- 浏览: 153951 次
- 性别:

- 来自: 郑州
-

文章分类
最新评论
-
loveseaside:
db2v9.1
db2许可证 -
uglypeak:
不对,你这个是哪个版本的??
db2许可证 -
uglypeak:
试过了,不行啊~~
db2许可证 -
yingjun055:
怎么样能修改后,能实时生效呢?
java 读取配置文件的例子
在本文中将介绍 DB2 V9.7 中的新功能 - 分区索引,如何使用和管理分区索引,以及分区索引如何改进大型数据库性能。
简介
分区索引(partitioned index)是 DB2 V9.7 中的新特性,在本文中将介绍什么是分区索引,如何创建和管理分区索引,分区索引如何改进大型数据库性能,读者将获得对分区索引的第一手体验。每个分区索引由多个索引分区(index partition)组成,每个索引分区只对相应的数据分区(data partition)的数据作索引。
开始之前
在开始讨论分区索引之前我们有必要复习一下 DB2 的表分区特性,这一特性是在 DB2 V9 引入的,developerworks 上的这篇文章 “ DB2 9 表分区 - 改进大型数据库的管理” 是一个很好的参考。
表分区是一种数据组织模式,在这种模式中,数据将以一个或多个表列的值为依据,分割到多个称为数据分区(或范围)的存储对象中。每一个数据分区被分别存储。这些存储对象可以位于不同的表空间中,可以位于相同的表空间中,也可能是这两种情况的组合。
表分区特性改进了大型数据库的管理,用户可以灵活的放置索引,在图 1 中,在分区表上建立了两个索引,每个索引分别放置在一个表空间中。但是我们同时也看到,每一个索引中的键值指向了所有数据分区的数据库,在表数据量很大的情况索引也会变得很大。
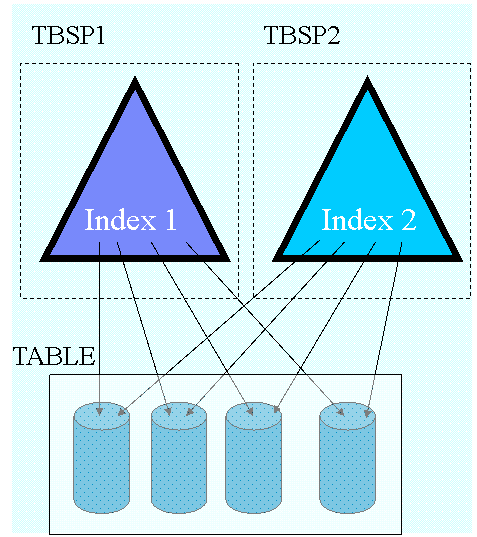 |
图 1. DB2 v9 中表分区特性及其索引
另外,表分区特性使得用户可以使用 ALTER TABLE … ATTACH PARTITION 命令和 DETACH PARTITION 命令轻易的实现表数据的转入( roll-in )和转出( roll-out) ,这两个操作都不需要有任何数据的移动,从而很大的提高性能。同时我们也看到,这两个操作之后需要对索引进行维护,例如 ATTACH 一个新的分区之后需要为这个分区的新数据进行索引, DETACH 一个分区之后需要将索引中相应的键值清除。
分区索引简介
在 DB2 V9.7 之前,分区表上的索引是不能分区的。由于分区表很多情况都是应用在数据仓库环境中,当数据量很大的时候,索引也随之变得很大,从而导致一些的性能上降低。
在 DB2 V9.7 中,索引也可以是分区的,这一特性称之为分区索引(partitioned index)。分区索引由多个索引分区(index partition)组成,每个索引分区中的键值指向相应的唯一一个数据分区(data partition)的数据,系统创建的索引或者用户的创建的索引都可以是分区索引。
在图 2 中,在一个有 4 个数据分区的分区表上建立了三个索引,其中 index1 和 index2 是分区索引,分别由 4 个索引分区组成,index3 是非分区索引(nonpartitioned index),或者称之为全局索引(global index),相对应的,我们可以把分区索引称为本地索引(local index)。
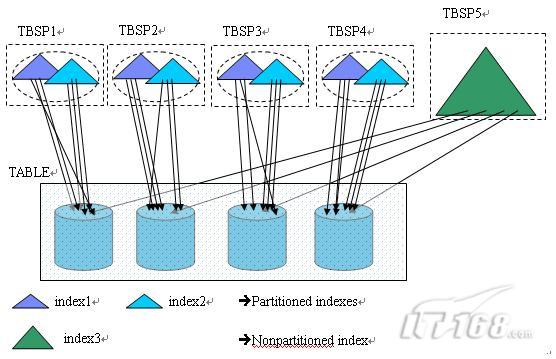 |
图 2. DB2 V9.7 中的分区索引
分区索引带来的一个显著优势在于,在使用 ALTER TABLE ATTACH PARTITION 和 DETAICH PARTITION 命令进行数据的转入( roll-in )和转出( roll-out) 时, 使用分区索引能够很大程度的提高性能。
在 DB2 V9.7 中,以下类型的索引不能是分区索引,只能是非分区索引。
XML 索引
空间数据( spatial data )索引
MDC 块索引( block index ,系统生成索引)
XML path index (系统生成索引)
准备工作
在开始之前,我们先创建一个新的数据库名字叫做 MYDB,如清单 1 所示。当然用已经存在的数据库也可以,但是为了能够简化环境,清楚的、逐步的进行我们接下来的讨论,建议使用一个全新的数据库。
