原文作者:Sergey Brin and Lawrence Page
原文链接:The Anatomy of a Large-Scale Hypertextual Web Search Engine
译者:小白
(断断续续地把它翻完了。第4部分是Google搜索引擎最核心的一块,有一些设计细节还不是很懂,希望能和大家一起探讨。翻译不当之处还请各位指出,谢谢。)
4 系统剖析(System Anatomy)
首先,我们对架构做一个高层的讨论。接着,对重要的数据结构有一个深入的描述。最后,我们将深入分析主要的应用程序:爬虫,索引和搜索。
4.1 Google架构概述
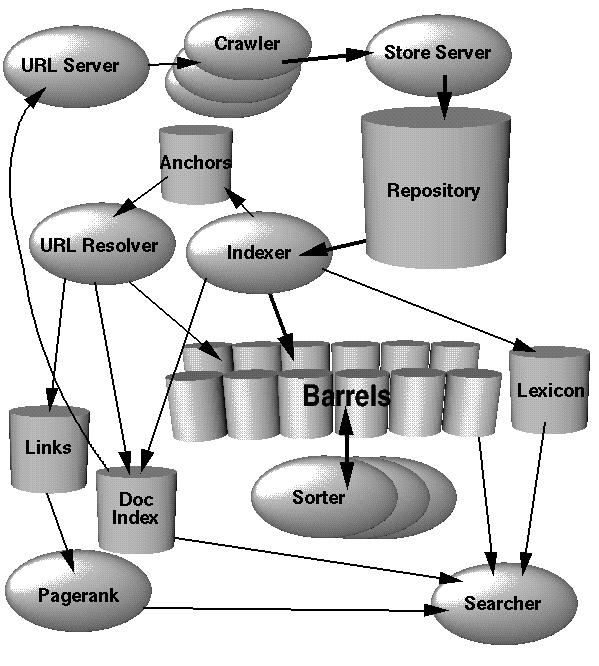
图1. Google高层架构
在这一部分,我们将对图1中整个系统是怎么运行的有一个高层的概述。这一部分没有提到应用程序和数据结构,这些会在接下来的几部分里讨论。考虑到效率,Google的大部分是用C或C++实现,可以在Solaris或者Linux下运行。
在Google中,网页抓取(下载web页面)的工作由分布式的爬虫(crawlers)完成。有一个URL服务器(图1中的URL Server)把需要抓取的URL列表发送给爬虫。网页抓取好之后被发送到存储服务器(图1中的Store Server)。接着存储服务器将抓取来的网页压缩并存放在仓库(repository)里。每一个网页都有一个与之相关的ID,叫docID。在一个网页里每发现一个新的URL,就会赋予它一个ID。索引功能由索引器(图1中的indexer)和排序器(图1中的sorter)完成。索引器有很多功能。它从仓库中读取,解压并分析文档。每个文档都被转化成一个词的集合,词出现一次叫做一个命中(hits)。每条命中记录了一个词,这个词在文档中的位置,字体大小的近似值以及大小写信息。索引器将这些命中分布到一系列“桶”(barrels)里面,建立一个半排序(partially sorted)的正排索引(forward index)。索引器还有一个重要的功能。它解析出每张网页里面的所有链接,并把这些链接的相关重要信息存放在一个锚(anchors)文件里。这个文件包含了足够的信息,以显示每个链接从哪里连接过来,链到哪里和链接的描述。
URL分解器(URLresolver)读取锚文件,将相对URL转化为绝对URL,再转化成docID。它为锚文本建立一个正排索引,并与锚指向的docID关联起来。它还产生一个有docID对组成的链接数据库。这个链接数据库哟功能来计算所有文件的PageRank值。
排序器(sorter)对按照docID排序的(这里做了简化,详情见4.2.5小节)“桶”(barrels)重新按照wordID排序,用于产生倒排索引(inverted index)。这个操作在恰当的时候进行,所以需要很少的暂存空间。排序器还在倒排索引中建立一个wordID和偏移量的列表。一个叫DumpLexicon的程序把这个列表与由索引器产生的词典结合起来,生成一个新的词典,供搜索器(searcher)使用。搜索器由一个Web服务器运行,根据DumpLexicon产生的词典,倒排索引和PageRank值来回答查询。
4.2 主要的数据结构
Google的数据结构经过了优化,这样大量的文档能够在较低的成本下被抓取,索引和搜索。尽管CPU和I/O速率这些年以惊人的速度增长,但是每一个磁盘查找操作仍需要大概10微秒才能完成。Google在设计时尽量避免磁盘查找,这一设计也大大影响了数据结构的设计。
4.2.1 BigFiles
