- жµПиІИ: 149275 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еЄЭйГљ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2013-07 ( 1)
- 2013-03 ( 1)
- 2012-03 ( 1)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
jackchen0227пЉЪ
ж±ЧпЉМи∞Ґи∞ҐеХК
joj 1817: Triangle дЄЙиІТ嚥зЪДеИ§еЃЪ -
RootJпЉЪ
иЊУеЗЇжЧґеАЩж≤°жЬЙеЖЩпЉЪеПЈгАВгАВгАВ
joj 1817: Triangle дЄЙиІТ嚥зЪДеИ§еЃЪ -
jackchen0227пЉЪ
еЧѓеЖНжН°жН°гАВгАВ
дЄНеЄ¶жЛђеПЈзЪДеЫЫеИЩињРзЃЧ -
ruby_windyпЉЪ
дЄНжШѓе§ІдЇМеЃЮй™МиѓЊеЖЩзЪДдєИ...
дЄНеЄ¶жЛђеПЈзЪДеЫЫеИЩињРзЃЧ
жЭ•иЗ™http://blog.csdn.net/v_july_v/article/details/6685962пЉМжО®иНРv_july_vзЪДеНЪеЃҐеНБдЄГйБУжµЈйЗПжХ∞жНЃе§ДзРЖйЭҐиѓХйҐШдЄОBit-mapиѓ¶иІ£
дљЬиАЕпЉЪе∞Пж°•жµБж∞іпЉМredfox66пЉМJulyгАВ
жЦЗзЂ†жАІиі®пЉЪжХізРЖгАВ
еЙНи®А
¬†¬†¬† жЬђеНЪеЃҐеЖЕжЫЊзїПжХізРЖињЗжЬЙеЕ≥жµЈйЗПжХ∞жНЃе§ДзРЖзЪД10йБУйЭҐиѓХйҐШпЉИеНБйБУжµЈйЗПжХ∞жНЃе§ДзРЖйЭҐиѓХйҐШдЄОеНБдЄ™жЦєж≥Хе§ІжАїзїУ пЉЙпЉМж≠§жђ°йЩ§дЇЖйЗНе§НдЇЖдєЛеЙНзЪД10йБУйЭҐиѓХйҐШдєЛеРОпЉМйЗНжЦ∞е§ЪжХізРЖдЇЖ7йБУгАВдїЕдљЬеРДдљНеПВиАГпЉМдЄНдљЬеЃГзФ®гАВ
¬†¬†¬† еРМжЧґпЉМз®ЛеЇПеСШзЉЦз®ЛиЙЇжЬѓз≥їеИЧ е∞ЖйЗНжЦ∞еЉАеІЛеИЫдљЬпЉМзђђеНБдЄАзЂ†дї•еРОзЪДйГ®еИЖйҐШзЫЃжЭ•жЇРе∞ЖеПЦиЗ™дЄЛжЦЗдЄ≠зЪД17йБУжµЈйЗПжХ∞жНЃе§ДзРЖзЪДйЭҐиѓХйҐШгАВеЫ†дЄЇпЉМжИСдїђиІЙеЊЧпЉМдЄЛжЦЗзЪДжѓПдЄАйБУйЭҐиѓХйҐШйГљеАЉеЊЧйЗНжЦ∞жАЭиАГпЉМйЗНжЦ∞жЈ±з©ґдЄОе≠¶дє†гАВеЖНиАЕпЉМзЉЦз®ЛиЙЇжЬѓз≥їеИЧзЪДеЙНеНБзЂ†дєЯжШѓињЩдєИжЭ•зЪДгАВиЛ•жВ®жЬЙдїїдљХйЧЃйҐШжИЦеїЇиЃЃпЉМ搥ињОдЄНеРЭжМЗж≠£гАВи∞Ґи∞ҐгАВ
зђђдЄАйГ®еИЖгАБеНБдЇФйБУжµЈйЗПжХ∞жНЃе§ДзРЖйЭҐиѓХйҐШ
1. зїЩеЃЪaгАБbдЄ§дЄ™жЦЗдїґпЉМеРДе≠ШжФЊ50дЇњдЄ™urlпЉМжѓПдЄ™urlеРДеН†64е≠ЧиКВпЉМеЖЕе≠ШйЩРеИґжШѓ4GпЉМиЃ©дљ†жЙЊеЗЇaгАБbжЦЗдїґеЕ±еРМзЪДurlпЉЯ
¬†¬†¬† жЦєж°И1пЉЪеПѓдї•дЉ∞иЃ°жѓПдЄ™жЦЗдїґеЃЙзЪДе§Іе∞ПдЄЇ50G√Ч64=320GпЉМињЬињЬе§ІдЇОеЖЕе≠ШйЩРеИґзЪД4GгАВжЙАдї•дЄНеПѓиГље∞ЖеЕґеЃМеЕ®еК†иљљеИ∞еЖЕе≠ШдЄ≠е§ДзРЖгАВиАГиЩСйЗЗеПЦеИЖиАМж≤їдєЛзЪДжЦєж≥ХгАВ
- йБНеОЖжЦЗдїґaпЉМеѓєжѓПдЄ™urlж±ВеПЦ
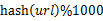 пЉМзДґеРОж†єжНЃжЙАеПЦеЊЧзЪДеАЉе∞ЖurlеИЖеИЂе≠ШеВ®еИ∞1000дЄ™е∞ПжЦЗдїґпЉИиЃ∞дЄЇ
пЉМзДґеРОж†єжНЃжЙАеПЦеЊЧзЪДеАЉе∞ЖurlеИЖеИЂе≠ШеВ®еИ∞1000дЄ™е∞ПжЦЗдїґпЉИиЃ∞дЄЇ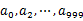 пЉЙдЄ≠гАВињЩж†ЈжѓПдЄ™е∞ПжЦЗдїґзЪДе§ІзЇ¶дЄЇ300MгАВ
пЉЙдЄ≠гАВињЩж†ЈжѓПдЄ™е∞ПжЦЗдїґзЪДе§ІзЇ¶дЄЇ300MгАВ - йБНеОЖжЦЗдїґbпЉМйЗЗеПЦеТМaзЫЄеРМзЪДжЦєеЉПе∞ЖurlеИЖеИЂе≠ШеВ®еИ∞1000е∞ПжЦЗдїґдЄ≠пЉИиЃ∞дЄЇ
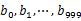 пЉЙгАВињЩж†Је§ДзРЖеРОпЉМжЙАжЬЙеПѓиГљзЫЄеРМзЪДurlйГљеЬ®еѓєеЇФзЪДе∞ПжЦЗдїґпЉИ
пЉЙгАВињЩж†Је§ДзРЖеРОпЉМжЙАжЬЙеПѓиГљзЫЄеРМзЪДurlйГљеЬ®еѓєеЇФзЪДе∞ПжЦЗдїґпЉИ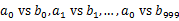 пЉЙдЄ≠пЉМдЄНеѓєеЇФзЪДе∞ПжЦЗдїґдЄНеПѓиГљжЬЙзЫЄеРМзЪДurlгАВзДґеРОжИСдїђеП™и¶Бж±ВеЗЇ1000еѓєе∞ПжЦЗдїґдЄ≠зЫЄеРМзЪДurlеН≥еПѓгАВ
пЉЙдЄ≠пЉМдЄНеѓєеЇФзЪДе∞ПжЦЗдїґдЄНеПѓиГљжЬЙзЫЄеРМзЪДurlгАВзДґеРОжИСдїђеП™и¶Бж±ВеЗЇ1000еѓєе∞ПжЦЗдїґдЄ≠зЫЄеРМзЪДurlеН≥еПѓгАВ - ж±ВжѓПеѓєе∞ПжЦЗдїґдЄ≠зЫЄеРМзЪДurlжЧґпЉМеПѓдї•жККеЕґдЄ≠дЄАдЄ™е∞ПжЦЗдїґзЪДurlе≠ШеВ®еИ∞hash_setдЄ≠гАВзДґеРОйБНеОЖеП¶дЄАдЄ™е∞ПжЦЗдїґзЪДжѓПдЄ™urlпЉМзЬЛеЕґжШѓеР¶еЬ®еИЪжЙНжЮДеїЇзЪДhash_setдЄ≠пЉМе¶ВжЮЬжШѓпЉМйВ£дєИе∞±жШѓеЕ±еРМзЪДurlпЉМе≠ШеИ∞жЦЗдїґйЗМйЭҐе∞±еПѓдї•дЇЖгАВ
¬†¬†¬† жЦєж°И2пЉЪе¶ВжЮЬеЕБиЃЄжЬЙдЄАеЃЪзЪДйФЩиѓѓзОЗпЉМеПѓдї•дљњзФ®Bloom filterпЉМ4GеЖЕе≠Ше§Іж¶ВеПѓдї•и°®з§Ї340дЇњbitгАВе∞ЖеЕґдЄ≠дЄАдЄ™жЦЗдїґдЄ≠зЪДurlдљњзФ®Bloom filterжШ†е∞ДдЄЇињЩ340дЇњbitпЉМзДґеРОжМ®дЄ™иѓїеПЦеП¶е§ЦдЄАдЄ™жЦЗдїґзЪДurlпЉМж£АжЯ•жШѓеР¶дЄОBloom filterпЉМе¶ВжЮЬжШѓпЉМйВ£дєИиѓ•urlеЇФиѓ•жШѓеЕ±еРМзЪДurlпЉИж≥®жДПдЉЪжЬЙдЄАеЃЪзЪДйФЩиѓѓзОЗпЉЙгАВ
