
و¦‚è؟°
وژ’ه؛ڈوœ‰ه†…部وژ’ه؛ڈه’Œه¤–部وژ’ه؛ڈ,ه†…部وژ’ه؛ڈوک¯و•°وچ®è®°ه½•هœ¨ه†…هکن¸è؟›è،Œوژ’ه؛ڈ,而ه¤–部وژ’ه؛ڈوک¯ه› وژ’ه؛ڈçڑ„و•°وچ®ه¾ˆه¤§ï¼Œن¸€و¬،ن¸چ能ه®¹ç؛³ه…¨éƒ¨çڑ„وژ’ه؛ڈè®°ه½•ï¼Œهœ¨وژ’ه؛ڈè؟‡ç¨‹ن¸éœ€è¦پè®؟é—®ه¤–هکم€‚
وˆ‘ن»¬è؟™é‡Œè¯´è¯´ه…«ه¤§وژ’ه؛ڈه°±وک¯ه†…部وژ’ه؛ڈم€‚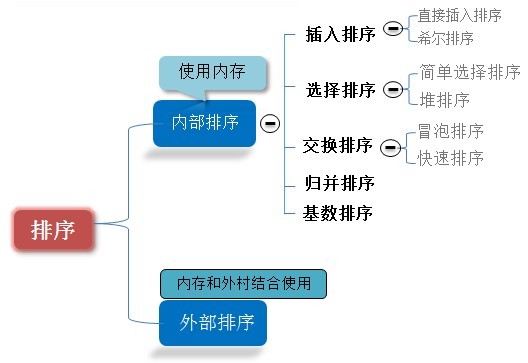
آ آ آ ه½“n较ه¤§ï¼Œهˆ™ه؛”采用و—¶é—´ه¤چو‚ه؛¦ن¸؛O(nlog2n)çڑ„وژ’ه؛ڈو–¹و³•ï¼ڑه؟«é€ںوژ’ه؛ڈم€په †وژ’ه؛ڈوˆ–ه½’ه¹¶وژ’ه؛ڈه؛ڈم€‚
آ آ ه؟«é€ںوژ’ه؛ڈï¼ڑوک¯ç›®ه‰چهں؛ن؛ژو¯”较çڑ„ه†…部وژ’ه؛ڈن¸è¢«è®¤ن¸؛وک¯وœ€ه¥½çڑ„و–¹و³•ï¼Œه½“ه¾…وژ’ه؛ڈçڑ„ه…³é”®ه—وک¯éڑڈوœ؛هˆ†ه¸ƒو—¶ï¼Œه؟«é€ںوژ’ه؛ڈçڑ„ه¹³ه‡و—¶é—´وœ€çںï¼›
1.وڈ’ه…¥وژ’ه؛ڈ—直وژ¥وڈ’ه…¥وژ’ه؛ڈ(Straight Insertion Sort)
هں؛وœ¬و€وƒ³:
ه°†ن¸€ن¸ھè®°ه½•وڈ’ه…¥هˆ°ه·²وژ’ه؛ڈه¥½çڑ„وœ‰ه؛ڈè،¨ن¸ï¼Œن»ژ而ه¾—هˆ°ن¸€ن¸ھو–°ï¼Œè®°ه½•و•°ه¢1çڑ„وœ‰ه؛ڈè،¨م€‚هچ³ï¼ڑه…ˆه°†ه؛ڈهˆ—çڑ„第1ن¸ھè®°ه½•çœ‹وˆگوک¯ن¸€ن¸ھوœ‰ه؛ڈçڑ„هگه؛ڈهˆ—,然هگژن»ژ第2ن¸ھè®°ه½•é€گن¸ھè؟›è،Œوڈ’ه…¥ï¼Œç›´è‡³و•´ن¸ھه؛ڈهˆ—وœ‰ه؛ڈن¸؛و¢م€‚
è¦پ点ï¼ڑ设立ه“¨ه…µï¼Œن½œن¸؛ن¸´و—¶هکه‚¨ه’Œهˆ¤و–و•°ç»„边界ن¹‹ç”¨م€‚
ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈç¤؛ن¾‹ï¼ڑ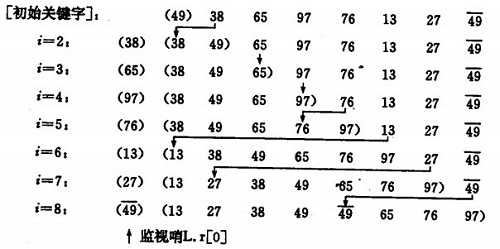
ه¦‚وœç¢°è§پن¸€ن¸ھه’Œوڈ’ه…¥ه…ƒç´ 相ç‰çڑ„,那ن¹ˆوڈ’ه…¥ه…ƒç´ وٹٹوƒ³وڈ’ه…¥çڑ„ه…ƒç´ و”¾هœ¨ç›¸ç‰ه…ƒç´ çڑ„هگژé¢م€‚و‰€ن»¥ï¼Œç›¸ç‰ه…ƒç´ çڑ„ه‰چهگژé،؛ه؛ڈو²،وœ‰و”¹هڈک,ن»ژهژںو— ه؛ڈه؛ڈهˆ—ه‡؛هژ»çڑ„é،؛ه؛ڈه°±وک¯وژ’ه¥½ه؛ڈهگژçڑ„é،؛ه؛ڈ,و‰€ن»¥وڈ’ه…¥وژ’ه؛ڈوک¯ç¨³ه®ڑçڑ„م€‚
void print(int a[], int n ,int i){
cout<<i <<":";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
void InsertSort(int a[], int n)
{
for(int i= 1; i<n; i++){
if(a[i] < a[i-1]){ //若第iن¸ھه…ƒç´ ه¤§ن؛ژi-1ه…ƒç´ ,直وژ¥وڈ’ه…¥م€‚ه°ڈن؛ژçڑ„è¯ï¼Œç§»هٹ¨وœ‰ه؛ڈè،¨هگژوڈ’ه…¥
int j= i-1;
int x = a[i]; //ه¤چهˆ¶ن¸؛ه“¨ه…µï¼Œهچ³هکه‚¨ه¾…وژ’ه؛ڈه…ƒç´
a[i] = a[i-1]; //ه…ˆهگژ移ن¸€ن¸ھه…ƒç´
while(x < a[j]){ //وں¥و‰¾هœ¨وœ‰ه؛ڈè،¨çڑ„وڈ’ه…¥ن½چç½®
a[j+1] = a[j];
j--; //ه…ƒç´ هگژ移
}
a[j+1] = x; //وڈ’ه…¥هˆ°و£ç،®ن½چç½®
}
print(a,n,i); //و‰“هچ°و¯ڈè¶ںوژ’ه؛ڈçڑ„结وœ
}
}
int main(){
int a[8] = {3,1,5,7,2,4,9,6};
InsertSort(a,8);
print(a,8,8);
}
آ
و•ˆçژ‡ï¼ڑ
و—¶é—´ه¤چو‚ه؛¦ï¼ڑO(n^2).
ه…¶ن»–çڑ„وڈ’ه…¥وژ’ه؛ڈوœ‰ن؛Œهˆ†وڈ’ه…¥وژ’ه؛ڈ,2-è·¯وڈ’ه…¥وژ’ه؛ڈم€‚
آ
2. وڈ’ه…¥وژ’ه؛ڈ—ه¸Œه°”وژ’ه؛ڈ(Shell`s Sort)
ه¸Œه°”وژ’ه؛ڈوک¯1959 ه¹´ç”±D.L.Shell وڈگه‡؛و¥çڑ„,相ه¯¹ç›´وژ¥وژ’ه؛ڈوœ‰è¾ƒه¤§çڑ„و”¹è؟›م€‚ه¸Œه°”وژ’ه؛ڈهڈˆهڈ«ç¼©ه°ڈه¢é‡ڈوژ’ه؛ڈ
هں؛وœ¬و€وƒ³ï¼ڑ
ه…ˆه°†و•´ن¸ھه¾…وژ’ه؛ڈçڑ„è®°ه½•ه؛ڈهˆ—هˆ†ه‰²وˆگن¸؛è‹¥ه¹²هگه؛ڈهˆ—هˆ†هˆ«è؟›è،Œç›´وژ¥وڈ’ه…¥وژ’ه؛ڈ,ه¾…و•´ن¸ھه؛ڈهˆ—ن¸çڑ„è®°ه½•â€œهں؛وœ¬وœ‰ه؛ڈâ€و—¶ï¼Œه†چه¯¹ه…¨ن½“è®°ه½•è؟›è،Œن¾و¬،ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€‚
و“چن½œو–¹و³•ï¼ڑ
آ آ آ 选و‹©ن¸€ن¸ھه¢é‡ڈه؛ڈهˆ—t1,t2,…,tk,ه…¶ن¸ti>tj,tk=1ï¼›
آ آ آ وŒ‰ه¢é‡ڈه؛ڈهˆ—ن¸ھو•°k,ه¯¹ه؛ڈهˆ—è؟›è،Œk è¶ںوژ’ه؛ڈï¼›
آ آ آ و¯ڈè¶ںوژ’ه؛ڈ,و ¹وچ®ه¯¹ه؛”çڑ„ه¢é‡ڈti,ه°†ه¾…وژ’ه؛ڈهˆ—هˆ†ه‰²وˆگè‹¥ه¹²é•؟ه؛¦ن¸؛m çڑ„هگه؛ڈهˆ—,هˆ†هˆ«ه¯¹هگ„هگè،¨è؟›è،Œç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€‚ن»…ه¢é‡ڈه› هگن¸؛1 و—¶ï¼Œو•´ن¸ھه؛ڈهˆ—ن½œن¸؛ن¸€ن¸ھè،¨و¥ه¤„çگ†ï¼Œè،¨é•؟ه؛¦هچ³ن¸؛و•´ن¸ھه؛ڈهˆ—çڑ„é•؟ه؛¦م€‚
