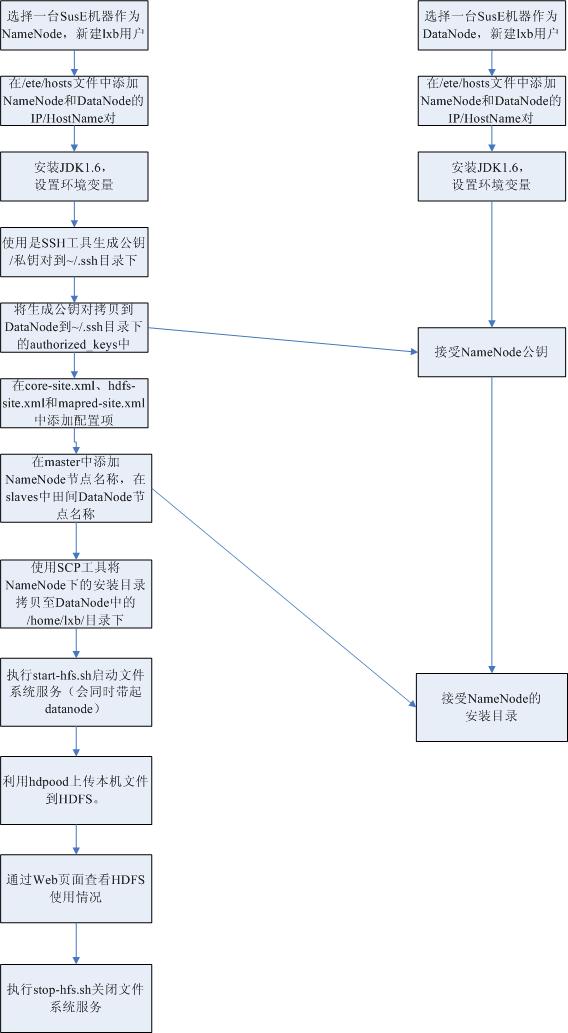
 在SuSE集群上安装配置HDFS
收藏
在SuSE集群上安装配置HDFS
收藏
1
、环境准备
需要环境:
PC-1
Suse Linux 9
10.192.1.1
PC-2
Suse Linux 9
10.192.1.2
PC-3
Suse Linux 9
10.192.1.3
PC-4
Suse Linux 9
10.192.1.4
其中,
PC-1
做
namenode
节点,
PC-2
、
PC-3
和
PC-4
做
datanode
节点。
2
、安装包准备
需要安装包:
jdk-6u16-linux-i586-rpm.bin
hadoop-0.20.1.tar.gz
(
stable
版本)
3
、安装步骤
3.1
操作系统配置
(
1
)新建用户。在
HDFS
文件系统中的每个节点(包括
namenode
节点和
datanode
节点)上,新建
hdfs
用户,并保证
hdfs
用户的当前目录一致。
(
2
)
HDFS
中的节点配置
在
root
用户中输入命令
yast
,使用
yast
工具。
Network Devices
—
>Network Card
—
>Already configured devices
—
>Change
—
>Edit
—
>Host name and name server
。
1
,
namenode
节点。
hostname
修改为“
namenode
”,
domian name
修改为“
hdfs
”;
2
,
datanode
节点。
hostname
修改为“
datanodeXXX
”,
domian name
修改为“
hdfs
”,其中“
XXX
”最好为该节点
IP
地址中的第四个数字。
(
3
)
HDFS
中的节点添加通讯对方主机名
1
,
namenode
节点。在
/etc/hosts/
文件中添加所有
datanode
节点的
IP/Hostname
对,如
10.129.126.205 datanode205.hdfs datanode205
2
,
datanode
节点。在所有
datanode
节点中的
/etc/hosts/
文件中添加所有
namenode
节点的
IP/Hostname
对,如
10.129.126.203
namenode.hdfs namenode
(
4
)
Windows
访问端配置
a)
参照
namenode
节点中的
hosts
文件的配置,在
windows
的
hosts
文件中添加
namenode
节点和
datanoe
节点的
IP/Hostname
对。
b)
在
IE
浏览器不使用代理列表中,添加“
*.hdfs
”。
3.2
安装
JDK
Hadoop
是基于
JDK1.6
编写的,为了运行
HDFS
文件系统,同时也为了后续的开发,需要安装
JDK1.6
。
(
1
)切换到
root
用户,并将安装包拷贝至
/usr/local/
目录,
chmod 755
使
root
用户获得执行安装包的权限。
(
2
)执行
sh jdk-6u16-linux-i586-rpm.bin
开始安装,接下来出现安装协议阅读界面。按“
q
”退出阅读,接着输入“
y
”表示统一安装协议,开始安装直到结束。
(
3
)配置
JAVA
环境在
/etc/profile
文件尾添加三项
:
export JAVA_HOME=/usr/java/jdk1.6.0_16
export CLASSPATH=/usr/java/jdk1.6.0_16/lib:/usr/java/jdk1.6.0_16/jre/lib:$CLASSPATH
export PATH=/usr/java/jdk1.6.0_16/bin:/usr/java/jdk1.6.0_16/jre/bin:$PATH
在
root
用户中,
chmod 755 /etc/profile
,使普通用户获得对该文件的执行权限。在
hdfs
的登录会话中,执行“
. /etc/profile
”(
“
.