¬†¬†¬† иѓїиАЕеПНй¶И @crowgnsпЉЪ
- hashеРОи¶БеИ§жЦ≠жѓПдЄ™жЦЗдїґе§Іе∞ПпЉМе¶ВжЮЬhashеИЖзЪДдЄНеЭЗи°°жЬЙжЦЗдїґиЊГе§ІпЉМињШеЇФзїІзї≠hashеИЖжЦЗдїґпЉМжНҐдЄ™hashзЃЧж≥ХзђђдЇМжђ°еЖНеИЖиЊГе§ІзЪДжЦЗдїґпЉМдЄАзЫіеИЖеИ∞ж≤°жЬЙиЊГе§ІзЪДжЦЗдїґдЄЇж≠ҐгАВињЩж†ЈжЦЗдїґж†ЗеПЈеПѓдї•зФ®A1-2и°®з§ЇпЉИзђђдЄАжђ°hashзЉЦеПЈдЄЇ1пЉМжЦЗдїґиЊГе§ІжЙАдї•еПВеК†зђђдЇМжђ°hashпЉМзЉЦеПЈдЄЇ2пЉЙ
- зФ± дЇО1е≠ШеЬ®пЉМзђђдЄАжђ°hashе¶ВжЮЬжЬЙе§ІжЦЗдїґпЉМдЄНиГљзФ®зЫіжО•setзЪДжЦєж≥ХгАВеїЇиЃЃеѓєжѓПдЄ™жЦЗдїґйГљеЕИзФ®е≠Чзђ¶дЄ≤иЗ™зДґй°ЇеЇПжОТеЇПпЉМзДґеРОеЕЈжЬЙзЫЄеРМhashзЉЦеПЈзЪДпЉИе¶ВйГљжШѓ1-3пЉМ иАМдЄНиГљaзЉЦеПЈжШѓ1пЉМbзЉЦеПЈжШѓ1-1еТМ1-2пЉЙпЉМеПѓдї•зЫіжО•дїОе§іеИ∞е∞ЊжѓФиЊГдЄАйБНгАВеѓєдЇОе±ВзЇІдЄНдЄАиЗізЪДпЉМе¶Вa1пЉМbжЬЙ1-1пЉМ1-2-1пЉМ1-2-2пЉМе±ВзЇІжµЕзЪДи¶БеТМ е±ВзЇІжЈ±зЪДжѓПдЄ™жЦЗдїґйГљжѓФиЊГдЄАжђ°пЉМжЙНиГљз°ЃиЃ§жѓПдЄ™зЫЄеРМзЪДuriгАВ
2. жЬЙ10дЄ™жЦЗдїґпЉМжѓПдЄ™жЦЗдїґ1GпЉМжѓПдЄ™жЦЗдїґзЪДжѓПдЄАи°Ме≠ШжФЊзЪДйГљжШѓзФ®жИЈзЪДqueryпЉМжѓПдЄ™жЦЗдїґзЪДqueryйГљеПѓиГљйЗНе§НгАВи¶Бж±Вдљ†жМЙзЕІqueryзЪДйҐСеЇ¶жОТеЇПгАВ
жЦєж°И1пЉЪ
- й°ЇеЇПиѓїеПЦ10дЄ™жЦЗдїґпЉМжМЙзЕІhash(query)%10зЪДзїУжЮЬе∞ЖqueryеЖЩеЕ•еИ∞еП¶е§Ц10дЄ™жЦЗдїґпЉИиЃ∞дЄЇ
 пЉЙдЄ≠гАВињЩж†ЈжЦ∞зФЯжИРзЪДжЦЗдїґжѓПдЄ™зЪДе§Іе∞Пе§ІзЇ¶дєЯ1GпЉИеБЗиЃЊhashеЗљжХ∞жШѓйЪПжЬЇзЪДпЉЙгАВ
пЉЙдЄ≠гАВињЩж†ЈжЦ∞зФЯжИРзЪДжЦЗдїґжѓПдЄ™зЪДе§Іе∞Пе§ІзЇ¶дєЯ1GпЉИеБЗиЃЊhashеЗљжХ∞жШѓйЪПжЬЇзЪДпЉЙгАВ - жЙЊдЄАеП∞еЖЕе≠ШеЬ®2GеЈ¶еП≥зЪДжЬЇеЩ®пЉМдЊЭжђ°еѓє
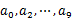 зФ®hash_map(query, query_count)жЭ•зїЯиЃ°жѓПдЄ™queryеЗЇзО∞зЪДжђ°жХ∞гАВеИ©зФ®ењЂйАЯ/е†Ж/ељТеєґжОТеЇПжМЙзЕІеЗЇзО∞жђ°жХ∞ињЫи°МжОТеЇПгАВе∞ЖжОТеЇПе•љзЪДqueryеТМеѓєеЇФзЪДquery_coutиЊУеЗЇеИ∞жЦЗдїґдЄ≠гАВињЩж†ЈеЊЧеИ∞дЇЖ10дЄ™жОТе•љеЇПзЪДжЦЗдїґпЉИиЃ∞дЄЇ
зФ®hash_map(query, query_count)жЭ•зїЯиЃ°жѓПдЄ™queryеЗЇзО∞зЪДжђ°жХ∞гАВеИ©зФ®ењЂйАЯ/е†Ж/ељТеєґжОТеЇПжМЙзЕІеЗЇзО∞жђ°жХ∞ињЫи°МжОТеЇПгАВе∞ЖжОТеЇПе•љзЪДqueryеТМеѓєеЇФзЪДquery_coutиЊУеЗЇеИ∞жЦЗдїґдЄ≠гАВињЩж†ЈеЊЧеИ∞дЇЖ10дЄ™жОТе•љеЇПзЪДжЦЗдїґпЉИиЃ∞дЄЇ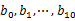 пЉЙгАВ
пЉЙгАВ - еѓє
 ињЩ10дЄ™жЦЗдїґињЫи°МељТеєґжОТеЇПпЉИеЖЕжОТеЇПдЄОе§ЦжОТеЇПзЫЄзїУеРИпЉЙгАВ
ињЩ10дЄ™жЦЗдїґињЫи°МељТеєґжОТеЇПпЉИеЖЕжОТеЇПдЄОе§ЦжОТеЇПзЫЄзїУеРИпЉЙгАВ
жЦєж°И2пЉЪ
¬†¬†¬† дЄАиИђqueryзЪДжАїйЗПжШѓжЬЙйЩРзЪДпЉМеП™жШѓйЗНе§НзЪДжђ°жХ∞жѓФиЊГе§ЪиАМеЈ≤пЉМеПѓиГљеѓєдЇОжЙАжЬЙзЪДqueryпЉМдЄАжђ°жАІе∞±еПѓдї•еК†еЕ•еИ∞еЖЕе≠ШдЇЖгАВињЩж†ЈпЉМжИСдїђе∞±еПѓдї•йЗЗзФ®trieж†С/hash_mapз≠ЙзЫіжО•жЭ•зїЯиЃ°жѓПдЄ™queryеЗЇзО∞зЪДжђ°жХ∞пЉМзДґеРОжМЙеЗЇзО∞жђ°жХ∞еБЪењЂйАЯ/е†Ж/ељТеєґжОТеЇПе∞±еПѓдї•дЇЖгАВ
жЦєж°И3пЉЪ
¬†¬†¬† дЄОжЦєж°И1з±їдЉЉпЉМдљЖеЬ®еБЪеЃМhashпЉМеИЖжИРе§ЪдЄ™жЦЗдїґеРОпЉМеПѓдї•дЇ§зїЩе§ЪдЄ™жЦЗдїґжЭ•е§ДзРЖпЉМйЗЗзФ®еИЖеЄГеЉПзЪДжЮґжЮДжЭ•е§ДзРЖпЉИжѓФе¶ВMapReduceпЉЙпЉМжЬАеРОеЖНињЫи°МеРИеєґгАВ
3. жЬЙдЄАдЄ™1Gе§Іе∞ПзЪДдЄАдЄ™жЦЗдїґпЉМйЗМйЭҐжѓПдЄАи°МжШѓдЄАдЄ™иѓНпЉМиѓНзЪДе§Іе∞ПдЄНиґЕињЗ16е≠ЧиКВпЉМеЖЕе≠ШйЩРеИґе§Іе∞ПжШѓ1MгАВињФеЫЮйҐСжХ∞жЬАйЂШзЪД100дЄ™иѓНгАВ
¬†¬†¬† жЦєж°И1пЉЪй°ЇеЇПиѓїжЦЗдїґдЄ≠пЉМеѓєдЇОжѓПдЄ™иѓНxпЉМеПЦ пЉМзДґеРОжМЙзЕІиѓ•еАЉе≠ШеИ∞5000дЄ™е∞ПжЦЗдїґпЉИиЃ∞дЄЇ
пЉМзДґеРОжМЙзЕІиѓ•еАЉе≠ШеИ∞5000дЄ™е∞ПжЦЗдїґпЉИиЃ∞дЄЇ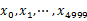 пЉЙ
дЄ≠гАВињЩж†ЈжѓПдЄ™жЦЗдїґе§Іж¶ВжШѓ200kеЈ¶еП≥гАВе¶ВжЮЬеЕґдЄ≠зЪДжЬЙзЪДжЦЗдїґиґЕињЗдЇЖ1Mе§Іе∞ПпЉМињШеПѓдї•жМЙзЕІз±їдЉЉзЪДжЦєж≥ХзїІзї≠еЊАдЄЛеИЖпЉМзЯ•йБУеИЖиІ£еЊЧеИ∞зЪДе∞ПжЦЗдїґзЪДе§Іе∞ПйГљдЄНиґЕињЗ1MгАВеѓє