BigFiles是分布在不同文件系统下面的虚拟文件,通过64位整数寻址。虚拟文件被自动分配到不同文件系统。BigFiles的包还负责分配和释放文件描述符(译者注:牵涉到操作系统底层),因为操作系统提供的功能并不能满足我们的要求。BigFiles还支持基本的压缩选项。
4.2.2 数据仓库(Repository)

图2. 数据仓库的结构
数据仓库包括了每个web页面的整个HTML代码。每个页面用zlib(参见RFC1950)压缩。压缩技术的选择是速度和压缩比的一个权衡。我们选择zlib是因为它的压缩速度要比bzip快很多。在数据仓库上,bzip的压缩比是4:1,而zlib的是3:1。在数据仓库中,文档一个一个连接存放,每个文档有一个前缀,包括docID,长度和URL(如图2)。要访问这些文档,数据仓库不再需要其他的数据结构。这使得保持数据一致性和开发都更简单;我们可以仅仅通过数据仓库和一个记录爬虫错误信息的文件来重建其他所有的数据结构。
4.2.3 文档索引(Document Index)
文档索引保存了每个文档的信息。它是一个根据docID排序的定长(fixed width)ISAM(索引顺序访问模式Index sequential access mode)索引。这些信息被存放在每个条目(entry)里面,包括当前文档状态,指向数据仓库的指针,文档校验和(checksum)和各种统计数据。如果文档已经被抓取了,它还会包括一个指针,这个指针指向一个叫docinfo的变长(variable width)文件,里面记录了文档的URL和标题。否则,这个指针将指向一个URL列表,里面只有URL。这样设计的目的是为了有一个相对紧凑的数据结构,在一次搜索操作中只需要一次磁盘查找就能取出一条记录。
另外,还有一个文件用来将URL转化成docID。这个文件是一个列表,包括URL校验和(checksum)和对应的docID,根据校验和排序。为了找到某一个URL的docID,首先计算URL的校验和,然后在校验和文件里做一次二分查找,找到它的docID。URL转化成docID是通过文件合并批量操作的。这个技术是在URL分解器(URL resolver)把URL转化成docID时使用的。这种批量更新的模式很关键,因为如果我们为每个链接做一次磁盘查找,一个磁盘需要1个月的时间才能为我们的3.22亿条链接的数据集完成更新。
4.2.4 词典(Lexicon)
词典多种不同格式。与早前的系统相比,一个重要的变化是现在的词典可以以合理的成本全部放在内存里面。目前的实现中,我们把词典放在一个256M的主存里面。现在的词典有1.4千万单词(尽管一些非常用词没有被包含进来)。它由两部分实现——一个单词列表(连接在一起,但是通过空白nulls分开)和一个指针的哈希表(hash table)。单词列表还有一些附加信息,但是这些不在本篇文章的讨论范围。
4.2.5 命中列表(Hit Lists)
一个命中列表对应着一个单词在一个文档中出现的位置、字体和大小写信息的列表。命中列表占用了正排索引和倒排索引的大部分空间,所以怎样尽可能有效的表示是很重要的。我们考虑了对位置,字体和大小写信息的多种编码方式——简单编码(3个整数),压缩编码(手工优化分配比特)和霍夫曼编码(Huffman coding)。命中(hit)的详情见图3。
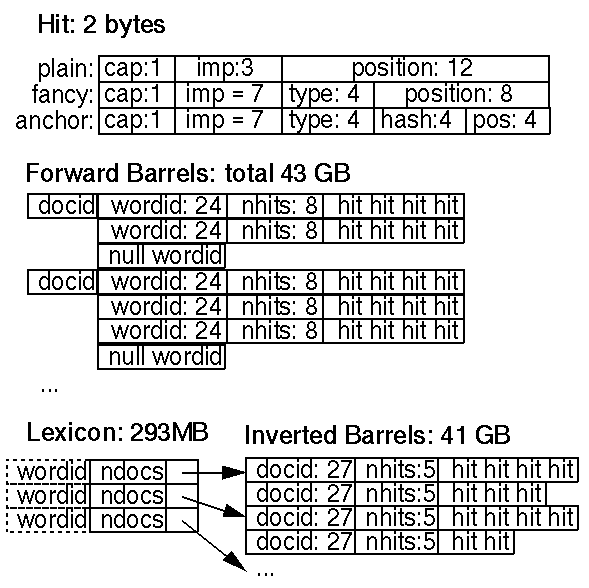
图3. 正、倒排索引和词典
