- 浏览: 117428 次
- 性别:

- 来自: 杭州
-

最新评论
-
张斌梁林:
楼上有高手为啥不说出具体办法呢?还是楼主最好了!!!!
关于豆丁在线文档,百度文库总结 -
bigarden:
LZ分析的很好,学习了
JAVA SSH框架简介 -
s103y:
q8q8q8 写道顶你 兄弟
谢啦,初步使用,感觉还不错
SSO单点登录 -
s103y:
finalljx 写道我最近也在研究这个,我觉得百度很可能是和 ...
关于豆丁在线文档,百度文库总结 -
gaowei52306:
挺好的
ANT简明教程[转载]
这可能是最有趣的一节。排序的考题,在各大公司的笔试里最喜欢出了,但我看多数考得都很简单,通常懂得冒泡排序就差不多了,确实,我在刚学数据机构时候,觉得冒泡排序真的很“精妙”,我怎么就想不出呢?呵呵,其实冒泡通常是效率最差的排序算法,差多少?请看本文,你一定不会后悔的。
1、冒泡排序(Bubbler Sort)
前面刚说了冒泡排序的坏话,但冒泡排序也有其优点,那就是好理解,稳定,再就是空间复杂度低,不需要额外开辟数组元素的临时保存控件,当然了,编写起来也容易。
其算法很简单,就是比较数组相邻的两个值,把大的像泡泡一样“冒”到数组后面去,一共要执行N的平方除以2这么多次的比较和交换的操作(N为数组元素),其复杂度为Ο(n²),如图:
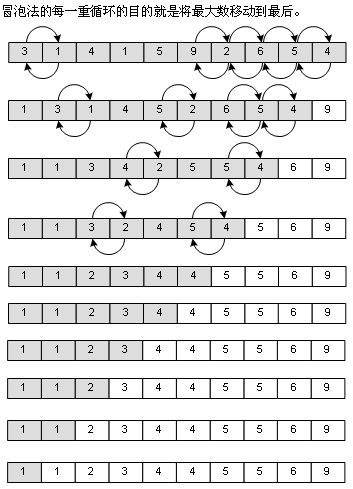
2、直接插入排序(Straight Insertion Sort)
冒泡法对于已经排好序的部分(上图中,数组显示为白色底色的部分)是不再访问的,插入排序却要,因为它的方法就是从未排序的部分中取出一个元素,插入到已经排好序的部分去,插入的位置我是从后往前找的,这样可以使得如果数组本身是有序(顺序)的话,速度会非常之快,不过反过来,数组本身是逆序的话,速度也就非常之慢了,如图:
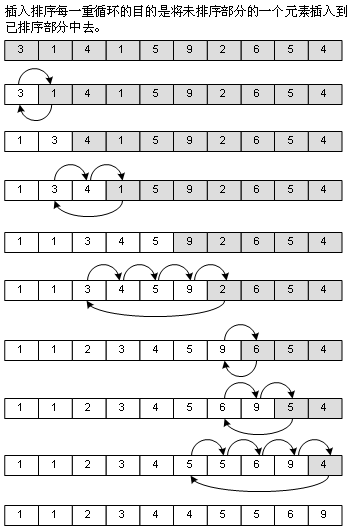
3、二分插入排序(Binary Insertion Sort)
这是对直接插入排序的改进,由于已排好序的部分是有序的,所以我们就能使用二分查找法确定我们的插入位置,而不是一个个找,除了这点,它跟插入排序没什么区别,至于二分查找法见我前面的文章(本系列文章的第四篇)。图跟上图没什么差别,差别在于插入位置的确定而已,性能却能因此得到不少改善。(性能分析后面会提到)
