- µĄÅĶ¦ł: 70458 µ¼Ī
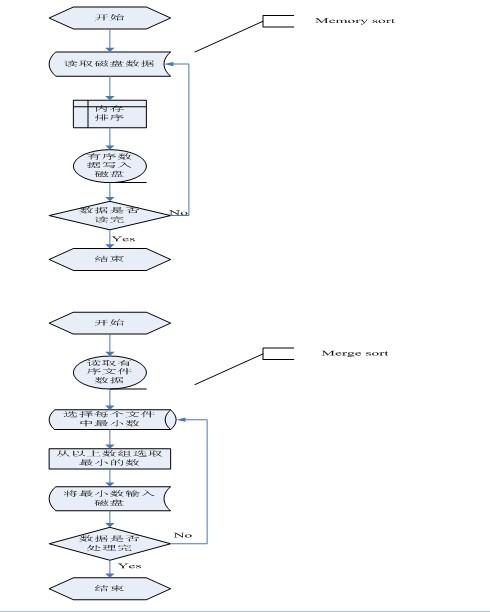
- µĆ¦Õł½:

- µØźĶć¬: µĘ▒Õ£│
-

µ¢ćń½ĀÕłåń▒╗
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 0)
- µłæńÜäĶ«║ÕØø ( 0)
- µłæńÜäķŚ«ńŁö ( 0)
ÕŁśµĪŻÕłåń▒╗
- 2011-06 ( 1)
- 2011-05 ( 2)
- 2011-04 ( 1)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
-
v_JULY_v’╝Ü
v_JULY_v ÕåÖķüōµÖĢµŁ╗’╝īµĆÄõ╣łńģ¦ńēćÕģ©µŁ╗õ║å...ÕÉäõĮŹ’╝īµ£ēķ£ĆĶ”üńÜä ...
ń╗ÅÕģĖń«Śµ│ĢÕ«×ńÄ░õ╣ŗõĖĆ’╝ܵĢÖõĮĀõĖƵŁźõĖƵŁźńö©cĶ»ŁĶ©ĆÕ«×ńÄ░siftń«Śµ│ĢŃĆüõĖŗ -
v_JULY_v’╝Ü
µÖĢµŁ╗’╝īµĆÄõ╣łńģ¦ńēćÕģ©µŁ╗õ║å...ÕÉäõĮŹ’╝īµ£ēķ£ĆĶ”üńÜäĶ»Ø’╝īĶ┐śµś»ń£ŗµ£¼õ║║ńÜäCSD ...
ń╗ÅÕģĖń«Śµ│ĢÕ«×ńÄ░õ╣ŗõĖĆ’╝ܵĢÖõĮĀõĖƵŁźõĖƵŁźńö©cĶ»ŁĶ©ĆÕ«×ńÄ░siftń«Śµ│ĢŃĆüõĖŗ
ń©ŗÕ║ÅÕæśń╝¢ń©ŗĶē║µ£»’╝łń«Śµ│ĢÕŹĘ’╝ē’╝Üń¼¼ÕŹüń½ĀŃĆüÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å
ń¼¼ÕŹüń½ĀŃĆüÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å
õĮ£ĶĆģ:July’╝īyansha’╝ī5’╝īń╝¢ń©ŗĶē║µ£»Õ«żŃĆé
Õć║Õżä’╝Ühttp://blog.csdn.net/v_JULY_vŃĆé
ÕēŹÕźÅ
ń╗ÅĶ┐ćÕćĀÕż®ńÜäńŚøĶŗ”µ▓ēµĆØ’╝īµ£Ćń╗łÕå│Õ«Ü’╝īµŖŖÕĤń©ŗÕ║ÅÕæśķØóĶ»Ģķóśńŗéµā│µø▓ń│╗ÕłŚµŁŻÕ╝ŵø┤ÕÉŹõĖ║ń©ŗÕ║ÅÕæśń╝¢ń©ŗĶē║µ£»ń│╗ÕłŚ’╝īÕÉīµŚČ’╝īńŗéµā│µø▓ÕłøõĮ£ń╗äµø┤ÕÉŹõĖ║ń╝¢ń©ŗĶē║µ£»Õ«żŃĆéõ╣ŗµēĆõ╗źĶ”üµö╣ÕÉŹ’╝īµłæõ╗¼ĶĆāĶÖæÕł░õĖēńé╣’╝Ü1ŃĆüõĖ║ķØóĶ»Ģµ£ŹÕŖĪõĖŹĶāĮµłÉõĖ║µłæõ╗¼µ£Ćń╗łµł¢µ£ĆõĖ╗Ķ”üńÜäńø«ńÜä’╝ī2ŃĆüµłæµø┤µä┐µŖŖĶ¦ŻńŁöõĖĆķüōķüōķØóĶ»Ģķóś’╝īACMķóśńŁēÕÉäń▒╗ń©ŗÕ║ÅĶ«ŠĶ«Īķóśńø«ńÜäĶ┐ćń©ŗ’╝īÕĮōÕüÜõĖĆń¦ŹĶē║µ£»µØźń£ŗÕŠģ’╝ī3ŃĆüĶē║µ£»ńÜäµÅÉńé╝µ£¼Ķ║½µś»õĖĆõĖ¬ķØ×ÕĖĖķØ×ÕĖĖĶē░ķÜŠńÜäĶ┐ćń©ŗ’╝īõĮåµłæõ╗¼õ╣ɵäÅµÄźÕÅŚĶ┐ÖõĖ¬µīæµłśŃĆé
ÕÉīµŚČ’╝īµ£¼ń│╗ÕłŚń©ŗÕ║Åń╝¢ń©ŗĶē║µ£»-ń«Śµ│ĢÕŹĘ’╝īÕż¦Ķć┤ÕłåõĖ║õĖēõĖ¬ķā©Õłå’╝Üń¼¼õĖĆķā©Õłå--ń©ŗÕ║ÅĶ«ŠĶ«Ī’╝īÕż¦ÕćĪÕ”éķØóĶ»Ģķóśńø«/ACMķóśńø«/pojńÜäķóśńø«ńŁēÕÉäń▒╗ń©ŗÕ║ÅĶ«ŠĶ«ĪńÜäķóś’╝īÕŬĶ”üµś»ÕźĮńÜä’╝īÕĆ╝ÕŠŚĶ«ŠĶ«Īµł¢µĘ▒ń®ČńÜäķóśńø«’╝īµłæõ╗¼ķāĮõĖŹµŗÆń╗ØŃĆéÕÉīµŚČ’╝īń┤¦µēŻÕ«×ķÖģ’╝īõĖŹµ¢ŁÕ»╗µēŠµø┤ķ½śµĢłńÜäń«Śµ│ĢĶ¦ŻÕå│Õ«×ķÖģķŚ«ķóśŃĆéń¼¼õ║īķā©Õłå--ń«Śµ│ĢńĀöń®Č’╝īõĖ╗Ķ”üõ╗źµłæõĖ¬õ║║µŁżÕēŹÕåÖńÜäÕÄ¤ÕłøõĮ£Õōü-ÕŹüõĖēõĖ¬ń╗ÅÕģĖń«Śµ│ĢńĀöń®Čń│╗ÕłŚõĖ║ķóśµØÉ’╝īÕŖøõ║ēķĆÜõ┐Śµśōµćé’╝īĶ»”ńĢźÕŠŚÕĮōńÜäÕē¢µ×ÉÕÉäń▒╗ń╗ÅÕģĖńÜäń«Śµ│Ģ’╝īÕ╣Čõ║łõ╗źń╝¢ń©ŗÕ«×ńÄ░ŃĆéń¼¼õĖēķā©Õłå--ń╝¢ńĀüń┤ĀÕģ╗’╝īõĖ╗Ķ”üÕīģµŗ¼ń©ŗÕ║ÅÕæśń╝¢ńĀüĶ┐ćń©ŗõĖŁõĖĆõ║øń╝¢ńĀüĶ¦äĶīāńŁēÕÉäń▒╗ÕÅŖÕģČķ£ĆĶ”üµ│©µäÅńÜäķŚ«ķóśŃĆé
Õ”éµ×£µ£ēÕÅ»ĶāĮńÜäĶ»Ø’╝īµŁżTAOPPń│╗ÕłŚÕ░åķććÕÅ¢TAOCPķ鯵ĀĘńÜäÕĮóÕ╝Å’╝īÕć║ń¼¼õĖĆÕŹĘŃĆüń¼¼õ║īÕŹĘŃĆü...ŃĆéń╝¢ń©ŗĶē║µ£»µØźĶć¬Õō¬ķćī?ń╝¢ń©ŗķććÕÅ¢ÕÉłķĆéńÜäµĢ░µŹ«ń╗ōµ×ä?Õ»╗µ▒éµø┤ķ½śµĢłńÜäń«Śµ│Ģ?µł¢ĶĆģ’╝īÕźĮńÜäń╝¢ńĀüĶ¦äĶīā?ÕĖīµ£ø’╝īµ£¼TAOPPń│╗ÕłŚµ£Ćń╗łĶāĮń╗ÖõĮĀõĖĆõĖ¬Õ«īµĢ┤ńÜäńŁöÕżŹŃĆé
ok’╝īÕ”éµ×£õ╗╗õĮĢõ║║Õ»╣µ£¼ń╝¢ń©ŗĶē║µ£»ń│╗ÕłŚµ£ēõ╗╗õĮĢµäÅĶ¦ü’╝īµł¢ÕÅæńÄ░õ║åµ£¼ń╝¢ń©ŗĶē║µ£»ń│╗ÕłŚõ╗╗õĮĢķŚ«ķóś’╝īµ╝ŵ┤×’╝ībug’╝īµ¼óĶ┐ÄķÜŵŚČµÅÉÕć║’╝īµłæõ╗¼Õ░åĶÖÜÕ┐āµÄźÕÅŚÕ╣ȵ䤵┐ĆõĖŹÕ░Į’╝īõ╗źõĖ║õ╗¢õ║║ÕłøķĆĀµø┤ÕźĮńÜäõ╗ĘÕĆ╝’╝īµø┤ÕźĮńÜäµ£ŹÕŖĪŃĆé
ń¼¼õĖĆĶŖéŃĆüÕ”éõĮĢń╗ÖńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å
ķŚ«ķóśµÅÅĶ┐░’╝Ü
ĶŠōÕģź’╝ÜõĖĆõĖ¬µ£ĆÕżÜÕɽµ£ēnõĖ¬õĖŹķćŹÕżŹńÜ䵣ŻµĢ┤µĢ░ńÜäµ¢ćõ╗Č’╝īÕģČõĖŁµ»ÅõĖ¬µĢ░ķāĮÕ░Åõ║ÄńŁēõ║Än’╝īõĖön=10^7ŃĆé
ĶŠōÕć║’╝ÜÕŠŚÕł░µīēõ╗ÄÕ░ÅÕł░Õż¦ÕŹćÕ║ŵÄÆÕłŚńÜäÕīģÕɽµēƵ£ēĶŠōÕģźńÜäµĢ┤µĢ░ńÜäÕłŚĶĪ©ŃĆé
µØĪõ╗Č’╝ܵ£ĆÕżÜµ£ēÕż¦ń║”1MBńÜäÕåģÕŁśń®║ķŚ┤ÕÅ»ńö©’╝īõĮåńŻüńøśń®║ķŚ┤ĶČ│Õż¤ŃĆéõĖöĶ”üµ▒éĶ┐ÉĶĪīµŚČķŚ┤Õ£©5ÕłåķƤõ╗źõĖŗ’╝ī10ń¦ÆõĖ║µ£ĆõĮ│ń╗ōµ×£ŃĆé
