- 浏览: 1151571 次
- 性别:

- 来自: 成都
-

文章分类
最新评论
-
Alice南京:
这个是cookies是取的同一个用户的吗?多用户如何模拟?是否 ...
LR使用web_add_cookie函数进行cookie模拟 -
绝杀fc小飞侠:
测试了以下,没有进度条出现,不知道是否这两个文件的原因,jqu ...
上传时显示进度条 -
libixionglbx:
[size=large][/size]12321
ASP.NET 缓存 -
GeneralSnow:
没有有一个共用的模板
自己编写程序批量合并多个“规范定义电子名片(vCard)”文件 -
John_Kong19:
莫非现在文章题目和内容不一样是种流行吗
在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能。但索引可以在大多数情况下大大提升查询性能,
翻译:袁晓辉
个人主页:www.farproc.com
Blog:blog.csdn.net/uoyevoli
转载请注明出处blog.csdn.net/uoyevoli www.farproc.com
On Bots
转载请注明出处blog.csdn.net/uoyevoli www.farproc.com
Introduction
引言In the previous edition - Binary Search Tree 2 - a large scale experiment on search engine behaviour was staged with more than two billion different web pages. This experiment lasted exactly one year, until April 13th. In this period the three major search engines requested more than one million pages of the tree, from more than hundred thousand different URLs. The home page of drunkmenworkhere.org grew from 1.6 kB to over 4 MB due to the visit log and the comment spam displayed there.
在上一版(Binary Search Tree 2)中我用了超过200亿个web页面进行了一个关于搜索引擎行为的大<wbr></wbr>规模试验。这个试验一直持续到4月13日,历时整整一年<wbr></wbr>。在这段时间中三大主要的搜索引擎在树上请求了100万个以上<wbr></wbr>的页面和超过10万个URL。由于访问日志的增长和垃圾评论的存在<wbr></wbr>,drunkmenworkhere.org 的主页也从1<wbr></wbr>.6KB增长为4MB多。(转载请注明出处blog.csdn.net/uoyevoli www.farproc.com)
This edition presents the results of the experiment.
本文就是这次试验的结果。
Setup
安装 2,147,483,647 web pages ('nodes') were numbered and arranged in a binary search tree. In such a tree, the branch to the left of each node contains only values less than the node's value, while the right branch contains only values higher than the node's value. So the leftmost node in this tree has value 1 and the rightmost node has value 2,147,483,647.
在这次试验中 二叉查找树 上总共放置了 2,147,483,647个标了值的网页。对于二叉查找树<wbr></wbr>,每个节点的左子树只包含比这个节点小的值,右子树上包含比这个节<wbr></wbr>点大的值。所以树的左边最远的节点值为1,右边最远的节点值为2<wbr></wbr>,147,483,647。
The depth of the tree is the number of nodes you have to traverse from the root to the most remote leaf. Since you can arrange 2n+1 - 1 numbers in a tree of depth n, the resulting tree has a depth of 30 (231 = 2,147,483,648). The value at the root of the tree is 1073741824 (230).
树的深度是从根到最远的树叶所要经过的节点总数。因为在深度为n的树上<wbr></wbr>你总共可以放置 2n+1 - 1个节点,所以这棵树的深度为30 (231 = 2,147,483,648),其根部的值为1073741824 (230)。
For each page the traffic of the three major search bots (Yahoo! Slurp, Googlebot and msnbot) was monitored over a period of one year (between 2005-4-13 and 2006-4-13).
试验监控了三大搜索爬虫( Yahoo! Slurp, Googlebot 和 msnbot)在一年的时间里(2005-4-13 到 2006-4-13)在每个页面上的流量。
To make the content of each page more interesting for the search engines, the value of each node is written out in American English (short scale) and each page request from a search bot is displayed in reversed chronological order. To enrich the zero-content even more, a comment box was added to each page (it was removed on 2006-4-13). These measures were improvements over the initial Binary Search Tree which uses inconvenient long URLs.