4、直接选择排序(Straight Selection Sort)
这是我在学数据结构前,自己能够想得出来的排序法,思路很简单,用打擂台的方式,找出最大的一个元素,和末尾的元素交换,然后再从头开始,查找第1个到第N-1个元素中最大的一个,和第N-1个元素交换……其实差不多就是冒泡法的思想,但整个过程中需要移动的元素比冒泡法要少,因此性能是比冒泡法优秀的。看图: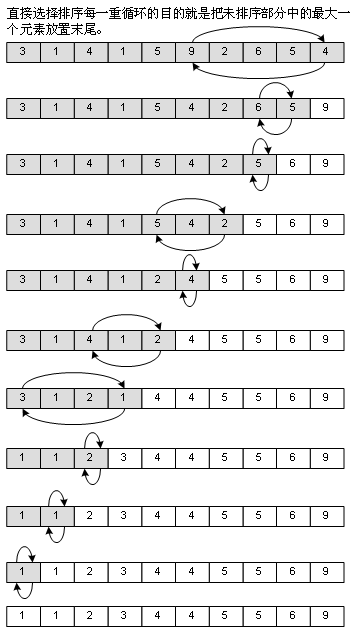
5、快速排序(Quick Sort)
快速排序是非常优秀的排序算法,初学者可能觉得有点难理解,其实它是一种“分而治之”的思想,把大的拆分为小的,小的再拆分为更小的,所以你一会儿从代码中就能很清楚地看到,用了递归。如图:
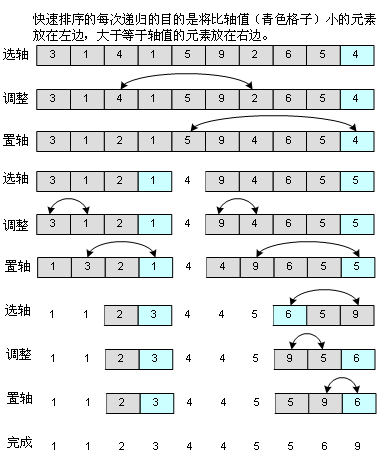
其中要选择一个轴值,这个轴值在理想的情况下就是中轴,中轴起的作用就是让其左边的元素比它小,它右边的元素不小于它。(我用了“不小于”而不是“大于”是考虑到元素数值会有重复的情况,在代码中也能看出来,如果把“>=”运算符换成“>”,将会出问题)当然,如果中轴选得不好,选了个最大元素或者最小元素,那情况就比较糟糕,我选轴值的办法是取出第一个元素,中间的元素和最后一个元素,然后从这三个元素中选中间值,这已经可以应付绝大多数情况。
6、改进型快速排序(Improved Quick Sort)
快速排序的缺点是使用了递归,如果数据量很大,大量的递归调用会不会导致性能下降呢?我想应该会的,所以我打算作这么种优化,考虑到数据量很小的情况下,直接选择排序和快速排序的性能相差无几,那当递归到子数组元素数目小于30的时候,我就是用直接选择排序,这样会不会提高一点性能呢?我后面分析。排序过程可以参考前面两个图,我就不另外画了。
7、桶排序(Bucket Sort)
这是迄今为止最快的一种排序法,其时间复杂度仅为Ο(n),也就是线性复杂度!不可思议吧?但它是有条件的。举个例子:一年的全国高考考生人数为500万,分数使用标准分,最低100,最高900,没有小数,你把这500万元素的数组排个序。我们抓住了这么个非常特殊的条件,就能在毫秒级内完成这500万的排序,那就是:最低100,最高900,没有小数,那一共可出现的分数可能有多少种呢?一共有900-100+1=801,那么多种,想想看,有没有什么“投机取巧”的办法?