立的硬盘上,千万不要和数据文件共用一块硬盘,日志操作属于写密集型操作,因此保证日志写入具有良好的I/O性能非常重要; 6)将“只读”表单独放到一个独立的文件组中,同样,将“只写”表单独放到一个文件组中,这样只读表的检索速度会更快,只写表的更新速度也会更快; 7)不要过度使用SQL Server的“自动增长”特性,因为自动增长的成本其实是很高的,设置“自动增长”值为一个合适的值,如一周,同样,也不要过度频繁地使用“自动收缩”特性,最好禁用掉自动收缩,改为手工收缩数据库大小,或使用调度操作,设置一个合理的时间间隔,如一个月。 第十步:在大表上应用分区 什么是表分区? 表分区就是将大表拆分成多个小表,以免检索数据时扫描的数据太多,这个思想参考了“分而治之”的理论。 当你的数据库中有一个大表(假设有上百万行记录),如果其它优化技巧都用上了,但查询速度仍然非常慢时,你就应该考虑对这个表进行分区了。首先来看一下分区的类型: 水平分区:假设有一个表包括千万行记录,为了便于理解,假设表有一个自动增长的主键字段(如id),我们可以将表拆分成10个独立的分区表,每个分区包含100万行记录,分区就要依据id字段的值实施,即第一个分区包含id值从1-1000000的记录,第二个分区包含1000001-2000000的记录,以此类推。这种以水平方向分割表的方式就叫做水平分区。 垂直分区:假设有一个表的列数和行数都非常多,其中某些列被经常访问,其余的列不是经常访问。由于表非常大,所有检索操作都很慢,因此需要基于频繁访问的列进行分区,这样我们可以将这个大表拆分成多个小表,每个小表由大表的一部分列组成,这种垂直拆分表的方法就叫做垂直分区。 另一个垂直分区的原则是按有索引的列无索引列进行拆分,但这种分区法需要小心,因为如果任何查询都涉及到检索这两个分区,SQL引擎不得不连接这两个分区,那样的话性能反而会低。 本文主要对水平分区做一介绍。 分区最佳实践 1)将大表分区后,将每个分区放在一个独立的文件中,并将这个文件存放在独立的硬盘上,这样数据库引擎可以同时并行检索多块硬盘上的不同数据文件,提高并发读写速度; 2)对于历史数据,可以考虑基于历史数据的“年龄”进行分区,例如,假设表中存储的是订单数据,可以使用订单日期列作为分区的依据,如将每年的订单数据做成一个分区。 如何分区? 假设Order表中包含了四年(1999-2002)的订单数据,有上百万的记录,那如果要对这个表进行分区,采取的步骤如下: 1)添加文件组 使用下面的命令创建一个文件组: ALTER DATABASE OrderDB ADD FILEGROUP [1999] ALTER DATABASE OrderDB ADD FILE (NAME = N'1999', FILENAME = N'C:\OrderDB\1999.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP [1999] 通过上面的语句我们添加了一个文件组1999,然后增加了一个次要数据文件“C:\OrderDB\1999.ndf”到这个文件组中。 使用上面的命令再创建三个文件组2000,2001和2002,每个文件组存储一年的销售数据。 2)创建分区函数 分区函数是定义分界点的一个对象,使用下面的命令创建分区函数: CREATE PARTITION FUNCTION FNOrderDateRange (DateTime) AS RANGE LEFT FOR VALUES ('19991231', '20001231', '20011231') 上面的分区函数指定: DateTime<=1999/12/31的记录进入第一个分区; DateTime > 1999/12/31 且 <= 2000/12/31的记录进入第二个分区; DateTime > 2000/12/31 且 <= 2001/12/31的记录进入第三个分区; DateTime > 2001/12/31的记录进入第四个分区。 RANGE LEFT指定应该进入左边分区的边界值,例如小于或等于1999/12/31的值都应该进入第一个分区,下一个值就应该进入第二个分区了。如果使用RANGE RIGHT,边界值以及大于边界值的值都应该进入右边的分区,因此在这个例子中,边界值2000/12/31就应该进入第二个分区,小于这个边界值的值就应该进入第一个分区。 3)创建分区方案 通过分区方案在表/索引的分区和存储它们的文件组之间建立映射关系。创建分区方案的命令如下: CREATE PARTITION SCHEME OrderDatePScheme AS PARTITION FNOrderDateRange TO ([1999], [2000], [2001], [2002]) 在上面的命令中,我们指定了: 第一个分区应该进入1999文件组; 第二个分区就进入2000文件组; 第三个分区进入2001文件组; 第四个分区进入2002文件组。 4)在表上应用分区 至此,我们定义了必要的分区原则,现在需要做的就是给表分区了。首先使用DROP INDEX命令删除表上现有的聚集索引,通常主键上有聚集索引,如果是删除主键上的索引,还可以通过DROP CONSTRAINT删除主键来间接删除主键上的索引,如下面的命令删除PK_Orders主键: ALTER TABLE Orders DROP CONSTRAINT PK_Orders; 在分区方案上重新创建聚集索引,命令如下: CREATE UNIQUE CLUSTERED INDEX PK_Orders ON Orders(OrderDate) ON OrderDatePScheme (OrderDate) 假设OrderDate列的数据在表中是唯一的,表将基于分区方案OrderDatePScheme被分区,最终被分成四个小的部分,存放在四个文件组中。