Õłåµ×É’╝ÜõĖŗķØóÕÆ▒õ╗¼µØźõĖƵŁźõĖƵŁźńÜäĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóś’╝ī
1ŃĆüÕĮÆÕ╣ȵÄÆÕ║ÅŃĆéõĮĀÕÅ»ĶāĮõ╝ܵā│Õł░µŖŖńŻüńøśµ¢ćõ╗ČĶ┐øĶĪīÕĮÆÕ╣ȵÄÆÕ║Å’╝īõĮåķóśńø«Ķ”üµ▒éõĮĀÕŬµ£ē1MBńÜäÕåģÕŁśń®║ķŚ┤ÕÅ»ńö©’╝īµēĆõ╗ź’╝īÕĮÆÕ╣ȵÄÆÕ║ÅĶ┐ÖõĖ¬µ¢╣µ│ĢõĖŹĶĪīŃĆé
2ŃĆüõĮŹÕøŠµ¢╣µĪłŃĆéń夵éēõĮŹÕøŠńÜäµ£ŗÕÅŗÕÅ»ĶāĮõ╝ܵā│Õł░ńö©õĮŹÕøŠµØźĶĪ©ńż║Ķ┐ÖõĖ¬µ¢ćõ╗ČķøåÕÉłŃĆéõŠŗÕ”éµŁŻÕ”éń╝¢ń©ŗńÅĀńÄæõĖĆõ╣”õĖŖµēĆĶ┐░’╝īńö©õĖĆõĖ¬20õĮŹķĢ┐ńÜäÕŁŚń¼”õĖ▓µØźĶĪ©ńż║õĖĆõĖ¬µēƵ£ēÕģāń┤ĀķāĮÕ░Åõ║Ä20ńÜäń«ĆÕŹĢńÜäķØ×Ķ┤¤µĢ┤µĢ░ķøåÕÉł’╝īĶŠ╣µĪåńö©Õ”éõĖŗÕŁŚń¼”õĖ▓µØźĶĪ©ńż║ķøåÕÉł{1,2,3,5,8,13}’╝Ü
0 1 1 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0
õĖŖĶ┐░ķøåÕÉłõĖŁÕÉäµĢ░Õ»╣Õ║öńÜäõĮŹńĮ«ÕłÖńĮ«1’╝īµ▓Īµ£ēÕ»╣Õ║öńÜäµĢ░ńÜäõĮŹńĮ«ÕłÖńĮ«0ŃĆé
ÕÅéĶĆāń╝¢ń©ŗńÅĀńÄæõĖĆõ╣”õĖŖńÜäõĮŹÕøŠµ¢╣µĪł’╝īķÆłÕ»╣µłæõ╗¼ńÜä10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅķŚ«ķóś’╝īµłæõ╗¼ÕÅ»õ╗źĶ┐Öõ╣łĶĆāĶÖæ’╝īńö▒õ║ĵ»ÅõĖ¬7õĮŹÕŹüĶ┐øÕłČµĢ┤µĢ░ĶĪ©ńż║õĖĆõĖ¬Õ░Åõ║Ä1000õĖćńÜäµĢ┤µĢ░ŃĆ鵳æõ╗¼ÕÅ»õ╗źõĮ┐ńö©õĖĆõĖ¬Õģʵ£ē1000õĖćõĖ¬õĮŹńÜäÕŁŚń¼”õĖ▓µØźĶĪ©ńż║Ķ┐ÖõĖ¬µ¢ćõ╗Č’╝īÕģČõĖŁ’╝īÕĮōõĖöõ╗ģÕĮōµĢ┤µĢ░iÕ£©µ¢ćõ╗ČõĖŁÕŁśÕ£©µŚČ’╝īń¼¼iõĮŹõĖ║1ŃĆéķććÕÅ¢Ķ┐ÖõĖ¬õĮŹÕøŠńÜäµ¢╣µĪłµś»ÕøĀõĖ║µłæõ╗¼ķØóÕ»╣ńÜäĶ┐ÖõĖ¬ķŚ«ķóśńÜäńē╣µ«ŖµĆ¦’╝Ü1ŃĆüĶŠōÕģźµĢ░µŹ«ķÖÉÕłČÕ£©ńøĖÕ»╣ĶŠāÕ░ÅńÜäĶīāÕø┤Õåģ’╝ī2ŃĆüµĢ░µŹ«µ▓Īµ£ēķćŹÕżŹ’╝ī3ŃĆüÕģČõĖŁńÜ䵻ŵØĪĶ«░ÕĮĢķāĮµś»ÕŹĢõĖĆńÜäµĢ┤µĢ░’╝īµ▓Īµ£ēõ╗╗õĮĢÕģČÕ«āõĖÄõ╣ŗÕģ│ĶüöńÜäµĢ░µŹ«ŃĆé
µēĆõ╗ź’╝īµŁżķŚ«ķóśńö©õĮŹÕøŠńÜäµ¢╣µĪłÕłåõĖ║õ╗źõĖŗõĖēµŁźĶ┐øĶĪīĶ¦ŻÕå│’╝Ü
- ń¼¼õĖƵŁź’╝īÕ░åµēƵ£ēńÜäõĮŹķāĮńĮ«õĖ║0’╝īõ╗ÄĶĆīÕ░åķøåÕÉłÕłØÕ¦ŗÕī¢õĖ║ń®║ŃĆé
- ń¼¼õ║īµŁź’╝īķĆÜĶ┐ćĶ»╗Õģźµ¢ćõ╗ČõĖŁńÜäµ»ÅõĖ¬µĢ┤µĢ░µØźÕ╗║ń½ŗķøåÕÉł’╝īÕ░åµ»ÅõĖ¬Õ»╣Õ║öńÜäõĮŹķāĮńĮ«õĖ║1ŃĆé
- ń¼¼õĖēµŁź’╝īµŻĆķ¬īµ»ÅõĖĆõĮŹ’╝īÕ”éµ×£Ķ»źõĮŹõĖ║1’╝īÕ░▒ĶŠōÕć║Õ»╣Õ║öńÜäµĢ┤µĢ░ŃĆé
ń╗ÅĶ┐ćõ╗źõĖŖõĖēµŁźÕÉÄ’╝īõ║¦ńö¤µ£ēÕ║ÅńÜäĶŠōÕć║µ¢ćõ╗ČŃĆéõ╗żnõĖ║õĮŹÕøŠÕÉæķćÅõĖŁńÜäõĮŹµĢ░’╝łµ£¼õŠŗõĖŁõĖ║1000 0000’╝ē’╝īń©ŗÕ║ÅÕÅ»õ╗źńö©õ╝¬õ╗ŻńĀüĶĪ©ńż║Õ”éõĖŗ’╝Ü
õĖŖķØóÕŬµś»õĖ║õ║åń«ĆÕŹĢõ╗ŗń╗ŹõĖŗõĮŹÕøŠń«Śµ│ĢńÜäõ╝¬õ╗ŻńĀüõ╣ŗµŖĮĶ▒Īń║¦µÅÅĶ┐░ŃĆ鵜ŠńäČ’╝īÕÆ▒õ╗¼ķØóÕ»╣ńÜäķŚ«ķóś’╝īÕÅ»õĖŹµś»Ķ┐Öõ╣łń«ĆÕŹĢŃĆéõĖŗķØó’╝īµłæõ╗¼Ķ»ĢńØĆķÆłÕ»╣Ķ┐ÖõĖ¬Ķ”üÕłåõĖżĶȤń╗ÖńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅńÜäÕģĘõĮōķŚ«ķóśń╝¢ÕåÖÕ«īµĢ┤õ╗ŻńĀü’╝īÕ”éõĖŗŃĆé
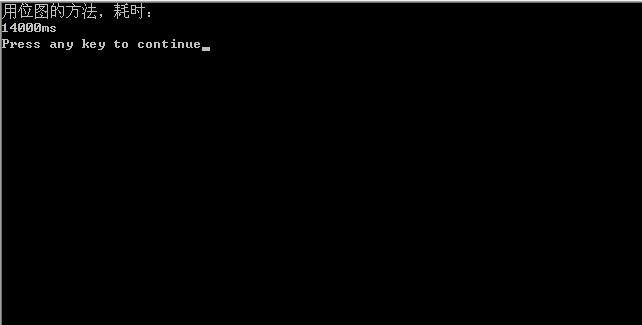
ĶĆīÕÉĵĄŗĶ»Ģõ║åõĖĆõĖŗõĖŖĶ┐░ń©ŗÕ║ÅńÜäĶ┐ÉĶĪīµŚČķŚ┤’╝īķććÕÅ¢õĮŹÕøŠµ¢╣µĪłĶĆŚµŚČ14s’╝īÕŹ│14000ms’╝Ü
µ£¼ń½ĀõĖŁ’╝īńö¤µłÉÕż¦µĢ░µŹ«ķćÅ’╝ł1000w’╝ēńÜäń©ŗÕ║ÅÕ”éõĖŗ’╝īõĖŗµ¢ćń¼¼õ║īĶŖéńÜäÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäc++Õ«×ńÄ░ÕÆīń¼¼õĖēĶŖéńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅńÜäń╝¢ń©ŗÕ«×ńÄ░õĖŁ’╝īńö¤µłÉńÜä1000wµĢ░µŹ«ķćÅõ╣¤µś»ńö©µ£¼ń©ŗÕ║Åõ║¦ńö¤ńÜä’╝īõĖöµ£¼ń½ĀÕåģńö¤µłÉńÜä1000wµĢ░µŹ«ķćÅńÜäµĢ░µŹ«µ¢ćõ╗Čń╗¤õĖĆÕæĮÕÉŹõĖ║ŌĆ£data.txtŌĆØŃĆé
õĖŹĶ┐ćÕŠłÕ┐½’╝īµłæõ╗¼Õ░▒Õ░åµäÅĶ»åÕł░’╝īńö©µŁżõĮŹÕøŠµ¢╣µ│Ģ’╝īõĖźµĀ╝Ķ»┤µØźĶ┐śµś»õĖŹÕż¬ĶĪī’╝īń®║ķŚ┤µČłĶĆŚ10^7/8Ķ┐śµś»Õż¦õ║Ä1M’╝ł1M=1024*1024ń®║ķŚ┤’╝īÕ░Åõ║Ä10^7/8’╝ēŃĆé
µŚóńäČÕ”éµ×£ńö©õĮŹÕøŠµ¢╣µĪłńÜäĶ»Ø’╝īµłæõ╗¼ķ£ĆĶ”üń║”1.25MB’╝łĶŗźµ»ÅµØĪĶ«░ÕĮĢµś»8õĮŹńÜ䵣ŻµĢ┤µĢ░ńÜäĶ»Ø’╝īÕłÖ10000000/(1024*1024*8) ~= 1.2M’╝ēńÜäń®║ķŚ┤’╝īĶĆīńÄ░Õ£©ÕŬµ£ē1MBńÜäÕÅ»ńö©ÕŁśÕé©ń®║ķŚ┤’╝īķéŻõ╣łń®Čń½¤Ķ»źõĮ£õĮĢÕżäńÉåÕæó?