方法就是创建801个“桶”,从头到尾遍历一次数组,对不同的分数给不同的“桶”加料,比如有个考生考了500分,那么就给500分的那个桶(下标为500-100)加1,完成后遍历一下这个桶数组,按照桶值,填充原数组,100分的有1000人,于是从0填到999,都填1000,101分的有1200人,于是从1000到2019,都填入101……如图:
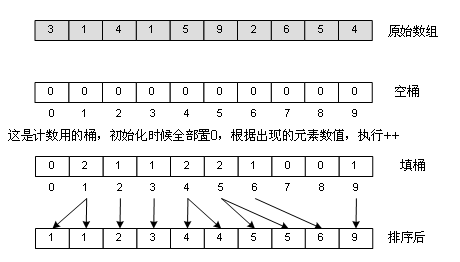
很显然,如果分数不是从100到900的整数,而是从0到2亿,那就要分配2亿个桶了,这是不可能的,所以桶排序有其局限性,适合元素值集合并不大的情况。
8、基数排序(Radix Sort)
基数排序是对桶排序的一种改进,这种改进是让“桶排序”适合于更大的元素值集合的情况,而不是提高性能。它的思想是这样的,比如数值的集合是8位整数,我们很难创建一亿个桶,于是我们先对这些数的个位进行类似桶排序的排序(下文且称作“类桶排序”吧),然后再对这些数的十位进行类桶排序,再就是百位……一共做8次,当然,我说的是思路,实际上我们通常并不这么干,因为C++的位移运算速度是比较快,所以我们通常以“字节”为单位进行桶排序。但下图为了画图方便,我是以半字节(4 bit)为单位进行类桶排序的,因为字节为单位进行桶排得画256个桶,有点难画,如图:
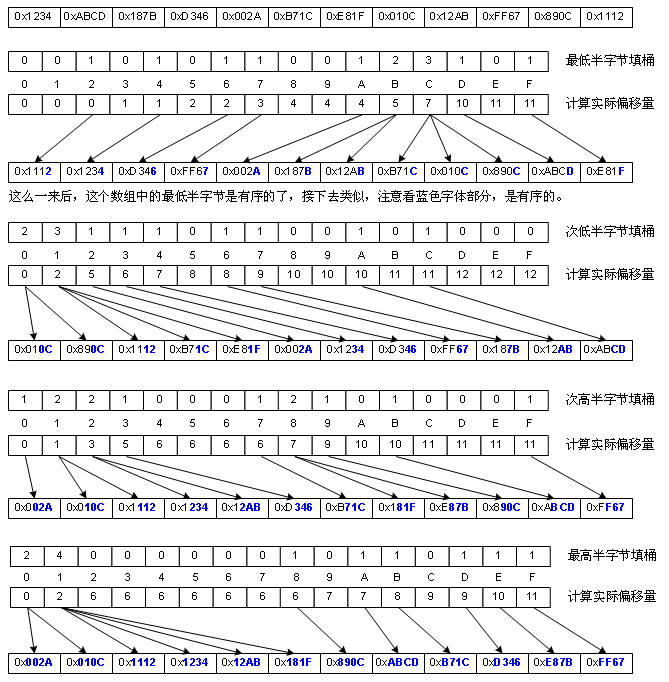
基数排序适合数值分布较广的情况,但由于需要额外分配一个跟原始数组一样大的暂存空间,它的处理也是有局限性的,对于元素数量巨大的原始数组而言,空间开销较大。性能上由于要多次“类桶排序”,所以不如桶排序。但它的复杂度跟桶排序一样,也是Ο(n),虽然它用了多次循环,但却没有循环嵌套。
9、性能分析和总结
先不分析复杂度为Ο(n)的算法,因为速度太快,而且有些条件限制,我们先分析前六种算法,即:冒泡,直接插入,二分插入,直接选择,快速排序和改进型快速排序。
我的分析过程并不复杂,尝试产生一个随机数数组,数值范围是0到7FFF,这正好可以用C++的随机函数rand()产生随机数来填充数组,然后尝试不同长度的数组,同一种长度的数组尝试10次,以此得出平均值,避免过多波动,最后用Excel对结果进行分析,OK,上图了。
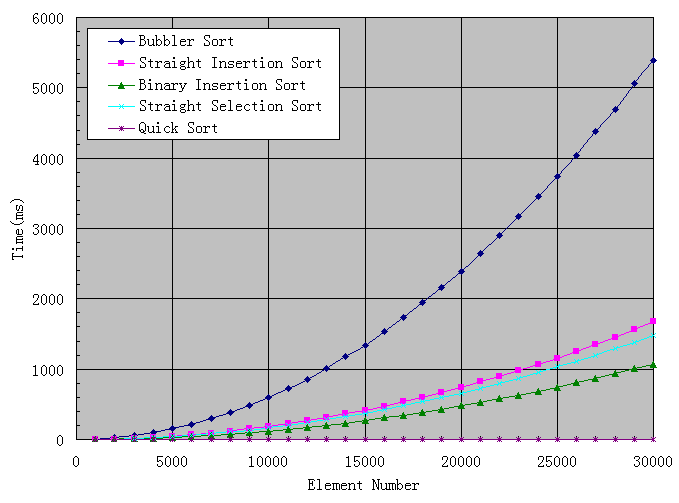