жѓПдЄ™е∞ПжЦЗдїґпЉМзїЯиЃ°жѓПдЄ™жЦЗдїґдЄ≠еЗЇзО∞зЪДиѓНдї•еПКзЫЄеЇФзЪДйҐСзОЗпЉИеПѓдї•йЗЗзФ®trieж†С/hash_mapз≠ЙпЉЙпЉМеєґеПЦеЗЇеЗЇзО∞йҐСзОЗжЬАе§ІзЪД100дЄ™иѓНпЉИеПѓдї•зФ®еРЂ100дЄ™зїУзВє
зЪДжЬАе∞Пе†ЖпЉЙпЉМеєґжКК100иѓНеПКзЫЄеЇФзЪДйҐСзОЗе≠ШеЕ•жЦЗдїґпЉМињЩж†ЈеПИеЊЧеИ∞дЇЖ5000дЄ™жЦЗдїґгАВдЄЛдЄАж≠•е∞±жШѓжККињЩ5000дЄ™жЦЗдїґињЫи°МељТеєґпЉИз±їдЉЉдЄОељТеєґжОТеЇПпЉЙзЪДињЗз®ЛдЇЖгАВ
пЉЙ
дЄ≠гАВињЩж†ЈжѓПдЄ™жЦЗдїґе§Іж¶ВжШѓ200kеЈ¶еП≥гАВе¶ВжЮЬеЕґдЄ≠зЪДжЬЙзЪДжЦЗдїґиґЕињЗдЇЖ1Mе§Іе∞ПпЉМињШеПѓдї•жМЙзЕІз±їдЉЉзЪДжЦєж≥ХзїІзї≠еЊАдЄЛеИЖпЉМзЯ•йБУеИЖиІ£еЊЧеИ∞зЪДе∞ПжЦЗдїґзЪДе§Іе∞ПйГљдЄНиґЕињЗ1MгАВеѓє
жѓПдЄ™е∞ПжЦЗдїґпЉМзїЯиЃ°жѓПдЄ™жЦЗдїґдЄ≠еЗЇзО∞зЪДиѓНдї•еПКзЫЄеЇФзЪДйҐСзОЗпЉИеПѓдї•йЗЗзФ®trieж†С/hash_mapз≠ЙпЉЙпЉМеєґеПЦеЗЇеЗЇзО∞йҐСзОЗжЬАе§ІзЪД100дЄ™иѓНпЉИеПѓдї•зФ®еРЂ100дЄ™зїУзВє
зЪДжЬАе∞Пе†ЖпЉЙпЉМеєґжКК100иѓНеПКзЫЄеЇФзЪДйҐСзОЗе≠ШеЕ•жЦЗдїґпЉМињЩж†ЈеПИеЊЧеИ∞дЇЖ5000дЄ™жЦЗдїґгАВдЄЛдЄАж≠•е∞±жШѓжККињЩ5000дЄ™жЦЗдїґињЫи°МељТеєґпЉИз±їдЉЉдЄОељТеєґжОТеЇПпЉЙзЪДињЗз®ЛдЇЖгАВ
4. жµЈйЗПжЧ•ењЧжХ∞жНЃпЉМжПРеПЦеЗЇжЯРжЧ•иЃњйЧЃзЩЊеЇ¶жђ°жХ∞жЬАе§ЪзЪДйВ£дЄ™IPгАВ
¬†¬†¬† жЦєж°И1пЉЪй¶ЦеЕИжШѓињЩдЄА姩пЉМеєґдЄФжШѓиЃњйЧЃзЩЊеЇ¶зЪДжЧ•ењЧдЄ≠зЪДIPеПЦеЗЇжЭ•пЉМйАРдЄ™еЖЩеЕ•еИ∞дЄАдЄ™е§ІжЦЗдїґдЄ≠гАВж≥®жДПеИ∞IPжШѓ32дљНзЪДпЉМжЬАе§ЪжЬЙ2^32дЄ™IPгАВеРМж†ЈеПѓдї•йЗЗзФ®жШ†е∞ДзЪД жЦєж≥ХпЉМжѓФе¶Вж®°1000пЉМжККжХідЄ™е§ІжЦЗдїґжШ†е∞ДдЄЇ1000дЄ™е∞ПжЦЗдїґпЉМеЖНжЙЊеЗЇжѓПдЄ™е∞ПжЦЗдЄ≠еЗЇзО∞йҐСзОЗжЬАе§ІзЪДIPпЉИеПѓдї•йЗЗзФ®hash_mapињЫи°МйҐСзОЗзїЯиЃ°пЉМзДґеРОеЖНжЙЊеЗЇйҐС зОЗжЬАе§ІзЪДеЗ†дЄ™пЉЙеПКзЫЄеЇФзЪДйҐСзОЗгАВзДґеРОеЖНеЬ®ињЩ1000дЄ™жЬАе§ІзЪДIPдЄ≠пЉМжЙЊеЗЇйВ£дЄ™йҐСзОЗжЬАе§ІзЪДIPпЉМеН≥дЄЇжЙАж±ВгАВ
5. еЬ®2.5дЇњдЄ™жХіжХ∞дЄ≠жЙЊеЗЇдЄНйЗНе§НзЪДжХіжХ∞пЉМеЖЕе≠ШдЄНиґ≥дї•еЃєзЇ≥ињЩ2.5дЇњдЄ™жХіжХ∞гАВ
¬†¬†¬† жЦєж°И1пЉЪйЗЗзФ®2-BitmapпЉИжѓПдЄ™жХ∞еИЖйЕН2bitпЉМ00и°®з§ЇдЄНе≠ШеЬ®пЉМ01и°®з§ЇеЗЇзО∞дЄАжђ°пЉМ10и°®з§Їе§Ъжђ°пЉМ11жЧ†жДПдєЙпЉЙињЫи°МпЉМеЕ±йЬАеЖЕе≠Ш2^32*2bit=1GBеЖЕе≠ШпЉМињШеПѓдї•жО•еПЧгАВзДґеРОжЙЂжППињЩ2.5дЇњдЄ™жХіжХ∞пЉМжЯ•зЬЛBitmapдЄ≠зЫЄеѓєеЇФдљНпЉМе¶ВжЮЬжШѓ00еПШ01пЉМ01еПШ10пЉМ10дњЭжМБдЄНеПШгАВжЙАжППеЃМдЇЛеРОпЉМжЯ•зЬЛbitmapпЉМжККеѓєеЇФдљНжШѓ01зЪДжХіжХ∞иЊУеЗЇеН≥еПѓгАВ
¬†¬†¬† жЦєж°И2пЉЪдєЯеПѓйЗЗзФ®дЄКйҐШз±їдЉЉзЪДжЦєж≥ХпЉМињЫи°МеИТеИЖе∞ПжЦЗдїґзЪДжЦєж≥ХгАВзДґеРОеЬ®е∞ПжЦЗдїґдЄ≠жЙЊеЗЇдЄНйЗНе§НзЪДжХіжХ∞пЉМеєґжОТеЇПгАВзДґеРОеЖНињЫи°МељТеєґпЉМж≥®жДПеОїйЩ§йЗНе§НзЪДеЕГзі†гАВ
6. жµЈйЗПжХ∞жНЃеИЖеЄГеЬ®100еП∞зФµиДСдЄ≠пЉМжГ≥дЄ™еКЮж≥ХйЂШжХИзїЯиЃ°еЗЇињЩжЙєжХ∞жНЃзЪДTOP10гАВ
жЦєж°И1пЉЪ
- еЬ®жѓПеП∞зФµиДСдЄКж±ВеЗЇTOP10пЉМеПѓдї•йЗЗзФ®еМЕеРЂ10дЄ™еЕГзі†зЪДе†ЖеЃМжИРпЉИTOP10е∞ПпЉМзФ®жЬАе§Іе†ЖпЉМTOP10е§ІпЉМзФ®жЬАе∞Пе†ЖпЉЙгАВжѓФе¶Вж±ВTOP10е§ІпЉМжИСдїђй¶Ц еЕИеПЦеЙН10дЄ™еЕГзі†и∞ГжХіжИРжЬАе∞Пе†ЖпЉМе¶ВжЮЬеПСзО∞пЉМзДґеРОжЙЂжППеРОйЭҐзЪДжХ∞жНЃпЉМеєґдЄОе†Жй°ґеЕГзі†жѓФиЊГпЉМе¶ВжЮЬжѓФе†Жй°ґеЕГзі†е§ІпЉМйВ£дєИзФ®иѓ•еЕГзі†жЫњжНҐе†Жй°ґпЉМзДґеРОеЖНи∞ГжХідЄЇжЬАе∞Пе†ЖгАВжЬАеРОе†Ж дЄ≠зЪДеЕГзі†е∞±жШѓTOP10е§ІгАВ
- ж±ВеЗЇжѓПеП∞зФµиДСдЄКзЪДTOP10еРОпЉМзДґеРОжККињЩ100еП∞зФµиДСдЄКзЪДTOP10зїДеРИиµЈжЭ•пЉМеЕ±1000дЄ™жХ∞жНЃпЉМеЖНеИ©зФ®дЄКйЭҐз±їдЉЉзЪДжЦєж≥Хж±ВеЗЇTOP10е∞±еПѓдї•дЇЖгАВ
пЉИжЫіе§ЪеПѓдї•еПВиАГпЉЪзђђдЄЙзЂ†гАБеѓїжЙЊжЬАе∞ПзЪДkдЄ™жХ∞ пЉМдї•еПКзђђдЄЙзЂ†зї≠гАБTop KзЃЧж≥ХйЧЃйҐШ зЪДеЃЮзО∞ пЉЙ
7. жАОдєИеЬ®жµЈйЗПжХ∞жНЃдЄ≠жЙЊеЗЇйЗНе§Нжђ°жХ∞жЬАе§ЪзЪДдЄАдЄ™пЉЯ