为了让搜索引擎对页面的内容更感兴趣,所有的节点值都以美国英语<wbr></wbr>(short scale)作为语言,并且爬虫请求到的每个页面按照时间倒序显示<wbr></wbr>。为了进一步丰富0内容(zero-content?)<wbr></wbr>,每个页面上都添加了一个评论框(于2006-4-13移除)<wbr></wbr>。这些措施是对 二叉查找树最初麻烦的长URL的改进。(转载请注明出处blog.csdn.net/uoyevoli www.farproc.com)
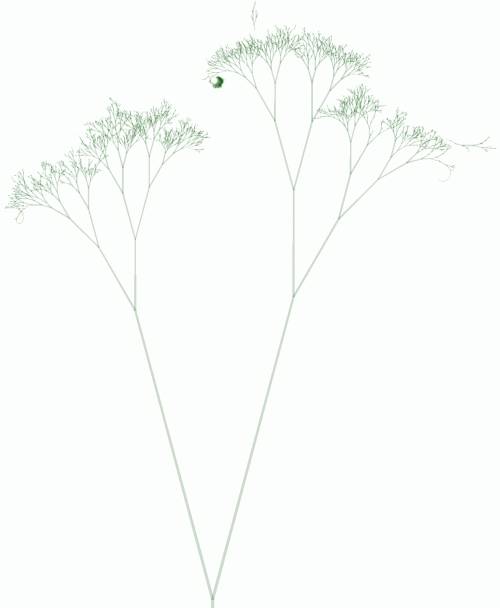
Every node shows an image of three trees. Each tree in the image visualises which nodes are crawled by each search engine. Each line in the image represents a node, the number of times a search bot visited the node determines the length of the line. The tree images below are modified large versions of the original image, without the very long root node and with disconnected (wild) branches.
每个节点上显示了一个“三棵树‘”的图像。图中每棵树展现了被每个搜索引擎爬过的每个节点。图像中的每根线代表<wbr></wbr>一个节点,爬虫访问该节点的次数决定了线的长度<wbr></wbr>。下面的图像是原始图像的修改版,去掉了很长的根节点<wbr></wbr>,添加了断开的(野)分枝。
Overall results
总体结果From the start Yahoo! Slurp was by far the most active search bot. In one year it requested more than one million pages and crawled more than hundred thousand different nodes. Although this is a large number, it still is only 0.0049% of all nodes. The overall statistics of all bots is shown in the table below.
从一开始,Yahoo! Slurp就是最活跃的爬虫。在一年中它请求了超过百万个页面<wbr></wbr>,爬过了数十万计个节点。这虽然是个大数目,但是只占总节点的0<wbr></wbr>.0049%。所有爬虫的全面统计数据见下表。
| 1,030,396 | 20,633 | 4,699 |
| 105,971 | 7,556 | 1,390 |
| 0.0049% | 0.00035% | 0.000065% |
| 120,000 | 554 | 1 |
| 113.23% | 7.33% | 0.07% |
| 1,030,396 | 20,633 | 4,699 |
| 105,971 | 7,556 | 1,390 |
| 0.0049% | 0.00035% | 0.000065% |
| 120,000 | 554 | 1 |
| 113.23% | 7.33% | 0.07% |
The growth of the number of pageviews and the number of crawled nodes over the year the experiment lasted, is shown in figure 1 and 2. The way the bots crawled the tree is visualised in detail with the animations for each bot in the sections below.
图1和图2是在这个历时一年的试验中页面访问量(pageview<wbr></wbr>)和爬过的节点数的增长趋势。爬虫们爬这棵树的行为方式在下面一<wbr></wbr>节中会以动画的形式详细说明。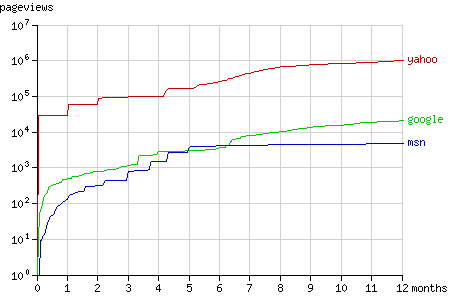
Fig. 1 - The cumulative number of pageviews by the search bots in time.
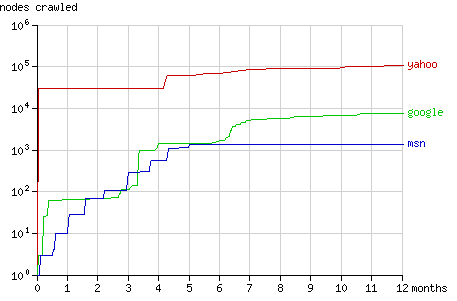
Fig. 2 - The cumulative number of nodes crawled by the search bots in time.
The graph below (fig. 3) shows how many nodes of each level of the tree were crawled by the bots (on a logarithmic scale). The root of the tree is at level 0, while the most remote nodes (e.g. node 1) are at level 30. Since there are 2n nodes at the level n (there is only 1 root and there are 230 nodes at level 30) crawling the entire tree would result in a straight line.
下图(图.3)显示了树的每个层次上被爬虫爬过的节点数<wbr></wbr>(对数比例)。树的根节点位于第0层,最远的节点位于第30层<wbr></wbr>。由于在第n层上有 2n个节点([第0层]只有一个节点,第30层有230个节点 )所以完整爬过整棵树会形成一条直线。(转载请注明出处blog.csdn.net/uoyevoli www.farproc.com)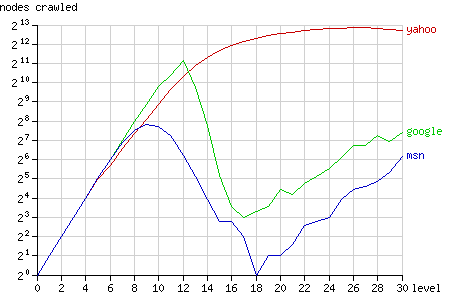
Fig. 3 - The number of nodes crawled after 1 year, grouped by node level.
