
写在前面
前两天想爬知乎,发现用selenium模拟登录时出现了问题——点击登录按钮没反应。。。
无论是用webdirver模拟点击,还是自己手动点击,都无法跳转到首页。
后来发现大概是知乎识别出selenium了。把我们给反爬了。
解决办法
解决办法就是——用webdirver接管我们自己打开的浏览器,然后再进行登录操作。
具体的接管方法,这篇文章已经说得非常清楚了:https://www.cnblogs.com/HJkoma/p/9936434.html
具体步骤
在环境变量中PATH里将chrome的路径添加进去:
打开控制面板,点击“高级系统设置”
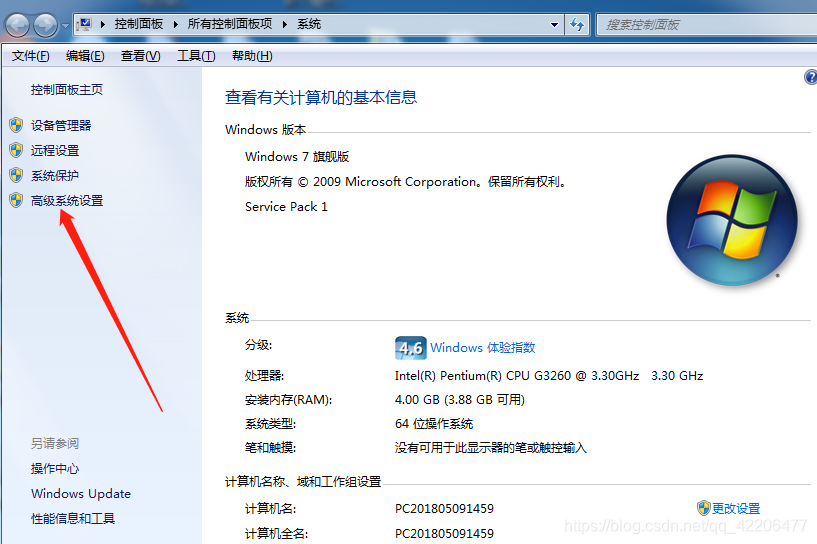
进入系统属性,点击下方“环境变量”
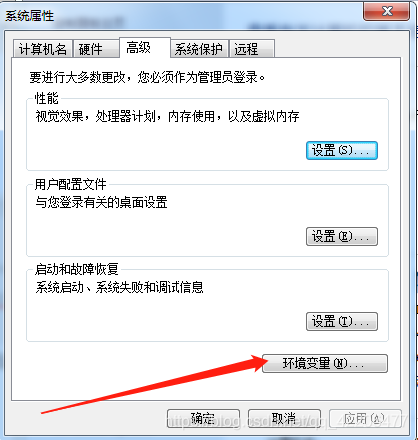
找到Path,点击“编辑”
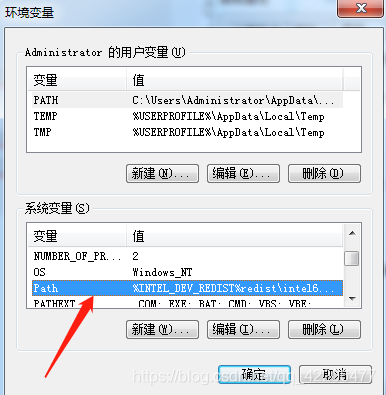
在变量值中添加配置路径 C:\Program Files (x86)\Google\Chrome\Application(注意要与前面的路径用分号隔开)
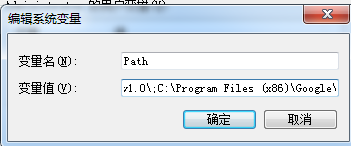
一路点“确定”就ok了
在cmd中运行命令:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\selenum\AutomationProfile"

这时,会打开一个浏览器。
然后我们回到pycharm,运行模拟登录知乎的代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(executable_path = 'D:\Documents\Downloads\chromedriver_win32\chromedriver.exe', options=chrome_options)
browser.get("https://www.zhihu.com/signin")
browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys("用户名")
import time
time.sleep(3)
browser.find_element_by_css_selector(".SignFlow-password input").send_keys("密码")
browser.find_element_by_css_selector(
".Button.SignFlow-submitButton").click()
发现登录成功了!
登录异常次数多了,就会出现验证码。关于知乎的验证码破解欢移步我的这篇博文(还没写好)
结语
这个方法比较笨
但是我目前还没找到别的解决办法
欢迎大家提供其他的解决办法~
今天在网上看到一个思路:http://www.site-digger.com/html/articles/20180821/653.html



相关推荐
在本示例中,我们将探讨如何使用Selenium来爬取知乎网站上的问答内容。 首先,我们需要安装Selenium库以及与之配合的Chrome驱动程序(chromedriver)。Selenium库提供了多种浏览器驱动,包括Firefox(GeckoDriver)...
7. **异常处理与反反爬策略**: 爬虫还需要处理各种可能出现的异常,如超时、页面结构改变等,并可能需要设置延迟以避免被知乎的反爬机制检测到。 **关键词爬虫的优化** 1. **使用代理**: 为了避免被目标网站封锁 IP...
谷歌webdriver118版本的selenium驱动包版本近期更新,网上比较难找。因此在这里上传一份方便大家下载。 ChromeDriver 是一个用于自动化控制和操作 Google Chrome 浏览器的工具。它是 WebDriver 协议的实现之一,提供...
在本项目中,"知乎问题回答信息爬取.zip" 是一个包含了使用Python编写的爬虫项目的压缩包。这个项目的主要目标是从知乎网站上抓取问题及其相关回答的信息,以供数据分析或研究使用。以下是该项目涉及的一些核心知识...
应用场景:网络爬虫、自动化测试、web自动化,例如与Selenium等自动化测试框架一起使用,提供更高级的浏览器自动化,实现自动访问、自动输入、自动点击、自动发送等操作。 需要注意,这个驱动只适用于谷歌浏览器...
chromedriver.exe是一个用于自动化控制和管理谷歌Chrome浏览器的执行文件,通常作为Selenium测试框架的一部分。它允许开发者在自动化测试和网页抓取中模拟用户与浏览器的交互。 【使用人群】 适用于软件测试工程师...
然而,需要注意的是,随着反爬策略的升级,这种自动化方式可能会失效,因此持续关注知乎的更新和调整策略是必要的。此外,学习更多相关技术,如验证码识别库tesseract、机器学习模型进行更高级的图像识别,都能帮助...
- 配置Scrapy设置,例如启用Selenium下载器中间件,指定浏览器驱动程序的路径(如ChromeDriver),并设置登录后的cookies保存路径,以便后续请求能携带这些cookies。 3. **编写登录逻辑**: - 使用Selenium打开...
import org.openqa.selenium.chrome.ChromeDriver; import java.util.concurrent.TimeUnit; public class Demo { public static void main(String[] args) throws InterruptedException { // 设置系统属性,指向...
项目说明 本项目是在之前的爬虫项目zhihu_spider和jobbole_spider的基础上进行重写的 重写的内容有: 新增代理IP池,防止IP屏蔽 新增user-agent随机切换 ...selenium chromedriver request elasticsearch-dsl 5.5.1
/Chrome/Application/chromedriver.exe 此版本chrome浏览器,为本人长期进行项目自动化测试的指定浏览器,运行状况非常稳定,且适合做界面的快照校验。 强烈推荐大家使用~~~~ 另外,本人还有全终端自动化测试框架...