updated && correct’╝Ü
@yansha’╝Ü õĖŖĶ┐░ńÜäõĮŹÕøŠµ¢╣µĪł’╝īÕģ▒ķ£ĆĶ”üµē½µÅÅĶŠōÕģźµĢ░µŹ«õĖżµ¼Ī’╝īÕģĘõĮōµē¦ĶĪīµŁźķ¬żÕ”éõĖŗ’╝Ü
- ń¼¼õĖƵ¼Ī’╝īÕÅ¬ÕżäńÉå1ŌĆö4999999õ╣ŗķŚ┤ńÜäµĢ░µŹ«’╝īĶ┐Öõ║øµĢ░ķāĮµś»Õ░Åõ║Ä5000000ńÜä’╝īÕ»╣Ķ┐Öõ║øµĢ░Ķ┐øĶĪīõĮŹÕøŠµÄÆÕ║Å’╝īÕŬķ£ĆĶ”üń║”5000000/8=625000Byte’╝īõ╣¤Õ░▒µś»0.625M’╝īµÄÆÕ║ÅÕÉÄĶŠōÕć║ŃĆé
- ń¼¼õ║īµ¼Ī’╝īµē½µÅÅĶŠōÕģźµ¢ćõ╗ȵŚČ’╝īÕÅ¬ÕżäńÉå4999999-10000000ńÜäµĢ░µŹ«ķĪ╣’╝īõ╣¤ÕŬķ£ĆĶ”ü0.625M’╝łÕÅ»õ╗źõĮ┐ńö©ń¼¼õĖƵ¼ĪÕżäńÉåńö│Ķ»ĘńÜäÕåģÕŁś’╝ēŃĆé
ÕøĀµŁż’╝īµĆ╗Õģ▒õ╣¤ÕŬķ£ĆĶ”ü0.625M
õĮŹÕøŠńÜäńÜäµ¢╣µ│Ģµ£ēÕ┐ģĶ”üÕ╝║Ķ░āõĖĆõĖŗ’╝īÕ░▒µś»õĮŹÕøŠńÜäķĆéńö©ĶīāÕø┤õĖ║ķÆłÕ»╣õĖŹķćŹÕżŹńÜäµĢ░µŹ«Ķ┐øĶĪīµÄÆÕ║Å’╝īĶŗźµĢ░µŹ«µ£ēķćŹÕżŹ’╝īõĮŹÕøŠµ¢╣µĪłÕ░▒õĖŹķĆéńö©õ║åŃĆé
3ŃĆüÕżÜĶĘ»ÕĮÆÕ╣ČŃĆéµŖŖĶ┐ÖõĖ¬µ¢ćõ╗ČÕłåõĖ║ĶŗźÕ╣▓Õż¦Õ░ÅńÜäÕćĀÕØŚ’╝īńäČÕÉÄÕłåÕł½Õ»╣µ»ÅõĖĆÕØŚĶ┐øĶĪīµÄÆÕ║Å’╝īµ£ĆÕÉÄÕ«īµłÉµĢ┤õĖ¬Ķ┐ćń©ŗńÜäµÄÆÕ║ÅŃĆékĶȤń«Śµ│ĢÕÅ»õ╗źÕ£©knńÜ䵌ČķŚ┤Õ╝ĆķöĆÕåģÕÆīn/kńÜäń®║ķŚ┤Õ╝ĆķöĆÕåģÕ«īµłÉÕ»╣µ£ĆÕżÜnõĖ¬Õ░Åõ║ÄnńÜ䵌ĀķćŹÕżŹµŁŻµĢ┤µĢ░ńÜäµÄÆÕ║ÅŃĆéµ»öÕ”éÕÅ»ÕłåõĖ║2ÕØŚ’╝łk=2’╝ī1ĶȤÕÅŹµŁŻÕŹĀńö©ńÜäÕåģÕŁśÕŬµ£ē1.25/2M’╝ē’╝ī1~4999999’╝īÕÆī5000000~9999999ŃĆéÕģłķüŹÕÄåõĖĆĶȤ’╝īķ”¢ÕģłµÄÆÕ║ÅÕżäńÉå1~4999999õ╣ŗķŚ┤ńÜäµĢ┤µĢ░’╝łńö©5000000/8=625000õĖ¬ÕŁŚńÜäÕŁśÕé©ń®║ķŚ┤µØźµÄÆÕ║Å0~4999999õ╣ŗķŚ┤ńÜäµĢ┤µĢ░’╝ē’╝īńäČÕÉÄÕåŹń¼¼õ║īĶȤ’╝īÕ»╣5000001~1000000õ╣ŗķŚ┤ńÜäµĢ┤µĢ░Ķ┐øĶĪīµÄÆÕ║ÅÕżäńÉåŃĆéÕ£©ń©ŹÕÉÄńÜäń¼¼õ║īĶŖéŃĆüń¼¼õĖēĶŖéŃĆüń¼¼ÕøøĶŖé’╝īµłæõ╗¼Õ░åĶ»”ń╗åķśÉĶ┐░Õ╣ČÕ«×ńÄ░Ķ┐Öń¦ŹÕżÜĶĘ»ÕĮÆÕ╣ȵÄÆÕ║ÅńŻüńøśµ¢ćõ╗ČńÜäµ¢╣µĪłŃĆé
4ŃĆüĶ»╗ĶĆģµĆØĶĆāŃĆéń╗ÅĶ┐ćõĖŖĶ┐░µĆØĶĘ»3ńÜäµ¢╣µĪłõ╣ŗÕÉÄ’╝īńÄ░Õ£©µ£ēõĖżõĖ¬Õ▒Ćķā©µ£ēÕ║ÅńÜäµĢ░ń╗äõ║å’╝īķéŻõ╣łĶ”üÕŠŚÕł░õĖĆõĖ¬Õ«īµĢ┤ńÜäµÄÆÕ║ÅńÜäµĢ░ń╗ä’╝īµÄźõĖŗµØźµö╣µĆÄõ╣łÕüÜÕæó?µł¢ĶĆģĶ»┤’╝īÕ”éµ×£µś»KĶĘ»ÕĮÆÕ╣Č’╝īÕŠŚÕł░kõĖ¬µÄÆÕ║ÅńÜäÕŁÉµĢ░ń╗ä’╝īµŖŖõ╗¢õ╗¼ÕÉłÕ╣ȵłÉõĖĆõĖ¬Õ«īµĢ┤ńÜäµÄÆÕ║ŵĢ░ń╗ä’╝īÕ”éõĮĢõ╝śÕī¢’╝¤µł¢ĶĆģ’╝īµłæÕåŹķŚ«õĮĀõĖĆõĖ¬ķŚ«ķóś’╝īKĶĘ»ÕĮÆÕ╣Čńö©Ķ┤źĶĆģµĀæ ÕÆī Ķā£ĶĆģµĀæ µĢłńÄćµ£ēõ╗Ćõ╣łÕĘ«Õł½?Ķ┐Öõ║øķŚ«ķóś’╝īĶ»ĘĶ»╗ĶĆģµĆØĶĆāŃĆé
ń¼¼õ║īĶŖéŃĆüÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäc++Õ«×ńÄ░
µ£¼ĶŖéÕÆ▒õ╗¼µÜéµŖøÕ╝ĆÕÆ▒õ╗¼ńÜäķŚ«ķóś’╝īķśÉĶ┐░õĖŗµ£ēÕģ│ÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäc++Õ«×ńÄ░ķŚ«ķóśŃĆéÕ£©ń©ŹÕÉÄńÜäń¼¼õĖēĶŖé’╝īÕÆ▒õ╗¼ÕåŹµØźÕģĘõĮōķÆłÕ»╣ÕÆ▒õ╗¼ńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅķŚ«ķóśķśÉĶ┐░õĖÄÕ«×ńÄ░ŃĆé
Õ£©õ║åĶ¦ŻÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│Ģõ╣ŗÕēŹ’╝īõĮĀĶ┐śÕŠŚõ║åĶ¦ŻÕĮÆÕ╣ȵÄÆÕ║ÅńÜäĶ┐ćń©ŗ’╝īÕøĀõĖ║õĖŗķØóńÜäÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢÕ░▒µś»Õ¤║õ║ÄĶ┐ÖõĖ¬µĄüń©ŗńÜäŃĆéÕģČÕ«×ÕĮÆÕ╣ȵÄÆÕ║ÅÕ░▒µś»2ĶĘ»ÕĮÆÕ╣Č’╝īĶĆīÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢÕ░▒µś»µŖŖ2µŹóµłÉõ║åk’╝īÕŹ│ÕżÜ’╝łk’╝ēĶĘ»ÕĮÆÕ╣ČŃĆéõĖŗķØó’╝īõĖŠõĖ¬õŠŗÕŁÉµØźĶ»┤µśÄõĖŗµŁżÕĮÆÕ╣ȵÄÆÕ║Åń«Śµ│Ģ’╝īÕ”éõĖŗÕøŠµēĆńż║’╝īµłæõ╗¼Õ»╣µĢ░ń╗ä8 3 2 6 7 1 5 4Ķ┐øĶĪīÕĮÆÕ╣ȵÄÆÕ║Å’╝Ü

ÕĮÆÕ╣ȵÄÆÕ║Åń«Śµ│Ģń«ĆĶ”üõ╗ŗń╗Ź’╝Ü
õĖĆŃĆüµĆØĶĘ»µÅÅĶ┐░’╝Ü
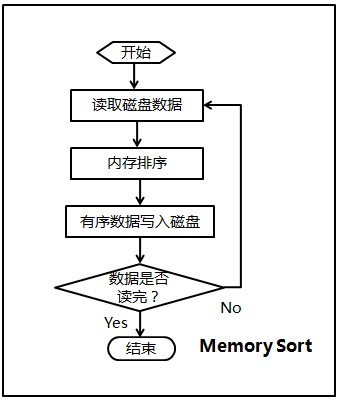
Ķ«ŠõĖżõĖ¬µ£ēÕ║ÅńÜäÕŁÉµ¢ćõ╗Č(ńøĖÕĮōõ║ÄĶŠōÕģźÕĀå)µöŠÕ£©ÕÉīõĖĆÕÉæķćÅõĖŁńøĖķé╗ńÜäõĮŹńĮ«õĖŖ’╝ÜR[low..m]’╝īR[m+1..high]’╝īÕģłÕ░åÕ«āõ╗¼ÕÉłÕ╣ČÕł░õĖĆõĖ¬Õ▒Ćķā©ńÜäµÜéÕŁśÕÉæķćÅR1(ńøĖÕĮōõ║ÄĶŠōÕć║ÕĀå)õĖŁ’╝īÕŠģÕÉłÕ╣ČÕ«īµłÉÕÉÄÕ░åR1ÕżŹÕłČÕø×R[low..high]õĖŁŃĆé
õ║īĶĘ»ÕĮÆÕ╣ȵÄÆÕ║ÅńÜäĶ┐ćń©ŗµś»’╝Ü
(1)µŖŖµŚĀÕ║ÅĶĪ©õĖŁńÜäµ»ÅõĖĆõĖ¬Õģāń┤ĀķāĮń£ŗõĮ£µś»õĖĆõĖ¬µ£ēÕ║ÅĶĪ©’╝īÕłÖµ£ēnõĖ¬µ£ēÕ║ÅÕŁÉĶĪ©’╝ø
(2)µŖŖnõĖ¬µ£ēÕ║ÅÕŁÉĶĪ©µīēńøĖķé╗õĮŹńĮ«ÕłåµłÉĶŗźÕ╣▓Õ»╣’╝łĶŗźnõĖ║ÕźćµĢ░’╝īÕłÖµ£ĆÕÉÄõĖĆõĖ¬ÕŁÉĶĪ©ÕŹĢńŗ¼õĮ£õĖ║õĖĆń╗ä’╝ē’╝īµ»ÅÕ»╣õĖŁńÜäõĖżõĖ¬ÕŁÉĶĪ©Ķ┐øĶĪīÕĮÆÕ╣Č’╝īÕĮÆÕ╣ČÕÉÄÕŁÉĶĪ©µĢ░ÕćÅÕ░æõĖĆÕŹŖ’╝ø