”与“
/
”之间有空格)使修改生效,使用
echo
命令确认这三项设置是否成功。
3.3
配置
SSH
服务
在
namenode
节点,使用
ssh
工具生成公钥
/
私钥对,并把公钥分发给
datanode
节点,可以实现
datanode
对来自
namenode
节点网络通讯请求的认证。
首先,在
namenode
节点生成公钥
/
私钥对
:
(
1
)在
/home/hdfs/
目录下新建“
.ssh
”目录。
(
2
)使用
DSA
算法生成公钥
/
私钥对。
$ssh-keygen -t dsa –P ’’
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hdfs/.ssh/id_rsa):
按回车
Enter passphrase (empty for no passphrase):
输入
hdfs
登录密码
Enter same passphrase again:
再次输入
hdfs
登录密码
Your identification has been saved in /home/hdfs/.ssh/id_rsa.
Your public key has been saved in /home/hdfs/.ssh/id_rsa.pub.
The key fingerprint is:
9a
:4f:a0:82:1d:f9:e3:31:17:46:b2:25:15:1a:52:56 hdfs@namenode
注:其中
id_dsa
存放了产生的私钥,
id_dsa.pub
存放了公钥。
接着,分发
namenode
节点的公钥
将
namenode
节点
id_rsa.pub
文件中的内容复制到所有节点的
/home/h/.ssh/authorized_keys
文件中。
(
1
)
namenode
节点。
1
,
authorized_keys
不存在。执行命令
cp id_rsa.pub authorized_keys
。
1
,
authorized_keys
存在。执行命令
cat
id_rsa.pub >> authorized_keys
。
(
2
)
datanode
节点。
在
namenode
节点中,对每一台
datanode
节点,执行命令
scp id_dsa.pub datanode205:/home/hdfs/.ssh/
。在
datanode
节点,仿照
namenode
节点的处理方法,将
namenode
节点的公钥拷贝到
authorized_keys
文件中。
(
3
)
ssh
验证。
在
namenode
节点执行
ssh datanode205.
,如果能不输入密码能登录到
datanode205
,则说明安装成功。
3.4
安装
Hadoop
在
namenode
节点
中,将
hadoop-0.20.1.tar.gz
,解压到
/home/hdfs/
目录下即可。
4
、配置说明
4.1 namenode
节点配置
在
namenode
节点的
conf
目录下。
(
1
)
core-site.xml
文件配置。
配置临时文件夹目录。
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/hadoop-datastore/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
配置
HDFS
文件系统外部访问地址,即
namenode
节点
IP
以及访问端口号。
<property>
<name>fs.default.name</name>
<value>hdfs://10.129.126.203:54310</value>
</property>
(
2
)
hdfs-site.xml
文件配置。
配置上传文件备份的份数,不能超过
datanode
节点个数,默认为
3
个。
<name>dfs.replication</name>
<value>3</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
(
3
)
masters
文件配置。
添加
namenode
节点在主机名“
namenode
”。
(
4
)
slaves
文件配置。
添加所有
datanode
节点的主机名,每行配置一个。
datanode203
datanode204
datanode205
4.2 datanode
节点配置
在
namenode
节点,执行命令
scp -r hadoop-0.20.1/ datanode205:/home/hdfs/
,将
namenode
节点的安装文件复制到每一个
datanode
节点。
分享到:





相关推荐
8. **Cloudera Manager安装**:提供了三种安装方式,离线安装在没有互联网连接或网络速度较慢的情况下更有优势,因为它允许预先下载所有需要的包,然后在目标系统上进行安装。 9. **Zypper包管理器**:在SUSE Linux...