¬†¬†¬† жЦєж°И1пЉЪеЕИеБЪhashпЉМзДґеРОж±Вж®°жШ†е∞ДдЄЇе∞ПжЦЗдїґпЉМж±ВеЗЇжѓПдЄ™е∞ПжЦЗдїґдЄ≠йЗНе§Нжђ°жХ∞жЬАе§ЪзЪДдЄАдЄ™пЉМеєґиЃ∞ељХйЗНе§Нжђ°жХ∞гАВзДґеРОжЙЊеЗЇдЄКдЄАж≠•ж±ВеЗЇзЪДжХ∞жНЃдЄ≠йЗНе§Нжђ°жХ∞жЬАе§ЪзЪДдЄАдЄ™е∞±жШѓжЙАж±ВпЉИеЕЈдљУеПВиАГеЙНйЭҐзЪДйҐШпЉЙгАВ
8. дЄКеНГдЄЗжИЦдЄКдЇњжХ∞жНЃпЉИжЬЙйЗНе§НпЉЙпЉМзїЯиЃ°еЕґдЄ≠еЗЇзО∞жђ°жХ∞жЬАе§ЪзЪДйТ±NдЄ™жХ∞жНЃгАВ
¬†¬†¬† жЦєж°И1пЉЪдЄКеНГдЄЗжИЦдЄКдЇњзЪДжХ∞жНЃпЉМзО∞еЬ®зЪДжЬЇеЩ®зЪДеЖЕе≠ШеЇФиѓ•иГље≠ШдЄЛгАВжЙАдї•иАГиЩСйЗЗзФ®hash_map/жРЬ糥дЇМеПЙж†С/зЇҐйїСж†Сз≠ЙжЭ•ињЫи°МзїЯиЃ°жђ°жХ∞гАВзДґеРОе∞±жШѓеПЦеЗЇеЙНNдЄ™еЗЇзО∞жђ°жХ∞жЬАе§ЪзЪДжХ∞жНЃдЇЖпЉМеПѓдї•зФ®зђђ6йҐШжПРеИ∞зЪДе†ЖжЬЇеИґеЃМжИРгАВ
9. 1000дЄЗе≠Чзђ¶дЄ≤пЉМеЕґдЄ≠жЬЙдЇЫжШѓйЗНе§НзЪДпЉМйЬАи¶БжККйЗНе§НзЪДеЕ®йГ®еОїжОЙпЉМдњЭзХЩж≤°жЬЙйЗНе§НзЪДе≠Чзђ¶дЄ≤гАВиѓЈжАОдєИиЃЊиЃ°еТМеЃЮзО∞пЉЯ
¬†¬†¬† жЦєж°И1пЉЪињЩйҐШзФ®trieж†СжѓФиЊГеРИйАВпЉМhash_mapдєЯеЇФиѓ•иГљи°МгАВ
10. дЄАдЄ™жЦЗжЬђжЦЗдїґпЉМе§ІзЇ¶жЬЙдЄАдЄЗи°МпЉМжѓПи°МдЄАдЄ™иѓНпЉМи¶Бж±ВзїЯиЃ°еЗЇеЕґдЄ≠жЬАйҐСзєБеЗЇзО∞зЪДеЙН10дЄ™иѓНпЉМиѓЈзїЩеЗЇжАЭжГ≥пЉМзїЩеЗЇжЧґйЧіе§НжЭВеЇ¶еИЖжЮРгАВ
¬†¬†¬† жЦєж°И1пЉЪињЩйҐШжШѓиАГиЩСжЧґйЧіжХИзОЗгАВзФ®trieж†СзїЯиЃ°жѓПдЄ™иѓНеЗЇзО∞зЪДжђ°жХ∞пЉМжЧґйЧіе§НжЭВеЇ¶жШѓO(n*le)пЉИleи°®з§ЇеНХиѓНзЪДеє≥еЗЖйХњеЇ¶пЉЙгАВзДґеРОжШѓжЙЊеЗЇеЗЇзО∞жЬАйҐСзєБзЪДеЙН10 дЄ™иѓНпЉМеПѓдї•зФ®е†ЖжЭ•еЃЮзО∞пЉМеЙНйЭҐзЪДйҐШдЄ≠еЈ≤зїПиЃ≤еИ∞дЇЖпЉМжЧґйЧіе§НжЭВеЇ¶жШѓO(n*lg10)гАВжЙАдї•жАїзЪДжЧґйЧіе§НжЭВеЇ¶пЉМжШѓO(n*le)дЄОO(n*lg10)дЄ≠иЊГе§ІзЪДеУ™дЄА дЄ™гАВ
11. дЄАдЄ™жЦЗжЬђжЦЗдїґпЉМжЙЊеЗЇеЙН10дЄ™зїПеЄЄеЗЇзО∞зЪДиѓНпЉМдљЖињЩжђ°жЦЗдїґжѓФиЊГйХњпЉМиѓіжШѓдЄКдЇњи°МжИЦеНБдЇњи°МпЉМжАїдєЛжЧ†ж≥ХдЄАжђ°иѓїеЕ•еЖЕе≠ШпЉМйЧЃжЬАдЉШиІ£гАВ
¬†¬†¬† жЦєж°И1пЉЪй¶ЦеЕИж†єжНЃзФ®hashеєґж±Вж®°пЉМе∞ЖжЦЗдїґеИЖиІ£дЄЇе§ЪдЄ™е∞ПжЦЗдїґпЉМеѓєдЇОеНХдЄ™жЦЗдїґеИ©зФ®дЄКйҐШзЪДжЦєж≥Хж±ВеЗЇжѓПдЄ™жЦЗдїґдїґдЄ≠10дЄ™жЬАеЄЄеЗЇзО∞зЪДиѓНгАВзДґеРОеЖНињЫи°МељТеєґе§ДзРЖпЉМжЙЊеЗЇжЬАзїИзЪД10дЄ™жЬАеЄЄеЗЇзО∞зЪДиѓНгАВ
12. 100wдЄ™жХ∞дЄ≠жЙЊеЗЇжЬАе§ІзЪД100дЄ™жХ∞гАВ
- ¬†¬†¬† жЦєж°И1пЉЪеЬ®еЙНйЭҐзЪДйҐШдЄ≠пЉМжИСдїђеЈ≤зїПжПРеИ∞дЇЖпЉМзФ®дЄАдЄ™еРЂ100дЄ™еЕГзі†зЪДжЬАе∞Пе†ЖеЃМжИРгАВе§НжЭВеЇ¶дЄЇO(100w*lg100)гАВ
- ¬†¬†¬† жЦєж°И2пЉЪйЗЗзФ®ењЂйАЯжОТеЇПзЪДжАЭжГ≥пЉМжѓПжђ°еИЖеЙ≤дєЛеРОеП™иАГиЩСжѓФиљіе§ІзЪДдЄАйГ®еИЖпЉМзЯ•йБУжѓФиљіе§ІзЪДдЄАйГ®еИЖеЬ®жѓФ100е§ЪзЪДжЧґеАЩпЉМйЗЗзФ®дЉ†зїЯжОТеЇПзЃЧж≥ХжОТеЇПпЉМеПЦеЙН100дЄ™гАВе§НжЭВеЇ¶дЄЇO(100w*100)гАВ
- ¬†¬†¬† жЦєж°И3пЉЪйЗЗзФ®е±АйГ®жЈШж±∞ж≥ХгАВйАЙеПЦеЙН100дЄ™еЕГзі†пЉМеєґжОТеЇПпЉМиЃ∞дЄЇеЇПеИЧLгАВзДґеРОдЄАжђ°жЙЂжППеЙ©дљЩзЪДеЕГзі†xпЉМдЄОжОТе•љеЇПзЪД100дЄ™еЕГзі†дЄ≠жЬАе∞ПзЪДеЕГзі†жѓФпЉМе¶ВжЮЬжѓФињЩдЄ™жЬАе∞ПзЪД и¶Бе§ІпЉМйВ£дєИжККињЩдЄ™жЬАе∞ПзЪДеЕГзі†еИ†йЩ§пЉМеєґжККxеИ©зФ®жПТеЕ•жОТеЇПзЪДжАЭжГ≥пЉМжПТеЕ•еИ∞еЇПеИЧLдЄ≠гАВдЊЭжђ°еЊ™зОѓпЉМзЯ•йБУжЙЂжППдЇЖжЙАжЬЙзЪДеЕГзі†гАВе§НжЭВеЇ¶дЄЇO(100w*100)гАВ
13. еѓїжЙЊзГ≠йЧ®жߕ胥пЉЪ
жРЬ糥еЉХжУОдЉЪйАЪињЗжЧ•ењЧжЦЗдїґжККзФ®жИЈжѓПжђ°ж£А糥䚜зФ®зЪДжЙАжЬЙж£А糥дЄ≤йГљиЃ∞ељХдЄЛжЭ•пЉМжѓПдЄ™жߕ胥дЄ≤зЪДйХњеЇ¶дЄЇ1-255е≠ЧиКВгАВеБЗиЃЊзЫЃеЙНжЬЙдЄАеНГдЄЗдЄ™иЃ∞ељХпЉМињЩдЇЫжߕ胥дЄ≤зЪДйЗНе§Н иѓїжѓФиЊГйЂШпЉМиЩљзДґжАїжХ∞жШѓ1еНГдЄЗпЉМдљЖжШѓе¶ВжЮЬеОїйЩ§йЗНе§НеТМпЉМдЄНиґЕињЗ3зЩЊдЄЗдЄ™гАВдЄАдЄ™жߕ胥дЄ≤зЪДйЗНе§НеЇ¶иґКйЂШпЉМиѓіжШОжߕ胥еЃГзЪДзФ®жИЈиґКе§ЪпЉМдєЯе∞±иґКзГ≠йЧ®гАВиѓЈдљ†зїЯиЃ°жЬАзГ≠йЧ®зЪД10дЄ™ жߕ胥дЄ≤пЉМи¶Бж±ВдљњзФ®зЪДеЖЕе≠ШдЄНиГљиґЕињЗ1GгАВ
(1) иѓЈжППињ∞дљ†иІ£еЖ≥ињЩдЄ™йЧЃйҐШзЪДжАЭиЈѓпЉЫ
(2) иѓЈзїЩеЗЇдЄїи¶БзЪДе§ДзРЖжµБз®ЛпЉМзЃЧж≥ХпЉМдї•еПКзЃЧж≥ХзЪДе§НжЭВеЇ¶гАВ
¬†¬†¬† жЦєж°И1пЉЪйЗЗзФ®trieж†СпЉМеЕ≥йФЃе≠ЧеЯЯе≠Шиѓ•жߕ胥дЄ≤еЗЇзО∞зЪДжђ°жХ∞пЉМж≤°жЬЙеЗЇзО∞дЄЇ0гАВжЬАеРОзФ®10дЄ™еЕГзі†зЪДжЬАе∞ПжО®жЭ•еѓєеЗЇзО∞йҐСзОЗињЫи°МжОТеЇПгАВ