ه¸Œه°”وژ’ه؛ڈçڑ„ç¤؛ن¾‹ï¼ڑ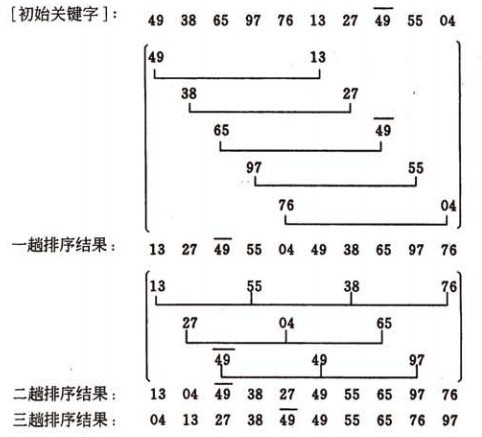
ç®—و³•ه®çژ°ï¼ڑ
آ
وˆ‘ن»¬ç®€هچ•ه¤„çگ†ه¢é‡ڈه؛ڈهˆ—ï¼ڑه¢é‡ڈه؛ڈهˆ—d = {n/2 ,n/4, n/8 .....1} nن¸؛è¦پوژ’ه؛ڈو•°çڑ„ن¸ھو•°
هچ³ï¼ڑه…ˆه°†è¦پوژ’ه؛ڈçڑ„ن¸€ç»„è®°ه½•وŒ‰وںگن¸ھه¢é‡ڈd(n/2,nن¸؛è¦پوژ’ه؛ڈو•°çڑ„ن¸ھو•°ï¼‰هˆ†وˆگè‹¥ه¹²ç»„هگه؛ڈهˆ—,و¯ڈ组ن¸è®°ه½•çڑ„ن¸‹و ‡ç›¸ه·®d.ه¯¹و¯ڈ组ن¸ه…¨éƒ¨ه…ƒç´ è؟›è،Œç›´وژ¥وڈ’ه…¥وژ’ه؛ڈ,然هگژه†چ用ن¸€ن¸ھ较ه°ڈçڑ„ه¢é‡ڈ(d/2)ه¯¹ه®ƒè؟›è،Œهˆ†ç»„,هœ¨و¯ڈ组ن¸ه†چè؟›è،Œç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€‚继ç»ن¸چو–缩ه°ڈه¢é‡ڈ直至ن¸؛1,وœ€هگژن½؟用直وژ¥وڈ’ه…¥وژ’ه؛ڈه®Œوˆگوژ’ه؛ڈم€‚
void print(int a[], int n ,int i){
cout<<i <<":";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈçڑ„ن¸€èˆ¬ه½¢ه¼ڈ
*
* @param int dk 缩ه°ڈه¢é‡ڈ,ه¦‚وœوک¯ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈ,dk=1
*
*/
void ShellInsertSort(int a[], int n, int dk)
{
for(int i= dk; i<n; ++i){
if(a[i] < a[i-dk]){ //若第iن¸ھه…ƒç´ ه¤§ن؛ژi-1ه…ƒç´ ,直وژ¥وڈ’ه…¥م€‚ه°ڈن؛ژçڑ„è¯ï¼Œç§»هٹ¨وœ‰ه؛ڈè،¨هگژوڈ’ه…¥
int j = i-dk;
int x = a[i]; //ه¤چهˆ¶ن¸؛ه“¨ه…µï¼Œهچ³هکه‚¨ه¾…وژ’ه؛ڈه…ƒç´
a[i] = a[i-dk]; //首ه…ˆهگژ移ن¸€ن¸ھه…ƒç´
while(x < a[j]){ //وں¥و‰¾هœ¨وœ‰ه؛ڈè،¨çڑ„وڈ’ه…¥ن½چç½®
a[j+dk] = a[j];
j -= dk; //ه…ƒç´ هگژ移
}
a[j+dk] = x; //وڈ’ه…¥هˆ°و£ç،®ن½چç½®
}
print(a, n,i );
}
}
/**
* ه…ˆوŒ‰ه¢é‡ڈd(n/2,nن¸؛è¦پوژ’ه؛ڈو•°çڑ„ن¸ھو•°è؟›è،Œه¸Œه°”وژ’ه؛ڈ
*
*/
void shellSort(int a[], int n){
int dk = n/2;
while( dk >= 1 ){
ShellInsertSort(a, n, dk);
dk = dk/2;
}
}
int main(){
int a[8] = {3,1,5,7,2,4,9,6};
//ShellInsertSort(a,8,1); //ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈ
shellSort(a,8); //ه¸Œه°”وڈ’ه…¥وژ’ه؛ڈ
print(a,8,8);
}
آ ه¸Œه°”وژ’ه؛ڈو—¶و•ˆهˆ†وگه¾ˆéڑ¾ï¼Œه…³é”®ç پçڑ„و¯”较و¬،و•°ن¸ژè®°ه½•ç§»هٹ¨و¬،و•°ن¾èµ–ن؛ژه¢é‡ڈه› هگه؛ڈهˆ—dçڑ„选هڈ–,特ه®ڑوƒ…ه†µن¸‹هڈ¯ن»¥ه‡†ç،®ن¼°ç®—ه‡؛ه…³é”®ç پçڑ„و¯”较و¬،و•°ه’Œè®°ه½•çڑ„移هٹ¨و¬،و•°م€‚ç›®ه‰چè؟کو²،وœ‰ن؛؛ç»™ه‡؛选هڈ–وœ€ه¥½çڑ„ه¢é‡ڈه› هگه؛ڈهˆ—çڑ„و–¹و³•م€‚ه¢é‡ڈه› هگه؛ڈهˆ—هڈ¯ن»¥وœ‰هگ„ç§چهڈ–و³•ï¼Œوœ‰هڈ–ه¥‡و•°çڑ„,ن¹ںوœ‰هڈ–è´¨و•°çڑ„,ن½†éœ€è¦پو³¨و„ڈï¼ڑه¢é‡ڈه› هگن¸é™¤1 ه¤–و²،وœ‰ه…¬ه› هگ,ن¸”وœ€هگژن¸€ن¸ھه¢é‡ڈه› هگه؟…é،»ن¸؛1م€‚ه¸Œه°”وژ’ه؛ڈو–¹و³•وک¯ن¸€ن¸ھن¸چ稳ه®ڑçڑ„وژ’ه؛ڈو–¹و³•م€‚
3. 选و‹©وژ’ه؛ڈ—简هچ•é€‰و‹©وژ’ه؛ڈ(Simple Selection Sort)
هں؛وœ¬و€وƒ³ï¼ڑ
هœ¨è¦پوژ’ه؛ڈçڑ„ن¸€ç»„و•°ن¸ï¼Œé€‰ه‡؛وœ€ه°ڈ(وˆ–者وœ€ه¤§ï¼‰çڑ„ن¸€ن¸ھو•°ن¸ژ第1ن¸ھن½چç½®çڑ„و•°ن؛¤وچ¢ï¼›ç„¶هگژهœ¨ه‰©ن¸‹çڑ„و•°ه½“ن¸ه†چو‰¾وœ€ه°ڈ(وˆ–者وœ€ه¤§ï¼‰çڑ„ن¸ژ第2ن¸ھن½چç½®çڑ„و•°ن؛¤وچ¢ï¼Œن¾و¬،ç±»وژ¨ï¼Œç›´هˆ°ç¬¬n-1ن¸ھه…ƒç´ (ه€’و•°ç¬¬ن؛Œن¸ھو•°ï¼‰ه’Œç¬¬nن¸ھه…ƒç´ (وœ€هگژن¸€ن¸ھو•°ï¼‰و¯”较ن¸؛و¢م€‚
简هچ•é€‰و‹©وژ’ه؛ڈçڑ„ç¤؛ن¾‹ï¼ڑ
آ 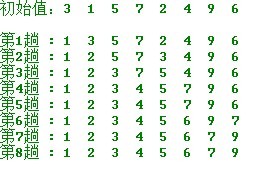
و“چن½œو–¹و³•ï¼ڑ
第ن¸€è¶ں,ن»ژn ن¸ھè®°ه½•ن¸و‰¾ه‡؛ه…³é”®ç پوœ€ه°ڈçڑ„è®°ه½•ن¸ژ第ن¸€ن¸ھè®°ه½•ن؛¤وچ¢ï¼›
第ن؛Œè¶ں,ن»ژ第ن؛Œن¸ھè®°ه½•ه¼€ه§‹çڑ„n-1 ن¸ھè®°ه½•ن¸ه†چ选ه‡؛ه…³é”®ç پوœ€ه°ڈçڑ„è®°ه½•ن¸ژ第ن؛Œن¸ھè®°ه½•ن؛¤وچ¢ï¼›
ن»¥و¤ç±»وژ¨.....