如果你对如何分区还有不清楚的地方,建议你去看看微软的官方文章“SQL Server 2005中的分区表和索引”(地址:http://msdn.microsoft.com/en-us/library/ms345146%28SQL.90%29.aspx)。 第十一步:使用TSQL模板更好地管理DBMS对象(额外的一步) 为了更好地管理DBMS对象(存储过程,函数,视图,触发器等),需要遵循一致的结构,但由于某些原因(主要是时间限制),我们未能维护一个一致的结构,因此后来遇到性能问题或其它原因需要重新调试这些代码时,那感觉就像是做噩梦。 为了帮助大家更好地管理DBMS对象,我创建了一些TSQL模板,利用这些模板你可以快速地开发出结构一致的DBMS对象。 如果你的团队有人专门负责检查团队成员编写的TSQL代码,在这些模板中专门有一个“审查”段落用来描写审查意见。 我提交几个常见的DBMS对象模板,它们是: Template_StoredProcedure.txt:存储过程模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_StoredProcedure.txt) Template_View.txt:视图模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_Trigger.txt) Template_Trigger.txt:触发器模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_ScalarFunction.txt) Template_ScalarFunction.txt:标量函数模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_TableValuedFunction.txt) emplate_TableValuedFunction.txt:表值函数模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_View.txt) 1)如何创建模板? 首先下载前面给出的模板代码,然打开SQL Server管理控制台,点击“查看”*“模板浏览器”; 点击“存储过程”节点,点击右键,在弹出的菜单中选择“新建”*“模板”,为模板取一个易懂的名字; 在新创建的模板上点击右键,选择“编辑”,在弹出的窗口中输入身份验证信息,点击“连接”; 连接成功后,在编辑器中打开下载的Template_StoredProcedure.txt,拷贝文件中的内容粘贴到新建的模板中,然后点击“保存”。 上面是创建一个存储过程模板的过程,创建其它DBMS对象过程类似。 2)如何使用模板? 创建好模板后,下面就演示如何使用模板了。 首先在模板浏览器中,双击刚刚创建的存储过程模板,弹出身份验证对话框,输入对应的身份信息,点击“连接”; 连接成功后,模板将会在编辑器中打开,变量将会赋上适当的值; 按Ctrl+Shift+M为模板指定值,如下图所示; 图 1 为模板参数指定值 点击“OK”,然后在SQL Server管理控制台中选择目标数据库,然后点击“执行”按钮; 如果一切顺利,存储过程就创建成功了。你可以根据上面的步骤创建其它DBMS对象。 小结 优化讲究的是一种“心态”,在优化数据库性能时,首先要相信性能问题总是可以解决的,然后就是结合经验和最佳实践努力进行优化,最重要的是要尽量预防性能问题的发生,在开发和部署期间,要利用一切可利用的技术和经验进行提前评估,千万不要等问题出现了才去想办法解决,在开发期间多花一个小时实施最佳实践,最后可能会给你节约上百小时的故障诊断和排除时间,要学会聪明地工作,而不是辛苦地工作!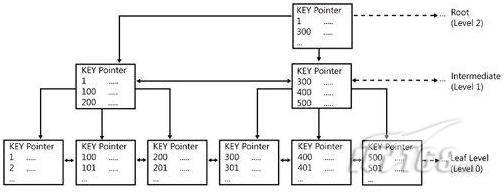
NCLIX_OrderDetails_ProductID ON
dbo.OrderDetails(ProductID)
ON dbo.Sales(ProductID)--Column on which index is to be created
INCLUDE(SalesDate, SalesPersonID)--Additional column values to include
IndexName,dt.avg_fragmentation_in_percent AS
ExternalFragmentation,dt.avg_page_space_used_in_percent AS
InternalFragmentation
FROM
(
SELECT object_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats (db_id('AdventureWorks'),null,null,null,'DETAILED'
)
WHERE index_id <> 0) AS dt INNER JOIN sys.indexes si ON si.object_id=dt.object_id
AND si.index_id=dt.index_id AND dt.avg_fragmentation_in_percent>10
AND dt.avg_page_space_used_in_percent<75 ORDER BY avg_fragmentation_in_percent DESC

smalltable.float_column = large_table.int_column
WHERE id = OBJECT_ID('dbo.Orders') AND indid < 2
@startYear DateTime,
@endYear DateTime,
@keyword nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