我们的压缩编码每个命中用到两个字节(byte)。有两种命中:特殊命中(fancy hit)和普通命中(plain hit)。特殊命中包括在URL,标题,锚文本和meta标签上的命中。其他的都是普通命中。一个普通的命中包括一个表示大小写的比特(bit),字体大小,和12个bit表示的单词在文件中的位置(所有比4095大的位置都被标示为4096)。字体在文档中的相对大小用3个比特表示(实际上只用到7个值,因为111标示一个特殊命中)。一个特殊命中包含一个大小写比特,字体大小设置为7用来表示它是一个特殊命中,4个比特用来表示特殊命中的类型,8个比特表示位置。对于锚命中,表示位置的8个比特被分成两部分,4个比特表示在锚文本中的位置,4个比特为锚文本所在docID的哈希(hash)值。由于一个词并没有那么多的锚文本,所以短语搜索受到一些限制。我们期望能更新锚命中的存储方式能让位置和docID哈希值能有更大的范围。我们使用在一个文档中的相对字体大小是因为在搜索时,你并不希望对于内容相同的不同文档,仅仅因为一个文档字体比较大而有更高的评级(rank)。
命中列表的长度存在命中的前面。为了节省空间,命中列表的长度在正排索引中与wordID结合,在倒排索引中与docID结合。这样就将长度分别限制在8个比特和5个比特(有一些技巧可以从wordID中借用8个比特)。如果长度超过了这个范围,会在这些比特中使用转义码,在接下来的两个字节(byte)里才存放真正的长度。
4.2.6 正排索引(Forward Index)
正排索引实际上已经部分排序(partially sorted)。它被存放在一系列的桶(barrels)里面(我们用了64个)。每个桶保存了一定范围内的wordID。如果一个文档包含了属于某个桶的单词,它的docID将被记录在桶里面,后面接着一个wordID的列表和相应的命中列表。这种结构需要一点多余空间,因为存储了重复的docID,由于桶的数量很小,所以存储空间的差别很小,但是它能在排序器(sorter)建立最终索引的时候大大节省时间并降低了程序复杂度。更进一步,我们并没有存储完整的wordID,而是存储每个wordID相对于其对应的桶里面最小wordID的差距。这样我们只用到了24个比特,从而为命中列表长度(hit list length)留出了8个比特。
4.2.7 倒排索引(Inverted Index)
倒排索引与正排索引有着相同的桶,但是它们是先经过排序器处理过的。对每一个合法的wordID,词典包含了一个指向对应的桶的指针。它指向一个docID的列表和相应的命中列表。这个文档列表显示了有这个单词出现的所有文档。
一个重要的事情是如何对这个文档列表排序。一个简单的方法是按照docID排序。在多个单词的查询中,这种方法可以快速地完成两个文档列表的归并。另一种方案是按照这个词在文档中出现的评分(ranking)排序。这种方式使得单个词的查询相当简单,并且多词查询的返回结果也很可能接近开头(译者注:这句不是很理解)。但是,归并要困难得多。而且,开发也会困难得多,因为每次评分函数变动就需要重新建立整个索引。我们综合了两种方案,设计了两个倒排桶集合——一个集合只包括标题和锚命中(译者注:后面简称短桶),另一个集合包含所有的命中(译者注:后面简称全桶)。这样我们首先检查第一个桶集合,如果没有足够的匹配再检查那个大一点的。
4.3 网页抓取(Crawling the Web)
运行网络爬虫是一项很有挑战性的任务。这里不光涉及到巧妙的性能和可靠性问题,更重要的,还有社会问题。抓取是一个很脆弱的应用,因为它需要与成百上千各种各样的web服务器和域名服务器交互,这些都不在系统的控制范围之内。
为了抓取几亿网页,Google有一个快速的分布式爬虫系统。一个单独的URL服务器(URLserver)为多个爬虫(crawler,一般是3个)提供URL列表。URL服务器和爬虫都用Python实现。每个爬虫同时打开大概300个连接(connecton)。这样才能保证足够快地抓取速度。在高峰时期,系统通过4个爬虫每秒钟爬取100个网页。这大概有600K每秒的数据传输。一个主要的性能压力在DNS查询(lookup)。每个爬虫都维护一个自己的DNS缓存,这样在它抓取网页之前就不再需要每次都做DNS查询。几百个连接可能处于不同的状态:查询DNS,连接主机,发送请求,接受响应。这些因素使得爬虫成为系统里一个复杂的模块。它用异步IO来管理事件,用一些队列来管理页面抓取的状态。