第i è¶ں,هˆ™ن»ژ第i ن¸ھè®°ه½•ه¼€ه§‹çڑ„n-i+1 ن¸ھè®°ه½•ن¸é€‰ه‡؛ه…³é”®ç پوœ€ه°ڈçڑ„è®°ه½•ن¸ژ第i ن¸ھè®°ه½•ن؛¤وچ¢ï¼Œ
ç›´هˆ°و•´ن¸ھه؛ڈهˆ—وŒ‰ه…³é”®ç پوœ‰ه؛ڈم€‚
ç®—و³•ه®çژ°ï¼ڑ
void print(int a[], int n ,int i){
cout<<"第"<<i+1 <<"è¶ں : ";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* و•°ç»„çڑ„وœ€ه°ڈه€¼
*
* @return int و•°ç»„çڑ„é”®ه€¼
*/
int SelectMinKey(int a[], int n, int i)
{
int k = i;
for(int j=i+1 ;j< n; ++j) {
if(a[k] > a[j]) k = j;
}
return k;
}
/**
* 选و‹©وژ’ه؛ڈ
*
*/
void selectSort(int a[], int n){
int key, tmp;
for(int i = 0; i< n; ++i) {
key = SelectMinKey(a, n,i); //选و‹©وœ€ه°ڈçڑ„ه…ƒç´
if(key != i){
tmp = a[i]; a[i] = a[key]; a[key] = tmp; //وœ€ه°ڈه…ƒç´ ن¸ژ第iن½چç½®ه…ƒç´ ن؛’وچ¢
}
print(a, n , i);
}
}
int main(){
int a[8] = {3,1,5,7,2,4,9,6};
cout<<"هˆه§‹ه€¼ï¼ڑ";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl<<endl;
selectSort(a, 8);
print(a,8,8);
}
آ 简هچ•é€‰و‹©وژ’ه؛ڈçڑ„و”¹è؟›â€”—ن؛Œه…ƒé€‰و‹©وژ’ه؛ڈ
简هچ•é€‰و‹©وژ’ه؛ڈ,و¯ڈè¶ںه¾ھçژ¯هڈھ能ç،®ه®ڑن¸€ن¸ھه…ƒç´ وژ’ه؛ڈهگژçڑ„ه®ڑن½چم€‚وˆ‘ن»¬هڈ¯ن»¥è€ƒè™‘و”¹è؟›ن¸؛و¯ڈè¶ںه¾ھçژ¯ç،®ه®ڑن¸¤ن¸ھه…ƒç´ (ه½“ه‰چè¶ںوœ€ه¤§ه’Œوœ€ه°ڈè®°ه½•ï¼‰çڑ„ن½چç½®,ن»ژ而ه‡ڈه°‘وژ’ه؛ڈو‰€éœ€çڑ„ه¾ھçژ¯و¬،و•°م€‚و”¹è؟›هگژه¯¹nن¸ھو•°وچ®è؟›è،Œوژ’ه؛ڈ,وœ€ه¤ڑهڈھ需è؟›è،Œ[n/2]è¶ںه¾ھçژ¯هچ³هڈ¯م€‚ه…·ن½“ه®çژ°ه¦‚ن¸‹ï¼ڑ
void SelectSort(int r[],int n) {
int i ,j , min ,max, tmp;
for (i=1 ;i <= n/2;i++) {
// هپڑن¸چ超è؟‡n/2è¶ں选و‹©وژ’ه؛ڈ
min = i; max = i ; //هˆ†هˆ«è®°ه½•وœ€ه¤§ه’Œوœ€ه°ڈه…³é”®ه—è®°ه½•ن½چç½®
for (j= i+1; j<= n-i; j++) {
if (r[j] > r[max]) {
max = j ; continue ;
}
if (r[j]< r[min]) {
min = j ;
}
}
//该ن؛¤وچ¢و“چن½œè؟کهڈ¯هˆ†وƒ…ه†µè®¨è®؛ن»¥وڈگé«کو•ˆçژ‡
tmp = r[i-1]; r[i-1] = r[min]; r[min] = tmp;
tmp = r[n-i]; r[n-i] = r[max]; r[max] = tmp;
}
}
آ
4. 选و‹©وژ’ه؛ڈ—ه †وژ’ه؛ڈ(Heap Sort)
ه †وژ’ه؛ڈوک¯ن¸€ç§چو ‘ه½¢é€‰و‹©وژ’ه؛ڈ,وک¯ه¯¹ç›´وژ¥é€‰و‹©وژ’ه؛ڈçڑ„وœ‰و•ˆو”¹è؟›م€‚هں؛وœ¬و€وƒ³ï¼ڑ
ه †çڑ„ه®ڑن¹‰ه¦‚ن¸‹ï¼ڑه…·وœ‰nن¸ھه…ƒç´ çڑ„ه؛ڈهˆ—(k1,k2,...,kn),ه½“ن¸”ن»…ه½“و»،足
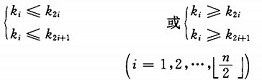
و—¶ç§°ن¹‹ن¸؛ه †م€‚ç”±ه †çڑ„ه®ڑن¹‰هڈ¯ن»¥çœ‹ه‡؛,ه †é،¶ه…ƒç´ (هچ³ç¬¬ن¸€ن¸ھه…ƒç´ )ه؟…ن¸؛وœ€ه°ڈé،¹ï¼ˆه°ڈé،¶ه †ï¼‰م€‚
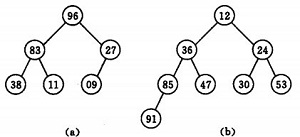
è‹¥ن»¥ن¸€ç»´و•°ç»„هکه‚¨ن¸€ن¸ھه †ï¼Œهˆ™ه †ه¯¹ه؛”ن¸€و£µه®Œه…¨ن؛Œهڈ‰و ‘,ن¸”و‰€وœ‰éهڈ¶ç»“点çڑ„ه€¼ه‡ن¸چه¤§ن؛ژ(وˆ–ن¸چه°ڈن؛ژ)ه…¶هگه¥³çڑ„ه€¼ï¼Œو ¹ç»“点(ه †é،¶ه…ƒç´ )çڑ„ه€¼وک¯وœ€ه°ڈ(وˆ–وœ€ه¤§)çڑ„م€‚ه¦‚ï¼ڑ
(a)ه¤§é،¶ه †ه؛ڈهˆ—ï¼ڑ(96, 83,27,38,11,09)
آ (b)آ ه°ڈé،¶ه †ه؛ڈهˆ—ï¼ڑ(12,36,24,85,47,30,53,91)
آ
هˆه§‹و—¶وٹٹè¦پوژ’ه؛ڈçڑ„nن¸ھو•°çڑ„ه؛ڈهˆ—看ن½œوک¯ن¸€و£µé،؛ه؛ڈهکه‚¨çڑ„ن؛Œهڈ‰و ‘(ن¸€ç»´و•°ç»„هکه‚¨ن؛Œهڈ‰و ‘),调و•´ه®ƒن»¬çڑ„هکه‚¨ه؛ڈ,ن½؟ن¹‹وˆگن¸؛ن¸€ن¸ھه †ï¼Œه°†ه †é،¶ه…ƒç´ 输ه‡؛,ه¾—هˆ°n ن¸ھه…ƒç´ ن¸وœ€ه°ڈ(وˆ–وœ€ه¤§)çڑ„ه…ƒç´ ,è؟™و—¶ه †çڑ„و ¹èٹ‚点çڑ„و•°وœ€ه°ڈ(وˆ–者وœ€ه¤§ï¼‰م€‚然هگژه¯¹ه‰چé¢(n-1)ن¸ھه…ƒç´ é‡چو–°è°ƒو•´ن½؟ن¹‹وˆگن¸؛ه †ï¼Œè¾“ه‡؛ه †é،¶ه…ƒç´ ,ه¾—هˆ°n ن¸ھه…ƒç´ ن¸و¬،ه°ڈ(وˆ–و¬،ه¤§)çڑ„ه…ƒç´ م€‚ن¾و¤ç±»وژ¨ï¼Œç›´هˆ°هڈھوœ‰ن¸¤ن¸ھèٹ‚点çڑ„ه †ï¼Œه¹¶ه¯¹ه®ƒن»¬ن½œن؛¤وچ¢ï¼Œوœ€هگژه¾—هˆ°وœ‰nن¸ھèٹ‚点çڑ„وœ‰ه؛ڈه؛ڈهˆ—م€‚称è؟™ن¸ھè؟‡ç¨‹ن¸؛ه †وژ’ه؛ڈم€‚
ه› و¤ï¼Œه®çژ°ه †وژ’ه؛ڈ需解ه†³ن¸¤ن¸ھé—®é¢کï¼ڑ
1. ه¦‚ن½•ه°†n ن¸ھه¾…وژ’ه؛ڈçڑ„و•°ه»؛وˆگه †ï¼›
2. 输ه‡؛ه †é،¶ه…ƒç´ هگژ,و€ژو ·è°ƒو•´ه‰©ن½™n-1 ن¸ھه…ƒç´ ,ن½؟ه…¶وˆگن¸؛ن¸€ن¸ھو–°ه †م€‚
首ه…ˆè®¨è®؛第ن؛Œن¸ھé—®é¢کï¼ڑ输ه‡؛ه †é،¶ه…ƒç´ هگژ,ه¯¹ه‰©ن½™n-1ه…ƒç´ é‡چو–°ه»؛وˆگه †çڑ„è°ƒو•´è؟‡ç¨‹م€‚
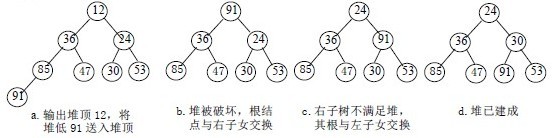
è°ƒو•´ه°ڈé،¶ه †çڑ„و–¹و³•ï¼ڑ
1)设وœ‰m ن¸ھه…ƒç´ çڑ„ه †ï¼Œè¾“ه‡؛ه †é،¶ه…ƒç´ هگژ,ه‰©ن¸‹m-1 ن¸ھه…ƒç´ م€‚ه°†ه †ه؛•ه…ƒç´ é€په…¥ه †é،¶ï¼ˆï¼ˆوœ€هگژن¸€ن¸ھه…ƒç´ ن¸ژه †é،¶è؟›è،Œن؛¤وچ¢ï¼‰ï¼Œه †è¢«ç ´هڈ,ه…¶هژںه› ن»…وک¯و ¹ç»“点ن¸چو»،足ه †çڑ„و€§è´¨م€‚
2)ه°†و ¹ç»“点ن¸ژه·¦م€پهڈ³هگو ‘ن¸è¾ƒه°ڈه…ƒç´ çڑ„è؟›è،Œن؛¤وچ¢م€‚
3)若ن¸ژه·¦هگو ‘ن؛¤وچ¢ï¼ڑه¦‚وœه·¦هگو ‘ه †è¢«ç ´هڈ,هچ³ه·¦هگو ‘çڑ„و ¹ç»“点ن¸چو»،足ه †çڑ„و€§è´¨ï¼Œهˆ™é‡چه¤چو–¹و³• (2).
4)若ن¸ژهڈ³هگو ‘ن؛¤وچ¢ï¼Œه¦‚وœهڈ³هگو ‘ه †è¢«ç ´هڈ,هچ³هڈ³هگو ‘çڑ„و ¹ç»“点ن¸چو»،足ه †çڑ„و€§è´¨م€‚هˆ™é‡چه¤چو–¹و³• (2).