SELECT
Name,
ProductNumber,
ProductRates.CurrentProductRate Rate,
ProductRates.CurrentDiscount Discount,
OrderQty Qty,
dbo.ufnGetLineTotal(SalesOrderDetailID) Total,
OrderDate,
DetailedDescription
FROM
Products INNER JOIN OrderDetails
ON Products.ProductID = OrderDetails.ProductID
INNER JOIN Orders
ON Orders.SalesOrderID = OrderDetails.SalesOrderID
INNER JOIN ProductRates
ON
Products.ProductID = ProductRates.ProductID
WHERE
OrderDate between @startYear and @endYear
AND
(
ProductName LIKE '' + @keyword + ' %' OR
ProductName LIKE '% ' + @keyword + ' ' + '%' OR
ProductName LIKE '% ' + @keyword + '%' OR
Keyword LIKE '' + @keyword + ' %' OR
Keyword LIKE '% ' + @keyword + ' ' + '%' OR
Keyword LIKE '% ' + @keyword + '%'
)
ORDER BY
ProductName
END
GO
(
@SalesOrderDetailID int
)
RETURNS money
AS
BEGIN
DECLARE @CurrentProductRate money
DECLARE @CurrentDiscount money
DECLARE @Qty int
SELECT
@CurrentProductRate = ProductRates.CurrentProductRate,
@CurrentDiscount = ProductRates.CurrentDiscount,
@Qty = OrderQty
FROM
ProductRates INNER JOIN OrderDetails ON
OrderDetails.ProductID = ProductRates.ProductID
WHERE
OrderDetails.SalesOrderDetailID = @SalesOrderDetailID
RETURN (@CurrentProductRate-@CurrentDiscount)*@Qty
END
WITH SCHEMABINDING
AS
SELECT…
(
-- Add the parameters for the function here
@UnitPrice [money],
@UnitPriceDiscount [money],
@OrderQty [smallint]
)
RETURNS money
WITH SCHEMABINDING
AS
BEGIN
return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty))
END
(
-- Add the parameters for the function here
@UnitPrice [money],
@UnitPriceDiscount [money],
@OrderQty [smallint]
)
RETURNS money
WITH SCHEMABINDING
AS
BEGIN
return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty))
END
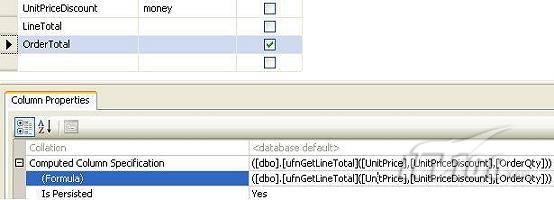
图 2 指定UDF为计算列的结算公式
index_name
ON <object> ( xml_column )
index_name
ON <object> ( xml_column )
USING XML INDEX primary_xml_index_name
FOR { VALUE | PATH | PROPERTY }
FROM OrderDetails INNER JOIN Products
ON OrderDetails.ProductID = Products.ProductID
WHERE SalesOrderID = 47057
FROM OrderDetails
WHERE SalesOrderID = 47057
Duration DESC



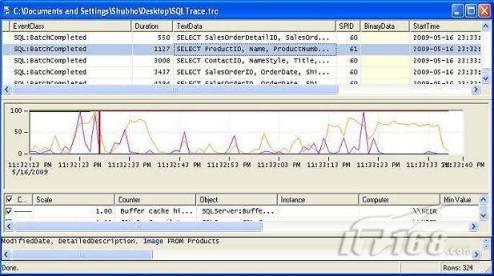
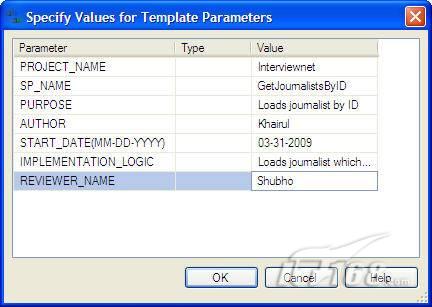


发表评论

相关推荐
SQLSERVER中实现跨服务器数据访问的几个方法
该文使用空间数据中间件技术实现在MapGIS K9平台上SQL Server空间数据的无缝集成。设计了MapGISK9和SQL Server空间...此外,这个中间件使用了缓存机制和空间索引来优化数据访问和操作的性能,大大提高了中间件的实用性。
例如,SQL Server中的`datetime`在SQLite中可能需要转换为`datetimeoffset`或`text`。工具需要进行这种类型转换,以确保数据能够正确存储和检索。 4. **SQL语句转换**:SQL Server的T-SQL语法与SQLite的SQL语法有...