(3)ÕÅŹÕżŹĶ┐øĶĪīĶ┐ÖõĖĆĶ┐ćń©ŗ’╝īńø┤Õł░ÕĮÆÕ╣ČõĖ║õĖĆõĖ¬µ£ēÕ║ÅĶĪ©õĖ║µŁóŃĆéõ║īĶĘ»ÕĮÆÕ╣ȵÄÆÕ║ÅĶ┐ćń©ŗńÜäµĀĖÕ┐āµōŹõĮ£µś»Õ░åõĖĆń╗┤µĢ░ń╗äõĖŁńøĖķé╗ńÜäõĖżõĖ¬µ£ēÕ║ÅĶĪ©ÕĮÆÕ╣ČõĖ║õĖĆõĖ¬µ£ēÕ║ÅĶĪ©ŃĆé
õ║īŃĆüÕłåń▒╗’╝Ü
ÕĮÆÕ╣ȵÄÆÕ║ÅÕÅ»ÕłåõĖ║’╝ÜÕżÜĶĘ»ÕĮÆÕ╣ȵÄÆÕ║ÅŃĆüõĖżĶĘ»ÕĮÆÕ╣ȵÄÆÕ║Å ŃĆé
ĶŗźÕĮÆÕ╣ČńÜäµ£ēÕ║ÅĶĪ©µ£ēõĖżõĖ¬’╝īÕŽÕüÜõ║īĶĘ»ÕĮÆÕ╣ČŃĆéõĖĆĶł¼Õ£░’╝īĶŗźÕĮÆÕ╣ČńÜäµ£ēÕ║ÅĶĪ©µ£ēkõĖ¬’╝īÕłÖń¦░õĖ║kĶĘ»ÕĮÆÕ╣ČŃĆéõ║īĶĘ»ÕĮÆÕ╣ȵ£ĆõĖ║ń«ĆÕŹĢÕÆīÕĖĖńö©’╝īµŚóķĆéńö©õ║ÄÕåģķā©µÄÆÕ║Å’╝īõ╣¤ķĆéńö©õ║ÄÕż¢ķā©µÄÆÕ║ÅŃĆéµ£¼µ¢ćńØĆķćŹĶ«©Ķ«║Õż¢ķā©µÄÆÕ║ÅõĖŗńÜäÕżÜ’╝łK’╝ēĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢŃĆéõĖēŃĆüń«Śµ│ĢÕłåµ×É’╝Ü
1ŃĆüń©│Õ«ÜµĆ¦:ÕĮÆÕ╣ȵÄÆÕ║ŵś»õĖĆń¦Źń©│Õ«ÜńÜäµÄÆÕ║ÅŃĆé
2ŃĆüÕŁśÕé©ń╗ōµ×äĶ”üµ▒é:ÕÅ»ńö©ķĪ║Õ║ÅÕŁśÕé©ń╗ōµ×äŃĆéõ╣¤µśōõ║ÄÕ£©ķōŠĶĪ©õĖŖÕ«×ńÄ░ŃĆé
3ŃĆüµŚČķŚ┤ÕżŹµØéÕ║”: Õ»╣ķĢ┐Õ║”õĖ║nńÜäµ¢ćõ╗Č’╝īķ£ĆĶ┐øĶĪīlgnĶȤõ║īĶĘ»ÕĮÆÕ╣Č’╝īµ»ÅĶȤÕĮÆÕ╣ČńÜ䵌ČķŚ┤õĖ║O(n)’╝īµĢģÕģȵŚČķŚ┤ÕżŹµØéÕ║”µŚĀĶ«║µś»Õ£©µ£ĆÕźĮµāģÕåĄõĖŗĶ┐śµś»Õ£©µ£ĆÕØŵāģÕåĄõĖŗÕØ浜»O(nlgn)ŃĆéŃĆé
4ŃĆüń®║ķŚ┤ÕżŹµØéÕ║”:ķ£ĆĶ”üõĖĆõĖ¬ĶŠģÕŖ®ÕÉæķćÅµØźµÜéÕŁśõĖżµ£ēÕ║ÅÕŁÉµ¢ćõ╗ČÕĮÆÕ╣ČńÜäń╗ōµ×£’╝īµĢģÕģČĶŠģÕŖ®ń®║ķŚ┤ÕżŹµØéÕ║”õĖ║O(n)’╝īµśŠńäČÕ«āõĖŹµś»Õ░▒Õ£░µÄÆÕ║ÅŃĆé
µ│©µäÅ:Ķŗźńö©ÕŹĢķōŠĶĪ©ÕüÜÕŁśÕé©ń╗ōµ×ä’╝īÕŠłÕ«╣µśōń╗ÖÕć║Õ░▒Õ£░ńÜäÕĮÆÕ╣ȵÄÆÕ║ÅŃĆé
µĆ╗ń╗ō’╝ÜõĖÄÕ┐½ķƤµÄÆÕ║ÅńøĖµ»ö’╝īÕĮÆÕ╣ȵÄÆÕ║ÅńÜäµ£ĆÕż¦ńē╣ńé╣µś»’╝īÕ«āµś»õĖĆń¦Źń©│Õ«ÜńÜäµÄÆÕ║ŵ¢╣µ│ĢŃĆéÕĮÆÕ╣ȵÄÆÕ║ÅõĖĆĶł¼ÕżÜńö©õ║ÄÕż¢µÄÆÕ║ÅŃĆéõĮåÕ«āÕ£©ÕåģµÄƵ¢╣ķØóõ╣¤ÕŹĀµ£ēķćŹĶ”üÕ£░õĮŹ’╝īÕøĀõĖ║Õ«āµś»Õ¤║õ║ĵ»öĶŠāńÜ䵌ČķŚ┤ÕżŹµØéÕ║”õĖ║O(N*Log(N))ńÜäµÄÆÕ║Åń«Śµ│ĢõĖŁÕö»õĖĆń©│Õ«ÜńÜäµÄÆÕ║Å’╝īµēĆõ╗źÕ£©ķ£ĆĶ”üń©│Õ«ÜÕåģµÄÆÕ║ŵŚČķĆÜÕĖĖõ╝ÜķĆēµŗ®ÕĮÆÕ╣ȵÄÆÕ║ÅŃĆéÕĮÆÕ╣ȵÄÆÕ║ÅõĖŹĶ”üµ▒éÕ»╣Õ║ÅÕłŚÕÅ»õ╗źÕŠłÕ┐½Õ£░Ķ┐øĶĪīķÜŵ£║Ķ«┐ķŚ«’╝īµēĆõ╗źÕ£©ķōŠĶĪ©µÄÆÕ║ÅńÜäÕ«×ńÄ░õĖŁÕŠłÕÅŚµ¼óĶ┐ÄŃĆé
ÕźĮńÜä’╝īõ╗ŗń╗ŹÕ«īõ║åÕĮÆÕ╣ȵÄÆÕ║ÅÕÉÄ’╝īÕø×Õł░ÕÆ▒õ╗¼ńÜäķŚ«ķóśŃĆéńö▒ń¼¼õĖĆĶŖé’╝īµłæõ╗¼ÕĘ▓ń╗Åń¤źķüō’╝īÕĮōµĢ░µŹ«ķćÅÕż¦Õł░õĖŹķĆéÕÉłÕ£©ÕåģÕŁśõĖŁµÄÆÕ║ŵŚČ’╝īÕÅ»õ╗źÕł®ńö©ÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢÕ»╣ńŻüńøśµ¢ćõ╗ČĶ┐øĶĪīµÄÆÕ║ÅŃĆé
µłæõ╗¼õ╗źõĖĆõĖ¬ÕīģÕɽՊłÕżÜõĖ¬µĢ┤µĢ░ńÜäÕż¦µ¢ćõ╗ČõĖ║õŠŗ’╝īµØźĶ»┤µśÄÕżÜĶĘ»ÕĮÆÕ╣ČńÜäÕż¢µÄÆÕ║Åń«Śµ│ĢÕ¤║µ£¼µĆصā│ŃĆéÕüćĶ«Šµ¢ćõ╗ČõĖŁµĢ┤µĢ░õĖ¬µĢ░õĖ║N(Nµś»õ║┐ń║¦ńÜä)’╝īµĢ┤µĢ░õ╣ŗķŚ┤ńö©ń®║µĀ╝ÕłåÕ╝ĆŃĆéķ”¢ÕģłÕłåÕżÜµ¼Īõ╗ÄĶ»źµ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢M’╝łÕŹüõĖćń║¦’╝ēõĖ¬µĢ┤µĢ░’╝īµ»Åµ¼ĪÕ░åMõĖ¬µĢ┤µĢ░Õ£©ÕåģÕŁśõĖŁõĮ┐ńö©Õ┐½ķƤµÄÆÕ║Åõ╣ŗÕÉÄÕŁśÕģźõĖ┤µŚČµ¢ćõ╗Č’╝īńäČÕÉÄõĮ┐ńö©ÕżÜĶĘ»ÕĮÆÕ╣ČÕ░åÕÉäõĖ¬õĖ┤µŚČµ¢ćõ╗ČõĖŁńÜäµĢ░µŹ«ÕåŹµ¼ĪµĢ┤õĮōµÄÆÕźĮÕ║ÅÕÉÄÕŁśÕģźĶŠōÕć║µ¢ćõ╗ČŃĆ鵜ŠńäČ’╝īĶ»źµÄÆÕ║Åń«Śµ│Ģķ£ĆĶ”üÕ»╣µ»ÅõĖ¬µĢ┤µĢ░ÕüÜ2µ¼ĪńŻüńøśĶ»╗ÕÆī2µ¼ĪńŻüńøśÕåÖŃĆéõ╗źõĖŗµś»µ£¼ń©ŗÕ║ÅńÜ䵥üń©ŗÕøŠ’╝Ü
µ£¼ń©ŗÕ║ŵś»Õ¤║õ║Äõ╗źõĖŖµĆصā│Õ»╣ÕīģÕÉ½Õż¦ķćŵĢ┤µĢ░µ¢ćõ╗ČńÜäõ╗ÄÕ░ÅÕł░Õż¦µÄÆÕ║ÅńÜäõĖĆõĖ¬ń«ĆÕŹĢÕ«×ńÄ░’╝īĶ┐Öķćīµ▓Īµ£ēõĮ┐ńö©ÕåģÕŁśń╝ōÕå▓Õī║’╝īÕ£©ÕĮÆÕ╣ȵŚČń«ĆÕŹĢõĮ┐ńö©õĖĆõĖ¬µĢ░ń╗äµØźÕŁśÕ驵»ÅõĖ¬õĖ┤µŚČµ¢ćõ╗ČńÜäń¼¼õĖĆõĖ¬Õģāń┤ĀŃĆéõĖŗķØóµś»ÕżÜĶĘ»ÕĮÆÕ╣ȵÄÆÕ║Åń«Śµ│ĢńÜäc++Õ«×ńÄ░õ╗ŻńĀü’╝łÕ£©ń¼¼ÕøøĶŖé’╝īÕ░åń╗ÖÕć║ÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäcÕ«×ńÄ░’╝ē’╝Ü
ń©ŗÕ║ŵĄŗĶ»Ģ’╝ÜĶ»╗ĶĆģÕÅ»õ╗źń╗¦ń╗Łńö©Õ░ŵ¢ćõ╗ČÕ░ŵĢ░µŹ«ķćÅĶ┐øõĖƵŁźµĄŗĶ»ĢŃĆé
ń¼¼õĖēĶŖéŃĆüńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅńÜäń╝¢ń©ŗÕ«×ńÄ░
ok’╝īµÄźõĖŗµØź’╝īµłæõ╗¼µØźń╝¢ń©ŗÕ«×ńÄ░õĖŖĶ┐░ńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅńÜäķŚ«ķóś’╝īµ£¼ń©ŗÕ║Åńö▒õĖżķā©Õłåµ×䵳ɒ╝Ü