14. дЄАеЕ±жЬЙNдЄ™жЬЇеЩ®пЉМжѓПдЄ™жЬЇеЩ®дЄКжЬЙNдЄ™жХ∞гАВжѓПдЄ™жЬЇеЩ®жЬАе§Ъе≠ШO(N)дЄ™жХ∞еєґеѓєеЃГдїђжУНдљЬгАВе¶ВдљХжЙЊеИ∞N^2дЄ™жХ∞дЄ≠зЪДдЄ≠жХ∞пЉЯ
¬†¬†¬† жЦєж°И1пЉЪеЕИе§ІдљУдЉ∞иЃ°дЄАдЄЛињЩдЇЫжХ∞зЪДиМГеЫіпЉМжѓФе¶ВињЩйЗМеБЗиЃЊињЩдЇЫжХ∞йГљжШѓ32дљНжЧ†зђ¶еПЈжХіжХ∞пЉИеЕ±жЬЙ2^32дЄ™пЉЙгАВжИСдїђжКК0еИ∞2^32-1зЪДжХіжХ∞еИТеИЖдЄЇNдЄ™иМГеЫіжЃµпЉМжѓПдЄ™ жЃµеМЕеРЂпЉИ2^32пЉЙ/NдЄ™жХіжХ∞гАВжѓФе¶ВпЉМзђђдЄАдЄ™жЃµдљН0еИ∞2^32/N-1пЉМзђђдЇМжЃµдЄЇпЉИ2^32пЉЙ/NеИ∞пЉИ2^32пЉЙ/N-1пЉМвА¶пЉМзђђNдЄ™жЃµдЄЇпЉИ2^32пЉЙ пЉИN-1пЉЙ/NеИ∞2^32-1гАВзДґеРОпЉМжЙЂжППжѓПдЄ™жЬЇеЩ®дЄКзЪДNдЄ™жХ∞пЉМжККе±ЮдЇОзђђдЄАдЄ™еМЇжЃµзЪДжХ∞жФЊеИ∞зђђдЄАдЄ™жЬЇеЩ®дЄКпЉМе±ЮдЇОзђђдЇМдЄ™еМЇжЃµзЪДжХ∞жФЊеИ∞зђђдЇМдЄ™жЬЇеЩ®дЄКпЉМвА¶пЉМе±ЮдЇОзђђ NдЄ™еМЇжЃµзЪДжХ∞жФЊеИ∞зђђNдЄ™жЬЇеЩ®дЄКгАВж≥®жДПињЩдЄ™ињЗз®ЛжѓПдЄ™жЬЇеЩ®дЄКе≠ШеВ®зЪДжХ∞еЇФиѓ•жШѓO(N)зЪДгАВдЄЛйЭҐжИСдїђдЊЭжђ°зїЯиЃ°жѓПдЄ™жЬЇеЩ®дЄКжХ∞зЪДдЄ™жХ∞пЉМдЄАжђ°зіѓеК†пЉМзЫіеИ∞жЙЊеИ∞зђђkдЄ™жЬЇеЩ®пЉМ еЬ®иѓ•жЬЇеЩ®дЄКзіѓеК†зЪДжХ∞е§ІдЇОжИЦз≠ЙдЇОпЉИN^2пЉЙ/2пЉМиАМеЬ®зђђk-1дЄ™жЬЇеЩ®дЄКзЪДзіѓеК†жХ∞е∞ПдЇОпЉИN^2пЉЙ/2пЉМеєґжККињЩдЄ™жХ∞иЃ∞дЄЇxгАВйВ£дєИжИСдїђи¶БжЙЊзЪДдЄ≠дљНжХ∞еЬ®зђђkдЄ™жЬЇеЩ® дЄ≠пЉМжОТеЬ®зђђпЉИN^2пЉЙ/2-xдљНгАВзДґеРОжИСдїђеѓєзђђkдЄ™жЬЇеЩ®зЪДжХ∞жОТеЇПпЉМеєґжЙЊеЗЇзђђпЉИN^2пЉЙ/2-xдЄ™жХ∞пЉМеН≥дЄЇжЙАж±ВзЪДдЄ≠дљНжХ∞зЪДе§НжЭВеЇ¶жШѓOпЉИN^2пЉЙзЪДгАВ
¬†¬†¬† жЦєж°И2пЉЪеЕИеѓєжѓПеП∞жЬЇеЩ®дЄКзЪДжХ∞ињЫи°МжОТеЇПгАВжОТе•љеЇПеРОпЉМжИСдїђйЗЗзФ®ељТеєґжОТеЇПзЪДжАЭжГ≥пЉМе∞ЖињЩNдЄ™жЬЇеЩ®дЄКзЪДжХ∞ељТеєґиµЈжЭ•еЊЧеИ∞жЬАзїИзЪДжОТеЇПгАВжЙЊеИ∞зђђпЉИN^2пЉЙ/2дЄ™дЊњжШѓжЙАж±ВгАВе§НжЭВеЇ¶жШѓOпЉИN^2*lgN^2пЉЙзЪДгАВ
15. жЬАе§ІйЧійЪЩйЧЃйҐШ
зїЩеЃЪnдЄ™еЃЮжХ∞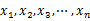 пЉМж±ВзЭАnдЄ™еЃЮжХ∞еЬ®еЃЮиљідЄКеРСйЗП2дЄ™жХ∞дєЛйЧізЪДжЬАе§ІеЈЃеАЉпЉМи¶Бж±ВзЇњжАІзЪДжЧґйЧізЃЧж≥ХгАВ
пЉМж±ВзЭАnдЄ™еЃЮжХ∞еЬ®еЃЮиљідЄКеРСйЗП2дЄ™жХ∞дєЛйЧізЪДжЬАе§ІеЈЃеАЉпЉМи¶Бж±ВзЇњжАІзЪДжЧґйЧізЃЧж≥ХгАВ
жЦєж°И1пЉЪжЬАеЕИжГ≥еИ∞зЪДжЦєж≥Хе∞±жШѓеЕИеѓєињЩnдЄ™жХ∞жНЃињЫи°МжОТеЇПпЉМзДґеРОдЄАйБНжЙЂжППеН≥еПѓз°ЃеЃЪзЫЄйВїзЪДжЬАе§ІйЧійЪЩгАВдљЖиѓ•жЦєж≥ХдЄНиГљжї°иґ≥зЇњжАІжЧґйЧізЪДи¶Бж±ВгАВжХЕйЗЗеПЦе¶ВдЄЛжЦєж≥ХпЉЪ
- жЙЊеИ∞nдЄ™жХ∞жНЃдЄ≠жЬАе§ІеТМжЬАе∞ПжХ∞жНЃmaxеТМminгАВ
- зФ®n-2дЄ™зВєз≠ЙеИЖеМЇйЧі[min, max]пЉМеН≥е∞Ж[min, max]з≠ЙеИЖдЄЇn-1дЄ™еМЇйЧіпЉИеЙНйЧ≠еРОеЉАеМЇйЧіпЉЙпЉМе∞ЖињЩдЇЫеМЇйЧізЬЛдљЬж°ґпЉМзЉЦеПЈдЄЇ
 пЉМдЄФж°ґi зЪДдЄКзХМеТМж°ґi+1зЪДдЄЛе±КзЫЄеРМпЉМеН≥жѓПдЄ™ж°ґзЪДе§Іе∞ПзЫЄеРМгАВжѓПдЄ™ж°ґзЪДе§Іе∞ПдЄЇпЉЪ
пЉМдЄФж°ґi зЪДдЄКзХМеТМж°ґi+1зЪДдЄЛе±КзЫЄеРМпЉМеН≥жѓПдЄ™ж°ґзЪДе§Іе∞ПзЫЄеРМгАВжѓПдЄ™ж°ґзЪДе§Іе∞ПдЄЇпЉЪ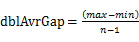 гАВеЃЮйЩЕдЄКпЉМињЩдЇЫж°ґзЪДиЊєзХМжЮДжИРдЇЖдЄАдЄ™з≠ЙеЈЃжХ∞еИЧпЉИй¶Цй°єдЄЇminпЉМеЕђеЈЃдЄЇ
гАВеЃЮйЩЕдЄКпЉМињЩдЇЫж°ґзЪДиЊєзХМжЮДжИРдЇЖдЄАдЄ™з≠ЙеЈЃжХ∞еИЧпЉИй¶Цй°єдЄЇminпЉМеЕђеЈЃдЄЇ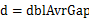 пЉЙпЉМдЄФиЃ§дЄЇе∞ЖminжФЊеЕ•зђђдЄАдЄ™ж°ґпЉМе∞ЖmaxжФЊеЕ•зђђn-1дЄ™ж°ґгАВ
пЉЙпЉМдЄФиЃ§дЄЇе∞ЖminжФЊеЕ•зђђдЄАдЄ™ж°ґпЉМе∞ЖmaxжФЊеЕ•зђђn-1дЄ™ж°ґгАВ - е∞ЖnдЄ™жХ∞жФЊеЕ•n-1дЄ™ж°ґдЄ≠пЉЪе∞ЖжѓПдЄ™еЕГзі†x[i] еИЖйЕНеИ∞жЯРдЄ™ж°ґпЉИзЉЦеПЈдЄЇindexпЉЙпЉМеЕґдЄ≠
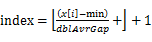 пЉМеєґж±ВеЗЇеИЖеИ∞жѓПдЄ™ж°ґзЪДжЬАе§ІжЬАе∞ПжХ∞жНЃгАВ