本文中所有操作都是在 LinuxAMD64 平台上的 DB2 V97 版本进行,V97 版本之前的版本都没有分区索引特性。
清单 1. 创建数据库
db2 CREATE DB mydb
创建数据库之后我们创建若干个表空间,如清单 2 所示。
清单 2. 创建表空间
CREATE TABLESPACE TbspT MANAGED BY DATABASE using (FILE 'tspT' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspX MANAGED BY DATABASE using (FILE 'tspX' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspD MANAGED BY DATABASE using (FILE 'tspD' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspY MANAGED BY DATABASE using (FILE 'tspY' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspW MANAGED BY DATABASE using (FILE 'tspW' 4 M) AUTORESIZE YES;
创建分区表
首先创建一个分区表,V9.7 中的分区索引特性为 CREATE TABLE 语法引入了新的子句,即分区级的 INDEX IN 子句。在创建分区表时,我们可以通过表级的 INDEX IN <tablespace> 来指定非分区索引的存放位置,同时可以通过分区级的 INDEX IN <tablespace> 为每一个数据分区对应的索引分区指定单独的表空间。如果没有对于某一个或者多个数据分区指定索引分区的存放表空间,默认是将索引分区存放在与数据分区相同的表空间内。
使用如清单 3 所示的语句创建一个分区表 datapartT,包括 5 个分区。
清单 3. 创建分区表
CREATE TABLE datapartT (a int, b int )IN TbspT INDEX IN TbspXPARTITION BY ( a,b )
(
PARTITION Part0 STARTING (0, 0) ENDING (0, 10)IN TbspD,
PARTITION Part1 ENDING (20,20)INDEX IN TbspY,
PARTITION Part2 ENDING (40,40)INDEX IN TbspW,
PARTITION Part3 STARTING (100,100) ENDING (150, 150)
INDEX IN TbspW,PARTITION Part4 ENDING (200, 200) );
创建分区索引
在 DB2 V9.7 中,创建索引的语法增加了两个保留字 PARTITIONED 和 NOT PARTITIONED,分别用来创建分区索引和非分区索引。如果在创建索引时没有指定这两个保留字中任何一个,默认将建立分区索引。这就意味着,当用户在 DB2 V9.7 上使用于之前相同的语句创建索引时,事实上 DB2 数据库管理系统自动的为用户应用了分区索引这一新特性。
我们已经知道,在 DB2 V9.7 之前,在分区表上创建索引(非分区索引)时可以使用“ CREATE INDEX … ON … IN <tablespace> ”语法将索引放到不同的表空间中,如图 1 所示。在 DB2 V9.7 中,我们仍然可以使用类似语句将非分区索引放到不同的表空间中,而对于分区索引,不允许在创建索引时指定“ IN <tablespace> ”子句,这是因为分区索引的特性,每个索引分区的存放位置取决于创建分区表时分区级“ INDEX IN <tablespace> ”子句,如果某个数据分区没有指定该字句,则相应的索引分区将存放在与数据分区相同的表空间中。
创建索引的语句如清单 4 所示,这里创建了两个分区索引 purpleidx 和 greenidx,以及一个非分区的索引 blueidx 。
清单 4. 创建分区索引以及非分区索引
CREATE INDEX purpleidx on datapartT(a,b) PARTITIONED;