图.3 - 1年中爬过的节点数,按层次分组
Google closely follows this straight line, until it breaks down after the level 12. Most nodes at level 12 or less were crawled (5524 out of 8191), but only very few nodes at higher levels were crawled by Googlebot. MSN shows similar behaviour, but breaks down much earlier, at the level 9 (656 out of 1023 nodes were crawled). Yahoo, however, does not break down. At high levels it gradually fails to request all nodes.
Google 在12层以下几乎是直线发展的,然后开始下跌。12层以下的节点大部分(8191个中的5524个)被Google爬过,但是Google很少去爬较高层 的节点。MSN的行为也类似,只是下跌得更早,在第9层就开始下跌(爬了1023个节点中的656个)。而Yahoo不同,它没有下跌,但是在高层上它渐渐不再访问所有节点了。
The nodes at high levels that were crawled by Yahoo, were requested quite often compared to the other bots: at level 14 to 30 each page was requested 10 times at average (see fig. 4).
和其他爬虫相比Yahoo对高层节点的访问要频繁地多:在14至30层,平均每个页面被请求多达10次(见图4)。
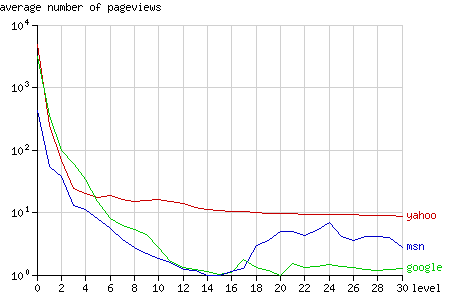
Fig. 4 - The average number of pageviews per node after 1 year, grouped by node level.
图.4 - 一年中每个节点的平均访问量(pageview),按节点层次分组。(转载请注明出处blog.csdn.net/uoyevoli www.farproc.com)
Yahoo! Slurp

- large version (4273x3090, 1.5MB)
- animated version over 1 year (2005-04-13 - 2006-04-13, 13MB)
- animated version of the first 2 hours (2006-04-14 00:40:00-02:40:00, 2.2MB)
- 查看大图 (4273x3090, 1.5MB)
- 一年来的动画 (2005-04-13 - 2006-04-13, 13MB)
- 最开始2小时的动画 (2006-04-14 00:40:00-02:40:00, 2.2MB)
Fig. 5 - The Yahoo! Slurp tree.
图.5 - Yahoo! Slurp的二叉树
Yahoo! Slurp was the first search engine to discover Binary Search Tree 2. In the first hours after discovery it crawled the tree vigorously, at a speed of over 2.3 nodes per second (see the short animation ). The first day it crawled approximately 30,000 nodes.
Yahoo! Slurp最早发现 二叉树2 。在它发现这个一个小时后,爬虫就全力开工了,速度超过2<wbr></wbr>.3个节点/秒(看小动画)。第一天它爬了大约30000个节点。
In the following month Slurp's activity was low, but after exactly one month it requested all pages it visited before, for the second time. In the animation you can see the size of the tree double on 2005-05-14. This phenomenon is repeated a month later: on 2005-06-13 the tree grows to three times it original size. The number of pageviews is then almost 90,000 while the number of crawled nodes still is 30,000. Figure 6 shows this stepwise increment in the number of pageviews during the first months.
在接下来的一个月里,Slurp的活跃度变低了,但是刚好一个月后它<wbr></wbr>又一次请求了曾经访问过的所有节点。在动画里你可以看到在2005-05-14树扩张了一倍<wbr></wbr>。这种现象随后又在2005-06-13重复了一次<wbr></wbr>,树增长到了原来的三倍。页面访问量(pageview<wbr></wbr>)为将近90,000,而爬过的节点数仍然为30,000<wbr></wbr>。图6展示了在第一个月里的这种阶梯式增长趋势。
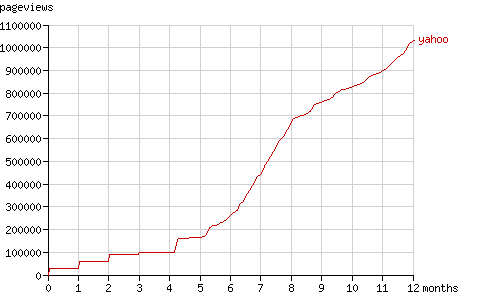
Fig. 6 - The cumulative number of pageviews by Yahoo! Slurp in time.