пЉМеєґж±ВеЗЇеИЖеИ∞жѓПдЄ™ж°ґзЪДжЬАе§ІжЬАе∞ПжХ∞жНЃгАВ - жЬА е§ІйЧійЪЩпЉЪйЩ§жЬАе§ІжЬАе∞ПжХ∞жНЃmaxеТМminдї•е§ЦзЪДn-2дЄ™жХ∞жНЃжФЊеЕ•n-1дЄ™ж°ґдЄ≠пЉМзФ±жКље±ЙеОЯзРЖеПѓзЯ•иЗ≥е∞СжЬЙдЄАдЄ™ж°ґжШѓз©ЇзЪДпЉМеПИеЫ†дЄЇжѓПдЄ™ж°ґзЪДе§Іе∞ПзЫЄеРМпЉМжЙАдї•жЬАе§ІйЧійЪЩдЄН дЉЪеЬ®еРМдЄАж°ґдЄ≠еЗЇзО∞пЉМдЄАеЃЪжШѓжЯРдЄ™ж°ґзЪДдЄКзХМеТМж∞ФеАЩжЯРдЄ™ж°ґзЪДдЄЛзХМдєЛйЧійЪЩпЉМдЄФиѓ•йЗПз≠ТдєЛйЧізЪДж°ґпЉИеН≥дЊње•љеЬ®иѓ•ињЮдЄ™дЊње•љдєЛйЧізЪДж°ґпЉЙдЄАеЃЪжШѓз©Їж°ґгАВдєЯе∞±жШѓиѓіпЉМжЬАе§ІйЧійЪЩеЬ®ж°ґi зЪДдЄКзХМеТМж°ґjзЪДдЄЛзХМдєЛйЧідЇІзФЯj>=i+1гАВдЄАйБНжЙЂжППеН≥еПѓеЃМжИРгАВ
16. е∞Же§ЪдЄ™йЫЖеРИеРИеєґжИРж≤°жЬЙдЇ§йЫЖзЪДйЫЖеРИ
¬†¬†¬† зїЩеЃЪдЄАдЄ™е≠Чзђ¶дЄ≤зЪДйЫЖеРИпЉМж†ЉеЉПе¶ВпЉЪ гАВи¶Бж±Ве∞ЖеЕґдЄ≠дЇ§йЫЖдЄНдЄЇз©ЇзЪДйЫЖеРИеРИеєґпЉМи¶Бж±ВеРИеєґеЃМжИРзЪДйЫЖеРИдєЛйЧіжЧ†дЇ§йЫЖпЉМдЊЛе¶ВдЄКдЊЛеЇФиЊУеЗЇ
гАВи¶Бж±Ве∞ЖеЕґдЄ≠дЇ§йЫЖдЄНдЄЇз©ЇзЪДйЫЖеРИеРИеєґпЉМи¶Бж±ВеРИеєґеЃМжИРзЪДйЫЖеРИдєЛйЧіжЧ†дЇ§йЫЖпЉМдЊЛе¶ВдЄКдЊЛеЇФиЊУеЗЇ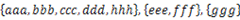 гАВ
гАВ
(1) иѓЈжППињ∞дљ†иІ£еЖ≥ињЩдЄ™йЧЃйҐШзЪДжАЭиЈѓпЉЫ
(2) зїЩеЗЇдЄїи¶БзЪДе§ДзРЖжµБз®ЛпЉМзЃЧж≥ХпЉМдї•еПКзЃЧж≥ХзЪДе§НжЭВеЇ¶пЉЫ
(3) иѓЈжППињ∞еПѓиГљзЪДжФєињЫгАВ
¬†¬†¬† жЦєж°И1пЉЪйЗЗзФ®еєґжЯ•йЫЖгАВй¶ЦеЕИжЙАжЬЙзЪДе≠Чзђ¶дЄ≤йГљеЬ®еНХзЛђзЪДеєґжЯ•йЫЖдЄ≠гАВзДґеРОдЊЭжЙЂжППжѓПдЄ™йЫЖеРИпЉМй°ЇеЇПеРИеєґе∞ЖдЄ§дЄ™зЫЄйВїеЕГзі†еРИеєґгАВдЊЛе¶ВпЉМеѓєдЇО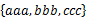 пЉМ
й¶ЦеЕИжЯ•зЬЛaaaеТМbbbжШѓеР¶еЬ®еРМдЄАдЄ™еєґжЯ•йЫЖдЄ≠пЉМе¶ВжЮЬдЄНеЬ®пЉМйВ£дєИжККеЃГдїђжЙАеЬ®зЪДеєґжЯ•йЫЖеРИеєґпЉМзДґеРОеЖНзЬЛbbbеТМcccжШѓеР¶еЬ®еРМдЄАдЄ™еєґжЯ•йЫЖдЄ≠пЉМе¶ВжЮЬдЄНеЬ®пЉМйВ£дєИдєЯжКК
еЃГдїђжЙАеЬ®зЪДеєґжЯ•йЫЖеРИеєґгАВжО•дЄЛжЭ•еЖНжЙЂжППеЕґдїЦзЪДйЫЖеРИпЉМељУжЙАжЬЙзЪДйЫЖеРИйГљжЙЂжППеЃМдЇЖпЉМеєґжЯ•йЫЖдї£и°®зЪДйЫЖеРИдЊњжШѓжЙАж±ВгАВе§НжЭВеЇ¶еЇФиѓ•жШѓO(NlgN)зЪДгАВжФєињЫзЪДиѓЭпЉМй¶ЦеЕИеПѓдї•
иЃ∞ељХжѓПдЄ™иКВзВєзЪДж†єзїУзВєпЉМжФєињЫжߕ胥гАВеРИеєґзЪДжЧґеАЩпЉМеПѓдї•жККе§ІзЪДеТМе∞ПзЪДињЫи°МеРИпЉМињЩж†ЈдєЯеЗПе∞Се§НжЭВеЇ¶гАВ
пЉМ
й¶ЦеЕИжЯ•зЬЛaaaеТМbbbжШѓеР¶еЬ®еРМдЄАдЄ™еєґжЯ•йЫЖдЄ≠пЉМе¶ВжЮЬдЄНеЬ®пЉМйВ£дєИжККеЃГдїђжЙАеЬ®зЪДеєґжЯ•йЫЖеРИеєґпЉМзДґеРОеЖНзЬЛbbbеТМcccжШѓеР¶еЬ®еРМдЄАдЄ™еєґжЯ•йЫЖдЄ≠пЉМе¶ВжЮЬдЄНеЬ®пЉМйВ£дєИдєЯжКК
еЃГдїђжЙАеЬ®зЪДеєґжЯ•йЫЖеРИеєґгАВжО•дЄЛжЭ•еЖНжЙЂжППеЕґдїЦзЪДйЫЖеРИпЉМељУжЙАжЬЙзЪДйЫЖеРИйГљжЙЂжППеЃМдЇЖпЉМеєґжЯ•йЫЖдї£и°®зЪДйЫЖеРИдЊњжШѓжЙАж±ВгАВе§НжЭВеЇ¶еЇФиѓ•жШѓO(NlgN)зЪДгАВжФєињЫзЪДиѓЭпЉМй¶ЦеЕИеПѓдї•
иЃ∞ељХжѓПдЄ™иКВзВєзЪДж†єзїУзВєпЉМжФєињЫжߕ胥гАВеРИеєґзЪДжЧґеАЩпЉМеПѓдї•жККе§ІзЪДеТМе∞ПзЪДињЫи°МеРИпЉМињЩж†ЈдєЯеЗПе∞Се§НжЭВеЇ¶гАВ
17. жЬАе§Іе≠РеЇПеИЧдЄОжЬАе§Іе≠РзЯ©йШµйЧЃйҐШ
жХ∞зїДзЪДжЬАе§Іе≠РеЇПеИЧйЧЃйҐШпЉЪзїЩеЃЪдЄАдЄ™жХ∞зїДпЉМеЕґдЄ≠еЕГзі†жЬЙж≠£пЉМдєЯжЬЙиіЯпЉМжЙЊеЗЇеЕґдЄ≠дЄАдЄ™ињЮзї≠е≠РеЇПеИЧпЉМдљњеТМжЬАе§ІгАВ
¬†¬†¬† жЦєж°И1пЉЪињЩдЄ™йЧЃйҐШеПѓдї•еК®жАБиІДеИТзЪДжАЭжГ≥иІ£еЖ≥гАВиЃЊb[i]и°®з§Їдї•зђђiдЄ™еЕГзі†a[i]зїУе∞ЊзЪДжЬАе§Іе≠РеЇПеИЧпЉМйВ£дєИжШЊзДґ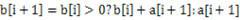 гАВеЯЇдЇОињЩдЄАзВєеПѓдї•еЊИењЂзФ®дї£з†БеЃЮзО∞гАВ
гАВеЯЇдЇОињЩдЄАзВєеПѓдї•еЊИењЂзФ®дї£з†БеЃЮзО∞гАВ
жЬАе§Іе≠РзЯ©йШµйЧЃйҐШпЉЪзїЩеЃЪдЄАдЄ™зЯ©йШµпЉИдЇМзїіжХ∞зїДпЉЙпЉМеЕґдЄ≠жХ∞жНЃжЬЙе§ІжЬЙе∞ПпЉМиѓЈжЙЊдЄАдЄ™е≠РзЯ©йШµпЉМдљњеЊЧе≠РзЯ©йШµзЪДеТМжЬАе§ІпЉМеєґиЊУеЗЇињЩдЄ™еТМгАВ
¬†¬†¬† жЦєж°И2пЉЪеПѓдї•йЗЗзФ®дЄОжЬАе§Іе≠РеЇПеИЧз±їдЉЉзЪДжАЭжГ≥жЭ•иІ£еЖ≥гАВе¶ВжЮЬжИСдїђз°ЃеЃЪдЇЖйАЙжЛ©зђђiеИЧеТМзђђjеИЧдєЛйЧізЪДеЕГзі†пЉМйВ£дєИеЬ®ињЩдЄ™иМГеЫіеЖЕпЉМеЕґеЃЮе∞±жШѓдЄАдЄ™жЬАе§Іе≠РеЇПеИЧйЧЃйҐШгАВе¶ВдљХз°ЃеЃЪзђђiеИЧеТМзђђjеИЧеПѓдї•иѓНзФ®жЪіжРЬзЪДжЦєж≥ХињЫи°МгАВ
 
зђђдЇМйГ®еИЖгАБжµЈйЗПжХ∞жНЃе§ДзРЖдєЛBti-mapиѓ¶иІ£