CREATE INDEX greenidx on datapartT(b) PARTITIONED;
CREATE INDEX blueidx on datapartT(a) NOT PARTITIONED;
此时分区表 datapartT 中各个数据分区和索引的存放如图 3 所示。
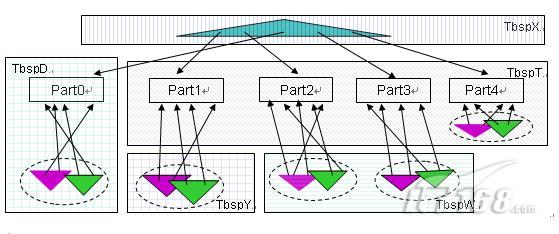 |
图 3. 分区表上分区索引和非分区索引的存放
在图 3 中, 分区 Part0,在创建表时指定了“ IN TbspD ”,没有分区级的 INDEX IN 子句,于是 Part0 的数据分区放在表空间 TbspD 中,相应的索引分区存放在相同的表空间 TbspD 中。
分区 Part1,在创建表时没有指定分区级的 IN 子句,但是由于存在表级的“ IN TbspT ”,于是 Part1 的数据分区放在 TbspT,同时对于 Part1 指定了分区级的“ INDEX IN TbspY ”,于是 Part1 相应的索引分区放在表空间 TbspY 上。
分区 Part2 和 Part3,都没有指定分区级 IN 字句,都有分区级的“ INDEX IN TbspW ”,于是这两个数据分区放在表空间 TbspT,相应的索引分区放在表空间 TbspW 中。
分区 Part4,即没有指定分区级的 IN 子句,也没有指定分区级的 INDEX IN 子句,于是这个数据分区放在表级“ IN TbspT ”所指定的表空间 TbspT 中,索引分区放在与数据分区相同的表空间 TbspT 中。
对于非分区索引 blueidx,在创建索引没有指定 IN 子句,根据规则这个索引将存放在创建表时的表级 INDEX IN 子句所指定的表空间中,即 TbspX 。
分区索引管理
在这里我们来介绍如何维护分区索引,包括
如何判断分区索引
如何取得分区索引的信息
如何把非分区索引移植为分区索引。
如何判断分区索引
对于已经存在的数据库中的索引,我们如何判断是分区索引或非分区索引,可以通过 DB2 提供的命令 DESCRIBE INDEXES 来判断,使用的命令和结果如清单 5 所示。
清单 5. 用 DESCRIBE 命令查看是否为分区索引
db2 describe indexes for table datapartt
Index Index Unique Number of Index Index
schema name rule columns type partitioning
------ ------ ------ ------- --------- --------
TESTUSERS PURPLEIDX D 2 RELATIONAL DATA P
TESTUSERS GREENIDX D 1 RELATIONAL DATA P
TESTUSERS BLUEIDX D 1 RELATIONAL DATA N 3 record(s) selected.
在 DESCRIBE INDEXES 的输出中有一列“ Index partitioning ”,“ P ”表示该索引为分区表上的分区索引,“ N ”表示该索引为分区表上的非分区索引。如果所指定的不是分区表,对于表上的索引 DESCRIBE 将输出“ _ ”。
如何取得分区索引的信息
在故障诊断和数据恢复时,我们需要获得表和索引的一些基本信息,除了表名、索引名之外我们经常需要获得表和索引的对象 ID(object ID),表空间 ID 以及其他的信息,其中对象 ID 和表空间 ID 是两个最重要的信息,可以用来唯一标识数据库中的一个对象。
我们可以通过熟知的 CATALOG 表中获取相应信息,我们已经知道,对于表和索引的基本信息,可以分别查询 SYSCAT.TABLES 和 SYSCAT.INDEXES 。查询语句和输出结果如清单 6 所示。
清单 6. 查询 CATALOG 表获取表和索引信息
select substr(tabname, 1,10) tabname, TABLEID ,TBSPACEID
from syscat.tables where tabname='DATAPARTT'
TABNAME TABLEID TBSPACEID
---------- ------- ---------
DATAPARTT -32768
-6 1 record(s) selected.