最差的一眼就看出来了,是冒泡,直接插入和直接选择旗鼓相当,但我更偏向于使用直接选择,因为思路简单,需要移动的元素相对较少,况且速度还稍微快一点呢,从图中看,二分插入的速度比直接插入有了较大的提升,但代码稍微长了一点点。
令人感到比较意外的是快速排序,3万点以内的快速排序所消耗的时间几乎可以忽略不计,速度之快,令人振奋,而改进型快速排序的线跟快速排序重合,因此不画出来。看来要对快速排序进行单独分析,我加大了数组元素的数目,从5万到150万,画出下图:
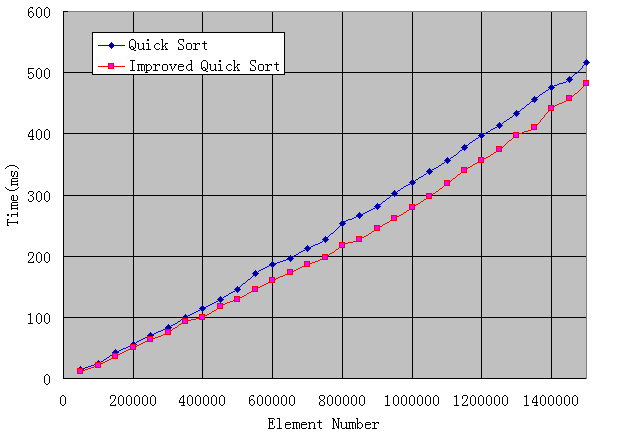
可以看到,即便到了150万点,两种快速排序也仅需差不多半秒钟就完成了,实在快,改进型快速排序性能确实有微略提高,但并不明显,从图中也能看出来,是不是我设置的最小快速排序元素数目不太合适?但我尝试了好几个值都相差无几。
最后看线性复杂度的排序,速度非常惊人,我从40万测试到1200万,结果如图:
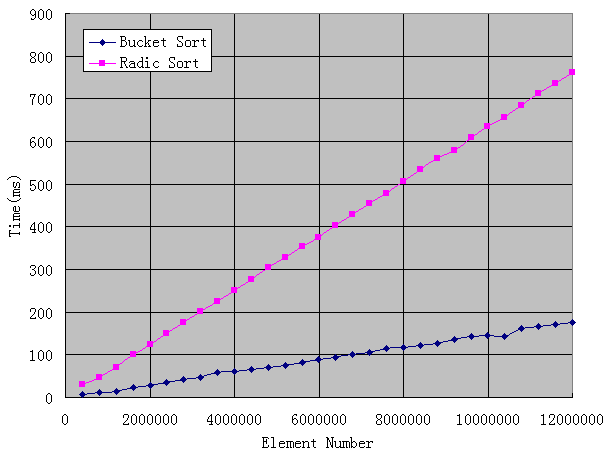
可见稍微调整下算法,速度可以得到质的飞升,而不是我们以前所认为的那样:再快也不会比冒泡法快多少啊?
我最后制作一张表,比较一下这些排序法:
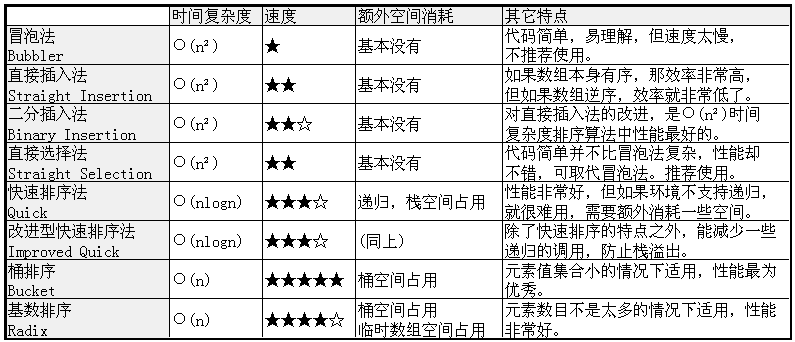
还有一个最后:附上我的代码。
#include "stdlib.h"
#include "time.h"
#include "string.h"
void BubblerSort(int *pArray, int iElementNum);
void StraightInsertionSort(int *pArray, int iElementNum);
void BinaryInsertionSort(int *pArray, int iElementNum);
void StraightSelectionSort(int *pArray, int iElementNum);
void QuickSort(int *pArray, int iElementNum);
void ImprovedQuickSort(int *pArray, int iElementNum);
void BucketSort(int *pArray, int iElementNum);
void RadixSort(int *pArray, int iElementNum);
//Tool functions.