After four months Slurp requested a large number of 'new' nodes, for the first time since the initial round. It simply requested all URLs it had. Since it had already indexed 30,000 pages, that each link to two pages at a deeper level, it requested 60,000 pages at the end of August (the number of pageviews jumps from 100,000 to 160,000 pages in fig. 6) and it doubled the number of nodes it had crawled (see the fig. 7).
4个月后,Slurp开始了初步阶段里第一次对"新<wbr></wbr>"节点的大规模请求。它直接访问了它拥有的所有URL<wbr></wbr>。因为他已经索引了30,000个页面而每个页面又连接了两个更深<wbr></wbr>层的页面,所以到八月底它总共请求了60,000个页面<wbr></wbr>(页面访问量从100,000飚升至160,000,参看图6<wbr></wbr>)而且它爬过的节点数也翻了一翻。
After 5 months Yahoo! Slurp started requesting nodes more regularly. It still had periods of 'discovery' (e.g. after 10 months).
5个月后Yahoo! Slurp对节点的请求变得更有规律,但仍然有"发现期"<wbr></wbr>(比如10个月后)。
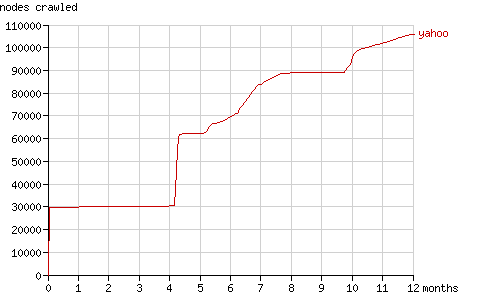
Fig. 7 - The cumulative number of nodes crawled by Yahoo! Slurp in time.
(转载请注明出处blog.csdn.net/uoyevoli www.farproc.com)
Yahoo reported 120,000 pages in it's index ( current value). This may seem impossible since it only visited 105,971 nodes, but every node is available on two different domain names: www.drunkmenworkhere.org and drunkmenworkhere.org.
120,000个页面被包含在Yahoo的索引中(当前值)。这看起来好像不大可能因为他仅仅访问了105,97个节点<wbr></wbr>,但是事实是每个节点都有两个不同的域名:www.drunkmenworkhere.org 和 drunkmenworkhere.org。
Note: the query submitted to Google and MSN yielded 35,600 pages on Yahoo. Yahoo is the only search engine that returns results with the query used above.
注意:向Google和MSN提交的查询比Yahoo的少 35,600页。Yahoo是唯一一个使用上述查询返回结果的搜索引擎。
Googlebot
- large version (4067x4815, 180kB)
- animated version (2005-04-13 - 2006-04-13, 1.2MB)
Fig. 8 The Googlebot tree.
图.8 Googlebot树
In comparison with Yahoo's tree, Google's tree looks more like a natural tree. This is because Google visited nodes at deeper levels less frequently than their parent nodes. Yahoo only visited the nodes at the first three levels more frequently, while Google did so for the first 12 levels (see fig. 4).
和Yahoo的树相比,Google的看起来更像一棵天然的数<wbr></wbr>。这是因为Google访问深层节点的频率小于访问它们父节点的频<wbr></wbr>率。Yahoo仅对前3层节点访问比较频繁,而Google是对前<wbr></wbr>12层(见图.4)。
The form of the tree follows from Google's PageRank algorithm. PageRank is defined as follows:
"We assume page A has pages T1...Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) "
Google树的形式遵循了Google的PageRank算法<wbr></wbr>。PageRank被defined如下:
"我们假设页面A有指向它的页面T1...Tn(比如A被它们引用<wbr></wbr>)。参数d为可以赋0到1之间值的阻尼因数。我们通常设置d为0.85。下面一节会有详细说明。同时C(A)被定义为从页面A链接出去的<wbr></wbr>页面数量。页面A的PageRank可计算如下:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) "
Since most nodes in the tree are not linked to by other sites, the PageRank of a node can be calculated with this formula (ignoring links in the comments):
PR(node) = 0.15 + 0.85 (PR(parent) + PR(left child) + PR(right child))/3
由于大部分的节点没有被别的站链接,PageRank可以用如下的<wbr></wbr>公式计算:
PR(node) = 0.15 + 0.85 (PR(parent) + PR(left child) + PR(right child))/3
The only unknown when applying this formula iteratively, is the PageRank of the root node of the tree. Since this node was the homepage of drunkmenworkhere.org for a year, a high rank may be assumed. The calculated PageRank tree (fig. 9) shows similar proportions as Googlebot's real tree, so the frequency of visiting a page seems to be related to the PageRank of a page.