¬†¬†¬† Bloom FilterеЈ≤еЬ®дЄКдЄАзѓЗжЦЗзЂ†жµЈйЗПжХ∞жНЃе§ДзРЖдєЛBloom Filterиѓ¶иІ£ дЄ≠дЇИдї•иѓ¶зїЖйШРињ∞пЉМжЬђжЦЗжО•дЄЛжЭ•зЭАйЗНйШРињ∞Bit-mapгАВжЬЙдїїдљХйЧЃйҐШпЉМ搥ињОдЄНеРЭжМЗж≠£гАВ
дїАдєИжШѓBit-map
¬†¬†¬† жЙАи∞УзЪДBit-mapе∞±жШѓзФ®дЄАдЄ™bitдљНжЭ•ж†ЗиЃ∞жЯРдЄ™еЕГзі†еѓєеЇФзЪДValueпЉМ иАМKeyеН≥жШѓиѓ•еЕГзі†гАВзФ±дЇОйЗЗзФ®дЇЖBitдЄЇеНХдљНжЭ•е≠ШеВ®жХ∞жНЃпЉМеЫ†ж≠§еЬ®е≠ШеВ®з©ЇйЧіжЦєйЭҐпЉМеПѓдї•е§Іе§ІиКВзЬБгАВ
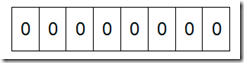
¬†¬†¬† е¶ВжЮЬиѓідЇЖињЩдєИе§ЪињШж≤°жШОзЩљдїАдєИжШѓBit-mapпЉМйВ£дєИжИСдїђжЭ•зЬЛдЄАдЄ™еЕЈдљУзЪДдЊЛе≠РпЉМеБЗиЃЊжИСдїђи¶Беѓє0-7еЖЕзЪД5дЄ™еЕГзі†(4,7,2,5,3)жОТеЇПпЉИињЩйЗМеБЗиЃЊињЩдЇЫеЕГ зі†ж≤°жЬЙйЗНе§НпЉЙгАВйВ£дєИжИСдїђе∞±еПѓдї•йЗЗзФ®Bit-mapзЪДжЦєж≥ХжЭ•иЊЊеИ∞жОТеЇПзЪДзЫЃзЪДгАВи¶Би°®з§Ї8дЄ™жХ∞пЉМжИСдїђе∞±еП™йЬАи¶Б8дЄ™BitпЉИ1BytesпЉЙпЉМй¶ЦеЕИжИСдїђеЉАиЊЯ 1ByteзЪДз©ЇйЧіпЉМе∞ЖињЩдЇЫз©ЇйЧізЪДжЙАжЬЙBitдљНйГљзљЃдЄЇ0(е¶ВдЄЛеЫЊпЉЪ)
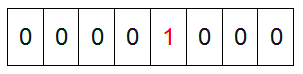
¬†¬†¬† зДґеРОйБНеОЖињЩ5дЄ™еЕГзі†пЉМй¶ЦеЕИзђђдЄАдЄ™еЕГзі†жШѓ4пЉМйВ£дєИе∞±жКК4еѓєеЇФзЪДдљНзљЃдЄЇ1пЉИеПѓдї•ињЩж†ЈжУНдљЬ p+(i/8)|(0√Ч01<<(i%8)) ељУзДґдЇЖињЩйЗМзЪДжУНдљЬжґЙеПКеИ∞Big-endingеТМLittle-endingзЪДжГЕеЖµпЉМињЩйЗМйїШиЃ§дЄЇBig-endingпЉЙ,еЫ†дЄЇжШѓдїОйЫґеЉАеІЛзЪДпЉМжЙАдї•и¶БжККзђђдЇФдљН зљЃдЄЇдЄАпЉИе¶ВдЄЛеЫЊпЉЙпЉЪ
     
зДґеРОеЖНе§ДзРЖзђђдЇМдЄ™еЕГзі†7пЉМе∞ЖзђђеЕЂдљНзљЃдЄЇ1,пЉМжО•зЭАеЖНе§ДзРЖзђђдЄЙдЄ™еЕГзі†пЉМдЄАзЫіеИ∞жЬАеРОе§ДзРЖеЃМжЙАжЬЙзЪДеЕГзі†пЉМе∞ЖзЫЄеЇФзЪДдљНзљЃдЄЇ1пЉМињЩжЧґеАЩзЪДеЖЕе≠ШзЪДBitдљНзЪДзКґжАБе¶ВдЄЛпЉЪ
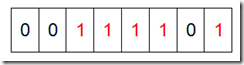
зДґеРОжИСдїђзО∞еЬ®йБНеОЖдЄАйБНBitеМЇеЯЯпЉМе∞Жиѓ•дљНжШѓдЄАзЪДдљНзЪДзЉЦеПЈиЊУеЗЇпЉИ2пЉМ3пЉМ4пЉМ5пЉМ7пЉЙпЉМињЩж†Је∞±иЊЊеИ∞дЇЖжОТеЇПзЪДзЫЃзЪДгАВдЄЛйЭҐзЪДдї£з†БзїЩеЗЇдЇЖдЄАдЄ™BitMapзЪДзФ®ж≥ХпЉЪжОТеЇПгАВ
//еЃЪдєЙжѓПдЄ™ByteдЄ≠жЬЙ8дЄ™BitдљН
#include пЉЬmemory.hпЉЮ
#define BYTESIZE 8
void SetBit(char *p, int posi)
{
for(int i=0; i пЉЬ (posi/BYTESIZE); i++)
{
p++;
}
*p = *p|(0x01пЉЬпЉЬ(posi%BYTESIZE));//е∞Жиѓ•BitдљНиµЛеАЉ1
return;
}
void BitMapSortDemo()
{
//дЄЇдЇЖзЃАеНХиµЈиІБпЉМжИСдїђдЄНиАГиЩСиіЯжХ∞
int num[] = {3,5,2,10,6,12,8,14,9};
//BufferLenињЩдЄ™еАЉжШѓж†єжНЃеЊЕжОТеЇПзЪДжХ∞жНЃдЄ≠жЬАе§ІеАЉз°ЃеЃЪзЪД
//еЊЕжОТеЇПдЄ≠зЪДжЬАе§ІеАЉжШѓ14пЉМеЫ†ж≠§еП™йЬАи¶Б2дЄ™Bytes(16дЄ™Bit)
//е∞±еПѓдї•дЇЖгАВ
const int BufferLen = 2;
char *pBuffer = new char[BufferLen];
//и¶Бе∞ЖжЙАжЬЙзЪДBitдљНзљЃдЄЇ0пЉМеР¶еИЩзїУжЮЬдЄНеПѓйҐДзЯ•гАВ
memset(pBuffer,0,BufferLen);
for(int i=0;iпЉЬ9;i++)
{
//й¶ЦеЕИе∞ЖзЫЄеЇФBitдљНдЄКзљЃдЄЇ1
SetBit(pBuffer,num[i]);
}
//иЊУеЗЇжОТеЇПзїУжЮЬ
for(int i=0;iпЉЬBufferLen;i++)//жѓПжђ°е§ДзРЖдЄАдЄ™е≠ЧиКВ(Byte)
{
for(int j=0;jпЉЬBYTESIZE;j++)//е§ДзРЖиѓ•е≠ЧиКВдЄ≠зЪДжѓПдЄ™BitдљН
{
//еИ§жЦ≠иѓ•дљНдЄКжШѓеР¶жШѓ1пЉМињЫи°МиЊУеЗЇпЉМињЩйЗМзЪДеИ§жЦ≠жѓФиЊГзђ®гАВ
//й¶ЦеЕИеЊЧеИ∞иѓ•зђђjдљНзЪДжО©з†БпЉИ0x01пЉЬпЉЬjпЉЙпЉМе∞ЖеЖЕе≠ШеМЇдЄ≠зЪД
//дљНеТМж≠§жО©з†БдљЬдЄОжУНдљЬгАВжЬАеРОеИ§жЦ≠жО©з†БжШѓеР¶еТМе§ДзРЖеРОзЪД
//зїУжЮЬзЫЄеРМ
if((*pBuffer&(0x01пЉЬпЉЬj)) == (0x01пЉЬпЉЬj))
{
printf("%d ",i*BYTESIZE + j);
}
}
pBuffer++;
}
}
int _tmain(int argc, _TCHAR* argv[])
{
BitMapSortDemo();
return 0;
}
¬†еПѓињЫи°МжХ∞жНЃзЪДењЂйАЯжЯ•жЙЊпЉМеИ§йЗНпЉМеИ†йЩ§пЉМдЄАиИђжЭ•иѓіжХ∞жНЃиМГеЫіжШѓintзЪД10еАНдї•дЄЛ
еЯЇжЬђеОЯзРЖеПКи¶БзВє
дљњзФ®bitжХ∞зїДжЭ•и°®з§ЇжЯРдЇЫеЕГзі†жШѓеР¶е≠ШеЬ®пЉМжѓФе¶В8дљНзФµиѓЭеПЈз†Б
жЙ©е±Х
Bloom filterеПѓдї•зЬЛеБЪжШѓеѓєbit-mapзЪДжЙ©е±ХпЉИеЕ≥дЇОBloom filterпЉМиѓЈеПВиІБпЉЪжµЈйЗПжХ∞жНЃе§ДзРЖдєЛBloom filter иѓ¶иІ£ пЉЙгАВ