void PrintArray(int *pArray, int iElementNum);
void StuffArray(int *pArray, int iElementNum);
inline void Swap(int& a, int& b);
#define SINGLE_TEST
int main(int argc, char* argv[])
{
srand(time(NULL));
#ifndef SINGLE_TEST
int i, j, iTenTimesAvg;
for(i=50000; i<=1500000; i+=50000)
{
iTenTimesAvg = 0;
for(j=0; j<10; j++)
{
int iElementNum = i;
int *pArr = new int[iElementNum];
StuffArray(pArr, iElementNum);
//PrintArray(pArr, iElementNum);
clock_t ctBegin = clock();
ImprovedQuickSort(pArr, iElementNum);
//PrintArray(pArr, iElementNum);
clock_t ctEnd = clock();
delete[] pArr;
iTenTimesAvg += ctEnd-ctBegin;
}
printf("%d\t%d\n", i, iTenTimesAvg/10);
}
#else
//Single test
int iElementNum = 100;
int *pArr = new int[iElementNum];
StuffArray(pArr, iElementNum);
PrintArray(pArr, iElementNum);
clock_t ctBegin = clock();
QuickSort(pArr, iElementNum);
clock_t ctEnd = clock();
PrintArray(pArr, iElementNum);
delete[] pArr;
int iTenTimesAvg = ctEnd-ctBegin;
printf("%d\t%d\n", iElementNum, iTenTimesAvg);
#endif
return 0;
}
void BubblerSort(int *pArray, int iElementNum)
{
int i, j, x;
for(i=0; i<iElementNum-1; i++)
{
for(j=0; j<iElementNum-1-i; j++)
{
if(pArray[j]>pArray[j+1])
{
//Frequent swap calling may lower performance.
//Swap(pArray[j], pArray[j+1]);
//Do you think bit operation is better? No! Please have a try.
//pArray[j] ^= pArray[j+1];
//pArray[j+1] ^= pArray[j];
//pArray[j] ^= pArray[j+1];
//This kind of traditional swap is the best.
x = pArray[j];
pArray[j] = pArray[j+1];
pArray[j+1] = x;
}
}
}
}
void StraightInsertionSort(int *pArray, int iElementNum)
{
int i, j, k;
for(i=0; i<iElementNum; i++)
{
int iHandling = pArray[i];
for(j=i; j>0; j--)
{
if(iHandling>=pArray[j-1])
break;
}
for(k=i; k>j; k--)
pArray[k] = pArray[k-1];
pArray[j] = iHandling;
}
}
void BinaryInsertionSort(int *pArray, int iElementNum)
{
int i, j, k;
for(i=0; i<iElementNum; i++)
{
int iHandling = pArray[i];
int iLeft = 0;
int iRight = i-1;
while(iLeft<=iRight)
{
int iMiddle = (iLeft+iRight)/2;
if(iHandling < pArray[iMiddle])
{
iRight = iMiddle-1;
}
else if(iHandling > pArray[iMiddle])
{
iLeft = iMiddle+1;
}
else
{
j = iMiddle + 1;
break;
}
}
if(iLeft>iRight)
j = iLeft;
for(k=i; k>j; k--)
pArray[k] = pArray[k-1];
pArray[j] = iHandling;
}
}
void StraightSelectionSort(int *pArray, int iElementNum)
{
int iEndIndex, i, iMaxIndex, x;
for(iEndIndex=iElementNum-1; iEndIndex>0; iEndIndex--)
{
for(i=0, iMaxIndex=0; i<iEndIndex; i++)
{
if(pArray[i]>=pArray[iMaxIndex])
iMaxIndex = i;
}
x = pArray[iMaxIndex];
pArray[iMaxIndex] = pArray[iEndIndex];
pArray[iEndIndex] = x;
}
}
void BucketSort(int *pArray, int iElementNum)
{
//This is really buckets.