select substr(TABNAME, 1,10)TABNAME,SUBSTR(INDNAME, 1, 10)
INDNAME, INDEXTYPE, TBSPACEID, INDEX_OBJECTID
from syscat.indexes where tabname='DATAPARTT'
TABNAME INDNAME INDEXTYPE TBSPACEID INDEX_OBJECTID
---------- ---------- --------- ----------- --------------
DATAPARTT PURPLEIDX REG 65530
32768
DATAPARTT GREENIDX REG 65530
32768
DATAPARTT BLUEIDX REG 10
4 3 record(s) selected.
对于分区表,从 SYSCAT.TABLES 中获取到的对象 ID 和表空间 ID 是逻辑 ID(-32768, -6),并不是表空间存储中真正的 ID,也并不存在这样一个物理的对象,这是因为分区表是由若干个数据分区组成的,每一个分区分别对应一个表空间中的数据对象。
类似的,对于分区索引从 SYSCAT.INDEXES 中获取到的对象 ID 和表空间 ID 也是逻辑 ID(65530, 32768),同样原因是因为分区索引是由若干个索引分区组成,每个索引分区分别对应着一个表空间的索引对象。
我们可以通过查询 SYSCAT.DATAPARTITIONS 来获取每一个数据分区的信息,使用的查询语句和输出的结果如清单 7 所示。
清单 7. 查询 CATALOG 表获取每个数据分区信息
select substr(DATAPARTITIONNAME, 1,10) DATAPARTITIONNAME, PARTITIONOBJECTID,
tbspaceid ,substr(tabname,1,10) tabname
from syscat.datapartitions where tabname='DATAPARTT'
DATAPARTITIONNAME PARTITIONOBJECTID TBSPACEID TABNAME
----------------- ----------------- ----------- ----------
PART0 4 11 DATAPARTT
PART1 4 9 DATAPARTT
PART2 5 9 DATAPARTT
PART3 6 9 DATAPARTT
PART4 7 9 DATAPARTT 5 record(s) selected.
在结果中我们可以看到每一个数据分区都有各自的对象 ID 和表空间 ID,这里的 ID 都是物理 ID,对应一个数据库对象。
对于分区索引的每一个索引分区,在 DB2 V9.7 中有一个新的 CATALOG 表 SYSCAT.INDEXPARTITIONS 来记录其信息,从这个表中我们也可以获取每一个索引分区唯一的对象 ID 和表空间 ID 。使用的查询语句和输出结果如清单 8 所示。
清单 8. 查询 CATALOG 表获取每个索引分区的信息
select substr(TABNAME, 1,10)TABNAME,SUBSTR(INDNAME, 1, 10) INDNAME,
INDPARTITIONTBSPACEID, INDPARTITIONOBJECTID, DATAPARTITIONID
from SYSCAT.INDEXPARTITIONS where tabname='DATAPARTT'
TABNAME INDNAME INDPARTITIONTBSPACEID INDPARTITIONOBJECTID DATAPARTITIONID
------ ----- ------------ ------------ ----------
DATAPARTT PURPLEIDX 11 4 0
DATAPARTT PURPLEIDX 12 4 1
DATAPARTT PURPLEIDX 13 4 2
DATAPARTT PURPLEIDX 13 5 3
DATAPARTT PURPLEIDX 9 7 4
DATAPARTT GREENIDX 11 4 0
DATAPARTT GREENIDX 12 4 1
DATAPARTT GREENIDX 13 4 2
DATAPARTT GREENIDX 13 5 3
DATAPARTT GREENIDX 9 7 4 10 record(s) selected.