1ŃĆüÕåģÕŁśµÄÆÕ║Å
ńö▒õ║ÄĶ”üµ▒éńÜäÕÅ»ńö©ÕåģÕŁśõĖ║1MB’╝īķéŻõ╣łµ»Åµ¼ĪÕÅ»õ╗źÕ£©ÕåģÕŁśõĖŁÕ»╣250KńÜäµĢ░µŹ«Ķ┐øĶĪīµÄÆÕ║Å’╝īńäČÕÉÄÕ░åµ£ēÕ║ÅńÜäµĢ░ÕåÖÕģźńĪ¼ńøśŃĆé
ķéŻõ╣ł10MńÜäµĢ░µŹ«ķ£ĆĶ”üÕŠ¬ńÄ»40µ¼Ī’╝īµ£Ćń╗łõ║¦ńö¤40õĖ¬µ£ēÕ║ÅńÜäµ¢ćõ╗ČŃĆé
2ŃĆüÕĮÆÕ╣ȵÄÆÕ║Å
- Õ░åµ»ÅõĖ¬µ¢ćõ╗ȵ£ĆÕ╝ĆÕ¦ŗńÜäµĢ░Ķ»╗Õģź(ńö▒õ║ĵ£ēÕ║Å’╝īµēĆõ╗źõĖ║Ķ»źµ¢ćõ╗ȵ£ĆÕ░ŵĢ░)’╝īÕŁśµöŠÕ£©õĖĆõĖ¬Õż¦Õ░ÅõĖ║40ńÜäfirst_dataµĢ░ń╗äõĖŁ’╝ø
- ķĆēµŗ®first_dataµĢ░ń╗äõĖŁµ£ĆÕ░ÅńÜäµĢ░min_data’╝īÕÅŖÕģČÕ»╣Õ║öńÜäµ¢ćõ╗Čń┤óÕ╝Ģindex’╝ø
- Õ░åfirst_dataµĢ░ń╗äõĖŁµ£ĆÕ░ÅńÜäµĢ░ÕåÖÕģźµ¢ćõ╗Čresult’╝īńäČÕÉĵø┤µ¢░µĢ░ń╗äfirst_data(µĀ╣µŹ«indexĶ»╗ÕÅ¢Ķ»źµ¢ćõ╗ČõĖŗõĖĆõĖ¬µĢ░õ╗Żµø┐min_data)’╝ø
- Õłżµ¢Łµś»ÕÉ”µēƵ£ēµĢ░µŹ«ķāĮĶ»╗ÕÅ¢Õ«īµ»Ģ’╝īÕÉ”ÕłÖĶ┐öÕø×2ŃĆé
µēĆõ╗ź’╝īµ£¼ń©ŗÕ║ŵīēķĪ║Õ║ÅÕłåõĖżµŁź’╝īń¼¼õĖƵŁźŃĆüMemory Sort’╝īń¼¼õ║īµŁźŃĆüMerge SortŃĆéń©ŗÕ║ÅńÜ䵥üń©ŗÕøŠ’╝īÕ”éõĖŗÕøŠµēĆńż║’╝łµä¤Ķ░óFńÜäń╗śÕłČ’╝ēŃĆé
ńäČÕÉÄ’╝īń╝¢ÕåÖńÜäÕ«īµĢ┤õ╗ŻńĀüÕ”éõĖŗ’╝Ü
ÕģČõĖŁ’╝īńö¤µłÉµĢ░µŹ«µ¢ćõ╗Čdata.txtńÜäõ╗ŻńĀüÕ£©ń¼¼õĖĆĶŖéÕĘ▓ń╗Åń╗ÖÕć║ŃĆé
ń©ŗÕ║ŵĄŗĶ»Ģ’╝Ü
1ŃĆüÕÆ▒õ╗¼Õ»╣1000WµĢ░µŹ«Ķ┐øĶĪīµĄŗĶ»Ģ’╝īµēōÕ╝ĆÕŹŖÕż®µ▓Īń£ŗÕł░µĢ░µŹ«’╝ī
2ŃĆüń╝¢Ķ»æĶ┐ÉĶĪīõĖŖĶ┐░ń©ŗÕ║ÅÕÉÄ’╝īdataµ¢ćõ╗ČÕģłĶó½ÕłåµłÉ40õĖ¬Õ░ŵ¢ćõ╗Čdata[1....40]’╝īńäČÕÉÄń©ŗÕ║ÅÕåŹÕ»╣Ķ┐Ö40õĖ¬Õ░ŵ¢ćõ╗ČĶ┐øĶĪīÕĮÆÕ╣ȵÄÆÕ║Å’╝īµÄÆÕ║Åń╗ōµ×£µ£Ćń╗łńö¤µłÉÕ£©resultµ¢ćõ╗ČõĖŁ’╝īĶ欵Łżresultµ¢ćõ╗ČõĖŁõŠ┐µś»ńö▒dataµ¢ćõ╗ČńÜäµĢ░µŹ«ń╗ŵÄÆÕ║ÅÕÉÄÕŠŚÕł░ńÜäµĢ░µŹ«ŃĆé
3ŃĆüõĖö’╝īµłæõ╗¼ĶāĮń£ŗÕł░’╝īdata[i]’╝īi=1...40ńÜäµ»ÅõĖ¬µ¢ćõ╗ČķāĮµś»µ£ēÕ║ÅńÜä’╝īÕ”éõĖŗÕøŠ’╝Ü
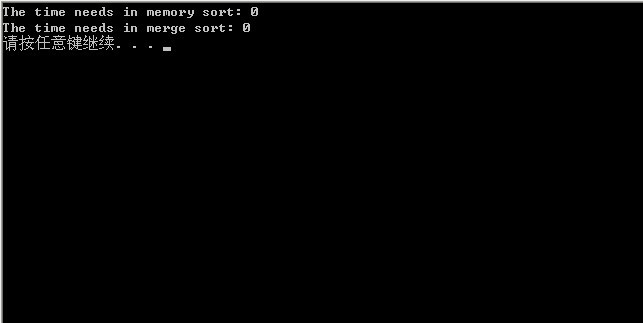
4ŃĆüµ£Ćń╗łńÜäĶ┐ÉĶĪīń╗ōµ×£’╝īÕ”éõĖŗ’╝īÕŹĢõĮŹń╗¤õĖĆõĖ║ms’╝Ü
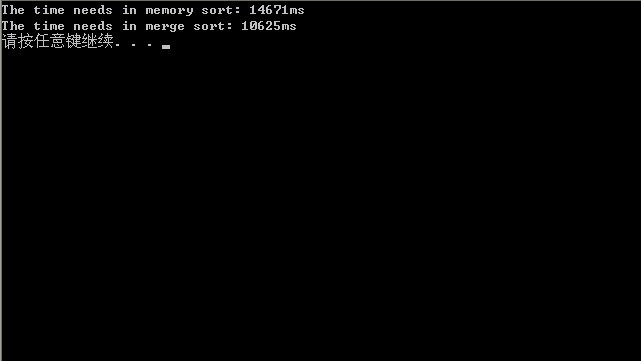
ńö▒õĖŖĶ¦éõ╣ŗ’╝īµłæõ╗¼ÕÅæńÄ░’╝īń¼¼õĖĆĶŖéńÜäõĮŹÕøŠµ¢╣µĪłńÜäń©ŗÕ║ŵĢłńÄ浜»µ£ĆÕ┐½ńÜä’╝īń║”õĖ║14s’╝īĶĆīķććńö©õĖŖĶ┐░ńÜäÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäń©ŗÕ║ÅĶ┐ÉĶĪīµŚČķŚ┤ń║”õĖ║25sŃĆ鵌ČķŚ┤õĖ╗Ķ”üµĄ¬Ķ┤╣Õ£©Ķ»╗ÕåÖńŻüńøśIOõĖŖ’╝īõĖöń©ŗÕ║ÅõĖŁńö©ńÜäÕ║ōÕćĮµĢ░qsortõ╣¤ĶĆŚĶ┤╣õ║åõĖŹÕ░æµŚČķŚ┤ŃĆéµēĆõ╗ź’╝īµĆ╗ńÜäµØźĶ»┤’╝īķććÕÅ¢õĮŹÕøŠµ¢╣µĪłµś»µ£ĆõĮ│µ¢╣µĪłŃĆé
Õ░ŵĢ░µŹ«ķćŵĄŗĶ»Ģ’╝Ü
µłæõ╗¼õĖŗķØóķÆłÕ»╣Õ░ŵĢ░µŹ«ķćÅńÜäµ¢ćõ╗ČÕåŹµĄŗĶ»ĢõĖƵ¼Ī’╝īķÆłÕ»╣20õĖ¬Õ░ŵĢ░µŹ«’╝īµ»ÅĶČ¤Õ»╣4õĖ¬µĢ░µŹ«Ķ┐øĶĪīµÄÆÕ║Å’╝īÕŹ│5ĶĘ»ÕĮÆÕ╣Č’╝īń©ŗÕ║ÅńÜäµÄÆÕ║Åń╗ōµ×£Õ”éõĖŗÕøŠµēĆńż║ŃĆé
Ķ┐ÉĶĪīµŚČķŚ┤’╝Ü
0ms’╝īÕÅ»õ╗źÕ┐ĮńĢźõĖŹĶ«Īõ║å’╝īµ»Ģń½¤µś»Õ»╣20õĖ¬µĢ░ńÜäÕ░ŵĢ░µŹ«ķćÅĶ┐øĶĪīµÄÆÕ║Å’╝Ü

µ▓ÖµĄĘµŗŠĶ┤Ø’╝Ü
µłæõ╗¼õĖŹÕ£©õ╣ĵś»ÕÉ”ĶāĮµŖŖõĖĆõĖ¬ĶĮ»õ╗Čõ║¦Õōüµł¢õĖƵ£¼õ╣”µ£Ćń╗łÕ«īµłÉ’╝īµłæõ╗¼µø┤Õ£©õ╣ÄńÜ䵜»’╝īÕ£©Õ«īµłÉĶ┐ÖõĖ¬õ║¦Õōüµł¢ÕłøõĮ£Ķ┐Öµ£¼õ╣”ńÜäĶ┐ćń©ŗõĖŁ’╝īĶ»╗ĶĆģÕŁ”Õł░õ║åõ╗Ćõ╣ł’╝īĶāĮÕŁ”Õł░õ╗Ćõ╣ł?µēĆõ╗ź’╝īõĖŹĶ”üõĖĆÕæ│ńÜäķ®¼õĖŖÕ░▒µā│ÕŠŚÕł░õĖĆķüōķóśńø«ńÜ䵣ŻńĪ«ńŁöµĪł’╝īĶ»ĘĶʤńØƵłæõ╗¼õĖĆĶĄĘķĆɵŁźĶĄ░ÕÉæÕ▒▒ÕĘģŃĆé
ń¼¼ÕøøĶŖéŃĆüÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäcÕ«×ńÄ░
µ£¼ÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢńÜäcÕ«×ńÄ░ÕĤńÉåõĖÄõĖŖĶ┐░c++Õ«×ńÄ░õĖĆĶć┤’╝īõĖŹÕÉīńÜäÕ£░µ¢╣õĮōńÄ░Õ£©õĖĆõ║øń╗åĶŖéÕżäńÉåõĖŖ’╝īõĖöÕ»╣õĖ┤µŚČµ¢ćõ╗ČńÜäµÄÆÕ║Å’╝īõĖŹÕåŹńö©ń│╗ń╗¤µÅÉõŠøńÜäÕ┐½µÄÆ’╝īÕŹ│õĖŖķØóńÜäqsortÕ║ōÕćĮµĢ░’╝īµś»ķććńö©ńÜäõĖēµĢ░õĖŁÕĆ╝ńÜäÕ┐½ķƤµÄÆÕ║Å’╝łõĖ¬µĢ░Õ░Åõ║Ä3ńö©µÅÆÕģźµÄÆÕ║Å’╝ēńÜäŃĆéĶĆīµłæõ╗¼ń¤źķüō’╝īń║»µŁŻńÜäÕĮÆÕ╣ȵÄÆÕ║ÅÕģČÕ«×Õ░▒µś»µ»öĶŠāµÄÆÕ║Å’╝īÕ£©ÕĮÆÕ╣ČĶ┐ćń©ŗõĖŁµĆ╗µś»õĖŹµ¢ŁńÜäµ»öĶŠā’╝īõĖ║õ║åõ╗ÄõĖżõĖ¬µĢ░õĖŁµīæÕ░ÅńÜäÕĮÆÕ╣ČÕł░µ£Ćń╗łńÜäÕ║ÅÕłŚõĖŁŃĆéok’╝īµŁżń©ŗÕ║ÅńÜäĶ»”µāģĶ»Ęń£ŗ’╝Ü
ń©ŗÕ║ŵĄŗĶ»Ģ’╝Ü