int buckets[RAND_MAX];
memset(buckets, 0, sizeof(buckets));
int i;
for(i=0; i<iElementNum; i++)
{
++buckets[pArray[i]-1];
}
int iAdded = 0;
for(i=0; i<RAND_MAX; i++)
{
while((buckets[i]--)>0)
{
pArray[iAdded++] = i;
}
}
}
void RadixSort(int *pArray, int iElementNum)
{
int *pTmpArray = new int[iElementNum];
int buckets[0x100];
memset(buckets, 0, sizeof(buckets));
int i;
for(i=0; i<iElementNum; i++)
{
++buckets[(pArray[i])&0xFF];
}
//Convert number to offset
int iPrevNum = buckets[0];
buckets[0] = 0;
int iThisNum;
for(i=1; i<0x100; i++)
{
iThisNum = buckets[i];
buckets[i] = buckets[i-1] + iPrevNum;
iPrevNum = iThisNum;
}
for(i=0; i<iElementNum; i++)
{
pTmpArray[buckets[(pArray[i])&0xFF]++] = pArray[i];
}
//////////////////////////////////////////////////////////////////////////
memset(buckets, 0, sizeof(buckets));
for(i=0; i<iElementNum; i++)
{
++buckets[(pTmpArray[i]>>8)&0xFF];
}
//Convert number to offset
iPrevNum = buckets[0];
buckets[0] = 0;
iThisNum;
for(i=1; i<0x100; i++)
{
iThisNum = buckets[i];
buckets[i] = buckets[i-1] + iPrevNum;
iPrevNum = iThisNum;
}
for(i=0; i<iElementNum; i++)
{
pArray[buckets[((pTmpArray[i]>>8)&0xFF)]++] = pTmpArray[i];
}
delete[] pTmpArray;
}
void QuickSort(int *pArray, int iElementNum)
{
int iTmp;
//Select the pivot make it to the right side.
int& iLeftIdx = pArray[0];
int& iRightIdx = pArray[iElementNum-1];
int& iMiddleIdx = pArray[(iElementNum-1)/2];
if(iLeftIdx>iMiddleIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iRightIdx>iMiddleIdx)
{
iTmp = iRightIdx;
iRightIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iLeftIdx>iRightIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iRightIdx;
iRightIdx = iTmp;
}
//Make pivot's left element and right element.
int iLeft = 0;
int iRight = iElementNum-2;
int& iPivot = pArray[iElementNum-1];
while (1)
{
while (iLeft<iRight && pArray[iLeft]<iPivot) ++iLeft;
while (iLeft<iRight && pArray[iRight]>=iPivot) --iRight;
if(iLeft>=iRight)
break;
iTmp = pArray[iLeft];
pArray[iLeft] = pArray[iRight];
pArray[iRight] = iTmp;
}
//Make the i
if(pArray[iLeft]>iPivot)
{
iTmp = pArray[iLeft];
pArray[iLeft] = iPivot;
iPivot = iTmp;
}
if(iLeft>1)
QuickSort(pArray, iLeft);
if(iElementNum-iLeft-1>=1)
QuickSort(&pArray[iLeft+1], iElementNum-iLeft-1);
}
void ImprovedQuickSort(int *pArray, int iElementNum)
{
int iTmp;
//Select the pivot make it to the right side.
int& iLeftIdx = pArray[0];
int& iRightIdx = pArray[iElementNum-1];
int& iMiddleIdx = pArray[(iElementNum-1)/2];
if(iLeftIdx>iMiddleIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iRightIdx>iMiddleIdx)
{
iTmp = iRightIdx;
iRightIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iLeftIdx>iRightIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iRightIdx;
iRightIdx = iTmp;
}
//Make pivot's left element and right element.