在结果中我们发现一个现象,索引 purpleidx 的索引分区 0 对应的对象 ID 和表空间 ID 为(4,11),而索引 greeninx 的索引分区 0 对应的对象 ID 和表空间 ID 也是(4,11),其他的分区也有相同的重复问题,我们在上文也指出每一个对象有唯一的对象 ID 和表空间 ID,这是否矛盾呢?其实,对于每一个数据分区的所有索引分区,都是存放在同一个索引对象中,例如,对于数据分区 Part0,它对应两个索引分区分别是 purpleidx 的分区 0 和 greenidx 的分区 0,这两个索引分区都存放在对象 ID 和表空间 ID 为(4,11)的索引对象里。假如我们继续在这个 datapartT 表上创建更多的分区索引,那数据分区 Part0 相应的所有索引分区都将共享这一个索引对象(4,11)。
<!-- 内容导航 -->
如何把非分区索引移植为分区索引
分区索引是 DB2 V9.7 中的新特性,但是在实际环境中,我们经常需要把数据库从一个之前的 DB2 版本移植到更新的 DB2 版本上来,对于移植到 DB2 V9.7 上的旧数据库来说,其中分区表上的索引都是非分区索引,这种情况下如何将非分区索引移植为分区索引而且要保证索引一直可用?
一个可行的方法是,创建一个分区索引,具有与原有的非分区索引相同的定义,在这个新索引建立的过程中,原有的非分区索引仍然可用,当新索引创建完成之后,删掉原有的非分区索引,最后用命令“ RENAME INDEX … TO … ”把新索引更改为与原有索引相同的名字。这是移植过程全部完成,整个过程中始终有索引可用。提示: DB2 V9.7 中允许在相同的一个或多个列上分别创建一个分区索引和一个非分区索引。
分区索引如何提高性能
之前提到,分区索引带来的一个显著优势在于,在使用 ALTER TABLE ATTACH PARTITION 和 DETAICH PARTITION 命令进行数据的转入( roll-in )和转出( roll-out) 时, 使用分区索引能够很大程度的提高性能。
在使用分区索引特性之前,分区表上的所有索引都是非分区索引,在进行数据的转入( roll-in )和转出( roll-out) 时,需要对索引进行维护,包括在数据的转入时需要在索引中建立新的键值对新数据分区作索引(如图 4 所示),在数据的转出时需要将索引中相应的键值清除(如图 5 所示)。当索引很大的时候,这些维护工作需要非常的代价,将会严重影响数据库系统的性能。
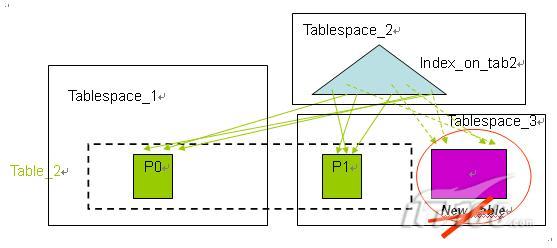 |
图 4. 使用非分区索引时的数据转入
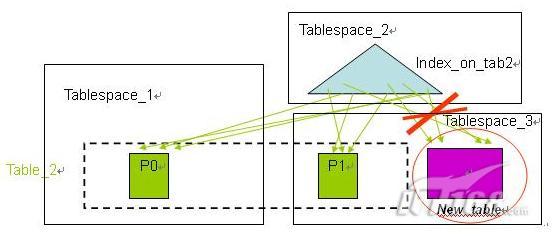 |
图 5. 使用非分区索引时的数据转出
在 DB2 V9.7 上有了分区索引特性,当分区表上只有分区索引时,这时的进行数据的转入和转出变得更加便捷。如图 6 所示,表 SalesTab 有两个数据分区和两个分区索引,表 New_table 是一个相同结构的普通表,并创建了相同定义的两个索引。
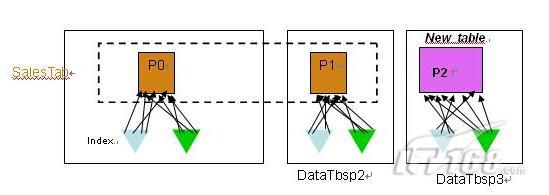 |
图 6. 使用分区索引时的数据转入
当使用数据转入方式把表 New_table 连接(ATTACH)到表 SalesTab 上时,表 New_table 的数据将成为表 SalesTab 的一个数据分区,表 New_table 上的两个索引分别成为表 SalesTab 上分区索引的新的索引分区,然后执行 Set Integrity 命令是所有的数据可用。整个过程不需要任何的数据移动,也不需要大量的索引维护,只需要很少的代价在很短的时间可以完成。类似的,当需要数据转出时,被转出的数据分区成为新表的数据对象,原有的分区索引的索引分区成为新表上的索引。
当然,在实际应用环境中可能遇到一些情况仍然需要对索引进行维护,例如
目标表上的分区索引在源表上没有定义;