5)继ç»ه¯¹ن¸چو»،足ه †و€§è´¨çڑ„هگو ‘è؟›è،Œن¸ٹè؟°ن؛¤وچ¢و“چن½œï¼Œç›´هˆ°هڈ¶هگ结点,ه †è¢«ه»؛وˆگم€‚
称è؟™ن¸ھè‡ھو ¹ç»“点هˆ°هڈ¶هگ结点çڑ„è°ƒو•´è؟‡ç¨‹ن¸؛ç›é€‰م€‚ه¦‚ه›¾ï¼ڑ
ه†چ讨è®؛ه¯¹n ن¸ھه…ƒç´ هˆه§‹ه»؛ه †çڑ„è؟‡ç¨‹م€‚
ه»؛ه †و–¹و³•ï¼ڑه¯¹هˆه§‹ه؛ڈهˆ—ه»؛ه †çڑ„è؟‡ç¨‹ï¼Œه°±وک¯ن¸€ن¸ھهڈچه¤چè؟›è،Œç›é€‰çڑ„è؟‡ç¨‹م€‚
1)n ن¸ھ结点çڑ„ه®Œه…¨ن؛Œهڈ‰و ‘,هˆ™وœ€هگژن¸€ن¸ھ结点وک¯ç¬¬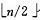 ن¸ھ结点çڑ„هگو ‘م€‚
ن¸ھ结点çڑ„هگو ‘م€‚
2)ç›é€‰ن»ژ第ن¸ھ结点ن¸؛و ¹çڑ„هگو ‘ه¼€ه§‹ï¼Œè¯¥هگو ‘وˆگن¸؛ه †م€‚
3)ن¹‹هگژهگ‘ه‰چن¾و¬،ه¯¹هگ„结点ن¸؛و ¹çڑ„هگو ‘è؟›è،Œç›é€‰ï¼Œن½؟ن¹‹وˆگن¸؛ه †ï¼Œç›´هˆ°و ¹ç»“点م€‚
ه¦‚ه›¾ه»؛ه †هˆه§‹è؟‡ç¨‹ï¼ڑو— ه؛ڈه؛ڈهˆ—ï¼ڑ(49,38,65,97,76,13,27,49)
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ 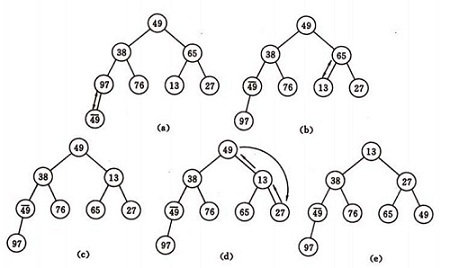
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ 
آ
آ ç®—و³•çڑ„ه®çژ°ï¼ڑ
ن»ژç®—و³•وڈڈè؟°و¥çœ‹ï¼Œه †وژ’ه؛ڈ需è¦پن¸¤ن¸ھè؟‡ç¨‹ï¼Œن¸€وک¯ه»؛ç«‹ه †ï¼Œن؛Œوک¯ه †é،¶ن¸ژه †çڑ„وœ€هگژن¸€ن¸ھه…ƒç´ ن؛¤وچ¢ن½چç½®م€‚و‰€ن»¥ه †وژ’ه؛ڈوœ‰ن¸¤ن¸ھه‡½و•°ç»„وˆگم€‚ن¸€وک¯ه»؛ه †çڑ„و¸—é€ڈه‡½و•°ï¼Œن؛Œوک¯هڈچه¤چ调用و¸—é€ڈه‡½و•°ه®çژ°وژ’ه؛ڈçڑ„ه‡½و•°م€‚
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* ه·²çں¥H[s…m]除ن؛†H[s] ه¤–ه‡و»،足ه †çڑ„ه®ڑن¹‰
* è°ƒو•´H[s],ن½؟ه…¶وˆگن¸؛ه¤§é،¶ه †.هچ³ه°†ه¯¹ç¬¬sن¸ھ结点ن¸؛و ¹çڑ„هگو ‘ç›é€‰,
*
* @param Hوک¯ه¾…è°ƒو•´çڑ„ه †و•°ç»„
* @param sوک¯ه¾…è°ƒو•´çڑ„و•°ç»„ه…ƒç´ çڑ„ن½چç½®
* @param lengthوک¯و•°ç»„çڑ„é•؟ه؛¦
*
*/
void HeapAdjust(int H[],int s, int length)
{
int tmp = H[s];
int child = 2*s+1; //ه·¦ه©هگ结点çڑ„ن½چç½®م€‚(i+1 ن¸؛ه½“ه‰چè°ƒو•´ç»“点çڑ„هڈ³ه©هگ结点çڑ„ن½چç½®)
while (child < length) {
if(child+1 <length && H[child]<H[child+1]) { // ه¦‚وœهڈ³ه©هگه¤§ن؛ژه·¦ه©هگ(و‰¾هˆ°و¯”ه½“ه‰چه¾…è°ƒو•´ç»“点ه¤§çڑ„ه©هگ结点)
++child ;
}
if(H[s]<H[child]) { // ه¦‚وœè¾ƒه¤§çڑ„هگ结点ه¤§ن؛ژ父结点
H[s] = H[child]; // é‚£ن¹ˆوٹٹ较ه¤§çڑ„هگ结点ه¾€ن¸ٹ移هٹ¨ï¼Œو›؟وچ¢ه®ƒçڑ„父结点
s = child; // é‡چو–°è®¾ç½®s ,هچ³ه¾…è°ƒو•´çڑ„ن¸‹ن¸€ن¸ھ结点çڑ„ن½چç½®
child = 2*s+1;
} else { // ه¦‚وœه½“ه‰چه¾…è°ƒو•´ç»“点ه¤§ن؛ژه®ƒçڑ„ه·¦هڈ³ه©هگ,هˆ™ن¸چ需è¦پè°ƒو•´ï¼Œç›´وژ¥é€€ه‡؛
break;
}
H[s] = tmp; // ه½“ه‰چه¾…è°ƒو•´çڑ„结点و”¾هˆ°و¯”ه…¶ه¤§çڑ„ه©هگ结点ن½چç½®ن¸ٹ
}
print(H,length);
}
/**
* هˆه§‹ه †è؟›è،Œè°ƒو•´
* ه°†H[0..length-1]ه»؛وˆگه †
* è°ƒو•´ه®Œن¹‹هگژ第ن¸€ن¸ھه…ƒç´ وک¯ه؛ڈهˆ—çڑ„وœ€ه°ڈçڑ„ه…ƒç´
*/
void BuildingHeap(int H[], int length)
{
//وœ€هگژن¸€ن¸ھوœ‰ه©هگçڑ„èٹ‚点çڑ„ن½چç½® i= (length -1) / 2
for (int i = (length -1) / 2 ; i >= 0; --i)
HeapAdjust(H,i,length);
}
/**
* ه †وژ’ه؛ڈç®—و³•
*/
void HeapSort(int H[],int length)
{
//هˆه§‹ه †
BuildingHeap(H, length);
//ن»ژوœ€هگژن¸€ن¸ھه…ƒç´ ه¼€ه§‹ه¯¹ه؛ڈهˆ—è؟›è،Œè°ƒو•´
for (int i = length - 1; i > 0; --i)
{
//ن؛¤وچ¢ه †é،¶ه…ƒç´ H[0]ه’Œه †ن¸وœ€هگژن¸€ن¸ھه…ƒç´
int temp = H[i]; H[i] = H[0]; H[0] = temp;
//و¯ڈو¬،ن؛¤وچ¢ه †é،¶ه…ƒç´ ه’Œه †ن¸وœ€هگژن¸€ن¸ھه…ƒç´ ن¹‹هگژ,都è¦په¯¹ه †è؟›è،Œè°ƒو•´
HeapAdjust(H,0,i);
}
}
int main(){
int H[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"هˆه§‹ه€¼ï¼ڑ";
print(H,10);
HeapSort(H,10);
//selectSort(a, 8);
cout<<"结وœï¼ڑ";
print(H,10);
}
آ
5. ن؛¤وچ¢وژ’ه؛ڈ—ه†’و³،وژ’ه؛ڈ(Bubble Sort)
هں؛وœ¬و€وƒ³ï¼ڑ
هœ¨è¦پوژ’ه؛ڈçڑ„ن¸€ç»„و•°ن¸ï¼Œه¯¹ه½“ه‰چè؟کوœھوژ’ه¥½ه؛ڈçڑ„范ه›´ه†…çڑ„ه…¨éƒ¨و•°ï¼Œè‡ھن¸ٹ而ن¸‹ه¯¹ç›¸é‚»çڑ„ن¸¤ن¸ھو•°ن¾و¬،è؟›è،Œو¯”较ه’Œè°ƒو•´ï¼Œè®©è¾ƒه¤§çڑ„و•°ه¾€ن¸‹و²‰ï¼Œè¾ƒه°ڈçڑ„ه¾€ن¸ٹه†’م€‚هچ³ï¼ڑو¯ڈه½“ن¸¤ç›¸é‚»çڑ„و•°و¯”较هگژهڈ‘çژ°ه®ƒن»¬çڑ„وژ’ه؛ڈن¸ژوژ’ه؛ڈè¦پو±‚相هڈچو—¶ï¼Œه°±ه°†ه®ƒن»¬ن؛’وچ¢م€‚
ه†’و³،وژ’ه؛ڈçڑ„ç¤؛ن¾‹ï¼ڑ
آ 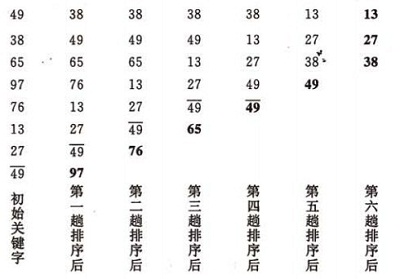
ç®—و³•çڑ„ه®çژ°ï¼ڑ
void bubbleSort(int a[], int n){
for(int i =0 ; i< n-1; ++i) {
for(int j = 0; j < n-i-1; ++j) {
if(a[j] > a[j+1])
{
int tmp = a[j] ; a[j] = a[j+1] ; a[j+1] = tmp;
}
}
}
}
آ
ه†’و³،وژ’ه؛ڈç®—و³•çڑ„و”¹è؟›