Õ£©µŁż’╝īµłæõ╗¼ÕģłµĄŗĶ»ĢõĖŗÕ»╣10000000õĖ¬µĢ░µŹ«ńÜäµ¢ćõ╗ČĶ┐øĶĪī40ĶȤµÄÆÕ║Å’╝īńäČÕÉÄÕåŹÕ»╣100õĖ¬µĢ░µŹ«ńÜäµ¢ćõ╗ČĶ┐øĶĪī4ĶȤµÄÆÕ║Å’╝łĶ»╗ĶĆģÕÅ»Ķ┐øõĖƵŁźµĄŗĶ»Ģ’╝ēŃĆéÕ”éÕ╝äÕćĀń╗äÕ░Åńé╣ńÜäµĢ░µŹ«,ĶŠōÕć║IDÕÆīµĢ░µŹ«Õł░Õ▒ÅÕ╣Ģ’╝īÕåŹń£ŗń©ŗÕ║ÅĶ┐ÉĶĪīµĢłµ×£ŃĆé
- 10õĖ¬µĢ░, 4ń╗ä
- 40õĖ¬µĢ░, 5ń╗ä
- 55õĖ¬µĢ░, 6ń╗ä
- 100õĖ¬µĢ░, 7ń╗ä


’╝łÕżćµ│©’╝Ü1ŃĆüõ╗źõĖŖµēƵ£ēÕÉäĶŖéńÜäń©ŗÕ║ÅĶ┐ÉĶĪīńÄ»ÕóāõĖ║windows xp + vc6.0 + e5200 cpu 2.5gõĖ╗ķóæ’╝ī2ŃĆüµä¤Ķ░ó5õĖ║µ£¼µ¢ćń©ŗÕ║ŵēĆõĮ£ńÜäÕż¦ķćŵĄŗĶ»ĢÕĘźõĮ£’╝ē
Õģ©µ¢ćµĆ╗ń╗ō’╝Ü
1ŃĆüÕģ│õ║ĵ£¼ń½ĀõĖŁõĮŹÕøŠÕÆīÕżÜĶĘ»ÕĮÆÕ╣ČõĖżń¦Źµ¢╣µĪłńÜ䵌ČķŚ┤ÕżŹµØéÕ║”ÕÅŖń®║ķŚ┤ÕżŹµØéÕ║”ńÜäµ»öĶŠā’╝īÕ”éõĖŗ’╝Ü
µŚČķŚ┤ÕżŹµØéÕ║” ń®║ķŚ┤ÕżŹµØéÕ║”
õĮŹÕøŠ O(N) 0.625M
ÕżÜõĮŹÕĮÆÕ╣Č O(Nlogn) 1M
’╝łÕżÜĶĘ»ÕĮÆÕ╣Č’╝īµŚČķŚ┤ÕżŹµØéÕ║”õĖ║O’╝łk*n/k*logn/k ’╝ē’╝īõĖźµĀ╝µØźĶ»┤’╝īĶ┐śĶ”üÕŖĀõĖŖĶ»╗ÕåÖńŻüńøśńÜ䵌ČķŚ┤’╝īĶĆīµŁżń«Śµ│Ģń╗ØÕż¦ķā©ÕłåµŚČķŚ┤õ╣¤µś»µĄ¬Ķ┤╣Õ£©Ķ┐ÖõĖŖķØó’╝ē
2ŃĆübit-map
ķĆéńö©ĶīāÕø┤’╝ÜÕÅ»Ķ┐øĶĪīµĢ░µŹ«ńÜäÕ┐½ķƤµ¤źµēŠ’╝īÕłżķ插╝īÕłĀķÖż’╝īõĖĆĶł¼µØźĶ»┤µĢ░µŹ«ĶīāÕø┤µś»intńÜä10ÕĆŹõ╗źõĖŗ
Õ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜõĮ┐ńö©bitµĢ░ń╗äµØźĶĪ©ńż║µ¤Éõ║øÕģāń┤Āµś»ÕÉ”ÕŁśÕ£©’╝īµ»öÕ”é8õĮŹńöĄĶ»ØÕÅĘńĀü
µē®Õ▒Ģ’╝Übloom filterÕÅ»õ╗źń£ŗÕüܵś»Õ»╣bit-mapńÜäµē®Õ▒Ģ
ķŚ«ķóśÕ«×õŠŗ’╝Ü
1)ÕĘ▓ń¤źµ¤ÉõĖ¬µ¢ćõ╗ČÕåģÕīģÕɽõĖĆõ║øńöĄĶ»ØÕÅĘńĀü’╝īµ»ÅõĖ¬ÕÅĘńĀüõĖ║8õĮŹµĢ░ÕŁŚ’╝īń╗¤Ķ«ĪõĖŹÕÉīÕÅĘńĀüńÜäõĖ¬µĢ░ŃĆé
8õĮŹµ£ĆÕżÜ99 999 999’╝īÕż¦µ”éķ£ĆĶ”ü99mõĖ¬bit’╝īÕż¦µ”é10ÕćĀmÕŁŚĶŖéńÜäÕåģÕŁśÕŹ│ÕÅ»ŃĆé
2)2.5õ║┐õĖ¬µĢ┤µĢ░õĖŁµēŠÕć║õĖŹķćŹÕżŹńÜäµĢ┤µĢ░ńÜäõĖ¬µĢ░’╝īÕåģÕŁśń®║ķŚ┤õĖŹĶČ│õ╗źÕ«╣ń║│Ķ┐Ö2.5õ║┐õĖ¬µĢ┤µĢ░ŃĆé
Õ░åbit-mapµē®Õ▒ĢõĖĆõĖŗ’╝īńö©2bitĶĪ©ńż║õĖĆõĖ¬µĢ░ÕŹ│ÕÅ»’╝ī0ĶĪ©ńż║µ£¬Õć║ńÄ░’╝ī1ĶĪ©ńż║Õć║ńÄ░õĖƵ¼Ī’╝ī2ĶĪ©ńż║Õć║ńÄ░2µ¼ĪÕÅŖõ╗źõĖŖŃĆ鵳¢ĶĆģµłæõ╗¼õĖŹńö©2bitµØźĶ┐øĶĪīĶĪ©ńż║’╝īµłæõ╗¼ńö©õĖżõĖ¬bit-mapÕŹ│ÕÅ»µ©Īµŗ¤Õ«×ńÄ░Ķ┐ÖõĖ¬2bit-mapŃĆé
3ŃĆü[Õż¢µÄÆÕ║ÅķĆéńö©ĶīāÕø┤]Õż¦µĢ░µŹ«ńÜäµÄÆÕ║Å’╝īÕÄ╗ķćŹÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜÕż¢µÄÆÕ║ÅńÜäÕĮÆÕ╣ȵ¢╣µ│Ģ’╝īńĮ«µŹóķĆēµŗ®Ķ┤źĶĆģµĀæÕĤńÉå’╝īµ£Ćõ╝śÕĮÆÕ╣ȵĀæµē®Õ▒ĢŃĆéķŚ«ķóśÕ«×õŠŗ’╝Ü1).µ£ēõĖĆõĖ¬1GÕż¦Õ░ÅńÜäõĖĆõĖ¬µ¢ćõ╗Č’╝īķćīķØóµ»ÅõĖĆĶĪīµś»õĖĆõĖ¬Ķ»Ź’╝īĶ»ŹńÜäÕż¦Õ░ÅõĖŹĶČģĶ┐ć16õĖ¬ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČÕż¦Õ░ŵś»1MŃĆéĶ┐öÕø×ķóæµĢ░µ£Ćķ½śńÜä100õĖ¬Ķ»ŹŃĆéĶ┐ÖõĖ¬µĢ░µŹ«Õģʵ£ēÕŠłµśÄµśŠńÜäńē╣ńé╣’╝īĶ»ŹńÜäÕż¦Õ░ÅõĖ║16õĖ¬ÕŁŚĶŖé’╝īõĮåµś»ÕåģÕŁśÕŬµ£ē1mÕüÜhashµ£ēõ║øõĖŹÕż¤’╝īµēĆõ╗źÕÅ»õ╗źńö©µØźµÄÆÕ║ÅŃĆéÕåģÕŁśÕÅ»õ╗źÕĮōĶŠōÕģźń╝ōÕå▓Õī║õĮ┐ńö©ŃĆé
4ŃĆüµĄĘķćŵĢ░µŹ«ÕżäńÉå
µ£ēÕģ│µĄĘķćŵĢ░µŹ«ÕżäńÉåńÜäµ¢╣µ│Ģµł¢ķØóĶ»ĢķóśÕÅ»ÕÅéĶĆāµŁżµ¢ć’╝īÕŹüķüōµĄĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»ĢķóśõĖÄÕŹüõĖ¬µ¢╣µ│ĢÕż¦µĆ╗ń╗ōŃĆ鵌źÕÉÄ’╝īõ╝ÜķĆɵŁźÕ«×ńÄ░Ķ┐ÖÕŹüõĖ¬ÕżäńÉåµĄĘķćŵĢ░µŹ«ńÜäµ¢╣µ│ĢŃĆéÕÉīµŚČ’╝īķĆüń╗ÖÕÉäõĮŹõĖĆÕÅźĶ»Ø’╝īĶ¦ŻÕå│ķŚ«ķóśńÜäÕģ│ķö«Õ£©õ║Äń夵éēõĖĆõĖ¬ń«Śµ│Ģ’╝īĶĆīõĖŹµś»µ¤ÉõĖĆõĖ¬ķŚ«ķóśŃĆéń夵éēõ║åõĖĆõĖ¬ń«Śµ│Ģ’╝īõŠ┐ķĆÜõ║åõĖĆńēćķóśńø«ŃĆé
µ£¼ń½ĀÕ«īŃĆé
ńēłµØāµēƵ£ē’╝īµ£¼õ║║Õ»╣µ£¼blogÕåģµēƵ£ēõ╗╗õĮĢÕåģÕ«╣õ║½µ£ēńēłµØāÕÅŖĶæŚõĮ£µØāŃĆéńĮæń╗£ĶĮ¼ĶĮĮ’╝īĶ»Ęõ╗źķōŠµÄźÕĮóÕ╝ŵ│©µśÄÕć║ÕżäŃĆé


- 2011-05-28 16:25
- µĄÅĶ¦ł 1977
- Ķ»äĶ«║(0)
- µ¤źń£ŗµø┤ÕżÜ
ÕÅæĶĪ©Ķ»äĶ«║

ńøĖÕģ│µÄ©ĶŹÉ
- ń¼¼ÕŹüń½ĀµÅÉõŠøõ║åÕ”éõĮĢń╗ÖÕż¦ķćŵĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ČĶ┐øĶĪīµÄÆÕ║ÅńÜäµ¢╣µ│ĢŃĆé **8. µ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ** - ń¼¼ÕŹüõĖĆń½ĀµÄóĶ«©õ║åµ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ’╝łLCS’╝ēķŚ«ķóśńÜäĶ¦ŻÕå│ńŁ¢ńĢźŃĆé **9. ÕżŹµØéķŚ«ķóśĶ¦ŻÕå│** - ń¼¼ÕŹüõ║īń½ĀĶć│ń¼¼õ║īÕŹüõ║īń½ĀĶ”åńø¢õ║åõĖĆń│╗ÕłŚÕżŹµØéķŚ«ķóś...