int iLeft = 0;
int iRight = iElementNum-2;
int& iPivot = pArray[iElementNum-1];
while (1)
{
while (iLeft<iRight && pArray[iLeft]<iPivot) ++iLeft;
while (iLeft<iRight && pArray[iRight]>=iPivot) --iRight;
if(iLeft>=iRight)
break;
iTmp = pArray[iLeft];
pArray[iLeft] = pArray[iRight];
pArray[iRight] = iTmp;
}
//Make the i
if(pArray[iLeft]>iPivot)
{
iTmp = pArray[iLeft];
pArray[iLeft] = iPivot;
iPivot = iTmp;
}
if(iLeft>30)
ImprovedQuickSort(pArray, iLeft);
else
StraightSelectionSort(pArray, iLeft);
if(iElementNum-iLeft-1>=30)
ImprovedQuickSort(&pArray[iLeft+1], iElementNum-iLeft-1);
else
StraightSelectionSort(&pArray[iLeft+1], iElementNum-iLeft-1);
}
void StuffArray(int *pArray, int iElementNum)
{
int i;
for(i=0; i<iElementNum; i++)
{
pArray[i] = rand();


发表评论

-
jsp和servlet的区别
2011-07-22 14:15 1287上次被别人问到这个问� ... -
ANT简明教程[转载]
2011-07-11 10:56 1214一、ant关键元素 1. project元素 ... -
ant copy命令
2011-07-08 10:31 1370Ant真是太方便了,以前� ... -
Java各种集合框架使用
2011-07-06 09:35 1052前言: 本文是对Java集合框架做了一个概括性的解说 ... -
java中四种操作xml方式
2011-07-06 09:34 7391. 介绍 1)DOM(JAXP ... -
web.xml配置详解
2011-07-06 09:32 6681 定义头和根元素部署描述符文件就像所有XML文件一样,必 ... -
MVC处理过程
2011-07-06 09:31 963MVC处理过程: 1. 控制器接受用户请求,然后决 ... -
Idap AD 验证用户名和密码
2011-07-06 09:29 3965import java.util.HashMap; im ... -
Java语言中抽取word、pdf的四种方法
2011-07-06 09:25 8071、用jacob. 其实jacob是一个bridage,连 ... -
Hibernate 包介绍
2011-07-06 09:19 795Hibernate一共包括了23个jar包,令人眼花缭乱 ... -
doGet()和doPost()的区别
2011-07-06 09:17 847get只有一个流,参数附加在url后,地址行显示要传送 ... -
java,hibernate,标准sql数据类型之间的对应表
2011-07-06 09:16 767Hibernate API简介 其接口分为以下 ... -
用正则表达式限制文本框的输入
2011-07-06 09:14 10081.文本框只能输入数字代码(小数点也不能输入) ... -
进程和并发
2011-07-05 16:04 722一.为何需要多进程(或者多线程),为何需要并发? 这个问题或 ... -
java浮点数
2011-06-15 17:03 798虽然几乎每种处理器和编程语言都支持浮点运算,但大 ... -
SSO单点登录
2011-03-08 11:22 1467一、教程前言 教程目的:从头到尾细细道来单点登录服务器及客 ... -
JS数据库(SQL)操作小例
2011-03-03 11:38 1120JS数据库(SQL)操作小例 IT 2010-03-15 1 ... -
session与cookie的区别?
2011-02-14 10:26 839session与cookie的区别? 我所知道的有以下区 ... -
HashMap与Hashtable的区别
2011-02-14 08:46 923HashMap与Hashtable的区别 HashTabl ... -
interface与abstract的区别
2011-02-14 08:37 815interface与abstract的区别 ...
相关推荐
在本系统中,我们主要实现了五种常用的排序算法:冒泡排序法、快速排序法、直接插入排序法、折半插入排序法和树形选择排序法。这些算法都是在计算机科学中最基本和最重要的排序算法,广泛应用于各种数据处理和分析...
常见的经典排序算法有希尔排序、二分插入法、直接插入法、带哨兵的直接排序法、冒泡排序、选择排序、快速排序、堆排序等。 一、希尔排序(Shell 排序法) 希尔排序法,又称宿小增量排序,是 1959 年由 D.L.Shell ...
常见的排序算法有插入排序、快速排序、选择堆积排序法等。 插入排序算法是一种简单的排序算法,适用于小规模的数据结构。该算法将数据结构分成已排序部分和未排序部分,并将未排序部分的元素插入到已排序部分中。...