ه¯¹ه†’و³،وژ’ه؛ڈه¸¸è§پçڑ„و”¹è؟›و–¹و³•وک¯هٹ ه…¥ن¸€و ‡ه؟—و€§هڈکé‡ڈexchange,用ن؛ژو ‡ه؟—وںگن¸€è¶ںوژ’ه؛ڈè؟‡ç¨‹ن¸وک¯هگ¦وœ‰و•°وچ®ن؛¤وچ¢ï¼Œه¦‚وœè؟›è،Œوںگن¸€è¶ںوژ’ه؛ڈو—¶ه¹¶و²،وœ‰è؟›è،Œو•°وچ®ن؛¤وچ¢ï¼Œهˆ™è¯´وکژو•°وچ®ه·²ç»ڈوŒ‰è¦پو±‚وژ’هˆ—ه¥½ï¼Œهڈ¯ç«‹هچ³ç»“وںوژ’ه؛ڈ,éپ؟ه…چن¸چه؟…è¦پçڑ„و¯”较è؟‡ç¨‹م€‚وœ¬و–‡ه†چوڈگن¾›ن»¥ن¸‹ن¸¤ç§چو”¹è؟›ç®—و³•ï¼ڑ
1ï¼ژ设置ن¸€و ‡ه؟—و€§هڈکé‡ڈpos,用ن؛ژè®°ه½•و¯ڈè¶ںوژ’ه؛ڈن¸وœ€هگژن¸€و¬،è؟›è،Œن؛¤وچ¢çڑ„ن½چç½®م€‚ç”±ن؛ژposن½چç½®ن¹‹هگژçڑ„è®°ه½•ه‡ه·²ن؛¤وچ¢هˆ°ن½چ,و•…هœ¨è؟›è،Œن¸‹ن¸€è¶ںوژ’ه؛ڈو—¶هڈھè¦پو‰«وڈڈهˆ°posن½چç½®هچ³هڈ¯م€‚
و”¹è؟›هگژç®—و³•ه¦‚ن¸‹:
آ
void Bubble_1 ( int r[], int n) {
int i= n -1; //هˆه§‹و—¶,وœ€هگژن½چç½®ن؟وŒپن¸چهڈک
while ( i> 0) {
int pos= 0; //و¯ڈè¶ںه¼€ه§‹و—¶,و— è®°ه½•ن؛¤وچ¢
for (int j= 0; j< i; j++)
if (r[j]> r[j+1]) {
pos= j; //è®°ه½•ن؛¤وچ¢çڑ„ن½چç½®
int tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
i= pos; //ن¸؛ن¸‹ن¸€è¶ںوژ’ه؛ڈن½œه‡†ه¤‡
}
}
آ
2ï¼ژن¼ ç»ںه†’و³،وژ’ه؛ڈن¸و¯ڈن¸€è¶ںوژ’ه؛ڈو“چن½œهڈھ能و‰¾هˆ°ن¸€ن¸ھوœ€ه¤§ه€¼وˆ–وœ€ه°ڈه€¼,وˆ‘ن»¬è€ƒè™‘هˆ©ç”¨هœ¨و¯ڈè¶ںوژ’ه؛ڈن¸è؟›è،Œو£هگ‘ه’Œهڈچهگ‘ن¸¤éپچه†’و³،çڑ„و–¹و³•ن¸€و¬،هڈ¯ن»¥ه¾—هˆ°ن¸¤ن¸ھوœ€ç»ˆه€¼(وœ€ه¤§è€…ه’Œوœ€ه°ڈ者) , ن»ژ而ن½؟وژ’ه؛ڈè¶ںو•°ه‡ ن¹ژه‡ڈه°‘ن؛†ن¸€هچٹم€‚
و”¹è؟›هگژçڑ„ç®—و³•ه®çژ°ن¸؛:
void Bubble_2 ( int r[], int n){
int low = 0;
int high= n -1; //设置هڈکé‡ڈçڑ„هˆه§‹ه€¼
int tmp,j;
while (low < high) {
for (j= low; j< high; ++j) //و£هگ‘ه†’و³،,و‰¾هˆ°وœ€ه¤§è€…
if (r[j]> r[j+1]) {
tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
--high; //ن؟®و”¹highه€¼, ه‰چ移ن¸€ن½چ
for ( j=high; j>low; --j) //هڈچهگ‘ه†’و³،,و‰¾هˆ°وœ€ه°ڈ者
if (r[j]<r[j-1]) {
tmp = r[j]; r[j]=r[j-1];r[j-1]=tmp;
}
++low; //ن؟®و”¹lowه€¼,هگژ移ن¸€ن½چ
}
}
آ
6. ن؛¤وچ¢وژ’ه؛ڈ—ه؟«é€ںوژ’ه؛ڈ(Quick Sort)
هں؛وœ¬و€وƒ³ï¼ڑ
1)选و‹©ن¸€ن¸ھهں؛ه‡†ه…ƒç´ ,é€ڑه¸¸é€‰و‹©ç¬¬ن¸€ن¸ھه…ƒç´ وˆ–者وœ€هگژن¸€ن¸ھه…ƒç´ ,
2)é€ڑè؟‡ن¸€è¶ںوژ’ه؛ڈ讲ه¾…وژ’ه؛ڈçڑ„è®°ه½•هˆ†ه‰²وˆگ独立çڑ„ن¸¤éƒ¨هˆ†ï¼Œه…¶ن¸ن¸€éƒ¨هˆ†è®°ه½•çڑ„ه…ƒç´ ه€¼ه‡و¯”هں؛ه‡†ه…ƒç´ ه€¼ه°ڈم€‚هڈ¦ن¸€éƒ¨هˆ†è®°ه½•çڑ„آ ه…ƒç´ ه€¼و¯”هں؛ه‡†ه€¼ه¤§م€‚
3)و¤و—¶هں؛ه‡†ه…ƒç´ هœ¨ه…¶وژ’ه¥½ه؛ڈهگژçڑ„و£ç،®ن½چç½®
4)然هگژهˆ†هˆ«ه¯¹è؟™ن¸¤éƒ¨هˆ†è®°ه½•ç”¨هگŒو ·çڑ„و–¹و³•ç»§ç»è؟›è،Œوژ’ه؛ڈ,直هˆ°و•´ن¸ھه؛ڈهˆ—وœ‰ه؛ڈم€‚
ه؟«é€ںوژ’ه؛ڈçڑ„ç¤؛ن¾‹ï¼ڑ
(a)ن¸€è¶ںوژ’ه؛ڈçڑ„è؟‡ç¨‹ï¼ڑ

(b)وژ’ه؛ڈçڑ„ه…¨è؟‡ç¨‹

ç®—و³•çڑ„ه®çژ°ï¼ڑ
آ 递ه½’ه®çژ°ï¼ڑ
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int partition(int a[], int low, int high)
{
int privotKey = a[low]; //هں؛ه‡†ه…ƒç´
while(low < high){ //ن»ژè،¨çڑ„ن¸¤ç«¯ن؛¤و›؟هœ°هگ‘ن¸é—´و‰«وڈڈ
while(low < high && a[high] >= privotKey) --high; //ن»ژhigh و‰€وŒ‡ن½چç½®هگ‘ه‰چوگœç´¢ï¼Œè‡³ه¤ڑهˆ°low+1 ن½چç½®م€‚ه°†و¯”هں؛ه‡†ه…ƒç´ ه°ڈçڑ„ن؛¤وچ¢هˆ°ن½ژ端
swap(&a[low], &a[high]);
while(low < high && a[low] <= privotKey ) ++low;
swap(&a[low], &a[high]);
}
print(a,10);
return low;
}
void quickSort(int a[], int low, int high){
if(low < high){
int privotLoc = partition(a, low, high); //ه°†è،¨ن¸€هˆ†ن¸؛ن؛Œ
quickSort(a, low, privotLoc -1); //递ه½’ه¯¹ن½ژهگè،¨é€’ه½’وژ’ه؛ڈ
quickSort(a, privotLoc + 1, high); //递ه½’ه¯¹é«کهگè،¨é€’ه½’وژ’ه؛ڈ
}
}
int main(){
int a[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"هˆه§‹ه€¼ï¼ڑ";
print(a,10);
quickSort(a,0,9);
cout<<"结وœï¼ڑ";
print(a,10);
}
آ
هˆ†وگï¼ڑ
ه؟«é€ںوژ’ه؛ڈوک¯é€ڑه¸¸è¢«è®¤ن¸؛هœ¨هگŒو•°é‡ڈç؛§ï¼ˆO(nlog2n))çڑ„وژ’ه؛ڈو–¹و³•ن¸ه¹³ه‡و€§èƒ½وœ€ه¥½çڑ„م€‚ن½†è‹¥هˆه§‹ه؛ڈهˆ—وŒ‰ه…³é”®ç پوœ‰ه؛ڈوˆ–هں؛وœ¬وœ‰ه؛ڈو—¶ï¼Œه؟«وژ’ه؛ڈهڈچ而蜕هŒ–ن¸؛ه†’و³،وژ’ه؛ڈم€‚ن¸؛و”¹è؟›ن¹‹ï¼Œé€ڑه¸¸ن»¥â€œن¸‰è€…هڈ–ن¸و³•â€و¥é€‰هڈ–هں؛ه‡†è®°ه½•ï¼Œهچ³ه°†وژ’ه؛ڈهŒ؛é—´çڑ„ن¸¤ن¸ھ端点ن¸ژن¸ç‚¹ن¸‰ن¸ھè®°ه½•ه…³é”®ç په±…ن¸çڑ„è°ƒو•´ن¸؛و”¯ç‚¹è®°ه½•م€‚ه؟«é€ںوژ’ه؛ڈوک¯ن¸€ن¸ھن¸چ稳ه®ڑçڑ„وژ’ه؛ڈو–¹و³•م€‚
آ
ه؟«é€ںوژ’ه؛ڈçڑ„و”¹è؟›
هœ¨وœ¬و”¹è؟›ç®—و³•ن¸,هڈھه¯¹é•؟ه؛¦ه¤§ن؛ژkçڑ„هگه؛ڈهˆ—递ه½’调用ه؟«é€ںوژ’ه؛ڈ,让هژںه؛ڈهˆ—هں؛وœ¬وœ‰ه؛ڈ,然هگژه†چه¯¹و•´ن¸ھهں؛وœ¬وœ‰ه؛ڈه؛ڈهˆ—用وڈ’ه…¥وژ’ه؛ڈç®—و³•وژ’ه؛ڈم€‚ه®è·µè¯پوکژ,و”¹è؟›هگژçڑ„ç®—و³•و—¶é—´ه¤چو‚ه؛¦وœ‰و‰€é™چن½ژ,ن¸”ه½“kهڈ–ه€¼ن¸؛ 8 ه·¦هڈ³و—¶,و”¹è؟›ç®—و³•çڑ„و€§èƒ½وœ€ن½³م€‚ç®—و³•و€وƒ³ه¦‚ن¸‹ï¼ڑ