- **ń¼¼ÕŹüń½Ā’╝ÜÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å** - Ķ«©Ķ«║õ║åÕż¢ķā©µÄÆÕ║ÅńÜäµŖƵ£»’╝īķĆéńö©õ║ÄÕż¦Ķ¦äµ©ĪµĢ░µŹ«ńÜäµÄÆÕ║ÅķŚ«ķóśŃĆé - **ń¼¼ÕŹüõĖĆń½Ā’╝ܵ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ(LCS)ķŚ«ķóś** - õĮ┐ńö©ÕŖ©µĆüĶ¦äÕłÆµ¢╣µ│ĢĶ¦ŻÕå│õ║åµ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚķŚ«ķóśŃĆé - **ń¼¼ÕŹüõ║ī~...
- **ń¼¼ÕŹüń½Ā**’╝ÜÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å - **ń¼¼ÕŹüõĖĆń½Ā**’╝ܵ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ(LCS)ķŚ«ķóś - **ń¼¼ÕŹüõ║īĶć│ÕŹüõ║öń½Ā**’╝ÜõĖŁńŁŠµ”éńÄćŃĆüIPĶ«┐ķŚ«µ¼ĪµĢ░ŃĆüÕø×µ¢ćńŁēķŚ«ķóś - **ń¼¼ÕŹüÕģŁĶć│ń¼¼õ║īÕŹüń½Ā**’╝ÜÕģ©µÄÆÕłŚŃĆüĶĘ│ÕÅ░ķśČŃĆüÕźćÕüȵÄÆÕ║ÅńŁēķŚ«ķóś...
- **ń¼¼ÕŹüń½Ā’╝ÜÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å** ŌĆöŌĆö µÅÉõŠøõ║åÕż¦Ķ¦äµ©ĪµĢ░µŹ«µÄÆÕ║ÅńÜäµ£ēµĢłńŁ¢ńĢźŃĆé - **ń¼¼ÕŹüõĖĆń½Ā’╝ܵ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ(LCS)ķŚ«ķóś** ŌĆöŌĆö µÄóĶ«©õ║åLCSķŚ«ķóśńÜäń╗ÅÕģĖĶ¦Żµ│ĢÕÆīõ╝śÕī¢µŖĆÕʦŃĆé - **ń¼¼ÕŹüõ║ī~ÕŹüõ║öń½Ā’╝ÜõĖŁńŁŠµ”éńÄć’╝īIP...
- **µĢ░µŹ«ÕżäńÉå**’╝Ü10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅŃĆüõĖŁńŁŠµ”éńÄćŃĆüIPĶ«┐ķŚ«µ¼ĪµĢ░ŃĆé - **ń«Śµ│Ģõ╝śÕī¢**’╝Üõ║īÕłåµ¤źµēŠŃĆüÕĆƵÄÆń┤óÕ╝ĢŃĆüõĖŹµö╣ÕÅśµŁŻĶ┤¤µĢ░õ╣ŗķŚ┤ńøĖÕ»╣ķĪ║Õ║Åķ揵¢░µÄÆÕłŚµĢ░ń╗äŃĆé - **ķ½śń║¦ķŚ«ķóś**’╝ܵ£ĆÕż¦Ķ┐×ń╗Łõ╣śń¦»ÕŁÉõĖ▓ŃĆüÕŁŚń¼”õĖ▓ń╝¢ĶŠæĶĘØń”╗ŃĆüÕŁŚń¼”õĖ▓...
- **ń¼¼ÕŹüń½Ā’╝ÜÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å** - Ķ«©Ķ«║Õż¦µĢ░µŹ«ķćŵÄÆÕ║ÅńÜäµ¢╣µ│ĢŃĆé - µČĄńø¢Õż¢ķā©µÄÆÕ║ŵŖƵ£»ÕÅŖÕģČÕ«×ńÄ░ń╗åĶŖéŃĆé - **ń¼¼ÕŹüõĖĆń½Ā’╝ܵ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ(LCS)ķŚ«ķóś** - Ķ«▓Ķ¦Żµ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚķŚ«ķóśńÜäÕ«Üõ╣ēÕÆīµ▒éĶ¦Żµ¢╣µ│ĢŃĆé - Õłåµ×É...
- **ń¼¼ÕŹüń½Ā’╝ÜÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å** - **ń¤źĶ»åńé╣**’╝ÜÕż¢ķā©µÄÆÕ║Åń«Śµ│ĢŃĆüÕĮÆÕ╣ȵÄÆÕ║ÅŃĆé - **Õ║öńö©Õ£║µÖ»**’╝ÜÕż¦µĢ░µŹ«ÕżäńÉåŃĆüµĄĘķćŵŚźÕ┐ŚÕłåµ×ÉńŁēŃĆé - **ń¼¼ÕŹüõĖĆń½Ā’╝ܵ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ(LCS)ķŚ«ķóś** - **ń¤źĶ»åńé╣**’╝ÜÕŖ©µĆüĶ¦äÕłÆ...
##### ń¼¼ÕŹüń½Ā’╝ÜÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å õ╗ŗń╗Źõ║åÕż¦Ķ¦äµ©ĪµĢ░µŹ«µÄÆÕ║ÅńÜäµŖƵ£»’╝īÕīģµŗ¼Õż¢ķā©µÄÆÕ║Åń«Śµ│ĢńÜäÕ║öńö©ŃĆé ##### ń¼¼ÕŹüõĖĆń½Ā’╝ܵ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ(LCS)ķŚ«ķóś LCSķŚ«ķ󜵜»ÕŁŚń¼”õĖ▓Õī╣ķģŹõĖŁńÜäõĖĆõĖ¬ÕģĖÕ×ŗķŚ«ķóś’╝īµ£¼ń½ĀĶ»”ń╗åķśÉĶ┐░õ║åÕ”éõĮĢ...
10. **Õ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å** - **ń¤źĶ»åńé╣**’╝ÜÕż¢ķā©µÄÆÕ║Åń«Śµ│ĢŃĆüÕĮÆÕ╣ȵÄÆÕ║Å - **ÕåģÕ«╣µ”éĶ┐░**’╝ܵÄóĶ«©õ║åÕ”éõĮĢÕ»╣Õż¦Ķ¦äµ©ĪµĢ░µŹ«Ķ┐øĶĪīµÄÆÕ║ÅńÜäµ¢╣µ│ĢŃĆéõĖ╗Ķ”üõ╗ŗń╗Źõ║åÕż¢ķā©µÄÆÕ║ÅńÜäµ”éÕ┐ĄÕÆīÕĮÆÕ╣ȵÄÆÕ║ÅÕ£©ńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅõĖŁńÜäÕ║öńö©ŃĆé #### ...
ÕĮōµĢ░µŹ«ķćÅĶ┐ćÕż¦µŚČ’╝īÕģłÕ░åµĢ░µŹ«ÕłåÕē▓µłÉÕ░ÅÕØŚĶ┐øĶĪīÕåģķā©µÄÆÕ║Å’╝īńäČÕÉÄķĆÜĶ┐ćÕżÜµ¼Īõ║żõ║ÆÕ░åĶ┐Öõ║øÕĘ▓µÄÆÕ║ÅńÜäÕ░ÅÕØŚÕÉłÕ╣ȵłÉµ£Ćń╗łńÜäµ£ēÕ║ÅÕ║ÅÕłŚŃĆé Õ£©C++ÕŁ”õ╣ĀõĖŁ’╝īÕ«×ńÄ░Ķ┐Öõ║øµÄÆÕ║Åń«Śµ│Ģķ£ĆĶ”üµÄīµÅĪÕ¤║µ£¼ńÜäń╝¢ń©ŗµŖĆÕʦÕÆīSTLÕ«╣ÕÖ©’╝īÕ”évectorÕÆīlist’╝īõ╗źÕÅŖń«Śµ│ĢÕ║ōÕ”é...