йЧЃйҐШеЃЮдЊЛ
1)еЈ≤зЯ•жЯРдЄ™жЦЗдїґеЖЕеМЕеРЂдЄАдЇЫзФµиѓЭеПЈз†БпЉМжѓПдЄ™еПЈз†БдЄЇ8дљНжХ∞е≠ЧпЉМзїЯиЃ°дЄНеРМеПЈз†БзЪДдЄ™жХ∞гАВ
¬†¬†¬† 8дљНжЬАе§Ъ99 999 999пЉМе§Іж¶ВйЬАи¶Б99mдЄ™bitпЉМе§Іж¶В10еЗ†mе≠ЧиКВзЪДеЖЕе≠ШеН≥еПѓгАВ пЉИеПѓдї•зРЖиІ£дЄЇдїО0-99 999 999зЪДжХ∞е≠ЧпЉМжѓПдЄ™жХ∞е≠ЧеѓєеЇФдЄАдЄ™BitдљНпЉМжЙАдї•еП™йЬАи¶Б99MдЄ™Bit==1.2MBytesпЉМињЩж†ЈпЉМе∞±зФ®дЇЖе∞Пе∞ПзЪД1.2MеЈ¶еП≥зЪДеЖЕе≠Ши°®з§ЇдЇЖжЙАжЬЙзЪД8дљНжХ∞зЪД зФµиѓЭпЉЙ
2)2.5дЇњдЄ™жХіжХ∞дЄ≠жЙЊеЗЇдЄНйЗНе§НзЪДжХіжХ∞зЪДдЄ™жХ∞пЉМеЖЕе≠Шз©ЇйЧідЄНиґ≥дї•еЃєзЇ≥ињЩ2.5дЇњдЄ™жХіжХ∞гАВ
¬†¬†¬† е∞Жbit-mapжЙ©е±ХдЄАдЄЛпЉМзФ®2bitи°®з§ЇдЄАдЄ™жХ∞еН≥еПѓпЉМ0и°®з§ЇжЬ™еЗЇзО∞пЉМ1и°®з§ЇеЗЇзО∞дЄАжђ°пЉМ2и°®з§ЇеЗЇзО∞2жђ°еПКдї•дЄКпЉМеЬ®йБНеОЖињЩдЇЫжХ∞зЪДжЧґеАЩпЉМе¶ВжЮЬеѓєеЇФдљНзљЃзЪДеАЉжШѓ 0пЉМеИЩе∞ЖеЕґзљЃдЄЇ1пЉЫе¶ВжЮЬжШѓ1пЉМе∞ЖеЕґзљЃдЄЇ2пЉЫе¶ВжЮЬжШѓ2пЉМеИЩдњЭжМБдЄНеПШгАВжИЦиАЕжИСдїђдЄНзФ®2bitжЭ•ињЫи°Ми°®з§ЇпЉМжИСдїђзФ®дЄ§дЄ™bit-mapеН≥еПѓж®°жЛЯеЃЮзО∞ињЩдЄ™2bit- mapпЉМйГљжШѓдЄАж†ЈзЪДйБУзРЖгАВ
жХізРЖиЗ™пЉЪ
- http://www.cnblogs.com/youwang/archive/2010/07/20/1781431.html гАВ
- http://blog.redfox66.com/post/2010/09/26/mass-data-4-bitmap.aspx гАВ


- 2011-08-17 10:43
- жµПиІИ 1428
- иѓДиЃЇ(0)
- еИЖз±ї:дЇТиБФзљС
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-иЕЊиЃѓ-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-дєРдњ°-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-OPPO-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШдЄКжµЈ-жРЇз®Л-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШеМЧдЇђ-зЩЊеЇ¶-JavaдЄ≠зЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШеМЧдЇђ-дЇђдЄЬ-JavaеЃЮдє†зФЯжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШеєњеЈЮ-еФѓеУБдЉЪ-Javaе§ІжХ∞жНЃеЉАеПСеЈ•з®ЛеЄИжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-еХЖ汧зІСжКА-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-йУґзЫЫжФѓдїШ-JavaдЄ≠зЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-дЄ∞еЈҐзІСжКА-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШдЄКжµЈ-жЛЉе§Ъе§Ъ-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШеО¶йЧ®-дЄ≠иљѓеЫљйЩЕ-JavaеИЭзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШеНЧдЇђ-иљѓйАЪеК®еКЫ-JavaеИЭзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЭ≠еЈЮ-йШњйЗМдЇС-JavaеЃЮдє†зФЯжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЭ≠еЈЮ-иЪВиЪБйЗСжЬН-иµДжЈ±еЈ•з®ЛеЄИжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЈ±еЬ≥-иЪВиЪБйЗСжЬН-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
е§ІеОВйЭҐиѓХзЬЯйҐШжЭ≠еЈЮ-иЪВиЪБйЗСжЬН-JavaйЂШзЇІжПРеПЦжЦєеЉПжШѓзЩЊеЇ¶зљСзЫШеИЖдЇЂеЬ∞еЭА
MySQLдЄАзЫіжШѓйЭҐиѓХдЄ≠зЪДзГ≠зВєйЧЃйҐШпЉМдєЯйЪЊйБУдЇЖеЊИе§ЪзЪДйЭҐиѓХиАЕгАВеЕґеЃЮMySQLж≤°йВ£дєИйЪЊпЉМеП™жШѓ...1.еП≤дЄКжЬАиѓ¶зїЖзЪДдЄАзЇње§ІеОВMysqlйЭҐиѓХйҐШиѓ¶иІ£ 2.еЉЇзГИжО®иНРMySQLйЭҐиѓХйҐШеТМз≠Фж°ИпЉИдїЕдЊЫеПВиАГпЉЙ 3.MySQLйЭҐиѓХйҐШпЉИеРЂз≠Фж°ИпЉЙ жЬЙйЬАи¶БзЪДеПѓдї•дЄЛиљљиІВзЬЛгАВ
еЬ®жЬђеОЛзЉ©еМЕвАЬGoogle-Map-Api.rarвАЭдЄ≠пЉМеМЕеРЂдЇЖдЄАдїљеЕ≥дЇОGoogle Map APIзЪДйЗНи¶БжЦЗж°£вАФвАФвАЬGoogle Map Api.docвАЭдї•еПКдЄАдЄ™еРНдЄЇвАЬzz.txtвАЭзЪДжЦЗжЬђжЦЗдїґгАВињЩдЄ™жЦЗж°£иѓ¶зїЖдїЛзїНдЇЖе¶ВдљХдљњзФ®Google Map APIињЫи°МеЬ∞еЫЊзЫЄеЕ≥зЪДзЉЦз®ЛеЈ•дљЬпЉМжШѓ...
ZZ-2022031 иЃ°зЃЧжЬЇж£АжµЛзїідњЃдЄОжХ∞жНЃжБҐе§НиµЫй°єиµЫйҐШ дЄ≠иБМиµЫй°є йАВеРИж≠£еЬ®еЗЖе§ЗжКАиГље§ІиµЫзЪДдЇЇзЊ§