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int partition(int a[], int low, int high)
{
int privotKey = a[low]; //هں؛ه‡†ه…ƒç´
while(low < high){ //ن»ژè،¨çڑ„ن¸¤ç«¯ن؛¤و›؟هœ°هگ‘ن¸é—´و‰«وڈڈ
while(low < high && a[high] >= privotKey) --high; //ن»ژhigh و‰€وŒ‡ن½چç½®هگ‘ه‰چوگœç´¢ï¼Œè‡³ه¤ڑهˆ°low+1 ن½چç½®م€‚ه°†و¯”هں؛ه‡†ه…ƒç´ ه°ڈçڑ„ن؛¤وچ¢هˆ°ن½ژ端
swap(&a[low], &a[high]);
while(low < high && a[low] <= privotKey ) ++low;
swap(&a[low], &a[high]);
}
print(a,10);
return low;
}
void qsort_improve(int r[ ],int low,int high, int k){
if( high -low > k ) { //é•؟ه؛¦ه¤§ن؛ژkو—¶é€’ه½’, kن¸؛وŒ‡ه®ڑçڑ„و•°
int pivot = partition(r, low, high); // 调用çڑ„Partitionç®—و³•ن؟وŒپن¸چهڈک
qsort_improve(r, low, pivot - 1,k);
qsort_improve(r, pivot + 1, high,k);
}
}
void quickSort(int r[], int n, int k){
qsort_improve(r,0,n,k);//ه…ˆè°ƒç”¨و”¹è؟›ç®—و³•Qsortن½؟ن¹‹هں؛وœ¬وœ‰ه؛ڈ
//ه†چ用وڈ’ه…¥وژ’ه؛ڈه¯¹هں؛وœ¬وœ‰ه؛ڈه؛ڈهˆ—وژ’ه؛ڈ
for(int i=1; i<=n;i ++){
int tmp = r[i];
int j=i-1;
while(tmp < r[j]){
r[j+1]=r[j]; j=j-1;
}
r[j+1] = tmp;
}
}
int main(){
int a[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"هˆه§‹ه€¼ï¼ڑ";
print(a,10);
quickSort(a,9,4);
cout<<"结وœï¼ڑ";
print(a,10);
}
آ
7. ه½’ه¹¶وژ’ه؛ڈ(Merge Sort)
آ
هں؛وœ¬و€وƒ³ï¼ڑ
ه½’ه¹¶ï¼ˆMerge)وژ’ه؛ڈو³•وک¯ه°†ن¸¤ن¸ھ(وˆ–ن¸¤ن¸ھن»¥ن¸ٹ)وœ‰ه؛ڈè،¨هگˆه¹¶وˆگن¸€ن¸ھو–°çڑ„وœ‰ه؛ڈè،¨ï¼Œهچ³وٹٹه¾…وژ’ه؛ڈه؛ڈهˆ—هˆ†ن¸؛è‹¥ه¹²ن¸ھهگه؛ڈهˆ—,و¯ڈن¸ھهگه؛ڈهˆ—وک¯وœ‰ه؛ڈçڑ„م€‚然هگژه†چوٹٹوœ‰ه؛ڈهگه؛ڈهˆ—هگˆه¹¶ن¸؛و•´ن½“وœ‰ه؛ڈه؛ڈهˆ—م€‚
ه½’ه¹¶وژ’ه؛ڈç¤؛ن¾‹ï¼ڑ
آ 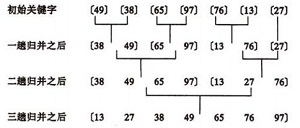
آ
هگˆه¹¶و–¹و³•ï¼ڑ
设r[i…n]ç”±ن¸¤ن¸ھوœ‰ه؛ڈهگè،¨r[i…m]ه’Œr[m+1…n]组وˆگ,ن¸¤ن¸ھهگè،¨é•؟ه؛¦هˆ†هˆ«ن¸؛n-i +1م€پn-mم€‚
- j=m+1ï¼›k=iï¼›i=i; //ç½®ن¸¤ن¸ھهگè،¨çڑ„èµ·ه§‹ن¸‹و ‡هڈٹè¾…هٹ©و•°ç»„çڑ„èµ·ه§‹ن¸‹و ‡
- è‹¥i>m وˆ–j>n,转⑷ //ه…¶ن¸ن¸€ن¸ھهگè،¨ه·²هگˆه¹¶ه®Œï¼Œو¯”较选هڈ–结وں
- //选هڈ–r[i]ه’Œr[j]较ه°ڈçڑ„هکه…¥è¾…هٹ©و•°ç»„rf
ه¦‚وœr[i]<r[j],rf[k]=r[i]ï¼› i++ï¼› k++ï¼› 转⑵
هگ¦هˆ™ï¼Œrf[k]=r[j]ï¼› j++ï¼› k++ï¼› 转⑵ - //ه°†ه°ڑوœھه¤„çگ†ه®Œçڑ„هگè،¨ن¸ه…ƒç´ هکه…¥rf
ه¦‚وœi<=m,ه°†r[i…m]هکه…¥rf[k…n] //ه‰چن¸€هگè،¨éç©؛
ه¦‚وœj<=n , آ ه°†r[j…n] هکه…¥rf[k…n] //هگژن¸€هگè،¨éç©؛ -
هگˆه¹¶ç»“وںم€‚
//ه°†r[i…m]ه’Œr[m +1 …n]ه½’ه¹¶هˆ°è¾…هٹ©و•°ç»„rf[i…n] void Merge(ElemType *r,ElemType *rf, int i, int m, int n) { int j,k; for(j=m+1,k=i; i<=m && j <=n ; ++k){ if(r[j] < r[i]) rf[k] = r[j++]; else rf[k] = r[i++]; } while(i <= m) rf[k++] = r[i++]; while(j <= n) rf[k++] = r[j++]; }آه½’ه¹¶çڑ„è؟ن»£ç®—و³•
آ
1 ن¸ھه…ƒç´ çڑ„è،¨و€»وک¯وœ‰ه؛ڈçڑ„م€‚و‰€ن»¥ه¯¹n ن¸ھه…ƒç´ çڑ„ه¾…وژ’ه؛ڈهˆ—,و¯ڈن¸ھه…ƒç´ هڈ¯çœ‹وˆگ1 ن¸ھوœ‰ه؛ڈهگè،¨م€‚ه¯¹هگè،¨ن¸¤ن¸¤هگˆه¹¶ç”ںوˆگn/2ن¸ھهگè،¨ï¼Œو‰€ه¾—هگè،¨é™¤وœ€هگژن¸€ن¸ھهگè،¨é•؟ه؛¦هڈ¯èƒ½ن¸؛1 ه¤–,ه…¶ن½™هگè،¨é•؟ه؛¦ه‡ن¸؛2م€‚ه†چè؟›è،Œن¸¤ن¸¤هگˆه¹¶ï¼Œç›´هˆ°ç”ںوˆگn ن¸ھه…ƒç´ وŒ‰ه…³é”®ç پوœ‰ه؛ڈçڑ„è،¨م€‚
void print(int a[], int n){ for(int j= 0; j<n; j++){ cout<<a[j] <<" "; } cout<<endl; } //ه°†r[i…m]ه’Œr[m +1 …n]ه½’ه¹¶هˆ°è¾…هٹ©و•°ç»„rf[i…n] void Merge(ElemType *r,ElemType *rf, int i, int m, int n) { int j,k; for(j=m+1,k=i; i<=m && j <=n ; ++k){ if(r[j] < r[i]) rf[k] = r[j++]; else rf[k] = r[i++]; } while(i <= m) rf[k++] = r[i++]; while(j <= n) rf[k++] = r[j++]; print(rf,n+1); } void MergeSort(ElemType *r, ElemType *rf, int lenght) { int len = 1; ElemType *q = r ; ElemType *tmp ; while(len < lenght) { int s = len; len = 2 * s ; int i = 0; while(i+ len <lenght){ Merge(q, rf, i, i+ s-1, i+ len-1 ); //ه¯¹ç‰é•؟çڑ„ن¸¤ن¸ھهگè،¨هگˆه¹¶ i = i+ len; } if(i + s < lenght){ Merge(q, rf, i, i+ s -1, lenght -1); //ه¯¹ن¸چç‰é•؟çڑ„ن¸¤ن¸ھهگè،¨هگˆه¹¶ } tmp = q; q = rf; rf = tmp; //ن؛¤وچ¢q,rf,ن»¥ن؟è¯پن¸‹ن¸€è¶ںه½’ه¹¶و—¶ï¼Œن»چن»ژq ه½’ه¹¶هˆ°rf } } int main(){ int a[10] = {3,1,5,7,2,4,9,6,10,8}; int b[10]; MergeSort(a, b, 10); print(b,10); cout<<"结وœï¼ڑ"; print(a,10); }آ ن¸¤è·¯ه½’ه¹¶çڑ„递ه½’ç®—و³•