当应用这个公式时唯一的例外是根节点,因为这个节点一年以来是drunkmenworkhere.org 的主页,理应拥有一个较高的rank。计算出来的PageRank<wbr></wbr>树(图.9)和Googlebot的真实树有相似之处<wbr></wbr>,所以一个页面的访问频繁程度看起来和它的PageRank有关。

Fig. 9 - A binary tree of depth 17 visualising calculated PageRank as length of each line, when the PageRank of the root node is set to 100.
图.9 - 一个深度为17的二叉树。计算出来的PageRank决定了每根线<wbr></wbr>的长度,根的PR被设置为100。
The animation of the Googlebot tree shows some interesting erratic behaviour, that cannot be explained with PageRank.
Googlebot树的动画表现出了一些无法用PageRank解释的奇怪行为。
A few hours later, Googlebot crawled node 2, which is linked as a parent node by node 1. These two nodes are displayed as a tiny dot in the animation on 2005-06-30, floating above the left branch. Then, a week later, on 2005-07-06 (two days after the attempt to find rightmost node), between 06:39:39 and 06:39:59 Googlebot finds the path to these disconnected nodes by visiting the 24 missing nodes in 20 seconds. It started at the root and found it's way up to node 2, without selecting a right branch. In the large version of the Googlebot tree, this path is clearly visible. The nodes halfway the path were not requested for a second time and are represented by thin short line segments, hence the steep curve.

This subtree is the reason the number of nodes crawled by Googlebot, grouped by level, increases again from level 18 to level 30 in fig. 3.(转载请注明出处blog.csdn.net/uoyevoli www.farproc.com)

Over the last six months Googlebot requested pages at a fixed rate (about 260 pages per month, fig. 10). Like Yahoo! Slurp it seems to alternate between periods of discovery (see fig. 11) and periods of refreshing it's cache.
在最后的6个月里,Googlebot以恒定的速率请求页面(大约260个页面/月,图.10)。和Yahoo! Slurp类似,它在发现新节点(图.11)和回顾旧节点之间交替运行。
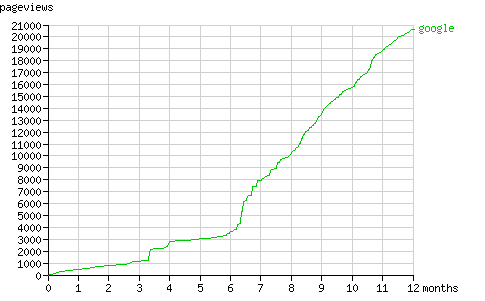
Fig. 10 - The cumulative number of pageviews by Googlebot in time.
图.10 - 按时间顺序显示的Googlebot累计页面访问量(pageview)。
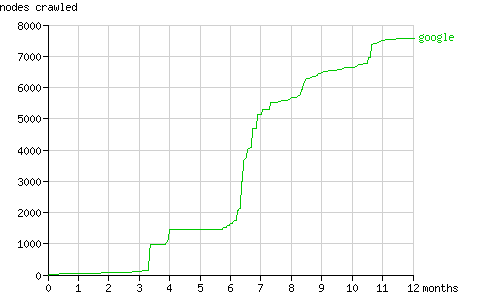
Fig. 11 - The cumulative number of nodes crawled by Googlebot in time.
图.11 - 按时间顺序显示的Googlebot累计爬过的节点数
Google returned 554 results when searching for nodes. The first nodes reported by Google are node 1 and 2, which are very deep inside the tree at level 29 and 30. Their higher rank is also reflected in the curve shown above (Searching node 1), which indicates a high number of pageviews. They probably appear first because of their short URLs. The other nodes at the first result page are all at level 4, probably because the first three levels are penalised because of comment spam. The current number of results can be checked here.
当搜索节点时Google返回554个结果。Google显示的首批节点为节点1和2,这是两个深深隐藏在29和30层里的节点。这两个节点的高PR值也可以从上面(搜索节点1)预示着高PV值的曲线看出来。它们首先出现可能是因为它们的URL较短的缘故。搜索结果的第一页上的其他节点都来自第4层,这可能是因为前3层由于有较多的评论垃圾而被惩罚了。当前搜索结果的数目可以看这里。
MSNbot

- large version (4200x2795, 123kB)
- animated version (2005-04-13 - 2006-04-13, 846kB)
Fig. 12 - The msnbot tree
图.12 - msnbot树
The Msnbot tree is much smaller than Yahoo's and Google's. The most interesting feature is the disconnected large branch to the right of the tree. It appears on 2005-04-29, when msnbot visits node 2045877824. This node contains one comment, posted two weeks before:
I hereby claim this name in the name of...well, mine. Paul Pigg.
Msnbot的树比Yahoo和Google的小很多。最有意思的是树右方一个的断开的大分枝,它发生在 2005-04-29 当msnbot 在访问节点2045877824时。这个节点中包含了一个两周前发布的评论:
I hereby claim this name in the name of...well, mine. Paul Pigg.