安装AIX hadoop集群注意项,与在suse上安装稍有不同。
- 在Linux系统上安装JDK并正确配置环境变量。 - 了解如何验证JDK安装是否成功。 4. **SSH远程免密登录设置**: - 掌握SSH服务的安装与配置。 - 实现主机之间的免密登录。 5. **Hadoop集群安装与配置**: - ...
推荐使用MySQL 5.5版本,但在安装前需要清除旧版本的数据库。安装过程中,需要创建多个数据库,包括metastore数据库和用于Cloudera管理器的数据库,以及为Hive和其他组件配置相应的数据库用户和密码。 #### 3. ...
本文将详细介绍HBase在Suse Linux环境下的安装、配置、管理和编程流程。 首先,环境准备至关重要。在这个例子中,我们设有四个节点:PC-1作为namenode节点,IP地址为10.192.1.1;PC-2、PC-3和PC-4作为datanode节点...
CDH支持在多种Linux发行版本上部署,推荐使用主流的64位操作系统。具体而言,包括Red Hat Enterprise Linux/CentOS 6.4至7.5版本、SUSE Linux Enterprise Server(SLES)11 SP3/SP4及12 SP1/SP2版本、Oracle Linux ...
建议在安装操作系统时使用RAID1以保证数据冗余。对于无法直连互联网的环境,需预先创建OS的repository,确保系统软件包的更新。所有节点间的通信需要可靠的IP配置,可以是静态或动态。静态配置下,务必确保每个节点...
- 如果需要启用Kerberos认证,需配置集群的DNS域名,例如: - `/etc/sysconfig/network`: ``` NETWORKING=yes HOSTNAME=sb-node1.example.com ``` - `/etc/hosts`: ``` 192.168.0.21 sb-node1.example....
在安装前,请检查当前的JDK版本。 #### 三、支持的浏览器 Transwarp Data Hub采用Web页面作为平台管理界面,支持的浏览器包括但不限于Google Chrome、Mozilla Firefox、Microsoft Edge等现代浏览器。 #### 四、...
在安装CDH4之前,确保已经满足以下条件: - **支持的操作系统**:CDH4支持多种Linux发行版,包括但不限于Red Hat Enterprise Linux、CentOS、Ubuntu等。 - **Java环境**:安装Oracle JDK,这是运行Hadoop集群的必要...
- **Hadoop安装**:下载Hadoop安装包(如hadoop-1.1.2.tar.gz),解压缩后,需要配置一系列文件,如hadoop-env.sh(设置JAVA_HOME等参数)、mapred-site.xml(配置jobTracker)、hdfs-site.xml(设置HDFS相关参数)...
HDFS由NameNode(运行在master节点)和DataNode(运行在集群的每个节点)组成。NameNode负责元数据管理,而DataNode则负责实际的数据存储。HDFS设计为高容错机制,能处理硬件故障,确保数据的可靠性。 3. MapReduce...
在处理HDFS上的ORC文件时,其支持向量引擎和Smart Scan技术,能有效减少网络数据交换,提高查询效率。 FusionInsight LibrA还具备极致的性能和高效的SQL交互分析。列存向量化引擎利用向量化和SIMD指令优化分析性能...
在系统架构上,FusionInsight LibrA由多个独立的逻辑节点组成,每个节点拥有自己的CPU、内存和存储资源。数据分散存储并就近处理,通过控制模块的协调,实现大规模数据的并行处理,从而实现快速的数据响应。该系统...
管理工具涵盖安装、集群管理、备份恢复、升级和扩容等。 技术指标显示,LibrA能够处理10PB级别的数据,最大支持1024个物理节点,单表大小可达1PB,单行数据最大1GB,每个字段的最大大小为1GB,单表最大记录数为248...
- **知识点**: 在SUSE Linux 10系统中,可以通过执行命令 `rpm -qalgrep open-iscsi` 来检测系统是否已经安装了ISCSI相关的RPM包。 - **详细说明**: `rpm -qa` 命令用于列出系统中所有已安装的RPM包,加上 `grep ...