在计算机科学领域,排序算法是数据处理中的核心部分,它涉及到如何有效地重新排列一组数据,使其按照特定的顺序排列。本资源"总结了各种排序算法,并用C++代码实现,并有演示",提供了丰富的学习材料,包括不同类型...
希尔排序是一种基于插入排序的算法,通过将待排序的数组元素按某个增量分组,然后对每组使用直接插入排序算法排序。随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止...
本篇文章将介绍一种经典的排序算法——**合并排序法**(Merge Sort),并通过C语言实现该算法。合并排序是一种非常有效的排序方法,其核心思想是分治法:将数据分为若干个子集,对这些子集分别进行排序,最后将排序...
最快的排序算法 最快的内部排序法—桶排序法,排序算法数据结构
在IT领域,排序算法是计算机科学中的基础但至关重要的概念,尤其在数据处理和算法设计中扮演着核心角色。本文将深入探讨标题中提到的几种基于比较的排序算法:选择排序、插入排序、归并排序、快速排序、堆排序、冒泡...
最快的排序算法 最快的内部排序法—桶排序法 (1),排序算法数据结构
在计算机科学领域中,排序算法是一种基本的算法,它可以将数据按照一定的顺序排列,以便更好地存储、检索和处理数据。排序算法的速度和效率对程序的性能有着至关重要的影响。 1.冒泡排序算法 冒泡排序算法是一种...
该程序包含7大排序算法: # sort.bubbleSort() #冒泡排序 # sort.shellSort() #希尔排序 # sort.insertionSort() #插入排序 # sort.Selectionsort1() #选择排序 # sort.heapSort() #堆排序 # sort.countSort() ...
根据给定文件的信息,本文将深入探讨C语言中的两种经典排序方法:插入排序法与冒泡排序法。这两种方法在实际编程中应用广泛,对于理解数据结构与算法的基础概念至关重要。 ### 一、冒泡排序法 #### 1.1 基本原理 ...
双向起泡排序法是一种在链表结构中实现的排序算法,尤其适用于双向链表。它借鉴了传统冒泡排序的基本思想,但在链表环境中进行了优化,以提高效率。本篇文章将详细探讨双向起泡排序法及其在带头结点的双向链表中的...
六种排序算法的排序系统 本篇文章主要讲解了六种排序算法的排序系统,包括插入排序、冒泡排序、选择排序、快速排序、堆排序和归并排序。该系统可以让用户选择六种排序算法中的任意一个,并输出结果。 插入排序 ...
在IT领域,排序算法是计算机科学中的基础但至关重要的部分,尤其在数据处理和数据分析中起着关键作用。本文将详细探讨标题所提及的几种排序算法:合并排序、插入排序、希尔排序、快速排序、冒泡排序以及桶排序,并...
在计算机科学中,排序算法是数据结构领域的重要组成部分,它涉及到如何有效地重新排列一组数据,使其按照特定的顺序排列。本资源提供了三种经典的排序算法的C语言实现:堆排序、直接插入排序和快速排序。 首先,让...
在计算机科学领域,排序算法是数据处理中至关重要的一部分,它涉及到如何有效地重新排列一组数据,使其按照特定的顺序排列。本资源提供了七大经典排序算法的实现程序,包括快速排序、冒泡排序、选择排序、归并排序、...
时间复杂度用于衡量排序算法的效率,通常以大O表示法来表示。文档中提到了几种不同排序算法的时间复杂度: - **O(n²)**:插入排序、冒泡排序和选择排序的时间复杂度均为O(n²),这意味着随着数据量的增加,这些...
排序算法是计算机科学中最基础和重要的算法之一,用于将一组数据按照特定的顺序进行排列。本文将对几种常见的内部排序算法和外部排序算法进行详细总结。 首先,排序的基本定义是:给定一个包含n个记录的序列,其...
在编程领域,排序算法是计算机科学中的重要组成部分,特别是在数据处理和算法效率分析上。本文将详细介绍C++中实现的希尔排序、快速排序、堆排序和归并排序这四种经典排序算法。 希尔排序,由Donald Shell于1959年...