A week before msnbot requested this node, Googlebot already visited this node. This random node at level 24 was crawled because of a link from Paul Pigg's website masterpigg.com (now dead, Google cache). All three search engines visited the node via this link, and all three failed to connect it to the rest of the tree. You can check this by clicking the 'to trunk' links starting at node 2045877824.
在msnbot请求这个节点前一周Googlebot已经访问了这个节点。它们是从Paul Pigg的网站masterpigg.com (现在没有了, Google cache)的一个链接访问到这个位于24层的随机节点的。三个搜索引擎都从这个链接找到了这个节点,但是都没有把它和其他节点连起来。你可以点击从 节点2045877824 开始的“to trunk”链接来查看。
Msnbot crawled from the disconnected node in upward and downward direction, creating a large subtree. This subtree caused the upward line between level 18 and 30 in figure 3.
Msnbot从这个孤立节点开始向上和向下爬行,产生了一个棵大子树。这棵子树造成了图3中18层和30层之间向上的走势线。
The second large disconnected branch, at the top in the middle, originated from a link on uu-dot.com. Both disconnected branches are clearly visible in the Googlebot tree as well.
中上部那个第二个断开的分枝是由 uu-dot.com 的一个链接而产生的。这两个断开的分枝在Googlebot树上也可以很清晰地看到。
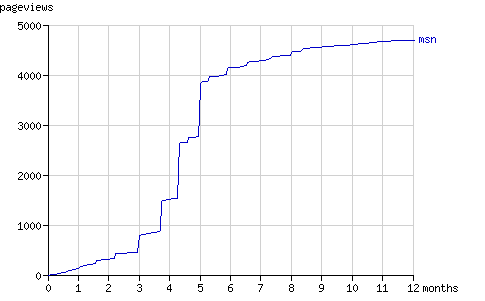
Fig. 13 - The cumulative number of pageviews by msnbot in time.
图.13 - 按时间顺序显示的msnbot累计页面浏览量(pageview)。
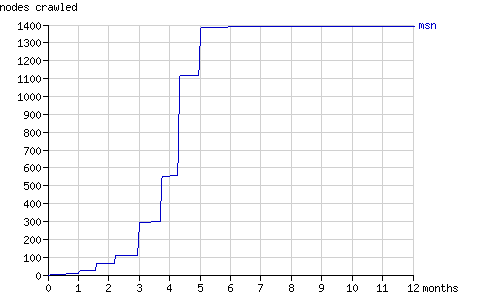
Fig. 14 - The cumulative number of nodes crawled by msnbot in time.
图.14 - 按时间顺序显示的msnbot累计爬过的节点数
As the graphs above show, msnbot virtually ceased to crawl Binary Search Tree 2 after five months. How the number of results MSN Search returns, relates to the above graphs is unclear.
从上图可以看出来msnbot在5个月后停止了,不再爬 二叉搜索树2。Msnbot返回的搜索结果和这个图的关系还不清楚。
Spam bots
In one year 5265 comments were posted to 103 different nodes. 32 of these nodes were never visited by any of the search bots. Most comments (3652) were posted to the root node (the home page). The word frequency of the submitted comments was calculated.
在一年中总人们共在103个不同的节点上发布了5265个评论。其中32个根本没有被任何搜索爬虫访问过。大部分评论(3652)是发布在根节点(首页)上的。下面是计算出来的所有评论中特定词出现的频率。
| 1 | 32743 | http |
| 2 | 23264 | com |
| 3 | 12375 | url |
| 4 | 8636 | www |
| 5 | 5541 | info |
| 6 | 4631 | viagra |
| 7 | 4570 | online |
| 8 | 4533 | phentermine |
| 9 | 4512 | buy |
| 10 | 4469 | html |
| 11 | 3531 | org |
| 12 | 3346 | blogstudio |
| 13 | 3194 | drunkmenworkhere |
| 14 | 2801 | free |
| 15 | 2772 | cialis |
| 16 | 2371 | to |
| 17 | 2241 | u |
| 18 | 2169 | generic |
| 19 | 2054 | cheap |
| 20 | 1921 | ringtones |
| 21 | 1914 | view |
| 22 | 1835 | a |
| 23 | 1818 | net |
| 24 | 1756 | the |
| 25 | 1658 | buddy4u |
| 26 | 1633 | of |
| 27 | 1633 | lelefa |
| 28 | 1580 | xanax |
| 29 | 1572 | blogspot |
| 30 | 1570 | tramadol |
| 31 | 1488 | mp3sa |
| 32 | 1390 | insurance |
| 33 | 1379 | poker |
| 34 | 1310 | cgi |
| 35 | 1232 | sex |
| 36 | 1198 | teen |
| 37 | 1193 | in |
| 38 | 1158 | content |
| 39 | 1105 | aol |
| 40 | 1099 | mime |
| 41 | 1095 | and |
| 42 | 1081 | home |
| 43 | 1034 | us |
| 44 | 1022 | valium |
| 45 | 1020 | josm |
| 46 | 1012 | order |
| 47 | 992 | is |
| 48 | 948 | de |
| 49 | 908 | ringtone |
| 50 | 907 | i |
complete list (360 kB)
完整列表 (360 kB)
As the top 50 clearly shows, most spam was related to pharmaceutical products. The pie chart below shows the share of each medicine.