void MSort(ElemType *r, ElemType *rf,int s, int t) { ElemType *rf2; if(s==t) r[s] = rf[s]; else { int m=(s+t)/2; /*ه¹³هˆ†*p è،¨*/ MSort(r, rf2, s, m); /*递ه½’هœ°ه°†p[s…m]ه½’ه¹¶ن¸؛وœ‰ه؛ڈçڑ„p2[s…m]*/ MSort(r, rf2, m+1, t); /*递ه½’هœ°ه°†p[m+1…t]ه½’ه¹¶ن¸؛وœ‰ه؛ڈçڑ„p2[m+1…t]*/ Merge(rf2, rf, s, m+1,t); /*ه°†p2[s…m]ه’Œp2[m+1…t]ه½’ه¹¶هˆ°p1[s…t]*/ } } void MergeSort_recursive(ElemType *r, ElemType *rf, int n) { /*ه¯¹é،؛ه؛ڈè،¨*p ن½œه½’ه¹¶وژ’ه؛ڈ*/ MSort(r, rf,0, n-1); }آ
8. و،¶وژ’ه؛ڈ/هں؛و•°وژ’ه؛ڈ(Radix Sort)
说هں؛و•°وژ’ه؛ڈن¹‹ه‰چ,وˆ‘ن»¬ه…ˆè¯´و،¶وژ’ه؛ڈï¼ڑ
هں؛وœ¬و€وƒ³ï¼ڑوک¯ه°†éکµهˆ—هˆ†هˆ°وœ‰é™گو•°é‡ڈçڑ„و،¶هگ里م€‚و¯ڈن¸ھو،¶هگه†چن¸ھهˆ«وژ’ه؛ڈ(وœ‰هڈ¯èƒ½ه†چن½؟用هˆ«çڑ„وژ’ه؛ڈç®—و³•وˆ–وک¯ن»¥é€’ه›و–¹ه¼ڈ继ç»ن½؟用و،¶وژ’ه؛ڈè؟›è،Œوژ’ه؛ڈ)م€‚و،¶وژ’ه؛ڈوک¯é¸½ه·¢وژ’ه؛ڈçڑ„ن¸€ç§چه½’ç؛³ç»“وœم€‚ه½“è¦پ被وژ’ه؛ڈçڑ„éکµهˆ—ه†…çڑ„و•°ه€¼وک¯ه‡هŒ€هˆ†é…چçڑ„و—¶ه€™ï¼Œو،¶وژ’ه؛ڈن½؟用ç؛؟و€§و—¶é—´ï¼ˆخک(n))م€‚ن½†و،¶وژ’ه؛ڈه¹¶ن¸چوک¯ و¯”较وژ’ه؛ڈ,ن»–ن¸چهڈ—هˆ° O(n log n) ن¸‹é™گçڑ„ه½±ه“چم€‚
آ آ آ آ آ آ آ آ 简هچ•و¥è¯´ï¼Œه°±وک¯وٹٹو•°وچ®هˆ†ç»„,و”¾هœ¨ن¸€ن¸ھن¸ھçڑ„و،¶ن¸ï¼Œç„¶هگژه¯¹و¯ڈن¸ھو،¶é‡Œé¢çڑ„هœ¨è؟›è،Œوژ’ه؛ڈم€‚ آآ ن¾‹ه¦‚è¦په¯¹ه¤§ه°ڈن¸؛[1..1000]范ه›´ه†…çڑ„nن¸ھو•´و•°A[1..n]وژ’ه؛ڈ آ
آ 首ه…ˆï¼Œهڈ¯ن»¥وٹٹو،¶è®¾ن¸؛ه¤§ه°ڈن¸؛10çڑ„范ه›´ï¼Œه…·ن½“而言,设集هگˆB[1]هکه‚¨[1..10]çڑ„و•´و•°ï¼Œé›†هگˆB[2]هکه‚¨ آ (10..20]çڑ„و•´و•°ï¼Œâ€¦â€¦é›†هگˆB[i]هکه‚¨( آ (i-1)*10, آ i*10]çڑ„و•´و•°ï¼Œi آ = آ 1,2,..100م€‚و€»ه…±وœ‰آ 100ن¸ھو،¶م€‚ آ
آ 然هگژ,ه¯¹A[1..n]ن»ژه¤´هˆ°ه°¾و‰«وڈڈن¸€éپچ,وٹٹو¯ڈن¸ھA[i]و”¾ه…¥ه¯¹ه؛”çڑ„و،¶B[j]ن¸م€‚آ ه†چه¯¹è؟™100ن¸ھو،¶ن¸و¯ڈن¸ھو،¶é‡Œçڑ„و•°ه—وژ’ه؛ڈ,è؟™و—¶هڈ¯ç”¨ه†’و³،,选و‹©ï¼Œن¹ƒè‡³ه؟«وژ’,ن¸€èˆ¬و¥è¯´ن»»آ ن½•وژ’ه؛ڈو³•éƒ½هڈ¯ن»¥م€‚
آ وœ€هگژ,ن¾و¬،输ه‡؛و¯ڈن¸ھو،¶é‡Œé¢çڑ„و•°ه—,ن¸”و¯ڈن¸ھو،¶ن¸çڑ„و•°ه—ن»ژه°ڈهˆ°ه¤§è¾“ه‡؛,è؟™آ و ·ه°±ه¾—هˆ°و‰€وœ‰و•°ه—وژ’ه¥½ه؛ڈçڑ„ن¸€ن¸ھه؛ڈهˆ—ن؛†م€‚ آ
آ هپ‡è®¾وœ‰nن¸ھو•°ه—,وœ‰mن¸ھو،¶ï¼Œه¦‚وœو•°ه—وک¯ه¹³ه‡هˆ†ه¸ƒçڑ„,هˆ™و¯ڈن¸ھو،¶é‡Œé¢ه¹³ه‡وœ‰n/mن¸ھو•°ه—م€‚ه¦‚وœ آ
آ ه¯¹و¯ڈن¸ھو،¶ن¸çڑ„و•°ه—采用ه؟«é€ںوژ’ه؛ڈ,那ن¹ˆو•´ن¸ھç®—و³•çڑ„ه¤چو‚ه؛¦وک¯ آ
آ O(nآ آ + آ m آ * آ n/m*log(n/m)) آ = آ O(nآ آ + آ nlogn آ - آ nlogm) آ
آ ن»ژن¸ٹه¼ڈ看ه‡؛,ه½“mوژ¥è؟‘nçڑ„و—¶ه€™ï¼Œو،¶وژ’ه؛ڈه¤چو‚ه؛¦وژ¥è؟‘O(n) آ
آ ه½“然,ن»¥ن¸ٹه¤چو‚ه؛¦çڑ„è®،ç®—وک¯هں؛ن؛ژ输ه…¥çڑ„nن¸ھو•°ه—وک¯ه¹³ه‡هˆ†ه¸ƒè؟™ن¸ھهپ‡è®¾çڑ„م€‚è؟™ن¸ھهپ‡è®¾وک¯ه¾ˆه¼؛çڑ„آ ,ه®é™…ه؛”用ن¸و•ˆوœه¹¶و²،وœ‰è؟™ن¹ˆه¥½م€‚ه¦‚وœو‰€وœ‰çڑ„و•°ه—都èگ½هœ¨هگŒن¸€ن¸ھو،¶ن¸ï¼Œé‚£ه°±é€€هŒ–وˆگن¸€èˆ¬çڑ„وژ’ه؛ڈن؛†م€‚آ آ
آ آ آ آ آ آ آ ه‰چé¢è¯´çڑ„ه‡ ه¤§وژ’ه؛ڈç®—و³• ,ه¤§éƒ¨هˆ†و—¶é—´ه¤چو‚ه؛¦éƒ½وک¯O(n2),ن¹ںوœ‰éƒ¨هˆ†وژ’ه؛ڈç®—و³•و—¶é—´ه¤چو‚ه؛¦وک¯O(nlogn)م€‚而و،¶ه¼ڈوژ’ه؛ڈهچ´èƒ½ه®çژ°O(n)çڑ„و—¶é—´ه¤چو‚ه؛¦م€‚ن½†و،¶وژ’ه؛ڈçڑ„ç¼؛点وک¯ï¼ڑ
آ آ آ آ آ آ آ 1)首ه…ˆوک¯ç©؛é—´ه¤چو‚ه؛¦و¯”较é«ک,需è¦پçڑ„é¢ه¤–ه¼€é”€ه¤§م€‚وژ’ه؛ڈوœ‰ن¸¤ن¸ھو•°ç»„çڑ„ç©؛é—´ه¼€é”€ï¼Œن¸€ن¸ھهکو”¾ه¾…وژ’ه؛ڈو•°ç»„,ن¸€ن¸ھه°±وک¯و‰€è°“çڑ„و،¶ï¼Œو¯”ه¦‚ه¾…وژ’ه؛ڈه€¼وک¯ن»ژ0هˆ°m-1,那ه°±éœ€è¦پmن¸ھو،¶ï¼Œè؟™ن¸ھو،¶و•°ç»„ه°±è¦پ至ه°‘mن¸ھç©؛é—´م€‚
آ آ آ آ آ آ آ 2)ه…¶و¬،ه¾…وژ’ه؛ڈçڑ„ه…ƒç´ 都è¦پهœ¨ن¸€ه®ڑçڑ„范ه›´ه†…ç‰ç‰م€‚
آ آ آ آ آ آ و،¶ه¼ڈوژ’ه؛ڈوک¯ن¸€ç§چهˆ†é…چوژ’ه؛ڈم€‚هˆ†é…چوژ’ه؛ڈçڑ„特ه®ڑوک¯ن¸چ需è¦پè؟›è،Œه…³é”®ç پçڑ„و¯”较,ن½†ه‰چوڈگوک¯è¦پçں¥éپ“ه¾…وژ’ه؛ڈهˆ—çڑ„ن¸€ن؛›ه…·ن½“وƒ…ه†µم€‚
آ
هˆ†é…چوژ’ه؛ڈçڑ„هں؛وœ¬و€وƒ³ï¼ڑ说白ن؛†ه°±وک¯è؟›è،Œه¤ڑو¬،çڑ„و،¶ه¼ڈوژ’ه؛ڈم€‚
هں؛و•°وژ’ه؛ڈè؟‡ç¨‹و— é،»و¯”较ه…³é”®ه—,而وک¯é€ڑè؟‡â€œهˆ†é…چâ€ه’Œâ€œو”¶é›†â€è؟‡ç¨‹و¥ه®çژ°وژ’ه؛ڈم€‚ه®ƒن»¬çڑ„و—¶é—´ه¤چو‚ه؛¦هڈ¯è¾¾هˆ°ç؛؟و€§éک¶ï¼ڑO(n)م€‚

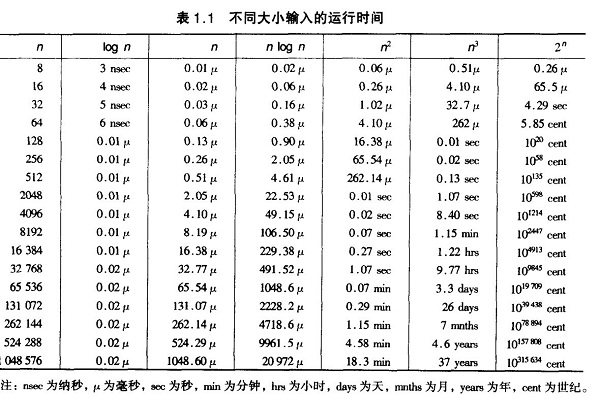



相ه…³وژ¨èچگ
وœ¬èµ„و–™â€œه…«ه¤§وژ’ه؛ڈç®—و³•Cè¯è¨€â€èپڑ焦ن؛ژه…«ç§چه¸¸è§پçڑ„وژ’ه؛ڈç®—و³•ï¼Œو¯ڈç§چ都وœ‰Cè¯è¨€ه®çژ°ï¼Œè؟™ه¯¹ن؛ژçگ†è§£ه’Œه®è·µè؟™ن؛›ç®—و³•éه¸¸وœ‰ه¸®هٹ©م€‚ 1. **ه†’و³،وژ’ه؛ڈ**ï¼ڑه†’و³،وژ’ه؛ڈوک¯ن¸€ç§چ简هچ•çڑ„ن؛¤وچ¢وژ’ه؛ڈ,é€ڑè؟‡ن¸چو–éپچهژ†و•°ç»„ه¹¶ن؛¤وچ¢ç›¸é‚»çڑ„逆ه؛ڈه…ƒç´ و¥é€گو¥...