源表上的索引与目标表上索引不一致;
目标表上既有分区索引又有非分区索引。
另外, DB2 V9.7 的优化器对分区索引也有相应的处理,能够根据情况选择更加优化的执行计划。限于篇幅以及复杂性,这个主题不在此介绍。
总结
本文可以使读者获得 DB2 V9.7 的分区索引特性的第一手体验,包括什么是分区索引,如何创建和维护分区索引,并且分析了分区索引带来的性能提高。分区索引这一特性,能够给数据仓库、商业智能数据库系统带来性能上的巨大的提高。


发表评论

-
DB2系统命令
2011-08-10 15:11 2653DB2系统命令 1、dasauto在$DB2DIR/da ... -
db2查看当前模式的sql
2011-08-09 15:05 1324通过DB2提供的专用寄存器current sche ... -
db2中会导致表处于reorg pending状态的alter语句
2011-08-09 14:57 5027会导致表处于reorg pending状态的alter tab ... -
db2系统编目表的实践
2011-08-03 15:34 1015一 根据此命令导出全部需要进行统计的表--导出runstats ... -
db2认证
2011-07-19 09:29 1111在这里,我把IBM的认证相关的资料整理下,希望对大家有点帮助。 ... -
db2pd 使用(二)
2011-07-19 09:23 2854分析 DB2 for Linux, UNIX, and ... -
db2pd 使用
2011-07-19 08:53 1441db2pd 工具 用于监控 DB2 实例和数据库的新的 DB ... -
db2的几个有用SQL
2010-11-04 14:47 990--查找函数SELECT * FROM SYSCAT.FUNC ... -
すばらしいnet ---------testpassport問題集のメリット
2010-09-17 14:16 849http://www.testpassport.jp/ ... -
DB2关于查看表空间是否启动了自动存储功能
2010-09-16 11:04 4017可以通过三种方式查看 进入命令行模式 d ... -
DB2约束
2010-09-09 09:53 1192DB2约束 DB2 约束用来对数据实施业务规则,主要 ... -
高级建表SQL
2010-08-16 09:15 894--建表AB 和已知表AA一样create table AB ... -
db2单表优化的命令
2010-08-16 09:04 1041reorg 和runstats 都是单个表优化 ... -
DB2常用语句总结
2010-06-03 16:41 818DB2常用语句 ... -
DB2使用笔记
2010-06-03 15:00 1519DB2使用笔 ... -
db2检索授权的SQL
2010-05-27 10:07 1014--检索具有特权的所有授权名 SELECT DISTINCT ... -
db2许可证
2010-05-27 09:54 1917许可证执行过程 1、windows下启动命令提示符。2、将目 ... -
[转载]DB2表合理映射到表空间
2010-05-26 08:18 1060在DB2数据库中,是� ... -
DB2 DATE 函数的使用一个陷阱
2010-05-19 09:27 4863DB2 DATE 函数的使用一个陷阱 1)DATE 函数正确 ... -
DB2 连接与谓词
2010-05-19 08:37 1127DB2 连接与谓词 ...
相关推荐
DB2 V9.7 license
3. **Blu Acceleration**:这是DB2 V9.7的一个重要特性,通过列式存储、压缩和并行计算加速数据分析性能。 4. **分区技术**:通过垂直分区和水平分区,可以提高大规模数据的处理效率和管理能力。 5. **安全性和...