事实证明,爬虫连接了50多万个服务器,产生了几千万条日志信息,会带来大量的电子邮件和电话。因为很多人在网上,他们并不知道爬虫是什么,因为这是他们第一次见到。几乎每天,我们都会收到这样的电子邮件:“哇,你看了好多我站上的页面,你觉得怎么样?”也有很多人并不知道爬虫禁用协议(robots exclusion protocol),他们认为可以通过在页面上声明“本页面受版权保护,拒绝索引”就可以保护页面,不用说,网络爬虫很难理解这样的话。而且,由于涉及到大量的数据,一些意想不到的事情总会发生。比如,我们的系统试图去抓取一个在线游戏。这导致了游戏中出现大量的垃圾消息!这个问题被证实是很容易解决的。但是往往我们在下载了几千万个页面之后这个问题才被发现。因为网络页面和服务器总是在变化中,在爬虫正式运行在大部分的互联网站点之前是不可能进行测试的。不变的是,总有一些奇怪的错误只会在一个页面里面出现,并且导致爬虫崩溃,或者更坏,导致不可预测的或者错误的行为。需要访问大量互联网站点的系统需要设计得很健壮并且小心地测试。因为大量像爬虫这样的系统持续导致问题,所以需要大量的人力专门阅读电子邮件,处理新出现遇到的问题。
4.4 网站索引(Indexing the Web)
- 解析——任何被设计来解析整个互联网的解析器都必须处理大量可能的错误。从HTML标签里面的错别字到一个标签里面上千字节的0,非ASCII字符,嵌套了几百层的HTML标签,还有大量超乎人想象的错误和“创意”。为了达到最快的速度,我们没有使用YACC产生CFG(context free gramma,上下文无关文法)解析器,而是用flex配合它自己的栈生成了一个词法分析器。开发这样一个解析器需要大量的工作才能保证它的速度和健壮。
- 为文档建立桶索引——每一个文档解析过后,编码存入桶里面。每一个单词被内存里的哈希表——词典转化成一个wordID。词典哈希表新加的内容都被记录在一个文件里。单词在被转化成我wordID的时候,他们在当前文档中的出现会被翻译成命中列表,并写入正排桶(forward barrels)中。建立索引阶段的并行操作主要的困难在于词典需要共享。我们并没有共享整个词典,而是在内存里保存一份基本词典,固定的1千4百万个单词,多余的词写入一个日志文件。这样,多个索引器就可以同时运行,最后由一个索引器来处理这个记录着多余单词的小日志文件。
- 排序——为了产生倒排索引,排序器取出各个正排的桶,然后根据wordID排序来产生一个标题和锚命中的倒排桶,和一个全文的倒排桶。每次处理一个桶,所以需要的暂存空间很少。而且,我们简单地通过用尽可能多的机器运行多个排序器做到排序的并行化,不同的排序器可以同时处理不同的桶。因为桶并不能全部放在主存里面,排序器会根据wordID和docID将它们进一步分割成可以放在内存里面的桶(basket)。接着,排序器将每个桶载入内存,排好序,把内容写入短的倒排桶和完整的倒排桶。
4.5 搜索(Searching)
搜索的目标是高效地返回高质量的结果。很多大型的商业搜索引擎在效率方面看起来都有很大的进步。所以我们更专注于搜索结果的质量,但是我们相信我们的解决方案只要花一点精力就可以很好的应用到商业的数据上。Google的查询评估流程如图4。
为了限制响应时间,一旦某个数量(现在是40,000)的匹配文档被找到,搜索器自动跳到图4中的第8步。这意味着有可能返回次优的结果。我们现在在研究新的方法来解决这个问题。在过去,我们根据PageRank值排序,有较好的效果。