8. ń¼¼Õģ½ń½ĀÕł░ń¼¼ÕŹüń½ĀĶ«©Ķ«║õ║åķØóÕÉæÕ»╣Ķ▒Īń╝¢ń©ŗõĖŁńÜäĶÖÜÕćĮµĢ░ŃĆüķōŠĶĪ©ķŚ«ķóśÕÆīÕż¦µĢ░µŹ«ÕżäńÉå’╝īõŠŗÕ”éÕ”éõĮĢÕ»╣10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ČĶ┐øĶĪīµÄÆÕ║ÅŃĆé 9. ń¼¼ÕŹüõĖĆń½ĀÕł░ń¼¼õ║īÕŹüõ║īń½ĀÕåģÕ«╣õĖ░Õ»ī’╝īµČĄńø¢õ║åՔ鵣ĆķĢ┐Õģ¼Õģ▒ÕŁÉÕ║ÅÕłŚ’╝łLCS’╝ēŃĆüÕģ©µÄÆÕłŚŃĆüĶĘ│ÕÅ░ķśČŃĆüÕźćÕüČ...
Õ£©ITķóåÕ¤¤’╝īµÄÆÕ║ÅÕÆīµ¤źµēŠµś»Õ¤║ńĪĆõĖöĶć│Õģ│ķćŹĶ”üńÜäń«Śµ│Ģ’╝īÕ«āõ╗¼Ķó½Õ╣┐µ│øÕ║öńö©õ║ÄÕÉäń¦ŹĶĮ»õ╗ČÕ╝ĆÕÅæÕÆīµĢ░µŹ«ÕżäńÉåõĖŁŃĆéĶ┐Öķćīµłæõ╗¼Õ░åµĘ▒ÕģźµÄóĶ«©µĀćķóśÕÆīµÅÅĶ┐░õĖŁµÅÉÕÅŖńÜäÕćĀń¦Źń╗ÅÕģĖµ¤źµēŠÕÆīµÄÆÕ║Åń«Śµ│Ģ’╝īÕ╣Čń╗ōÕÉłC++ń╝¢ń©ŗĶ»ŁĶ©ĆĶ┐øĶĪīĶ«©Ķ«║ŃĆé ķ”¢Õģł’╝īµłæõ╗¼µØźń£ŗµ¤źµēŠń«Śµ│ĢŃĆé...
5. **µ¢ćõ╗ȵōŹõĮ£**’╝ÜCĶ»ŁĶ©ĆµÅÉõŠøõ║åµĀćÕćåI/OÕ║ō’╝īÕģüĶ«Ėń©ŗÕ║ÅÕæśĶ»╗ÕåÖńŻüńøśµ¢ćõ╗ČŃĆéõ╣”õĖŁõ╝Üõ╗ŗń╗Ź`fopen`ŃĆü`fwrite`ŃĆü`fread`ŃĆü`fprintf`ńŁēÕćĮµĢ░ńÜäńö©µ│Ģ’╝īõ╗źÕÅŖµ¢ćõ╗ČńÜäķöÖĶ»»ÕżäńÉåŃĆé 6. **ķĆÆÕĮÆõĖÄń«Śµ│Ģ**’╝ÜķĆÆÕĮƵś»CĶ»ŁĶ©ĆõĖŁĶ¦ŻÕå│ķŚ«ķóśńÜäÕ╝║Õż¦ÕĘźÕģĘ’╝īõ╣”...
µ▒ćń╝¢Ķ»ŁĶ©ĆÕ«×ńÄ░Õ┐½ķƤµÄÆÕ║ÅĶÖĮńäČÕżŹµØé’╝īõĮåÕģČĶ┐ÉĶĪīµĢłńÄćķ½ś’╝īńē╣Õł½ķĆéÕÉłÕżäńÉåÕż¦µĢ░µŹ«ķćÅńÜäµāģÕåĄŃĆéńö▒õ║Äńø┤µÄźµōŹõĮ£ńĪ¼õ╗Č’╝īÕÅ»õ╗źÕģģÕłåÕł®ńö©CPUńÜäµĆ¦ĶāĮ’╝īÕćÅÕ░æõĖŹÕ┐ģĶ”üńÜäµĢ░µŹ«ń¦╗ÕŖ©ÕÆīµ»öĶŠāµōŹõĮ£ŃĆéńäČĶĆī’╝īĶ┐Öõ╣¤Ķ”üµ▒éń©ŗÕ║ÅÕæśµ£ēµēÄÕ«×ńÜäÕ║ĢÕ▒éń¤źĶ»åÕÆīń╗åĶć┤ńÜäń╝¢ń©ŗµŖĆÕʦ...
3. **µ¢ćõ╗ȵśĀÕ░äµ£║ÕłČ**’╝ÜÕ╗║ń½ŗÕåģÕŁśÕ£░ÕØĆÕÆīńŻüńøśµ¢ćõ╗ČÕüÅń¦╗ķćÅńÜ䵜ĀÕ░äÕģ│ń│╗’╝īµ¢╣õŠ┐µĢ░µŹ«ńÜäĶ»╗ÕåÖŃĆé 4. **õ╝śÕī¢µĆ¦ĶāĮ**’╝ÜĶĆāĶÖæµ¢ćõ╗ČĶ«┐ķŚ«ķƤÕ║”’╝īÕÅ»ĶāĮķ£ĆĶ”üķóäĶ»╗ÕÆīń╝ōÕŁśńŁ¢ńĢź’╝īÕćÅÕ░æńŻüńøśI/Oµ¼ĪµĢ░ŃĆé ķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Å’╝īµłæõ╗¼õĖŹõ╗ģÕÅ»õ╗źÕŁ”õ╣ĀÕÆīÕ«×ĶĘĄC++ńÜä...
Õåģķā©µÄÆÕ║ŵś»µīćµĢ░µŹ«Õ£©µĢ┤õĖ¬µÄÆÕ║ÅĶ┐ćń©ŗõĖŁÕģ©ķā©ÕŁśÕ£©õ║ÄÕåģÕŁśõĖŁńÜäµÄÆÕ║Åń«Śµ│Ģ’╝īõŠŗՔ鵣©µĪȵÄÆÕ║ÅŃĆé **Õż¢ķā©µÄÆÕ║Å** Õż¢ķā©µÄÆÕ║ŵś»µīćµĢ░µŹ«Ķ¦äµ©ĪÕż¬Õż¦µŚĀµ│ĢÕģ©ķā©µöŠÕģźÕåģÕŁśõĖŁ’╝īķ£ĆĶ”üÕżÜµ¼ĪĶ»╗ÕåÖńŻüńøśńÜäµÄÆÕ║ŵ¢╣µ│ĢŃĆé #### ÕåģÕŁśÕłÆÕłå ÕåģÕŁśÕłÆÕłåµś»µīćÕ”éõĮĢÕÉłńÉåÕ£░...
9. **µ¢ćõ╗ČõĖÄÕż¢ķā©ÕŁśÕé©**’╝ÜÕ£©Õż¦Õ×ŗµĢ░µŹ«ÕżäńÉåõĖŁ’╝īµĢ░µŹ«õĖŹĶāĮÕģ©ķā©ÕŁśÕé©Õ£©ÕåģÕŁś’╝īķ£ĆĶ”üõ║åĶ¦ŻńŻüńøśµ¢ćõ╗ČÕÆīÕż¢ķā©ÕŁśÕé©ńÜäń╗äń╗ćµ¢╣Õ╝Å’╝īÕ”éķĪ║Õ║ŵ¢ćõ╗ČŃĆüń┤óÕ╝Ģµ¢ćõ╗ČŃĆüńø┤µÄźÕŁśÕÅ¢µ¢ćõ╗ČńŁēŃĆé 10. **ÕŖ©µĆüĶ¦äÕłÆõĖÄĶ┤¬Õ┐āńŁ¢ńĢź**’╝ÜĶ┐Öõ║øµś»Ķ¦ŻÕå│ķŚ«ķóśńÜäµ£ēµĢłµ¢╣µ│Ģ’╝ī...
µ»ÅõĖ¬ķŚ«ķóśńÜäĶ¦ŻńŁöķĆÜÕĖĖõ╝ܵČēÕÅŖµĢ░µŹ«ń╗ōµ×ä’╝łÕ”éķś¤ÕłŚŃĆüµĀłŃĆüÕøŠŃĆüµĀæńŁē’╝ēŃĆüń«Śµ│ĢĶ«ŠĶ«Ī’╝łÕ”éµÄÆÕ║ÅŃĆüµÉ£ń┤óŃĆüÕŖ©µĆüĶ¦äÕłÆŃĆüĶ┤¬Õ┐āŃĆüÕø×µ║»ńŁē’╝ēÕÆīń╝¢ń©ŗµŖĆÕʦŃĆéķĆÜĶ┐ćĶ¦ŻÕå│Ķ┐Öõ║øķŚ«ķóś’╝īõĖŹõ╗ģÕÅ»õ╗źµĘ▒Õī¢Õ»╣Ķ┐Öõ║øÕ¤║ńĪƵ”éÕ┐ĄńÜäńÉåĶ¦Ż’╝īĶ┐śĶāĮµÅÉÕŹćĶ¦ŻÕå│Õ«×ķÖģķŚ«ķóśńÜäĶāĮÕŖø’╝īÕ»╣...
õĖ╗Ķ”üµ£ēõĖżń¦ŹÕłåń▒╗’╝ÜÕåģķā©µÄÆÕ║Å’╝łµĢ░µŹ«Õ£©ÕåģÕŁśõĖŁÕ«īµłÉµÄÆÕ║Å’╝ēÕÆīÕż¢ķā©µÄÆÕ║Å’╝łµĢ░µŹ«ķćÅÕż¬Õż¦’╝īķ£ĆĶ”üÕƤÕŖ®ńŻüńøśńŁēÕż¢ķā©ÕŁśÕé©’╝ēŃĆéÕ£©Õåģķā©µÄÆÕ║ÅõĖŁ’╝īÕĖĖĶ¦üńÜäń«Śµ│Ģµ£ē’╝Ü 1. ÕåƵ│ĪµÄÆÕ║Å’╝ÜķĆÜĶ┐ćõĖŹµ¢ŁÕ£░õ║żµŹóńøĖķé╗Õģāń┤ĀµØźķĆɵŁźĶ░āµĢ┤Õ║ÅÕłŚ’╝īµŚČķŚ┤ÕżŹµØéÕ║”õĖ║O(n^2)ŃĆé ...
ŃĆŖĶĮ»ĶĆāń©ŗÕ║ÅÕæśĶŠģÕ»╝ ń©ŗÕ║ÅÕæśĶĆāĶ»ĢĶŠģÕ»╝µĢÖµØÉŃĆŗµś»õĖƵ£¼õĖōķŚ©õĖ║ÕćåÕżćÕÅéÕŖĀÕøĮÕ«ČĶĮ»ĶĆāń©ŗÕ║ÅÕæśĶĆāĶ»ĢńÜäĶĆāńö¤ń╝¢ÕåÖńÜäĶŠģÕ»╝ĶĄäµ¢ÖŃĆéĶ┐Öµ£¼õ╣”µŚ©Õ£©ÕĖ«ÕŖ®ĶĆāńö¤Õģ©ķØóńÉåĶ¦ŻÕÆīµÄīµÅĪń©ŗÕ║ÅÕæśĶĆāĶ»ĢµēƵČēÕÅŖńÜäń¤źĶ»åńé╣’╝īµÅÉķ½śÕżćĶĆāµĢłńÄć’╝īńĪ«õ┐ØÕ£©ĶĆāĶ»ĢõĖŁÕÅ¢ÕŠŚńÉåµā│ńÜ䵳Éń╗®ŃĆé...