近期因为测试需要要下载各个版本的安装包,花了很长时间长找到的安装包,分享出来,让大家少走点弯路 自己已在centos7的环境上成功安装,window环境下自行验证 资源清单: ...v9.7fp1_ntx64_server.exe
2. **BLU Acceleration**:这是DB2 V9.7引入的一项创新特性,它利用列式存储、压缩、并行处理和动态内存优化来加速数据分析,尤其对大数据处理和查询性能有显著提升。 3. **性能优化**:对SQL查询进行了优化,提供...
### 在Linux下安装DB2 V9.7 #### 安装概述 本文将详细介绍如何在Linux环境下(以Red Hat Enterprise Linux 5.4为例)安装IBM DB2 Version 9.7 Express-C Edition(以下简称DB2 V9.7)。DB2 V9.7是一款功能强大的...
DB2 V9.7还支持多种高级特性,比如存储过程、触发器、视图、索引、事务控制等。开发者可以根据需要使用这些功能来设计复杂的数据处理逻辑。此外,DB2还提供了优秀的性能优化工具,如SQL解释器、统计信息收集、索引...
别下载了,很多年前的了,时间太久了现在可能不能用了,有人花分下载还来骂人,真无语,我设置为0分的,之前是CSDN自动给我调分了,现在我重新设为0分,关闭了自动调分,能不能用你们自己试
DB2 V9.7升级新特性建议列表
- **性能调优**:利用DB2 9.7的新特性,如改进的查询优化器、增强的索引管理和存储优化,进行性能调优,以提高数据库的响应速度和处理能力。 - **安全加固**:审查并更新数据库的安全策略,包括用户权限管理、数据...
在IT领域,尤其是在数据库开发与Java应用结合的场景下,IBM DB2 v9.7 Java开发成为了一项关键技能。本文将深入解析DB2 v9.7与Java开发的关联,探讨其技术要点、配置需求及实践应用。 ### 关于DB2 v9.7与Java开发 ...
此外,DB2 v9.7引入了多项新功能和优化,包括支持更大的表和索引、增强的数据加密、改进的性能和内存管理,以及对XML数据类型的支持。在AIX环境下,这些特性结合AIX的稳定性,为用户提供了强大的数据库解决方案。 ...
DB2数据库 V9.7安装手册 DB2数据库 V9.7安装手册是 IBM 公司推出的关系型数据库管理系统的安装指南。该手册旨在指导用户正确地安装和配置 DB2 数据库 V9.7,确保数据库的稳定运行和高效性能。 安装环境 在安装 ...
### IBM DB2 9.7新特性解析 #### 一、概述 IBM DB2 9.7作为IBM继DB2 9之后推出的一款里程碑式的产品,不仅延续了DB2系列的强大功能,还在多个方面进行了显著的增强。据IBM软件集团大中华区信息管理业务总经理黄越...
2、tar -xzvf v9.7_linuxia32_server.tar.gz 得到文件夹server 二、 语言包整合 cp -r nlpack/* ./server/ 三、 安装 1、cd server 2、sudo ./db2setup 必须sudo 安装,要不然安装的选择少很多,且不能创建DB2用户 ...
db2 v9.7 企业版 License 注册文件 附带注册说明
DB2数据库驱动9.7版的jar包是Java开发者用于连接IBM DB2数据库的重要组件。在Java编程环境中,为了能够与DB2数据库进行交互,如执行SQL查询、更新数据或管理数据库对象,需要引入特定的驱动程序。在这个案例中,我们...
在Windows 7环境下安装DB2 V9.7.0.441的过程涉及到多个步骤,包括环境检查、下载安装文件、配置选项选择以及后续的系统设置。以下是对这个过程的详细解析: 1. **环境准备**: 在开始安装之前,确保你的Windows 7...
### DB2 v9.7 Development CLI Volume 1:关键技术知识点详解 #### 一、概述 IBM DB2 v9.7 是一款广泛应用于 Linux、UNIX 和 Windows 平台上的数据库管理系统,它提供了强大的数据管理和处理能力。《DB2 v9.7 ...
产品名: "DB2 企业服务器版" ...DB2 数据库分区: "未许可" DB2 性能优化 ESE: "已许可" DB2 存储器优化: "已许可" DB2 高级访问控制: "已许可" DB2 地理数据管理: "已许可" IBM 同构复制 ESE: "已许可