- 解析查询(Query)。
- 把单词转化成wordID。
- 从每个单词的短桶文档列表开始查找。
- 扫描文档列表直到有一个文档匹配了所有的搜索词语。
- 计算这个文档对应于查询的评分。
- 如果我们到达短桶的文档列表结尾,从每个单词的全桶(full barrel)文档列表开始查找,跳到第4步。
- 如果我们没有到达任何文档列表的结尾,跳到第4步。
- 根据评分对匹配的文档排序,然后返回评分最高的k个。
图4 Google查询评估
4.5.1 评分系统(The Ranking System)
Google比典型的搜索引擎维护了根多的web文档的信息。每一个命中列表(hitlist)包含了位置,字体和大小写信息。而且,我们综合考虑了锚文本命中和页面的PageRank值。把所有的信息综合成一个评分是很困难的。我们设计了评分函数保证没有一个因素有太大的影响。首先,考虑简单的情况——一个单词的查询。为了对一个单词的查询计算文档的分值,Google首先为这个单词查看这个文档的命中列表。Google将命中分为不同类型(标题,锚,URL,普通文本大字体,普通文本小字体,……),每一种类型都有自己的类型权重值(type-weight)。类型权重值构成一个由类型寻址(indexed)的向量。Google数出命中列表中每种类型命中的数量。每个数量转化成一个数量权重(count-weight)。数量权重开始随着数量线性增长,但是很快停止增长,以保证单词命中数多于某个数量之后对权重不再有影响。我们通过数量权重向量和类型权重向量的点乘为一个文档算出一个IR分数。最后这个IR分数与PageRank综合产生这个文档最终的评分。
对于一个多词搜索,情况要更复杂。现在,多个命中列表必须一次扫描完,这样一个文档中较近的命中才能比相距较远的命中有更高的评分。多个命中列表里的命中结合起来才能匹配出相邻的命中。对每一个命中的匹配集(matched set),会计算出一个接近度。接近度是基于两个命中在文档(或锚文本)中相隔多远计算的,但是被分为10个等级从短语匹配到“一点都不近”。不光要为每一种类型的命中计数,还要为每一种类型和接近度都计数。每一个类型和接近度的组有一个类型-接近度权重(type-prox-weight)。数量被转化成数量权重。我们通过对数量权重和类型-接近度权重做点乘计算出IR分值。所有这些数字和矩阵都会在特殊的调试模式下与搜索结果一起显示出来。这些显示结果在开发评分系统的时候很有帮助。
4.5.2 反馈(Feedback)
评分函数有很多参数比如类型权重和类型-接近度权重。找出这些参数的权重值简直就跟妖术一样。为了调整这些参数,我们在搜索引擎里有一个用户反馈机制。一个被信任的用户可以选择性地评价所有的返回结果。这个反馈被记录下来。然后在我们改变评分系统的时候,我们能看到修改对之前评价过的搜索结果的影响。尽管这样并不完美,但是这也给我们一些改变评分函数来影响搜索结果的想法。
添加评论
相关文章:
2006 年互联网技术发展趋势
Google 的临界点
三条提高gmail工作效率的可靠忠告
分享到:





相关推荐
综上所述,"大规模超文本网络搜索引擎剖析"这篇论文揭示了构建高效搜索引擎的关键技术和设计原则,特别是Google的PageRank算法,它对现代搜索引擎的发展产生了深远影响。通过对Web结构的深刻理解和创新,Google成功...
根据文章描述,Google搜索引擎的设计重点在于提升搜索质量,解决传统搜索引擎在面对大规模数据时的不足之处,并充分利用超文本中的附加信息来改善搜索结果。 #### 二、技术挑战与解决方案 ##### 2.1 技术挑战 - **...