从前50个出现最频繁的词可以看出大部分的“垃圾”是和药物产品。下面的饼型图显示了每种药物占的比例。
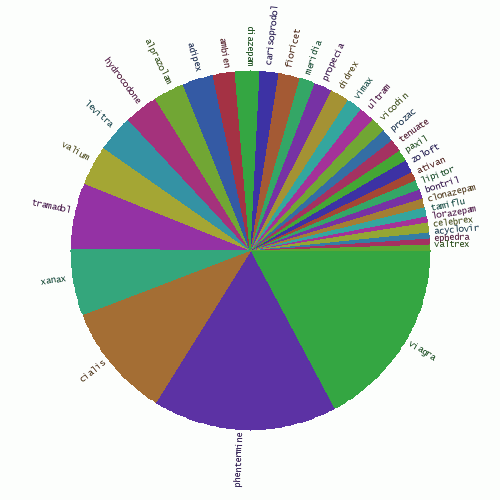
Fig. 15 - The share of various medicines in comment spam.
图.15 - 评论垃圾中不同药物占的比例。
Submitted domain names were filtered from the text. All top-level domain names are shown in figure 16, ordered by frequency.
提交的评论中的域名也被过滤出来。图.16按照出现的频率列出了所有的顶级域名。
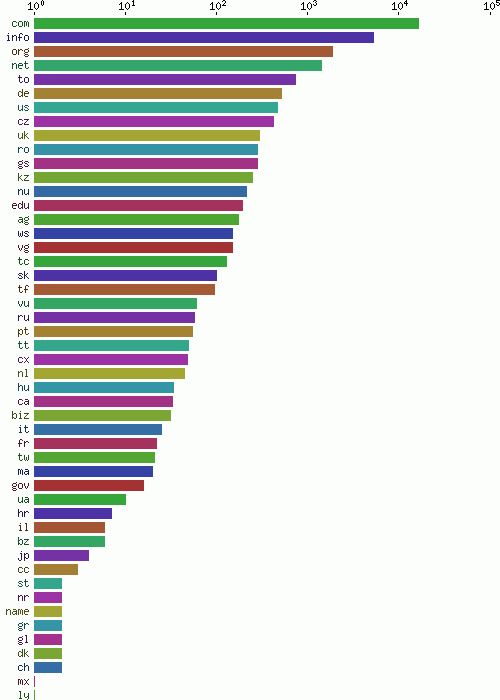
Fig. 16 - Number of spammed domains by top level domain
图.16 - 顶级域名提交的“垃圾”域名个数
Many email addressses submitted by the spam bots were non-existing addresses @drunkmenworkhere.org, which explains the high rank of this domain in the chart of most frequently spammed domains (fig. 17).
被垃圾bots提交的email地址中的很多都是”不存在的地址"@drunkmenworkhere.org。这也解释了为什么这个域名在上图中的比例那么大。
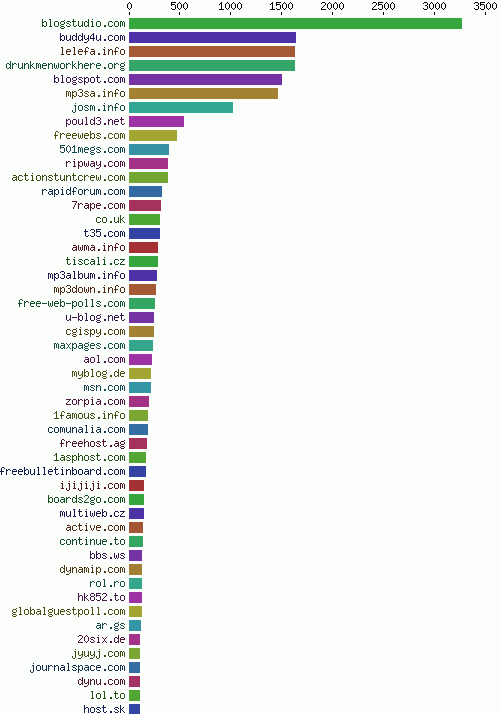
Fig. 17 - Most frequently spammed domains
图.17 - 发垃圾最多的域名
<完>
相关链接:


发表评论

相关推荐
open-source-bots, 开放源代码机器人的完整列表 开源机器人在对 Botwiki.org 站点的一些重大改进之后,这个存储库的内容被移动到了原来的站点中,。 搜索已经得到改进,你还可以按类别轻松浏览僵尸机器人,例如:...