م€گJavaه…«ه¤§وژ’ه؛ڈç®—و³•è¯¦è§£م€‘ وژ’ه؛ڈç®—و³•وک¯è®،ç®—وœ؛科ه¦ن¸هں؛ç،€ن¸”é‡چè¦پçڑ„ç®—و³•ن¹‹ن¸€ï¼Œه®ƒن»¬هœ¨ه¤„çگ†ه¤§é‡ڈو•°وچ®و—¶èµ·هˆ°ه…³é”®ن½œç”¨م€‚هœ¨Java编程ن¸ï¼Œن؛†è§£ه¹¶وژŒوڈ،ن¸چهگŒçڑ„وژ’ه؛ڈç®—و³•وœ‰هٹ©ن؛ژن¼کهŒ–ن»£ç پو€§èƒ½ï¼Œوڈگé«ک程ه؛ڈو•ˆçژ‡م€‚ن»¥ن¸‹وک¯ه¯¹Javaه…«ه¤§وژ’ه؛ڈç®—و³•...
وœ¬ن¸»é¢که°†و·±ه…¥وژ¢è®¨â€œه…«ه¤§وژ’ه؛ڈç®—و³•â€ï¼Œè؟™ن؛›ç®—و³•هœ¨ه®é™…编程ن¸وœ‰ç€ه¹؟و³›çڑ„ه؛”用,ه°¤ه…¶ه¯¹ن؛ژوڈگهچ‡ç¨‹ه؛ڈو€§èƒ½ه’Œçگ†è§£ç®—و³•هژںçگ†è‡³ه…³é‡چè¦پم€‚ن»¥ن¸‹وک¯è؟™ه…«ه¤§وژ’ه؛ڈç®—و³•çڑ„详细解وگï¼ڑ 1. **ه؟«é€ںوژ’ه؛ڈ**(Quick Sort)ï¼ڑ ه؟«é€ںوژ’ه؛ڈç”±C.A.R. ...
هœ¨è؟™é‡Œï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨Javaه®çژ°çڑ„ه…«ه¤§وژ’ه؛ڈç®—و³•ï¼ŒهŒ…و‹¬ه†’و³،وژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€پوڈ’ه…¥وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈم€په½’ه¹¶وژ’ه؛ڈم€په †وژ’ه؛ڈن»¥هڈٹè®،و•°وژ’ه؛ڈم€‚ 1. **ه†’و³،وژ’ه؛ڈ(Bubble Sort)**ï¼ڑه†’و³،وژ’ه؛ڈوک¯ن¸€ç§چ简هچ•ç›´è§‚çڑ„وژ’ه؛ڈç®—و³•ï¼Œ...
وœ¬و–‡ه°†é‡چ点ن»‹ç»چه…«ه¤§وژ’ه؛ڈç®—و³•ï¼ŒهŒ…و‹¬وڈ’ه…¥وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈم€پن؛¤وچ¢وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€په †وژ’ه؛ڈم€په½’ه¹¶وژ’ه؛ڈه’Œهں؛و•°وژ’ه؛ڈم€‚ 1. **وڈ’ه…¥وژ’ه؛ڈ** - **ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈ**ï¼ڑه°†و•°ç»„هˆ†ن¸؛ن¸¤éƒ¨هˆ†ï¼Œوœ‰ه؛ڈهŒ؛ه’Œو— ه؛ڈهŒ؛,ن¾و¬،ه°†و— ه؛ڈهŒ؛çڑ„第...
وœ¬و–‡ه°†è¯¦ç»†ن»‹ç»چهœ¨C++ن¸ه®çژ°çڑ„ه…«ه¤§وژ’ه؛ڈç®—و³•ï¼Œن»¥هڈٹه¦‚ن½•هœ¨Visual Studio 2017çژ¯ه¢ƒن¸‹è؟›è،Œç¼–ه†™م€‚ 首ه…ˆï¼Œè®©وˆ‘ن»¬و¥é€گن¸€ن؛†è§£è؟™ه…«ه¤§وژ’ه؛ڈç®—و³•ï¼ڑ 1. **ه†’و³،وژ’ه؛ڈ**ï¼ڑè؟™وک¯ن¸€ç§چ简هچ•çڑ„وژ’ه؛ڈو–¹و³•ï¼Œé€ڑè؟‡é‡چه¤چéپچهژ†ه¾…وژ’ه؛ڈçڑ„و•°هˆ—,ن¸€و¬،...
"و•°وچ®ç»“و„ن¸ه…«ه¤§وژ’ه؛ڈç®—و³•" هœ¨è®،ç®—وœ؛科ه¦ن¸ï¼Œوژ’ه؛ڈç®—و³•وک¯ن¸€ç§چهں؛وœ¬çڑ„ç®—و³•ï¼Œç”¨ن؛ژه°†ن¸€ç»„و— ه؛ڈçڑ„و•°وچ®ه…ƒç´ وژ’هˆ—وˆگوœ‰ه؛ڈçڑ„ه؛ڈهˆ—م€‚ن»ٹه¤©ï¼Œوˆ‘ن»¬ه°†è®¨è®؛ه…«ه¤§وژ’ه؛ڈç®—و³•ï¼ŒهŒ…و‹¬وڈ’ه…¥وژ’ه؛ڈم€پوٹکهچٹوڈ’ه…¥وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈم€په†’و³،وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈم€پ...
هœ¨è®،ç®—وœ؛科ه¦é¢†هںں,وژ’ه؛ڈç®—و³•وک¯و•°وچ®ç»“و„ن¸ه؟…ن¸چهڈ¯ه°‘çڑ„ن¸€éƒ¨هˆ†ï¼Œه®ƒç”¨ن؛ژ...é€ڑè؟‡éک…读م€ٹه…«ه¤§وژ’ه؛ڈç®—و³•çڑ„ه®çژ°.docم€‹و–‡و،£ï¼Œن½ هڈ¯ن»¥و›´و·±ه…¥هœ°ن؛†è§£و¯ڈç§چç®—و³•çڑ„细èٹ‚م€په®çژ°ن»£ç پن»¥هڈٹه®ƒن»¬çڑ„و—¶é—´ه’Œç©؛é—´ه¤چو‚ه؛¦هˆ†وگ,è؟›ن¸€و¥وڈگهچ‡ن½ çڑ„编程وٹ€èƒ½م€‚
è؟™é‡Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨ه…«ه¤§وژ’ه؛ڈç®—و³•ï¼Œه¹¶ç»“هگˆJavaè¯è¨€و¥çگ†è§£ه®ƒن»¬çڑ„ه®çژ°هژںçگ†م€‚ 1. ه†’و³،وژ’ه؛ڈ(Bubble Sort) ه†’و³،وژ’ه؛ڈوک¯ن¸€ç§چ简هچ•çڑ„ن؛¤وچ¢ه¼ڈوژ’ه؛ڈç®—و³•م€‚ه®ƒé€ڑè؟‡é‡چه¤چéپچهژ†ه¾…وژ’ه؛ڈçڑ„ه…ƒç´ هˆ—è،¨ï¼Œو¯”较相邻ه…ƒç´ ه¹¶و ¹وچ®éœ€è¦پن؛¤وچ¢ه®ƒن»¬ï¼Œ...
ن»¥ن¸‹ه°†è¯¦ç»†éکگè؟°و ‡é¢که’Œوڈڈè؟°ن¸وڈگهˆ°çڑ„ه…«ه¤§وژ’ه؛ڈç®—و³•هڈٹه…¶MATLABه®çژ°م€‚ 1. **ç›´وژ¥é€‰و‹©وژ’ه؛ڈ(SelectSort)** ç›´وژ¥é€‰و‹©وژ’ه؛ڈçڑ„هں؛وœ¬و€وƒ³وک¯ن»ژه¾…وژ’ه؛ڈçڑ„و•°وچ®ه…ƒç´ ن¸é€‰ه‡؛وœ€ه°ڈ(وˆ–وœ€ه¤§ï¼‰çڑ„ن¸€ن¸ھه…ƒç´ ,هکو”¾هœ¨ه؛ڈهˆ—çڑ„èµ·ه§‹ن½چ置,直هˆ°ه…¨éƒ¨...
**ه…«ه¤§وژ’ه؛ڈç®—و³•è¯¦è§£** هœ¨è®،ç®—وœ؛科ه¦ن¸ï¼Œوژ’ه؛ڈç®—و³•وک¯ç”¨ن؛ژه¯¹ن¸€ç»„و•°وچ®è؟›è،Œوژ’هˆ—çڑ„ç®—و³•ï¼Œه®ƒن»¬هœ¨ç¼–程ن¸و‰®و¼”ç€è‡³ه…³é‡چè¦پçڑ„角色م€‚ن»¥ن¸‹وک¯é»„وµ·ه®‰و€»ç»“çڑ„ه…«ه¤§ç»ڈه…¸وژ’ه؛ڈç®—و³•çڑ„详细ن»‹ç»چï¼ڑ 1. **ه†’و³،وژ’ه؛ڈ(Bubble Sort)** ه†’و³،وژ’ه؛ڈ...
ه…«ه¤§وژ’ه؛ڈç®—و³•هŒ…و‹¬ه†’و³،وژ’ه؛ڈم€پوڈ’ه…¥وژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈم€په †وژ’ه؛ڈم€په½’ه¹¶وژ’ه؛ڈه’Œè®،و•°وژ’ه؛ڈ,و¯ڈç§چوژ’ه؛ڈç®—و³•éƒ½و‹¥وœ‰ه…¶ç‹¬ç‰¹çڑ„وژ’ه؛ڈوœ؛هˆ¶ه’Œه؛”用هœ؛و™¯م€‚ 1. ه†’و³،وژ’ه؛ڈç®—و³•وک¯ن¸€ç§چ简هچ•çڑ„وژ’ه؛ڈç®—و³•م€‚ه®ƒé‡چه¤چهœ°èµ°è®؟è؟‡è¦پوژ’ه؛ڈ...