《大规模超文本网络搜索引擎的解剖》 这篇论文由Sergey Brin和Lawrence Page撰写,两位作者来自斯坦福大学计算机科学系。他们的研究工作主要集中在如何利用超文本中的结构来构建一个大规模的搜索引擎——Google。这...
【好一搜超级搜索引擎源码 V4.0 商业版】是一个专为用户提供高效搜索体验的软件产品。作为一款开源的搜索引擎,它允许用户深入理解搜索引擎的内部运作机制,并可以根据需求进行定制化开发。源码的开放使得技术爱好者...
通过上述分析可以看出,《大规模超文本网络搜索引擎的结构》这篇论文不仅详细介绍了Google搜索引擎的工作原理和技术实现,更重要的是提出了PageRank算法这一创新性的解决方案。PageRank算法不仅极大地提高了搜索引擎...
通过深入研究和技术创新,Google成功地建立了一个能够有效处理大规模超文本信息的搜索引擎。它不仅极大地改善了用户的搜索体验,也为后续的搜索引擎技术发展奠定了坚实的基础。未来,随着人工智能等新技术的发展,...
在此背景下,《大规模超文本网络搜索引擎解析》一文介绍了Google搜索引擎的设计理念和技术实现,旨在解决现有搜索引擎存在的诸多问题。Google不仅能够处理庞大的数据量,更重要的是,它利用网页间的超链接结构显著...
这篇文章详细阐述了Google搜索引擎的构建理念和技术核心,是Sergey Brin和Lawrence Page两位创始人对大规模超文本搜索引擎的深入剖析。Google搜索引擎的设计旨在克服当时搜索引擎的诸多问题,如返回过多低质量的匹配...
这篇论文深入探讨了Google搜索引擎的核心技术和设计,它是一个大规模的超文本搜索引擎,能够有效地爬取和索引互联网上的海量信息。Google的出现为信息检索带来了革命性的变化,它不仅解决了传统搜索引擎的诸多问题,...
- b) 分析网页的超文本链接,将 Anchor Text 和 URL 关键信息存入 Anchor 文档库。 - c) 生成索引词表,包括关键词列表和指针列表,用于倒排档文档连接。 - d) 编排文档索引,记录网页的URL和标题,并将未分析的...
- **关键技术改进**:1993年底,JumpStation、The World Wide Web Worm 和 Repository-Based Software Engineering (RBSE) spider等搜索引擎开始出现,这些搜索引擎改进了传统“蜘蛛”程序的工作原理,通过跟踪网站...
总的来说,"搜啊聚合搜索SOOUA(元搜索引擎(仿百度))PHP版.zip" 提供了一个基于PHP的元搜索引擎实现,它展示了如何利用PHP处理大规模数据抓取、解析、整合和返回,以及如何构建一个类似百度的搜索体验。这个项目...
1. **The Anatomy of a Large-Scale Hypertextual Web Search Engine**(《大型超文本网页搜索引擎的解剖》): 这是Google的创始人拉里·佩奇和谢尔盖·布林在1998年发表的开创性论文。他们提出了PageRank算法,这...
### 大型超文本网络搜索引擎剖析 #### 一、引言与背景 互联网技术的快速发展催生了大量的信息资源,其中搜索引擎成为人们获取信息的关键工具之一。文章《The Anatomy of a Large-Scale Hypertextual Web Search ...
最后,第三篇论文是"The Anatomy of a Large-Scale Hypertextual Web Search Engine"(中文版:《大型超文本网络搜索引擎的构造》),这是Google创始人Larry Page和Sergey Brin提出的PageRank算法的原始论文。...
### 大型超文本网络搜索引擎的核心技术解析 #### 一、引言 1998年,谷歌创始人Sergey Brin和Lawrence Page发表了《The_Anatomy_of_a_Large-Scale_Hypertextual_Web_Search_Engine》一文,详细介绍了Google搜索引擎...
通过学习这些论文,读者不仅可以了解谷歌是如何处理和分析大规模数据的,还能掌握到构建高效、可扩展的互联网服务的关键技术。无论是对研究人员、工程师还是对互联网技术感兴趣的普通读者,这些资料都能提供丰富的...