《Game Hacking: Developing Autonomous Bots for Online Games》是一本专为那些对游戏修改和自动化机器人(bots)开发感兴趣的读者准备的技术指南。作者Nick Cano以其丰富的游戏黑客社区经验和反恶意软件经验,深入...
完整版PDF,带自制书签,纯文字版,非扫描版,纯英文版,截至目前无翻译版。下载后直接解压,无任何密码。 Game Hacking Developing Autonomous Bots for Online Games.PDF
Game Hacking Developing Autonomous Bots for Online Games 英文无水印pdf pdf所有页面使用FoxitReader和PDF-XChangeViewer测试都可以打开 本资源转载自网络,如有侵权,请联系上传者或csdn删除 本资源转载自...
Bots自动化威胁报告
Robocode机器人该项目包含用于的EvBot机器人代码自2014年7月30日起,该机器人的开发工作已停止:该代码即使对于作者来说也很复杂。执照随意查看,使用和修改您的代码。 没有任何附加条件。
Telegram Bot Java 库 一个简单易用的 Java 库,用于创建 Telegram 机器人贡献随意分叉此项目,对其进行开发,然后针对DEV分支发出拉取请求。大多数情况下,如果他们为代码添加了有价值的内容,我都会接受它们。请...
Volafile-bots 是一个基于 Python 的项目,用于创建自定义的机器人,可以在 Volafile 平台上与用户互动和执行各种任务。Volafile 是一个文件分享和聊天平台,而 bots 则为该平台增加了自动化功能,可以提高效率,...
本项目为铛铛-bots聊天机器人设计源码,采用Java和Kotlin双语言编写,共计29个文件,包括18个Java源文件、3个Kotlin源文件、3个XML配置文件、1个Markdown文件、1个文本文件、1个JAR包文件、1个批处理脚本文件以及1个...
视频游戏机器人(Game Bots)是一种可以自动化游戏过程的程序,通常用于辅助玩家进行游戏...对于有志于深入研究和开发视频游戏机器人的IT从业者和爱好者来说,《Practical Video Game Bots》无疑是一本宝贵的参考资料。
在AngryBots中,机器人的运动、子弹飞行轨迹以及对环境的互动,如弹射、碰撞反弹等,都依赖于物理引擎。 4. **光照和渲染**:Unity的光照系统提供了实时全局光照解决方案,如 baked lighting 和 real-time lighting...
协作机器人的发展现状与前景 2017年11月 协作机器人的发展现状与...因此,协作机器人(co-bots)最初的市场就是中小企业。 同年Esben ostergaard,Kasper Stoy和Kristian Kassow在南丹麦大学一起做研究时创办了Universa
一个简单易用的库来用Java创建电报机器人 会费 随意分叉此项目,对其进行处理,然后对DEV分支发出拉取请求。 在大多数情况下,如果它们为代码添加了一些有价值的东西,我会接受它们。 请不要使用任何令牌或API密钥...
如何使用要在模拟器模式下运行它: 克隆这个仓库运行bundle install来安装文件通过要求bots.rb创建机器人控制器文件使用pry -r ./hex.rb在 REPL 中运行机器人控制器文件(假设您的控制器文件名为hex.rb ) 要退出 ...
聊天机器人技术架构、挑战和机遇都是当前聊天机器人研究的热点。通过知识图谱的应用,聊天机器人可以变得更加智能、个性化和人性化,从而更好地服务于用户。 知识点: 1. 聊天机器人的技术架构包括Bot框架、Bot...
聊天机器人有许多不同的名称,例如:chatterbots(唠叨机器人)、talkbots(聊天机器人)、bots(机器人)、chatterboxes(闲聊盒)、artificial conversation entities(ACE,人工智能对话实体)、virtual ...
这是基于一个机器人射击的项目,通过这个源码可以了解3D射击游戏的知识点,主角武器射击、反射实现,敌人的距离感应,帮助大家轻松的完成一个单机的机器人射击项目。 做为Unity早期的经典demo,一直从3.5以后沿用到...
Reddit机器人各种reddit机器人的集合。Reddit Feeds自动海报Reddit Feeds Auto-Poster是一个Python脚本,可将Feed中的新条目自动发布到subreddit。 即将推出! (以阀门时间为单位)Reddit Self Posts复印机Reddit ...
大连理工大学1024程序员日机器人战斗平台DUT BOTSDUT-BOTS.zip
本地化前端在您的服务器上运行此命令,以允许用户帮助您本地化项目。... - ./DATA/mongo-volumes:/data/db backend : image : alexstep/localizer-backend container_name : localizer_backend depends_on : -