在现代企业的数据处理场景中,SQL Server 作为一款广泛使用的数据库管理系统,其性能优化对于提高业务效率至关重要。特别是在面对大规模数据处理需求时,如何有效地优化SQL Server查询性能成为了一个核心议题。本文...
在 SQL Server 2005 中,创建一个数据库可以通过控制面板/管理工具/数据源(ODBC)来实现。首先,需要创建一个新的数据源,然后关联一个已创建的数据库。这样,Citect 就可以通过 ODBC 连接到 SQL Server 数据库。 ...
C#操作SQL Server中的Image类型数据 C#操作SQL Server中的Image类型数据 C#操作SQL Server中的Image类型数据 C#操作SQL Server中的Image类型数据 详细介绍请参考: ...
在SQL Server数据库管理中,有时我们需要将表中的数据导出为Insert语句,这在数据迁移、备份或测试环境中非常常见。"SQL Server表数据导出成Insert语句的工具"是一个专门为此目的设计的应用程序,它能帮助数据库管理...
标题中的“java jsp sqlserver数据表转移到oracle实例 源代码”表明这是一个关于使用Java和JSP技术,将SQL Server数据库中的数据表迁移至Oracle数据库的实际操作案例。这个过程通常涉及数据迁移、数据转换以及可能的...
如何通过Excel来获取SQLServer数据 方便对数据库中的某些数据取数!
在设备创建过程中,你需要指定数据类型,例如数值、字符串或布尔值,这些数据类型应该与SQL Server中的列类型相对应。然后,在表中选择要读取的特定列,这些列将成为OPC标签,可以在OPC客户端应用程序中访问。完成...
- SQL Server的链接服务器是一个数据访问技术,它允许SQL Server实例通过分布式查询和事务,访问其他异构数据库系统中的数据。 - 通过链接服务器,SQL Server可访问的数据库类型不限于SQL Server,还包括Oracle、...
将mysql数据库转换为sql server的数据库,或者将sql server数据库转换...这里介绍一个使用sql的mmc的方法 ,将sql server的数据转化为mysql的数据库,将源和目的反之,就可以将mysql的数据库转化为sql server的数据库。
Buffer Pool是SQL Server中最重要的内存区域,优化其大小可以显著提高性能。如果查询经常访问相同的数据集,增加Buffer Pool大小将减少磁盘I/O次数,加快查询速度。然而,过大的Buffer Pool可能导致频繁的页面替换,...
在Windows操作系统中,可以通过ODBC数据源管理器来配置新的数据源,选择适用于SQL Server的ODBC驱动,例如“SQL Server Native Client 10.0”(对应SQL Server 2008及更高版本),或者“SQL Server”(支持SQL ...
SQL Server Native Client 10.0 是微软推出的一款用于访问SQL Server数据库的客户端库,它在SQL Server 2005版本中首次引入,并在后续的SQL Server 2008中得到进一步增强。这个库提供了OLE DB供应商和ODBC驱动程序,...
此外,SQL Server 还提供了多种安全机制,包括Active Directory 模式、密钥版本、访问控制等。 数据虚拟化和机器学习 SQL Server 提供了数据虚拟化功能,可以将关系数据、HDFS 数据、CSV 数据等虚拟化为关系数据。...
对于远程访问和跨平台需求,我们可以使用SQL Server的Web版管理工具,如Azure Data Studio。它是一款轻量级且跨平台的工具,支持Windows、macOS和Linux,提供类似SSMS的功能,但更加专注于云和现代数据库工作流。...